
Abstract
Obtaining answers from community-based question answering (CQA) services is typically a lengthy process. In this light, the authors propose an algorithm that recommends answer providers. A two-step framework is developed, in which a query likelihood language model is constructed that enables the determination of the interests of answer providers. The model is then used to identify answer providers who are interested in answering questions related to the identified topics. At the same time, a maximum entropy model is designed to estimate answer quality. Finally, an answer-quality-based algorithm is developed to model the expertise of answer providers for the purpose of differentiating answer providers of various capacities. The proposed scheme leverages answer provider interest and expertise, allowing for more effective differentiation. Experiments on real-world data from Baidu Knows, a renowned Chinese CQA service similar to Yahoo! Answers, reveal significant improvements over the baseline methods, and test results demonstrate the effective of the novel approach.
Keywords
1. Introduction
Recent years have seen the rapid development of Q&A systems because of the disadvantages of conventional search engines and rising user demand for fast information access. In contrast to existing document retrieval systems, a Q&A system can answer users’ questions in accurate, simple, and natural language. Early Q&A systems based on the auto-answering framework rely primarily on natural language processing, knowledge representation and reasoning, and machine learning. Thus far, however, no ideal open-domain question answering system has been developed.
With the development of Web 2.0 and social networking services, community-based question answering (CQA) services have become popular. An increasing number of users rely on CQA to resolve daily problems. Baidu Knows, a renowned Chinese CQA service similar to Yahoo! Answers, has currently accumulated more than 200 million questions, with an increase of more than 100,000 new questions daily. However, problems arise along with CQA development and the increase in the volume of system data. Given the rise in the quantity of questions submitted in CQA systems, users spend a considerable amount of time waiting for other users to answer the inquiries. In many cases, some of the questions remain unanswered. Meanwhile, users who are willing to answer questions encounter difficulties in finding topics that they are interested in. To prove this point, the authors randomly selected 1000 newly raised questions from Baidu Knows, and checked them again after two days. The result reveals that 68.2% of the questions were responded to with users’ answers, but only 13.2% of them were resolved. Therefore, research on recommending answer providers is essential to CQA service development. An effective system is characterized by the immediate forwarding of newly raised questions to potential answer providers; this allows for the efficient resolution of questions, thereby reducing waiting time and enhancing user experience.
In this article, the authors propose an algorithm that recommends answer providers, with comprehensive consideration for factors related to the interests and expertise of the answer providers. This consideration is based on an extensive analysis of research on answer provider recommendation. First, a query likelihood language model was constructed to analyse answer provider interest for the purpose of identifying groups of suitable answer providers. Because the quality of the answers to questions varies, individuals who address a large number of questions may be not suitable as answer providers. For example, a user may provide a lot of answers, while few of them are effective, so this user must not be a reliable answer provider. Thus, a maximum entropy model is designed to determine answer quality. On the basis of the quality of answers provided, an answer provider expertise model is established to distinguish amongst the capacities of different answer providers and reveal individual characteristics.
2. Related work
Extensive research has been devoted to CQA services in an effort to reduce user waiting time and improve the efficiency of question-answering systems. Before inquiries are submitted, searching for similar questions can provide high-quality answers that may already be available in the system. This feature not only reduces waiting time, but also conserves system resources. In view of this mechanism, Jeon et al. [1] presented an algorithm intended to search for semantically similar questions in a question-answering system. This algorithm calculates question similarities through a language translation model, and considers answers for the corresponding question. Wang et al. [2] proposed a syntax tree structure-based, rather than training-based, query framework to search for similar questions.
The sources of knowledge or information in CQA systems are the question–answer pairs. The number of question–answer pairs generated by a system is relatively limited, whereas more knowledge or information is available in user-generated internet forums. Therefore, these question–answer pairs can be extracted from internet forums as a supplement to Q&A systems. Cong et al. [3] studied the extraction of question–answer pairs from forums and proposed a classification-based sequential pattern algorithm that enables searching for question posts. A transfer-based graph theory was then used to detect answer information in question candidates. Wang et al. [4] examined answer ranking issues by building models of the relationship between questions and answers in Q&A systems. On the assumption that several different types of direct associations exist between questions and answers, the authors used a statistical regression model to calculate such associations and proposed an approach based on analogy to identify the most matched answers.
Some studies are focused on recommending answer providers for newly raised questions in the community. Li et al. [5] used the source codes released by users to build a ‘concept network’, accomplished through the analysis of the class inheritance and class call relationships. A user network is set up by examining the interdependence of posts in the forums. Then, ‘expert’ recommendations are provided in accordance with the concept of question posts and conceptual similarity of answer providers. Zhou et al. [6] used a statistical language model to represent answer provider information, and recommended answer providers in accordance with the dependence amongst posts as well as post topics. Nevertheless, building a ‘reply relationship’ between users/answer providers for most answering systems is difficult, making this method impractical. In the literature [7–9], the probabilistic latent semantic analysis (PLSA) model [8] was implemented to resolve issues related to recommendations on answer providers. PLSA was used to analyse the questions addressed by answer providers and build a model that depicts the interests of the answer providers. The similarity between answer provider interests and questions for recommendation was then calculated. Finally, a recommended list of answer providers was drawn. Given that answer quality varies, recommending answer providers solely on the basis of an interest model is not a sufficiently accurate approach. Moreover, question description in question-answering systems is usually shorter than ordinary document information. Because of limited data availability, constructing a precise answer provider interest model using latent semantic analysis techniques is difficult. In the present work therefore, different methods to model answer provider interest are used, whilst comprehensively considering answer quality. To further improve the accuracy of the recommendations, an expertise model is proposed.
3. Recommendation algorithm
3.1. Formal definition
First, a formal definition and description of the problem are presented.
An answer provider can be defined as follows. It pertains to a given set of users

where
The conditions that the recommended answer provider should satisfy can be analysed from two perspectives: (a) the recommended answer provider should show considerable interest in the question (topic). Constructing an interest model for evaluating the degree of answer provider interest in the question is therefore necessary; (b) the recommended answer provider should have the capacity (expertise) to answer the questions. Thus, constructing an expertise model is also necessary to determine whether the expertise matches the corresponding topic.
3.2. Modelling answer provider interest
Answering a question is usually an indication that the answer provider is interested in the topic. Therefore, to identify the appropriate answer to a newly raised question, the authors set up an answer provider interest model and then recommend a suitable answer on the basis of the matching degree between answer provider interest and question.
To evaluate interest, other questions previously addressed by the answer provider are explored. The information from these answered questions may reflect interest to a certain extent.
In the Q&A community, the interests of answer providers reflect stability over long periods, and an answer provider is usually interested only in questions that fall within specific topics. Meanwhile, the terms combined within a topic are easily distinguished, indicating that topics may differ significantly in terms of vocabulary. All questions in Baidu Knows are divided into many categories, such as sports, business/financial, computer/network, and so on. Before a new question is submitted, the question asker should choose a category for their question. By analysing words included in questions and answers of Baidu Knows, the authors find that questions in the sports category include a few keywords with high probability, such as ‘football’, ‘basketball’, ‘NBA’, and other specific terms. Conversely, questions in the business/financial category are more likely to contain keywords such as ‘stock’, ‘transaction’, and ‘shop’, amongst others. Frequently occurring words in the set of questions addressed by answer providers (questions raised by users and answers given by answer providers) characterize answer provider interest, as shown in Table 1.
Distribution of answer provider vocabulary
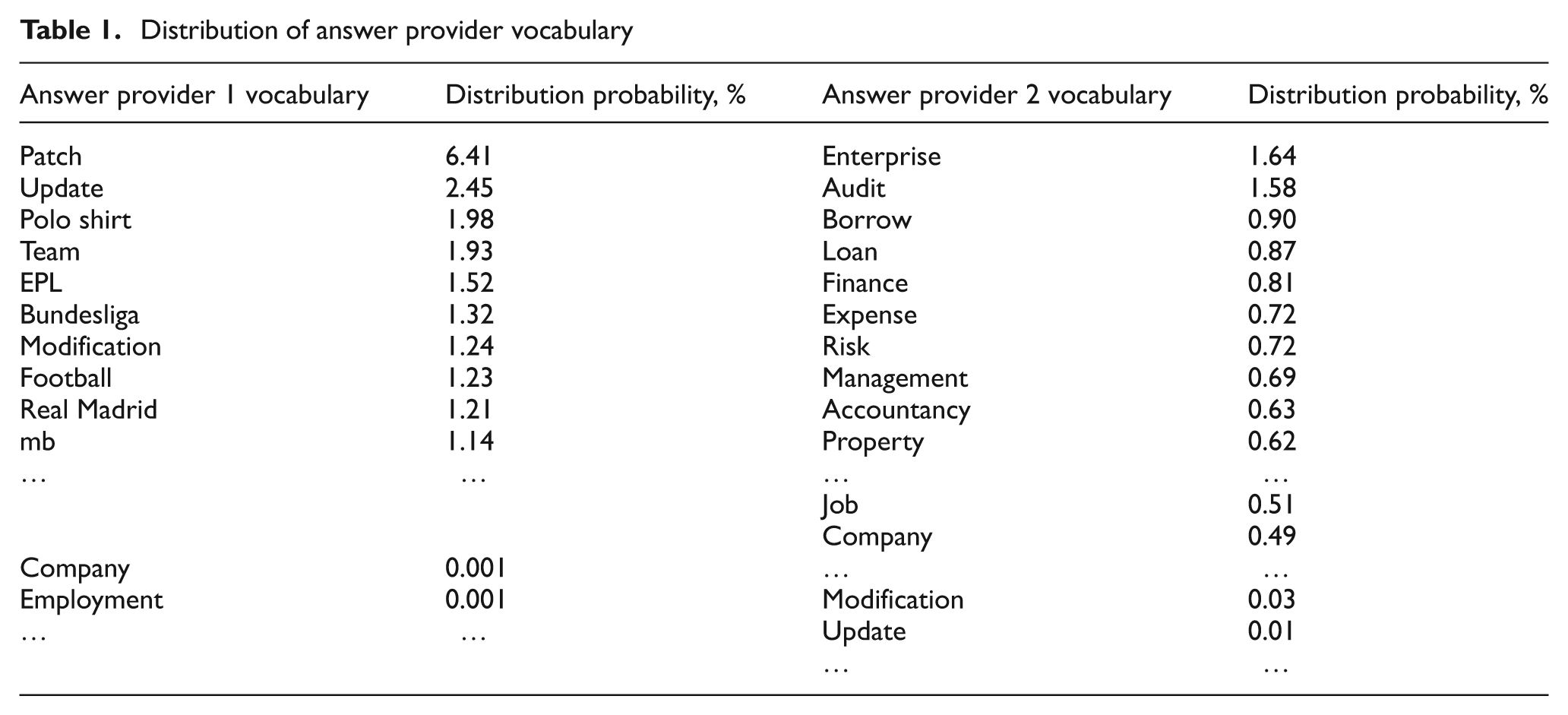
If the keywords of a newly raised question can be derived from a set of questions previously addressed by an answer provider, then it may be inferred that the answer provider may have considerable interest in the question. Thus, the query likelihood language model [9] is implemented to measure the degree of interest in the question. The measurement is accomplished by calculating the probability that the newly raised question will be generated from previously answered questions.
From the perspective of the language model, the degree of interest of answer provider

where
Figure 1 illustrates the method that indicates the degree of answer provider interest on the basis of the query likelihood model. In all the sets of questions addressed by the answer provider (Figure 1), corresponding language model
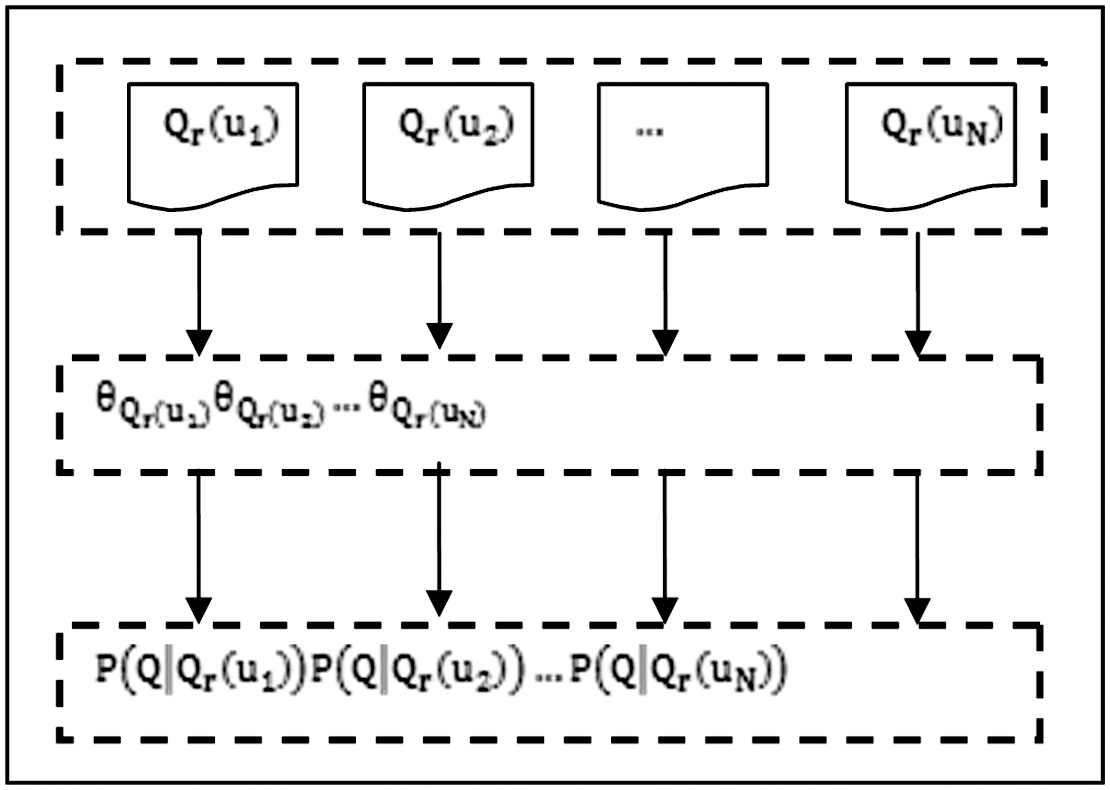
Diagram of the query likelihood language model.
In this method, the problem of determining the degree of interest is transformed into a calculation process for generating the probability (or query likelihood) that a question will be raised under a given language model. To calculate the query likelihood of question
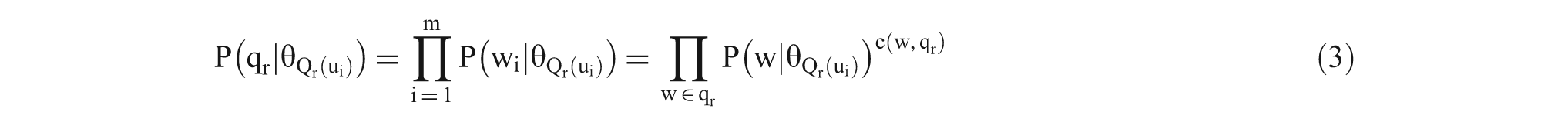
In the formula,

where
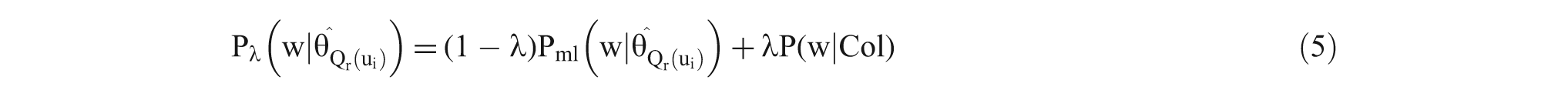
where
Thus, the formula for calculating answer provider interest is:
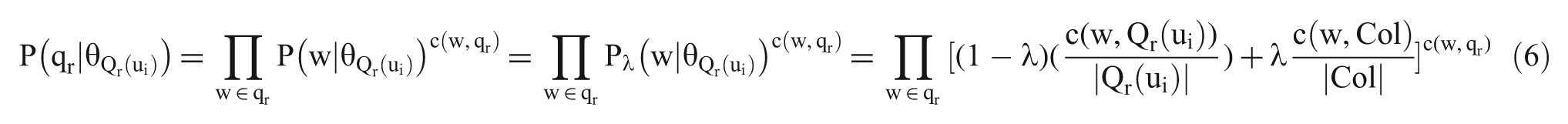
3.3. Answer provider expertise model
Determining recommended answer providers by analysing interest only on the basis of historical information in the questions addressed by answer providers is an insufficiently accurate approach because of the prevalence of spam and the varying quality of answers given by answer providers. The answer providers to be recommended should not only be interested in the question, but also be an expert in the topic; these characteristics guarantee high-quality answers. Thus, to derive a more effective recommendation algorithm, answer quality is also taken into consideration by constructing an answer provider expertise model, which is based on the answer provider interest model.
Assuming that the responses of the answer provider for a given topic exhibit a greater probability of being high-quality answers (such as the Baidu Knows community answers that exhibit high adoption rates), it can be inferred that the answer provider possesses sufficient expertise in a particular field. Thus, the quality of answers already given by answer providers is used to determine answer provider expertise. To determine who should be recommended, his/her expertise is matched with the topic.
Because a newly raised question has not been addressed by a potential answer provider, the quality of the answer to be provided necessitates prediction. The weighted average of the answers already given by the answer provider is used to estimate the quality of the answer to the newly raised question:
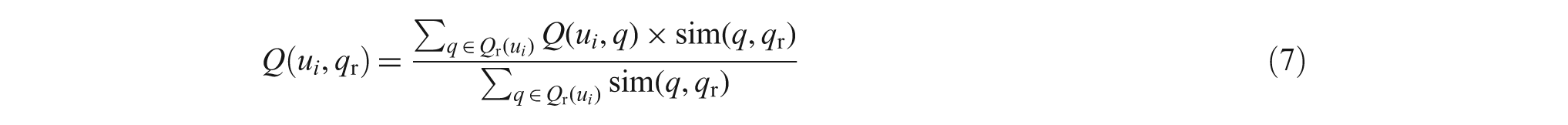
where
In the answering community, a user (the individual submitting an inquiry) can select the answer with which he is most satisfied as the best answer. Apart from this criterion, no other standard for the quality of answers is used in the answering community. More than one correct answer may exist amongst those given by different answer providers, but the user can only choose one best answer. The quality of answers to the question should therefore be estimated using a specific method.
The quality of answers can be measured in terms of different aspects, such as accuracy, completeness, timeliness, reliability, verifiability, etc. [12]. Zhu et al. [13] proposed an evaluation framework for estimating answer quality. However, the indicators they used were mostly descriptive and could not be obtained and calculated automatically. The current study uses this evaluation to label experiment training data. In addition, the maximum entropy model is trained by extracting some question–answer characteristics that can be calculated directly and obtained to derive the method for automatically calculating answer quality. The general framework of the maximum entropy model is shown in Figure 2 [14].
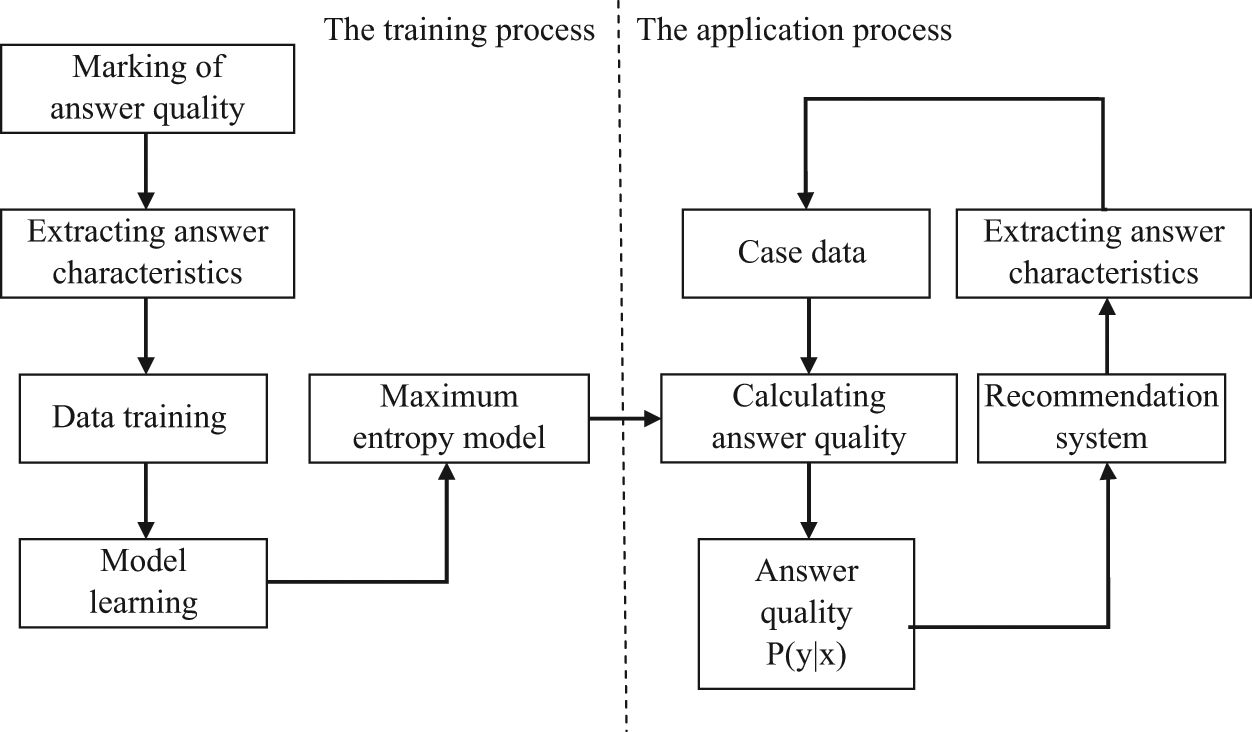
Frame diagram of the maximum entropy model.
Answer quality is evaluated as either good or bad. Estimating answer quality means determining the probability of occurrence for an event

where
On the basis of the parameter form of the maximum entropy model, the probability distribution function can be generated, after which the maximum entropy model is fully constructed, provided that parameter values
According to the discussion above, characteristic selection is a key factor in the maximum entropy model. For the features of questions and answers in this article, selection mainly focuses on text and non-text characteristics. Text characteristics pertain to answer content, whose characteristics include answer length, ratio of answer lengths, number of different words in an answer, and number of words both in the question and answer. Non-text characteristics refer to the features of an answer provider; these include the features of answers [answer provider’s credit (answer provider’s empirical value], answer provider’s authority (adoption rate of answers, number of praise acquired), number of answers, ratio of questions to answers, number of answers to the question, etc.
The values of text characteristics can be calculated by extracting the corresponding question content. Before calculating answer length and number of words, text content is pre-processed by removing stop words, such as ‘the’. Given the unique quality of the Chinese language, Chinese words are first segmented for text. With regard to non-text characteristics, the corresponding information is directly extracted by analysing the structure of web pages. In addition, the probability of characteristics in the maximum entropy model monotonically increases, that is, the larger the characteristic value, the higher the event occurrence probability. Adoption rate is defined as the rate of user acceptance of the answer. A high adoption rate for the responses given by the answer provider indicates a high probability that the answer provider can respond well to the question. However, a longer answer cannot always be regarded as a better answer. For this reason, conversion is essential for characteristic values. The method given in [15] is adopted for converting the calculation for such non-monotonic characteristic values.
The model that predicts answer quality is established for newly raised questions given by recommended answer providers (that is, the answer provider expertise model). First, the maximum entropy model is constructed by model training. In model training, the characteristics of the answers already addressed by answer providers are first extracted and calculated. The quality of answers is marked by artificial marking and the training samples are generated. The learning parameters of the maximum entropy model are then proposed using the GIS algorithm, and the weights of all the characteristics in the model are calculated. This step completes the construction of the maximum entropy model for answer-quality measurement. After this, the quality of answers
3.4. Recommendation algorithm
An algorithm that recommends answer providers is developed in this article, with comprehensive consideration for the degree of answer provider interest in questions, as well as matching the degree of answer provider expertise and topic. This process is expressed as follows:
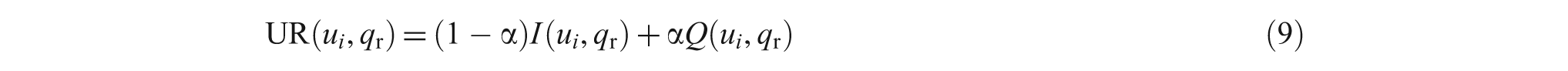
where
4. Experimental results and analysis
4.1. Experimental data
The experimental data were automatically extracted by our programs from Baidu Knows. The Q&A data from Baidu Knows was crawled for a half-month period (1–15 January 2010). A total of 1,017,461 valid data items (only questions with answers) were used. Statistical data information is shown in Table 2 and Figures 3 and 4.
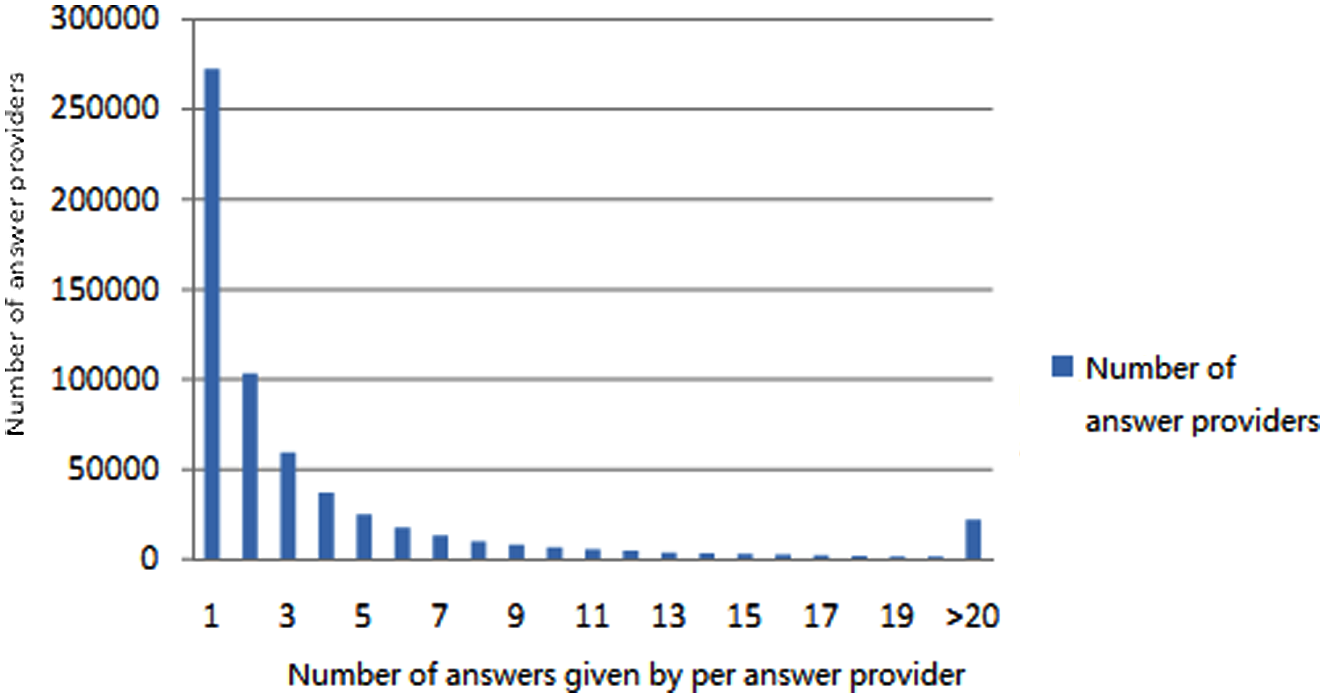
Distribution of number of answers given by per answer provider.
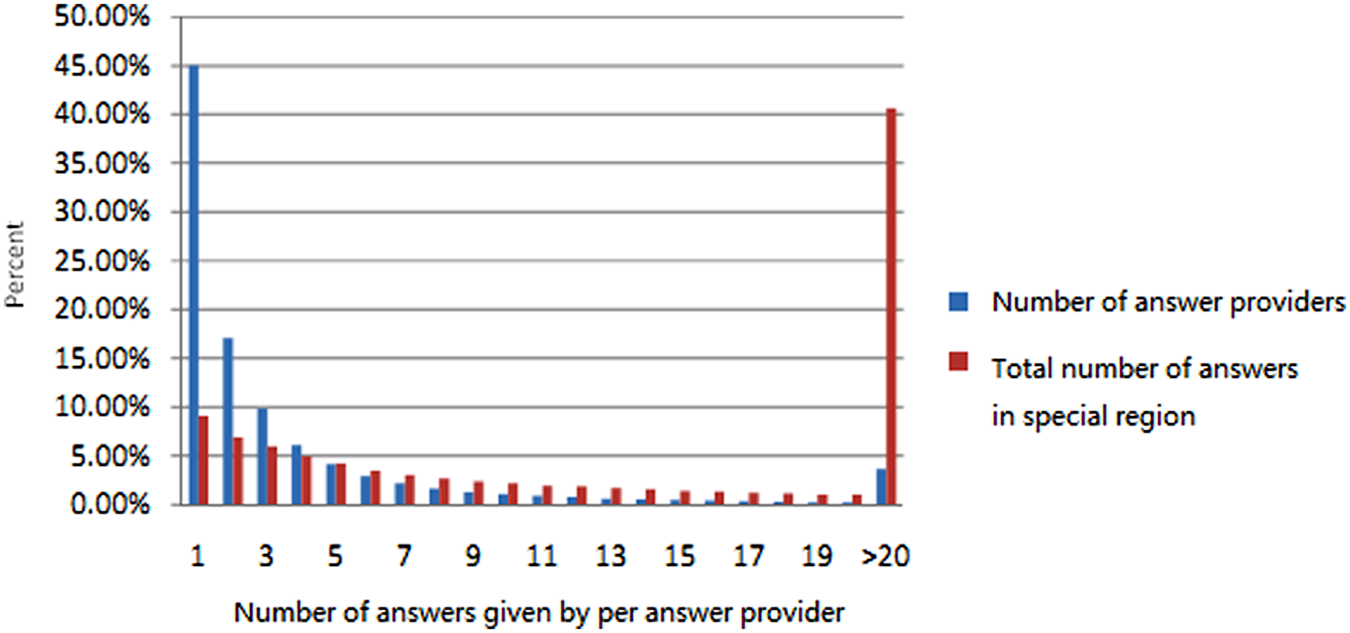
Comparison diagram of number of answers given by per answer provider and total number of answers in special region.
Statistical information on the crawled data set

Figures 3 and 4 show that, in a Q&A community, most users rarely answer questions. In the statistical data, there are more than 270,000 users (more than 45% of users who have answered questions) who only answer questions once, and the number of their answers is only 9.10% of all answers provided by all users. On the contrary, the number of users who answer questions more than 20 times is 3.66% of users who have answered questions, but they produce 40.62% of all answers.
Because most answer providers in the data set addressed very few questions (more than 45% answered only once), this aspect cannot be used to learn answer provider interest and construct the expertise model. Answer providers recommended by the system should be the more active ones with reasonable response records. Therefore, the data set is filtered to answer providers who have addressed more than 20 questions. Experimental data were collected from these Q&A data sets in accordance with the responses given by the answer providers. Data set information obtained after screening is shown in Table 3.
Statistical information on the experimental Q&A data set

The experimental data covering 1–10 January 2010 were chosen as training data for the construction of the answer provider model; data on the answer providers for the last five days were chosen as test data for the evaluation of the proposed recommendation algorithm.
4.2. Evaluation method
Two basic assessment parameters (precision and recall) were used to evaluate the proposed algorithm. Precision indicates the proportion of highly relevant answer providers out of all answer providers to be recommended, and is expressed as:

where
Recall indicates the proportion of recommended relevant answer providers in all highly relevant answers:

Recall is denoted by the proportion of highly relevant answers contained in the first N results as R–P@N.
However, because precision does not consider result rank, it cannot satisfy our goal of evaluating the overall recommended results. Thus, average precision is calculated instead:

where
Given that more than one test data item is used in the experiment, the mean average precision (MAP) is taken as the indicator of precision evaluation for the recommendation algorithm. In addition, the mean of reciprocal rank (MRR) of the first ‘correct result’ from the recommendation results is also used. This indicator can be used to measure how many answer providers should be recommended before the first highly relevant answer provider is recommended.
4.3. Experimental results
In the experiment, the historical information was first segmented on the answers already given by answer providers using ICTCLAS1.0 2 and Lucene 3 The models for answer provider interest and answer provider expertise were then constructed. Different methods were tested and compared. These methods are as follows:
the baseline model (BM), which is the recommendation algorithm for constructing the answer provider interest model based on PLSA;
the interest-based model (IM), which is the recommendation algorithm for constructing the answer provider interest model based on language model; and
the IM + expertise, which is the recommendation algorithm that comprehensively considers answer provider expertise.
With regard to IM, Equation (6) was used to calculate the answer provider rating, selecting recommended answer providers. The experimental result for IM is shown in Figure 5, which shows traversal from
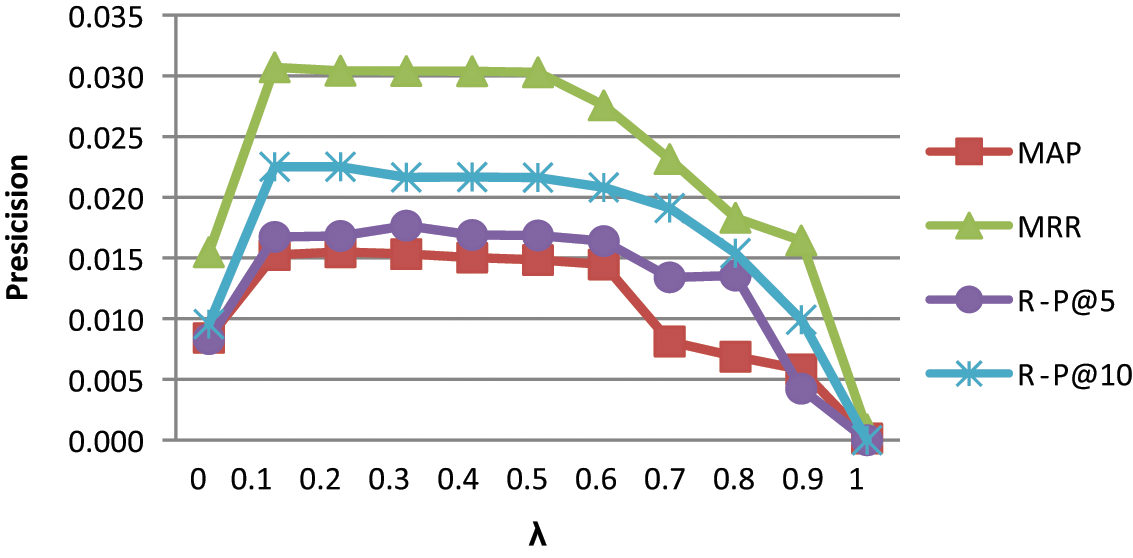
Recommendation results of the IM algorithm.
Figure 3 shows that, when
The results of the recommendation algorithm using PLSA to construct the answer provider interest model are shown in Table 4. The table shows that the IM algorithm improves in terms of precision and recall compared with the BM algorithm, primarily because the latter adopts the proportion of the word frequency sum of answer provider responses instead of the overall responses. The scarcity of the answer data and the prevalence of spam cause inaccuracy in answer provider interest learning, resulting in the low validity of the recommendation results.
Recommendation results of the BM and IM algorithms

To understand the effect of answer provider expertise on the recommendation results, answer provider expertise was taken into consideration in conjunction with the answer provider interest in the question, resulting in the recommendation algorithm [IM-expertise algorithm, Equation (9)]. The experimental result is shown in Figure 6.
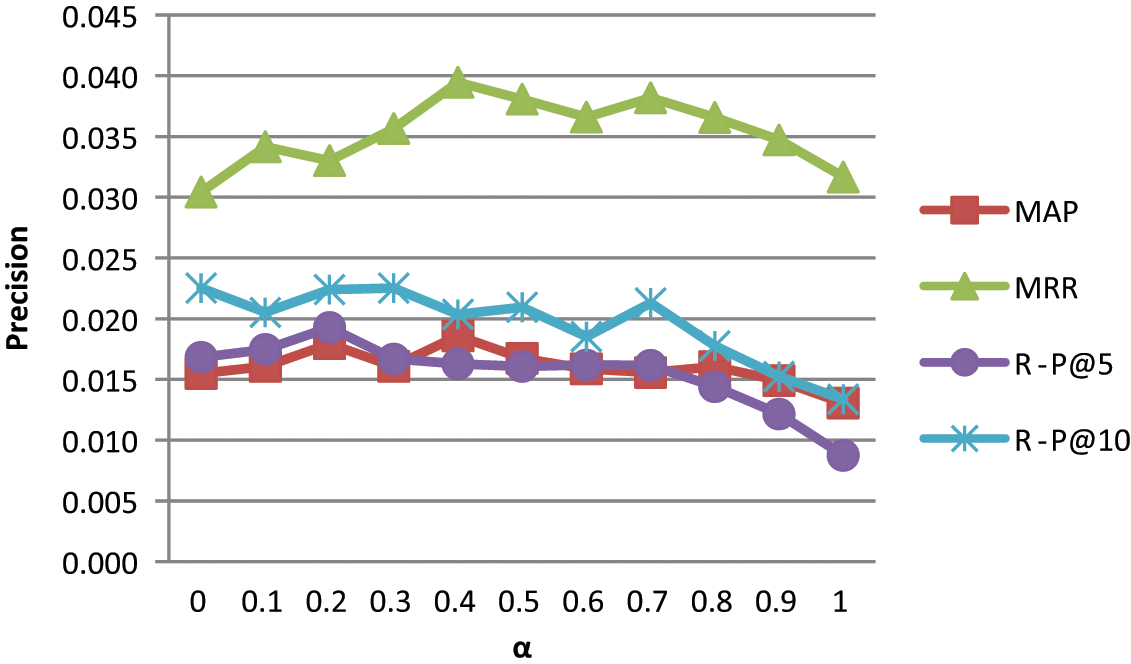
Recommendation results of IM-expertise.
After the incorporation of the answer provider expertise factor, the accuracy of the recommendation result further improves. When
Upon a comprehensive view (Table 5), the IM-expertise algorithm improves MAP and MRR by 20.1% and 29.7%, respectively, compared with the IM model at the expense of the decline in recall (R–P@5, R–P@10 reduced by an average of 6%). This indicates that a comprehensive recommendation algorithm achieves better results in recommending answer providers.
Recommendation effect of IM and IM-Expertise

5. Conclusion
This article presented an algorithm that recommends answer providers, with comprehensive consideration for number of factors such as answer provider interest and expertise. The algorithm is aimed at reducing waiting time and helping answer providers in the Q&A community address questions that they are interested in. The experimental results for the Baidu Knows Q&A community shows that significant enhancement in the accuracy of the recommendation algorithm can be achieved when the answer provider expertise factor is taken into consideration.
Further research work will involve the incorporation of answer provider availability and answer provider load balance into the current algorithm because users/answer providers can be highly active for a certain period, but may gradually rarely participate in asking/answering questions. By analysing answer provider availability, the probability that answer providers will address recommended questions can be estimated within a certain period, thereby preventing the system from recommending inactive answer providers. In addition, answer provider recommendation can be balanced to reduce the workload of some active answer providers, possibly further improving the efficiency with which questions are addressed.
Footnotes
Acknowledgements
This work is supported by the National Key Technology R&D Program (no. 2008BAH24B03) and the National Natural Science Foundation of China (no. 61003254) and Zhejiang Provincial Natural Science Fund of China (no. Y1080130) and the Fundamental Research Funds for the Central Universities.