
Abstract
In this paper, we are interested in XML multimedia retrieval, the aim of which is to find relevant multimedia objects such as images, audio and video through their context as document structure. In context-based multimedia retrieval, the most common technique is based on the text surrounding the image. However, such textual information can be irrelevant to the image content. Therefore many works are oriented to the use of alternative techniques to extend the image description, such as the use of ontologies, relevance feedback, and user profiles. We studied in our work the use of links between XML elements to improve image retrieval. More precisely, we propose dividing the document into regions through the document structure and image position. Then we weight links between these regions according to their hierarchical positions, in order to distinguish between links that are useful and those that are not useful. We then apply an updated version of the HITS algorithm at the region level, and compute a final image score by combining link scores with initial image scores. Experiments were done on the INEX 2006 and 2007 multimedia tracks, and showed the potential of our method.
Keywords
1. Introduction
Multimedia information retrieval (IR) is divided into content-based and context-based retrieval. In this paper we are interested in the second type, in which the most-used contextual factor is the text. With the advent of the web, to improve retrieval accuracy new factors should be taken into account, such as links between documents and document structure (markup language tags). The work described here is carried out with images, but can be extended to any other media.
The most common technique in context-based image retrieval is the use of the text surrounding the image. However, the page text can be irrelevant to the image content, or may form an insufficient description of the multimedia object. Therefore many works are oriented to the use of other techniques to extend the image description, such as ontologies, relevance feedback, and user profiles. We studied in our work the use of links between XML elements to improve image retrieval. More precisely, we propose a link-based multimedia retrieval algorithm, inspired by the HITS algorithm, to re-rank multimedia objects retrieved by an XML multimedia retrieval system.
This paper is organized as follows. Section 2 presents a state-of-the-art description of link analysis techniques in IR. In Section 3, we discuss the motivations. Section 4 describes our link analysis algorithm. Experiments and results are shown in Section 5, and our evaluation and results are discussed in Section 6. We conclude in Section 7.
2. Related work: link analysis in IR
In this section, we review the existing techniques using hyperlink analysis algorithms in information retrieval. These techniques are divided into two categories: link analysis algorithms in textual retrieval (document or part of document); and link analysis algorithms in multimedia retrieval. (In this paper, we consider the case of images.)
2.1. Link analysis algorithms in textual IR
Many techniques have been used in link analysis approaches. The most famous algorithms in web information retrieval are HITS [1] and PageRank [2]. In both algorithms, the web is presented as a linked graph G = {U, V}, where U is the set of web pages (nodes), and V is the set of links (edges) between pages.
The PageRank algorithm, which is used in the well-known web search engine Google, exploits the whole web-linked graph to calculate a query-independent rank value (PR) for each web page p. This rank value is calculated by the following formula:
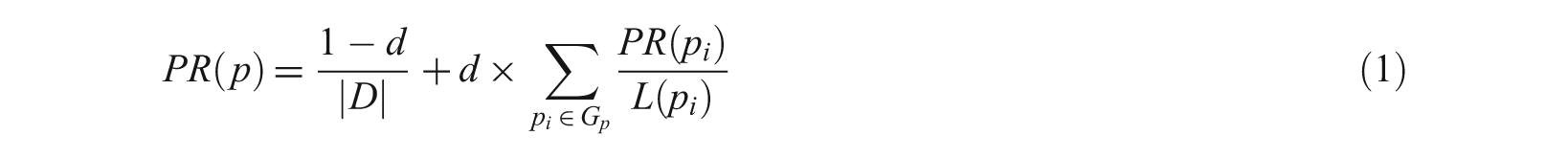
where d is a damping factor in the range [0..1], usually set to 0.85; |D| is the number of documents in the whole collection; PR(p i ) is the rank value of page p i ; L(p i ) is the number of outgoing links on page p i ; and G p is the set of pages that link to the page p.
Authorities and hubs have a mutually reinforcing relationship: a good hub points to many good authorities, and a better authority is pointed by many good hubs. The authority score
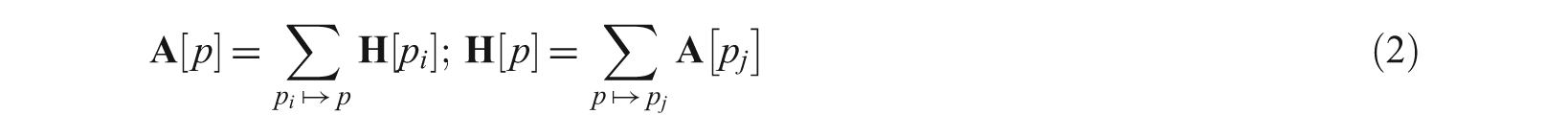
The final authority and hub scores of a web page are obtained through an iterative application of equation (2) until the values converge. Several studies have been performed to improve the HITS and PageRank algorithms [4–10]. Many other link analysis algorithms have been proposed in the literature, such as SALSA (Stochastic Algorithm for Link Structure Analysis) [11], which combines both PageRank and HITS, and PathRank [12], which applies a path-based method to use the multi-step navigation information discovered from website structures for web page ranking.
Recently, many works have studied the impact of link analysis in XML documents. An early work [13] proposed a method (called XRANK) that takes hierarchical and hypertext information into account to rank keyword search.
First, for each element, it computes an ElemRank score, which is similar to Google’s PageRank [2], except that ElemRank is defined as the granularity of an element, and takes the nested structure of XML into account. The ElemRank for an element v, denoted by e(v), is computed according to the formula
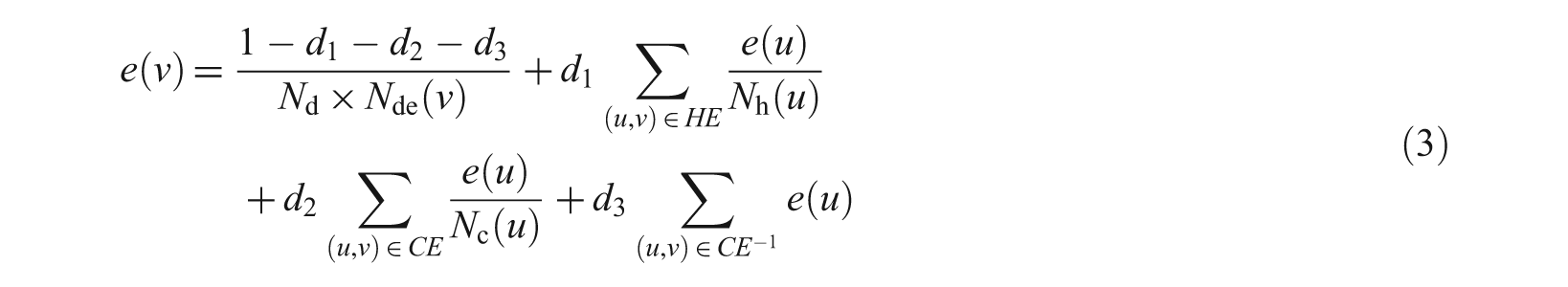
where CE is the ancestors to descendants relationship; HE is the XLink link between nodes; CE−1 is the same set as CE, except that the direction is reversed (descendants to ancestors); d1, d2 and d3 are the probabilities of navigating through hyperlinks, forward containment edges and reverse containment edges, respectively; Nd is the total number of documents; Nde(v) is the number of elements in the XML documents containing the element v; Nh(u) is the number of outgoing hyperlinks from element u; and Nc(u) is the number of subelements of u.
Then, a Rank score is computed for each result element E according to the query keywords. Consider a query Q = {k1, …, k n } and a result element E. k i is contained directly in a subelement w i of E. Rank of E with respect to k i is computed as follows:
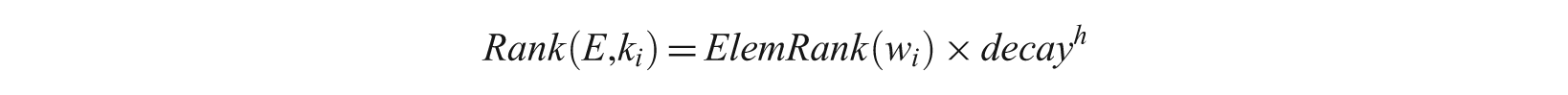
where decay is a parameter between 0 and 1, and h is the length of the path from E to w i .
Finally, the overall ranking of E is computed as follows:
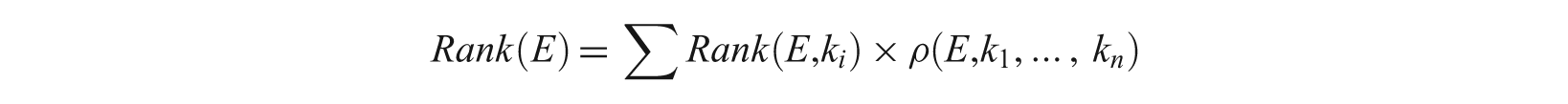
The overall ranking is the sum of the ranks with respect to each query keyword, multiplied by a measure of keyword proximity.
Other studies [14,15] have used XML links to re-rank returned results by two degrees: local indegree, representing the number of incoming links from the collection to a document; and global indegree, representing the number of incoming links to a document from the documents returned as results to a given query. Kimelfeld et al. [16] use a language model with the HITS algorithm [1]. First, they apply a preliminary ranking to the documents, and filter out those that have low relevance scores. Then they calculate a score for elements of each returned document. The best results are obtained by using HITS for document filtering rather than for element ranking.
The use of link analysis algorithms in textual information retrieval has shown its relevance in both plain and structured documents. This source of evidence is also used in the case of multimedia retrieval. In the next section we present some works using link analysis in multimedia retrieval.
2.2. Link analysis algorithms in multimedia IR
In hypermedia collections, Dunlop [17] has proposed defining a graph composed of multimedia objects (called multimedia nodes) linked to textual documents (called textual nodes). Using this graph, a representation for each multimedia node is constructed from the textual content of all nodes directly linked to it. This algorithm can be extended by taking into account not only direct neighbours of a multimedia node, but also all nodes that can be reached from the multimedia node by following, at most, two links, and which consequently consider a larger representation.
Based on this model, Harmandas et al. [18] have proposed dividing the textual content of the document containing the multimedia object and the textual content of linked documents into blocks (image caption, neighbouring image captions, and the text of the one-step-linked documents). A score is calculated for each block, and is then combined with the representation score of the multimedia node to obtain a final score.
Another work inspired by HITS and PageRank is the PicASHOW system [19]. This system applies approaches based on co-citation and methods influenced by PageRank. Two assumptions are at the origin behind using the co-citation measure: (1) images that are contained in the same page are likely to be related to the same topic; (2) images that are contained in pages that are co-cited by a certain page are likely to be related to the same topic.
Furthermore, according to the PageRank algorithm, images belonging to authoritative pages related to topic t are assumed to be good candidates for relevance to that topic. The authors have concluded that link analysis helps to improve image retrieval accuracy on the web.
In the PicASHOW system, only textual queries are supported. For this reason, Voutsakis et al. [20] and Petrakis [21] enhanced this system by incorporating the text and image content of the query and the page. The new system, called WPicASHOW (Weighted PicASHOW), has given improved results.
He et al. [22] have also proposed a system for clustering and searching WWW images, called iFind. Using a vision-based page segmentation algorithm (VIPS: VIsion-based Page Segmentation), a web page is partitioned into blocks. The textual and link information of an image can be then accurately extracted from the block containing the image concerned. The textual information is used for image indexing. By extracting the page-to-block, block-to-image and block-to-page relationships through link structure and page layout analysis, an image graph is constructed. This system is less sensitive to noisy links than previous methods such as PageRank, HITS and PicASHOW, and consequently the image graph can better reflect the semantic relationship between images.
In the literature of link analysis techniques in semi-structured documents, few studies have been realized. To the best of our knowledge, the only existing method has been proposed by Kong and Lalmas [23]. This method is based on XLink. In fact, textual information of different linked resources may contribute differently in describing the multimedia object content. However, this method has never been evaluated.
To summarise, state-of-the-art link analyses approaches are, most of the time, applied to non-structured data. Only a few approaches have offered a real study of the impact of links in XML multimedia retrieval. In this paper, we study the impact of the use of links on the accuracy of multimedia retrieval in XML documents.
3. Motivations
As already indicated in Section 2, there are many algorithms for using link analysis in multimedia retrieval. However, in these approaches, the multimedia objects are contained in textual documents or web pages, which are structured according to the visual presentation using predefined HTML tags such as bold or italic.
The problem is that most existing works consider a page as an atomic unit that discusses a single topic. However, a page can contain several topics related to a generic concept. According to this idea, not all links should be used to retrieve a multimedia object, but only those that are likely to be the most representative of the multimedia object. He et al. [22] have proposed segmenting a web page into blocks according to the visual separators of the page (horizontal and vertical lines). The problem with this proposition is that the segmentation is not semantic: each author has his or her own way of editing pages, and these separators do not always exist.
Since the documents in our work are structured semantically, we propose defining a document part for each multimedia object according to the hierarchical structure of the XML document tree. This document part, called the multimedia object region, should be defined as the most significant representation of the multimedia object.
Another problem is that there is no multimedia specificity in the literature on algorithms for link analysis in multimedia retrieval; links have been processed in the same way, whatever their hierarchical positions.
In our link analysis algorithm, we propose weighting each link according to its hierarchical position in relation to the element containing the multimedia object. Consequently, links close to the multimedia object have more importance than links that are far away.
We have chosen to adapt the HITS algorithm to XML multimedia retrieval for several reasons. First, it is performed for each new query, which allows it always to be close to the subject of that query. In addition, pages added in the extension phase are probably related to the same subject, and may be relevant even if they do not contain query terms. However, direct adaptation of the HITS algorithm is not possible in our case.
First, in the extension phase of the HITS algorithm, several pages that are irrelevant to the query are added to the initial set of pages. This problem is called topic drift. Some works on web textual information retrieval have suggested adding, for each page in the initial set, all pages pointed to by this page, and randomly selecting L pages pointing to this page to penalize the importance of popular pages. Borodin et al. [24], for example, set the value of L at 50; others [20] have set it at 100. However, the problem remains in the random selection of these pages; even the pages pointed to by the root set may not be related to the query subject. In our work, we propose extending the part of the document containing the multimedia object by the most similar part of the document part, using the co-citation measure [26].
Second, in the built graph, composed of regions of the root set and added regions, we do not guarantee that nodes are strongly connected. As a result, several regions that may contain relevant multimedia objects will be isolated from the graph, and therefore they do not receive any score. Our solution proposes combining the scores returned by the link analysis algorithm with the initial scores for multimedia objects.
4. XMRank: a link analysis algorithm in XML multimedia retrieval
In this section we present our method, called XMRank (XML Multimedia Ranking), which aims to improve multimedia retrieval accuracy by exploiting the links between XML elements.
4.1. Basic idea
XMRank incorporates links in the computation of final scores of multimedia elements returned initially by an XML multimedia retrieval system. More precisely, we propose adapting the HITS algorithm used in web retrieval to XML multimedia retrieval. This adaptation consists in applying HITS not at a document level, but for a document part (multimedia object region).
First, we select the most relevant multimedia elements, 1 called the initial set, obtained by an XML multimedia retrieval system such as the OntologyLike model [25] (described in Section 5.4). For each multimedia element, we propose not to use the whole document, but to define the best part of the document (region) representing the multimedia object. Then we extend this subset by the most similar regions. In addition, we propose weighting links between regions according to the hierarchical structure.
After obtaining the link weights, we apply the HITS algorithm to re-rank the initial results. Therefore the hub and the authority scores formulae are applied in the weighted graph of multimedia object regions, and modified into the following form:
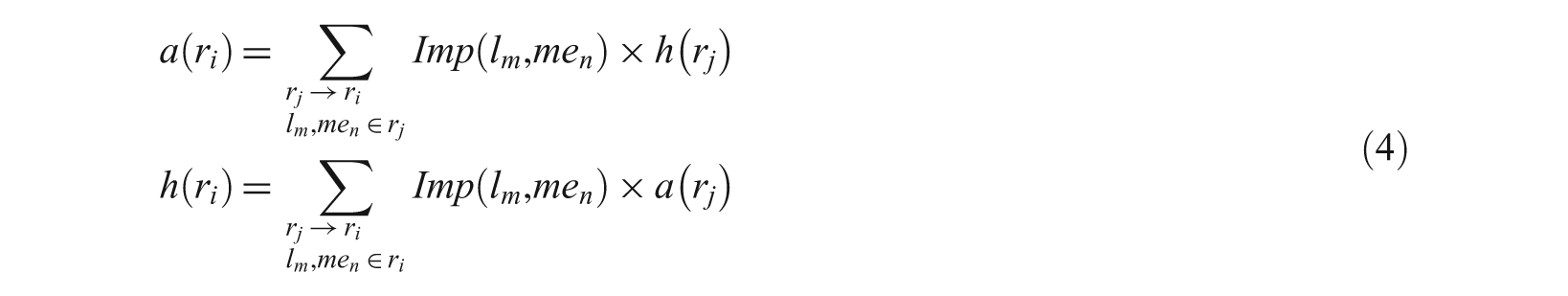
where r i and r j are two different regions; r j →r i is a link from region r j to region r i , and r i →r j is a link from region r i to region r j ; l m and me n are respectively a link and a multimedia element of a region r j (or r i ); m is the number of links; and n is the number of multimedia objects in the subgraph of regions. The link weighting is represented by the function Imp discussed later in Section 4.4.
Although the use of link analysis allows us to find relevant multimedia objects, even though their regions are not related to the query terms, there are problems: (1) isolated regions (i.e. regions that are not pointed to, and do not point other regions) are ignored, even if they have relevant multimedia elements; and (2) an irrelevant region with a high hub score can influence the authority scores of the pointed regions, which tends to favour non-relevant regions over relevant ones.
For these reasons, we propose using a linear combination of the initial score (Sinitial(me i )) of a multimedia element and the link score Slink(r i ) (which can be the authority score or the hub score, or a combination of both) of the region containing this multimedia element. The final score SF of a multimedia element me i is then obtained as follows:
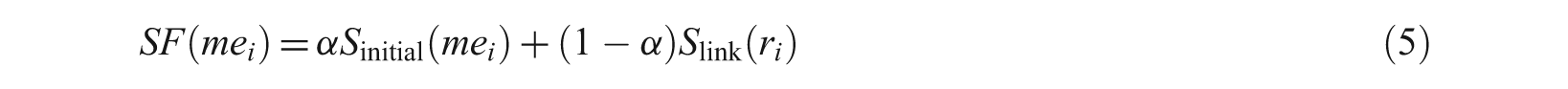
where α is the linear combination factor.
4.2. Definition of region of multimedia element
In order always to have specificity of the multimedia object subject, we propose to use not all links in the document, but only links in elements surrounding the multimedia object, as they have the highest probability of sharing the same subject as the multimedia object. This part of the document is defined as the region of the multimedia object.
An XML document can be represented as a hierarchical tree, composed of a root (document), simple nodes (elements and/or attributes) and leaf nodes (values as text and images). An inner node is any node of the tree that has child nodes (i.e. a non-leaf node).
The easiest way to define the multimedia object region is to consider the multimedia element and its descendant elements, as they are the most specific elements – that is, those that contain only information specific to the multimedia object. However, this region can be very small, or even absent (if there is no textual description for the multimedia object). For this reason, we propose to study different hierarchical levels of the XML document. Figure 1 shows an example of different possible multimedia object regions.
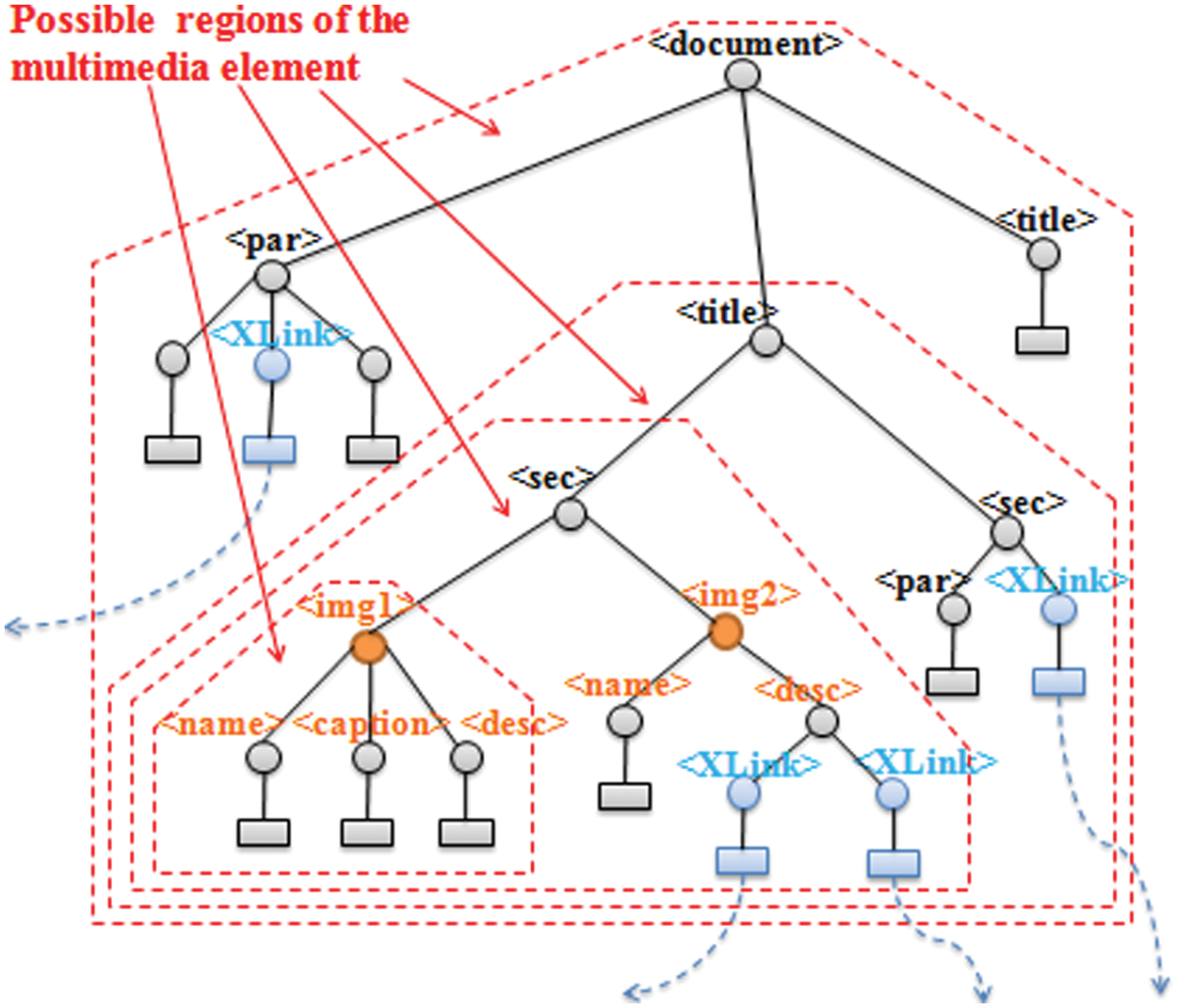
Example of different possible regions of a multimedia object.
In this example, if we consider only the direct descendants of the multimedia object as the region, no links will be used later. However, if the region is defined by the first ancestor’s descendants of the multimedia object, two links will be used; and so on.
In some cases, where the document tree has a low depth, we can even have the whole document as a region. Once the best region is fixed, each multimedia object will have one region, whereas each region can contain one or more multimedia objects
In the example of Figure 1, images img1 and img2 both have the same first ancestor, and consequently they have the same region of the first ancestor, sec.
4.3. Extension of initial regions set
This phase aims to add other relevant multimedia elements to the initial set through incoming and outgoing links. Applying the traditional HITS algorithm, the initial region set should be extended by the regions that are pointed to or which point to this set. The idea behind this extension type is that added regions are likely to be related to the same subject of the initial set, and consequently the constructed graph will share the same topic. A link from one region to another is then considered as a recommendation, and if two regions are connected by a hyperlink, they might be sharing the same topic. However, these two assumptions are not always checked, and many added regions can be irrelevant. As a conclusion, if the number of irrelevant regions is important, the graph will focus around the main topic of the input graph. For this reason, we propose to extend the initial set of regions by the most similar regions.
To calculate the similarity between two regions, various link-based measures can be used, such as co-citation [26] or bibliographic coupling [27]. In our work, we propose to use the co-citation measure, since it has shown its relevance in the case of web documents [28].
Let P r be the set of regions that point to a region r. The similarity score between two regions r1 and r2 using the co-citation measure is calculated as follows:

where
For each region in the root set, we calculate its similarity score according to all other regions, and we add only the K most similar ones. The final region set is considered as a graph, where nodes are regions, and edges are links between them.
4.4. Weighting links between regions
In the same region, links should not have the same importance. Links of the descendants of the multimedia element are more specific to the multimedia object concerned than other links: therefore they should have the highest importance. Similarly, links of the first ancestor of the multimedia element should have greater importance than links of the second ancestor, and so on, until we reach the document root, the associated links of which should have the lowest importance. Figure 2 represents a region of a multimedia object where L and K are nodes that contain links to other parts of the graph. In this example, since the link of node L belongs to the direct descendants of the multimedia object, it should be more important than the link of node K, which belongs to the first ancestor’s descendants of the multimedia object.
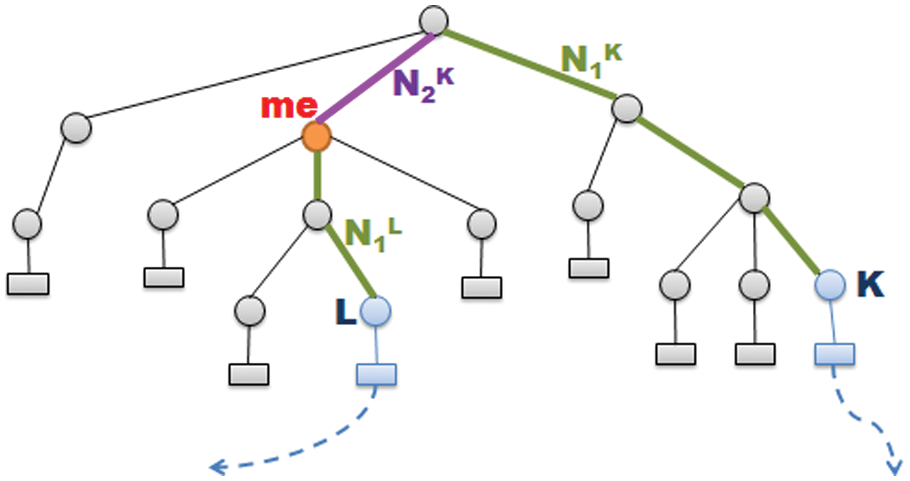
Relationship between nodes containing links and the multimedia object.
More precisely, we propose to weight the links according to the distance between their container elements and the multimedia object concerned. Two formulae are evaluated below in Section 5.6. The better of the two is

where Imp(l,me) is the importance of a link l to a multimedia object me; N1 is the number of edges between the node containing the link and its common ancestor with the multimedia element me; and N2 is the number of edges between the multimedia element me and its common ancestor with the node containing the link.
The distance N2 is used to distinguish links with different levels in the tree. This distance should play the role of damping factor when going back in the hierarchical tree. Links in the descendant nodes of the same ancestor are also distinguished, thanks to the distance N1.
In the example in Figure 2, the distance N2 of the link belonging to node L is null. To avoid a zero division, we increment this distance by 1 in our equation. We use the multiplication of the two distances in order to promote the importance of descendant nodes of the multimedia element in comparison with the most distant nodes. The maximum importance value (Equation (7)) equals 1 when N1 = 1 and N2 is null. This value tends to 0 when N2 increases.
4.5. The algorithm
We present in algorithm 1 pseudo-code for the XMRank approach. This algorithm receives a preliminary list of relevant multimedia elements obtained by an XML multimedia retrieval system, and returns a results list of multimedia elements. The first step allows construction of the region subgraph, and the second step concerns computing of the final scores of the multimedia elements.

5. Experiments and results
In this section, we discuss the experimental data set, our evaluation metrics, some experimental problems related to the collection used, and the results of our proposition. To our knowledge, the only existing collection to evaluate the use of document structure in multimedia retrieval (that is, a real structure and not a structure for annotation) is the INEX (INitiative for the Evaluation of XML Retrieval) multimedia one.
The INEX multimedia (INEXMM) track was organized only in 2005, 2006 and 2007. In INEXMM 2005, images in the collection used are all located at the end of a document. Consequently, our approach cannot be evaluated, as we cannot create image regions, and link weighting will not have a significant role. In INEXMM 2006 only nine queries are provided by the organizers, and in INEXMM 2007 only 19. In our experiments, we have used a 1.8 GHz Pentium dual-core processor with 1 GB of main memory.
5.1. Data set
The core collection of the INEX multimedia track (2006 and 2007) was the English version of the Wikipedia XML collection. This latter contains about 660,000 XML documents (4.6 gigabytes without images), 30 million elements, and more than 300,000 images. On average, an article contains 161.35 XML nodes, where the average depth of an element is 6.72. More details of the document collection are given by Ludovic and Patrick [29].
As mentioned above, the 2006 and 2007 query sets of the multimedia track are composed of 9 and 19 queries respectively. We used only the title field (keywords terms) to express queries.
In the official campaign, both query sets (2006 and 2007) are assessed on multimedia fragments (i.e. XML elements containing at least one image) and not on multimedia elements such as images. In order to evaluate our proposition in multimedia element retrieval, we therefore constructed a new base of assessments composed only of relevant multimedia elements (i.e. image elements) extracted from the original assessments provided by the organizers. We ignore the textual part, and extract only the images contained in the multimedia fragments of the original assessments.
5.2. Evaluation metrics
To evaluate the performance of our approach, we used the MAP (mean average precision) measure. The precisions are calculated for each relevant retrieved document. The average precision (AP) reflects the query performance. The MAP is the average of the average precisions for all queries, and is obtained from the following formula:

where AP q is the average precision of a query q, Q is the query set, and |Q| is the number of queries.
To validate our results statistically, we used the Wilcoxon signed-rank test [31], which is the non-parametric equivalent of the paired-samples t-test. This test consists in calculating the value of significance p∈ [0,1], which estimates the probability that the difference between two methods is due to chance. We can conclude that the two methods are statistically different (and not by chance) when p < α, where α < 0.05 is commonly used [32]; the nearer p approaches zero, the more likely it is that the two methods are different.
In our experiments, we consider that the difference between two methods is significant if p < 0.1, and it is very significant if p < 0.05.
5.3. Problems related to the Wikipedia collection
Usually, links in XML documents are divided into two types: element-to-document links, from an XML element to the root of the XML document; and element-to-element links, from an XML element to a part (fragment) of a document. Figure 3 illustrates these two types of link.
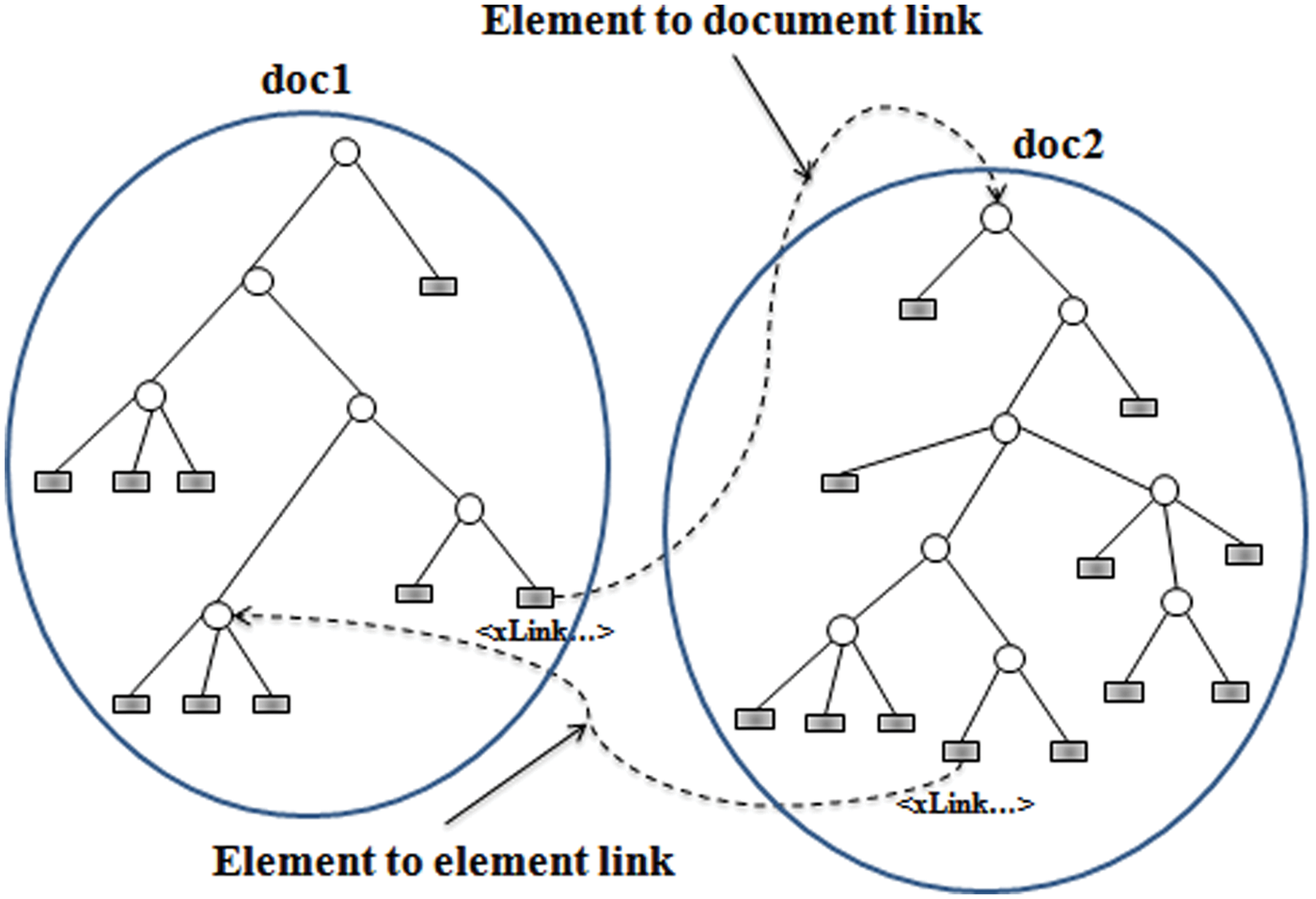
Link types in XML documents.
However, the Wikipedia collection contains only the first type of link, that is, element-to-document links. This kind of link causes two problems for our algorithm.
The first problem concerns the extension phase. Although computing of the co-citation-based similarity between regions requires links from one region to another region, we calculate the similarity score at the document level, and not at the region level.
The second problem relates to calculation of the regions’ authority scores. Recall that the authority of a region equals the sum of hub scores of regions that point to it (i.e. a region receives its authority score by incoming links). Thus, to calculate the authority of a region, we must know its incoming links. However, in the Wikipedia collection we cannot know the exact destination (destination element) of a link, because all links point to the document root. As a solution to this problem, we have proposed calculating an authority score for the whole document, and then diffusing this score equitably among the various regions. Finally, the hub scores are calculated for each region.
5.4. Multimedia element retrieval: OntologyLike approach
To calculate the initial scores of the multimedia elements, an approach based on the document content and structure can be used, as our documents are semi-structured. In this paper, we used the OntologyLike approach [25].
This approach consists in first computing content scores of leaf nodes using the vector space model with a cosine similarity measure, and then calculating the multimedia element scores using the content scores and the hierarchical structure of XML documents.
According to this approach and the tree representation, an XML document is considered as a simple ontology: nodes are considered as concepts linked with the IsPartOf relationship. The main idea of the OntologyLike approach is to use a semantic similarity measure between ontological concepts to evaluate how much each textual node in the XML document should participate in calculating the multimedia element relevance score. The final score of each multimedia element (ME) is computed by the following formula:
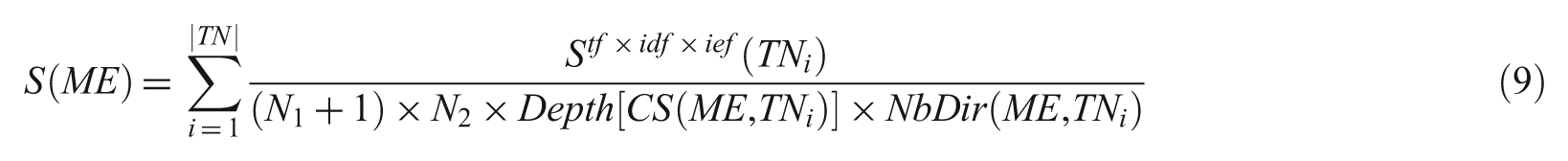
where |TN| is the number of all textual nodes, having a positive content score, of a document containing the multimedia element ME; S tf×idf×ief (TN i ) is the content relevance score of a textual node TN i calculated by the vectorial model using the tf×idf×ief weighting scheme and the cosine measure; CS(ME,TN i ) is the most specific common ancestor between TN i and ME; N1 and N2 are respectively the distance between ME and CS(ME,TN i ), and the distance between TN i and CS(ME,TN i ); and NbDir(ME,TN i ) is the number of changed directions between ME and TN i (if TN i is a descendant of a multimedia element then NbDir = 1, otherwise NbDir = 2).
The OntologyLike approach is considered as our baseline model, and the evaluation of our link analysis algorithm is presented in the following section.
5.5. Experimental results
The experiments presented in this part were designed to assess the impact of links in the case of re-ranking initial retrieved images. We fixed the initial number of images used to construct the initial set of regions at 200. First, it is necessary to fix some parameters, such as the best image region, and the best extension of the initial set of regions according to our algorithm.
5.5.1. Best image region
The aim of this evaluation phase was to determine the best part of the document containing the elements that are most likely to be related to the image subject. We then studied various region granularities: regions composed only of the direct descendants of the image (Desc); then first ancestor’s descendants of the image –1Anc, 2Anc, etc. – according to the XML document tree, until we had the whole document tree as a region.
Table 1 presents the results obtained according to the MAP measure by varying the region granularity, and without extension of the initial set of regions. Although direct descendants of the image contained the most descriptive and specific information on this image, the first ancestor’s descendants of the image give the best results for both query sets 2006 and 2007. Using the Wilcoxon test, there is no significant improvement in the 2006 query set, but there is a very significant improvement in the 2007 query set (p < 0.05).
Impact of various image regions

Indeed, the use of only image direct descendants as a region is not sufficient, since this region can be very small, or even absent. In this case, the number of links used in our algorithm will be very low. Another reason for these results is that information related to the image can be distributed in the closest elements, and not necessarily in the descendant elements.
Conversely, the use of a very large region (fourth ancestor’s descendants, for example) degrades the result. Using the Wilcoxon test between the 1Anc and 4Anc runs, there is no significant difference in the 2006 query set, but the results decreases very significantly in the 2007 query set (p < 0.05). This means that the greater the distance is from the image, the more the information is generic, and does not relate to the image.
In conclusion, we adopt the image’s first ancestor’s descendants as the best region; this will be used in the remainder of our experiments.
5.5.2. Best extension of root set
In Section 4 we proposed using the co-citation measure to extend the initial region set with the most similar regions. We used documents containing the top 200 image elements obtained by the OntologyLike method (Section 5.4), and computed the similarity score between these documents and the other documents in the collection. Then, for each document of the initial subset, we added the top K most similar documents. Table 2 presents the MAP measure as a function of the K added documents. In these experiments we used the best region as defined in Section 5.5.1 – that is, the descendants of the first ancestor of the concerned image.
Variation of the K added documents
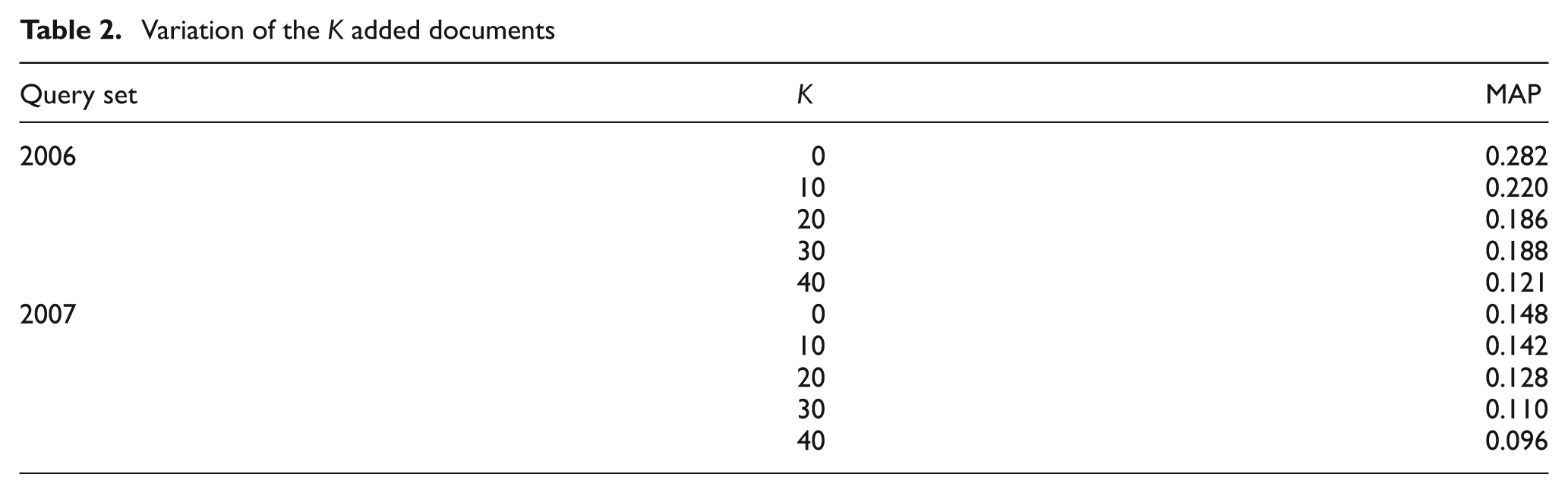
The results show that extending the initial region set by other regions extracted from the K added documents decreases the performance of both query sets. The Wilcoxon test validated our interpretations for the 2007 query set (p < 0.1) between K = 0 and K = 10, but not for the 2006 set query. A possible reason for this behaviour is that all regions of the same document are assigned the same relevance score, owing to the second problem of the collection, mentioned above (i.e. in the Wikipedia collection, the links are of the element-to-document type).
As a conclusion, we shall not extend the initial region set in our re-ranking method.
5.5.3. Combining hub and authority scores
The aim of this section is to compare the separate use of authority and hub scores, and the the combination of the two. To make this comparison we used a classic linear combination, represented by the following formula:

where S(r) is the combination score; h(r) is the region hub score; a(r) is the region authority score; and λ is the combination factor.
In these experiments we used the best parameters obtained in previous sections: that is, the first 200 image elements without extension, and the image region defined by the descendants of the image’s first ancestor. Table 3 shows the results.
Combination of hub score and authority score of regions
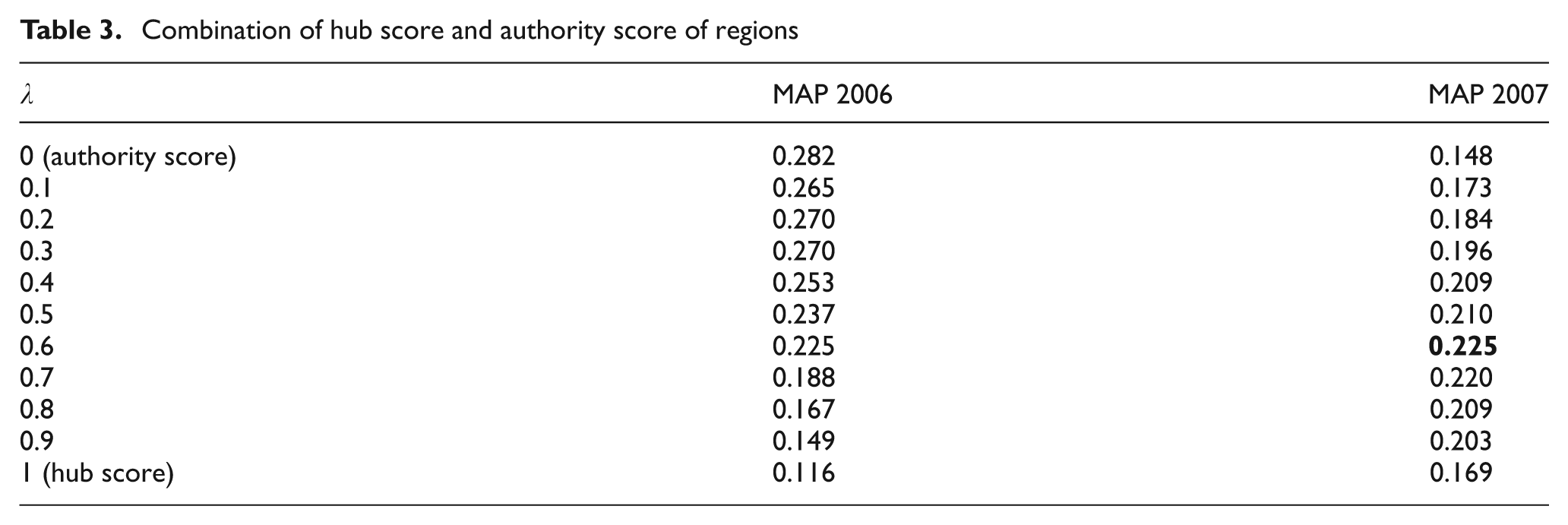
Comparing the hub and authority scores without combination, we notice that the authority score (MAP = 0.282) is better than the hub score (MAP = 0.116) in the 2006 query set, whereas the hub score (MAP = 0.169) is better than the authority score (MAP = 0.148) in the 2007 query set. This difference can be explained by the specific/generic notion of the vocabulary used in the queries.
According to Torjmen et al. [25], 56% of the queries in the 2006 query set are specific, 2 whereas 78% of the queries in the 2007 query set are generic. 3 Indeed, in specific queries (the INEX 2006 query set), the most relevant region is normally composed of image descendants, and in generic queries (the INEX 2007 query set), the most relevant region is normally composed of image ancestors.
Figure 4 illustrates the relationship between the vocabulary of the query and the image region. In Figure 4(a), the number of outgoing links in the best region of the multimedia element is very low. Therefore the hub score becomes less important than the authority score, because the hub importance depends on the number of outgoing links; otherwise the authority importance depends on the number of incoming links. However, the most important information for the multimedia element in Figure 4(b) contains a significant number of outgoing links. Therefore the hub score becomes more significant, and plays a more important role than the authority score.
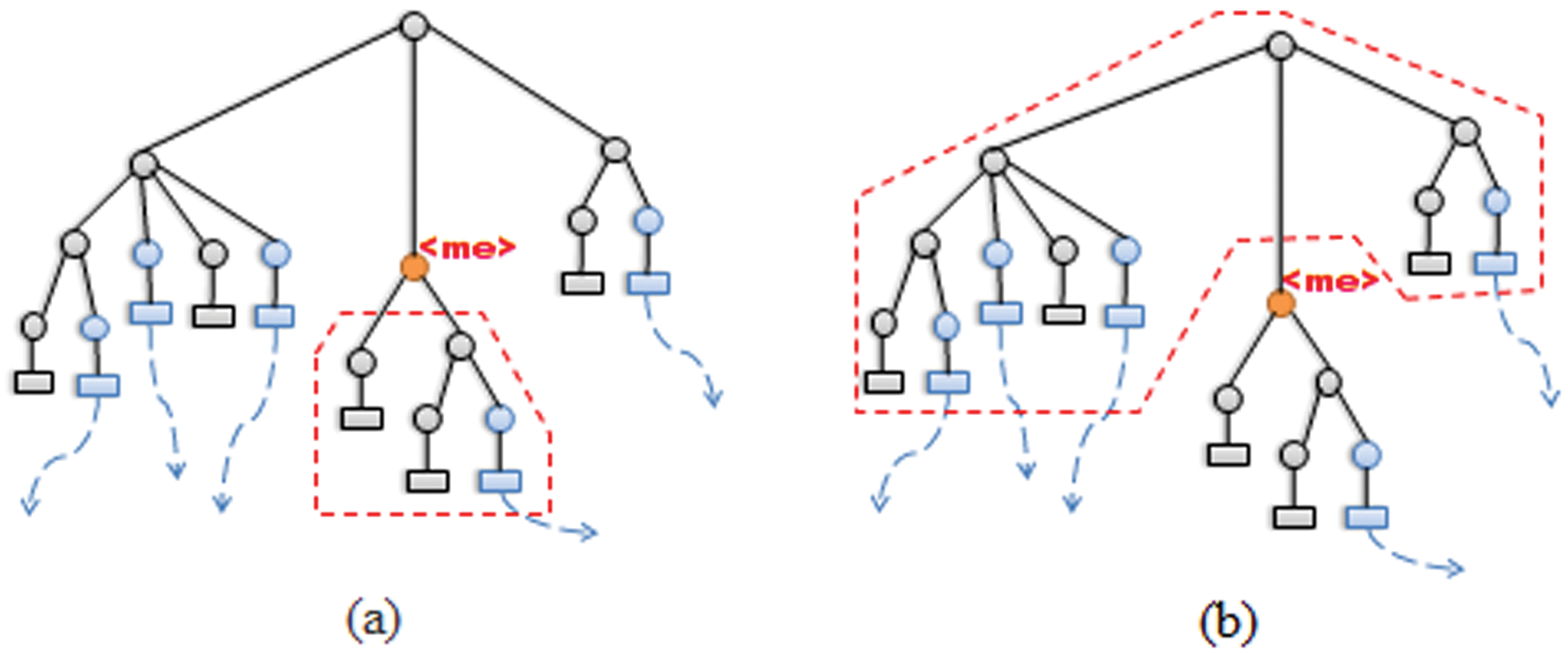
Illustration of the relationship between query vocabulary and image region: (a) most important information for a specific query; (b) most important information for a generic query.
To conclude, for specific queries it is better to use authority scores, and for generic queries it is better to use hub scores.
The combination of hub and authority scores improves the results significantly for the 2007 query set (this improvement is very significant using the Wilcoxon test –p < 0.05 – when comparing the run for λ = 0.6 with the two runs for λ = 0 and λ = 1). However, for the 2006 query set, using only the authority score is better than the combination of hub and authority scores. Nonetheless, by analysing the results query by query, we note that in 67% of queries the combination of both scores (with λ = 0.3) exceeds the use of the authority score alone. In conclusion, the use of a combination of hub and authority scores gives better results than those obtained using only the hub scores or the authority scores. Typically, authority scores are the most important indicators of pertinence, but since all incoming links point to the document root, the authority scores for images of the same document are equal, which diminishes the importance of this score.
5.5.4. Combination of initial scores and scores obtained by link analysis
For this combination we use the best scores obtained in the previous section – that is, the scores obtained by combining hub and authority scores (with λ = 0.3 for the 2006 query set, and λ = 0.6 for the 2007 query set). Table 4 shows the MAP values for the final combination.
Combination of initial scores with best link-based scores
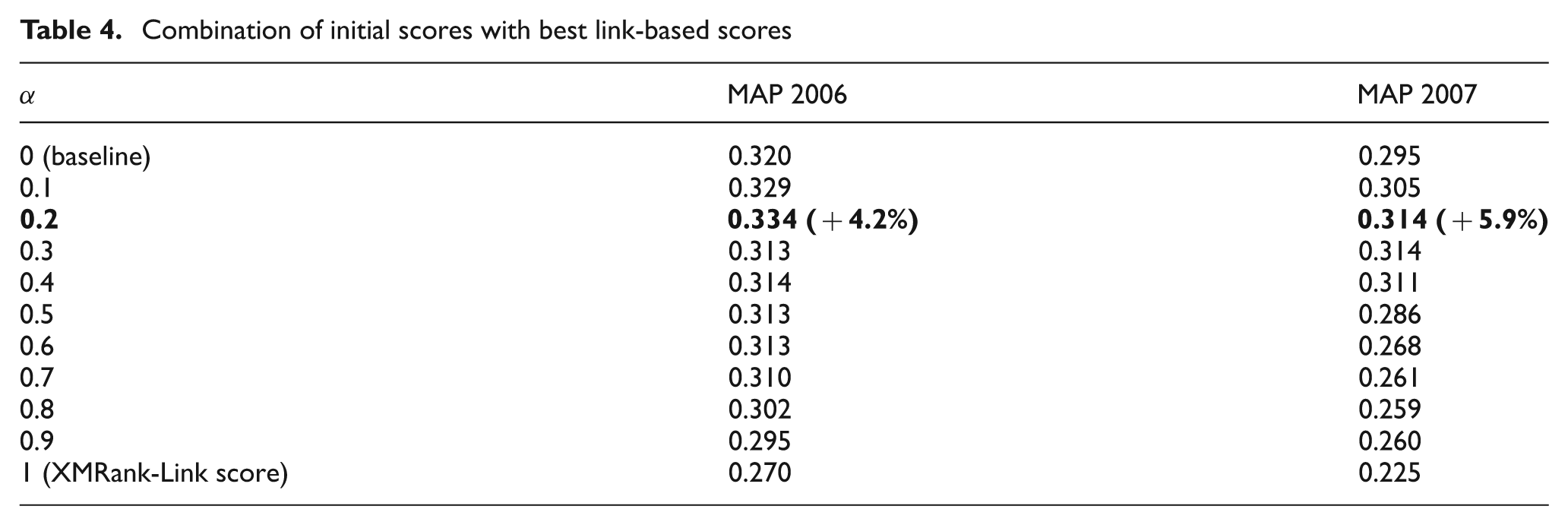
We note that the results of the baseline (OntologyLike) method are better than those obtained by link-based scores of XMRank. Moreover, in addition to the problems mentioned in Section 4 – that isolated regions are ignored, and that an irrelevant region with a high hub score can influence the authority scores of the pointed regions – these results can be explained by the Wikipedia collection problems related to the link types.
Despite the problems involved in the use of links and the Wikipedia collection, we succeeded in improving the MAP by about 4% for the 2006 query set and 6% for the 2007 query set by combining the two scores with α = 0.2, compared with the baseline. According to the Wilcoxon test, there is no significant improvement for the 2006 query set (nine queries), but a very significant improvement (p < 0.05) for the 2007 query set (19 queries). These results show the interest of our proposal for re-ranking results.
5.6. Comparison between the two proposed formulae for importance of links
We have proposed elsewhere [30] the following link-weighting formula (an exponential function):

where N1 is the number of edges between the node containing the link and its common ancestor with the multimedia element me, and N2 is the number of edges between the multimedia element me and its common ancestor with the node containing the link.
The aim of this section is to compare this formula with the formula used in our experiments (the multiplication function), and the use of our approach without link weighting. Table 5 shows the results obtained without image regions and without extension of the root set.
Comparison between formulae for importance of links

These results show that link weighting gives better results than those obtained without weighting, which validates our intuition that links do not have the same importance compared with the image elements. We also note that the multiplication function that we use in this paper gives the best results for both query sets. More precisely, using the Wilcoxon test, we have obtained a very significant improvement (p < 0.05) using the multiplication function for the 2007 query set, compared with not using link weighting. A possible explanation for obtaining better results with the multiplication function than with the exponential function is that the latter has the effect of neglecting links that are outside the direct descendants of the image. Nevertheless, more experiments on link weighting should be performed.
5.7. Comparison of XMRank with literature algorithms
The aim of this section is to compare the results of the original HITS and PageRank algorithms with the results of our algorithm.
5.7.1. XMRank vs HITS
We compare in this section our algorithm with the HITS algorithm. Table 6 shows the performing of the modified HITS algorithm by varying the different parameters.
Comparison between XMRank and literature algorithms
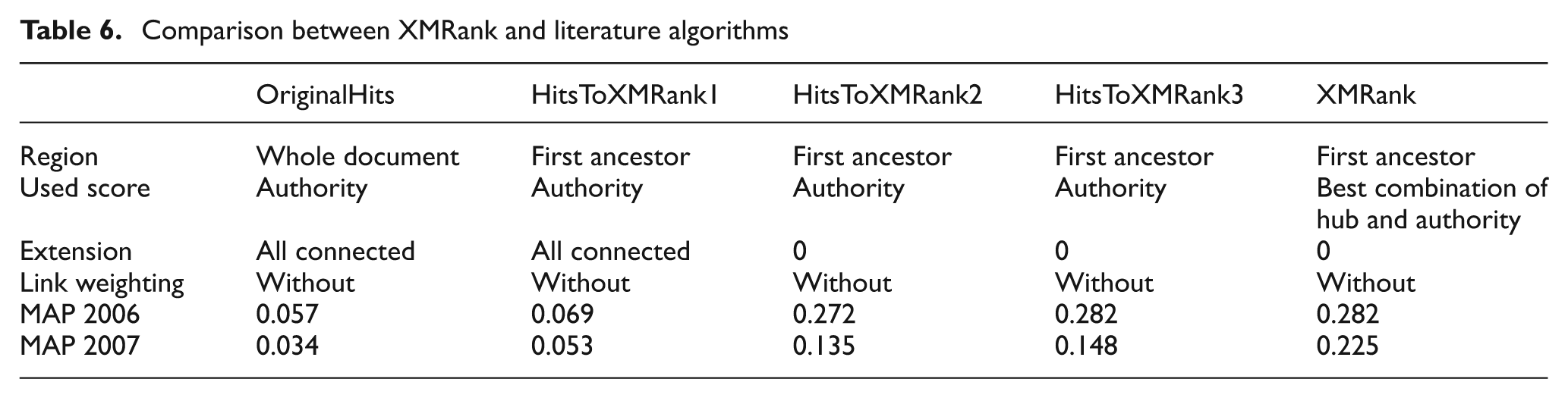
According to Table 6, the results of the original HITS algorithm are very bad compared with the results of our algorithm. To explain this, we have done a factor by factor study. When we modify the original HITS algorithm by using only the nodes of the first ancestor of the image (HitsToXMRank1 run) instead of the whole document (OriginalHits run), we obtain better results. This improvement is 21% for the 2006 query set and 55% for the 2007 query set.
Continuing our update of the HITS algorithm, we have ignored the extension step (HitsToXMRank2 run). This run improves the results with a surprising significance (>100%), which could be explained by topic drift. More precisely, the HITS algorithm considers all pages linked to the basic subset (both forward and backward links). This extension adds many irrelevant images, and consequently decreases the accuracy of the HITS algorithm.
In the HitsToXMRank3 run we have added the link-weighting factor, and we have obtained an improvement greater than 6%.
Finally, instead of using only the authority score, we have used the best combination of hub and authority scores (XMRank run), and the results are improved by 54% for the 2007 query set (recall that this latter is larger than the 2006 query set).
As a conclusion, we can note that all the factors have contributed in the result improvement. Two factors used are related to the document structure: the region and the link weighting.
5.7.2. XMRank vs PageRank
This section is intended for comparison of our algorithm with the PageRank algorithm. In the PageRank algorithm, we do not have the notion of hub and authority, just a single relevance score. In addition, the PageRank algorithm performs in a graph composed of all pages (or regions) in the collection. Table 7 shows the results obtained.
Comparison between XMRank and literature algorithms
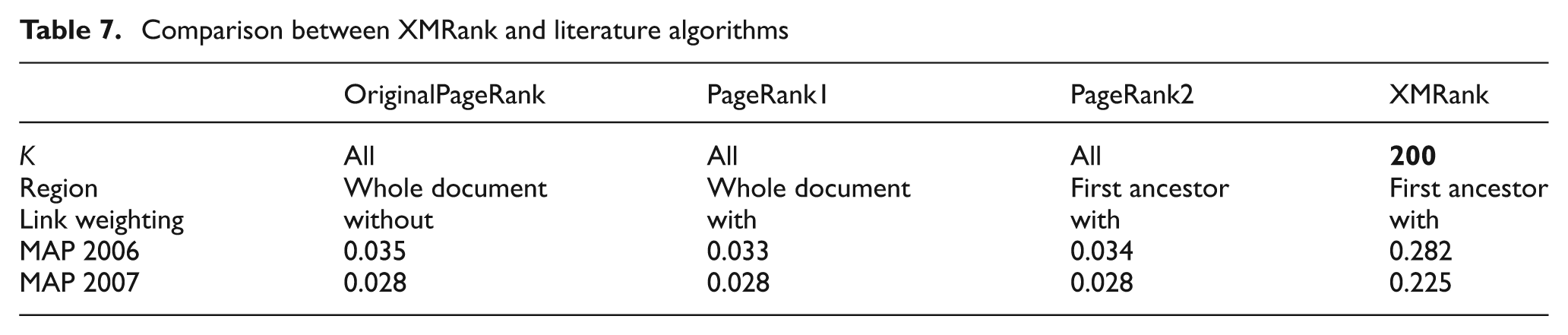
According to Table 7, the link weighting and the region factors did not show their interest. Nevertheless, we cannot really draw any conclusions, as all documents are used, and not only the relevant ones. This problem can be seen very clearly when comparing the runs of PageRank with the XMRank run. A highly significant improvement is realized, which can be explained by the use of only relevant documents.
This comparison confirms our motivations and our choice of the HITS algorithm.
6. Discussion
As a result of the various experiments, we note that the use of an image region is better than the use of the whole document in XML multimedia retrieval. Our idea of defining an image region allows us to take into account only the useful links that are related to the query, and which can improve the image description.
Link weighting also showed its relevance in XML image retrieval by assigning more importance to the links closest to the image than to the other links of the same region. Furthermore, the hierarchical information is very interesting for evaluating the link weights. However, the current setting of our XMRank algorithm is not optimal, and can be improved. The extension of the initial region set by the most similar regions based on the co-citation measure did not lead to the expected results. This could be related to the Wikipedia collection problems of link types (i.e. element to document). The extension of the HITS algorithm has also degraded results significantly because of topic drift.
According to our experiments, we have also found that the generality/specificity query criterion is an important factor in selecting the hub and authority scores of the HITS algorithm.
Another conclusion to note is that it is not sufficient to use only the links between elements; the text of the document containing the multimedia object is still the most significant factor in retrieving relevant multimedia objects.
7. Conclusion
We have proposed the XMRank algorithm, which represents an adaptation of the HITS algorithm for XML multimedia retrieval. The results show that, despite the problems encountered in the Wikipedia collection, there is an improvement in XML multimedia retrieval when using links between XML elements.
We also showed that the best image region is composed of the descendants of the first ancestor of the image element. In addition, weighting the links is necessary to improve results, which means that links should not be processed similarly, and using the hierarchical information between the image and links is very motivating.
For extending the results, the use of the co-citation measure has not realized its potential, as there is a problem of link types in the collection, but it remains more efficient than the classic extension of HITS.
For the future, we anticipate further work in improving the extension step by applying other similarity measures. In addition, we hope to develop an automatic tuning for the hub and authority combination parameter according to the generality/specificity degree of the query. We also expect to test other factors in the link-weighting function. For the Wikipedia collection, we plan to resolve the problem related to the link type by making element-to-element links rather than element-to-document links. Finally, we hope to study the use of the links in multimedia fragments that are composed not only of the image element, but include associated text.
Footnotes
Acknowledgements
We should like to thank Professor Mohand Boughanem and Dr Karen Pinel-Sauvagnat, members of IRIT, University of Paul Sabatier Toulouse, for their cooperation and their help in evaluating our proposition.