
Abstract
The advancements in the multimedia technologies result in the growth of the image databases. To retrieve images from such image databases using visual attributes of the images is a challenging task due to the close visual appearance among the visual attributes of these images, which also introduces the issue of the semantic gap. In this article, we recommend a novel method established on the bag-of-words (BoW) model, which perform visual words integration of the local intensity order pattern (LIOP) feature and local binary pattern variance (LBPV) feature to reduce the issue of the semantic gap and enhance the performance of the content-based image retrieval (CBIR). The recommended method uses LIOP and LBPV features to build two smaller size visual vocabularies (one from each feature), which are integrated together to build a larger size of the visual vocabulary, which also contains complementary features of both descriptors. Because for efficient CBIR, the smaller size of the visual vocabulary improves the recall, while the bigger size of the visual vocabulary improves the precision or accuracy of the CBIR. The comparative analysis of the recommended method is performed on three image databases, namely, WANG-1K, WANG-1.5K and Holidays. The experimental analysis of the recommended method on these image databases proves its robust performance as compared with the recent CBIR methods.
1. Introduction
From past one decade, the storage capacity of the image databases is increasing due to the accessibility of different low-price image acquisition devices, for example, digital cameras and mobile phones. Therefore, saving, searching and organising digital databases have become significant and essential for efficient content-based image retrieval (CBIR). Several penetrating and retrieval utilities are essential for end users from different domains, such as medical, education, weather forecasting, criminal investigation, advertising, social media, web, art design and entertainment, to retrieve the images efficiently from these types of the image databases. Different methods for image retrieval have been developed for this purpose [1]. They are distributed into two contexts: text-based image retrieval (TBIR) and CBIR. TBIR was introduced in 1970 for searching and retrieving images from image databases. According to this method, the images are by hand described using text or annotated descriptors [2]. These manually annotated descriptors are then used by database management system (DBMS) to perform image retrieval. There are some drawbacks of TBIR-based methods: first, it is based on manual annotation of the images, which is time-wasting and second is that the accuracy of manual annotation–based method is affected due to the different levels of perception of individuals as well as these methods are also language dependent [3,4]. CBIR was familiarised in early 1990 to overwhelm the complications of the TBIR methods [5]. In CBIR, the visual attributes of the images are normally described using shape, colour and texture-based local features [6]. These features are utilised along with machine learning methods to retrieve images from image databases [7]. In past era, different systems for efficient CBIR are introduced like Netra [8], Virage [9] and Photobook [10]. Researchers are currently concentrating on challenging problems in CBIR in different domains such as machine learning and computer vision. The review on the most challenging issues in CBIR is presented in the work by Smeulders et al. [7]. According to Smeulders et al. [7], some of the challenges in CBIR are the searching of objects from a large number of classes. There is the absence of explicit phase of training to select features and to tune the classification. The semantic gap between visual contents and human semantics and the exponential growth in multimedia archives, the variation in illumination and spatial layout are some of the main reasons for making CBIR a challenging research problem [11,12].
The focus of computer vision–based methods is to discover, characterise, understand and improve features to detect and extract local characteristics in images for efficient image classification. Many features have been designed either automated like deep learning (DL) or handcrafted like support vector machine (SVM) to resolve different issues, such as occlusions and variations due to scale and illumination. In order to make concise decisions, the DL needs extensive unlabeled learning data. The DL implies a hierarchical artificial neural network (ANN)-based approach to automatically learn the most significant characteristics from the data. It requires high-performance hardware like graphics processing unit (GPU) and tensor processing unit (TPU) and a lot of time for training. In DL, problems are solved on end-to-end basis building functionality by itself as long as available at the current time, whereas handcrafted approaches utilise small amounts of data presented by users and need features to be appropriately determined by the users. They split tasks into small pieces and then merge received results into one conclusion providing adequate transparency for its decisions [13]. The images are shown in Figure 1, which may decrease the performance of the image retrieval due to the close visual appearance among the visual attributes of the images.

Semantic gap-WANG database images of two different classes (mountains and beach) with adjacent visual attributes [14].
According to the visual attributes of the images, the CBIR methods are grouped into two groups known as global attributes and local attributes. Global attributes are used to retrieve those images, which are visually similar [5]. The global attributes capture the overall features of the image. These attributes represent the abstract-level of semantic similarity between the images [5,15], but these attributes are not able to classify significant visual characteristics of the images because they are oversensitive to the location of the salient objects. On the other hand, local attributes represent the details of the image. They designate some parts or keypoints of the images such as edges or corners acquired via gradient or segmentation process. During local attributes extraction, attributes of each pixel of the image are computed by considering the attributes of its neighbourhood. The image may be divided into small non-overlapping blocks and attributes are computed for each block that reduces computation [16]. In contrast with early years, the research attention is shifted from the representation of the visual attributes of the images using global attributes to the local attributes. As local attributes–based descriptors are invariant to scale and rotation as well as uses robust way of matching in various situations, they have many advantages as compared with global attributes [12]. The recent CBIR literature shows that local attributes improve the image retrieval performance as compared with the global attributes [15,17,18]. Local attributes–based features like maximally stable extremal regions (MSER) [19], speeded-up robust features (SURF) [20], histogram of oriented gradients (HOG) [21] and binary robust invariant scalable keypoints (BRISK) [22] have been used to achieve the vigorous performance of the CBIR. Numerous studies are conducted on local attributes that are utilised in different applications [15,17,23].
In CBIR, image retrieval established on the single feature has not been yet effective for reporting perfect retrieval results. So, the different attributes of the images are integrated to increase the efficiency of the image retrieval [24,25]. This article presents a novel method to extract local attributes of the images using local intensity order pattern (LIOP) and local binary pattern variance (LBPV) descriptors to achieve complementary features which also advances CBIR performance. Local attributes represent the image in form of local patches, so they are more robust and perform better for object recognition even in substantial clutter and occlusion. The performance of the proposed method is also equated with the feature integration of LIOP-LBPV descriptors and single feature–based LIOP and LBPV descriptor methods based on the BoW method. The proposed method which employs visual words integration performs better than its competitor CBIR methods as well as recent CBIR methods due to the robust demonstration of the visual attributes of the images.
The subsequent sections of this article are as follows. Section 2 describes the literature review of CBIR methods. Section 3 describes the proposed method. Section 4 describes the performance evaluation parameters, experimental results and analysis on three standard image databases (i.e. WANG-1K, WANG-1.5K and Holidays) and running cost of the proposed method. Section 5 describes conclusion analysis of the proposed method and future directions.
2. Literature review
The first CBIR system was introduced by the IBM, which is known as QBIC. Later on, several feature abstraction methods were introduced, which were established on spatial layout, shape, texture and colour attributes for image retrieval. The one of the challenging issue to enhance CBIR performance is the problem of the semantic gap, which occurs during machine learning process and local features extraction of the image [5]. This gap is reduced by introducing complementary feature integration-based methods as well as using spatial information of an image [26–28].
Yuan et al. [24] present a local descriptor that integrates SIFT and LBP to obtain a high-dimensional feature vector for every image. Two fusion models, that is, patch-level and image-level, are employed for feature fusion. For the compact representation of high-dimensional feature vector, a clustering technique based on the k-means is smeared to construct a dictionary. The appropriate images are retrieved according to the semantic category of the inquiry image and ranked based on the similarity measure. Yu et al. [25] propose a framework of feature integration using HOG and SIFT with LBP. The clustering method based on the k-means is applied for clustering the data. The new features were not dependent on image segmentation process and automatically detected interest points in an image. Experimental results show that the image retrieval results are improved using feature integration of SIFT and LBP. The properties of the mage can be effectively described using Gabor filter and three-dimensional (3D) colour histogram, but the integration of multiple features may result in the curse of dimensionality, which in turn increase the calculation cost and time in the process of the image retrieval. Therefore, ElAlami [29] address this problem by proposing feature selection technique to extract only relevant features. This technique uses Gabor filter and 3D colour histogram for extracting texture and colour features, respectively. The optimal segmentation of features is obtained by applying a genetic algorithm (GA). The most relevant features are extracted by feature selection algorithm using preliminary and deeply reduction. The main contribution of this method is to make image retrieval precise in a short time. As LBP lacks spatial information of texture features, Xia et al. [30] presented an improved version of LBP and a novel texture feature descriptor called multi-scale local spatial binary patterns (MLSBPs) for CBIR. The feature vector is constructed by computing LBP at different scales and in different directions for image retrieval. The experimental results show that MLSBP performs better than traditional CBIR techniques. Walia and Pal [31] propose a hybrid method for image retrieval. In this method, all the local attributes of the image are combined. The shape, texture and colour attributes of the image are extracted by applying the angular radial transform (ART) and colour difference histogram (CDH) methods. The propose system is made effective by suggesting a modification of hybrid features in the original CDH method.
Tian et al. [32] propose a feature demonstration descriptor, which is established on edge orientation difference histogram (EODH) descriptor. This descriptor is rotation-invariant and scale-invariant. Steerable filter and vector sum are used to acquire the main orientation of individual edge pixel. EODH and colour-SIFT descriptors are then integrated to obtain a weighted word distribution. Alkhawlani et al. [33] propose a CBIR technique based on a BoW layout, which integrates local features (SIFT and SURF). For compact feature representation, clustering technique based on the k-means is smeared to construct a codebook, and the SVM is employed for the classification of semantic categories. Kaur and Verma [34] propose an image retrieval technique rely on enhanced SURF descriptor, which also uses the SVM classifier and neural networks. The SURF descriptor is applied for image features extraction and for classification, SVM is employed along with the neural networks to achieve better retrieval results. Dubey et al. [35] propose a hybrid image descriptor that is rotation and scale-invariant to make image retrieval efficient. The quantisation based on the RGB colour space is used to extract the colour features, whereas the patterns generated from locally structuring element are assembled to extract the texture features. The colour and texture features are integrated together to build the hybrid feature descriptor known as rotation and scale-invariant hybrid descriptor (RSHD). The RSHD descriptor is robust in case of rotation and scaling. Feng et al. [36] propose an innovative image descriptor to extract the colour and texture features of the image. This descriptor is known as global correlation descriptor (GCD). The colour feature is characterised using global correlation vector (GCV), whereas the texture feature is characterised using directional global correlation vector (DGCV). Experimental results show that the performance of the GCD outperforms as compared with the recent CBIR techniques. Karakasis et al. [26] propose a framework that uses affine image moment invariants as a feature descriptor for image retrieval. The moments are fed into the BoW model to produce feature vectors. The novelty of this work is that the affine moment invariants are used as local features and are extracted using SURF feature descriptor. Zeng et al. [37] propose an image representation technique in which Gaussian mixture models (GMMs) are employed to characterise an image as a spectrogram (i.e. general histogram of colours). The expectation-maximisation (EM) technique is employed to determine quantised colour space from the training data set. Gaussian components, that is, the number of colour bins, are characterised according to the Bayesian information criterion (BIC). Spatiogram is modified and incorporated into a quantised Gaussian mixture colour model. Finally, a comparative analysis of two spectrograms is done and a new measurement adopting technique is suggested known as Jensen–Shannon divergence (JSD) to make image retrieval more efficient.
Zhao et al. [38] propose a descriptor based on the local and multi-trend structure for feature representation called multi-trend structure descriptor (MTSD). This descriptor integrates features like colour, edge orientation, shape and intensity information for robust image representation. It also represents the local spatial structure information to extract image features. The experimental results demonstrated that MTSD produced discriminative results for effective CBIR. Douik et al. [39] present a hybrid method by integrating local and global features The local features are extracted by applying SIFT descriptor, while the global features are extracted by applying upper-lower of LBP (UL-LBP) descriptor based on LBP. Then, features are quantised into the BoW model to improve image retrieval performance. Although LBP is not suitable for colour images, it is not suitable for capturing similarity between colour images. LBP only captures textual information from the images. Liu et al. [40] overcame this problem by proposing a descriptor with an additional colour feature called colour information feature (CIF) incorporated with LBP for image retrieval. Experimental results show that combining these two features yields good performance in a retrieval system. Srivastava and Khare [41] propose a CBIR method that combines LBP and wavelet transform. In this method, the texture features of the image are extracted by computing LBP codes using the coefficients of discrete wavelet transform (DWT). Then, shape features are extracted from texture features by computing Legendre moments using these LBP codes to construct a feature vector. The experimental results show improved performance on small image databases as compared with the large image databases. Bala and Kaur [42] propose a novel descriptor for CBIR called local texton XOR patterns (LTxXORP). Then, the LTxXORP feature vector is integrated with the feature vector of the HSV colour space–based colour histogram to improve CBIR performance. A novel method using a low-level feature called composite moment (CoMo) for image retrieval is proposed by Vassou et al. [43]. This method combines moment invariants and colour unit of the colour and edge directivity descriptor (CEDD). This method improves CBIR performance by overcoming rotation, translation and scaling issues.
3. Proposed methodology
3.1. Methodology of the traditional BoW model for image retrieval
The BoW model is adapted from the bag-of-features (BoF) model, which is used for document retrieval. In a traditional BoW model, features of the image are extracted using feature descriptors [44]. The single visual vocabulary (which is a formation of the salient objects or visual attributes) is constructed by applying a quantisation algorithm like k-means on the extracted features, which transform high-dimensional feature space into low-dimensional feature space. These visual attributes of each image are used to build an order-less histogram. Due to the formation of the order less histogram from each image, the spatial relationship between salient objects of the image is lost, which affects the performance of the CBIR [45,46]. The learning of the classifier is performed using these orderless histograms of the training images. The images are retrieved by selecting a sample image from the test group and evaluating closeness between sample image and images stored in an image database by applying similarity measure method.
The complete layout of the proposed method which employs visual words integration of the LIOP and LBPV descriptors is shown in Figure 2. The detailed methodology of the proposed method is described in the subsequent sections. The proposed method improves the performance of the image retrieval as compared with recent CBIR methods. The first step of the proposed method is the splitting of the each reported image database into training and test groups and then extracting the LIOP and LBPV features (i.e. complementary features) from each image, whose details are mentioned in the following sub-sections.
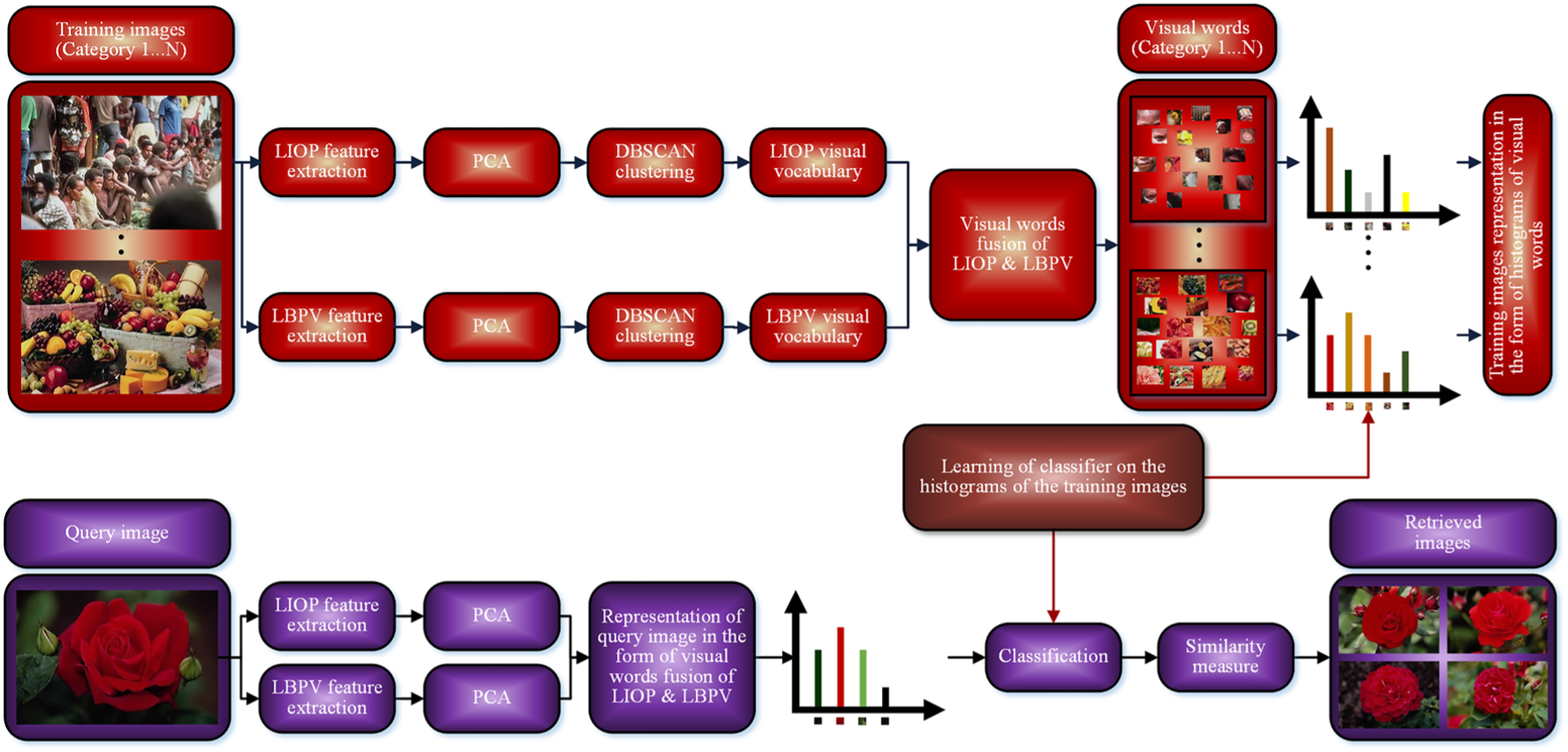
The complete layout of the proposed method that employs visual words integration of the LIOP and LBPV descriptors.
3.2. Extraction of the LIOP features
The LIOP descriptor [47] is selected for the feature extraction of the proposed method so that the relative order of pixel intensities remain unchanged even when monotonic intensities change within an image, which affects the performance of the CBIR. It considers the intensities of all sample points to describe the relationships between local intensity of an image. The overall intensity order is used to divide the local patch into sub-regions. These sub-regions are called ordinal bins. Then, a LIOP of each point is derived representing a binary vector based on the relationship between intensities of its adjacent sample points. The binary LIOPs of points are accumulated in each ordinal bin and concatenated together to form an LIOP descriptor. This descriptor is highly discriminative because it encodes both local and global intensity order information of each local patch. The mathematical foundation for the computation of an LIOP descriptor on an image pixel denoted by x is defined as follows
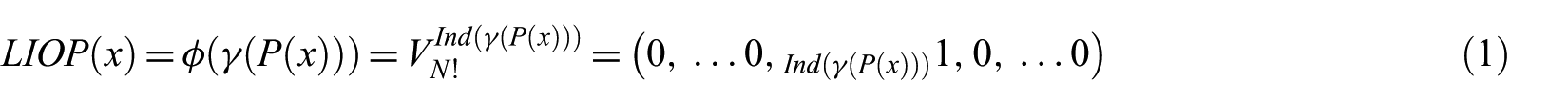
where

All the elements in this vector are 1 except for the


where
3.3. Extraction of the LBPV features
The drawback of local invariant features, for example, LBP is that they do not preserve global spatial information, while the global features represent the local texture information. The LBPV is proposed to solve this issue as it characterises the local contrast information [48]. Usually, the variance is high in the regions with higher frequency texture and their contribution is significant for discrimination of texture images. The LBPV feature vector is generated by embedding variance of the local region of the image. Hence, the variance is added as a weight to obtain the LBPV feature vector. Although the feature dimensions of LBPV is same as LBP, the additional contrast methods are added into the LBPV feature vector. The mathematical representation of the LBPV descriptor is as follows
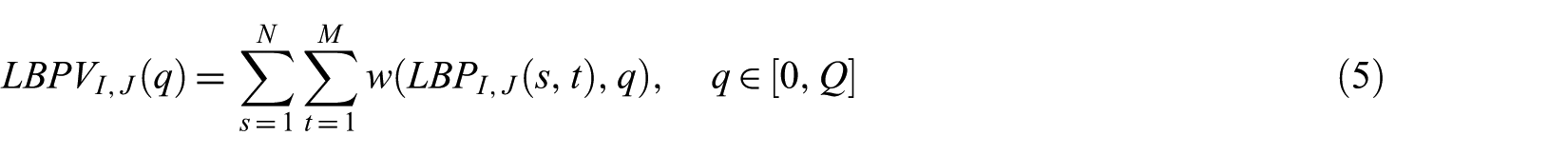
and
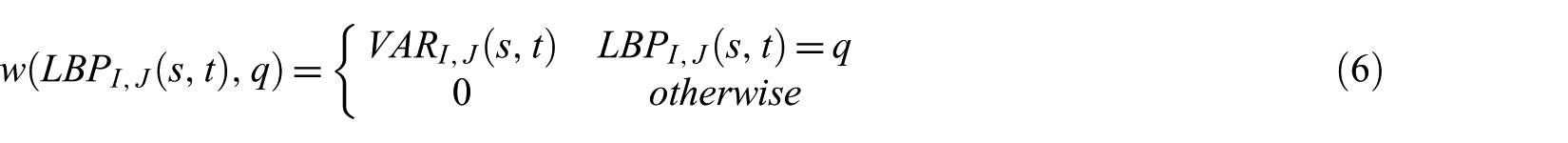
and

where

and

where
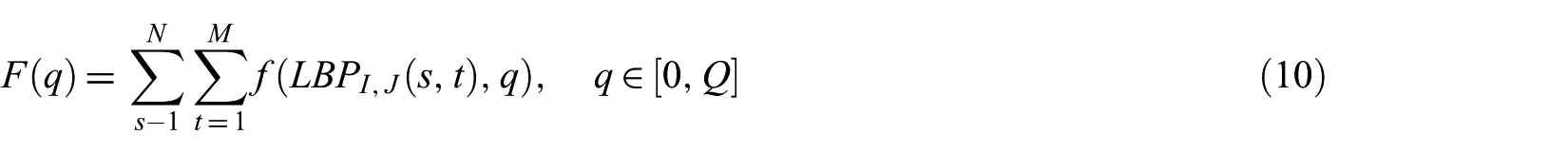
and

where Q represents the highest value of the LBP pattern.
3.4. Reduction in feature dimensions
To resolve an issue of the high-dimensional feature space for less memory configured systems, which occurs due to visual words integration and features integration of the LIOP-LBPV descriptors, the principal component analysis (PCA) method [49] is applied on the extracted features of each descriptor for dimensions’ reduction as well as for selecting best feature representations for the proposed method. After applying PCA method on the extracted features of each reported descriptor, feature dimensions are further reduced by applying equation given below to select different feature percentages per image (i.e. 10%, 25%, 50%, 75% and 100%), whose details are given in Table 1. The feature percentages per image after applying PCA method are selected by applying following mathematical equation

where
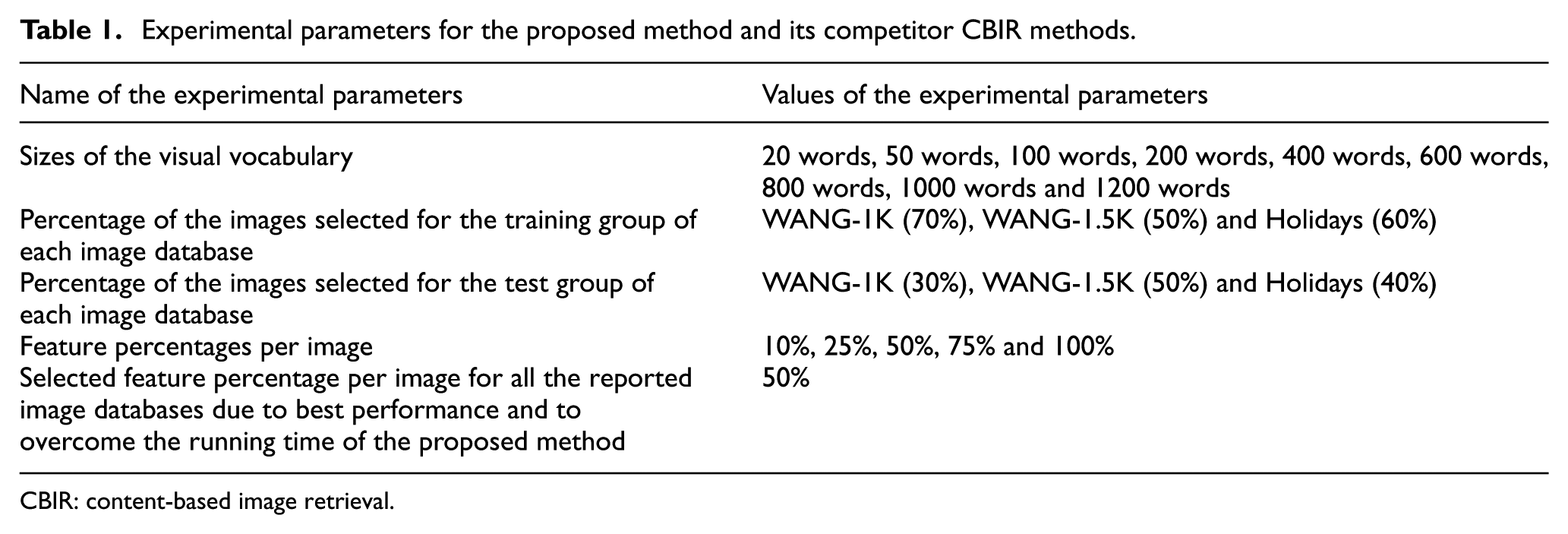
Experimental parameters for the proposed method and its competitor CBIR methods.
CBIR: content-based image retrieval.
3.5. Complementary attributes and formation of visual vocabularies
In this step, after applying dimension reduction method on the extracted features of the LIOP and LBPV descriptors, the feature space of each descriptor is further concentrated by applying clustering method called density-based spatial clustering of applications with noise (DBSCAN) [50] to build a visual vocabulary for each descriptor. The DBSCAN clustering method requires two parameters: distance of the point from core point is to be considered as part of a cluster called epsilon denoted by ∈ and the least number of points essential to form a cluster is denoted by minPts. In DBSCAN clustering method, an arbitrary point that has not been visited is selected as starting point. The parameter ∈ is used to extract the locality of this point. The neighbourhood includes all the points, which are within ∈. If that point has an adequate neighbourhood, then the process of clustering starts and it will be marked as visited otherwise labelled as noise. This point will be part of the cluster afterward in the process. If any point becomes part of a cluster, then its neighbourhood also becomes the part of the cluster. The process is repeated for the unvisited points unless they all are marked as visited. The centres of these clusters are called visual words. These visual words are combined to build a visual vocabulary. The DBSCAN clustering method is applied separately on the resultant features of the LIOP and LBPV descriptors, which produce two visual vocabularies. These two visual vocabularies are mathematically represented as follows



where
For the proposed method based on the features integration, LIOP and LBPV features are computed separately from each image, concatenated to obtain complementary features, and DBSCAN clustering method is applied on the integrated features, which formed a single visual vocabulary.
3.6. Formation of the histograms
After formation of the resultant visual vocabulary, the histogram is built using these visual words of each image and mapping of the visual words is performed [51].
3.7. Learning of the classifier
The SVM is a supervised classification procedure and is used for classification of the proposed method. The kernel of SVM computes the dot product in high-dimensional feature space that can produce non-linear decision regions. The kernel lets it use the data with varying dimensions. After representing each image visual contents in the form of the histogram, each histogram is normalised. The Hellinger kernel is selected for learning of the classifier for the proposed method due to its best performance and low running cost as compared with other kernels of the SVM. It is mathematically denoted as follows

where
3.8. Image matching and retrieval
To retrieve images from the image database, a sample image is given and matching of the visual contents between the score of the sample image and database images is performed by applying Euclidean distance to retrieve images. Mathematically, it is represented as follows

4. Experimental parameters, results and discussions
4.1. Evaluation metrics and experimental parameters
The following evaluation metrics of the CBIR are used to measure the performance of the proposed method.
4.1.1. Specificity
The ‘Specificity’ of the image retrieval framework is also known as ‘Precision’, which evaluates the capability of the CBIR framework to retrieve only the visually related images in response to the given sample image. Mathematically, it is defined by the following equation

where the overall number of the retrieved images are represented by
4.1.2. Sensitivity
The ‘Sensitivity’ of the image retrieval framework is also known as ‘Recall’, which evaluates the capability of the CBIR framework to retrieve only the visually related images over the total number of images in a particular class of the image database. Mathematically, it is defined by the following equation

where the overall number of the images in a particular class of the image database is represented by
4.1.3. Precision–recall graph
The precision–recall (PR) graph is used to express the precision as a function of recall and it shows a rapid sign of the CBIR performance of the proposed method. The PR graph illustrates the relationship between precision and recall for every possible cut-off. Every point on the PR curve shows the cut-off and at every cut-off, we get the precision and recall of that point.
4.1.4. F-score
The ‘Specificity’ and ‘Sensitivity’ are used to measure the accuracy of the image retrieval method, which indicates the effectiveness of the image retrieval method. These two parameters are not enough to measure the complete accuracy of image retrieval method. So, these two parameters can be combined to get a single measure, which calculates the complete accuracy of the image retrieval method known as F-score. The F-score is also known as a weighted average or a harmonic mean of the ‘Specificity’ and ‘Sensitivity’. Mathematically, it is calculated as follows
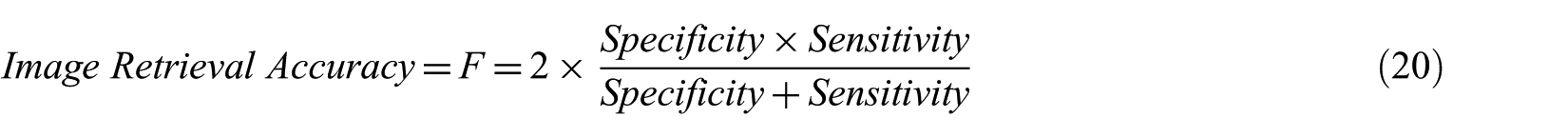
4.1.5. Details of the experimental parameters
The details of the different experimental parameters, which are selected for the experimental setup of the proposed method that employs visual words integration and its competitor CBIR methods for the WANG-1K, WANG-1.5K and Holidays image database, are mentioned in Table 1. Each experiment is repeated 10 times to report the mean average precision (mAP) values of the proposed method for effective CBIR.
4.2. Experimental details on the WANG-1K image database
The WANG-1K image database [52] is selected for evaluating the performance of the proposed method. It is a subset of the WANG image collection [53]. This image database consists of 1000 images. These images are gathered into 10 groups. Each group consists of 100 images. The images in this database include some special features like translation, scaling, rotation and noise injection. Each image in these 10 groups has a dimension sizes of

Image samples taken from the WANG-1K and WANG-1.5K image databases [52].
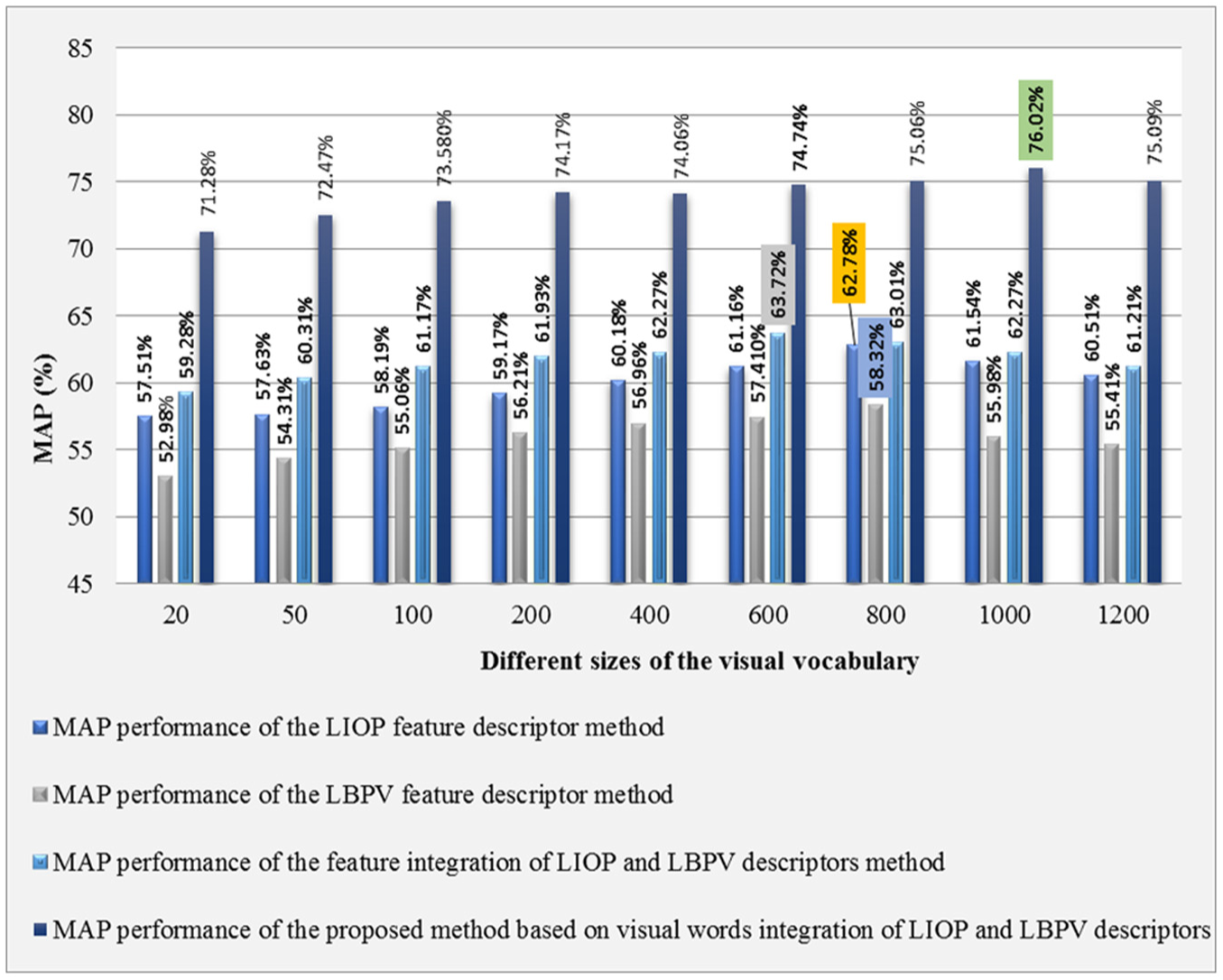
The comparative analysis of the proposed method that employs visual words integration of LIOP-LBPV features is performed with features integration of the LIOP-LBPV features, and single feature of the LIOP descriptor, as well as LBPV descriptor established on the BoW method, is shown in Figure 4. The experimental results performed by making a visual vocabulary of different sizes show that proposed method that employs visual words integration outperforms its competitor methods on all of the reported sizes of the visual vocabulary. The best performance of the proposed method and its competitor methods is highlighted in Figure 4. As visual vocabulary of the proposed method consists of the complementary features of the LIOP-LBPV features and its size is double than the present visual contents of the images, the performance of the proposed method is better than its competitor methods and standard CBIR methods [31,37,54–56] as experimental facts shown in Figure 4 and Table 2, respectively.
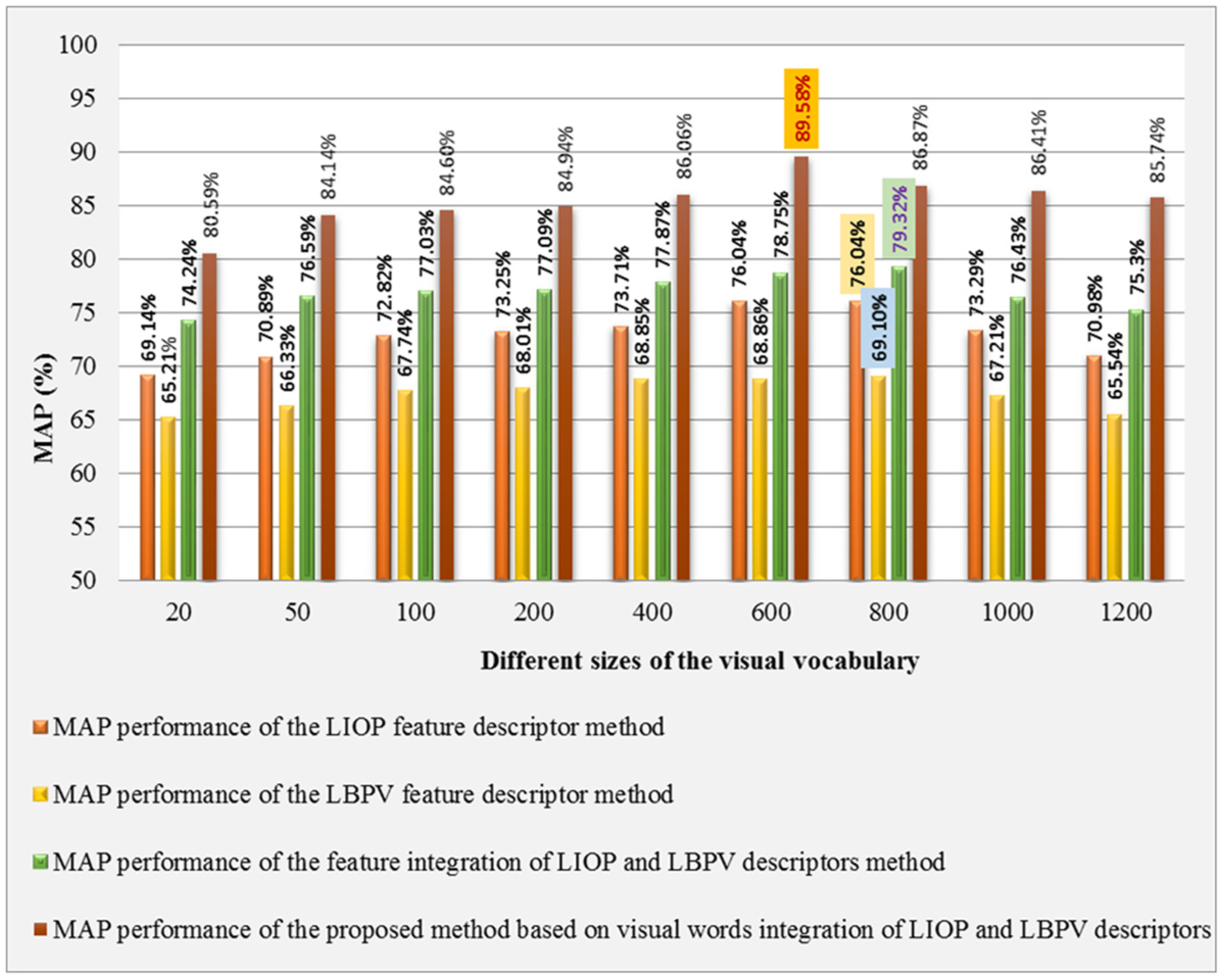
mAP performance comparison of the proposed method that employs visual words integration with its competitor methods based on the BoW framework on various sizes of the visual vocabulary using the WANG-1K image database.
Comparative analysis in terms of the evaluation metrics of the proposed method that employ visual words integration with the standard CBIR methods on the WANG-1K image database.
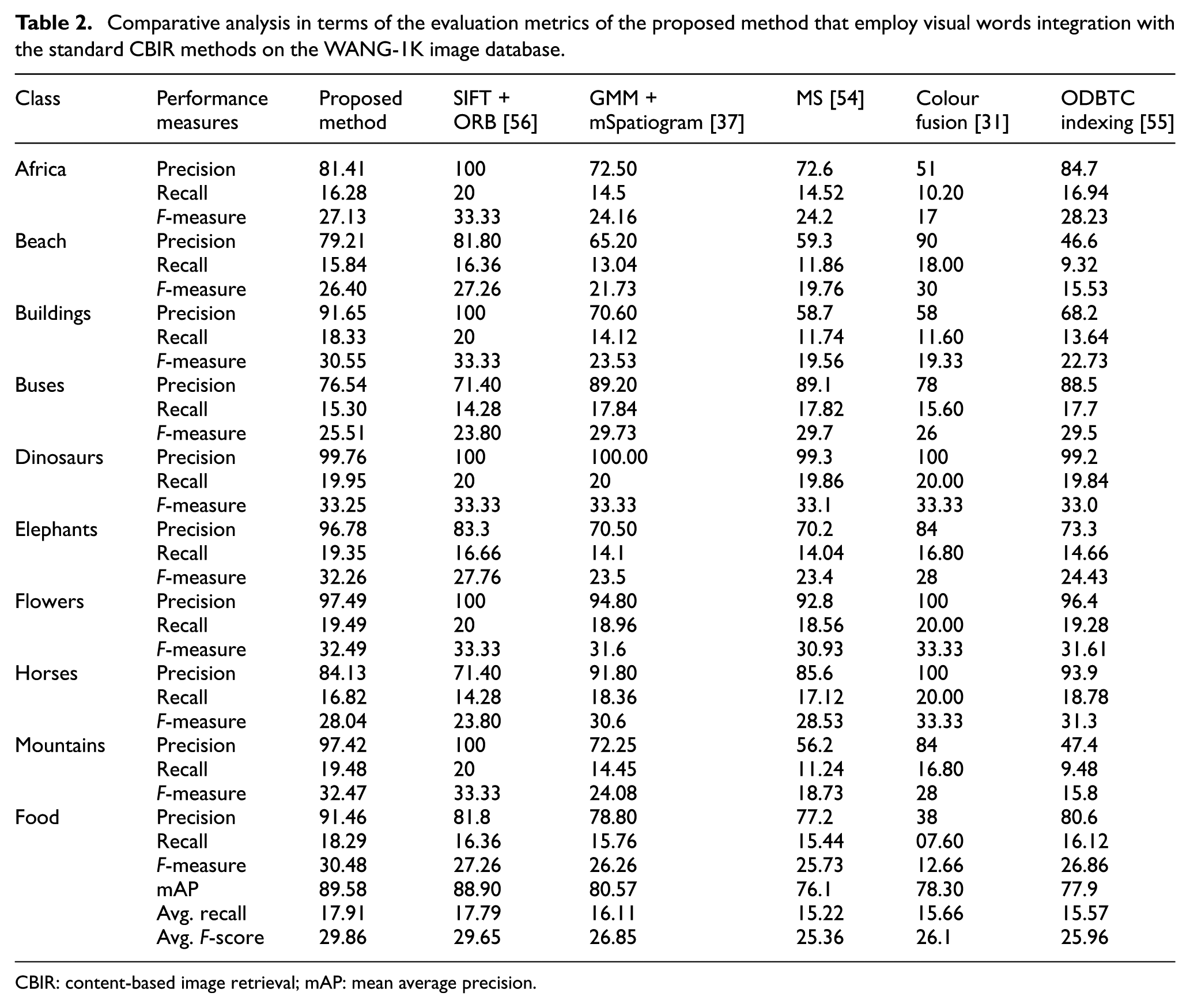
CBIR: content-based image retrieval; mAP: mean average precision.
In order to retrieve images, the results of the image retrieval by taking a query image from the groups or classes, namely, ‘Buses’, ‘Buildings’ and ‘Horses’ of the WANG-1K image database, are shown in Figures 5–7, respectively. The comparative analysis in the form of the PR graph of the proposed method that employs visual words integration and its competitor method of feature integration on different reported image databases is shown in Figure 8. The comparative analysis shows that the proposed method that employs visual words integration performs better than its competitor method of the feature integration on all the reported image databases.

Retrieved images showing overcoming of the semantic gap issue in reply to the question image that is taken from the ‘Buses’ class of the WANG-1K image database.

Retrieved images showing overcoming of the semantic gap issue in reply to the question image that is taken from the ‘Buildings’ class of the WANG-1K image database.

Retrieved images showing overcoming of the semantic gap issue in reply to the question image that is taken from the ‘Horses’ class of the WANG-1K image database.
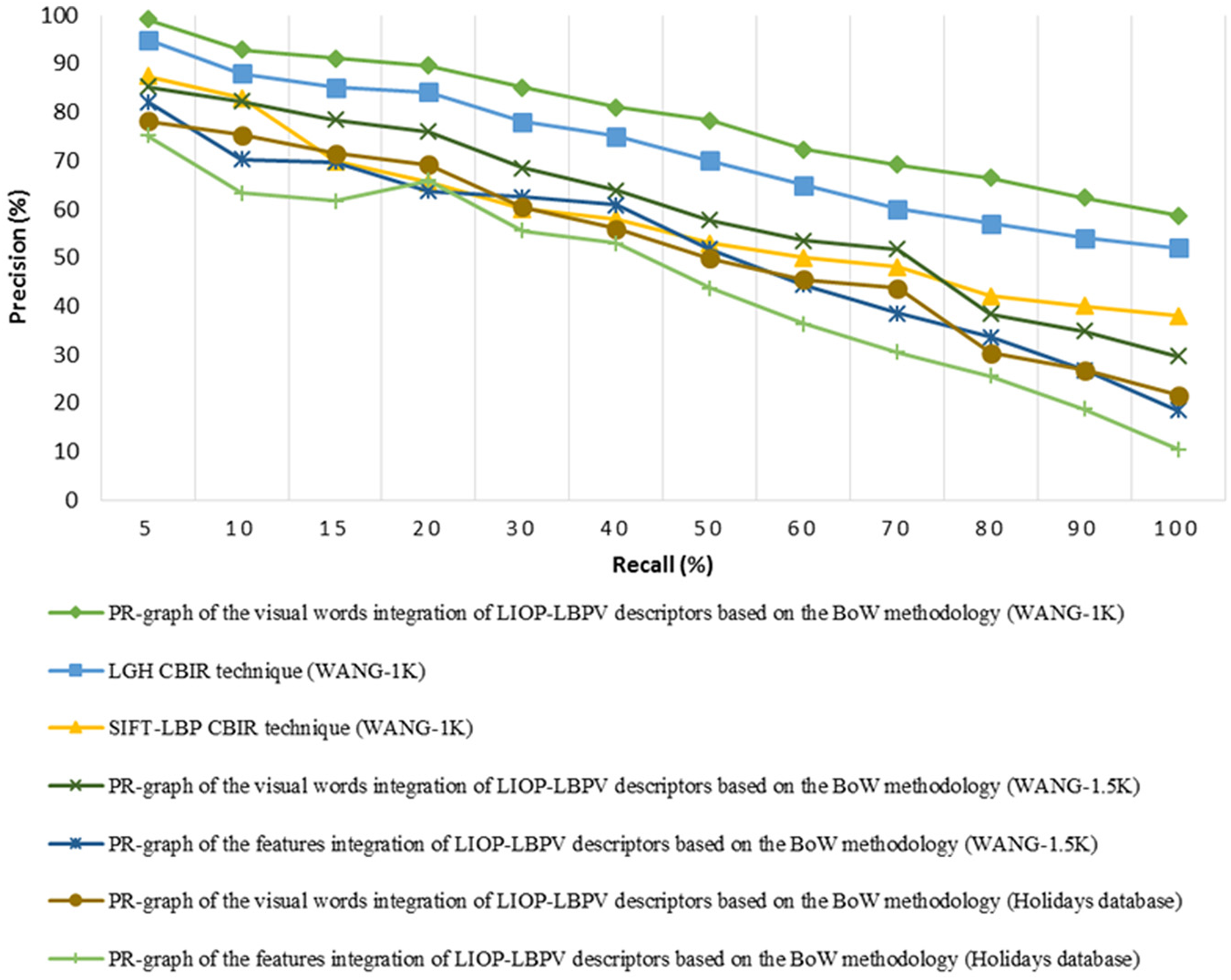
Comparative analysis of the proposed method that employs visual words integration with features integration on the reported image databases using PR graph.
4.3. Experimental details on the WANG-1.5K image database
The WANG-1.5K image database [52] is also the subset of WANG image database [53]. The overall number of images in this database is 1500. These images are gathered into 15 classes. The classes are semantically grouped, namely, ‘Elephants’, ‘Africans’, ‘Buses’, ‘Mountains’, ‘Postcards’, ‘Architecture’, ‘Sunsets, ‘Horses, ‘Tigers’, ‘Dinosaurs’, ‘Women’, ‘Food’, ‘Beach’, ‘Caves’ and ‘Roses’. The dimensions of the image in this database are
For WANG-1.5K image database, the comparative analysis in the form of the mAP performance of the proposed method that employs visual words integration of the LIOP-LBPV descriptors is performed with feature integration of the LIOP-LBPV descriptors, a single feature of the LIOP and LBPV descriptors based on the BoW method is presented in Figure. 9. The experimental details presented in Figure 9 clearly indicate that the proposed method that employs visual words integration of the LIOP-LBPV descriptors performs better than its competitor method on a visual vocabulary of all the reported sizes. The best performance of the proposed method and its competitor method is highlighted in Figure 9. The performance comparison of the proposed method that employs visual words integration of the LIOP-LBPV descriptors is also performed with standard CBIR methods [37,57], whose details are presented in Table 3, which also proves the robust performance of the proposed method. The image retrieval results of the proposed method that employ visual words integration are shown in Figures 10 and 11 for the ‘Food’ and ‘Postcards’ classes of the WANG-1.5K image database, respectively.
mAP performance comparison of the proposed method that employs visual words integration with its competitor methods based on the BoW framework on various sizes of the visual vocabulary using the WANG-1.5K image database.
Comparative analysis in terms of the evaluation metrics of the proposed method that employ visual words integration with the standard CBIR methods on the WANG-1.5K image database.
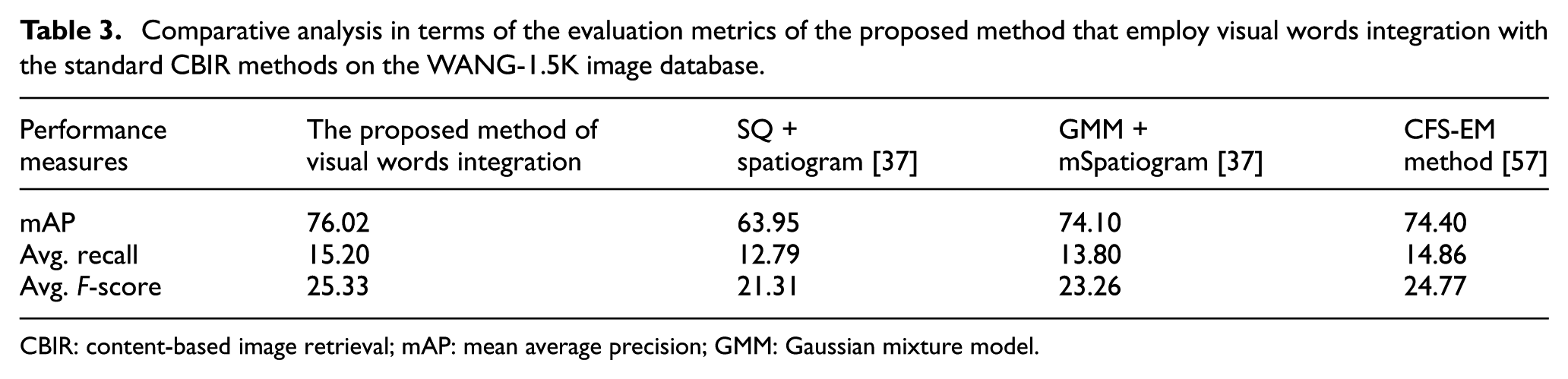
CBIR: content-based image retrieval; mAP: mean average precision; GMM: Gaussian mixture model.

Retrieved images showing overcoming of the semantic gap issue in reply to the question image that is taken from the ‘Food’ class of the WANG-1.5K image database.

Retrieved images showing overcoming of the semantic gap issue in reply to the question image that is taken from the ‘Postcards’ class of the WANG-1.5K image database.
4.4. Experimental details on the Holidays image database.
The overall number of images in the Holidays image database [58] is 1491, which are organised into 500 classes. This database contains images with various perspectives like scale and rotation-invariant, blurring and images with varying illumination. The images in this database are organised into different classes like ‘Water’, ‘Man-made’, ‘Fire effects’ and so on. Each image in this database is a high-resolution image with dimensions of
The experimental analysis on various sizes of the visual vocabulary using a proposed method that employs visual words integration is performed with its competitor CBIR methods and standard CBIR methods [59,60], whose experimental details are shown in Figure 12 and Table 4, respectively. The comparative analysis presented in Figure 12 and Table 4 clearly indicates the robustness of the proposed method that employs visual words integration as compared with its competitor CBIR methods and standard CBIR methods [59,60]. The best performance of the proposed method and its competitor methods are highlighted in Figure 12.
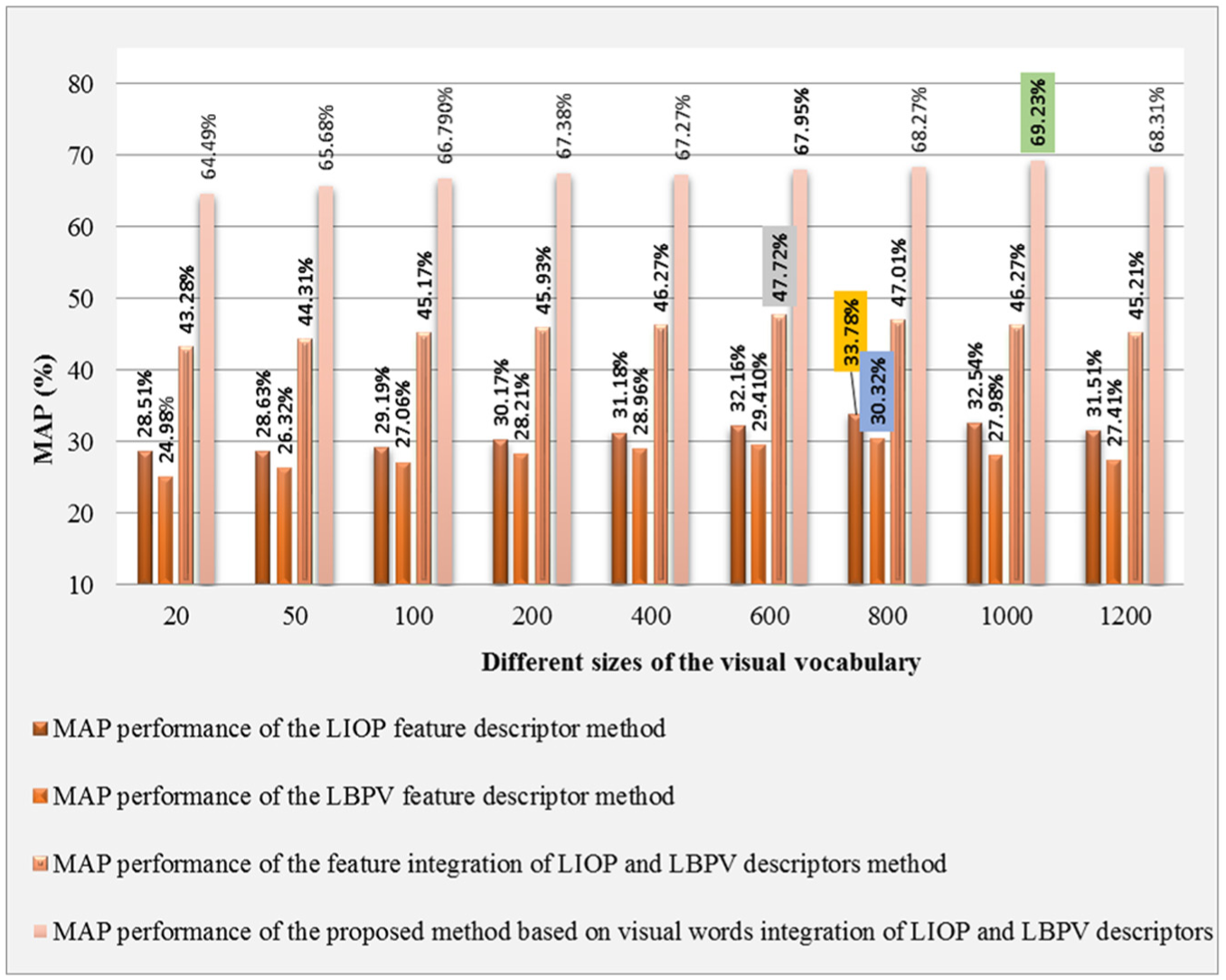
mAP performance comparison of the proposed method that employs visual words integration with its competitor methods based on the BoW framework on various sizes of the visual vocabulary using the Holidays image database.
Comparative analysis in terms of the evaluation metrics of the proposed method that employ visual words integration with the standard CBIR methods on the Holidays image database.
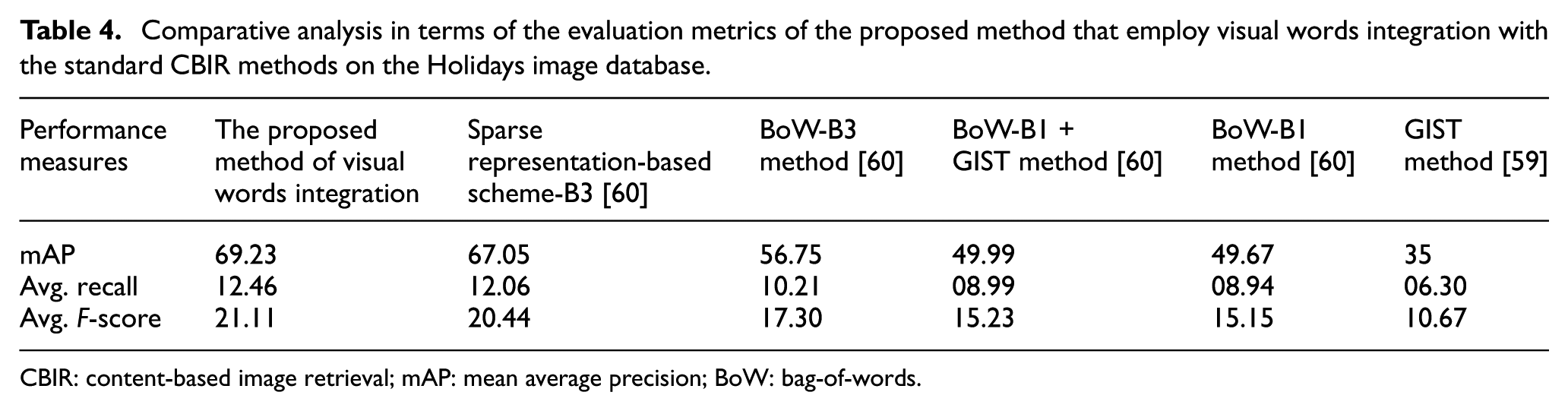
CBIR: content-based image retrieval; mAP: mean average precision; BoW: bag-of-words.
4.5. Running cost of the proposed method
The running cost of the proposed method that employs visual words integration is calculated on a Dell laptop, whose hardware specifications are as follows: ‘RAM with 2 GB of storage capacity’, ‘external SSD hard drive with a storage capacity of 120 GB’, ‘Windows 7 64 bit OS’ and ‘Intel (R) Pentium CPU B950 @ 2.10 GHz’. The required software resources for the proposed method are ‘VLFeat 0.9.21’ and ‘MATLAB R2015b’. The size of the visual vocabulary affects the running cost as well as image retrieval performance in CBIR. The WANG-1K image database is selected to report the running time of the proposed method and selected size of the visual vocabulary is 600 visual words due to the best performance of the proposed method on this size. The running cost (time in seconds) of the proposed method that employs visual words integration and its comparison with the standard CBIR methods are presented in Table 5, which also proved the robustness of the proposed method in the form of the running cost.
Comparative analysis of the complete framework in the form of the running cost (time in seconds) of the proposed method that employs visual words integration with the standard CBIR methods.

CBIR: content-based image retrieval.
5. Conclusion and future work
The proposed method uses complementary features in the form of visual words integration of the LIOP and LBPV descriptors to overcome the issue of the semantic gap of the CBIR, which also improves the performance of the CBIR. The proposed method increases the recall by forming the visual vocabulary of smaller size (i.e. forming individual vocabulary from each descriptor). It also improves the precision or accuracy of the CBIR system by forming the visual vocabulary of larger size, which is formed by performing visual words integration of the LIOP and LBPV descriptors, which are in the form of the two smaller sizes visual vocabularies. The proposed method that employs visual words integration also performs better as compared with the feature integration method and recent CBIR methods because the proposed method of the visual words integration assigns twice visual words to each image (due to visual words integration after clustering and forming two visual vocabularies) as compared with the feature integration method, which assigns half visual words to each image (due to feature integration before clustering and forming a single visual vocabulary). The running cost of the proposed method is reduced by applying PCA on the extracted features as a dimension reduction method and after that by selecting specific feature percentages per image. In future, we will plan to measure the performance of the proposed method by applying deep hashing methods due to their robust performance using huge size ImageCLEF and ImageNet databases for CBIR.
Footnotes
Acknowledgements
All the authors listed in the current author list contributed equally. We are also thankful to Kamran Abbas, Department of Statistics, University of Azad Jammu & Kashmir, Pakistan for thoroughly analyzing the "Experiment and Result" section of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This work was partially supported by the Machine Learning Research Group; Prince Sultan University Riyadh; Saudi Arabia [RG-CCIS-2017-06-02]; The authors are grateful for this financial support.