
Abstract
XML has become the dominant standard for data exchange and representation on the Web. The Relational Database (RDB) possesses is widely used as a storage and retrieval medium in the business field. With the expanding utilization of XML data on the Web, the size of this data type has increased rapidly, and more complicated queries are issued by users through this data. This expansion has prompted numerous researchers to propose various approaches in managing XML data through RDB. In this study, the most cited and the latest model-mapping approaches are reviewed in terms of the description, the technique used and the RDB schema produced using each approach. The limitations of these approaches are discussed, in terms of the storage space and query response time. At the end of this study, a solution to these limitations is proposed. It is hoped that this paper will give some insight into storing XML documents in RDB schema and contribute to the XML community.
1. Introduction
The World Wide Web is an important medium used by many people for numerous daily activities, such as e-management, e-learning, e-mail, e-library and e-business. A number of enterprises are collaborating through XML technologies when exchanging Web service data [1]. XML is a semi-structured data language with various features such as platform independence, easy expansion, better interaction, ample semantics and good formatting. With these features, communication among different computing systems has been enabled by XML, something that used to be extremely difficult or even impossible. Thus, XML presents a global structure for data exchange regardless of the platforms and data models of the applications [2]. A considerable amount of data on the Web is represented in XML. Therefore, XML data management has recently become a research challenge with regard to storage and querying.
Numerous researchers [3–6] have introduced various approaches for XML data management in terms of storage and querying, including file systems, object-oriented databases, native XML databases and relational databases. Previous studies [7] have indicated that a file system could be used with minimal effort to store XML data, but the file system has shortcomings in XML data querying. In addition, an object-oriented database would allow XML elements and sub-element clustering, which might be useful for certain applications, but the current generation of object-oriented databases are insufficiently mature to evaluate queries on significantly huge databases. Relational Databases (RDBs) have overcome other approaches because of their storage efficiency and their ability to overcome most data access challenges. RDBs have garnered commercial strength from giant vendors, in fact RDBs are the most appropriate XML data storage mechanisms to date.
Despite the maturity of the RDB technology, a conflict exists in the structure between the hierarchical nature of the XML data model and the two-level nature (row and column) of the relational data model. Given this conflict, mapping techniques are needed to map XML documents into RDBs. Several researchers have focused on the mapping approach from XML documents into RDBs by considering the properties of both XML and RDB. Additionally, creating an effective relational storage model for XML document storage with less query response time has been the main focus in database research.
The main contribution of this paper is to comprehensively review topical research development for different kinds of mapping approaches, which are called ‘model mapping approaches’. The reviews are in terms of storage and querying XML data. The model mapping approaches consist of the 13 most cited and latest approaches: Edge [7], XRel [4], XParent [6], XPEV [8], LNV [9], Sainan–Caifeng [10], SMX/R [11], Xlight [12], XRecursive [13], Suri–Sharma [14], Ying–Cao [15], Wang et al. [16] and s-XML [17]. The approaches essentially need to preserve the relationships among XML nodes such as parent–child, ancestor–descendant, levels and siblings during the mapping. Hence, accurate query retrieval is needed, and the responses provided to the user should be precise. This study reviews 13 approaches and discusses them in terms of the description, the technique used and the RDB schema produced as well as the drawbacks. The explanation includes the ways in which these approaches preserve the relationships among XML nodes in terms of the efficiency of query processing and data retrieval. These approaches are the most cited and the latest model-mapping approaches found in the literature. Finally, this study concludes with possible issues for rendering efficient XML storage and querying in the future.
The remainder of this paper is organized as follows: Section 2 presents a brief background on the XML data model. Section 3 explains the two common types of mapping approaches and the differences between these approaches. Section 4 reviews the most cited and the latest model-mapping approaches found in the literature and comments on these approaches in terms of the storage space and query response times. Section 5 categorizes the mapping approaches into six main techniques. Section 6 summarizes these approaches and the method used in preserving the relationships among the nodes. Section 7 discusses these approaches in terms of the storage and query issues, and some recommendations for improvement. Finally, the conclusion and future works are presented in section 8.
2. XML data model
As shown in Figure 1, an XML document can be modelled as a rooted, nested, hierarchical, ordered edge-labelled or node-labelled data tree [18]. These two models are similar except for the label location; the labels of the edge-labelled model are on the edges, whereas the labels of the node-labelled model are on the nodes. The node-labelled model is used in most research. The edge-labelled model is used in some situations, such as when representing most structural indices and shredding XML data into an RDB. Figure 2 shows examples of the edge-labelled model and the node-labelled model, respectively, based on the XML document in Figure 1 [6].

Part of XML document.
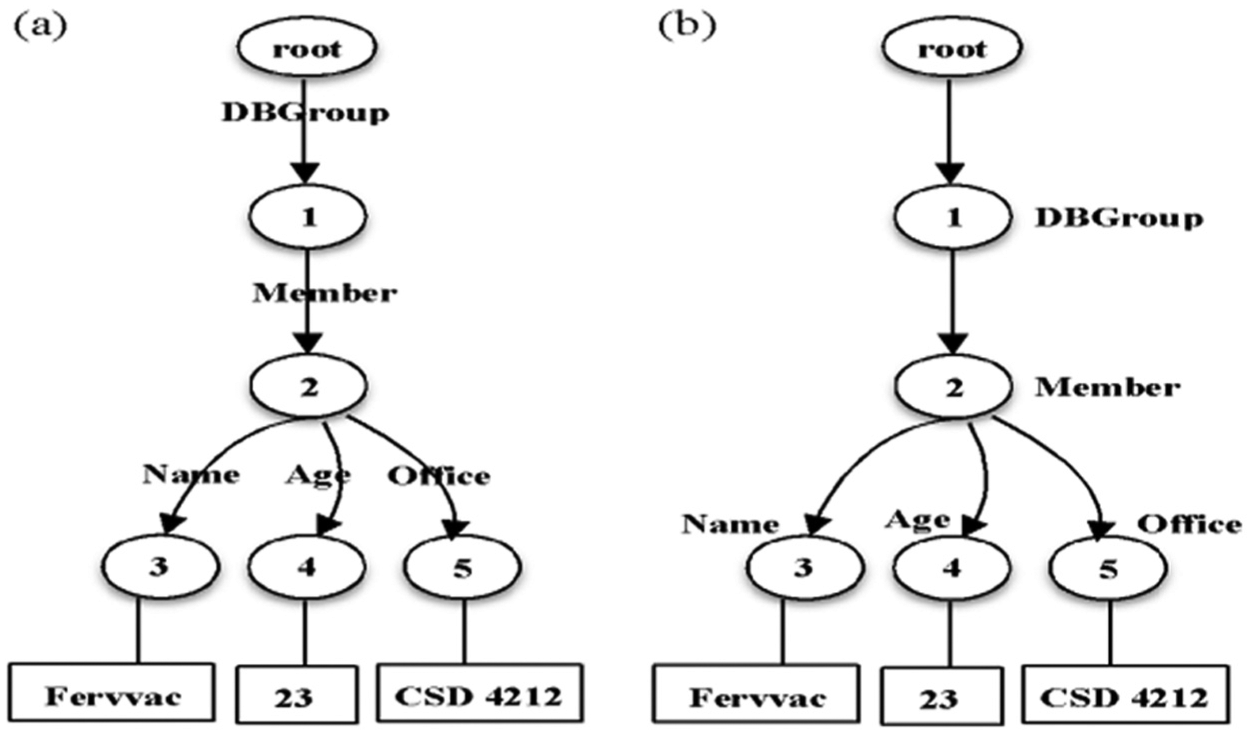
XML data models: (a) edge-labelled; and (b) node-labelled.
Four main node types in the XML data model (tree) are depicted in previous studies [4], as shown in Figure 2. The first node type is the root node, which represents the XML tree root. The second node type is the element node of the XML tree. An element node has an expanded name, which is the element type name specified in the tag. In this example, this element has zero or more children. The type of each child node is an element or a text. Figure 2b comprises five element nodes: DBGroup, Member, Name, Age and Office. These elements are regarded as tag names in the XML document as shown in Figure 1. Figure 2a indicates these tag names as labels of the XML tree edges, which are applied in the Edge approach. The third node type is the attribute node, which is related to the element node. An attribute node is not a child of the element node. An attribute name and an attribute value are assigned to each attribute node. Moreover, attribute nodes have no child nodes. For simplicity, the examples presented in this paper do not include this node type. The last node type is the text node, which represents a string-value. A text node does not have an expanded name and has no child nodes. Figure 2 comprises three text nodes: ‘Fervvac’, ‘23’ and ‘CSD 4212’.
3. The types of mapping approaches
Numerous mapping approaches for storage and querying XML documents have been introduced. These approaches include Edge [7], XRel [4], XParent [6], XPEV [8], LNV [9], Sainan–Caifeng [10], SMX/R [11], Xlight [12], XRecursive [13], Suri–Sharma [14], Ying–Cao [15], Wang et al. [16] and s-XML [17]. These approaches have improved the storage space of RDBs and have reduced the number of join operations in the query, which lessens the query response time. Therefore, the research in Wang et al. [16] has divided the mapping approaches into two. The first comprises structure-mapping approaches, where the RDB schema is created according to the XML document structures identified via the Document Type Definition (DTD) or XML-schema. The RDB schema varies with the type of XML document. Hence, the XML schema diversifies the size and number of the mapping relational tables, which makes the XML data query difficult. The second comprises model-mapping approaches, where the XML document nodes and edges are mapped to the RDB schema. The obtained RDB schema is not related to the XML document structures, which means that, in this approach, a fixed RDB schema is used for storing XML document structures. This approach is appropriate for XML data management and queries.
XML documents on the Web may have a well-formed schema (DTD or XML-schema for data description) or may not (without DTD or XML-schema). Managing the large number of XML documents on the Web in terms of storage and querying is difficult because of the various forms of XML documents. The model-mapping approaches solve this issue by using RDBs for storing and querying XML documents. Therefore, this study reviews the model-mapping approaches instead of the structure-mapping approaches for the following two reasons: first, model-mapping approaches support any modern XML applications that are either static (the DTDs are unchanged) or dynamic (the DTDs are changed frequently). These applications cannot be performed using the structure-mapping approaches. Second, model-mapping approaches support well-formed XML applications (without a schema for data description) on the Web, whereas structure-mapping approaches only support XML documents with a DTD or XML-schema structure. In fact the expressive power of database models is not needed to support XML documents in the model-mapping approaches. The database model in the structure-mapping approach does not include constructs to describe the elements in the DTD content of the XML document. Thus, structure-mapping approaches need to extend the expressive power of database models in order to map data structures of XML documents into RDB schema in a natural way [4].
4. A review of the model-mapping approaches
This study reviews and compares 13 approaches that are the most cited and the latest model-mapping approaches found in the literature. The reviews are based on the descriptions and drawbacks of these approaches in terms of storage space and query response time that might affect the query performance. The reviews also include the relational database schema produced by each mapping approach based on the XML document shown in Figure 1, and the XML data models (tree) shown in Figure 2.
4.1. Edge approach
An edge-based technique is utilized by the Edge approach [7]. This approach is the simplest and most basic in terms of shredding and loading XML data into a single Edge table. Each edge is mapped in the XML tree to a tuple in a single relation. Based on the XML document in Figure 2a, the RDB schema shown in Table 1 is yielded through the model mapping process in the Edge approach.
Edge scheme: Edge table.
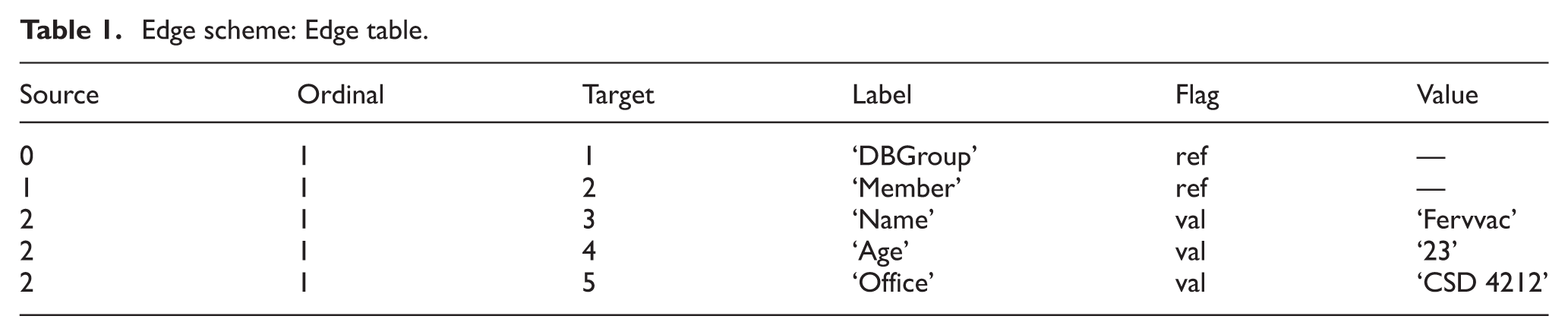
The Edge table stores the identifier of the source and target nodes of each edge of the XML tree and the edge label, a flag indicates whether the edge represents an internal node or a value (i.e. a leaf), and an ordinal number reflects the ordered edges.
This study concludes that the Edge approach is imperfect because the edge label is retained instead of the label paths. For a path to be created, this approach needs an edge concatenation. Therefore, multiple joint operations are required compared with the path expression length to check the edge connections for handling user queries. This multiple joint operation will increase the query response time. This approach is only appropriate for simple XML documents that do not contain complicated combinations of tables because it may deteriorate owing to an ‘excessive table size error’. Storing the entire XML document into a single table identifies this as an error [17].
4.2. XRel approach
A path-based technique is utilized by the XRel approach in the insensible schema type [4]. The data model employed by this approach is XPath [19], where an XML document is represented as a tree node structure. These nodes are stored in relations according to the node type, with distinctive path information from the root to any node. A simple path expression is preserved by the XRel approach, which is the path of a node from the root, and the region information of a node (a pair of start and end positions of a node in an XML tree). Moreover, a containment relationship is managed by this region, where the relationships among the XML nodes are easily maintained. Therefore, node identifiers are unnecessary for storing XML data graphs. According to the XML document in Figure 2b, the RDB schema shown in Table 2 is produced through the model mapping process in the XRel approach.
XRel scheme: (a) path; (b) element; (c) text; and (d) attribute tables.
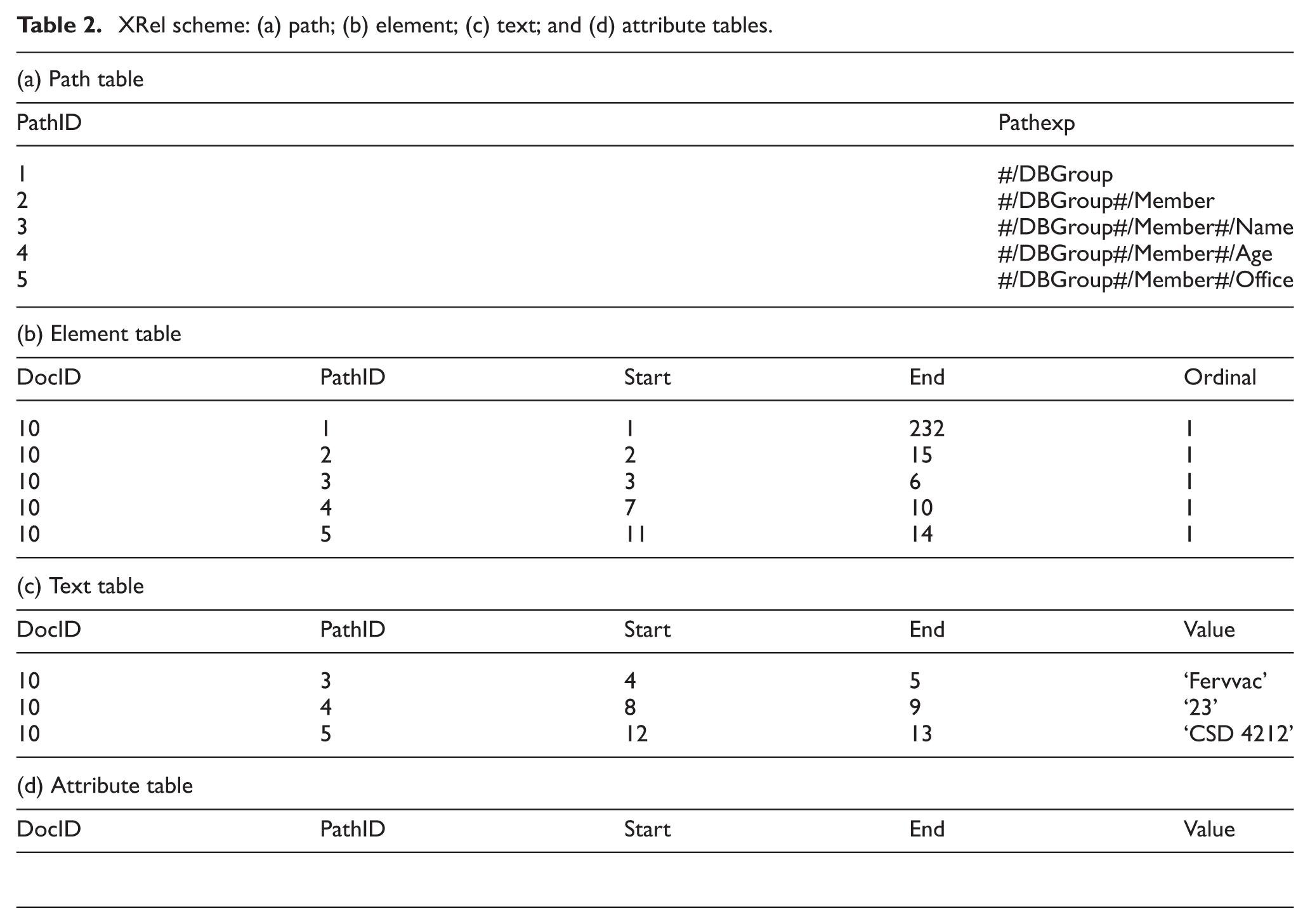
The DocID, PathID, Start, End, Ordinal and Value are stored by the XRel schema, which are the document identifier, simple path expression identifier, start and end positions of a region, and ordinal number of anode based on the siblings and string-value of the anode.
This study concludes that the XRel approach is imperfect because the high number of joint tables and tuples increases the relational database size produced [9]. Through this approach, the paths for any existing nodes in the XML tree are stored. This will increase the storage space requirements and leads to a slower search in the path tables. This approach uses the containment relationship to preserve ancestor–descendant relationships. In addition, this approach uses Θ-join (<, >) operators, which are expensive in joining the tables because of the way the RDB Management System (RDBMS) processes joint tables [12]. In the XRel approach, the querying cost for verifying the parent–child relationship is high. Thus, the verification of the parent–child relationship of any two nodes from the tag positions confirms that the non-existence of a node between the two nodes is important [20].
4.3. XParent approach
The XParent approach is an improved version of the Edge and XRel approaches [6]. A hybrid technique between Edge and Path-based is used in this approach. Similar to XRel, a Path Index Table (LabePath) is also used by XParent. Edge and Edge-Value elements are used to store the parent–child relationship, where a separate table (DataPath) is used to preserve this relationship. The XParent scheme is similar to the XRel scheme, the difference being that a data-path Identifier (Did) is used in the XParent scheme, while XRel uses start and end position elements to preserve the parent–child relationship. An Ancestor table (Did, Ancestor, Level) is used to store all of the ancestors of a specific node in a single table. The existence of the ancestor table enables the query response time to be increased by replacing Θ-joins with equijoins over the set of ancestors. The XPath data model is employed by the XParent schema [19] to represent XML documents. This document is modelled as an ordered tree, which is then mapped into four relational tables. According to the XML document in Figure 2b, the model mapping process in the XParent approach produces the RDB schema in Table 3.
XParent scheme: (a) LabelPath; (b) DataPath; (c) Data; and (d) Element tables.

In the LabelPath table, the ID, Len and Path attributes represent a unique label–path identifier, the number of edges of the label-path and a distinct simple expression path, respectively. In the DataPath table, the Pid and Cid attributes represent the parent-node and child-node IDs of an edge, respectively. The attributes of the Element and Data tables, such as the PathId, are foreign keys of the ID in the LabelPath table, and Did is a data-path identifier. Those values found in the table are Ordinal numbers and string values.
This study concludes that the XParent approach is limited because a high disk space may be required by the ancestor table to store data paths. This approach may lead to an overhead because of the redundant information in the table [17]. XParent used a similar approach to that in XRel, where paths for all existing nodes are preserved. However this will increase the storage space requirements [15]. The ParentId and ancestor information remain for all existing nodes in a document. Therefore, determining an ancestor of a specific node is exorbitant because the nodes need to be joined with tables frequently [12].
4.4. XPEV approach
The XPEV approach is an improved version of the Edge and XRel approaches [8]. This approach is a hybrid technique between Edge- and Path-based that uses three-table schema. The Path table stores distinctive (root-to-any) paths, the Edge table preserves parent–child relationships and the Value table stores all of the element and attribute values. The XQuery 2.0 and XPath 1.0 data models are applied in this approach [21]. Based on XML document in Figure 2b, the RDB schema as shown in Table 4 is produced using XPEV.
XPEV scheme: (a) Path; (b) Edge; and (c) Value tables.
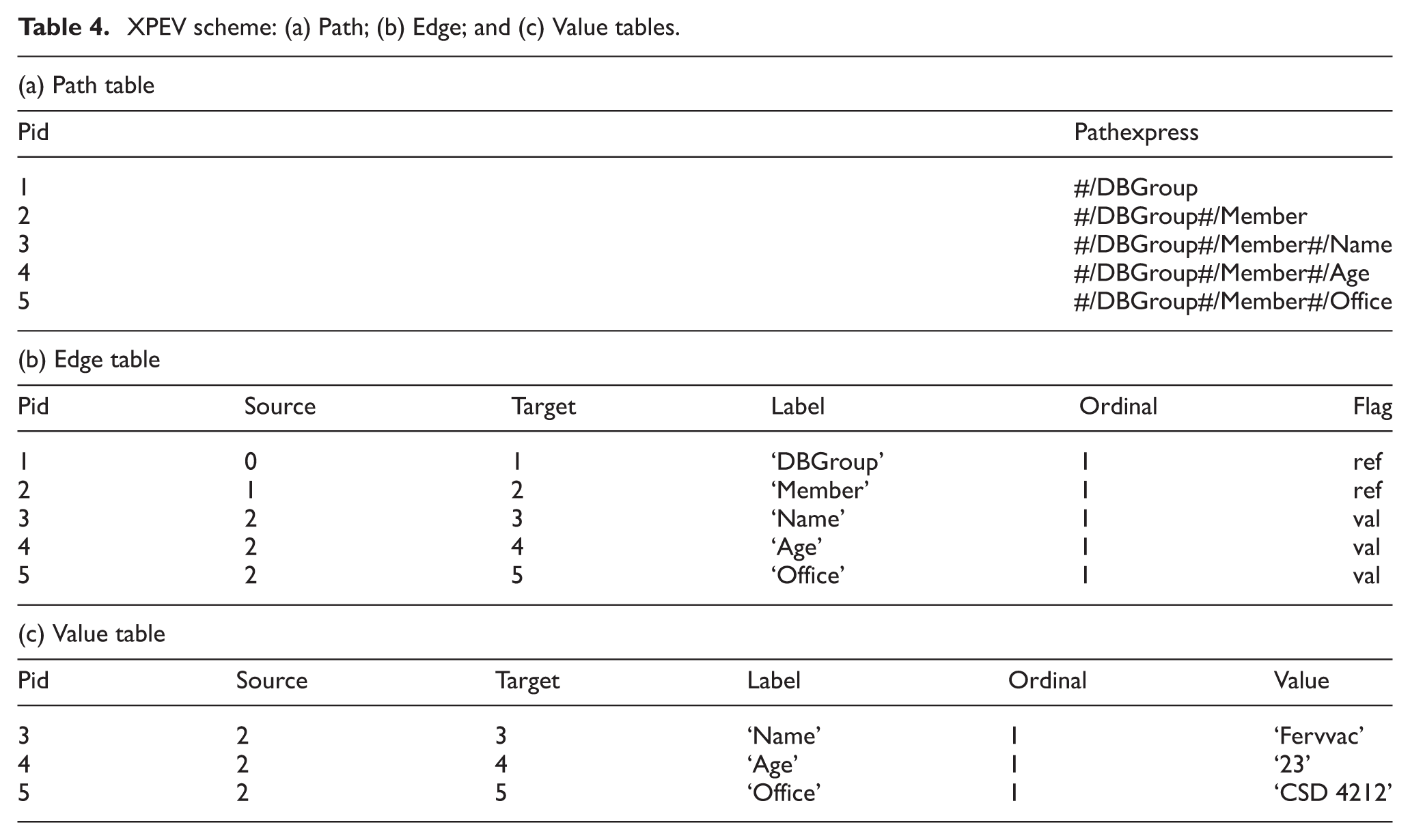
In the Path table, the Pid and Pathexpress attributes represent the path identifier and the distinct simple path expression, respectively. In the Edge and Value tables, the Pid, Source, Target, Label, Ordinal, Flag and Value attributes denote a path identifier, the identifier of the source node, the identifier of the target node, the label of the edge, a flag indicating an internal node or a value (a leaf), and an ordinal number of the node among all siblings that share the same parent because the edges are ordered and string-valued, respectively.
This study identifies that the XPEV approach is limited because the RDB schema remains large, given that entire XML documents are stored in two tables, namely, the Edge and the Value. Similar to XRel, the XPEV approach stores paths for any existing nodes in the XML tree, which increases the storage space requirements and slows down the path table searches. The two tables (Edge, Value) need to combine in this approach to determine ancestor–descendant relationships. The two tables Edge and Value are joined using Source and Target element, which increases the query response time and affects the query performance.
4.5. LNV approach
An indexing technique is employed by the LNV approach [9]. In this approach, each distinctive node in the XML document is provided with a signature and these signatures in the table are stored and named as ‘label’s Signatures.’ For each leaf node in the XML document tree, a path expression can signify the Path from the root to the leaf node, and a list of label’s signatures can interpret this path expression. A compact storage structure for large XML documents is then achieved. While traversing the XML tree, the LNV storage structure is constructed. During the query process this structure will be analysed without traversing the XML document several times. According to the XML document in Figure 2b, the RDB schema in Table 5 is created through the model mapping process of the LNV approach.
LNV scheme: (a) signatures; and (b) path tables.
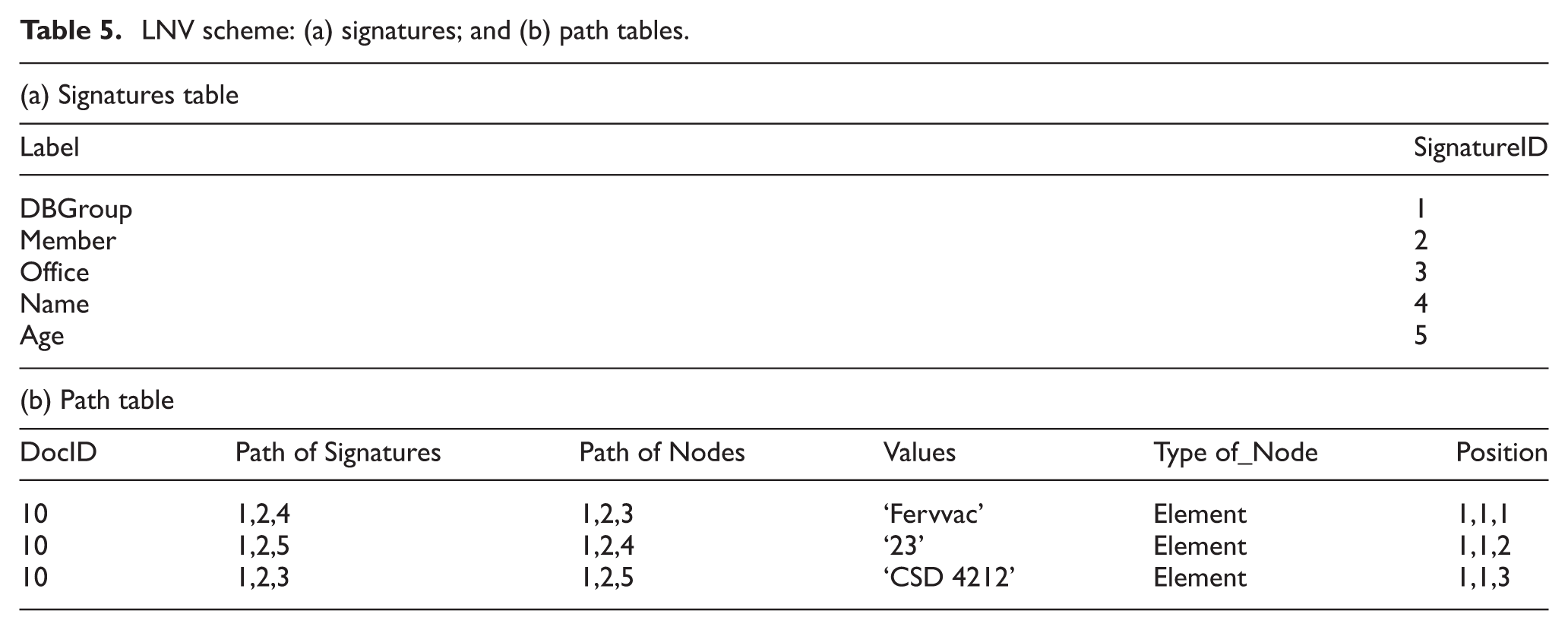
In the Signatures table, the Label and SignatureID attributes represent the name of a node and the signature identifier (sequence of integer numbers start from 1), respectively. The Path table consists of six attributes. The DocID attribute is a document identifier. The Path_of_Signatures attribute refers to the list of signatures of path labels that are ordered from the root. The Path_of_Nodes attribute is the list of nodes in the path that are ordered from the root. The Values attribute denotes the value associated with the end of the path. The Type_of_Node attribute pertains to the leaf node type (element, attribute, comment, or text), and Position depicts the positions that represent the occurrence of each element node among the siblings of the node.
This study concludes that the LNV approach is limited because an overhead of the size of the Path_of_Signature and Path_of_Nodes columns in storing sizable XML documents may occur. The substr() and instr() functions are employed to calculate the relationships among the nodes. In addition, the XPath query is processed in two steps. First, the XPath query is translated into the path of the label’s signatures according to the Path table. Second, the query produces a structure query language (SQL) statement according to the RDB schema. These steps increase the query response time, which affects the query performance, especially in a complicated XPath query.
4.6. The Sainan–Caifeng approach
An indexing technique is employed by the Sainan–Caifeng approach [10]. This approach is an improved version of the LNV approach. Each distinctive node in the XML document has a signature, and these signatures are stored in the label’s Signature table. For each leaf node in the XML document tree, a path expression can characterize the Path from the root to a leaf node, and this Path is interpreted as a list of the label’s Signatures. The LNV storage structure is enhanced through the elimination of the Path_of_nodes column in the Path table, thus decreasing the storage space. In addition, the query response time is enhanced through the reduction of the number of join operations and the elimination of the instr() function, where the clause of the translated SQL is found. Based on the XML document in Figure 2b, the RDB schema in Table 6 is produced using Sainan–Caifeng approach.
Sainan–Caifeng scheme: (a) Signature; and (b) Path tables.
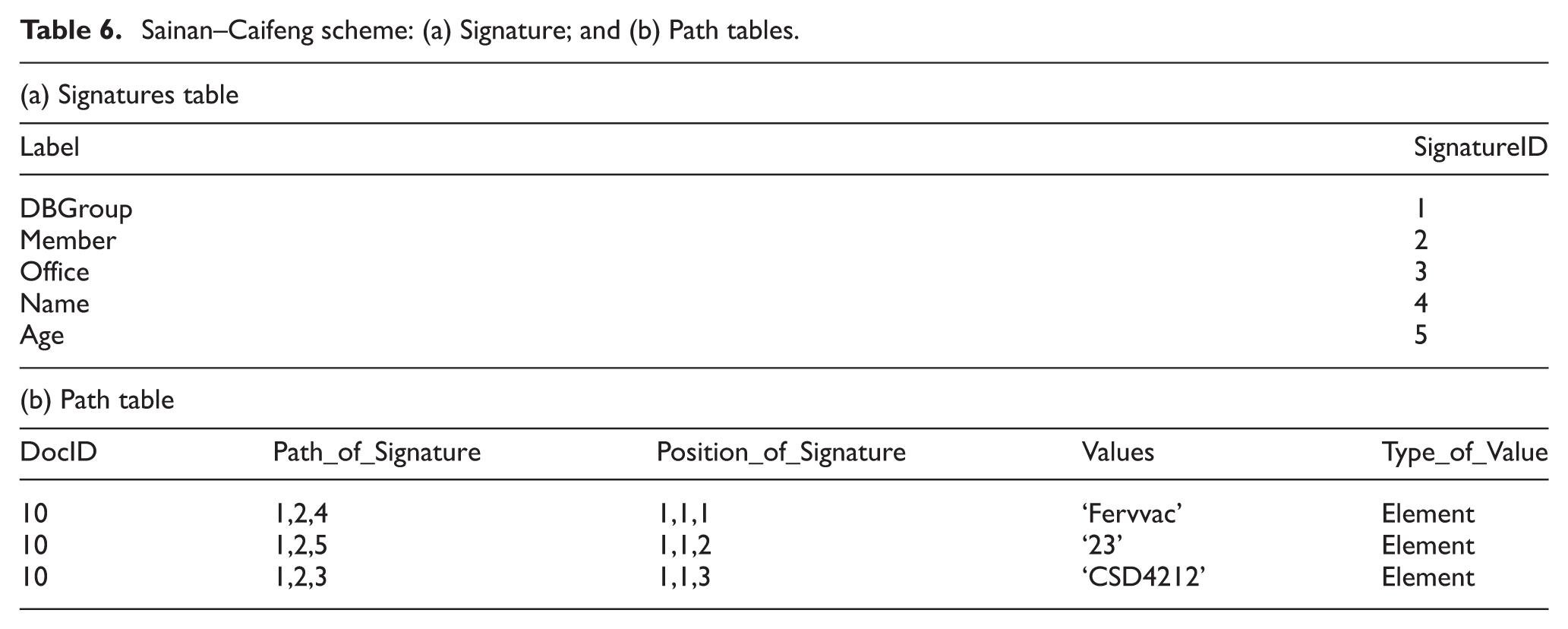
The Label and SignatureID attributes in the Signature table pertain to a node and a signature identifier (the sequence of the integer numbers start at 1), respectively. In the Path table, the DocID attribute is the number of XML document, the Path_of_Signature attribute pertains to the list of signatures of the labels in the path that are ordered from the root. The Values attribute is the value related to the end of the path. The Type_of_Value attribute refers to the leaf node type (element, attribute, comment or text). The Position_of_Signature attribute denotes the positions pertaining to the occurrence of each node among the siblings of the node.
This study concludes that the Sainan–Caifeng approach is limited because this approach suffers from the overhead size of the Path_of_Signature and Position_of_Signature when large XML documents are stored. Substr functions are needed for querying string matching and for joining the tables. Moreover, the XPath query is applied in two steps. First, the XPath query is converted into a label’s signature path according to the Path table. Second, the SQL statement is yielded according to the RDB schema of the approach. These steps may increase the query response time, thus affecting the query performance, especially in a complicated XPath query.
4.7. SMX/R approach
A path-based technique is applied in the SMX/R approach [11]. This approach is an improved version of the XRel approach. The parent–child and path information of the node is utilized by this approach to mapping XML documents into the RDB schema. Hence, both the parent–child and ancestor–descendant relationships are effortlessly preserved and established. This approach is beneficial in terms of more generic solutions for storing any XML collection efficiently and/or precise filtering for large subsets of XPath expressions, and better extraction of fragments based on the XPath expressions. Start and end positions are provided to each node (tag) through the pre-order and post-order traversal numbers. Similar to the XRel approach, a NodeID is non-existent in the schema of SMX/R. Based on the XML document in Figure 2b, the RDB schema in Table 7 is produced from the model mapping process in the SMX/R approach.
SMX/R scheme: (a) Path_Index_Table; and (b) Path_Table.
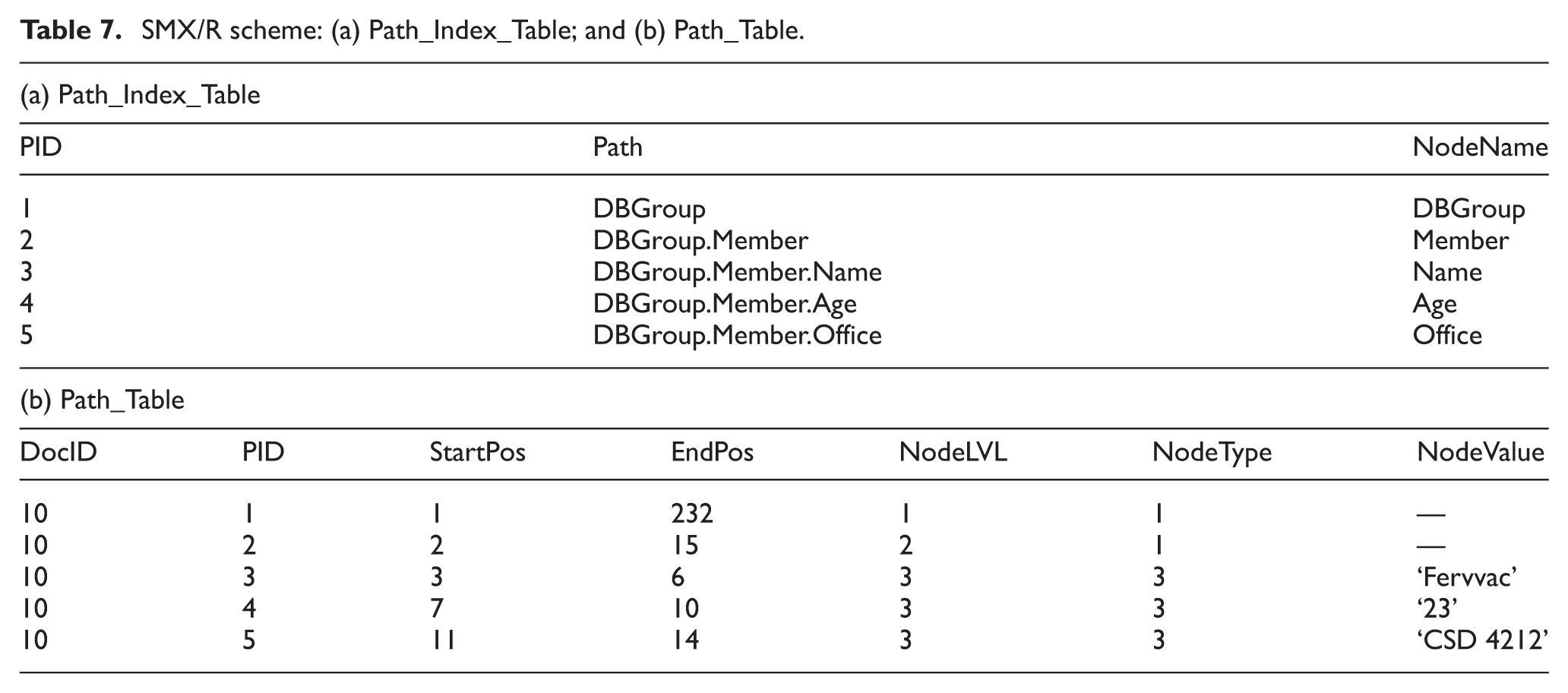
In the Path_Index_Table, the PID, Path and NodeName attributes are special IDs for the path, path string from the root to each node and the node name, respectively. Path_Table consists of seven attributes. The DocID attribute is a distinct ID for the XML document, the PID attribute is a unique ID for a path (key to Path_Index_table). The StartPos attribute is the start location of the node (Pre-order number), EndPos is the end location of the node (post-order number). NodeLVL is the nesting depth within the document, NodeType is the type of node (1 = element, 2 = attribute, and 3 = text), and NodeValue depicts the value of the node.
This study identifies that the SMX/R approach is limited because, if the storage space is decreased, the query response time is increased. This situation happens when the distinct paths for all existing nodes are stored; this will increase the search space in the Path_Table. Θ-joins (<, >) employed in this approach will check the edge connections, that is, the containment relationship for preserving the parent–child and ancestor–descendant relationships. This checking process is an expensive process in RDBMS. Even the search space for the elements, attributes or texts will expand since a single table is used for storage.
4.8. Xlight approach
A path-based technique is employed in the Xlight approach [12], where the existing root–to–leaf paths in the XML document are stored. Unlike XParent, nodes with similar parents will have equal LeafGroup values and ancestors; this will reduce the use of ancestor tables. Only information on the ancestor is stored. Similar to XRel, the Path table is also employed in this approach, and this will reduce the large number of joints during queries. The storage space is significantly reduced, and the search conducted in the path table is hastened. The Θ-joints problem (as in XRel) is resolved through the ancestor table where all of the ancestors of the leaf nodes are stored in a single table. Equi-joints are utilized to replace the Θ-joints over this set of ancestors. Based on the XML document in Figure 2b, the RDB schema in Table 8 is produced from the model-mapping process in the Xlight approach.
Xlight scheme: (a) Document; (b) Ancestor; (c) Path; (d) Attribute; and (e) Data tables.
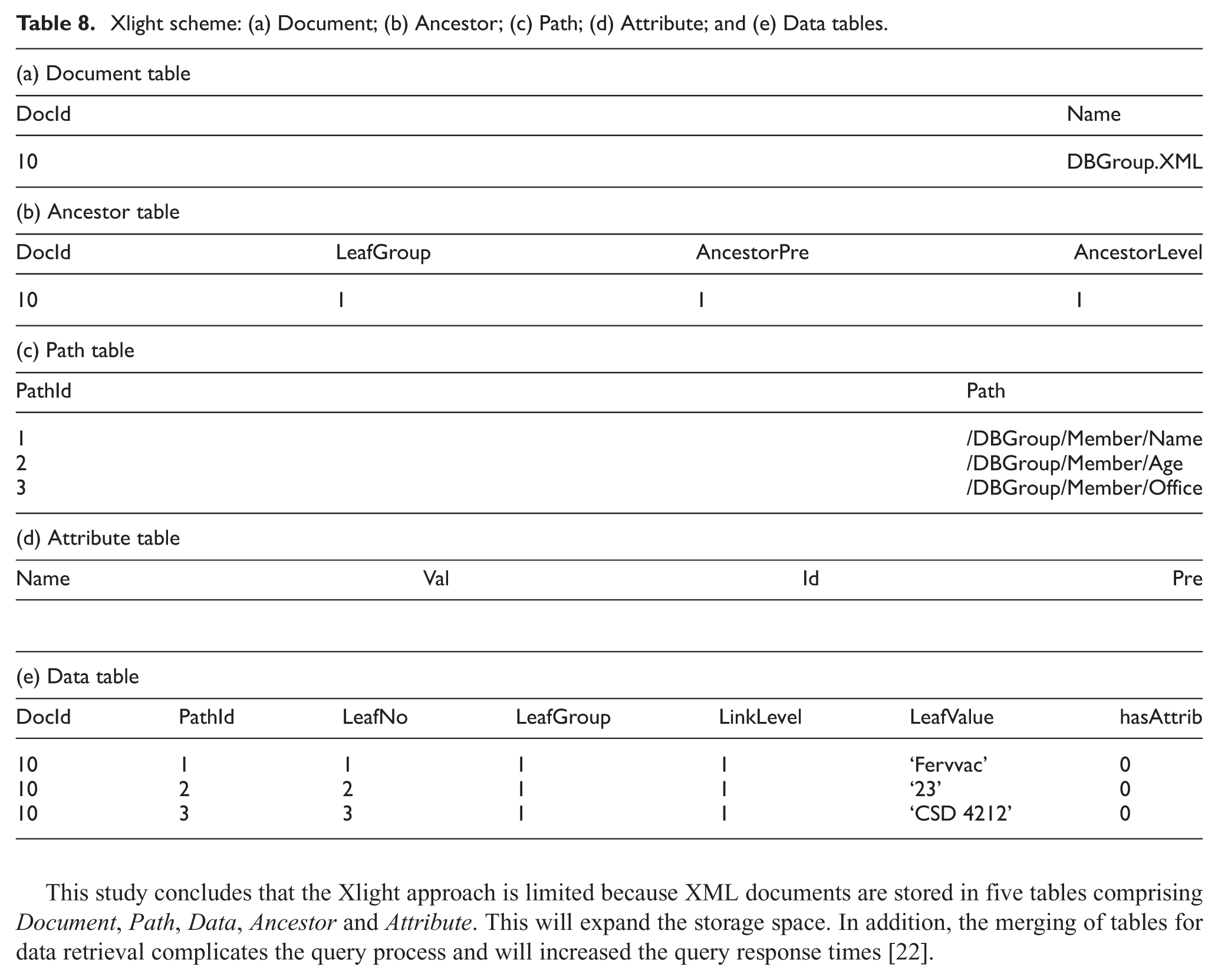
The path identifier in the PathId attribute and all of the existing root-to-leaf paths in the XML document are stored in the Path table within a Path attribute. The related information of the leaf nodes in the XML document is stored in a Data table, which consists of seven attributes. The DocId attribute represents the document identifier: PathId, depicting the the root-to-leaf paths; LeafNo, pertaining to the order of the leaf nodes in the document; LefGroup, representing the same number for any participant leaf node with the same parent; LinkLevel, denoting the level where two adjacent paths should link to each other; LeafValue, indicating the textual contents of the leaf node; and hasAttrib, showing the number of attributes in each path. The Ancestor information of each leaf node is preserved by the Ancestor table through the storage of the distinct ancestor information for the nodes with similar parents. The information of the existing attributes in the XML documents is stored in the Attribute table.
This study concludes that the Xlight approach is limited because XML documents are stored in five tables comprising Document, Path, Data, Ancestor and Attribute. This will expand the storage space. In addition, the merging of tables for data retrieval complicates the query process and will increased the query response times [22].
4.9. XRecursive approach
A node-labelling technique is employed in this approach [13] through the used of ORDPATH, as the node-labelling scheme [23]. Storing the path value or path structure is unnecessary because the parent–child relationships among the nodes are preserved through the parent ID (pId) attribute. A similar attribute for the ancestor–descendant relationship among nodes is preserved. Based on the XML document in Figure 2b, the RDB schema in Table 9 is produced using this approach.
XRecursive scheme: (a) Tag_Structure; and (b) Tag_Value tables.

In the Tag_Structure table, the tagName attribute pertains to the name of the node, the Id attribute represents the node ID, which is the primary key, and the pId attribute represents the parent ID of the node. In the Tag_Value, the tagId attribute only represents the tag ID (elements or attributes) that contains a value. Value shows the tag value, Type ‘A’ denotes an attribute and ‘E’ pertains to the element.
This study claims that the XRecursive approach is limited even though less storage space is used but the paths in the table are not stored. The parent ID (pId) is used recursively in forming the path, and hence will increase query processing in RDBMS.
4.10. Suri–Sharma approach
A node-labelling technique is employed in the Suri–Sharma approach [14]. The nodes, including the values, type, name and node position of the nodes, are stored in a single table. The Path concept is not utilized in this approach. Instead of storing the distinct paths, the parent node ID along every node is stored for the preservation of the parent–child relationships of the nodes. In addition, this approach uses the parent node ID recursively for the preservation of the ancestor–descendant relationships among the nodes. A smaller number of joins operations is also needed in the query processing of this approach than for the other approaches. Based on the XML document in Figure 2b, the RDB schema in Table 10 is yielded through the model mapping process in the Suri–Sharma approach.
Suri–Sharma scheme: (a) Node; and (b) Data tables.
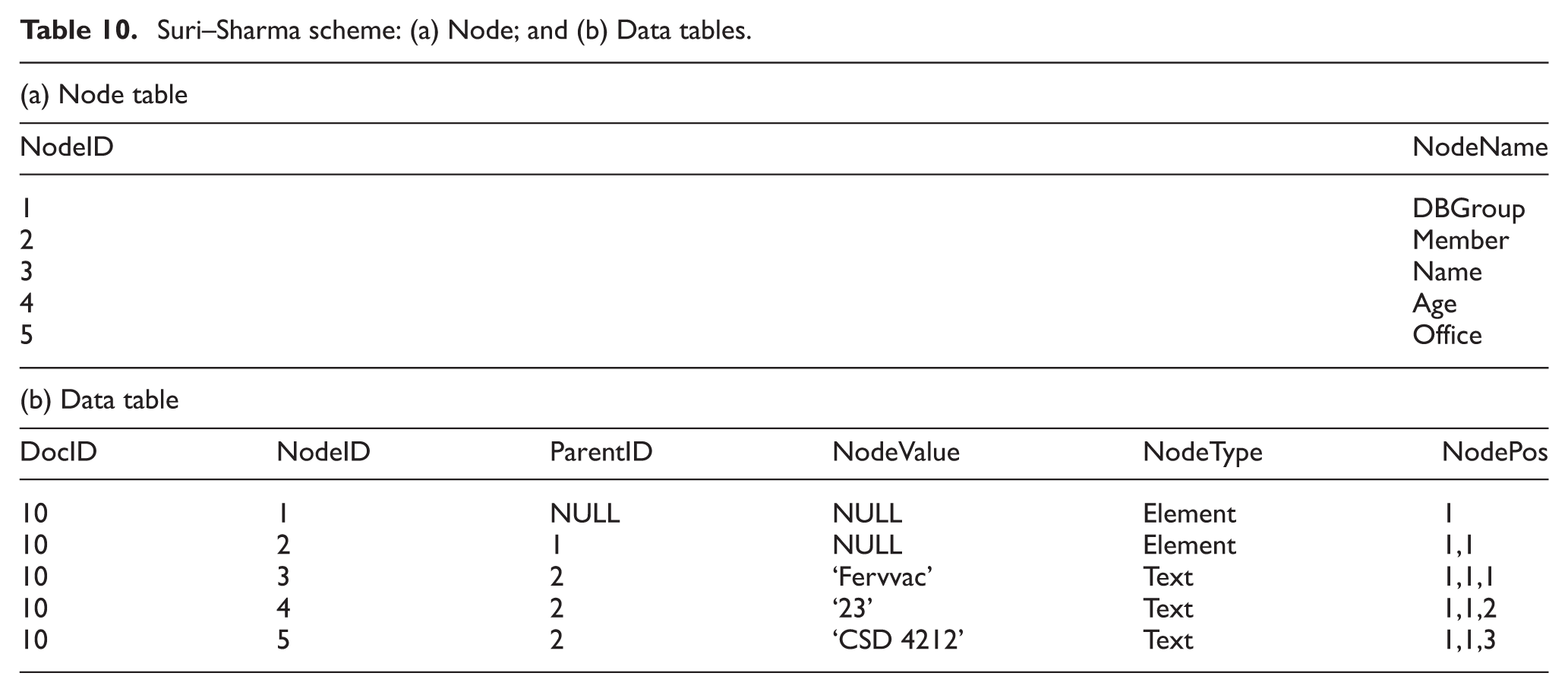
The NodeID attribute, which pertains to the node identifier, and the NodeName, which depicts the node name, are stored in the Node table. In the Data table, the DocID attribute refers to the ID of the particular XML document; NodeID pertains to the node identifier; ParentID denotes the parent node ID of a node; NodeValue signifies the node value, that is, the text values are stored in this node; NodeType indicates whether the node is an element, an attribute or a text; and NodePos is the node position among the siblings of the node in the XML data graph.
This study concludes that the Suri–Sharma approach is limited because the redundant data are stored in two tables, which expands the RDB storage space. Furthermore, the paths are not stored in the RDB schema where the parent–child and ancestor–descendant relationships among the nodes are preserved through the recursive utilization of the parent ID, which makes the RDBMS more exorbitant. Therefore, the query processing in this approach deteriorates because the query response time increases for any kind of query.
4.11. Ying–Cao approach
A hybrid technique is employed in the Ying–Cao approach [15]. Path-based and node-labelling techniques (for inner nodes) are combined in this approach for transferring the major content of the XML document to the RDB schema. The Path table is utilized for storing each distinct path expression of the leaf node (i.e. distinct path from the root node to the leaf node) in this approach. This storage will decrease the RDB storage size, especially for complex XML documents. Complex structural queries, such as in the twig and recursive queries, can be obtained according to the relationship preserved by the labels (parent IDs) of the inner nodes in the InnerNodes table. A more intense structural search of the XML document is sustained by the Ying–Cao approach, which will improve query processing (less query response time). Based on the XML document in Figure 2b, the RDB schema in Table 11 is yielded through the Ying–Cao approach.
Ying–Cao scheme: (a) File; (b) Path; (c) InnerNodes; and (d) LeafNodes tables.
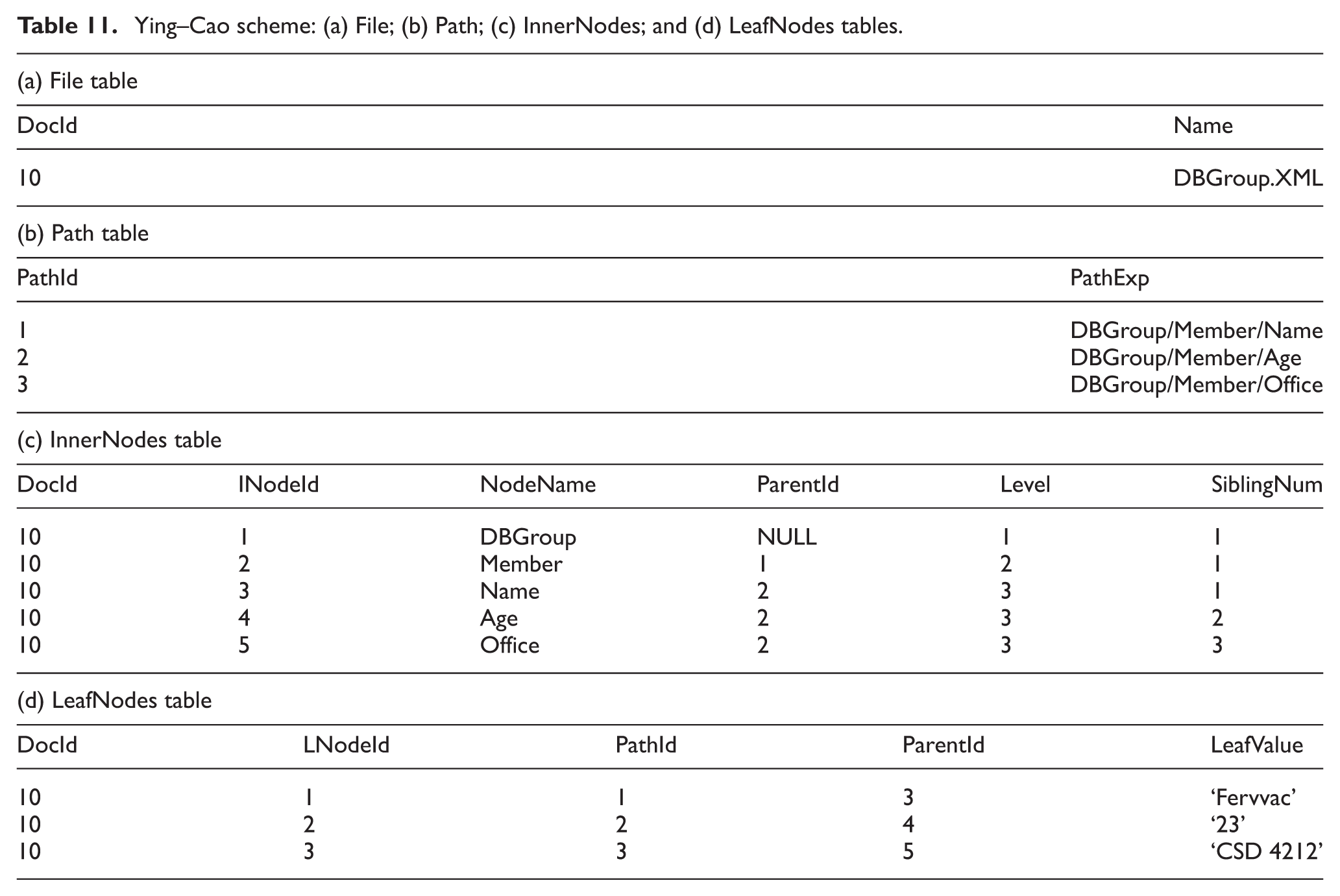
In the File table, DocId refers to the distinct ID for each XML document, and Name pertains to the XML document name. In the Path table, PathId denotes the path identifier, and the distinct path expressions of the leaf node are stored in PathExp. In the InnerNodes table, INodeId refers to the label provided for each inner node, NodeName exhibits the name of the inner node, ParentId denotes the INodeId of the parent node, Level conveys the level of the inner node and SiblingNum depicts the position of each inner node in accordance with the siblings of the node in an XML tree. Aside from the attributes that are akin to the InnerNodes table, the LeafNodes table employs the LeafValue attribute to store the text content or attribute value.
This study concludes that the Ying–Cao approach is limited because a large amount of storage space may be needed for complex RDB schema. The InnerNodes table needs to be joined several times or recursively by the parent ID to preserve the ancestor–descendant relationships. Therefore, the query response time is increased, particularly in a complex query.
4.12. Wang et al. approach
A hybrid technique is employed by the Wang et al. approach [16]. Path-based and node-labelling techniques (for inner nodes) are combined in this approach to map the contents of XML document to the RBD schema. This approach introduces a unique utilization of relational databases for storing and querying the XML data. The nodes possess text values, and two relational tables are used to store non-text values in the XML document tree. The significant properties of the Wang et al. approach ease XML querying because the index structure does not need to be determined, which is equivalent to B+-tree [24] and R-tree [25]. The information on the leaf nodes with the node paths is stored in the same table. The parent–child relationship among the XML nodes is preserved through the ParentId attribute, and this approach employs a similar attribute recursively for preserving the ancestor–descendant relationship among the nodes. Based on the XML document in Figure 2b, the RDB schema in Table 12 is produced through the model mapping process in the Wang et al. approach.
Wang et al. scheme: (a) No_Value_Table; and (b) Value_Table.
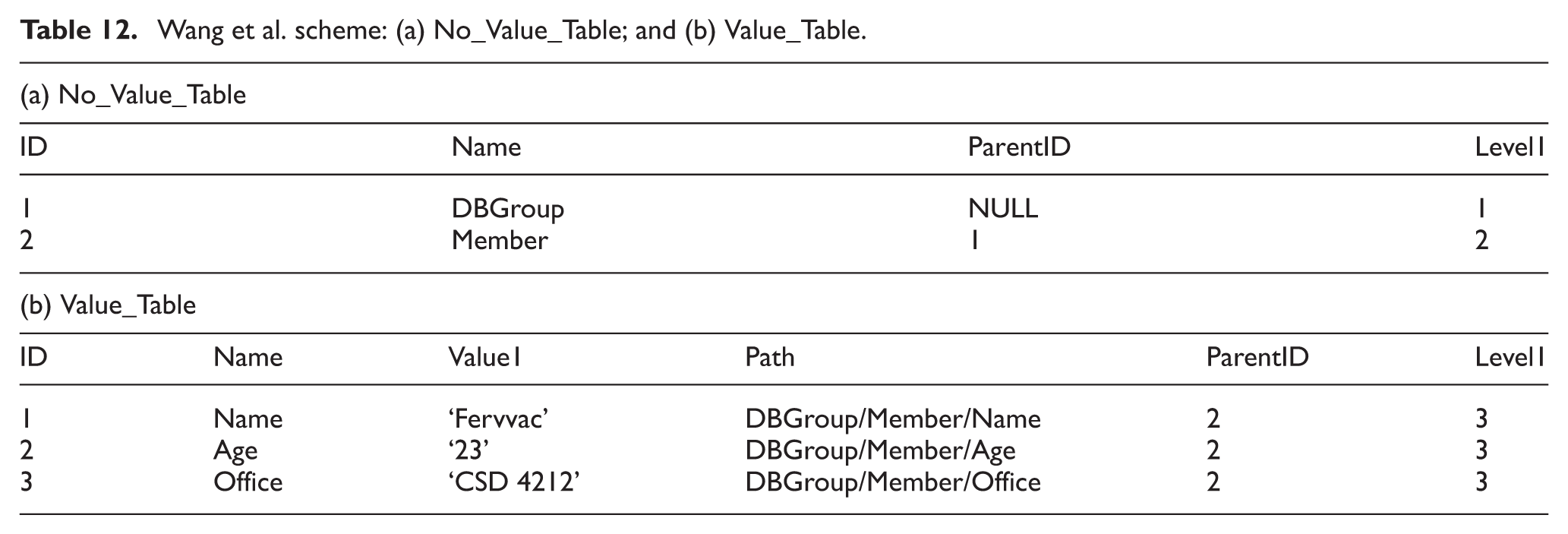
Value_Table is used to store the relevant information on the elements (or attributes) of the XML document. The attributes of this table are the following: ID refers to the node sequence number, which reflects the order of appearance during pre-order traversing of the document tree; the Name attribute depicts the element (or attribute) name; Value1 denotes the element (or attribute) value; Path confirms the path from a root node to the present node (leaf node); ParentID pertains to the parent node ID of the element (or attribute); and Level1 indicates the layer number of the node location. No_value_Table is for storing the relevant information of the elements (or attributes) of the invaluable XML document. Four attributes are included in this table, namely, ID, Name, ParentID and level1. The meanings of the contents stored in these four attributes are similar to those in Value_Table.
This study concludes that the Wang et al. approach is limited because it increases the storage size and query response times. The path in this approach is stored as a string in a similar table where the values of the leaf nodes are stored; this will introduce data redundancy. Furthermore, the inner node information of the path from the root to the present node (leaf node) is stored, and thus will increase the size of the RDB. With regard to query processing, the use of ParentID will expand the search space for the path in the Value_Table. Moreover, a high number of joins is needed in the Wang et al. approach for complex queries, which will increase the query response time.
4.13. s-XML approach
A node-labelling technique is employed by the s-XML approach [17]. A persistent-labelling schema is the basis of the development of this approach [26]. A dynamic update is supported by this labelling schema, and the competence of the XML processing is enhanced. The support for the recovery of structural queries is efficient, as well as complex chain and twig queries. The parent–child relationship among nodes is preserved through the utilization of the LParent attribute. Moreover, the ancestor–descendant relationship among the nodes is effortlessly preserved through the reduction of the level by one and the corresponding parent-label and self-label. Based on the XML document in Figure 2b, the RDB schema in Table 13 is yielded through the model mapping process in the s-XML approach.
s-XML scheme: (a) ParentTable; and (b) ChildTable.
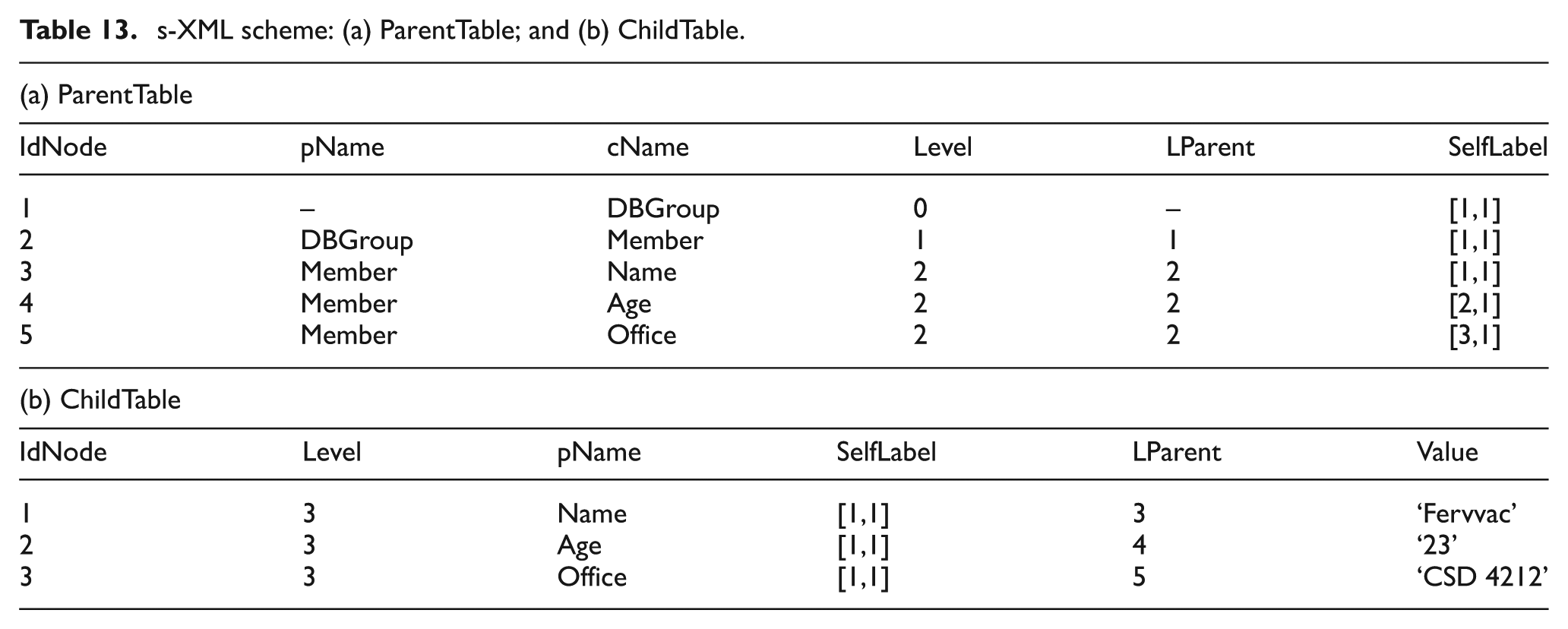
This approach uses ParentTable and ChildTable to describe the relational schema. In the ParentTable, the IdNode attribute denotes a unique node identifier; pName stores the parent node name; cName preserves the child name; Level retains the level information; LParent conserves the parent label of the node, where the reference of the parent label (IdNode) is stored; and SelfLabel preserves the self-label or local label of the node, which is [n,d] in the Persistent Labeling. In the ChildTable, IdNode is a unique node identifier; Level stores the node level information in the XML document; pName stores the element name of the parent node; SelfLabel preserves the self-label or local label of the node [n,d] in the Persistent Labeling; LParent conserves the node parent-label; and Value stores the node value
This study indicates that the s-XML approach is limited because it increased the storage space and query response times. The inner node information stored in the RDB will expand the storage space. With regard to query processing aspects, the paths for each node are not stored in a separate table, but multiple joins in the tables or the recursive utilization of the LParent attribute (nested queries) are used instead, causing expensive RDBMS. Hence, the s-XML approach increases the query response time for all kinds of queries.
5. Model mapping techniques
Many studies and giant vendors such as Oracle, Sybase, IBM and Microsoft have proposed techniques for storing and querying XML documents in relational tables [27]. New techniques are put forward by some of the approaches, and prevailing techniques are even improved. This section discusses 13 techniques found in the literature, which are the most cited and the latest model mapping techniques for storing and querying XML documents through RDB. These techniques are categorized into six main techniques, as shown in Figure 3.
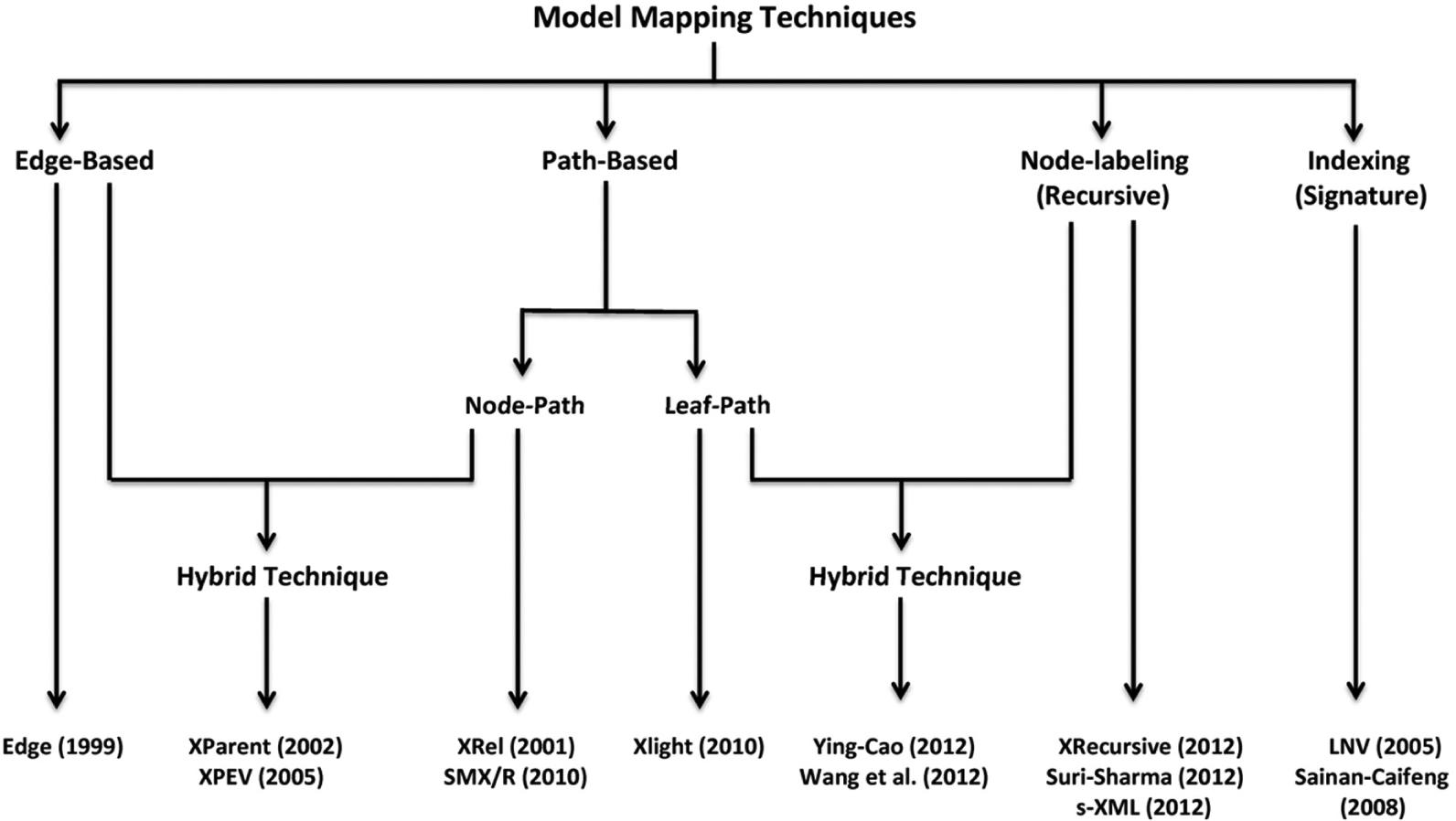
Model mapping techniques.
The six main techniques are categorized as follows:
Edge-based: this is the simplest and the most basic, where all the edges of the XML tree that represent an XML document in a single table are stored. However, a large amount of storage space is needed for storing XML documents because all of the document edges are stored in a single table. This will increase the query response time, particularly in complex queries with large XML documents. Excessive self-joins are required, which is actually the most exorbitant application in RDBMS. The Edge approach is one example of a mapping approach that employs this technique.
Path-based: hierarchical querying is required in this technique. This will lead to a great number of join operations, which increase the query response time. The path expressions are a conventional and compact way to represent hierarchical relationships by embedding them within SQL queries and compiling them to standard SQL [28]. The utilization of the path table in the RDB schema of the mapping approach is the main concept of this technique. The path identifier and path string for a node are stored in the path table. The concept of storing information in a path table reduces the search space for a node in other tables.
This technique can be categorized into two sub-techniques according to the path type stored in this table. First, the path information from the root to each node of the XML document is stored in one table, while the node information of the document is stored in a separate table. The XRel and SMX/R approaches are examples of approaches that employ this technique. Second, the path information from the root to each leaf node of the XML document is stored in one table. Storing all the inner nodes of the document in a separate table is unnecessary; only the leaf node information is stored. The Xlight approach is one example of a mapping approach that employs this technique.
When comparing these sub-techniques, the second is evidently superior to the first in terms of reducing the storage space of the RDB and query response times. This is because the second sub-technique stores the leaf node information in a separate table.
Therefore, the search space between the path table and in the other table where the leaf nodes information is stored will be reduced, and the query response time will be reduced as well. The study concludes that the path-based technique is the best compared with other techniques in terms of storage and querying. However, this technique is still not considered as efficient, particularly in complex queries with large XML documents.
Hybrid (Edge- and Path-based): Edge and Path-based techniques are combined to form this hybrid technique. In this technique, all of the edges between the XML document nodes are stored. The path information from the root to any XML document node is stored in a separate table. The drawback of this technique is that a large amount of storage space is needed to store all of the edge information for large XML documents. This technique employs the Path table to store the path information of each node in the XML document, and because of this, the search space will increase, hence lessening the query response time. However, the containment relationships (<,>) that are utilized between nodes to preserve the parent–child and ancestor–descendant relationships among the nodes improve the query response time. The approaches XParent and XPEV and the enhancement of XParent, called XPred [29], are examples of mapping approaches that employ the hybrid technique.
Node-labelling: the node-labelling scheme of the XML tree is utilized in this technique to enhance the query processing and dynamic updates. In this technique, a number is allocated to each node to denote the identifier or the absolute position of the node in the document. This technique primarily aims to preserve the parent–child and ancestor–descendant relationships through the recursive employment of the parent node label in forming nested queries for answering the queries.
Numerous node-labelling techniques have been proposed, such as the Interval encoding, which relates to the number of words [30], Global order label [3], Local order label [3], Dewey order label [3], Pre-order post-order [31], ORDPATH [23], Prime number labelling [32], Variable Length Endless Insertable [33], Cluster-based order [34], Dynamic interval-based labelling [35] and the Persistent labelling scheme [26]. The node-labelling technique still has a drawback in terms of the high need for storage space, which may cause the column size to appear overhead in that particular label in the RDB. Another drawback of this technique is the high query response time, particularly for complex queries with large XML documents, where the parent node label is utilized recursively through nested queries. The XRecursive, Suri–Sharma and s-XML approaches are examples of mapping approaches that employ this technique.
Hybrid (Path-based and Node-labelling): Path-based and Node-labelling techniques are combined to form this hybrid technique. The Path Table that stores the path information for all leaf nodes of the XML document is stored through this technique. All of the inner node labels of the XML document are stored according to one of the node-labelling schemes, where the label of the parent node is utilized recursively for the query processing. The drawback of this technique is the high storage space requirement, particularly in large XML documents, because all of the inner node information is stored in separate tables. Another drawback is the high query response time, particularly in complex queries with large XML documents, where the parent–child and ancestor–descendant relationships among the nodes are preserved through the recursive process on the parent node label in the inner nodes table and through the path information of the leaf nodes. The Ying–Cao and Wang et al. approaches are examples of mapping approaches that employ this technique.
Indexing (Signature): this technique will traverse and parse the XML document only once. When the XML document is being traversed, the signatures for all of the labels of the distinct nodes that contain a number starting from 1 are stored in a separate table, and all the path information of the leaf nodes is stored in another table. Only leaf node paths in the document are stored in this technique, excluding the nodes. Thus, this technique reduces the storage space required for sizable XML documents. Two steps for query processing are needed before the query is being executed. First, the XML query (XPath) is replaced into a path of signatures according to the label signatures of the nodes. Second, the XPath query (path of signatures) is translated into a SQL statement. Therefore, the query response time is increased, particularly in complex queries with large XML documents. The LNV and Sainan–Caifeng approaches are examples of mapping approaches that employ this technique.
6. Summary of model mapping approaches
Research [36] shows that XML documents can be effectively stored in RDB schema through a model mapping approach by aiming for less storage space. In addition, the model mapping approach should be able to query XML documents, through an efficient preservation of the structural information of the relationships among the XML nodes. Hence, the query processing and the results generated will be accurate and will be in accordance with the data stored in the original XML document. Structural information should be stored in the RDB schema to identify the connection among the nodes in the XML document. Most practical applications use the parent–child and ancestor–descendant relationships, which received the most research interest [37].
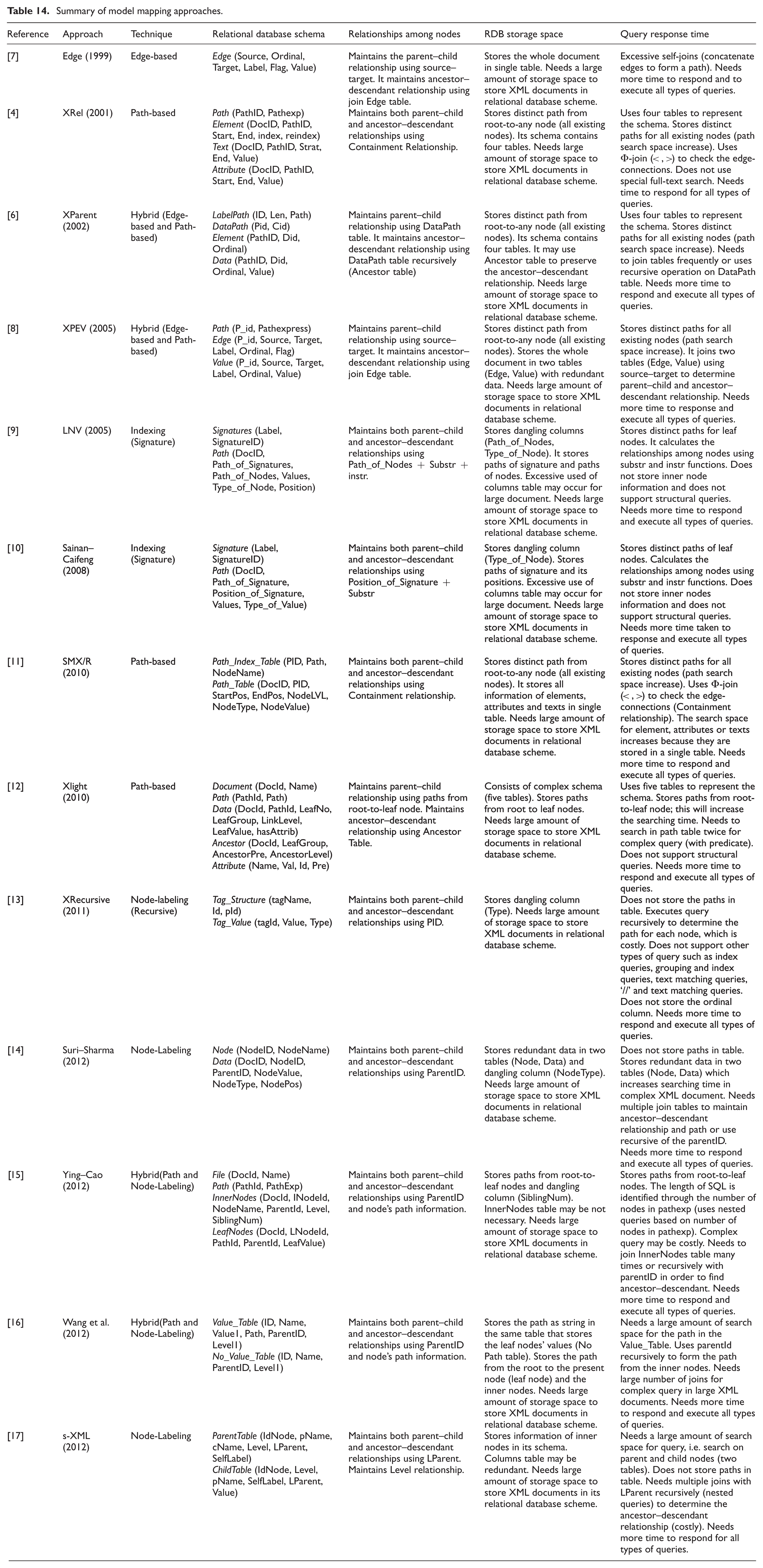
The reviewed 13 approaches are summarized in Table 14, and compared against the techniques used, RDB schema produced, the relationships among the XML nodes and the effect of each approaches on RDB storage space and query response time.
Summary of model mapping approaches.
7. Discussion
As summarized in Table 14, the model mapping approaches discussed in this study have some drawbacks in mapping XML documents to RDB. The drawbacks are discussed in terms of the storage space used to store RDB schema and time taken to process the query.
7.1. RDB storage space
This study concludes that the main problem of the existing model mapping approaches is the requirement for large amounts of RDB storage space because of the techniques they use in preserving the contents and structures of the XML documents in RDB schema. These approaches store all information of the XML documents in complex RDB schemes with unnecessary information, redundant data, dangling tables and columns, and column size overhead. This will increase the storage space requirement of their RDB schema, particularly in large XML documents.
The RDB schema storage space created by the mapping process is expanded because of the techniques they employ. In the Edge approach, the entire XML documents are stored in a single table. In the Xlight approach, XML documents are stored in a complex RDB schema, where the table created suffers from dangling tables and columns. In the approach used by Suri–Sharma, Ying–Cao and Wang et al., the internal node information of the XML document is stored in RDB schemas. This technique will lead to extra storage space requirements. For the XRel and SMX/R approaches, the path information of each XML document node, which is from the root node, is stored in the RDB schema. This technique will also lead to an extra storage space. In the XParent and XPEV approaches, redundant data are stored for the preservation of ancestor–descendant relationships among the XML nodes, such as the Ancestor and Edge tables. The technique employed to preserve the ancestor–descendant relationships can be improved further if we want to reduce the storage space used to store XML document in RDB schemas.
7.2. Query response time
This study concludes that the existing model mapping approaches suffer from high query response timese because of the techniques they use in preserving all relationship information among the nodes of the XML document. In particular, while trying to preserve the relationship between the parent–child and ancestor–descendant, a high number of join operations in the SQL queries is needed. This will increase the query response time as well.
The Edge approach uses Edge-based technique for maintaining these relationships by concatenating the edges of the XML tree using (source, target) attributes. Therefore, this technique needs multiple self-join operations during SQL queries and this will contribute to longer processing time. XRecursive, Suri–Sharma and s-XML approaches employ Node-labelling techniques to preserve parent–child relationships by storing the (parent id) in the RDB schema. However storing parent id attribute and other similar attributes to preserve ancestor–descendant relationships will introduce extra RDB storage and long query times because these attributes need to be recalled frequently in nested SQL queries. The XRel, SMX/R and Xlight approaches employ Path-based techniques to preserve the relationships among the nodes. These approaches store the path information for each node of the XML tree in the Path table. However these kind of techniques will increase the time taken in the presence of twig queries. The XParent and XPEV approaches employ hybrid (Edge and Path-based) techniques, where the labels of the edges are concatenated for the path needed for multiple self-joins. The Ying–Cao and Wang et al. approaches employ hybrid techniques (Node-labelling and Path-based), where the parent id is used recursively for the internal nodes and leaf node of the path table. The LNV and Sainan–Caifeng approaches employ a certain indexing technique called ‘Signature’, where the node paths are stored as paths of the label signatures of the nodes. These kinds of techniques will increase the query response time, particularly in complicated queries with large XML documents.
7.3. Solutions
The study indicates that the existing model mapping approaches were unable to provide efficient storage and query processing when XML documents are stored in RDB. To overcome the issue of RDB storage space, this study proposes that the XML document contents and the structural information (structural relationships among the nodes) of the document need to be stored in optimal RDB schemas. The optimal RDB schemas must be free from dangling tables and columns, and free from data redundancy. Since path expressions frequently appear in XML queries, particularly in XPath queries, it is essential to efficiently store and handle the path information of the XML document. The technique of storing path expression information of XML trees done by the existing approaches is inadequate because it might happened that more than one node may share similar path expressions. If this situation occurs, the precedence information among the nodes will lost. Therefore, this study suggests that, in order to produce optimal RDB schemas, the technique needs to store the order or the position of the nodes in the XML tree. In order to reduce the query response time, the model mapping approach should consider several issues. The information on the structural relationships among the XML nodes, such as the parent–child and ancestor–descendant relationships, needs to be stored. The XPath query types, such as the short simple path, long simple path expression, query with one ‘//’, query with two ‘//’, complex query (twig query) with one predicate or more, and complex query with ‘//’, need to be handled efficiently. The mapping techniques should consider how to handle SQL statement such as ‘Like’ matching operator used in the path expression, because this statement is an expensive operation in RDBMS.
This study only focuses on proposing an efficient model mapping approach for storing and querying XML documents in terms of reducing storage space and improve query response time. However, several challenging issues have not been reviewed and, therefore, require extensive research. The following issues may need to be considered in order to improve the existing model mapping approaches:
Loading time – the time taken to load the XML document into RDB scheme. Although some of these approaches such as XRecursive and s-XML examined this issue, they still did not resolve it efficiently. Therefore, the loading time is a critical issue to be considered in proposing an efficient model mapping approach.
Extraction time – the time taken to retrieve the records from RDB scheme and reconstruct an XML document. Although some of these approaches such as Edge, Xlight, and XRecursive examined this issue, they still have some drawbacks. Consequently, the extraction time of the model mapping approaches requires further review.
Dynamic update – considering that XML is a popular language for data representation and exchange on the web, this type of data updates as time passes. Dynamic updating does not require modification and relabelling of existing data stored in its RDB, such as when inserting a new element in the XML documents. Numerous node-labelling techniques have been proposed, such as Interval Encoding Based on the Number of Words [30], Global Order Label [3], Local Order Label [3], Dewey Order Label [3], ORDPATH [23], Prime Number Labelling [32], Cluster-Based Order [34], Dynamic Interval-Based Labelling [35] and Persistent Labeling Scheme [26]. These techniques were used in most of the existing model mapping approaches. However, these approaches still have drawbacks in supporting dynamic updates efficiently. Therefore, the dynamic update is an important issue to be considered in future research.
Full-text and structural queries – based on user demand, XML queries can be classified into two forms, full-text query and structural query. In a full-text query, users usually do not know the entire or the exact structure of the XML document. They might be aware of names of the element nodes or values of attribute nodes and leaf nodes. These texts are used as constraints in querying for statistical information. Although full-text querying involves certain keywords or paths, and is simple in most scenarios, the answers provided by the search engine are excessive to retrieve accurate and limited answers. The query can be fulfilled by matching the Path provided in the Path table. The structural query is more complicated. The user often has a deeper understanding about the content within the XML document. Structural queries include complex chain and twig queries. Therefore, an efficient model mapping approach should support both full-text and structural queries.
Relationships among XML nodes – there are four relationships among XML nodes that an efficient model mapping approach needs to cater for: the parent–child, ancestor–descendant, level and sibling relationships. The information on these relationships needs to be stored in the RDB schema to preserve the content and structure of the XML document by identifying the connections between XML nodes. Although the existing model mapping approaches preserved these relationships among XML nodes in their RDB, the query response time was still high. Therefore, further research is necessary in order to propose a new model mapping approach that able to overcome this issue efficiently.
8. Conclusion and future work
This study has reviewed 13 approaches which are the most cited and the latest model mapping approaches for storing and querying XML documents in RDBs found in the literature. These approaches are the Edge, XRel, XParent, XPEV, LNV, Sainan–Caifeng, SMX/R, Xlight, XRecursive, Suri–Sharma, Ying–Cao, Wang et al. and s-XML. This review discusses the techniques used by each approach, the RDB scheme produced and the issues that lead to high storage space requirement and query response time. The review emphasizes the preservation of parent–child and ancestor–descendant relationships by each approach. This preservation will determine efficient model mapping approach in terms of storing and querying XML documents through RDBs. This study demonstrated the techniques used and the drawbacks by each of the approaches in terms of the storage space and query response time.
This study concludes that the 13 model mapping approaches have some drawbacks in storing and querying XML documents through RDBs. Regarding the storage space drawbacks, the XML documents that were stored in RDBs suffered from dangling tables, dangling columns and column overhead size. This will increase the storage space required for storing XML documents in the RDB (i.e. the cost of storage space was very high). Regarding the query response time drawbacks, these approaches processed different kinds of queries through numerous join operations and nested queries (recursively). This will expand the search space, affecting the execution and query response times. Additionally, these approaches did not store all the relationship information among the XML nodes, such as the parent–child, ancestor–descendant, level and sibling relationships, which were needed to obtain precise answers for the queries and reduced query response time. Given these reasons, the performance for these kinds of queries was reduced, particularly in complex queries with large XML documents.
There is a need to develop an effective model mapping approach that can overcome the drawbacks on storing and querying XML documents in RDB schema. To overcome the RDB storage space problems, the proposed approach should store XML document contents and the structural information without dangling tables and columns, and less data redundancy. To overcome the query response problems, the proposed approach should preserve the parent–child and ancestor–descendant relationships among XML nodes in an optimal way by reducing the search space and reduce the number of join operations in the SQL statements. Proposing an effective model mapping approach to overcome the limitation of the existing approaches will be the next agenda in this study.
The results of this study will be useful for the research community and will serve as an appropriate introductory material for researchers in this area. In addition, this study will lead the practical study on the 13 model mapping approaches through experimental evaluation with regard to the RDB storage space and query response time.
Footnotes
Funding
This research is funded by Universiti Kebangsaan Malaysia under Fundamental Research Grant Scheme FRGS/1/2014/ICT07/UKM/02/3.