
Abstract
There has been a lack of research on how people with individual differences learn with multimedia materials, in particular with regard to individuals with dyslexia. Dyslexia is a learning disability characterized by subpar ability in reading, spelling, writing, word recognition, and phonological decoding. This population could potentially benefit from multimedia learning materials according to the cognitive theory of multimedia learning and Orton–Gillingham multisensory instructional approach. This study examined how learning in four multimedia conditions influences dyslexic college students’ ability to recall and recognize information. Seventy-three college students with dyslexia were assigned to one of the four conditions that integrated the modality (spoken text vs. on-screen text) and multimedia (picture present vs. picture absent) principles. They completed a cued-recall and a content recognition test. The results indicated pictures facilitated recognition, which validated the multimedia principle. On-screen text led to a superior performance in recall and recognition compared to spoken text. This finding suggested the modality principle did not hold for participants with dyslexia in this study, which is especially surprising given that dyslexics have difficulty processing written text. Possible explanations of the findings are discussed.
With the continued expansion of online learning in higher education (Allen & Seaman, 2014) and K–12 education (Picciano, Seaman, Shea, & Swan, 2012), the ability to support all learners in multimedia learning environments is increasingly important. Multimedia learning has been defined as learning from verbal and pictorial information (Mayer, 2014b). Verbal information can be presented in the form of on-screen text or spoken text. Pictorial information can be retrieved from pictures, diagrams, videos, animations, and so on. Multimedia learning includes learning from animation, video, screen-casting, and other instructional materials that involve pictorial and verbal information in the instructional method.
Researchers have conducted a multitude of studies to examine how multimedia materials can be designed to facilitate learning (Mayer & Fiorella, 2014; Mayer & Pilegard, 2014). Most of this empirical work has been done with typically developing learners and using convenience samples of undergraduate psychology or education majors (Mayer, 2014a). Consequently, empirical findings from these studies have provided implications on how to optimize multimedia materials for typical learners, but educational researchers and practitioners have little understanding of how individual differences such as dyslexia moderate learning with multimedia. In fact, only one chapter in the latest edition of the Cambridge Handbook of Multimedia Learning (Mayer, 2014a) explicitly focuses on the issue of individual differences in multimedia instruction (Wiley, Sanchez, & Jaeger, 2014), and none focuses on the effects of multimedia in populations with learning disabilities such as dyslexia.
The current study is informed by the cognitive theory of multimedia learning (CTML; Mayer, 1997, 2014) and the Orton–Gillingham (OG) multisensory instructional approach to teach students with dyslexia (Gillingham & Stillman, 1997). The CTML is based on the assumption that the human mind processes information in two channels—visual and auditory (Paivio, 1991). Further, it stipulates that presenting verbal information via the auditory channel and the visual information via the visual channel will facilitate learning. This theory is popular among educational researchers, designers, and practitioners because it provides a set of cognitive science–based principles to inform the design of multimedia learning (Mayer, 2014b). In this study, we tested two relevant CTML principles—multimedia principle and modality principle. The multimedia principle suggests presenting visual information along with verbal information rather than presenting verbal information alone (Mayer & Sims, 1994). In a series of 11 experimental comparisons, Mayer (2009) found that students performed significantly better on a transfer test when they learned from words and visuals than from words alone, yielding a median effect size of 1.39. On the other hand, the modality principle highlights the importance of supplying visuals with narrated text rather than on-screen text (Moreno & Mayer, 1999). This principle was supported in 53 of the 61 experimental tests, yielding a median effect size of 0.76 (Mayer, 2009).
Similar to CTML, the OG multisensory instructional approach stresses that, for students with dyslexia, activating multiple sensory areas of the brain (e.g., both visual and auditory areas) will improve cognitive processing associated with reading. Ritchey and Goeke (2006) reviewed 12 studies and found that OG-based reading instruction resulted in significantly enhanced comprehension outcomes with a mean effect size of .76. Both the CTML principles and the OG multisensory instructional approach suggest the effectiveness of presenting materials in multiple modalities (e.g., visuals and narrated text) for individuals with dyslexia. The current study explored how four multimedia learning conditions influence recall and recognition performance for college students with dyslexia. This study is important, and timely, as it tests two widely adopted multimedia learning principles (i.e., the multimedia principle, Mayer et al., 1996; and the modality principle, Mayer & Moreno, 2003) with individuals with dyslexia and provides insights into how learners with dyslexia perform under different multimedia conditions.
Literature Review
CTML
An important theoretical perspective informing this study and research on multimedia instruction in general is the CTML (Mayer, 1997, 2014). CTML relies on three well-known theoretical assumptions. The first assumption is that of dual coding (Paivio, 1991). It discusses working memory as consisting of two separate channels. The visual channel is responsible for holding and processing pictorial information, whereas the auditory channel handles the processing of verbal information. Second, CTML relies on the limited working memory capacity assumption (Cowan, 2001; Miller, 1956), a theoretical proposition that working memory and each of the two channels can only hold and actively process about 3–4 items at a time. Third, CTML posits that learning is an active process of filtering, selecting, organizing, and integrating information. Specifically, learners process verbal and pictorial information in three steps: (a) select incoming verbal and pictorial information for further processing in working memory, (b) organize selected verbal and pictorial information into mental representations, and (c) integrate the already-organized verbal and pictorial models with prior knowledge that is retrieved from long-term memory. Given that dyslexia impedes verbal processing (Authors, 2011), it is reasonable to expect that individuals with dyslexia may struggle with processing verbal information and rely on visual information to a larger extent.
Limitations of human cognitive architecture and cognitive load
A fundamental assumption underlying multimedia learning research is that humans learn better when multimedia is designed to support how the human mind processes information or human cognitive architecture (Mayer, 2009). Constraints of human cognitive architecture render certain designs of multimedia instruction effective or ineffective (Sweller, van Merriënboer, & Paas, 1998).
Human cognitive architecture includes three memory structures—sensory memory, working memory, and long-term memory—and their interaction to process information (Sweller et al., 1998). Working memory is the central processing unit of human cognitive architecture (Baddeley & Hitch, 1974) and is constrained by a severely limited capacity (Cowan, 2001; Miller, 1956). Considering the limited capacity of working memory, cognitive load theory (Sweller et al., 1998) defines the amount of information being stored and manipulated in working memory as “cognitive load” and explains and predicts how various working memory processes (e.g., split attention) and their interaction with long-term memory may induce cognitive load (Sweller et al., 1998). When the information learners need to process exceeds the limited working memory capacity, the learners experience a cognitive overload and learning is hindered due to excessive demands on the cognitive resources.
Cognitive load theory has been a useful framework to explain the effects of different multimedia designs relative to the limited capacity of working memory (Mayer & Moreno, 2003). Cognitive load theory distinguishes between three types of cognitive load: intrinsic load, extraneous load, and germane load (Paas, Tuovinen, Tabbers, & Van Gerven, 2003). Different topics (e.g., solving a calculus problem vs. adding two single digits) differ in how many information elements they contain and how these elements interact to produce understanding and learning. The amount of information elements and the level of element interactivity (Sweller, 2010) impose different levels of intrinsic cognitive load on the learner. In contrast, extraneous cognitive load is mainly associated with poor presentation of information and design of learning materials. For example, presentation slides designed using poor contrast between the text and background, or slides that include extraneous animations that distract the learner from the relevant content, cause high levels of extraneous load. Finally, germane load occurs when the learning content and instructions help people concentrate on learning and integrate new information with existing knowledge more effectively and efficiently without overwhelming them. In this sense, one could say that the art of teaching is about designing learning experiences to increase germane load for all learners in the classroom while keeping learners’ extraneous load low. From the perspective of multimedia learning design, multimedia instructional materials should be designed to minimize extraneous cognitive load and allow more cognitive resources for germane processing of content imposing either high or low level of intrinsic load.
Multimedia principle
From the perspective of the dual coding theory (Paivio, 1991), the verbal system and pictorial system of human memory separately process verbal and pictorial information. Dual coding is superior to single coding of information in that pictorial information elicits an enhanced memory of verbal information and vice versa. Referential connections between the mental representations (e.g., verbal and pictorial representations) facilitate meaningful learning, and so dual channel processing is hypothesized to be superior to learning with verbal or pictorial information alone (Paivio, 1991).
Extending the dual coding theory, Mayer and Sims (1994) posited that people learn better from words and pictures than from words alone, which CTML refers to as the multimedia principle. When learners process both verbal and pictorial information, they have the opportunity to build verbal and pictorial models and integrate them with each other. Empirically, Mayer and colleagues (1996) conducted a study with typically developing participants who read a passage about lightning, and the experimental manipulation was whether the text included simple illustrations depicting the process or not. Findings showed the illustrations led to higher retention of the main steps of the lightning process. Later, Mayer (1997) reviewed eight studies that compared multimedia instruction with single-media instruction and consistently found the positive effect of multimedia instruction. Learners who received multimedia instruction performed significantly better on retention and transfer tests than those who received verbal instruction alone.
Modality principle
The modality principle accounts for the limited capacity of working memory and the resulting cognitive load to capitalize on working memory’s capability of dual channel processing. The modality principle explains that people learn better from visual information and spoken text than from visual information and on-screen text (Moreno & Mayer, 1999). Both on-screen text and pictures constitute visual information, and so they compete for cognitive resources in the visual channel, potentially overloading it. The modality principle suggests effective multimedia instruction should allow information to be processed via both the visual and the auditory channels simultaneously expanding the limited capacity of working memory. Spoken text (auditory information) is processed by the auditory channel, and on-screen pictures (visual information) are processed by the visual channel. Thus, both the visual and auditory channels are utilized to process verbal and auditory information, respectively, resulting in a more efficient processing of information. As the learner simultaneously organizes verbal and visual information into representational structures in working memory, the construction of referential connections between verbal and pictorial information is also facilitated.
Several studies with typically developing participants found that retention of scientific process was improved when verbal information was delivered as spoken text rather than as on-screen text (Mayer & Moreno, 1998; Moreno & Mayer, 1999; Moreno, Mayer, Spires, & Lester, 2001). For example, in the research by Moreno and Mayer (1999), college students viewed a 3-min computer animation depicting the process of lightning and concurrently viewed on-screen text or listened to spoken text. The spoken text group recalled significantly more major points than the groups who viewed the on-screen text. Researchers obtained similar results as they presented multimedia learning topics in various domains via on-screen text or spoken text, for example, operation of a car’s braking system (Mayer & Moreno, 1998) and design of plant parts for survival (Moreno et al., 2001).
Multimedia Learning and Dyslexia
Historically, multimedia learning research has focused on typical college students at traditional 4-year universities. Very few studies have focused on individuals with learning disabilities and examined how multimedia learning conditions could influence performance for these individuals (Mayer, 2014a). With this substantial gap in knowledge, educational researchers, designers, and practitioners have little idea about whether multimedia learning principles can be generalized to populations with learning disabilities such as dyslexia. Considering that individuals with dyslexia have different learning strengths and weaknesses than typically developing individuals (Lombardino, 2011), it is reasonable to hypothesize that multimedia learning principles may influence this population differently. Our study extends multimedia learning research to learners with dyslexia; a population currently underresearched despite the fact that dyslexia represents 80–90% of all learning disabilities (Shaywitz, 2008).
Defining dyslexia
Dyslexia has been recognized as a specific developmental reading disability in medically oriented disciplines for over a century (Geschwind, 1982; Hinshelwood, 1907; Orton, 1925). Dyslexia is characterized by cognitive deficits in word identification, phonological (letter sound) decoding, spelling, writing, and short-term memory (Vellutino, 2004). To better understand the differences between individuals with and without dyslexia, researchers have also examined the potential talents of people with dyslexia in nonlinguistic domains such as visuospatial processing (Brunswick, Martin, & Marzano, 2010; Von Károlyi, Winner, Gray, & Sherman, 2003; Author, 2016; Author, 2016). Although the research findings regarding processing advantages among individuals with dyslexia are not consistent, dyslexia should not be identified only as a “disability” but rather as an individual difference with predictable deficits and a range of potential strengths (Tamboer, Vorst, & Oort, 2016).
Dyslexia and OG multisensory instructional approach
Instructional strategies have been developed to help individuals with dyslexia learn reading and writing, and an effective method is the OG multisensory instructional approach (Gillingham & Stillman, 1997; Henry, 1998). According to the multisensory instructional approach, reading can be enhanced when multiple sensory areas of the brain (e.g., auditory, visual, kinesthetic, tactile) are activated and interact with each other (Odegard, Ring, Smith, Biggan, & Black, 2008). This increased interaction employs all pathways of learning at the same time, for example, seeing, hearing, touching, writing, and speaking. Research has shown the multisensory instructional approach can improve skills in reading (Montali & Lewandowski, 1996; Schneps et al., 2016), writing (Kast, Meyer, Vögeli, Gross, & Jäncke, 2007), and spelling (Kast, Baschera, Gross, Jäncke, & Meyer, 2011) among students with dyslexia. For example, Montali and Lewandowski (1996) tested whether bimodal presentation in the form of on-screen text and voice can facilitate comprehension. Typical readers and readers with dyslexia were presented with social studies and science passages in three conditions: on-screen text, voice, and bimodal. Findings indicated the bimodal condition led to the highest level of comprehension among readers with dyslexia compared to the two unimodal conditions. Kast, Meyer, Vögeli, Gross, and Jäncke (2007) examined whether building visuo–auditory associations might help to mitigate writing errors in children with dyslexia. The participants with dyslexia received a computer-based writing training with the purpose to recode a sequential textual input string (e.g., ed-u-ca-tion) into a multisensory representation comprising visual and auditory codes. The findings showed that children with dyslexia who underwent the visual–auditory multimedia training significantly improved their writing skills. More recently, Schneps and colleagues (2016) found individuals with dyslexia benefited from an accelerated multimodal presentation of text via visual and auditory pathways, which was superior to reading using either modality separately.
Multimedia learning research for individuals with dyslexia
From the perspective of a multisensory instructional approach such as OG, students with dyslexia could benefit from multimedia materials. These materials are generally designed using multiple types of media and modalities such as text, visualizations, and sound. These multimedia elements could simultaneously engage learners with dyslexia via more than one sensory pathway (Sidhu & Manzura, 2011) and thus facilitate learning. In particular, multimedia learning applications have been found to be useful in improving understanding in mathematics learning among individuals with dyslexia. For example, MathLexic, a multimedia mathematical learning tool offering multimedia tutorials on mathematics topics (e.g., recognizing numbers and mathematical operations) in the form of text and voice, improved mathematics skills for students with dyslexia, in addition to increasing their motivation to learn mathematics (Ahmad, Jinon, & Rosmani, 2013).
Few studies have compared different combinations of multimedia relative to their effect on learning for individuals with dyslexia. Beacham and Alty (2006) compared three types of multimedia learning materials for learning statistics among individuals with dyslexia: sound and diagrams, text and diagrams, and text alone. The text alone condition resulted in the highest increase from pretest to posttest, and the condition involving sound and diagram improved the score the least. This finding was unexpected and the explanation offered for the results was that the text alone condition required the least effort in switching between modalities while the other two conditions led to cognitive overload due to split attention between modalities.
With regard to the multimedia effect among individuals with dyslexia, the visuals could potentially assist students with dyslexia who have difficulty processing text. Visuals can be especially useful in forming a pictorial representation of a concept, considering that forming a representation of verbal information can be challenging for learners with dyslexia. A previous study has noted using visual aids with cognitively or visually impaired students assisted them with text comprehension (Murphy, 2005). However, there has been little research examining the effectiveness of visualizations among individuals with dyslexia. Taylor, Duffy, and Hughes (2007) compared two multimedia conditions—animation and static text with a sample of undergraduate students with and without dyslexia. Both groups perceived the animated materials as more useful than the static text materials. However, the perceived usefulness was relatively higher for the individuals without dyslexia. In the study by Beacham and Alty (2006), no difference in retention performance was identified between the text condition and text with diagram condition among learners with dyslexia.
Based on these findings, it is reasonable to assume that multimedia learning materials can have different effects on people with and without dyslexia. A multimedia condition that works best for typical readers might not necessarily be the most efficient approach for individuals with dyslexia. So, further research is needed to test whether and how the multimedia principle and modality principle are applicable to individuals with dyslexia.
Given the theoretical perspectives and empirical evidence discussed above, the purpose of the current study was to understand how the effects of multimedia and modality influence learning among college students with dyslexia. This study employed information retention tests (recall and recognition) to assess participants’ learning. The current study was designed to explore the following research question: How do the multimedia conditions based on the multimedia principle (picture present vs. picture absent) and modality principle (spoken text vs. on-screen text) influence recall and recognition performance within a sample of college students with dyslexia?
Method
Research Design
The current study utilized a multimedia presentation entitled Discovering Australia, which has been used and validated in previous studies of multimedia learning with typically developing individuals (Ritzhaupt et al., 2008, 2011, 2015). This study was a 2 multimedia (picture present vs. picture absent) × 2 modality (spoken text vs. on-screen text) factorial design with both multimedia and modality serving as between-subject conditions. Using an a priori power analysis (Cohen, 1992, p. 158), with an α level set at α = .05, an estimated large effect size, four groups in the analysis of variance (ANOVA), and a desired power of 0.8, the study calls for approximately 18 participants in each of the four conditions, for a total of 72 participants. Seventy-three participants were recruited, and each was assigned to one of the four multimedia learning conditions (see Table 1).
Distribution of Participants Per Condition.

Participants
Table 2 provides the descriptive characteristics of the participants with dyslexia. Twenty-one participants were male, and 52 of the participants were female. The age range of participants with dyslexia was 18–56 with an average age of the participants at 25.08 (standard deviation [SD] = 7.69). Approximately 77% of the participants classified themselves as White/Caucasian, and 12% were classified as Black or African American. Thirty percent of the participants held a bachelor’s degree with another 27% at the junior or senior level of their undergraduate education.
Descriptive Characteristics of Participants.

Note. AA = Associate of Arts; AS = Associate of Science; BA = Bachelor of Arts; BS = Bachelor of Science.
Materials
Participants viewed the multimedia presentation titled Discovering Australia. The presentation in each of the four conditions comprised 2 introductory slides and 10 slides containing information about different aspects of Australia. The 10 slides were presented in random order after the 2 introductory slides were shown. The passages, 76 words on average with a Flesch reading ease of 36.4 and a Flesch–Kincaid 12th-grade-level reading score (Flesch, 1949), lasted approximately 30 s in the spoken text conditions. For the picture present condition, representational pictures were provided for 10 slides (e.g., Camel in the example), and they represented the textual information from the passages. The spoken text and picture absent condition only provided a neutral shape of Australia throughout the slides. Examples of the presentation in each of the four conditions are presented in Figure 1.

Experimental stimuli for the four conditions: on-screen text and picture present (a), on-screen text and picture absent (b), spoken text and picture present (c), and spoken text and picture absent (d).
The presentation of Discovering Australia was displayed on an external 20-in. flat panel monitor, with a resolution of 1,600 by 900 pixels and a refresh rate of 60 Hz. Participants used a Bluetooth mouse to navigate the presentation by clicking on the “next” button located at the bottom right corner of the screen. Figure 2 shows the setup.

Experimental setup.
Measures
Recall
First, 20 cued-recall questions assessed participants’ retention of key information covered in the presentation, and the cued-recall items included hints or cues that were supposed to help participants recall information from the intervention. Two cued-recall questions corresponded to each of the 10 slides. No questions were developed for the introductory slides. For the stimuli used in Figure 1, the two questions were “Who prefers to use feral camels as beasts of burden? ______; What do Australia’s feral camels eat? ______.” No time limit was imposed on participants. Test scores were calculated by assigning one point for the correct response and zero points for an incorrect response. The cued-recall items have been used and validated in previous studies (Ritzhaupt et al., 2008, 2011). Internal consistency reliability was calculated using Kuder–Richardson Formula 20 (K-R 20) = .739 for the cued-recall items.
Recognition
After completing 20 cued-recall items, participants responded to the same questions, but multiple choices were provided. Figure 3 presents two recognition items pertaining to Figure 1. These recognition prompts have also been used and validated in previous studies (e.g., Lombardino, 2011). Test scores were calculated by assigning one point for the correct response and zero points for an incorrect response. Internal consistency reliability reached K-R 20 = .717 for the recognition items.

Example recognition items.
Procedure
After obtaining institutional review board approval at a large Southeastern University in the United States, college students from five public institutions of higher education were recruited and screened for dyslexia. Participants were recruited from the disability resource centers at five universities, and 63 already had diagnoses and were registered with the disability resource centers. Participants were screened using methods consistent with high-quality studies of learners with dyslexia (Wiseheart, Altmann, Park, & Lombardino, 2009). In the first phase of screening, a trained researcher conducted phone interviews in which she took a detailed developmental history for each of the potential participants. Those who had a developmental history of slow reading and spelling difficulties along with their personal descriptions of the typical characteristics of dyslexia were selected for the second phase of screening. Widely used norm-referenced tests were employed to ensure that the students showed the typical pattern of strengths and weaknesses that characterize individuals with dyslexia. These tests included the Test of Word Reading Efficiency-2 (TOWRE-2; Torgesen, Wagner, & Rashotte, 1999) consisting of timed phonemic decoding and word recognition tasks, the Comprehensive Test of Phonological Processing-2 (CTOPP-2; Wagner, Torgesen, & Rashotte, 1999), which included tasks of elision, memory for digits, rapid digit naming, rapid letter naming, and the verbal comprehension and concept formation tests from the Woodcock–Johnson-III (WJ-III) test of cognitive ability (Woodcock, McGrew, & Mather, 2001). Students were selected for participation in this study if they (1) scored at least 1 SD below the mean on either the phonemic decoding or word recognition tests from TOWRE-2; (2) scored at least 1 SD below the mean on one of the following tests from CTOPP-2 including elision, memory for digits, nonword repetition, and rapid digit naming; and (3) scored within or above 1 SD of the mean on both the verbal comprehension and concept formation tests from the WJ-III. The researchers completed a full screener (i.e., phone interview, survey, and screening battery) for a total of 77 participants. Seventy-six participants met the inclusionary criteria for the diagnosis of dyslexia and data from 73 college students (age 18–56, 21 male) were used in the study. Three participants withdrew from the study.
After having been screened and assigned to a treatment condition, participants with dyslexia completed a brief demographics survey on the computer. Each participant viewed the presentation of Discovering Australia (in one of the four conditions) and did not take notes while viewing the presentation. Afterward, participants completed the computerized retention tests including 20 cued-recall items and 20 content recognition items without being able to refer back to the slides. Participants completed the cued-recall test before the recognition items to prevent a testing effect. The entire session lasted about 30 min for each participant.
Results
Table 3 shows the descriptive statistics for the recall scores by multimedia and modality conditions. Two assumptions were tested: (1) normality and (2) homogeneity of the variance. Data appeared to be normally distributed with skewness at 0.257 and kurtosis at −0.511. The Levene’s test was conducted to test the homogeneity of the variance on the recall measure, and the result was statistically insignificant at F(3, 69) = 1.244, p = .30. In addition, independence of observation was achieved through the systematic assignment procedures. Thus, the data seemed well suited for ANOVA. The data were entered into a 2 multimedia (picture present vs. picture absent) × 2 modality (spoken text vs. on-screen text) factorial design.
Mean Scores and Standard Deviations on Recall Performance.
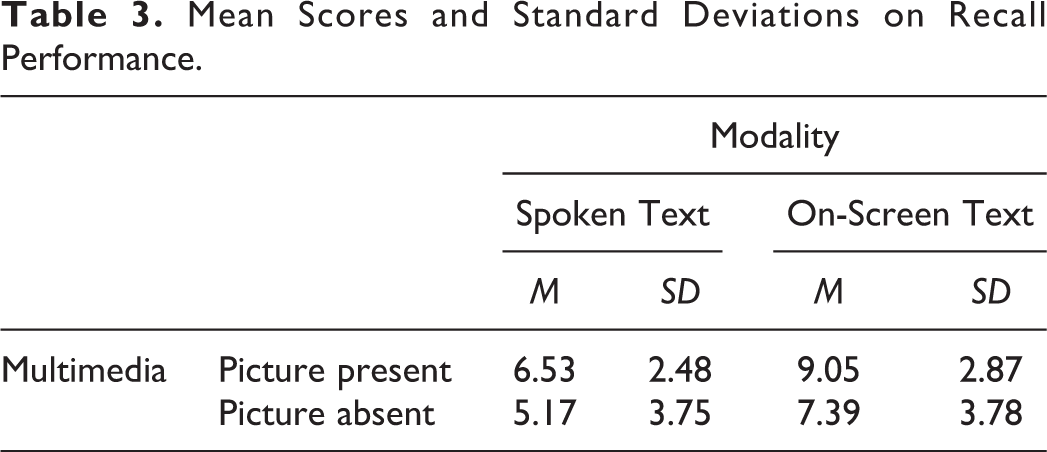
The results show that modality was statistically significant at F(1, 69) = 9.589, p = .003, partial η2 = .122, which indicates that approximately 12% of the variability in the cued-recall measure is explained by modality variable. This would be classified as a small effect size (Ferguson, 2009). As can be gleaned in Table 3, the on-screen text conditions outperformed the spoken text conditions for both the picture present and picture absent conditions. With regard to the multimedia principle, the results were not statistically significant at F(1, 69) = 3.898, p = .052, partial η2 = .053. However, the multimedia variable was approaching statistical significance. Finally, the interaction effect between Multimedia × Modality was not statistically significant at F(1, 69) = .038, p = .846, partial η2 = .001.
Table 4 shows the descriptive statistics for the recognition measures by multimedia and modality conditions. Following the same procedures for the recognition measure, skewness was at −0.424 and kurtosis was at −0.540, suggesting the data are normally distributed. The Levene’s test was not statistically significant at F(3, 69) = 2.656, p = .055, suggesting the variances are equal across groups. Again, the data appeared to be well suited for ANOVA and were entered into a 2 multimedia (picture present vs. picture absent) × 2 modality (spoken text vs. on-screen text) factorial design with both multimedia and modality serving as between-subject conditions.
Mean Scores and Standard Deviations on Recognition Performance.
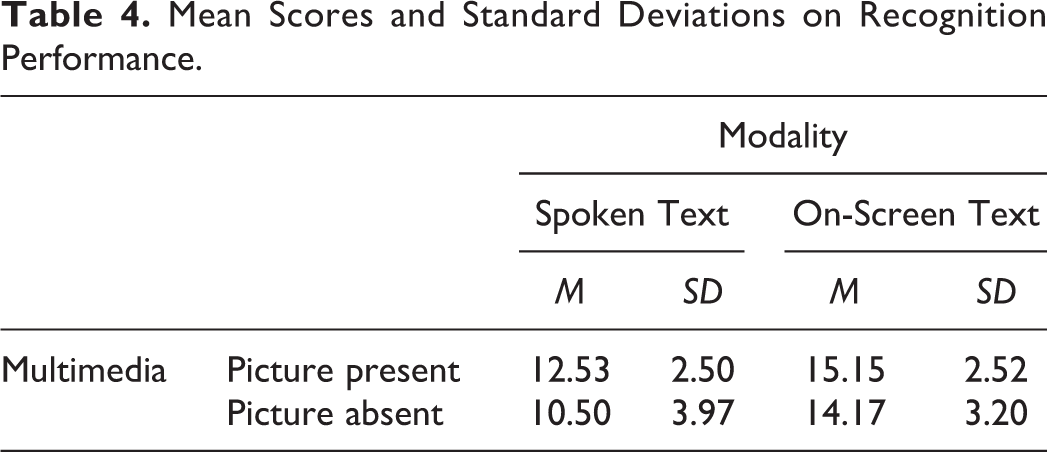
The multimedia variable was statistically significant at F(1, 69) = 4.290, p = .042, partial η2 = .059, which indicates that approximately 6% of the variability in the recognition measure is explained by the multimedia variable. This is classified as a small effect size (Ferguson, 2009). A review of the descriptive statistics shows that the picture present conditions outperformed the picture absent conditions. Regarding the modality effect, the ANOVA detected a statistically significant difference at F(1, 69) = 18.683, p < .001, partial η2 = .213, demonstrating a small effect size explaining approximately 21% of the variability in the recognition measure. The on-screen text conditions outperformed the spoken text conditions, irrespective of the multimedia principle as shown in Table 4. Akin to the recall model, the interaction effect between Multimedia × Modality was statistically insignificant at F(1, 69) = .517, p = .474, partial η2 = .007.
Discussion
This study contributes to our understanding of how individuals with dyslexia learn with multimedia. This study extends CTML research by testing two multimedia learning principles—the modality principle and the multimedia principle—with a population that will likely benefit differently from multimedia instruction—learners with dyslexia.
Similar to a host of studies exploring multimedia effects with typically developing learners, the findings of this study support the multimedia principle among participants with dyslexia for the recognition measure. The influence of the multimedia principle on the cued-recall measure was approaching significance. Learners with dyslexia in the two picture-present conditions had significantly better recognition performance. According to the dual coding theory, pictures help participants build an important referential connection with text, thus eliciting enhanced memory of the verbal information and leading to better retention (Paivio, 1991). This study lends support to the claim that individuals with dyslexia benefit from visualizations (Taylor, Duffy, & Hughes, 2007) and further provides evidence of the robustness of the multimedia principle in general and with special populations.
Conversely, the modality principle (Ginns, 2005) that has been observed with typically developing individuals in a host of studies was not supported by the data generated in this study. In fact, participants with dyslexia who read the on-screen text significantly outperformed those who listened to the spoken text. This result is surprising in that the spoken text conditions were expected to better align with the hypothesized information processing strengths (i.e., listening) for individuals with dyslexia. There may be two possible interpretations for this anomalous finding. First, the reason for increased retention from two on-screen text conditions could be that the participants we recruited are high-functioning college students with dyslexia who thrive in an academically intensive and text-heavy university environment. It is likely these students have developed strategies for learning with traditional text (Cavalli, Duncan, Elbro, El Ahmadi, & Colé, 2017) and may no longer be described as disadvantaged relative to their reading performance. To explore this further, an eye-tracking study may be able to provide additional insights into the text processing strategies used by high-functioning college students with dyslexia. Another reason for the reverse modality effect may be the transient information effect of the spoken text (Leahy & Sweller, 2011; Singh, Marcus, & Ayres, 2012; Wong, Leahy, Marcus, & Sweller, 2012). The transient information effect occurs when explanatory information disappears before it can be sufficiently processed by the learner, which causes poorer learning performance compared to nontransient information like on-screen text (Singh et al., 2012; Wong et al., 2012).
Spoken text could be considered a type of transient information as the information is being replaced by new information as the narrator reads along the passage. Spoken text, unlike its textual counterpart, is sequential and dependent on the speed of the narrator (Barron, 2004). The pace of the spoken text in this study could not be controlled and neither could the participants pause, rewind, and replay the spoken text. So, whereas in the case of on-screen text participants had the opportunity to review the previously read information before proceeding to the next slide, it was not possible to replay the narration in the spoken text conditions. It has been suggested that long and transient spoken text cannot be easily processed in working memory (Leahy & Sweller, 2011). To be more specific, Leahy and Sweller (2011) manipulated the length of text and tested the influence of transient information on the modality effect. In their first experiment, two groups of elementary school students were randomly assigned to one of the two multimedia conditions: visuals with on-screen text or visuals with spoken text. Visuals with on-screen text led to superior learning, and this finding reversed the well-established modality effect. As the length of the auditory text might amplify the transient information effect, in the follow-up experiment, the researchers decreased the number of words in each slide from 13.9 to 7.6 for both experimental conditions. They found the traditional effect of modality after breaking the presentation into shorter segments—that is, spoken text produced better learning results than on-screen text. Similarly, Wong, Leahy, Marcus, and Sweller (2012) were able to replicate the finding that the modality effect could disappear or reverse if long and transient spoken text is used, but the modality effect could be reinstated with shorter text. In the current study, it is reasonable to speculate that the reverse modality effect was due to the transient information effect imposed by the length of text in each passage (i.e., 76 words per passage). It is likely that learners had difficulty adequately processing the spoken text before it disappeared, thus causing the modality effect to be reversed similar to Leahy and Sweller (2011) and Wong and associates’ (2012) findings.
To our knowledge, the current study is the first one informed by CTML to test the multimedia and modality principles (Mayer & Moreno, 2003) among learners with dyslexia. Several recommendations for future research can be provided to extend the findings and contribute to this research area. First, additional research is needed to evaluate the robustness of our results among other populations with dyslexia, for example, K–12 students. It is possible that college students with dyslexia have developed alternative strategies for processing text because their studies require a considerable amount of text reading, and so, future studies can corroborate if on-screen text indeed is superior to spoken text among younger individuals with dyslexia. Further, while this study focused only on the modality and multimedia principles, future research could explore the effects of other multimedia learning principles (e.g., segmenting principle or redundancy principle) that have been instrumental in guiding the design of multimedia materials to improve learning among typically developing learners. It is not clear how these principles of multimedia design can influence the learning of students with dyslexia.
One in 10 individuals in today’s society is diagnosed with dyslexia (Shaywitz, 2008), and so there is a strong need to better understand the effectiveness of multimedia learning designs and strategies for the population with dyslexia. For example, segmenting learning material into smaller units could benefit learners with dyslexia similar to the well-known effects of segmentation on typically developing learners. The redundancy principle, which discourages the use of on-screen text with visual information when spoken text is available, might not necessarily hold true for individuals with dyslexia as they might benefit from the additional support provided by the spoken text. In fact, many technology-based interventions to help people with dyslexia make use of both on-screen text and spoken text (e.g., Voice Dream Reader; Schneps et al., 2016). These possible effects need to be tested in rigorous empirical studies. Future research might also consider incorporating the eye-tracking methodology to examine the visual attention distribution strategies used by learners with dyslexia while processing on-screen text or spoken text with images and how their viewing behavior relates to learning performance. Finally, a future study can test the materials with typically developing participants, and thus researchers can examine to what extent the efficacy of modality principle and multimedia principle will be influenced by individual differences in reading ability.
Limitations
Despite the contributions, this study was limited by the characteristics of learners, the nature of the multimedia learning materials, and the measures of learning. First, because recruiting a sufficient number of students with dyslexia is incredibly difficult, the participants in this study represented both the undergraduate and graduate populations of college students. It is not clear whether and how participants at different levels of postsecondary education used compensatory strategies when reading text. Second, a comparison with typically developing participants without dyslexia was not conducted. Third, the multimedia presentation contains text at the 12th-grade reading level, and the findings could be different if more complex reading passages were used. Fourth, short-term retention measures were used to examine learning performance in the current study. Measures of long-term retention, comprehension, inference, and transfer of knowledge could possibly yield dramatically different results. Finally, the Discovering Australia materials intentionally used representational pictures in the intervention to mirror some or all of the target text. Other types of pictures, such as organizational (e.g., maps or diagrams) or transformational (e.g., music notation), might have different effects on learning outcomes.
Conclusion and Significance
Multimedia learning research focusing on individuals with dyslexia is very limited despite the fact that they represent 10% of the population (Shaywitz, 2008). Our study expanded multimedia learning research by testing the multimedia principle and the modality principle among college students with dyslexia. For the participants with dyslexia in our study, pictures supported recognition, whereas on-screen text facilitated recall and recognition better than spoken text. The findings from this study can inform the design of multimedia learning materials and improve learning for individuals with dyslexia.
Footnotes
Acknowledgment
This article is based on work supported by the University of Florida Research Opportunity Fund. The funder had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript. We wish to thank Dr. Carole Beal for her insightful feedback to improve the article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.