
Abstract
Web search engines have become the dominant tools for finding information on the Internet. Owing to their popularity, users of all educational backgrounds and professions use them for a wide range of tasks, from simple look-up to rather complex information-seeking needs. This paper presents the results of a study that investigates the behavioural search characteristics of ordinary Web search engines users. The aim of the study was to investigate (1) what makes complex search tasks distinct from simple search tasks and whether it is possible to find simple measures for describing their complexity, and (2) whether successful searchers show different search behaviours than unsuccessful searchers and whether good searchers can be identified via simple measures. The study included 56 ordinary Web users who carried out a set of 12 search tasks using current commercial search engines. Their behaviour was logged with the Search-Logger tool. The results confirm that the behaviour in the case of complex search tasks has significantly different inherent characteristics than in the case of simple search tasks. This can be proven by using simple measures such as task time, number of queries, or number of browser tabs used. We also observed that it is difficult to distinguish successful from unsuccessful search behaviour simply by using these measures. The implications of our findings for search engine vendors are discussed. The results of this study with a sample of ordinary users are insofar unique as they are valid for a wider population while most studies in the field are usually done using convenience samples such as university students.
Keywords
1. Introduction
For people, information seeking is a fundamental activity [1]. While it was previously done in places such as libraries, it is now increasingly done through electronic media such as the Internet [2]. The ever-growing amount of information available on the Web increasingly overburdens Web users and impacts their Internet experience [3–5]. Search engines are the most prominent tools to help users find information on the Web and people are usually satisfied with their performance [6]. However, search engines do not support all information needs equally well. For example, despite the huge amount of research on search and search behaviour, complex Internet search is not well supported by current search engines [4], although there is strong agreement in the research community that search engines should support such tasks better [7]. According to research by Microsoft [8], many queries issued to search engines during longer search sessions ‘yield terrible satisfaction’ and only 25% of these queries are successful. These sessions often span longer time frames, with 20% of sessions lasting between one week and one month [8].
Users often face a situation in which there is no simple answer for their information need available. For example, a growing number of people use search engines to make decisions that require aggregated information [8]. Therefore, they have to review a large number of documents and/or synthesize results from different sources, discovering new facts that are relevant for their information needs along the way. Today’s search systems are mainly designed to follow the ‘query–response’ or ‘look-up’ concept. Search engines usually offer their users only a simple query interface. Users enter queries into those search systems and receive ranked lists of search results. Search engines support basic types of search tasks that can be solved with a simple query–result pairing. These search tasks happen in the context of question-answering and fact-finding [9]. We will call these simple search tasks. Studies show that the performance of current search engines for simple tasks is usually satisfactory for the users [6].
In this paper, we will investigate how users behave when dealing with complex search tasks (to be defined in the next section). Examples are open tasks such as comparing the development of various religions in different countries or finding the differences between the composers Mozart and Bach.
We conducted an experiment involving 56 ordinary Web users from mixed demographics carrying out 12 tasks of varying complexity. The users’ activities were logged using the Search-Logger tool [10] (to be described in the Methods section). We analysed their search behaviour in relation to the complexity of the tasks. We want to suggest measures that will enable search engine providers to detect when users perform complex search task and enable the providers to offer extended support. This quest for more support is also in line with research on Web Information Retrieval Support Systems [11].
2. Related work
We have divided our related work section into papers related to tasks, task complexity, logging user behaviour, users’ search characteristics, logging tools and articles related to query reformulation to cover all relevant aspects of the research presented in this paper.
2.1. Tasks
‘Tasks are activities people attempt to accomplish in order to keep their work or life moving on’ [12, p. 1823]. According to Vakkari [13], tasks usually have a goal, and information searching is a contributing activity to finding relevant information to achieve that goal. A work task is a special kind of task that appears in the work context, where the task’s goal is also work-related. People usually carry out activities such as information searching as the result of such work tasks or simply out of interest. Work tasks can trigger both information-seeking tasks and information-search tasks [14–18]. According to Li [12], information-seeking tasks result from people’s general information needs. People typically search through multiple sources such as books in libraries, papers and digital information systems. An information-seeking task usually becomes a search task once people start searching with information retrieval (IR) systems.
2.2. Task complexity
Researchers disagree to a large extent on what makes a task complex [19]. There is a common understanding that task complexity can be either objective [20, 21] or subjective [22]. The first definition is independent of the person carrying out the task. The second definition is dependent on the individual by looking at the cognitive demands [23] that are required of the performer of the task. To find out more about what makes a task objectively complex, Li et al. [22] conducted a survey with 100 university students. According to their study, the main objective predictors for task complexity were the number of words in the task description, the number of domain areas that the task required the users to have knowledge about, and the number of languages needed to interpret and understand the search results. Task complexity also relates to the number of sub-tasks that the user needs to carry out [24]. As far as subjective task complexity is concerned, it reflects how complex the person who carries out the task sees it as [22].
Byström and Järvelin [25] defined task complexity as information seekers having to deal with ‘a priori determinability of, or uncertainty about, task outcomes, process, and information requirement’ [25, p. 194]. According to Byström and Järvelin [25], search tasks are typically characterized by three types of information needs: problem information, domain information and problem-solving information. The latter (i.e. known methods to tackle this problem) clearly distinguishes complex tasks from their simpler counterparts. Another classification of task complexity was developed by Campbell [19]. It is based mainly on a number of complexity-impacting factors that are present, such as multiple paths to a desired end-state, multiple desired end states, conflicting interdependence, and uncertainty or probabilistic linkages.
Singer et al. [26] decomposed the complex search process into the aggregation, discovery and synthesis steps. A complex search is defined as a multistep, interactive and time-consuming process. It is not answerable with one query, instead requiring the searcher to aggregate and synthesize information from more than one (usually many) retrieved Web page or document. A complex search task is defined as one that leads to a complex search activity. Hence, a complex search task is described in relation to the complex search itself, which is an interactive process.
Finally, exploratory search tasks are defined as tasks related to open-ended information needs. They are usually abstract, not very well defined, and often have a multifaceted character [7, 9]. They require the searcher to apply large amounts of interaction while learning, investigating or making decisions. Another characteristic is that they are usually ambiguous and/or uncertain and require the searchers to discover new facets (problem aspects) of their search need. We see complex search tasks as being similar to exploratory search tasks but still different, as there are many tasks that require much interaction with the system (such as multiple queries or tabbed browsing) and are hence complex, but do not necessarily carry all standard attributes of exploratory search tasks (such as learning or decision-making) [7, 9]. For a more detailed discussion on classifying exploratory searches please refer to Singer et al. [26].
2.3. Logging user behaviour
Transaction logs recorded in search engines have been analysed by several scholars [27–29]. One of the first larger-scale studies reflecting the search behaviour of Internet search users was conducted by Jansen et al. [30]. They analysed transaction logs from the search engine Excite. The authors reported that query modification was not happening very regularly, and the sessions were short. Users seldom looked at more than two SERPs (search engine results page) per session. Jansen and Spink [29] gave an overview of nine transaction-log studies of five Web searches. They reviewed session length, query length and query complexity and viewed content in different search engines. They observed that users were visiting very few results pages (even fewer than in their first study). Höchstötter and Koch [28] gave an extensive overview of query length and query complexity in Web searches and summarized their findings for multiple transaction log-based studies carried out between 1995 and 2008. They confirmed the findings of Jansen et al. [27]. They mentioned standard parameters to measure search engines and showed how these parameters reflected the online searching behaviour of search engine users. Joachims et al. [31] carried out a study with 34 undergraduate students, examining their interaction behaviour with SERPs by asking them to carry out five simple navigational and five informational search tasks. The study showed the preferences of users and confirmed their trust in search engines, as expressed by their clicking behaviour in the SERPs.
Most of the presented studies are only transaction-based and do not take the actual task and user into account. Other studies use very specific user samples (such as only undergraduate students). Queries are generally short [29] (only around two words) and users tend to look only at the first few results in the SERP. Most of the task-based studies were carried out with simple tasks, where the majority of search sessions is short [27–29]. The only exception is the study described in Hölscher and Strube [3] that investigated more complex search tasks.
2.4. Users’ search characteristics
As we are investigating search and its characteristics in this paper, we also looked at other works in this area. Kellar et al. [32] carried out a user study with 21 study participants. They had them carry out a number of tasks and the users were required to classify those tasks into the four predefined categories: ‘Fact Finding, Information Gathering, Browsing and Transactions’ [32, p. 999]. They also logged the participants’ user behaviour and investigated several measures such as task time and number of pages opened. They identified task specific characteristics for each category. Jansen et al. [33] conducted an experiment with 72 study participants, where they asked them to carry out six search tasks each to research the information searching characteristics of a learning process. They, amongst others, observed that users often showed simple search behaviour (such as fact checking) despite having high-level information needs. This seems to contradict the common understanding that people searching on the Web mostly try to satisfy simple information needs. They conclude that search systems should also account for the learning needs of users. White and Drucker [34] present the results of a long term log-based study carried out with over 2000 participants. They analysed the search trails the users followed from issuing the first query to ending their search and observed two extreme styles of searching, namely ‘navigators’ (17% of the participants showing a very consistent search behaviour with little variance) and ‘explorers’ (3% of the users considerably varying their search strategies while searching). Wolfram [35] investigated the search behaviour of users in various Web-based IR environments such as search engines, specialized search systems, bibliographic databases and online public access catalogues. His results show differences in the user behaviour in terms of measures such as query length, pages viewed per query, queries per session and also inter-query time.
2.5. Logging tools
A number of logging tools have been developed for information research purposes, for example, the ‘Wrapper’ by Jansen et al. [36]. This tool was designed with a focus on evaluating exploratory search systems. Although it allows to log a wide range of user events, the software does not offer the possibility to administer pre-compiled search tasks to a group of users or relate user action to tasks and it does not collect explicit user feedback. Another tool is a browser plug-in for the Internet Explorer that was created by Fox et al. [37]. It was the first tool to simultaneously gather explicit as well as implicit information during searches. It evaluates the query level and gathers explicit feedback after each query. Fox’s approach also came with a sophisticated analysis environment for the logged data. A third tool is Lemur’s Query Log Toolbar [38], which is a toolkit, implemented as an add-on for Firefox and Internet Explorer browsers. It logs implicit data on the query level. Other tools are the HCI browser [39], the Curious Browser [40], WebTracker [41] and Weblogger [42].
All tools offer to log user-triggered events. Yet, none of these tools allows work task-based experiments (administering tasks to users and relating their user action to those tasks) to be carried out. As a consequence, we developed a logging tool called Search-Logger [10] to cost-efficiently carry out task-based user studies (for a more detailed description, please refer to the Methods section).
2.6. Query reformulation
As query reformulation measures are an important part of our analysis, we also reviewed related papers. Jansen et al. [43] investigated 1.5 million queries from a search engine log to better predict the query reformulation behaviour of online users. Their results showed that 63% of the queries were new, about 8.3% were reformulated queries, 8.2% were queries suggested by the search engine and the rest were specialized and generalized queries. Anick [44] presents a number of log-based studies from the AltaVista Prisma search tool. He observed that most query reformulations were still done by hand and not by selecting one of the automatically suggested terms. People who used suggested terms aimed to search more precisely and favoured suggestions that were based on their own initial search terms. Huang and Efthimiadis [45] have taken AOL query logs and investigated users’ query reformulations approaches. They identified a number of reformulation types such as spelling correction, expanding acronyms, expanding the query by adding or removing words and simply changing words as being effective for users. Rieh and Xie [46] analysed over 300 search sessions (consisting of six or more queries) of a search engine log file. They observed that 80% of the query reformulations were related to content (which words were used), over 14% were related to format (which operators were used) and about 3% were related to resource (specification of file formats or Web domains).
3. Research questions
To guide our research, we formulated the following research questions:
The spectrum of search tasks ranges from simple to rather complex tasks. While it is quite well researched what makes a task objectively complex [24, 26, 47, 48], it is less clear how to exactly distinguish between simple and complex tasks in terms of user behaviour-related measures. We analyse transaction logs to find relations between the monitored behaviour and the actual task that a user is carrying out.
As the next step, we want to understand what makes successful search behaviour distinct. Therefore we compare good searchers (according to their performance in the experiment) with bad searchers and analyse their characteristics.
4. Methods
4.1. Data collection
The experiment was conducted in a laboratory environment in August 2011. The original user sample consisted of 60 volunteers who were being paid for their efforts (four study participants had to be excluded from the experiment owing to corrupt log data or insufficient computer skills). These volunteers were recruited using a demographic structure model to be representative of a cross-section of society in terms of age and gender (Table 1). The sample is relatively large for a laboratory-based user study, and with the wide span of users, the results of our study are not limited to a certain user group such as university students only (often taken in other studies). The experiment was conducted in Hamburg, Germany, and the language of the search tasks was German. The sample consisted of 32 women and 28 men, aged between 18 and 59.
Basic description of the user sample

4.2. Experimental design
The study participants were invited to the laboratory in four cohorts consisting of 15 people each. Before starting the experiment, all study participants were briefly instructed how to use the Search-Logger tool [10] (described below). After the instruction, each person was assigned a computer to be used throughout the experiment. At each computer the Search-Logger tool was installed. The Search-Logger is an add-on for Firefox browsers that allows administering work tasks to users and also their search behaviour to be logged. The Search-Logger runs in the background and has minimal interference with the user’s normal search flow. While the study participants carry out their assigned tasks, it automatically creates a log of a number of performed user events such as links clicked, queries entered, browser tabs opened and closed, and bookmarks added and deleted, and automatically adds time stamps to each of those events. User-specific information such as demographics and also user feedback about tasks is collected through automatic questionnaires at the beginning of the experiment and before and after each task. During the experiment, users can access their assigned tasks by clicking on the Search-Logger icon in the browser’s status bar, which opens a new window. The tasks can be selected using a drop-down button in this window. Selecting a task closes the Search-Logger window. During searches, users can switch between tasks; for example, they can start with one task, pause it to work on another one, and return to the previously started task whenever they want. When they are satisfied with the amount of information they have found for a task, they can finish the task with a click. The users were assigned a set of 12 simple and complex search tasks (see below). They were given 3 hours to complete all the tasks.
4.3. Operationalization of variables
To answer the research questions by empirical research, the variables involved have to be operationalized. We investigated the relationship between independent variables such as task complexity and dependent variables such as search time or number of queries. The complete list of dependent variables and their according description is illustrated in Table 2.
Description of variables
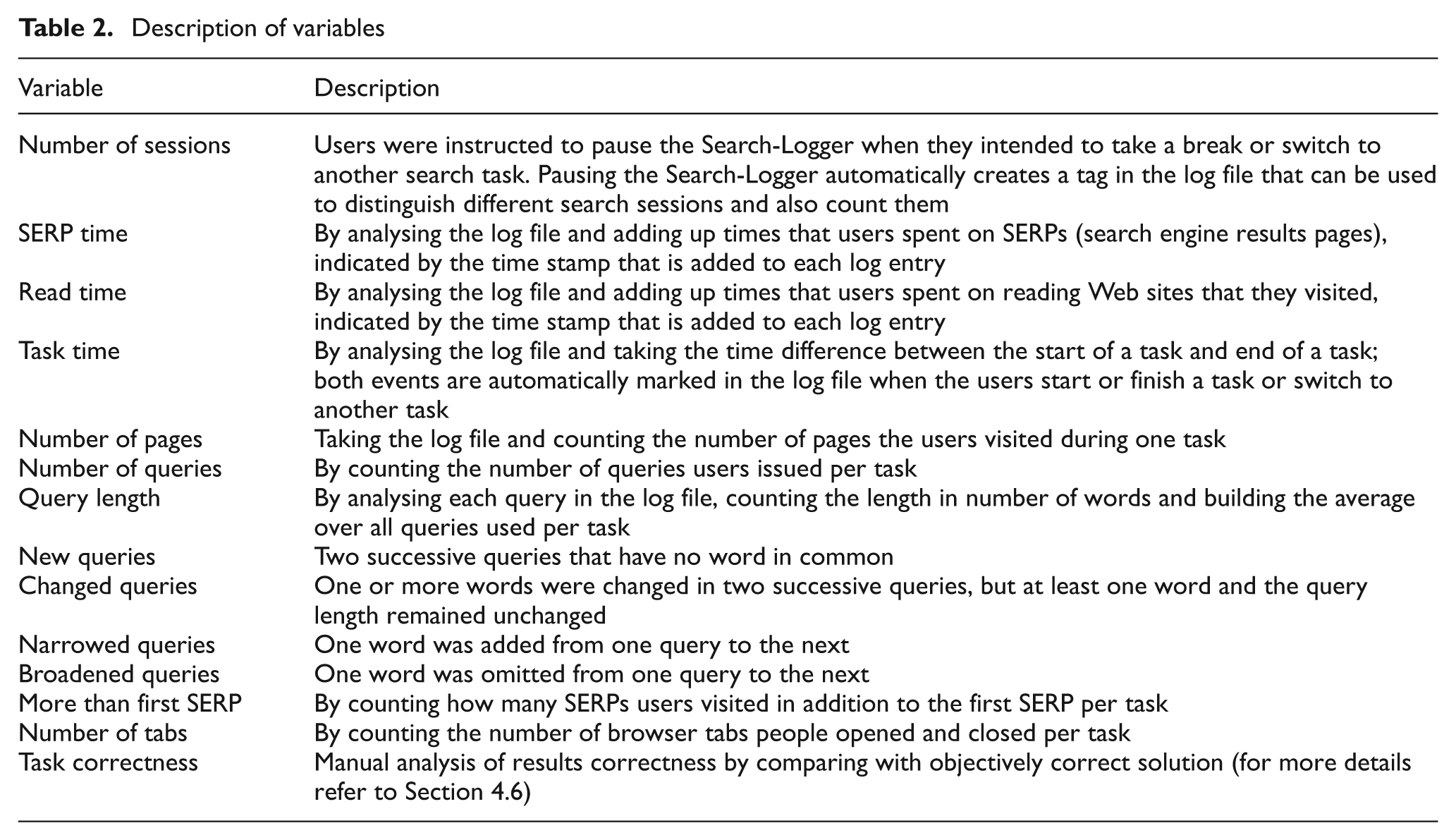
4.4. Tasks
The search experiment consisted of 12 search tasks that were classified as either simple or complex. Simple search tasks typically allow users to find the required information in a single document. We made sure they could retrieve this document with a single right query [47]. In the case of complex search tasks we made sure that the first interaction of the user with the system would not directly yield the answer to the information need [47]. The complex search tasks that we used are characterized by an open task description, accompanied by uncertainty and ambiguity and an open outcome as postulated by Kules and Capra [48] for exploratory search tasks. In addition the tasks were designed such that the users had to interact a lot with the search system and had to search for multiple aspects of the search need [47]. Finally, we made sure that the answers were available on German public Web sites as of August 2011; of course, the users were also allowed to search in other languages. We tested seven out of our 12 tasks in the course of a pilot study [10] and found them suitable for our experiments.
We set up the sequence of tasks such that the users could alternatively solve simple and complex ones. The aim was to keep the participants interested and not to discourage them through a sequence of complex search tasks that they might be unable to solve. Users were allowed to switch between tasks (as described above). An overview of all the tasks is presented in Table 3.
Search tasks used for the experiment

4.5. Logging user behaviour
Using the Search-Logger tool [10], we collected implicit user interaction data during the study by logging a number of standard events (see above).
4.6. Data analysis
Before analysing the data, we cleaned the log file partly automatically and partly manually from log entries that were of any kind of non-search-related origin such as advertising. To analyse query reformulations, we went through all queries (independent of the search tool used) and analysed two successive queries regardless of whether the second query was changed (two unequal successive queries of equal length and at least one word in common), new (no word was the same), narrowed (contained more words), broadened (contained fewer words) or equal (same query). This approach might be simple compared with more elaborate approaches to query refinement [44] (see also the discussion of query reformulation approaches in Hearst [49], pp. 141–156), but it allows for a clear distinction and captures the most common query reformulation types in a distinctive way. In addition, we analysed equal queries regarding change of search tool (e.g. Web to image search or vice versa), spelling correction or visiting earlier or number of SERPs visited.
The users compiled the search results by copying and pasting text and images into a separate document. This document was submitted and the results were analysed manually. Each submitted solution was compared with the objectively correct sample solution and rated as follows:
correct;
partly correct;
wrong;
user did not submit a solution.
In the case of simple tasks, where the study participants were required to find facts, a task was graded correct if it was the right fact and the result was complete. For example if somebody worked on the task ‘When and by whom was penicillin discovered?’, and submitted ‘Alexander Fleming’, this task was graded as ‘Partly correct’. If this user also submitted the correct date of birth ‘6 August, 1881’, the user would be graded ‘Correct’. If the user submitted an incorrect date along with the right name it would also be ‘partly correct’.
In the case of complex tasks we graded a result as correct if it covered all the main and relevant aspects of the search need. If the submitted solution covered only some aspects, or some of the aspects were wrong, we graded it as ‘partly correct’. Results were graded as ‘wrong’ if they contained the wrong information. For example in the case of the task ‘What are the most important five points to consider if you want to plan a budget wedding?’ a participant would find the points ‘Save food – rent the wedding dress instead of buying it – print your own invitation letters instead of having them printed by a company’, each of the points is valid. As this user only submitted three instead of five aspects, this task was graded ‘partly correct’. If this user submitted five points and only three were valid it would also be graded as ‘partly correct’.
For research question 2 it was necessary to rank the users according to their search performance in the experiment (considering complex search tasks only). We ranked the users first by the number of correct answers and then, in cases of users with the same number of correct answers, by answers that were graded partly correct. For example if User 1 had correctly carried out eight tasks and partly correctly carried out four tasks and User 2 also had correctly carried out eight tasks and partly correctly carried out only three tasks, then User 1 would be ranked higher. If both had the same number of correct and partly correct tasks, then they would receive the same rank.
Of the 60 people who were scheduled to take part in the study, we had to exclude four people from our analysis. The reasons were Search-Logger malfunction (two study participants) and insufficient computer knowledge of the study participant (two users). We used t-tests to evaluate the statistical significance of our results and assumed a confidence interval of 95%.
5. Results
In this section, we present the results to answer the previously stated research questions.
5.1. RQ1: Can we find simple measures to describe the complexity of search tasks? If yes, which ones are appropriate?
We used the task complexity model by Singer et al. [26] and analysed a number of task complexity indicating measures. Table 4 presents mean values for selected complexity indicators for the simple and complex tasks. The first row shows the mean values for those measures averaged over the six simple tasks and the second row illustrates the averages for the six complex tasks. As expected, all measures are significantly different between simple and complex tasks (as indicated by low p-values).
Task measures for simple and complex tasks

The first measure was the average number of sessions that users needed to complete the task. The complex search tasks were carried out in a larger number of sessions than the simple ones (1.1 vs 1.0). Next, we looked at the time that users spent on SERPs. This measure was approximately four times as high for complex tasks as for simple ones: 122 vs 33 seconds. The next measure was the time spent for scanning and reading results pages, depicted by ‘read time’. This time was about three times as high for complex search tasks as for simple tasks: 307 vs 107 seconds. Searchers spent considerably more time scanning and reading search results pages in complex search tasks. The average task time was about three times as high for complex tasks as for the simple ones (431 vs 141 seconds).
Next, we looked at the average number of pages users visited when carrying out a task. It was more than twice as high for complex tasks as for the simple ones: 7.4 vs 2.5. The number of queries issued during a task was three times as high for complex search tasks as for simple ones: 6.4 to 2.0. The average query length of the queries issued per task, as outlined in Table 5, was 60% higher for complex search tasks than for simple tasks: 4.4 vs 3.1. Finally, we looked at how often queries were changed. We investigated five types of query changes: (1) how often queries were newly entered (the query was totally different from the one entered directly before); (2) how often queries were changed (at least one word of two consecutive queries was the same); (3) how often queries were narrowed (one or more search terms were added to the query); (4) how often a query was broadened (a term was deleted from a query); and (5) how often users visited more than the first SERP (i.e. the query stayed the same, but more results were requested).
Query-related task measures for complex and simple search tasks (continuation of Table 3)
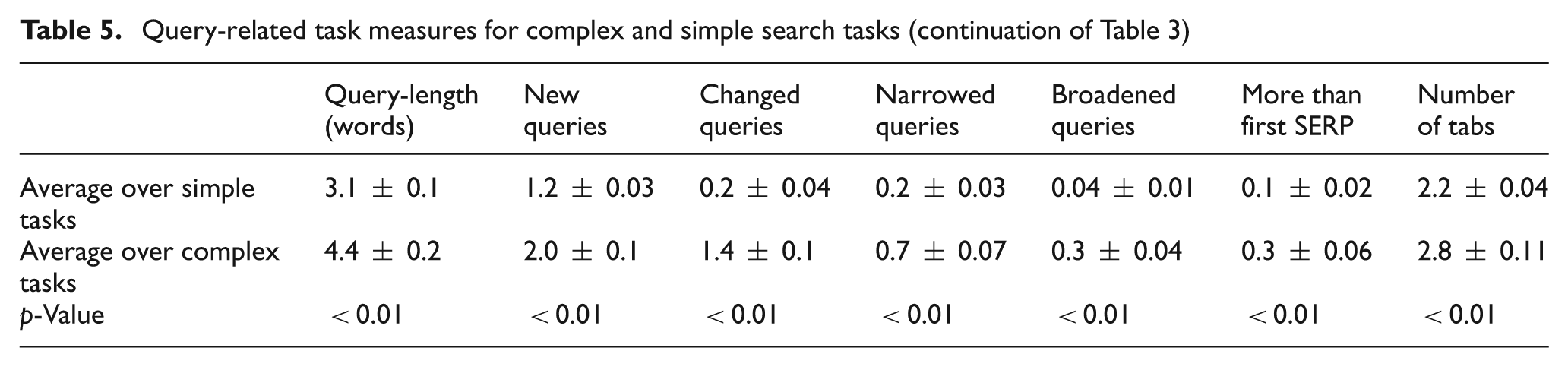
The number of new queries was approximately twice as high for complex search tasks as for simple tasks: 2.0 vs 1.2. In the case of changed queries, this number was seven times as high for complex tasks as for simple ones: 1.4 vs 0.2. The number of narrowed queries was about three times as high complex tasks as for simple tasks: 0.7 vs 0.2. For broadened queries, the number was about 8 times as high for complex search tasks as for simple ones: 0.3 vs 0.04. The number of SERPs users visited in addition to the first one was about three times as high for complex tasks as for simple tasks: 0.3 vs 0.1. The difference between the total number of queries and the sum of the number of specific query changes came from queries, where users navigated back to the first SERP and where users used the search engine’s spelling correction function. Finally, the number of browser tabs opened during the task was significantly higher for complex tasks than for simple ones (2.8 vs 2.2).
5.2. RQ2: Can successful searchers be distinguished from unsuccessful searchers? If yes, what measures should be used to make this distinction?
In this section we focus on the question analysing what makes successful complex search behaviour unique and what measures we can use to identify this successful complex search behaviour and distinguish it from unsuccessful search behaviour. We compared good searchers with bad searchers. We created a ranking of the users according to their performance in the whole experiment taking into account all complex search tasks. We ranked the users first by the number of correct tasks and then, in cases of users with the same number of correct tasks, by partly correct tasks (for a more detailed explanation about the grading procedure please refer to Section 4.6). Table 6 compares the mean values for various measures for the best searchers in the first quartile of the ranking (14 users, ranked 1–7) with the worst performing searchers in the fourth quartile of the ranking (14 users, ranked 18–25).
Task measures for the first and fourth quartile of users ordered by their ranking in the experiment

Successful users spent significantly less time on SERPs than unsuccessful ones: 82 vs 166 seconds. The average time per task was significantly smaller for successful searchers than for unsuccessful ones: 338 vs 526 seconds. The other measures did not show a significant difference. The overall search time (the time it took searchers to carry out all complex tasks) was higher for the unsuccessful searchers: 2969 vs 2027 seconds. The corresponding p-value of 0.05 is slightly too high to accept this measure as being significantly different. None of the query-related task measures outlined in Table 7 shows significant differences between the best and worst searchers.
Query-related task measures for the first and fourth quartile of users ordered by their ranking in the experiment

6. Discussion
Complex search tasks can be distinguished from their simple counterparts using standard measures. Our findings show that for complex search tasks all time-based measures (such as search time, time on SERPs and reading time) are higher than for simple search tasks. While this may sound trivial at first, our findings confirm that time-based measures may be a good indicator for search engines to offer help within a search task/session. Users seldom use help pages offered by the search engines, but automatic contextual help may be useful in supporting users in achieving their search goals. The larger average number of sessions in complex search tasks can be an indicator for users having difficulty in completing the tasks in one go. They possibly use the break (and the time they spend on other tasks) to re-think their search approach and their strategies. In Web search, short queries are usually used [29]. Users break down their information needs into just a few keywords and assume that a search engine will present results suitable for this information need. It is only seldom that users enter whole sentences or questions into the search boxes. Studies have shown that this behaviour is even rarer in German-language queries than in English-language queries [50]. We therefore assume that, when users enter long queries or questions, they may be unsure about how to express their information need. Therefore, long queries could be a good indicator for search engines to offer some support to the user. Also, query changes show that users are not successful with their initial queries. Therefore, also query reformulations could be a good indicator for offering support. Overall, the results of our study confirm our understanding of tasks complexity and the corresponding complex search behaviour. Simple user behaviour-based measures are suitable for determining the complexity of a search task. This information is useful, as a search engine can use these measures to determine what kind of support to offer to a user.
The second research question was whether there are measures that enable us to identify search behaviour indicating successful task performance. Our results confirm that successful searchers spend less time on SERPs and have a smaller task time. The fact that successful searchers spend less time on the SERPs could also result from their experience in examining SERPs. As SERPs are increasingly ‘crowded’ with results from a wide variety of sources and the results presentation changes from a simple list (where each result is presented as equal) to an extended list presentation (universal search) [51], there is an increased need for orientation on the SERPs. We conclude that more experienced searchers are able to obtain an overview of the results more quickly than inexperienced searchers. All other measures show p-values too high to be accepted as significant. As our user sample was comparably small (n = 56) and the users had diverse search experience (ranging from an inexperienced housewife to an experienced student of information science), we assume that a larger sample in combination with a more homogeneous average search experience would lead to smaller standard errors and clearer results. However, the high standard errors of means show that Web searching is very diverse and that care should be taken when extrapolating results from small user studies to a larger population.
For a search engine provider, it should theoretically be possible to project the positive or negative outcome of a search task in terms of success by using simple measures. We assume that the search engine operator is unable to automatically identify an individual user, but instead needs to identify task complexity just from the current search session (using information from just the current search task). Nevertheless, deriving more information from the individual search session is a problem that should be investigated further.
One remark on preparing work tasks and controlling the work task complexity is necessary: the results of our study confirm that the choice of work tasks and their complexity was well done, as also tested in the pilot study [10]. All complex tasks (as outlined in Table 3) triggered complex search behaviour (reflected, for example, by longer search times, multiple queries and tabbed browsing). Also, all simple tasks except for one task triggered simple search behaviour. Task 7, ‘Italy Public Debt’, was the only task that we had assumed to be simple, but showed characteristics of a complex search task. For example, it took users on average 331 seconds to complete it, resulting mainly from the high reading time. We assume that many of the study participants might have struggled with the difficulty of the topic (economics), so it took them longer to qualify the results that they found. We therefore reclassified task 7 as a complex task for our analysis.
We are aware that the time variable and its derived measures such as SERP time and read time have their subtleties that deserve some explanation. Overall, time seems to be a coarse measure to be taken outside of a controlled experiment and in addition time as a variable is not distinct from other variables such as number of browser tabs opened or number of queries issued (e.g. the more browser tabs users open and close the longer the task automatically takes). While both are valid points, time is an established measure and as such part of most of the user studies conducted. As Tullis and Albert stated, ‘Time-on-task (sometimes referred to as task completion time or simply task time) is an excellent way to measure the efficiency of any product’ [52, p. 74], and despite it being not totally distinct from other variables, it is most often measured along with other variables. We also see time as a standard success measure to express the difference between tasks of different complexities.
7. Conclusion
Complex search tasks are not well supported by current commercial search engines. The aim of our experiment was to find out how ordinary search engine users behave when being confronted with search tasks requiring them to split the task into several elements and to synthesize information from a variety of documents. Overall, we can conclude that complexity can be expressed by the effort needed (in terms of time, sessions, queries and browser tabs) to carry out a search task. This can be shown and proven by means of the measures that we investigated.
In regards to supporting the users of commercial search engines better, we suggest that search engine operators put more emphasis on the fact that complex search tasks have significantly different characteristics than simple ones. These differences can be measured, as shown in this paper, and depending on the character of the search task, search engines could offer different kinds of support for the searcher. It is conceivable that the search process should be monitored, not on a query basis (as it is done now), but on a task basis. When erratic user behaviour is identified (such as identical queries being repeated), struggling searchers could be identified and be offered help. We suggest that a different, enhanced service should be offered to these struggling searchers. In addition, it is conceivable that the whole search process is logged and a list of used queries is presented to the user so that entering identical queries will be easier to avoid for the searcher.
Our study also has its limitations, for example, in regards to the user sample used. While it was our intention to carry out a study with a sample of ordinary users of a wide age span, and men and women alike, we had to pay a price in the form of wide variances of the measures used. Therefore, we were often unable to strongly confirm many of our hypotheses owing to too high standard errors of means. This leads us to the conclusion that, in further studies, we should either use an even bigger sample or restrict our research to certain users groups. The latter approach, however, would not allow for universally valid results. A major drawback of most user studies is exactly that they use only small samples (n < 20) that are restricted to a certain user group, usually students from the researchers’ universities.
Another limitation is that users were given limited time to complete the search tasks. Some users asked for more time after they had used up the 3 hours that we had reserved for the experiment. Therefore, it could well be that some users would have (successfully) completed more tasks if they were given more time. However, as users were given money to participate in the experiment, they may have been more willing to work on the difficult tasks than they may have been if they were working on the same tasks at home, not part of an experiment – and were therefore possibly quicker. It is well known that users put more effort into completing search tasks in a laboratory setting [53], and this limitation is not unique to our study. Another minor limitation is that all tasks were administered in the exactly same order. Although users were free to choose the task and also switch between tasks, the predefined task sequence in the menu could still have resulted in learning effects. In future studies, each user should be given a different task order. Also, it would be helpful to conduct even more intensive pre-testing of tasks to avoid events such as the one that occurred in the context of the ‘Italy’ task (Task 7), where the complexity assumed by the researchers differed considerably from the real complexity as confirmed by the users in the experiment.
In the future, we plan to further analyse the patterns in the sequence of queries that the users issued and whether those patterns could be used to identify strategies and erratic and chaotic search behaviour. It would also be interesting to investigate the differences between complex search tasks more deeply, for example, if the complexity specifically originates from the effort to aggregate, discover or synthesize information.
Footnotes
Acknowledgements
This research was supported in part by the Estonian Information Technology Foundation and the Tiger University program, as well as by the European Union (Archimedes).