
Abstract
Emotion regulation is a key developmental skillset, but many existing measures rely on self-report or laboratory-based measurement approaches. This study aimed to develop a training and implementation protocol for the widely used Facial Expression Coding System (FACES) to be used in real-world settings with pre-recorded video data. A revised coding system with supplemental guidelines and training procedures was developed to use FACES with video data recorded in special education classrooms. This system resulted in adequate interrater reliability as well as reduced training time for coders. Specific training methods included close study of code definitions, coding of practice video, quantitative analysis of observation data to generate interrater agreement and kappa statistics, review of comparison charts to identify discrepancies between coder and training observations using the Noldus Observer XT software, and post-observation discussions. The revised FACES protocol and new training method presented here offer a more robust, efficient, and versatile tool that can be applied to systematic behavior observations conducted of students in real-world classroom settings.
Keywords
Introduction
The ability to regulate emotions during childhood and adolescence has long-lasting impacts on mental health and wellbeing (Beauchaine & McNulty, 2013; Eisenberg et al., 2010). Lack of emotion regulation skills, or use of maladaptive ones, is associated with mental health disorders including mood, anxiety, substance use, and eating disorders (Berking & Whitley, 2014; Brockmeyer et al., 2014; Buckholdt et al., 2015; Compas et al., 2017; Gratz & Roemer, 2004; Mennin & Fresco, 2009; Weiss et al., 2013). Measurement of emotion regulation is conducive to transdiagnostic assessments that can guide intervention planning and support research in areas including emotional experience, self-regulation, interpersonal dynamics, and physiological arousal (Kring, 2010). Most emotion regulation research has been conducted in laboratory settings with a focus on habitual emotion regulation (Aldao et al., 2010; Gross, 2015).
A need remains for robust quantitative tools that can be used in real-world settings to measure momentary changes in emotion regulation in adolescents. This is particularly true for populations with complex diagnoses and psychosocial or learning impairments that would preclude participants from being able to provide valid self-report information (McCullough et al., 2019). Even in neurotypical populations, use of self-report instruments to assess emotional expressivity can be problematic. Research has shown that when individuals reflect on their own emotional experience, their response is influenced by their memory of recent situations, beliefs about how they should respond, and cultural norms (Robinson & Clore, 2002). An observational measure of emotional expressivity that is reliable for use with video recordings of behaviors occurring in real-world settings and capable of detecting momentary changes in emotion regulation would provide objective data that will allow for assessment of the efficacy of interventions for promoting emotion regulation and inform clinical screenings of psychosocial problems in children and adolescents (Riley-Tillman et al., 2005).
Existing observational measures of facial expression of emotion focus on discrete emotions and often rely on small segments of data. These measures are difficult to implement reliably in real-life settings, compared with controlled laboratory experiments that use specific tools or prompts to elicit target emotions. Study of emotion in real-world settings is needed to avoid obfuscation of natural progressions of expressive behavior (Kring & Sloan, 2007) and to capture data that hold greater ecological validity. The widely used Facial Action Coding System (FACS) and Emotion Facial Action Coding System (EMFACS) developed by Ekman and Friesen (1976, 1978), and other measurement systems like these, can be cost-prohibitive due to the substantial time needed to train coders to use the system reliably. The Facial Expression Coding System (FACES; Kring & Sloan, 2007) is a more economical option that uses a dimensional model of emotion to gather information on the valence of facial expression (positive or negative). This system represents a shift away from the need to detect micro expressions and, while this system has predominantly been used in controlled laboratory settings that utilize emotion-eliciting stimuli, the greater simplicity of the system reduces the cognitive burden on coders and requires less training time. The FACES system is well suited for use in real-world contexts where visibility of subject’s facial expressions and study contexts can vary greatly.
FACES has been tested for use with diverse populations including college students, adults, and psychiatric patients (Kring & Sloan, 2007). It has had high intra class correlations among coders with an average of 0.92% and 82% of correlations above .70 when compared with the Emotional Expressivity Scale, “a self-report measure of individual differences in the degree to which people outwardly express their emotions” (Kring et al., 1994). In addition, the FACES instrument had high test–retest reliability for both clinical (.84 mean intraclass correlation) and nonclinical populations (.62 mean intraclass correlation) (Earnst & Kring, 1999). A systematic report on the validity of the FACES instrument compiled five additional validity studies, where FACES ratings were related in predictable ways to another observational coding system (average ICC .86), facial muscle activity (average ICC .88), individual-difference measures of expressiveness and personality, skin conductance, heart rate, and reports of experienced emotion (Kring & Sloan, 2007). Kring and Sloan (2007) illustrated that the FACES instrument is aligned with the dimensional model of emotion, while also being correlated with more traditional emotional measurements from different theoretical backgrounds emphasizing the instruments construct validity. FACES has been used in studies of emotion expression in the context of depression (Sloan et al., 2001), posttraumatic stress disorder (Wagner et al., 2003), and childhood sexual abuse (Luterek et al., 2005). While this observational measure has strong validity and reliability in highly controlled settings, it has not been rigorously tested in real-world settings. While this study does not explore validity of the FACES instrument, reliable rating of the instrument in a new context is explored.
The purpose of this article is to present our 2-year FACES training and instrument validation data that are the basis for the revised observation system and training protocol that are presented here. Specifically, we tested the FACES system in a classroom setting using video recordings, rather than live observations, without a standardized stimulus to elicit a target emotion, and among youth with psychosocial challenges, a population where early measurement and intervention can be crucial to long-term health. Novel methods for analyzing behavior observation data based on our revisions to the FACES User’s Guide (Kring & Sloan, 1991) are discussed.
Method
Training methods included close study of code definitions, coding of practice video, quantitative analysis of observation data to generate interrater agreement and kappa statistics, review of comparison charts to identify discrepancies between coder and training observations, and post-observation discussions.
Participants
A total of 10, 17, and 8 coders were trained to administer the FACES at the beginning of each of the three rounds of testing, respectively. Training included three steps: introduction to the Observer XT software, guided practice video coding facilitated by a FACES trainer, and independent coding of training videos. Interrater reliability (IRR) was calculated for all independently coded training videos to determine when training was complete, and the coder could begin to code research data. IRR was assessed using Cohen’s κ, a commonly used statistic for point-by-point agreement (Bakeman & Quera, 2011). This equation was chosen based on the information it provides to coders in training. The Observer XT software calculates the κ score and agreement or confusion matrices, identifying both agreements and confusions between a pair of coders. This calculation is more rigorous than percent agreement as it controls for the probability that agreement occurred by chance (Cohen, 1960). While appropriate magnitudes for κ scores are dependent on study type and field, a training benchmark of .70 was selected based on Fleiss’ (1981) guidelines that κ scores of .4–.75 represent fair to good interrater agreement.
Training was considered complete when the coder coded one video for each of the ten study participants and achieved an IRR of .70 for three video clips consecutively. Before training Round 1, three social work graduate students who received formal training on FACES through review of the FACES User’s Guide (Kring & Sloan, 1991) were selected to be lead coders for the study. These coders completed an in-depth literature review of the FACES and became FACES trainers. Through group discussions about recurring code discrepancies related to unclear guidelines, the lead coders compiled the preliminary draft of supplemental guidelines and trained coders for Rounds 1, 2, and 3 of testing. All the subsequent trainee coders were unfamiliar with the FACES method. Some coders had prior experience working with children with mental health diagnoses and in special education settings.
Training observations were completed using 5-min video clips recorded of study participants (N = 10) in one of two seventh grade special education classrooms in New York (Green Chimneys, Brewster, New York). For participants included in the research data set, a training video was created to familiarize coders with unique behaviors of all participants during training. Coders were not informed as to whether students they were observing had been diagnosed with learning disabilities, mental health disorder, or any other disorder. The development of the enhanced and clarified FACES training protocol for use in classrooms with approximately 10 students was carried out over 3 years for a larger study.
Materials
User’s Guide for the FACES
The FACES User’s Guide (Kring & Sloan, 1991) provides a foundation for training. It provides the rationale for using the observational tool and a description of the three categories for observation: the frequency, intensity, and duration of facial expressions. The FACES User’s Guide defines expression as a facial change from a neutral display to a non-neutral display or from one type of display (e.g., positive) to another (e.g., negative). Valence of expression (positive and negative) are defined by two lists of affect descriptors, which use discrete facial expressions (i.e., angry, happy) rather than facial movements (i.e., corners of mouth raised upward). Intensity ratings are defined using facial movements (e.g., a low positive is given for a smile where a participant slightly raises the corners of their mouth but does not show teeth and there is very little movement around the eyes). FACES is validated for use with diverse adult populations including individuals experiencing posttraumatic stress disorder, schizophrenia, and mood and eating disorders (Kring & Sloan, 1991). High rater agreement has been consistently achieved among coders using FACES in controlled settings that used standardized stimulus to elicit a target emotion (Kring & Sloan, 1991). Convergent validity has been established for FACES and the EMFACS as well as measures of individual personality, expressive behavior, skin conductance, heart rate, and self-reports of experienced emotion (Kring & Sloan, 2007).
FACES Coding Form
The FACES Coding Form is included in the FACES User’s Guide (Kring & Sloan, 1991) and is used to record the frequency, intensity, and duration of positive and negative valence for each time segment. A time-mark in seconds is noted on the coding form any time an expression is detected and again when the participant returns to a neutral display or changes to a different type of expression. Duration is calculated for positive and negative expressions by subtracting the beginning time from the end time and recorded on the form. The coder records whether the expression was positive or negative and rates the intensity on a 4-point Likert-type scale. Subjective global ratings are assigned to rate the degree to which seven specific emotions are expressed using a 6-point scale and the overall level of expressiveness for the segment using a 5-point scale. The original FACES coding form was adapted for use within observational data management software (Observer XT; Noldus, Inc., Wageningen, the Netherlands) to reduce coding errors and increase efficiency of the coding process.
Supplemental Guidelines
The supplemental guidelines were developed to explain behaviors that were identified as causing repeated coding errors when coding students in a classroom environment and without a specified sensory stimulus (Supplemental Appendix 1). They increase the standardization of the FACES training and therefore increase IRR and decrease length of training. They also support the application of FACES to recorded video of study participants which provide richer data that can increase accuracy of coding but also requires greater specificity of code definitions for interpretation of the greater level of detail present in this data type. These guidelines correspond with the revised FACES coding form (Supplemental Appendix 2) that is designed for use with digital data management and behavior observation software. Information is provided for calculation of interrater agreement in Microsoft Excel and Observer XT to use in training procedures and ongoing fidelity monitoring. These guidelines are organized as general information and guidelines for each behavior category of FACES.
Procedure
This study was completed in accordance with the protocol approved by the University of Denver Institutional Review Board (protocol number 1000610-9). For all observations, the hypothesis of the study, diagnostic status of the participants, and intervention were masked and unknown to the coders.
Development of New Standardized Material
The revised FACES Coding Form, new supplemental guidelines, and training procedure were developed during training Rounds 1 and 2 by the research team. Revisions completed during one round were tested in each subsequent round. The FACES Coding Form and supplemental guidelines are explained below:
Revised FACES Coding Form: Data were rearranged in table format to be compatible with digital forms of data entry. Distinct emotion categories (e.g., interest, sadness) were removed due to the inability to sufficiently define these terms to support high IRR. For similar reasons, the overall level of expressiveness and subjective global ratings were removed.
Supplemental guidelines: During training Round 1, coders were unable to achieve a .70 κ score due to repeated coding errors when following the FACES User’s Guide (Kring & Sloan, 1991). The FACES Coding Form was reviewed to determine where repeated errors occurred frequently. This review showed that neutral behaviors and intensity of expression were the least specific and most difficult to accurately code. To address this, five additional guidelines related to general coding procedure and eight code categories were compiled to resolve the recurring confusion (Supplemental Appendix 1). These guidelines were expanded upon in Rounds 2 and 3 and some additional clarifications were added.
Observations and Post-Observation Discussions
An observation is a single video clip that is approximately 5 min in length. Observations are the foundation of research data creation and provide the basis for training. Observations may be viewed by a single coder or multiple coders depending on if the coder has reached an adequate average IRR level. IRR is increased through post-observation discussions between an experienced coder and a coder in training that focus on the accurate application of codes. A list of codes that the experienced coder and coder in training agreed and disagreed upon is generated by the behavioral coding software. This comparison list highlights each of the discrepancies between coders taken into account during calculation of the IRR score.
The frequency of IRR calculation and post-observation discussion is determined by the coder’s level of expertise. During training, a post-observation discussion occurs after every three observations coded by a coder in training, which is a critical component of the learning process. In comparison, once a coder has completed their training by achieving an adequate average IRR score, post-observation discussions are used for one-third of research videos to ensure continued reliability. After the development of new standardized materials, four training and observation procedures below were identified:
Practice observations: the goal of these observations is to learn the pace of the FACES observation and gain fluency with the FACES supplemental guidelines and the eight code categories of the revised FACES coding manual. First, coders review the revised FACES coding manual and the supplemental guidelines. Then they learn how to record information in the FACES coding form within the Observer XT software. Trainees complete the observation together with an experienced coder, who provides feedback and explanations on the rationale for why a code should or should not be applied. This procedure allows for the coder in training to immediately ask questions and clarify their understanding of the codes. After practice observations are complete, coders are ready to conduct training observations.
Training observations: coders in training are assigned an initial set of three observations to code independently. Only three observations are assigned at one time so that incorrect coding patterns can be remedied before they become reinforced. After coding a set of three observations, these observations are systematically compared with those of an experienced coder resulting in comparison lists that identify discrepancies. The experienced coder discusses with the trainee the rationale for why a code was or was not applied. Additional sets of three videos are assigned, followed by the generation of an interrater comparison list and post-observation meeting with an experienced coder to discuss discrepancies until the trainee has coded at least one observation for each of the 10 participants and achieves three consecutive .70 IRR scores indicating competency and reliability in administering the FACES. Through this process, for a study with 10 participants, coders viewed a minimum of 12 training videos, or four sets of three videos, to gain exposure to each of the 10 participants and complete training. Consecutive observations may lead to cognitive fatigue and reduced interrater agreement, resulting in lower κ scores, therefore observations should not exceed three videos in a row without taking a break. After three consecutive .70 IRR scores are achieved, coders are considered fully trained and ready to conduct research observations.
Research observations: after completing practice and training observations, coders are prepared to rate research data observations independently. A third of the observations completed by a fully trained coder should be coded by another experienced coder to ensure continued reliability. Observations that will be viewed by two individuals, also known as double observations, should be selected using stratified random sampling. This ensures that double observations are selected evenly across the period that coding is conducted and for all coders on the team. Again, due to cognitive fatigue, consecutive observations should be limited to three per coding session, followed by at least 15 min away from the computer.
Refresher training observations: To account for coder drift, the tendency for coders to inaccurately select codes after a lapse in active coding or simply due to error in memory from the passage of time, refresher training is needed to maintain high levels of reliability. If there is a lapse of more than 2 weeks between observations, or if a coder’s double observations fall below .70, a refresher training should be completed. During refresher training, the coder does not complete any research videos and reverts to training observation procedures. Sets of three observations followed by a post-observation discussion are completed until the coder has successfully coded a set of three consecutive observations with κ scores above .70.
Results
Rounds of Testing and Development
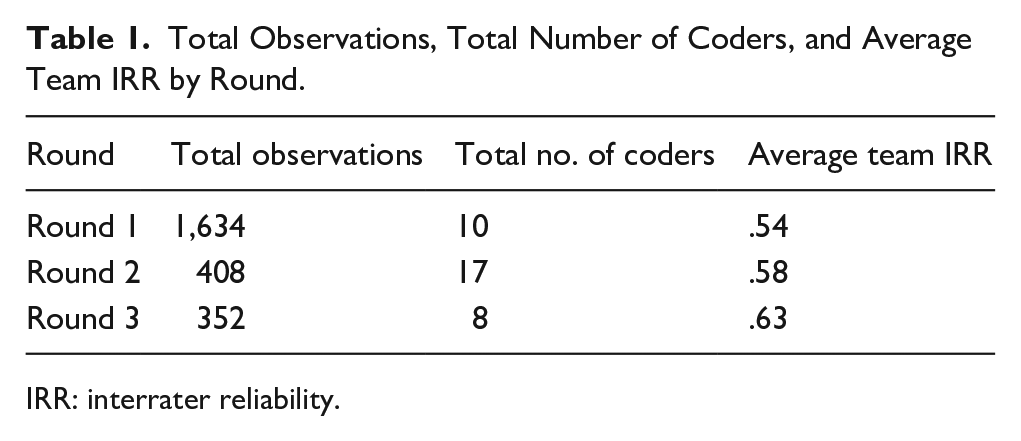
Three rounds of testing and development were required to create, standardize, and apply the revised FACES coding manual, supplemental guidelines, and new training method. Each round required a team of graduate researchers to be trained in the observation and post-observation discussion procedures described above. During Round 1, 1,634 total observations of 10 participants were completed by 10 coders (see Table 1). Round 2 consisted of 408 observations that were completed by seventeen coders. The third, and final, round was completed by eight coders who rated a total of 352 observations. The average IRR attained in Round 1 was .54. Rounds 2 and 3 resulted in average IRRs of .58 and .63, respectively. Since average IRR above .70 was not attained in Round 1 using the implementation materials provided with the original FACES system, supplemental guidelines were created and Round 2 was initiated during which additional specificity was added to these guidelines. The revised materials were applied during Round 3 to further increase IRR scores.
Total Observations, Total Number of Coders, and Average Team IRR by Round.
IRR: interrater reliability.
Interpretation of average IRR scores across manual iterations is limited as variables such as exposure to multiple versions of the manual were not controlled for. While summary agreement statics would be helpful in alleviating this limitation, the complexity of this data set restricts the use of common statistics such as intraclass correlation. Given the resource intensive nature inherent to behavioral observations, truly independent observations were unattainable. Given these constraints, our full data set of paired kappa calculations has been provided in the Supplemental Appendix for those who may be interested in fitting a model appropriate to this context.
Training Styles
Multiple rounds of training and development allowed for testing different levels of intensity of training. While observation and post-observation discussion procedures remained consistent, hours of training provided at one time and number of training sessions conducted in a week were modified. Two different styles of training were tested during 2 academic years when there was turnover in the team of graduate research assistants as graduating students left the team and new students joined.
Training Style 1 is compatible with coders who can only complete a limited number of hours training each week. In this style, coders spent between 8- and 10-hr training each week over 10 weeks. Coders completed two 4-hr days per week and coded one or two sets of three training observations. Other activities completed by the trainee included transferring data to an experienced coder, completing the post-observation discussion with an experienced coder, and integrating their learning from the post-observation discussion into their next set of independent training observations.
Training Style 2, or “intensive” training, is compatible with coders who can dedicate several days to training each week and consists of 4 to 8 hr of training daily on at least 3 days during a week. At most in 1 day, three cycles of training occurred where one iteration involved coding of three training videos and a post-observation discussion. No more than three iterations of observation and post-observation are recommended per day as four or more iterations resulted in coder fatigue and decreased reliability. The benefits of Training Style 2 far surpassed Training Style 1. A shorter period between coding videos and completing post-observation discussions allowed for trainees to integrate the feedback of experienced coders more immediately and before incorrect recall of the coding system is reinforced and engrained.
Supplemental Guidelines
Experienced coders created and modified the revised FACES coding manual and supplemental guidelines in Rounds 1 and 2 of training and development. The guidelines and manual were consistently applied in Round 3. Experienced coders also created training materials to aid trainees in practice coding. Like a test with an answer key, experienced coders created an accurate list of codes that matched existing training video data. These lists were provided to trainees after they coded an observation so they could be quickly compared with the codes selected by trainees to understand patterns in code selection and deviations from the revised FACES coding manual.
Supplemental guidelines were created throughout the rounds of development as the research team became sensitized to code application and unique nuances in the data. While the original FACES behavior codes are intuitive, audiovisual recordings constitute an expansive data set and the ability to pause, slow down, and replay video recordings allowed for substantially greater detail to be observed. This additional level of control was not addressed in the original User’s Guide. In each round of development, if a situation occurred in the recorded video data that diverged from the context for which the original User Guide was developed, specificity was added to the supplemental guidelines to maintain consistency and agreement for how the situation was rated. Additional guidelines led to higher IRR scores.
Before Round 1, the subjective global ratings and overall level of expressiveness variables were removed from the coding process due to low levels of interrater agreement and inability to identify strategies to improve agreement on ratings for these variables. Guidelines added in Rounds 1 and 2, attempted to stay as consistent as possible with the intentions of the original manual.
Supplemental guidelines created during development Round 1 included visual examples of facial expressions, guidance for instances when the subject changed expressions quickly, and an explanation of appropriate code application during subject verbalization. Visual examples were particularly helpful as human emotional expression varies greatly across individuals. Images provided a point of reference for coders to compare participants’ data against. Interpretation of emotion using video data presents additional unique challenges. Often participants switch from a positive low or closed mouth smile to a neutral expression within the span of hundredths of seconds. Other times, the participant would look toward a wall where their face could not be seen or coded and then back at the cameras interrupting the expression coded. Instructions that specified the code to be applied in each of these contexts made coders less reliant on assumptions of expression continuity when the participant changed expressions quickly or looked away from the camera. Similarly, participant verbalization complicated the coders’ ability to discern emotion intensity. Since verbalization often requires an open mouth, and the “openness” of the mouth is an important indicator of intensity of expression, coders found it difficult to determine emotional intensity during verbalization. Guidance was added to indicate which code should be applied based on whether the expression or the talking began first.
Round 2 expanded the guidelines by including specific biomechanical descriptions of facial features associated with each expression intensity. Originally, valence of expression (positive and negative) was defined by two lists of affect descriptors that used discrete facial expressions (i.e., angry, happy) rather than facial movements (i.e., corners of mouth raised upward). This caused difficulty since participants’ facial features and expressed emotion were frequently misaligned. A participant could smile while ironically talking about how much they liked solving math problems or frown while they were engaging in imaginative play with a friend. This left coders in disagreement as to what would be the appropriate code. Ultimately, because internal emotions cannot be directly observed, the supplemental guidelines focused on defining codes using biomechanical movements of the face as a proxy for internal emotions and prioritized these data as the basis for code application even if they were contrary to the tone or body language expressed by the participant.
The specificity of code definitions and guidelines for application that were added in Rounds 1 and 2 were combined during Round 3 and applied to the remaining research data to test for reliability. The full supplemental guidelines can be found in Supplemental Appendix 1.
Discussion
We tested the FACES system in a classroom setting using video recordings and without a standardized stimulus to elicit a target emotion for youth with psychosocial challenges. We developed supplemental guidelines and a training protocol to account for the increased variability that occurs in naturalistic settings. The revised FACES protocol and new training method presented here offer a more robust, efficient, and versatile tool that can be applied to systematic behavior observations conducted of students in real-world, special education classroom settings. The supplemental coding system allowed for use of FACES with video data recorded in dynamic classroom settings with adequate IRR. The methods for training researchers to use FACES in dynamic contexts increased IRR and reduced training time.
Recommendations
Through the process of manual revisions and development of training guidelines, our research team identified strategies that enhanced the reliability of the FACES coding system that should be considered in future studies. The supplemental guidelines for the coding system and training guidelines increased efficiency of coder training and made the application of the coding system feasible in highly dynamic, real-world settings, an outcome that aligns with the extant literature on the adaptation of coding manuals for new research questions (Steiner et al., 2013; Yoder et al., 2018). Furthermore, these guidelines supported the completion of observations using video recordings which, though they can yield richer data that increase the validity of ratings compared with live coding, can also present unique challenges to ensuring reliability. For example, when coding data continuously, difficulties can arise from increases in the granularity of details from the ability to review changes in behaviors at the level of seconds and microseconds. Use of the supplemental guidelines and training guidelines can decrease the resource investment required by researchers who want to use the FACES observation system and support IRR for research conducted in real-world settings.
Several strategies are recommended to support efficient training and data coding processes. First, creating a training data set that was coded prior to training was essential. Preparing training videos for which appropriate codes had been selected gave trainees concrete examples of how each type of behavior appeared in the video data and accelerated learning. Second, employing coders who maintained a high level of familiarity with the coding manual and data set and who could support creation of training videos and facilitate post-observation discussions was key to maintaining an efficient training process. Third, differentiating between beginner-level and expert-level coders supported efficiency and quality of training and research coding. Expert coders expedited training by providing guidance to trainees that was informed by their own coding experience. Expert coders also supported the capacity for completion of frequent IRR analysis. Having team members who were responsible for continual oversight of IRR analyses also supported efficient coding by providing capacity for the team to determine whether a coder could be directed to further research data or needed to be sent to refresher training based on IRR scores. Team members who oversaw IRR analyses were also likely to notice patterns of coding errors that may occur across coders. These error patterns can be used to provide coders-in-training with feedback about common code misapplication that may be unique to a given research setting. Such feedback can support the creation of additional supplemental guidelines when further clarification is needed for consistent code application. Finally, training style selection determined the speed at which feedback could be provided to coders in training. Both training styles are useful and can be used to meet the needs of different team structures. Where possible, we recommend use of Training Style 2, as it was found to facilitate the most efficient training process as multiple post-observation discussions could be hosted in 1 day.
Ongoing research data quality assurance is a key strategy to maintain adequate IRR scores across time (i.e., ⩾.70). Once trainees have achieved an IRR of at least .70 for three video clips consecutively and have observed each participant in the study at least once, they can begin coding research data independently. To ensure coders continue to apply the observational system with validity, one-third of the research data created by each coder should be rated by a second coder. Videos coded by a second coder are randomly selected. If the IRR analysis of the videos coded by two coders is less than .70, the coder must complete retraining. This process supports coders in maintaining consistency with the revised FACES coding manual after transitioning from training to research data.
If a study population includes neuroatypical participants or co-occurring disorders, the revised FACES manual and training guidelines should be evaluated for goodness of fit. The revised coding system may not be valid for use with diagnoses and medications in which symptoms or side effects involve limited facial expression, given the system’s reliance on the biomechanics of expression. Participant skin tone should also be considered. Video data quality can be diminished for participants with darker skin tones, compared with lighter skin tones, when recording conditions are compromised (e.g., insufficient lighting, camera distance from subject). Video data quality can also limit the extent to which IRR can be improved, as was the case in the present study, in which the distance of subjects from the camera and variability in lighting reduced the amount of visual data available as the basis for code application. It is thus important to attend to the technical set up of the recording equipment to ensure the setting is sufficiently well-lit to generate high-quality data for all participants. This may include keeping room lights on during recording, installation of additional lighting, or installation of cameras that would allow for cameras to zoom in on focal subjects to capture the nuances of individuals’ facial expressions. Audio data are necessary for use of the revised FACES instrument. To accurately assess the intensity of expression, coders may need to consider the biomechanics of expression amid a context that involves the participant talking, chewing, or laughing while simultaneously engaged in a facial expression. Audio data are needed so that coders may differentiate what visual data may be attributed to non-emotive activities.
Limitations
While observational measures circumvent self-report instrument issues and provide a unique depth to emotion evaluation, there remain significant limitations to the widespread implementation of this method. Despite the efficiency measures taken in this method to applying FACES, the labor required to build a team of coders with adequate IRR is still significant. Training of successful coders can take 30–100 hr of practice, and 5 min of research observation data requires an average of 30 min for an experienced coder to complete. It is therefore imperative that data selected for coding is of high video quality, as described above, and appropriately selected to inform the research question.
The specific results of this study are limited to a population of youth aged 12–13 years in a special education setting and may not be generalizable to other populations, age groups, or settings. Research teams should assess the FACES for use within their specific research contexts. In some contexts, high-quality pre-recorded video data may not be feasible to obtain. Although prior work has indicated that the FACES has sufficient convergent and divergent validity, this study did not assess validity within the revised protocol, which may be an area for future exploration. While observational measures are notoriously resource intensive, high-quality video data and modification of existing instruments can reduce the investment required to produce meaningful outcomes.
Conclusion
The revised FACES coding manual, supplemental guidelines, and training protocol were supportive of increased IRR from Round 1 through Round 3 of testing and development. These procedural changes supported adequate, though not high, IRR which may have been due in part to limitations related to the low quality of the video data itself. Experienced coders and continued quality assurance contributed to increasing IRR scores over time.
The materials developed can be applied to a variety of settings and populations and may be particularly contributive to research with populations experiencing complex diagnoses that would limit valid self-report approaches to measurement (McCullough et al., 2019). The revised FACES coding manual and supplemental guidelines allow for clarity of code application to audiovisual data of real-world settings. The training protocol provides instructions to increase efficiency of training by identifying strategies that promote learning such as quick feedback and increased number of training hours per week. Two levels of coders aided the team’s ability to maintain this training style.
Observational measures provide the opportunity to study populations for whom other measures are unreliable (Robinson & Clore, 2002). In combination with audiovisual data observational measures can increase the ecological validity of research studies by removing the researcher from the setting observed (Brooks & Baumeister, 1977; Cicourel, 2007). Real-world contexts are also more closely captured by this method as emotional expressions occur unprompted. The revised FACES coding manual, supplemental guidelines, and training protocol allow for this observational system to be utilized more accurately and efficiently with large amounts of audiovisual data from complex real-world settings. These materials also lend themselves to the use of data coding software that helps organize, code, and analyze audiovisual data. While more work is needed to identify strategies for data collection and analysis to further increase reliability, observational measures adjusted for use with audiovisual data remain a unique tool for quantifying developmental change.
Supplemental Material
sj-docx-1-jbd-10.1177_01650254231167313 – Supplemental material for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol
Supplemental material, sj-docx-1-jbd-10.1177_01650254231167313 for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol by Erin Flynn, Marisa Motiff, Megan K. Mueller and Kevin N. Morris in International Journal of Behavioral Development
Supplemental Material
sj-docx-2-jbd-10.1177_01650254231167313 – Supplemental material for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol
Supplemental material, sj-docx-2-jbd-10.1177_01650254231167313 for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol by Erin Flynn, Marisa Motiff, Megan K. Mueller and Kevin N. Morris in International Journal of Behavioral Development
Supplemental Material
sj-xlsx-3-jbd-10.1177_01650254231167313 – Supplemental material for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol
Supplemental material, sj-xlsx-3-jbd-10.1177_01650254231167313 for Testing of the Facial Expression Coding System (FACES) for middle school–aged special education students and development of a training protocol by Erin Flynn, Marisa Motiff, Megan K. Mueller and Kevin N. Morris in International Journal of Behavioral Development
Footnotes
Acknowledgements
The authors thank all participating Green Chimneys students and staff and the University of Denver graduate student research assistants who contributed to this project, including Alexandria Kurtz, Amanda Mattila, Breanna Davidson, Brynn Wiessner, Catie Rodgers, Courtney Stain, Deanna Herbol, Edgar Casillas, Em Moratto, Emma Boillotat, Eva Kasyon, Gokul Krishnaswamy, Gowtham Krishnaswamy, Jenni Sides, Julia Senecal, Jocelyn Medina, Katherine Nunez, Katie Leiter, Lauren Kalvaitis, Marisa Motiff, Mary Ramatici, Mckayla McMullen, Myleah Coleman, Rebecca Overlock, Shreejay Parmar, Stephanie Lohn, Tracy Harris, and Xichao Wang.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research received funding through grants from an anonymous donor to the University of Denver’s Graduate School of Social Work, and through grants to the PI from the A&P Sommer Foundation (Paris France) and the Green Chimneys Board of Directors. The grant contract for the latter includes a statement that the PI has full authority to publish both positive and negative findings regarding the impacts of these programs.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.