
Abstract
We investigated the ability to detect a face among other visual objects in a complex visual array in 3-, 4-, and 5-year-old children, as well as in adults. To this end, we used a visual search paradigm implemented on a touch-tablet device. Subjects (N = 100) saw up to eighty 3 × 3 visual search arrays and had to find and tap upon a target—a face or a car—among eight objects that served as distractors. Our data revealed a relative face detection advantage, which did not differ in its extent between children and adults. This suggests that, beginning in young childhood and ending in adulthood, face detection performance advances as a consequence of other cognitive functions such as a general advance in visual search performance. Our study closes a gap in the knowledge about the development of face detection—as a prototype for social stimuli and their capacity to attract attention—from early to middle childhood.
Introduction
Detecting a face in a visual scene is as essential for young children as it is for adults. Humans are social beings and interact with each other on a daily basis. Thus, the presence of another human is highly important to us. Faces can provide helpful information about other people—such as their identity, emotional state, or gender. However, without face detection, this further processing of relevant information derived from a face cannot take place (Lewis & Ellis, 2003). Hence, the question of how face detection develops over the life span is of central importance.
Face detection can be probed by several paradigms in adults. When presented with very short flashes of intact or disorganized face images, the minimum presentation time to accurately detect the stimulus is shorter for intact faces (Purcell & Stewart, 1986). If participants are instructed to look at two images simultaneously, participants prefer to look at images that contain a face—starting with the first saccade already (Fletcher-Watson, Findlay, Leekam, & Benson, 2008). In a two-alternative saccadic-choice task, subjects are faster and more accurate at making saccades towards faces than towards cars and animals (Crouzet, Kirchner, & Thorpe, 2010). In addition, more complex and ecologically more valid search arrays can be used: under such conditions of greater spatial uncertainty, the relative face advantage increases even further (Hershler, Golan, Bentin, & Hochstein, 2010)—face-stimuli exhibit a pop-out effect. In contrast to objects, their detection speed is only marginally affected by the search array size (Hershler & Hochstein, 2005). In summary, several face detection paradigms show the superiority of upright and intact face processing over the processing of other visual objects, hence demonstrating the importance of face detection as an essential part of face recognition.
Detection advantages and a preference for faces are not exclusive to adults. A general looking and tracking preference for faces and face-like stimuli is evident in newborns already (Johnson, Dziurawiec, Ellis, & Morton, 1991; Morton & Johnson, 1991; Valenza, Simion, Cassia, & Umiltà, 1996). Also, 6-month-old infants direct their first saccade preferably toward faces in complex visual arrays containing object distractors (Gliga, Elsabbagh, Andravizou, & Johnson, 2009).
However, the tendency to look at and attend to faces is not a stable feature—it becomes more pronounced with age. Studies show that face detection performance as measured by looking paradigms increases between 3 and 9 months of age, but still does not match adult behavior (Di Giorgio, Turati, Altoè, & Simion, 2012; Frank, Vul, & Johnson, 2009). Still, to our best knowledge, there are no studies that investigate the quantitative development of face detection in young children after 12 months—an ability that is crucial for further processing of face stimuli and therefore relevant for more complex processes like the development of face perception or face memory in childhood (Lewis & Ellis, 2003; Weigelt et al., 2014).
Thus, the major aim of our study was to extend the existing knowledge about face detection performance in infants and adults to young childhood. To this end, we used a visual search paradigm with a complex array in 3-, 4-, 5-year-old children, and adults, in which they had to detect faces and cars. We used touch device technology to implement the task, because looking tasks are difficult to use in childhood and touch device technology has proved to be a suitable data acquisition method in our targeted age range (Semmelmann et al., 2016). To control for age-related effects that are not attributable to a development of visual search, we factored out age-dependent motor responses by standardizing visual search reaction times with individual reaction time baselines, yielding a reaction-time-to-baseline ratio.
First, due to this standardization of visual search reaction times with baseline reaction times, we did not expect a large effect of age group on the reaction-time-to-baseline ratio. Second, in line with common findings, we expected to find a strong relative detection advantage for faces compared to cars in all age groups. Last, we expected that a relative detection advantage for faces would become stronger with age and reach adult levels in young childhood—analogous to an early maturity of face perception (Weigelt et al., 2014).
Method
Participants
Seventy-four children aged 3 to 5 years and 26 adults participated in the study (Table 1).
Age and gender distribution of participants.

Note: M = Mean, SD = Standard deviation.
Children were mainly recruited through visits to day care centers in the Rhine-Ruhr area in Germany. Adults were mainly recruited at the Ruhr-Universität Bochum. All participants (and children’s parents) gave informed consent and participated voluntarily. Adult participants received course credit or participated out of good will; children received little presents as a reimbursement, regardless of completion of the experiment. The local ethics committee approved the study. Participants had normal or corrected-to-normal vision (2 children excluded) and neither past nor present neurological or psychiatric disorders (2 children and 2 adults excluded). Twenty children were not analyzed because they either did not participate in both experiments (6), did not provide demographic data (2), did not comply with instructions (7), or only produced data for one stimulus category (resulting in an unbalanced within-subject predictor) in the visual search task (5).
We also piloted our paradigm in 2-year-old children. However, the vast majority of the 2-year-olds had pronounced problems to produce a “tap” that was recognized as such by the touch device. Moreover, they were often distracted and aborted a trial after the search array was presented, resulting in reaction times that did not reflect an attentive reaction. We tried to provide more training and instruction, but the problem persisted. With older children, these problems were less pronounced and could be targeted successfully by the experimenters. Consequently, we aborted data collection of 2-year-olds, excluded the remaining ten 2-year-olds from the analysis and accepted that our design was not appropriate for 2-year-olds.
Task, stimuli, and material
Subjects participated in a visual search task (similar to Di Giorgio et al., 2012) that consisted of 8 blocks with 10 trials each. Each block started with a representative image of the target category (face or car, alternating) in both viewpoints (Figure 1) and ended with an applause sound and a short break to motivate subjects to continue. Each trial started with a placeholder image (Figure 1). After tapping the placeholder, a 3 × 3 array (Figure 1) containing eight distractors and the target stimulus was displayed at random positions until any of the array’s images was tapped upon. An inter-trial interval of 1000 ms with a blank screen separated the trials. The whole experiment was run in full-screen mode. Before the actual experiment, participants completed a variable number of training trials during which we explained the task. We instructed both adults and children alike to find and tap the target stimulus in the search array as fast as possible. The training included verbal feedback by the experimenter and lasted until the task was understood, or at least five trials. The whole procedure took about 15 minutes. Participants could choose to quit at any time during the experiment. In this case, all data up to this point were used in the analysis. Mean completed blocks (M (SD), maximum of 8 blocks) were: 3-year-olds: 4.52 (1.97), 4-year-olds: 5.20 (2.20), 5-year-olds: 4.71 (2.51), adults: 8 (0).
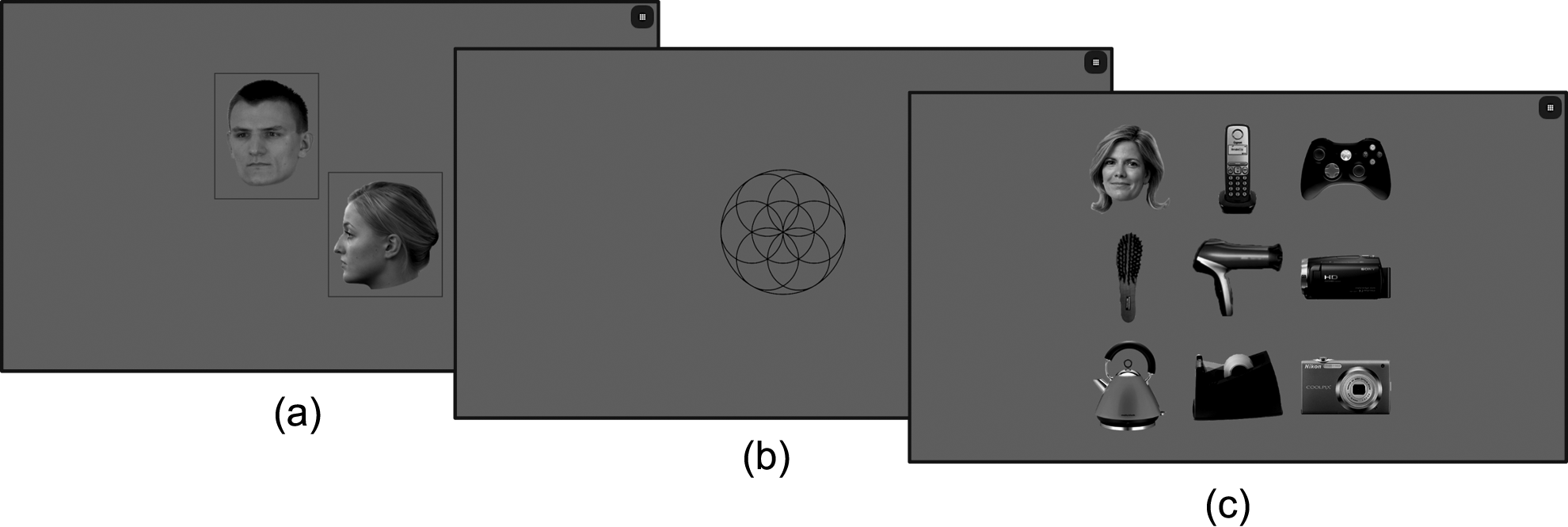
Screenshots showing the experimental paradigm: (a) representative image of the target category in both viewpoints, which is shown at the start of each block; (b) placeholder image, that has to be tapped to start each trial; and (c) 3 × 3 test array, including one target (here: face in front view) and eight distractors.
Target stimuli were 40 neutral Caucasian faces (20 female) from the Radboud Faces Database (Langner et al., 2010), the Karolinska Directed Emotional Faces database (Lundqvist, Flykt, & Öhman, 1998), the Aging Mind database (Minear & Park, 2004), as well as from the Internet, and 40 cars. Half of the stimuli were presented in front view, half of them in profile view. Distractor stimuli were 640 man-made roughly face-sized objects belonging to 25 different categories (e.g., microscopes, shoes, staplers, toasters, irons, binoculars, etc.; Figure 1). Images of cars and objects were downloaded from the Internet and edited for the study using Photoshop (version CS 6, Adobe Systems, San José, USA). All images were presented in grayscale at 250 × 250 pixels (∼7° visual angle, ∼ 41 cm viewing distance) and were randomly selected out of 720 possible images for each participant.
We used an ASUS Transformer Book T300FA (12.5 in. touch screen, 27.6 cm × 15.5 cm, ∼38° × 22° screen size, resolution: 1366 × 768 pixels, Intel Core M 5Y10a @0.8 GHz processor, Windows 8.1 64-bit). To achieve a higher touch sensitivity, we increased the touch-screen’s sampling rate while decreasing its sampling latency (registry edit of parameters Latency and Sample Time from eight to four). The task was programmed using web technology (HTML5/JavaScript), but was conducted offline with a locally installed webserver in Google Chrome. To prevent unintentional resizing or other manipulations, Google Chrome’s “Overscroll history navigation” and “Enable Pinch” features were disabled.
Data analysis
A problem that is inherited with the use of reaction times as an outcome variable in developmental studies is that effects are usually less pronounced for fast reaction times and more pronounced for slow reaction times (Crookes & McKone, 2009). This is a potential bias, as reaction times generally decrease with age from childhood to adulthood (see Semmelmann et al., 2016 for a touch device specific decrease). Following the suggestion of Crookes and McKone (2009), we used a baseline measure—a simple reaction time task—to standardize our outcome variable detection time. Before the actual experiment, children completed a brief reaction time baseline task (Semmelmann et al., 2016), in which they had to “catch a frog”, that appeared in 15 trials in decreasing size at varying locations, by tapping on the frog. The mean reaction times of this performance task constituted subject-specific baselines. We used these subject-specific baselines and the reaction times from the actual visual search task to compute a reaction-time-to-baseline ratio. Accordingly, a reaction-time-to-baseline ratio of 2 indicates that a participant took twice as long to detect the target in the visual search task compared to his/her individual reaction time baseline. For completeness, the original reaction times are also shown in Figure 2.

(a) reaction times (milliseconds) per age group and target category for the visual search task. Points depict the baseline reaction time; and (b) reaction-time-to-baseline ratio per age group and target category. Error bars = 95% confidence intervals of the mean. Age group sample sizes: n3-year-old = 25; n4-year-old = 25; n5-year-old = 24; and nadult = 26.
Statistical data analysis was performed using R (version 3.2.2) in RStudio (version 0.99.491). Bayesian statistics were computed using JASP (version 0.8.1.2). Training trials (for both baseline and visual search task) and error trials (for the visual search task, 240/5665 = 4.24%) were excluded. Trials with reaction times that were physiologically impossible (defined as below 200 ms) were excluded in both tasks (baseline task: 1/2100 trials = 0.05%, visual search: 15/5425 trials = 0.28%). Additionally, reaction times below or above each participant’s individual mean reaction time ± 2 individual SD were not regarded as deliberate or attentive responses and therefore excluded (baseline task: 138/2099 trials = 6.57%, visual search: 268/5410 trials = 5.00%).
Results
Main analyses
To investigate differences between age groups in detection performance for faces and cars, we calculated a mixed analysis of variance (ANOVA) with between-subject factor age group (3, 4, 5, and adult) and within-subject factor stimulus category (car, face) to the reaction-time-to-baseline-ratio data (Figure 2). Moreover, we employed Bayesian analyses to further determine the evidence for the effects of interest. ANOVA and post-hoc t-test results as well as Bayesian analysis of effects are listed in Table 2. The mixed ANOVA model comparison with Bayesian statistics are listed in Table 3.
Mixed analysis of variance/post-hoc t-test results and Bayesian analysis of effects for reaction-time-to-baseline-ratio data.

Notes: post-hoc t-test p values are Bonferroni corrected. If variances were unequal, a Welch test with corrected degrees of freedom (dfs) was used. For illustrative purposes, uncorrected dfs are reported. Age group sample sizes: n3-year-old = 25; n4-year-old = 25; n5-year-old = 24; and nadult = 26. incl = Inclusion.
Mixed analysis of variance model comparison with Bayesian statistics.
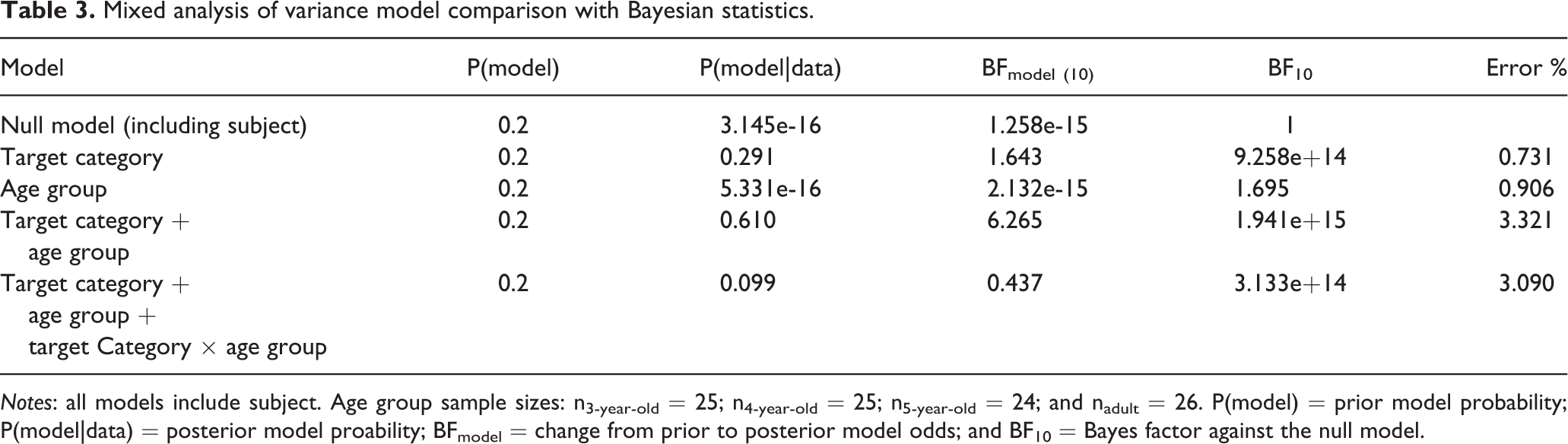
Notes: all models include subject. Age group sample sizes: n3-year-old = 25; n4-year-old = 25; n5-year-old = 24; and nadult = 26. P(model) = prior model probability; P(model|data) = posterior model proability; BFmodel = change from prior to posterior model odds; and BF10 = Bayes factor against the null model.
With our first hypothesis, we tested if—despite factoring out age-dependent motor responses by using a reaction-time-to-baseline-ratio—detection time would differ between age groups. In contrast to our expectation, we found a medium main effect of age group that was clearly driven by a difference between adults and the (pooled) child age groups (M (SD) for age groups: 3-year-olds, 1.81 (0.55); 4-year-olds, 2.00 (0.78); 5-year-olds, 1.91 (0.54); adults, 1.60 (0.40); see Table 2). However, the estimated Bayes factor (alternative/null) for the model with only the main effect of age group was only 1.695 (Table 3). Investigating the effect of age group in all models that contain the factor age group through model averaging suggested that the data were only 1.623:1 in favor of the alternative hypothesis (Table 2). In other words, the data were only 1.623 times more likely to occur under a model including age group effects, than a model without age group effects.
Our second hypothesis, based on common findings—predicted that faces would be generally detected faster than cars. Our results supported this hypothesis, showing a strong relative detection advantage for faces compared to cars in all age groups (M (SD) for target categories: faces, 1.62 (0.53); cars, 2.03 (0.59); see Table 2). The Bayesian analysis provided decisive evidence in support of these results with a Bayes factor (alternative/null) of 9.258e+14 for the model that only contained the main effect of target category (Table 3). Estimating the effect of target category with model averaging the Bayes factor for the inclusion was 7.506e+14—the data were more than one billion times more likely to occur under a model including a target category effects, than a model without a target category effects (Table 2).
Last, we explored a possible age group × target category interaction that would indicate if face–car differences changed with age. Our data revealed that the difference between face and car reaction times did not change with age but was stable, both within childhood as well as between childhood and adulthood (Table 2, Figure 2). The Bayesian analysis supported these findings. Model comparisons revealed that adding the target category × age group interaction to the model that only contained the two main effects decreased the Bayes factor (alternative/null) from 1.941e+15 to 3.133e+14 (Table 3). The posterior probability to include the age group × target category interaction into the model was only 0.099 while the estimated Bayes factor (alternative/null) suggested that the data were 0.437:1 in favor of the alternative hypothesis (Tables 2 and 3). In other words, the data were 2.289 times more likely to occur under the model that does not incorporate an age group × target category interaction, than under the model incorporating the interaction. Hence, children age 3–5 seem to show the same face detection advantage as adults do.
Explorative and control analyses
Our study focused on a possible target category × age group interaction. However, we conducted an additional analysis for two reasons. First, as stated in the “Methods—Task, stimuli, and material” section, faces and cars were presented in front view or profile view. We used this approach to achieve a higher ecological validity and generalizability of our study, as we encounter faces from various viewpoints in real life. We did not expect that viewpoint effects would be affected by development in this study, as in the order of face processing, face viewpoint, and identity are retrieved after face detection in adults (Or & Wilson, 2010). Still, we intended to test if our expectation was accurate. Second, we aimed to control for the influence of participant gender. Participant gender distribution in our sample was not equal across age groups (Table 1) and therefore could potentially bias our results.
Hence, we conducted an exploratory mixed ANOVA, in which we added target viewpoint as an additional within-subject predictor and participant gender as an additional between-subject predictor (Table 4). Again, we also analyzed the effects of interest using Bayesian statistics. Results of the exploratory mixed ANOVA confirmed our prior findings of medium and strong main effects for age group and target category, respectively, as well as no notable age group × target category interaction. Bayesian analyses revealed a tendency against an effect of age group (BFincl (10) = 0.497), but confirmed the findings of a strong main effect of target category (BFincl (10) = 1.652e+14), and no age group × target category interaction effect (BFincl (10) = 0.581; Table 4). Furthermore, the exploratory mixed ANOVA revealed a gender × target category as well a target category × target view interaction, which were both confirmed (the first as a tendency, BFincl (10) = 2.148, the latter with strong evidence, BFincl (10) = 20.493) by Bayesian analyses (Table 4). However, neither target viewpoint nor gender showed a significant interaction with the target category × age group interaction of interest. Most importantly, Bayesian analyses confirmed this finding by indicating strong evidence against these threefold interactions (target category × target view × gender BFincl (10) = 0.29, all other BFincl (10) < 0.055; Table 4).
Mixed analysis of variance results and Bayesian analysis of effects for reaction-time-to-baseline-ratio data with additional predictors target view and gender.
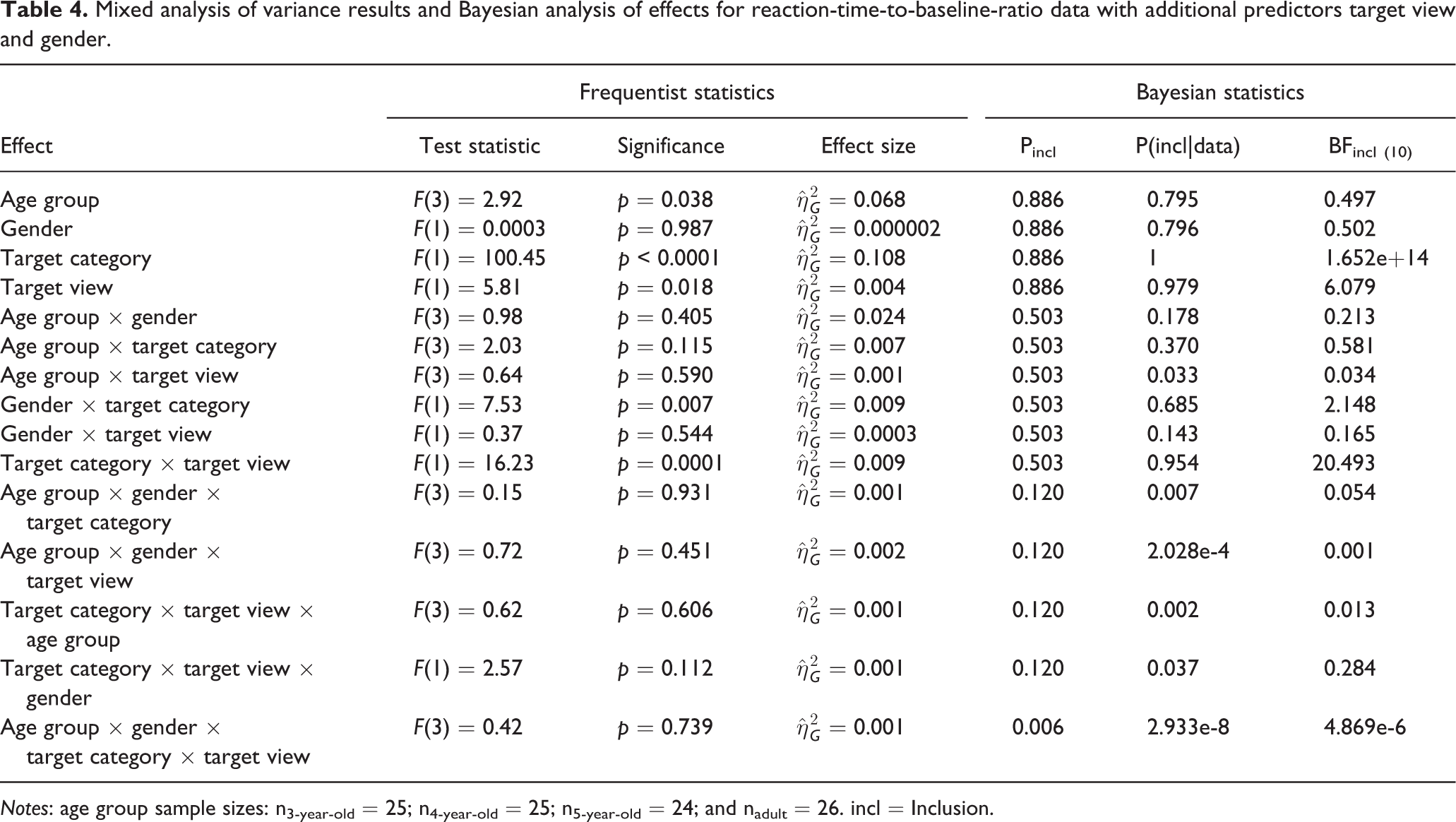
Notes: age group sample sizes: n3-year-old = 25; n4-year-old = 25; n5-year-old = 24; and nadult = 26. incl = Inclusion.
Discussion
The aim of this study was to investigate a possible maturation of face detection in young childhood in a visual search task using reaction times from touch responses. Our study revealed the following three findings: first, despite factoring out age-dependent motor responses by individually correcting visual search reaction times with baseline reaction times, in contrast to our expectation, adults were faster than children in detecting visual stimuli; second, confirming our hypothesis, faces were detected faster than cars, in both children and adults; and third, contrary to our expectation, this relative face detection advantage did not increase with age. Astonishingly, 3-year-old’s face detection performance does not differ from adult’s face detection performance quantitatively, as measured in relation to their baseline reaction time. Without baseline-correction of the data, however (Figure 2), children become faster with age as expected. Nevertheless, this increase is equally evident for faces and cars and hence driven by general improvements in visual search, attention, or motor abilities over development.
Several findings support this assumption. Visual attentional abilities, which are relevant for detecting faces in complex scenes, show an increase within the first year (Amso & Johnson, 2008; Colombo, 2001; Dannemiller, 2005; Frank, Amso, & Johnson, 2014; Richards, 2010) and develop further in young childhood (Plude, Enns, & Brodeur, 1994). In addition, 12–36-month-old infants are quantitatively slower in visual search tasks than adults, while the basic perceptual processes that mediate visual search (parallel search ability, and pop-out effect) are qualitatively equal between infants and adults (Gerhardstein & Rovee-Collier, 2002). In conclusion, 3-year-olds are already as good in detecting faces in complex visual search arrays as adults are. The only limits that prevent children from reaching adult performance levels of face detection might be those of other cognitive systems such as attention and visual search.
An interesting point to consider in future studies is the nature of the distractor stimuli. In our study, we followed Di Giorgio et al. (2012) in employing man-made objects as distractor stimuli exclusively. However, the nature of the distractor stimuli could have an influence on the visual search performance (Duncan & Humphreys, 1989). A high similarity between target and distractors as well as a low similarity among distractors both increase the search difficulty. In our study, 25 different distractor categories ensured that similarity among distractors was always high. However, in the face detection task, but not in the car detection task, similarity between the target and the distractors was low in terms of faces being animate/organic targets among manmade/non-organic objects. This aspect might have affected age groups in a different way and should be subject to further research.
Our results suggest that face detection—as a very early process in the sequence of face processing—matures early in childhood. Comparing face detection with other key face processing abilities, it seems that face detection develops in accordance with early developing face perception, as opposed to late developing face memory abilities (Weigelt et al., 2014).
Footnotes
Acknowledgements
Author contributions
TWM, HP, MN, and SW designed the study. HP developed the stimuli with advice from TWM, MN, and SW. KS programmed the experimental paradigm and set up the touch devices. HP collected the data. TWM analyzed and interpreted the data with help from HP. TWM drafted the manuscript with help from HP and advice from SW. All authors critically revised the manuscript for important intellectual content and gave final approval of the manuscript to be published.
Funding
The authors declared receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a scholarship of the Konrad-Adenauer-Foundation (Konrad-Adenauer-Stiftung) to TWM, a scholarship of the German Academic Scholarship Foundation (Studienstiftung des deutschen Volkes) to MN and KS and grants from the German Research Foundation (Deutsche Forschungsgemeinschaft, WE 5802/1-1) and the Mercator Research Center Ruhr (AN-2014-0056) to SW.