
Abstract
Typically studies of information retrieval and interactive information retrieval concentrate on the identification of relevant items. In this study, rather than stop at finding relevant items, we considered how people use a search system in the completion of a broader work task. To conduct the study, we created 12 tasks that required multiple queries and document views in order to find enough information to complete the task. A total of 381 people completed three tasks each in a laboratory setting using the wikiSearch system that was embedded into WiIRE. Results found that two-thirds of time spent on the task was spent after finding a relevant set of documents sufficient for task completion, and that time was mainly spent reviewing documents that had already been retrieved. Findings suggest that an open-source information retrieval system, such as Lucene, was adequate for this task. However, the ultimate challenge will be in building useful systems that aid the user in extracting, interpreting and analysing information to achieve work task completion.
1. Introduction
The evaluation of information retrieval (IR) systems, and evaluation in interactive information retrieval (IIR) are founded on finding the most relevant documents to respond to a particular topic or search task. Both use artificial tasks (or topics) that have a pre-determined set of relevant documents as defined by expert assessors. In essence, IR assesses systems output, while IIR assesses the human behaviour and effort associated with getting to a system’s output. In IR, the intended objective is to identify a ranked list of relevant documents in response to a query or topic submitted to the system; in IIR, it is about examining the process of finding the most suitable relevant documents in that list and understanding how that process can be made more efficient and effective. Both stop short of assessing whether the ranked set of relevant documents is indeed adequate and sufficient to do the work task that would have activated such a quest for information in the first place; ‘[i]nformation seeking does not occur in a vacuum but invariably is motivated by some wider task’ [1]
In this research, we start with work tasks – those designed to lead to a particular outcome – to assess how well an IR system assists in getting to that outcome. While finding relevant documents is important to this process, this is not just about identifying any and all relevant documents; it is about identifying a parsimonious and sufficient set of relevant documents that will enable task completion. How are search systems used in the completion of a work task? How is the search task intertwined with the work task?
2. Prior research
At its very simplest, a task is just a ‘piece of work to be done’ (Oxford English Dictionary, 8th edn). It has a defined goal or objective, and an outcome and may have some conditions associated with it. A task may exist at many levels of complexity, from a simple single action such as entering the keywords into a search box or finding the definition of a word in a dictionary, to one that contains multiple actions and activities such as planning a three-week trip to South America, or writing a research paper such as this one.
Tasks may be classified in many different ways including the types of formal employment (e.g. accountant, lawyer, plumber) and the domain in which the task is done (e.g. health sector, education sector). It is these types of task that we typically equate with the concept of work task, although even within a work task, there are also many levels of granularity such that a work task may be considered a complex object with multiple components. Generic types of tasks cut across those broad areas, including data analysis tasks and writing tasks as well as information tasks. This has led to some confusion in our use of the concept, task, particularly in IR and IIR research.
Within information science and the examination of IR in particular, task is a concept used at multiple levels [2], and in multiple ways [3]. On the one hand, it is associated with the work to be done, and the activities, actions, information and resources needed to complete it; on the other, it is one component of a user study or more formal experiment, quite simply ‘a vehicle to conduct the research’ [3] and to observe the process of interactivity while a person is engaged in IIR. Over time, the concept of task has unfortunately also been associated with and in some cases considered synonymous to the query used to interrogate a system.
How this mixed interpretation of task came about can perhaps be attributed to the operationalization of task in information science research dating back to the 1960s Cranfield tests [4], which set the scope of IR system evaluation of the past two decades, as demonstrated by TREC, INEX and CLEF; the emphasis in these programs is on topics with a matching set of findable documents to be found using a search algorithm. However, a topic or its associated queries may not necessarily be equated to a work task. In IIR studies, the practice follows typical experimental design, deploying a set of experimental tasks for which there are relevant documents to be found.
The exception in IR to finding relevant documents has been the research behind Q&A systems in which acquiring an accurate answer is core to the evaluation of the algorithm. These types of questions have sometimes also been used in IIR research. Outside of Q&A research, the examination of the task outcome is a rarity [5]. In IIR, research has tended to focus on describing human physical behaviour or cognitive activity given certain experimental scenarios, or describing the features and characteristics of documents that participants found relevant. Sometimes those experimental tasks are Q&A-like tasks or known-item questions (e.g. find a specific document or website), such as
‘are arterial blood gases useful in the diagnosis of pulmonary embolus?’
‘find a website likely to contain reliable information on the effect of second-hand smoke’.
While participants identify relevant or useful documents, they are rarely asked to provide an answer. However, the fact that a document is relevant does not necessarily mean that the task can be done; it simply indicates that the documents are relevant to the query. When a task is other than a Q&A or known-item task, then a single query is unlikely to be sufficient to find what is required to respond to that task.
In general, our systems tend to provide a set of all relevant documents in the database in order of decreasing relevance to the query, although the probabilistic model of retrieval [6] is also concerned with identifying when to ‘cut off’ the ranking, that is, determining which documents are relevant, and which non-relevant. The assumption in most publicly available systems is that users work their way through the list. However, when do they stop? Kraft and colleagues [7, 8] first speculated that people were likely to examine the list until satiated (a specified number of relevant documents was examined), or people stopped in disgust, an unfortunate word, used to indicate that a specified set of non-relevant documents had been examined. On the other hand, research has speculated that it is more about satisficing [9, 10], which suggests that people constantly assess the value of continuing to search. Others have contributed the continued searching to the type of task, and time constraints of the person [11–13]. In recent research, users tend to stop at the first page of results and are more likely to look only at the ones ranked in the top five. However, for much of that research we do not know whether they discarded the search or actually found what they needed because we do not know if a work task was ever accomplished.
The objective of this research is to explore the boundaries of the work task and search process to examine how users integrate search with the larger task. Do users collect a useful set of items for their task by systematically working their way through a list of results? If so, when do they actually stop and get on with the task? Or is it an iterative process of search for relevant items and write a response? In particular, we address the research question: When carrying out a task how much time and effort is expended in searching for the required information within the overall task activity?
3. Methods
To examine the problem of search within work task completion, we designed a human experiment in which participants were assigned a work-type task to resolve. The task required a search for information and participants were required to provide an answer.
3.1. Experimental tasks
The tasks used were decision-making tasks that required one to make a decision between two options based on a set of criteria. Tasks were crafted so that the participants would look at two items either holistically or using a set of pre-ordained criteria. Each task followed a similar pattern to tightly control the experimental task:
Brief background, for example, ‘A friend recently got a job that requires him to do a lot of travelling within the province and he is planning to buy a new car for the first time.’
Provision of two alternatives, for example, ‘He wants to get either a Toyota Prius or Ford Focus.’
Participant asked to make a choice between the two alternatives, half with a designated set of criteria and half with the task to also designate three reasons for choosing an option.
Twelve tasks (six followed the pattern in Example 1 and six were based on Example 2) were devised for this study. To avoid some of the bias and interpretation problems, the following rules were applied:
An acceptable response to each task was found in two documents and required two queries to be submitted. This did not limit participants from examining more than two documents or using more than two queries, but it did mean that each task could not be degenerated into a simple Q&A type of task.
Each task was designed so the decision was made on behalf of someone else to remove personal bias. That is, the task was being performed on behalf of a friend, co-worker, committee member, etc.
The motivation for doing the task – its story – was maintained across types so that the parallel tasks were consistent. As illustrated in the two examples above, the first two sentences are identical.
The phrasing of each task within each type was made consistent to eliminate variability among the task instants within each type.
3.2. System – wikiSearch
We used a customized system that contained the Wikipedia XML documents, used Lucene 2.2, an open source search engine, and created a customized interface built using a combination of server-side PHP and client-side Javascript. A more complete description can be found in Toms et al. [14]; an abbreviated description of the interface is provided below. The interface (see Figure 1) was divided into three vertical frames:
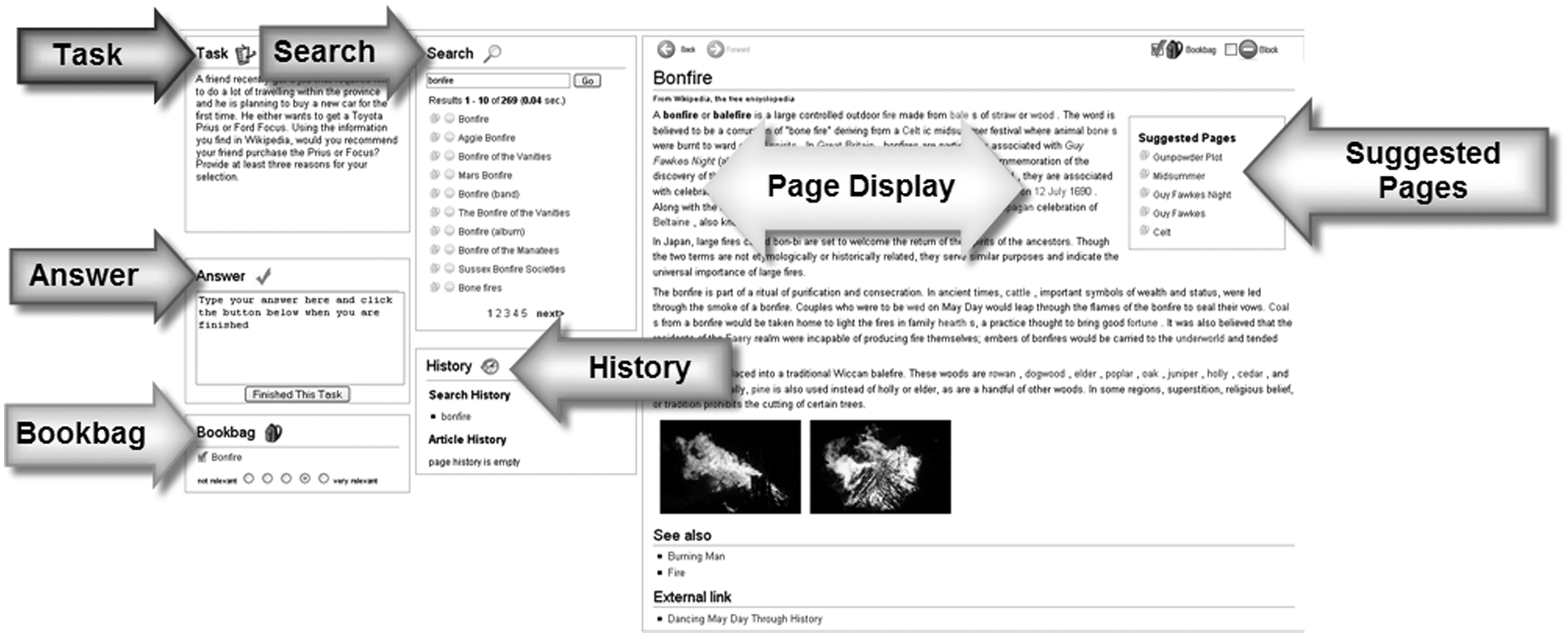
wikiSearch interface.
Documents could be removed from the Bookbag, and added to the Bookbag from the Document Display, the Search Results and the History sections. In addition, a document could be blocked so that it would never need to be viewed again for this search task. The interface was fixed; that is, there was no labyrinth of pages to scan.
3.3. Measures
To assess how the work task was performed, we extracted a variety of performance measures from the WiiRE (Web Interactive Information Retrieval Experimentation) system [15], which automatically logged a range of user actions as well as guiding the participant through the experimental procedure from Introduction to Thank-you page (as explained in the Procedure section). Each action in the logfile included a record of both the user and the particular task being performed by the user. This included the queries used to find relevant information; the documents, that is, the documents viewed in the process and the documents placed in the Bookbag (see Table 1).
Measures used in the analysis
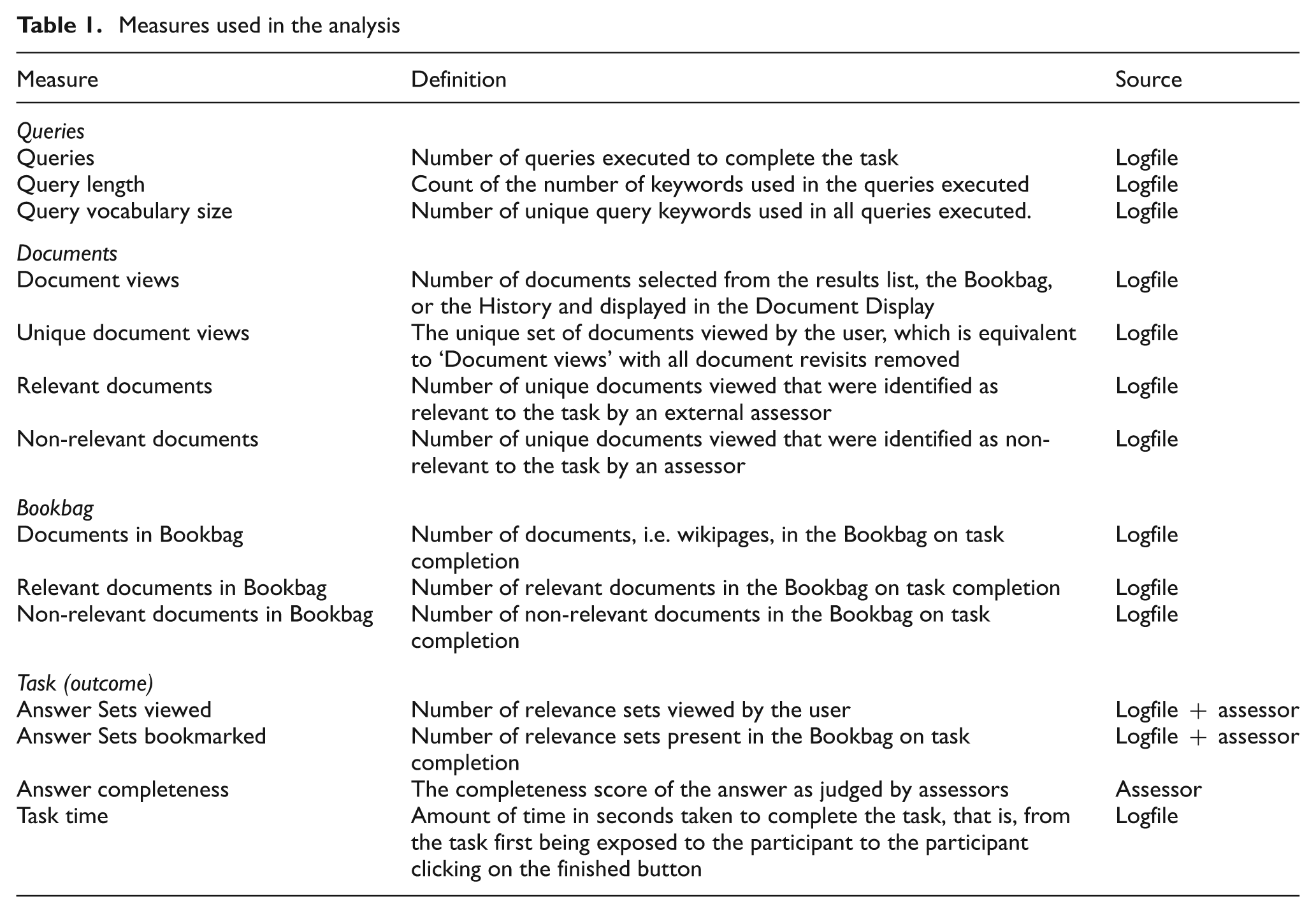
While most measures were extracted from data contained in the logfiles, the task outcome measures (with the exception of task time) required external assessors to provide expert judgement about the documents retrieved.
3.3.1. Assessment of relevance
All documents viewed by all participants for a particular task were pooled into a single list. Two members of the research team then assessed the relevance of each document to the task using the following scale:
5 = documents directly related to the topic and containing clear information on the topic;
4 = documents that were related, or led directly to an answer;
3 = documents that were about the topic but may be broader or narrower that the topic;
2 = documents tangentially related but not really in the task topic area;
1 = documents that are clearly not about the topic at all.
3.3.2. Identification of Answer Sets
A task may have multiple approaches to how it is accomplished; multiple but different documents may be used by different people, and still result in an acceptable answer. While a participant could examine many documents on the same topic, not all of these examined documents would necessarily be required to complete the task. We identified the most parsimonious set(s) of documents that could be used to respond to a task, and labelled these the ‘Answer Set(s)’.
To identify Answer Sets, we examined by task, documents with a relevance score of 3–5 (see previous section) to ascertain which subset(s) of documents could theoretically provide a complete answer to the task. This activity resulted in a series of complete and incomplete sets. The number of relevant documents and the resulting number of sets per task are contained in Table 2. For most tasks a single relevance set was identified, typically containing two documents. Other tasks, most notably tasks 1, 3 and 7, have four or five relevance sets, where any one of these sets of documents may be used to answer the respective task. These sets may not necessarily be disjoint for any one task (the same documents may appear in multiple sets); however, no set is a subset of another.
Number of relevant documents and Answer Sets per task

3.3.3. Answer completeness
To create a measure of task success, the same assessors also judged the completeness of each answer written by the participants. Each answer was judged between 1 and 5, where 5 was considered to be a complete answer to the task, and where 1 indicated that the answer was incorrect, that is, given what was asked, the answer had no relationship. Intermediary values were used to indicate levels of incompleteness in the provided answer, for example, if a user failed to provide a recommendation, answer completeness was judged to be ‘4’. In 7% of sessions a blank answer was provided, which was coded ‘NA’.
3.4. Participants
Participants (N = 381) ranged in age from 18 to 64, although most (73.8%) were 18–24 years old, and in total, 85% were under 35. The sample had a gender balance with 52.8% of participants male. Most participants were students, although some indicated that they were also employed in other capacities (13.1%). The majority of the participants (N = 344, 90.3%) used search engines one or more times every day, and were frequent users of Wikipedia: almost three-quarters of the sample used Wikipedia one or more times per week (N = 201; 52.8%) or per day (N = 74; 19.4%). Participants were recruited through listservs, and in response to a ‘sandwich board’ placed in a public thoroughfare in a university building with constant traffic flow, advertising the study as a ‘drop in anytime …’ to participate.
3.5. Procedures
Participants were recruited over a six-month period, were advised in advance that the study would take about 45 minutes, and were paid an honorarium of CAN$10. Participants were processed in a seminar room, laboratory-setting style, in which up to 10 people participated simultaneously. Each used the same model of laptop to interact with the system. wikiSearch was embedded in a PHP version of WiIRE [16] that led participants through the experimental process as a series of web pages; a person could move forwards but not backwards. On arrival and on log-in, a participant was randomly assigned three of the 12 tasks and a unique identification number to track their activity.
WiIRE controlled the procedure that unfolded in the following steps, each of which represents one web page:
Introduction to the study describing the purpose and what was to take place.
The formal Consent Form.
Demographics Questionnaire to acquire a profile of the participant group.
Tutorial and practice time using the wikiSearch system.
Pre-Task Questionnaire (not included in this analysis).
Task assigned to be completed using the wikiSearch system (see Figure 1, upper left).
Post-Task Questionnaire (not included in this analysis).
Steps 5–7 were repeated for each of the three tasks
Three scales that measured selected individual differences (not included in this analysis)
Thank-you for participating page that included a debriefing explanation.
3.6. Data analysis
Before analysis, the data for each participant was examined to ensure that all three tasks were completed (i.e. each task had an answer), the participant had viewed more than one document per task, and the questionnaires had all questions answered. This process eliminated 30 participants (including the pilot test participants). The resulting dataset contained the interactions of 381 users, resulting in a total of 1143 task sessions, that is, the interactions of one participant performing one of the three assigned tasks.
As described under Measures, the relevant documents were extracted and assessed by two of the research team until agreement was reached. Each set of relevant documents was then examined to assess which set or sets of documents could be used to respond to the task. The result of this analysis is contained in Table 2.
We used these ‘Answer Sets’ to identify the point at which each participant had viewed all documents required to complete the task. This point in each individual task log may be described as the point of ‘search success’, that is, the point at which participants have examined enough information to provide an answer, that is, make a decision among the options. For each participant, we used this point in the log to divide a participant’s overall search process into two parts:
Pre-success – from the start of the log to the point where one Answer Set had been retrieved.
Post-success – from the point of search success to the end of the search log.
This process identified a two-level variable, Pre-success and Post-success, that was used to investigate how the search activity relates to the larger task with which the participant was engaged.
In our analysis of activities before and after the point of search success, we used the Mann–Whitney U-test, and thus report both the mean and the median in our results.
4. Results
From the data analysis, we first provide a summary of the measures that we used in the subsequent analyses across all tasks. Then we examine the points in the work task process when a participant acquired an Answer Set, that is the set of relevant documents that could provide an answer to the task, which we called the point of search success, as well as, when in the process they started to respond to the task. We finish by examining the types of actions that occurred before and after that point of success, including queries executed and documents examined.
4.1. Summary of search behaviour
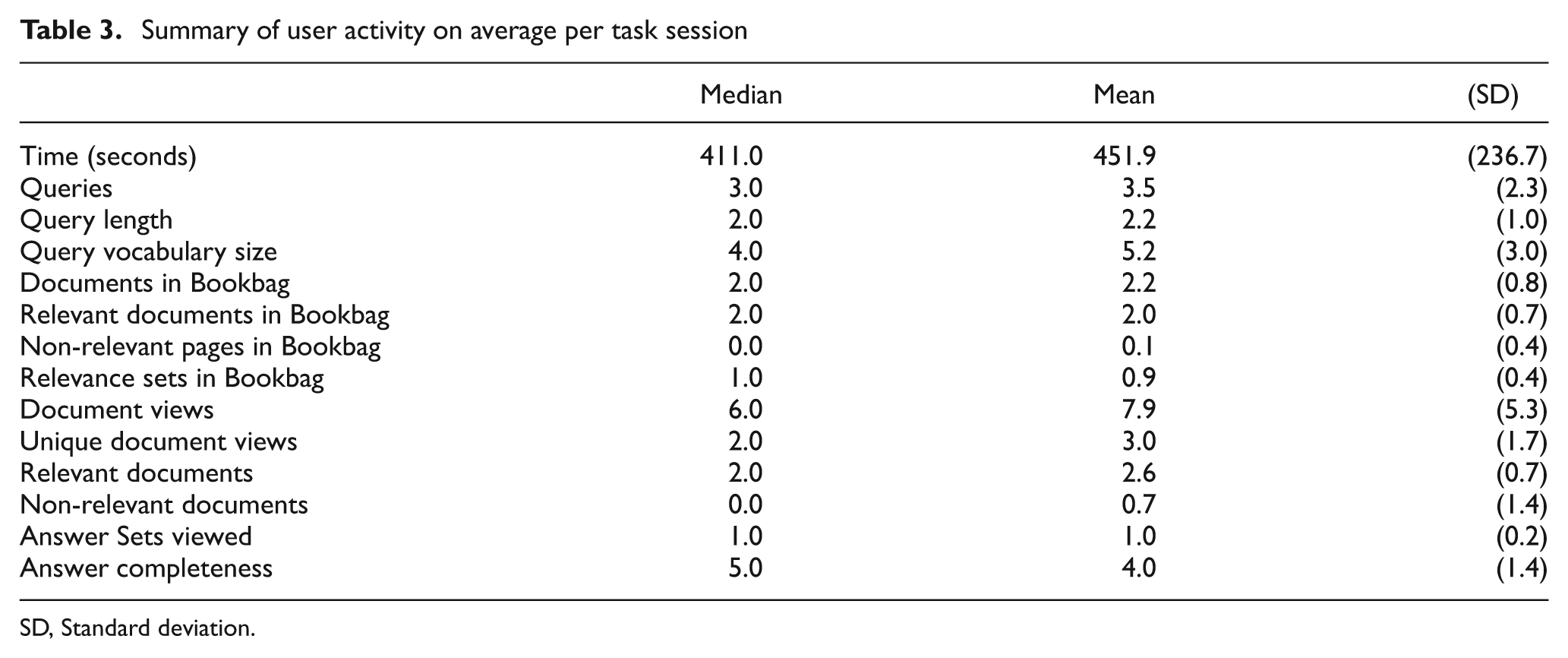
Table 3 provides a summary of the overall user search activities, each of which are briefly described next.
Task – on average, tasks were completed in 6–7 minutes, although for nine tasks users took more than 20 minutes to complete the task. About half of the answers (51%) were judged as ‘5’, with 17% of the data judged with score ‘2’ or ‘4’.
Queries – 72% of participants executed between two and four queries over each session, which includes re-executing queries stored in the History section. Some 13% of the queries executed by users were from the history, across the whole data set. Queries were short; 91% of all queries contained three terms or fewer. In 78% of tasks, between two and six unique terms were used in queries.
Document views – on average, participants viewed eight documents (median = 6), of which three (median = 2) were relevant. Some 7% of participants accessed more than five documents, while seven participants accessed 10 or more documents over the course of a task (0.6%). Of those documents, 24% of all documents accessed were not relevant to the task being carried out.
Documents in Bookbag – 83% of participants added on average two documents to the Bookbag, most of which were identified by participants as relevant; 6% of the documents were assessed by participants to be non-relevant.
Answer Sets – on average participants examined one complete Answer Set, that is, one set of relevant documents that could be used to make a decision. Participants did not view at least one relevant set in 39 (3.4%) of the 1143 tasks, The majority of participants (86%) had added one complete relevance set to the Bookbag. By the end of the task, participants had added more than one relevance set to the Bookbag in 1% of tasks.
Summary of user activity on average per task session
SD, Standard deviation.
4.2. Points of search task completion
As described earlier, we identified the point in the process when participants had acquired sufficient relevant documents to respond to the task. Participants spent, on average, approximately 160 seconds finding a completely relevant set of documents that could be used to respond to the task, and an additional 300 seconds continuing to use the system after that point. They spent more time after (median = 254, mean = 294, standard deviation = 200) finding a set of documents sufficient to do the task, than they spent looking for documents (median = 130, mean = 157.7, standard deviation = 121.6) to do the task in the first place (U = 345016, p < 0.001).
Figure 2 illustrates the actions before and after search success was achieved, which is represented by the vertical dotted line. In this figure, the proportion of the time taken (rather than absolute time values) is shown on the x-axis to normalize the different lengths of time that participants spent completing the tasks. It also visualizes three events from the logfiles: executing a query, viewing a page, and adding a page to the Bookbag. Each data point is plotted at the mean time for the first event, second event, and so on throughout the task log. Since not all users execute the same number of queries, or view the same number of pages, the size of each data point has been scaled to indicate the proportion of users who executed the appropriate event at that point. For example, for ‘execute query’, all users executed a first query at the start of the task (data point on far left, top row, of Figure 1). After the point of success, the number of users who continue to search decreases, with a few querying near the end of the task time. A similar trend occurs for view page events. For the ‘add page to bookbag event’, there is a single large data point both before and after the success point. As illustrated, very little search activity occurred after search success.
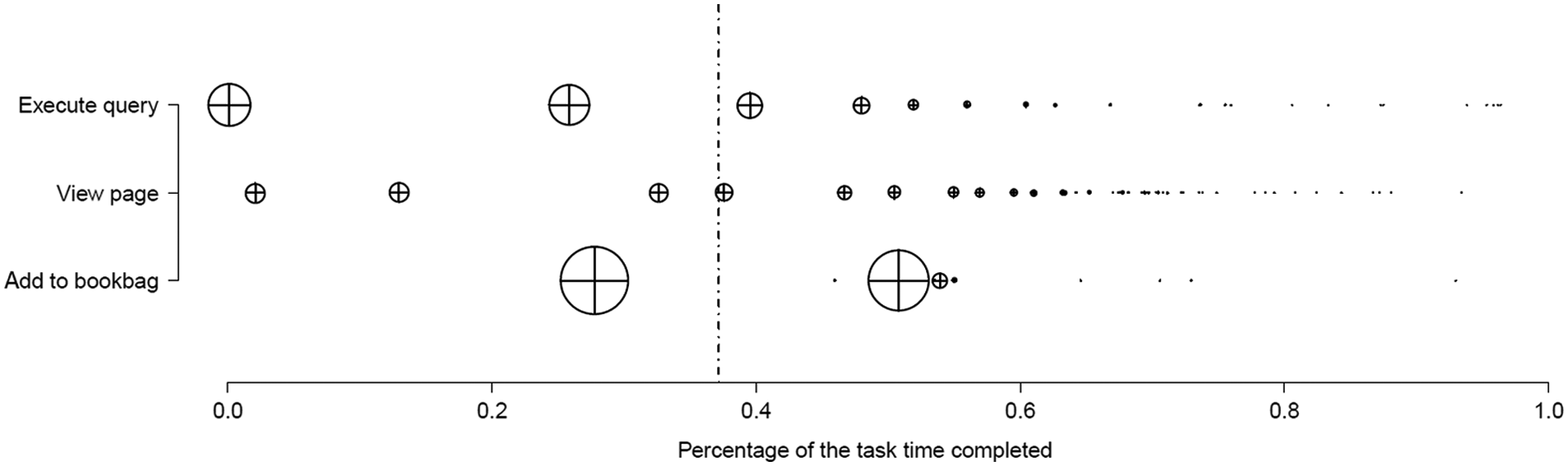
Plot showing the mean time of first query, second query, etc., across the data, along with the equivalent results for page views and the event of adding a document to the bookbag. Time to search success is shown by the vertical dotted line. The x-axis indicates the proportion of the task completed, rather than absolute time value.
Given that participants had a lot of activity after success should have been achieved, what did they do before and after that point? Were they reviewing documents that had already been viewed, or looking for new ones? The next three sections examine what participants did before and after that success point.
4.3. Query behaviour before and after search success
How did participants query the system before and after success was achieved? Do participants keep searching after the discovery of all documents necessary to respond to the task? As illustrated in Table 4, participants on average executed three queries prior to the success and one after. In 62% of the tasks, participants did not execute any queries after the success point. In addition, the queries were shorter after the point of success. On average, participants issued two-word queries prior to success and one-word queries thereafter. Of the queries issued after success, no new terminology was used in 81% of the tasks. On average, participants used five unique words across all queries used in responding to the task.
Queries executed, query length,and query vocabulary sizes before and after the point of search success

4.4. Rank positions of viewed results
The results page rank position of documents viewed before and after task success was investigated, with results shown in Table 5. The majority of document views were selected from the top of the search results with rank position 2 being, on average, the most viewed document. This was also the case regardless of whether the document was relevant or not. In addition, in only 3% of tasks did a participant view a document at a rank beyond position 10.
Rank position of documents viewed by users, before and after the point of task success

4.5. Document views before and after search success
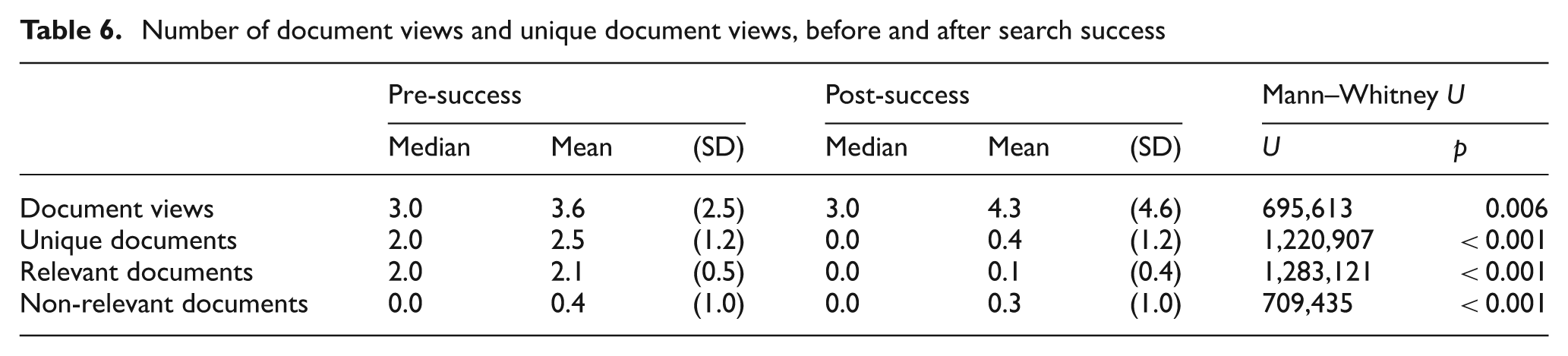
As illustrated in Table 6, participants examined 3.6 documents before success and 4.3 after. Of these, 2.5 were unique documents prior to success, and on average no additional new documents were viewed after search success. In 78% of the tasks, users did not view any new, unseen documents after search success had been achieved. It should be noted that, for the unique pages, relevant pages and non-relevant pages for the post-success period, pages viewed in the pre-success period are not counted, the results recording only those pages never seen before by a particular participant in a task.
Number of document views and unique document views, before and after search success
5. Discussion
How is search integrated into a larger work task? In this study we identified a point in the search process when all of the documents that were needed to provide a complete answer were retrieved, and we defined this as the point of search success. The end of the task occurred when an answer was provided. Unlike the typical IR and IIR studies, identifying relevant documents was only part of the task. What did they do with the documents?
In general our results show a relatively successful search system that enables people to respond successfully to work tasks. Given that the tasks required multiple queries and multiple document views to provide an answer, people queried the system as expected with a modest number of queries, and efficiently found a set of relevant documents to respond successfully to the task (as judged by external assessors). They viewed primarily only the first ‘page’ of results, that is, the first 10 documents, and only highly ranked items on that page. Thus one considers this a successful search system.
Our results showed that participants spent about the first third of their time on task searching for relevant information. Interestingly, after the point of search success, participants did not spend the remaining two-thirds of their time searching for more information. Instead they spent that time reviewing documents that had already been found. After identifying a relevant set, they executed significantly fewer queries, and viewed very few new documents that had not been viewed before. However. the number of document views primarily of material that had already been seen increased after success. Since few new documents were discovered after search success, this suggests that the time after success was used to revisit and review found material.
One of the striking results of the analysis is the efficiency of search: the time required by users to gather all documents required to complete the task is relatively small, just over 2 minutes, on average. Yet almost twice this length of time typically elapsed before the end of the task, or indeed, until users then started to respond to the task requirement. This suggests that the search system, an off-the shelf open-source system (Lucene), is not the bottleneck in completing the job. Rather, the results suggest the bottleneck is the viewing, interpreting and extracting of useful pieces of information from the documents to successfully complete the task.
The results of this study came from a laboratory experiment with artificial work tasks. That said, the work tasks were tightly controlled and were completed by a very large participant pool. Would participants have behaved differently in a different environment? Undoubtedly. The system they used was an off-the-shelf search system with a value-added interface that removed the usual labyrinth effect of typical search systems. What effect did this have on participant behaviour? We know from previous studies about the positive effect of this interface [14]. The Bookbag enables the ease of document collection, not unlike the ubiquitous shopping cart in e-commerce, and the History section also displays all past document views and queries, and this information remains constant in the user’s focus. Thus in this study, participants knew past actions that need not be repeated, and had a record in the Bookbag of what they deemed useful. Potentially the presence of the Bookbag may have avoided the need for refinding. However, the process that we observed is not unlike what Kulthau, Vakkari and their respective colleagues [16–22] have found in the past: people first need to understand and gain focus on a topic before moving on. In our study, participants first needed to find useful information, and once they comprehended that information, they responded to the task. We do not know if this behaviour would be the same if the interface features were not present.
Recent years have seen the development of search applications that tailor IR systems to particular workplace environments. Much like their predecessors, these systems are based on a document collection and not on a design process that would typically be used to develop a new application. Booking travel, finding a partner on dating sites, or purchasing a product are applications in which the work task is the focus of the system.
In most work task situations, finding relevant information is only part of the puzzle. Deconstructing the task into a series of logical sub-tasks and then comprehending, interpreting, extricating and synthesizing, before reaching a decision of some sort, are integral to work. What features or tools could have assisted our participants in responding more quickly to the task? We do not know how much of that post-success time was spent finding or refinding the precise parts of the document that were pertinent to the task, and how much was cognitive information processing – a human analysis of what has been read – before reaching a decision. Existing systems tend not to provide support for cognitive activities; work that is primarily ‘work in head’ needs a type of cognitive prosthesis that aids the user in digesting the volumes of information that need to be consumed, somewhat analogous to the support provided by data analysis tools for similar examinations of data.
6. Conclusions
Our research has shown in a laboratory study how people integrate the search for information into a larger work task. People tend first to search for and collect useful information as the search process proceeds, and then to digest the information to perform a task. Given that they used a specialized interface to an open-source search system, we do not know how much the system may have contributed to this process. That said, the process we observed fits with how others have conceptualized it.
Notably our results show that an open-source system is highly effective in supporting the task, that is, helping the person to identify useful relevant items. Clearly what is now needed is a richer interface that supports a worker in interpreting, analysing and integrating the new information so that the worker can more efficiently achieve task resolution.
Footnotes
Acknowledgements
Data for this study was collected at the iLab, Dalhousie University, Canada. The authors acknowledge the contributions of Chris Jordan, Sam Hall and Tayze Mackenzie, who built the wikiSearch system, and re-created WiIRE, and research assistants, Jason Smith, Alexandra MacNutt, Emilie Dawe, Samantha Dutka, Jennifer Weldon and Sarah Gilbert.
Funding
This work was funded by grants to E.G. Toms: Canada Research Chairs, Canada Foundation for Innovation and the National Science and Engineering Research Council, and also from the Social Sciences and Humanities Research Council Canada to M. Haufner and B. Detlor (McMaster University) and E. Toms and V. Trifts (Dalhousie University).