
Abstract
Predicting future events from text data has been a controversial and much disputed topic in the field of text analytics. However, far too little attention has been paid to efficient prediction in textual environments. This study has aimed to develop a novel and efficient method for news event prediction. The proposed method is based on Markov logic networks (MLNs) framework, which enables us to concisely represent complex events by full expressivity of first-order logic (FOL), as well as to reason uncertain event with probabilities. In our framework, we first extract text news events via an event representation model at a semantic level and then transform them into web ontology language (OWL) as a posteriori knowledge. A set of domain-specific causal rules in FOL associated with weights were also fed into the system as a priori (common-sense) knowledge. Additionally, several large-scale ontologies including DBpedia, VerbNet and WordNet were used to model common-sense logic rules as contextual knowledge. Finally, all types of such knowledge were integrated into OWL for performing causal inference. The resulted OWL knowledge base is augmented by MLN, which uses weighted first-order formulas to represent probabilistic knowledge. Empirical evaluation of real news showed that our method of news event prediction was better than the baselines in terms of precision, coverage and diversity.
Keywords
1. Introduction
Recent developments in the field of natural language processing (NLP) have led to a renewed interest in textual inference and analytics. One of the most significant ongoing discussions in the field involves predicting future events from text. It is becoming increasingly difficult to ignore the role of event prediction for decision-making in areas such as politics, economics and society. To predict future events, people generally use common-sense knowledge about how the world behaves. This knowledge that expresses their beliefs has already been obtained under specific conditions of causal relationships. Much of this causal knowledge is expressed in unstructured texts produced by them on traditional/social media such as news archives. The process of drawing a conclusion about a causal relationship based on the conditions of the occurrence of an effect is called causal inference. 1 The goal of this research is to provide a model that performs causal inference in textually represented unrestricted and uncertain environments such as online newspapers.
Our investigation did not attempt to extract named entity and relation [1] including causal relation (textual entailment) [2], specifically temporal information (TDT) [3] and future-related information [4] from text. Rather, we performed open information extraction (OIE) [5] in order to extract the semantic event content of the news. Since our goal was to find all the potentially useful facts/events from news corpora on the web, we could not assume any specific target relation type.
While some related works focused on predicting news importance (news impact/volume) [6–8] and news interests (news filtering/recommendation) [9–11], other works dealt with predicting dynamic content on the web, often using time-series [12] and state-space models [13]. Several works [14–16] are also proposed based on numerous comments provided by social networks. Users on networking sites such as Facebook and Twitter usually reflect social changes in their writings simultaneously. This content can be used for predicting future events. A notable characteristic of such approaches is the use of high volume of short texts about social issues. Similar problems are also faced when it comes to event prediction, but this issue has been taken up by many researchers. Stock market prediction [17] poses a similar problem. Here, the problem involves predicting the occurrence of a certain event. Yet another issue related to this area is the use of web search history to predict which documents a user is likely to request next [18] and which top terms will appear in the news of tomorrow [19].
Some studies also focused on computational history [20] in their attempt to harness computational power to support history analysis. From this perspective, history could help us understand the present and predict the future to some extent. A number of studies explored the use of text mining techniques over a large corpus of news articles to extract collective memories [21] and collective expectations [22]. The authors in Michel et al. [23] developed ‘culturomics’, an approach to studying how culture develops in societies, by applying text mining techniques to millions of digitalised books. While these works focused just on the perception of history through studies of societal views of different countries, several attempts [24, 25] have been made for identifying and modelling the broad social forces. Goldstone et al. [24] developed a model for identifying countries that experienced instability, by examining onsets of political instability in countries. They offered a predictive model based on both violent civil wars and nonviolent democratic reversals, suggesting common factors in both types of change. While some historians believed that computational techniques cannot be used to illuminate the past, advocates of ‘cliodynamics’, which was first founded by Turchin and colleagues [26, 27], maintain that the occurrence of various events such as political instability [28] is not a coincidence. The approach to studying cliodynamics is part of a groundswell of efforts to apply scientific methods to history by identifying and modelling broad social forces [25]. One of the limitations of this explanation is that cliodynamics is useful only for looking at broad trends, and it cannot predict specific historical events. However, the patterns and causal relations exposed by it can enlighten politicians and decision-makers.
Our work stands out in many ways from those mentioned above. We present a semantic and language-independent model to predict news events in textually represented unrestricted and uncertain environments. Our approach is based on the semantic analysis and understanding of natural language news texts, as well representing in standard web ontology language (OWL) and reasoning via Markov logic. We use state-of-the-art NLP techniques to extract a large amount of primary propositions (OWL triples) from news text corpora. This study aims to build a predictive model of news events that leverages all types of knowledge generating and representing in standard ontology language OWL and reasoning with a set of causal rules in a probabilistic logic schema.
Recent literature on the topic offers findings about explicit or implicit causal relations between phenomena in the real world that are used for predicting special events. For example, it is observed that when a flood occurs in some countries, cholera also breaks out. So when a flood occurs in a country – considering this country’s geographical and climatic conditions are similar to those countries’– we can expect that cholera will outbreak; hence, we should take urgent action to deal with it. However, modelling these phenomena is very difficult and expensive for many reasons. Foremost among these difficulties and challenges are the following: (1) lack of appropriate sources of data: existing computational models often require appropriate resources with a considerable amount of data for training. Usually, the sources of data are not available with this specification. These resources are very costly and time-consuming to produce. Moreover, before producing it, the design of the data resources, which includes production method, determining the type of data and so on, also necessitates in-depth research. (2) Lack of appropriate computational models: modelling these complex and uncertain phenomena requires computational models that receive a heterogeneous and large data source as input and provide their outcome while determining the weight and effect of each.
To the best of our knowledge, previous studies have not dealt with these challenges. The only outstanding work in this field has been conducted by Radinsky et al. [29–31], which was used as a logical approach to dealing with a large-scale artificial intelligence (AI) problem of textual events prediction. However, their work still suffers from the problems raised above. One major criticism of Radinsky’s work is that in his research the causal relations were extracted just from the news titles rather than the entire text. Consequently, many of these relations were not discovered by the algorithm and remained overlooked. Another problem with this approach is that it requires a high-precision NLP system for extracting these relations. Besides, it uses the inappropriate approach to extract causal event pairs. Since prior works have dealt with causal relation extraction for causality rule induction, we posit that using logical rule base (a priori knowledge) represented in the first-order logic (FOL) formalism would be efficient for predicting the effect events. Indeed, the aim is to use logical rules that, if any person or machine follows all of these rules, then, for each input sentence (fact/event), it will derive facts (or predict events) close to the output of the other person or machine. The advantage of the formulation and using these logical rules is that first it is a solution to the problem, and second, it can be considered a semi-labelled collection by reforming the outputs, which can be then used in machine-learning methods. One question that needs to be asked, however, is how we can deploy these logical causality rules in the various events for machine common-sense understanding and employ this uncertain knowledge to perform news event prediction. Moreover, dealing with the uncertainty – which is one of the main characteristics of the research problem – has also been ignored in the abovementioned studies, which is perhaps the most serious disadvantage of those methods. In this problem domain, it is not possible to create complete, consistent models of the world. Therefore, the system must act in uncertain worlds, which the real world is. When implementing some uncertainty scheme, we must be concerned with three issues: (1) How to represent an uncertain event? (2) How to generalise an uncertain event? and (3) How to draw inference using an uncertain event?
The authors in another study [32] using a probabilistic approach had made two assumptions for future event prediction. The first assumption is that all events in the real world are generated by a probabilistic model, so causality occurs only within storylines in which events are correlated and interlinked. The other assumption is that all events within the storyline are independent. For the first assumption, it is clear that a correlation between two events does not necessarily imply that one causes the other, as has been emphasised in statistics. The latter also is obviously wrong because events are not necessarily independent, and it is very likely that some events may depend on each other. A serious weakness of this argument, however, is that it requires very complex models for representing a wide variety of knowledge and that it was difficult to incorporate a wide range of domain knowledge. This leads to our second research question. How can we incorporate both types of static (e.g. a priori and contextual) and dynamic (a posteriori) knowledge extracted from multiple and heterogeneous sources of information and base our inference on imperfection and contradictory knowledge? Furthermore, due to the complexity of the problem, the size of the system and its many components, errors are unavoidable [29]. Another challenge resulting from such a complex task is the accumulation of errors between the stages of the pipeline [33] that considerably affects the value of the results. To fix the problem, joint inference [34] was proposed as a key solution. However, we have ever assumed that there exist sufficient training examples for predicting news events, but what if we don’t have any examples? In this case, we need to leverage indirect supervision. To tackle these limitations, a more sophisticated approach for representation and reasoning about future events is necessary in textual environment.
Prior research into textual event prediction has almost exclusively relied on lexical, factual and shallow semantic representations of large amounts of natural language text. While these approaches have proven useful for the task we faced, we feel a deeper semantic understanding of news texts is required to predict future events, leading us to our next research question. Which combination of semantic text analytics techniques is most valuable to represent language-independent and semantically rich event model for textual event prediction?
We used state-of-the-art NLP techniques to extract the semantic event content of news texts. We perceive that it is efficient to extract news events from texts in a semantically deep manner, thus representing it into a machine-readable ontology language OWL model for predicting future events. Ontology models are able to represent a large amount of information using a small number of individuals and relationships, while also developing semantically rich applications such as the one presented in this work. We also feel that enrichment of textual representation schemes by adding semantic roles to OWL triples may contribute to better splitting the sentence (fact/event) into its clause constituents and provide better predictive ability.
Yet a major problem with causal inference in text is supporting both complexity and uncertainty in a much richer semantic way. Complexity can be handled with FOL [35]. It enables us to succinctly represent a wide variety of knowledge. A problem solution for efficiently handling uncertainty is also a probabilistic approach [36], which certainly is very useful for doing this. Given that prior research on textual event prediction has focused solely on the purely logical [29–31] or purely probabilistic [32] methods, we ask whether combining logic and probability to use the advantages of both in a semantic representation is effective to predict news events. This seeks to address the following question: How effective is the combination of logic and probability in handling both complexity and uncertainty and leveraging both direct and indirect supervision?
This study proposes solutions to fill the gaps in previous research on event prediction. The goal of our investigation is to provide approaches for causal inference to predict future events in textual environments. We intend to develop a new prediction method that can predict effect events it can cause based on a given event represented in natural language. To this end, as an addition to the text news corpus (dynamic knowledge), a set of domain-specific causal rules are fed into the machine to define the probabilistic logical rules in FOL formalism with their weights as a priori knowledge or common-sense knowledge (a part of static knowledge). These rules were injected into the machine independently of natural language by a human expert in line with the formalism of Markov logic. Then, several large-scale ontologies, including general ontologies such as Wikipedia and DBpedia [37], word ontologies such as WordNet [38] and FarsNet [39] and verb ontologies such as VerbNet [40], are employed as contextual knowledge (the other part of static knowledge) to generalise events and generate the predictions. This model is represented in standard OWL to obtain the most appropriate generalisation of the given cause event and then use the probabilistic logical rules to predict output effect events.
The main contributions of this research are as follows. The first contribution is a novel and scalable method that uses a semantic and language-independent technique to predict news events. Second, we propose an event and causality representation model to handle both complexity and uncertainty. The proposed model enables us to define and deploy causal rules to facilitate user intervention for machine common-sense understanding, so the user can comprehend and modify the rules of the model. This common-sense knowledge is formulated by a human expert in a probabilistic logic formalism called the Markov logic network (MLN). The model also leverages indirect supervision through employing small amount of domain knowledge (FOL formulas) plus large-scale joint inference. Third, we propose a framework to fuse different types of knowledge, consisting of both static (e.g. a priori and contextual) and dynamic (a posteriori), in ontology language OWL and support for uncertainty to perform prediction. Finally, we propose to automate our experiments without human involvement in order to measure precision and coverage of predictions, which has not been observed in previous studies and will allow providing richer metrics of performance such as diversity.
The rest of this article is organised as follows. Owing to importance and extent of ontology construction and utilisation to predict future events, this issue will be discussed separately in section 2. In section 3, the problem definition and solution are described in detail. The evaluation metric and experimental results are discussed in section 4. Finally, the conclusion and future work are presented in section 5.
2. Domain ontology
One of the most important aspects of this research is to implement and manipulate a variety of ontologies. Notably, all the knowledge acquired and extracted from multiple heterogeneous sources must be stored and represented in the formalism of ontology language. An ontology language is a formal language used to construct an ontology. It represents the encoding of knowledge about specific domains and commonly includes logical rules for reasoning of the knowledge.
Ontology construction is generally an important step of ontology-based information extraction (OBIE) [41], which is to say that it follows the paradigm of OIE [5]. An OBIE is a system that processes unstructured or semi-structured natural language text through a mechanism guided by ontologies to extract certain types of information and presents the output using ontologies [42]. We can extract information related to an ontology for representing them as instances of the ontology and reasoning of future events. We describe the ontology representation and reasoning tasks in subsections 2.1 and 2.2, respectively, and investigate the prerequisites of an appropriate ontology construction for probabilistic schema in subsection 2.3.
2.1. Ontology representation
A prerequisite of ontology utilisation in the Semantic Web is developing a standard for definition and interchange of ontologies. Knowledge representation languages enable us to define and communicate among ontologies and to achieve passivity and compatibility with each other. The most important current standards for ontology representation express information as linked data [43]. Linked data is a method for representing and publishing huge amount of related data on the web in a standard, machine-readable format for drawing inferences. For this purpose, the World Wide Web Consortium (W3C) has designed Resource Description Framework (RDF) as a standard model for data interchange on the web. RDF is a general framework for conceptual description or representation of knowledge performed in the World Wide Web, by extending the linking structure of the web to use uniform resource identifiers (URIs) to name the relationship between things and the two ends of the link, together referred to as a ‘triple’. An extension language based on RDF was the Defense Advanced Research Projects Agency (DARPA) Agent Markup Language (DAML). This language was then followed by an extension called DAML + OIL (Ontology Inference Layer or Ontology Interchange Language). Later, it was the starting point for the OWL.
OWL is a computational logic-based language designed to represent rich and complex knowledge for authoring ontologies. There are three variants of OWL – OWL Lite, OWL DL and OWL Full (ordered by increasing their expressiveness). Out of these three, only OWL Full is compatible with RDF schema. The current version of OWL is also referred to as ‘OWL 2’. Ontologies in OWL format provide for a standardised means of representing, querying and reasoning over large-scale knowledge bases. They comprise a syntax for illustrating and incorporating ontologies and formal semantics that give them meaning.
The classes, subclasses and instances are used to semantically classify things in OWL. OWL semantics are based on description logics (DLs) [44]. DL is a family of logic-based formal knowledge representation languages that can be used to represent the knowledge of an application domain in a structured and formally well-understood way [45]. Most DLs can be considered as (decidable) fragments of FOL and less expressive than it, although some provide operators such as transitive closure of roles that requires second-order logic [46]. In this article, we have developed a framework that augments and reinforces the ontology language OWL for representing and reasoning with uncertainty based on the combination of the expressive power of FOL and the probabilistic uncertainty management of Markov random fields (aka Markov networks). A Markov network is a set of random variables having a Markov property described by an undirected graph. Using Markov networks associated with FOL allows us to support uncertainty reasoning.
2.2. Ontology reasoning
Ontology reasoning is the process of inferring logical consequences using an inference engine to derive facts that are not expressed in ontology explicitly. The inference rules are generally determined by means of an ontology language and often a DL language. Reasoning in most DLs is sound and complete, which is ensured to conclude every consequence of the knowledge in the ontology. Baader et al. [45] showed that DL interpretations can be viewed as FOL interpretations and vice versa. This is done through two translation functions, which preserve the semantics. Accordingly, both DL and FOL semantics are convertible to each other, so that all concepts and roles in DLs can be depicted as unary and binary predicates (relations) in FOL, respectively, as well as corresponding classes and properties in OWL.
Using only FOL in ontology language OWL depends on the assumption that all facts/events are true, though not in the real world. To handle the uncertainty arising from this crisp logic, we extend the ontology language OWL to obtain the weighting of the concepts, properties and instances in the domain and to perform reasoning with imperfection and contradictory knowledge. We propose to incorporate Markov networks and ontology language OWL, which together form a MLN. More details are provided in subsection 3.3.
2.3. Investigated ontologies
Nowadays, there are numerous ontologies for research projects. One of the largest existing ontologies containing more than 1 billion facts has been used in Radinsky et al. [29]. To use these large-scale ontologies, it is required to use high-performance servers and parallel processing infrastructure. For operational usage of ontologies, we should consider their scale (number of triples), size of dataset and required physical memory. Table 1 shows specifications of the investigated ontologies from this perspective. Since we need general knowledge in this study, the domain-specific ontologies were not considered in this comparison.
Specifications of the investigated general ontologies
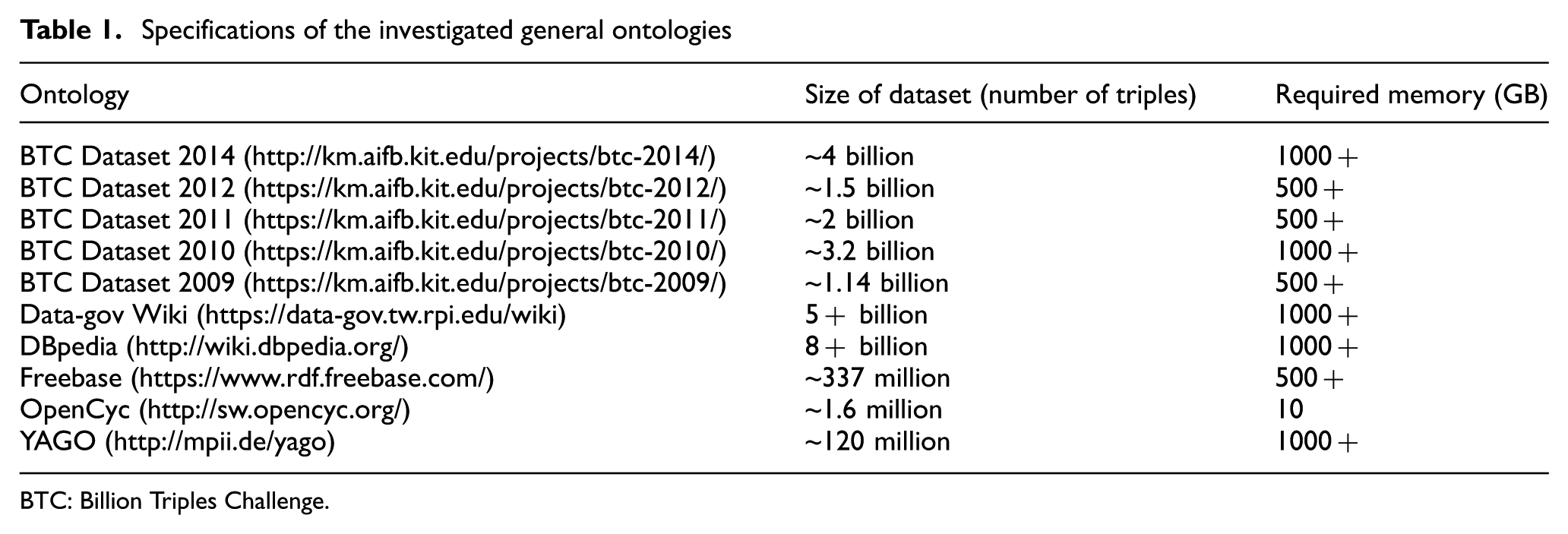
BTC: Billion Triples Challenge.
In this article, we focused on entities available on DBpedia [37], the most important open web source of data that essentially makes the content of Wikipedia available in RDF using Semantic Web and linked data technologies. The DBpedia 2015–10 2 release contains 8.8 billion facts (RDF triples), out of which 1.1 billion were extracted from the English edition of Wikipedia, 4.4 billion were extracted from other language editions and 3.2 billion came from DBpedia Commons and Wikidata. This release consists of 127 different language editions of Wikipedia, currently describing 6.2 million instances. These were extracted only from the English edition of Wikipedia.
DBpedia is interlinked with various other data sources following linked data on the web, for example, with Freebase, Flicker, GeoNames, LinkedGeoData, OpenCyc, Wikidata, Wordnet and YAGO. By incorporating facts from those extra links (in terms of RDF triples), we may obtain further and more accurate knowledge to draw inference and subsequently predict news events. In brief, the main reasons for using DBpedia in this research are as follows:
It is a large-scale ontology that covers a wide range of topics and many domains.
It serves as multilingual knowledge base facilitating knowledge transfer into other languages.
It includes Wikipedia data which automatically evolves as Wikipedia changes.
It represents real community agreement.
It incorporates links to other Semantic Web source of data, which can be used to further enrich the content of the knowledge base.
According to the experiments conducted by previous researchers [29–31], manipulation of large-scale ontologies usually is not possible on a single computer and needs parallel or distributed computing platforms. On the one hand, DBpedia is a large-scale, multilingual, cross-domain ontology comprising more than 1 billion RDF triples. On the other hand, all this information is not necessary for reasoning and predicting future events. To this end, we suggested two techniques for generalisation and summarisation of instances in DBpedia ontology, which are described, respectively, in subsections 2.3.1 and 2.3.2. The implementation of a parallel and distributed platform for processing and reasoning ontology can be considered in future work.
2.3.1. Generalisation of instances in ontology
The DBpedia dataset was widely used in many research communities, and so far numerous applications, algorithms and tools have been developed to manipulate or apply the ontology. Due to its large schema, size of the dataset and the diversity of topics, manipulation of DBpedia poses a major challenge in this domain. Especially, development of powerful systems using DBpedia in this field based solely on simple patterns or domain-specific dictionaries is difficult due to its size and broad coverage. Therefore, a prediction system that provides reliable answers by drawing inference from DBpedia can be considered as an intelligent system. So, in order to increase the performance of using DBpedia, we have processed the DBpedia instances and properties in comma-separated values (CSV) file format. The goal of the processing performed in this subsection is illustrated with an example in the following:
Example 1. Suppose that there is a triple in the CSV file of DBpedia properties as follows:
<http://dbpedia.org/resource/Tehran> <http://dbpedia.org/ontology/capital> <http://dbpedia.org/resource/Iran>
First, the system should search the first entries of DBpedia instances according to each entry in the given triple and then take the most frequent ‘type’ in DBpedia instances for that entry. For example, assume that the most frequent ‘type’ for the first entry of the above triple is as follows:
<http://dbpedia.org/resource/Tehran> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://dbpedia.org/ontology/City>
And also for the third entry, the most frequent ‘type’ is as follows:
<http://dbpedia.org/resource/Iran> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://dbpedia.org/ontology/Country>
Eventually, a rule can be added to the system as follows:
<http://dbpedia.org/resource/City> <http://dbpedia.org/ontology/capital> <http://dbpedia.org/resource/Country>
This result indicates that the ‘capital’ relation is established between the two entities of City and Country. This process was repeated for each triple entry in the CSV file of DBpedia properties and so the need for powerful servers and parallel processing infrastructures is decreased significantly.
2.3.2. Summarisation of instances in ontology
One of the most useful aspects of the proposed framework is providing facilities for ontology summarisation. General ontologies such as DBpedia include a lot of entities. The large amount of data in these ontologies can slow down the process of loading and inference in ontology. It is noteworthy that most data in general ontology are not related to the local language news and entities that are required for prediction. Besides, many of them are not in the domain of the prediction system. Hence, summarisation of instances in the ontology does not hamper system performance. Accordingly, we used the summarisation of both classes and properties to reduce the number of ontology instances. For this purpose, we can first select the domain-specific classes from the list of DBpedia classes that are used to predict in specific domain. We then only take the instances containing those classes. Similarly, we can also select interest properties from the list of DBpedia properties and then take the instances associated with those specific properties. Using these two approaches significantly reduced the number of ontology instances.
For example, if we want to predict events in a domain in which there are concepts such as city and country, we should select City and Country classes and ‘capital’ property while taking the instances of selected classes and properties in DBpedia ontology.
3. Event prediction
In this section, we aim to develop a general framework for news event prediction. We call it general because the proposed framework does not consider any assumptions about common goals of prediction systems in textual environments. However, despite the generality of the framework, it is specific enough to obtain stable and reliable results, as will be discussed in the following. The proposed framework uses contextual knowledge available in ontology and the arguments extracted from online news sources and satisfies the rules that had been fed into the system to predict new events. Figure 1 shows the overall operation of the proposed framework for predicting news events.
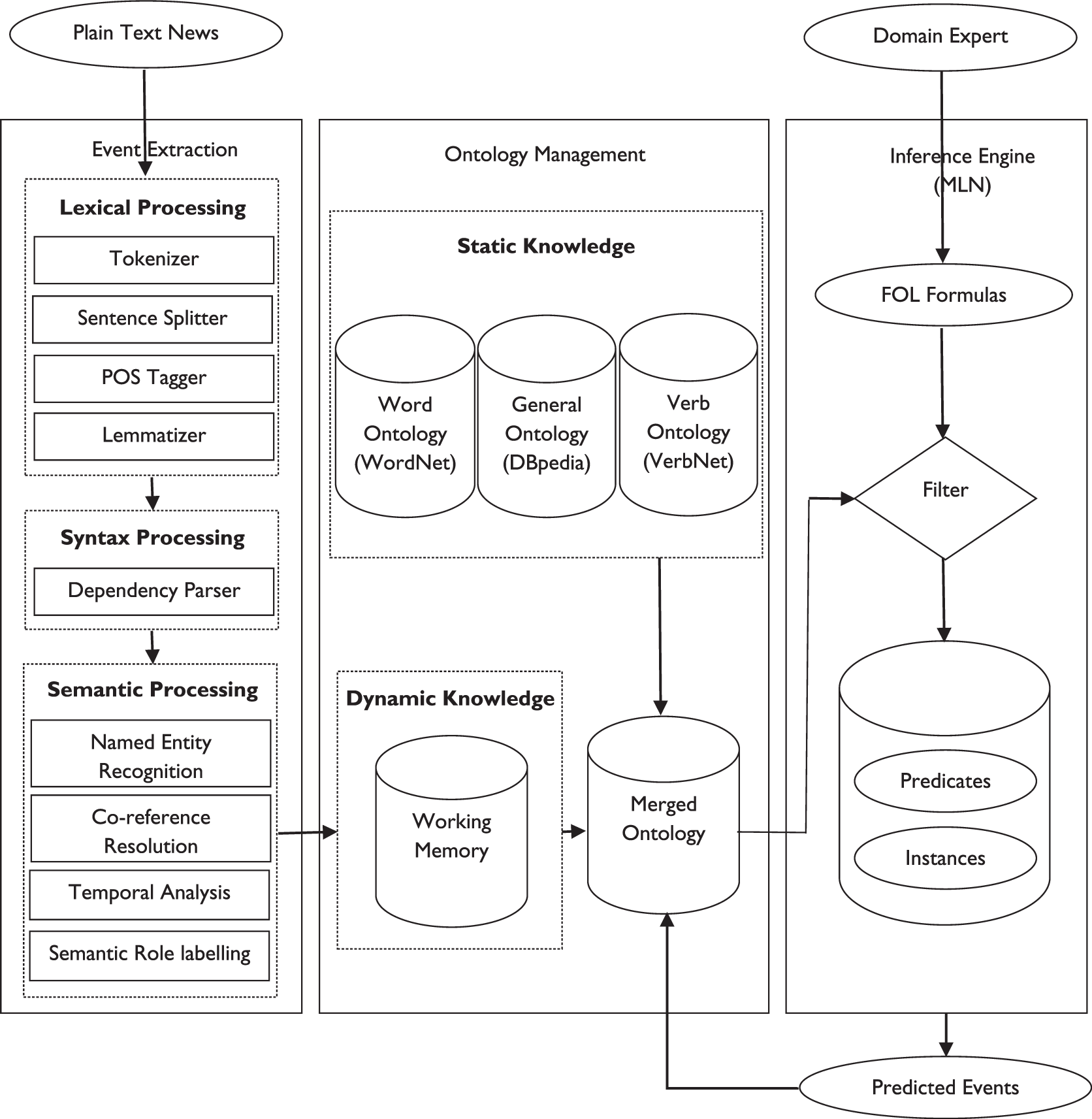
Overall architecture of the proposed framework for news event prediction.
The contextual knowledge was added to the system through a large-scale OWL ontology, which was the Persian ontology extracted from DBpedia. As mentioned in subsection 2.3.2, an approach is considered for summarising general otology into the framework; it summarises contextual knowledge according to the classes and properties of the given ontology. The summarised OWL knowledge base is stored and loaded on the main (merged) ontology of the system. Subsequently, the domain-specific rules acquired by human experts in weighted FOL formulas are transformed into OWL-encoded syntaxes in order to be considered for reasoning. While pre-processing the corpus of news collected from online sources (the working memory), events are extracted from the main textual content of each article using a deeper processing technique by semantic role labelling (SRL). They are then post-processed through the automatic generation of a semantically meaningful structure (OWL format).
All the identified, extracted and obtained knowledge is then transformed into an expedient machine-readable OWL format for the news. An inferential model is then built on these OWL triples using probabilistic logical scheme via the MLN. Afterwards, the user is able to draw inferences via the user interface. Notably, this interface receives only events from working memory that matches the ‘if’ part of the rules. Hence, by filtering the news events, additional and unnecessary processing is avoided and inference is accelerated. The outputs of inference are facts/events that can be converted into triple arguments in OWL format. After drawing inferences, the user can add and incorporate the inference outputs into the main ontology in an OWL-supported file format. The following subsections describe these steps in detail.
3.1. Representation of events extracted from news archives in OWL format
According to the recent events extracted from news archives and considering the FOL causality rules written by a human expert, the prediction system could predict future events. The events extracted from news (the working memory) was added to the system and transformed into an OWL structure for generating semantic graphs as a representation of the meaning of a text. OWL triples are inherently usable for reading, reasoning and eventually prediction by the machine. These triple arguments are effective to semantically understand a text without the need for reading it in detail. Moreover, it is possible to incorporate it into other forms of knowledge represented in the same format. Furthermore, it is easier to search, retrieve and perform logical inference on the large-scale text corpora. These were the motivations that guided us to represent the facts/events extracted from news archives in the OWL format.
In this work, events are considered predicates in news sentences that describe a situation or condition in which something establishes or changes at a certain time. Accordingly, each sentence available in news articles is stored in the OWL ontology in the form of triple arguments. To read sentences in news articles and extract a large set of (OWL) verb-based triples from each article, we used OIE. An OIE takes all types of (verbal) binary relations found in each sentence, comprising a verb relation and two arguments. The core OIE is accomplished by linguistic pre-processing including tokeniser, sentence splitter, parts of speech (POS) tagger and lemmatiser, followed by named-entity recognition (NER) and co-reference resolution components. For a more semantic understanding of texts, temporal semantic analysis and SRL were used to represent semantically rich event model.
Before any language processing beyond the lexical level can be performed, it is necessary to break the news text up into words, phrases, punctuation marks or other meaningful units called tokens. Sentence splitting assembles the tokenised text into sentences. Texts without sentence mark-ups require pre-processing to add it without disturbing the existing mark-ups. This enables further processing of the texts, especially POS tagging. The POS tagger marks up words (and other tokens) in the text and tags them as POS such as nouns, verbs, adjectives and adverbs. After tagging the part of speech of a word, different normalisation rules were applied for each part of speech to determine the lemma for each given word. The goal of the lemmatiser is to reduce inflectional and sometimes derivationally related forms of a word to the canonical form.
NER is a subtask of information extraction that seeks to label sequences of words as named entities in a text such as the names of things, people, organisations and products. When two or more expressions in the text refer to the same person or thing, the co-reference resolution is used to find all expressions that refer to the same entity. A temporal tagger for recognising and normalising temporal expressions (SUTIME [47]) was also used to annotate documents with temporal information. It is a deterministic rule-based system designed for extensibility as part of the Stanford CoreNLP [48] pipeline.
Our approach to news event prediction is based on a semantic understanding of news, one that goes beyond lexical, factual and shallow syntactic representations. Such levels of processing could be evolved from SRL, which extracts the events contained in news, the entities included in the events and the roles that each entity plays according to the events. SRL is an important step towards deep semantic processing of sentences (facts/events) in order to make sense of its meaning. This deep processing comprises detecting semantic arguments associated with a verb in a sentence and their classification into (semantic) thematic roles.
We investigate the applicability of SRL for the task of OIE, which extracts any type of relation from unrestricted text without requiring a pre-specified domain. All the verbs and thematic roles extracted from SRL-based OIE are depicted in corresponding classes and properties of the main ontology in the OWL structure.
To extract semantic relations between words in a sentence, they first need to be established at the syntactic level. For this purpose, we used a dependency-based method [49] that defines how the words in a sentence are connected to each other. Dependency grammar provides verbal relations between the words of a text, in which the main verb of the sentence is usually independent and other words are dependent on some others. Specially, we used the Persian dependency treebank [50] comprising 30,000 annotated Persian sentences and nearly 4800 distinct verb lemmas in its sentences based on dependency grammar. We then used the Malt parser [51] to generate a dependency parser model for Persian language.
After parsing each sentence of the news article using the generated dependency parser, we found out the verb clauses that it constituted. We then proceeded to identify the thematic roles corresponding to each clause. Finally, we applied a set of rules on the clause constituents to extract OWL triples.
In this model, each sentence contains a verb and several thematic roles, in which the verb clauses and their thematic roles are, respectively, represented as classes and properties of the OWL ontology. Thematic roles connected a verb with the instances of other classes. The number and type of these roles are predefined. This model bears points of comparison with the Kim’s [52] extended model for representing the events. Kim’s [52] extended model assumes that a specific set of entities is available. For example, these entities can be humans, things or abstract concepts. In this method, the events are represented by an ordered triples in notation [Xn, P, T], where entities Xn = (x1, x2, …, xn) exemplify the n-adic empirical property P at time T.
Based on this approach, we propose to represent the events in each sentence as <X1, X2, …, X17, P, T>, in which variables X1 to X11 contain action labels and variables X12 to X17 contain description labels used in thematic roles. Table 2 shows the list of the proposed (semantic) thematic roles corresponding to each variable presented in Kim’s extended model.
The proposed thematic roles for corresponding variables of the Kim’s extended model

Example 2. Consider the following news sentence: ‘Iran’s production of uranium increased by at least 20% due to centrifugation at Isfahan in April 2014’. The variables of the extended model in this event are represented in the form of: <P = product, O1 = Iran, O2 = null, O3 = uranium, O4 = increased, O5 = null, O6 = Isfahan, O7 = null, O8 = null, O9 = null, O10 = null, O11 = centrifugation, O12 = at least, O13 = 20, O14 = percent, O15 = null, O16 = null, O17 = null and T = Apr 2014>.
Each of these roles in the representation model shows the name of a relation with two arguments, and this relation is stored in OWL or other standards. So, the event extracted for this sentence including 10 arguments will be as follows:
<…/product_001> <…/Type> <…/product>
<…/product_001> <…/Agent> < …/Iran>
<…/product_001> <…/Theme> <…/uranium>
<…/product_001> <…/Manner> <…/increased>
<…/product_001> <…/Location> <…/Isfahan>
<…/product_001> <…/Cause> <…/centrifugation>
<…/product_001> <…/Attribute> <…/at least>
<…/product_001> <…/Value> <…/20>
<…/product_001> <…/Measurement> <…/percent>
<…/product_001> <…/Time> <…/Apr 2014>.
Note that product_001 is an instance of the class product. The dynamic ontology can have countless instances of this type of action. The corresponding number to this verb (i.e. 001) is also considered as a sentence or news identifier. Figure 2 shows how Example 2 is represented in ontology.
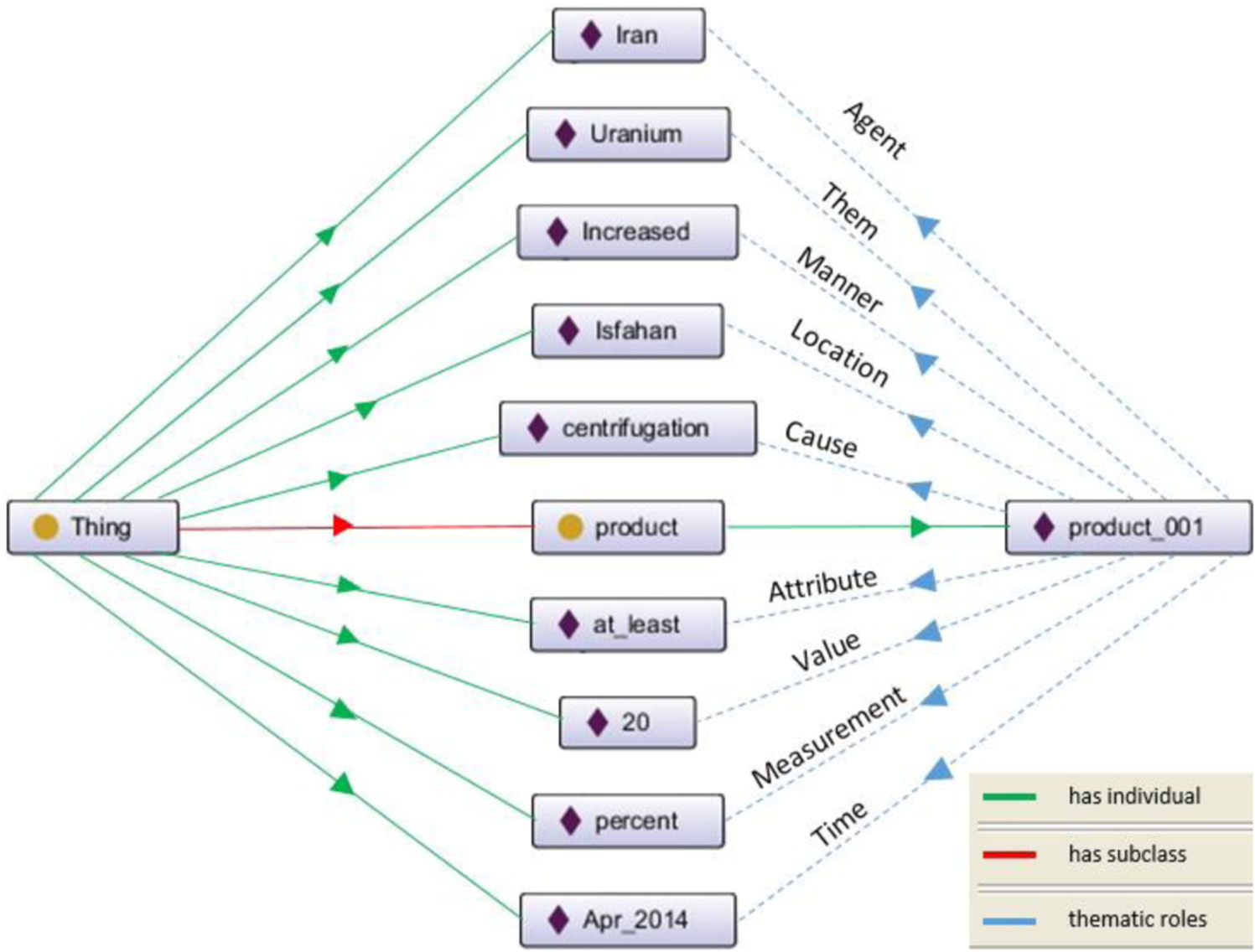
Graph representation of an event mapped on the ontology language OWL.
The proposed verb-based approach is effective to handle complex sentence structures and extract semantically deep events from news text, as well as to represent them into a machine-readable OWL structure. This deep structure leads to a more distinctive and elaborate semantic representation. Making sentences distinctive and elaborate means their representations will comprise a more coherent set of other things, which will make each sentence correspond to one and only one sentence. As a result, such deep semantic processing should lead to better understanding of texts.
3.2. Representation of rules
We employed the probabilistic first-order rules of MLNs to represent common-sense knowledge for making inference about imperfection and contradictory knowledge. These rules are represented in the form of OWL to be used for reasoning and eventually for prediction. Each rule consists of a number of nodes. These nodes can be added to the ‘if’ or ‘then’ part of the rules. Indeed, with the satisfaction of the ‘if’ part nodes, all of the ‘then’ part nodes are satisfied. Both the ‘if’ and ‘then’ parts of the nodes consist of one of the four types, namely, class, property, verb and thematic role. Example 3 shows how to create rules.
Example 3. Suppose we want to add a rule to the rule set that ‘If two countries negotiated on nuclear issues, then the one which is a member of P5+1 would sign a nuclear agreement’. The rule will be added to rule set as follows:
[rule i:
(?A RDF:Type negotiate)//verb
(?A Theme nuclear_issues)//thematic role
(?A Agent?B)//thematic role
(?B RDF:Type country)//class
(?A Patient?C)//thematic role
(?C RDF:Type country)//class
(?B member-of P5+1)//property
→
(?D RDF:Type sign)//verb
(?D Theme nuclear_agreement)//thematic role
(?D Agent?B)//thematic role
]
Each line of the rule i contains a node that expresses one of the four types of proposition, for example, suppose the user wants to create the node (?A Theme nuclear_issues) and add it to the ‘if’ part of the rule. First, the user should select the thematic role Theme for the type of node and ?A as a variable, and then choose nuclear_issues from general ontology as a value of the thematic role. This process can be used for adding other nodes to the given rule. After creating all the desired rules, the rule set is saved in the OWL file format to be used for reasoning and eventually for prediction.
3.3. MLN
We seek to deal with the complex and uncertain knowledge and to enrich textual representation of an event model by combining logic and probability. Statistical relational learning [53] is one of the most practical ways of uncertain inference to unify logical and probabilistic models. Especially, Markov logic [54] is considered as a unifying framework for statistical relational learning.
The MLN is a probabilistic logic that utilises Markov networks to represent first-order formulas in which one formula is worth a thousand labels. MLNs are appropriate for solving joint inference problems [34] that model complex interdependencies and propagate information from more certain decisions to resolve ambiguities in others. Additionally, they provide the principal way to leverage both direct and indirect supervision and are an easy way to acquire knowledge provided by a domain expert. These characteristics compensate for its lack of training examples.
So far, MLNs have been applied to applications such as information extraction [55], entity resolution [56], text mining [57], social recommender systems [58], opinion mining [59] and sentiment analysis [60]. However, the present work highlights the first attempt at semantically deep processing of complex and uncertain events using MLN, which has made it possible to predict news events. Example 4 shows how MLNs work for this purpose.
Example 4. Suppose we have two rules with their corresponding weightings: ‘If two countries negotiated on nuclear issues, then the probability is high (1.5) that either would sign the nuclear agreement or both would not’ and ‘If a country signs a nuclear agreement, then the chance for lifting sanction is high (1.1)’. First, we translate them into FOL with associated weightings as shown in equations (1) and (2)
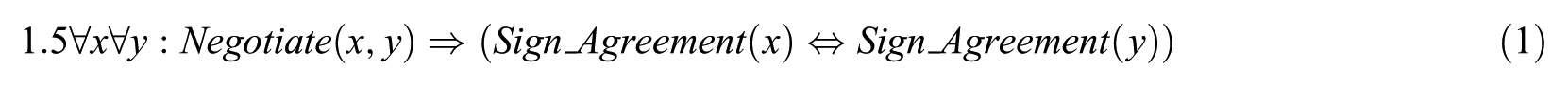
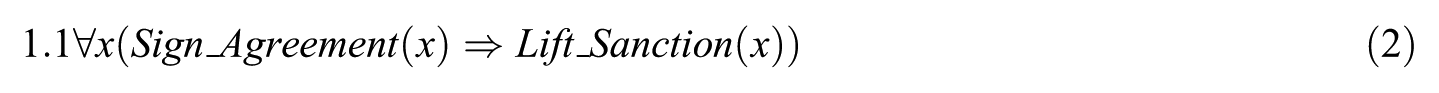
Each sentence or formula in FOL should be converted into the clausal form, as shown in equations (3)–(5), which can be then used to perform first-order resolution.
Formulas are constructed using four types of symbols – constants, variables, functions and predicates. For a more detailed overview, the reader is recommended to refer to Domingos and colleagues [35, 54]
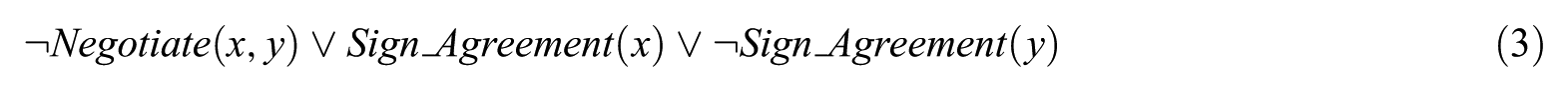
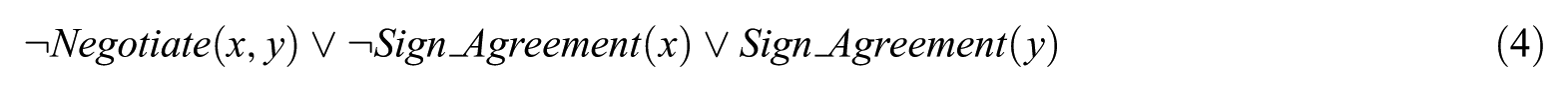
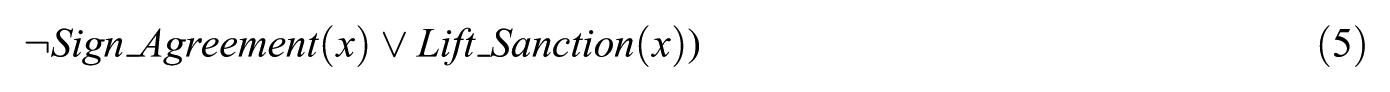
We then construct an MLN template, so that each formula owns a weighting and matches one clique. Given the different sets of constants, different networks will be constructed, known as ground Markov networks. The probability of a particular truth assignment x to the variables in a ground Markov network is defined as equation (6)
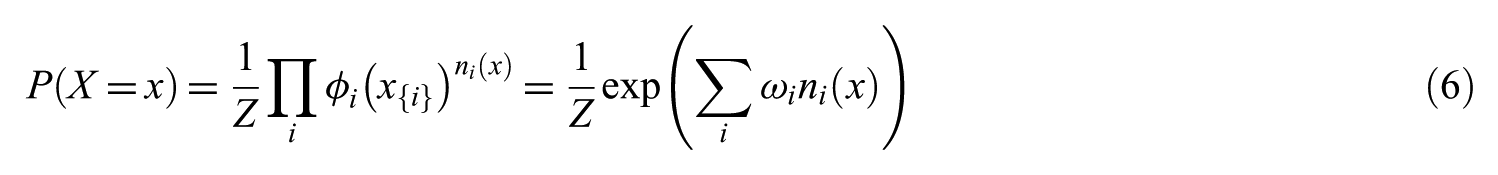
where wi is the weighting of the formula i, ni(x) is the number of true groundings of formula in x and
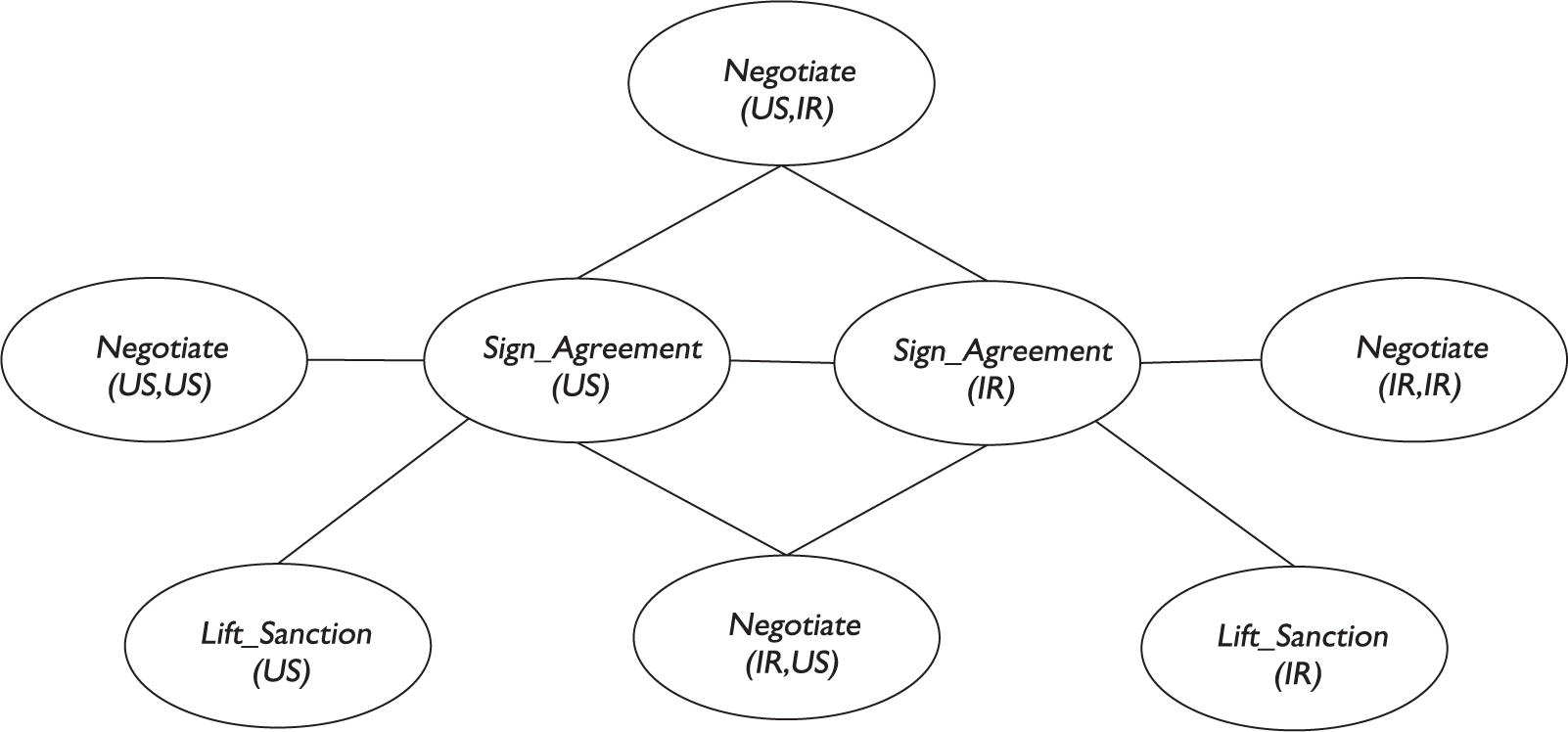
Ground Markov network obtained by applying the formulas in equations (3) and (4) to the constants IR and US.
Notably, the relations Country (Iran) and Country (US) can be implicitly extracted from DBpedia ontology as follows:
<http://dbpedia.org/resource/Iran> <http://www.w3.org/rdf-syntax-ns#type> <http://dbpedia.org/ontology/Country>
<http://dbpedia.org/resource/US> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://dbpedia.org/ontology/Country>
Finally, we can compute whatever we want to predict. For example, suppose we want to know the probability that Iran and the US have negotiated, both have signed a nuclear agreement, but none have lifted the sanction. The probability value is calculated as equation (7)
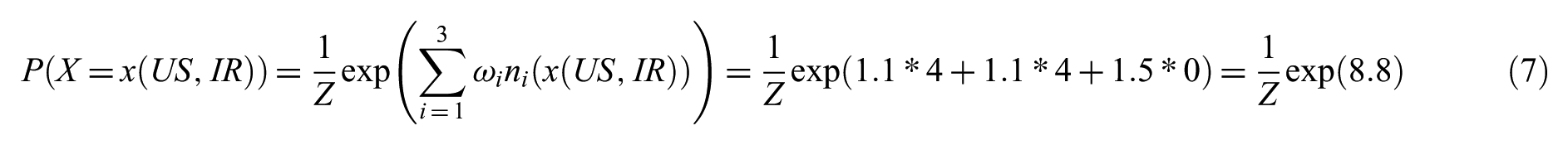
4. Prediction evaluation
4.1. Dataset
The required data for evaluation included static knowledge (information extracted from DBpedia), dynamic ontology (events extracted from news corpora) and common-sense knowledge (rules extracted from domain expert), all of these transformed into an OWL format.
The information extracted from news texts and inference rules provided by the human expert are very important for evaluating the system. This is because the power of inference depends on both of these. The evaluation procedure is described in subsection 4.3.
4.2. Evaluation criteria
In previous works, most evaluation approaches focused only on the accuracy of the generated predictions based on human involvement. However, users are more likely to explore and provide a list of specific events. Accordingly, accuracy-based measures such as mean absolute error (MAE), mean square error (MSE) and root mean square error (RMSE) are not efficient to evaluate the prediction system. To this end, we use precision and coverage metrics to evaluate the proposed method and compare it with the other methods. However, these metrics alone are not indicative of the better performance of the news prediction system because users usually tend to have a more diverse prediction in addition to high precision and coverage. Therefore, in this article we used precision, coverage and diversity metrics to evaluate our experiments.
Precision and coverage are, respectively, defined as equations (8) and (9)
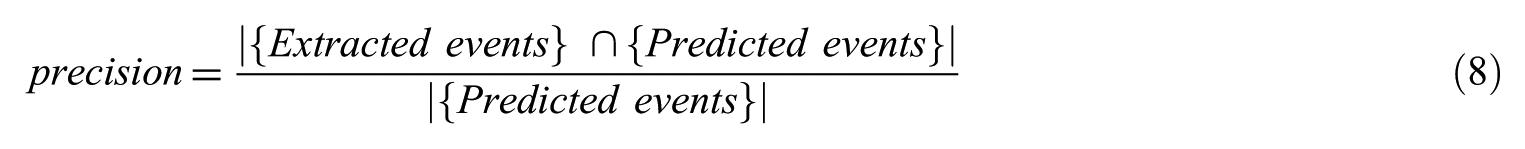
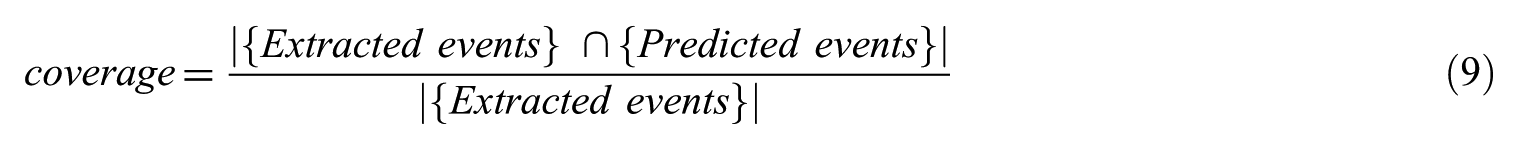
Diversity refers to how the generated predictions vary with regard to each other. Inter-diversity (DInter) of the generated predictions for two news topics T and T′ can be measured using the Hamming distance [61]. The Hamming distance is calculated by the sum of the absolute values of positions at which the corresponding events are different, which is defined as equation (10)

where CTT′(L) is the number of common events in the top L places of the predicted lists of T and T′. The higher its value, the more diverse are the events predicted for topics.
Intra-diversity (DIntra) is defined by considering the prediction lists of the variety of events. By denoting the predicted events for a specific domain as {e1, e2, …, eL}, the similarity of these events s(ei, ej) can be used to compute the intra-diversity as shown in equation (11). The lower its value, the more diverse is the prediction given to the user

We define the similarity of two events ei and ej, s(ei, ej), according to Radinsky et al. [29]. We considered an event as ordered set e = <X1, X2, …, X17, P, T>, which is described in subsection 3.1. We also used FarsNet [39], a lexical ontology for Persian language, and localised VerbNet extracted from verbs’ argument structures instead of WordNet [38] and VerbNet [40] ontologies.
4.3. Evaluation procedure
There are no benchmarks to evaluate the task we tackled in this article, and as with many other AI problems, we also encountered the lack of training data with certain labels. To this end, we collected the Persian news articles about foreign policy (specifically Iran’s nuclear programme) contained in FarsNews, 3 AsrIran 4 and Tabnak 5 archives from June 2015 to September 2015. The news corpus was collected in three topics – nuclear deal (T1), sanctions relief (T2) and development of economic relations (T3). Two human groups informed about domestic and foreign policy news were considered to generate cause-effect data and causal rules for evaluation. The first group was asked to annotate the cause and effect events extracted from 200 news articles that were randomly selected from the overall gathered data, where each pair of cause and effect consists of a fact and at least two possible effects. It is noteworthy that the cause events (Ec) annotated by this human group should be necessarily extracted from the texts of given news articles, but for the extraction of effect events (Ee) the group could additionally employ other source of news published in specific domains. The second group was also responsible for creating the causal rules in a predefined form of FOL associated with their weighting according to the given news texts and Ec as the premise of the rules. This group was not aware of the effect events (Ee) specified by the first group, so their opinion did not exactly tally with the other one.
All of the human-labelled events were manually marked with semantic tags, which include thematic roles listed in Table 2. To provide such information for the system, we initially pre-processed and parsed all documents as mentioned in subsection 3.1. There were 300 sentences (facts/events), with 1190 semantic tags for cause events and 496 semantic tags for causal rules. Figure 4 shows the distributions of training and test data for various domains of foreign policy news.
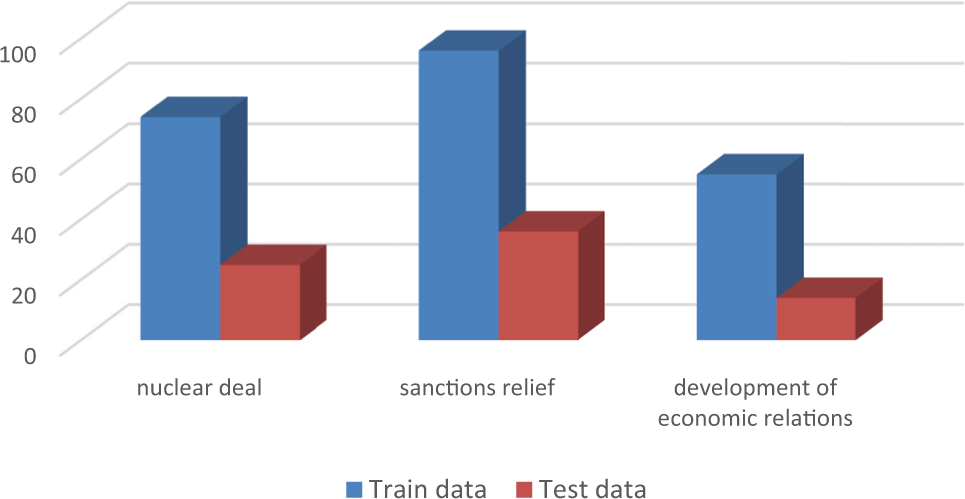
Distributions of training and test data for various domains of foreign policy news dataset.
First, all cause events of training data were given to the experts for generalisation and production of the rules. Thereafter, all cause events of test data (Ec_test) and production rules were fed into the system that generated new effect events as prediction outputs. Finally, the generated predictions are automatically compared with the desired outputs (Ee_test), so the precision, coverage and diversity of generated predictions are evaluated using equations (7)–(9). The experimental results are presented in the following subsection.
4.4. Experimental results
To evaluate the proposed method, which uses logic and probability for inference, we compared its performance with baseline methods, which use only logic or only probability. The main research question we purposed to answer with these experiments is whether adding probability to the logical rule base improves its prediction of the news events. To this end, we observe the results of the generated prediction using only inference with FOL rules. We use the Jena 6 rule engine to derive consequences from RDF models to provide OWL reasoning.
Another question that must be answered with the experiments is whether available probabilistic models are now strong enough to be used in problems domain without requiring a deeper structure proposed by MLN. To answer this question, we used the Naive Bayes (NB) algorithm as a propositional learner [54] in which the domain first requires to be propositionalised. In this article, we employed the MLN interface engine Tuffy [62], which leverages time-tested relational database management system (RDBMS) infrastructure for joins to achieve high performance at scale.
We were also interested in considering the influence of adding semantic tags and different sources of world knowledge to the performance of predictions. Notably, the work presented by Radinsky et al. [29–31] added only 4+1 semantic tags (including agent, theme, instrument, location and time) for event representation schema and used only logical approach (CBR 7 algorithm) to infer future events. Therefore, we will also be able to compare the performance of the proposed method with this baseline algorithm. We employed a small number of FOL formulas as domain knowledge instead of performing large-scale learning [29] over the large data corpus, with almost the same performance.
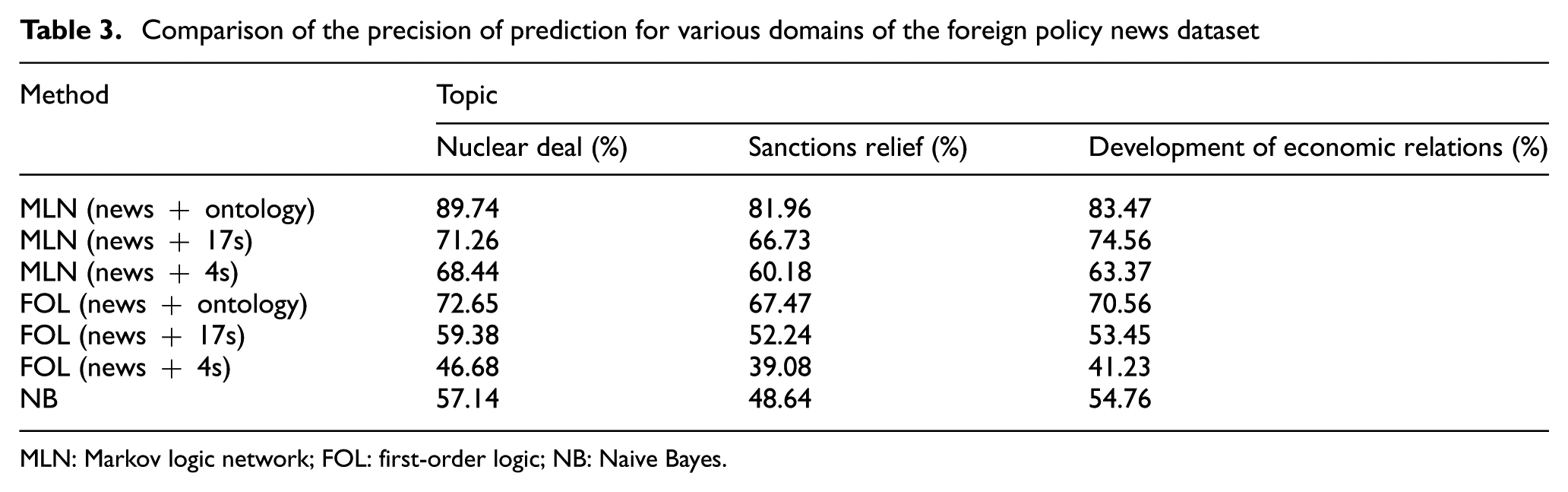
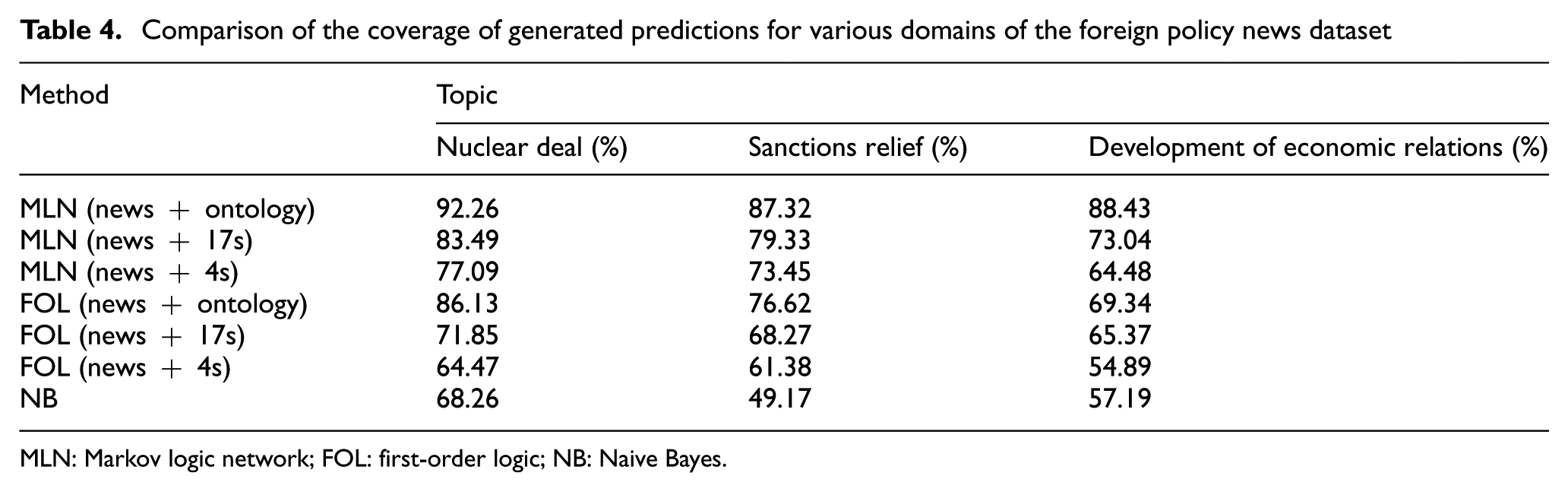
For this purpose, we consider predictors solely based on using the 4+1 semantic roles (news + 4s), on all the 17+1 semantic roles (news + 17s) and on both the semantic roles and the ontological hierarchies (news + ontology). The experimental results in precision, coverage and intra-diversity of generated predictions are shown in Tables 3–5, respectively, for three domains T1, T2 and T3.
Comparison of the precision of prediction for various domains of the foreign policy news dataset
MLN: Markov logic network; FOL: first-order logic; NB: Naive Bayes.
Comparison of the coverage of generated predictions for various domains of the foreign policy news dataset
MLN: Markov logic network; FOL: first-order logic; NB: Naive Bayes.
Comparison of the intra-diversity of generated predictions for various domains of the foreign policy news dataset
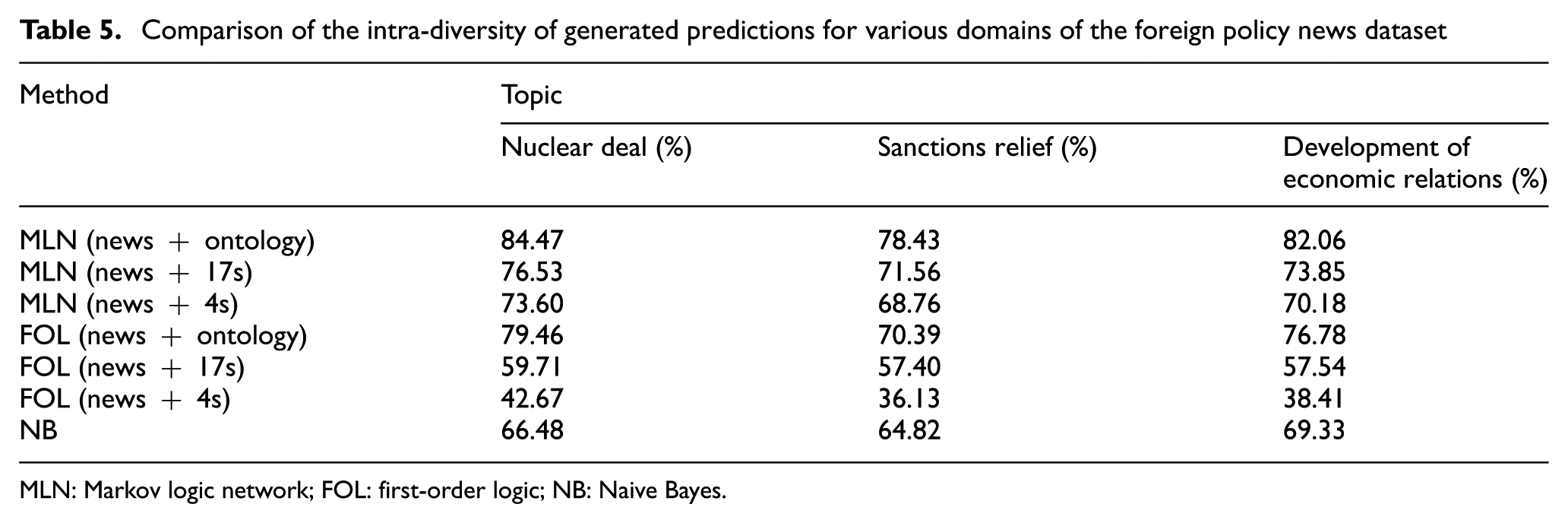
MLN: Markov logic network; FOL: first-order logic; NB: Naive Bayes.
As shown in the above tables, the proposed method is significantly more precise, has more coverage and is more diverse than other methods, showing the promise of this approach. It is probably that these results are due to a combination of the expressive power of logic and the probability of handling both complexity and uncertainty. The purely logical and purely probabilistic methods mostly stand when intercurrent relations should be derived, while MLN is greatly free-standing. The NB algorithm performs poorly compared with the other methods. A possible explanation for this might be the lack of appropriate training data and the nature of the algorithm. FOL works well on using both semantic roles and ontological hierarchies but poorly on ignoring ontological triples and reducing semantic roles. On the whole, out of the purely logical and purely probabilistic methods, the best-performing method is FOL, but its results fall well short of the best MLN.
Figure 5 shows the inter-diversity of the generated predictions for various domains of foreign policy T1, T2 and T3. As has been shown, the results of news prediction for T3 and T2, respectively, have the most and the least diversity compared with other similar domains.
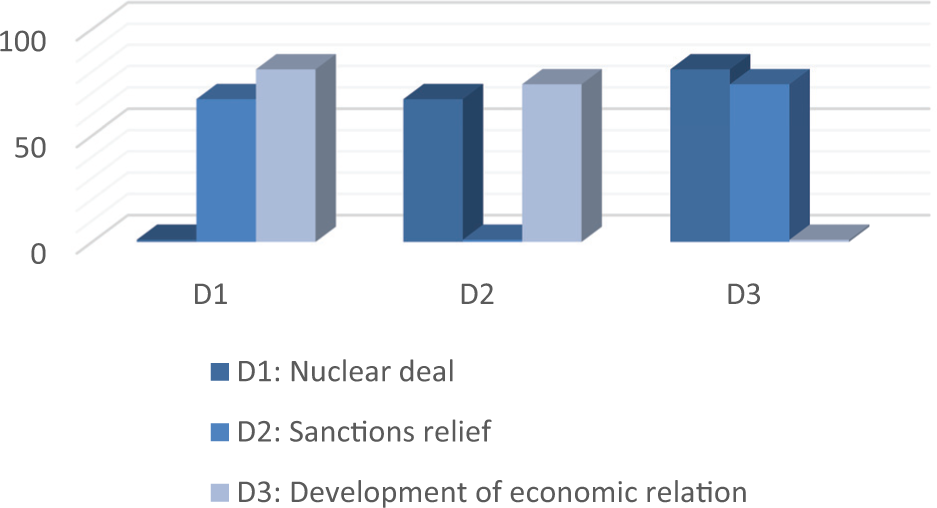
Comparison of the inter-diversity of generated predictions for various domains of foreign policy news dataset.
Furthermore, we conducted another experiment to evaluate the matching of every semantic role extracted from the news corpus to the localised (Persian) ontology extracted from DBpedia. The purpose of this experiment is to show whether the labelled semantic roles from the news corpus was mapped precisely to a concept in the ontology. The results are summarised in Table 6.
Precision of matching semantic roles extracted from the news corpus to concepts in the ontology

We find that adding knowledge, either these semantic tags or the ontological triples, improves the performance of predictions. The highest performance is achieved when applying both refinements by MLN. Returning to the question raised at the beginning of this study, it is now possible to state that using the combination of these semantic roles is efficient to extract news events from texts in a semantically deep manner.
5. Conclusion
The purpose of this study was to develop an efficient and generalisable knowledge framework for predicting future events in textual environments. We have proposed a method to realise this framework using MLN, which simply combines probability and FOL. Within this framework, different types of knowledge, such as static (e.g. a priori and contextual) and dynamic (a posteriori) knowledge extracted from multiple, heterogeneous and uncertain sources of information can be incorporated together in standard OWL to be used for common-sense reasoning and eventually prediction. We have consequently suggested a testing methodology for evaluating news prediction algorithms. Experimental results with respect to real news datasets showed that the proposed framework achieved significant improvements in prediction compared with the baselines, which used purely logical and purely probabilistic models. Moreover, enrichment of textual event representation by a deeper semantic structure lent better predictive ability to all the methods.
The most obvious finding from this study is that our method provides a promising framework for representing general-purpose, language-independent and semantically rich event model that can combine semantic analysis with different types of knowledge resources. Another finding of the study is reasoning under uncertainty to predict news events. These findings further support the contribution to machine common-sense understanding and a deeper semantic natural language understanding. In future research, we intend to extend our framework to include parallel and distributed environments. We also plan to investigate our framework in other related tasks such as textual entailment and question answering. Besides, there is a great potential for adapting the proposed method for applications such as stock event analysis and health-care event monitoring by utilising their specialised domain ontologies.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This paper was extracted from the dissertation prepared by Sina Dami to fulfil the requirements required for earning the degree of Doctor of philosophy which was accomplished with the support of the Department of Information and Communication Technology (ICT), Malek-Ashtar University of Technology (MUT), funded by Research and Development Centre at MUT.