
Abstract
Finding k-nearest neighbours (k-NN) is one of the most important primitives of many applications such as search engines and recommendation systems. However, its computational cost is extremely high when searching for k-NN points in a huge collection of high-dimensional points. Locality-sensitive hashing (LSH) has been introduced for an efficient k-NN approximation, but none of the existing LSH approaches clearly outperforms others. We propose a novel LSH approach, Signature Selection LSH (S2LSH), which finds approximate k-NN points very efficiently in various datasets. It first constructs a large pool of highly diversified signature regions with various sizes. Given a query point, it dynamically generates a query-specific signature region by merging highly effective signature regions selected from the signature pool. We also suggest S2LSH-M, a variant of S2LSH, which processes multiple queries more efficiently by using query-specific features and optimization techniques. Extensive experiments show the performance superiority of our approaches in diverse settings.
Keywords
1. Introduction
Finding k-nearest neighbours is one of the most important tasks performed by various applications such as search engines and recommendation systems. The performance of k-nearest neighbour (k-NN) computation becomes increasingly important when finding k-NN points in a large collection of high-dimensional points representing images (e.g. Google image search) or videos (e.g. YouTube video recommender). Furthermore, there are situations in which k-NN lists need to be updated frequently and promptly in response to diverse user behaviour such as clicks. Therefore, an efficient approach for finding k-NN points is highly demanded.
Locality-sensitive hashing (LSH) is an efficient method for approximate k-NN search [1]. Given a collection of data points, LSH functions assign close points to the same hash bucket with high probability. Therefore, points sharing a bucket with a query point can be considered as good candidates for k-NN search. However, the performance of the state-of-the-art LSH approaches such as Collision Counting LSH [2], LSB-tree and forest [3], and Exact Euclidean LSH [1, 4] is heavily affected by the characteristics of a given dataset such as the number of dimensions, the number of points and the feature extraction method used to generate the dataset.
In this paper, we propose a novel LSH approach for a fast k-NN approximation, called Signature Selection LSH (S2LSH), which performs consistently well in various types of datasets. To explain our main idea clearly, we introduce three concepts, a signature, a signature region and a k-NN region of a given point. When an LSH function g projects a point p onto a lower-dimensional space, the projected coordinate of p, g(p), is called the signature of p by g. A signature region of p by g, Rsig(g, p), is defined as the smallest region containing all the points whose signature is g(p). The k-NN region of p, Rknn(p), is defined as the smallest region containing all the exact k-NN points of p.
Notice that the sizes and the shapes of the k-NN regions of queries can be highly diverse. Therefore, even if there exist multiple signature regions, there is no guarantee that a signature region covers the entire k-NN region of a given query q. Some LSH approaches select candidates from the union or the intersection of all the signature regions. However, their performance can be seriously degraded by signature regions containing many non k-NN points of q. Instead, we suggest generating a query-specific signature region by using only highly effective signature regions.
Figure 1 shows a motivating example where some signature regions are more effective in finding k-NN points of q than others. Let us assume that there exist three signature regions of q (the star point), Rsig,1, Rsig,2 and Rsig,3. Now, assuming that k is 3, we need to select five points as k-NN candidates of q. Instead of the union or the intersection of Rsig,1, Rsig,2 and Rsig,3, we generate a query-specific signature region by using the most effective signature regions. Rsig,1 is a large signature region containing five neighbours of q, but four points are relatively far from q. In contrast, Rsig,2 and Rsig,3 are smaller, so the points in them are closer to q. Therefore, the points in Rsig,2 and Rsig,3 are better k-NN candidates of q than those in Rsig,1.
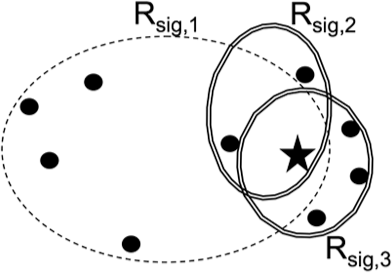
Finding k-NN candidates (k=3) of a query point (the star point) using three signature regions (spheres), Rsig,1, Rsig,2 and Rsig,3.
Based on this observation, we assume that small signature regions are more effective for k-NN approximation. However, we need large signature regions as well, since the actual k-NN points of q can be far from q if q is in a sparse region or k is large. Therefore, we construct a large pool of highly diversified signature regions with various sizes and shapes, not just small ones, so that we can dynamically generate a query-specific signature region for any given query.
Even though the size of a signature region is a good indicator of the effectiveness of a signature region, it can be estimated more accurately by using query-specific features of a signature region. Let us consider a signature region containing two query points, qb and qc. If qc is near its centre while qb is near its border just as in Rsig,1, its effectiveness for qb may not be as high as that for qc, especially when it partially covers the points very close to qb. For example, the maximum distance from a query q to the points in the signature region is a query-specific feature that can be used to estimate the effectiveness of a signature region more accurately; it usually becomes larger as q moves from the centre of a signature region to the border. However, given a large set of data points and a large pool of signature regions, the computational cost to compute the exact values of such features is very expensive, slowing down the overall execution time of k-NN approximation significantly. Later, we present a variant of LSH, S2LSH-M, which exploits query-specific features of a signature region, together with additional optimization techniques, to further improve the efficiency of k-NN approximation, given a large set of queries. When many queries are given, we can approximate the query-specific distance values efficiently using intermediate computation results of k-NN approximation of other queries.
The contributions of this paper are summarized as follows:
We propose a novel k-NN approximation approach, S2LSH, which constructs a large pool of signature regions (Section 3) and finds k-NN candidates by using highly effective signature regions (Section 4).
We suggest S2LSH-M that uses query-specific features of a signature region and optimization techniques in order to further improve the efficiency of k-NN approximation, given multiple query points (Section 5).
Extensive experiments with various types of datasets show that our approaches, S2LSH and S2LSH-M, consistently outperform the state-of-the-art algorithms for k-NN approximation (Section 6).
2. Related works
Three types of k-NN computation tasks are mainly performed in various applications: k-NN search, k-NN graph construction, and partial k-NN graph construction. For a given dataset D and a given query, k-NN search finds k-NN points of the query among the points in D. It is an essential part of Google image search and k-NN classification. Then, let Q denote a set of queries. k-NN graph construction considers all the points in D as queries, that is, Q=D, and constructs a k-NN graph of D in which each point is connected to its k-NN points. It is important in the YouTube video recommendation system and agglomerative clustering. Partial k-NN graph construction is the same as k-NN graph construction except that Q is a subset of D. It can be used for the incremental update of a large k-NN graph.
2.1. k-NN search
Let D be a set of data points in a d-dimensional space. Given a query point q, we define an approximate k-NN search as a task of finding approximate k-nearest neighbours in D. It is challenging especially when the data points in D are high dimensional. For instance, documents and logs are usually represented by a huge number of words or items, and images and videos by a large number of extracted features. Tree-based space partitioning approaches such as kd-tree, quadtree, and R-tree have been proposed to speed up this process, but they suffer from the curse of dimensionality [4].
2.1.1. Locality-sensitive hashing
Locality-sensitive hashing is introduced as one of the most effective techniques for finding approximate k-nearest neighbours in a high-dimensional space [1]. LSH reduces the dimensionality of high-dimensional points by converting them into low-dimensional signatures while preserving their relative distances. Formally, a signature of a point p consists of an ordered set of hash values, each calculated by the corresponding LSH function
The main difference between LSH and conventional hash functions can be explained as follows: let us consider two points, p1 and p2, that are good k-NN candidates of each other because of their close proximity to each other. While conventional hash functions map same points to the same buckets, different points such as p1 and p2 are usually mapped to different buckets. Even if conventional hash functions map different points to the same bucket, we cannot regard them as neighbours because the distances between the points are not considered when determining bucket numbers. In contrast, LSH hashes points to buckets so that close points are mapped to the same buckets with high probability. Therefore, it is highly likely that p1 and p2 are located in the same LSH bucket if they are close enough, and thus we can consider points located in the same bucket as k-NN candidates.
Various types of LSH functions have been proposed, and random projection [1, 5] is one of the most popular ones. It projects a high-dimensional point onto a small line segment as follows:
2.1.2. k-NN approximation using LSH
Once high-dimensional data points in D are converted into signatures, we need a way to find k-NN candidates for a given query q. The simplest way is to calculate the distances between the signature of q and the signatures of data points in D and select k data points closest to q. This approach, however, is not adequate for many applications for the following reasons: (1) if signatures are short (e.g. 100), even the state-of-the-art data-dependent LSH algorithms such as spherical hashing [8] do not achieve the level of accuracy (e.g. MAP@100) higher than 0.15 for large datasets; (2) if signatures are long, it takes much time to calculate the similarities between signatures.
To cope with this problem, Exact Euclidean LSH (E2LSH) is proposed [1, 4]. It constructs a set of compound LSH functions, g1, g2, …, gL, each consisting of an equal number of binary LSH functions. Given a query point q, if q and a data point
C2LSH outperformed other LSH approaches such as E2LSH, LSB-tree and LSB-forest [2]. However, we consider E2LSH as one of the baselines since we observed that E2LSH significantly outperforms C2LSH on some datasets. In fact, both of C2LSH and E2LSH use multiple signature regions. However, since the size and the shape of the actual Rknn(q) of each query q may differ significantly across queries, the union of all the corresponding signature regions (E2LSH) or their intersection with a threshold value (C2LSH) does not cover Rknn(q) effectively for some queries.
2.2. k-NN graph construction
Given a set of data points D and a set of query points Q, k-NN graph construction finds k-nearest neighbours in D for each query point in Q. In fact, we set Q to be D, that is, every point in D is considered as a query. It is one of the primitive operations performed in data mining, information retrieval, recommender systems and machine learning [9–23]. There are three groups of algorithms for k-NN graph construction: LSH-based algorithms, clustering-based algorithms and heuristic or data-distribution based algorithms.
A naive way to construct a k-NN graph is to execute an LSH-based k-NN search algorithm for every point in D. However, k-NN graph construction algorithms [9, 11] are usually more efficient than multiple executions of LSH-based k-NN search algorithms, since they reuse the computation results obtained during k-NN search of other queries. In order to cope with this problem, the two-hop neighbours of each query are exploited and random projection is applied to compound LSH functions, which is a variant of LSB-tree and LSB-forest [18].
The key intuition behind clustering-based algorithms is that the points in a cluster are highly likely to be k-nearest neighbours of each other. K-means and canopy clustering are known to be slightly faster than brute-force search while maintaining a high level of accuracy [24]. Also, iterative execution of two-means clustering is shown to be effective in constructing a k-NN graph [17]. Recursive Lanczos bisection [10] uses a hyperplane to make clusters; first, it draws a hyperplane that splits a set of points in D such that it maximizes the sum of squared distances between
NN-Descent [9] also exploits the two-hop neighbours heuristic but in a more efficient way: it first randomly selects the k-nearest neighbours for every point in D. Then, it repeatedly improves the k-NN lists by comparing each point against its neighbours’ neighbours. It also uses two techniques, one for avoiding many redundant distance computations without consuming much memory, and the other for slowing down the convergence of the algorithm. Greedy filtering [11] assumes that each point is sparse and thus represented as an array of elements, each consisting of a dimension and a value, and that cosine similarity and the TF-IDF (or BM25) weighting scheme are used. Based on the observation that a dataset often follows a certain data distribution, it prunes out a significant amount of search space.
3. Signature pool generation
Given a set of data points, D, we construct a highly diversified signature pool of size L. We first define a set of L compound LSH functions,
We target constructing a large signature pool containing signature regions with various sizes and shapes, since we want to improve the chance to find a set of effective signature regions of any given query. However, when L and |D| are large, it turns out that the preprocessing time to generate values of gi separately and precompute the signatures of points in D using each gi is extremely long. Instead, we generate a large collection of binary LSH functions,
3.1. Generating a set of underlying binary LSH functions
We first generate a set of binary LSH functions,
3.2. Generating a set of compound LSH functions
Given the size of a signature pool, L, we generate L compound LSH functions in
For instance, let us assume that H=300, m1=5, and m2=15, and spherical hashing is used. After generating 300 hyperspheres, we construct each gi by combining hyperspheres randomly chosen among them. The number of hyperspheres is between m1 and m2, and corresponds to the length of signatures defined by gi. Notice that we execute spherical hashing only once to generate 300 hyperspheres and generate values of gi, instead of performing spherical hashing L times to generate values of gi separately. This significantly reduces the preprocessing time to construct a signature pool without affecting k-NN approximation accuracy. In addition, generating values of gi in
3.3. Signature diagrams and signature regions
The ith signature diagram is defined by the ith compound LSH function gi in

A signature pool of size 4 (L=4). The signature diagram i depicts a given dataset partitioned by the ith compound LSH function, gi. Points in a signature region have the same signature; g2(E)=g2(D) and g3(E)=g3(F)=g3(H).
3.4. Signature pool for fast retrieval of points in a signature region
S2LSH finds k-NN candidates by retrieving points in each selected signature region. If a signature pool provides only the compound LSH functions in
The pseudocode of constructSignaturePool (

Using the example in Figure 2, we explain how we generate
Algorithm 1 is the pseudocode of the signature pool generation of S2LSH. The inputs are (1) D (a set of data points), (2) H (the number of binary LSH functions), (3) L (the size of a signature pool), (4) m1 (the minimum size of gi in
3.5. Parameter settings
S2LSH uses four parameters to control the size and the diversity of a signature pool: H, L, m1, and m2. To achieve high k-NN approximation accuracy within a fixed time budget, these parameters need to be set carefully, especially when D is a large-scale high-dimensional dataset. For instance, we set H=1000, L=H/2, m1=5, and m2=15 for some experiments.
As H and L grow, the size and the diversity of a signature pool increase, which consequently improves the k-NN approximation accuracy. However, this requires more preprocessing time and space. For our experiments, we tune H mainly by considering the type of the LSH scheme and the characteristics of a given dataset. L is set to H/2, since the k-NN approximation accuracy improves as L grows but the improvement becomes marginal after L exceeds H/2.
We determine m1 and m2 based on the cardinality of D. Assuming that each binary LSH function hi in
4. k-NN approximation using S2LSH
Once a signature pool of size L is constructed, we need to select k-NN candidates of q from the signature regions in the signature pool. To compare the effectiveness of the signature regions of q, we define an effectiveness measure, E′.
We first discuss on two observations on the effectiveness of a signature region of q. First, the ith signature region of q, Rsig, i(q), is effective for the efficient k-NN computation of q if it contains many exact k-NN points of q, that is, |Rsig,i(q) ∩ Rknn(q)| is large. Here, we assume that a signature region can be also viewed as a set of points in it. If |Rsig,i(q)∩Rknn(q)| is k, this means that we can find all the exact k-NN points among the points in Rsig,i(q). Next, when two signature regions contain the same number of exact k-NN points of q, we prefer a smaller one containing fewer false positives. Therefore, the effectiveness of the ith signature region of q can be represented as follows:

However, notice that we can calculate the above effectiveness score only if we know the exact k-NN points of q in Rknn(q) in advance. In fact, even if Rknn(q) is known, it is NP-hard to find the optimal set of signature regions that cover the k-NN points of q with minimum cost. This problem is equivalent to the weighted set cover problem that finds the set of signature regions covering all the k-NN points of q while introducing the minimum number of non k-NN neighbours of q. Therefore, we identify a set of features that are highly correlated with the effectiveness of a signature region in terms of the k-NN approximation accuracy and the computation time, and use them to define a new effectiveness measure E′.
4.1. Effectiveness measure for S2LSH
Since the distance between q and a point in a signature region is bounded by the size of the signature regions, a point in a smaller signature region of q tends to be closer to q. A small signature region may not cover some of the actual k-NN points of q, but they are highly likely to be covered by other small signature regions in our large pool of signature regions. If two signature regions are of similar size, we consider the proximity of q to the centres of the signature regions. If Rsig,i(q) contains q near its border while q is near the centre of Rsig,j(q), Rsig,i(q) is considered less effective since there can be points that are very close to q but located just outside of its border.
In this way, we measure the effectiveness of each signature region to generate a query-specific signature region. We selected six features of a signature region that seem to be highly correlated to the effectiveness of a signature region and the proximity of a query to the centre of the signature region, while able to be calculated with low computational cost.
Signature length (FSigLen) – as the length of a binary signature of q grows, the corresponding signature region tends to shrink to a smaller one. The average size of a signature region decreases as more hyperspheres are used as in Figure 3(a). Therefore, a signature region corresponding to a longer signature tends to be smaller, and thus more effective for k-NN approximation. It is also shown that popular LSH schemes achieve a higher mean average precision by using longer binary LSH codes [8].
Cardinality (FCard) – when two regions are of similar size (e.g. regions with the same signature length), a signature region with fewer points tends to introduce less false positives as depicted in Figure 3(b), and is thus more effective for k-NN approximation.
Average radius of hyperspheres that contain (or do not contain) a given query point q (FAvgRadIn, FAvgRadOut) – a signature region of q is located in the intersection of the hyperspheres containing q and out of the union of the hyperspheres that do not contain q. Therefore, if the average radius of hyperspheres containing q is small, it is likely that the corresponding signature region of q is also small. Likewise, if the average radius of a hypersphere not containing q is large, it is likely that the corresponding signature region of q is small.
Average distance to the centres of the hypersphere that contain (or do not contain) a given query point q (FAvgDistIn, FAvgDistOut) – a hypersphere captures Rknn(q) effectively if q is located near its centre. In contrast, if a hypersphere contains q, but q is near its border, it is likely that the hypersphere covers Rknn(q) partially. Therefore, if the average distance to the centres is small, q is near the centres of the hyperspheres containing q, and thus the corresponding signature region is likely to cover Rknn(q) effectively. In contrast, if the average distance to the centres of the hyperspheres that do not contain q is small, it is likely that Rknn(q) is just partially covered by the signature region. Since the distances from points in D to the centres of hyperspheres have been calculated to determine the signatures of points during the preprocessing stage of S2LSH, these two features can be computed efficiently.

Four features highly relevant to the effectiveness of a signature region for the k-NN approximation. (a) and (b) are used to define E′, the effectiveness measure of S2LSH. (c) and (d) are used to define E
Even if we replace spherical hashing with a different LSH scheme, we can still define these six features by slightly modifying them. For instance, if we use random hyperplanes, we can define FAvgRadIn by replacing the average radius of hyperspheres with the average angle of hyperplanes. The effectiveness of a signature region was roughly proportional to its signature length (FSigLen) and the inverse of its cardinality (1/FCard) in every dataset in Table 1. However, the correlation between the effectiveness of a signature region and the other four features was not clear in some datasets. Therefore, we define a new effectiveness measure for S2LSH, E′, by combining FSigLen and 1/FCard, as shown in equation (2). The weights of the two features, FSigLen and 1/FCard, leading to the best performance were significantly different across datasets, so S2LSH uses a simple effectiveness measure E′ that considers both features equally important in order to avoid overfitting to a particular dataset. If we need to improve the performance of S2LSH on a specific dataset, we can use a machine-learned effectiveness measure. Let FSigLen(Rsig,i(q)) and FCard(Rsig,i(q)) denote the signature length and the number of points of Rsig,i(q), respectively. Then, the effectiveness measure E′ for S2LSH is defined as follows:

The summary of various datasets

4.2. Finding k-NN candidates using signature selection
Given a signature pool of D and a query point q, we estimate the effectiveness of each signature region of q using the effectiveness measure E′ to select highly ranked signature regions. For simplicity, we assume that all the points except for q in the selected signature regions are included as k-NN candidates of q. Let
The pseudocode of findKNN-S2LSH (

Algorithm 2 describes how S2LSH finds k-NN points of q by selecting highly effective signature regions from a given signature pool, (
Initialize
Compute E′(Rsig,j(q), q), the effectiveness score of the jth signature region of q, for every
Choose the most effective signature region of qi, say the lth signature region, among the unselected ones, and retrieve a set of k-NN candidate points of qi using the corresponding bucket hash table (lines 8–10).
Calculate the distance between q and each candidate point cj and update the k-NN list if necessary (lines 11–13).
If the total number of candidates of q exceeds
4.2.1. An example of k-NN approximation using S2LSH
Assume that a signature pool of size 4 is given as in Figure 2, and we want to find 2-NN of point E, namely D and F. The value of
Now, we rank the four signature regions of E based on their effectiveness scores; Rsig,2(E)>Rsig,3(E)> Rsig,4(E)>Rsig,1(E). Since the most effective signature region of E is Rsig,2(E), we select D in Rsig,2(E) as a candidate. Since
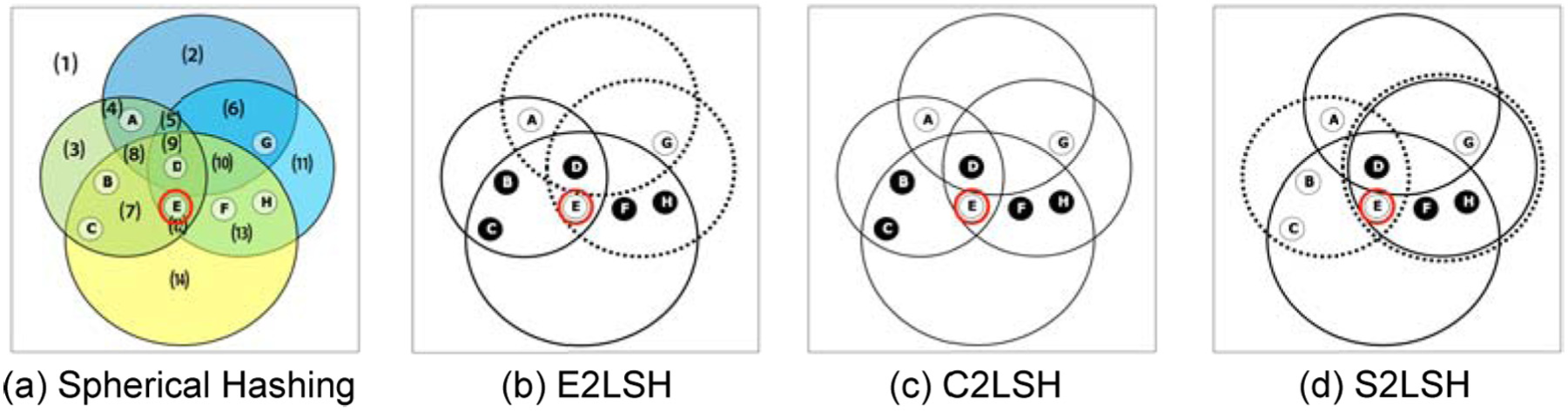
k-NN candidate selection by various approaches to find the 2-NN of a query point E (the red circle).
5. Multi-query k-NN approximation using S2LSH-M
Let us consider that a large set of queries, Q
5.1. Effectiveness measure for S2LSH-M
To measure the effectiveness of a signature region more accurately, we use query-specific features of a signature region. Since calculating exact values of such features during runtime is computationally very expensive, we identify a set of query-specific features of a signature region that we can approximate efficiently using distance values computed during the k-NN approximation of other queries in Q. The following are three query-specific features we consider:
Maximum distance between q and the points in a signature region (FMaxDist) – if the maximum distance between q and the points in Rsig,i(q), denoted by FMaxDist(Rsig,i(q), q), is shorter than FMaxDist(Rsig,j(q), q), it is likely that either the size of Rsig,i(q) is smaller than that of Rsig,j(q) or q is closer to the centre of Rsig,i(q) than to the centre of Rsig,j(q) if the two signature regions are of similar sizes. The distances from q to the points in a signature region Rsig,i(q) is bounded by FMaxDist(Rsig,i(q), q), so it is certain that there is no point in Rsig,i(q) whose distance to q is farther than FMaxDist(Rsig,i(q), q), as depicted in Figure 3(c).
Average distance between q and the points in a signature region (FAvgDist) – if the average distance between q and the points in Rsig,i(q), denoted by FAvgDist(Rsig,i(q), q), is shorter than FAvgDist(Rsig,j(q), q), it is likely that either Rsig,i(q) is smaller than Rsig,j(q) or Rsig,j(q) contains more points that are far from q than Rsig,j(q) does, as illustrated in Figure 3(d). Figure 3(d) depicts a situation where, even if maximum distances of two signature regions are the same, we can choose a more effective signature region using the average distances to q.
Minimum distance between q and the points in a signature region (FMinDist) – if the minimum distance between q and the points in Rsig,i(q), denoted by FMinDist(Rsig,i(q), q), is shorter than FMinDist(Rsig,j(q), q), this means that Rsig,i(q) contains a point that is closer to q than all the points in Rsig,j(q).
Notice that FMaxDist and FAvgDist provide information on the distances between q and all the points in the signature region. However, FMinDist gives information only on the distance between q and the point closest to q, thus the size of the corresponding signature region can be arbitrarily large. In fact, we observed through experiments that the correlation between FMinDist and the actual effectiveness of a signature region is not as strong as expected. Therefore, we use only FMaxDist and FAvgDist to define a new effectiveness measure E″ for S2LSH-M.
Calculating the exact values of FMaxDist and FAvgDist of a query for each signature region in a signature pool is computationally very expensive. Recall that the features such as FSigLen and FCard used in E′ are not query-specific, so the values of such features are the same for all the points in a signature region, and available as soon as a signature pool is constructed. In contrast, query-specific features such as FMaxDist and FAvgDist can be computed after calculating all the pairwise distances from a given q to the points in each signature region. This massive number of distance calculations per query requires a significant amount of computation time because query-specific features need to be computed for every signature region in a signature pool. We can sample a subset of points in a signature region, and estimate such feature values. Although this solution is effective with a small signature pool, it can still slow down the overall execution time significantly when a large signature pool is used.
In S2LSH-M, we approximate values of query-specific features of the current query
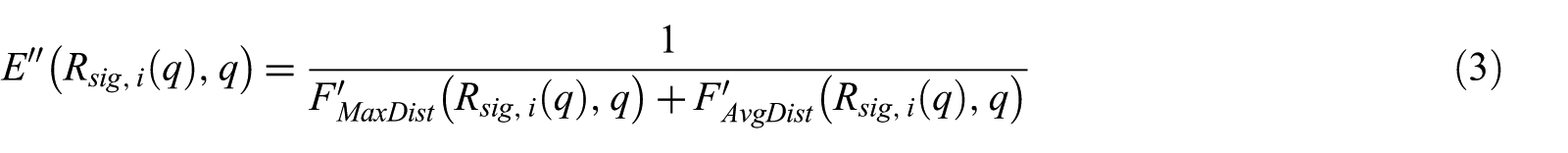
5.2. Finding k-NN candidates using signature selection of S2LSH-M
Let us assume that Q={q1, q2, …, qN} and we want to find the k-NN list of qc after processing (c− 1) previous queries, {q1, q2, …, qc−1}. To select good k-NN candidates of qc, S2LSH-M compares the effectiveness of signature regions of qc using both E′ and E″. It first compares the effectiveness score E′ of each signature region of qc. Then, it calculates the new effectiveness score E″. The approximate values of FMaxDist and FAvgDist of qc in a signature region can be computed only if distance values between qc and some points in the signature region are available.
Let Computed(Rsig,i(qc), qc) be a set of points in Rsig,i(qc) whose distance to qc, dist(qc, p), has already been computed and thus available before finding k-NN candidates of qc. This means that p is one of the previous queries, that is, p ∈{q1, q2, …, qc-1}, and qc was one of the k-NN candidates of p. When Computed(Rsig,i(qc), qc) is nonempty, we define F′MaxDist(Rsig,i(qc), qc) and F′AvgDist(Rsig,i(qc), qc) as max(dist(qc, p)) and avg(dist(qc, p)) for all p ∈ Computed(Rsig,i(qc), qc), respectively. S2LSH-M first calculates E′ of each signature region of qc in a signature pool, and rank them by E′. Then, for each signature region Rsig,i(qc) with |Computed(Rsig,i(qc), qc)|>0, it computes E″, reorders them using E″, and selects highly ranked signature regions. Notice that, as the size of points in |Computed(Rsig,i(qc), qc)| grows, F′MaxDist(Rsig,i(qc), qc) and F′AvgDist(Rsig,i(qc), qc) become more accurate.
5.3. Optimization techniques
In order to improve the performance of S2LSH-M, we use two optimization techniques: one is for eliminating duplicate distance calculations for better efficiency, and the other is for refining an approximate k-NN graph for better approximation accuracy.
Because of memory limitation, we cannot use the duplicate elimination technique used for S2LSH. For instance, if there are 1M points in D and each distance value occupies 4 bytes, 2 TB of memory is required to store all the pairwise distance values in a |D|*|D| triangular matrix. To reduce memory consumption, recursive Lanczos bisection (RLB) [10] used a hash table to store the distance values in which a distance value from the ith point is allocated to the ith position. However, it still requires about 200 GB of memory even if only 10% of all the distances are computed. In practice, RLB fails in constructing a k-NN graph if |D| is large. For this reason, a duplicate elimination technique has not been applied to k-NN graph construction algorithms such as Zhang’s approach [18] and greedy filtering [11].
We suggest a simple but efficient technique that removes all the duplicate distance calculations while requiring only O(|D|) memory. Like S2LSH, S2LSH-M also uses bucket hashing to construct a signature pool for an efficient retrieval of points in a selected signature region. Let us assume that the points in the lth signature region of q reside in the same bucket in the corresponding bucket hashing table, tl. For each query point q, we calculate the distance between q and each of its neighbours in the lth signature region of q only if needed. Once distance calculations are finished, we remove q from tl, to avoid any distance calculation involving q. Also, while calculating the distances between q and each point in the signature region, we update the k-NN lists of query points that might have q as a k-NN candidate.
The pseudocode of findKNN-S2LSH-M(

Our second optimization technique is for improving the accuracy of an approximate k-NN graph using multi-hop neighbourhood propagation. Existing approaches [9, 10, 16, 18] applied a widely used neighbourhood propagation technique based on two-hop neighbours. In S2LSH-M, we modify the neighbourhood propagation such that all the neighbours within maxHops hops are considered, where maxHops≥2. If maxHops is 3, for each point q, we calculate the similarities between the k-NN list of q and the k-NN lists of its two- and three-hop neighbours, and update the k- NN list of q accordingly. Through experiments, we observed that, even though we include three-hop neighbours, relatively small number of additional distance calculations is required, while generating a more accurate k-NN graph. Let us define the scan rate of an algorithm as the number of distance calculations of the algorithm divided by the number of distance calculations performed by the brute-force approach. Then, for instance, when the number of points is 100,000 and we are refining an approximate 10-NN graph (k=10), the scan rate of S2LSH-M increases by at most 0.022 including duplicate calculations. In our experiments, we set maxHops parameter as 3.
Algorithm 3 is the pseudocode of the k-NN approximation performed by S2LSH-M. Given a set of queries Q and data points D, S2LSH-M first constructs a signature pool of D as described in Algorithm 1, and then finds k-NN lists of Q as in Algorithm 3. The inputs are the following: (1) Q (
Initialize
Compute E′(Rsig,j(qi), qi), the effectiveness score of the jth signature region of qi, for every
Choose the most effective signature region of qi, say the lth signature region, among the unselected ones, and retrieve a set of k-NN candidate points of qi using the corresponding bucket hash table (lines 11–13).
Calculate the distance between qi and each candidate point cj, dist(qi, cj), if A[cj]=FALSE, and then set A[cj] to TRUE (lines 15, 16, 21).
Update the k-NN list of qi,
If cj is a query in Q, update E″(Rsig,l(cj), cj) if needed. Also, update the k-NN list of cj,
Remove qi from the lth bucket hash table, tl (line 22).
If the total number of candidates of qi exceeds
Perform the neighbourhood propagation technique using the specified
6. Experiments
6.1. Experimental setup
6.1.1. Datasets
In order to show the performance superiority of our approach, we use various types of datasets. Table 1 shows the number of dimensions, the number of points and the description of features of the datasets used for our experiments. The datasets are constructed from various sources such as images, music and texts, using various feature extraction methods. For detailed comparison of algorithms, we mainly use two datasets, NUS-WIDE-CH and NUS-WIDE-BoW.
6.1.2. Three types of k-NN computation tasks
We compare the performance of our approach with the state-of-the-art k-NN computation approaches by executing three different types of k-NN computation tasks: (1) k-NN search (k-NNS); (2) k-NN graph construction (k-NNG); and (3) partial k-NN graph construction (Pk-NNG). We perform k-NN search task to compare S2LSH with the state-of-the-art approximate k-NN search approaches. Then, we construct a k-NN graph or a partial k-NN graph to compare the performance of S2LSH-M with existing approximate k-NN search approaches and k-NN graph construction methods.
6.1.3. Performance evaluation measure
Since there is a tradeoff between the k-NN approximation accuracy and the execution time, we compare the performance of our approaches and the baseline algorithms by measuring the execution time required to generate k-NN results of the target k-NN approximation accuracy. As we choose more candidate points to improve the approximation accuracy, the overall execution time grows since the number of pairwise distance calculations that need to be performed to select k-NN points among the candidates also increases. We performed the experiments on one core of an Intel Xeon CPU X5472 @ 3.00GHz with 16 GB RAM, running Linux Ubuntu 12.02.
For our experiments, we set the target k-NN approximation accuracy to 90%. Application-based evaluations using applications such as agglomerative clustering, dimensionality reduction and recommendation [10, 34] showed that the k-NN approximation accuracy that leads to the best application-specific quality is heavily dependent on various factors such as the characteristics of a dataset, the type of a quality measure and the type of an application. Therefore, we decided to fix our target k-NN accuracy to 90%, assuming that the performance of applications such as search engines and recommendation systems do not degrade significantly by replacing exact k-NN lists with 90% accurate ones.
The k-NN search time reported in Figures 5 and 6 is the average execution time of 1000 randomly selected queries. For the k-NN graph construction task and the partial k-NN graph construction task, we measure the total elapsed time to process all the query points in Q. For k-NN graph construction, Q is set to D. For the partial k-NN graph construction, we use a set of randomly selected points from D as Q, and |Q| is set to 20% of |D|. k is set to 10. The preprocessing time is measured separately since the signature pool generation is executed just once for all queries. Also, the preprocessing times of S2LSH and that of S2LSH-M are the same, since they use the same signature pool. The preprocessing time of S2LSH is not significantly longer than those of existing algorithms. For example, S2LSH spends 310 s constructing a signature pool for 50K data points of NUS-WIDE-BoW while it takes 302 s for E2LSH+ to preprocess the same dataset. The k-NN approximation accuracy is defined as the average precision of k-NN lists.
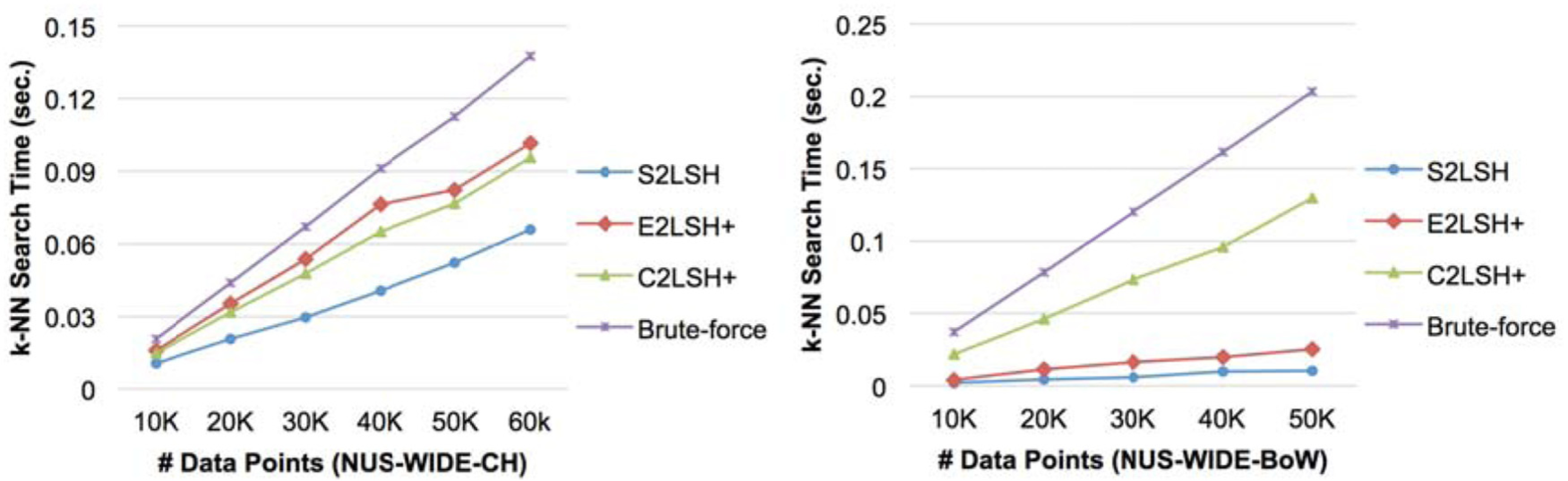
The average k-NN search time and the size of D (spherical hashing is used).
The average k-NN search time and the size of D (random hyperplanes are used).
6.1.4. Baseline algorithms
There are two main reasons why our approaches, S2LSH and S2LSH-M, show superior performance: one is the quality of candidates in a query-specific signature region that is dynamically generated using a signature pool, and the other is the optimization techniques we applied to our approaches such as bucket hashing, neighbourhood propagation, eliminating duplicate distance calculations and incremental k-NN updates. In order to precisely analyse the impact of the query-specific signature region of S2LSH and S2LSH-M, we applied the same set of optimization techniques to the baselines if applicable. C2LSH+ and E2LSH+ are the implementations of C2LSH and E2LSH with these optimization techniques. In this paper, we do not compare S2LSH with algorithms such as LSB-tree and LSB-forest, since the performance of C2LSH is better [2]. In Section 6.2.1, we compare S2LSH, the brute-force approach, C2LSH+ and E2LSH+, by measuring the performance of k-NN search. We can observe a larger performance gap between our approaches and the baselines if we do not apply the optimization techniques aforementioned to the baselines.
To evaluate the performance of S2LSH-M more rigorously, we include two more algorithms to our baselines, RLB and NN-Descent (NND). Both are the state-of-the-art k-NN graph construction algorithms, but they are different in that RLB is hyperplane-based and NND is heuristic-based. Since NND terminates even if the target approximation accuracy is not reached, it sometimes shows very poor approximation accuracy when its heuristics failed on some types of datasets such as the NUS-WIDE-BoW dataset. Therefore, we enhanced NND to NND+ by applying the optimization techniques we applied to S2LSH-M and, more importantly, executing NND iteratively until the minimum approximation accuracy t is reached. However, since NND+ can be executed only if the exact k-NN lists are known in advance, NND+ is not feasible in the real world scenario. We do not include clustering-based k-NN graph construction algorithms as baselines since their performance is worse than that of NND, or changes significantly depending on input parameters. In Sections 6.2.2 and 6.2.3, we compare S2LSH-M with baselines by measuring the performance of k-NN graph construction and partial k-NN graph construction.
6.2. Performance comparison using three k-NN computation tasks
6.2.1. k-NN search
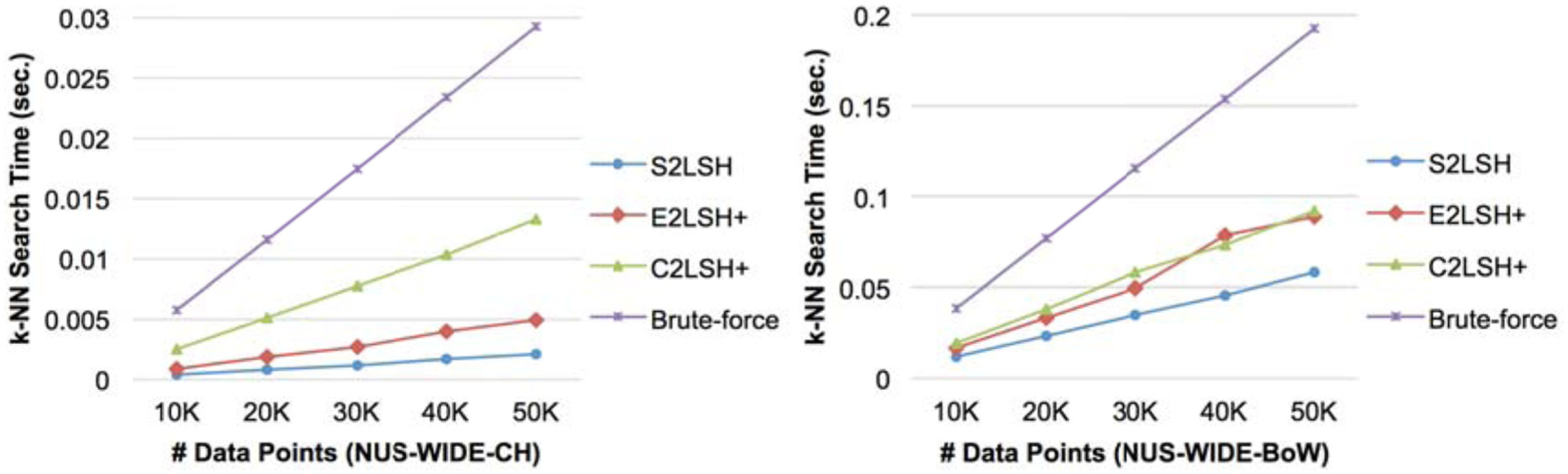
Figures 5 and 6 show the impact of the cardinality of D (10–50K), source datasets (NUS-WIDE-CH and NUS-WIDE-BoW) and the LSH scheme used to generate underlying binary LSH functions (spherical hashing and random hyperplanes) on the performance of k-NN search. Three approximate k-NN search algorithms, S2LSH, E2LSH+ and C2LSH, and a brute-force approach are compared.
In Figure 5, we compare the execution time of k-NN search algorithms, assuming spherical hashing is used. First, notice that S2LSH consistently outperforms the other k-NN search algorithms. Also, the performance superiority of S2LSH is observed in both datasets, NUS-WIDE-CH and NUS-WIDE-BoW, although these datasets are significantly different in terms of the number of dimensions and feature extraction method. In contrast, while E2LSH+ outperforms C2LSH+ in NUS-WIDE-CH, they show a similar performance in NUS-WIDE-BoW. In Figure 6, we perform the same set of experiments after replacing spherical hashing with random hyperplanes. Even though underlying binary LSH functions are generated using a completely different LSH scheme, S2LSH still performs the best on both datasets. C2LSH+ is better than E2LSH+ in NUS-WIDE-CH, which is opposite when they use spherical hashing, as shown in Figure 5. Also, E2LSH+ performs much better than C2LSH+ in NUS-WIDE-BoW, while they show a similar performance on the same dataset when using spherical hashing in Figure 5.
In summary, even though we change the cardinality of D, source datasets and the LSH scheme used in generating underlying binary LSH functions, S2LSH consistently shows a superior performance, while the performance of other state-of-the-art k-NN search algorithms is highly sensitive to such factors.
6.2.2. k-NN graph construction
Figure 7 shows the performance of k-NN construction in two different datasets (NUS-WIDE-CH and NUS-WIDE-BoW). The k-NN graph construction time is the total elapsed time of executing k-NN search for each query in D. The algorithms compared are S2LSH-M, two approximate k-NN search algorithms (E2LSH+ and C2LSH+), two state-of-the-art approximate k-NN construction algorithms (RLB and NND+), and the brute-force approach.
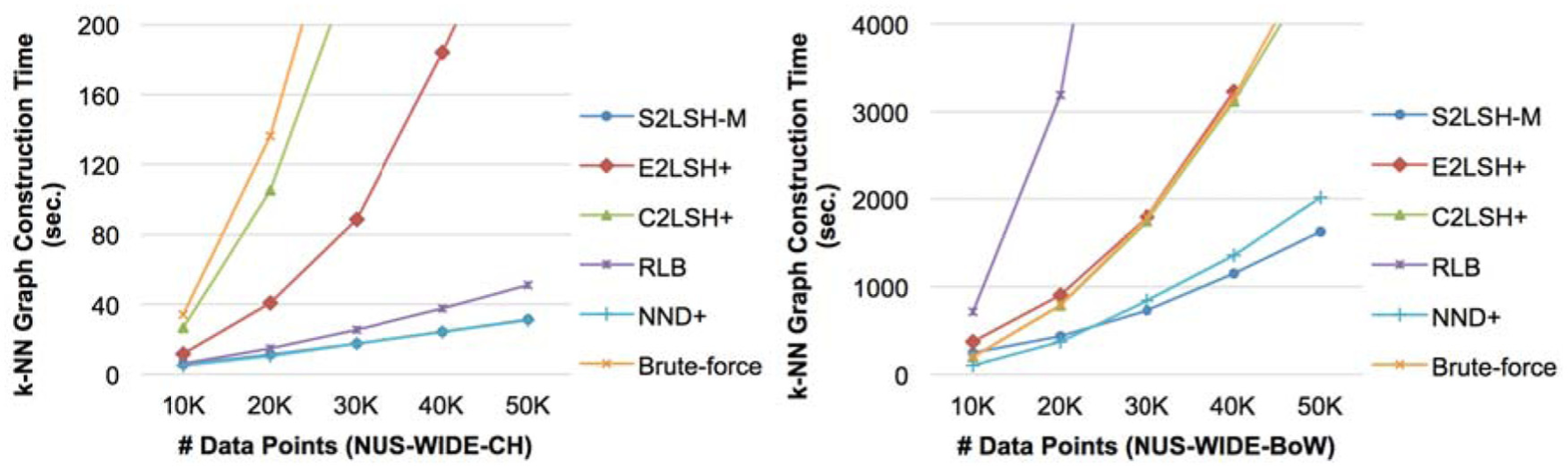
The average k-NN graph construction time and the size of D (spherical hashing is used).
In Figure 7, we measured the k-NN graph construction time of six k-NN computation approaches, assuming that spherical hashing generates the underlying binary LSH functions. First, the k-NN graph construction time of S2LSH-M is much less than that of approximate k-NN search algorithms, E2LSH+ and C2LSH+, which is consistent with the comparison results in Section 6.2.1. In fact, the performance gap between S2LSH-M and other k-NN search algorithms is more evident than in Figure 5, which indicates that the performance of S2LSH-M is improved by using E″ and applying optimization techniques. Second, let us compare S2LSH-M with the state-of-the-art k-NN graph construction algorithms, RLB and NND+. S2LSH-M is comparable with or slightly faster than them even though they are specifically designed for k-NN graph construction, while S2LSH-M is a variant of S2LSH, a k-NN search algorithm. Lastly, we can see that RLB can be extremely inefficient in some datasets such as NUS-WIDE-BoW, sometimes slower than the brute-force exact k-NN approach.
6.2.3. Partial k-NN graph construction
Figure 8 shows the performance of partial k-NN construction in two different datasets (NUS-WIDE-CH and NUS- WIDE-BoW). The partial k-NN graph construction time is the total elapsed time of executing k-NN search for every query in Q. The points in Q used for the partial k-NN graph construction in Figure 8 are randomly selected from the specified source dataset, and the size of Q is set to 20% of |D|. Partial k-NN graph construction is useful for incremental update or distributed construction of a large k-NN graph. We compare S2LSH-M with two approximate k-NN search algorithms (E2LSH+ and C2LSH+), two state-of-the-art approximate k-NN construction algorithms (RLB and NND+), and the brute-force approach.
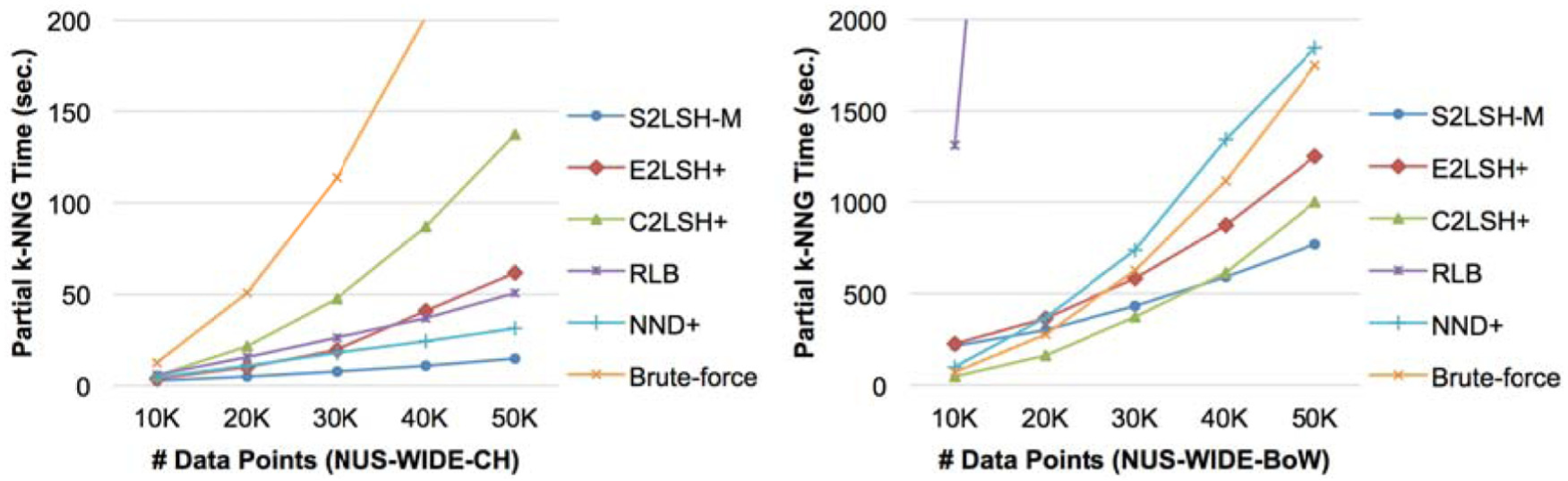
The partial k-NN graph construction time and the size of D. |Q| is 20% of |D| (spherical hashing is used).
In Figure 8, as |D| increases, S2LSH-M outperforms other approaches including approximate k-NN search algorithms (E2LSH+ and C2LSH+) and k-NN graph construction algorithms (NND+ and RLB). Notice that NND+ performs better than E2LSH+ and C2LSH+ in the NUS-WIDE-CH dataset, while it performs the worst in the NUS-WIDE-BoW dataset. This is because the k-NN graph construction algorithms such as RLB and NND+ can be executed only when Q=D. Partial k-NN graph construction is conceptually considered as a task located between k-NN search (|Q|=1) and k-NN graph construction (|Q|=|D|). Therefore, k-NN graph construction algorithms perform worse than k-NN search algorithms when |Q| is small, but their performance improve as |Q| approaches |D|. In the following section, we analyse the impact of the size of Q on the performance of S2LSH-M and the baseline approaches.
6.2.4. Impact of the number of queries in Q
We examine the impact of the size of Q on the average k-NN computation time per query. The set of data points, D, contains 50K data points that are randomly selected from NUS-WIDE-CH or NUS-WIDE-BoW. The query set, Q, contains points randomly selected from D, and the number of queries in Q, |Q|, changes from 10K to 50K, that is, 20% of |D| to 100% of |D|. The average k-NN computation time of C2LSH+ in NUS-WIDE-CH is not included in Figure 9, since C2LSH+ is extremely slow compared with other three approaches.
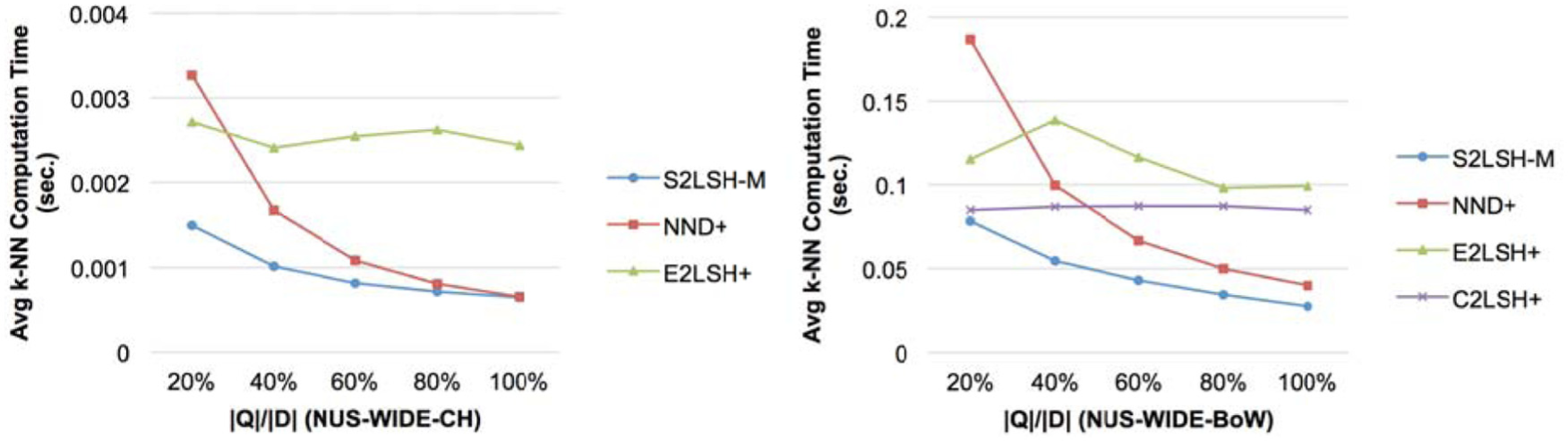
The k-NN computation time per query and the ratio of |Q| to |D|. |D| is 50K (spherical hashing is used).
In Figure 9, we can see that S2LSH-M outperforms the baselines, given Q of any size. The performance of NND+ becomes similar to that of S2LSH-M as |Q|/|D| approaches 100%. However, NND+ is less efficient than E2LSH+ or C2LSH+ when |Q| is small, such as 20% of |D|. Second, the performance of approximate k-NN search algorithms, E2LSH+ and C2LSH+, does not change significantly even though |Q|/|D| changes from 20 to 100%. Recall that they can find k-NN points of each query efficiently, but even when Q contains many query points, they perform k-NN search separately for each query in Q without improving the quality of k-NN candidates by reusing distance values computed to find k-NN points of other queries. Notice that the average k-NN computation time of S2LSH-M monotonically decreases as the size of Q grows, because S2LSH-M further improves the quality of k-NN candidates using such distance values and thus requires fewer candidates in achieving the target k-NN approximation accuracy.
6.3. Performance comparison using various datasets
Table 2 presents the average execution time of k-NN computation algorithms when they perform three types of k-NN computation tasks in various datasets. The k-NN computation algorithms are brute-force exact k-NN search algorithm (Brute-force), two state-of-the-art approximate k-NN search algorithms (E2LSH+ and C2LSH+), a k-NN graph construction algorithm (NND+) and our approach (S2LSH and S2LSH-M).
The overall performance comparison using various datasets. Each cell contains the average execution time followed by the corresponding k-NN approximation accuracy in the parentheses. The shortest execution time is in bold.

First, when performing approximate k-NN search, the performance superiority of S2LSH is clear in every dataset; S2LSH finds the most accurate k-NN lists using the shortest k-NN search time. Next, we compare the performance of k-NN graph construction in various datasets. S2LSH-M outperforms NND+ in almost every dataset since it generates a more accurate k-NN graph faster than NND+ does, except for the Corel dataset. When performing partial k-NN graph construction with Q such that |Q|/|D|=20%, S2LSH-M performs better than NND+ in almost every dataset, except for NUS-WIDE-CH. In the NUS-WIDE-CH dataset, the performance of NND+ and S2LSH-M is not directly comparable, since NND+ constructs a more accurate partial k-NN graph (0.95 vs 0.90) but it requires a much longer execution time (315 vs 94 s).
7. Conclusions
We presented a novel LSH approach, S2LSH, which efficiently performs an approximate k-NN search on various types of datasets. It constructs a large pool of highly diversified signature regions of various sizes and shapes, and selects a subset of highly effective signature regions to generate a query-specific signature region. Then, we proposed S2LSH-M, a variant of S2LSH, which constructs a k-NN graph more efficiently than multiple executions of S2LSH. It exploits query-specific features and uses additional optimization techniques. Extensive experiments show that our approaches, S2LSH and S2LSH-M, consistently outperform the state-of-the-art k-NN computation algorithms in diverse settings.
As future work, we plan to perform a theoretical analysis on the joint relationship between features of a signature region and its effectiveness for efficient k-NN computation. Also, we want to suggest a method to determine important runtime parameters such as the number of k-NN candidates dynamically for a given query by considering pre-specified information such as k, the target approximation accuracy, the execution time budget and the distance measure with the corresponding LSH scheme. Lastly, we want to develop a parameter-free self-organizing k-NN approximation framework that suggests good combinations of parameter values by analysing characteristics of datasets.