
Abstract
There is compelling empirical evidence in support of the use of grouped self-assessment data to measure program outcomes. However, other credible research has clearly shown that self-assessments are poor predictors of individual achievement such that the validity of self-assessments has been called into question. Based on the reanalysis of two previously published studies and an analysis of two original studies, we show that grouped self-assessments may be good predictors of and hence valid measures of performance at the group level, an outcome commonly used in program evaluation studies. We found statistically significant correlation coefficients (between 0.56 and 0.87), when comparing across performance items using the group means of self-assessments with the group means of individual achievement on criterion tests. We call for further research into the conditions and circumstances in which grouped self-assessments are used, so that they can be employed more effectively and confidently by program evaluators, decision makers, and researchers.
Background and Purpose
The literature is clear that individual self-assessments are notoriously inaccurate and often subject to systematic biases (D’Eon, Sadownick, Harris, & Nation, 2008; Eva, Cunningham, Reiter, Keane, & Norman, 2004; Nimon, Zigarmi, & Allen, 2011; Ross, 1989; Violato & Lockyer, 2006). These analyses of individual self-assessments call into question their validity (Lam, 2009). Many are therefore justifiably skeptical of self-assessments. For example, one journal states on their website that “… self-assessed measures of confidence or competence may well appear to show large differences in response to an educational intervention, but are themselves weak surrogates for actual achievement” ( Advances in Health Sciences Education ). We concur that self-assessments are weak surrogates for actual individual achievement, but we also acknowledge that there is growing empirical evidence in support of the use of group means of self-ass-essment data to measure learning and performance outcomes (Blanche-Hartigan, 2011; D’Eon et al., 2008; Litzelman, Stratos, & Skeff, 1994; Moore & Tanansis, 2009; Pratt, McGuigan, & Katzev, 2000; Reuland et al., 2009; Skeff, Stratos, & Bergen, 1999). We therefore intend to provide a way out of this seeming contradiction and demonstrate that grouped self-assessment data can be used to obtain accurate outcome measurements.
Outcome data often form an important part of a program evaluation (Kirkpatrick, 1994; Steinert et al., 2006). Yet, many educational and training interventions lack the resources or the opportunity to undertake rigorous and expensive evaluation designs that collect and use objective outcome data (Bamberger, Rugh, Church, & Fort, 2004; Pratt et al., 2000). Learning and performance outcome data from self-assessments, including retrospective self-assessment pretests, are convenient, inexpensive, and, as we hope to demonstrate, rigorous as well.
Validity accrues to the interpretation of the data, not to the data or tests themselves (Gall, Gall, & Borg, 2003; Messick, 1988, 1994). Messick (1988) states that validity attaches to the “adequacy and appropriateness of influences and actions … ” based on the data. Certain data may be used validly for certain purposes but not for others. For example, scores obtained from a rigorous interview process for admission to a health science program may help predict communication skills and other nonacademic achievement but may not accurately predict success in biomedical based academic courses. Similarly, pre-med physiology course marks might predict achievement in biomedical courses better than they could in communication skills development. Self-assessment data and tests, therefore, like all data and tests, are not themselves valid or invalid. What really matters is that people use the data appropriately.
One question concerning the validity of self-assessments might be expressed thus “Are self-assessments valid indicators of an individual’s actual performance or ability?” Decision makers may want to know how self-assessments might be used in individual summative or formative assessment of learning, as was the hope of Violato and Lockyer (2006). Since the correlations of self-assessments and objective measures of performance across individuals are almost always near zero (Davis et al., 2006; D’Eon et al., 2008; Eva et al., 2004; Lam, 2009; Violato & Lockyer, 2006) they appear not to be valid measures for these particular purposes. Self-assessments are thus not valid measures of (or, in the words of the journal website quoted above, are only weak surrogates for) individual achievement.
The question related to the validity of the use of grouped self-assessments for the purpose of measuring learning and performance outcomes might be expressed in this way: “Are grouped self-assessments valid measures of the overall achievement or mean performance of the group?” or “May we use grouped self-assessments as proxy measures (surrogates) of the mean achievement and performance of the group?” An appropriate statistic to help answer this question would be found by calculating correlations using the means of the self-assessments and the means of the objective measures for each performance item, not the self-assessments and scores for each individual. If there are acceptable correlations between grouped self-assessments and mean performance on criterion measures compared across performance items, then grouped self-assessments are acceptable proxy measures for the criterion test and valid measure of outcomes suitable for program evaluation.
Early evidence seems to indicate that grouped self-assessments can in fact correlate highly to more objective criterion measures. Peterson et al. (2012) found high correlations between grouped self-assessments of medical students and faculty raters on items related to readiness for clerkship (r = .88 and r = .91). In this article, we approach more directly and demonstrate more confidently the validity of grouped self-assessments to estimate program outcomes. We have also contrasted self-assessments used for predicting individual achievement with grouped self-assessments used as surrogates for measures of program outcomes. The four separate studies we present in this article involve different outcomes and subjects from different health sciences. Taken together, our results should give us all more confidence in using grouped self-assessments to determine outcomes for use in program evaluation.
Method
Using data sets from four different studies, we will demonstrate that grouped self-assessments may in fact be used to obtain group performance outcome data. These studies, two previously published and two new ones, are briefly described below.
Study 1: Physician Self and Peer Assessments
Violato and Lockyer (2006) studied physician self-assessments for use in the self-regulation of continuing professional development. Each of the 304 specialist physicians completed a self-assessment and was assessed by eight peers (N = 2,306) using an instrument with 38 items reported to have strong psychometric properties. Violato and Lockyer classified the 304 physicians into quartiles based on mean peer assessment data and, using discrepancy analysis, compared the self-assessments of the physicians in each quartile.
We obtained and reanalyzed the original data set from this study. Using correlational analysis, we compared the means obtained through self-assessment to those obtained through peer assessment across the 38 performance items. For the original study and this reanalysis, human subjects’ permission was obtained through the University of Calgary.
Study 2: Supervisor and Resident Self-Ratings of Performance
Distlehorst, Dawson, and Klamen (2009), on 17 performance areas, compared the ratings of supervisors and the self-assessments of first- and third-year residents from both a standard and a Problem-based Learning (PBL) undergraduate curriculum track. Totally, 163 first-year residents from the standard curriculum and 83 from the PBL curriculum along with 137 third-year residents from the standard curriculum and 68 from the PBL curriculum participated in this study. The resident response rates were between 30.2% and 42.6% and supervisor response rates fell between 44.2% and 51.3%. Effect sizes for statistically significant results comparing the two curriculum tracks were calculated and generally found to be small indicating no differences of practical importance between the standard and PBL curricula.
We used the data provided in Table 2: Evaluations for the First Postgraduate Year (p. 294) and Table 3: Evaluations for the Third Postgraduate Year (p. 295) from the published article. We calculated correlations between the mean ratings of supervisors and the means of the self-assessments by residents for the two tracks separately for the PGY1 and PGY3 (four calculations). Ethics approval was not needed since the data we used for our analyses were contained within the body of the published article.
Study 3: Teaching Evaluations by Resident Doctors and Trained Raters
At the University of Saskatchewan College of Medicine, all resident doctors are required to take a 2-day course on the fundamentals of teaching. This course includes two approximately 7-min practice teaching sessions planned and presented by each resident. We digitally recorded these teaching episodes: one at the end of the first day of the course and one at the end of the second day. To enhance the research, we also asked residents to present a similarly short teaching episode before the course to determine the baseline precourse teaching skill level. All these teaching episodes were then scored by trained and blinded raters using a previously tested form (D’Eon, 2004). Residents also completed a self-assessment on each of the three teaching episodes using the same set of items. For this study, the instrument showed strong psychometric properties (α = .71–.95). We calculated correlations between (1) resident self-assessments and rater assessments across individuals and (2) the group means obtained from individual self-assessments and the mean of raters’ assessments across performance items. For this article, we used the data for the teaching episode done at the end of the second day (see Table 1). From the 183 residents who were enrolled in the second day of the course, we were able to collect 92 complete data sets for a rate of 50%. Attrition was due to incomplete or missing self-assessments, our inability to record the practice teaching, or dropping out of the study. Ethics permission was sought and obtained from the Behavioural Research Ethics Board of the University of Saskatchewan.
Self-Assessment Correlation Calculations Across Individuals and Across Performance Items.
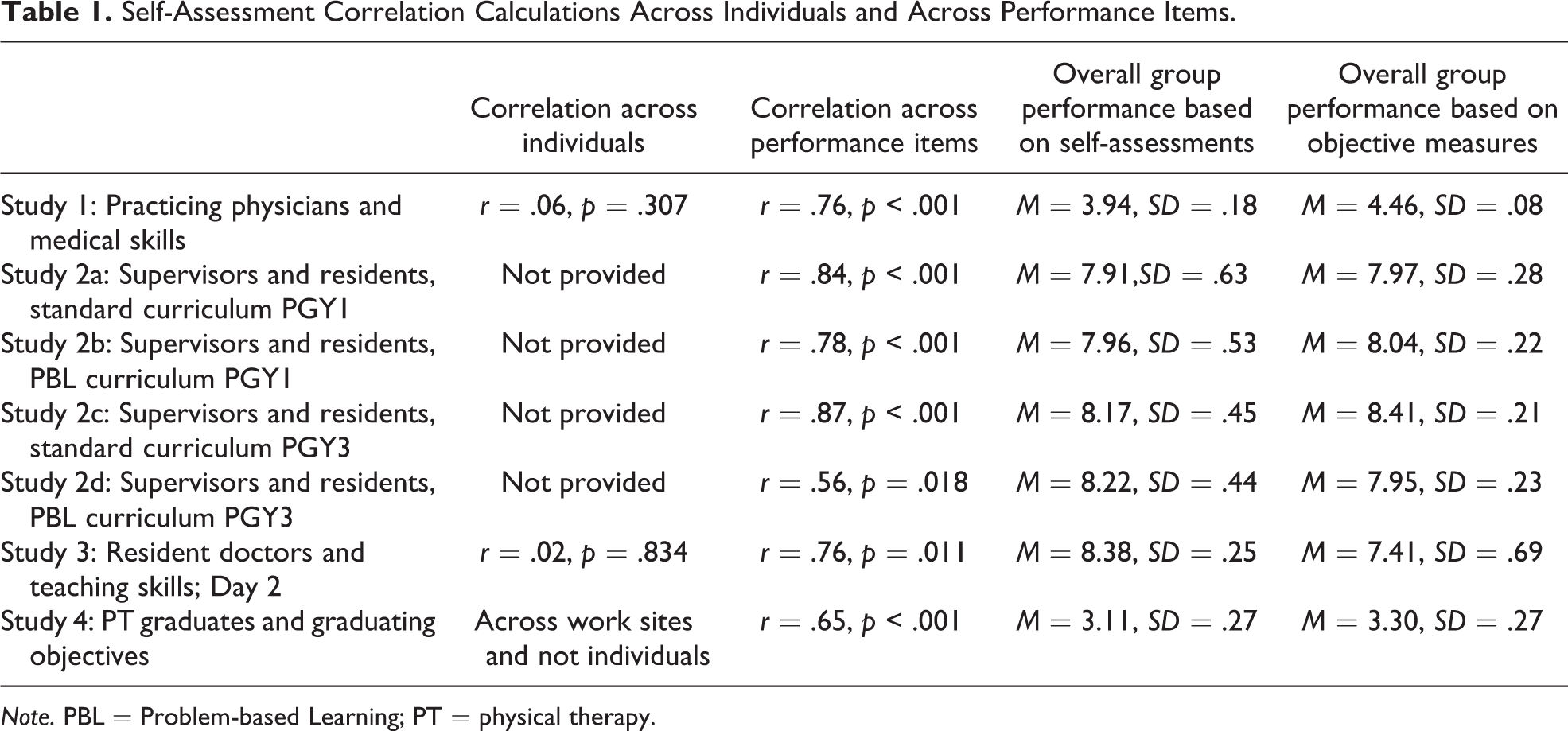
Note. PBL = Problem-based Learning; PT = physical therapy.
Study 4: On-the-Job Evaluations by Recent Graduates of a Physical Therapy Program and Employers
The School of Physical Therapy (SPT) at the University of Saskatchewan gathered outcome data to help determine the effectiveness of their new program. The SPT asked 39 graduates one year into practice to assess themselves on 25 performance items and asked the 17 employers of these new graduates to rate the graduates as a whole (some employers had more than one recent graduate in their clinic) on the same performance items. This instrument was locally developed based on graduating goals and objectives and showed strong psychometric properties (α = .85; .92). Fifteen graduates and 12 employers completed the assessments for response rates of 38% and 71%, respectively. We then analyzed these data by calculating correlations between the mean of the graduates’ self-assessments and employer assessments across the 25 performance items. We could not run correlations comparing self and employer assessments since employers rated the new graduates working for them as a group when there were multiple graduates at their clinic. Permission to use the data previously collected as part of a program evaluation project at the SPT was obtained from the University of Saskatchewan Behavioural Research Ethics Board.
Results
The results from each of these four studies are presented below. There were moderate to high correlations (from r = .56 to r = .87) when mean ratings obtained from self-assessments and more objective criterion measures were compared across performance items. Table 1 contains a summary of our findings from these four studies. The shading helps to distinguish among the various studies and parts of studies.
Study 1: Physician Self and Peer Assessments
In this study, 304 specialist physicians evaluated themselves and their peers. The analyses from the original study showed that physicians assessed in the lowest quartile rated themselves 30–40 percentile ranks higher than their peers rated them and those in the highest quartiles rated themselves 30–40 percentile ranks lower than their peers rated them. This resulted in finding no relationship between self and peer assessment for individuals.
We reanalyzed the original data set to calculate the correlation between the means obtained from the self-assessments and the means of the peer assessments. We found a high, statistically significant correlation (r = .76) between means on the performance items obtained by self-assessment and those obtained from the peer assessments, the more objective criterion measure.
Study 2: Supervisor and Resident Self-Ratings of Performance
For this study, Distlehorst et al. (2009) compared the ratings of supervisors and residents on 17 performance areas in two programs. Using Tables 2 and 3 from their published data (pp. 294 and 295), we ran correlation calculations between the mean ratings of supervisors and the means from the residents self-assessments for the PGY1 and PGY 3 data and the Standard the PBL tracks separately. Table 1, therefore, shows the results of our calculations on four separate rows. Again, we found moderate-to-strong, statistically significant correlations between the grouped self-assessments and the supervisor ratings across the 17 performance items.
Study 3: Teaching Evaluations by Resident Doctors and Trained Raters
In this study, residents assessed themselves on specific teaching episodes and in turn these were assessed by trained, blinded raters. We ran correlations between the grouped self-assessment scores of residents and the scores from trained raters on each performance item for their third and final practice teaching session done at the end of the second day of the workshop.
The correlation between self-assessments and objective ratings was essentially zero when comparing individual scores (r = .02). When looking at mean ratings of performance items by self-assessment and trained raters, we found a strong and statistically significant correlation (r = .76).
Study 4: On-the-Job Evaluations by Recent Graduates of a Physical Therapy Program and Employers
In this previously unpublished study, 15 graduates of an SPT assessed themselves on 25 items and were in turn assessed by 12 employers. We calculated the correlation across performance items using grouped self-assessments by recent graduates and the mean assessments from their employers. We found a moderate, statistically significant correlation (r = .65) as shown in Table 1.
Discussion
For all four studies, as summarized in Table 1, the correlations comparing grouped self-assessments and criterion measures across performance items were acceptable to high. These results were obtained in spite of the fact that when comparing, where possible, self-assessments and objective measures across individuals we found very low and statistically insignificant correlations. This might be explained by pointing out that the scores vary by accuracy of the self-assessments and cluster around a mean whereas the scores in the criterion measures vary by actual performance but likewise cluster around a mean. Though the nature of the variations are different (ability to self-assess and actual performance), the means end up being similar and yielding moderate to high correlations across performance items. Perhaps, as Surowiecki (2004) writes and Peterson et al. (2012) echo, there is really some wisdom even in the flawed but collective opinions and perceptions of crowds. The precise mechanisms by which self-assessments and criterion measures obtain their relationship is an interesting research question.
Previous studies have shown that the means of the performance of the entire group obtained from individual self-assessments are similar to those obtained from more objective measures. Blanche-Hartigan (2011) especially has presented convincing evidence and analysis of this phenomenon. Even findings from studies that (correctly) disparaged the use of individual self-assessments show that the overall group means obtained from self-assessments were very similar to the criterion measures (see Eva et al., 2004, table III, p. 220). In spite of some empirical evidence, many researchers and academics continued to question the validity of grouped self-assessments due to the poor correlations obtained between self-assessments and criterion measures when compared across individuals (Lam, 2009). We too have found poor correlations between individual self-assessments and more objective individual scores but have in this article successfully argued and demonstrated that correlations across individuals are irrelevant to questions of validity of grouped self-assessments to determine program outcomes. Instead, we have found from these four studies that the means obtained from self-assessments correlate well with those obtained from tests or criterion measures when compared across performance items. In other words, it appears that we may use grouped self-assessments as proxy measures of the mean achievement and performance of the group. We conclude, therefore, that reliable grouped self-assessments may be valid measures of group performance when used as outcome data in program evaluation studies. Peterson et al. (2012) similarly concluded with respect to only one set of performance items and one set of subjects that self-assessment were valid. Readers are cautioned to avoid the erroneous conclusion that individual self-assessments are therefore also shown to be valid through these analyses of grouped self-assessment. Individual self-assessments are not valid or proxy measures for individual achievement. We have only demonstrated that grouped self-assessments may be valid indications of group outcomes.
There are many valuable applications for grouped self-assessments. Many small-scale projects need important outcome data for proper evaluations and these are often difficult and expensive to gather. Self-assessments with a retrospective pretest make it possible to collect relatively accurate preintervention and postintervention data on important objectives of the program. Even for larger, more elaborate, and well-resourced programs grouped self-assessments could provide a simple and inexpensive mechanism by which initial data are collected and analyzed after which more elaborate studies can be targeted in specific areas. Over the last several years, we have even used this approach successfully to gather preoutcome and postoutcome data for graduation objectives for the preclerkship and clerkship stages of our medical school program. Whether the program is a short course, a half-day workshop, or an extended program grouped self-assessments have the potential to make valuable outcome data easily available and at little expense.
There are obvious limitations to these studies that call for further research in this area. The instrument used in Study 4 with the SPT was not validated and needs to be addressed. The relatively small number of individuals in Studies 3 and 4 is also of some concern though this is mitigated by the same results in all four studies. As with other research, it is important to collect self-assessment data from enough individuals to yield results representative of the overall group. That none of these studies have yet been replicated is a more serious weakness that we hope can be easily addressed in the near future. Furthermore, Studies 2 and 4 reported low response rates that indicate possible biased samples and threaten the validity of the findings. Though our findings from the four studies are supported by Peterson et al. (2012), who involved medical students and faculty in a large-scale study, additional studies with large numbers of subjects with respectable response rates and from more and different program evaluation contexts are needed to confirm our results so that we can all be more confident in the use of grouped self-assessments to yield accurate outcome data.
Though our conclusion that grouped self-assessments are valid measures of program outcomes should be challenged and repeatedly tested, we also believe that future research ought to focus more on how best to construct and use self-assessment instruments. Pratt, McGuigan, and Katzev (2000), Klatt and Taylor-Powell (2005), Moore and Tananis (2009), and Ross (1989) have all called for greater understanding into the conditions under which grouped self-assessments, including retrospective postintervention pretest data, can be used. Our data show some variation in the correlation coefficients indicating better matches between grouped self-assessments and criterion measures in some cases than in others and we wonder why. Nimon, Zigarmi, and Allen (2011) and Howard (1980) have in fact looked into the conditions that make for more accurate retrospective self-assessments and their work needs to be extended and expanded. We therefore call for further research into the conditions that make for the most accurate grouped self-assessments, the type of research that has already been done for survey methodology in general (e.g., Schwartz, 2007). We hope that we can all soon move beyond simply testing the validity of grouped self-assessments and direct our energies to learning when and how best to use them.
Footnotes
Acknowledgments
The authors thank Drs. Violato and Lockyer from the University of Calgary for their gracious permission to use the data from their previously published study and similarly Dr. Busch and the School of Physical Therapy, University of Saskatchewan, for kind permission to use their data.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Study 3 was supported by the Royal College of Physicians and Surgeons’ Medical Education Research Grant [10-/MERG-06]