
Abstract
OLAP (On-line Analytical Processing) can provide users with aggregate results from different perspectives and granularities. With the advent of heterogeneous information networks that consist of multi-type, interconnected nodes, such as bibliographic networks and knowledge graphs, it is important to study flexible aggregation in such networks. The aggregation results by existing work are limited to one type of node, which cannot be applied to aggregation on multi-type nodes, and relations in large-scale heterogeneous information networks. In this paper, we investigate the flexible aggregation problem on large-scale heterogeneous information networks, which is defined on multi-type nodes and relations. Moreover, by considering both attributes and structures, we propose a novel function based on graph entropy to measure the similarities of nodes. Further, we prove that the aggregation problem based on the function is NP-hard. Therefore, we develop an efficient heuristic algorithm for aggregation in two phases: informational aggregation and structural aggregation. The algorithm has linear time and space complexity. Extensive experiments on real-world datasets demonstrate the effectiveness and efficiency of the proposed algorithm.
1. Introduction
OLAP can provide users with aggregate results from different perspectives and granularities, which is one of the core techniques in data warehousing and data mining. Aggregation allows users to observe and model data in different dimensions and to perform drill-down, roll-up and other OLAP operations. It is the foundation of OLAP techniques. With the advent of graph data widely used to model real-world nodes and relations, aggregation on graph data becomes important for users to analyse graphs and mine valuable information.
Heterogeneous information networks are newly emerged graph data, which involve multi-type nodes and relations, such as bibliographic networks, social media networks and knowledge graphs. We give an example to illustrate heterogeneous information networks.
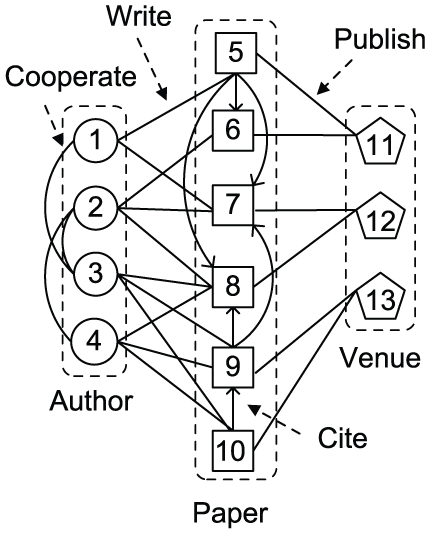
Bibliographic network.
Attribute values of Author.

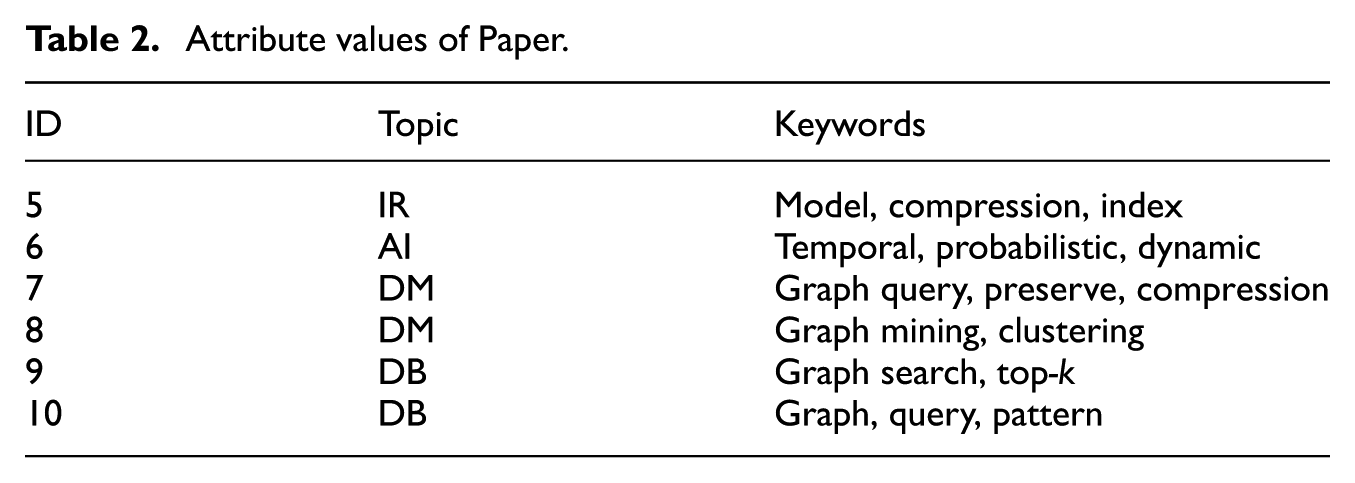
Attribute values of Paper.
Attribute values of Venue.

Heterogeneous information networks contain much more information than homogeneous information networks, which contain one type of node and one type of relation. Therefore, applying OLAP techniques to heterogeneous information networks is crucial for users to observe and analyse the networks from different perspectives and granularities to mine potential valuable information. Thus in this paper, we investigate the problem of aggregation on multi-type nodes and relations on large-scale heterogeneous information networks.
Figure 2(a) displays the aggregate result of query 1. From Figure 2(a) we can see that Paper nodes in the same aggregate nodes have the same values of Topic, for example, nodes 7 and 8 are both ‘DM’ Topic. Meanwhile, they also have the same Cite relations as the other aggregate nodes of Paper. For example, they are both cited by ‘IR’ and ‘DB’ Papers. Nodes 9 and 10 are not in the same aggregate nodes although they both have ‘DB’ Topic. This is because node 9 cites ‘DM’ Paper, while node 10 does not. Figure 2(b) gives the aggregate result of query 2. From Figure 2(b) we can see that Author nodes in the same aggregate nodes have the same values of Location and the same Write relations was the aggregate nodes of Paper, for example, nodes 3 and 4 are both in ‘CA’, and they both write papers in ‘DM’ and ‘DB’ Topics. Similarly, Paper nodes aggregated together have the same values of Topic and the same Write relations as the aggregate nodes of Author.
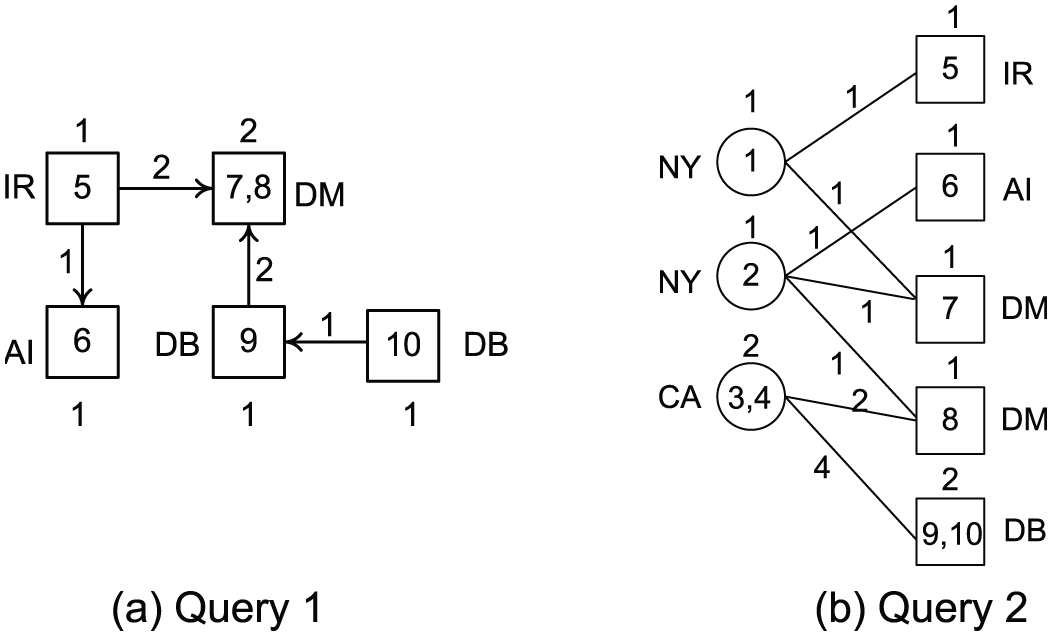
Aggregate results.
From the two examples, we can see that flexible aggregation on multi-type nodes and relations is meaningful, since it can help users to observe the networks from their interests and focuses. Therefore, we propose a flexible aggregation framework on large-scale heterogeneous information networks in this paper.
Aggregation on graphs has attracted some attention in recent years. The existing work can be divided into two categories: aggregation on homogeneous information networks [1–3] and aggregation on heterogeneous information networks [4, 5]. Chen et al. [1] study the aggregation problem on multiple homogeneous networks. It cannot be used for aggregation on a single network. Zhao et al. [2] propose an aggregation algorithm on a single homogeneous network by leveraging the attributes of nodes, where nodes are aggregated according to the selected attributes. The problem is that it does not concern the relations between nodes. Tian et al. [3] investigate how to get a summarization on a homogeneous network. It considers both attributes and structures, but it cannot aggregate different types of nodes and relations simultaneously. The aggregate results of existing work on homogeneous networks are all limited to one type of nodes. Yin et al. [4, 5] investigate the problem of aggregation on heterogeneous information networks, but their resulting aggregate graphs only contain one type of node. It cannot handle the aggregation queries with multi-type nodes and relations like query 2. Above all, the existing work cannot satisfy the demand for aggregation on multi-type nodes and relations. We need to construct a flexible framework to aggregate large-scale heterogeneous information networks.
In this paper, we investigate the flexible aggregation problem on large-scale heterogeneous information networks. In order to aggregate nodes with similar attributes and structures together, we employ graph entropy to measure the similarities of nodes. Since the aggregation involves two dimensions of networks, the informational dimension (node types, node attributes) and the structural dimension (edge types), we propose a two-phase aggregation algorithm: informational aggregation and structural aggregation.
The main contributions of this paper are:
We introduce a flexible aggregation framework on large-scale heterogeneous information networks, which can aggregate multi-type nodes and relations.
A novel function based on graph entropy is proposed, which is effective to measure the structural similarities of nodes with regard to different types of relations.
The aggregation problem based on the function is proved to be NP-hard. Furthermore, an efficient aggregation algorithm from two phases is proposed: informational aggregation and structural aggregation. The algorithm has linear time and space complexity.
Experiments on real-world datasets demonstrate the effectiveness of the algorithm by comparison with other algorithms. The good scalability of our algorithm has also been verified.
The remainder of this paper is organized as follows. Section 2 states related work. Section 3 defines the aggregation problem. Section 4 introduces the aggregation algorithm and Section 5 describes experiments. Section 6 draws conclusions.
2. Related work
In this section, we discuss the related work from four aspects: social data, multiple information sources, aggregation on information networks and heterogeneous information networks.
2.1. Social data
Recently, social data has become popular, for example, social media, online shopping, social networks, knowledge bases and so on. Many researchers have contributed to investigating social data.
Hu et al. [6], Kempe et al. [7], Azadeh et al. [8] and Jung [9, 10] have investigated the spread of influence in social networks. Hu et al. [6] models community and topic as latent variables to characterize the topic diffusion at community level. Kempe et al. [7] models the processes by which ideas and influence propagate through a social network. Azadeh et al. [8] propose the time-sensitive influence maximization problem, which takes into account the time dependence of the information value. Jung [9] proposes a robust information diffusion model to detect the malicious peers from which a risk has been generated on a P2P network. Jung [10] focuses on online social tagging systems to understand information propagation.
Jung [11], Lai et al. [12], Corbellini et al. [13] and Mao et al. [14] make recommendations to users by analysing social networks. Jung [11] proposes a recommendation method based on different types of influences: social, interest and popularity, using personal tendencies with regard to these factors to recommend photos in a photo-sharing website. Lai et al. [12] state an attribute reduction-based mining method to select the long-tail user groups. The long-tail user groups as domain experts are employed to provide more trustworthy information. Corbellini et al. [13] present a novel architecture and a corresponding implementation for designing distributed recommending algorithms. The algorithms are expressed in terms of graph traverse operations defined by API. Mao et al. [14] explore new methods of tag-based personalized recommendation without assuming that tags assigned by a user occur independently of each other. The new methods profile users using tag co-occurrence networks, upon which link-based node weighting methods are applied to refine the weights of tags.
Bohlouli et al. [15] and Vilares et al. [16] study the sentiments in social networks. Bohlouli et al. [15] mine customer needs and market-oriented productions by analysing the sentiments in social networks. Vilares et al. [16] use sentiment analysis to rank political leaders, parties and personalities for popularity. Ajao et al. [17] and Xu et al. [18] discuss the location research in social data. Ajao et al. [17] survey a range of techniques applied to identify the locations of Twitter users. Xu et al. [18] summarize popular information from massive tourism blogs to explore hot tourism locations.
2.2. Multiple information sources
Nowadays, data analysis often needs to integrate multiple information sources to obtain better results. Li et al. [19] and Wu et al. [20] investigate the problem of integrating multiple information sources in biological science. Li et al. [19] develop mine patterns across many biological networks. Such patterns include frequent dense subgraphs, frequent dense node sets, generic frequent patterns and differential subgraph patterns. Wu et al. [20] mine frequent coherent dense subgraphs across large numbers of massive networks to discover biological modules.
Wu et al. [21] and Boden et al. [22] study the problem of subgraph mining in multiple networks. Wu et al. [21] investigate the problem of finding the densest connected subgraph in dual networks, in which one network represents the physical world and the other network represents the conceptual world. Boden et al. [22] introduce the multi-layer coherent subgraph model, which defines clusters of nodes that are densely connected by relations with similar labels in a subset of the graph layers.
Furthermore, Dong et al. [23] address the problem of combining different layers of multi-layer graphs for improved clustering compared with using layers independently. Zhao et al. [24] propose three sampling methods on a hybrid social-affiliation network to estimate target graph characteristics. Cui et al. [25] incorporate multiple networks from the publication datasets, such as the paper citation network and author citation network, and analyse how people are citing papers by applying the logistic regression model to the paper citation network. This can obtain improved results of link prediction in the citation network. Nguyen and Jung [26] propose a privacy-aware framework for a social identity matching method across multiple social networks. Jung [27] finds the semantic relationships between the information sources in order to distribute user queries to a large number of sources.
2.3. Aggregation on information networks
Aggregation is the foundation of OLAP, which allows users to view the data from different perspectives and granularities. Traditional aggregation is implemented on a relational database [28, 29], which only focuses on the attributes of tuples. The existing aggregation work on graph data can be classified into two categories: aggregation on homogeneous information networks and aggregation on heterogeneous information networks.
Chen et al. [1, 30, 31] were the first to propose the idea of aggregation on graph data. They study the aggregation problem on multiple homogeneous networks, which cannot be used for aggregation on a large network. Zhao et al. [2] were the first to study aggregation on a single homogeneous network. It is assumed that nodes of networks have the same types and attributes. The network aggregates nodes according to their attributes, and does not consider the structures. Actually, the aggregate results show no difference from traditional aggregation. Wang et al. [32] extend the work of Zhao et al. [2] to a parallel environment. However, both of them are applied to homogeneous networks. Tian et al. [3] and Zhang et al. [33] propose an aggregation algorithm on homogeneous graphs. They utilize both attributes and structures to summarize the networks into k groups. Since the aggregate results are restricted to one type of node and the number of groups is restricted to k, it cannot handle the aggregate queries with multi-type nodes and relations on heterogeneous information networks.
Yin and Gao [4] were the first to propose aggregation on heterogeneous information networks. They compute iceberg aggregate graphs whose aggregate function values are larger than a specific value. Yin et al. [5] investigate the aggregation and partial materialization on heterogeneous information networks. Unfortunately, their aggregate results only contain one type of nodes, which cannot handle aggregate queries on multiple types of nodes and relations.
There is also some research work on clustering of heterogeneous information networks [34–39]. Zhou et al. [35] display a clustering algorithm on multiple meta-paths over one type of node in heterogeneous information networks. Sun et al. [36] address the problem of generating clusters for a specified type of nodes, as well as ranking information for all types of nodes based on these clusters. However, clustering is quite different from aggregation. Clustering results only relate to the networks, without the user-selected types of nodes and relations. Clustering cannot support users to observe the networks from different perspectives and granularities. It only provides results from one certain perspective which has been fixed by the algorithm.
In summary, there is no existing work on the flexible aggregation problem of large-scale heterogeneous information networks. Thus we investigate this problem in this paper.
2.4. Heterogeneous information networks
There has been some research work on heterogeneous information networks. Similarity search is an important topic in heterogeneous information networks [40, 41]. Sun et al. [40] search the top-k similar nodes, where nodes are connected by different types of relations in heterogeneous information networks. Shi et al. [41] measure the similarities between nodes with different types in heterogeneous information networks. Sun et al. [42, 43] study the link prediction problem in heterogeneous information networks. Sun et al. [42] study the problem of co-author relationship prediction. Sun et al. [43] investigate the problem of predicting when a certain relationship will happen. Yu et al. [44] and Gupta et al. [45] study the problem of subgraph query. Given a subgraph query, Yu et al. [44] search a given large information network and find a set of subgraphs that are structurally identical and semantically similar. Gupta et al. [45] compute the top-k similar subgraphs with respect to query. Sun et al. [46] build a unified generative topic model that is able to consider both text and structure information for documents. Ji et al. [47] combine ranking and classification in order to perform more accurate analysis. Integrating ranking with classification generates more accurate classes. Shen et al. [48] focus on entity identification in web text networks which can be formalized as heterogeneous information networks. Jayaram et al. [49, 50] and Yang et al. [51] propose query structure-flexible data, that is, knowledge graphs, for example entity tuples, without requiring users to write complex graph queries.
3. Preliminaries
3.1. Basic concepts
It is easy to see that the graph projection of G on Q and L is an induced graph of G, in which the types of nodes belong to Q and the types of edges are in L. Figure 3 is a graph projection of the bibliographic network, in which Q = {Author, Paper} and L = {Write}. Given a heterogeneous information network
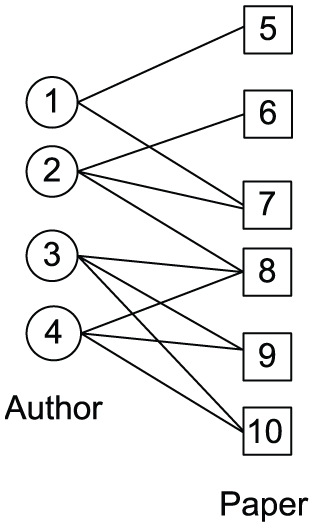
Graph projection.
For
For For For For
The graph partition on a graph projection
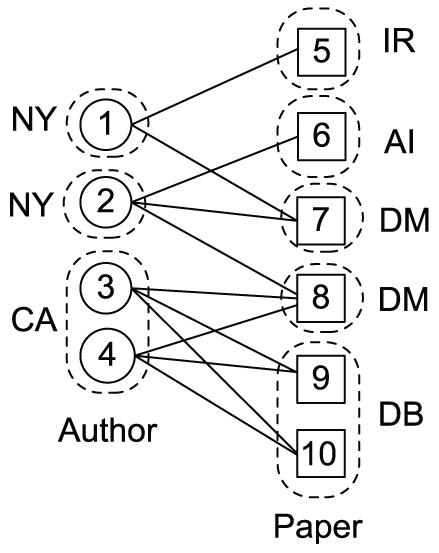
Graph partition.
Figure 5 shows an aggregate graph on the bibliographic network. The selected node types Q = {Author, Paper}, with selected attributes S = {
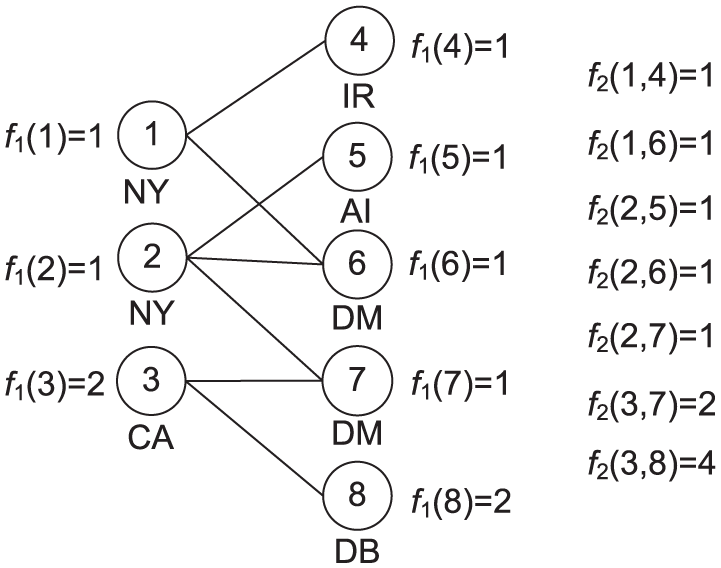
Aggregate graph.
3.2. Graph entropy
As shown in Definition 4, nodes with the same values of selected attributes and the same neighbours whose types belong to selected types of relations are aggregated. Unfortunately, these constraints often seem too strict in practice. The constraint of the same values of attributes is easy to satisfy; however, the restriction of the same neighbours is difficult to realize. We relax the limitation to aggregate nodes that have the same values of selected attributes and similar structures according to the selected types of relations. We propose a novel notion to measure the structure similarities.
In information theory [52], entropy is a measure of uncertainty associated with a random variable. Shannon entropy [53] is proposed for measuring the uncertainty, disorder and confusion of the system in information theory. Dehmer proposes to quantify the complexity of a graph using Shannon’s definition of entropy such that the probability distribution is computed from node degrees [54]. The original definition of graph entropy is introduced by Korner [55], who quantifies the lower bound on the complexity of graphs. Graph entropy [56, 57] based on Shannon entropy has been widely used in graph mining. This measure quantifies entropy using the localized features of a graph’s nodes such as closeness centrality and degree centrality. These centrality measures, however, do not fully capture the complexity of a graph, that is, they are limited to local neighbourhoods, and the approach appears to be ad hoc owing to the arbitrary choice of distribution functions. Intuitively, entropy is a means to quantify the amount of uncertainty in a distribution. We employ graph entropy to measure the structural consistency of nodes. Next we propose a graph entropy definition which is a variant of the classic graph entropy called topological information content [58].
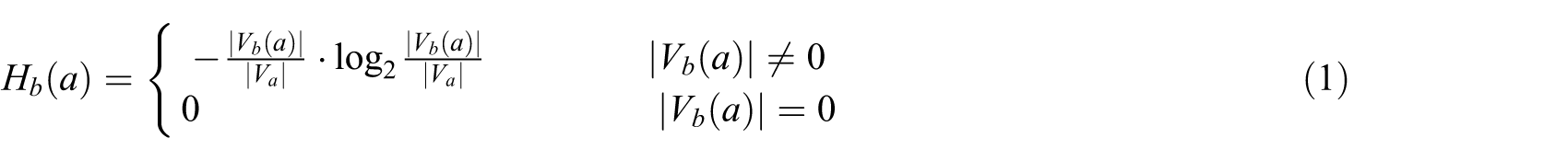
where

The entropy from a to b measures the structural similarities of nodes in a regarding to b.


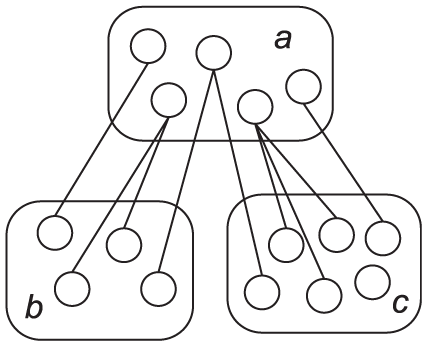
Graph entropy.
The entropy of b is the lowest. All nodes in b have neighbours in a. None have neighbours in c. They have the same structures. The entropy of a is the largest. Three nodes have relations with b, and three are relative with c. Graph entropy provides a powerful mechanism to aggregate nodes with similar structures.
When graph entropy is 0, nodes in the same aggregate nodes have the same structures. As mentioned before, this constraint is too strict, which will cause the large size of aggregate graph. We use the size of aggregate graph to control the structural similarities of nodes in the same aggregate nodes, which is a balance between them.

where
3.3. Problem definition
The complexity of this problem is NP, because a non-deterministic algorithm only needs to guess an aggregation and check in polynomial time. The aggregation can be generated by a polynomial time algorithm. We make restrictions that
4. Aggregation algorithm
In this section, we introduce an efficient aggregation algorithm for aggregate queries. Since the aggregation problem is NP-hard, it is intractable to give an exact solution in polynomial time. We propose a heuristic algorithm to aggregate networks with linear time cost. To distinguish nodes in semantics of attributes and structures, we design a two-phase aggregation framework, containing informational aggregation and structural aggregation.
4.1. Informational aggregation
This process depends on the selected node types and attributes. First search the network to get the graph projection of G on Q, then partition nodes in graph projection according to S to get the graph partition. Nodes with the same values of S are aggregated together. Finally, compute aggregate value. Table 4 presents the pseudo-code of Algorithm 1.
Informational aggregation on heterogeneous information networks.

In Algorithm 1, we first initialize the node and edge sets of aggregate graph to be NULL (Line 1). Then we traverse heterogeneous information network G. For each node u in V, if the type of u belongs to query types and there is not an aggregate node with the same attributes of u, create
4.2. Structural aggregation
Informational aggregation makes nodes in the same aggregate nodes have identical types and attribute values. However, this is not enough due to the complex structural characteristics of heterogeneous information networks. We can reduce the value of the C-function by decreasing graph entropy. The task of structural aggregation is to iteratively partition aggregate nodes according to their graph entropies. Structural aggregation is faced with three challenges: how to choose the partitioned aggregate nodes; what strategy should be used for partition; and when the iteration should stop. Next we discuss how to tackle the three challenges.
4.2.1. Challenge 1
In order to decrease the value of C-function, we choose the aggregate node with the largest graph entropy. This is reasonable, since nodes in it have diverse structures. After partitioning, the structural similarities of nodes are improved. Meanwhile, in order to improve the readability of aggregate graphs, for the aggregate nodes with the same graph entropy, alternatively, we first choose the one with the larger size, since dividing small aggregate nodes into smaller ones is not meaningful. We give Definition 7 to measure the balance between readability and structural consistency. In each iteration, we choose the aggregate graph with the largest partition level. Next we give the definition of partition level.

4.2.2. Challenge 2
In each iteration, we select an aggregate node to partition according to the structures of nodes in the aggregate node. How do we partition the aggregate nodes? We can aggregate the nodes which have the same relations of L to the other aggregate nodes. However, this would result in high time cost. Meanwhile, it is almost impossible that nodes have the same relations of L as the other aggregate nodes. It would be better to make nodes with similar relations together. In order to make the algorithm efficient, we design a heuristic strategy for this challenge. In each iteration, we divide the aggregate node into two aggregate nodes according to the nodes’ neighbours with t, where
4.2.3. Challenge 3
In view of C-function minimization, the size of aggregate graphs should be moderate. It is a balance between the size of the aggregate graph and the nodes’ structural similarities. From the aspect of users, a large number of aggregate nodes ais hard to analyse and summarize. We should constrict the size of aggregate graphs. In the beginning, the C-function value is decreasing along with the partition of aggregate nodes. After that, for the number of aggregate nodes increasing, C-function value also increases. If we do not stop the partition it will lead to a large aggregate graph. The iteration does not terminate until the C-function reaches the first maximal value or the size of aggregate graph exceeds a specific threshold. Algorithm 2 as shown in Table 5 describes the pseudo-code of structural aggregation. Next we make a detailed analysis.
Structural aggregation on heterogeneous information networks.
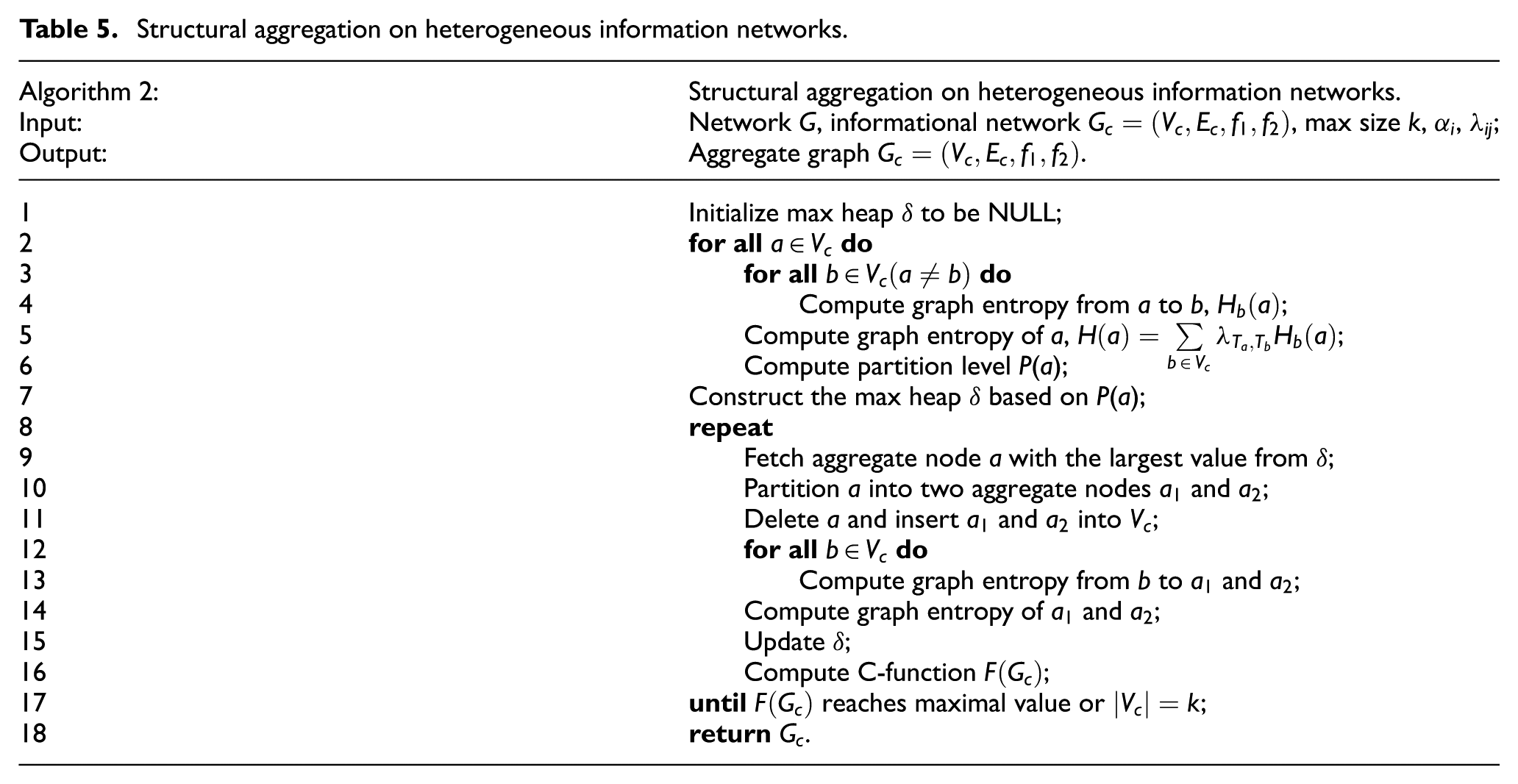
In Algorithm 2, we first construct a max heap (line 1). Compute the partition levels of all aggregate nodes (lines 2–6), which costs
5. Experimental evaluations
All experiments were done on a Microsoft Windows 7 machine with an Intel® Core i5-2400 CPU 3.1 GHz and 4 GB main memory. Programs were compiled by Microsoft Visual Studio 2010.
5.1. Datasets and experimental setup
We used the real-world heterogeneous information network from Amazon [60]. The network form is given in Figure 7. It contains three types of nodes: Customer; Product; and Category. Four types of relations exist among nodes: Co-Purchase relations between products; Purchase relations between customers and products; Classify relations between products and categories; and Like relations between customers, which represent customers who have reviewed the same products. Each type of nodes has a set of attributes: Customer (Name, Purchase times); Product (Name, Rank, Score, Price, Reviews); and Category (Name). In the effectiveness evaluation, the dataset includes 53,182 customers, 5000 products and four categories, which are Music, Book, DVD and Video. There are 147 edges of Co-Purchase, 77,997 edges of Purchase, 7231 edges of Like and 5000 edges of Classify. We use COUNT as the aggregate functions of nodes and edges. The parameters are set as follows:
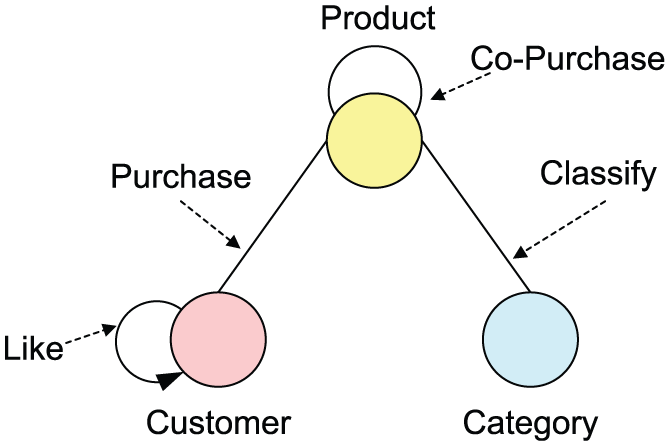
Amazon network.
5.2. Effectiveness evaluation
We first evaluate the performances of aggregate algorithms. We compare our algorithm with Zhao et al. [2], who aggregate nodes with the same values of attributes in homogeneous networks, and do not consider the structure of graphs. In our experiments, we make a few changes to the compared algorithm. We apply the compared algorithm to each type of node in heterogeneous information networks, without taking the structures into consideration. Actually, the compared algorithm is equal to informational aggregation. Our experimental results demonstrate that our algorithm performs better by taking the structural aggregation into consideration, which can provide more accurate and implicit knowledge with a wealth of information.
In our experiments, we evaluate the effectiveness of the algorithms on queries 1 and 2.
Figure 8 shows the aggregate graph of query 1 by the compared algorithm. The values of nodes and edges represent their aggregate values. In order to describe them clearly, we use dotted lines to represent the edges whose function values are below 10, and the other edges are represented by solid lines. From Figure 8 we can observe that the largest category of products is books, music stands second, and DVD and videos last. The co-purchased DVD products are not co-purchased with music and DVD. The same situation exists in the co-purchased products of videos. Products of music and DVD are not co-purchased, as are music and videos. Figure 9 presents the aggregate results of query 1. From Figure 9 we can see that our algorithm presents a deeper result than the compared algorithm. Besides the information we can get from Figure 8, much richer information can be obtained from Figure 9. Books that were co-purchased with music products are not likely to be co-purchased with DVD and video products. Meanwhile, the co-purchased music products are not co-purchased with books, which may be co-purchased with DVD and video products. The aggregate results are interesting after considering structures.

Aggregate graph of query 1 by the compared algorithm.

Aggregate graph of query 1 by our algorithm.
Figure 10 presents the aggregate result of query 2 by the compared algorithm. Edges between customers and products with aggregate values below 1000 are displayed by dotted lines. Otherwise, customers and products are connected by solid lines. In Figure 10, we can see that more than 80% of customers have low Purchase-Power. Only a few customers have high Purchase-Power. Figure 11 presents the aggregate result of query 2. After adding structural information, we can see that 25% of customers with low Purchase-Power only buy music products, which are never co-purchased with books. Customers who have purchased once are prone to buy music products. All these three types of customers have co-purchased books and music products. Book, music and DVD products are never co-purchased, as are book, music and video products. Query 2 is a drill-down operation of query 1 by adding a node type Customer and a relation type Purchase. Similarly, query 1 is a roll-up operation of query 2 by removing the node type Customer and relation type Purchase. OLAP on heterogeneous information networks can help users to mine valuable information from different perspectives. For example, the mutual complicated relationships between products and categories can be observed from a coarse view such as in query 1, or in a detailed way such as in query 2.
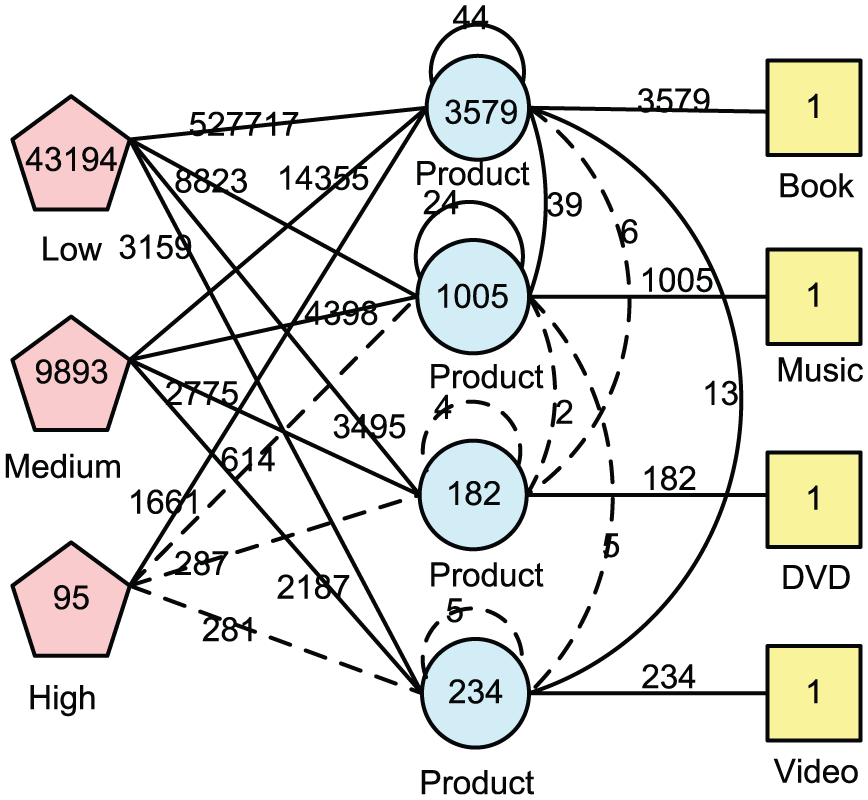
Aggregate graph of query 2 by the compared algorithm.
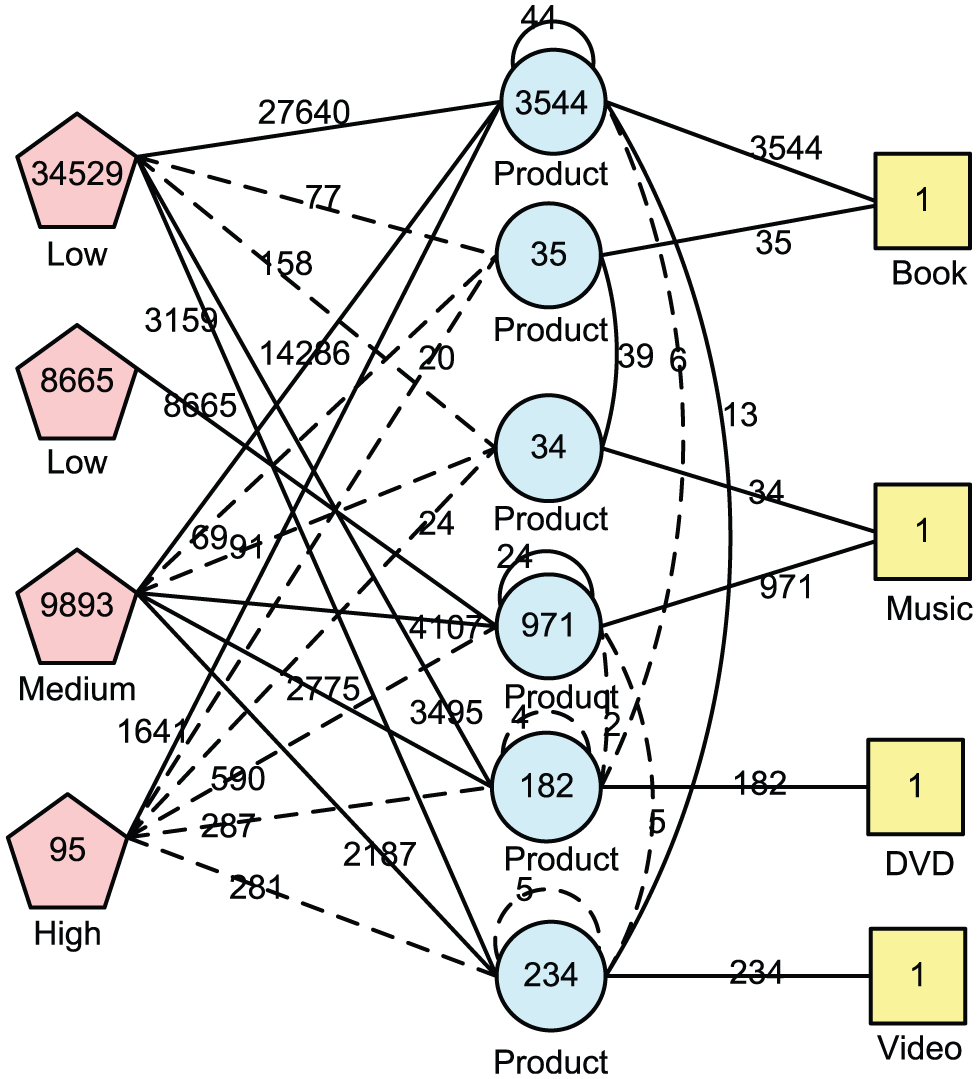
Aggregate graph of query 2 by our algorithm.
5.3. Efficiency evaluation
We first evaluate the runtime and C-function values by varying queries. We use four queries, and two of them have been described before. We give another two queries. Query 3 is the same as query 2 except for
Figure 12 presents the runtime comparisons of different algorithms by varying queries. The x-axis represents the queries from 1 to 4 and the y-axis stands for the average runtime of queries. Each query is run 10 times and we compute the average runtime. Previous work only focuses on the attributes of nodes, while our work also considers the structures of networks. Therefore our method takes more time than the previous work. In query 1, the two algorithms cost almost the same time, while in query 2, our algorithm costs 13.2s more than the compared algorithm. This is because query 2 adds a new relation type. Query 3 takes more time than query 2 since it draws a new attribute of Product. The same situation exists between queries 3 and 4. However, query 4 adds a new type of relation into the aggregation. The compared algorithm does not regard the relations in aggregation, so it costs almost the same time as queries 3 and 4. To the contrary, our algorithm takes more runtime in query 4 than query 3. As we can see in the effectiveness evaluation, although our algorithm costs more time than the compared one, we can get much richer results.
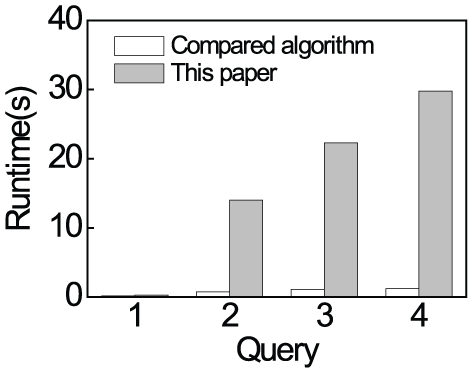
Runtime.
Figure 13 displays the comparisons of C-function values of different algorithms. The x-axis represents queries 1–4 and the y-axis shows the values of the C-function. Although the aggregation including structural aggregation costs more time, the C-function values of aggregate graphs are much smaller than those of the compared algorithm. Nodes aggregated together have high similarities of attributes and structures. The compared algorithm only considers the attributes of nodes. The values of C-function by the compared algorithm increase from query 1 to query 4, since the numbers of aggregate nodes increase. Ono the contrary, our algorithm performs much better. The values of C-function decrease from query 1 to query 4. Our algorithm decreases the graph entropy by taking the structures into consideration.
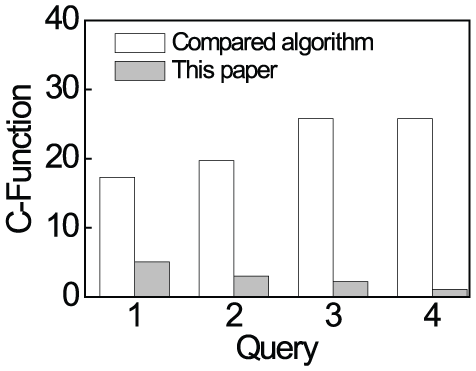
C-function.
Next we test the scalability of our algorithm by varying sizes of datasets: 1000, 2000, 3000, 4000, 5000, 10,000, 15,000 and 20,000 products are selected, and nodes of other types corresponding to these products are added. The number of categories is always 4. The scalable datasets are displayed in Table 6. We use the four queries mentioned before to test the scalability. In our experiments, we set k = 20 on datasets 1–5, and k = 40 on datasets 6–8. The last column of Table 6 shows the performances of algorithm on different sizes of data. As we can see, runtime increases with increasing size of dataset. The total edges have a more obvious impact than the total nodes on runtime. More edges would cost more time in structural aggregation. Not only does each iteration last longer but the times of iteration also increase. When experimental data reaches 500,000, the runtime is longer than 1 min. It is acceptable to apply the algorithm to large datasets.
Scalability testing with various datasets.

6. Conclusion and future work
In this work we have investigated the problem of aggregation on different types of nodes and relations in large-scale heterogeneous information networks. We prove that this problem is NP-hard. To solve the problem, we have presented an aggregation algorithm that has linear time and space complexity. The algorithm consists of two phases. In the first phase, we partition the nodes according to the selected types and attributes, so that the nodes aggregated together share the same types and attribute values. In the second phase, we further make sure the aggregated nodes have similar structures. We employ graph entropy to define a function that can effectively measure the structural similarities of nodes with regard to different types of relations.
From the experiments we can see that graph entropy can effectively help users aggregate the nodes with similar structures together. The experimental results show that a great improvement of C-function values is achieved by the proposed algorithm. Our aggregation algorithm performs much better than the compared algorithm, which only adopts informational aggregation. Additionally, our algorithm is also demonstrated to have a good scalability on large datasets. When the experimental data reaches 500,000, the runtime is about 1 min. In summary, taking into account both attributes and structures is a good and solid idea for investigating flexible aggregation on large-scale heterogeneous information networks.
As further work, we will extend our work to knowledge graphs, which are schemaless and structureless. Aggregation on such graphs is not an easy task, especially for non-professional users: either no standard schema is available, or schemas become too complicated for users to completely possess. It is difficult for them to illustrate the querying node and edge types explicitly. We will modify our algorithm to make it feasible on knowledge graphs.
Footnotes
Funding
This work is supported by the National Grand Fundamental Research 973 Program (grant number 2012CB316200), the Major Program of National Science Foundation (grant number 61190115), the General Program of Natural Science Foundation (grant number 61173023) and the Key Program of Natural Science Foundation (grant number 61532015).