
Abstract
Evaluating the performance of collaborative information seeking (CIS) systems and users can be challenging, often more so than individual information-seeking environments. This can be attributed to the complex and dynamic interactions that take place among various users and systems processes in a CIS environment. While some of the aspects of a CIS system or user could be measured by typical assessment techniques from single-user information retrieval/seeking (IR/IS), one often needs to go beyond them to provide a meaningful evaluation, helping to provide not only a sense of performance, but also insights into design decisions (regarding systems) and behavioural trends (regarding users). This article first provides an overview of existing methods and techniques for evaluating CIS (synthesis). It then extracts valuable directives and advice from the literature that inform evaluation choices (suggestions). Finally, the article presents a framework for CIS evaluation with two major parts: system-based and user-based (structure). The proposed framework incorporates various instruments taken from computer and social sciences literature as applicable to CIS evaluations. The lessons from the literature and the framework could serve as important starting points for designing experiments and systems, as well as evaluating system and user performances in CIS and related research areas.
1. Introduction
Evaluating a collaborative information-seeking (CIS) environment can be a huge challenge owing to its complex design, which involves a set of users and integrated systems and a variety of interactions. One can evaluate a CIS system using typical measures of information retrieval (IR). However, information seeking is not merely about retrieving information [1], and thus, evaluating a CIS system simply by its retrieval effectiveness may not be sufficient. While traditional IR evaluations can still be used to measure the retrieval performance of a collaborative filtering system, just as Smyth et al. [2] did, we need additional and more comprehensive measures for CIS systems.
Baeza-Yates and Pino [3] first presented some initial work on trying to come up with a measure that can extend the evaluation of a single-user IR system for a collaborative environment. While this was based on the retrieval performance, Aneiros and Estivill-Castro [4] came up with the proposal of evaluating the goodness of a collaborative system with usability measures. It is important to note that Baeza-Yates and Pino [3] treated the performance of a group as the summation of the performances of the individuals in the group. While this may work for simple information seeking and retrieval, we can imagine situations in which this is not true. For instance, if two people working together could find twice as much information as either of them working independently, was that a good thing? How about the amount of time they spent cumulatively? The participants may not be able to find twice as many results, but what if they achieved better understanding of the problem or the information owing to working in collaboration? Then there are other factors, such as engagement [5], social interactions [6] and social capital [7], which may be important depending upon the application, but are usually overlooked in non-interactive or single-user IR evaluations.
To address these concerns with existing evaluation techniques for CIS, we will look at a broader context in which CIS is situated, namely at the intersection of information retrieval/seeking (IR/IS), human–computer interaction (HCI) and computer-supported cooperative work (CSCW). Specifically, in this article we will review a number of methodologies that have been used for CIS evaluation (Section 2). To make the literature synthesis more applicable, we will extract specific lessons learned and suggestions/advice given by the authors and scholars of various CIS-related studies (Section 3). Then we will talk about specific measures taken primarily from IR, HCI, and CSCW literature that help to evaluate CIS systems and approaches. These measures will be divided in two categories: system-based (Section 4.1), and user-based (Section 4.2). We will conclude (Section 5) with a summary and various ideas for future work in evaluating CIS.
2. Synthesis of evaluation methodologies for CIS
To commence our discussion on evaluation in this field, we will first look at a broad overview of how researchers have approached this issue using different methodologies. To aid our discussion, these methodologies are being presented using three major approaches for conducting research in this area: user/laboratory studies, system-based training-testing and ethnographic/field studies.
2.1. User/laboratory studies
The majority of the work reported in the literature that has attempted to evaluate the effectiveness of a collaborative system and/or people in collaboration has looked at the usability of the collaborative interface in a laboratory setting. For instance, Morris and Horvitz [8] tested their SearchTogether system with a user study to evaluate how users utilize various tools offered in their interface and how those tools affect the act of collaboration. The authors used seven pairs of users and let each pair choose their topic of mutual interest to work with. The evaluation was based on the log, observations and questionnaire data. While they showed the effectiveness of their interface in letting people search together, there was no evaluation of performance or learning that took place in the group due to collaboration. Laurillau and Nigay [9], on the other hand, demonstrated how multiple users could navigate the Web in a collaborative environment with their CoVitesse system. They presented evaluations for the user interface as well as various network-related parameters. However, no clear understanding of the effects on the retrieval performance was reported. Aneiros and Estivill-Castro [4] presented a questionnaire to the participants of their user study to evaluate the usability of their group unified history. Typical questions on their questionnaire were ‘how difficult was it to interpret the user identity symbols used in the tool?’ and ‘did you visit any Websites found by your team/peers using the group history?’
For user studies with CIS, it is very common to measure aspects of usability [10] – sometimes to simply see how the users like a new CIS interface, and other times to see how it impacts their work. For instance, Amershi and Morris [11] conducted an experimental study to determine the usability of CoSearch, a system they ‘developed to improve the experience of co-located collaborative Web search by leveraging readily available devices such as mobile phones and extra mice’ (p. 1647). By studying 12 groups’ interactions with CoSearch, they determined the effectiveness of the system in relation to user expertise, preference, communication, collaboration, participation and task outcome.
In their development of CoSense, Paul and Morris [12] sought to frame sensemaking in a collaborative information-seeking context. They aimed to understand sensemaking challenges presented during collaborative Web search tasks by evaluating their new tool, CoSense, ‘a tool for collaborative sensemaking’ that ‘takes information about group members’ search process and products and provides visualization and contextualisation of that information to enhance sensemaking’ (p. 1772). Their evaluation of this tool showed that CoSense did, in fact, enable support of sense-making both during synchronous and asynchronous collaboration.
Blackwell et al. [13] evaluated a prototype interface for collaborative searching in a real context of use and confirmed that it could improve relevance rankings compared with single-user dedicated search engines such as Google. Preliminary results achieved three original design goals: to allow multiple users to contribute to query construction, to allow multiple users at once to interact with the interface and to support this activity as a secondary task.
Smeaton et al. [14] tested a new co-located Collaborative Video IR system with the goal of determining how pairs of users, charged with an information need task, interacted with it. They analysed the use of the system in terms of overall system effectiveness (more specifically, search efficiency), various types of user interactions and the degree to which users’ personalities impact each of these. What the study found was that users preferred awareness over efficiency. In other words, users would sacrifice efficiency and strength of results to a design that made it easier for them to collaborate.
Sometimes researchers have employed survey and interview methods for gathering information regarding CIS systems and interfaces. For instance, after collecting surveys from 204 knowledge workers at a large technology company, Morris was able to make suggestions for key collaboration features that new web search interfaces could potentially provide. The surveys indicated a need for features that support persistence, awareness and division of labour. Survey participants expressed a strong desire to ‘resume a search after elapsed time and/or after switching computers, and the desire to collaborate with others in order to search the web’ [15]. Web interfaces that allow and support such activity would improve collaborative searching.
Wilson and schraefel [16] analysed an evaluation framework for information-seeking interfaces in terms of its applicability to collaborative search software. Extending Bates’s tactics model [17] and Belkin’s model of users [18], they showed that the framework could be just as easily applied to collaborative search interactions as individual information-seeking software, but pointed out that there are additional considerations about the individual’s involvement within a group that must be maintained as the assessment is carried out.
As evident from various evaluations performed with user studies in CIS domain, a majority of them opt for user-focused measures, with some of them focusing on user productivity and search performance. Some of the typical elements of study design and evaluation methodology for user studies involve:
a control setup like a lab;
selective group of participants, often recruited through convenience of snowball sampling;
supervised or semi-supervised execution of task;
typical types of data recorded – log, questionnaire, interviews;
typical study instruments are brought from HCI and psychology literatures; and
analysis typically involves both quantitative and qualitative approaches.
2.2. System-based training-testing
Several researchers in CIS, especially those coming from the IR domain, have employed various system-focused measures for evaluating the effectiveness of a CIS system. These approaches often use simulations and/or batch processing in lieu of actual user interactions.
Smyth et al. [2] tested their I-Spy system with leave-one-out evaluation methodology. From 20 users, they left one user as a testing user and used the other 19 users as the training users. The relevancy results of the training users were used to populate I-Spy’s hit matrix and the results of each query were re-ranked using I-Spy’s relevancy metric. Then they counted the number of those results listed as relevant by the test user for various result-list sizes and, finally, they made the equivalent relevancy measurements by analysing the results produced by the untrained version of I-Spy to serve as a baseline. A recently published study by the same group [19] provides more details about this form of evaluation.
Not surprisingly, this line of evaluation is more popular with system or algorithmically mediated collaboration. For instance, Pickens et al. [20] used search query suggestions provided by individuals and showed how their algorithm could achieve an effective collaboration by way of simulation. Shah et al. [21], similarly, used the notions of relevance and novelty to demonstrate how search processes that were virtually combined could result in achieving results that are both relevant and diverse.
Golovchinsky et al. [22] provided a framework for understanding how systems supporting collaborative searching work and how system design can be improved. Their model contains four dimensions: intent, depth, concurrency and location. Interestingly, the proposed model also included a prioritization of ‘the most important dimensions for distinguishing between existing and future online, collaborative retrieval systems’ [22]. While their own work was primarily based on simulation-based experiments that did not allow actual user interactions, they name ‘searcher intent’ as the most important driving force to consider when building collaborative retrieval systems.
Some of the typical elements of study design and evaluation methodology for system-based experiments involve:
the use of various objects constructed by humans in search process, such as queries and documents, as well as relevance judgments;
an approach that typically involves an algorithm/system that provides system-mediated collaboration;
experiments run using partial or full simulations; and
analysis typically involving quantitative approaches.
2.3. Ethnographic/field studies
Ethnographic approaches for studying CIS issues is more common with researchers primarily coming from information and social sciences. The evaluations usually focus on behavioural aspects of CIS, with qualitative analysis of data.
One such work is by Prekop [23], who presented a qualitative way of evaluating collaborative information-seeking studies. He proposed this by measuring information seeking patterns. These patterns describe prototypical actions, interactions and behaviours performed by participants in a collaborative endeavour. The three patterns that the author described were information seeking by recommendation, direct questioning and advertising information paths. On a similar line of method that involves studying participants by analysing their behavioural patterns, Olson et al. [24] studied 10 design meetings from four projects in two organizations. The meetings were videotaped, transcribed and then analysed using a coding scheme that looked at participants’ problem solving and the activities they used to coordinate and manage themselves. The authors also analysed the structure of their design arguments. The authors claimed that the coding schemes developed might be useful for a wide range of problem-solving meetings other than design.
Similarly, Haseki et al. [25] asked a class of graduate students working on a literature review-based collaborative project to keep track of their activities using a diary. The authors devised a coding scheme using a grounded theory approach [26] and found interesting patterns across time as the groups engaged in a collaborative project through a semester.
Tao and Tombros [27] recently conducted an observational user study where 24 participants, in groups of three, completed a travel-planning task. Using qualitative analysis of screen captures during the participants’ sessions, they found problems encountered by the searchers in executing the assigned task in collaboration. The authors also pointed out the lack of a framework for analysing such activities in order to draw conclusions about the effectiveness of a CIS system and/or the users involved in such a project.
Birnholtz et al. [28] have noted that collaborative work is also impacted by the potential for social conflict. Systems that allow for collaborative writing, in which multiple users can see, in real time, edits and additions to a group document, have the potential for inciting disagreement between users and decreasing the system’s overall effectiveness. The study found that ‘participants’ reactions to others’ actions were affected by social messages perceived in edits, and that many participants do consider how their edits will be interpreted’ [28] (p. 815). Systems that include high peer visibility run the risk of decreasing productivity as users might censor or spend considerable time editing and/or explaining their actions rather than focusing on the project.
Fidel et al. [29] sought to understand various dimensions explaining motives for engaging in collaborative information retrieval rather than working individually. After studying a sample of design engineers from Microsoft, they found that some motives ‘include when they are new to the organization or the team, when the information lends itself to various interpretations, or when most of the needed information is not documented’ [29] (p. 939). The study emphasized that motivations behind engaging in CIS are multidimensional and interdependent and require further study.
In a study evaluating two social networks developed and put into action for collaborative engagement at a medium-sized software development company called Medical Software Company, McDonald sought to understand how new systems impact users. The group conducted an ethnographic study followed by intensive data collection for a total three-year time span and found, through user observations, that individuals have mixed feelings about social networks as a CIS system but that ‘the application of social networks by groupware designers and implementers will continue’ [30] (p. 599).
Reddy and Spence [31] also conducted a study that sought to define ‘triggers’ for collaborative information-seeking behaviours. They conducted an ethnographic study of a multidisciplinary patient care team in an emergency department to test for collaborative information-seeking triggers and what this specific team’s information needs were. Members of the medical team had organizational and clinical information needs that often arose from a lack of information flow within the team. Triggers for collaborative information seeking were found to be: (1) lack of expertise; (2) lack of immediately accessible information; and (3) complex information needs.
Some of the typical elements of study design and evaluation methodology for ethnographic/field studies involve:
data collection through observations, surveys, and interviews;
studies usually lasting several days to several months;
semi-supervised to unsupervised execution of task;
typical study instruments brought from social sciences literature; and
analysis typically involvig qualitative approaches.
3. Suggestions for evaluating CIS
The previous section presented an overview of some of the research works in CIS that are representative of various evaluation methods in this area. In the current section, we will look at more specific entities that are commonly measured during CIS evaluation, along with lessons, advice and suggestions offered by the authors of these studies. They can be divided in three categories: system-focused, user-focused and collaboration-focused. Some of the works also provide general suggestions about employing multidimensional and balanced approaches for evaluation as reflected in the final two subsections of this section.
3.1. System-focused evaluations
One of the primary reasons for promoting and supporting CIS activities is to enhance productivity in an information-seeking process. Measuring productivity depends on what the outcome of the information-seeking process may be.
For instance, focused on enhancing retrieval performance, Pickens et al. [20] measured the increase in relevance of retrieved results in a video retrieval system. Shah et al. [21], on the other hand, argued that simply enhancing relevance is not enough for a CIS system, and suggested measuring novelty/diversity of discovered information as well.
In addition to relevance in information retrieval and filtering context, other aspects that are commonly measured while evaluating productivity include information coverage [32], collective sense-making [12], learning [60], collaborative synthesis [24] and communication behaviours [33]. Focused on the collaborative writing aspect of a CIS system, Birnholtz et al. [28] pointed out that collaborative writing features should aim towards future action rather than what happened the past. Based on this, they suggested considering group maintenance, presenting changes as possibilities (this is more favourably received than definitive edits) and considering features for new groups while evaluating a CIS system that provides collaborative writing support. When it comes to evaluating writing or synthesis in collaboration, the same authors found that the conflicts of participants described tended to be around relatively large or conceptual changes to documents. For example, grammar corrections were appreciated while larger, conceptual changes were not often taken well in their study. This concept of ‘size of edit’ requires further consideration during evaluation. Similarly, Pickens et al.’s [20] work suggested that measuring the effects of intertwined streams of computer retrieval and partner search activity as presented to each user is an open question worthy of further research.
3.2. User-focused evaluations
A primary way to evaluate user-focused goodness of a CIS environment is by usability measures [10]. As described in Section 2.1, most researchers employ instruments taken from HCI and cognitive science literature. Shah and Marchionini [40] suggested applying a multi-modal approach for measuring usability, where the typical questionnaires relating to user interactions are analysed in the context of the usage data collected through logging.
Another aspect of user-focused measurements that is often disregarded according to González-Ibáñez et al. [35] is the affective dimension of user-to-user and user-to-system interactions. The authors recommended using the Positive and Negative Affect Scale [36], derived from positive psychology, for measuring users’ affective states during a CIS process.
One of the core aspects of user-focused CIS, as recognized by many researchers, is awareness. It, therefore, is no surprise that suggestions and ways for measuring awareness frequently come up in the literature. It is important to first ask ‘awareness of what?’ Schmidt [37] argued that we should talk about awareness not as a separate entity, but as somebody’s being aware of some particular occurrence. In other words, the term awareness is only meaningful if it refers to a person’s awareness of something. Heath et al. [38] suggested that awareness is not simply a ‘state of mind’ or a ‘cognitive ability’, but rather a feature of practical action, which is systematically accomplished within the course of everyday activities.
For the purpose of clarifying and measuring awareness, Liechti and Sumi [39] divided it into four categories: group awareness, workspace awareness, contextual awareness and peripheral awareness. Some of the recent works have studied specific kind(s) of awareness to measure its effects on CIS activities. For instance, Shah and Marchionini [40] focused on peripheral awareness and concluded that in the absence of appropriate awareness support, collaborators could end up wasting a lot of effort in unnecessary communication. Shah further explored [41] effects of awareness on coordination efforts. In both of these cases, the authors recommend measuring awareness using multiple instruments, including log data and questionnaires. Amershi and Morris [11] remind us that task-focused workspace awareness information, such as visible edits to a shared document, can have relational consequences. Such awareness, often ignored in many CIS evaluations, could end up being one of the most important aspects to measure.
3.3. Collaboration-specific evaluations
One of the common strategies for people working in collaboration, including in CIS, is division of labour [42,43]. There are two potential benefits of doing this: reduce workload on an individual, and accomplish something more than individual contributions by first dividing up the work and bringing the results together in a way that an individual could not do. Based on this understanding, for a CIS solution, it is important to measure various elements relating to division of labour as suggested in the literature:
evaluate how well collaborators are able to negotiate and divide the work [42];
measure the cost of doing the division of work [29]; and
investigate the trade-offs (risk vs. benefits) of doing CIS using division of labour [32].
Another important aspect to measure in collaborative activities is cognitive load – a measure of mental effort induced on one while performing a task. There are several instruments, primarily developed in cognitive science and HCI fields, that can be used for measuring such load. One such instrument is NASA’s Task Load Index [44].
During a CIS task, in addition to the regular mental effort that one has to face, the collaborators encounter an additional cognitive load, called collaborative load [29]. Often, a way to measure this is by finding the difference between cognitive loads for doing a task individually, and doing the same task collaboratively. Showing that there is very little increase in cognitive load in collaboration (i.e. collaborative load) with respect to individual work is a common technique to argue for the advantages of CIS [32].
3.4. Apply a multidimensional approach
While it may be desirable to focus on one or two aspects of CIS based on the context and the application, for a more comprehensive understanding, one should look at various dimensions of a CIS process. This is especially true in CIS research that aims to study behavioural elements of CIS in addition to information aspects. For instance, Golovchinsky et al. [22] suggested four dimensions – intent, depth, concurrency, and location – that can be used to classify existing CIS approaches and to suggest possible opportunities for design in this space.
It is common in the literature to classify and study CIS approaches using time and space dimensions [45]. One could also look at more elaborate framework consisting 12 dimensions proposed by Shah [46].
3.5. Apply a balanced approach
Similar to the suggestion for multidimensional approach, one needs to take a balanced approach to CIS evaluations. Such balance can come in general form of balancing system-based measures and user-focused measures. For instance, McDonald [30] found that Groupware systems face the challenge of perceived trade-off: the user’s perception that there will be a trade-off, when working within system social networks, of socially compatible and professionally helpful contacts. Users want a system to complement, not replace, their natural behaviour when searching for and finding matches – one should design accordingly to give the user a degree of control that is appropriate. In other words, an approach that disregards the user side while optimizing system performance does not provide a comprehensive or useful evaluation measurement.
A balanced approach may also appear as relevant for more specific scenarios. For instance, in Shah et al.’s work [21], measurements were employed to evaluate both relevance and novelty in a collaborative IR project. Smyth et al. [62] also indicated that it would be helpful to remain aware of and try to solve the problem of older sources having an ‘in-built bias’ because of increased clicks and therefore better relevancy scores. Newer pages have a harder time finding an audience while older pages have a too easy time.
As evident from the previous two sections, most of the efforts of evaluating various factors in CIS are driven by extending existing approaches for extending individual processes and users to incorporate multiple participants and/or search systems. These efforts can be summarized as measuring (1) retrieval performance of the system; (2) effectiveness of the interface in facilitating collaboration; and (3) user satisfaction and involvement. Despite these efforts, there is still a lack of clarity and methods in evaluating CIS environments that can measure factors such as learning, user engagement and group performance. Specifically, given that no single measure or even methodology can be sufficient in providing a meaningful assessment of users and systems in CIS, we are missing a framework that allows us to perform a multifaceted evaluation. In the following section we will describe a number of measures that one could employ for overcoming this gap. It should also be acknowledged that (1) information seeking is more than information retrieval/search and (2) collaboration is more than adding outcomes of individual entities [47].
4. A proposed structure for evaluating CIS
Before presenting an evaluation framework based on prior work, it is important to contextualize CIS. Foster [49] defined CIS as ‘the study of the systems and practices that enable individuals to collaborate during the seeking, searching, and retrieval of information’ (p. 330). Shah [48] referred to CIS as a process of information seeking ‘that is defined explicitly among the participants, interactive, and mutually beneficial’ (p. 1). There have been several other attempts to provide definitions and/or frameworks of CIS [49]. However, our purpose here is to look at how different quantities of interest can be measured in a CIS activity by taking inspirations from fields such as IR, HCI and CSCW. We, therefore, use a variation of the conceptual depiction provided by Shah [47], as shown in Figure 1. As shown in this figure, IR is considered a part of information seeking, and CIS incorporates information seeking as well as collaboration. To accommodate this view on CIS, our framework will include system-focused measures from information seeking (that includes IR) as well as user-focused measures from HCI and CSCW.
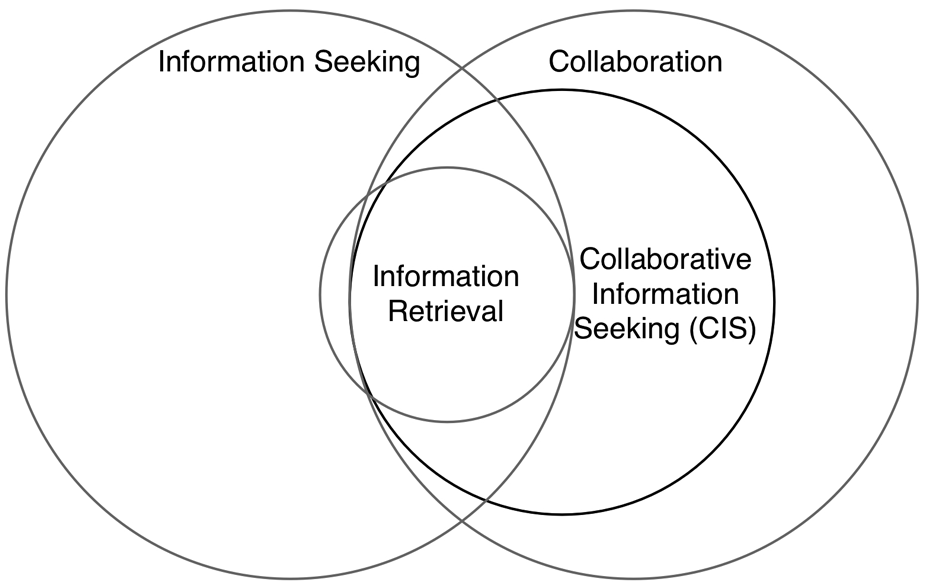
A variant of the depiction presented in Shah [47] to demonstrate how CIS is related to other concepts.
This section, thus, will present a set of measures – divided into system-based and user-based. 1 While the framework assumed a Web-based environment, one can easily modify it to suit one’s needs for a different setup such as digital libraries or databases.
4.1. System measures
We will first look at measures that evaluate different aspects related to the system used for CIS. Many of these measures are taken from traditional and non-traditional IR evaluation metrics. The data for running these evaluations are typically obtained by capturing various objects and processes during the CIS processes. For a grounded discussion on these measures, let us consider a Web-based application, where the collaborators in their CIS project are searching, viewing, and collecting information from the Web. The unit of information here, therefore, will be a Web page, but one could easily substitute any other reasonable objects (e.g. documents, pictures, videos) without affecting these measures.
As noted before, information seeking is more than search and retrieval. Without going into discussions about what all that information seeking involves, we will divide it into two parts as far as evaluation goes: search and exploration. For a more comprehensive treatment of information seeking, the reader is referred to an excellent review by Marchionini [1].
The search-related measures will be taken from IR, comprising precision, recall and F-measure. Of course, there are many other popular measures of evaluation in IR including MAP (mean average precision), NDCG (non-discounted cumulative gain) and MRR (mean reciprocal rank). However, our discussion of a few basic measures should inform the reader about how other quantities can also be computed given such need. For exploration, we will follow Shah and González-Ibáñez [32] and present measures such as coverage, likelihood of discovery, and diversity. Note that some of these measures were used in an article published earlier in this journal [34].
4.1.1. Precision, recall and F-measure
First, we will talk about traditional IR measures – precision, recall and F-measure. To compute these quantities, we need a universal set of Web pages. Assuming that the search domain is open Web, we need a more confined set that we could use for comparison. For this, we can take the union of all the Web pages visited by all the participants involved. Thus, the universe of Web pages is defined by combining the visited Web pages of each participant/team in every condition. This can be expressed as:

Here, Coverage(t) is the coverage (Web pages visited) by team t.
We also need to calculate how much of this coverage is relevant. We can map the relevant coverage to the Web pages that participants save or collect. Bookmarking, saving or printing actions may correspond to this. Once again, we can take the union of all such Web pages by each team to form a universe of relevant Web pages.

Here, RelevantCoverage(t) is the set of Web pages that team t visited and found as relevant.
Using these two quantities, we can now define precision, recall, and F-measure, which are listed below:
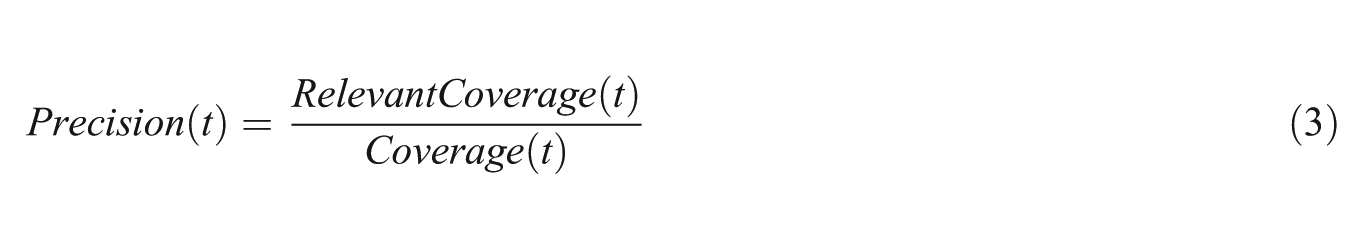


4.1.2. Coverage
To expand our analysis beyond the most common measures used in information retrieval, we can look at the coverage of information by each team. Let us define coverage of a given team as the total number of distinct Web pages visited within the universe of Web pages.
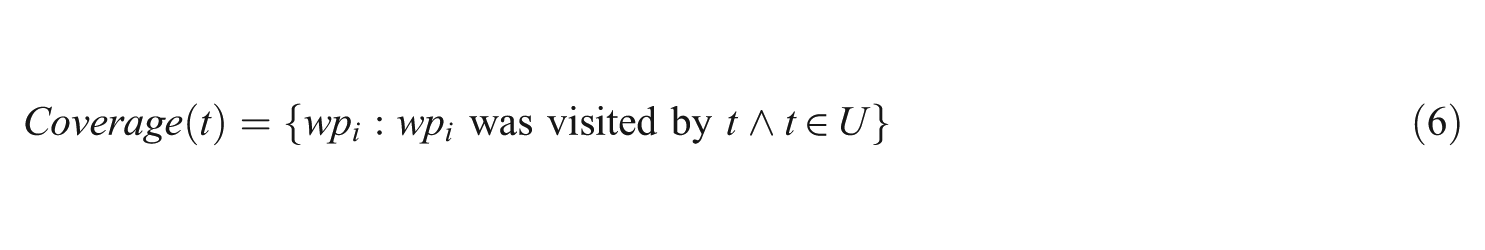
We could also consider a particular region of the coverage of teams that was unique within the universe. Let us call such region unique coverage, which consists of all Web pages within the coverage of a given team t that were visited only by t.

In addition, we can define relevant coverage as the region of coverage of a given team that intersects with the universe of relevant Web pages.
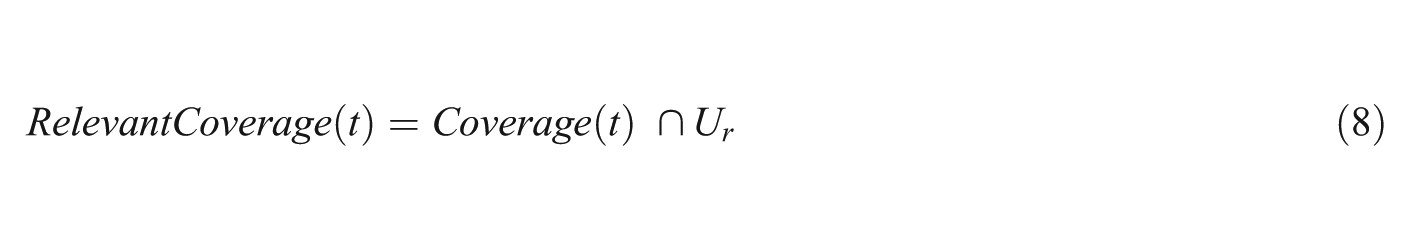
In a similar way, we can call unique relevant coverage to the set of Web pages within the unique coverage of a given team that intersects with the universe of all relevant Web pages.

Figure 2 depicts a conceptual relationship among different quantities described above.
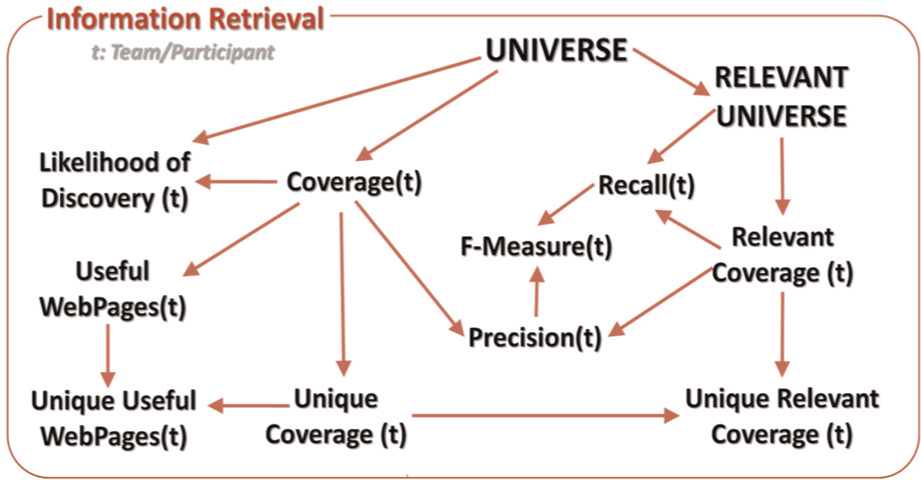
A framework for IR-focused system-based evaluation measures that includes both search and exploration activities.
4.1.3. Effectiveness
To go deeper into understanding each team’s accomplishment and effectiveness, let us look at two factors: the usefulness of Web pages; and the diversity of their search queries. To derive the usefulness of Web pages visited, we can use an implicit measure based on the dwell time on a Web page as described in White and Huang [50], which is supported by previous findings [51]. As reported in these prior works, we can consider a Web page to be useful if a participant spent at least 30 seconds on it. Using the log data, we can compute dwell time on a given Web page by a participant/team, and if it was greater than or equal to 30 seconds, mark it as useful for that participant/team. Note that we should only consider content pages, discounting any search engine homepage or search engine results pages.
Note that usefulness is different than relevance, which is based on explicit judgements (save, print, bookmark) by a user. In other words, relevance typically reflects explicit evaluation of information, whereas usefulness is a measure of implicit validation of information objects.
4.1.4. Likelihood of discovery
To evaluate effectiveness of a team/participant in discovering hard to find information, we can use a measure called likelihood of discovery proposed in Shah and González-Ibáñez [32]. Here, we assume that Web pages with a high likelihood are easier to find and are common among the majority of the users. On the other hand, those Web pages with a low likelihood are difficult to reach and probably beyond the first results page of search engines. A participant/team finding these Web pages is being more effective in discovering information that is not just relevant, but also diverse.
In order to operationalize this idea, we can use a formulation similar to that of inverse document frequency (IDF). Using the frequency of each Web page in our log data, we can compute its likelihood to be visited; in addition, we can multiply each Web page’s likelihood by −1 in order to denote the IDF. As a result, each Web page is assigned with a normalized value between −1 and 0. In this sense, those Web pages with a value close to 0 are rare (and even unique) in being reached by teams/participants, while those close to −1 are more likely to be visited.
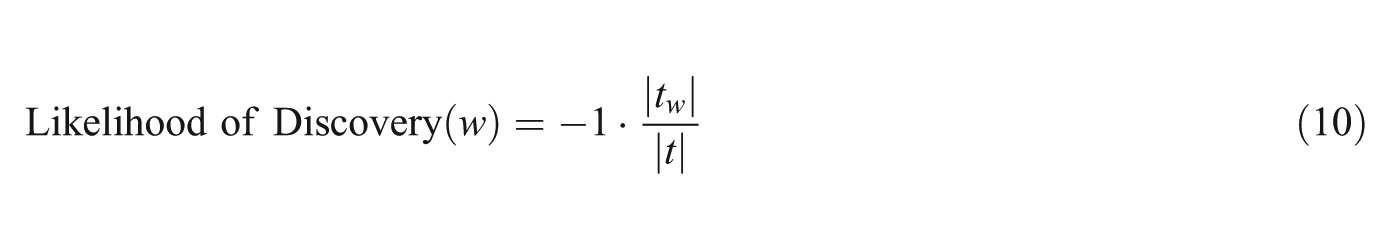
Here, |t_w| is the number of teams that discovered Web page w, and |t| is the total number of teams being studied. As we can see, the value of this measure ranges from −1 to 0, providing a quantitative sense of how difficult it is to find a Web page/resource. Note that this does not help with assessing likelihood of discovery for the Web pages that no team/participant found.
4.1.5. Diversity
In addition to the sources that teams visited during the tasks, we could also study how they approach the task in terms of the queries they issued to find information. We can study how similar or different were the queries formulated by participants in a given team. In order to evaluate query diversity, Lavenshtein distance [52] is a good choice for computing the distance between pairs of queries for each team as reported in Shah and González-Ibáñez [32]. Based on the results of this computation, for a given pair of queries, the closer the distance to 0, the higher the similarity between them. On the other hand, the higher the distance between queries, the more different (therefore diverse) were the queries formulated within a team. Query diversity calculation can be formalized as the following:
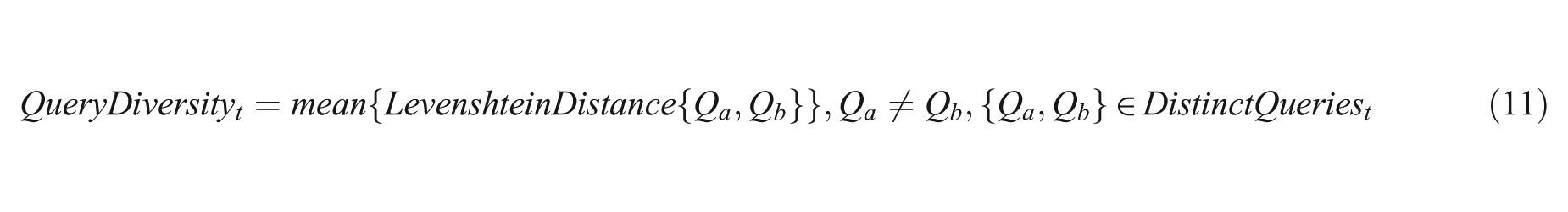
Here, Qa and Qb are any given two distinct queries in a set of queries for user/team t.
4.2. User measures
Now we will look at a number of measures that are user-focused. Common ways for collecting data for these measures are questionnaires, interviews and focus groups. These measures are primarily taken from HCI and CSCW. Specific sources are indicated while discussing each of these measures.
4.2.1. Communication
Shah [45, 61] argued that communication is one of the most essential elements of any collaboration, and certainly of CIS. Several attempts have been made in the recent years that measure various aspects of communication in a collaborative project. For instance, González-Ibáñez et al. [33, 53] described a framework to evaluate communication in CIS. This evaluation framework comprises a coding scheme and a set of measures. The coding scheme adapted from Strijbos et al. [54] consists of a group of four major categories of messages: task coordination (TC), task content (TN), task social (TS), and non-task related (NT).
The first of these categories, TC, corresponds to ‘[s]tatements involving decision making about how the task should be performed’ [33] (p. 5). The second category, TN, represents messages where participants discuss issues around the task such as topic and evaluation of sources to address the task. The third category, TS, corresponds to ‘statements that concern group functioning, effort, or attitude as well as opinions in regard to information obtained or information sources’ (p. 5). Finally, NT comprises messages with ‘a social orientation that are not related to the assignment or regarding technical issues of system being used’ (p. 5). Within each category, messages can be classified in particular subcategories such as questions, answers, control, awareness, information seeking and polarity-based classification in order to determine the affective tone of the messages.
While the above categories are broad enough to characterize a wide spectrum of communication messages, the coding scheme also includes a fifth category (non-codable) to denote messages that cannot be classified following the criteria specified in the other four categories. The procedure to code messages as described by the authors should be performed by two or more coders in order to check inter-coder reliability.
In addition to classifying messages according to the coding scheme above, the authors described a set of quantitative measures that can be used to measure the balance and effort of the interactions during the collaboration process. The first of these measures is communication volume (Vol), which corresponds to the overall number of messages issued by an individual participant p during the collaboration process. This measure is denoted by:

The second measure attempts to evaluate the effort of participants while communicating. Assuming text-based communication, González-Ibáñez et al. [33] expressed the communication effort within each minute as the sum of the individual efforts to produce each message, which was represented as the proportion between the number of words in each message and average words per minutes (wpm) that users are expected to type. This measure is expressed as follows:
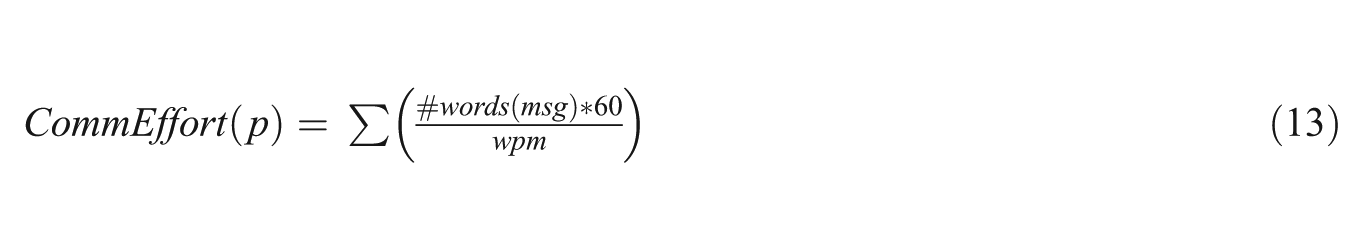
While the authors reported communication effort for the overall communication taking place in the collaboration process, this measure, as well as the measure of communication volume, can be also applied to individual categories of messages. For example, it would be possible to compute the communication volume and effort of TC, TN, TS and NT.
The authors also described a measure to investigate how communication was distributed among team members. González-Ibáñez et al. [33] referred to this measure as communication balance (B), which can be computed with respect to the volume of messages or with respect to the effort required to produce the messages. Both approaches to describing communication balance are expressed below:

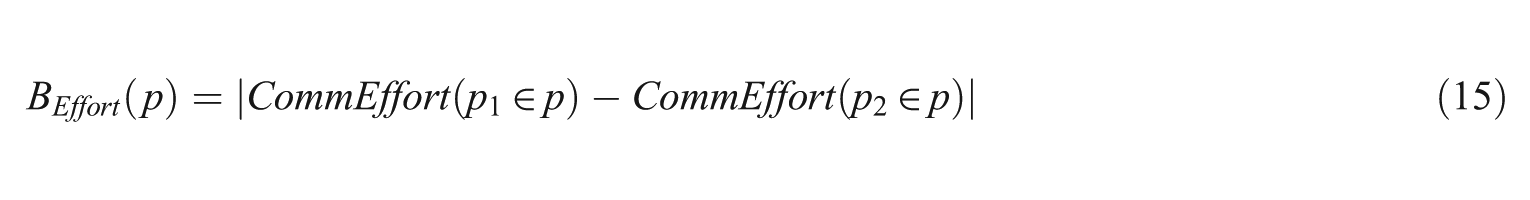
Similar to communication volume and effort, these measures can be independently computed for each message category.
4.2.2. Collaborative aptitude
Based on the principles of collaboration developed by Johnson et al. [55], Olivares [56] developed a set of questions to obtain information about a person’s collaborative background. These questions are focused on five dimensions of collaboration as presented below. The original questionnaire was designed to be responded to using a seven-points Likert scale, but one could change it to a five-point scale.
When I work in group, it is important that all the work is done by me.
If I work in group, I do everything.
When I participate in group works, it is important that everybody cooperate in order to finish them.
When I participate in a team, I cooperate in the work for finishing it.
When I work in group, it is important that everybody make sure to do the tasks they were given.
When I work in group, I make sure to do the tasks that were given to me.
When a member of the group make their tasks, it is good for the whole group.
When I do my part in a group work, it is good only for me.
When group members make sure of performing their tasks, it is good only for them.
When I do my part in a group work it is good for the rest of the team.
When I work in group, if something goes wrong I am the only one responsible.
When I work in group, if something goes wrong the others are responsible for everything.
When I work in group, if something goes wrong all of us are responsible for that.
When I work in group, if the work ends well, I am the only one responsible for that.
When I work in group, if the work ends well, all of us are responsible for that.
When I work in group, it is important to know what tasks have to be performed by each of us.
When I work in group, I am aware of the tasks that my mates have to perform.
When I work in group, it is important congratulate others for what they do well.
When I work in group, I congratulate others when they do their tasks well.
When I participate in a group and others congratulate me for my work, I feel more confident of what I do.
When I work in group, I care that others tell me that I am doing well.
When I work in group, I tell to my mates when they do something well.
When I work in group, it is important to provide help to my mates when they make mistakes or when they do not know what to do.
When I work in group, I provide help to my mates if they make mistakes or if they do not know what to do.
When I work in group, it is important to receive help from others if I have problems in solving something.
When I work in group, I am capable of receiving help from my mates for solving some problem.
When I work in group, it is important to agree and coordinate.
When I work in group, I agree with my mates on dividing the work and coordinating.
When I work in group, it is important that each member has a defined task assigned.
When I work in group, we define tasks for each group member.
When I work in group, it is important to feel like doing the task.
I like to work in a group.
When I work in a group, it is important to talk about the things we have done and also about the things that remain for finishing the work.
When I work in group, we meet to talk about the things we have done and also about the things that remain for finishing our work.
When I work in group, it is important to express my opinion about the things that my mates are doing.
When I work in group, I provide ideas and also I comment about my mates’ work.
When I work in group, it is important to review if we are doing well our work and redistribute tasks if necessary.
When I work in group, we review how we are doing our work and if something goes wrong we exchange tasks.
4.2.3. Usability
Almost any interface-driven system is likely to employ usability measurements for evaluation that involves actual users. Evaluating usability typically involves measuring ease of learning, ease of use and user satisfaction [55]. It is also common to measure things like effectiveness (typically of accomplishing the task) and efficiency (of the user doing a task). Here we will look at some of the popular instruments used in the literature for measuring various usability aspects during a user study.
Often questions about ease of learning, ease of use and user satisfaction are combined in one questionnaire. For instance, the participants can be asked to rate (scale 1–5 or 1–7 is most common) several factors about the system at the end of each session, as shown in the following set of questions. The questionnaire was derived from the original Computer System Usability Questionnaire [57], 2 removing those questions that were not relevant for CIS evaluation. Responses to these questions shed light on their perceived ease of use and satisfaction:
Q1. Overall, I am satisfied with how easy it is to use this system.
Q2. I can effectively complete my work using this system.
Q3. I am able to efficiently complete my work using this system.
Q4. I feel comfortable using this system.
Q5. It was easy to learn to use this system.
Q6. I believe I became productive quickly using this system.
Q7. It is easy to find the information I need.
Q8. The information provided for the system is easy to understand.
Q9. The organization of information on the system screens (toolbar, sidebar) is clear.
Q10. The interface of this system is pleasant.
Q11. I like using the interface of this system.
Q12. This system has all the functions and capabilities I expect it to have.
Q13. Overall, I am satisfied with this system.
4.2.4. Cognitive load
The mental effort or cognitive load is typically measured using a questionnaire derived from NASA’s Task Load Index, 3 which can be presented to each participant at the end of every task. This questionnaire is a subjective workload self-assessment test [44]. The test consists of six questions and seven-point scales that are used to provide the responses. Each point in the scale is subdivided in three increments representing low, medium and high estimates. As a result, the overall scale has 21 gradations.
Q1. How mentally demanding was this task? (Very low to Very high)
Q2. How physically demanding was this task? (Very low to Very high)
Q3. How hurried or rushed was the pace of the task? (Very low to Very high)
Q4. How successful were you in accomplishing what you were asked to do? (Perfect to Failure)
Q5. How hard did you have to work to accomplish your level of performance? (Very low to Very high)
Q6. How insecure, discouraged, irritated, stressed and annoyed were you? (Very low to Very high)
4.2.5. Engagement
Since we are studying interactive collaborative activities, it is important to consider the level of users’ engagement through these interactions. In order to measure this, we can ask each participant to individually fill in a questionnaire at the end of the study. This questionnaire was taken from Ghani et al. [58], and consists of questions relating to perceived engagement with the system and the collaborative project. Note that the scale here is for 1–5, but one could make it 1–7.
Using the system was …
Q1. Uninteresting … Interesting
Q2. Not enjoyable … Enjoyable
Q3. Dull … Exciting
Q4. Not fun … Fun
How did you feel while collaborating with this system?
Q5. Not absorbed intensely… Absorbed intensely
Q6. Attention was not focused … Attention was focused
Q7. Did not concentrate fully … Concentrated fully
Q8. Not deeply engrossed … Deeply engrossed
For a more recent work on a comprehensive framework that allows one to measure engagement in user-driven process, the reader is referred to O’Brien and Toms [5].
4.2.6. Awareness
In addition to measuring their perceived awareness about the project, direct questions related to various aspects of situational self-awareness, derived from Govern and Marsch [59], can be asked as shown below for the participants to rate. See Shah and Marchionini [40] for an example of how these questions can be used and their responses are interpreted.
Q1. Right now, I am keenly aware of everything in my environment.
Q2. Right now, I am conscious of what is going on around me.
Q3. Right now, I am conscious of all objects around me.
Q4. Right now, I am concerned about what my teammate thinks of me.
Q5. Right now, I am aware of what my teammate just did.
Q6. Right now, I am conscious that my teammate is aware of my actions.
Q7. Right now, I am aware of how well we performed together in the team.
4.2.7. Affects/emotions
Measuring emotions or affective dimension in a CIS process could be an important part of gaining a comprehensive understanding of the given CIS project and the collaborators involved. There are several methods that we could obtain from psychology and sociology fields. An example is the Positive and Negative Affect Scale [36]. This instrument asks users to rate how they are feeling at the moment along 20 different emotional dimensions (see below) using five-point scale (Very slightly or not at all, A little, Moderately, Quite a bit, Extremely).
Interested
Ashamed
Guilty
Jittery
Irritable
Upset
Determined
Enthusiastic
Distressed
Inspired
Scared
Active
Alert
Strong
Attentive
Proud
Excited
Nervous
Hostile
Afraid
See Wilson and schraefel [16] for an example of how such an instrument can be used to study CIS.
5. Conclusion
Evaluation is one of the important (and perhaps the most difficult) issues of any methodology in general, and certainly for empirical research specifically. Often, reviews are written in the literature that point out strengths and weaknesses of current approaches for evaluation. For instance, Saracevic’s reviews on evaluations in IR [63, 64] outline how various approaches to measurement in IR have evolved and what are they still lacking. Since many of the evaluations used for CIS come from IR literature, the same strengths and limitations apply.
To make matters more complex, CIS is much more than simply retrieving information in collaboration. Specifically, as we saw in this article, one needs to pay attention to aspects of information seeking including information coverage, synthesis and sense-making, as well as aspects of collaboration including communication, collaborative aptitude and collaborative load. Beyond these measures, one may need to consider various personal and social aspects of human information behaviours, including awareness and engagement. Finally, as one considers CIS as mediated by systems, one may need to measure interaction-related aspects, including ease of use and ease of learning with regard to the system, and user satisfaction.
The current article presented some of the relevant approaches to CIS evaluation (synthesis), along with specific lessons and guidelines derived from them (suggestions). Finally, an attempt was made to present a framework for CIS evaluation (structure). This framework incorporates system-based as well as user-focused measures, and can be applied to a wide range of CIS studies, including simulations, user studies and field experiments.
There are, however, some limitations. First, the framework has implicit assumptions about information (seen as object) and collaboration (explicitly defined, interactive, mutually beneficial and mediated by a system). Second, much of the framework, especially the system side, assumes information seeking done in online environments. Finally, the framework does not implicitly support space (co-located vs remote) and time (synchronous vs asynchronous) dimensions associated with various measures. These limitations could be overcome by extending the proposed framework in those missing dimensions and by relaxing the assumptions, albeit with additional complexity to it.
In the end, the decision to use – partially or fully – or extend this framework comes down to the context and the goal for evaluation. We hope the guidelines and the framework presented here at least serve as the starting points for those conducting research in CIS and related areas.
Footnotes
Acknowledgements
The author is grateful to Roberto González-Ibáñez for contributions to several elements of the evaluation framework described here, and Emily LaBeaume for helping with a portion of the literature review presented in this article.
Funding
This work was supported by The Institute of Museum and Library Services (IMLS) Early Career Development grant # RE-04-12-0105-12.