
Abstract
It has been pointed out in the literature that misspecification of the level-1 error covariance structure in latent growth modeling (LGM) has detrimental impacts on the inferences about growth parameters. Since correct covariance structure is difficult to specify by theory, the identification needs to rely on a specification search, which, however, is not systematically addressed in the literature. In this study, we first discuss characteristics of various covariance structures and their nested relations, based on which we then propose a systematic approach to facilitate identifying a plausible covariance structure. A test for stationarity of an error process and the sequential chi-square difference test are conducted in the approach. Preliminary simulation results indicate that the approach performs well when sample size is large enough. The approach is illustrated with empirical data. We recommend that the approach be used in LGM empirical studies to improve the quality of the specification of the error covariance structure.
Keywords
Latent growth modeling (LGM) is a useful tool for the analysis of change over time and has appeared frequently in behavior research. LGM can be well handled by using structural equation modeling (SEM) (Bollen & Curran, 2006). The within-subject errors over time are the time-specific deviations from individual growth curves, and are referred to as the level-1 errors. The between-subject errors reflect the random effects in growth (i.e., the individual deviations from the mean of the initial status and the rate of change) and are referred to as the level-2 errors. While level-2 errors are time-invariant and their covariance structure is usually specified to be unstructured, level-1 errors may be time-varying, autocorrelated, or both. Autocorrelation is a nuisance because it very often occurs in data consisting of serial observations, yet it is rarely of theoretical interest, and because if a researcher fails to add its specification to the longitudinal model of theoretical interests, parameter estimates are likely to be biased. (Sivo & Fan, 2008, p. 365)
Since the correct covariance structure is difficult to specify by theory (Kwok et al., 2007, p. 588), the identification needs to rely on a specification search. Ding and Jane (2012) gave a brief review on this issue. A systematic approach to facilitate identifying level-1 error covariance structures seems still unavailable. Therefore, the purpose of the present research is to fill this gap. The proposed systematic approach is based on the chi-square difference test under the principle of achieving both model fit and parsimony (e.g., Wolfinger, 1996). Here a more parsimonious covariance structure is defined as one having fewer parameters. Frequently seen error covariance structures in the LGM literature, summarized in Ding and Jane (2012), are considered in the proposed approach. Preliminary simulation results have indicated that the proposed approach performs well when the sample size is large enough.
Level-1 error covariance structures in LGM
One type of growth model used often in practice is the polynomial growth model. The level-1 mth-order polynomial sub-model in LGM is given by

where
The unconditional level-2 submodel corresponding to the level-1 submodel in Equation 1 is given by

where
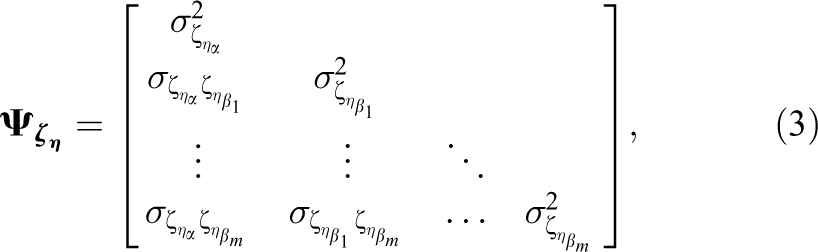
in which all variances and covariances are to be freely estimated. It is assumed that
The most general covariance structure is UN. The unstructured covariance matrix of

where
There are T(T + 1)/2 parameters [T variances and T(T −1)/2 autocorrelations] in UN. We summarize the parametric constraints placed on UN for different error covariance structures in Table 1. For each one, we show the constraints on autocorrelations, variances, or both and the number of parameters (reflecting the degree of parsimony). For example, for TOEP(T), the variances are constrained to be equal, and the autocorrelation at lag k is also constrained to be equal for 1 ≤ k ≤ T−1, so there are T parameters. For ARMA(1,1), there are three parameters (one constant variance, one autoregressive parameter φ1, and one moving average parameter θ1). The constant autocorrelation at lag k is further constrained by a specific relation through φ1 and θ1. Each covariance structure in the table was assigned a hypothesis number. When and how they are tested will be discussed in the next section.
Parametric constraints placed on UN for different level-1 error covariance structures

Note. T is the number of time points. CS = compound symmetry; AR(1) = the first-order autoregressive; AR(2) = the second-order autoregressive; ARMA(1,1) = autoregressive and moving average process of order (1, 1); TOEP(q) = Toeplitz with q bands, q = 1, …, T; TOEP = TOEP(T); CSH = heterogeneous CS; ARH(1) = heterogeneous AR(1); TOEPH(q) = heterogeneous TOEP(q); TOEPH = TOEPH(T); ANTE(1) = the first-order ante-dependence; UN(q) = unstructured with q bands; UN = UN(T).
The nested relations among the error covariance structures are easy to obtain based on the constraints placed on UN summarized in Table 1. They are explicitly presented with a tree diagram in Figure 1 (by following Widaman and Thompson, 2003). In this article, p* and q* are used to represent the order of the ARMA process to distinguish from the q in TOEP(q), TOEPH(q), and UN(q). Note that AR(p*) = ARMA(p*,0) and MA(q*) = ARMA(0,q*). Because the model fit with MA(q*) and that with TOEP(q*+1) are identical, MA(q*) is ignored. In Figure 1, stationary and non-stationary structures are separated with a horizontal dashed line. Stationary structures appear below the line and non-stationary ones above the line. The lines with single-headed arrow connect two covariance structures from a more constrained one to a less constrained one in such a way that the former is nested within the latter. The constraints are indicated beside the lines. For example, TOEPH(1) is nested within CSH as well as within ARH(1) by the constraint of ρ = 0. CS is nested within TOEP by the constraint of ρ
k
= ρ. The vertical lines through the dashed line indicate the constraint of invariant variance (i.e.,
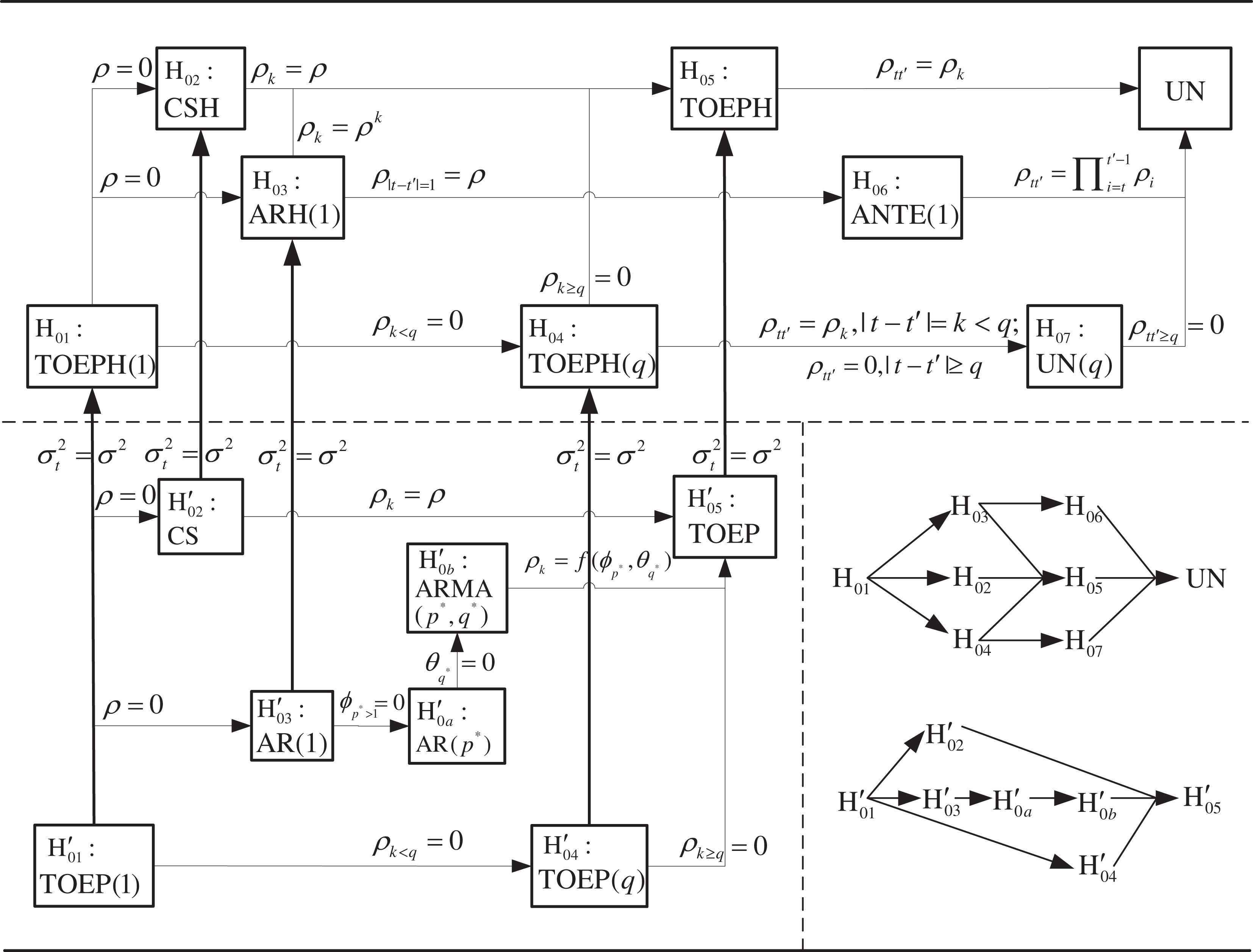
Tree diagram showing the nested relations among the level-1 error covariance structures based on the constraints placed
UN is called the saturated structure and TOEP is called the saturated stationary structure. TOEPH(1) and TOEP(1) are the simplest (the most constrained) non-stationary and stationary structures, respectively. For non-stationary structures, TOEPH(1) is nested within CSH, ARH(1), and TOEPH(q), ARH(1) is nested within TOEPH and ANTE(1), TOEPH(q) is nested within TOEPH and UN(q), and they are all nested within UN. For stationary structures, TOEP(1) is nested within CS, AR(1), and TOEP(2). AR(1) is nested within AR(p*), which is nested within ARMA(p*,q*). They are all nested within TOEP. The nested relationships among the structures are simplified in the lower right corner of Figure 1. Note that there exists no nested relation for the structures in each of the sets of {CS, ARMA(p*,q*)}, {TOEP(q), AR(p*)}, and {CSH, ARH(1), TOEPH(q)}.
A systematic approach for identifying level-1 error covariance structures
In this section, a systematic approach is proposed to search for a plausible level-1 error covariance structure. The approach is then evaluated by two simulation studies with the linear growth model, one of which is based on a non-stationary level-1 covariance structure, and the other is based on a stationary covariance structure. The approach is finally illustrated with empirical data.
Because the error covariance structures shown in Figure 1 are all nested within UN, the chi-square difference test (Bollen & Curran, 2006, p. 51) can be used to test the adequacy for each of them by assessing if the resulting model fit is not significantly worse than that from the saturated structure UN. Moreover, all stationary structures are also nested within TOEP, so the chi-square difference test can also be conducted based on the saturated stationary structure TOEP. The latter test facilitates identifying a simple plausible structure. Note that TOEP is nested within UN, and therefore the chi-square difference test can also be used to test stationarity of the level-1 error covariance structure.
Before we conduct the chi-square difference test, we need to examine the condition for model identification. The unknown parameters in an unconditional growth model include
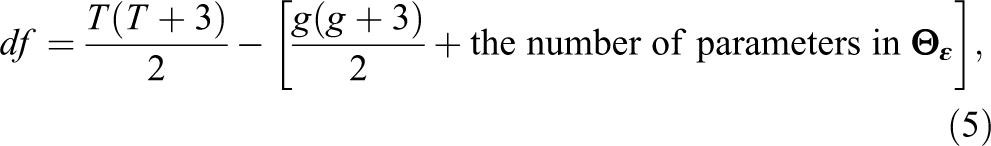
where g denotes the number of growth parameters. The df for the model with
The minimum number of time points required to achieve model identification for the unconditional linear, quadratic, and cubic growth models with
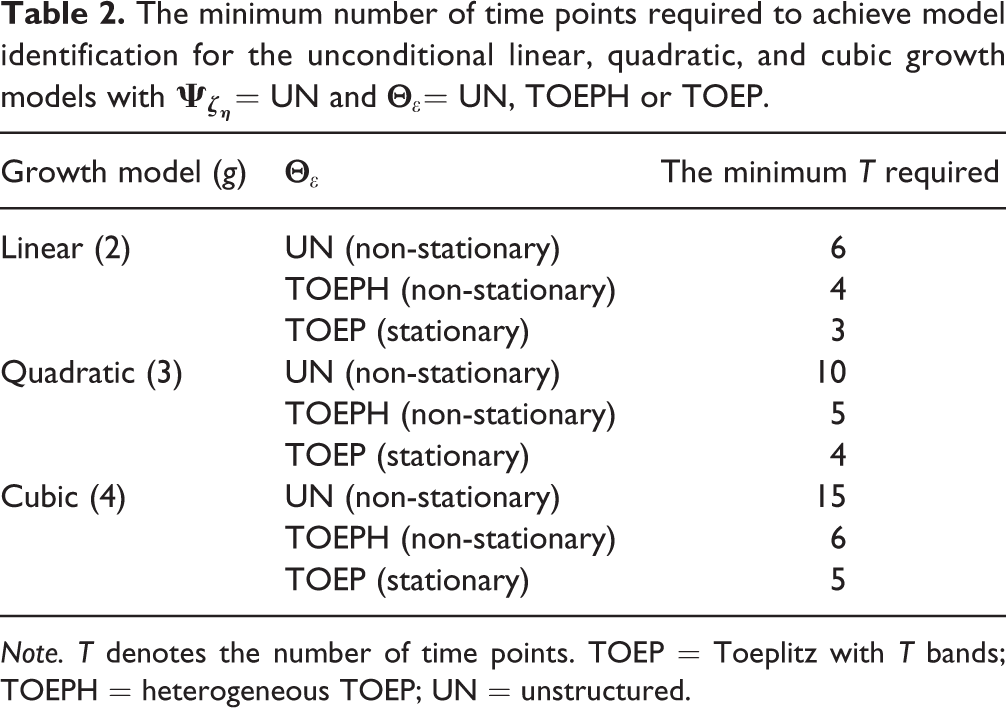
Note. T denotes the number of time points. TOEP = Toeplitz with T bands; TOEPH = heterogeneous TOEP; UN = unstructured.
The search procedure for a level-1 error covariance structure consists of two stages:
Stage 1: Testing the stationarity of a level-1 error covariance structure.
For the linear growth model (g = 2) with
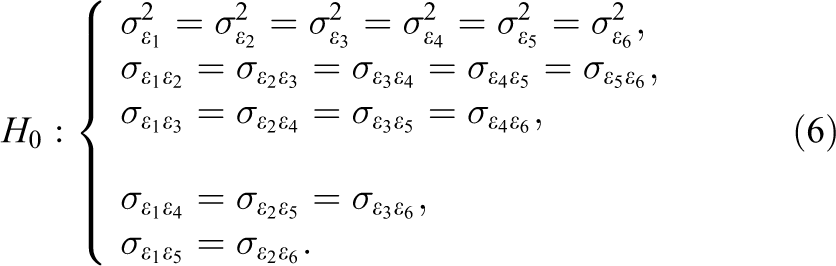
The df associated with the test for stationarity by using the saturated structure UN is T(T −1)/2. When T < 6 and
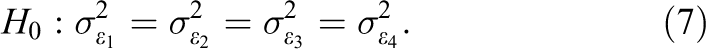
The df associated with the test for stationarity by using TOEPH as the least constrained structure is T −1. Under stationarity, UN and TOEPH both reduce to TOEP, the saturated stationary structure. Although, for T = 4, UN(2) and ANTE(1) could also achieve model identification (df > 0), neither of them is considered because, under stationarity, they cannot reduce to TOEP (see Figure 1), on which the subsequent search procedure for a more parsimonious stationary structure is based. In fact, they reduce to TOEP(2) and AR(1), respectively, both nested within TOEP.
The ways for handling the quadratic or higher-order growth model are similar.
Stage 2: Identifying a plausible level-1 error covariance structure.
If stationarity, tested in Stage 1, is supported, then identify the structure within the stationary group; otherwise identify the structure within the non-stationary group. The search procedure, shown in Figure 2 with a flowchart, basically follows the sequential chi-square difference test (SCDT) given by Anderson and Gerbing (1988). The structure to be identified is as simple as possible under the condition that it is nested within the least constrained structure and it produces no significantly worse model fit than the least constrained structure. Structure search is conducted sequentially, starting from the simplest (i.e., the most constrained) model and then a less constrained one. The process is terminated when the test becomes nonsignificant. If there exist two or more equally parsimonious structures, they all need to be compared with the least constrained structure used.
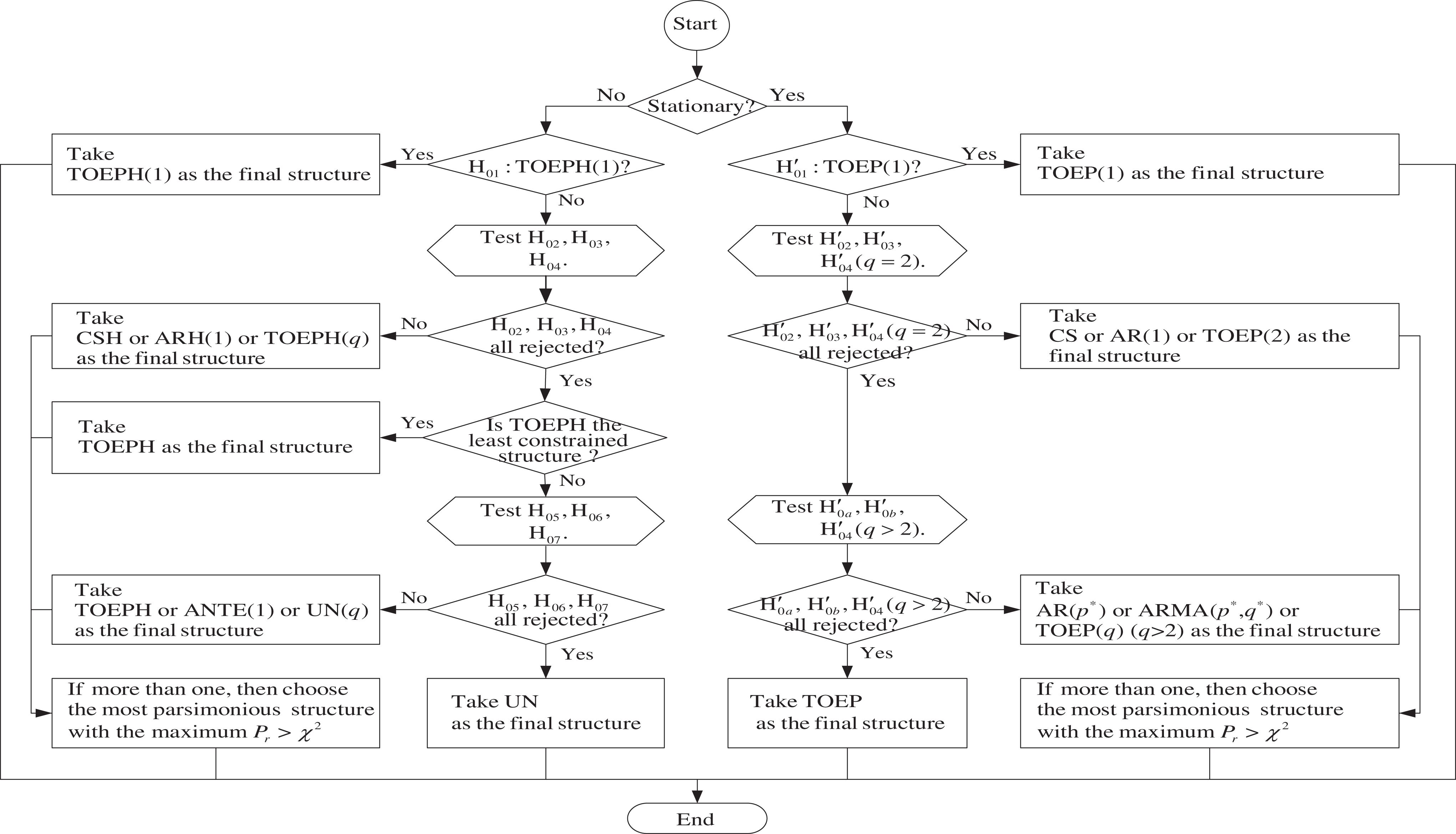
Flowchart for identifying a plausible level-1 error covariance structure
Stationarity holds
The procedure to search for a plausible stationary structure, shown on the right side of Figure 2, starts from testing b. Stationarity does not hold
The procedure to search for a plausible non-stationary structure, shown on the left side of Figure 2, starts from testing H01: TOEPH(1). When T is large enough, use UN as the least constrained structure; otherwise use TOEPH. If H01 is not rejected, then take TOEPH(1) as the final structure; otherwise test H02: CSH, H03: ARH(1), and H04: TOEPH(q) (q = 2, …, T−1). Starting from TOEPH(2), we test H04 sequentially until the occurrence of nonsignificance, thereby determining the value of q. If the tests for q = 2, …, T−1, are all significant, then H04 is rejected. If two or all of CSH, ARH(1), and TOEPH(q) do not show significantly worse model fit, choose the structure with the least parameters. If H02, H03, and H04 are all rejected, check if TOEPH is used as the least constrained structure. If it is, then take it as the final structure; otherwise test H05: TOEPH, H06: ANTE(1), and H07: UN(q) (q = 2, …,T−1). The value of q for H07 is also determined by the same principle as above. If H05, H06, and H07 are not all rejected, then choose the most parsimonious one from those showing nonsignificance; otherwise take UN as the final choice.
During the search procedure, if there exist two or more structures with the same number of parameters and with no significant difference in model fit from the least constrained structure, then choose the one with the largest p value of the chi-square test (e.g., de la Torre, van der Ark, & Rossi, 2015). Whenever comparing models that are not nested, model selection indices such as AIC and BIC can be used. When the structures have the same number of parameters, AIC and BIC will lead to the same result as the p value. Note that the procedure and the corresponding flow chart apply to the cases where T ≥ 4. When T = 3, TOEPH(1) is the only non-stationary structure that can achieve model identification for the zunconditional linear growth model, and therefore it is used as the least constrained non-stationary structure in this case. However, TOEP, the saturated stationary structure, is not nested within TOEPH(1). The constraints on TOEPH(1) for stationarity are given by
Simulation
We conducted two simulation studies to assess the performance of the proposed approach. Although AR(1) may be the most commonly used one to capture the level-1 error correlations (Murphy & Pituch, 2009, p. 256), ARH(1) is more appropriate when error variances and autocovariances are not homogeneous. Therefore, ARH(1) and AR(1), representing a non-stationary structure and a stationary one, respectively, were selected for
An effective replication is defined as one with convergent and proper solutions. The percentage of effective replications out of 1000 was examined in each study. We then calculated the relative frequencies of the level-1 error covariance structures identified by the proposed approach out of effective replications. The percentage of the agreement between the covariance structure identified and the population structure is the rate of correct identification, which is used to evaluate the effectiveness of the proposed approach in recovering the correct covariance structure.
The relative biases of parameter estimates resulting from fitting different level-1 error covariance structures were also examined. The relative bias of each parameter estimate
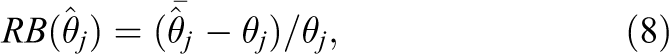
where θj is the population value of the jth parameter (θj ≠ 0), and
Misspecifications in LGM come from the mean, covariance, or both structures. The covariance structure is the combination of the level-1 and level-2 error covariance matrices. Wu, West, and Taylor (2009) indicated that, for balanced designs with complete data, RMSEA, CFI, and TLI among the SEM-based fit indices have shown good potential performance in evaluating the fit in both mean and covariance structures. In addition, SRMR is more sensitive to misspecification in the covariance structure than to the misspecification in the mean structure. Since it is assumed that there exists no misspecification in the mean structure and the level-2 error covariance structure is unconstrained (saturated), any misfit is due to the level-1 error covariance structure. Under these conditions, RMSEA, CFI, TLI, and SRMR can be considered. RMSEA, CFI, and TLI are chi-square-based fit indices. They are not included because the p value associated with chi-square test for model fit (denoted by Pr > χ2) has been reported. Instead, SRMR, a residual-based fit index, is used.
Simulation was implemented by using SAS. SAS codes by PROC CALIS to fit various level-1 error covariance structures are available in Ding and Jane (2012). The simulation results are summarized in Table 3 and Table 4 (for Study 1) and Table 5 and Table 6 (for Study 2). In Study 1, when ρ = 0.7, the number of effective replications out of 1000 was 945 for N = 150, 993 for N = 300, and 995 for N = 500 (see Table 3). Of the effective replications, the proportion of rejecting stationarity was found to be 100%, regardless of the sample size. In each replication, we followed the procedure shown on the left side of Figure 2 to identify a non-stationary level-1 error covariance structure. TOEPH(1) was rejected in all replications. As shown in the table, the frequencies of correctly identifying ARH(1) were 850, 971, and 995 for N = 150, 300, and 500, respectively. Therefore, the relative frequencies (i.e., the rates of correct identification) were 89.95%, 97.78%, and 100%. On the other hand, the relative frequency of incorrectly identifying TOEPH(2) was 8.68% when N = 150, and was reduced to 1.01% when N = 300. CSH was not identified. ARH(1) and TOEPH(2) were the most parsimonious identified structures and they together occupied the majority. Other structures, which were non-stationary and less parsimonious, were ascribed to the category of “Others,” whose relative frequency was 1.37% when N = 150 and 1.21% when N = 300.
Simulation results based on ARH(1) for different sample sizes (Part A)

Note. The number of replications is 1000. ARH(1) = heterogeneous first-order autoregressive; TOEPH(1) = heterogeneous Toeplitz with 1 band; TOEPH(2) = heterogeneous Toeplitz with 2 bands. The ARH(1) with ρ = 0 is actually TOEPH(1).
Simulation results based on ARH(1) for different sample sizes (Part B)
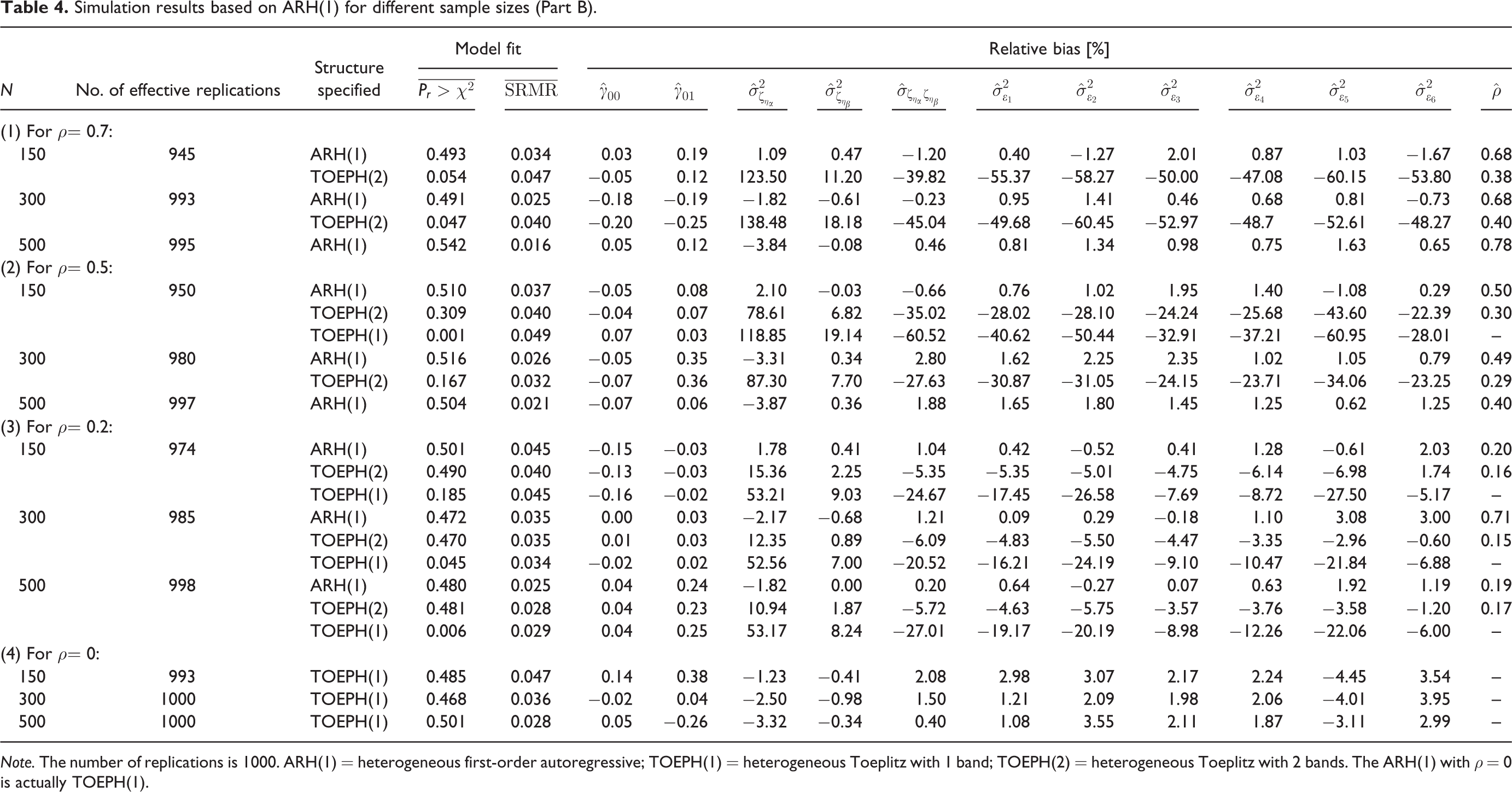
Note. The number of replications is 1000. ARH(1) = heterogeneous first-order autoregressive; TOEPH(1) = heterogeneous Toeplitz with 1 band; TOEPH(2) = heterogeneous Toeplitz with 2 bands. The ARH(1) with ρ = 0 is actually TOEPH(1).
Simulation results based on AR(1) for different sample sizes (Part A)
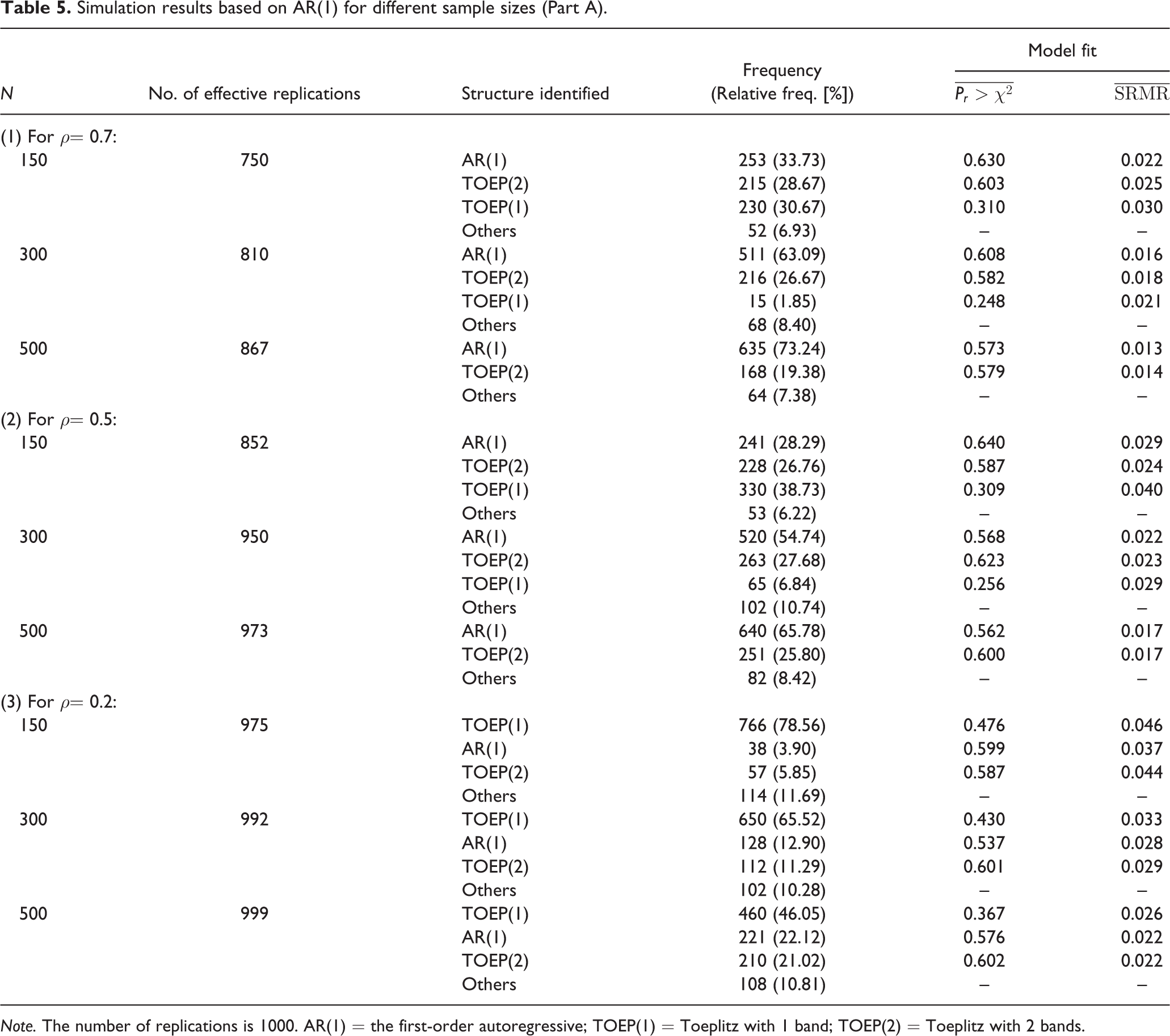
Note. The number of replications is 1000. AR(1) = the first-order autoregressive; TOEP(1) = Toeplitz with 1 band; TOEP(2) = Toeplitz with 2 bands.
Simulation results based on AR(1) for different sample sizes (Part B)
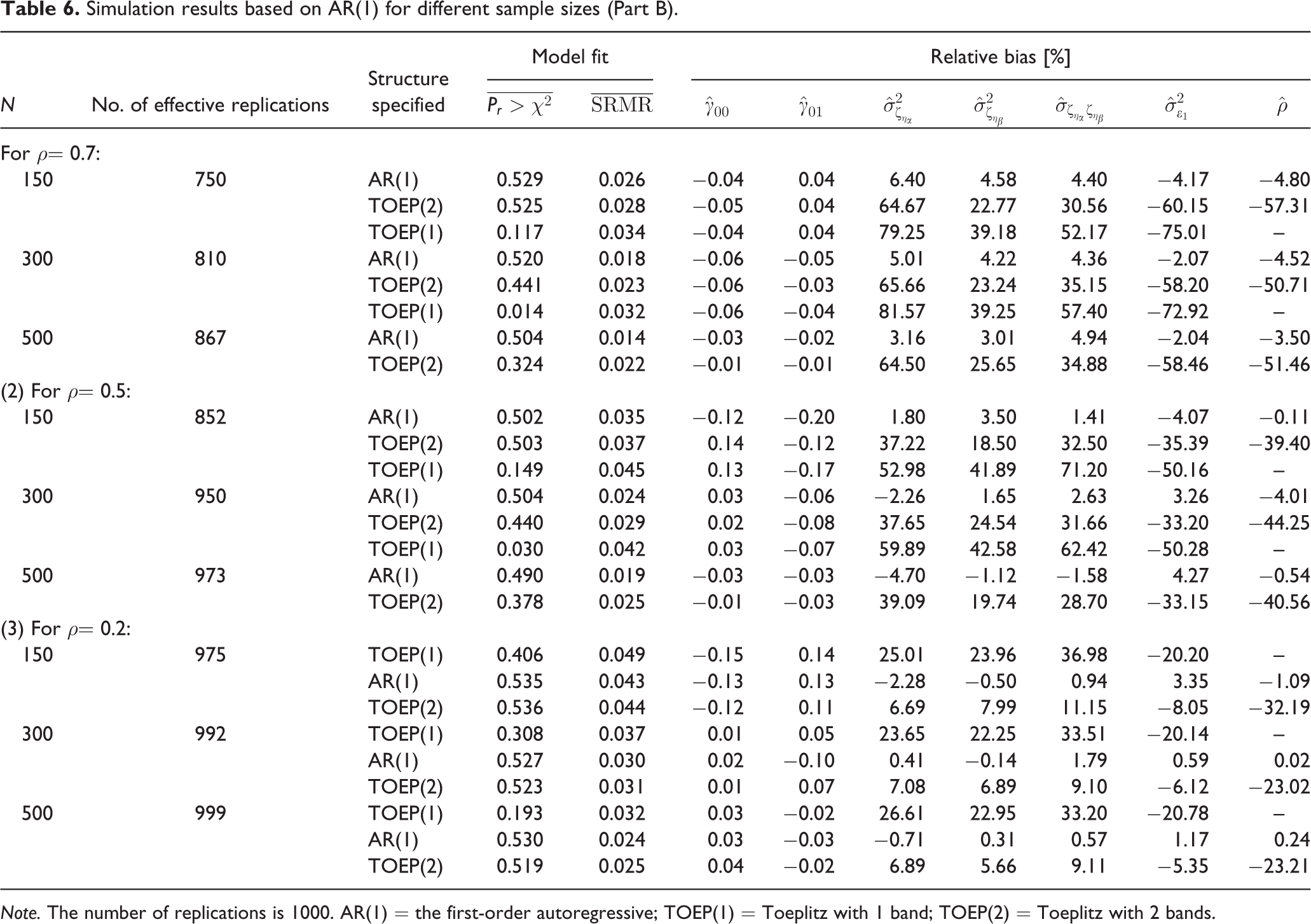
Note. The number of replications is 1000. AR(1) = the first-order autoregressive; TOEP(1) = Toeplitz with 1 band; TOEP(2) = Toeplitz with 2 bands.
When ρ = 0.5 or 0.2, the percentages of effective replications were also high (at least 95%). Although the proportions of rejecting stationarity were still large (close to 100%) for all cases, the rate of correct identification was much reduced when N = 150 (74.21% for ρ = 0.5 and 12.11% for ρ = 0.2). When ρ is low, the difference among ARH(1), TOEPH(2), and TOEPH(1) is not salient, so ARH(1) becomes difficult to identify. However, misidentification can be improved by using larger sample sizes. When ρ = 0, ARH(1) is actually TOEPH(1), and the replications were almost all effective. The rates of correctly identifying TOEPH(1) were greater than 96%.
In Table 3, the model fit, reported based on the means of Pr > χ2 and SRMR (denoted by
In Study 2, when ρ = 0.7, the percentages of effective replications were 75.0%, 81.0%, and 86.7% for N = 150, 300, and 500, respectively (see Table 5). Of the effective replications, the proportions of rejecting stationarity were all less than 10%, revealing slightly inflated Type-I error rates. In each replication, we followed the flowchart shown in Figure 2 to identify a level-1 error covariance structure. The rates of correctly identifying AR(1) were 33.73%, 63.09%, and 73.24% for N = 150, 300, and 500. For lower levels of ρ (0.5 and 0.2), the proportions of rejecting stationarity were about 10%, regardless of the sample size, but the performance in correct identification became much worse. When ρ is low, AR(1), TOEP(2), and TOEP(1) are difficult to discriminate, and therefore misidentification is quite likely to occur. A larger sample size is needed to achieve the same rate of correct identification as that for a higher level of ρ. The results agree with Ferron et al. (2002), indicating that generally larger series lengths, larger sample sizes, and higher levels of autocorrelation led to larger proportions of correct identification.
The model fit for each case in Table 5 was satisfactory as well. Using the same set of effective replications, we further computed the relative biases resulting from specifying AR(1) and the structures misidentified and summarized the results in Table 6. Again, the estimates of model parameters were acceptable only when the structure was correctly specified. Misspecifying AR(1) to be TOEP(1) or TOEP(2) led to underestimation of the level-1 error variance and overestimation of the level-2 error variances, in spite that the model fit was not much affected and the fixed-effects parameter estimates were acceptable. The detrimental impacts of misspecification are similar to those shown in Study 1.
Illustration
Biesanz, Deeb-Sossa, Papadakis, Bollen, and Curran (2004) demonstrated the estimation and interpretation of the quadratic growth model using the weight (in pounds) of 155 children at ages 5, 7, 9, 11, and 13 obtained from the U.S. National Longitudinal Survey of Youth. The TOEPH(1) was fitted for the level-1 error covariance structure but no reason was provided. We reconducted the analysis with the proposed approach.
As shown in Table 2, when T = 5, TOEPH should be used as the least constrained structure for the quadratic growth model. The results obtained are summarized in Table 7. Let
Results of identifying a plausible level-1 error covariance structure in Biesanz et al. (2004)
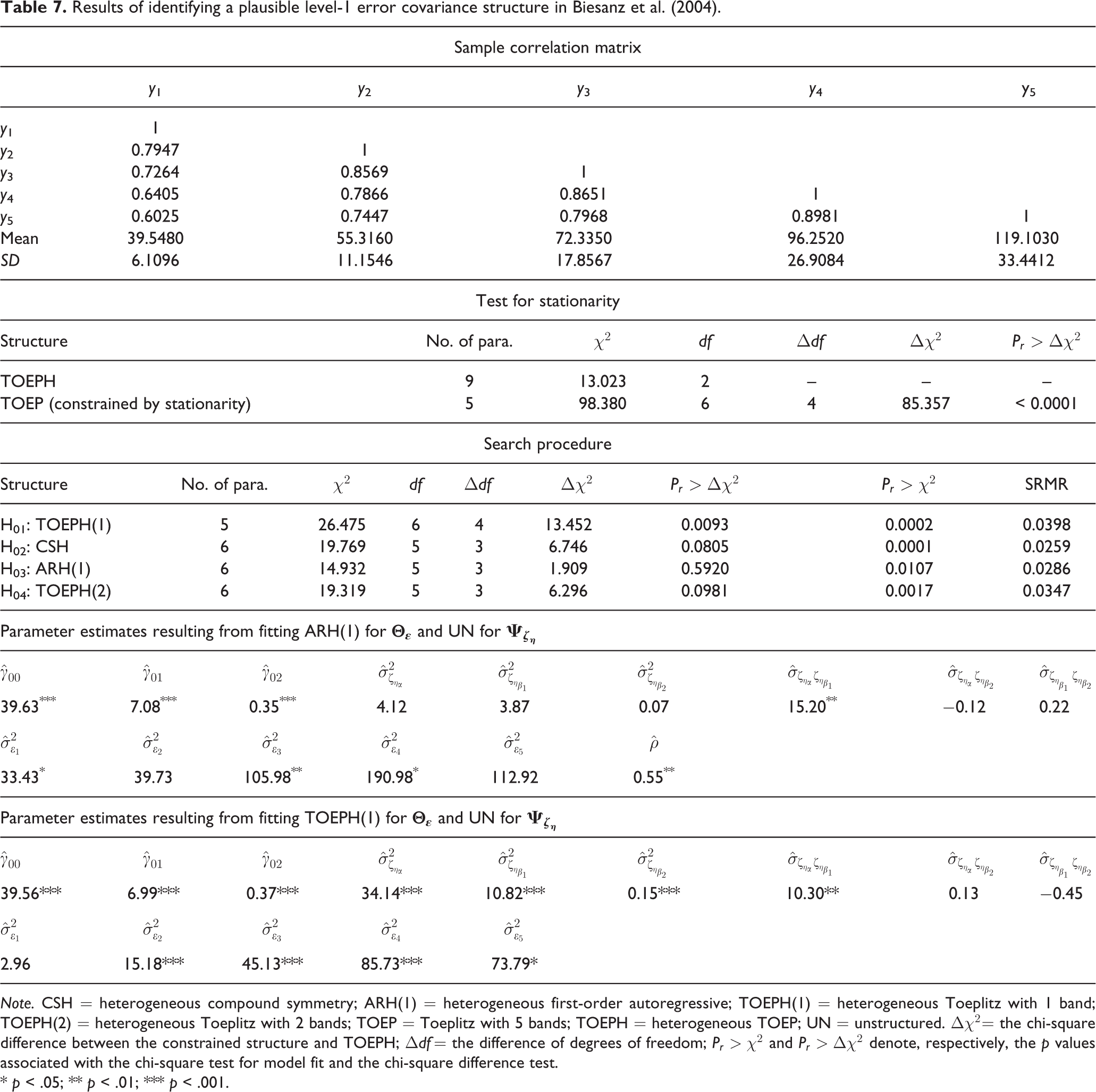
Note. CSH = heterogeneous compound symmetry; ARH(1) = heterogeneous first-order autoregressive; TOEPH(1) = heterogeneous Toeplitz with 1 band; TOEPH(2) = heterogeneous Toeplitz with 2 bands; TOEP = Toeplitz with 5 bands; TOEPH = heterogeneous TOEP; UN = unstructured.
* p < .05; ** p < .01; *** p < .001.
Discussion
As mentioned previously, the impact of the misspecification of the level-1 error covariance structure could be substantial. In this study, we have, under the principle of achieving both model fit and parsimony, proposed a systematic approach, based on the chi-square difference test, to facilitate identifying a plausible covariance structure. Preliminary simulation results have shown the usefulness of the proposed approach. The rate of correct identification is an increasing function of sample size. Moreover, we have verified that acceptable parameter estimates result from the correct covariance structure only.
Computational convergence problems may occur during the process of estimation. To handle the problems, researchers need to provide appropriate initial values for the parameters to be estimated (Li, Duncan, Duncan, & Acock, 2001). In our simulation studies, we used their population values as initial values to facilitate estimation, as frequently seen in the literature (e.g., Chen, 2007). In practice, however, population parameter values are unknown. SAS PROC CALIS determines initial values by using a combination of such methods as two-stage least squares estimation, instrumental variable method, approximate factor analysis method, ordinary least squares estimation, estimation method of McDonald, and observed moments of manifest exogenous variables (SAS Institute Inc., 2014). Although they perform reasonably well in most common applications, there is no guarantee of convergence. If non-convergence occurs during the search procedure, we suggest that the parameter estimates resulting from fitting a structure that has achieved convergence be used as initial values and rerun. To further reduce the chance of encountering estimation problems, we suggest using larger series lengths (larger than the minimum T required, shown in Table 2) and larger sample sizes.
When the covariance structure is less constrained, the estimates of variances/covariances are more likely to be linearly related. Although their linear relationships do not affect the model fit and the effectiveness of the chi-square difference test, if the structure identified by the proposed approach contains linearly related parameter estimates, restrictions need to be imposed to obtain unique solutions.
Although our demonstrations were based on unconditional linear and quadratic growth models, the approach is applicable for more general situations such as polynomial level-1 submodels with time-varying predictors, conditional LGM, with time-invariant predictors in level-2 submodels, and the second-order LGM (for investigating the trajectory of a construct over time) (e.g., Bollen & Curran, 2006, Ch. 8; Hancock, Kuo, & Lawrence, 2001). For non-linear growth functions (non-linear in the parameters), non-linear transformations of either time or the repeated measures could be used, and then the usual linear model is fitted to transformed outcome (e.g., Bollen & Curran, 2006, Sec. 4.4).
There exist some limitations of the proposed approach. First, the growth function needs to be well determined (by substantive theory) before searching for a suitable error covariance structure. When a growth model is misspecified, parameter estimates converge to different values from those of a correctly specified model, and the chi-square difference test can be misleading (Yuan & Bentler, 2004). When the theoretical support for a growth function is absent, Kim, Kwok, Yoon, Willson, and Lai (2016) gave a strategy to search for a correct polynomial growth model. They showed that the starting model with the saturated level-1 error covariance structure (UN) resulted in higher rates of correct identification than that with the simplest covariance structure, i.e., TOEP(1). Moreover, the chi-square difference test performs well in searching for the optimal mean trajectory. Once the true mean structure has been identified, the true level-1 error covariance structure can be subsequently determined by using the proposed approach, completing the two-step approach mentioned by Kim et al. (2016). Second, the data are assumed to be equally spaced in time in order to test stationarity, because, for unequally spaced data, some autocovariances at lag k, k ≥ 1 are unestimable. One way to deal with unequally spaced data is to interpolate the data to even spacing before conducting the stationarity test, assuming that the growth function has been well determined. Third, larger samples are needed to attain a required rate of correct identification for smaller numbers of time points and/or lower autocorrelations. Fourth, since there may be many model comparisons in the proposed approach, the Type-1 error rate of rejecting a specific covariance structure when it is true may be much inflated. Fifth, a plausible level-1 error covariance structure is selected from those shown in Table 1. If the true structure is not nested within the least constrained structure, the procedure will miss the true structure. Including more covariance structures and developing a more comprehensive identification approach deserve future research.
Footnotes
Acknowledgments
The authors thank Dr. Todd D. Little, the Methods and Measures Editor, and three anonymous reviewers for their constructive comments and suggestions, which greatly improved the quality of the paper.
Funding
The author(s) declared receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by grants NSC98-2410-H-009-010-MY2 and NSC100-2410-H-009-008-MY2 from the Ministry of Science and Technology, R.O.C.