
Abstract
Mobile technologies, including apps, have become increasingly popular, and are being used to support daily activities among a variety of individuals. While the use of mobile technologies will not eliminate barriers often faced by individuals with disabilities, these systems have the potential to help minimize some of these barriers. As the popularity of apps is increasing, the purpose of this study was to evaluate the reliability, internal consistency, and social validity among novice raters on two app evaluation rating scales. A total of 17 adults, with and without identified disabilities, evaluated apps using two team-designed app rating scales. Overall, findings indicated that the ratings completed during the pilot phase by the research team were more reliable than those completed by novice raters during the testing phase; that the dimension of individualization was the most reliable among team raters and novice participants without disabilities; and that the highest level of inconsistency in the reliability was among novice participants with disabilities. Practical implications, limitations, and future research directions are discussed.
Advances in technology over the past two decades have led to increased use of mobile technologies, such as tablets, in educational settings (Kumar & Goundar, 2019). These practices have expanded to special education teachers who use educational applications (apps) to engage learners in academic content, track classroom behaviors, and communicate with caregivers (Bouck et al., 2016). Mobile technologies have given individuals with disabilities increased access to academic opportunities by providing practitioners the ability to personalize the complexity of the content (Anderson & Putman, 2020). In turn, this has led to more accessible and inclusive practices (Cihak et al., 2015; Xie et al., 2018), by making the environment more equitable for a wider range of individuals with disabilities (Ciampa, 2017). Specifically, mobile technologies have been used to help decrease the number of prompts needed to complete a task (Laarhoven et al., 2018), increase independence in daily living activities (Cakmak & Cakmak, 2015; Laarhoven et al., 2018), promote social interactions (Vaala et al., 2015), provide differentiation, (Anderson & Putman, 2020), and enhance motivation and independence (Anderson & Putman, 2020). The support that may come from the use of mobile technologies can also contribute to self-directed learning (Ayres et al., 2013; Lee & Kim 2015), pacing (Thomas et al., 2019), and goal setting (Thomas et al., 2019).
Due to the wide range of possibilities mobile technology may support, an increased focus on the identification of effective and meaningful apps is warranted. The process of identifying apps requires knowledge on how the user may integrate the system into real-world opportunities (Courduff & Szapkiw, 2015) and the functions of the app (Weng & Taber-Doughty, 2015). The opportunity for users to select which app they prefer, will in turn, increase their motivation to use the selected app (Ciampa, 2017), and enhance the user’s engagement, independence, and self-determination skills (Frielink et al., 2018). As such, the process of evaluating apps is an essential step in the effective selection of an app. Unfortunately, it has been suggested that a major challenge with apps is that many of them are developed by individuals with limited child development or educational expertise (Vaala et al., 2015). The lack of expertise of app developers, combined with the absence of comprehensive information about the quality of an app is troublesome; and can lead for users to purchase apps based on star ratings, reviewer comments, the number of downloads (Bouck et al., 2016; Papadakis & Kalogiannakis, 2017), or the app stores’ algorithm, rather than through a systematic evaluation of an app (Papadakis & Kalogiannakis, 2017). Although the evaluation of an app may be a daunting task, without a comprehensive evaluation, it is possible to choose useless and ineffective apps (Lee & Kim, 2015; MacSuga-Gage et al., 2015), that are not compatible with the user (DeCarlo et al., 2019).
Attempts have been made to support practitioners, individuals with disabilities, and their families in the evaluation process by developing user-friendly app evaluation tools. Often these tools are in the form of a rating scale, rubric, or checklist. A key to successfully evaluating apps is to better understand the rationale for selecting a specific evaluation instrument. For example, a rating scale uses a scoring system that is hierarchical and based on assigning a value to specific categories, components, or questions. The purpose of using a rating scale is to represent a perceived quality for each dimension being evaluated. A rubric, on the other hand, uses a scoring guide that evaluates the perceived quality of specific levels of categories or components, and it includes a pre-determined description of each level; and lastly, a checklist follows a dichotomous list that includes multiple categories, components, or dimensions, that are used to determine whether a characteristic is present or absent (Brookhart, 2013).
Based on a systematic literature review conducted by Boesch et al., (in review), from 2008 to date, most of the existing app evaluation tools are non-empirical (see Authors for details), and only two of the tools were empirically evaluated, the Rubric for the Evaluation of Education Apps for preschool Children (REVEAC), by Papadakis et al. (2017), and the App Evaluation Rubric by Weng and Taber-Doughty (2015). Papadakis et al. (2017) developed a rubric that was grounded in a literature review conducted by the authors, to rate preschool educational apps. Following a suggested set of standards for scale-classified criteria, Papadakis et al. considered: (a) the total number of dimensions to be evaluated; (b) operational definitions for each dimension according to the performance level; and (c) total number of performance levels. The first draft of the rubric was evaluated by key stakeholders (preschool teachers), and their feedback was applied to the rubric. The final rubric included the evaluation of four dimensions, (a) content, (b) design, (c) functionality, and (e) technical quality of the app. Weng and Taber-Doughty (2015) designed a rubric for practitioners to evaluate educational apps for students with disabilities. Although they describe their tool as a rubric, based on the definitions from Brookhart (2013), Weng and Taber-Doughty’s tool should be described as a checklist and a rating scale. The checklist portion gathers general information and design features of the app, and the rating scale evaluated the quality of the following dimensions: (a) design features, (b) individualization, (c) support, and (d) overall impression and comments (open-ended).
Although app evaluation tools exist, most of these tools have not been empirically validated. Beyond this, the available tools have been designed to be used by practitioners, not by individuals with disabilities. As a result, the purpose of this study was to design, evaluate, and create two empirically grounded app evaluation tools (rating scales) that can be used across apps categories and by variety of users. To develop these app evaluation tools, the systematic review conducted by Boesch et al., (in review) was used to identify key elements and dimensions needed for the evaluation of apps. The research questions to be answered included: (1) is the app rating scale a reliable tool among future practitioners (globally)? (2) is the adapted app rating scale a reliable tool among individuals with disabilities (globally)? (3) were the dimensions of content, individualization, usability, and quality of an app reliable among future practitioners (local)? (4) were the dimensions of content, individualization, usability, and quality of an app reliable among individuals with disabilities (local)? and (5) what were the perspectives of participants, both future practitioners and of adults with disabilities, on the app rating scales?
Methods and Results
Research Design
Usability testing was implemented to evaluate a real-life activity, such as the evaluation of apps (Barnum, 2011). The aim was to determine the reliability of the two app rating scales across phases (pilot and testing) and participants (users with no identified and with identified disabilities). Both qualitative and quantitative data were collected from target stakeholders. The independent variable for this study was the background and characteristics of the participants, and the dependent variables were the reliability and validity of the app rating scales.
Procedures
The App Rating Scales
Two app rating scales, the app rating scale and the adapted app rating scale, were created based on the available literature (see Boesch et al., (in review)). The app rating scale was intended to be completed by practitioners or family members of complex disabilities. On the other hand, the adapted app rating scale was designed for users with complex disabilities, including those with autism, multiple, and intellectual disabilities. The differences between the two rating scales related to (a) the simplicity of the language on the adapted app rating scale to make it accessible to individuals with disabilities; and (b) the elimination of five questions on the adapted app rating scale to only include those relevant to the target user (e.g., “I would recommend this app to other professionals” was not included).
Number and Example of Questions on The App Rating Scales within Each Dimension.
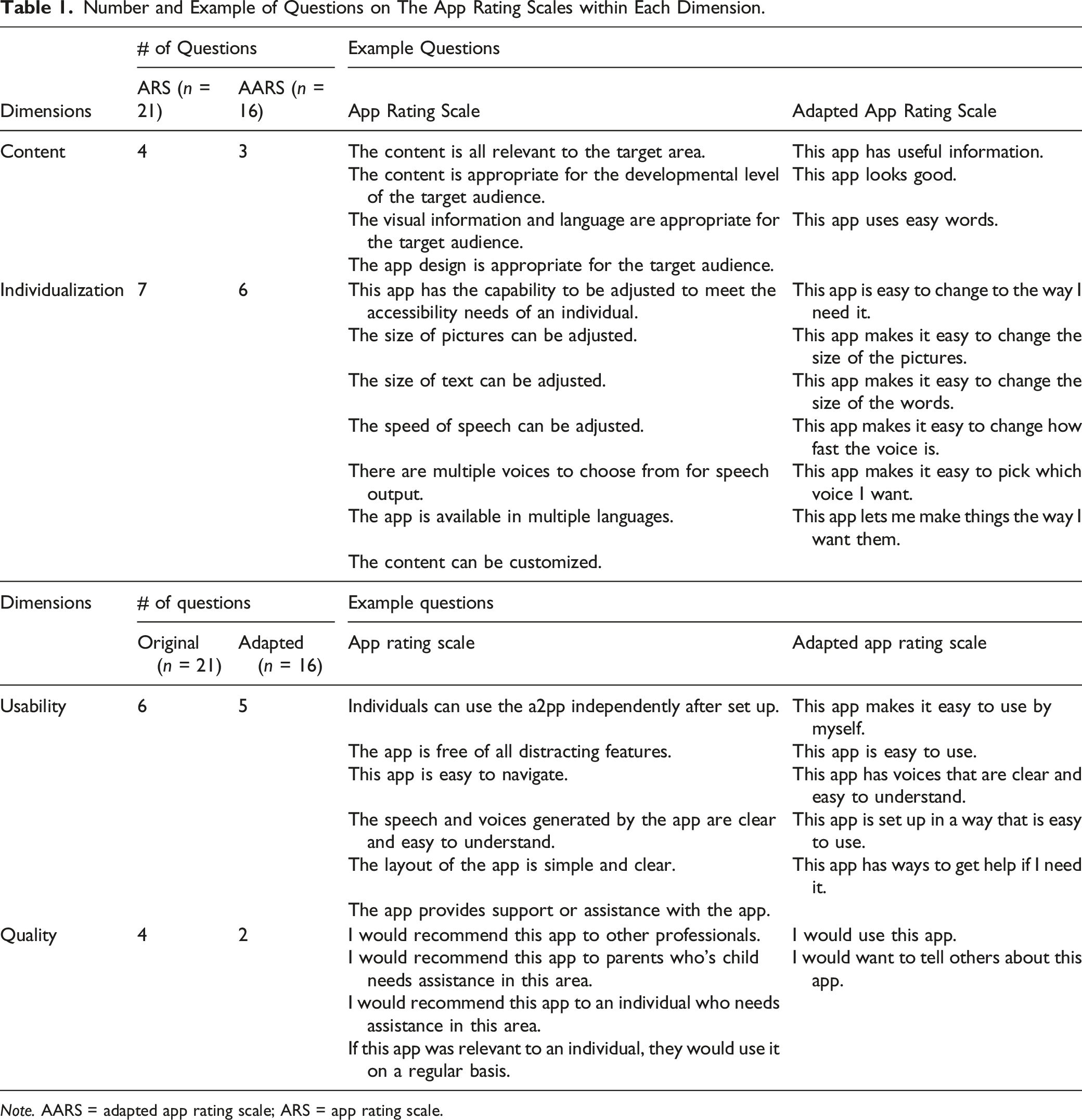
Note. AARS = adapted app rating scale; ARS = app rating scale.
Application Selection
Two state agencies (the state chapter of a national organization for individuals with disabilities and their families, and state office of developmental and intellectual disabilities) contacted the first author as they were interested on creating a system for individuals with disabilities to evaluate apps. As result, the two state agencies selected the apps used during the testing phase (n = 7). A key feature for their selection was that all apps were accessibility to all individuals and had the potential to be use as means to increase the independence of individual with disabilities. The apps represented three domains, including communication (n = 2), daily routines (n = 3), and time management (n = 2). The intent of the collaborating state agencies was to consider apps that represented functional skills, as they are essential skills to increase the independence of individuals with disabilities (Ayres et al., 2013). Beyond the apps identified by the collaborating state agencies, the research team selected an addition 18 apps across the same domains to be used during the pilot phase. Altogether there were: (a) 11 apps for daily routines, which could be used to support the completion of everyday activities or independent living skills; (b) 7 apps for communication, which helped develop or aid an individual’s communication skills or interactions; and (c) 7 apps related to time management, which supported the individual in self-monitoring and scheduling. Apps selected represented a wide range of Apple Store® ratings from 1-5 (M = 3.15), including 13 apps with a rating ≤3.5 and 11 apps with a rating ≥ 3.6. All apps were downloaded onto iPads®, with screen sizes of 9.4 inches by 6.6 inches.
Data Analysis
Formative and summative data were collected and analyzed during the pilot and testing phase (Barnum, 2011). For the formative data, internal consistency and reliability were calculated for both app rating scales. Summative data were collected for each app rating scale globally, by determining the reliability of the app rating scales as a whole (one construct), and locally, by evaluating the reliability of each dimension in the app rating scale (content, individualization, usability, and quality). Reliability was used to describe if there were differences among and across raters, and if there were, how far apart the results were while using the same tools (Roberts & Priest, 2006). The goal was to determine the trustworthiness of both app evaluation rating scales.
Reliability of both app rating scales was calculated during the pilot and testing phases, across novice participants groups, and across dimensions using SPSS (version 27.0). Multiple measures were used to calculate reliability across participants, including: (a) Cronbach’s alpha was calculated to determine the internal consistency of the app rating scales. The criterion set was “good” (0.8 ≤ α ≤ 0.89) to “excellent” (α ≥ 0.9; Gliem & Gliem, 2003). By default, questions that correlated negatively with the overall scale were reverse coded and any questions with no variance, where ratings across participants were the same, were eliminated (n = 2; 1 for content and 1 for usability dimension); (b) Pearson’s correlation coefficient was used to determine the correlation between participant responses, with a set criterion of “strong to perfect” (.70 to 1.0; Hinkle et al., 2003); (c) Weighted Cohen’s kappa was also used to determine inter-rater reliability, with a set criterion of “substantial” (.61 to .80) to “almost perfect agreement” (.81 to 1.0; Landis & Koch, 1977); and (d) inter-rater adjacent agreements was used to evaluate the agreement between novice participants by calculating the percentages of agreements within plus or minus (±) 1 point of each other. The criterion for this measure was set as “acceptable” (75% to 89%) to “high” (≥90%; Shweta et al., 2015).
Pilot Phase
In the pilot phase, the app rating scales were evaluated by the team raters. Team raters were members of the research team and had previous exposure to the evaluation tools, as they were part of the development, design, and evaluation process of both app rating scales. During the design process of both app rating scales, 18 apps were evaluated by two team raters. Both team raters were White females with a bachelor’s as their highest earned degree, who were enrolled in a master’s degree special education low incidence program and had 1 to 2 years of teaching experience. To safeguard the reliability of the adapted app rating scale, two consultants from one of the collaborating state agencies were asked to examine the adapted app rating scale for clarity of each question and provide feedback. The two consultants were White males, ages 43 and 49, and had identified disabilities of traumatic brain injury and intellectual disability, respectively.
Global and local formative reliability data were collected to determine the degree to which the team raters did or did not agree on questions within the app rating scales. If disagreements occurred on a question by ±1 point, the research team evaluated the language used and determined the need for the question to be reworded or deleted. Once the team raters reached criteria for high reliability for each app rating scale, these were considered finalized. Using the final app rating scales, team raters evaluated seven additional apps, which were identified to be used in the testing phase by both novice groups.
Pilot Phase Reliability and Internal Consistency.

Note. Significant levels for Pearson’s and Cohen’s kappa at .01, and Cronbach’s alpha at .05; Criteria for Pearson’s set at .70, Cohen’s kappa set at .61, and Cronbach’s alpha at set .80.
Recruitment
Institutional Review Board (IRB) approval was obtained prior to recruiting and distributing information about the study. Convenience sampling was used to recruit participants (Etikan et al., 2016). Novice participants with no identified disabilities (novice-ND) were recruited by the research team through an email list from the Department of Special Education at the Southern University. The email list was of undergraduate and graduate students from across program areas within the department. The email contained information on the purpose of the study and time commitment. Email was sent once a week for a month. The inclusion criteria for novice-ND participants were: (a) pursing a master’s degree in low incidence special education; and (b) seeking a teaching licensure or endorsement in a low incidence program.
Novice participants with an identified disability (novice-WD) were recruited by an advertisement post on the website, Facebook™ page, and Twitter® account of a state chapter of a national organization that focuses on supporting individuals with disabilities. The post contained information provided by the research team on the purpose of the study and time commitment. An initial post was uploaded on the social media platforms and was re-posted weekly for a month. The inclusion criteria for novice-WD included: (a) a medical diagnosis of a developmental or acquired disability; (b) over the age of 18; (c) previous exposure to mobile technology, which was defined as the individual owning or having used one or more mobile technology systems, such as an iPhone®, Android™ phone, or tablets; and (d) previous experience with navigating apps, which was referred to as when an individual indicated knowing how to use apps on their mobile technology systems. After potential participants from both novice groups indicated they were interested, a member of the research team scheduled an in-person meeting with each individual to verbally explain the purpose and time commitment for the study.
Participants
Participant Profiles.

Note. A = Asian; B = Black or African American; B.S. = bachelor’s degree; C.C. = college or university certificate; F = female; H.C. = high school certificate; H.D. = high school diploma; H/L = Hispanic or Latino; ID = intellectual disability; Level of education = the highest level degree earned by participants; M = male; MD = multiple disabilities; Novice-ND = novice without disability; Novice-WD = novice with disability; OHI = other health impairment; TBI = traumatic brain injury; W = white.
Testing Phase
During the testing phase, both app rating scales were evaluated by novice participants. Novice participants were adults who had no previous exposure to the app rating scales. The app rating scale was evaluated by novice participants with no identified disabilities (novice-ND) and the adapted app rating scale was evaluated by novice participants with an identified disability (novice-WD). Data were analyzed for each tool, globally and locally, with the purpose of determining the reliability among raters. Social validity among the novice rater groups were analyzed for both app rating scales.
To compare ratings, all novice participants (novice-ND and novice-WD) were provided a list of the same apps, an iPad®, and paper copies of their respective app rating scale. The apps list included the same apps that were evaluated by team raters once the rating scales were finalized. For participants in the novice-ND group, no additional training or instructions were provided beyond the instructions included within the app rating scale. The rationale for additional training was to evaluate if the instructions provided on the rating scale were sufficient to complete the app rating scale effectively and accurately. Novice-ND completed the evaluation of each app independently in office cubicles at the university they attended. The schedule was set by participants’ and research team availability, and no time constraints were given.
For novice-WD, a two-hour training was created by the research team on how to use the adapted app rating scale (task analysis) and visuals on how to navigate similar apps (pre-evaluation). The training was created using PowerPoint™ and occurred one week prior to the evaluation of the apps. The purpose of the training was two-fold, (a) to provide the collaborating consultants from one of the state agencies a systematic script to train, guide, and support participants in novice-WD (same guidelines to novice-ND); and (b) to provide participants a task analysis on how to evaluate apps. Novice-WD independently completed the app evaluation at the national organization office during pre-determined dates and times. Participants were scheduled to evaluate two apps per session with no time constraints and were given the opportunity to request guidance or supports as needed. If assistance was requested, a member of the research team recorded the participant number, and the type and frequency of their request.
Procedural Fidelity
To determine if the procedures for each group were applied as intended (Gresham et al., 2000), two forms were created to collect procedural fidelity during interactions with novice participants. For novice-ND, a 10-step checklist was created to evaluate the interactions between a research team member and novice-ND group. The checklist was completed by two members of the research team. The research team followed the script with the directions for novice-ND in 98.2% of the interactions.
Based on the agreements with the two collaborating state agencies, the research team created a training protocol, materials, and provided training on how to interact and present materials to participants in the novice-WD group to two consultants employed by one of the collaborating state agencies. A 24-step checklist was created by the research team to evaluate the consultants on their provision of the training, interactions, and directions provided to novice-WD participants. The checklist consisted of six overarching headings of (a) agenda, (b) rating scale, (c) parts of the rating scale, (d) rating, (e) conducted training, and (f) time for clarifying questions. For each heading an outline of the task to be completed (protocol) was included to determine if all steps were implemented. The checklist was completed by two members of the research team during the training and app evaluation section. Overall, the collaborating consultants followed the training protocol in 91.7% of the experiences. Anecdotal notes indicated that the research team deviated from the initial protocol by taking the lead during the app evaluation sessions to support the collaborating consultants and to provide novice-WD with the information needed to complete the rating scales to evaluate the apps.
Anecdotal notes from both novice groups were also collected on questions asked by participants, participant’s ability to navigate each app, barriers that were observed during the sessions (if any), and the assistance each participant was provided (if applicable). Two members of the research team were present during the app evaluation with the purpose to collect procedural fidelity data, assist the collaborating consultants (with the novice-WD group), and support participants (if needed). Anecdotal data indicated that no questions arose from novice-ND. On the contrary, novice-WD asked questions related to (a) how to use the iPad (e.g., getting locked out); (b) task procedures (e.g., if all questions on the adapted app rating scale needed to be completed); and (c) the app itself (e.g., if the sound settings could be changed).
App rating Scale
Testing Phase Reliability and Internal Consistency.

Note. Significant levels for Pearson’s and Cohen’s kappa at .01, and Cronbach’s alpha at .05; Criteria for Pearson’s set at .70, Cohen’s kappa set at .61, and Cronbach’s alpha at set .80.
Adapted App Rating Scale
As demonstrated on Table 4, global findings indicated that internal consistency was “excellent,” yet the correlation was “weak,” and the inter-rater reliability was “slight.” For novice-WD, the percentage of questions being ±1 point of each other was “unacceptable” (69.1%), as it did not meet the set criteria. Like novice-ND, internal consistency was reached for content (“good”), individualization (“good”), and quality (“excellent”) dimensions; however, for usability, results fell below criteria. Yet, the highest correlated dimension among novice-WD was in the usability dimension, even though results were overall weak for correlation and inter-rater reliability across all dimensions. The inter-rater adjacent agreement was considered acceptable only for the content dimension (79.5%), and fell below criteria for individualization (59.3%), usability (73.8%), and quality (65.5%) dimensions.
Social Validity
Triangulation analysis was used to assess multiple perspectives of the data collected in relation to social validity (Barnum, 2011). The goal was to provide participants the opportunity to share their overall experience, highlights, and challenges when using the rating scales. The perspectives of participants were collected in the form of observations (for novice-WD), social validity survey (for novice-ND), and participant comments (all participants).
App rating Scale
A social validity survey was created by the research team for participants in the novice-ND group. The survey consisted of 15 questions related to participants’ (a) perspectives on the app rating scale (n = 9 close ended questions); (b) experience using the app rating scale, (n = 3 close ended questions); and (c) recommendations or suggestions on potential changes to enhance the app rating scale (n = 3 open ended questions). A 5-point scale Likert scale was used, including: (a) not at all, which refers to participants’ disagreeing with the statement; (b) slightly, defined as vaguely agreed with the statement; (c) somewhat, which was defined as partially agreeing with the statement; (d) a fair amount, defined as mostly agreed with the statement; and (e) very much, which was referred to as strongly agreed with the statement participants were asked to respond to each question. The survey was disseminated using REDCap™, a platform to build and manage online surveys (Harris et al., 2009). To determine the validity of the survey prior to dissemination, four external reviewers were asked to provide feedback on the questions, language, format, and type of potential responses. Reviewers included two master’s level graduate students in special education (not included as participants in this study), one without a teaching background and one with a special education teaching background, a special education teacher with 7+ years of teaching experience, and a university professor with survey expertise. The survey was revised for clarity of the questions, and the final version was piloted by the external reviewers.
The social validity survey was used to calculate descriptive statistics (means and standard deviations) across novice-ND’s demographic characteristics, including educational background and years of teaching experience. The total mean scores for participants’ perspectives and experiences were calculated by summing the items of each question within each section of the social validity survey and dividing by the total number of items. One-way ANOVAs were used to determine statistical differences between the novice-ND’s demographic information and their responses. Repeated measures were used to compare questions to each other to find if there was any significance between questions.
Post completion of the app evaluation, the survey was disseminated to participants in the novice-ND group. Results of the social validity survey were divided into two sections, perspectives, and experiences. The response rate for the social validity survey was of 88.9%. The mean score was M = 4.0 (SD = .971) on the participants’ perspectives section, indicating that participants reported that “a fair amount” of the rating scale was accessible and easy to use. The mean of the experience section was 3.9 (SD = .839), indicating that participants agreed “a fair amount” that they would recommend the scale to a fellow practitioner. Although not significant, the highest ranked items under the perspectives section included the rating scale’s ability to be completed easily (M = 4.3; SD = .951), to be completed in a feasible amount of time (M = 4.3; SD = .951), and that it is practical to complete (M = 4.3; SD = .951); F (8, 48) = 2.151, p = .49. Under the experience section, results indicated ranking similarities among participants, with a range of .14 between the highest and lowest ranked items. Participant educational background and number of years of teaching experience were used to determine correlations on the extent of satisfaction across sections, and no significant differences were found.
Thematic analyses were conducted on open-ended questions completed by participants in the novice-ND group. Each question was coded independently by two coders (research team) to determine coding reliability, with a Cohen’s Kappa of 0.968 (almost perfect agreement). A total of 4 participants responded to the question on the “possible future use of the app evaluation system,” indicating that they would use the app rating scale to meet the needs of their students (50% of responses), and to help examine an app prior to purchasing (50% of responses). A total of 5 participants responded to the question related if the “app rating scale was helpful,” and responses indicated that the app rating scale was helpful in meeting the needs of their current students (80%), examining apps before purchasing (20%), and evaluating features of the app using this tool (20%). Lastly, a total of 7 participants responded to “suggestion on changes to the app rating scale,” 71% indicated that no changes should be made, and the remaining participants (29%) mentioned adding an overall score for the app evaluated and making some changes to the language used to be more concise.
Adapted App Rating Scale
To obtain social validity from participants in the novice-WD group, anecdotal notes were collected on their perspectives on the adapted app rating scale. Post completion of the app evaluation, a member of the research team asked participants from the novice-WD group to share their overall experience when using the adapted app rating scale. An additional team member collected responses from participants. Overall, 75% of the participants in the novice-WD group indicated that they “agreed” or “strongly agreed” that the app rating scale was easy to use, and that they could use it independently. The remaining participants (25%) indicated that they “disagreed” or “strongly disagreed” to this question, suggesting that the adapted ap rating scale was not easy to use, or they could use it independently.
Two additional members of the research team collected anecdotal notes while participants in the novice-WD group were using the adapted app rating scale to evaluate the apps. The purpose was to gather notes on the challenges faced by novice-WD through the observations. These notes were collected by describing the challenge faced and during what evaluation phase. Overall, data suggested that approximately 60% of the participants in the novice-WD group had the skills needed to independently navigate, evaluate, and complete the adapted app rating scale. Yet, the remaining participants presented barriers during the app evaluation process including in the domains of motor skills (writing), literacy (reading abilities), and the ability to follow directions (receptive language), all which occurred while completing the navigation of the app or while completing the evaluation on the adapted app rating scale.
Discussion
The growing prevalence of technology across settings has led to greater equity and accessibility for all learners (Anderson & Putnam, 2020). Yet, exposure to these resources is not the only component to consider, as the technological competency may be a key element to the successful use and selection of an app (Foulger et al., 2017). For individuals with disabilities, training the individual to use the technology is essential in providing the opportunity to increase self-management skills (Ayres et al., 2013), increase motivation (Maich et al., 2019), and decrease system abandonment (McNaughton & Light, 2013; Weng & Taber-Doughty, 2015).
As practitioners continue to identify ways to integrate mobile technology into daily activities, challenges will be faced on how to meet the user’s needs effectively and efficiently (Baran et al., 2017). Current practices suggest that apps are being treated as consumables, requiring no long-term commitment (Douglas et al., 2012; McNaughton & Light, 2013); which in turn has led to the selection of apps that do not meet the specific needs of the target user (MacSuga-Gage et al., 2015). To increase the effective identification of apps, it is essential that the individual’s abilities are matched to the app (Anderson & Putman, 2020; Bouck et al., 2016). By implementing a systematic evaluation process, practitioners may be able to thoughtfully identify apps (MacSuga-Gage et al., 2015), and provide the user with the supports needed.
Currently several non-empirical app evaluation tools exist and can be found online. Yet, only a few authors, Papadakis et al. (2017) and Weng and Taber-Doughty (2015), have created app evaluation tools that have been empirically evaluated (see Boesch et al., (in review) for complete review). Both tools evaluate apps based on the dimensions of content, design, individualization capabilities, functionality, and usability, and described the outcomes of the evaluation of the app after using the tool. Although these two evidence-based tools offer a systematic means to evaluate apps, more research is needed to understand how to comprehensively evaluate apps, the dimensions needed to match the individual’s ability to an appropriate app, and to determine the possibility of identifying a valid and reliable tool to evaluate apps. As a result, two user- and time-friendly app rating scales were created and evaluated to determine the reliability, internal consistency, and social validity.
Overall, findings indicated that team raters were more reliable than novice participants; that the individualization dimension was most reliable across both team raters and novice-ND participants; and novice-ND participants found the app rating scale to be easy and feasible to complete. Yet, findings should be viewed with caution as reliability did not reach the set criteria for certain dimensions among team raters and novice participants. However, given that team raters consistently reached higher reliability, it seems as knowledge and skills may have been gained through their involvement in the development, design, and evaluation of the app rating scales. These findings may be the result of “experts” having the background knowledge to make more accurate judgements (Jones & Alcock, 2014); implying that practice using the app rating scales, and having the opportunity to discuss the process, may be a key element to increase the reliability among raters (Grainger & Adie, 2014).
Findings also suggest unique similarities and differences among novice-ND and novice-WD. Both groups reached the criteria for internal consistency across three of the four evaluation dimensions (content, individualization, and quality), and both groups reached internal consistency for the rating scales as a whole. The difference was that novice-ND were overall more reliable in their app evaluations than the novice-WD. Findings could be attributed to the notion that individuals with disabilities, particularly those with intellectual disabilities, often respond to Likert scales with a response bias (Hartley & MacLean, 2006; Stancliffe et al., 2015). In fact, it has been suggested that individuals with intellectual disabilities tend to select responses from either end of a given scale (Hartley & MacLean, 2006; Stancliffe et al., 2015). Findings support previous research as anecdotal notes suggest that novice-WD evaluated the apps with a personalized mindset, which in turn, may have led to the evaluation of an app based on preference, rather than the overall quality of the app. The personal approach to the evaluation of apps may have led to lower reliability among novice-WD, as it has been suggested that higher reliability often occurs when participants belong to the same subgroup (Barnum, 2011). Although novice-WD were all given the same training and apps, novice-WD all had different characteristics, which may help explain their different ratings. A potential consideration is to ensure that participants gain knowledge and skills through training, where they are provided guidance and feedback, while at the same time, become comfortable and familiar with the response format (Hartley & MacLean, 2006).
Although reliability was not reached across novice participants, the notion of applying a user-centered approach is essential in effectively identifying apps (McNaughton & Light, 2013; Ok et al., 2015). By doing so, practitioners can consider the strengths and areas of need of the user and select an app that appropriately will supports the individual (Ok et al., 2015). This process can only be applied if practitioners develop the technology competencies needed to comfortably utilize technological tools (Anderson & Putman, 2020). Ultimately, the goal should be for those evaluating apps to have the knowledge and skills needed to effectively identify apps that can help decrease the mismatch between a system (app) and the users.
Limitations and Future Directions
Although findings may be promising, there were a few limitations to this study. First, the apps used in this study were all free apps, for both the pilot and testing phase. The lack of purchased apps may have impacted and skewed the results. For example, Cohen’s kappa can be misleadingly low if majority of ratings are at highest or lowest level (Shweta et al., 2015); therefore, future research should consider the use of both free and purchased apps with low and high ratings, to decrease the lack of variance, and possibly increasing the inter-rater reliability across participants.
Second, apps evaluated among all raters were selected by the funding agency in collaboration with the state chapter of a national organization. As a result, not the same number of apps were evaluated across app categories, which in turn, eliminated the possibility of determining reliability differences across categories. Future research should consider evaluating the reliability within apps from the same category and ensuring that the same number of apps are selected across these. Potential results may shed information on if a general app rating scale can be used across apps or if there is a need to for a specific evaluation tool for certain app categories (e.g., communication apps for AAC users).
Third, due to the request from the two collaborating state agencies, the research team were not directly involved in the recruitment and selection of novice-WD. Although an inclusion criterion was set by the research team, this was not consistently applied by the two collaborating state agencies. Therefore, future research should clearly outline a set skill level criterion to ensure that all participants are able to complete the task independently. A consideration is to use the skill set suggested by Powell (2014) as a guideline for the effective use of mobile technology, including fine-motor skills, ability to follow multi-step directions, reading level, self-management abilities, and reinforcement needs.
Lastly, replications are also warranted to continue to evaluate the procedures, reliability, and dimensions of the app rating scales. Future research could also evaluate more in-depth the training, by considering implementing a training session for all participants and assess the length and type of training needed across participants to effectively use an app evaluation tool. Future research could also consider increasing the sample size and giving in-depth attention to the participants primary disability, age of the participants, and participants’ level of education as potential influencing factors on the use of the app rating scale.
Conclusions
While mobile technology and apps have become an important component of daily life, evaluation of these systems has not been a common practice. Due to the high demand of mobile technologies, future research is needed to determine the impact of an app evaluation tool on the user’s motivation, learnability, and independence. Furthermore, there is still a need to identify key dimensions for the evaluation of apps, and if there is a need for training to effectively use app evaluation tools. Only by furthering the research in this area will apps be identified by considering the individual’s abilities and needs; leading to increasing the user’s skill level and independence, and the same time, decrease system abandonment. Without a systematic, valid, and reliable app evaluation tool, the capabilities of an app may be minimized; and instead of the app being used to support and enhance the user’s abilities, opportunities, and experiences, the app being used may hinder the individual’s independence.
Footnotes
Acknowledgments
We would like to thank Robert Hodapp and Richard Urbano for their guidance with the data collection and analysis, Haley P. Neil for help during early faces of this project, Theresa Szydlik and Ava Lehavi for their help in components of this project, and Katie Shaw, Hanneh Shiheiber, Gillian Neff, and Stephanie Camacho for their support with final editing of this project. We are grateful for all your support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was partially funded by Tennessee’s Department of Intellectual and Developmental Disabilities in collaboration with The Arc of Tennessee.