
Abstract
Keyphrases facilitate finding the right information in digital sources. Keyphrase assignment is the alignment of documents or text with keyphrases of any standard taxonomy/classification system. Kea++ is an automatic keyphrase assignment tool using a machine learning-based technique. However, it does not effectively exploit the hierarchical relations that exist in its input taxonomy and returns noise in its results. The refinement methodology was designed as a top layer of Kea++ in order to fine tune its results. It was an initial step and focused on a single Computing domain. It was neither validated on multiple domains nor evaluated to determine whether the improvement in the results is significant or not. The aim of this task was to solidify the refinement methodology. The main contributions of this work are (a) to extend the methodology for multiple domains and (b) to statistically verify that the improvement in the Kea++ results is significant.
1. Introduction
From the plethora of information that is available online, accessing relevant content efficiently and accurately is important. Keyphrases are one of several ways to facilitate finding the desired information from any digital source. Keyphrases (keywords) are terms that describe the whole content of a document precisely and accurately [1–3]. Over the last two decades, the amount of digital content has been growing and people are relying more and more on search engines. Keywords and keyphrases are a kind of metadata [4], and this metadata has great significance in digital repositories. Similarly they can be used to index documents [4], assist in browsing collections [5, 6] and help in clustering documents [7]. Two approaches to keyphrase generation are keyphrase extraction and keyphrase assignment. In keyphrase extraction, keyphrases are assigned to a document from the document text. Keyphrases are assigned to a document from the domain-specific taxonomy in keyphrase assignment. Kea++ is a tool that can perform both keyphrase assignment and extraction based on the given input and it is therefore termed a keyphrase indexing algorithm [8]. There are many other tools that can perform keyphrase extraction, but very few that can perform keyphrase assignment. Our main focus in this work is on keyphrase assignment. However, the assignment performed by Kea++ often contains irrelevant terms in the result set.
The refinement methodology [9] was an initial step to fine tune the result set of Kea++. The refinement algorithm of [9] is composed of refinement rules that exploit the hierarchical structure of the taxonomy to reduce noise in the Kea++ result set. It works as a top layer to Kea++. This algorithm was validated on a single Computing domain dataset and showed improvement. However the methodology is tilted towards the Computing domain because the rules were formulated by keeping only the ACM Computing Classification System (CCS) 1 in mind and ignored the remainder. Different taxonomies vary in their structures such as hierarchical level, as discussed in Section 2. We applied the methodology to various taxonomies, such as agriculture and mathematics, and found that it did not perform well for taxonomies with a deep hierarchical tree structure. Moreover, it was not confirmed that the improvement shown in Kea++ results was significant or not. Our main focus in this work is to solidify the refinement methodology. The main contributions of this task are: (a) to extend the methodology for multiple domains; and (b) to statistically verify that the improvement in the Kea++ results is significant. In order to procure our objectives, different domain-specific taxonomies were analysed. The refinement rules were revised in order to handle multiple taxonomies and were evaluated on different domain taxonomies and datasets. The evaluation metrics used were (a) precision, recall and F-measure and (b) average number of keyphrases assigned to test documents. It was confirmed by applying the t-test that the improvement in Kea++ result was significant.
The rest of the paper is organized as follows: Section 2 explains and analyses different domains taxonomies. Section 3 briefly surveys the related literature. Section 4 presents the proposed extended refinement methodology. Section 5 discusses two walk-through examples; one is related to Computing domain and the other one is related to Agricultural domain. Section 6 deals with the testing and evaluation of the proposed methodology. Section 7 concludes the paper as well as suggesting future directions.
2. Taxonomies
A taxonomy is a collection of controlled vocabulary terms, when they are organized into a hierarchical structure. Terms are linked with each other using relation such as Broader (Parent) term (BT) and Narrower (Child) term (NT) [10]. We studied and analysed various taxonomies, such as computing, agriculture, alcohols and drugs, 2 art and architecture, 3 health sciences, 4 engineering 5 and mathematics 6 . The properties and structural behaviours of these taxonomies differ from each other. We selected agriculture, computing and mathematics domain taxonomies for the evaluation of the proposed methodology as these are three significant taxonomy structures, as discussed in the following subsections. We will briefly explain the structure of the computing and agriculture taxonomies. The details of mathematics domain taxonomy can be seen in Irfan [11]. Moreover, we will use both the terminologies keyphrase and term alternatively throughout this paper.
2.1. ACM Computing Classification System
The ACM CCS is used as a standard topic hierarchy for computer science domain. The taxonomy comprises more than 1250 keyphrases (terms) and also specifies relations between them. The structure of the ACM CCS is given as:
B.2 ARITHMETIC AND LOGIC STRUCTURES B.2.0 General B.2.1 Design Styles (C.1.1, C.1.2)
Calculator
Parallel
Pipeline
B.2.2 Performance Analysis and Design Aids (B.8)
Simulation
Verification
Worst-case analysis
B.2.3 Reliability, Testing, and Fault-Tolerance (B.8)
Diagnostics
Error-checking
Redundant design
Test generation
B.2.4 High-Speed Arithmetic
Algorithms Cost/performance
B.2.m Miscellaneous
The tree consists of 11 first level keyphrases denoted by the letter identifiers A–K, and one or two sublevels under each of them. The tree has a depth of four, in which first three levels are coded and the fourth level is not. Alphanumeric codes are assigned to the second and third levels. Keyphrases at the uncoded level are called subject descriptors. The organization of keyphrases in broader and narrower levels forms the hierarchical structure of the taxonomy. In ACM CCS, some keyphrases have semantically similar keyphrases associated with them. These keyphrases are mentioned in parentheses, for instance, B.2.1 Design Styles (C.1.1, C.1.2). There is also a set of 16 separate keyphrases (i.e. concepts) called General that apply to all areas. The Miscellaneous keyphrase in the given area is used to classify those documents that cannot be classified under any other keyphrase. We can see in the ACM CCS structure shown earlier that B.2.0 and B.2.m are examples of General and Miscellaneous keyphrases respectively.
2.2. Agrovoc
Agrovoc 7 is a multilingual taxonomy (thesaurus) developed for agriculture, forestry, fisheries, food and related domains, such as the environment. It was developed by the UN Food and Agriculture Organization (FAO). The English Agrovoc defines over 28,000 concepts, with preferred terms (descriptor) and associated non-descriptors. In this way, it extends its size up to 40,000 terms. The concepts in Agrovoc are interconnected with each other through relationships such as Related Term (RT), Narrower Term (NT) and Broader Term (BT). The number of such semantic links goes up to 83,000 in Agrovoc. Keyphrases that appear similar but are semantically different are identified by parentheses, for instance Vanilla (genus) and Vanilla (spice). If needed, a scope note is also added with terms to make clear their intended meaning.
2.3. Comparison of different taxonomies
The analysis shows that each taxonomy has specific implementation and structural details according to the specific requirements of its domain. For instance, in ACM CCS, general and miscellaneous terms are used but in Agrovoc they are not applied. Semantically related or equivalent terms are considered as non-descriptors in Agrovoc, while they are descriptors in ACM CCS. Some taxonomies have a large number of major categories (top level nodes), but fewer hierarchical levels in each category, such as MSC; on the other hand, the opposite is the case in Agrovoc. Some taxonomies fall between these two extremes, such as ACM CCS. These were the reasons why we selected ACM CCS, Agrovoc and MSC for the evaluation of our proposed methodology.
3. Literature review
In this section we briefly look at the related works and describe various issues that exist in the refinement methodology.
3.1. Language dependent approach
Tomokiyo and Hurst [12] developed a language model based on statistical techniques. It checks the informativeness and phraseness of keywords, which are combined to form a single score. This score is listed in descending order to pick the most suitable keywords. The higher the combined score, the greater is the appropriateness of a keyword. They have proved the effectiveness of the approach by applying it on sample datasets and obtained some quality keywords. However, the method lacks the simplicity of quantitative analysis on the results that are obtained.
3.2. Language independent approach
Paukkeria et al. [13] presented an approach that has a lightweight pre-processing phase and does not require any prior parameter settings. They named their approach Language Independent Keyphrase Extraction (Likey). Keyphrase assignment and extraction depends heavily on the language used. The need for pre-processing tasks, like part-of-speech tagging, stemming, use of stop-word lists and other language-dependent filters, is extensive. Likey was developed for keyphrase extraction tasks and is based upon the ranking and frequency of occurrence of a phrase. Frequently occurring phrases are assigned higher ranks. The only language-dependent factor is the use of Reference Corpora, which is a large collection of documents used to take into account the idea of language used. They compared Likey with the tf×idf (term frequency–inverse document frequency) factor and the results for precision and recall were higher in comparison.
3.3. Machine learning approach
Kea [1], its later version, Kea++ [14, 15], and GenEx [4] are all supervised machine learning techniques. As Kea++ is a supervised learning approach, it works in two phases, that is, training and extraction (testing). During each phase it works in two substeps: candidate identification and filtering. During the candidate identification step, language-dependent techniques such as input cleaning and stemming are applied to form pseudo-phrases. During the filtering step, those keyphrases are identified which are the most suitable candidates depending on four features: term frequency–inverse document frequency (tf×idf), phrase’s first occurrence, length of a candidate phrase in words and node degree. Then by applying a Naive Bayes algorithm, a training model is generated. The extraction phase uses the model to assign keyphrases from a taxonomy to the document.
On the other hand, GenEx is a combination of two algorithms: Genitor (genetic algorithm) and Extractor (keyphrase extraction algorithm). It works in such a way that Extractor takes a document as an input and produces a list of keyphrases based on some parameters, whereas Genitor is required to tune the parameters of Extractor and is only needed during training process of GenEx. Therefore, the training process is termed GenEx (includes Genitor and Extractor), whereas the extraction process is called Extractor as it does not involve Genitor. Frank et al. [16] and Jones and Paynter [17] compared Kea with GenEx. They stated that Kea performed comparably to GenEx. They also discussed factors that can boost Kea’s performance, such as document size, number of keyphrases per document and length of a document. GenEx uses a specialized algorithm for training and extraction, but Kea utilized Naive Bayes, which makes it quicker than GenEx. It has also been proved through experiments that Kea performs well when trained for about 50 documents; after that the improvement is very slow.
The inclusion of natural language processing techniques by Hulth [18] in the keyphrase extraction process results in some improvement. The idea behind Hulth’s keyphrase extraction algorithm is to add the linguistic knowledge to the extraction process, rather than only using frequency and n-gram factors for extracting keyphrases. However, this approach only performs keyphrase extraction and not keyphrase assignment.
3.4. Refinement rules and algorithm
Fatima and co-workers [9, 19, 20] developed the refinement methodology in order to reduce noise (i.e. the irrelevant keyphrases) from the results of Kea++. They exploited the semantics embedded in the hierarchical structure of the taxonomy to eliminate noise from the relevant keyphrases. They found that the hierarchical levels of the taxonomy and their generalization and specialization play significant role in the training and extraction process of Kea++. In the work, refinement rules were developed. Afterwards they were applied on the keyphrases returned by Kea++ to fine tune them.
The most important factor for these rules is that of training level. This is the hierarchical level of taxonomy adjusted for manually extracted keyphrases in documents. It is the deciding factor for the selection of keyphrases. The need for carefully selecting the training level is mentioned in the work, as its impact will be on the final result set. Based on these rules, a refinement algorithm was developed. This algorithm controls the application of rules based on the level label of the keyphrase contained in result produced by Kea++. If the level label returned for a keyphrase is equal to training level which is found as a result of execution of rule I, then it is preserved in the final keyphrases result set. If lower-level keyphrases are there, they will be discarded except those that belong to the general category of lower-level keyphrases. Lower-level keyphrases belonging to the general category are stemmed to the training level and will be added to the final result set. For upper level keyphrases, equivalent training level keyphrases are searched for. If found, then they are replaced by that training level keyphrase in the final result set, otherwise they are discarded. Moreover, if no keyphrase in the result produced by Kea++ contains training level keyphrases, then lower-level keyphrases in the final result set are preserved. However, the rules focused only on a single Computing domain and did not perform well when applied to other taxonomies because they have different hierarchical structures and these differences were not presumed in their rules.
4. Extended refinement methodology
This section is divided into two subsections; first we will describe the extended refinement rules and then we will describe the algorithm that has been proposed to apply those rules in order to reduce noise in Kea++ result set. The extended refinement rules are developed as a result of the analysis of various taxonomies that was performed as discussed in Section 2.3. It was observed that the properties and structure of these taxonomies differ from each other. On the other hand refinement rules developed in Fatima and co-workers [9, 19, 20], when analysed, were not found to address the requirements of varying taxonomic structures such as taxonomies having a deep hierarchy. It was found that rules needed adjustment in order to choose an efficient training level. Not only this, but keyphrases that are aligned at multiple levels in the taxonomy were also not considered in the development of refinement rules.
4.1. Extended refinement rules
The training level is a hierarchical level of taxonomy that is computed from manually generated keyphrases for documents in the training dataset of Kea++. In the extended refinement methodology, the training level is the key parameter for selection or rejection of any keyphrase in a Kea++ result set.
This proposed rule prioritizes the level where most of keyphrases are aligned within a training dataset. For example, consider a training dataset which comprises 50 documents and their manually assigned keyphrases. The hierarchical level of each keyphrase in a training dataset is identified from its taxonomy. Suppose the taxonomy has five hierarchical levels and the number of keyphrases aligned with levels 1–5 are 25, 67, 89, 26 and 0, respectively. According to rule I, the training level is 3 in this dataset. Moreover in ACM CCS, the keyphrase Distributed Systems, aligned with C.2.4 having level 3, comes under D.4.7 at level 4 and under H.3.4 at level 4. In this case, the keyphrase is counted once at level 4, despite the fact that it occurs twice at level 4. Finally, the level having the maximum number of keyphrases aligned with it is selected as the training level.
For example, an Agricultural result set contains two terms, Deforestation and Reforestation, occurring at levels 7 and 5, respectively, in Agrovoc. Suppose that the training level is 2. Then they are replaced by their training level common parent, Management, at level 2.
4.2. Extended refinement algorithm
First of all, Kea++ parameters are set according to the values provided in Table 1. Afterwards Kea++ is applied on each document in test datasets to generate keyphrases. The extended refinement algorithm is illustrated by a flow chart in Figures 1 and 2.
Kea++ parameters setting.

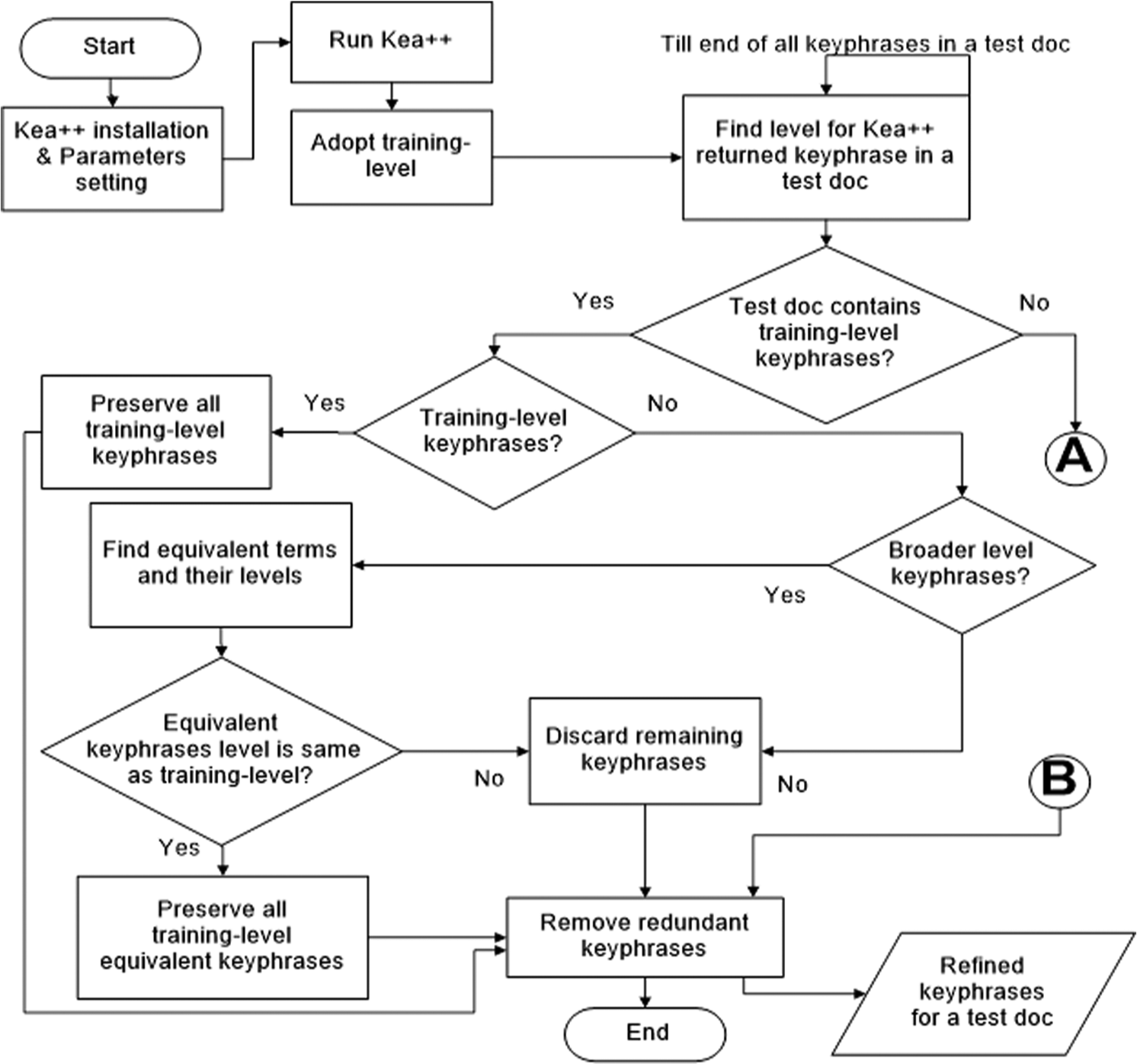
Flow chart for the extended refinement algorithm (part 1).
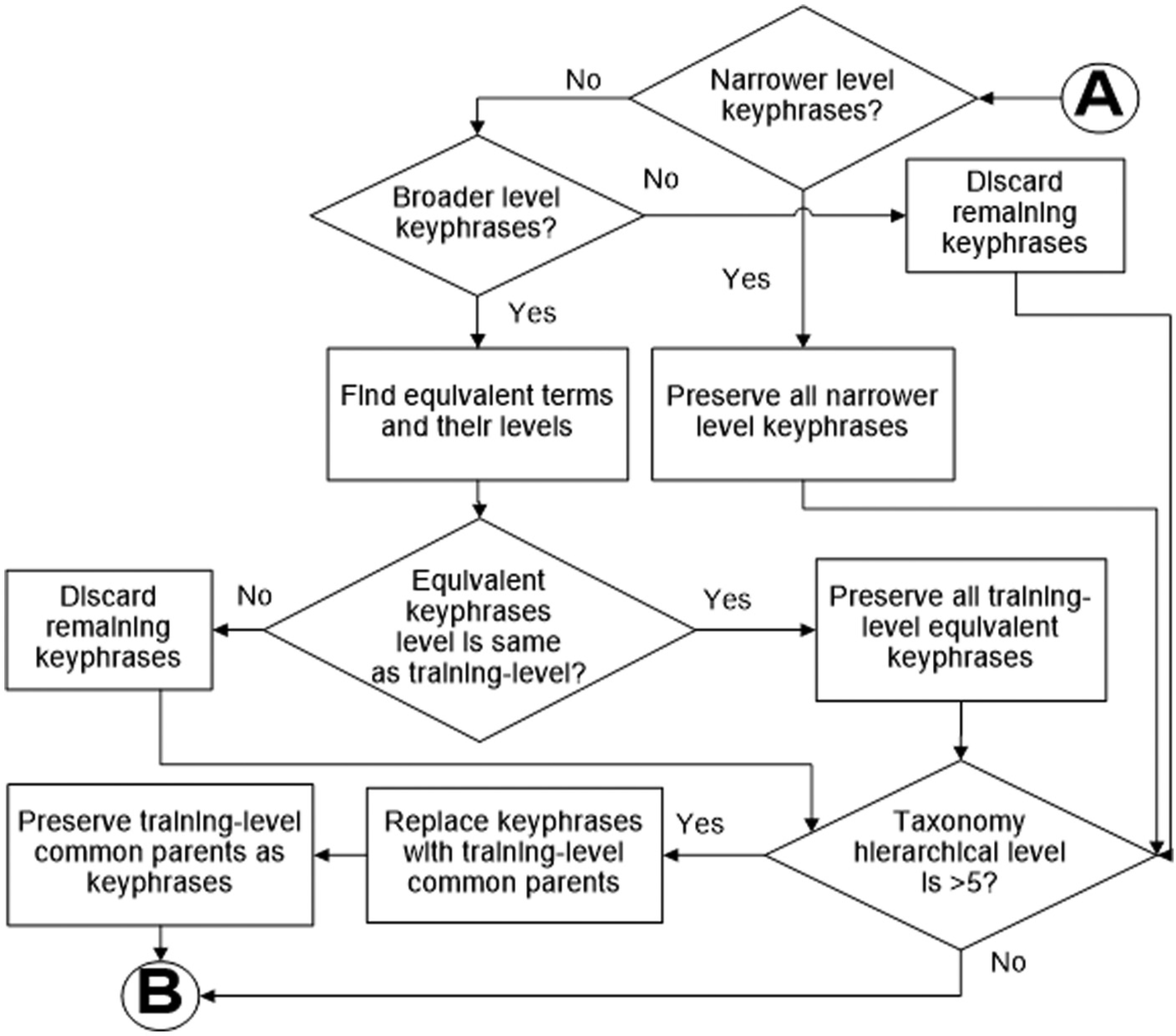
Flow chart for the extended refinement algorithm (part 2).
Manually assigned keyphrases in a training dataset are read by the algorithm for calculating the training level. Counter variables are used for each level of taxonomy and are incremented for every/each manually assigned keyphrase. Finally, the level having the maximum value is selected as the training level. The algorithm reads the keyphrase result set produced by Kea++ and processes it based on the presence or absence of training level keyphrases. If the result set contains training level keyphrases, then all those keyphrases that are aligned with the training level are preserved in the final result set. For keyphrases aligned with a broader level than the training level, their equivalent keyphrases are searched in the taxonomy. Those equivalent keyphrases are selected which are aligned with the training level and the rest of them are discarded. All those keyphrases that are aligned with narrower level than the training level are simply discarded, and are not included in the refined result set.
The next part of the algorithm deals with situation when a result set contains no keyphrases aligned with the training level. In that case, all keyphrases aligned with a narrower level than the training level are preserved in the final result set. For the keyphrases aligned with broader level than the training level, the same strategy is followed when a result set comprises training level keyphrases. If the number of taxonomy hierarchical levels is greater than five, then those keyphrases possessing training level common parents are replaced with their respective training level common parent keyphrases and are preserved. Finally redundant keyphrases are discarded from the refined result set.
5. Walk-through examples
Two walk-through examples are discussed here to explain the working of the methodology.
5.1. Walk-through example 1 (Computing domain)
The document used in this example belongs to the Computing domain as shown in Table 2. Kea++ is first applied to assign keyphrases to the document. These keyphrases are given as input to the extended refinement algorithm. The algorithm first finds the training level. The training level is 3 here because most of keyphrases in the training set of documents are aligned with level 3. The keyphrase identifiers generated by the algorithm are shown in the second column of Table 2. The algorithm computes levels for each keyphrase, which is also shown in parentheses in the second column. The result set does not contain any training level keyphrase. All the keyphrases aligned with narrower level(s) than the training level, that is, Data Mining, Main Memory, Sampling and Analysis of Algorithms, are preserved in the final result set. Moreover there are two broader level keyphrases, that is, Data Structures and Information Systems, aligned with levels 2 and 1, respectively. The algorithm examines the existence of some equivalent training level keyphrases for these keyphrases. There are no equivalent training level keyphrases in the taxonomy, so they are discarded. Moreover, there are no repeated keyphrases in the final result set. This shows that the algorithm has successfully reduced irrelevant keyphrases from the Kea++ result set.
Extended refinement algorithm example 1

5.2. Walk-through example 2 (Agricultural domain)
The document used in this example belongs to Agricultural domain as shown in Table 3. Kea++ is first applied to assign keyphrases to the document. These keyphrases are given as input to the extended refinement algorithm. The algorithm first finds the training level. The training level is 3 here because most of keyphrases in the training set of documents are aligned with level 3. The keyphrase identifiers generated by the algorithm are shown in the second column of Table 3.
Extended refinement algorithm example 2

The algorithm computes levels for each keyphrase, which are also shown in parentheses in the second column. The algorithm identified two keyphrases, that is, Harbours and Fishes, in the Kea++ result set that are aligned with the training level, so they are preserved in the final result set. The keyphrases aligned with levels narrower than the training level are simply discarded. Moreover, the algorithm checks the training level equivalent keyphrases for keyphrases aligned with the broader levels than the training level. Finally for the keyphrases that occur at broader levels in the taxonomy, the algorithm checks for their equivalent training level keyphrases. For two keyphrases, Smoked fish and Retail marketing, their equivalent training level keyphrases exist in taxonomy, that is, Smoking and Shops, respectively, so they are preserved in the final result set. The number of hierarchical levels of Agrovoc is greater than five. However, rule VI is not applicable because the result contains training level keyphrases. There are no repeating keyphrases in the final result set. This confirms that the algorithm reduced irrelevant keyphrases from the Kea++ result set as shown in Table 3.
6. Results and evaluation
This section presents the evaluation of the extended refinement algorithm (ERA). Kea++ is applied on every domain dataset before the use of the refinement algorithm (RA) and then ERA. The objective is to evaluate the performance efficiency of the ERA.
6.1. Dataset specifications
Three hundred PDF documents were randomly downloaded from the journal ACM Computing Survey for the Computing domain. This set includes 100 documents used previously [9]. The taxonomy used for testing was ACM CCS. For the Agricultural domain, 400 documents were randomly downloaded from the FAO. The taxonomy used for testing was Agrovoc. The data was divided into different sets in order to evaluate the methodology by varying training and test dataset sizes and their details are shown in Table 4. The testing for Agriculture domain datasets was carried out in two phases: (a) without rule VI and (b) with rule VI. Datasets belonging to any domain were reshuffled three times and underwent the same test three times to obtain accurate values of the evaluation metrics.
Dataset specifications

6.2. Evaluation metrics
The evaluation metrics used for evaluating the extended refinement algorithm are as follows:
6.2.1. Precision, recall and F-measure
Precision is the ratio of relevant keyphrases retrieved out of the total keyphrases retrieved and recall is the ratio of relevant keyphrases retrieved out of all the relevant keyphrases related to a document. The F-measure is a single measure that is used to check the accuracy and relevancy of results. It defines the harmonic mean of precision and recall [21, 22]. We chose them for two main reasons. First, in the field of information retrieval they are the most commonly used metrics. By using them we can very clearly state the effectiveness of the result obtained. Second, they have been used in the works [9, 19, 20] with which we will compare the results to check for any improvement achieved.
6.2.2. Average number of assigned keyphrases
This describes the average number of keyphrases that are produced by a tool/algorithm in comparison with manually assigned keyphrases. It represents the elimination of noise and irrelevant terms in the result. It gives us another way of looking at our results, so that we can check whether our technique has reduced the noise and irrelevant terms from the Kea++ result set or not.
6.2.3. t-Test
It might be the case that the precision, recall and F-measure results are showing improvement but the improvement has occurred by chance for the sample under test. Various statistical tests exist to determine that the differences in performance between retrieval methods are significant. The t-test is a statistical test for the mean of the population. It determines whether differences in performance between different retrieval methods are significant or not [23]. It is applied in a case, where the (a) population curve is normally distributed or approximately normally distributed (b) population standard deviation is unknown and (c) the sample size is less than 30 [24, 25]. In all our tests, we performed the t-test on critical values of 0.05. To verify ERA effectiveness, before values must be significantly smaller than the after values, therefore the mean of differences must be less than zero. This shows that the tests are left-tailed t-tests. The critical value obtained from the t distribution table at the level of significance, 0.05, and at n − 1=24 for the left-tailed test, is −1.711. Moreover, we assumed that samples used in tests are approximately normally distributed.
6.3. Results for Computing domain datasets
This section describes evaluation of the ERA using Computing domain datasets.
6.3.1. Precision, recall and F-measure
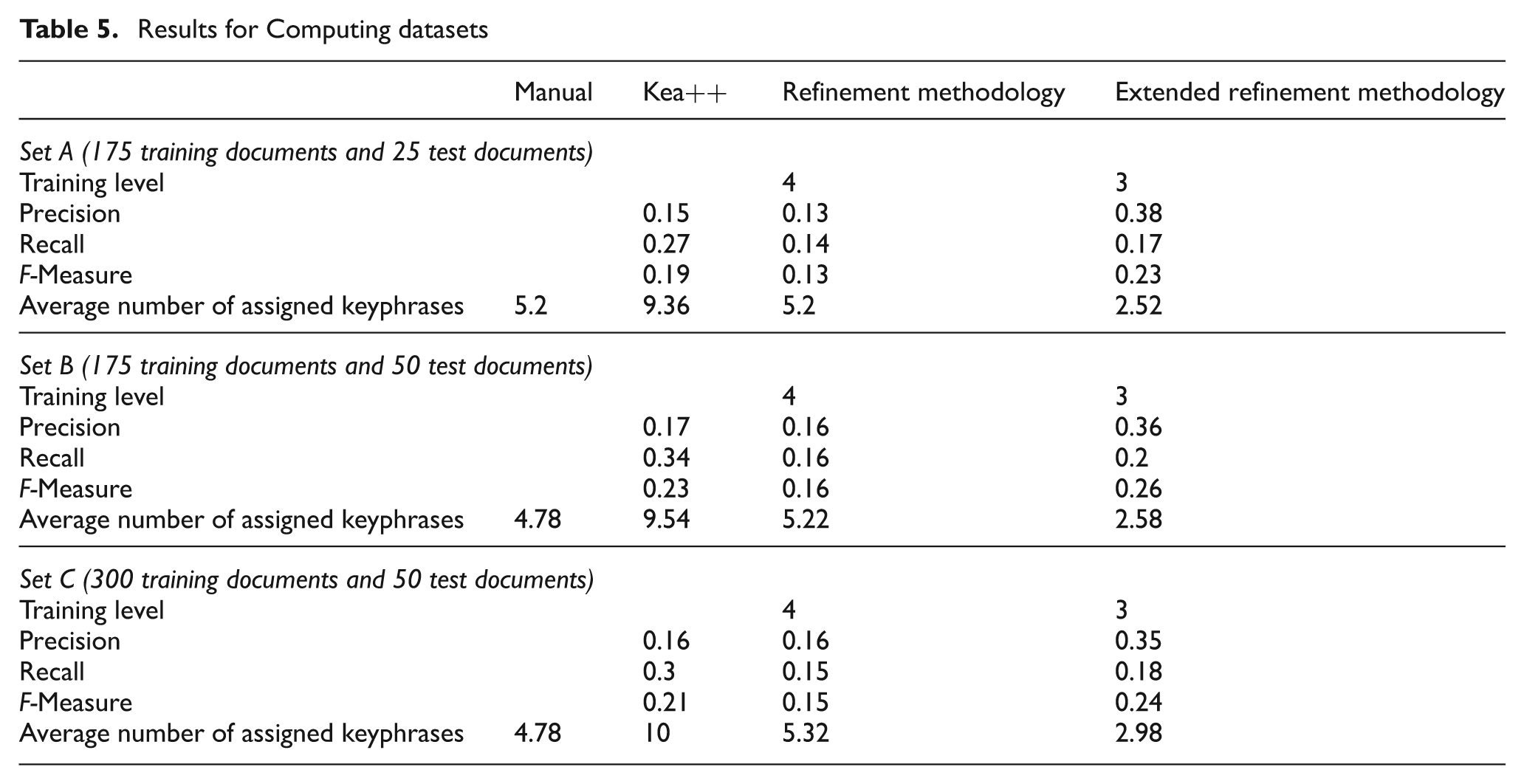
The computed value of training level was 4 in the case of RA and it was 3 in the case of ERA for all three datasets of the Computing domain. We can see in Table 5 that precision is considerably higher in case of ERA as compared with Kea++ and RA. This means that the number of extracted keyphrases that are not relevant to documents is lower in the case of ERA compared with Kea++ and RA. The recall of ERA is less than that of Kea++; however it is higher than that of RA. This shows that the keyphrases that are relevant but not extracted are greater in number in the case of RA and ERA when compared with Kea++. This is an area where more work is needed. However precision and recall always counter one another, so we calculated the F-measure to get the overall picture. The F-measure of ERA is higher compared with Kea++ and RA. The F-measure value of RA is lower than that of other two algorithms in all three sets. This shows that ERA is helpful in improving the overall performance of keyphrase assignment in the case of the Computing domain.
Results for Computing datasets
6.3.2. Average number of the assigned keyphrases
Table 5 also shows the average number of keyphrases produced by Kea++, RA and ERA for the test datasets in comparison with manually assigned keyphrases. We can see that the average number of keyphrases for test datasets is lowest in the case of ERA. Kea++ produced greater noise and its value for the average number of keyphrases is much larger than that of manually assigned keyphrases. The result produced by RA in all three tests is closer to the number of manually assigned keyphrases.
6.3.3. t-Test
We selected set A of the Computing domain for this test, because its sample size is less than 30. A statistical t-test was performed for precision, recall and F-measure values to check the significance of improvement in ERA results. The t-test results, given in Table 6, show significant improvement of ERA over Kea++ and RA with respect to precision and F-measure; however, its improvement is not significant with respect to recall. This is due to the fact that Kea++ when applied to a document for assigning keyphrases is not able to generate all the relevant keyphrases related to a document. As the number of all the relevant keyphrases belonging to a document is less in the result of Kea++, the ratio of relevant keyphrases out of all the relevant keyphrases belonging to a document is less (recall is less in other words).
t-Test for Computing domain

6.4. Results for Agriculture domain dataset
This section describes the evaluation of ERA using Agriculture domain datasets. In ERA we proposed rule VI for taxonomies having hierarchical level greater than 5. This evaluation was performed in two phases: without rule VI and with rule VI, to determine the improvement obtained with rule VI.
6.4.1. Precision, recall and F-measure without rule VI
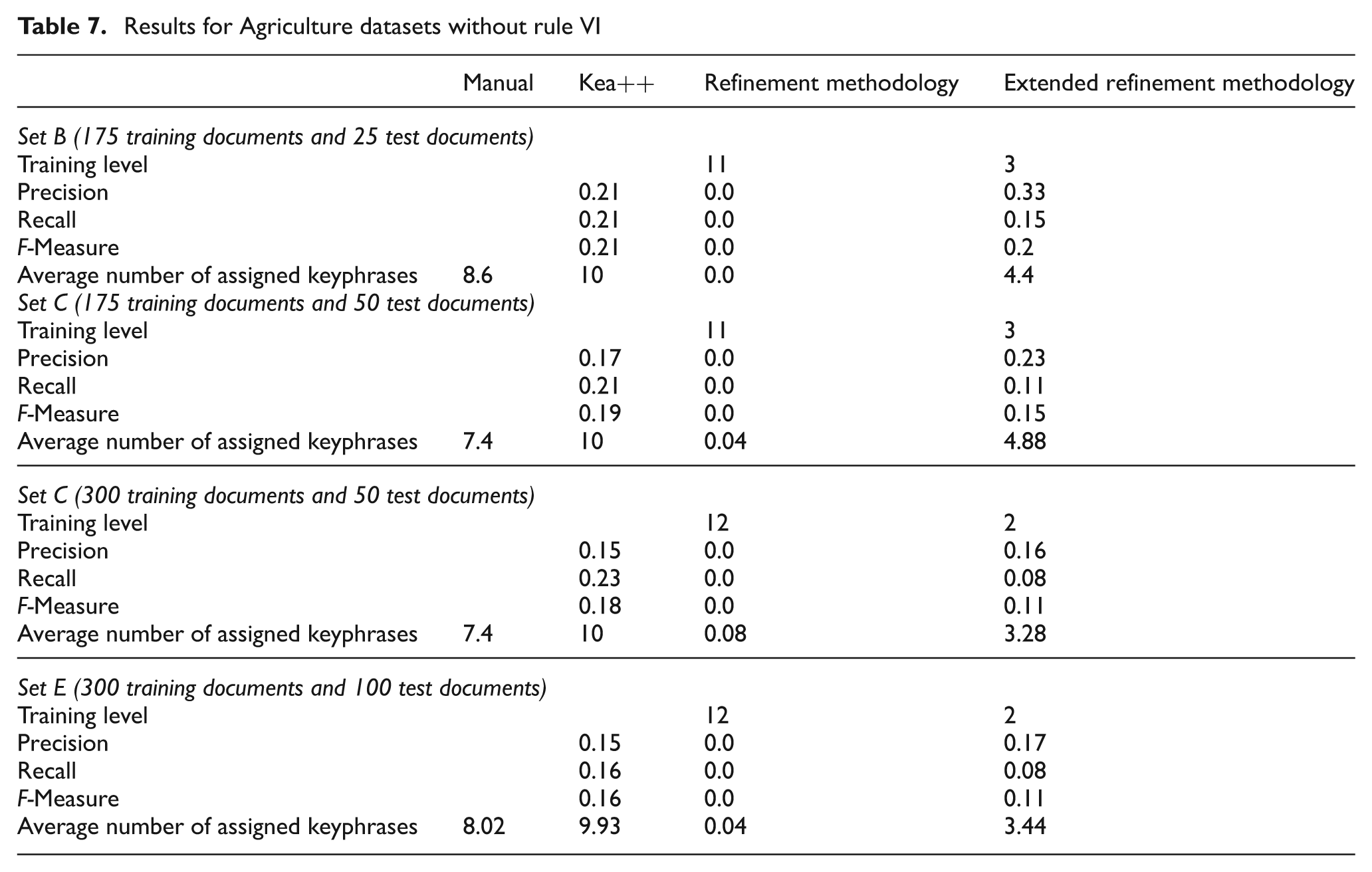
The computed value of training level was 11 for sets B and C, whereas it was 12 for sets D and E in the case of RA. This value was 3 for sets B and C and 2 for sets D and E in the case of ERA. Table 7 shows higher precision of ERA in all four tests as compared with Kea++. RA did not return any value owing to the very large value of its training level. It shows that RA does not perform well with taxonomies having deep hierarchy. Moreover, the results illustrate that the number of extracted keyphrases that are not relevant to the documents is less in the case of ERA compared with Kea++. The recall of ERA is lower than that of Kea++. Similarly RA does not return any result for recall either. This graph illustrates that keyphrases that are relevant but not extracted are greater in number in case of ERA as compared with Kea++. The F-measure value is lower for ERA than for Kea++ in all four datasets. This shows that, unlike the Computing domain datasets, ERA is not very helpful in improving the overall performance of the system for Agriculture domain datasets. This shows ERA needs further enhancement to handle taxonomies with deep hierarchies.
Results for Agriculture datasets without rule VI
6.4.2. Average number of assigned keyphrases without rule VI
Table 7 also shows the average number of keyphrases produced by Kea++, RA and ERA for test datasets in comparison with manually assigned keyphrases. We can see that the average number of keyphrases for test datasets is lowest in the case of ERA, whereas RA did not return any values. The average number of keyphrases produced by Kea++ for a document is greater than the number of manually assigned keyphrases. We can say that ERA resulted in reduced noise, but since this value is too low as compared with the manually assigned keyphrases, the overall results produced by ERA are not very satisfactory.
6.4.3. Precision, recall and F-measure with rule VI
This evaluation was performed on datasets: A and B. The training level value in both sets is 3 and 11 for ERA and RA respectively. Table 8 shows that ERA precision values are higher than those of Kea++.
Results for Agriculture datasets (including rule VI)
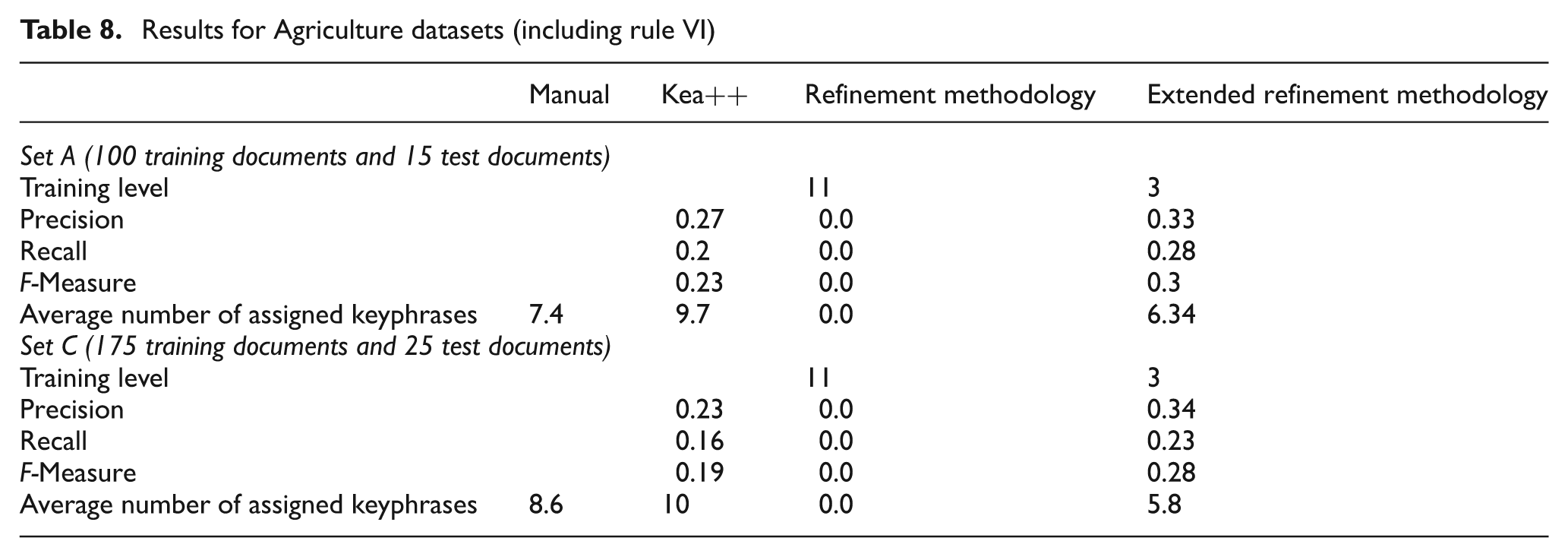
RA did not produce any result for the datasets. So we can say that the number of extracted keyphrases that are not relevant to documents is lower in the case of ERA compared with Kea++. ERA’s recall values for both datasets are greater than those of Kea++. This is the point where we can say that the earlier approach without rule VI was not producing good results. This means that the keyphrases that are relevant but not extracted are greater in number in the case of Kea++ in comparison to ERA. F-Measure values for both of the datasets in case of ERA are higher than those for Kea++. Inclusion of rule VI for taxonomies having hierarchical levels greater than five produced better results as compared with omission of rule VI.
6.4.4. Average number of assigned keyphrases with rule VI
The average number of keyphrases needed to test documents is lowest in the case of ERA when compared with manually assigned keyphrases, as shown in Table 8. This illustrates the elimination of irrelevant terms from the result set produced by Kea++.
6.4.5. t-Test
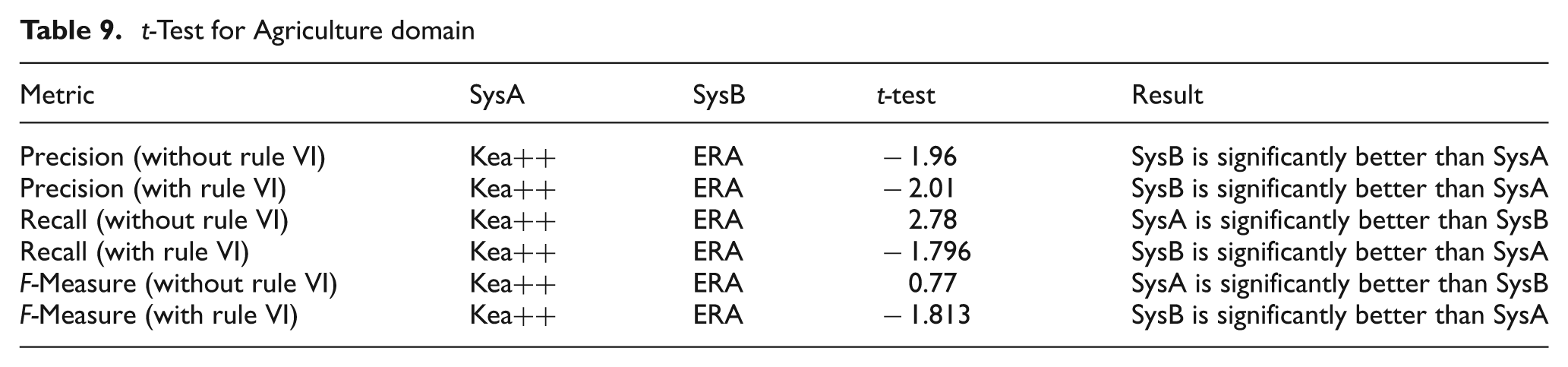
We selected set B of the Agriculture domain for this test, because its sample size is less than 30. A statistical t-test was performed for precision, recall and F-measure values. The t-test results given in Table 9 show significant improvement of ERA over Kea++ with respect to precision in both tests, that is, with and without rule VI. Recall and F-measure of ERA are not significant in Kea++ without rule VI; however they are significant while using rule VI. Moreover we could not apply a t-test to check any significant improvement between RA and ERA because RA was not producing any results for the Agriculture datasets.
t-Test for Agriculture domain
6.5. Analysis of results
The results show that improvement has been achieved in keyphrase assignment by applying ERA. F-Measure, the harmonic mean of precision and recall, has increased particularly for datasets belonging to the Computing domain because a moderate taxonomy, that is, ACM CCS, was used in these experiments. However, evaluation of Agricultural datasets, where taxonomy has deep hierarchical levels, shows that the improvement is not significant without rule VI. In other words, rule VI plays an important role in increasing F-measure value if the taxonomy has deep hierarchical structure. The results have also proved that ERA can be applied with taxonomies of different domains for obtaining optimum keyphrase assignment.
7. Conclusion
The usage of keyphrases has extended beyond the data organization and retrieval task. The refinement methodology was developed to reduce noise in the results produced by Kea++ for keyphrase assignment. However, the methodology is tilted towards the Computing domain because the rules were formulated by keeping only the ACM CCS in mind. The focus of this work was to extend the refinement methodology for multiple domains because taxonomic structure and its implementation differ from domain to domain. We have confirmed by statistical means that improvement in the keyphrase assignment is significant. In order to accomplish our objectives, different domain-specific taxonomies were analysed from areas such as computing, agriculture and mathematics. Refinement rules were revised to handle multiple taxonomies. The methodology was evaluated on different domain taxonomies and datasets. The evaluation metrics used were (a) precision, recall and F-measure and (b) average number of keyphrases assigned to test documents. The significance of improvement in the obtained result sets was confirmed through statistical test (t-test).
We have drawn the following conclusions, after undergoing all the testing and evaluation of the proposed methodology on the datasets belonging to Computing and Agriculture domains: (a) keyphrase assignment was improved by applying extended refinement algorithm and the significance of improvement was verified by statistical t-test; and (b) the algorithm was extended to be applied in multiple domains with various taxonomies. In other words, the algorithm can be equally applied in different domains with their respective taxonomies. We can call this domain-independent. The extended refinement methodology is an upper layer over Kea++. An attempt can be made in future to enhance the Kea++ algorithm by incorporating deeper semantics in the assignment process. Moreover, multiple training levels can also be used to further improve the refinement process.
Footnotes
Acknowledgements
We would like to thank Dr Khalid Latif, Assistant Professor, School of Electrical Engineering and Computer Science, National University of Sciences and Technology, and Dr Hamid Mukhtar, Assistant Professor, School of Electrical Engineering and Computer Science, National University of Sciences and Technology. They helped us out at various stages of this work, particularly the implementation and testing phases.
Funding
This work was made possible by the funding support provided by National University of Sciences and Technology, School of Electrical Engineering and Computer Science, Islamabad, Pakistan under Mega IT Funds.