
Abstract
The literature often views the emergence of social tagging as a potential alternative method to controlled vocabulary for organizing and indexing large-scale information resources. In this paper, we present an in-depth examination of the relationship between social tagging and controlled vocabulary-based indexing and organization in two unique contexts: the information science domain and when comparing data gathered from both English and Chinese sources. Our results show that the information science domain has more overlap between social tags and controlled vocabulary-based subject terms. This is reflected in the higher percentage of overlapping terms between tags and subject terms, as well as in the strong similarity (measured by Jaccard’s coefficient) in frequently used keywords among tags and subject terms. However, social tags in the information science domain still possess limitations in terms of uncontrolled terms, where inconsistencies and noisy usages exist. Our results also show that language difference does have an impact on social tagging. The numbers of Chinese tags overall and per book are less than those of English tags. The most frequently used English tags are single-word terms, which are different from multi-word controlled vocabulary terms. In comparison, the character difference between the most frequently used Chinese tags and Chinese subject terms is just one character (3 vs 4). However, English and Chinese users do share many similar behaviours when they tag books in the information science domain. Many of the most frequently used tags are shared between the two languages and the patterns of overlap between topical tags and subject terms are also similar between the two languages. Overall, despite the application limitations for social tagging in cataloguing and indexing, we believe that tagging has the potential to become a complementary resource for expanding and enriching controlled vocabulary systems. With the help of future technology to regulate and promote features related to controlled vocabulary in social tags, a hybrid cataloguing and indexing system that integrates social tags with controlled vocabulary would greatly improve people’s organizational and access capabilities within information resources.
Keywords
1. Introduction
Owing to the rapid development of computer and network technologies, accessing information has become an important task in people’s personal and professional lives [1]. To facilitate content-based access, index terms are identified through either manual assignment (thus, manual indexing) or automatic extraction (automatic indexing). Traditionally, manual indexing is conducted by highly trained information professionals, and controlled vocabulary-based subject terms (in short, subject terms) are used ‘to ensure effective indexing and to maintain the overall efficacy’ [2]. By rationalizing natural languages, removing ambiguities and consolidating similar terms [3], controlled vocabulary-based manual indexing can help to reduce the difficulty inherent in accessing relevant information. It is these benefits that give established bibliographic classification schema an advantage in the context of knowledge representation and organization [4, 5].
Despite their many benefits, it has been recognized that subject terms are not always adequate to access appropriate online information. Commonly noted problems include subject terms that lack specificity in some search subject areas [6], and the significant investment of time, money, training, expertise and professional intervention to further expand subject terms in a specific context [7]. These problems discouraged the wider adoption of controlled vocabulary-based manual indexing within particular communities of practice.
By using keywords extracted directly from the full content of the documents, automatic indexing has the advantage in issues of scaling, efficiency and cost. It is the default content representation method for almost all modern internet search engines. However, the lack of human intellectual mediation in automatic indexing is often cited as the main reason that current internet searches tend to be imprecise; thus, they are not adequate to facilitate resource discovery and knowledge organization on the internet [2,3].
Social tagging (or collaborative tagging) is a distributed practice performed by internet users when they assign uncontrolled keywords to information resources (e.g. web pages, video clips and images). On the surface, such keywords (tags) are used to enable the organization and the indexing of information within a personal information space; however, through (implicit or explicit) sharing and collaborating on tags, information annotated by tags can then be browsed and searched by other users [8]. Compared to the traditional way of organizing information, social tagging exhibits ‘the proactive participation of information users in the process of information organization and management, and the sharing of collective tags with everyone including individuals not participating in the practice’ [9].
However, social tagging suffers from the following problems [2]: (1) a lack of control over synonyms or near-synonyms, homonyms and homographs; (2) potential lexical anomalies, inconsistencies and ambiguous assignation of tags; and (3) personal and idiosyncratic tags. Each of these can have a negative impact on retrieval effectiveness, as well as limiting the ability to locate similar or related resources.
Nonetheless, the emergence of social tagging provides a potential alternative method for controlled vocabulary-based manual indexing which has the ability to avoid the scalability and cost problems. There have been many studies examining the nature of social tagging [2,10], the relationship between social tagging and controlled vocabulary-based indexing and organization [3, 9, 11, 12], and the application of social tagging in library services [8, 13, 14].
In this paper, our research goal is to study the relationship between social tagging and controlled vocabulary-based indexing and organization. In particular, we study social tags and subject terms in the domain of information science, and examine that relationship looking at two different languages: English and Chinese. We believe that domain specific requirements and issues can be revealed by our study and that, because social tagging is an online activity on a global scale, language and culture differences can be important factors. These two angles help us to offer a unique contribution to the literature through an exhaustive analysis within a domain and with a global multilingual perspective.
The remainder of the paper is organized as follows. We will first review the related work on social tagging in Section 2; then discuss our research questions and research design in Section 3. In Section 4, we will present the results of the study, and discuss the insights garnered from the study, and conclude with suggestions for future work in Section 5.
2. Related work
Aligned with the internet’s social general principle of sharing and participating, social tagging quickly established itself as one of the major phenomena transforming the internet from a static platform into a participatory information space [15]. Owing to its popularity, there are many studies on different perspectives about social tagging, which include different views on the nature of social tagging, on the usages of social tags and on bridging social tagging with other internet functionalities [15]. Readers who seek more general discussions on social tagging should consult Gupta’s overview article [16] or Smith’s book [10]. Here, our discussions will primarily focus on social tagging in relation to knowledge representation, controlled vocabulary indexing and library services.
2.1. Social tagging and knowledge representation
For many years, people have sought methods to organize large collections of data by using uncontrolled vocabularies in browsing or other related tasks. Heymann et al. [17] pointed out that knowledge representation systems aiming for large-scale organization should have consistency, quality and completeness as three major features. Their study showed that social tagging has the potential to be used for large-scale collection organization. Macgregor and McCulloch [2] examined the social tagging phenomenon including its emergence, problems and potential for knowledge organization and general resource discovery. Their results showed that there are numerous difficulties with social tagging systems, such as low levels of precision and a lack of collocation, which originate from the absence of controlled vocabularies. However, they also urged librarians and information professionals to learn from the interactive and social aspects exemplified by social tagging systems, as well as their success in engaging users in information management.
On the topic of the ‘messiness’ of social tags, Thomas et al. [18] collected tags from LibraryThing and studied the usefulness of the tags for general searches in library catalogues. Their results showed that social tags suffer from a certain degree of messiness and inconsistency, and that more than a third of this messiness is in the form of tag variations followed by tags containing non-alphabetic characters. However, they also stated that libraries should remember that part of the attraction of social tagging is its open and self-created environment and that too many rules and regulations may discourage participation.
Semantic relationships and hierarchical data structures can be explored to support users in their social tagging related activities [19]. Semantic similarity is determined by using probabilistic techniques, so that hierarchical structures based on such similarity among tags can be created and visualized. Users can explore tags dealing with their interests according to desired semantic granularities and then find those tags best expressing their information needs.
2.2. Social tagging and controlled vocabulary
Classification and indexing using controlled vocabulary has been a common method for removing ambiguities and consolidating similar terms [3]. Therefore, ever since the emergence of social tagging, there has been active research and great debate about the advantages and disadvantages of tags and controlled vocabularies. Kipp [3] examined the keywords used by users, authors and intermediaries in the context of online indexing, and found important differences among the three groups. In a similar study, Heymann and Garcia-Molina [20] compared online tags to a controlled vocabulary – the Library of Congress Subject Headings (LCSH) – and found that many of the keywords designated by tags and LCSH were similar or the same; however, the use of keywords by annotators was quite different. Lawson [21] compared and evaluated LCSH over each of 31 different subject divisions with user tags from Amazon.com and LibraryThing assigned to the same titles. Thomas et al. [12] provided a quantitative analysis of the extent to which social tags obtained from LibraryThing replicate those found in LCSH. They found that social tagging does indeed augment LCSH by providing additional access to resources, such that a hybrid catalogue combining both LCSH and social tags would result in richer metadata. Ding et al. [15] took a different angle, and argued that established bibliometric methodologies can be applied to analyse tagging behaviour on the Web. Based on an Upper Tag Ontology (UTO) and 12.1 million tags harvested from Delicious, Flickr and YouTube, they identified and discussed some patterns and variations in tagging.
Utilizing social tags as the user vocabulary, and LCSH as the controlled vocabulary, Yi and Chan [9] investigated the linking of the two on the basis of word matching with the goal of examining the potential use of LCSH in organizing social tags. The experimental results showed that the total proportion of tags being matched with LCSH constituted approximately two-thirds of all tags involved, with an additional 10% of the remaining tags having potential matches. Three important tag distribution patterns over the LCSH tree were identified and supported: skewedness, multifaceted and Zipfian-pattern. Another research work on the same topic is by Lu et al. [11]. Their results showed that it is possible to use social tags to improve the accessibility of library collections. However, the existence of non-subject-related tags may impede the application of social tagging in traditional library cataloguing systems.
Kipp and Campbell [22] examined the usefulness of social tags in the process of information retrieval. They found that users used tags in their search process as guides to searching and as hyperlinks to potentially useful articles, just as they used controlled vocabularies in the journal database to locate useful search terms and to link to related articles supplied by the database.
Controlled vocabulary can be used to help social tagging as well. Matthews et al. [23] investigated methods of augmenting social tagging using controlled vocabulary to permit subject indexing of papers in online repositories. The results showed that augmented tagging does increase the effectiveness of non-specialist users (that is, without information science training) in subject indexing.
2.3. Social tagging in library services
Understanding the close connection between social tagging and controlled vocabulary, researchers also studied the application of social tags in other related library services. Schwartz [24] reviewed the changes in subject analysis over three decades and stated that thesauri, guided navigation and folksonomy based on social tags are the three activity areas in which subject analysis researchers have been attempting to address rapidly changing environments. Through a case study in an academic library setting, Kakali and Papatheodorou [25] revealed that users’ tagging behaviours mainly enhance the subject description of documents, and that there needs to be an articulation of alternative policies concerning knowledge organization schemes, technological infrastructures and information services.
Library cataloguing is another area to which social tagging can contribute. Spiteri [26] evaluated the social features and comprehensiveness of the catalogue records of 16 popular social cataloguing sites to determine whether their social and cataloguing features could or should impact the design of library catalogue records. Their results showed that, although the bibliographic content of most of the catalogue records examined was poor when assessed in terms of professional cataloguing practice, the social features can help make the library catalogue a lively community of interest where people can share their reading interests with one another. Jeffries [13] highlighted the recent developments in interface design of social cataloguing sites. Mendes et al. [8] presented the implementation of LibraryThing for Libraries (LTFL) in an academic library, and analysed the usage of LTFL data and their potential to facilitate resource discovery in the library catalogue. McFadden and Weidenbenner [27] examined social tagging practices in selected libraries as an added value to the library catalogue. Steele [14] listed many problems and concerns associated with a library choosing to adopt tagging as part of its catalogue, which included the options of using outside websites to provide the tags as well as creating tagging systems on the library’s own website. The paper concluded that access to information is the main purpose of cataloguing; thus, the use of both traditional methods of cataloguing as well as interactive methods such as tagging is a valid way to reach library users of the future.
Within the broader library service context, Redden [28] explored the potential usefulness of social tagging in academic libraries with an emphasis on collaborating, networking, organizing and sharing electronic resources as well as teaching information literacy. Anfinnsen et al. [29] surveyed users’ reactions to a Web 2.0 system designed and deployed in a university library. Their results showed that social tagging has a beneficial effect on users’ involvement as active library participants as well as encouraging users to browse the catalogue in more depth.
3. Research design
Our research is a further examination of the relationship between social tagging and controlled vocabulary-based indexing and organization. In particular, compared to the existing studies in the literature, the significance of our study rests on two important distinctions. First, we study social tags and subject terms in the domain of library and information science (LIS). As stated in Section 2, the existing literature has examined the relationship in the generic context of the internet. However, different domains could have specific requirements and issues that might not be apparent outside of that discipline. Particularly, the information science domain has the tradition of heavily using controlled vocabulary-based indexing and organization methods, while at the same time, it is a very active domain in social tagging. Second, we study the relationship under two different languages: English and Chinese. Social tagging is an online activity on a global scale. Although there have been numerous studies on social tagging and its relationship to controlled vocabularies, none have evaluated its effectiveness across languages or cultures. By incorporating these two unique foci, our study will contribute to the literature of social tagging through a deep domain-specific analysis and a multilingual perspective.
3.1. Research questions
Information science is one of several domains which provide an interesting angle to study the relationship between social tagging and controlled vocabulary-based indexing and organization. Its subdomain (library science) has a long tradition of training professional indexers for controlled vocabulary-based manual indexing, so many information science domain users have reasonable experience with existing well known and widely used controlled vocabulary systems, such as LCSH. At the same time, many mature social tagging systems such as LibraryThing and GoodReads provide a collaborative platform that resembles, to some degree, cataloguing tasks conducted by many librarians. The third interesting feature of information science is that many of these online users are domain experts as well as experienced internet users, who are different from general internet users. All of these characteristics make information science an interesting and important domain for study. Therefore, the first research question is:
RQ1: What are the relationships between social tags and an established traditional controlled vocabulary such as LCSH when they are used to annotate books in the information science domain?
Social tagging is an online activity on a global scale. People who speak different languages or who are from different cultures are performing tagging daily. Taking advantage of the fact that the authors live in the USA and China, we want to examine the potential language and cultural differences using English and Chinese as exemplars. Although there have been numerous studies on social tagging and its relationship to controlled vocabularies, none of them make comparisons across languages. Therefore, the second research question is:
RQ2: Among the relationships identified between social tags and LCSH when annotating books in the information science domain, which ones exhibit differences between English and Chinese?
Finally, we want to examine how to apply social tags to enrich and update controlled vocabulary index terms, so the third research question is:
RQ3: In what aspects can social tags and expert-created subject headings complement each other?
3.2. Data collection design
Even though our study concentrates on the information science domain, there is still too much data to be collected. We thus adopted the Purposive Sampling strategy [30]. In their study of iSchool researchers’ high quality publications between 2005 and 2010, Wu et al. [31] identified 50 keywords that were used most often in approximately 2000 articles published by iSchool researchers. These keywords can be seen as representing the state-of-the-art research foci in the information science domain [32]. Therefore, with the intention to maximize our ability to ‘identify emerging themes that take adequate account of contextual conditions and cultural norms’ [30], we used these 50 keywords to purposively create our data sets for this study.
The data collection procedure is as follows. First, on the English social tagging side, we collected tags from LibraryThing, 1 which is probably the most widely used online social site for users to catalogue and share books online. On the Chinese social tagging side, we used one of the most popular social networking and tagging sites called DouBan. 2 Its book section, which is called ‘Douban Dushu’, is a service with a long history and millions of users. Then, using the aforementioned 50 English keywords and their Chinese translations, we searched on LibraryThing and Douban Dushu respectively. We aimed to select 10 books for each keyword based on their search results on LibraryThing or Douban Dushu, respectively. It was often the top-10-returned books which were selected. However, if any selected book was found to contain no tags, we discarded it and went further into the result list. Through this, we identified 500 English books and 500 Chinese books in the information science domain which contained at least one social tag. This search was conducted in August 2010.
We checked for duplicate books in each data set, and did not find English books that were in numerous editions. However, we found four pairs of Chinese books (8 books in total) that were different editions of the same work. As this was only 1.6% of the data set (8 out of 500), it should not affect our data analysis in a significant way. We also found that 10 of the 500 Chinese books were translations of 10 of the English books.
Second, using the ISBNs of the selected books, we trawled the OPAC of the Library of Congress in the US and that of the National Library of China for both the English and Chinese books, respectively. The downloaded bibliographic records are in variants of MARC (for example, Figure 1 shows parts of a record from the Library of Congress using USMARC, and that of a record from the National Library in China using CNMARC).
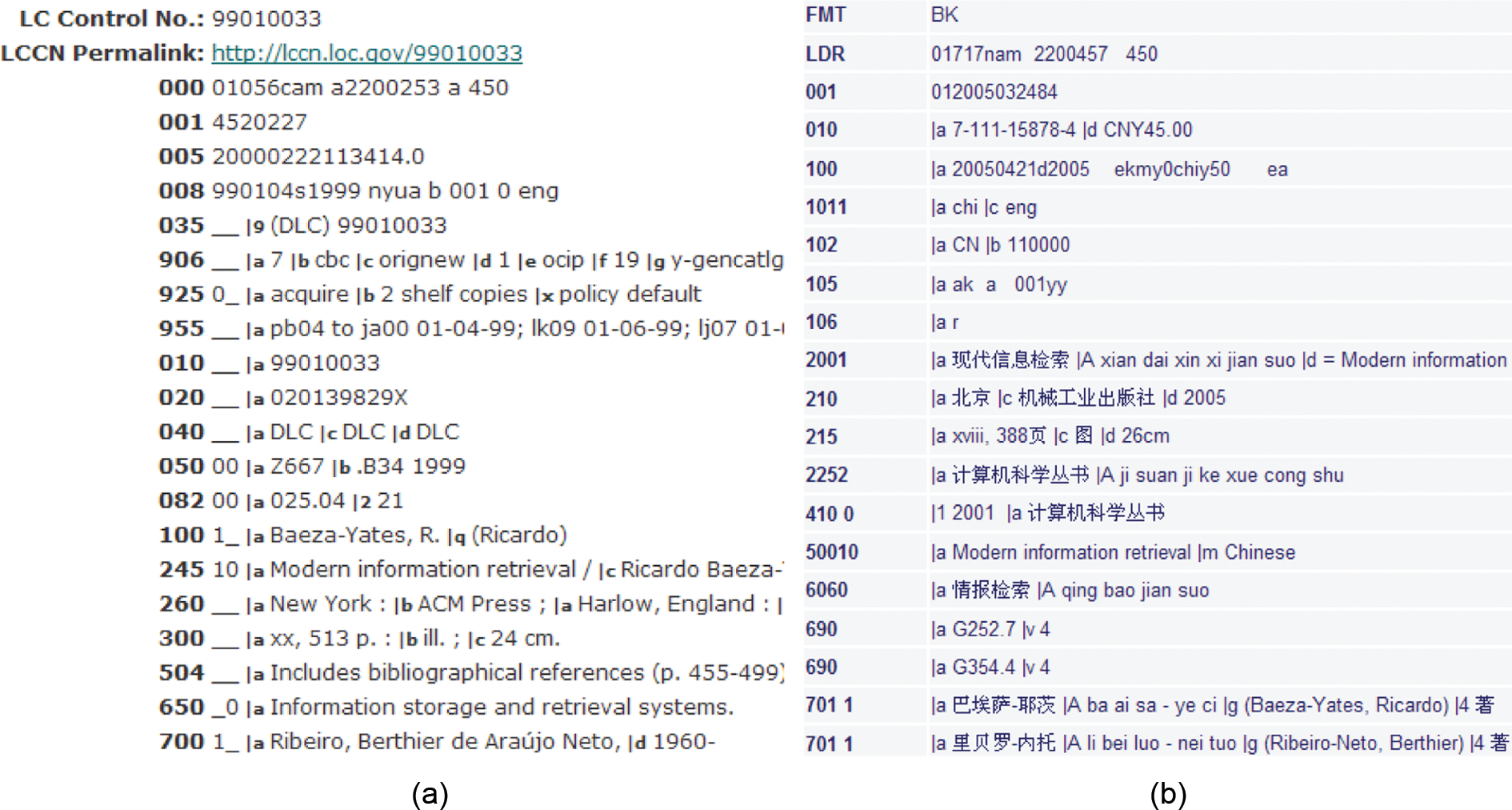
(a) An example of a USMARC record; (b) an example of a CNMARC record.
We concentrated our efforts on Field 650 (Topical Heading) of USMARC and Field 606 (Topical Heading) of CNMARC. This is because these two fields contain subject terms assigned by expert cataloguers using LCSH (http://authorities.loc.gov/cgi-bin/Pwebrecon.cgi?DB=local&PAGE=First) or Classified Chinese Thesaurus (CCT, http://cct.nlc.gov.cn/login.aspx), respectively. A book was replaced if its MARC record did not have a 650 or 606 field. We acknowledge that subject information might not exist only in fields 650 and 606, so this action could discriminate against some records. However, as we sampled only a small set of records from a large collection for our study, it was feasible to carry out this requirement and it was consistent with our adopted sampling strategy.
3.3. Data analysis design
Before analysing the collected data, we further processed them. On the social tag side, we manually classified the tags into topical and non-topical tags. Topical tags are defined as keywords describing the content or topic areas of a book. Two examples of topical tags are ‘information retrieval’ and ‘web design’. Non-topical tags, on the other hand, are keywords describing an individual’s own interests (such as ‘like’, ‘favorite’), keywords for self-reference (such as ‘read’, ‘unread’, ‘read in 2009’ and ‘owned’), keywords describing physical features of the book (such as ‘hardcover’ and ‘paperback’), and keywords about edition information (such as ‘first edition’). In total, we collected 5241 English tags, among which there were 3403 topical tags and 1838 non-topical tags. We also collected 2628 Chinese tags, among which there were 1972 topical tags and 656 non-topical tags. The classification of tags was conducted by two student coders under the close supervision of the faculty authors of this paper. One student coder took charge of classifying tags in English and the other student worked on Chinese tags. During the process of classification, there were periodic reviews by sampling to maintain the quality and consistency of the classification, but we did not obtain any coder agreement scores. We acknowledge the limitations of this.
We further divided subject terms as well. Both USMARC and CNMARC records contain subfields in the 650 or 606 fields. These subfields describe topical, chronological, geographic and form information. Similar to the treatment of social tags, we further divided the subject terms into topical and non-topical subject terms. However, with the help of the subfields, we did not have to perform manual classification on subject terms. We treated all terms in the $a subfield of the 650 field in USMARC or the 606 field in CNMARC as the topical subject terms, and all terms in other subfields of the 650 field in USMARC or the 606 field in CNMARC as non-topical subject terms. In this way, we collected 1705 English subject terms, among which there were 1107 topical terms and 598 non-topical terms. We also collected1494 Chinese subject terms (1069 topical terms and 425 non-topical terms).
These methods helped us to locate controlled vocabulary terms in either LCSH or CCT that were selected as index terms in MARC. However, there could be overlap between the social tags we collected with the LCSH or CCT terms that were not index terms, in which case the methods described above would fail. We, therefore, searched directly in LCSH and CCT for the topical tags that did not match a topical subject term using the aforementioned methods. In this search, any topical tag that was an exact match with the controlled vocabulary terms in LCSH or CCT was also recorded as the identified overlap between the topical tags and the controlled vocabulary terms. Through this method, we further identified 1125 English tags and 699 Chinese tags as the overlap to subject terms.
On top of these processed data, we performed several quantitative techniques in our data analysis. These methods include using descriptive statistics (such as overlap percentages, means, standard deviations, maximum and minimum), calculating keyword similarity (such as Jaccard) and computing correlations (such as Spearman correlation).
4. Result analyses and discussions
Our result analyses cover three dimensions. The first points out that the analyses can be performed at the level of collection for all of the obtained books or at the individual book level. The second dimension tells us that the analyses should be performed on all of the terms, topical/non-topical terms, and overlapping terms/terms in other semantic relationships. The third dimension specifies the language difference in English and Chinese. Therefore, the analyses and discussions in this section are divided into the following subsections.
4.1. Overview of social tags and subject terms at the collection level
Among the social tags and subject terms collected for the 1000 books, after removing the case difference, we identified 3781 unique social tags and 1116 unique subject terms. From Table 1, we can see that the number of unique English social tags is much larger than that of the English subject terms (2507 vs. 721), and this is also true in Chinese (1274 vs. 395). Possible reasons for these results can be garnered from the characteristics of social tags as identified in the literature [2,11]: social tags are uncontrolled, assigned by a large number of untrained users and there is no limit to the number of tags to be assigned to a book. In contrast, subject terms are assigned by a small number of trained information professionals based on a controlled vocabulary, and there is often a limit on the number of subject terms that can be assigned to each book.
Unique social tags and subject terms
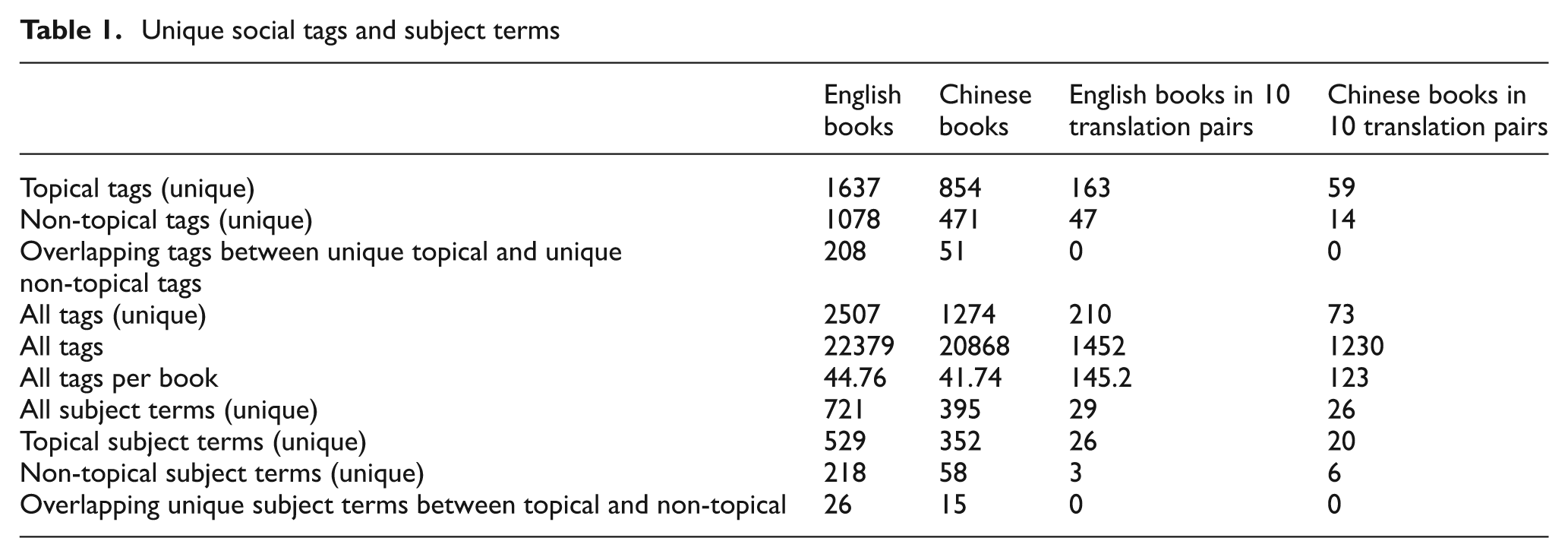
Table 1 also shows that the number of unique topical tags is larger than that of non-topical tags regardless of whether they are in English (1637 vs. 1078) or Chinese (854 vs. 471). At the same time, the number of topical subject terms is larger than that of non-topical subject terms in both languages (529 vs. 218 in English and 352 vs. 58 in Chinese). This indicates that both common internet users (who generated the social tags) and the library professionals are more concerned about the content of the books rather than other aspects. Of course, we acknowledge that our manual classification of social tags into topical and non-topical tags can suffer from inconsistency, which is the reason that there is overlap between topical and non-topical tags in both languages (see the overlapping tags row in Table 1). However, the percentage of the overlapping tags is only 8.3% among all tags, so we do not think that this inconsistency would invalidate our results. It is interesting to see that there is overlap between topical subject terms and non-topical subject terms as well, which shows that the professionals’ work could also have an inconsistency problem. Of course, the percentage of overlapping keywords in subject terms is much smaller, only 3.6%. Except for the inconsistency of manual classification, the overlapping tags or terms may be due to the fact that a subject term, which is classified as topical for book A, could be non-topical for book B. The same can happen for social tags. For example, ‘reference’ is a non-topical tag for the book Cataloging and Classification: An Introduction, but it is a topical tag for the book Reading and the Reference Librarian: The Importance to Library Service of Staff Reading Habits. Another example of subject terms is that ‘united states’ is a topical subject term for the book United States Government Internet Manual: 2005–2006 (US E-Government Directory), however, it is a non-topical subject term for the book Library Research Models: A Guide to Classification, Cataloging, and Computers.
When we look at all the unique tags, or unique topical tags, or unique non-topical tags, the total number of tags for English books is almost double that of Chinese books. However, looking at the total tags we collected between the two languages, English tags are just slightly higher than Chinese tags under total counts (22,379 vs. 20,868) and per book (44.76 vs. 41.74). We could think of several possible reasons for this outcome. First, the English and Chinese books could be very different in their content so that the required tags for describing them are different. However, considering that we used the queries and their translations to obtain the books in two languages, we think that their contents should not be that dramatically different. Second, the English books are culled from LibraryThing, and the Chinese books are from Douban. Perhaps users in LibraryThing are more active in general and would assign more tags to a book. However, this cannot explain why the number of unique English tags is much higher than that of unique Chinese tags, but not the overall number of tags in the two languages. Further, we observed a similar pattern between the number of English subject terms and that of Chinese subject terms (see the last four rows of Table 1), which should not be affected by the activities of users. Therefore, we are considering rejecting this reason. This then leads us to the third conclusion that the difference is due to language or culture specific characteristics. Maybe there are more ways in English to describe the same information/concept than in Chinese, which results in more tags in English, or maybe English culture favours individualism whereas the Chinese culture focuses on unity.
To study further the differences between English and Chinese books, we examined the 10 pairs of books known to us as translations of each other. As shown in the two right hand columns in Table 1, the number of English unique tags (all, topical or non-topical) all show patterns similar to the entire 500 books when compared with Chinese counterparts. This evidence further demonstrates that the pattern is not related to content difference, and therefore strengthens our tentative belief that it is probably the language or culture difference that creates these differences between English and Chinese tags. It is interesting to see that the patterns between English subject terms and those between Chinese subject terms are different from those of the whole 500-book data set. Because of the limited data available (only 10 pairs of books), we cannot make any generalization about this.
Again using these 10 pairs of books that are translations of each other, we gain some insights on the tags that can be identified as translations of each other or which share very close meanings. Table 2 shows such English and Chinese tags that we found in the 10 pairs of books. There are 33 pairs of them, which consist of 15.9% of all unique English tags, and 50.7% of all unique Chinese tags. As our book collections are related to information science, so are the tags in Table 2. The majority of them are technical terms used in the information science domain. Second, some Chinese users are English speakers as well, so the tags they used are in English (see ‘ui’, ‘datamining’ and ‘management’). Last but not least, as half of the Chinese tags on these books have their translations in English, these may be used as translation resources for enhancing multilingual information retrieval.
English and Chinese tags found in the 10 pairs of books that are translations of each other or share close meanings

4.2. Overview of the social tags and subject terms at the individual book level
In addition to the examination at the collection level, we performed results analysis at the individual book level. To capture the variances in the data, we calculated the average number, standard deviation, maximum number, and minimum number for each analysed component of a book, which includes all tags, topical tags, all subject terms, and topical subject terms. The results are shown in Table 3.
Statistical information on tags and subject terms per book

Table 3 shows that there are more social tags than subject terms per book, just as there are more topical tags than topical subject terms. The variances in social tags are also larger than those in subject terms, which are reflected by a larger standard deviation and a larger difference between the maximum and the minimum numbers. On average, the majority of the tags per book are topical tags (68% for English, 75% for Chinese), and a slightly lower number of subject terms per book are topical subject terms (65% for English, 72% for Chinese).
The data collected from both the English and Chinese books allows us to see that the average number of tags per English book is 10, much higher than those of Chinese books which is 5.28. At the same time, the average number of topical tags per English book is 6.81, also higher than that of Chinese books which is 3.95. Their standard deviations (9.94 vs. 2.59) and maximum numbers (31 vs. 11) show that the number of tags per English book changes much more dramatically than that of Chinese books. As stated, we excluded those books that do not contain any tag or have a 650 or 606 field in their MARC records, so the minimal numbers of all tags and all subject terms are all 1. Because the subfield $a of 650 or 606 field in USMARC or CNMARC is mandatory, the minimal numbers of topical subject terms are 1 too.
4.3. Overlapping terms between social tags and subject terms at the collection level
We performed further analysis on the overlaps between social tags and subject terms. The analyses were again conducted at both the overall collection level and the individual book level. During the word-comparison process, the overlapping terms were defined as being identical at the surface form without any semantic level matching nor further normalization beyond case folding. For instance, the social tag ‘library administration’ and the subject term ‘Library Administration’ are considered to be equivalent, but the tag ‘computers’ and subject term ‘computer’ are different even though they share the same meaning. The decision to not use stemming in this study was due to the fact that we think that existing English stemmers (Porter and Krovetz stemmers) are still too aggressive. For example, the Porter stemmer gives the same stem ‘comput’ for words ‘computer’, ‘computers’, ‘compute’, ‘computation’ and ‘computational’, whereas there are not subtle meaning differences among these words.
We first compared the most frequent topical tags with the topical subject terms. Table 4 shows the top 20 most frequent topical tags and topical subject terms. All Chinese tags in Table 4 are given their English translation (separated by a hyphen) for easy understanding.
Top 20 most frequent topical tags and topical subject terms (the numbers in brackets indicate the frequency)

Comparing English topical tags and English topical subject terms, the majority are unique objects. Only three terms – ‘information technology’, ‘cataloguing’, and ‘internet’ – are in both categories. Confirming that subject terms are often multiple-word phrases, only three English topical subject terms in Table 4 are single-word terms. In contrast, the majority of the English topical tags in Table 4 contain a single word, while only four such tags are multiple-word phrases. This may reflect the different purposes of topical tags and topical subject terms. Tags are still primarily used for organizing and classifying online information resources for personal use, whereas subject terms are the professionals’ tools for traditional classification and indexing purposes. The fact that tags are uncontrolled is reflected in Table 4 – ‘computers’, ‘computing’ and ‘computer’ are topical tags that basically express the same meaning but in different forms.
A similar result is observed between Chinese topical tags and Chinese topical subject terms. First, the majority of Chinese topical tags and Chinese topical subject terms in Table 4 are unique, and only two terms (‘情报检索-information retrieval’ and ‘知识产权- intellectual property’) are shared. However, the length of the topical tags and that of topical subject terms are not as different as in the English case. The average length for the Chinese topical tag in Table 4 is about three characters, whereas that of the Chinese topical subject terms in Table 4 is four characters.
In comparison, there are more shared tags between the English topical tags and the Chinese topical tags, such as ‘library science’, ‘library’, ‘computer’, ‘business’, ‘information’, ‘history’, ‘internet’, and ‘management’. This is probably due to tagging using the same domain knowledge, English and Chinese users share a good part of the domain vocabulary. As for topical subject terms between the two languages, there are also more shared terms within the top 20 most frequent words, such as ‘management information system’, ‘electronic commerce’, ‘computer networks’, ‘digital libraries’, ‘information retrieval’, and ‘internet’. These words represent the hot topics in the information science domain.
We further identified the following observations about both the English and Chinese sides. The topical tags in both languages include many terms that refer to a broader discipline such as ‘library science’, ‘history’, ‘business’, ‘art’, ‘sociology’, ‘economics’ and so on. However, both languages’ topical subject terms often refer to more specific topics – subfields or research areas in the information science domain, such as ‘electronic commerce’, ‘digital library’, ‘information literacy’ etc. This seems again to demonstrate the different usages of social tags and subject terms.
Another angle of analysing the overlapping terms at the collection level is to look at social tags and subject terms as two sets of terms. To capture the distribution of the two sets, we organized the tags or the subject terms based on the number of times that they were used in the books respectively. Through this effort, we obtained several ranked lists: each has the most frequently used terms at the top, and the least used terms at the bottom. Here, we first use the Jaccard similarity coefficient [33] to examine the term similarity between these two sets. The Jaccard coefficient measures similarity between sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets. The value of Jaccard coefficient is between 0 and 1. A ‘0’ means that the sample sets have no similarity and 1 means that they are identical. A number n is introduced as the size of the sets, so the top n frequently used social tags are compared with top n frequently used subject terms by using Equation (1):

where n is the number of terms, X is the set of n frequently used tags and Y is the set of n frequently used subject terms.
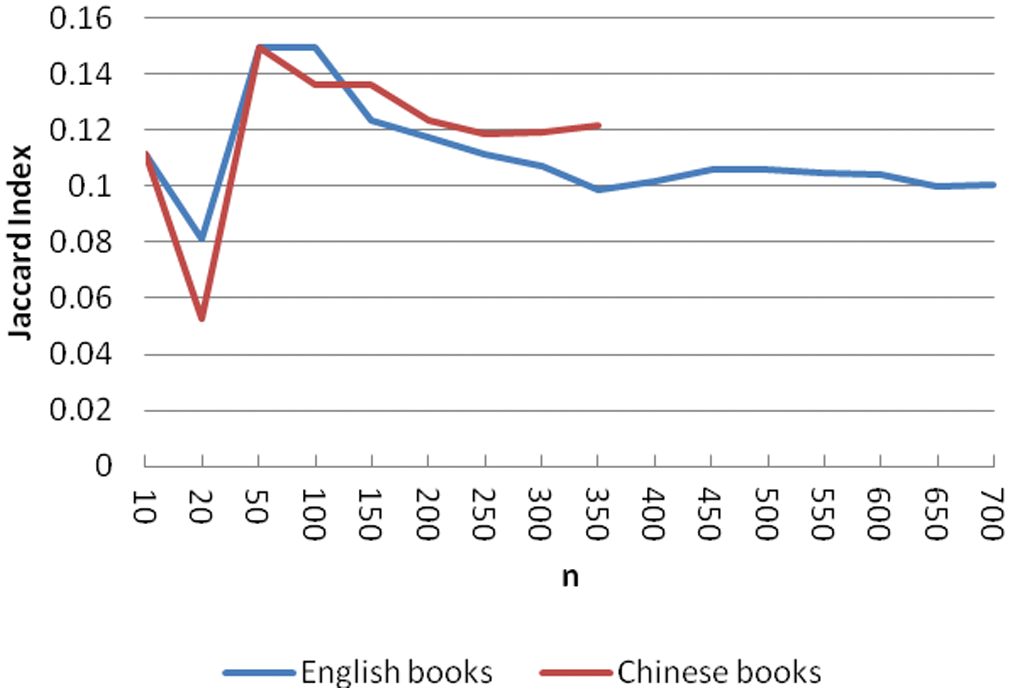
Figure 2 shows the Jaccard index of all tags vs. all subject terms when n takes the value 10, 20, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700 (Chinese books stop at n = 350 because of their fewer number of terms). From the figure, we can see that the Jaccard indexes for both English and Chinese books are always smaller than 0.2, indicating a relatively low overlap between the top used social tags and the top used subject terms. It is interesting to see that the lowest value of Jaccard indexes was at n = 20, and the highest value was at n = 50. These results highlight the differences between the most frequently used tags by end users and of the most frequently used subject terms used by professionals.
Jaccard index at different ranks of all tags and subject terms.
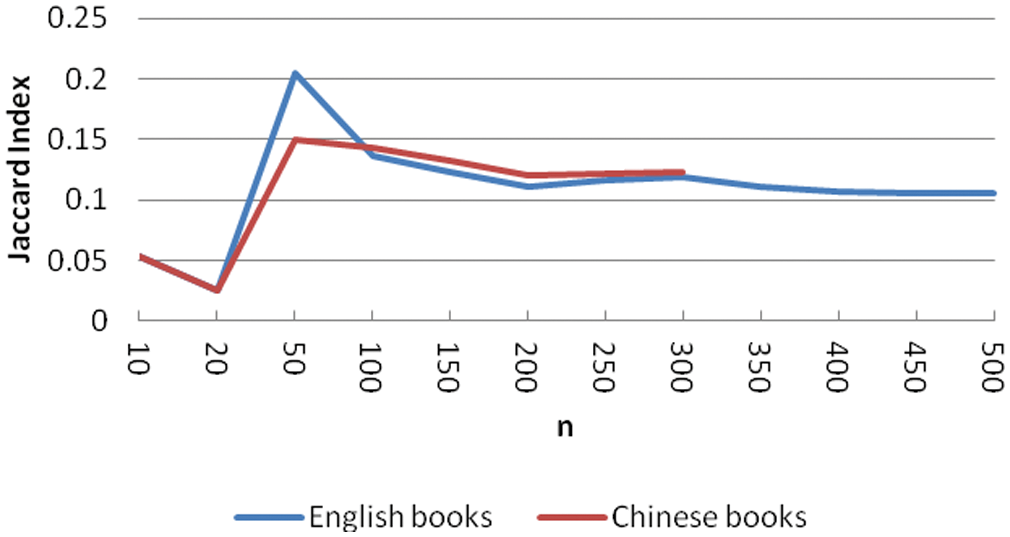
Figure 3 shows the Jaccard index of topical tags vs. topical subject terms when n takes the value of 10, 20, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500 (Chinese books stop at n = 300 because of their fewer number of terms). We can see that the overlap between the most frequently used topical tags and that of topical subject terms are lower than the overlap between all tags vs. all subject terms. This is shown in the lower Jaccard index at n = 10 and n= 20 in Figure 3 as compared to Figure 2. However, English books in Figure 3 do peak at a Jaccard index of 0.2 when n = 50, which is higher than that in Figure 2. This shows that when n = 50, the number of overlapping topical tags in English books is larger than that of overlapping tags in English, but this is not true for Chinese books. After the peak at n = 50, the Jaccard index values in Figure 3 are relatively similar to those in Figure 2.
Jaccard index at different ranks of topical tags and topical subject terms.
The Jaccard index of Chinese books is slightly lower than that of English books when n is between 10 and 50; after that, the Jaccard index of Chinese books is slightly larger than that of English books, no matter whether for all tags or only topical tags. We did not compare non-topical tags and non-topical subject terms because there is no expectation that they should have overlap.
The third aspect for examining the overlapping terms is to look at the correlation between the two sets based on the terms that they share. We used the Spearman correlation coefficient method to examine the ranks of overlapping terms in the ranked list of tags and of subject terms. The ranking of overlapping terms is based on the frequency of social tags or subject terms. The coefficient has a range of [−1, 1], with an absolute value indicating the strength of correlation and a positive or negative sign indicating the direction of correlation. In general, people assume an absolute value of 0.3 or less as a small correlation, between 0.3 and 0.5 as a moderate correlation, and above 0.5 as a strong correlation [34].
Table 5 illustrates the Spearman correlation coefficients on various overlaps between the social tags and the subject terms. From the social tags point of view, the overlaps between social tags and subject terms are low (206 or 8.22% for English and 132 or 10.36% for Chinese). This is also true for topical tags (160 or 9.77% for English, 117 or 13.70% for Chinese). This shows that about 92% of English tags and 90% of Chinese tags cannot be found in the subject terms. However, due to the relatively small size of subject terms, the percentage of overlap is higher: 28.57% of English subject terms, 33.42% of Chinese subject terms, 30.25% of English topical subject terms, and 33.24% of Chinese topical subject terms are also social tags. The Spearman correlation coefficients of the two rankings (the ranked overlapping terms according to their frequency in all tags and subject headings) are 0.3446 for English books and 0.4519 for Chinese books. This indicates a positive and moderate correlation between the social tags and the subject terms, which is statistically significant (p = 0.000). The positive correlation means that when a social tag is popular as shown by its use frequency, we would also find its identical subject terms to be popularly used in controlled vocabulary as well. So the trend of the behaviours of the terms in social tags and subject terms are the same. However, the actually number of use frequency between social tags and subject terms has only a middle range connection. That is to say, the connection is neither very tightly related (indicating high correlation) nor loosely related (indicating low correction).
Statistical information of overlapping vocabulary in the whole set

Table 5 also shows that social tags and subject terms have a higher agreement when describing content. There are 160 overlapping terms between topical tags and topical subject terms in English and 117 overlapping terms in Chinese. They stand for 9.77% of the English topical tags and 13.70% of the Chinese topical tags, or 30.25% of the English topical subject terms and 33.24% of the Chinese topical subject terms. There is a moderate positive Spearman correlation between topical tags and topical subject terms in both languages, and we have high confidence (p = 0.000) in this correlation. The exact reason for this deserves further study. Of course, we also acknowledge that content is a relatively clear focus, whereas non-topical feelings or non-topical attributes are rather vague, which could contribute to the differences in overlapping percentages.
English books have higher numbers of overlapping terms in all of the comparisons. But the Spearman correlation coefficients of Chinese books are all higher than 0.4, moderate but very close to a strong correlation. All of the coefficients for Chinese books have a higher than 95% confidence. In contrast, English books have moderate coefficient values close to 0.3 between all tags vs. all subject terms and between topical tags vs. topical subject terms, and the confidence is higher than 95%.
4.4. Overlapping terms between social tags and subject terms at individual book level
We further calculated the overlap between topical tags and topical subject terms (see Table 6). For those tags that were not identical to the topical subject terms we collected, we confirmed with the LCSH and CCT that they were still controlled vocabulary terms.
Overlap between topical tags, topical subject terms, and controlled vocabulary terms
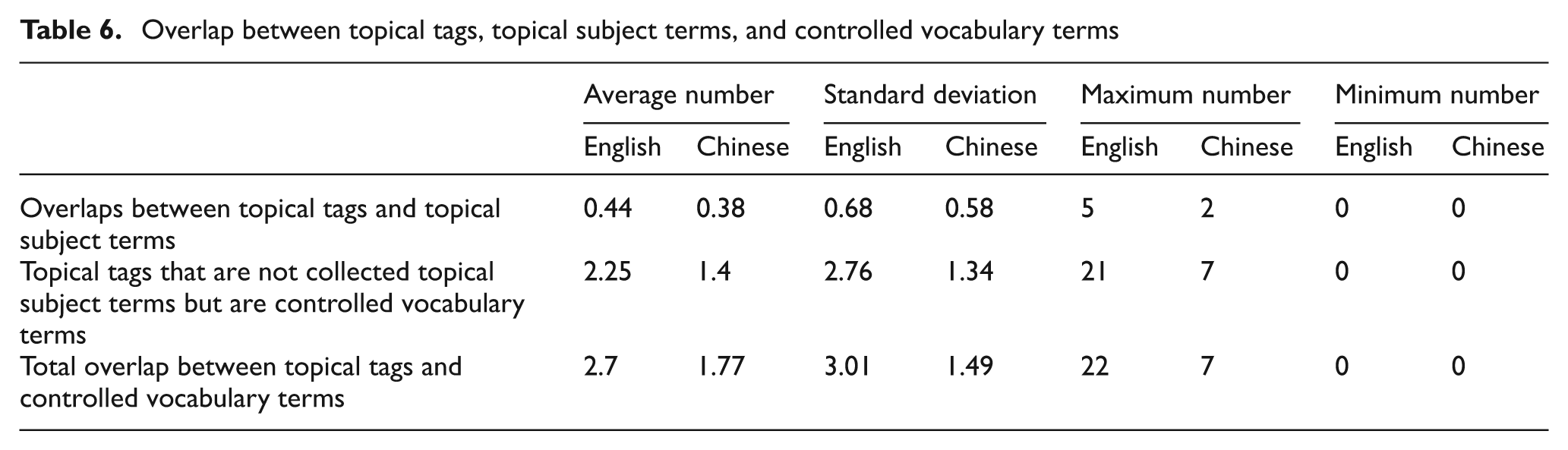
By examining the overlap between the topical tags and the collected topical subject terms or all of the identified controlled vocabulary terms, as shown in Table 6, we find that only a small number of the topical tags are topical subject terms (0.44 out of 6.81 for English, 0.38 out of 3.95 for Chinese). However, as stated previously, some topical tags that are not topical subject terms are still controlled vocabulary terms: on average 2.25 English topical tags or 1.4 Chinese topical tags per book are controlled vocabulary terms. This brings the total overlap between topical tags and controlled vocabulary terms up to 2.7 out of 6.81 per book in English and 1.77 out of 3.95 per book in Chinese. English tags are slightly less controlled than Chinese tags, since approximately 40% of all English tags are controlled vocabulary terms, whereas 45% of all Chinese tags are controlled vocabulary terms.
We further compared social tags and subject terms at the individual book level. Since the content of the book is the most important aspect, we only looked at the relationship between topical tags and topical subject terms. For this part of the study, we again used the Jaccard index, so Equation (1) was reinterpreted to calculate the overlap. In this new interpretation of Equation (1), n becomes the number of books, X is the set of unique topical tags of the n books and Y is the set of unique topical subject terms in the same set of books. Because the value of Jaccard index is inside the interval [0,1], we divided the value of Jaccard into 10 zones with increments of 0.1, and calculated the number of books falling into each zone. Figure 4 shows the distribution of the Jaccard index values. Both the Chinese and English books have more than 60% of the samples (more than 300 books among the 500 sampled in the experiment) falling into the zone 0–0.1, about 10% of the books are between 0.2 and 0.3, and almost no books are in the zones 0.6 and up. All these show again that topical tags and topical subject terms have relatively low overlap, indicating that end users and information professionals use different terms to describe the content of books.
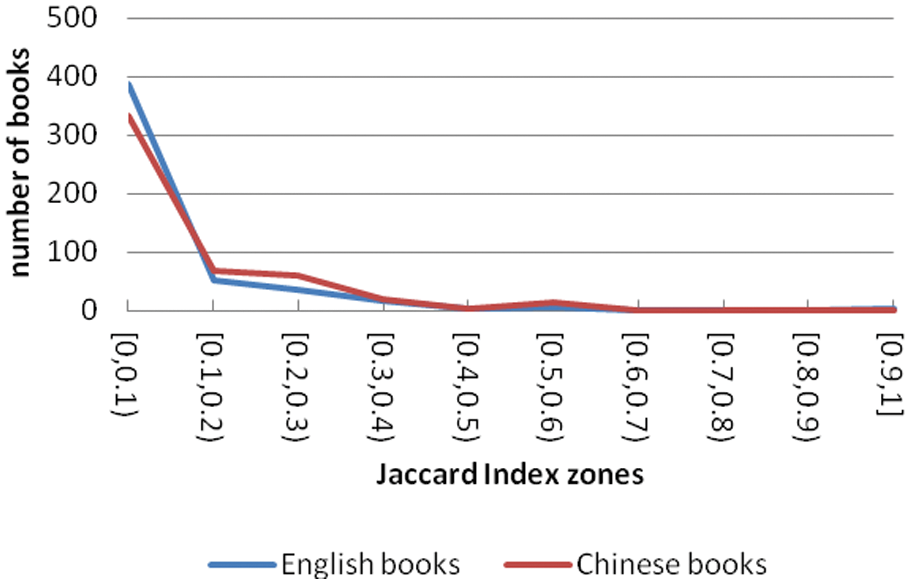
Distribution of similarity between the topical tags and the topical subject terms at the individual book level measured by Jaccard index.
Table 6 shows that we also studied the overlap between the topical tags and the identified controlled vocabulary terms (including those terms found in LCSH or CCT but not in the MARC records we collected). The distribution of the percentages is shown in Figure 5 as falling into 10 zones.
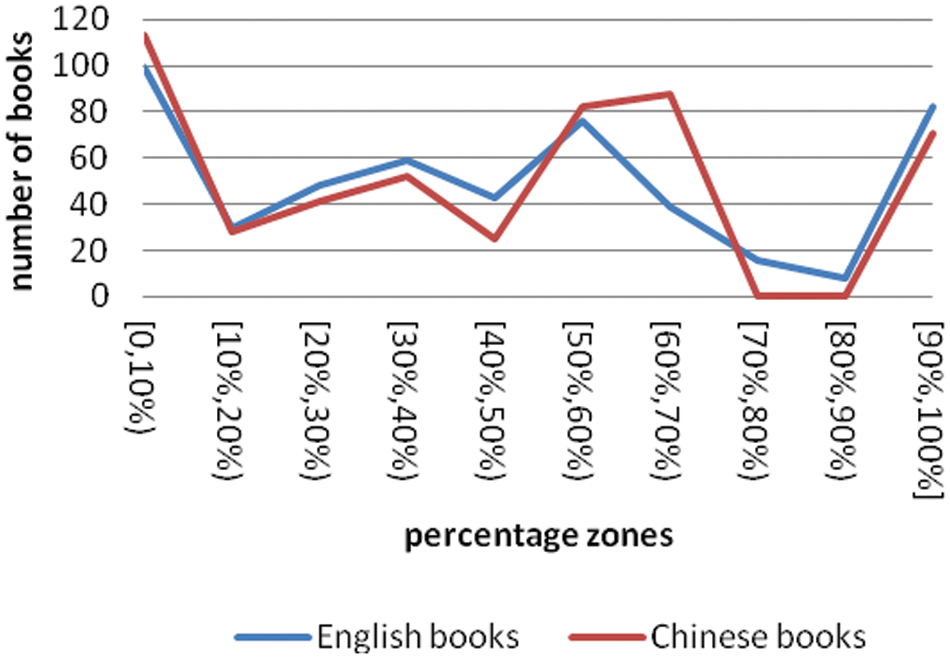
Number of books in the 10 zones that show the percentage of topical tags that are identified as controlled vocabulary terms.
Figure 5 shows that 99 (19.8%) of the English books and 113 (22.6%) of the Chinese books have little or no (<10%) overlap between their topical tags and the identified controlled vocabulary terms. However, 82 (16.4%) English books and 71 (14.2%) Chinese books had nearly all (≥90%) of their topical tags also serving as controlled vocabulary terms. In total, there are 221 (44.2%) English books and 241 (48.2%) Chinese books that have more (≥50%) topical tags being controlled vocabulary terms than not. This demonstrates that those topical tags that are controlled vocabulary terms in thesauri are important resources which shouldn’t be ignored when using tags in cataloging and indexing. When comparing between English books and Chinese books, the numbers of the books in both languages in each zone are often very close to each other except in zones [40%,50%), [60%,70%) and [70%,80%). The most significant difference is in zone [60%,70%).
4.5. Other semantic relationships between social tags and subject terms
In the above analyses, we paid attention to only those keywords that are identical between social tags and subject terms. However, there are many other possible semantic relationships between two keywords. Inspired by the semantic relationships discussed in [3], we identified the following semantic relationships:
Synonym (SN): a social tag and a subject term are synonyms (equal to USED FOR in a thesaurus).
Broader Term (BT): A social tag is a broader version of a subject term.
Narrower Term (NT): A social tag is a narrower version of a subject term.
Related Term (RT): A social tag is not in a SN, BT, or NT relationship with a subject term, but it is still related to the subject term.
Not Related (NR): A social tag has no apparent relationship to a subject term.
We then manually classified the connections between the social tags that had not been found to match subject terms using the relationships described above. Our classification was in the category of all tags rather than topical tags. Table 7 lists the numbers and the percentages of identified relationships, and the numbers and the percentage of books that have those corresponding relationships. The numbers of the relationships were calculated by two coders who looked at the unmatched social tags and subject terms within each book. We calculated the percentages of the identified relationships based on the total number of the relationships which is 3108. It should be pointed out that one tag may be counted more than once as it may have more than one relationship when compared with different subject terms. We again acknowledge that we only used two coders to classify the semantic relationships, and each coder worked on only one language. Although we periodically checked the quality and consistency of the classification, there is no inter-coder agreement value to report.
Frequency of the semantic relationship
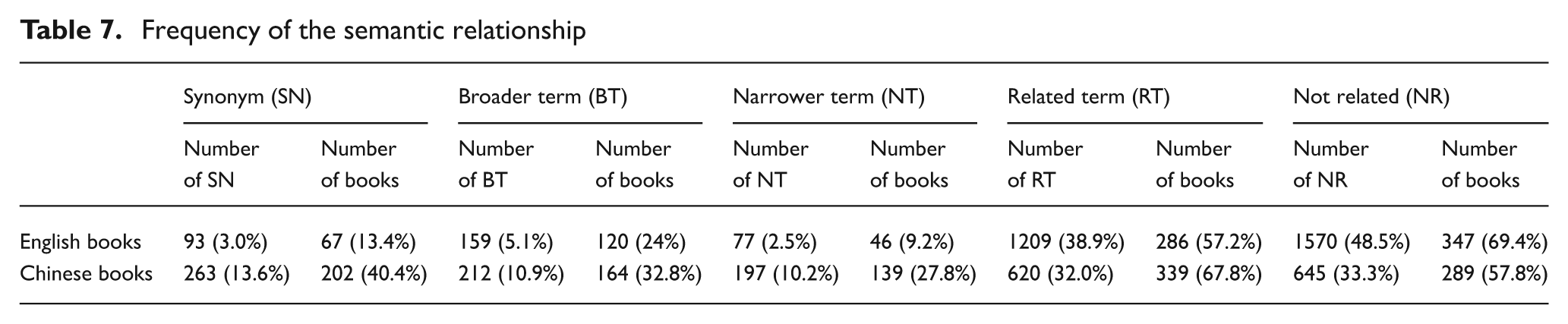
SN, BT and NT are three clearly defined semantic relationships that are used in thesauri, but their instances are relatively small in our study. In total, they account for only 329 (10.6%) instances for English books and 672 (34.7%) instances for Chinese books. The RT relationship is often included in a thesaurus, but its meaning is relatively vague in comparison to those of SN, BT and NT relationships. We identified 1209 instances (38.9%) of an RT relationship for English books and 620 instances (32%) for Chinese books. There are 286 (57.2% of 500) English books and 339 (67.8% of 500) Chinese books which have this relationship. Examples of related terms include ‘information seeking’ and ‘information retrieval’, where the former talks about the process or activity of obtaining information in certain contexts, and the latter refers to techniques used to find specific information from large stored data collections.
The most common relationship discovered in the experiment is NR. We found 1570 instances (48.5%) for English books and 645 instances (33.3%) for Chinese books. There are 347 (69.4% of 500) English books and 289 (57.8% of 500) Chinese books which have this relationship. We were curious about the types of tags in this relationship, so we sampled several instances and grouped them into the following eight categories:
Task management tags are those indicating that users wish to be reminded about what they want to do or have done with the book. Examples of the tags in this category are ‘to read’, ‘how to be perfect’, ‘sort – nature study’.
Code tags are those tags that are only meaningful to the individual users or the people who are close to them. Often these tags look like a course code, a standard code, or a technology code. Examples include ‘LIS5270’, ‘BS7799’, ‘TP-650.180’, ‘msu class 545’, etc.
Abbreviation tags are those non-standard abbreviations generated by users themselves to represent some domain terminology. As these tags are not generally used within a community, they are difficult to understand. For example, the tag ‘eb’ is used for ‘e-books’, and ‘gd’ is used for ‘graphic design’.
Geographic location tags are the geographic locations associated with a book, such as ‘Hong Kong (China)’, ‘New York City’, ‘USA’, ‘Russia’, and so on.
Idiosyncratic tags are those known only to the users themselves. The meaning of some tags is difficult to guess. For example, ‘*el’, ‘#lingusitic torpedo’, ‘rob-05-ft’.
Foreign language tags are another type of barrier/challenge to understand tags, such as ‘informática’, ‘jürgen müller’, ‘politiques développement de’, etc. This is because either the content of the book is bilingual or the user is bilingual.
Typo tags are typing mistakes, such as ‘informacion’.
Other tags: tags that cannot be classified into the above categories.
The discussion in this subsection suggests that, while many keywords in tags are somewhat like those in a thesaurus, they tend not to follow the clearly defined semantic relationships described in a thesaurus. Therefore, social tags might be very useful in modelling end-users’ vocabularies that are different or complementary to the traditional controlled vocabulary. The combination of them would produce benefits from both end-users’ vocabulary and expert’s terms.
4.6. Insights from the results
4.6.1. Relationship between social tags and subject headings in information science domain
Overall, social tags in the information science domain demonstrate connections between the subject terms and them. We obtained evidence on direct overlapping between social tags and subject terms, and through more elaborate measures such as the Jaccard index and Spearman correlation coefficient, we further quantified the connection. Although many studies used LibraryThing data [11, 18, 20, 21], we could only establish a direct comparison to Lu et al.’s study [11]. Using Lu et al.’s results, which were obtained based on the overlap between all social tags obtained from LibraryThing and LCSH terms in generic domains, we could see that the overall overlap between social tags and subject terms in the information science domain in our study is higher than that in the generic domains (8.22% vs. 2.2%). This could be attributed to several reasons. First, there could be more LibraryThing users in the information science domain who had professional training in classification and cataloguing, so there is a higher chance for these users to select LCSH terms as their social tags. This demonstrates the necessity of conducting domain specific studies on social tags. The Jaccard index values obtained in the Lu et al. study for the most frequent tags and LCSH subject terms are in the range 0.08–0.1, whereas the Jaccard index values of tags and LCSH subject terms in the information science domain in our study are mostly between 0.1 and 0.14. This again shows that the tags in the information science domain have higher overlap with LCSH subject terms, which is consistent with our hypothesis on the higher percentages of professionally trained information science LibraryThing users. However, it is interesting to note that the Spearman correlation coefficient value obtained in Lu et al.’s study is 0.507, whereas the coefficient that we obtained in the information science domain is only 0.3446. Compared to the Jaccard index, the Spearman correlation coefficient not only examines the overlap of social tags and LCSH subject terms, but also reveals the ranks of social tags and LCSH subject terms by their respective frequency. Therefore, the difference between our Spearman value and that of Lu et al. shows that social tags in the generic domains in LibraryThing, if they are identical to LCSH subject terms, have frequencies that are more similar to those of the identical LCSH subject terms than to the overlap social tags in the information science domain.
Social tags in the information science domain still have the limitations inherent in all uncontrolled languages: homographs, synonyms and polysemes are very common among social tags, and the shared keywords between social tags and subject terms are still relatively low, even among the most frequently used tags and subject terms. Beyond the identical shared keywords, there are synonyms, broader terms, narrower terms, and related terms between social tags and subject terms.
In summary, the information science domain is a very interesting academic research area because users in this domain often have had some training in classification or cataloguing before they utilize social tags. Our study points out possible directions for studying information science domain-specific social tag issues. Such issues could be the reasons behind the higher overlap of terms between social tags and subject terms, but lower correlation for their use frequencies.
4.6.2. Relations between English and Chinese language tags
Razikin et al. [35], by citing Lakoff [36], state that social tagging systems (being systems undertaken by ordinary people) are dependent on the persons’ language and culture. Overall, we found that language difference does have an impact on English and Chinese tags. Probably due to language or culture differences, we found that the number of unique English tags were much higher than unique Chinese tags, although the total numbers of the tags between the two languages were not that significantly different. It seems that users of English tags tend to use diverse words as their tags, even though the meanings might not be that different among the tags, whereas users of Chinese tags tend to cluster around a smaller number of tags and keep using the same tags again and again. This is why Chinese tags all have larger usage frequencies (shown by similar numbers of total Chinese tags with usage frequencies but smaller numbers of unique tags). Also for the English side, we only saw English words being used for tagging, whereas on the Chinese side, some tags are actually English words. This is probably a reflection of the fact that many Chinese users have certain levels of skill in English, whereas a much lower percentage of English users know any Chinese.
It is also very interesting to see that slightly more than half of the Chinese tags used in those 10 pairs of books that are Chinese translations of works originally in English are the translations of the English tags themselves. From a user behaviour point of view, this might indicate that Chinese users learn their corresponding concepts through English words or the Chinese translations of the English words, which may reflect the relatively advantageous position of the development of the information science discipline in the USA. Another interesting insight is that the tags between Chinese and English books, particularly those books that are translations of each other, can be harvested to build up domain specific translation resources for multilingual information retrieval.
We also found that most top frequently used English tags are single-word terms, whereas the obtained frequently used LCSH subject terms are multi-word phrases. Upon examining the Chinese side, we found that the character difference between the most frequently used Chinese tags and that of Chinese subject terms is just one character (3 vs. 4). Of course, as a relatively compact semantic language, this one character difference in Chinese might be enough to convey the semantic differences between English tags and English subject terms. However, all of this demonstrates that it is necessary to study social tags in different languages separately.
However, English and Chinese users do share many similar behaviours when they tag books in the information science domain. For example, they share many tags within the top 20 frequently used tags. The patterns in the overlap of topical tags and topical subject terms are similar for English books and Chinese books. This means that many tagging behaviour patterns are language independent, and some insights obtained from studying in one language can be borrowed (with careful examination) for describing behaviours in another language.
4.6.3. Uses of social tags and expert-created subject headings
The emergence of social tagging applications based on Web 2.0 technology has been viewed by many researchers as an opportunity for libraries to enhance access to their resources. Our study shows that people do provide many tags to describe the books in the information science domain, and the average number of unique tags is almost double compared to the number of LCSH subject terms assigned to the same books by professional cataloguers and indexers. Because the majority of the tags describe the book content and valid topics in the information science domain, these tags should be able to be used to enhance organizing and accessing information science books and information resources in general.
However, social tags created by end users are still very different from LCSH subject terms created by experts. There is more uncontrolled inconsistency and noise, the overlap is still relatively low, and the style of the keywords (single-words vs. multi-word phrases) is still very different. Therefore, social tagging cannot be viewed as an immediate complementary schema for controlled vocabulary systems in cataloguing and indexing. However, we do believe that it has the long-term potential to evolve to become a complementary source for expanding and enriching controlled vocabulary systems. There are already multiple semantic relationships between social tags and controlled vocabulary terms, there are also tags that are controlled vocabulary terms even though they are not index terms selected by the indexer.
4.7. Limitations of the study
A major limitation of the study derives from the fact that our comparison analyses were performed at the syntactical level. Terms which have different syntactic forms but similar semantic meanings are prevalent. Taking into account the semantics of the tags may lead to different findings. In our future work, we plan to conduct a semantic comparison analysis of tags and subject headings on academic resources beyond books.
5. Conclusions and future work
In this paper, we presented an in-depth examination of the relationship between social tagging and controlled vocabulary-based indexing and organization. In particular, we studied the domain of LIS, and observed the relationship in both English and Chinese. Our results show that the information science domain has higher overlap between social tags and controlled vocabulary-based subject terms. This is reflected in the higher percentage of overlapping terms between tags and subject terms, as well as in the higher similarity (measured by the Jaccard coefficient) of frequently used keywords between tags and subject terms. However, social tags in the information science domain still possess the limitations of uncontrolled terms, where inconsistency and noises widely exist.
Our results also show that language difference does have an impact on social tagging. The numbers of Chinese tags overall and per book are smaller than those of English tags. The most frequently used English tags are single-word terms, which is different from controlled vocabulary terms which are multi-word phrases. The character difference between the most frequently used Chinese tags and Chinese subject terms is just one character (3 vs 4). However, English users and Chinese users do share many similar behaviours when they tag books in the information science domain. Many top frequently used tags are shared between the two languages and the patterns of overlap in terms of topical tags and subject terms is similar between the two languages as well.
Overall, despite the limitations of applying social tagging in cataloguing and indexing, we do believe that it has the potential to become a complementary source to expand and enrich controlled vocabulary systems. With the help of future technology to check consistency and promote features related to controlled vocabulary in social tags, a hybrid cataloguing and indexing system that integrates social tags with controlled vocabulary would greatly improve people’s abilities to organize and access information resources.
Our future directions can include such extensions as studying more academic domains in addition to information science and studying more social tagging sites other than LibraryThing. This will help us to confirm and enrich some of the findings obtained here. We will also perform more in-depth examinations of the impact of language/culture differences on social tagging. We have identified some differences; however, we have found more interesting discrepancies between English tags and Chinese tags.
Footnotes
Appendix
Acknowledgements
This work was partially supported by the Fundamental Research Funds for the Central Universities (grant number 2012GSP074), National Social Science Foundation of China (grant number 09CTQ026), Wuhan International Science and Technology Cooperation Fund (grant number 201070934337), the 3rd Special Award of China Postdoctoral Science Foundation (grant number 201003497) and National Science Foundation of USA (grant number NSF/IIS 1052773).