
Abstract
Aara’ is a system for mining opinion polarity through the pool of comments that readers write anonymously at the online edition of Saudi newspapers. We use a nave Bayes classifier with a revised n-gram approach to extract the public opinion polarity, which is expressed in Arabic, classifying it into four categories. For training we manually marked the comments as belonging to one of the categories. All the words in the documents of the training set were removed except those with explicit connotations. After the training the words designated as vocabulary were classified into one of the categories. Our system carries out polarity classification over informal colloquial Arabic that is unstructured and with a reasonable proportion of spelling errors. The result of testing our system showed a macro-averaged precision of 86.5%, while the macro-averaged F-score was 84.5%. The accuracy of the system is 82%.
1. Introduction
Certain events in history may take the world by surprise, such as the Arab Spring. Indeed this and other similar events cannot pop out of nowhere but the symptoms may have been so miniscule that most people did not pay attention to them. The consequences of some of these events are far reaching and it would be useful to be able predict a future crisis ahead of time. The virtual world provides a treasure trove for pundits seeking to predict the next big event. These days millions of web surfers express their opinions about any topic through forums, blogs, social networks and many online editions of newspapers that enable their visitors to record their comments related to specific news. Although often associated with sentiment analysis, opinion mining is a new discipline that recently has attracted increased attention. It is an area that is related to natural language processing and text mining, with an objective of identifying opinions and thoughts expressed in natural language. The majority of the work in this area is devoted to English with very little in other Latin-based languages. Despite the fact that Arabic is one of top 10 most used language on the internet, 1 it lags behind in many NLP applications. With the just recent Arab spring there have been a surge of works devoted to opinion mining in Arabic.
One of the geopolitically important countries in the Arab world is the Kingdom of Saudi Arabia. It is a vast country that is sparsely populated and has one of the largest known oil reserves in the world. Moreover, two of the three most sacred sites for Muslims are in Saudi Arabia. Given its importance, little is known about the country and its population as there are no official or private organizations that conduct public survey/polling. Recently the state’s grip on the media has been relaxed and people are allowed to post their written comments in most of the online editions of local newspapers. This provides a golden opportunity to peek into the local peoples’ minds and we suppose it to be an excellent alternative to organized polling. In this work we introduce Aara’ (
Sample of comments by readers along with English translation by the authors. For those who can read Arabic, some of the comments may not be clear as they are written in local dialect.

Arabic is a Semitic language which surprisingly predates Islam. This is confirmed by the discovery of many pre-Islamic Arabic inscriptions dating from the second to fourth centuries CE [1]. Arabic can be classified into Classical and Modern. The Classical Arabic represents the pure language spoken by the Arabs, whereas Modern Standard Arabic (MSA) is an evolving variety of Arabic with constant borrowing and innovations to meet modern challenges [2]. The Arabic orthographic system uses small diacritical markings to represent the short vowels (a, i, u). These markings, which are placed either above or below the letter, are used to clarify the sense and meaning of the word. For example,
Owing to its large geographic area, there are several dialectical groups within Saudi Arabia. Chief among them is the Hejazi dialect in the western region, the Nejdi in the central region, and the Sharqiyya in the eastern region of the country. This work deals with the Arabic Nejdi dialect. As we just mentioned, this dialect is commonly used in the central region of Saudi Arabia, including the capital Riyadh. Overall there are about 10 million people who speak this dialect. 3 In this work we had to deal with many challenges, including the high possibility of written comments being a textual mix of MSA and dialectical Arabic, and the lack of a unified spelling for dialectical words, making it likely to have more than one spelling for a single word. To this we may add the fact that people often write and submit the comments without re-editing or checking for errors, so we cannot discard the possibility of spelling errors. To accomplish our task, we used a naive Bayes classifier with revised n-gram model to extract the public opinion, classifying it into four categories: strongly positive, positive, negative and strongly negative.
To the best of the authors’ knowledge, there is no study specifically in Arabic that makes use of readers’ comments in e-newspapers to probe for the public sentiment, nor of sentiment analysis in Arabic that goes beyond binary (positive and negative) classification. We believe that this is an untapped rich source to mine for the public sentiment given that news stories cover all genres: politics, religion, sports, business, etc. The two local newspapers we used for this study appear in printed and electronic editions. The latter is free and allows for anonymous comments from the readers. Indeed Twitter is very popular in Saudi Arabia and makes for a good source to probe for public sentiment. However, the ability to comment on news stories pre-dates Twitter, which was introduced into the kingdom in late 2010/early 2011. A certain age group dominates Twitter users while we believe that commenting on news stories is more uniformly distributed among all age groups. The archives of these two e-newspapers keep their news stories and all the written comments accessible to the public for free. One of them has faithfully retained all the comments in their news archive since January 2005. This makes for a great study in shifts of public sentiment over certain events.
This paper is organized as follows. Section 2 briefly describes related works in the area of automatic public opinion extraction. Section 3 details the major components of our system. In Section 4 we introduce the experiments carried out to evaluate the performance of our system and the results along with their interpretation. The conclusion and future work direction are provided in Section 5.
2. Related work
The basic task in sentiment analysis is classifying the polarity of a given text. Some of the early works include Pang et al. [7] who applied machine learning technique to determine whether a movie review is positive or negative. Another early work is that of Turney [8], who used unsupervised learning to classify product reviews. The recent turmoil in many parts of the world has fuelled research to answer questions about what and where the next big event will be. This is evident from the number of papers which appeared in the first half of 2013 and 2012 as compared with earlier years tackling various aspects related to opinion mining and/or sentiment analysis.
Abu-Jbara et al. [9] used NLP techniques to analyse debates in Arabic, identifying subgroups with opposing opinions. Hamouda and Akaichi [10] investigated the positive and negative sentiments of Tunisian Facebook users from a dataset collected during the Tunisian revolution. The authors reported an accuracy of 75.31% using a combination of unigram and bigram and Support Vector Machine (SVM) classifiers. The precision was 60% (89.2%) for negative (positive) polarity respectively, while recall was 83.3% (71.2%) for negative (positive) polarity, respectively. Repeating the same experiment using naive Bayes (NB) classifier lowered accuracy to 74.05%.
Mohammad et al. [11] worked on sentiment analysis of tweets written in English language. The objective was to classify the tweet as being positive, negative or neutral. Narr et al. [12] proposed a scheme to analyse the sentiment of a tweet written in any language. They tested their system on tweets in four languages: English, German, French and Portuguese. The best accuracy of 81.3% was reported for English while the lowest accuracy of 64.9% was for Portuguese.
Elarnaoty et al. [13] tackled the problem of mining for the opinion holder in Arabic text. For this the authors used a combination of semi-supervised pattern classification and conditional random fields. They were able to achieve a precision of 85.52% and a recall of 39.49%. Al-Subaihin [14] and Al-Subaihin et al. [15] presented a sentiment analysis tool for opinions pertaining to restaurant reviews. The interesting part of the work was the author’s novel approach to using human computation to handle colloquial Arabic. The author was able to achieve a precision of 60.5%. Abdul-Mageed et al. [16] presented SAMAR, a system for subjectivity and sentiment analysis for Arabic social media genres. For their study, the authors used different datasets: chats, tweets, Wikipedia talk pages and forums. Each dataset was divided into 80/10/10% for training/development/testing respectively. Employing different pre-processing, their best accuracy was 81.36% (from forum dataset). The F-score for positive sentiment ranged between 49.41% (tweet dataset) and 88.64% (forum dataset), and for the negative sentiment the F-score ranged between 48.1% (forum dataset) and 77.78% (Wikipedia talk pages).
Danowski [17] developed a network-based method which he called the ‘Semantic Network Analyzer’ to quantify sentiment in Taleban propaganda materials that originate from Afghani and Pakistani sources over a period of five years. According to the author, the Taleban content generally showed evidence of system flourishing. Glass and Colbaugh [18] presented two methods for estimating social media sentiment. Both methods rely on text classification which models the data as a bipartite graph of documents and words. The system was used to estimate regional public opinion regarding 2009 Jakarta hotel bombing and 2011 Egyptian revolution.
Rushdi-Saleh et al. [19] presented an Opinion Corpus for Arabic that contains 500 movie reviews collected from a variety of web pages and blogs. The reviews were equally split, 250 positive and 250 negative. The authors used a word-based n-gram model (n = 1–3) and both NB and SVM to determine the polarity of a review. The system was tested using 10-fold cross-validation and both TF-IDF and TF for a weighting scheme. The best results were achieved using a trigram model, TF-IDF and SVM classifier with a precision of 87.4%, a recall of 95.2% and an accuracy of 90.6%. Using NB classifier instead lowered the accuracy to 89%. Almas and Ahmad [20] proposed a language-informed framework for financial news analysis in English, Arabic and Urdu. The authors resorted to some statistical scheme to extract terms, collocations and n-gram. Some steps were taken for pattern generalization and pruning. For evaluation they experimented using the top 10 keywords for each language and achieved a precision over 90%; however, the recall was low (ranged between 8.6 and 22.2%).
Silva et al. [21] used an SVM classifier for classification of opinions related to Portuguese political actors. They experimented with several feature sets, for example, bag-of-words, n-gram, and Parts of Speech. The authors reported that for several possible feature combinations the precision rate was over 90%. Froelich et al. [22] presented a case study of the use of text mining to evaluate citizen comments on public issues; they used word counting to obtain a list of most frequent terms and they built a dictionary to include different words with the same meaning. After the terms were generated, many tools in the system were used to give better information about the problem. One of these tools is text categorization, which clusters the comments into suggested groups with each cluster or group containing a number of related comments. Overall the authors achieved a precision of over 90% with an F-score of over 80% for classifying the news polarity.
3. Our proposed system
In this paper we introduce Aara’, a system for mining public opinion, specifically Saudi popular opnion. Aara’ uses an NB classifier. It also uses the revised n-gram algorithm to further improve the classifier’s performance. Once the system is trained, it can be supplied with the full set of comments pertaining to specific news and the system will provide the percentage of comments in each category. The main components of the system are shown in Figure 1.

The general architecture of Aara’.
3.1. Preparing the material for the training session
We manually compiled a set of 815 comments gathered from two online editions of local newspapers, Alriyadh
4
and Aljazirah.
5
Comments were picked from different news genres (politics, sports, editorial, health, religion, science, etc.). These comments were manually classified into four different categories/polarities: strongly positive (
Sample comments used for the training. The underlined words are those with explicit overtone. All the remaining words (in grey) will be removed as they do not have any connotation.

3.2. Training module
In general the classifiers can be grouped into supervised, semi-supervised and unsupervised classifiers. The NB classifier belongs to the first group and is a major part of our system. The NB classifier assumes that the probability of word occurrence is independent of its position within text. Let

where
Our NB-based training module is listed in Figure 2. The main task of this module is to train the system from a set of labelled comments with predefined classes. This is accomplished in two steps:
Vocabulary building. A table is created which includes all the distinct keywords that we manually compiled for the training set (see the previous section). We will refer to this table as
Computing probabilities.

Naive Bayes-based training module. The training set has been pre-processed. We removed all words with no explicit connotations.
Recall that the training set has been pre-processed. We removed all the words leaving only those with some kind of explicit connotation. At the end of the training session each word is assigned a probability and it is accordingly classified into one of four categories: strongly positive, positive, negative and strongly negative overtones. For example after the training, the word
3.3. Comment classification module
This module returns the estimated polarity of the target comment. The NB-based classifier (Figure 3) searches for each word

Naive Bayes-based comment classifier module.
What complicates the process is that most of the nouns and verbs in Arabic are prefixed. The definite article (
3.4. Revised n-gram
The pure n-gram model can be used to compute the similarity of two strings through counting the number of common n-grams they have. The n-gram similarity coefficient
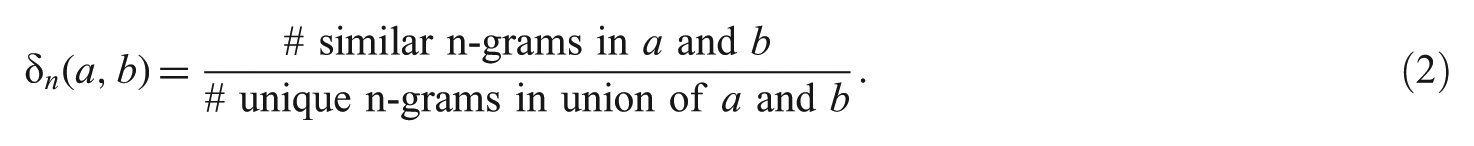
When computing the similarity coefficient, the pure n-gram approach does not consider the order of the n-gram in the target word [25]. This means a higher probability of the matching score between two strings even though they may not share the same concept [23], see Figure 4a. The revised n-gram approach helps to overcome this problem.

The bigram similarity measure between the Arabic word التحالفات (the alliances) and الفاتح (the conqueror). (a) Using a pure bigram the similarity coefficient is 6/7 ≈ 85.72%, and (b) with a revised bigram it is 2/7 ≈ 28.57%. The latter is favoured as both words do not belong to the same meaning class.
Ahmad and Nürnberger [23] proposed a language-independent approach for conflation that does not require a prior knowledge of the language or the predefined rules. The revised n-gram approach is applied for cases
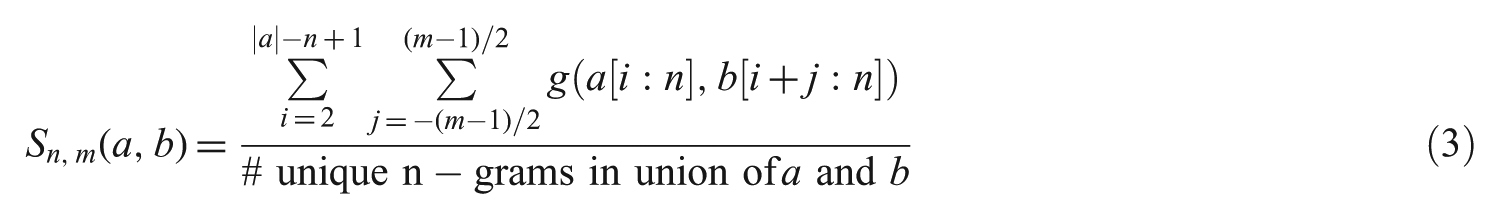
where

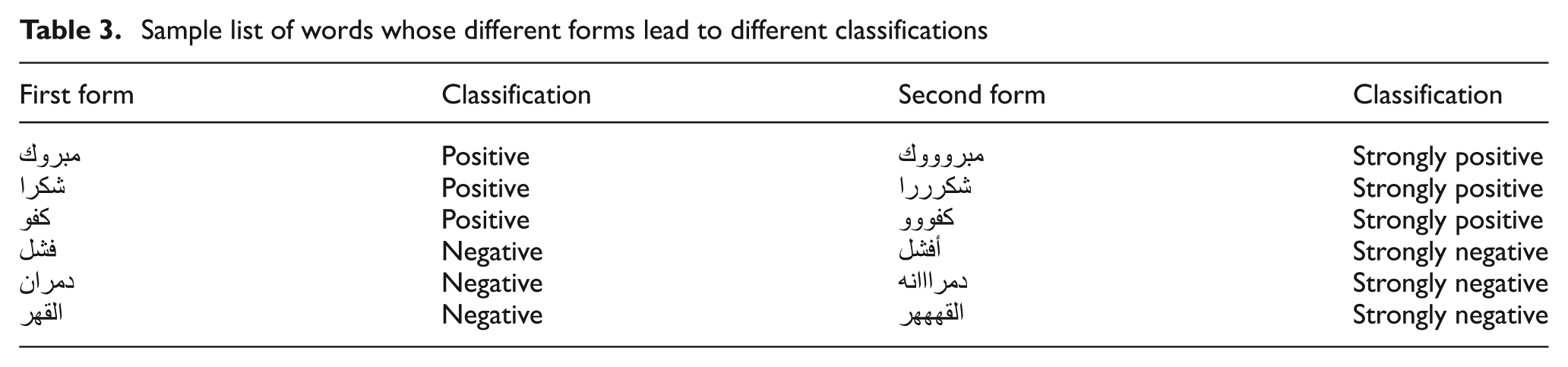
Using a revised bigram for the similarity measure of two forms of the same word leading to different classifications. Here the similarity score is 80%.
Sample list of words whose different forms lead to different classifications
Spelling errors were a common problem in this work. Most of the comments we came across contained some sort of typo. We identified three groups of spelling errors. In the first group we have errors owing to the proximity in the sound of the pair of letters:
Using the revised n-gram in the text classification phase of our system improved its ability to classify the comments. Each word
As we said earlier, the training set was pre-processed, which included removing all the words with no explicit connotation. It was possible to just ignore words with neutral overtone and leave them in the comment. However, there are two reasons why we decided against this. First, leaving these words in will prolong the training process. This is because the theoretical time complexity of NB classifier is
4. Results and discussion
We implemented Aara’ using Java programming language and Microsoft Access. We manually collected a total of 815 comments and these were split into two disjoint sets. The ‘training set’ had 620 comments that were used to train the system through two phases – building vocabulary and computing probabilities (Figure 6); and the ‘testing set’ comprised 195 comments, of which 39% were labelled as positive, 36% as negative, 17% as strongly positive and the rest as strongly negative. Figure 7 shows a screen shot of the testing window.
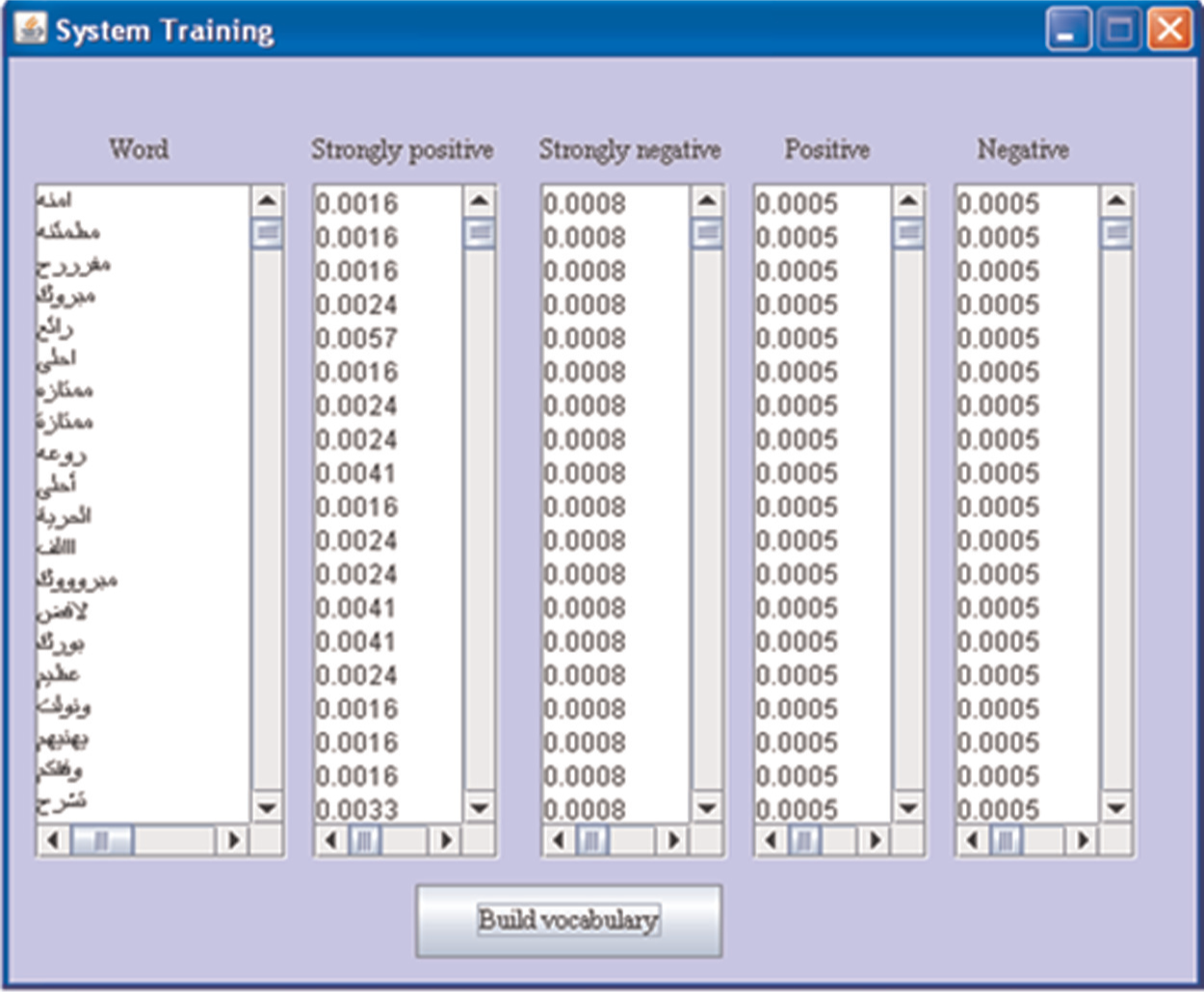
A screen shot of the training window showing the vocabulary and their corresponding probabilities.

A sample screen shot of the testing window showing individual testing set comment along with Aara’s auto classification and our own manual classification.
Four measures are used to evaluate the system: precision
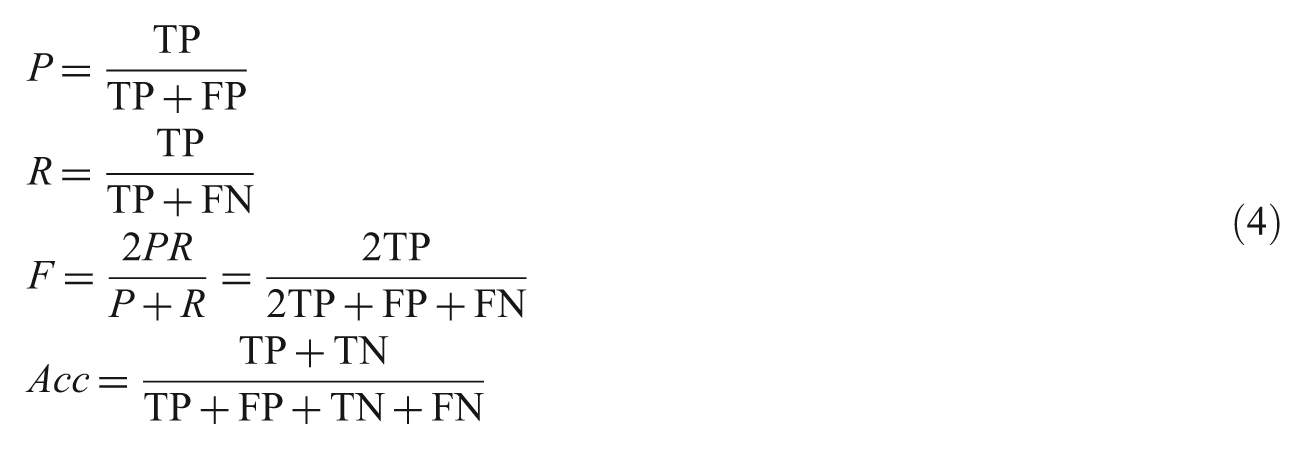
where TP (true positive) is the number of comments correctly classified as belonging to class
Summary of evaluating the testing set (195 comments) over the four categories

One clear reason for the misclassification of some comments is the existence of new words in the testing set that were missing in the vocabulary table. This can be resolved by a larger training set that should minimize the possibility of unseen words in the testing set. The best precision of 96.4% is in the negative category and we can attribute it to the large number of negative words in our vocabulary. About 53.5% words in the vocabulary are those with negative connotation. The lower recall in the negative category is attributed to the nature of Arabic sentences. In English, the negation is often expressed by a prefix, for example, un- or im-. For example ‘unclean’ or ‘imperfect’. This is not the case with Arabic, where the negation is expressed by a separate term preceding the word. For example,
When multiple class labels are involved, as in our case, then averaging the evaluation measures can give a view on the general results. Two names are used to refer to averaged results: micro-averaged and macro-averaged results. Let

where

where
All the systems we reviewed supported either binary (positive and negative) or ternary (positive, negative and neutral) classes. Ours supports four categories. Therefore it would be unfair to compare between them; however, for the sake of completeness we will list the performances of the different systems we reviewed that explicitly support Arabic. Where the authors used SVM and NB classifiers, we will list the performance of the NB classifier as this is the one we used. Also, some authors report measures for each class, for example, precision for positive and another for negative class. To simplify the comparison, we will use macro-averaged measures. Micro-averaged measures were not possible as this requires unavailable pieces of information. Table 5 summarizes the performance of different systems.
Performance summary of different systems. Blank entries mark information unavailable. Note that all the systems (except ours) handle either two or three classes. All the performance measures are taken from the literature
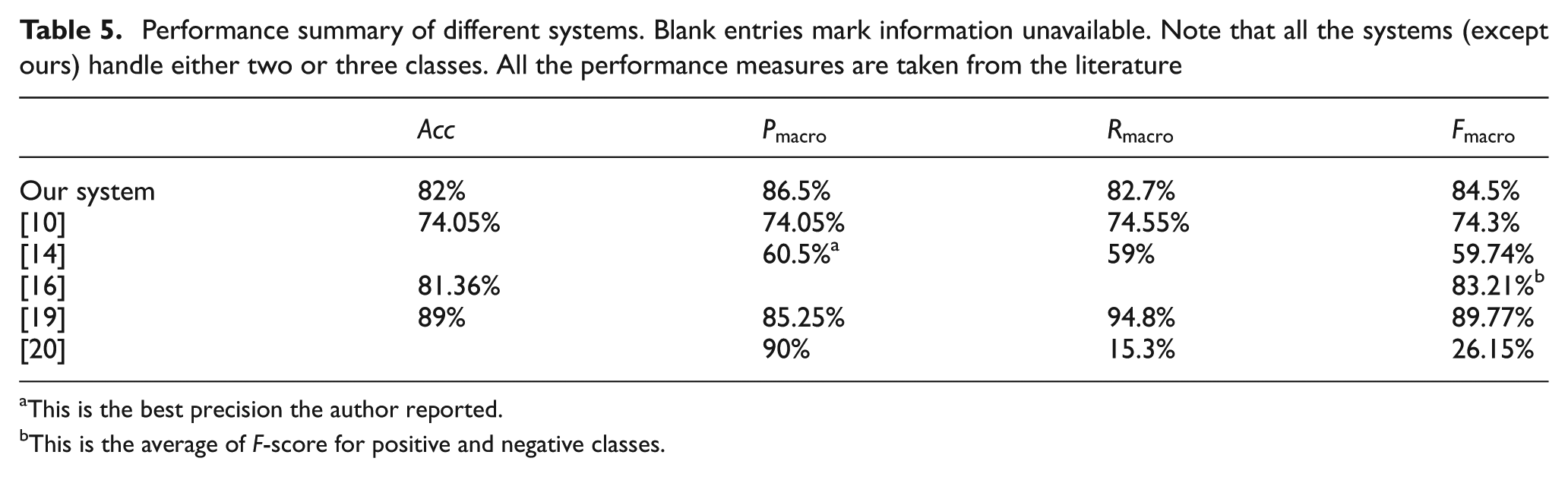
This is the best precision the author reported.
This is the average of F-score for positive and negative classes.
From Table 5 we can say that the only system that has a better accuracy than ours is that by Rushdi-Saleh et al. [19], although our system has a slightly better precision. There are two reasons why it has a better performance: fewer classes and a smaller vocabulary. It is worth noting that the aforementioned system was trained to handle movie reviews as either good or bad, whereas our system had to classify the comments into one of four classes. Unlike opinions expressed in comments to any news genre, reviews of movies tend to have a limited vocabulary. That may explain why it has a better accuracy. Given that our system handles four classes, we believe its performance is very competitive.
5. Conclusion and future work
Aara’ was developed to extract the polarity of Saudi public opinion automatically using a naive Bayes classifier and the revised bigram approach. For input the system uses the set of all comments which readers wrote anonymously in the online edition of local newspapers. Our system classifies the comments into one of four categories: strongly positive, positive, negative and strongly negative. This is the first system in Arabic that classifies text in more than three classes. We trained the system using the Nejdi Arabic (colloquial mostly used in central Arabian Peninsula). Some of the challenges were handling unstructured text written in local slang with plenty of typos. For the test data the system achieved an accuracy of 82%. The precision ranged between 78.9% (for strongly positive comments) and 96.4% (for negative comments), while the recall ranged between 76.8% (negative comments) and 88.2% (strongly positive comments). The corresponding F-score was 85.2% (micro-averaged) and 84.5% (macro-averaged). Our system is flexible and can be easily be adapted to work with any set of Arabic comments.
For future work, we need to handle the negation terms properly and this will improve the accuracy of the system. Also we need to filter out the comments that are irrelevant to the news story, classifying only those that explicitly express an opinion on what is in the article. A long-term goal is to output a brief summary of what the readers are saying in their comments. Using the archives of news stories and their associated comments we can track the shifts in public sentiment over time pertaining to certain events.
Footnotes
Funding
This work was supported by a special fund in the Research Centre of the College of Computer and Information Sciences at King Saud University.