
Abstract
Extracting patterns from web usage data helps to facilitate better web personalization and web structure readjustment. The classical frequency-based sequence mining techniques consider only the binary occurrences of web pages in sessions that result in the extraction of many patterns that are not informative for users. To handle this problem, utility-based mining technique has emerged, which assigns non-binary values, called utilities, to web pages and calculates pattern utilities accordingly. However, the utility of a pattern cannot always be determined from distinct web page utilities. For instance, the number of distinct users that traverse an extracted pattern or some demographic data about those users may affect the value of the extracted patterns. However, such information cannot be calculated directly from web page utilities. In this paper, we present a new approach based on a user-defined scoring mechanism so as to extract patterns from web log data. The proposed approach can limit the size of the search space; therefore it has the ability to extract patterns even for large and sparse datasets. The framework is hybrid in the sense that it combines clustering with a heuristic-based pattern extraction algorithm. Substantial experiments on real datasets show that the proposed solution effectively discovers patterns under user-defined evaluation.
1. Introduction
There is a huge growth of information sources on the Internet and, together with this growth, the user base is also growing. In such a situation, it is very important and necessary to facilitate users’ navigation of the web. Web logs are valuable resources to learn about navigation behaviours. Analysis of web log files to extract useful patterns is studied under web usage mining [1], which uses various techniques including clustering, association rule mining, classification and sequential pattern mining [2]. Extracted web access patterns are useful for various purposes such as web page recommendation, next page prediction, web site improvement and ad recommendation [3–6].
Most of the approaches to web access pattern mining are frequency-based solutions which find patterns that have web pages co-occurring together frequently in sessions [7–9]. However, an important limitation of frequency-based techniques is that they assume that each web page has the same importance (weight, unit profit or value) and only the frequency of a pattern determines its significance. These assumptions often do not hold in real applications. For example, for some application domains, not the frequent but the rare patterns may be of interest. Moreover, considering user interests, different web pages may have different impacts. To address this issue, a utility-based mining model is adapted to the pattern mining research [10].
Existing utility-based web access pattern mining techniques calculate pattern utilities based on the utility of the web pages. However, a pattern’s value cannot always be calculated from the distinct web page utilities. For instance, a user may be interested in patterns that exist in at least a number of distinct users’ sessions in the dataset. Similarly, the value of a pattern may depend on the average income of the users that traverse that pattern. In utility-based frameworks, such values cannot be calculated from the web page utilities. Instead, they should be calculated for each extracted pattern on its own.
In addition, common to both frequency-based and utility-based techniques, one important challenge is that there exists a huge number of possible patterns that are hidden in databases and the mining algorithm should find the set of patterns, when possible, satisfying the minimum support or the minimum utility threshold. For especially huge and sparse datasets, however, it is not possible to extract patterns under high threshold values. On the other hand, even state-of-the-art algorithms may fail to respond under low thresholds.
Motivated by the above real-life scenarios and the limitations of the existing techniques, we present a new approach to the problem of extracting web access patterns under user-defined pattern scoring. Different from the existing techniques in the literature, the proposed solution is based on a new pattern extraction algorithm, WaPUPS (Web Access Pattern Extraction Under User-Defined Pattern Scoring), which uses an evaluation function that can be defined according to the preferences or needs of the users. The algorithm controls the size of the search space by defining a parameter, BF (Branching Factor), which enables the solution to extract high-valued patterns even in cases for which existing frequency based techniques cannot generate any pattern. Although the proposed pattern extraction technique is not complete, it allows the size of the search space to be managed, which is one of the challenges of sequence mining, especially for large and sparse datasets. We experimentally analysed the number of patterns that are not generated owing to BF-based filtering.
The initial version of the solution is presented in Alkan and Karagoz [11], which is enhanced by a new pattern-extraction approach and extensive evaluation of the framework by well-known datasets from the literature in the current version. The proposed solution is a hybrid framework in the sense that it combines clustering with a search-based pattern extraction algorithm. The role of clustering in the framework is that, considering different behavioural patterns, it may not be very useful to construct access paths directly from all the sessions, resulting in a general and cumulated profile of the users. Therefore, the solution first discovers different navigation behaviours through clustering user sessions. After related session groups in terms of the navigation behaviour are identified, the system utilizes the search-based pattern extraction algorithm so as to construct access patterns. The solution can be used in any problem domain where the resulting web access patterns can be utilized, such as adaptive web, web page recommendation, next page prediction, ad recommendation and user-behaviour analysis. In addition, it can be applied to any other sequence data as well. We present a detailed experimental evaluation of our solution under well-known datasets from the literature. The evaluation phase includes experiments for determining the efficiency of the technique under different values of the system parameters and comparison of the proposed framework with a well-known sequential pattern mining algorithm, PrefixSpan [12]. Major contributions of this work can be summarized as follows:
A hybrid approach is proposed for extracting web access patterns that combines clustering with a new pattern-extraction algorithm.
The proposed pattern extraction algorithm utilizes a user-defined evaluation function that reflects the preferences of users in terms of the properties of the extracted patterns.
The proposed solution introduces the BF parameter, which gives control over the size of the search space and enables the solution to generate high-value patterns even for cases where the state-of-the-art techniques cannot respond.
We demonstrate the proposed approach on an example user-defined path evaluation function in web domain.
A comprehensive evaluation of the solution is performed on four real datasets in comparison to a well-known sequential pattern mining algorithm from the literature.
The rest of the paper is organized as follows: in Section 2, a summary of the related work is presented. In Section 3, the proposed framework is described in detail. Next, in Section 4, the evaluation of the system and the discussion of the results are given. Finally, concluding remarks are presented in Section 5.
2. Related work
Web usage mining has been studied by various researchers and different techniques [13–15] have been applied to process click-stream data. The extracted patterns collected from the mining process are used in various applications, including web page recommendation, adaptive web and personalization of the web sites. The learning of users’ navigation behaviours for web page recommendation has attracted much attention and various attempts have been exploited to achieve web page access prediction [13]. Web data clustering is another technique to analyse web usage data and solutions in this area are generally grouped into those that are sessions based [16] and those that are link based [17].
Sequential pattern mining solutions have been applied to process sequence data from different domains including mobile data, biological data and web log data [18, 19]. In order to analyse web log data, sequential pattern mining is heavily used, and in this area a variety of approaches have been proposed [20, 21]. WEBMINER [20] was presented to apply data-mining techniques to data collected in WWW transactions. In Chen et al. [7], two efficient algorithms, called full-scan and selective-scan are proposed for determining large reference sequences for web traversal paths. IncWTP and WssWTP algorithms, which are designed for incremental and interactive mining of web traversal patterns, are described in Lee and Yen [9]. The WAP-mine algorithm [8] is another solution that uses a tree structure called WAP-tree to avoid the level-wise candidate generation-and-test problem of the existing algorithms. The main limitation of these existing sequential pattern-mining approaches is that they cannot respond to cases where different web pages have different significance values. To handle this problem, constraint-based mining techniques have been proposed [22, 23]. The aim of constraint-based mining is to discover more user-centred patterns by integrating certain constraints with the sequential mining process. However, the main limitation of these techniques is that the users may be interested in high-valued patterns and the value definition cannot always be handled by filtering patterns based on specified constraints, which is solved by the utility-based mining approaches [24–26].
The theoretical model and the definitions of the high-utility pattern mining are given in Yao et al. [10]. Utility-based solutions include techniques to mine both high-utility itemsets [27] and sequences [24–26]. In Zhao et al. [24], the authors adopted the definitions of utility from the high-utility pattern-mining model [10] and they used the browsing time of a user as the internal utility of a web page. By doing so, more interesting web-traversal patterns can be discovered in comparison to the classical frequency-based solutions. A pattern growth sequential mining technique is applied to prune a huge number of candidates in Ahmed et al. [25], which save several scanning of the database. In Bayir et al. [26], the authors represent a pattern’s utility with two tree structures, that is, the UWAS-tree and IUWAS-tree, to mine web access patterns. The limitation of these utility-based approaches is that they based the calculation of pattern utilities on the utility of distinct web pages, which may not cover users’ needs for real-life scenarios. In this paper, we propose a new technique that calculates pattern values using a user-defined evaluation function. In other words, value calculation is not bounded by web page utilities, and it can be defined using any parameter that is considered to be important for the users.
3. Proposed solution: web access pattern extraction under user-defined pattern scoring
The proposed solution is based on a two-step process for extracting access patterns under user-defined criteria. In the first step, user sessions are clustered. Next, in the second step, patterns are extracted from each cluster using a new algorithm, WaPUPS. Extracted patterns are denoted as (seq, val), where each seq is a web access pattern, represented as <p1, p2, …, pn>, such that each pi is a web page, and val is the score of the pattern assigned by the evaluation function.
3.1. Clustering user sessions
In order to discover distinct behaviour groups, sequences are first clustered into groups of similar interests. The role of clustering in the framework is two-fold. First, it aims to discover different navigation behaviour groups. Since in web usage domain, the number and the variety of the users are high, it may not be very useful to extract patterns directly from all the sessions, resulting in a one general and cumulated profile of the users. Therefore, the solution first identifies related session groups in terms of the navigation behaviour, then it utilizes the search-based pattern extraction algorithm so as to construct access patterns. Second, clustering enables the solution to partition the search space and this increases the efficiency of the pattern extraction per partition.
Partitioning based clustering techniques, specifically the k-means algorithm, have been proven to be efficient for identifying the intrinsic common attributes in web log data [28], and it is efficient on large datasets owing to its linear time complexity. Hence, k-means clustering is utilized at this step. Clustering is performed on a session-access matrix, where each column is an access and each row is a session of any user represented as a vector. The matrix values comprise the frequency of the corresponding web page’s visits within that session.
3.2. WaPUPS algorithm
For user-defined scoring-based web access pattern extraction, we propose the WaPUPS algorithm, which constructs patterns in a recursive manner. The algorithm can be considered as the construction of a tree, where at each recursive call, one level of the tree is built, which corresponds to adding a new access to the parent pattern. At each level of the tree, at most, BF nodes exist.
The algorithm is presented in Figure 1. WaPUPS takes a list of BF number of parents and cluster numbers from which the patterns are extracted, as input. The output of the algorithm is the set of extracted patterns of that cluster. For each recursive call, the parent_list keeps the patterns that have been constructed up to the current call. These are the best BF patterns of the previous call that are kept in the child_array. Therefore, child_array always keeps BF patterns with the highest evaluation values that will be the parent nodes of the next recursive call.

WaPUPS algorithm.
The algorithm iterates over the parent_list, and for each parent pattern in the list, it tries to enhance it by adding a new access (lines 3–12). For each possible access (line 4), the constructed pattern is evaluated using the Evaluate function (line 6). The value returned by the Evaluate function is compared with the values of other nodes in the child_array. If the new node becomes one of the top BF nodes in terms of its value set by the Evaluate function, the number of the child nodes of the corresponding parent is incremented (lines 7–10). This value is used to check whether the parent has produced a child or not. If it cannot produce a child to be carried to the next call, that is, none of its children exists in the child_array, that node’s pattern is included in the output and it does not grow any more (lines 13–17).
The construction of the child_array, which will become the parents of the next recursive call, is completed with the first for-loop, when all the parent nodes are checked with all possible requests to get enhanced with a new access (lines 3–12). As mentioned before, in the second for-loop (lines 13–17), if any parent node in the parent_list cannot grow, it is outputted as a pattern for that cluster. Finally, if the child_array contains at least one member, the function is recursively called with the child_array as the parent_list for that cluster (line 18-20).
3.2.1. Evaluation function
The Evaluate function examines a pattern and assigns a value to it. In this work, in order to demonstrate the proposed solution and the evaluation function, we consider access patterns as paths that will be recommended to web users for faster web site traversals and we design a sample evaluation function accordingly. We aim to assign values to patterns considering the degree they are assumed to facilitate the users’ navigation in the web sites. In this sample evaluation function, the value of a pattern depends on the following factors:
the number of sequences in cluster cl_no in which the pattern exists;
the number of distinct users that traverse the pattern in their sessions;
the total duration of the pattern in sequences (calculated as the sum of the page visit durations of all the accesses from the start access of the pattern to the final access).
We assume that the value of a pattern increases as the number of sessions it exists in increases. However, it is possible that these sessions belong to a small number of users who access the web page frequently. Therefore, our assumption is based on the idea that a pattern that claims to shorten long access sequences of web users should be useful for as many users as possible. Hence it should exist in many distinct users’ access sequences. In addition, the aim is to shorten long access sequences; therefore, the value of a pattern increases as the length of the path it shortens increases. The evaluation algorithm that realizes these ideas is given in Figure 2. Although the current evaluation function uses these values, it can be modified to depend on other factors as well.

Evaluation function used in WaPUPS algorithm.
As it is shown in Figure 2, the algorithm finds all of the dataset sequences that contain the pattern to be evaluated (line 5). These sequences are examined in order to find out how many distinct users own them and the total duration of the pattern in them (lines 7–13). The value of the pattern is finally evaluated by normalizing these three values and weighting them with the three parameters of the solution: w_session_count, w_user_count and w_duration (line 14). We have evaluated different values of the weight parameters in this formula; however, it should be mentioned that the weights can be adjusted for different web site configurations, and the formula can be modified so as to take any information available to the web site into account.
4. Experimental evaluation
In this section, the details of the evaluation phase are presented. All of the experiments were performed on an Intel Core i5, 2.67 GHz computer with a 4 GB main memory, running Microsoft Windows 7. The programs were coded in Java.
4.1. Datasets
In the experiments, we use four datasets, namely, NASA, SASKA, MSNBC and CENG, whose basic specifications are given in Table 1. The NASA dataset (http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html) is from the NASA Kennedy Space Center server logs from July 1995 to August 1995. It originally contained 3,461,612 page requests. After the data preparation phase, 737,148 accesses, 90,707 sessions, 2459 distinct requests and 6406 distinct users were left.
Dataset characteristics

The second dataset, SASKA (http://ita.ee.lbl.gov/html/contrib/Sask-HTTP.html), is from the University of Saskatchewan’s WWW server. This server log was collected from June 1995 through to December 1995. The dataset originally contained 2,408,625 requests. After pre-processing, 288,727 accesses and 40,784 sessions were left.
The MSNBC dataset (http://kdd.ics.uci.edu/databases/msnbc/msnbc.html) includes the page visits of users who visited msnbc.com on 28 September 1999. The visits are recorded at the level of URL category and it includes visits to 17 categories. Therefore, 17 distinct requests exist. The number of users in the dataset after pre-processing is 17,824.
The CENG dataset is from the Computer Engineering Department of Middle East Technical University (http://www.ceng.metu.edu.tr). The dataset consists of many sub-web sites including web pages of individuals (i.e. students, teachers), newsgroups and courses. The web server logs are from 3 July 2011 to 13 November 2011, and the dataset originally contained 7,041,032 accesses. After pre-processing, there remained 1,752,771 accesses and 304,567 distinct sessions.
Datasets used in the evaluation were selected based on the fact that they had different characteristics in terms of web site context and number of page views. Specifically, both NASA and MSNBC datasets include visits to big portals, which essentially translate to a high number of sessions with very long paths, whereas SASKA and CENG datasets refer to academic web sites. The MSNBC dataset, on the other hand, has the characteristic of very few page views, since the visits are recorded at the level of web page categories.
4.2. Evaluation methodology and metrics
To evaluate the presented solution, a case study has been designed so as to clearly demonstrate the performance of the system in a real-world scenario and a possible application of the technique to an existing problem. In the case study, extracted patterns are considered as paths that can be recommended to users so as to assist their navigation in the web sites. For the experiments, we perform 5-fold cross-validation for each dataset. We form the clusters from the training set, and we extract paths for each cluster. Evaluation of the extracted patterns for each test session is performed in four steps: assigning test session to a cluster; finding the patterns that match the test session; forming a list of all matching paths; and checking whether the paths in the list are successful.
The first step assigns each test session to a cluster by comparing the session and the cluster means. A test session is composed of two parts. The first 70% of the accesses is used to match a path and the remaining 30% is used for finding out whether the path is successful. In the second step, each path in the assigned cluster is checked to find out whether the first 70% of the accesses in the test session contain the path except for its last access. If this is the case, that path is added to the list. We consider a path in the list to be successful if its last access exists in 30% of the second part of the test session. Metrics are calculated considering this evaluation process. For measuring the performance of the system, we used accuracy and coverage metrics. The following parameters are used in the formulation of them:
p_exc_l – path except its last access;
session_count – total number of sessions;
session_count_p – number of sessions in which any of p_exc_l exists;
session_count_p_succ – number of sessions in which any of the paths becomes successful.
Accuracy measures the degree to which the extracted patterns successfully summarize the data. Considering our system, we check each test session and find out whether any of the paths except its last access (p_exc_l) exist in that session. If it exists, the rest of the session is examined to find whether the last access of our path exists in the rest of the session. Accuracy is calculated as shown in equation (1):
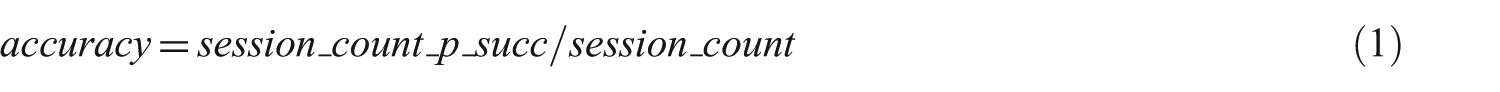
Coverage concerns the degree to which the extracted patterns cover the set of test sessions. To achieve this, the number of the test sessions that any of the path (except its last access) exists in is calculated as given in equation (2):
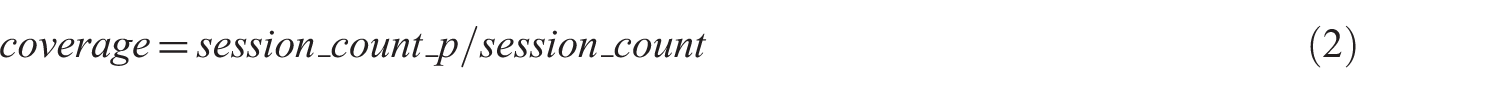
4.3. Results
For the evaluation of the proposed technique, we performed experiments on the solution parameters so as to analyse the effect of changing the size of the search space, number of clusters and weight parameters on the efficiency of the solution under datasets of different volumes and domains. In addition, in order to test the value difference between the patterns identified by our solution and the patterns identified purely by frequent sequential pattern mining, we performed experiments with the PrefixSpan algorithm. In these experiments, we also measured the performance of our solution so as to observe the hit ratio of the high-value patterns. For all of the experiments, parameter values are chosen in an unbiased manner such that the proposed solution and the compared technique can respond within the computational limits of the evaluation environment.
4.3.1. Experiments on BF and the cluster count
We performed tests with different numbers of clusters ranging from 5 to 30 and BF for values {8, 10, 15, 20, 25, 30, 40, 50, 100}. In order to find the effect of clustering, we also conducted experiments in which clustering was not performed. The results of these experiments were obtained by fixing w_session_count, w_user_count and w_duration parameters to 0.33, 0.33 and 0.34, respectively. Figures 3 and 4 plot the accuracy and coverage results, respectively. In these figures, CL05 corresponds to the configuration of a system where five clusters are used, and the others are labelled in the same way.
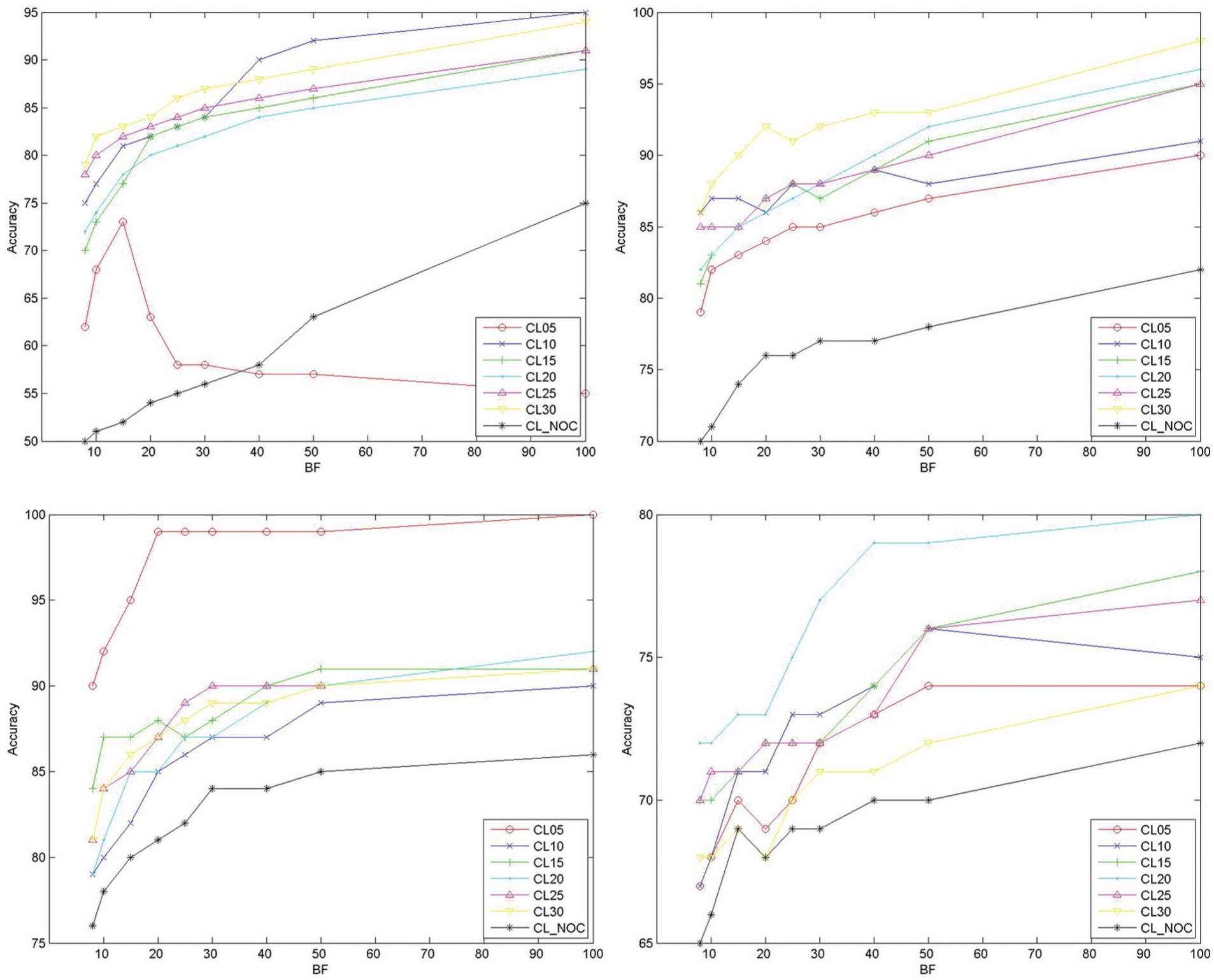
Effect of change in BF parameter on the accuracy with varying number of clusters for NASA, SASKA, MSNBC and CENG datasets.
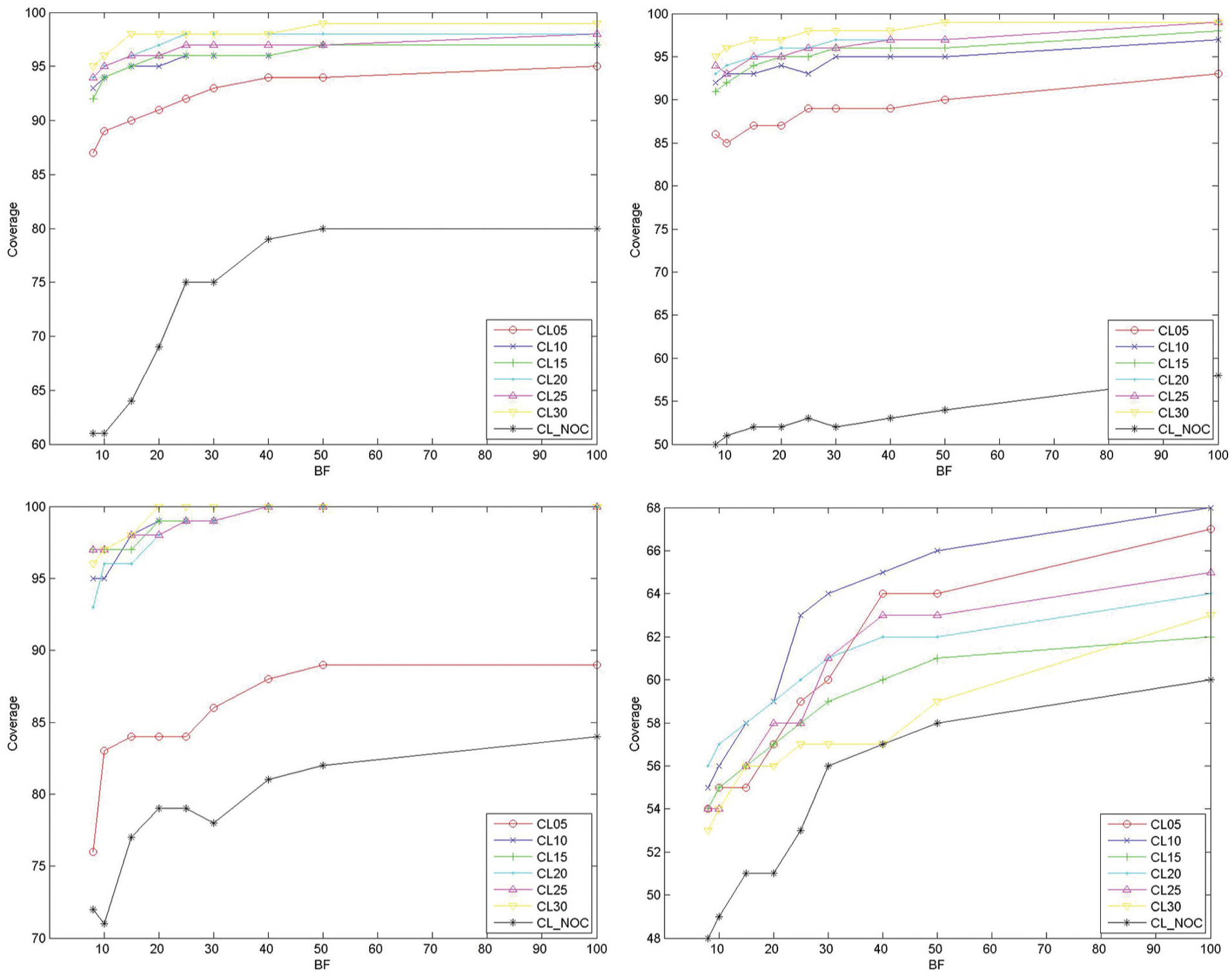
Effect of change in BF parameter on the coverage under varying number of clusters for NASA, SASKA, MSNBC and CENG datasets.
Considering all of the datasets, when no clustering was performed, the performance of the system was lower than for all other configurations for more than 90% of the cases independent of the number of clusters used. This result is valuable for us to see how clustering increases both the coverage and the accuracy of the solution. Clustering enables the system to extract more patterns where these patterns better reveal the users’ interests. In addition, when we examine the effect of the number of clusters on the accuracy of the system, for the NASA dataset, for BF smaller than or equal to 15, accuracy increased as the number of clusters increased for more than 80% of the cases. For the SASKA dataset, the behaviour of the accuracy was similar. For 30 clusters, the system always achieved the best performance for all BF values. Clustering the data to five and 20 groups gave the best performance for all BF values under MSNBC and CENG datasets, respectively. Finally with 20 clusters, the CENG dataset achieved the best accuracy for all BF values.
From these results, we observe that the proper number of clusters to use in the system depends on the nature of the dataset. Large websites with many possible requests result in the identification of many different usage behaviour groups by clustering. NASA and SASKA are examples of such datasets. However, MSNBC has a smaller number of possible navigation paths in comparison to NASA and SASKA, which results in fewer usage characteristic groups. In addition, when coverage results are examined, it is observed that coverage increases in parallel with accuracy for different cluster counts. Considering these results, we can conclude that clustering affects the performance of the system and its effect depends on the nature of the web site in terms of distinct usage characteristics.
When we examine the effect of BF on the accuracy and coverage, we observe that, in more than 80% of the cases, both accuracy and coverage increased as the number of child nodes kept at each level increased. This results from the fact that, as BF increases, more patterns can be constructed. In other words, the algorithm highlights patterns that have lower evaluation values than their siblings at the same level, but have higher evaluation values than their siblings at lower levels. However, one other effect of the increased coverage is the increased number of estimations, which can decrease the accuracy.
4.3.2. Experiments on the evaluation function parameters
In order to find the effect of evaluation function parameters, namely, w_session_count (W SC), w_user_count (W_UC) and w_duration (W_D), we conducted experiments using WaPUPS for all four datasets. We included only the results of NASA and CENG datasets, since for the other datasets, results were similar and the conclusions we reached were the same when the effect of the weight parameters on the system’s accuracy was taken into account.
The parameters were tested for the values {0, 0.2, 0.4, 0.6, 0.8, 1}. The sum of these parameters was always 1 in the system. The results of these experiments were obtained by fixing the number of clusters and BF to 10. Figure 5 displays the accuracy of the proposed algorithm as we change the weight parameters. For both datasets, the behaviour of the weight parameters was similar. As w_session_count and w_user_count increased, accuracy increased. However, as the weight of the duration increased, accuracy decreased. Therefore, covering more distinct user sessions increased the performance of the solution. The results, however, show an inverse relationship between the accuracy of the system and w_duration. Considering this, we can conclude that the best setting for the parameters should assign higher values to w_session_count and w_user_count in comparison with w_duration. However, since the solution is based on user-defined evaluation criteria, we believe that the evaluation function should be constructed and the values of the weight parameters should be set in cooperation with the pattern users.
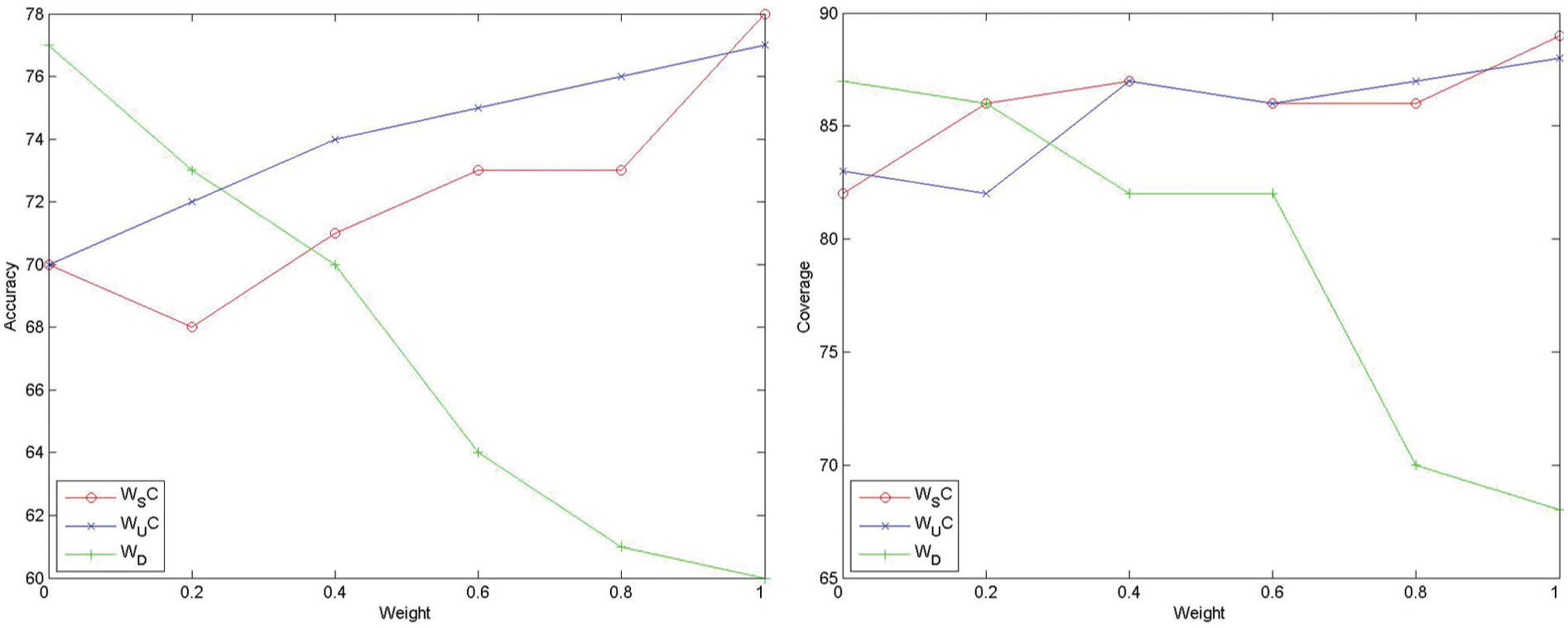
Effect of change in weight parameters on the accuracy for NASA and CENG datasets.
4.3.3. Comparison with frequent pattern mining
We performed experiments using the PrefixSpan algorithm (we used the PrefixSpan implementation given in http://www.philippefournier-viger.com/spmf/) so as to compare our solution with frequent sequential pattern mining. In order to achieve this, we performed two sets of experiments. In the first set, the values of the patterns extracted by WaPUPS and by frequent sequential pattern mining were compared. In the second set, we aimed to measure the performance of our method regarding the hit ratio of high-value patterns.
The results of the first set of experiments where the extracted pattern scores of WaPUPS and PrefixSpan were compared are displayed in Figure 6. In this figure, for the graphs in the first column, the x-axis refers to the top n number of patterns extracted by PrefixSpan and WaPUPS. On the other hand, the y-axis represents the sum of the scores of the top n extracted patterns. In addition, the graphs in the second column display the average values of the extracted patterns with respect to different pattern lengths, where the x-axis refers to the lengths of patterns and the y-axis shows the average values per pattern. When these figures are examined, it can be concluded that the proposed solution can identify higher-value patterns when both the cumulative sum of the top-value patterns and the average value of the extracted patterns with respect to different pattern lengths are taken into account. Although the number of pattern scores accumulated by the proposed algorithm is always higher than that of PrefixSpan for both the sum and average cases, the rate of change in the pattern scores is not the same for NASA and CENG datasets. The behaviour is not steady, but overall there is an increase and the rate of change may vary depending on the dataset.
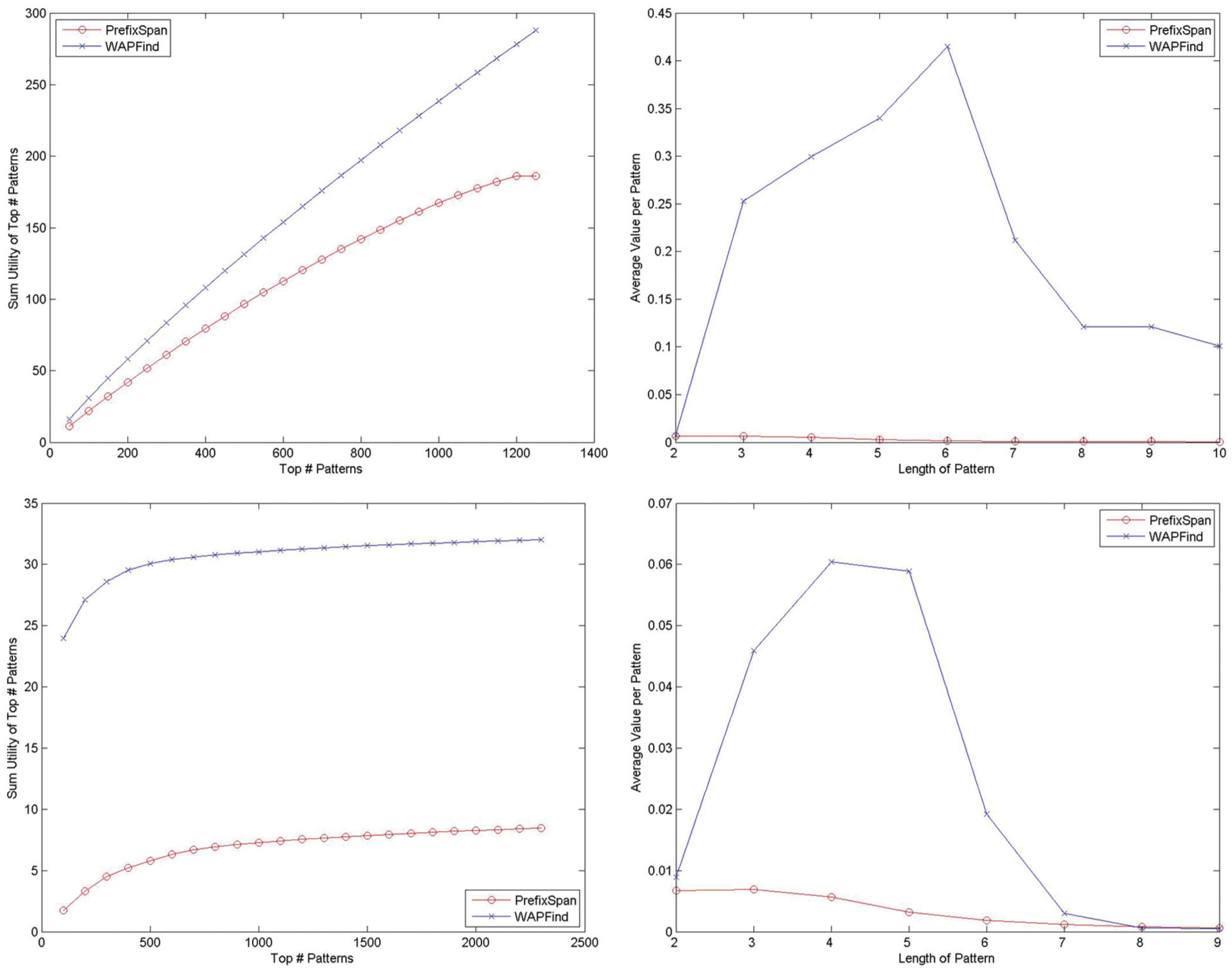
Accumulated value vs top n patterns and average pattern value vs pattern length extracted by WaPUPS and PrefixSpan for NASA and CENG datasets.
There exist two motivations behind the second set of experiments. First of all, our proposed algorithm is not a complete algorithm since it is based on the heuristic that the best BF patterns at each level leads to the extraction of high-value patterns in terms of the user’s evaluation scoring. Therefore, we aimed to find out the hit ratio of high-value patterns considering all possible sequential patterns that can be extracted from the datasets under consideration. Second, although BF results in an algorithm that is not complete, it allows management of the size of the search space and extraction of the highest-value patterns among all of the extracted patterns, which is a solution to one of the main challenges of sequential pattern mining research.
In this experiment, we aimed to extract all exiting patterns, that is, sequential patterns having non-zero support. However, practically this is not feasible. Instead, we lowered the support threshold as much as possible and aimed to extract all the sequence patterns that we could. We found the user’s evaluation score for each pattern and considered this set in the experiment. We applied this procedure to all datasets; however, we cannot take the response from PrefixSpan for the datasets into consideration, since it cannot complete processing for low support values owing to memory limitations of the experimental environment. For the support values where PrefixSpan can complete its processing, it cannot generate any patterns. One important observation to point out here is that, for those datasets, WaPUPS can extract patterns by controlling the size of the search space using the BF parameter. In addition, it extracts patterns with highest scores among all the extracted patterns. Therefore, for this experiment, we used only 73.7 and 78.2% of the NASA and CENG datasets, where we eliminated sessions that had accesses greater than 40 and 25, respectively. We used support values 0.015 for the NASA and 0.007 for the CENG dataset. For WaPUPS, number of clusters, BF, w_session_count, w_user_count and w_duration parameters were set to 20, 100, 0.33, 0.33 and 0.34, respectively.
In this second set of experiments, we compared the top k patterns extracted by WaPUPS and PrefixSpan in terms of user-based evaluation score. In Figure 7, we present the hit ratio in the top n patterns. For the graphs in this figure, we divide the set of patterns extracted by PrefixSpan into value intervals represented on the x-axis. The y-axis displays the total number of patterns extracted by WaPUPS that fall into these value intervals. First of all, the extracted patterns of WaPUPS almost uniformly fall into the value intervals defined by the top-value patterns of PrefixSpan. In total, WaPUPS extracted 8503 and 2880 patterns from the NASA and CENG datasets, respectively. In addition 274 and 129 of the patterns extracted by WaPUPS had scores greater than the highest valued pattern of PrefixSpan for NASA and CENG datasets, respectively. The ratios of the value of the maximum-value pattern of WAPUPS to that of the PrefixSpan were 1.348 for NASA and 13.402 for the CENG dataset. When all of these results are considered, it can be concluded that patterns extracted by WaPUPS have significantly higher evaluation values than those extracted by PrefixSpan. In addition, with BF, the solution can always generate patterns by controlling the size of the search space. Overall, it can be concluded that the proposed solution can generate better patterns in terms of the evaluation criteria set by the users.

Number of patterns extracted by WaPUPS vs PrefixSpan (in terms of top n patterns).
5. Conclusion
In this paper, we present a new model for extracting web access patterns under user-defined criteria. The framework is based on a novel approach that combines clustering with a new pattern-extraction algorithm. The role of clustering in the framework is to group user sessions on the basis of similar navigational behaviours that increase the accuracy of the system as shown by the experiments. For the pattern-extraction phase, the core of the proposed algorithm is the evaluation function, which captures the user’s definition for the value of a pattern. We propose the WapUPS algorithm to traverse the search space for high-value patterns. In addition, in order to examine how the system performance changes when more patterns are allowed to grow, we implemented and tested another version of WapUPS. In that version, child nodes of each parent are considered separately and the best BF children of each parent are allowed to proceed to the next level. This increases the search space at each level from BF to BF times the number of nodes that exist in the previous level. However, from the results of the experiments we made with that version, this enhancement does not improve the performance of the solution; therefore it is not included in the paper.
Experimental results have shown that proposed approach is capable of effectively discovering user access patterns and revealing the underlying value defined by the evaluation function. In addition, using the BF parameter to control the size of the search space, it can generate high-score patterns even for the cases where the state-of-the-art techniques cannot extract any pattern. Future work will focus on adapting system to work on other domains and performing experiments over sequence datasets other than web log data. In addition, since clustering is an important step for improving the efficiency of the solution, as shown by the experiments, the effect of the other clustering techniques such as Label Propagation [29], Mean-Shift Clustering [30], Dominant Sets and Pairwise Clustering [31] techniques on the performance of the proposed framework can be analysed.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.