
Abstract
The proliferation of social networking services has resulted in a rapid growth of their user base, spanning across the world. The collective information generated from these online platforms is overwhelming, in terms of both the amount of content produced every moment and the diversity of topics discussed. The real-time nature of the information produced by users has prompted researchers to analyse this content, in order to gain timely insight into the current state of affairs. Specifically, the microblogging service Twitter has been a recent focus of researchers to gather information on events occurring in real time. This article presents a survey of a wide variety of event detection methods applied to streaming Twitter data, classifying them according to shared common traits, and then discusses different aspects of the subtasks and challenges involved in event detection. We believe this survey will act as a guide and starting point for aspiring researchers to gain a structured view on state-of-the-art real-time event detection and spur further research in this direction.
1. Introduction
With around 310 million monthly-active Twitter users 1 producing content from all over the world, Twitter has essentially become a host of sensors for events as they happen. An event, in the context of social media, is an occurrence of interest in the real world which instigates a discussion on the event-associated topic by various users of social media, either soon after the occurrence or, sometimes, in anticipation of it.
Similar to our definition, Dou et al. [1] defined an event as ‘An occurrence causing change in the volume of text data that discusses the associated topic at a specific time. This occurrence is characterized by topic and time, and often associated with entities such as people and location’. In the collection on Topic Detection and Tracking (TDT) [2], an event is defined as ‘Something that happens at specific time and place along with all necessary conditions and unavoidable consequences’. Dou et al. [1] state that ‘Collectively, events serve as a succinct summary of social media streams. Individually, an event and its sub-events, reveal the evolution of certain social phenomena over time’. In accordance with these definitions, the series of coordinated terrorist attacks in Paris on 13 November 2015 were an event in the context of social media, prompting a high volume of tweets as soon as the attacks took place. The various aspects of this event were tweeted by general users and news agencies all over the world, for example, ‘BREAKING.This is what we know: 35 dead, 100 hostages taken at a concert venue. Various drive by shootings. Explosions at a #Paris stadium’. The given example was a high-profile event of global consequence; however, an event detection system should also be able to detect newsworthy events at a smaller scale, with a smaller burst of tweets at any given time.
Petrovic et al. [3] analysed major and minor events reported within a 2-month period in the newswire and on Twitter streams, finding that major events were equally covered by both the traditional newswire providers and Twitter. In addition, they found Twitter has better coverage of events related to sports, unpredictable high impact phenomena, and small or local events which fall outside the radar of newswire sources. Petrovic et al. [3] also noted that, in some cases, Twitter leads on reporting events related to politics and business.
Osborne and Dredze [4] compared the coverage and latency of breaking news reported on Facebook, Google Plus and Twitter, based on major events 2 identified from Wikipedia which occurred between the 10 and 31 December 2013. These social media sites were also compared based on the long-tailed events detected by the event detection system proposed by Petrovic et al. [5]. Osborne and Dredze [4] found Twitter to be faster in reporting breaking news than other social media sites, but was still outperformed by the newswires.
The findings by Petrovic et al. [3] and Osborne and Dredze [4] confirm the utility of an efficient Twitter-centric event detection system which is capable of detecting events, tracking event-related updates and providing meaningful summaries of the detected events. The challenge of doing so, however, is the limited context provided by tweets resulting from the length restriction of 140 characters imposed on each tweet. On top of that, the majority of information propagated on Twitter is irrelevant for the event detection task, and the noise generated by spammers and the use of an informal language, coupled with spelling and grammatical errors, can adversely affect the event detection process.
An early study on event detection techniques by Atefeh and Khreich [6] mostly focussed on the literature from before the year 2012, but there has since been rapid and wide-ranging development in this research area. The work done by Li et al. [7], Gaglio et al. [8], Stilo and Velardi [9], Xie et al. [10], Zhou et al. [11], McMinn and Jose [12], De Boom et al. [13] and Guille and Favre [14] are examples of contemporary developments in this area, employing a wide variety of techniques.
In contrast to our work, the organising of content in the study conducted by Atefeh and Khreich [6] is based on three major categories: (1) the type of event being detected by an event detection system (i.e. specified events and unspecified events), (2) the detection task (i.e. New Event Detection and Retrospective Event Detection) and (3) event detection methods (i.e. supervised, unsupervised and hybrid). As the focus of our study is on event detection methods, we believe that a different method of organising content is required instead of simply dividing the event detection methods based on whether they are supervised, unsupervised or a hybrid.
In this article, we classify the various detection methods based on the common traits they share (i.e. using probabilistic topic modelling, identifying interesting properties in a tweet’s keywords/terms and using incremental clustering). These categories will allow readers to gain a perspective on each of the general research directions, along with the finer details which separate one event detection technique from the other. In the study by Atefeh and Khreich [6], a total of 16 different research articles were discussed in detail. Our focus in this study is to provide a wider range of coverage on different event detection methods, as necessitated by the large number of recent studies. We intend to introduce readers to the recent literature, with a self-contained summary of each of the surveyed works and a comparison of the different proposed methods. This article does not contain an exhaustive review of the Twitter-centric event detection literature; however, representative methods are discussed from various fields, such as information extraction and retrieval, machine learning, data mining and natural language processing.
The remainder of this article is organised as follows: Section 2 contains a discussion of the general event detection framework and its components. Sections 3–6 contain discussions on the event detection techniques, categorised into approaches based on term interestingness, topic modelling, incremental clustering and miscellaneous approaches, respectively. We then briefly describe the different methods employed in the literature for system performance evaluation in Section 7. Pre-processing techniques are discussed in Section 8 and different event summarisation techniques are discussed in Section 9. Finally, a number of general observations on different event detection approaches are presented in Section 10. Section 11 concludes the article with a brief summary.
2. Event detection systems: a general framework
In order to detect an event which adheres to the definitions we have sketched in the introduction, a general event detection system framework (Figure 1) is presented containing a number of components to deal with the different stages of operation in event detection. A pre-processing component receives tweets from a streaming endpoint using a Twitter streaming API and processes them to be used in the subsequent stages by different components. Part-of-Speech (POS) tagging, slang-words conversion and Named Entity Recognition (NER) are all examples of pre-processing performed on tweets. A detailed discussion of the common pre-processing techniques is provided in Section 8. After the pre-processing stage, the Detecting Events component employs an event detection technique to detect events from the processed tweets. The event detection technique employed by this component belongs to any one of the general event detection approaches based on term interestingness, topic modelling and incremental clustering. There are also miscellaneous event detection techniques found in some studies in the literature which do not directly belong to the above-mentioned three general approaches, but are used in the Detecting Events component. The Detecting Events component is responsible for grouping tweets that are related, and each group/cluster of tweets corresponds to a candidate event.
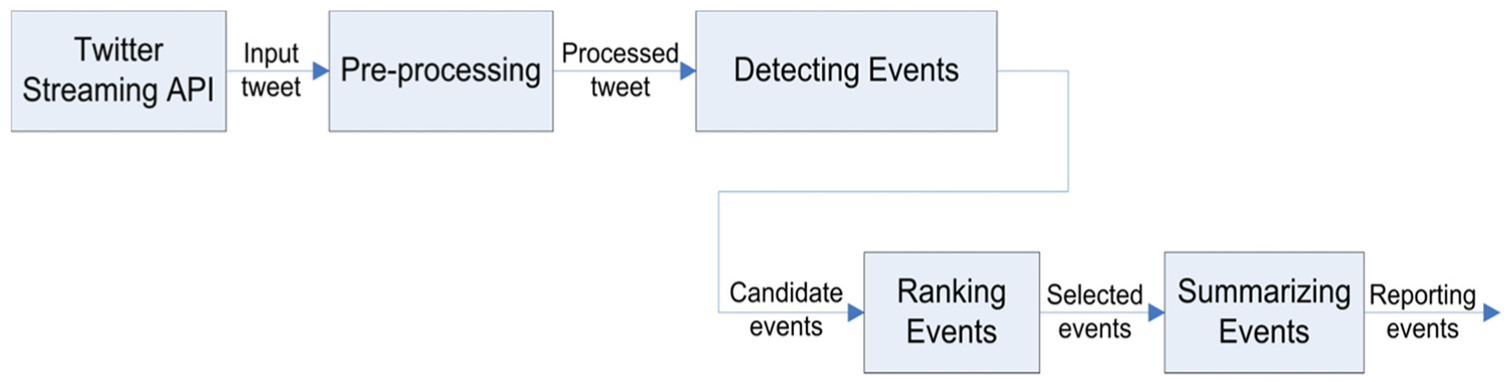
A general framework for event detection systems.
Once the candidate events are detected, the Ranking Events component ranks them based on criteria to determine the events that are of interest in the real world. In some cases, a threshold value or a supervised method is used to filter out trivial events using the Ranking Events component. In Section 3, we provide a discussion of the techniques applied by the Detecting Events and the Ranking Events component within the context of term-interestingness-based approaches. Similarly, these two components are discussed in Sections 4–6 within the context of topic modelling, incremental clustering and miscellaneous approaches, respectively. In addition, a selective number of methods which are commonly used to evaluate the performance of the event detection techniques studied in Sections 3–6 are discussed in Section 7.
Some event detection systems also include a Summarising Events component which creates a summary of tweets associated with an event. This component is responsible for presenting the events to the users in a meaningful way. Further discussion of the Summarising Events component is presented in Section 9. Finally, the detected newsworthy events are rendered by a desktop or web-based application. A sample event from the streaming Twitter data is displayed in Table 1 as an example.
Sample event: the 2012 Nobel prize winner in literature

3. Term-interestingness-based approaches
This section discusses the event detection methods which rely on tracking the terms (from the Twitter data stream) likely to be related to an event. These methods are summarised in Table 2, focussing on the approaches taken to determine term interestingness, clustering techniques used to group the tweets related to an event and the techniques employed to rank the events that were detected by an event detection system.
Summary of term-interestingness-based approaches
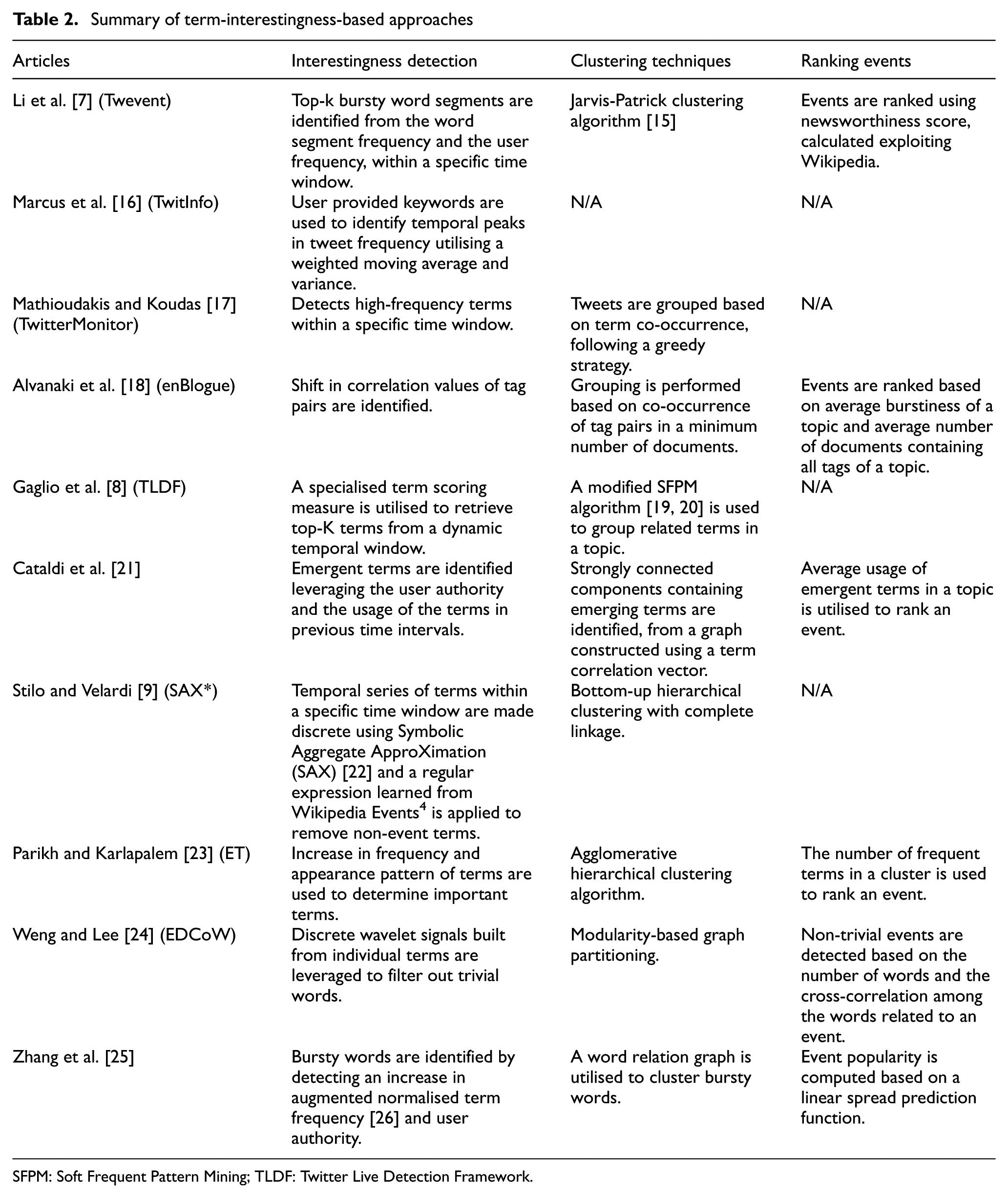
SFPM: Soft Frequent Pattern Mining; TLDF: Twitter Live Detection Framework.
The event detection system ‘Twevent’ [7] initially extracts continuous and non-overlapping word segments (single words or phrases) from each tweet. Statistical information obtained from the Microsoft Web N-gram Service
3
and Wikipedia is used to detect nontrivial word segments. The top-k bursty event segments within a fixed time window are then calculated from the frequency of bursty segments in conjunction with the user frequency of the bursty segments. Finally, a variant of the Jarvis-Patrick clustering algorithm [15] is used to group related event segments by using the content of their associated tweets and the frequency pattern of the segments within the specified time window. The events are then filtered based on their newsworthiness score,
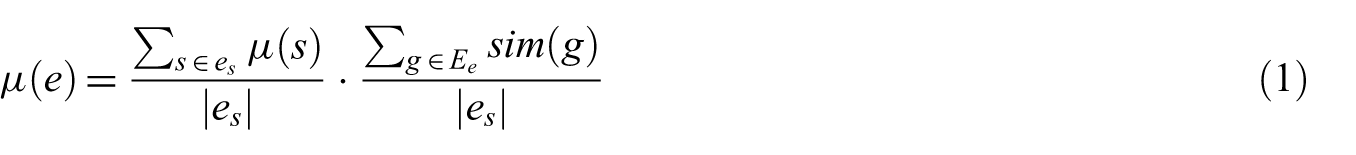
where Ee denotes the set of edges obtained after applying the clustering algorithm, with each edge representing the similarity between the event segment nodes they connect; sim (g) is the similarity score of an edge,

Events detected by Twevent [7] are highly dependent on the Microsoft Web N-gram Service and Wikipedia. This dependency can yield a set of events that are influenced by the service itself. Moreover, events that are not yet reported in Wikipedia might not be detected.
TwitInfo [16] allows a user to input event-related keywords to track an event. The system then starts logging tweets which match the user-specified keywords, detects spikes in tweet data as sub-events and automatically labels them with frequently occurring meaningful terms from the tweets. The approach taken by TwitInfo, to detect sub-events based on the peak in conversation about a topic, is inspired by the online algorithm used in Transmission Control Protocol (TCP) congestion control to detect unusual delays in packet transmission [27]. Tweets that arrive within a fixed time frame are binned, and the frequency of tweets within the bins is measured to detect spikes in the tweet frequency over time. Analogous to the approach used by TCP to determine an unusual delay in the transmitted packet being acknowledged, TwitInfo uses a weighted moving average and variance to determine an unusually large number of tweets in a bin. A significant increase in the tweet arrival rate, with respect to the weighted average of the historical mean tweet rate, is registered as a spike by the system. The local maximum of the spike is identified using a hill climbing algorithm to detect the time frame of the sub-event. The top-ranking
TwitInfo allows aggregate sentiment visualisation using a Naïve Bayes classifier for sentiment analysis and employs a recall-normalised approach to provide an overview on the sentiment associated with an event. TwitInfo also allows users to drill down through a graphical interface into the sub-events of an event, although it is limited by the fact that the system is intended to track only the events specified by users and cannot distinguish between overlapping events.
TwitterMonitor [17] detects emergent topics by utilising an elementary queuing model to identify the high-frequency (bursty) terms from the tweets within a small time window. The bursty terms detected by the system as co-occurring in a large number of tweets are placed in the same group, where each group qualifies as a trend. A greedy search strategy is used to generate groupings, in order to avoid the high computational cost of enumerating all possible groups. To provide an accurate description of the detected trends, TwitterMonitor uses context extraction algorithms [28], which find terms that are not necessarily bursty in nature, but are correlated to the trend.
EnBlogue [18] detects emergent topics from blogs and Twitter data by computing statistical values for hashtag pairs within a given window of time and monitoring unusual shifts in their correlations. The strength of these shifts in hashtag pairs is used to rank emergent topics, and the top-k ranked topics are returned by the system. There are three major stages of system operation in enBlogue: seed hashtag selection, correlation tracking and shift detection.
EnBlogue reduces the computational cost by considering only popular hashtags as a seed. The popular hashtags are determined based on a sliding-window average of elements found in the document stream. The extracted named entities are also included as part of the seed. Any combination of the hashtags which contains at least one of the seed hashtags is further considered for the calculation of the correlation. The correlation between the hashtag pairs in a given time window is measured based on the average number of documents containing both the hashtags and the similarity between these documents. The hashtag pairs are then monitored to detect a shift in their correlation and the strength of the shift is measured using exponential smoothing as a forecasting technique. The exponential smoothing equation computes the score for possible emergent topics by giving higher weights to the most recently observed correlation values and lower weights to observations from the distant past. Finally, a post-processing phase is employed to group hashtag pairs which refer to the same event. To minimise the occurrence of multiple hashtag pairs referring to the same event, two hashtag pairs that co-exist in at least 80% of tweets are grouped in the same event.
The Twitter Live Detection Framework (TLDF) [8] adapts the Soft Frequent Pattern Mining (SFPM) algorithm [19], to detect relevant topics within a generic macro-event while addressing the dynamic nature of the Twitter data stream. Unlike enBlogue [18] and TwitterMonitor [17], TLDF uses a sigmoidal function-dependent dynamic temporal window, sized to detect events based on term co-occurrence in real time. The dynamic temporal window allows the TLDF to adapt its event detection behaviour based on the actual volume of tweets related to an event. To reduce the number of terms to be considered, the term selection method in the modified SFPM generates top-K terms from the set of tweets within the current time window. Each term is weighted based on a value which is decided depending on, first, the term being recognised as a named entity (i.e. persons, organisations and locations) by the NER [29] and its
The event detection scheme proposed by Cataldi et al. [21] initially creates a term vector representation from the tweets within a given time window. The term weights are represented as augmented normalised term frequencies [21] to reduce noise. In the next step, the system determines the authority of a user based on the number of followers of the user and the authority of the followers. The approach taken to determine user authority is similar to the PageRank algorithm [30]. A life-cycle-based content model is applied within a given time interval to determine the life cycle of each of the detected terms. The life cycle of a term is modelled by calculating the energy of the term. Energy is computed by leveraging the user authority and the usage of the term in previous time intervals. Afterwards, a threshold is dynamically set at each time interval; the terms with a higher energy value than the threshold are considered as emergent terms for that interval. Finally, a correlation vector for each of the terms is created. It represents the semantic association of a term with all the other terms in the corpus. By leveraging this correlation vector, a directed and edge-weighted graph is constructed. This allows for topic detection from the graph by identifying strongly connected sub-graphs containing an emergent term.
Stilo and Velardi [9] use temporal co-occurrence of terms instead of contextual co-occurrence to detect events. The temporal co-occurrence-based approach has been adopted to overcome the problem of limited context provided by individual tweets. The Stilo and Velardi [9] have utilised the Symbolic Aggregate ApproXimation (SAX) [22] technique to provide a temporal characterisation of events within a specific temporal window, W, by converting the time series associated with terms into a sequence of symbols. Anomalous behaviours are detected by learning a regular expression on a subset of the Wikipedia Events,
4
which reduces the number of terms to be considered in the subsequent clustering phase. A bottom-up hierarchical clustering technique with complete linkage is applied on the remaining terms to group the terms that share similar string representations within window, W. The overall computational complexity of the event detection system is
The event detection system, Events from Tweets (ET), proposed by Parikh and Karlapalem [23] extracts event-representative terms based on the increased frequency of the terms in consecutive time intervals. A list of intervals are associated with each term, in which they are frequent. A combination of frequency increase and appearance pattern of the terms is utilised to filter out terms that are bursty in nature but not related to any event. ET uses bigrams as candidate terms to reduce the computational cost incurred by a large number of bursty unigrams. Similar terms (bigrams) are clustered using an agglomerative hierarchical clustering technique which does not require the number of clusters to be specified in advance. The clustering algorithm utilises a similarity matrix which contains the similarity score between each pair of terms and starts by merging the terms with the highest similarity score. After a merge operation is applied, the similarity matrix is updated; this process continues until there are no pairs of terms/clusters with a similarity score above a certain threshold remain. The overall similarity between two terms is calculated based on content similarity,
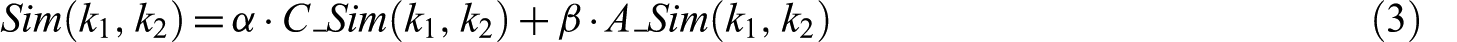
The content similarity,

The appearance similarity is calculated based on the frequent time intervals (FI) of

Bursty terms are detected in Event Detection with Clustering of Wavelet-based Signals (EDCoW) [24] by building a signal for each word using wavelet theory [31]. Modularity-based graph partitioning has been utilised to detect events by calculating cross-correlation among the signals generated from each word. A drawback of this method is that the process of wavelet generation for each word and the calculation of correlations are computationally expensive.
The event detection system proposed by Zhang et al. [25] detects bursty terms, where a term burst is identified from an increase in the term weight within a given time window. Each term is weighted by a combination of augmented normalised term frequency [26] and user authority. User authority is incorporated into term weighting using the assumption that the use of a term in a microblog post by an influential user (with many followers) will boost the use of the term through their followers. The approach taken to estimate user authority is similar to the PageRank algorithm [30].
Zhang et al. [25] have used a two-state automata model based on the Hidden Markov Model to detect bursty terms, proposing an incremental strategy with a complexity of
4. Topic-modelling-based approaches
In this section, we discuss the event detection methods which are dependent on the probabilistic topic models to detect real-world events by identifying latent topics from the Twitter data stream. The topic-modelling-based approaches for event detection associate each tweet with a probability distribution over various latent topics to find the hidden semantic structures from a collection of tweets used to guide the event detection task. These methods rely on sophisticated models to infer latent topics. In the following, we describe the motivations for using more complex modelling to account for the different aspects of topic detection with respect to event detection.
The topic-modelling-based approaches discussed in this section revolve around complex mathematical models to estimate the probability distribution of the latent topic variables. We have focussed our discussion on the different tweet-related attributes which were used to estimate the joint probability distribution, along with the other unique aspects of these approaches which distinguish them.
TwiCal [32] populates an open-domain calendar for important events in order to provide a structured representation of significant events extracted from the Twitter data stream. TwiCal extracts the named entities [33], along with associated event phrases and dates [34], from each of the streaming tweets. A supervised approach to extracting event phrases by using Conditional Random Fields [35] was adopted. A multitude of features including, but not limited to, contextual, dictionary and orthographic features were used to guide the learning and inference of event phrases. Due to the highly volatile nature of topics in Twitter data, a latent variable model is used to discover the important event types from a large body of tweets. From the discovered event types, only the coherent types found during inspection were retained and manually annotated with informative labels. These event types can be used to categorise event phrases extracted from subsequent new data. Events are ranked by measuring the association strength between an entity and a specific date, based on the
The Latent Event and Category Model (LECM) [11] uses a latent variable model similar to TwiCal [32], which detects events in a structured manner. In the LECM, each tweet is modelled as a joint distribution over the named entities, date/time and location of the event occurrence, and the event-related terms. This distribution is expected to ensure that two events occurring in the same place and time are distinguishable. To categorise events of different types, each named entity is mapped to its related semantic concepts using Freebase API.
5
Afterwards, each tweet is modelled as a joint distribution of the event-related terms and the semantic concepts of the named entities. The LECM uses the Collapsed Gibbs sampling algorithm to infer the parameters used in the model, the event types and their semantic class. Unlike TwiCal [32], the LECM uses a Bayesian modelling approach which can extract event-related keywords directly from the tweets without requiring supervised learning. Moreover, the LECM model can produce a structured representation of events directly, whereas TwiCal depends on the
The General and Event-related Aspects Model (GEAM) [36] is a hierarchical Bayesian model based on Latent Dirichlet allocation (LDA). It is similar to the LECM [11], but each tweet in the GEAM is modelled not only on event-related aspects (i.e. time, locations and entities) but also on general topics. Each named entity or hashtag in a tweet is assigned an event-related aspect. Other terms in a tweet are assigned a general topic or an event-related aspect based on a switching variable drawn from a binomial distribution. The Collapsed Gibbs sampling algorithm is used to estimate the multinomial (i.e. events, general topics and event’s aspect) and binomial distributions.
TopicSketch [10, 37] detects bursty events by maintaining a novel data sketch to detect acceleration in three quantities: the whole Twitter stream, every word and every pair of words. The system provides a low-cost solution for maintaining and updating this information. The sketch-based topic modelling approach triggers topic inference when an acceleration on these stream quantities is detected. As this strategy will result in data with dimensions in the order of millions, a set of the most recently encountered active words monitored and a hashing-based dimension reduction scheme is utilised to address this issue. A lazy maintenance scheme is employed using H hash functions to limit the number of accelerations to be updated to
Bursty Event dEtection (BEE+) [38] is an incremental topic model which discovers bursty events by modelling the temporal information of events. It utilises a distributed execution framework to achieve real-time processing capability. Compared with documents processed in the standard topic models, where a large document has a probability distribution over a mixture of topics, a post in a microblog containing only a few sentences is more likely to be associated with a single topic, and thus a single event. Unlike most of the other topic models for event detection, in BEE+ a microblog post related to an event is determined by associating only a single hidden variable with an additional background topic which has a distribution over the common words. Burst detection in BEE+ is similar to the approach used in TwitInfo [16], which was inspired by the TCP congestion control algorithm. The process to estimate the parameters in BEE+ has a faster convergence time than traditional topic models. Moreover, the incremental parameter update process in BEE+ is able to keep track of topic drifts over time.
Spatio-Temporal Multimodal TwitterLDA (STM-TwitterLDA) [39] is a topic-model-based framework for event detection which extracts text, image, location, timestamp and hashtag-based Twitter features from each tweet in the Twitter data stream as input and then jointly models the probability distribution of these features to detect events. Note that these features, apart from plain text, may not always be present in a tweet. STM-TwitterLDA employs an Support Vector Machine (SVM) classifier to remove noisy images, a latent filter to remove general images and words, and Convolutional Neural Networks (CNN) [40] to extract visual features from images to leverage in event detection. Finally, maximum-weighted bipartite graph-matching is applied in consecutive periods to track the evolution of the detected events.
Shepard [41] proposed a theoretical framework for retrospective event detection. The proposed system combines the unified model proposed by Diao and Jiang [42] with the Nonparametric Pachinko Allocation Method (NPAM) [43] in order to detect nested hierarchies of topics, called super-topics and sub-topics. Here, the super-topics correspond to long lasting super events and sub-topics are the smaller sub-events contained within the super-topics.
Madani et al. [44] applied a nonparametric Bayesian model, called Hierarchical Dirichlet Processes (HDP) [45], to detect trending topics from the Twitter data stream. For this method, a vector of topics is initially discovered by applying the generative model of HDP on tweets so that, for each tweet, a distribution of topics is calculated by exploiting the vector of topics. The topic with the highest probability in a distribution of topics is considered a trending topic. Tweets with similar trending topics are grouped into clusters. The authors used the Gibbs sampling algorithm to estimate the parameters used in their model. In addition, the system utilises a thesaurus of terms, created using the YAGO (Yet Another Great Ontology), 6 to incorporate semantic information which can aid in the clustering of trending topics.
5. Incremental-clustering-based approaches
As traditional clustering algorithms usually require that the total number of clusters be fixed, it is difficult to predict the total number of expected event clusters in advance for high-volume, real-time Twitter data where a wide variety of topics are discussed. The event detection methods discussed in this section follow, at their very core, a clustering strategy, which is incremental in nature in order to avoid having a fixed number of clusters. These methods are summarised in Table 3, focussing on the approaches taken to determine the term weights to generate a tweet vector, methods applied along with the incremental clustering to group event-related tweets, and the techniques employed to rank events that were detected by an event detection system.
Summary of incremental-clustering-based approaches
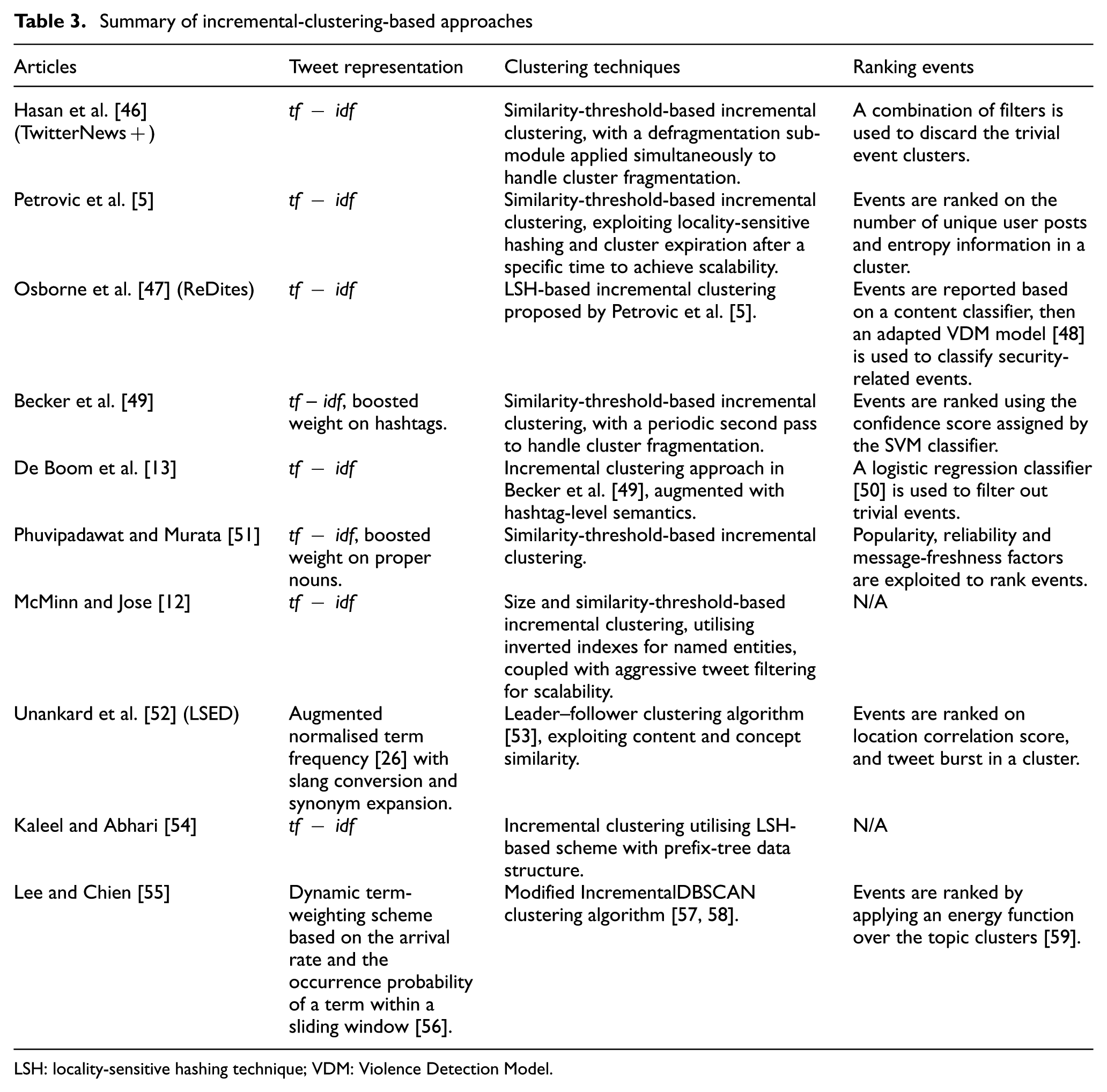
LSH: locality-sensitive hashing technique; VDM: Violence Detection Model.
TwitterNews+ [46] employs a two-stage operation for event detection, where the first stage involves detecting a burst in the number of tweets discussing an event, while the second stage involves clustering the tweets which discuss the same event. The first stage of operation in TwitterNews+ is handled by a Search Module. For each tweet, the Search Module facilitates the fast retrieval of similar tweets which are obtained from the set of most recent tweets maintained by TwitterNews+. The Search Module utilises an inverted index where each entry contains a term and a regularly updated, finite list of the most recent tweets containing the term. For each tweet in the system, the top-k
Petrovic et al. [5] have implemented a First Story Detection (FSD) system based on an adapted variant of the locality-sensitive hashing technique (LSH). The LSH-based approach provides a fast way to compare the similarity of the input tweet with previously encountered tweets to determine its novelty while complying with the constant time and space requirements of a streaming FSD system. A novel tweet represents a new story, which will be assigned to a newly created cluster. However, a tweet determined as ‘not novel’ will be assigned to an existing cluster containing the nearest neighbour. The proposed system uses the number of unique user posts and the entropy information in a cluster to rank event clusters. Besides relying on the aforementioned redundancies, the system lacks the capability to distinguish between significant and trivial events. In their later work [60], the authors have used Wikipedia as an external source to identify significant events. The approach taken to track unusual spikes in Wikipedia page views suffers from latency means that real-time event detection is delayed, as the Wikipedia stream has a substantial time lag compared with the Twitter stream.
ReDites [47] is built on the LSH-based FSD system [5], tailored for the security domain to detect events related to security (e.g. violent events, natural disasters and emergency situations). In order to improve the precision of the LSH-based event detection system [5], a content classifier was built on a passive-aggressive algorithm and trained on manually labelled events that were automatically discovered by the FSD system. Out of the entire set of detected events, security-related events are extracted, using a weakly supervised Bayesian modelling approach based on the Violence Detection Model (VDM) proposed by Cano et al. [48]. The VDM starts with a security-related word lexicon created from DBpedia 7 and subsequently discovers new words related to security events for better classification.
Becker et al. [49] have used an incremental clustering algorithm to detect events from the Twitter stream. For each tweet, its similarity is computed against each of the existing clusters. If the similarity of a tweet is not higher than a specific threshold in any of the existing clusters, a new cluster is created. Otherwise, the tweet is assigned to a cluster with the highest similarity. Once the clusters are formulated, a Support-Vector-Machine-based classifier is used to distinguish between real-world events and non-events. The classifier is trained on temporal, social, topical and Twitter-centric features. Events are ranked based on the confidence score assigned by the classifier.
De Boom et al. [13] augmented semantic information with individual tweets in the incremental clustering approach adopted by Becker et al. [49]. The authors used TwitterLDA [61] to assign a semantic topic to each tweet and reported that, instead of using semantic topics for individual tweets, assigning semantic labels based on a coarser hashtag-level provides a significant gain in precision and recall over the Becker et al. [49] baseline. However, the hashtag-level semantics will work only when the event-related tweets contain hashtags. A similar observation was pointed out by Mehrotra et al. [62], mentioning the problem with hashtag-based pooling when a lot of tweets do not contain any hashtags, although automatic hashtag labelling can improve this situation to some extent.
An incremental-clustering-based approach similar to Becker et al. [49] is taken by Phuvipadawat and Murata [51]. The authors used pre-defined search queries, such as #breakingnews, to fetch a more focussed set of tweets from Twitter for the event detection task and boosted the
McMinn and Jose [12] worked on the idea that named entities are the building blocks of events and implemented a system that identifies bursty named entities for the detection and tracking of events. A drawback of this approach is that it is dependent on the accuracy of the underlying Named Entity Recognizer [63] it uses. A Tweet is clustered based on the named entities it contains; thus, the same tweet might be placed in clusters for each of the named entities contained in the tweet. A unique inverted index for each entity is maintained, where an entity is associated with a cluster of tweets that are near neighbours. This is done to reduce the computational complexity to find the nearest neighbour of a tweet based on the entity it contains. By leveraging the inverted indices, a tweet is assigned to the cluster associated with an entity where its nearest neighbour belongs. If no such cluster exists, a new one is created where both the tweet and its nearest neighbour are assigned, and the tweet is added to the inverted index of the entity. A burst on a cluster associated with an entity in a given time window is detected based on the Three Sigma rule [64], which states that, with an empirical near-certainty of 99.7%, all values in a normal distribution lie within 3 standard deviations of the mean. If the number of tweets in a cluster within a given time window exceeds 3 standard deviations from the mean, the entity is considered bursty based on the Three Sigma rule.
Once a burst is detected on an entity, an event associated with the bursty entity is created. If the average timestamp of the tweets in the cluster occurs after the initial burst, the cluster of tweets is assigned to an event. An event is considered to be expired when all the entities associated with it are no longer bursty.
Location Sensitive Emerging Event Detection (LSED) [52] detects emerging hotspot events within a sliding time frame by identifying strong correlations between the user locations and event locations. LSED clusters similar tweets from a combination of content similarity and concept similarity, using an incremental clustering approach called leader–follower clustering [53]. Tweet clustering is triggered when the timestamp of the incoming tweet is greater than the current sliding temporal window. Terms are weighted based on the augmented normalised term frequency [21], and then WordNet [65] is used for the synonym expansion of nouns and verbs from the top 20% weighted terms in a tweet, in order to ensure efficient clustering.
Content similarity is calculated based on the cosine similarity measure. In order to reduce duplicate clusters, the top terms are extended with the hypernyms derived from WordNet, calculating the concept similarity based on the Jaccard similarity measure [66]. Once the clusters are formed by the LSED system, each candidate event cluster,
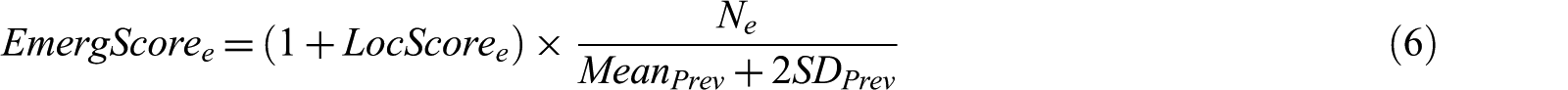
where
Kaleel and Abhari [54] used a locality-sensitive-hashing-based scheme with a prefix-tree data structure to discover the event-related clusters. Each cluster is labelled with the most frequent terms which represent the cluster centroid. A new cluster is created for a tweet that does not belong to any cluster. Lee and Chien [55] proposed an event detection system which incorporates a dynamic term-weighting scheme [56] to handle the concept drifts in a topic. It adapts the IncrementalDBSCAN algorithm [57, 58] which utilises neighbourhood relations among the tweets to detect events.
6. Miscellaneous approaches
This section discusses the event detection methods that adopt hybrid techniques, which do not directly fall under the three categories discussed above.
Chierichetti et al. [67] proposed a linear classifier to detect events, which relies on mathematically formalising the Twitter users’ communication behaviour, instead of using textual information. The proposed system follows the users’ activity around a key event by monitoring the shift in the amount of tweets/retweets produced and the level of communication between individual users.
Guille and Favre [14] proposed an event detection system called MABED (Mention-Anomaly-Based Event Detection), which detects events by exploiting the statistical values calculated from the textual contents of tweets and the frequency of user interactions through user-name mentions. Each event produced by MABED is characterised from the duration of the event, a main event word and its related weighted words, and the magnitude of impact of the event on Twitter users.
Huang et al. [68] proposed a pattern-mining-based approach to detect events by clustering event-representative High Utility Patterns (HUPs) from microblog texts. An HUP is determined based on the importance of the terms contained in a pattern. Patterns are generated using the FP-Growth algorithm [69], which provides an efficient and scalable method for mining the complete set of frequent patterns by exploiting an adapted prefix-tree structure. To reduce the computational and the memory cost incurred with a high number of generated patterns, a top-K HUP mining algorithm is proposed that performs HUP selection and pattern generation simultaneously. HUP mining is performed from a set of microblog texts within a fixed time window by maximising the detected pattern utilities where the overlap-degree between each pair of patterns is always below a certain threshold.
Once the HUPs are detected, an incremental pattern clustering is applied to group-related patterns in clusters. As the HUPs contain little text, additional texts associated with HUPs are used while measuring pattern similarity. The clustering process is a combination of kNN classification and modularity-based clustering [70], which allows simultaneous identification of emergent and coherent topics.
Adedoyin-Olowe et al. [71] focussed on detecting events from the sport and political domains by extracting newsworthy hashtag keywords. They used a Transaction-based Rule Change Mining framework built on the Apriori method for association rule mining [72]. Dang et al. [73] proposed a Dynamic-Bayesian-Network-based model [74], which utilises the networks formed by the retweet chains on a topic and the follower–followee relations among the users, in order to infer the emergent keywords from the Twitter data stream within a specific time interval. Finally, the emergent topics are detected by applying the DBSCAN algorithm [75] to cluster the emergent keywords based on their co-occurrence relations. Fang et al. [76] proposed a MultiView Topic Detection (MVTD) framework that fuses semantic, hashtag and temporal relations among tweets to perform Co-training-based Multiview Clustering (CMC) [77–79] for topic detection. The MVTD framework uses a suffix-tree-based vector space model as a document similarity measure.
Thapen et al. [80] proposed an event detection system to detect disease outbreaks by adapting the existing bio-surveillance early aberration reporting system (EARS) algorithm [81] to detect location-sensitive spikes in Twitter data. A linear SVM classifier was used to remove tweets that do not discuss disease outbreaks. Robinson et al. [82] applied statistical process control methods, such as dynamic bi-plots [83], Adaptive Exponentially Weighted Moving Averages (AEWMA) and Adaptive Cumulative Sums (ACUSUM) [84], on the tweets posted by the users of Twitter in Australia to identify unusual tweets that correspond to potential disease outbreaks.
Yin et al. [85] proposed an event detection framework for emergency situation awareness that utilises a probabilistic burst-detection module [86] to filter out the trivial tweets and perform incremental clustering on the tweets containing bursty features. A similar specialised event detection technique is proposed by Sakaki et al. [87], which predicts earthquakes and provides early warnings. In their work, each Twitter user is considered to be a sensor that propagates tweets as sensory information (i.e. text, time and location). A probabilistic approximation algorithm, called a particle filter [88], is used to estimate the centre and trajectory of the event location.
7. Evaluation methods
In this section, we discuss the widely employed evaluation methods from a selected number of articles (summarised in Table 4). This discussion focusses on the various performance metrics and the information regarding the tweet data sets used in different articles. As there is no standard evaluation method, the articles discussed in this section were selected to cover the measures most commonly employed (with small variations) by researchers, along with a few exceptional ones. Note that the different data sets collected by the researchers are usually from a small sample (around 1%) of the public data made available by the Twitter Streaming API, which can be filtered by location, keywords, language and so on.
Summary of the evaluation approaches
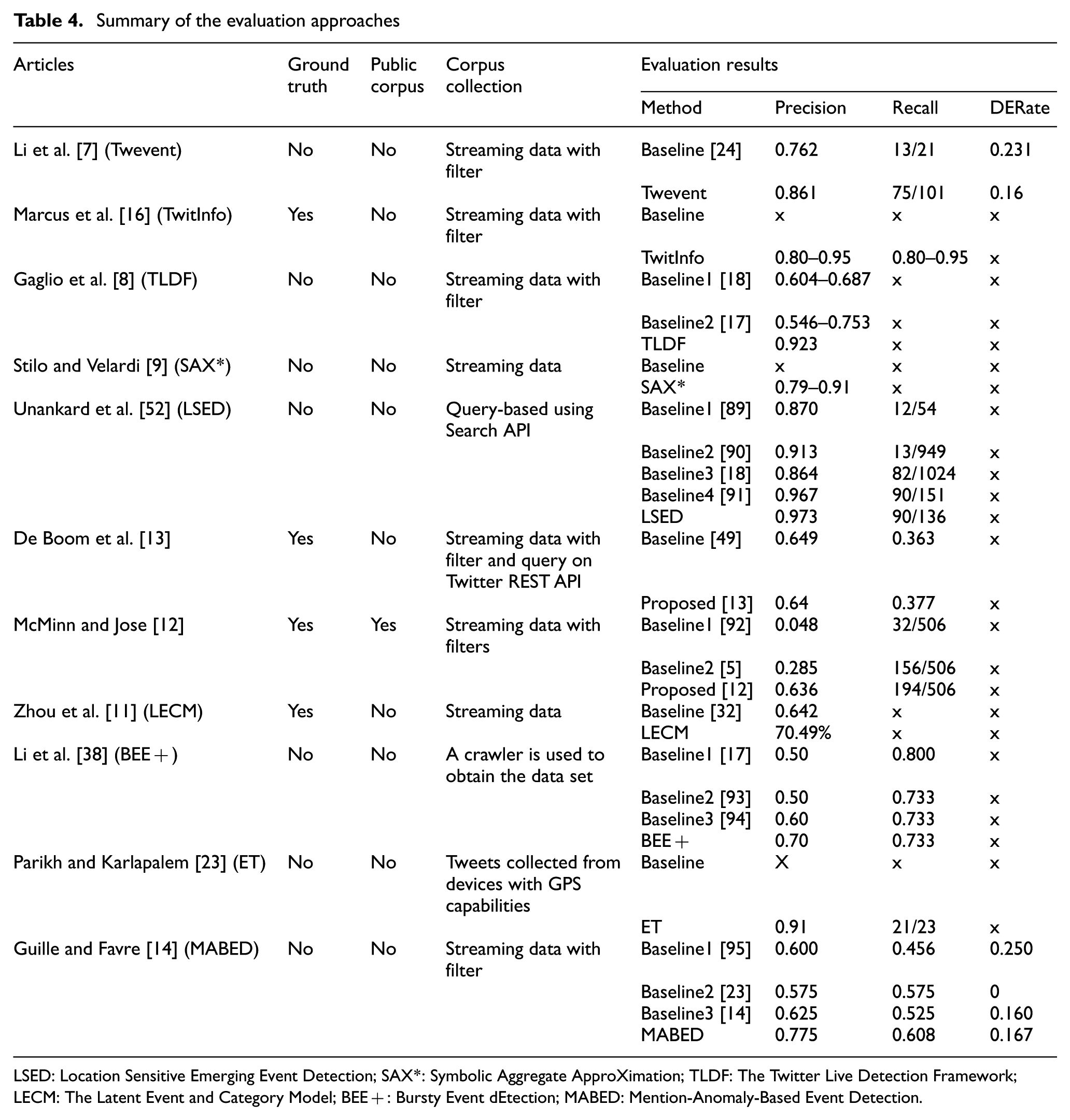
LSED: Location Sensitive Emerging Event Detection; SAX*: Symbolic Aggregate ApproXimation; TLDF: The Twitter Live Detection Framework; LECM: The Latent Event and Category Model; BEE+: Bursty Event dEtection; MABED: Mention-Anomaly-Based Event Detection.
Twevent [7] is evaluated using a collection of 4.3 million tweets published by Singapore-based users, collected over a period of 1 month. To evaluate Twevent, Li et al. [7] defined ‘precision’ as the fraction of detected events that are related to realistic events, ‘recall’ as the number of distinct realistic events detected from the data set on a daily basis and the ‘Duplicate Event Rate’ (DERate) as the percentage of events among all the detected realistic events which are duplicates. The system proposed by Weng and Lee (EDCoW) [24] is used as the baseline for Twevent. Marcus et al. [16] used tweets related to three soccer games and 1 month of earthquakes to evaluate their system. A human annotator was used to produce the ground truth for evaluation, using game videos from online, web-based game summaries and US Geological Survey on major earthquakes, in order to identify major soccer events and earthquakes within a specific time period.
TLDF [8] was evaluated on the data collected from Twitter, during the 64 matches of FIFA World Cup 2014. The precision is defined as the number of distinct events the system is able to detect compared with the actual number of distinct events observed during a session. The evaluation is also performed to determine redundancy, which is defined as the complimentary of the number of distinct events the system is able to detect, compared with the total number of detected events. TwitterMonitor [17] and enBlogue [18] were used as the baselines. Stilo and Velardi [9] propose an evaluation based on forming a web query using the detected event clusters and their associated dates. A candidate event cluster is considered as an actual event if a direct match is found using the web query formulated from the candidate event cluster. The evaluation was performed on 1% of a 1-year Twitter stream, with system parameters tuned to reduce the total number of events to be manually labelled for evaluation.
Unankard et al. [52] evaluated their system based on 1 week of around 200,000 tweets. No ground truth was used for the evaluation. The recall and precision were reported by manually inspecting the events detected by the system. Location-based emerging event detection (LEED) [91], enBlogue [18] and the systems proposed by Sayyadi et al. [89] and Ozdikis et al. [90] were used as the baselines. De Boom et al. [13] gathered 2 weeks’ worth of tweets collected from Flanders, Belgium-based users. A pool of hashtags gathered from the data set was used to query Twitter REST API to collect additional tweets. Finally, all the tweets in the data set were clustered to generate the ground truth; only the events containing hashtags were considered for the evaluation. The system proposed by Becker et al. [49] was used as the baseline.
McMinn and Jose [12] used the Events2012 corpus for evaluation. The corpus contains 120 million tweets and relevance judgments for 506 events. Crowdsourcing was utilised to evaluate the performance of their system, and the LSH approach of Petrovic et al. [5] and Cluster Summarisation approach of Aggarwal and Subbian [92] were used as the baselines. Zhou et al. [11] evaluated their work on a data set of 64 million tweets collected in December, 2010, with TwiCal [32] as the baseline. Only the precision of the system was reported; however, the authors used a small manually labelled data set to evaluate the system recall and reported a recall of 25.73%. BEE+ [38] was evaluated on a Weibo (Chinese Microblog) data set, with PLSA [93], TwitterMonitor [17] and BEE [94] as baselines. The authors reported the best result achieved by their system with the maximum number of topics (clusters) set to 10. Parikh and Karlapalem [23] used a small data set of 33579 tweets. No ground truth was used for the evaluation. The recall and precision were reported based on a manual inspection of the events detected by the system.
Guille and Favre [14] evaluated their system on an English language text corpus containing around 1.4 million tweets, published in November, 2009. TS [95], ET [23], and
8. Pre-processing
The common pre-processing techniques applied on the Twitter data stream are as follows: POS tagging, NER, resolving temporal expressions, slang-word conversion, tweet filtering based on specific criteria (i.e. discarding retweets and/or non-English language tweets), and removing stop words, URL and user-name mentions from tweets.
The named entity tagger called T-NER [33] was developed to deal with the noisy data present in a tweet. The authors have reported that T-NER outperforms the Stanford tagger by a 52% increase in the F1 score. T-NER was used for named entity tagging in TwiCal [32] and also by the GEAM event detection system [36]. McMinn and Jose [12] used the GATE Twitter POS model [63] for POS tagging and the NER task. Zhou et al. [11] used a Twitter-trained POS tagger by Gimpel et al. [96] to perform POS tagging, and named entity tagging was performed using T-NER [33].
A temporal expression extracted from a tweet in TwiCal [32] is resolved into an unambiguous calendar reference by using a tool called TempEx [34]. LECM [11] used SUTime [97] to resolve temporal expressions. You et al. [36] used the natural language date parser – Natty 8 – to extract time information.
Unankard et al. [52] performed slang conversion based on the Internet slang dictionary. 9 Each term is searched in the dictionary to convert the matching slang into a proper English word. Madani et al. [44] used the Porter algorithm [98] to transform variants of words into a single stem by removing suffixes or prefixes. Different word forms are mapped to their base forms using WordNet [99] for lemmatisation.
McMinn and Jose [12] use different filtering approaches as part of their pre-processing. They discard retweets and all the tweets which do not contain any named entities. Term-level filters are also employed to remove the tweets which contain terms that are usually associated with spam and noise (e.g. ‘follow’ and ‘watch’). Collectively, these filters remove more than 90% of tweets, significantly reducing the amount of data to be processed by the system. You et al. [36] discard tweets that do not contain any named entities or hashtags. Zhou et al. [11] have experimented with two different tweet filtering techniques. The first one involved creating a word lexicon based on the terms extracted from the newspaper articles that were published around the same time as the collected body. The second approach was to build an SVM-based classifier using a multitude of word features and event-related features. They have reported that the word-lexicon-based approach gives a higher precision result than the SVM-based approach.
9. Event summarisation
Once an event is detected from the Twitter data stream, it needs to be presented to the user in a meaningful and informative way, as the tweets themselves do not necessarily provide a good summary of an event.
Sharifi et al. [100] developed an algorithm that can automatically generate one-line summaries from tweets related to a given topic. Provided with a topic, the proposed Phrase Reinforcement (PR) algorithm retrieves tweets related to the topic. From each tweet, the longest sentence containing the topic is extracted. These sentences act as an input to the PR algorithm, allowing construction of a graph which represents the common sequences of words encompassing the topic. The topic is the root node or the central node, and each input sentence is a sequence of nodes containing a single word. The weight of a node is calculated based on the frequency of the word contained in the node and the distance of the node from the root node. Once the graph is generated, the PR algorithm finds the path with the highest total weight from the root node to a leaf node in order to generate the summary.
Madani et al. [44] used TextRank [101], a graph-based, unsupervised ranking model for natural language processing which derives extractive summaries from the given texts. From the tweets associated with a topic cluster, a dependency graph is created where the nodes are the tweets in the cluster and the edges between the nodes correspond to the similarity between tweets. The similarity between two tweets
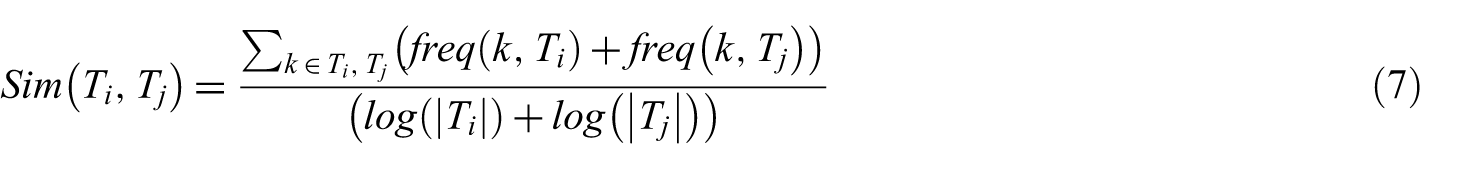
TextRank is applied on the tweet dependency graph created from a cluster and the score of a given tweet
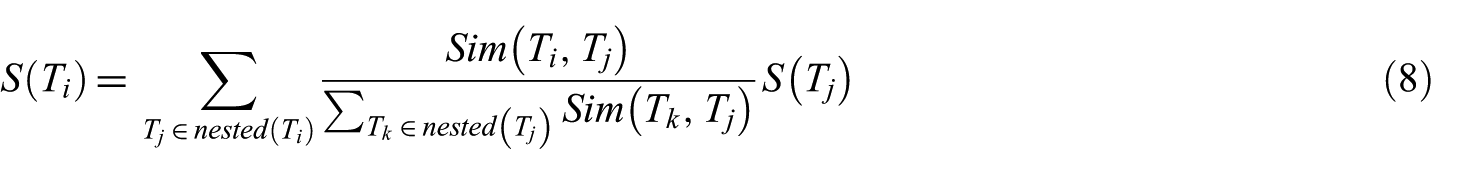
where
The ReDites system [47] contains a Tracking and Summarization (TaS) component. When an event is created, the real-time tracking sub-component retrieves new tweets about the event based on the most informative terms contained in the event-related tweet. The summarisation sub-component removes tweets that are textually similar to generate an extractive summary of tweets based on their temporal order.
10. Discussion
Not all approaches discussed in this survey may be applicable in the real world. This is mostly due to an issue of scalability, as some event detection methods are not equipped to handle the high volume of streaming data. Moreover, the use of a clustering approach which requires the total number of clusters to be fixed is often not useful for a streaming data environment, where a wide variety of topics are discussed, making it difficult to predict the total number of expected event clusters in advance.
Term-interestingness-based approaches usually differ in the term selection methods they employ, as well as in the way term correlations are computed and changes in term correlations are tracked. The approaches based on term interestingness can often capture misleading term correlations, while measuring term correlations can be computationally prohibitive in an online setting.
Topic-modelling-based approaches work under the assumption that some latent topics always exist in the tweets that are processed. Tweets are modelled as a mixture of topics, and each topic has a probability distribution over the terms contained in those tweets. LDA [102] has been the most used probabilistic topic model, where the topic distribution is assumed to have a Dirichlet prior. Due to the limit imposed on the length of a tweet, capturing good topics from the limited context is a problem that needs to be addressed. Moreover, the topic-modelling-based approaches usually incur too high a computational cost to be effective in a streaming setting and are not quite effective in handling the events that are reported in parallel [103]. Stilo and Velardi [9] noted that LDA-based methods usually only work in an offline manner, as the temporal aspect of the events are not often considered.
Incremental-clustering-based approaches are prone to fragmentation and are usually unable to distinguish between two similar events taking place around the same time. The fragmentation refers to phenomena where the same event is detected multiple times as a new event. Becker et al. [49] and McMinn and Jose [12] incorporated a separate component to address the fragmentation issue. Incremental-clustering-based approaches usually employ a similarity threshold value to perform clustering. Caution needs to be taken while empirically setting the threshold for determining the similarity of a tweet with a cluster, to ensure that the threshold value works well with the dynamic nature of fast changing topics in the Twitter stream.
Lehmann et al. [104] and Yang and Leskovec [105] have shown the existence of a number of different temporal patterns of events besides the event-pattern with bursty characteristics; therefore, event detection approaches which are solely dependent on identifying the bursty characteristic can fail to detect other event-patterns such as events with a relatively slow but lengthy burst of related tweets [9].
Some papers incorporate specific measures into rank events to directly address the task of identifying real-world events from a set of candidate events which were generated by their system. The supervised approaches adopted in De Boom et al., [13] Osborne et al. [47] and Becker et al. [49] might not be able to account for situations where there is a concept drift in the Twitter data stream. In addition, training a classifier in an offline manner, by labelling the Twitter data manually, can be very time-consuming. There are also unsupervised approaches [5, 24, 25, 21, 51, 52] adopted by the researchers with varying degrees of success, which rank events for the purpose of filtering trivial events out of the system-generated candidate event set.
Event ranking depends a good deal on the system’s ability to filter out spam tweets. Determining the credibility of tweets can also help in the event ranking process. Castillo et al. [106] adopted a supervised learning approach to determine the credibility of a given set of tweets, with a maximum precision and recall of nearly 80%. The features used in their supervised learning technique were based on the information found in the microblogging social media platform. The most important features to determine tweet credibility were, generally, message-based, topic-based, user-based and propagation-based features. First, TwitterMonitor [17], along with a J48 decision tree algorithm implemented in the Weka data mining tool, is used to automatically identify news events from a Twitter data set. Once the news events are identified, supervised classification is used to assess the credibility of the news. Gupta and Kumaraguru [107] have also used a supervised learning and pseudo-relevance-feedback-based approach to determine the credibility score of tweets. Regression analysis was used to discover the best features for credibility assessment. Tweet credibility detection can be used as part of the pre-processing stage, or even at the post-processing stage, to detect the credibility of the related tweets of a detected event.
Although most of the proposed approaches are evaluated using tweet data sets collected from varying locations and durations, the unavailability of a publicly available text corpus, along with the ground truth for a system performance evaluation, is a major setback for the event detection techniques discussed in our survey. To the best of our knowledge, at the time of writing this survey, the only publicly available corpus of data with the ground truth for evaluation purposes is the one provided by McMinn et al. [108]. The use of this can help us conduct a fair performance comparison among the different event detection approaches proposed by the researchers.
The survey conducted by Atefeh and Khreich [6] discussed the event detection techniques as either unsupervised or supervised event detection approaches. The Atefeh and Khreich [6] pointed out the benefit for unsupervised approaches of not requiring any labelled data, over supervised approaches which require a manually labelled data set to train a classifier. However, they suggested that the unsupervised clustering approaches can be further optimised to avoid cluster fragmentation and improve clustering efficiency by incorporating additional indicators such as location proximity for clustering, besides the temporal aspect of the tweets. Using geotags as a measure of location proximity can determine whether the tweets under consideration belong to the same event. The problem of sparsely labelled data used in supervised clustering can be handled by semi-supervised learning [109], where a small set of labelled data can be coupled with a large unlabelled data set to build a classifier, or by transfer learning [110], where useful information can be extracted from different, but related, domains. Atefeh and Khreich also stressed the need for representative data sets and a common test bed for the performance evaluation of event detection systems. In addition, combining different social-media-based information sources such as Facebook, Flickr and YouTube, along with Twitter, was suggested to provide a more robust solution for event detection.
11. Conclusion
We have conducted a survey on the noteworthy and recent event detection techniques that focus on detecting real-world events of global and/or local interest from the Twitter data stream, broadly categorising different approaches based on term interestingness, topic modelling, incremental clustering and hybrid methods. We have discussed the specific detection methodologies employed by researchers and the measures taken to distinguish between real-world events and trivial events of no consequence. This article has also briefly discussed the evaluation methods adopted by different researchers and the common Twitter data pre-processing techniques involved in the proposed systems. In addition, we have discussed a few techniques that focus on summarising the tweets of an event. We note that efficient temporal summarisation of event-related tweets is a less explored research area and an important avenue for future work.
Further work is required to propose effective measures to filter out spam and trivial events. In addition, it is imperative that proposed event detection systems are evaluated on a publicly available text corpus of data, with a rich collection of a variety of events, to facilitate a fair comparison of different systems. This article provides a structured representation of the various aspects of Twitter-centric event detection techniques, which can be a helpful starting point for researchers endeavouring to work in this field.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
M.H. has been supported by a Macquarie University Research Excellence Scholarship (MQRES).