
Abstract
Blogs are one of the main user-generated contents on the web and are growing in number rapidly. The characteristics of blogs require the development of specialized search methods which are tuned for the blogosphere. In this paper, we focus on blog retrieval, which aims at ranking blogs with respect to their recurrent relevance to a user’s topic. Although different blog retrieval algorithms have already been proposed, few of them have considered temporal properties of the input queries. Therefore, we propose an efficient approach to improving relevant blog retrieval using temporal property of queries. First, time sensitivity of each query is automatically computed for different time intervals based on an initially retrieved set of relevant posts. Then a temporal score is calculated for each blog and finally all blogs are ranked based on their temporal and content relevancy with regard to the input query. Experimental analysis and comparison of the proposed method are carried out using a standard dataset with 45 diverse queries. Our experimental results demonstrate that, using different measurement criteria, our proposed method outperforms other blog retrieval methods.
1. Introduction
After the prevalence of Web 2.0 technologies, different technologies have emerged that have enabled internet users to share their knowledge in a fast and easy manner. This has led to a growing mass of user-generated content on the Web. Weblogs are one of the simplest and most common content generation tools on the Web. A large number of people write about their experience and opinion in their blogs, which provides a tremendous amount of useful information on the blogosphere. Recently, the number of blogs has been growing extremely fast, and thus this phenomenon cannot be ignored [1]. The total number of blogs in the world is not known exactly; according to BlogPulse 1 (one of the major blog search engines), there existed more than 182 million blogs at January 2012. Based on the latest statistics presented by Tumblr, 2 the total number of blogs was over 248 million (with more than 116.9 billion posts) in August 2015. Also, according to WordPress, 3 each month about 53.6 million new posts and 59.3 million new comments are written by WordPress blog users. Owing to the large number of blogs, various interrelated research activities have been carried out to answer the users’ information needs, such as opinion retrieval [2–4], topic detection and tracking [5], top news stories identification [6, 7], blog post search [8, 9] and blog retrieval [10–13].
The size of blogosphere and the special characteristics of blogs, such as vulnerability to spam, the informal and conversational language of blogs and their short lifespan, make the search for high-quality content on the blogosphere a challenging task [14]. Information retrieval in the context of the blogosphere usually includes one of the following two main tasks:
After initializing a related task by the organizers of TREC conference in 2007 [16, 17], many other studies have been started on blog retrieval. Different solutions that have been used for similar problems, like ad-hoc search methods, expert search algorithms and resource selection in distributed information retrieval environments, have also been adopted for blog retrieval. These solutions are summarized in Section 2.
The temporal properties of blog posts have been used in different ways. Nunes et al. [18] defined two new measures called temporal span and temporal dispersion to evaluate how long and how frequently a blog has been written about a specific topic. Similarly, Macdonald and Ounis [19] used a heuristic measure to capture the recurring interests of blogs over time. Some other approaches considered a higher score for more recent posts [20, 21] and some others, like Keikha et al. [22], proposed a time-based query expansion method.
However, none of the previous methods according to our knowledge have considered temporal properties of different kinds of input queries. All blog retrieval methods act the same for all queries, while usually queries have different temporal properties that can be taken into account for blog retrieval tasks.
Suppose the input query is ‘FIFA World Cup 2010 in Africa’; if the writing time of a post about FIFA World Cup 2006 is ignored, such post can get a high score in a blog retrieval method. However, this post is not relevant as the user needs to find posts that are written about the World Cup of 2010. Also, for event-sensitive queries like ‘Oscar Film Awards’, ‘Fajr Film Festival’ or ‘Tehran International Book Fair’, considering the time of the posts is very important; posts that are written at the time of the festival or immediately after the awards are more relevant. Therefore, we propose to classify the user’s queries based on their temporal properties as follows:
periodic time-sensitive queries;
event-sensitive queries or queries that are sensitive to a certain time interval;
recency-sensitive queries;
time-insensitive queries.
We propose an approach that leverages the temporal property of queries to retrieve relevant blogs. The proposed approach starts by retrieving relevant posts by use of content-based relevance score. Then it builds a temporal profile for the query according to its importance in different time intervals, and computes a temporal score for each relevant post using this profile. Finally, the content and temporal scores are combined and are used in different retrieval methods to generate the final ranking. Consequently, for a query such as ‘FIFA World Cup 2010 in Africa’, a lower temporal score is assigned to a post written about World Cup 2006. More specifically, in this paper we will:
cross-validate the existing blog retrieval methods on a new collection;
discuss classification of user’s queries based on their temporal properties;
investigate the impact of temporal properties of queries on blog retrieval accuracy;
introduce a method for calculating a temporal score for blog posts with respect to the input query;
propose an efficient time-sensitive blog retrieval algorithm.
The rest of this paper is organized as follows: Section 2 discusses a general review and a classification of blog retrieval methods and our proposed method is presented in Section 3. Then our experimental setup is presented in Section 4, and the results and comparisons are discussed in Section 5. Finally the paper is concluded in Section 6.
2. Related works
In this section, different blog retrieval methods will be reviewed briefly. In the literature, the blog retrieval systems use two different types of representations for blogs:
Considering the above representations, blog retrieval methods can be classified into two approaches; the first category includes the blog retrieval methods that rank blogs according to the relevancy score of the whole blog. These methods use GR model of blog representation. The approaches of the other category, rank blogs based on a combination of the relevancy scores of individual posts weighted by their post importance. These methods represent blogs using LR model. The next sub-section surveys the approaches that use GR and LR models of blogs and the second sub-section introduces the blog retrieval methods that use temporal properties of blogs.
2.1. Blog retrieval methods based on GR of blogs
Elsas et al. [23], propose a Large Document (LD) model for blog retrieval. The LD model regards the whole blog as a single document and calculates its relevancy score with regard to any input query.

where P(b) is the blog prior, and the query likelihood P(Q|B) is estimated with Dirichlet smoothing. Weerkamp et al. [24] use a language modelling framework for blog retrieval. They adopt an expert search model for blog retrieval and nam it the blogger model. In their model, the probability of a query being generated by a given blog is estimated by representing the blog as a multinomial distribution of terms. Furthermore, Weerkamp et al. [21] extend the blogger model by using a number of blog-specific features in posts prior in the blogger model such as document structure, social structure and temporal structure.
Similar to the LD of Elsas et al. [23], Seo and Croft [25] create a virtual document for a blog by concatenating all posts in a blog. The virtual document is represented using a language model, and the query likelihood of the document for a query Q is used as a ranking function.
2.2. Blog retrieval methods based on LR of blogs
In this approach, blog retrieval methods use a ranking function F that is computed based on the individual post scores (PostScore) of each post P in a blog B.

Different solutions for similar problems like expert search or methods from resource selection have been adopted for defining the F function. Elsas et al. [23], propose the Small Document (SD) model, which considers each blog as a collection of posts; having the relevancy score of each post calculated, a blog B is scored based on the sum of the individual scores of its posts weighted by their post centrality.
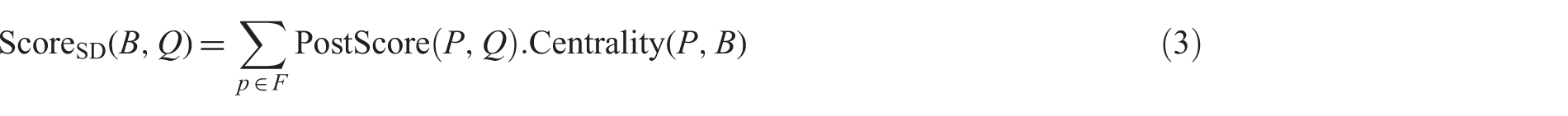
where P is a post in the blog B, and
Seo and Croft [25] approach blog retrieval as a resource selection problem. They consider a Pseudo-Cluster Selection (PCS) model for blog representation. PCS is similar to the SD model of Elsas et al.; however, it utilizes a different principle. In PCS, a blog is considered as a query-dependent cluster containing highly ranked blog posts for the input query.
Lee et al. [26], similar to SD and PCS models, proposed the Global Evidence Model (GEM) and Local Evidence Model (LEM) . The GEM calculates the final score of a blog B using average

Furthermore, the LEM is calculated in the same way. The difference is that GEM considers every post P in a given blog B, whereas LEM only considers the top K retrieved posts.

A linear combination of GEM and LEM provided the best efficiency among the participants of TREC 2008 Blog track. Keikha and Crestani [27] model each post as evidence of a blog’s relevancy to the input queries, and use aggregation methods like Ordered Weighted Averaging operators to combine the evidence. In particular, given a query Q, the score of blog B is estimated as:

where
2.3. Blog retrieval methods based on temporal properties of blogs
Temporal information has been used in ad-hoc information retrieval in many different ways. Jones and Diaz use time-based query profiles for predicting query precision [33]. Dakka et al. [34] incorporate temporal distributions in different language modelling frameworks. They apply several standard normalizations to temporal distributions and use global temporal distributions as a prior. Li and Croft [35] and Efron and Golovchinsky [36] use time-based methods in order to rank information for queries for which recency is an important factor. Peetz et al. [37] propose a query modelling approach where terms are sampled from bursts in temporal distributions of initially retrieved set of documents. They define a burst to be a time period where an unusually large number of documents is published and propose different approximations for both continuous and discrete bursts. Amodeo et al. [38] select top-ranked documents in the highest peaks as pseudo-relevant, and consider documents outside peaks as non-relevant. They use Rocchio’s algorithm [39] for relevance feedback based on the top-10 documents.
Also time has been used in blog retrieval. Many researchers utilize the time stamp of posts in various ways; Keikha et al. [22] use temporal properties of posts in a query expansion method that selects terms for query expansion based on the relevant days of a given topic.
Nunes et al. use temporal properties of blogs to find relevant blogs [18]. They use temporal span and temporal dispersion as two measures of relevancy over time, and show that these features can improve blog retrieval. Keikha et al. [40] propose a framework, named TEMPER, that selects time-dependent terms for query expansion, generates one query for each point of time and calculates a distance measure based on temporal distributions.
Some models are designed to retrieve the blogs based on frequency of discussion about topics of interest. Such models show improvements over the baselines that solely use the content of the blogs [20, 21]. MacDonald and Ounis try to capture recurring interests of blogs over time [19]. Following the intuition that a relevant blog will continue to publish relevant posts throughout the timescale of the collection, they divide the collection into a series of equal time intervals. Then blogs are scored based on their number of relevant posts in different time intervals. Keikha et al. [41] aim to measure the stability of a blog relevance to a query over time. Their idea is that a blog that has many related posts during a short period of time is not highly relevant. Thus they define TRS (Temporal Relevance Stability), which scores a blog higher if it has more related posts in more time intervals, which is believed to be an indication of greater stability.
In this paper, a new approach is proposed to use temporal properties of queries for blog retrieval. Through different experimental results, we will show that our approach considerably outperforms already existing methods.
3. Temporal-based approach to blog retrieval
Various blog retrieval methods utilize temporal properties of blogs. However, none of them use the temporal properties of queries and treat all the queries in the same way. However, in this paper, we propose a temporal-based approach for blog retrieval that uses both temporal and content relevancy of blogs with regard to the input query to find an efficient ranking of blogs. Using the proposed approach, we can extend all the existing blog retrieval methods (using LR to blog representations such as voting model [19], blogger model [24], posting model [24], small document model [23] and local evidence model [26] to be time sensitive. Figure 1 shows an overview of the proposed temporal-based approach to blog retrieval. This approach contains the following steps:
Step 1 – retrieve top N relevant posts named R(Q) set.
Step 2 – create a temporal profile for each query using R(Q) set.
Step 3 – calculate a temporal score for each post in R(Q) set based on the temporal profile of query.
Step 4 – use combined temporal and content score of blog posts to make already existing methods sensitive to time.
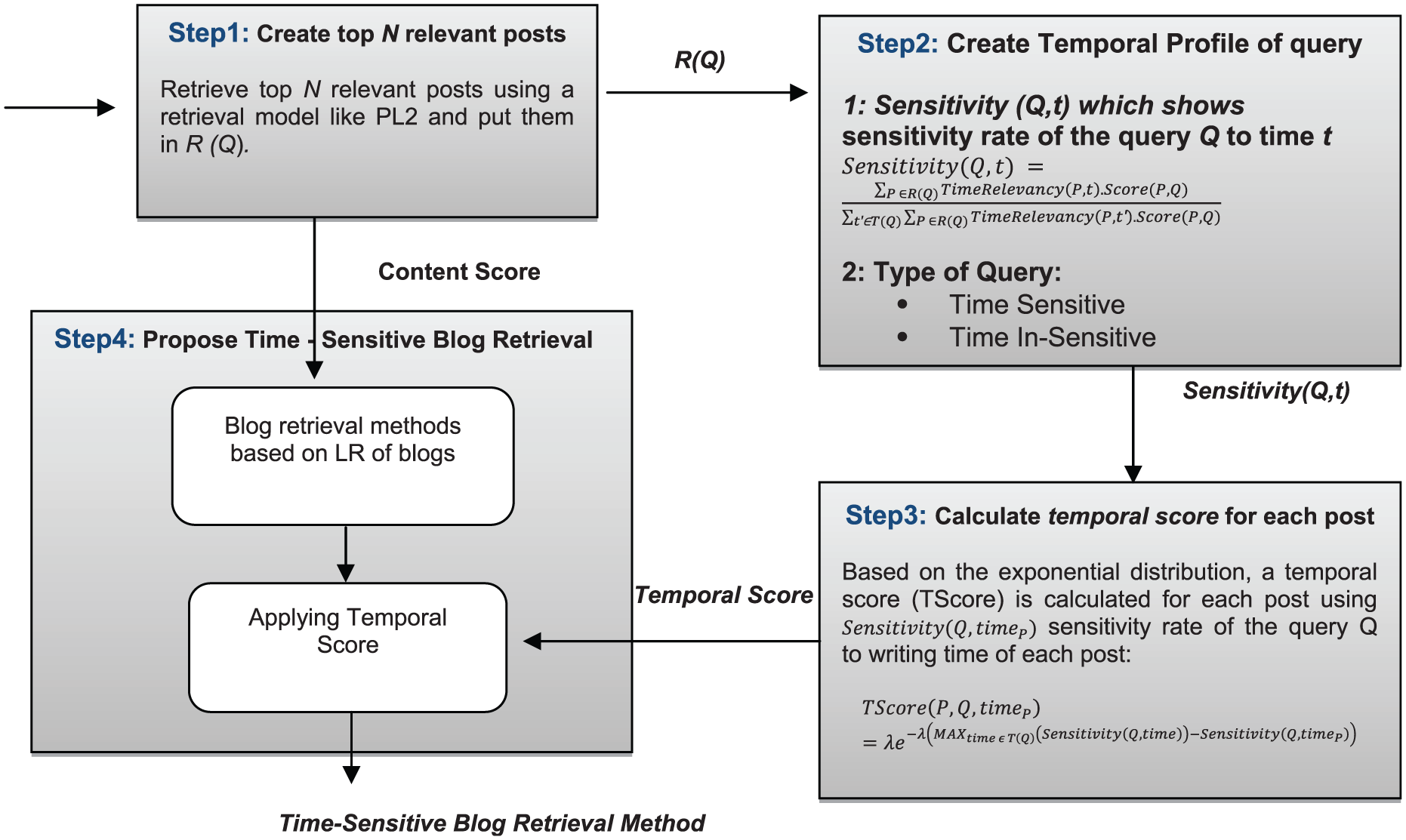
An overview of proposed temporal-based approach to blog retrieval.
3.1. Step 1: retrieve top N relevant posts
In the first step of the temporal-based approach, top N relevant posts are identified using the PL2 [42] retrieval method and we call them the R(Q) set. This set contains the candidate relevant posts for the input query. Our experiments on different values of N show that the optimum value is N = 1000. Previous studies show that using the most relevant posts improves the performance of blog retrieval methods [26]. Therefore, we use the top 1000 relevant posts to create the R(Q) set. Figure 2 shows the effect of N on the performance of voting model in the irBlogs dataset.
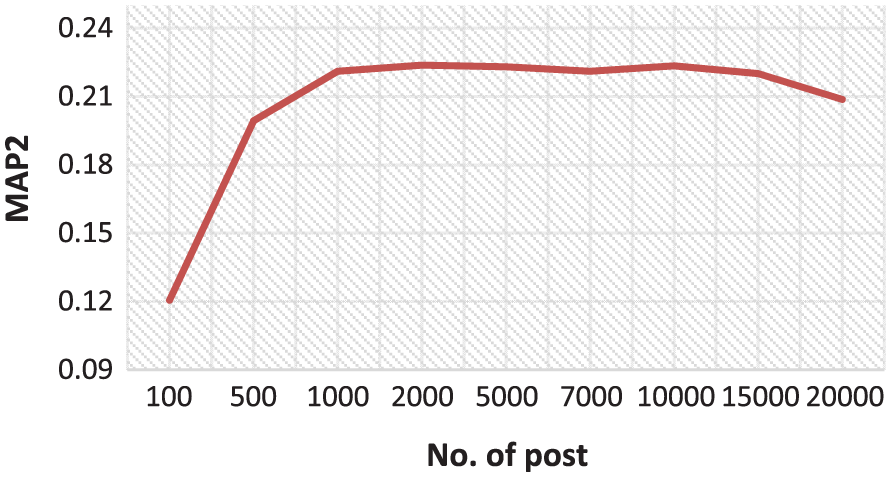
Effect of N, on the performance of voting model over the irBlogs dataset.
3.2. Step 2: create temporal profile of queries
Retrieving candidate relevant posts, a temporal profile is created for each query according to the occurrence of relevant posts to the query in the time interval. This profile includes:
Sensitivity(Q,time) – calculate sensitivity of the input query Q to different time intervals time, that is, calculate the importance of each time interval time for query Q. Here, time is the publish time of the post and Q is a given query.
Temporal query type (time-sensitive or time-insensitive) – time-sensitive queries are those whom the majority of their relevant posts belong to a specific time interval, whereas time-insensitive queries are the ones whom their relevant posts are uniformly distributed over all time intervals, that is, the queries that have similar Sensitivity(Q,time) values for all time intervals are time insensitive queries and the queries that have greater Sensitivity(Q,time) values for some of the time intervals are time sensitive ones.
3.2.1. Calculating sensitivity of the input query to different time intervals
Calculating the sensitivity of the input queries to different time intervals, we introduce Sensitivity(Q, time) as the sensitivity of query Q to time interval time. We consider two different ways of calculating sensitivity of the input query Q to time time in equations (8) and (9).
In equation (8), the ratio of the number of posts being published in a certain time to the number of all posts defines the sensitivity of query Q to time time. In this equations, P denotes a given post, and

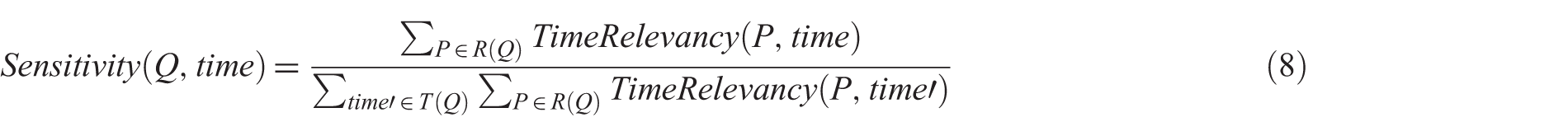
Equation 9 differs from equation 8 because of inclusion of the relevancy score in the calculations as a weighting measure. In this equations, P denotes a given post and
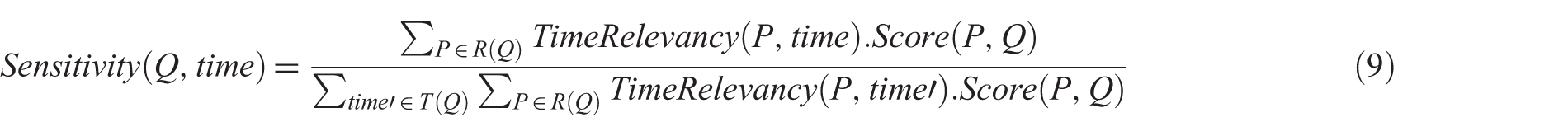
In equations (8) and (9),

3.2.2. Temporal classification of queries
In order to find out whether a query is time-sensitive or not, we extract the posting time of the candidate relevant blog posts in R(Q) and draw a posting time distribution histogram as shown in Figure 3. The horizontal axis indicates the posting time of the blog posts and the vertical axis is the number of posts that are published in a specific time.
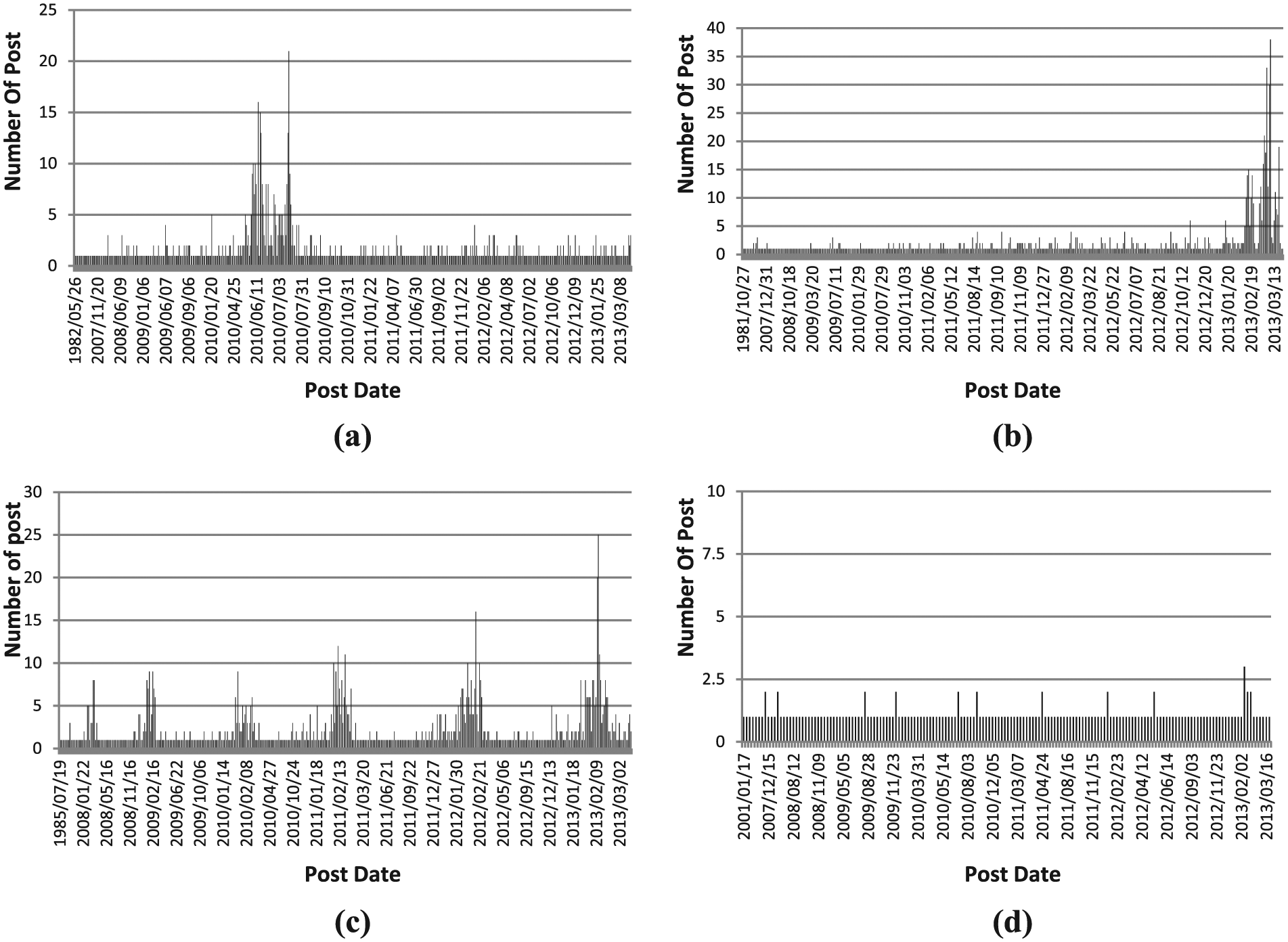
Relevant post distribution histograms of (a) ‘FIFA 2010 World Cup in Africa’ event-sensitive query, (b) ‘gold and currencies prices and exchange’ time-recency query, (c) ‘Fajr Film Festival’ periodic time-sensitive query and (d) ‘Classical Music’ time-insensitive query.
The time line could be split based on different time intervals such as year, month, day, hour or minute. In fact, selection of the proper time interval to use depends on the social media type. For example, in a media such as Twitter with high update ratio, selecting small time intervals such as hour or even minute is reasonable. However for blogs, a larger time interval such as a day or a week is more appropriate. For this research, we used a day as the time interval for the blog posts.
Depending on how the relevant posts are distributed over different time intervals, the input queries are divided into two groups of time-sensitive and time-insensitive. The time-sensitive queries have a non-uniform distribution of the posts over the time intervals, indicating that the number of related posts may have a sudden increase in some time intervals.
Time-sensitive queries can be divided into several other subcategories such as:
Event-sensitive queries – these queries are sensitive to certain time intervals, such as ‘FIFA World CUP 2010’, a tournament which was held from 11 June to 11 July 2010 in Africa. Figure 3a shows distribution of the relevant posts for this query.
Recency-sensitive queries– for these queries newer posts have higher probability of relevancy. For example query ‘gold and Currency prices and exchange’ is recency-sensitive, since the price of the gold changes over time and users need to know the latest price. This fact can also be seen in Figure 3b in which most related posts are published in the most recent time intervals.
Periodic time-sensitive queries– these queries have spikes in their posting time distribution. That is periodically there are intervals with higher number of relevant posts. For example, a query about ‘Fajr Film Festival’ (Iran’s annual film festival), which is held every February in Tehran, is a periodic time sensitive query as every year around February there are a lot of posts about it. This fact can be seen in Figure 3c (in each year, the number of retrieved posts increases in January and February)
Similarly, the time-insensitive queries can be identified by looking at the distribution of their posts as well. Time-insensitive queries have nearly uniform distribution of posts over all time intervals. Figure 3d shows the distribution of the posts for time-insensitive query ‘Classical Music’.
3.3. Step 3: calculating temporal score of posts
A temporal score is calculated for each candidate post in R(Q), based on the exponential distribution in equation (11):
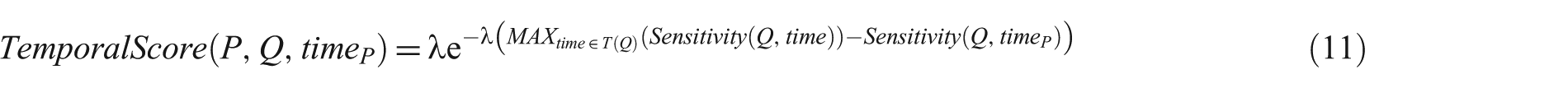
In the equation (11), P is the intended post, Q is the input query,
Higher sensitivity of the input query Q to the published time of the post P will result in higher TemporalScore value for the post P. In other words, the spiky points in the relevant post distribution histogram get higher TemporalScores than other points.
3.4. Step 4: proposed time-sensitive blog retrieval methods
In this section, we will illustrate how to combine the proposed temporal score with the existing blog retrieval methods that use individual post scores. In other words, we will make voting, blogger, posting, SD and local evidence models time sensitive. All the other blog retrieval models (that were mentioned in Section 2.2) which use individual post scores to calculate the final score of the blogs can also be modified in the same way to be time sensitive. Here, we introduce two approaches to make the blog retrieval methods time sensitive:
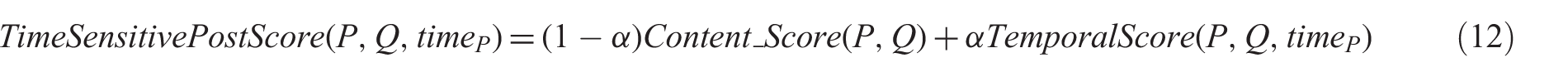
In equation (12), α is a weighting coefficient,
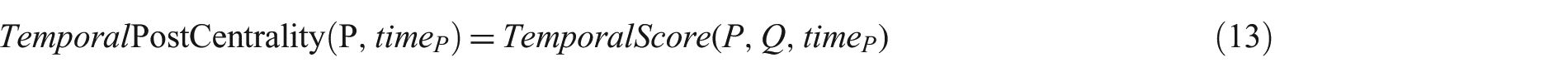
3.4.1. Time- sensitive voting method
Macdonald and Ounis [19] adopt the voting method of Macdonald and Ounis [28] for blog retrieval. It works according to a list of initially retrieved posts for a query, named R(Q), which is supposed to be the set of probably relevant posts. Then each blog’s score is calculated based on the posts that exist in R(Q). In this method, bloggers are considered as experts in different topics. A blogger who is interested in a particular topic blogs regularly about that specific topic and it is highly probable that his/her posts are retrieved in response to a related query. Considering this approach, blog retrieval can be modelled as a voting process: a post that is retrieved in response to a query is considered as a weighted vote for the expertise of its blogger about the query. In Macdonald and Ounis [19], different fusion methods are used to aggregate the weighted votes and finally rank related blogs. ExpCombMNZ is the best fusion method in their experiments which is calculated as follows:
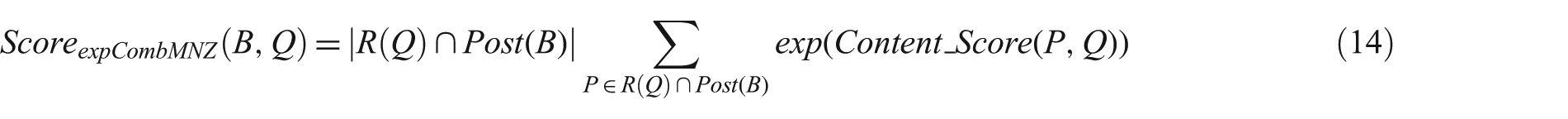
where Post(B) is the set of posts from the blog B,
In order to present a time-sensitive voting model, we calculate the final score of each post in R(Q) using Time sensitive PostScore in equation (12). Therefore, the final score of a blog is calculated using equation (15):
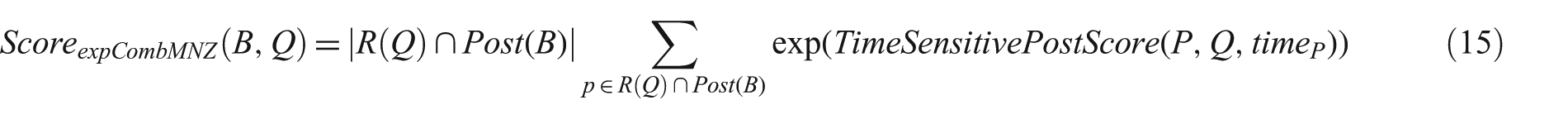
3.4.2. Time- sensitive posting and blogger method
Weerkamp et al. [24] adapt two expert search models based on language modelling for blog retrieval. The first model, known as the blogger model, estimates the probability of a query given a blog by representing the blog as a multinomial probability distribution over the vocabulary of terms as shown in equation (16):

In this equation, n(t, Q) represents the frequency of term t in query Q, θbloger (blog) is the blog’s language model, and P(t|θbloger (blog)) is the probability of term t in the blog’s language model, which is calculated using equation (17):
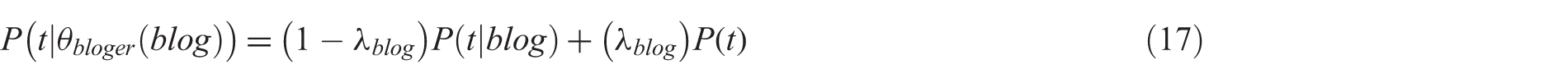
where P(t) is the probability of a term in the document repository and

Assuming that terms are conditionally independent from the blog (given a post), thus P(t|post,blog) = P(t|post) and P(t|post) is approximated using standard maximum likelihood estimate. Also, P(post|blog) or the importance of a post in a blog is considered the same for all posts of a blog.
In the second model presented in Seo and Croft [24], named the posting model, each blog post is modelled instead of the entire blog. Then the final score of a blog is the total relevance scores of individual posts

In Weerkamp et al. [24],
3.4.3. Time-sensitive small document model (TSSD)
The SD model considers each post within a blog as a separate document. After calculating the relevancy score of each post, a blog B is scored based on the sum of the individual scores of its constituent posts weighted by their post centrality:
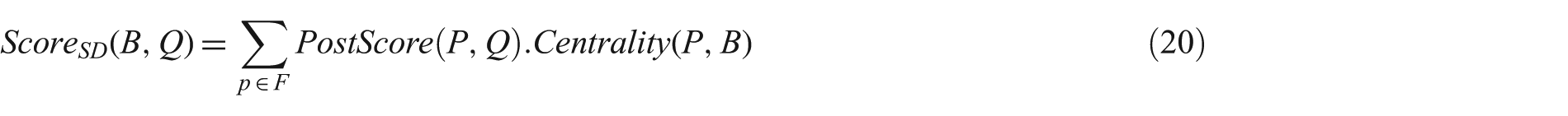
Considering post centrality, the model uses a measure of similarity between the post and the blog to calculate the centrality of the post. Generally, any measure of the similarity can be used, for example, K-L divergence or cosine similarity. In Elsas et al. [23] the post centrality score is computed based on the geometric mean of term generation probabilities, weighted by their likelihood in the blog language model. Also, in Keikha et al. [30] the authors considered a uniform prior for the blogs, since post centrality uses a uniform distribution over posts in each blog.
In order to present a time sensitive small document model, we compute the post centrality of equation (20) using the

3.4.4. Time-sensitive local evidence model (TSLE )
Lee et al. [26] present global and local evidence of blog feeds to calculate blog scores, which corresponds to the document-level and passage-level evidence used in passage retrieval. They calculate the final score of a blog using a linear combination of its local evidence and global evidence based on equation (22):
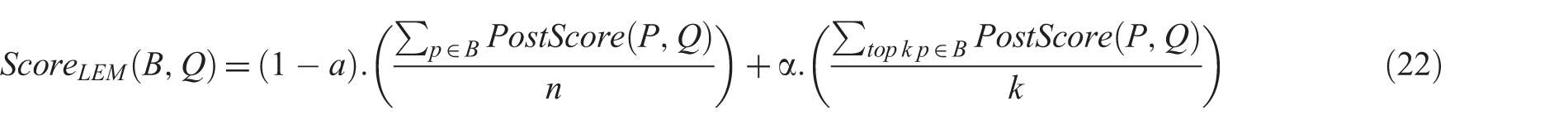
Instead of
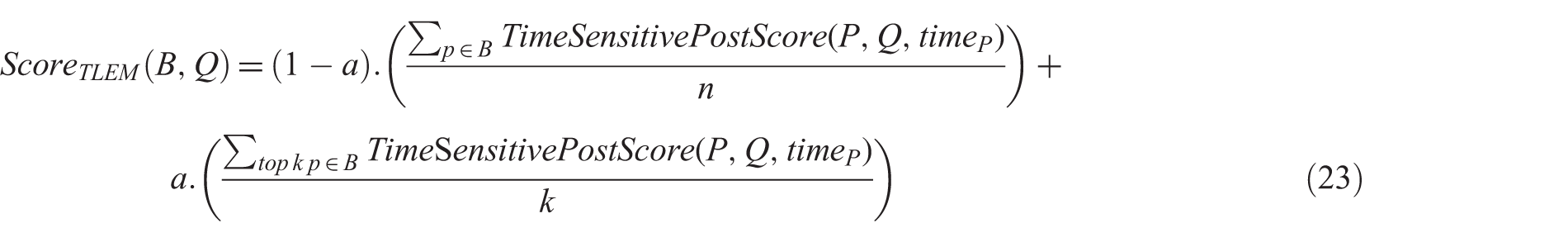
4. Experimental setup
4.1. Dataset
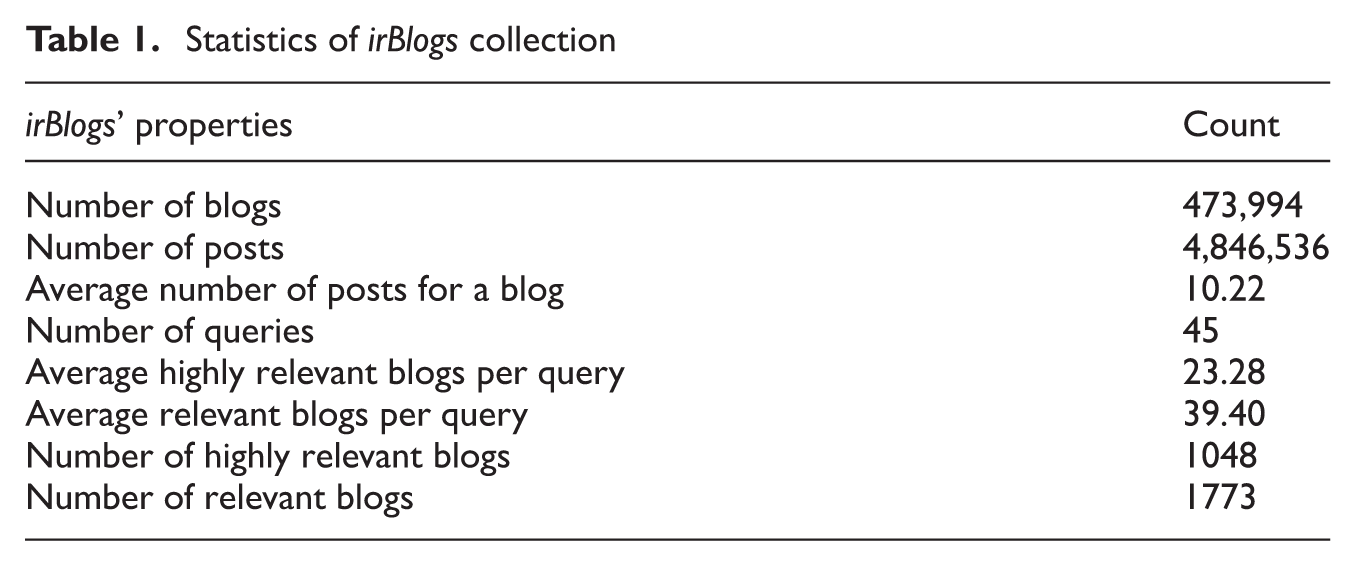
In order to evaluate and compare the proposed time-sensitive blog retrieval methods, we use the irBlogs dataset [43]. This collection is used as a basis for some other researches [44, 45]. This dataset is a standard dataset prepared for the evaluation of blog retrieval methods in Persian blogosphere. It includes: (a) a set of blogs with their posts and their published time; (b) a set of 45 topics about different subject categories which are prepared in TREC standard format, including a title, a description and a narrative; and (c) relevance judgements (ground truth) in a four-level scale of: Highly Relevant, Relevant, Irrelevant and Spam. Table 1 shows some general information about the irBlogs dataset.
Statistics of irBlogs collection
The irBlogs dataset has some temporal properties that distinguish it from TREC datasets. One of them is the query set of rBlogs. Figure 4 indicates the percentage of the time-sensitive queries compared with the time insensitive queries of irBlogs dataset. About 80% of the queries are time-sensitive and 82% of posts have writing time. Another important property of the irBlogs is the distribution of the writing time of the posts that is depicted in Figure 5. As it is shown in Figure 5, there are sufficient posts in the dataset for all the time intervals. The queries of TREC datasets are time-insensitive queries that are not suitable for the evaluation of our approach, therefore we chose the irBlogs dataset instead. Also, recently it is proven that even widely accepted TREC collections are not as reliable as generally accepted collections [46], so irBlogs can also be useful for cross-validation of already existing blog retrieval methods.
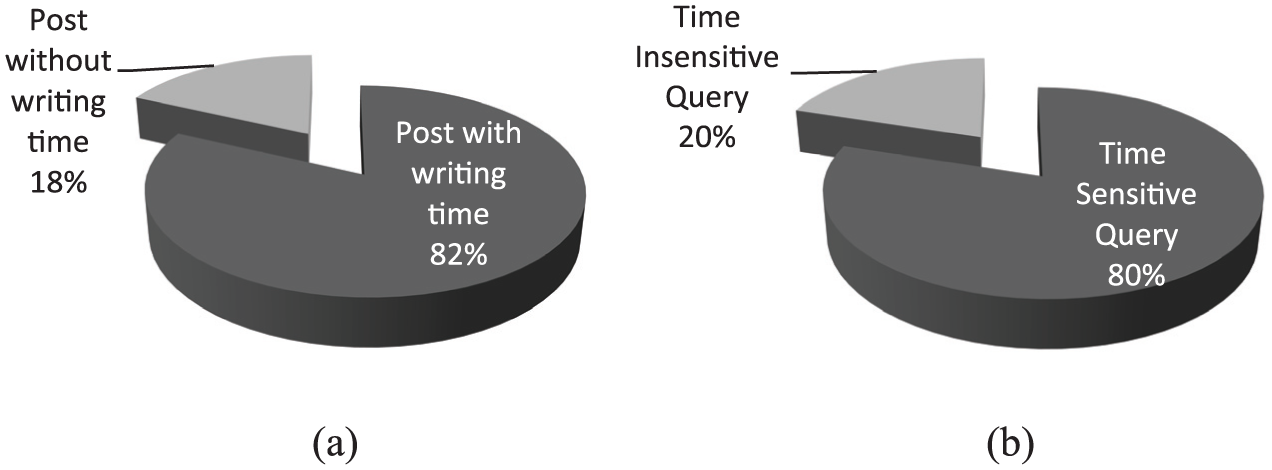
(a) The percentage of post with/without writing time.
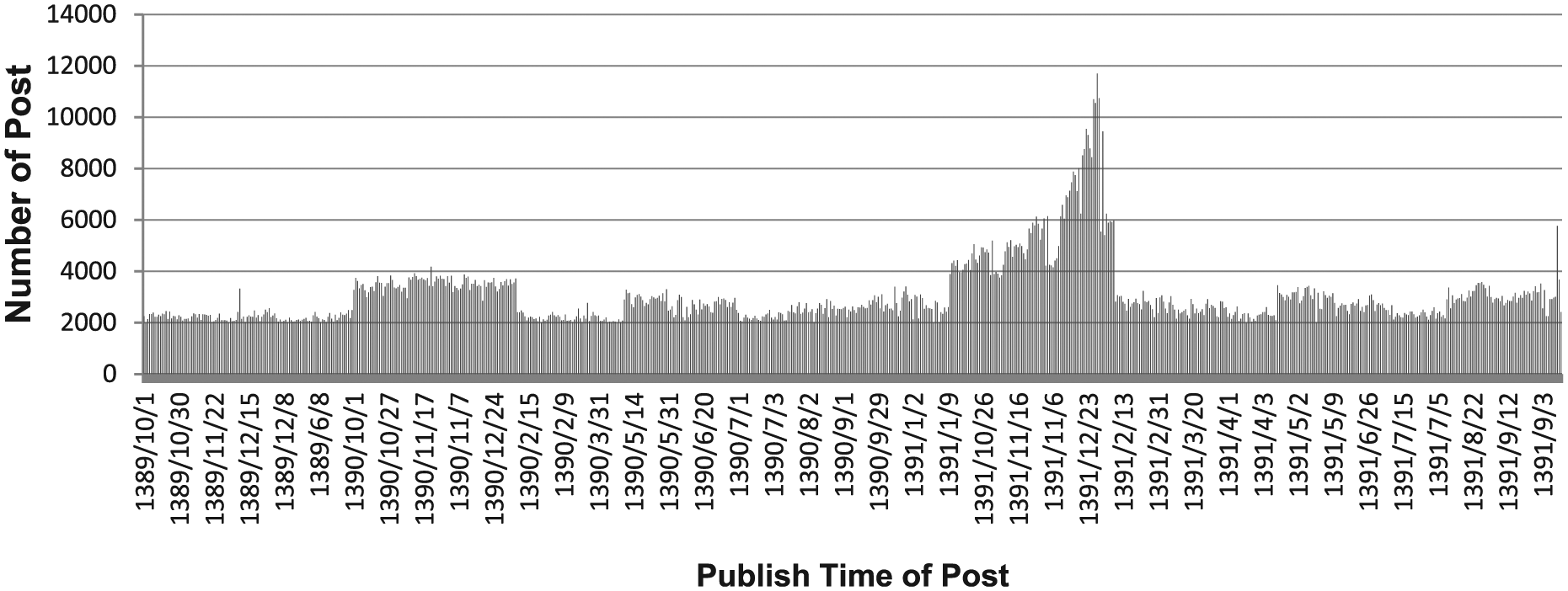
Distribution of writing time of irBlogs’s posts.
4.2. Training
We performed an exhaustive grid search to find the optimal parameters for the proposed methods. In the time-sensitive voting model and the time-sensitive local evidence model, we have two parameters to be trained, λ in equation (5) and α, which balances the weight of the temporal score of equation (7). Time-sensitive blogger/posting and time-sensitive small document models require training for one parameter λ in equation (13), which defines the exponential distribution coefficient.
4.3. Evaluation
In order to evaluate the performance of the proposed approaches, 10-fold cross-validation is performed. Partitioning process of the 45 queries of irBlogs dataset is done randomly. For one partition, the parameters are trained with all the other partitions and its performance is evaluated with the trained parameters. Thus, in each step we use 90% of the queries for the training procedure, and 10% for the test procedure.
Also, various common standard evaluation measures are used and the parameter trainings are also carried out for each measure. The measures are mean average precision (MAP) as well as a number of the precision-oriented measures such as precision at rank 10 (P@10), mean reciprocal rank (MRR) and normalized discounted cumulative gain (NDCG). MAP1 denotes the MAP of a run, when those blogs that are judged as highly relevant are considered to be relevant and MAP2 denotes the MAP of a run, when both highly relevant and relevant blogs are considered to be relevant. We compare the proposed method with some state-of-the-art blog retrieval methods that are listed in Table 2.
The best blog retrieval methods reported in the literature
5. Experimental results
In this section, several blog retrieval methods are analysed based on their top 1000 retrieved blogs and their performances are compared with the proposed methods.
5.1. Cross-validate the existing blog retrieval methods
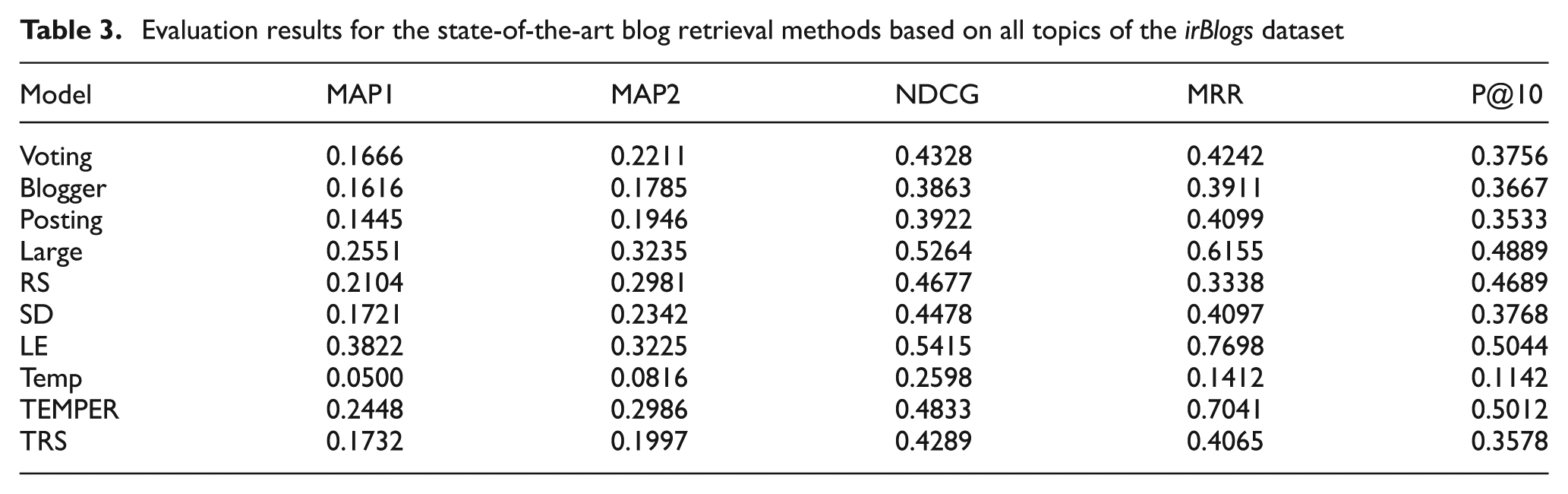
Table 3 provides a comparison of the performance of the blog retrieval methods on the irBlogs dataset. Based on these results, among the non-temporal blog retrieval methods, local evidence [26], resources selection [25] and large documents model [23] are the best. For temporal blog retrieval methods, TEMPER [40] performs considerably better than other temporal methods. Figure 6 shows the results of the comparisons of the blog retrieval methods based on MAP2 for the irBlogs and TREC 2007 datasets.
Evaluation results for the state-of-the-art blog retrieval methods based on all topics of the irBlogs dataset
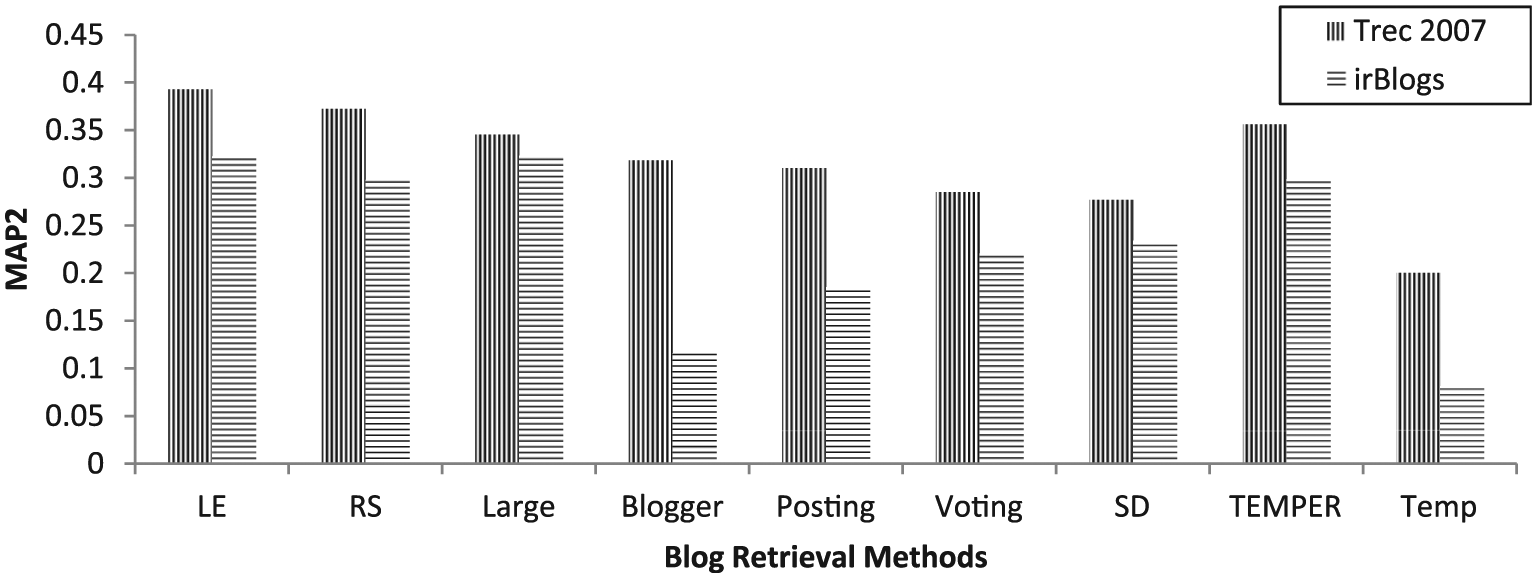
Comparison of the state-of-the-art blog retrieval methods based on Map 2 on TREC2007 and irBlogs collections.
As it can be seen in Figure 6, local evidence, resources selection and the large documents model are ranked the same in both collections but the ranking of the other ones are slightly changed. It should be noted that most of the existing blog retrieval methods do not perform well on the Persian dataset. This fact is also reported for text retrieval methods [47], which means that new methods should be developed by considering the characteristics of the Persian blogosphere.
5.2. Evaluation of the proposed time-sensitive methods
Since the irBlogs dataset contains time-sensitive queries (80% of the queries are time-sensitive), it is used for evaluation of the proposed time-sensitive methods. Table 5 provides information about the results of comparisons between our proposed time-sensitive methods and the state-of-the art temporal blog retrieval methods (listed in table 4).
List of already existing temporal blog retrieval methods
In order to test the statistical significance of our results, Student’s paired t-test is computed for each of the queries at α=0.05 level. Statistically significant improvements of the proposed time-sensitive methods over the best existing temporal blog retrieval methods (TRP, RS and TEMPER) are shown by ↑, ╤, ▲ symbols respectively. As shown in Table 5, the proposed TSV and TSLE methods perform considerably better than all existing temporal blog retrieval methods. In all cases this improvement is statistically significant. Also the other proposed methods TSB, TSP and TSSD perform considerably better than all the other existing temporal blog retrieval methods except the TEMPER method.
Comparison of already existing temporal blog retrieval methods with proposed time sensitive methods
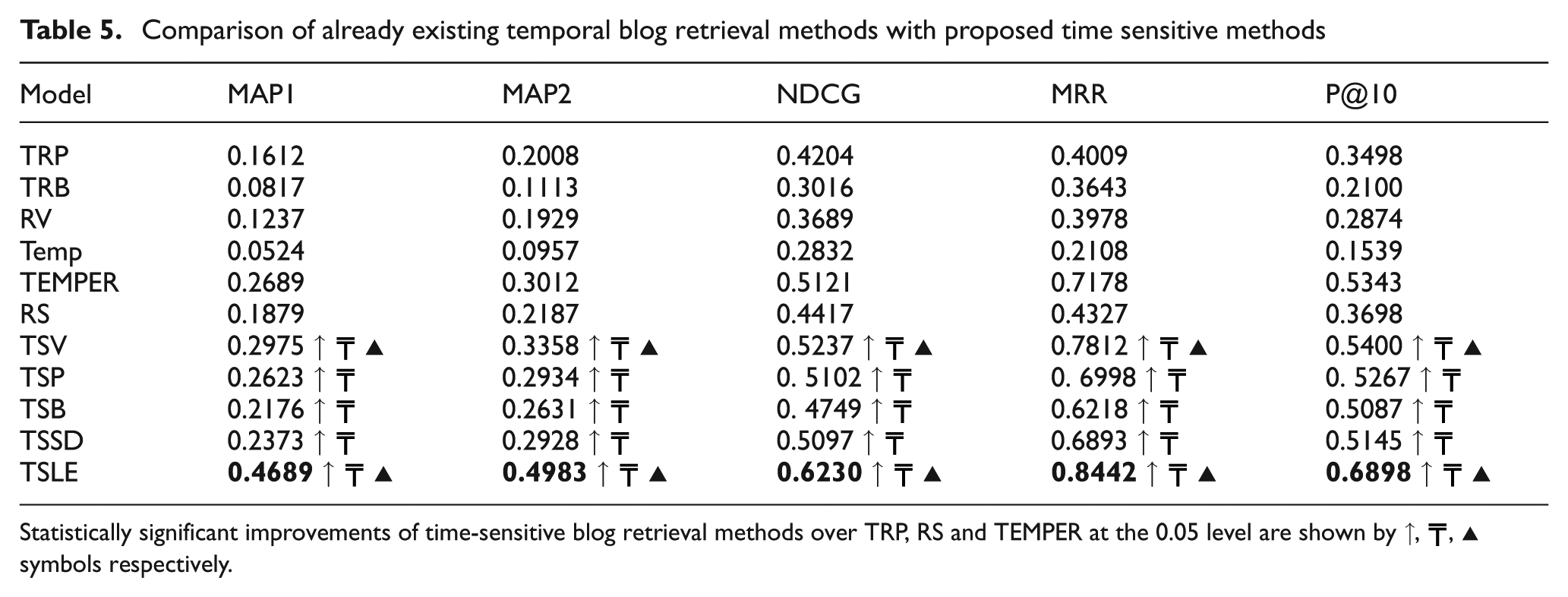
Statistically significant improvements of time-sensitive blog retrieval methods over TRP, RS and TEMPER at the 0.05 level are shown by ↑, ╤, ▲ symbols respectively.
Table 6 compares the result of the proposed time-sensitive methods and their corresponding time-insensitive versions based on different measures. As it is evident, all of the proposed methods perform considerably better than their counterparts based on all of the criteria. The best results are achieved based on precision-oriented measures (P@10 and MRR). This means that the proposed methods provide better ranking of the relevant blogs by listing highly relevant blogs at the top of the results.
Evaluation results for the proposed time-sensitive methods and original blog retrieval methods using time-sensitive test topics of irBlogs
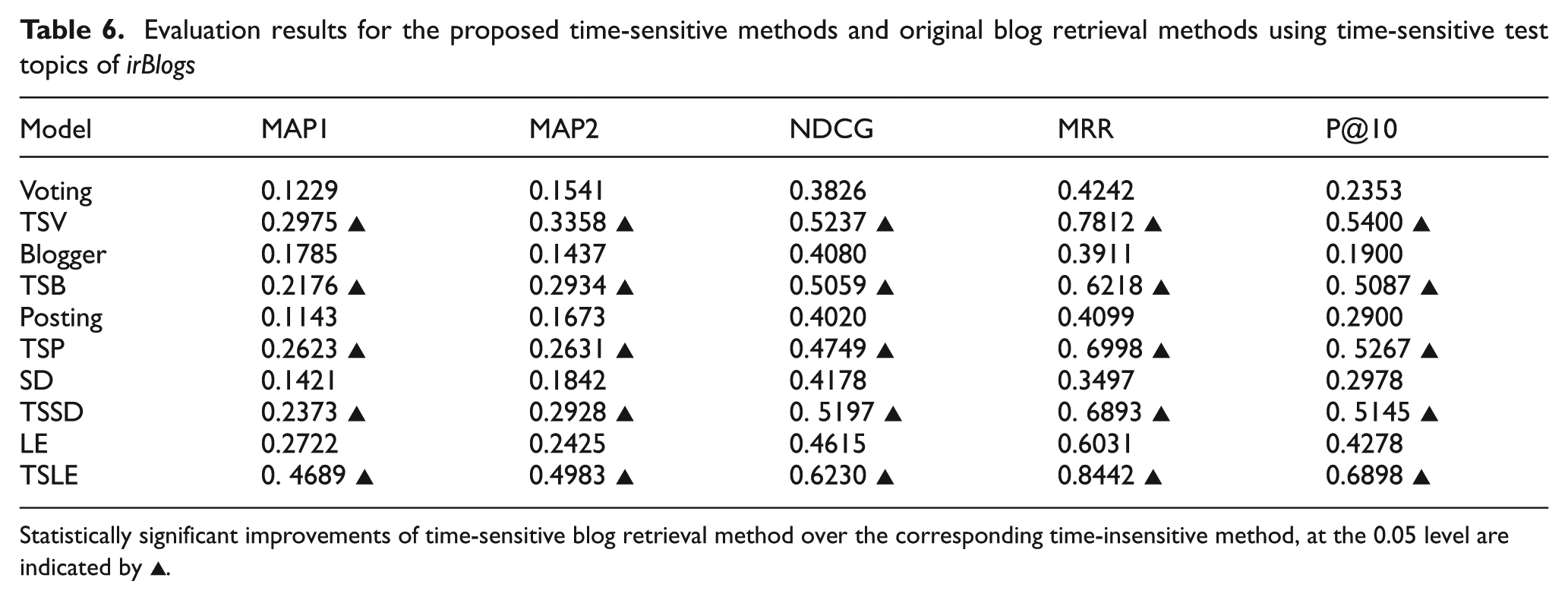
Statistically significant improvements of time-sensitive blog retrieval method over the corresponding time-insensitive method, at the 0.05 level are indicated by ▲.
5.3. Temporal query type analysis
This section presents an analysis to show what types of the queries are more suitable in time-sensitive blog retrieval methods. First, we discuss the performance of the proposed methods for time-sensitive and time-insensitive queries and then we look into the performance of the proposed methods for different types of time-sensitive queries that were discussed in Section 3.2.2.
Figure 7 shows the MAP1 score of the proposed time-sensitive blog retrieval methods for time-sensitive and time-insensitive queries of the irBlogs dataset. As can be seen, all of the proposed methods perform better for time-sensitive queries. The advantage of the proposed methods is that their performance does not degrade for time-insensitive queries and match or outperform their time-insensitive counterparts.
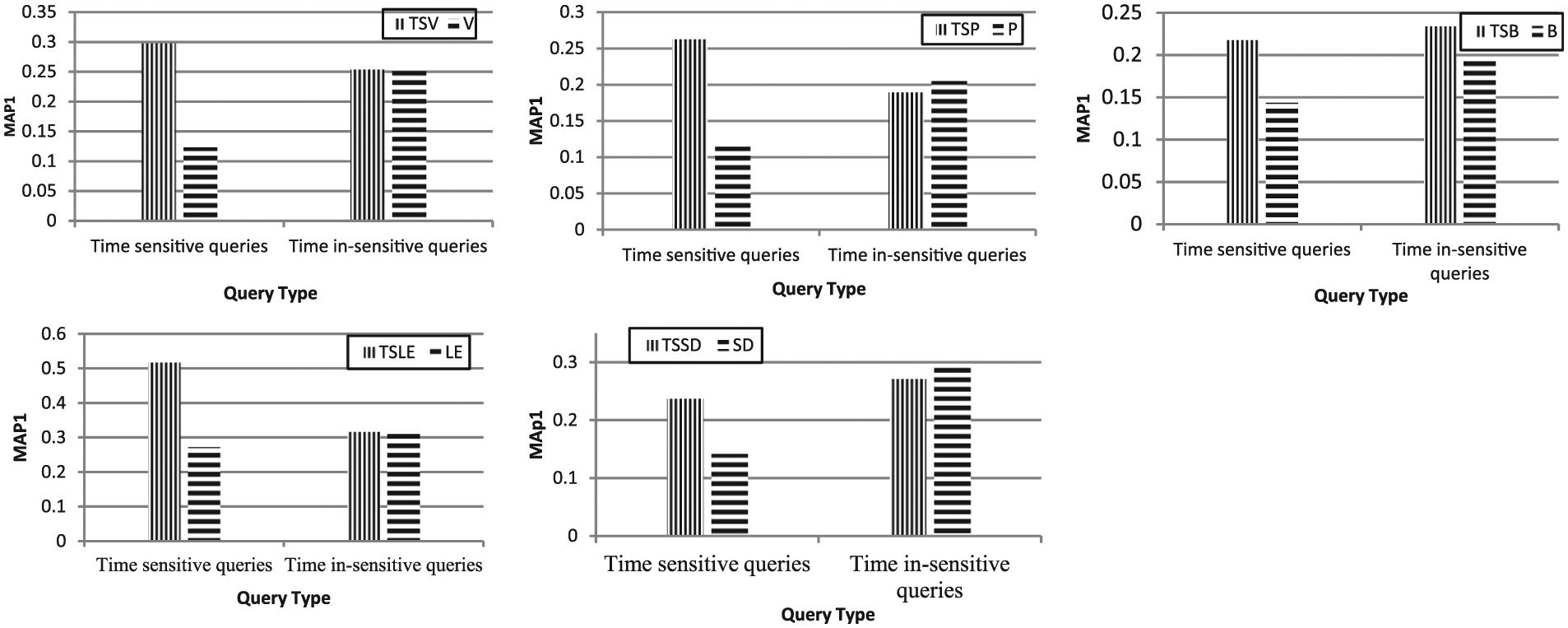
Evaluation results of proposed time-sensitive blog retrieval methods for time-sensitive and time-insensitive topics of irBlogs.
Figure 8 depicts a comparison of MAP1 scores of the proposed time-sensitive methods and the corresponding time-insensitive methods for different types of time-sensitive queries.
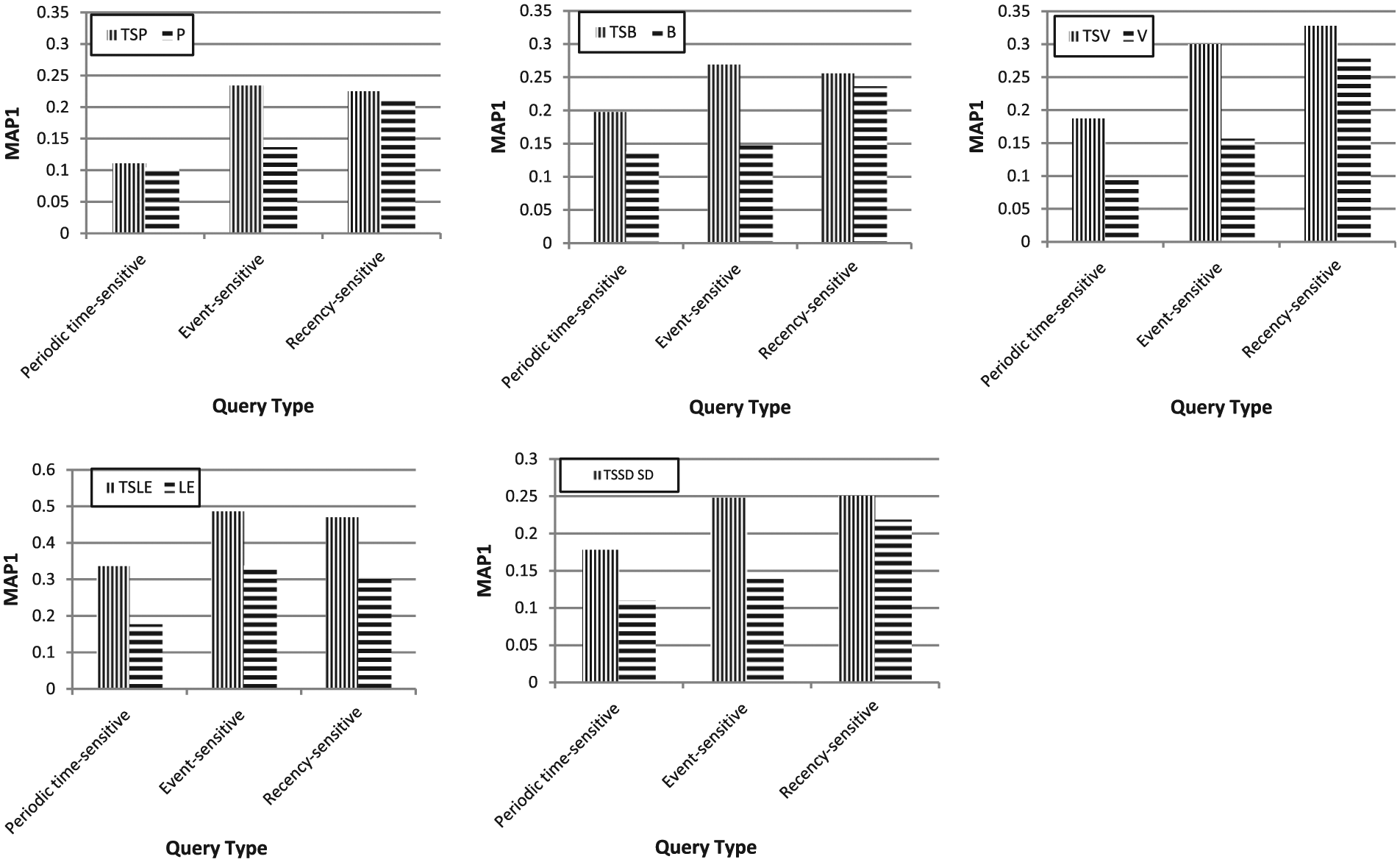
Evaluation results of the proposed time-sensitive blog retrieval methods for different type of time-sensitive test topics of irBlogs.
The time-sensitive posting (TSP) method performs better on event-sensitive queries. For the other two types (i.e. periodic time-sensitive queries and recency time-sensitive queries) its performance is similar to time insensitive methods. The time-sensitive blogger method (TSB) performs much better for event-sensitive and periodic time-sensitive queries than recency-sensitive queries. The time-sensitive voting method (TSV) and time-sensitive local evidence (TSLE) perform better than other methods; they perform better on all three types of queries and in all cases this improvement is statistically significant, that is to say, TSV and TSLE methods are independent form temporal queries.
In general, the proposed time sensitive methods perform better for periodic time-sensitive and event-sensitive queries.
5.4. Discussion
5.4.1. Comparison of the proposed time sensitive approaches
In this paper, our aim was not to propose a new blog retrieval method but to propose an approach to make already existing blog retrieval methods time sensitive. It was shown that considering both content and time stamp of the posts results in finding more relevant blogs. Therefore, the accuracy of the proposed approaches depends on the structure of the already existing blog retrieval methods. For example, the proposed TSV method improved MAP1 of the original voting method by around 142%. The main reason behind this considerable improvement is that the voting method is highly dependent on the list of initially retrieved posts for the input query, named R(Q). Therefore, improving the quality of R(Q) can highly improve the voting methods. Our proposed method made use of this fact by introducing a time-sensitive post score for reordering the posts of the initial R(Q). Our proposed method assigns a higher score to the posts that are written in the period of time that the input query belongs to; in this way a better R(Q) is obtained for time-sensitive queries that impacts the precision of the voting method in a positive way. Also, the TSLE method uses the top k retrieved posts of R(Q), so our proposed method could improve this method in the same way.
We propose two approaches for incorporating time-sensitiveness in blog retrieval methods: (a) linear combination of our proposed temporal score with the content score computed by already existing methods; and (b) biasing the score of retrieved posts by use of the proposed temporal score. For time-sensitive queries, two proposed approaches improved the results of all the blog retrieval methods under investigation and in all cases this improvement was statistically significant. From our experimental results it can be seen that first one is a better choice; it could improve TSLE and TSV methods 35 and 37%, respectively, in comparison with original blog retrieval methods based on the NDCG criterion.
For time-insensitive queries as stated in Section 5.3, the first proposed approaches do not deteriorate the precision of the previous method. In the case of time-insensitive queries, blog posts are distributed uniformly (e.g. Figure 3d). Therefore, our proposed TemporalScore is approximately the same for all retrieved posts. This means that the TimeSensitivePostScore is computed merely based on the content score of the posts and the final results are roughly the same as the results of the original blog retrieval methods. For the second approach, the precision of TSP and TSSD is decreased for time-insensitive queries. In these methods, we compute post centrality using
5.4.2. Very high early precision
It is generally accepted that search engine users use the first page of the retrieve results. Therefore, we used MRR and P@10 criteria for evaluation of the top retrieved blogs of the proposed methods. The results of Table 5 state that the proposed methods show considerable improvement based on MRR and P@10. The TSLE and TSV methods performed better than other methods based on MRR and P@10. We inspected the first retrieved document of the two methods and it was shown that TSLE and TSV retrieved a relevant blog in the first rank of their results for 83 and 75% of the queries and the two methods retrieved the first relevant blog after fifth place of their rankings for only 5% of the queries. This implies that the proposed methods provide better ranking of the relevant blogs by populating top of the retrieved list with highly relevant blogs.
5.4.3. Per-topic analysis
In order to find out the main reason behind the better performance of the proposed methods, we looked at the retrieved lists of blogs for all queries. For query number 3 entitled ‘FIFA World Cup 2010 in Africa’, the original voting method ranks a non-relevant blog that published general news about football in the first place, while the proposed method placed it as 219th in the ranking. Instead, the time-sensitive voting method ranks a highly relevant blog in the first place which was specially devoted to ‘World Cup 2010 Africa’ (i.e. most of its posts were related to the 2010 FIFA World Cup in Africa), which is clearly due to the proposed temporal score. Another example is a blog that is ranked 55 by voting method while it is ranked as 3rd by our approach. The content of the blog was about the real-time Africa’s world Cup news. In this blog, there were few words such as ‘FIFA’, ‘World Cup’ and ‘Africa’, but there are a lot of analyses about a specific players or matches in the mentioned cup. As the voting method uses just the content score of the blogs to rank them, so it ranks this highly-relevant blog as 55th. Since time-sensitive voting method also uses the temporal score of the post to rank the blogs, so it performs more accurately than the voting method. This fact was also noted for many other blogs in the retrieved lists.
Also, for query ‘Iran’s ninth parliament elections’, the proposed method ranks a highly relevant blog with long posts about the candidates and their future plans about the ninth parliament election at the top of the retrieved list, while the original voting method places this blog in the 18th place.
The voting method ranks a blog as fourth only because it contains some posts about the eighth parliament election and keywords related to parliament election, although the period of the election was irrelevant. The TSV method ranks that blog as 67th by considering published time of the posts.
Another example is the query ‘Night of worship (Qadr)’ that happens periodically each year. Our proposed method ranks a highly relevant blog at ninth place in the ranking while the original voting method ranks it at 40th place in the ranking.
According to the analysis conducted, our proposed method can improve a blog’s score in the following situations:
A blog that is relevant to the query, but its content does not necessarily contain the query terms and there are some equivalent terms or some comments about the query. Therefore if only the content score is taken into consideration, such a blog cannot gain a good score. However, if the published time of the blog posts is considered, the blog can achieve a more temporal score. Thus, this will compensate for the lack of the content score.
The second case is a blog that is not relevant, but, owing to the existence of some query words in abundance, they have a good content score such as query ‘Iran’s ninth parliament elections’ discussed before.
The third situation is when queries are event-sensitive such as queries related to festivals, celebrations, etc. From the user’s perspective, it is crucial that the retrieved blog posts are within the duration of that event. For example, for the ‘Fajr film festival’, the user prefers blogs that have published news at the holding’s festival time. The proposed method will assign higher temporal score to such blogs and will push them to top of the retrieved list.
6. Conclusion and future works
Time plays a vital role in blog retrieval methods and its importance cannot be ignored. In this paper, we proposed a temporal-based approach to blog retrieval that makes use of temporal properties of the input queries. First, the input queries were divided into time-sensitive and time-insensitive categories based on their relevant posts’ distribution. Then, a time importance score was calculated for each post in the initially retrieved list of relevant posts. We applied the temporal scores to improve voting, posting and blogger method. Since the irBlogs collection contains enough time-sensitive queries to guarantee a reliable evaluation, the proposed method was evaluated and compared based on irBlogs. The evaluation results indicated significant improvement of the blog retrieval methods, especially in terms of P@5, P@10 and MRR. The proposed method may be improved even more by applying temporal query expansion method such as the TEMPER method.
In this paper, the input queries were manually categorized into two time-sensitive and time-insensitive categories to simplify the problem. Therefore, automatic categorization of the input queries remains as a future research topic. Also, we believe that the proposed method can be used for other related problems, for example, information retrieval in microblogs in which time is an even more important feature.
Footnotes
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.