
Abstract
Linking a learning dataset to useful information on the Web of Data enriches its learning resources, as it enhances learners’ knowledge. This enrichment is usually achieved by creating links between datasets using the interlinking tools, which facilitate connecting any kind of data in a semi-automatic manner. This paper evaluates the interlinking results between an e-learning repository and several educational datasets on the Web of Data, which leads to enrichment of the contents. Many related resources were discovered during this experimentation already matched to the GLOBE learning objects. Furthermore, this research presents a data model to find similarity between two datasets and a workflow to identify the duplicate resources by performing a semi-automatic evaluation process. A case study was also assessed by human experts.
1. Introduction
The Semantic Web, as a collaborative movement led by the World Wide Web Consortium (W3C), promotes common data formats for publishing data on the World Wide Web. The aim of Semantic Web is to convert the current Web, dominated by unstructured and semi-structured documents, into a ‘Web of Linked Data’. It also facilitates the sharing and availability of different kinds of information on the Web. In particular, the Linked Data approach [1] has emerged as the de-facto standard for integrating data on the Web. It offers significant potential to tackle the interoperability issues in different contexts. In an e-learning context, for example, Linked Data enhances the discovery of Open Educational repositories contents established by the educational institutions [2] and connects the learning objects to useful knowledge on the Web [3, 4]. Data connectivity in Linked Data is performed by providing RDF links between two entities – so-called interlinking.
The Linked Data applications have also facilitated data enrichment by applying several techniques for automatic and intelligent linking. In particular, an interlinking tool establishes links between different datasets on the Web by discovering similarities among their entities. It also helps data publishers to connect their contents to useful datasets. In this paper, we evaluate the outcomes of an interlinking approach on a large learning repository, Global Learning Objects Brokered Exchange (GLOBE) [5], by applying a promising interlinking tool. It connects the GLOBE resources to 20 educational datasets in the LOD cloud. We also assess the matched links to answer the following research questions:
How are the GLOBE resources distributed in each target dataset and which datasets include more similarities with GLOBE?
What are the benefits of this interlinking when a large learning dataset is linked to several educational datasets on the Web?
How can the related and duplicate resources be identified by applying the interlinking approach?
The rest of the paper is structured as follows. Section 2 describes the importance of interlinking on the Web of Data and outlines the current studies in this context. In Section 3, we will present the proposed approach for interlinking and finding the duplicates. Section 4 will discuss the interlinking results and evaluate the approach using a case study. Finally, conclusions are presented in Section 5.
2. Background and related work
Interlinking tools perform the creation of links semi-automatically and connect two datasets using different kinds of links (e.g. owl:sameAs) by similarity discovery among the entities. Most of these applications follow a similar routine to carry out the interlinking process. For example, in Silk [6], a user should set the following information to run the tool:
source and target datasets;
source and target entities (e.g. resource title in the source dataset to book title in a library);
criteria under which two entities are matched.
Given the criteria above, the software discovers similarities between pairs of entities and generates a set of results. Several studies have been undertaken in recent years to investigate the interlinking issues in the Linked Data context. Simperl et al. [7] have compared various linking tools by addressing the important aspects such as required input, resulting output, considered domain and matching techniques used. This comparison was applied from two specific perspectives: degree of automation (to what extent the tool needs human input) and human contribution (the way in which users are required to do the interlinking). Scharffe and Euzenat [4] also proposed a framework for data interlinking applied in different systems in which several linking tools were discussed. In a technology-enhanced learning context, Dietze et al. [3] documented an approach for interlinking educational resources based on the Linked Data principles [1] and exploiting the abundance of existing data on the Web. Several Linked Data projects such as LinkedUp [8] and Linked Education [9] have also been aimed at advancing the exploitation of the vast amounts of public, open data available in an educational context. In another empirical study, Rajabi et al. [10] applied two matching techniques to interlink a semi-structured dataset to the Web of Data and discussed the generated results in details. In the context of Open Educational Repositories, Piedra et al. [2] applied the Linked Data principles to interoperate and mash-up data from distributed and heterogeneous repositories of open educational materials. The same author, in another study [11], leveraged the principles of Linked Data to enhance the discovery of Open Course Ware (OCW) contents created and shared by the universities. The authors also developed a query method to access the OCW data using linked data techniques and linked the contents to the LOD cloud.
The aforementioned studies have demonstrated that several fundamental works have been carried out in this direction and data publishers can trust the interlinking tools to interconnect their contents to other datasets [12]. However, none of the mentioned studies investigates an interlinking approach between an educational repository and several e-learning datasets on the Web of Data. Furthermore, they do not mention duplicate identification amongst the interlinking results. Following our previous studies [10, 12, 13], we extended our approach on 20 educational datasets on the Web and scrutinized the results to discover the duplicate resources among the educational datasets.
3. Experimental setting
The GLOBE repository [5], which includes around 1 million learning object metadata [14], was selected as our source dataset. To examine the GLOBE resources and for the sake of exposing them as RDF [15], we harvested around 830,000 learning metadata from this repository and imported them into a relational database to analyse its metadata effectively and select the best possible elements for interlinking. All harvested files were in XML format based on IEEE LOM schema [16]. As we will discuss later, the candidate elements of GLOBE metadata were selected and exposed as RDF. On the other hand, we collected a set of educational datasets on the Web of Data and prepared several queries to retrieve their available elements for interlinking. Finally, we carried out the interlinking between GLOBE and the selected educational dataset using an appropriate tool.
In a previous study [12], we evaluated several interlinking tools on the Web of Data and demonstrated that LIMES [17] is a promising tool in this context. In LIMES, a user specifies the endpoints of datasets, comparable entities and thresholds of acceptance of output. When a threshold is set to 0.98, for example, it means that two concepts are considered to be matched if their syntax similarity is more than 98%. The tool runs a number of matching techniques and reports the results to the user based upon the configuration and similarities between the two datasets. Figure 1 depicts the workflow we followed to perform the interlinking process, as we explained above. In brief, we used LIMES to interlink GLOBE to 20 datasets in the LOD cloud and analysed the results by writing a program. In the following subsections we will describe the analysis of the GLOBE metadata elements and target datasets.

Workflow of proposed approach.
3.1. Source dataset
We categorized the data types applied by the GLOBE metadata in Table 1 along with some examples. From the interlinking point of view, most of the elements cannot be used in the interlinking as they include ‘Dates’, ‘Boolean’ or controlled vocabularies. Focusing on the elements usage by the GLOBE resources, we realized that more than 90% of resources applied local values (e.g. identifiers), controlled vocabularies (Lifecycle.Status) and language codes, while the title of learning objects (General.Title) was highly used (97%) and more than half of the GLOBE resources included Keyword (61%) and Classification elements (59%) in their metadata. It should be noted that the Coverage element was only used by 7% of resources. As we discussed in the previous study [10, 13], four metadata elements including title (‘General.Title’), coverage (‘General.Coverage’), keywords (‘General.Keyword’) and classification taxonomy (‘Classification.Taxon.Entry’) were identified as candidate elements for interlinking.
LOM elements data type and sample values
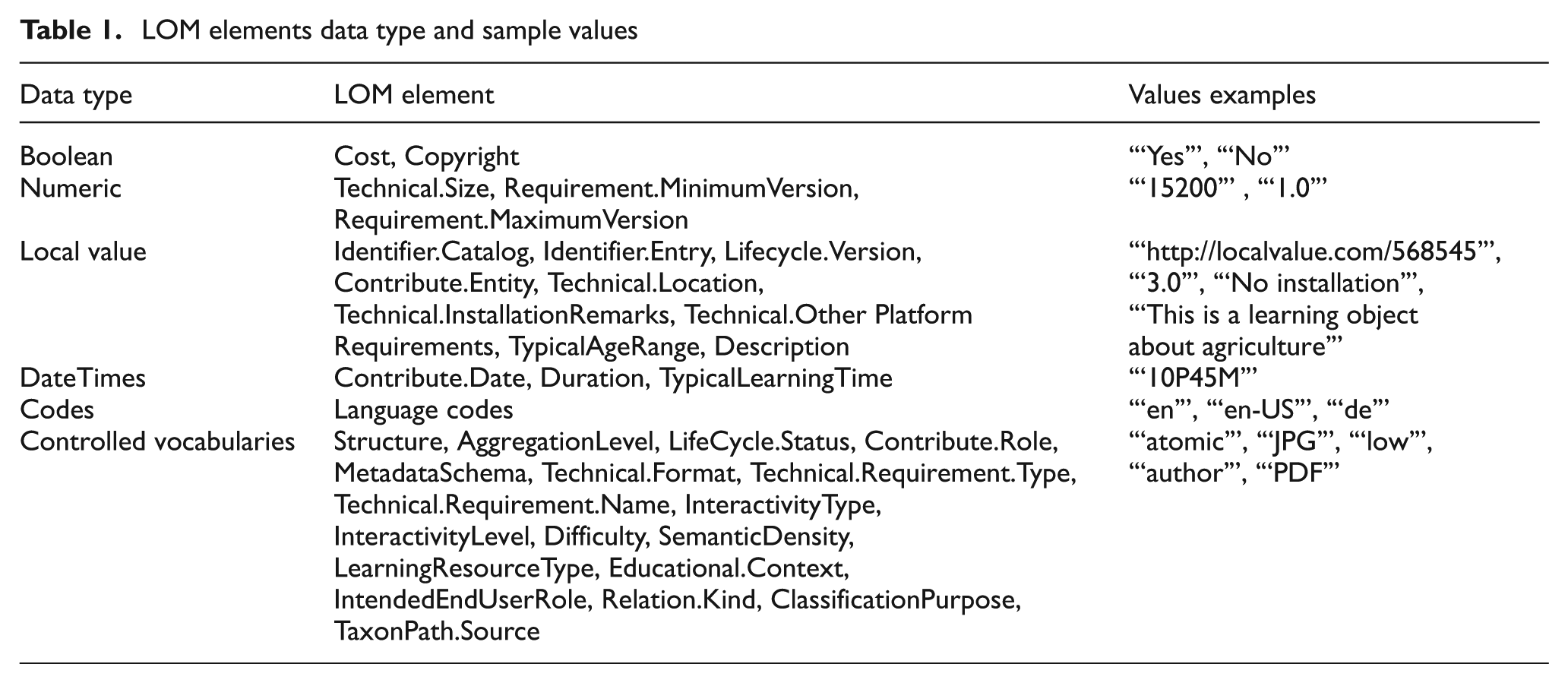
Given that the most prominent language of resources in GLOBE is English [14] and for the sake of manual evaluation of results by human experts, we selected those resources that provided the candidate elements in English language. Bearing this in mind, around 53% of GLOBE included English titles, while there were more than 1.6 million English keywords used by 38% of GLOBE (consider Figure 2). Regarding the other candidate elements, only 2% of GLOBE resources provided the Coverage element and 22% (around 176,000 resources) of taxonomy of learning objects were in English language. Having the selected elements for interlinking, we exposed the selected elements as RDF using a mapping service (D2RQ [18]) for mapping data to RDF and carrying out the interlinking afterwards.
GLOBE elements in English language.
3.2. Target datasets
To find appropriate targets for interlinking, we investigated several educational datasets in the LOD cloud. From a technical perspective, both source and target datasets should include either a SPARQL endpoint or an RDF dump. At first glance, it is obvious that most of the educational datasets lack any specific endpoint or RDF dump. Examining the datasets’ endpoints illustrated that most targets were not accessible at the time of this research. Finally, we could collect 20 educational datasets who responded to the queries or included an RDF dump to download. Afterwards, we calculated the size of each dataset using SPARQL queries. Appendix 1 illustrates the size of datasets (in triples) along with their full name. Amongst candidate datasets, ‘Charles University of Prague’ with more than 93 million triples of publications, was the biggest dataset. ‘Key Information Sets’ (UNISTAT-KIS), which includes a set of information about full- or part-time undergraduate courses, was the second one found in this context, with more than 8 million triples.
3.3. Interlinking process
When running the LIMES tool, the output is a number of links in RDF (N-TRIPLE format) that connects source and target entities using the sameAs relationship. Appendix 2 illustrates a sample output generated by the tool that indicates that seven GLOBE resources were linked to 10 resources in the OpenUK dataset. As can be seen, four GLOBE resources were linked to more than one target resource, and three resources in OpenUK matched to more than one resource in GLOBE.
Figure 3 depicts the data model we followed to find similarities between two datasets. In this model, we showed each dataset along with its properties as entities and the similarities between datasets as relationships. Each dataset has a title, endpoint URI, size and other specifications as attributes. It may include many entities and have many similarities to other datasets. The similarity relationship may have different attributes itself for finding the related resources in two datasets. We will apply another workflow after the interlinking later in this paper.
Similarity data model.
It should be highlighted that throughout this study we used JAVA programming language, because of the many advantages that this programming environment provides, including various libraries (e.g., JSON, SET, Jena) in both analysis and Linked Data contexts. Figure 4 depicts the procedure we followed to perform the following tasks in our study:
find the GLOBE resources linked to each target dataset;
discover the total number of resources in GLOBE linked to all targets.
Workflow of finding linked resources in targets.
To address the first goal, we used a set, as a distinct list of elements, to remove the duplicates in both source and target datasets. In some of the outputs, we had to split the file into several small ones, as the size of file was more than 1 Gb (as it included a million records) and the program could not process them with the available hardware resources. To achieve the second goal, we used the same approach extended for all datasets. In particular, the program retrieved the GLOBE resources in each output and added them to a final set to calculate the total number of resources overall. Appendix 2 illustrates the final output of LIMES result after running it against GLOBE and 20 educational datasets.
4. Discussion and results
As mentioned earlier, we used LIMES as the interlinking tool, to connect the candidate metadata elements (Title, Keyword, Taxon and Coverage) to the LOD datasets. Here, we categorize the results in four sections and present an analysis for each one.
4.1. Interlinking GLOBE elements to educational datasets
Figure 5 illustrates the interlinking results between GLOBE resources and the selected datasets. Figure 6 also depicts the GLOBE resource distribution among the target datasets. Below we report each element analysis in detail.
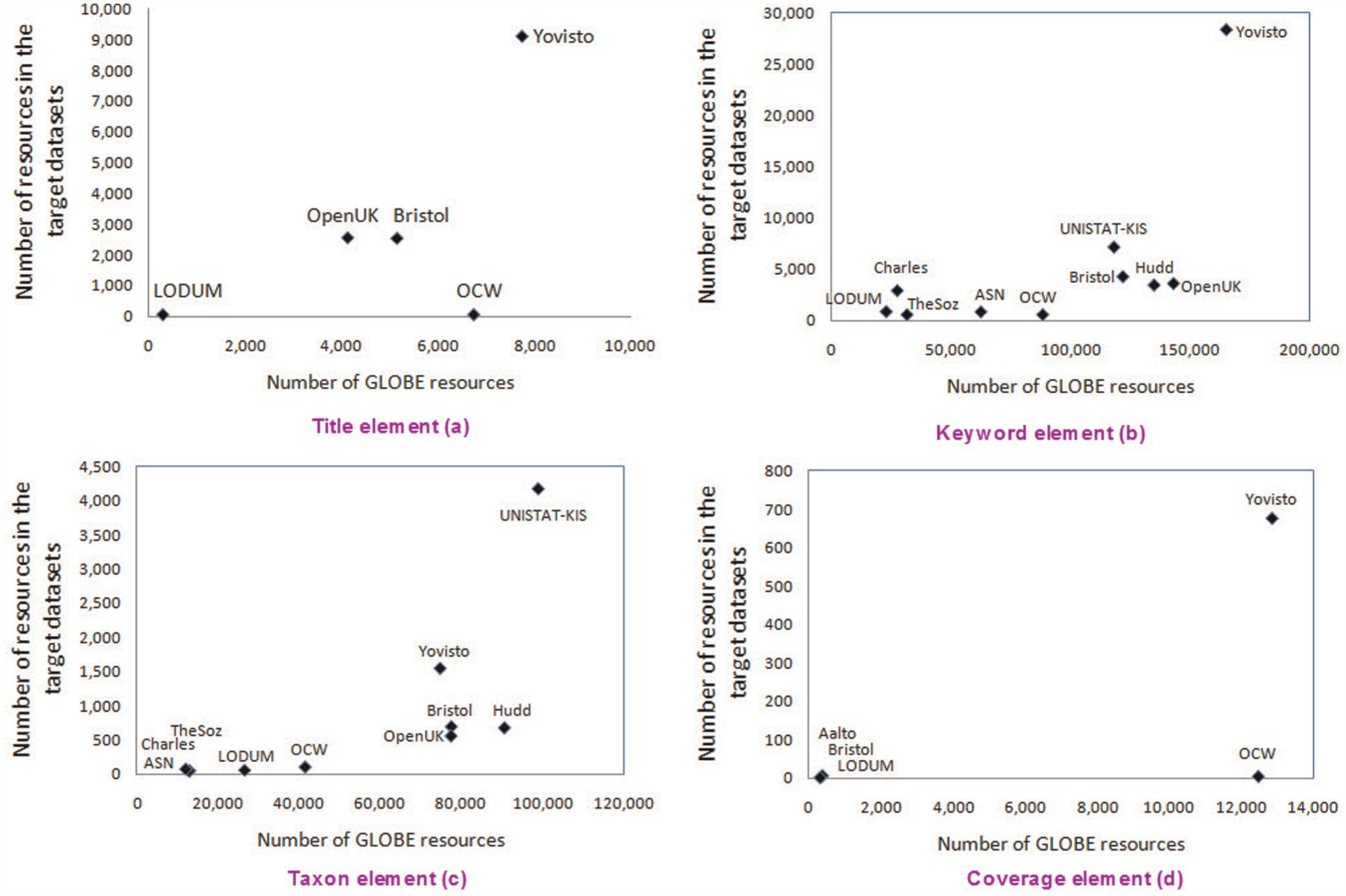
Interlinking results between GLOBE and target datasets based on four elements in GLOBE.
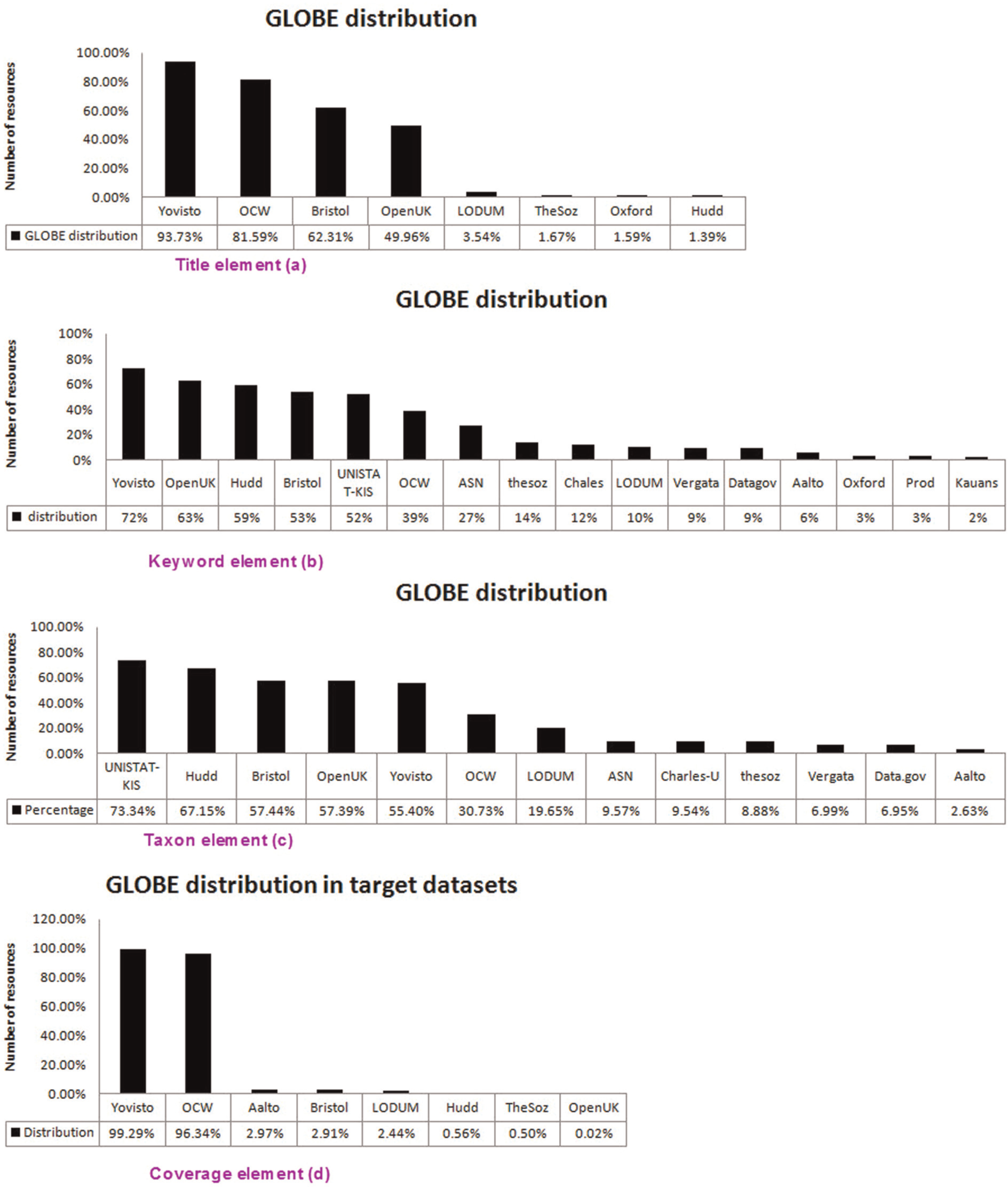
GLOBE resources distributions among target datasets over each element.
4.1.1. Title element
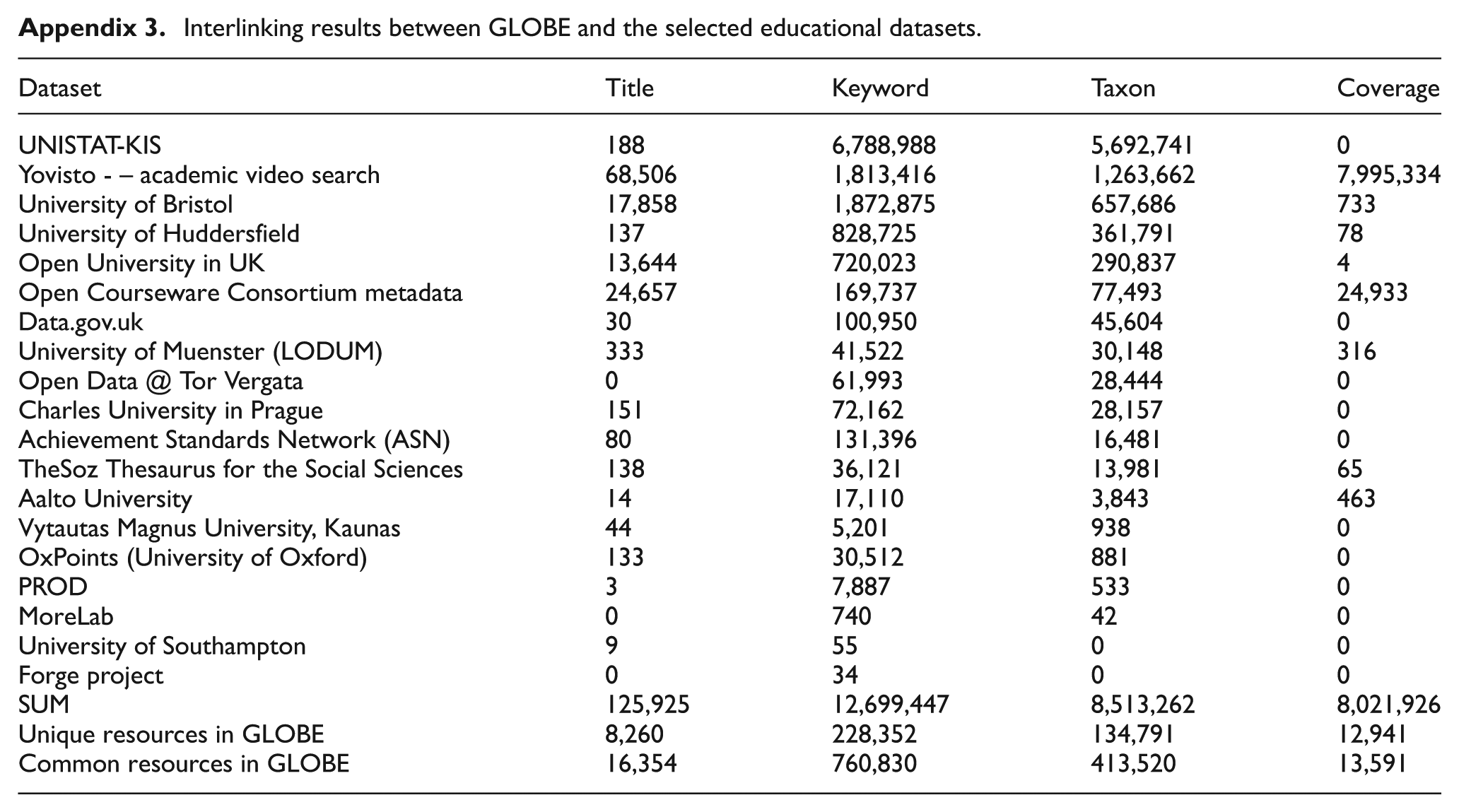
Figure 5 (a) depicts the interlinking results for the top five datasets with high similarities to the ‘title’ element. The x-axis in the figure refers to the number of GLOBE resources matched to the target dataset, while the y-axis shows the number of resources in the target dataset. In particular, Yovisto, with around 9117 resources, followed by OCW (the Open Course Ware consortium) and University of Bristol, had the greatest similarity to GLOBE. There were also 4127 resources in GLOBE connected to 2560 learning objects in The Open University of the UK, with around 13,600 matched links overall (see Appendix 3).
In total, five datasets (Data.gov.uk, Forge project, Semantic ISVU, MoreLab and Vergata) did not have any similarity with GLOBE. Table 2 also shows two GLOBE resources connected to several resources in the target datasets in which, for example, one resource about ‘Nuclear Energy’ matched three different datasets (ASN, Bristol and Huddersfield) specified with their URIs.
A sample of GLOBE titles matched to several resources

Analysing the interlinking outputs, we found that only a small number of GLOBE resources (around 24,000 overall) matched the target datasets through the title element. This result indicates that finding similarities for large texts is difficult for interlinking tools, as the resource titles in GLOBE mostly (around 83% of all English titles) include at least two words (e.g. ‘Alternating Current Circuits’). Also, we realized that there were around 16,000 resources in GLOBE linked to at least two target datasets and 8260 resources linked to all of them. Figure 6(a) depicts the distribution of GLOBE resources among the target datasets (with more than 1% GLOBE distribution).
4.1.2. Keyword element
In the case of the Keyword element, the range of acceptance reported by LIMES was far larger than the title element (Section 4.1.1), as only one dataset (Semantic ISVU) did not have any similarity to any keywords. As mentioned earlier, there were more than 1.6 million English keywords in GLOBE ranging from science in education to environment literature. The large number of generated results for the Keyword element may refer to the fact that more than 50% of these keywords include exactly one term and 33% contain two words, which helps an interlinking tool to discover more similarities. As it can be seen in Figure 5(b), we observed that only one dataset (UNISTAT-KIS) had more than 6.7 million links to GLOBE (around 118,000 GLOBE metadata to 7166 resources in the target datasets).
Analysing the results, we realized that around 228,000 resources in GLOBE (74%) were matched to the target datasets and there was also a large amount of resources (almost 760,000) in common among all the results. Figure 6(b) shows the distribution of GLOBE resources among the target datasets in which Yovisto (an academic video search), the Open University of the UK and the University of Hudders field were the most referred datasets.
4.1.3. Taxon element
Most of the taxonomies of learning objects in GLOBE included terminologies in one or two words and referred to the classification of resources. In particular, around 60% of taxonomies in GLOBE contained only one word and almost 25% of them included two words ranging from science to historical concepts. As Figure 5(c) shows, around 99,000 resources in GLOBE were identified by LIMES and matched to more than 4000 resources in the UNISTAT-KIS dataset, followed by the University of Huddersfield (with 90,512 GLOBE resources) and the University of Bristol (with 77,420 GLOBE resources). Overall, only two datasets did not link to GLOBE and around 135,000 resources (76%) were connected to one or more datasets. Figure 6(c) also illustrates 13 datasets with more than 1% resource distribution in GLOBE, of which the UNISTAT-KIS dataset and the University of Huddersfield included the highest similarities to the GLOBE resources through the Taxon element.
4.1.4. Coverage element
As Figure 5(d) illustrates, eight datasets could link to GLOBE, but mostly with small numbers of results. Yovisto, as an exception, was connected to 13,000 GLOBE resources with 676 resources (with around 8 million links). There were also around 12,941 (78%) resources in GLOBE linked to all the target datasets (mostly to Yovisto and OCW). It should be highlighted that most of the matched terms referred to geographical places and countries. Figure 6(d) also shows that the references to Yovisto and OCW datasets were distributed throughout most of the GLOBE resources via the Coverage element.
4.2. Human evaluation of the interlinking results
As we discussed earlier, the interlinking tool reported a set of records as an output with similar values in the source and target datasets. For example, the term ‘Photosynthesis’ was the title of a learning object in the ASN dataset (http://www.pbslearningmedia.org/resource/tdc02.sci.life.stru.photosynth/photosynthesis/) and the GLOBE repository (http://ariadne.cs.kuleuven.be/finder/globe/?query=Photosynthesis). However, the question under discussion is to what extent these learning resources are semantically matched or related. To this aim, we reviewed the generated results to discover an appropriate target and evaluate the outputs manually. In the manual evaluation, we focused on duplicate and related resources, as we will discuss in the following sections.
4.2.1. Duplicate resources
As Figure 7 depicts and according to the data model proposed in Section 3.3, a workflow is presented for finding the duplicate resources. Having the interlinking results, we retrieved the other metadata elements including URI and description of learning objects from datasets after identifying their metadata schema (e.g. dcterms in Open UK). This task was carried out using the SPARQL queries. In the next step, we analysed the value of metadata elements. In particular, if the actual URIs of resources in both datasets point to the same internet address, they are proposed as duplicate resources. In the case of unavailability of URIs, the duplicate finding is focused on the descriptions of learning resources and analysing their values using the text-matching functions. If both resources have high similarities in their descriptions, they can also be presented as duplicates.
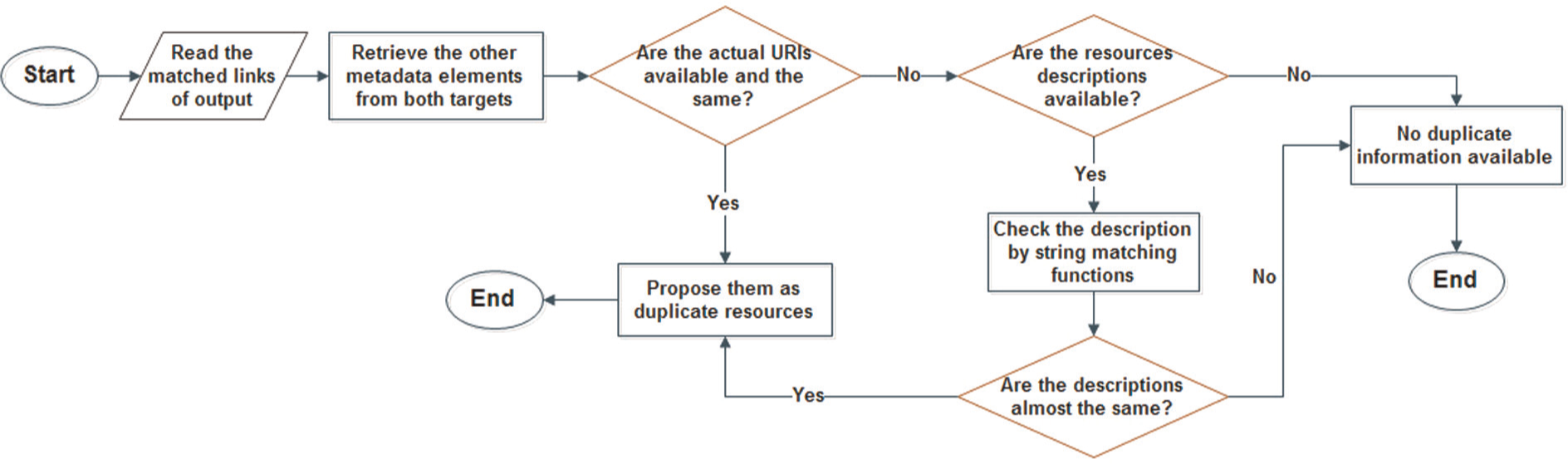
Duplicate finding workflow.
4.2.2. Related resources
From a technical perspective, if no similarities exist among the other metadata elements, the evaluation is continued on exploring the actual address of the resource (URI) where the learning object exists. This helps a domain expert to identify the relatedness of two resources semantically by exploring the content. Moreover, the other metadata elements of linked resources (such as description or subject) might be different in syntax, but an expert identifies them as related resources conceptually owing to their content similarity. As an example in our case study, a course about ‘Latitude and Longitude’ in Text/HTML format in GLOBE linked to a resource in the target dataset, but in another format (sound recording), which means that a human expert can identify their relatedness as well.
4.2.3. Case study
As a consequence of evaluating the records and given that the human evaluation of links manually requires significant effort, we selected the results between GLOBE and the Open University of the UK (OpenUK) on the title element as our case study by taking the following notes into account:
Interlinking results usually include two identifiers which usually point to the internet addresses. Given that the resource identifiers were not implemented properly in some cases or they might be broken, we selected those that followed the good URIs [19].
Despite providing available URIs, the metadata schema should be rich enough so that an expert can compare the information in both targets. For example, the target metadata in some cases included only three elements (title, format and subject), which is insufficient for the evaluation.
Nevertheless, the learning object metadata in OpenUK had an acceptable quality, as most of the resources included an accessible URI and a well-formed schema with a clear description. Following the proposed approach presented in Section 4.5.1, we realized that none of them pointed to the same address on the Web, but the matching analysis showed that they referred to the same learning object published by different data providers. According to our analysis, 374 resources (out of 4127) in GLOBE were identified as duplicate resources with OpenUK. Turning to the related resources, we selected 300 records of the non-duplicate results and realized that around 246 (82%) of them were semantically related to each other. Also, 48 resources (16%) were not accessible as the URLs were broken or unreachable, and the rest (2%) were not semantically the same (false positive). Notably, we found two resources about ‘functions’ but in two different contexts and thus we could not categorize them as related.
To justify the proposed approach, we asked two experts to follow the workflow (Figure 7) and evaluate a set of resources that we had marked as duplicates. To this aim, we randomly selected 20 resources (out of 374) from the results and asked the experts to assess the resource URLs along with the other metadata elements by following the proposed instruction. On receiving the experts’ responses, we applied the kappa measure of agreement to analyse the agreement between the observers and gauge the reliability of the responses. The maximum value of kappa is 1, which represents perfect agreement, and kappa will take the value 0 if there is only chance agreement. We later imported the experts’ input to SPSS19 and analysed the measure of agreement of results. The output of the software was valid and equal to 0.828, which demonstrates that the experts strongly agreed on the results. A closer look at the responses given by the raters indicates that most of the resources were marked as duplicates (rater 1 with 17 and rater 2 with 16 resources). The experts could not also judge the rest of resources owing to insufficient information in their metadata.
5. Conclusions
The purpose of this research was to evaluate the results of interlinking between a large learning dataset (GLOBE) to educational datasets in the Web of Data. After analysing the GLOBE metadata and selecting appropriate elements for interlinking, we applied a tool to interlink GLOBE to 20 educational datasets on the Web and evaluated the generated results. In conclusion, we outline the implications of this study as follows:
Interlinking a learning repository to several educational datasets in the LOD cloud leads to the enrichment of content, as this approach links one e-learning resource to several other resources in different datasets on the Web.
Evaluating the results of interlinking among the candidate elements of GLOBE demonstrates that the semantic accuracy of matched links for the Title element was higher than the Keyword and Taxon elements, although the distribution of GLOBE resources for this element was minor. Furthermore, the high percentage of GLOBE contribution in a few datasets for the Coverage element indicates that connection of this element to geographical datasets like Geonames or Factbook is appropriate. However, around 93% of GLOBE resources did not provide this element in the metadata.
Apart from resource enrichment, one of the other benefits of an interlinking process is duplicate identification. Our examination on a set of resources illustrates that several resources are published by different data providers and point to different internet addresses on the Web, although they refer to the same learning resource. We carried out this identification by proposing a data model along with a workflow in which we compared the other metadata elements retrieved from both targets after performing the interlinking process.
Footnotes
Appendix
Interlinking results between GLOBE and the selected educational datasets.
| Dataset | Title | Keyword | Taxon | Coverage |
|---|---|---|---|---|
| UNISTAT-KIS | 188 | 6,788,988 | 5,692,741 | 0 |
| Yovisto - – academic video search | 68,506 | 1,813,416 | 1,263,662 | 7,995,334 |
| University of Bristol | 17,858 | 1,872,875 | 657,686 | 733 |
| University of Huddersfield | 137 | 828,725 | 361,791 | 78 |
| Open University in UK | 13,644 | 720,023 | 290,837 | 4 |
| Open Courseware Consortium metadata | 24,657 | 169,737 | 77,493 | 24,933 |
| Data.gov.uk | 30 | 100,950 | 45,604 | 0 |
| University of Muenster (LODUM) | 333 | 41,522 | 30,148 | 316 |
| Open Data @ Tor Vergata | 0 | 61,993 | 28,444 | 0 |
| Charles University in Prague | 151 | 72,162 | 28,157 | 0 |
| Achievement Standards Network (ASN) | 80 | 131,396 | 16,481 | 0 |
| TheSoz Thesaurus for the Social Sciences | 138 | 36,121 | 13,981 | 65 |
| Aalto University | 14 | 17,110 | 3,843 | 463 |
| Vytautas Magnus University, Kaunas | 44 | 5,201 | 938 | 0 |
| OxPoints (University of Oxford) | 133 | 30,512 | 881 | 0 |
| PROD | 3 | 7,887 | 533 | 0 |
| MoreLab | 0 | 740 | 42 | 0 |
| University of Southampton | 9 | 55 | 0 | 0 |
| Forge project | 0 | 34 | 0 | 0 |
| SUM | 125,925 | 12,699,447 | 8,513,262 | 8,021,926 |
| Unique resources in GLOBE | 8,260 | 228,352 | 134,791 | 12,941 |
| Common resources in GLOBE | 16,354 | 760,830 | 413,520 | 13,591 |
Funding
The work presented in this paper has been part-funded by the European Commission under the ICT Policy Support Programme CIP-ICT-PSP.2011.2.4-e-learning with project no. 297229 ‘Open Discovery Space (ODS)’ and INFRA-2011-1.2.2-Data infrastructures for e-Science with project no. 283770 ‘AGINFRA’.