
Abstract
Approximate string matching (ASM) is a challenging problem, which aims to match different string expressions representing the same object. In this paper, detailed experimental studies were conducted on the subject of toponym matching, which is a new domain where ASM can be performed, and the creation of a single string-matching measure that can perform toponym matching process regardless of the language was attempted. For this purpose, an ASM measure called DAS, which comprises name similarity, word similarity and sentence similarity phases, was created. Considering the experimental results, the retrieval performance and system accuracy of DAS were much better than those of other well-known five measures that were compared on toponym test datasets. In addition, DAS had the best metric values of mean average precision in six languages, and precision/recall graphs confirm this result.
1. Introduction
The aim of approximate string matching (ASM), which is a challenging problem with a long history, is matching two or more reference names representing the same real-world object with their original name. ASM is applied in many different domains such as text processing, pattern recognition [1, 2], network security [3] and computational biology [4]. ASM is often a complex and time-consuming process that needs a huge amount of computing resources. Therefore, today there is still a need for efficient ASM measures.
Considering the literature, there are many studies that have reviewed various subjects such as entity resolution, record linkage and fuzzy matching, which are similar to approximate string matching in basic terms. Sarawagi and Bhamidipaty [5] and Tejada and Knoblock [6] employed committee-based active learning method in order to enter correct records into the record-level classifier in the training phase. Bilenko and Mooney [2] presented a machine learning-based adaptive string matching approach. Bunke et al. [7] studied rule-based fuzzy object similarity. Cohen et al. [8] evaluated many string similarity measures to solve the name-matching problem and obtained the best result with Jaro-Winkler using the combination of token-based distance functions. Bhattacharya and Getoor [9] attempted to solve the entity resolution problem using the model of latent Dirichlet allocation [10], which is a probabilistic method. Al-Ssulami [11] proposed a hybrid exact string-matching algorithm, which scans the text from left to the right and matches the pattern from right to the left. Christen [12] studied the subject of name-matching using the well-known 21 string-matching measure and concluded that there is not a single matching method that can perform all kinds of tasks.
In this paper, unlike previous studies, the subject of toponym matching, which is a new domain for ASM implementation, is discussed in detail. A toponym is defined as a geographical location name [13]. Today, it is possible to come across toponym information from digital libraries to World Wide Web content, and the amount of this type of data is increasing continuously. The biggest problem in toponym data is that toponym information regarding same location frequently differs. Incorrect or missing translations and the existence of different names for the same location depending on culture may be the cause of this problem. Toponym matching is performed using ASM criteria in order to associate official names and alternative names of these locations. Toponym matching is defined as matching similar names indicating the same location. For example, although the names of ‘Aksaagac’, ‘Ağsaağaç’ and ‘Agsaagac’ contain some different characters, they are all alternative names for the same location.
Although there are a few studies on the subject of toponym matching, considering similar studies, most of the studies have focused on the fields of geographic information retrieval (GIR) and geographic record linkage. In the study of Sehgal et al. [14], Edit-Distance, Jaccard and Jaro-Winkler string similarity measures were used to match the names of the locations in Afghanistan, and they showed that Edit-Distance measure had better performance compared with other measures. Martins [15] tried various features of the machine learning classification approach to find duplicate and non-duplicate ones among gazetteer records, and achieved some success. Hastings [16] developed a new string similarity measure to be used in the automatic matching of the gazetteer data. The only study focused on toponym matching was conducted by Recchia and Louwerse [17]. In their study, they evaluated the performance of different string similarity measures, and they showed that the performance of string similarity measures is largely dependent on language. For instance, if it is an agglutinative or root-inflected language depending on gender or conjunctions that are used frequently, then the matching results will be affected directly.
In this study, the creation of a single ASM measure, which is unique to this domain, that can perform the toponym matching process regardless of the language, was attempted. For this purpose, an ASM measure called DAS, comprising name similarity, word similarity and sentence similarity phases, was created. The matching performance of DAS was performed on the toponym dataset of six different countries (Egypt, France, Germany, Russia, Turkey and America), which were downloaded from National Geospatial-Intelligence Agency (NGA) GEOnet Names Server, and compared with five well-known ASM measures. Considering the experimental results, the retrieval performance and system accuracy of DAS are much better than those of other measures that were compared on all datasets. For example, the DAS measure found an alternative name for 289,164 toponym data out of 311,437, which is an important retrieval achievement. In addition, the DAS string-matching measure had the best MAP metric values in all languages, and precision/recall graphs confirm this result. Contributions of this paper can be listed as follows:
toponym matching is a newly introduced application domain of approximate string matching;
we developed a unique ASM measure named DAS, which is created for the task of toponym matching only;
we tested DAS on six datasets with five well-known ASM measures and we saw that DAS had the best retrieval performance and system accuracy among all others.
The rest of the paper is organized as follows. In Section 2, the ASM measures compared are introduced briefly. Section 3 presents the details of proposed ASM measure, which is named DAS. In Section 4, the experimental setup is described and the obtained experimental results are discussed in Section 5. Finally, the conclusion is given in Section 6.
2. An overview of string-matching measures
String-matching measures try to compare two string expressions through a variety of ways. These measures are usually built on a similarity function. If the similarity score obtained from
2.1. Jaro Winkler similarity measure
The Jaro-Winkler [18] similarity measure is based on the Jaro [19, 20] similarity measure and located in the edit-based category. It was developed by considering misspellings. When calculating similarity ratios with Jaro-Winkler, greater importance is given to the starting characters compared with other characters [12]. If the string expression contains more than one word phrase, it returns the highest value by calculating all possible permutations.
2.2. Levenshtein similarity measure
The Levenshtein similarity measure [21] is also located within the edit-based category. The similarity ratio is determined based on the least number of addition, deletion and substitution processes required for conversion of
2.3. Monge Elkan similarity measure
The Monge Elkan similarity measure [22, 23] is in the hybrid category, and works in recursive logic. The similarity ratio of two string expressions containing more than one token is found using an internal measure of similarity.
2.4. N-gram similarity measure
The N-gram similarity measure [24, 25], in the token-based category, determines common substring numbers with a length of n owned by two string expressions compared with each other. If the length of n is equal to 1, it is named a unigram, whereas it is named a bigram if the length is equal to 2 and a trigram if it is equal to 3. In the N-gram similarity measure, the similarity ratio is obtained by dividing the number of N-grams in the short and long expressions by the number of common N-grams for each one.
2.5. Jaccard similarity measure
The Jaccard similarity measure [24] is also located in the token-based category. The Jaccard similarity measure score for two strings
3. Proposed DAS similarity measure
The DAS similarity measure that we have developed using C programming language is in the hybrid similarity category, which includes the features of the token-based and edit-based categories together. The term DAS consists of the first letters of the names of the author’s family. The DAS measure contains three different stages as follows: name similarity, word similarity and sentence similarity. In the first stage, word similarity is performed and the score of
3.1. Word similarity measure
The algorithm of word similarity is shown in Figure 1. First, the weight of characters of the longer string among


Word similarity algorithm of DAS.
For example, while computing similarity ratio of two words ‘kasa’ and ‘kiraz’ in Turkish using the word-matching measure, after trimming spaces from the longer word (kiraz), the weight of each character is assigned. The weight of the ‘k’ character is calculated by the formula wk = 1/max(|‘kasa’|, |‘kiraz’|), which gives 1/5 = 0.20. After defining the character weight of the longer expression, words in expressions are tokenized. The similarity ratio of every word in both expressions is calculated and stored in order. The similarity ratio between two tokens,

where,
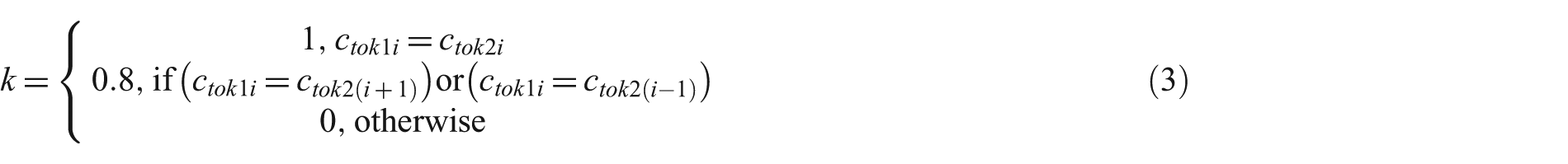
First, character comparison of the paired tokens is performed, and the weight of character is multiplied by the similarity coefficient k, then it is added to the token similarity ratio. If there are the same characters in the same indices, the similarity constant k is considered as 1, which gives the maximum similarity. Missing or extra letter writing is one of the most common writing errors causing no similarity to be found between two words when in fact they are similar. In order to overcome this problem, word similarity measure is designed by considering the importance of adjacent characters. If there is a match with either the previous or the next index, then k is taken as 0.8. In order to determine the appropriate value of similarity coefficient k when there is a match with either the previous or the next index, we design an experimental study that compares the performances of different k values. In this study, the value of similarity coefficient k is selected as 0.8 based on the experimental results. It should be noted that the value of k is adjustable and can vary according to dataset. Lastly, if there is no match with the same or adjacent indexes, k is selected as 0.
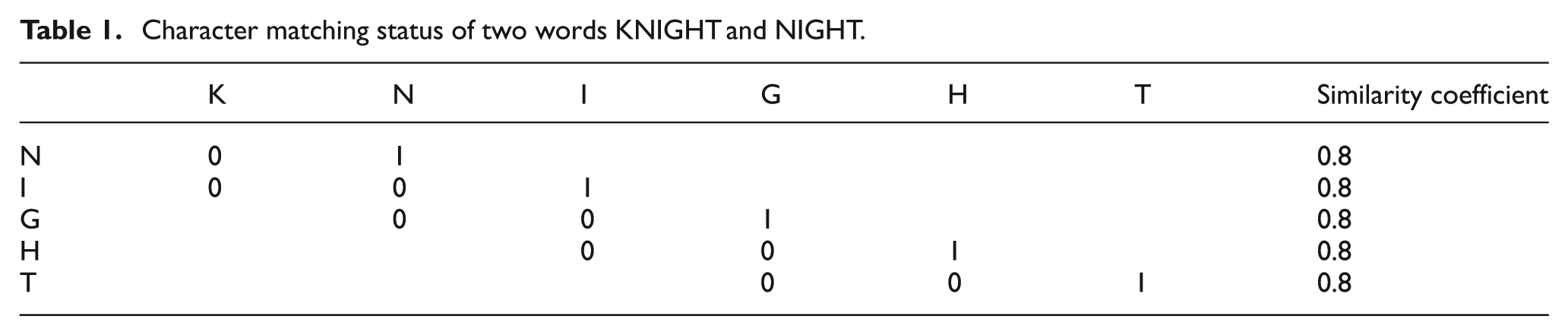
For example, while comparing two words ‘KNIGHT’ and ‘NIGHT’, the weight of each character is calculated as
Character matching status of two words KNIGHT and NIGHT.
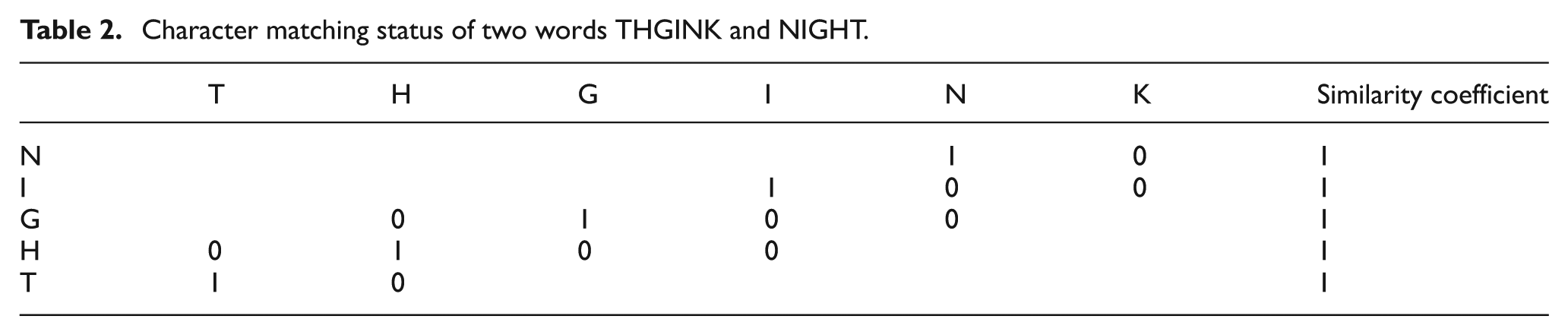
This process is also performed for reverse versions of the words ‘KNIGHT’ and ‘NIGHT, which are ‘THGINK’ and ‘THGIN’. In Table 2, the character-matching status of these two reversed words is given. Their character weights
Character matching status of two words THGINK and NIGHT.
3.2. Sentence similarity measure
Sentence similarity measure is based on the logic of matching words of two string expressions by searching these words in each other. The algorithm details of this measure are given in Figure 2. First,
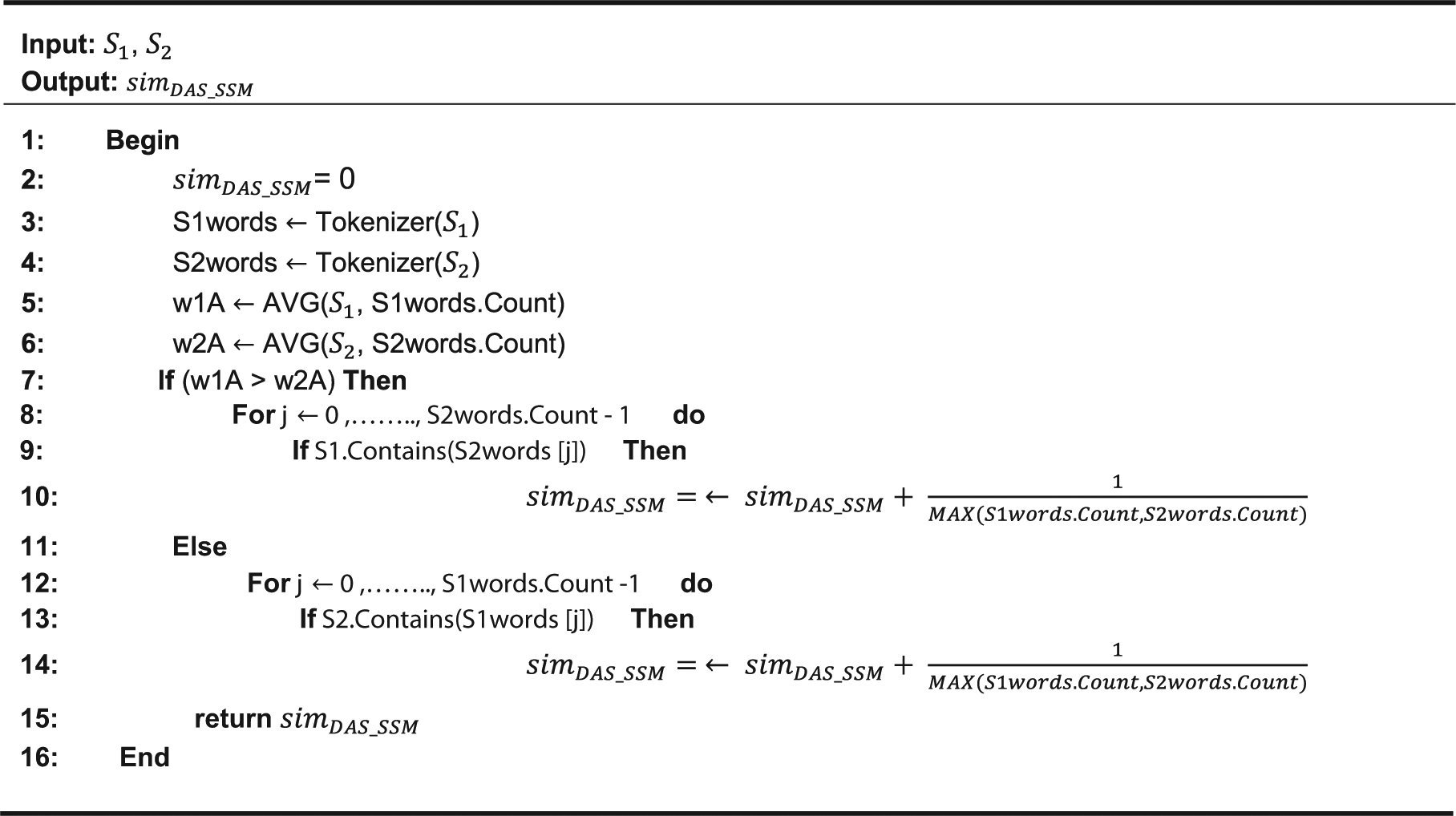
Sentence similarity algorithm of DAS.
For example, while comparing two toponym data
As seen in Table 3, ‘Mount’ and ‘Alp’ tokens are matched. As a result, the sentence similarity score is calculated as follows:
Token matching status of two expressions.

3.3. Name similarity measure
The calculation approach of the name similarity measure is substantially different from other stages. If the greater of the similarity scores calculated at the end of the sentence and word similarity stages is above a certain threshold value, then the name similarity measure can be performed. Otherwise, this stage will not work. The mainstay of this approach can be explained as follows: if similarity scores of

Name similarity algorithm of DAS.
Since the threshold value directly affects the selection of name-matching stage and the matching performance of the DAS measure, it is very important to find the optimum value of this parameter. In this study, this case is considered as a mathematical optimization problem. Mathematical optimization is a search process that uses real or integer values within a set systematically for solving the problem of either maximizing or minimizing a real function. If we consider the DAS similarity measure as a real mathematical function, the optimum value of the threshold t parameter of this function would give us the maximum MAP value.
One dimensional Grid Search [26] algorithm is utilized in order to solve the optimization problem. The Grid Search algorithm has a simple straightforward logic along with a naive structure. In this study, the number of grid points, which were searched in the state space, is reduced by using the Grid Search algorithm as iterated. The toponym datasets of 10 countries were selected as test sets in order to find the optimum values of threshold parameter. In the selection process, it has been considered that structures of the language of test datasets are different from each other and it was important to create as heterogeneous a test dataset as possible. In the test set of each country, the following steps of the Grid Search algorithm were performed:
After running the Grid Search algorithm for 10 test sets, the best grid points (threshold values) were obtained for each country. As presented in Table 4, in the first run, the point value was found as 0.25 for eight out of 10 country test sets and found as 0 for the remaining two sets. To increase the accuracy of the threshold value obtained, the Grid Search algorithm was run 2 more times with an iterative approach. In the second run, the five new grid points were determined as {5, 10, 15, 20, 25} and the Grid Search algorithm was run again. In general, the same or higher MAP values were obtained. Finally, the Grid Search algorithm was run for the third time within the range of five new grid points {15, 17, 19, 21, 23} and the iteration was terminated.
Calculating the best Grid Points corresponding to MAP values by running the Grid Search Algorithm iteratively.
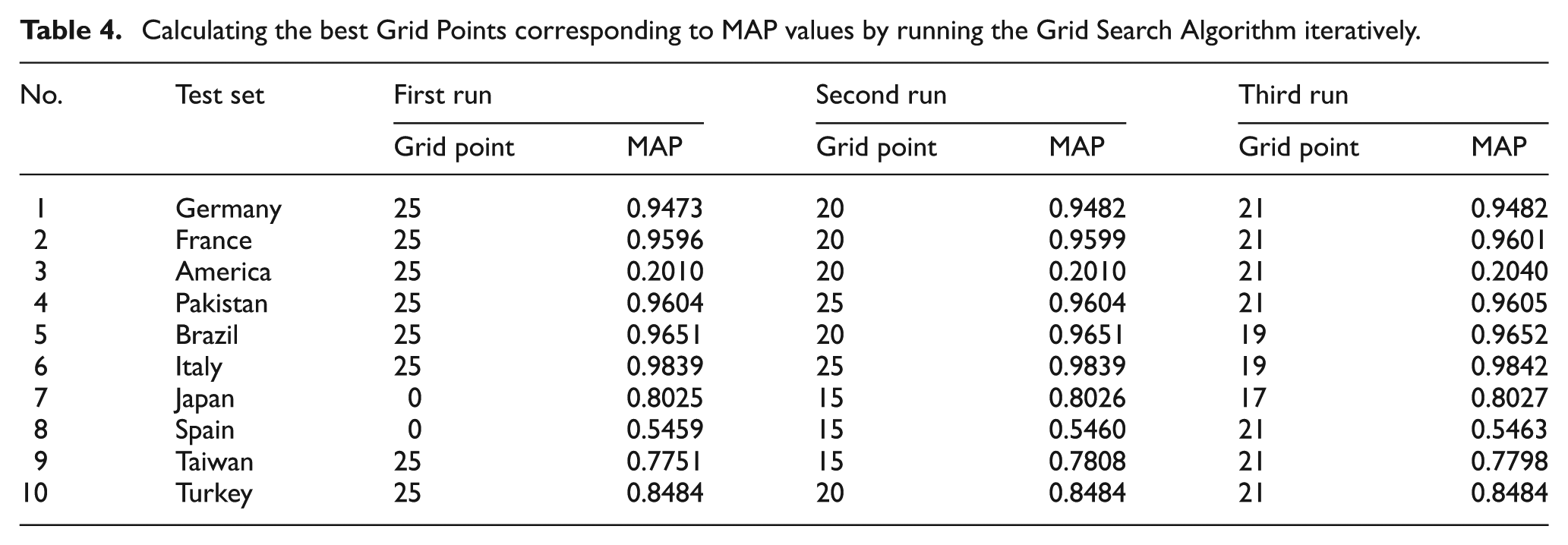
In Table 4, the grid points obtained as a result of each of three runs and the corresponding MAP values are presented. Considering the results of the third run, 21 point values were selected in seven datasets, whereas 19 were selected in two datasets and 17 were selected in one dataset; and the threshold values were found close to each other in these datasets. In this study, the mathematical average of all grid point values found as 20.2 and this average value was determined as the justified threshold value that achieves optimum MAP values. The threshold value was calculated in the dataset-preparation step and was experimentally used in order to evaluate the DAS measure in all datasets.
4. Experimental study
4.1. Dataset preparation
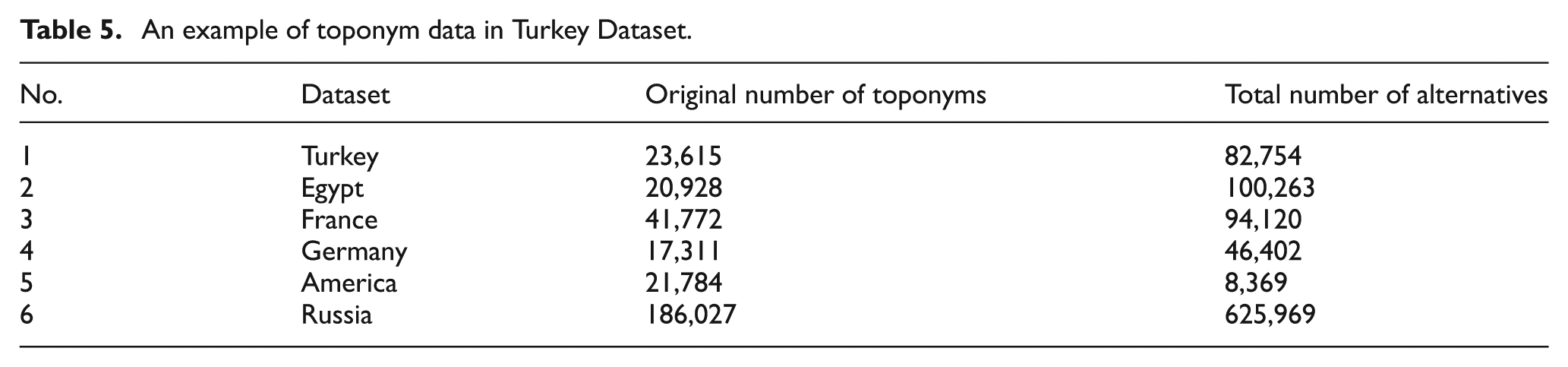
First, 12 toponym files containing the toponym information belonging to the countries Egypt, France, Germany, Russia, America, Japan, Pakistan, Taiwan, Spain, Brazil, Italy and Turkey were downloaded from NGA GEOnet Names Server. Then, 12 separate datasets were created by performing parsing and tokenization processes for each file. During these processes, location names with no alternative names or the same alternative names as themselves were deleted from the datasets. Ten out of 12 datasets were employed to calculate the optimum value of the threshold parameter using the Grid Search algorithm. Six of these datasets were also used for experimental comparison of the DAS string-matching measure with other measures. The toponym information included by these datasets to be used for comparison is presented in Table 5. Accordingly, the Turkey Dataset has a total of 82,754 alternative names for a total of 23,615 toponym data. The highest number of toponym data is in the Russia Dataset, and there are 625,969 alternative names for a total of 186,027 toponym data. There are 311,437 toponym data for all languages, and 957,877 alternative names for all of these toponym data.
An example of toponym data in Turkey Dataset.
4.2. Experimental methodology
An information retrieval-based evaluation system was experimentally set up rather than a matching-based evaluation system in order to measure the performance of the DAS similarity measure compared with other measures. Information retrieval is a discipline dealing with bringing the relevant documents back in response to the query Q in D collection, which does not have a defined structure [27].
In this system, the toponym data in each dataset represent the queries. For example, the Turkey Dataset has a total of 23,615 units of toponym (queries) and all of these toponyms have a total of 82,754 units of correct alternative names that are already identified by NGA. A test collection containing location names was also created to run the queries and obtain the results. There are both relevant and irrelevant toponym data in this collection, which is specific to the dataset of each country. While relevant toponym data contain correct alternative names belonging to each query, irrelevant toponym data were created by selecting five toponyms starting with different letters from original datasets. In the test collection, a similarity score between each toponym and query was computed according to an approximate string-matching measure, followed by ranking all toponym results in accordance with the similarity score. Finally, evaluation metrics were calculated in order to check the performance of each measure.
4.3. Evaluation metrics
Since the experimental infrastructure of the study is created based on information retrieval, standard evaluation metrics were used to measure accuracy and effectiveness of information retrieval system. Precision and recall metrics are two important metrics of these. Recall is the fraction of actual alternative names that are identified, whereas precision is the fraction of retrieved alternative names that are correct;

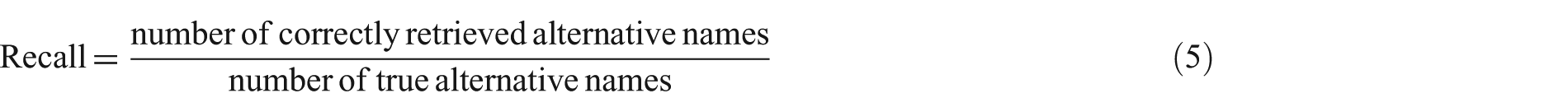
Precision–recall charts are used to measure the performance of the system. In this graph, precision values are given at a certain cut-off level in case of the recall [25]. One of the most optimistic metrics to measure the quality of information retrieval systems is mean average precision (MAP). This metric was used to find the mean of the average value of precisions via a set of queries [28]:

where Q represents a number of original toponym data. Each qj toponym data has an alternative location name relevant to itself (mj). Rk is a series of results starting from the alternative toponym at the highest similarity ratio to the toponym data k, which is really looked for. Higher values for MAP metric mean that more effective toponym retrieval is performed.
5. Experimental results
In order to accurately evaluate the performance of the DAS string similarity measure, toponym datasets of Turkey, Germany, France, Russia, the USA and Egypt were selected in particular, since they have different language structures. The DAS string-matching measure was compared with five well-known similarity measures – Levenshtein, Jaro-Winkler, Monge Elkan, Bi-Gram and Jaccard. All experimental evaluations were performed using a justified threshold value to trigger the name similarity measure of DAS. In Table 6, string matching performances of all measures on six datasets are summarized.
Experimental comparison results of DAS measure.
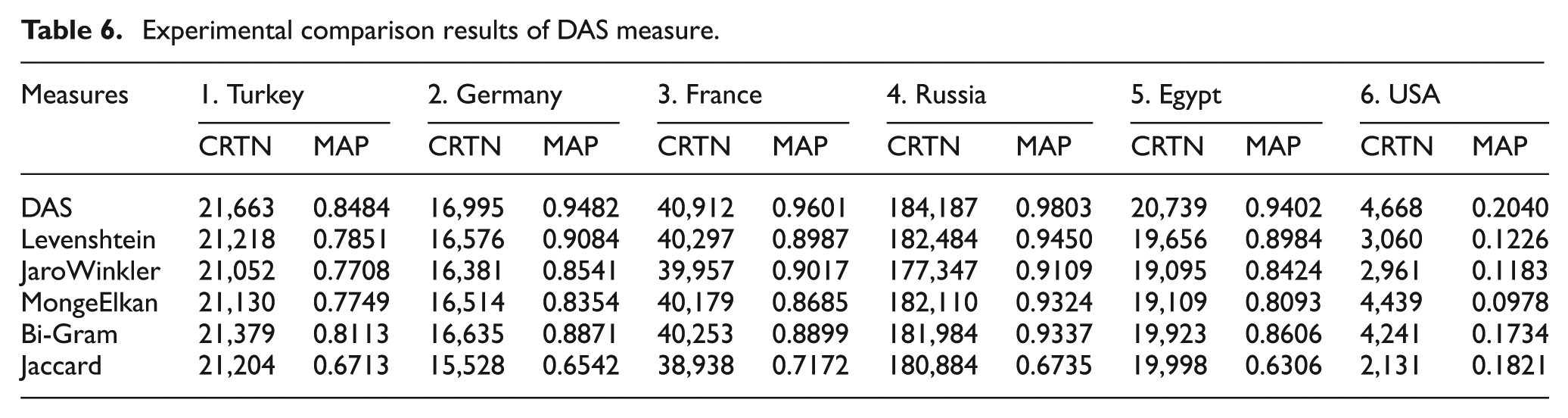
MAP metric results and correctly retrieved toponym names (CRTN) values were used for performance comparison. The CRTN value was calculated depending on any toponym data having at least one alternative name. The DAS string-matching measure obtained the best MAP results in datasets of Turkey, Germany, France, Russia, Egypt and the USA as follows: 0.8484, 0.9482, 0.9601, 0.9803, 0.9402 and 0.2040, respectively. Considering CRTN numbers for each language dataset, the DAS measure found 284, 360, 615, 1703, 1083 and 229 more alternative names compared with the measure having the closest performance to DAS measure.
Figure 4 presents the precision–recall curves for toponym-matching experiments of each dataset. A higher area under the curve represents both higher precision and higher recall. According to these results, we can conclude that the DAS measure not only increased the CRTN values in six datasets, but also obtained the best results for overall system accuracy by increasing the MAP values in a consistent manner. As a result, the success of DAS string-matching measure is proven.
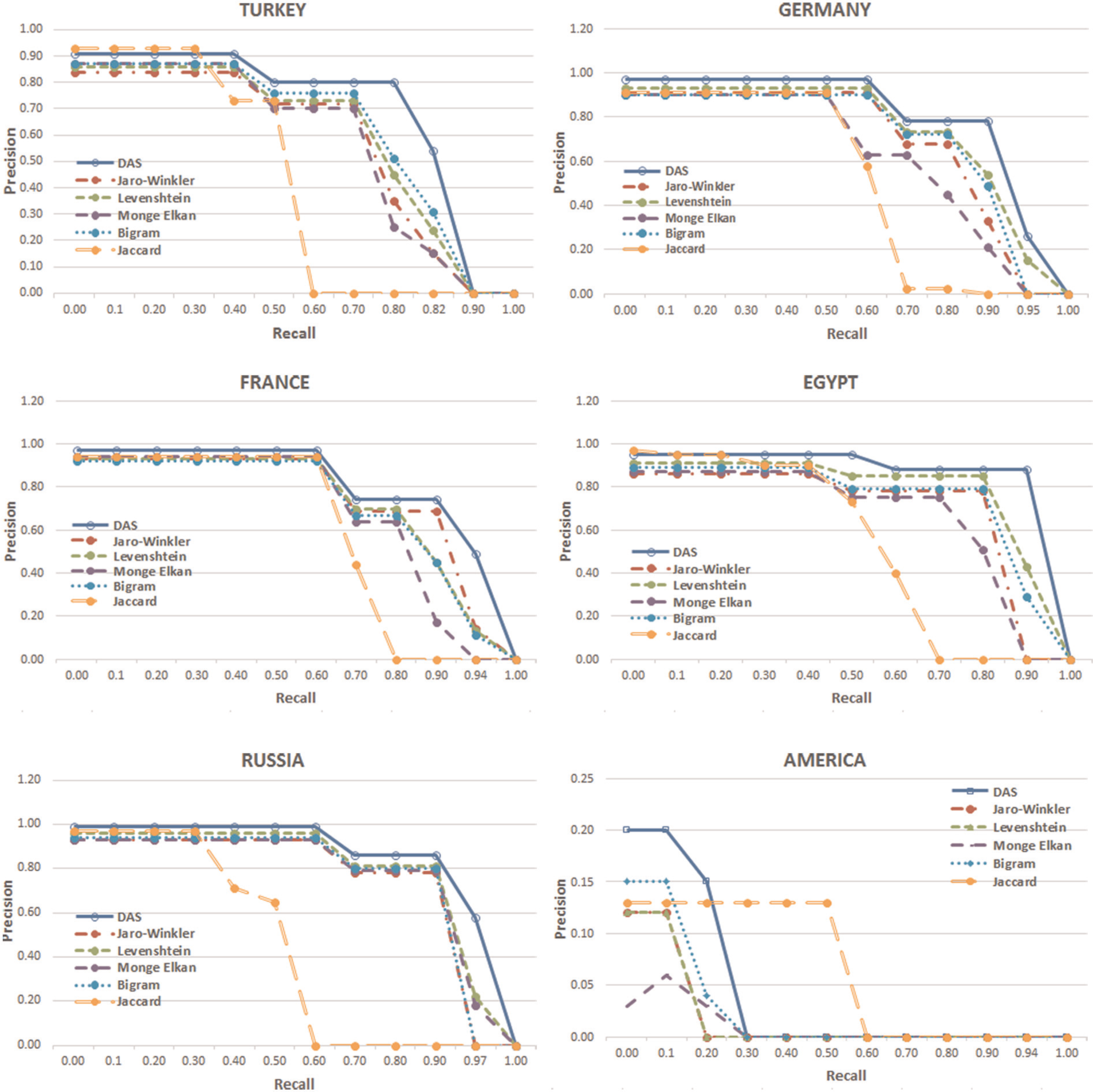
Toponym-matching results for the Turkey, Germany, France, Egypt, Russia and USA datasets.
As can be seen in Table 6, the DAS measure has the best retrieval performance and highest MAP values in the six datasets. Only the MAP results of America dataset are differentiated from the others. It can be seen from Table 5 that only the dataset of America has fewer alternative names than its original toponym data. Furthermore, in the America dataset, most of the toponyms do not have correct alternative names. Therefore, correctly matched alternative names and the MAP values are decreased for all similarity measures, including DAS. Considering that the languages selected differ from each other in terms of their structures, it has also been proven that a single string similarity measure can be developed specific to the toponym-matching task regardless of the language.
6. Conclusion
In this paper, detailed experimental studies were conducted on the subject of toponym matching, which is a new domain where ASM can be performed, and it was intended to create a single string-matching measure that can perform the toponym-matching process regardless of the language. For this purpose, a string-matching measure named DAS was developed and proposed.
An experimental information retrieval-based evaluation system was created in order to evaluate the performance of the DAS-matching measure compared with other measures. The DAS string-matching measure was continuously modified by performing hundreds of different experiments in toponym datasets. After performing all modifications, it has become a three-stage measure specific to the toponym-matching task. In particular, the calculations in the Name Similarity Measure stage and computing the optimum value of the Threshold parameter using the Grid Search algorithm positively affected the performance of DAS measure. As can be seen in Figure 4 and Table 6, according to comparisons with other similarity measures, the DAS measure had the best retrieval performance and the highest MAP values. As a result, considering the structural differences of languages selected for experimental tests, it has been proven that a single string similarity measure can be created specific to the toponym-matching task regardless of the language.
One of the future directions for the DAS measure consists of researching practical application areas. For example, GIR is one of the most appropriate application areas for DAS. We would like to integrate the DAS measure into a GIR-based application to be used in the toponym disambiguation task. In addition, the task of entity name matching might also be appropriate for the DAS measure. Specifically, patient name matching is a convenient task to evaluate and compare DAS with well-known similarity measures in the medical record linkage area. Another future work is researching the effect of structural differences for languages on the similarity score computation by considering the computational linguistics. Finally, the word similarity stage of DAS can be improved using edit-based, q-gram or pattern matching approaches.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.