
Abstract
With the increase of online tourists reviews, discovering sentimental idea regarding a tourist place through the posted reviews is becoming a challenging task. The presence of various aspects discussed in user reviews makes it even harder to accurately extract and classify the sentiments. Aspect-based sentiment analysis aims to extract and classify user’s positive or negative orientation towards each aspect. Although several aspect-based sentiment classification methods have been proposed in the past, limited work has been targeted towards the automatic extraction of implicit, infrequent and co-referential aspects. Moreover, existing methods lack the ability to accurately classify the overall polarity of multi-aspect sentiments. This study aims to develop a predictive framework for aspect-based extraction and classification. The proposed framework utilises the semantic relations among review phrases to extract implicit and infrequent aspects for accurate sentiment predictions. Experiments have been performed using real-world data sets crawled from predominant tourist websites such as TripAdvisor and OpenTable. Experimental results and comparison with previously reported findings prove that the predictive framework not only extracts the aspects effectively but also improves the prediction accuracy of aspects.
1. Introduction
Tourism is a dynamically growing industry and a key to a country’s economic growth. Its significance and importance cannot be overemphasised [1]. Every year, thousands of tourists visit various places around the world and share their sentiments in the form of online reviews on traveller’s websites such as TripAdvisor and OpenTable. These sentiments present the feeling of tourists regarding various aspects of a specific place. Due to the diversity of the sentiments posted regarding a tourist place, it is a challenging task to extract and classify the sentiments into positive or negative. A number of sentiment mining methods [2–13] have been proposed in the past to classify the sentiments. However, in majority of the online reviews, multiple aspects regarding a particular place are mentioned which are not considered by the aspect-less sentiment classification techniques [2–13]. Aspect-based sentiment classification deals with this issue of mining sentiment polarity of aspect categories referred in each online review.
Aspect-based sentiment classification methods [14–31] not only assist in extracting the various aspects mentioned in the reviews but also help in classifying each aspect into positive or negative polarity. Take an example of an opinion ‘Food is delicious but service is ordinary’. In this short review, ‘food’ and ‘service’ are the two aspects which are explicitly mentioned. Food is classified as a positive aspect due to the positive sentiment word ‘delicious’ and service is classified as negative aspect because of the negative word ‘ordinary’.
Aspect-based sentiment classification methods basically consist of two tasks: (1) aspects identification and (2) sentiment classification of identified aspects into positive or negative.
In aspect identification task, there are three main issues. First is the difficulty of identifying implicit aspects. For example, take an opinion about a restaurant ‘Last night my wife and I visited Hasten restaurant, the taste was awesome’. In this opinion, tourist implicitly gives a sentiment about an important aspect ‘food’ that was not mentioned explicitly in review text. The second problem is the identification of co-referential aspects. Co-referential aspects are those aspects which are mentioned in the reviews using synonyms. For example, atmosphere and ambience are co-referential aspects because both refer to the environment. The third issue is the identification of infrequent aspects, the aspects that are not frequently mentioned in the review but are of great importance for a domain. For example, swimming pool and Wi-Fi are less frequent aspects but both carry a lot of importance in hotel and restaurant domain.
In the existing aspect identification methods [14–24], there is not a single method which deals with all the three aforementioned aspect identification issues effectively. For each issue, separate methods have been proposed in the literature, and there is a dire need of a method that can cater these issues together, with reasonable effectiveness. This motivated us to develop a single-aspect identification method for handling implicit, co-referential and infrequent aspects.
Similarly, for the second task of sentiment classification of identified aspects, there is a major problem of handling multi-aspect reviews. Classification of the multi-aspect reviews is a complex task as multiple aspects are discussed in a review and each aspect has either a positive or a negative sentiment. For example, take a review posted about a hotel ‘The hotel staff were extremely rude, but our room was very comfortable. Perfect location for a family with children. Clean bathroom, beautiful views’. In this review, tourist gives sentiments about multiple aspects namely ‘staff’, ‘room’ and ‘location’. It can be seen from the review that aspects have different sentiments, that is, for ‘staff’, there is negative sentiment while for ‘room’ and ‘location’ the sentiment is positive.
Approaches reported in the literature [19,25–31] have not dealt with this daunting issue of multi-aspect classification. To the best of our knowledge, there is not a single machine learning (ML)–based approach available for aspect classification which effectively handles this complex problem. We argue that aspect-based sentiment classification could only be improved if multi-aspect problem is adequately handled by aspect classification methods.
In this article, we propose a predictive aspect-based sentiment classification framework, and our contributions are three fold; (1) a tree-based method has been proposed for implicit aspect extraction; (2) an extension of rule-based aspect identification method has been devised for accurate identification of infrequent aspects and (3) an effective mechanism has been developed for transforming multi-aspect reviews into single-aspect phrases for accurate classification of aspects.
Experiments have been performed using real-world data of hotels and restaurants collected from TripAdvisor and OpenTable. Five predominant ML algorithms, namely naïve Bayes multinomial (NBM) [32], support vector machine (SVM) [33], maximum entropy (ME) [34], random forest tree (RFT) [35] and fuzzy lattice reasoning (FLR) [36] were selected for experimentation. The results were compared with similar ML approaches reported in literature [19,25–26,29–30]. The comparison shows considerable improvement in performance of our proposed framework with 89.34% and 91.53% accuracy on restaurant and hotel data sets, respectively, using NBM technique.
The rest of the article is organised as follows. Section ‘Related work’ presents the overview of the related work. In section ‘Proposed framework for predictive aspect-based sentiment classification’, the details of our predictive aspect-based sentiment classification are given. Followed by section ‘Experimental results and discussion’, in which experimental results are presented and discussed. In section ‘Comparative analysis of the results’, comparative evaluation of the proposed framework with the similar approaches has been given. Finally, the findings of our work are concluded in section ‘Conclusion and future work’.
2. Related work
This section presents the related work of aspect-based sentiment classification for tourism domain. The objective of this section is to critically evaluate the existing approaches of aspect identification and classification to identify the existing gaps and limitations.
2.1 Aspect identification
Aspect identification is a primary task in opinion mining. The work done in this area has been broadly categorised into three types of methods namely rule-based methods, seeds-based methods and topic models–based methods [37].
Rule-based methods identify aspects by employing rules based on importance score and frequency of occurrence. Such an approach has been proposed by Jiménez-Zafra et al. [14] which utilises a bag of words containing aspect terms based on frequency using Freebase. Freebase is a collaborative knowledge base that contains information about more than 70 different domains including tourism. Similarly, Muangon et al. [15] extracted high-rated aspects by employing rank-based approach. In this approach, features were obtained using LexToPus lexicon and ranked according to their frequency of occurrence in reviews. Their approach helped in extracting the aspects having high ranks.
A different approach of utilising part-of-speech (POS) tagger has been proposed by Wang et al. [16]. In order to select the potential aspects, common morphological and inflexional endings were removed by employing a novel porter stemming algorithm. This algorithm helped in tagging similar aspects to enhance the classification process. Words with identical spellings were easily and automatically identified using the porter algorithm. A similar POS–based approach has been exploited by Marrese-Taylor et al. [17,18]. In their work, the authors transformed reviews into sentences and later applied POS tagger on sentences to extract nouns. A frequency threshold of 10 was set to extract similar aspects. To advance the rule-based approaches, Afzaal et al. [19] proposed an improved method using fuzzy-based learning. Authors adopted ML-based algorithm called fuzzy unordered rule induction algorithm (FURIA). In this method, frequent nouns and noun phrases from the reviews were extracted, and rules were generated using FURIA.
Although rule-based methods are easy to adopt and very effective in the identification process, there are a number of problems which are not tackled by such methods. For instances, rule-based methods tend to produce very limited number of rules. Moreover, the generated rules are unable to identify infrequent aspects, as a number of irrelevant aspects are extracted by the limited number of rules produced by these methods.
There is another category of approach called seeds-based approach. In seed-based methods, aspects are identified using the grammatical connection between seed sets and review words. In line with this category of approaches, Colhon et al. [20] chose five most-discussed aspects from reviews and formed a seed set for each aspect. In order to build seed sets, grammatical connections between the terms in sentences and every aspect in seed sets is checked; afterwards these terms were assembled accordingly. It helps in identifying the important aspects of a review by using co-occurrence of different words.
In the quest of finding interconnection of review words, Mukherjee et al. [21] proposed a method of finding semantic relationship between review words. Words which have semantic relationships are grouped in the form of a seeds set. This approach helps in identifying not only the co-occurrence of aspect terms but also the semantic relationships between them. A slightly different seed-based approach has been proposed by Kayaalp et al. [22], which uses an index-based aspects extraction method. The index-based method consists of three main steps. First, four most-discussed aspects in restaurants reviews such as food, service, price and ambience are selected. Second, reviews words were indexed and stored in different files with proper tagging. Finally, indexed words were categorised under the selected aspects based on similarity between aspects and indexed words.
Unlike the rule-based methods which did not utilise the relationships among the different review words, the seed-based methods offer a number of advantages in terms of identification of co-referential aspects. However, the limitation of seeds-based methods is that extensive domain knowledge is required for the selection of aspects and seeds key words. In addition, the words extracted with limited number of aspects are not enough to cover the complete domain. For instance, food, service, price and ambience cannot cover the complete domain of a typical hotel or restaurant, as this domain has a large number of other important aspects, that is, location and room facilities.
The last category of aspect identification is topic model–based techniques, which depend on the assumptions that every sentiment is a blend of different topics and each topic under discussion is basically a probability distribution of various words. Wu et al. [23] proposed a brought together probabilistic model on clients inclinations about different aspects. In this model, it is expected that every sentiment is associated with an aspect. Aspect importance can be described by the sentiment that relies upon three components: global importance, user importance and how much probability that an aspect will be specified in different sentiments. In light of these assumptions, they utilised added substance-generative technique to identify the aspects.
Similarly, Shams et al. [24] proposed an enriched latent Dirichlet allocation (LDA) model to discover more precise aspects from reviews by incorporating co-occurrence relations as prior domain knowledge into the LDA topic model. In the proposed method, first, the preliminary aspects are generated based on LDA. Then, in an iterative manner, the prior knowledge is extracted automatically from co-occurrence relations and similar aspects of relevant topics. Finally, the extracted knowledge is incorporated into the LDA model. The iterations improve the quality of the extracted aspects as compared to simple LDA model.
In conclusion, all the aspect identification methods have three major issues. First, aspects identification methods do not provide effective means of removing irrelevant aspects and completely neglected the extraction of infrequent aspects. Second, implicit aspects extraction has not targeted by the existing approaches. Implicit aspects are discussed in reviews but not with an explicit aspect name. For instance, ‘food’ is an understood aspect in ‘The taste was awesome’ review sentence. Finally, the co-referential aspects were less emphasised in the literature. Review sentences have different synonym words and expressions to depict an aspect; for instance, environment and atmosphere mentioned to a similar aspect in restaurant reviews. These issues motivated us to form a method which can tackle these challenging problems of aspect extraction.
2.2 Aspect-based sentiment classification
In this section, we present the review of the work conducted under aspect-based sentiment classification in the tourism domain. It is important to highlight here that we only review the ML-based approaches in this study.
In order to get accurate classification using ML, Mubarok et al. [25] proposed a naïve Bayes-based model to classify the restaurants reviews of various aspects. In this model, three simple steps were performed to achieve the classification task. First, reviews were pre-processed to remove irrelevant information and converted into POS tags. Second, feature selection was applied on POS tags by utilising chi square to select highly relevant words from each review. Finally, naïve Bayes classifier was employed on selected features to classify the reviews into polarity classes for each aspect. Results showed that the proposed model achieved 77% accuracy of aspect-based classification.
Another ML-based approach was presented by Xueke et al. [26], where the authors have used SVM on tourist reviews to predict sentiments about different aspects discussed in reviews. In this method, natural language processing (NLP) toolkit was applied for sentence segmentation and to improve the classification performance. Sentences annotated with either ‘positive’ or ‘negative’ sentiments were used for achieving better accuracy results. Experimental results on real-world data sets showed 83.9% accuracy using seven-fold cross-validation. Authors proved that for sentiment classification, SVM produces better results than naïve Bayes algorithm.
The aforementioned algorithms were utilised using an ensemble approach by Catal et al. [27] to develop a newly vote ensemble classifier. This classifier utilised each algorithm on individual basis to predict the sentiment class in tourist reviews. First, bagging algorithm was used as base classifier for ensemble classifier. Second, naïve Bayes was employed due to its features-handling power. Third, SVM was applied to find maximum margin and provide maximum separation between sentiment classes. Finally, voting mechanism was adopted to predict the sentiment class on the basis of majority voting.
In the quest of achieving better accuracy, ME algorithm was employed by Pontiki et al. [28, 29] to classify the aspect-related opinions into positive or negative. In this system, unigram features from the given sentence are extracted and then integer-valued functions were used to identify the aspect category of tuple being used. ME classifier was trained on extracted features, and prediction was tested using golden data set labelled by experts of that domain. The results of the system indicate the robustness and more stable performance with 78.69% on restaurants reviews.
Instead of adopting the traditional ML algorithms Afzaal et al. [19] utilised fuzzy-based algorithms for aspect-based sentiment classification. In the proposal, a three-stage fuzzy method was developed for classification. In the first stage, opinion-less sentences were reviewed from the reviews. In the second stage, features were built from filtered opinion sentences like n-grams and POS tags. In the last stage, fuzzy logic algorithms were applied on the built features to classify the sentiments into positive and negative.
A number of approaches have been proposed recently, which worked on features selection before classifying the reviews in order to improve the classification results. Akhtar et al. [30] utilised the particle swarm optimisation (PSO) for features selection to improve the classification of tourist reviews. In this approach, authors extracted different feature sets from reviews using lexical and semantic information and then selected the most suitable feature set based on PSO. After that ML algorithms such SVM, ME and conditional random field were employed on selected features to classify the reviews.
Similarly, Ali et al. [31] worked on feature selection to remove irrelevant reviews and enhance the performance of classification reviews. In this technique, raw reviews were converted into words to generate tokens using semantic information. Fuzzy domain ontology was developed to select the relevant features from generated tokens. In feature selection process, the authors make sure that each review should contain a noun and a verb. On selected features set, SVM was applied to classify the reviews into different polarity classes.
Although ML-based methods are easy to adopt and very effective in the classification process, there are a number of challenges which are not handled by these methods. First, existing methods are unable to classify the multi-aspect opinions into positive or negative. Review data contain sentences that discuss multiple aspects in a single sentence. Another related issue is about data noise. When reviews are crawled from third-party websites like TripAdvisor and OpenTable.com, then these reviews are assigned to different classes by the reviewers. In such a case, some irrelevant and opinion-less sentences like self-introductions and previous stories are present in the review text and affects the opinion classification accuracy of aspects in a negative way.
In order to overcome the issues of ML-based classification, there is a need of a predictive framework that is capable of extracting the various types of aspects effectively and also has the power to predict unlabelled reviews accurately.
3. Proposed framework for predictive aspect-based sentiment classification
In this section, we propose an enhanced aspect-based sentiment classification framework. The primary focus of this framework is to identify the explicit and implicit aspects from tourist reviews and then classify the sentiments about identified aspects into positive or negative. Figure 1 describes the main phases of the framework. In the first phase of data collection, tourist reviews are collected about different tourist places like hotel and restaurant from social media websites. In the second phase of data pre-processing, data redundancy is removed and transforms the reviews into sentences. In the third phase of aspect identification, a novel aspect identification approach is proposed to identify the explicit and implicit aspects from pre-processed data sets. In the last phase of classification, an ML-based sentiment classification approach is proposed, in which multi-aspect opinions are transformed into single-aspect phrases, and then generate features from these phrases to build the model for classification of aspects. Models are evaluated in the last step on the basis of advance evaluation measures, and the model with best results is selected for prediction.

Proposed framework for aspect-based sentiment classification.
3.1 Data collection
In data collection phase, we collected reviews from different travel websites such as TripAdvisor, OpenTable and Expedia using existing Application Programming Interfaces (APIs). Each data set has different size and different domain. In restaurant domain, 2000 reviews were collected, including 1000 positive and 1000 negative reviews. In hotel domain, 4000 reviews were collected, including 2000 positive and 2000 negative reviews. For hotels and restaurants selection, we have chosen the top five hotels and restaurants in London city to crawl the user reviews.
3.2 Data pre-processing
The second component of the framework is for the pre-processing of reviews data. Data crawled from the travel websites contain noise and inconsistencies. Such data require data cleansing to avoid redundancies. Moreover, as mentioned previously, we intend to apply sentence-level classification; therefore, sentences are separated from each review text using the sentence stop characters, that is, full stop (.) or question mark (?). Moreover, the duplicate sentences and identical review texts are removed.
The rationale behind this is that a review is often posted by the same user twice, and it affects the accuracy of sentiment classification. Finally, data ambiguity is removed to correct all vague terms like ‘greaaaat, yummmyy and coooool’ that are not standard English terms. After performing pre-processing on review data sets, a smaller sample of cleansed data remains for further analysis and aspect identification. It is important to mention here that for our experiments, we pre-processed both the two data sets and got 3787 sentences for the restaurant data set and 7802 sentences for the hotel data set.
3.3 Aspect identification
The next component of the framework deals with the main task of aspect identification. Aspect identification is a relatively complex task, as it involves the identification of implicit and co-referential aspects. In this study, we have developed approach to identify explicit, implicit and co-referential aspects. In the following sub-sections, the approaches are explained for each type of aspect identification.
3.3.1 Explicit aspects identification
For explicit aspect identification, an extension to the already existing rule-based methods [14–19] has been proposed. The proposed method assists in handling irrelevant and infrequent aspects. Our extension consists of three important steps namely noun recognition, pattern extraction and irrelevant aspect removal.
For noun recognition step, existing rule-based methods [18,19] are employed which takes sentences one by one and split into single words using delimiters such as space and punctuation marks. Each word of a sentence is then checked by employing POS tagger to determine whether the word is a noun or not. If it is, it checks the adjacent word to make sure whether that particular aspect is a single word or a combination of two words such as ‘food quality’ and ‘service quality’. If both adjacent words are nouns, it combines the words using space and adds it in the nouns list. If next adjacent word is not a noun but an adjective or verb, it is not added in the list. Table 1 shows a set of extracted nouns from hotels data set.
Recognised nouns.

It can be seen from Table 1 that a large number of irrelevant aspects were recognised which have no relevance with the domain under analysis (hotel and restaurant). These include ‘anniversary’, ‘ ads’, ‘night’, ‘agent’, ‘afternoon’ and so on.
For the second step of pattern extraction, irrelevant aspects are identified and removed after deriving meaningful patterns from sentences. Patterns are derived from sentences between sentiment words and extracted aspects. The rationale behind this extraction is that irrelevant explicit aspects are not usually discussed in specific patterns. Thus, if patterns are derived, irrelevant aspects can be identified and removed.
In order to achieve this, we propose a pattern extraction algorithm (PEA). The steps of PEA are shown in Algorithm 1. It takes reviews and POS tagger as input and provides a list of patterns with their corresponding frequencies as output. Algorithm 1 initialises the patterns list and frequency list with empty array shown at line 1. Second, it employs POS tagger on each sentence to get POS tags such as NN (Noun), JJ (Adjective) and VB (Verb) as shown in lines 4 and 5. Third, it initialises the single pattern extraction array that stores the POS tag from starting position to ending position of a pattern. Fourth, process all POS tags one by one to extract the possible patterns from a sentence. In pattern extraction procedure, noun and adjective are considered as the starting and ending points of a pattern. For example, consider a review sentence ‘The service was excellent and lovely food’. This sentence contains two patterns, the first pattern starts from ‘service’ which is a noun (NN) tag and ends at ‘excellent’ which is an adjective (JJ) tag. Second pattern starts with the word ‘lovely’ which is an adjective and ends at ‘food’ which is a noun. Fifthly, extracted patterns from a sentence are added in the pattern list. After pattern extraction, frequency of each pattern is counted and duplicate patterns are removed as shown in lines 26–30. Finally, algorithm returns the pattern list with their associated frequencies in reviews.

Algorithm 1 generates a large number of patterns, and generalised sequential pattern (GSP) algorithm [38] has been employed on generated patterns to select the candidate patterns. GSP takes patterns, associated frequencies, number of sentences and appropriate percentage for candidate patterns such as ‘1%’ in whole as input and provides a list of selected sequential patterns as output. Table 2 shows the candidate patterns generated after applying GSP algorithm.
Derived patterns.

The final step is the removal of irrelevant aspects. Once the patterns are derived, relevance of each aspect is calculated to identify and remove the irrelevant aspects. Relevance of an aspect is calculated by the patterns in terms of number of times aspect appeared in reviews as extracted patterns.
Equation (1) shows the formula used to calculate the relevance of an aspect

where p represents the derived patterns list, m indicates the number of patterns in the list, a is the target aspect whose relevance is being checked in given reviews. Equation (1) checks the aspect appearance in reviews according to derived patterns from the last step. If such patterns are not identified for any aspect, then such aspect is considered as an irrelevant aspect. Hence, it is removed from the list of explicit aspects. For example ‘Food’ aspect has two appearances in given reviews such as ‘Food is delicious’ and ‘Awesome Food’. The derived patterns list has two patterns such as NN/IS/VB or VB/NN.
Now using the patterns derived, we calculate the relevance of ‘food’ aspect. As it can be seen that the appearance of food aspect is in line with the derived patterns; therefore, ‘Food’ is considered as a relevant aspect. Table 3 shows the explicit aspects from hotel and restaurants data set after removing the irrelevant aspects. This approach helped in removing irrelevant aspects to improve the quality of aspect identification process.
Explicit aspects.

3.3.2 Grouping co-referential aspects
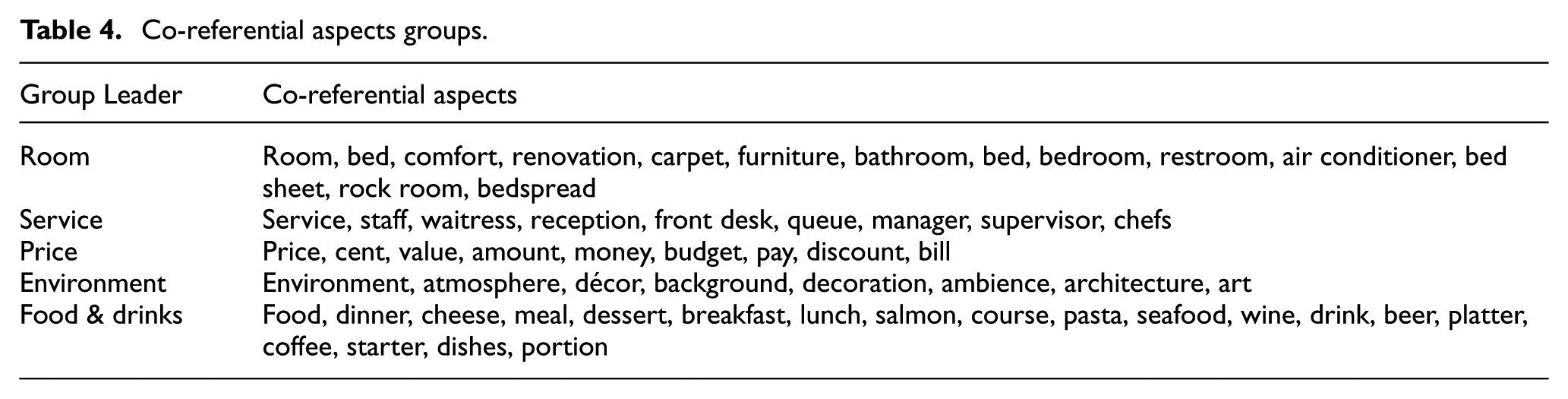
The next step for the proposed framework is grouping the co-referential aspects. Aspects referring to the same category with different meanings are grouped in this step. For example, location, place and venue refer to the same aspect. In order to achieve automatic grouping, we apply WordNet synonym set [39] on each identified aspect and determine the relation between aspects regarding meaning, indication and synonym. If aspects are similar in meaning, or if a synonym is used, a group of these aspects is created. Among that group, the word with the highest frequency is selected as a leader. Table 4 shows the grouping of co-referential aspects.
Co-referential aspects groups.
3.3.3 Implicit aspects identification
After extracting the explicit aspects, the implicit aspects are identified from each review sentence. In this article, a novel implicit aspects extraction method has been proposed, which builds binary trees using the aspect-specific lexicon to recognise the implicit aspects. First, the aspect-specific lexicon is created by extracting the sentiment words. Such words co-occur with explicit aspect in either a sequential manner or in a random order. Second, a binary tree for each aspect is being created by utilising the aspect-specific lexicon. Finally, the tree structure is employed on each sentence to identify the implicit existence of aspects. The details of each of implicit aspect identification are given in the following sub-sections.
3.3.3.1 Creation of aspect-specific lexicon
In the first step of implicit aspects identification, sequential or random co-occurrences between explicit aspects and sentiment words are extracted to create an aspect-specific lexicon. In sequential co-occurrence, the sentiment words that co-occur with aspects before clauses such as ‘and’ and ‘but’ are extracted. For example, if we take a review sentence ‘Food was delicious but expensive’, in this sentence only ‘delicious’ sentiment word is extracted with ‘food’ aspect. In random co-occurrence, the sentiment words that co-occur after the clauses in a review sentence are extracted. Considering the same example, only ‘expensive’ sentiment word is extracted. The rationale behind non-extraction of ‘expensive’ as sentiment word in sequential co-occurrence is that in majority of the sentences multiple aspects are discussed in a single sentence and aspects sentiment are often changed after ‘and’ and ‘but’ clauses. Thus, if only clause-less sentiment words are extracted in sequential co-occurrence, then aspect-specific lexicon becomes more meaningful in creating binary trees for implicit aspects extraction. Table 5 shows the created aspect-specific lexicon from hotels data set that consists of a set of sentiment words of ‘food’ and ‘price’ aspects.
Aspect-specific lexicon
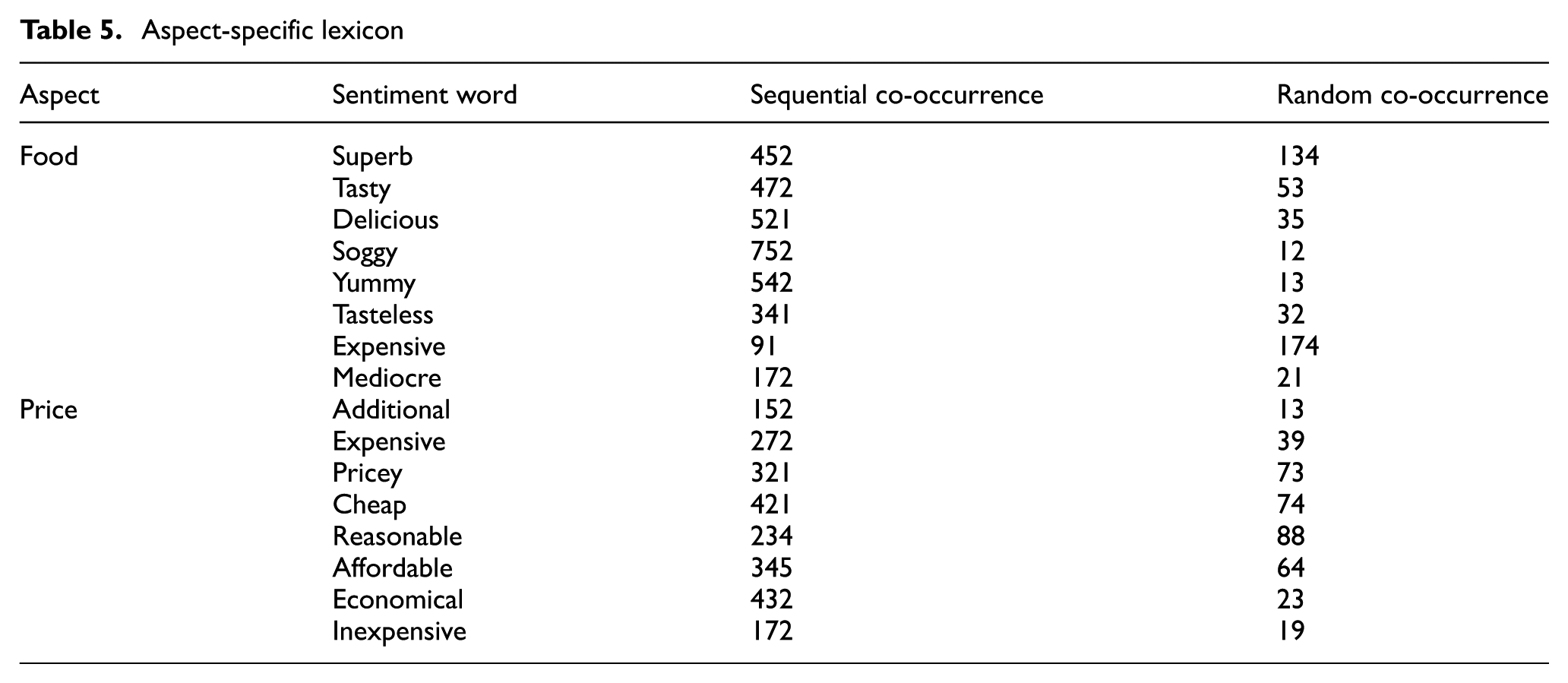
It can be seen from Table 5 that each aspect is associated with a number of sentiment words based on sequential and random co-occurrences. In this aspect-specific lexicon, each sentiment word can be associated with more than one aspect on the bases of co-occurrences. For example, if we take ‘expensive’ sentiment word, this is associated with both ‘food’ and ‘price’ aspects. The next step of the proposed method is to compute the relational score of each sentiment word with all associated aspects to formulate the final association of a sentiment word with the respective aspect.
3.3.3.2 Binary trees building
In the second step of implicit aspects extraction, binary trees are created for each aspect by utilising the aspect-specific lexicon. A tree-builder algorithm, titled Algorithm 2, has been proposed, which compares the co-occurrence of a sentiment word with aspects and uses as tree node for generating an appropriate aspect tree. The workflow of the proposed algorithm for implicit aspects is as follows.
First, initialise the nodes array and process lexicon words one by one as shown in lines 1 and 2 of Algorithm 2. Second, the relational score is calculated by dividing the sequential co-occurrences with random co-occurrences of lexicon words with the current aspect. Third, calculated relational score is compared with others aspects relational scores. If current aspect score is greater than other aspects scores, this lexicon word is added into nodes array of current aspect as shown from line 4–8 of Algorithm 2. Suppose that a sentiment word ‘expensive’ sequentially co-occurs with ‘food’ 50 times and randomly co-occurs 75 times, the relational score becomes 0.70. Similarly, if sentiment word ‘expensive’ that sequentially co-occurs with ‘price’ 15 times and randomly co-occurs 16 times, the relational score becomes 0.93 and ‘expensive’ sentiment word is then added in ‘price’ nodes array due to high relational score. Finally, binary tree is created for targeted aspect using additional nodes. Figures 2 and 3 show the binary trees generated for ‘food’ and ‘room’ aspects.
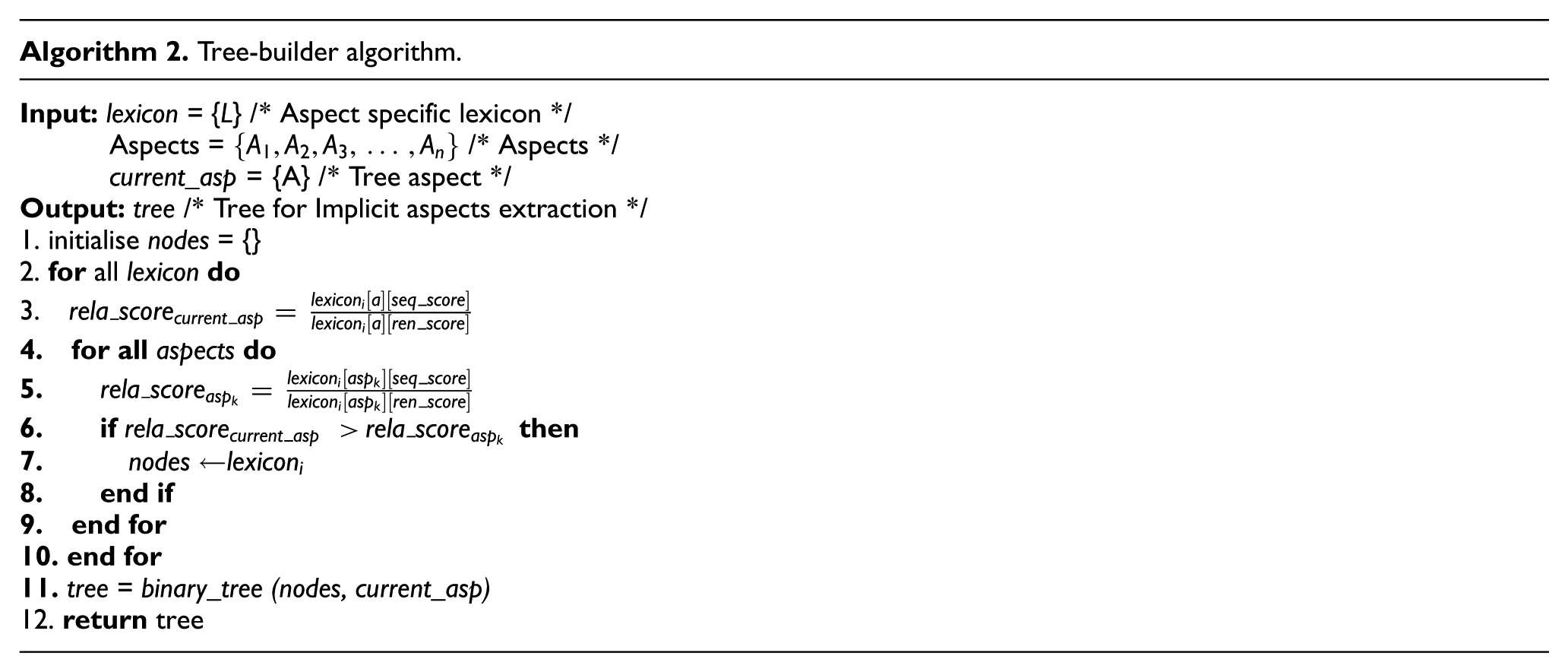
Binary tree for food aspect identification in restaurants reviews.
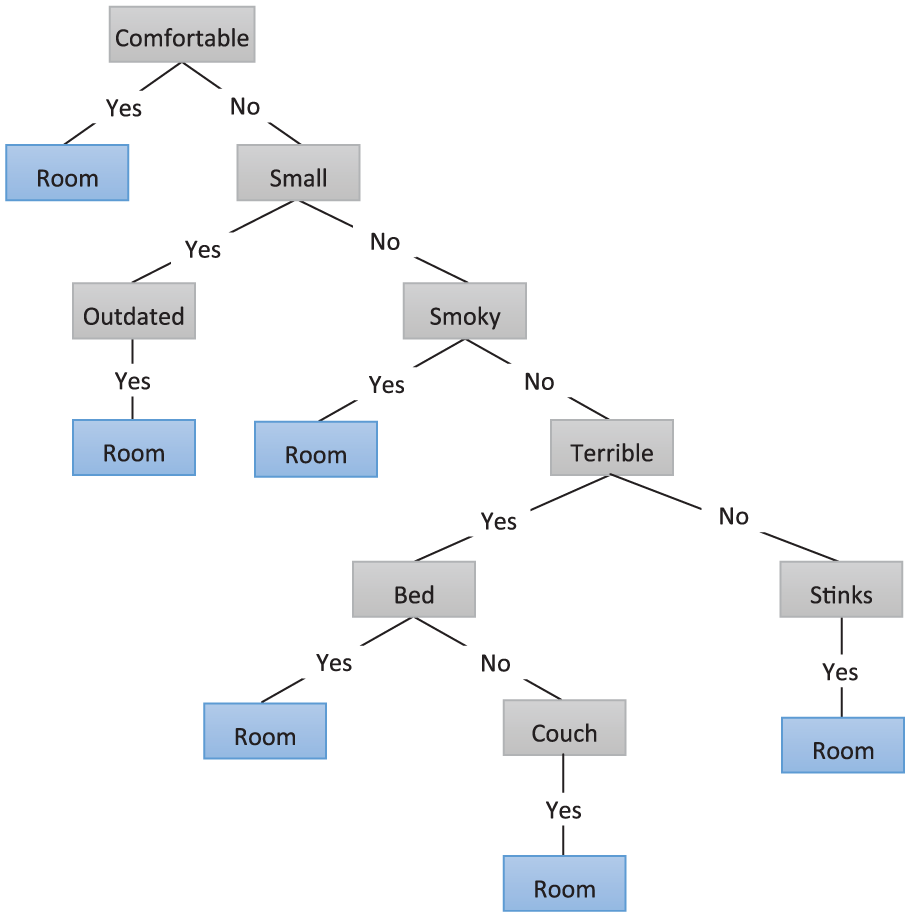
Binary tree for room aspect identification in hotels reviews.
3.3.3.3 Employment of binary trees
In the last step of implicit aspects extraction, the binary trees created in the last step are employed on sentences to identify the implicit aspects. The procedure of employment is as follows. First, the sentences are broken down into words by using delimiters such as space and punctuation marks. Second, binary trees are employed one by one on sentence words to check the existence of implicit aspects. Finally, if a binary tree returns the TRUE value, the tree aspect is assigned to the review, else it moves forward to check the next binary tree. Table 6 shows the set of sentences from hotels data set after extracting implicit aspects using binary tree generated using Algorithm 2.
Implicit aspects extraction.

3.4 Aspect-based sentiment classification
After the identification of various types of aspects, the framework provides an ML-enabled aspect-based sentiment classification. In order to perform ML-based classification, we exploited the predominant ML classifiers for predicting the positive or negative sentiments for each aspect. Our proposed method consists of three basic stages. First, it transforms the multi-aspect sentiment sentences into single-aspect sentiment phrases and discards the irrelevant sentences. Second, it generates feature vectors from single-aspect sentiment phrases like (n-grams and POS). Finally, it builds classifiers on generated features using ML algorithms to classify the single-aspect sentiment phrases into positive or negative.
3.4.1 Transformation
A large number of sentences in online reviews contain multiple aspects, and each aspect has a sentiment associated with it. We propose a grammatical relationship-based transformation method that splits multi-aspect sentences into single-aspect phrases. In this method, we utilise typed dependency [40] to identify the grammatical relations between review words and then extract phrases having sentiments using these relations. Each opinion phrase contains one aspect and multiple sentiment words that depend on that particular aspect. Three grammatical relations amod, nsubj and advmod were identified. Amod is a relation in which adjectival phrase serves to modify the meaning of the noun phrase. Nsubj is two words relation consisting of one noun and an adjective, in which noun represents the aspect and adjective expresses the sentiment of that aspect.
For instance, consider a sentence ‘Food is good and service is bad’. In this sentence, two nsubj phrases were extracted {food – good} and {service – bad}. Advmod is the short form for adverb modifier; for example, a sentence ‘food is very good’, the advmod is {good – very}. Once the grammatical relations were identified, their opinion phrases are extracted in which each phrase consisted of one aspect and multiple sentiment words (adjective, adverb) that expressed the opinion towards the aspect. Figure 4 shows the visual representation of transforming the multi-aspect sentences into single-aspect phrases.
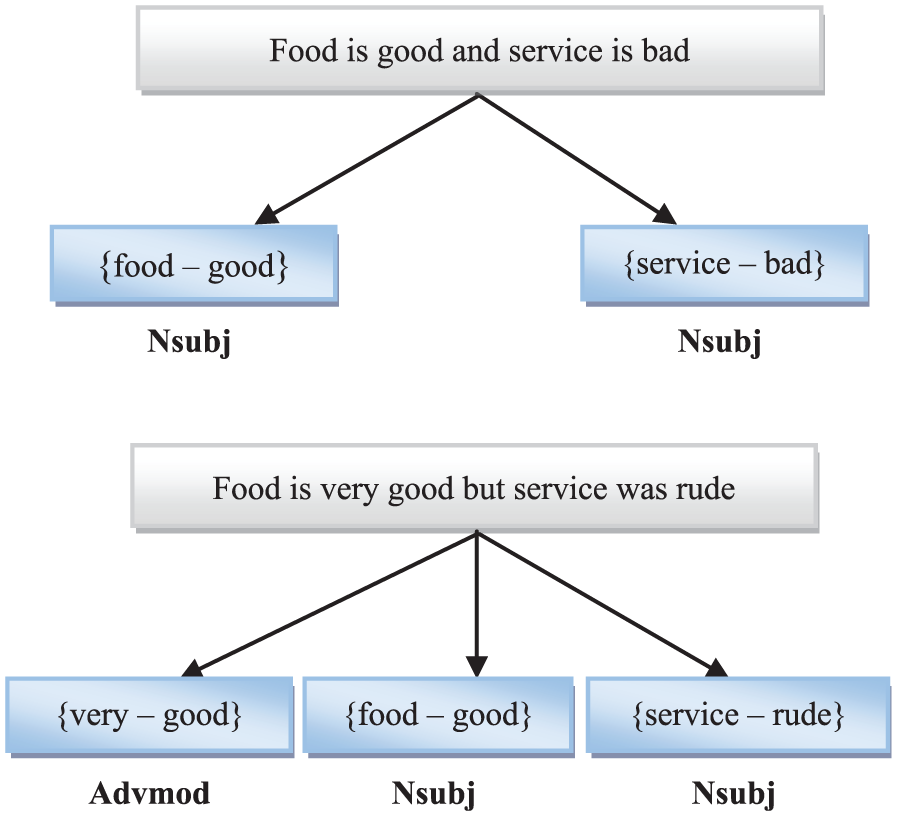
Transformation of multi-aspect sentences to single-aspect phrases.
3.4.2 Feature generation
In this phase, we generate features from single-aspect phrases that are to be used to train ML algorithms. Four types of features were generated (unigrams, bigrams, trigrams and POST) from each data set. The process of obtaining n-grams and POS tags is as follows: in the first step of the process, we tokenised the phrases to split by spaces and punctuation marks and generated a bag of words. However, we made sure that short forms such as ‘don’t’, ‘I’ll’, ‘she’d’ are considered as a single word. For POS tags, we extract only verb, adverb and adjective from the data set. In the second step, we remove stop words (‘a’, ‘an’ and ‘the’) from the bag of words. In the last step, we dealt with negation, negation (such as ‘no’ and ‘not’) is attached to a word which precedes it or follows it. For example, a sentence ‘I do not like fish’ will form three bigrams: ‘I do + not’, ‘do + not like’, ‘not + like fish’. The last step allows improving the accuracy of the classification since the negation plays a crucial role in sentiment expressions.
3.4.3 Classifier building
The mechanism of aspect-based sentiment classification framework is based on ML algorithms. These algorithms are commonly used by the ML community. For sentiment classification, the classifiers decide the class of sentiment sentence by considering all aspects and their linkages to sentiment words. The situation becomes more complex when there exist a large number of aspects. In such cases, ML algorithms are very pivotal in predicting the correct class for each aspect discussed in a review.
In this study, we experimented with five predominant ML algorithms which were used for sentiment classification namely, NBM, SVM, RFT, ME and FLR. The purpose is to compare and evaluate these classifiers thoroughly to determine which one consistently performs better.
3.4.3.1 NBM
Generally, the term naïve Bayes is referring a model having strongly independent assumptions instead of distributing each feature particularly. In a naïve Bayes model, it is assumed that all features being used are conditionally independent of one another given some class. Formally, the calculation of probability of observing features from

Equation (2) [32] means that when a new example is classified using naïve Bayes model, it becomes simpler to work with posterior probability

Equation (3) [32] described that independence of assumptions is not always true, and that is the reason why some refer the model as ‘idiot Bayes’ model. The feature distribution has not been discussed until now. In simple words,
3.4.3.2. SVM
In this algorithm, data analysis is performed to define decision boundaries by hyper-planes. In binary classification, the document vectors are separated using hyper-planes. This separation is desired to be kept possibly large. For a training set having a labelled pair
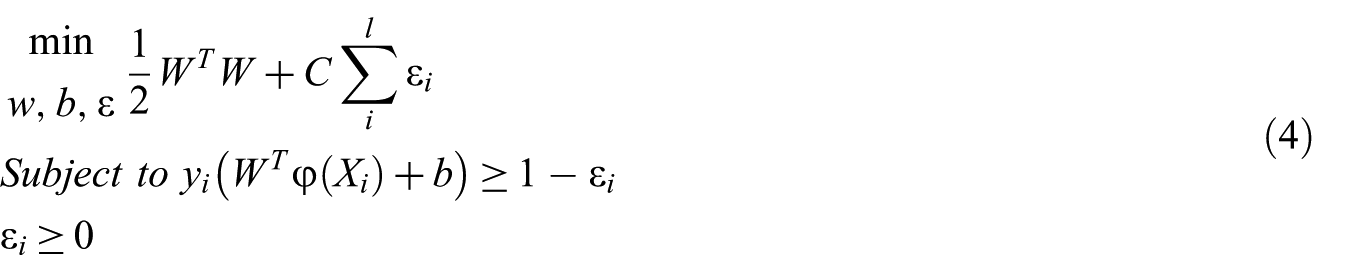
In equation (4) [33] ‘W’ represents weight assigned to variables,
3.4.3.3 ME
This algorithm sets conditional distribution constraints using training data. These constraints are used to express the characteristics of training data. So, in terms of exponential function, the ME value can be expressed as
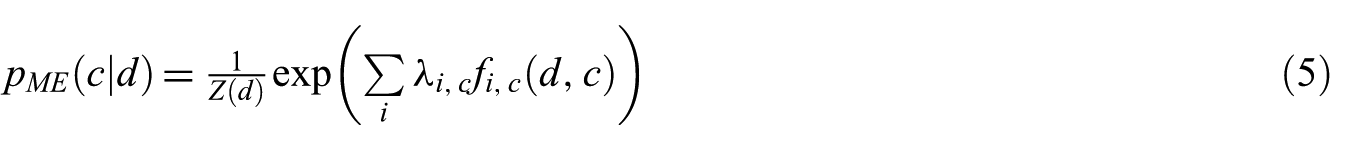
In equation (5) [34],

In equation (6) [34],
3.4.3.4 RFT
This algorithm is consisted of a set of free-structured classifiers. In this algorithm, two ML techniques are very helpful. These are bagging and random feature selection. This algorithm is a developed stage of bagging as only randomly selected subset of features is split at each node of growing tree. The prediction performance of this algorithm is assessed while algorithm performs a type of cross-validation by using the so-called out-of-bag (OOB) samples in parallel with the training step. The bootstrapping is sampling by performing the replacement from training data. Some sequences will be ‘left out’ of the sample, which will constitute OOB sample, while others will be repeated. On average, each tree is using
3.4.3.5 FLR
In this algorithm, some rules are derived from training data and then used to classify the testing data [36]. These rules are called as fuzzy lattice rules. Let us assume U as a set of data objects of all types that exist in this universe, but we will consider lattices only. A fuzzy lattice is designated as
3.5 Classifier evaluation
After a classification model is available, the model is used to predict the sentiments of tourists regarding the various aspects. As one of the important step to ensure the model generalise well, the performance of the predictive model has to be evaluated using advanced measures such as precision, recall, F-measure and area under the curve (AUC).
Precision and recall are the measures that actually evaluate the accuracy of sentiment classification prediction model. Precision is basically the ratio of relevant records (TP) identified to the total number of irrelevant and relevant records. It is usually expressed as a percentage. In our example precision will be calculated as TP/(TP + TN).
Similarly, recall is the ratio of the number of relevant records (TP) retrieved to the total number of relevant records in the data set. It is also expressed in percentage as recall, that is, TP/(TP + FN).
A sentiment classification system should be measured by its ability to positive and negative sentiments, and we therefore use the true positive rate and receiver operating characteristic (ROC) curve to give a comprehensive evaluation of our prediction model, where value of AUC measures the effective of sentiment prediction framework.
AUC is obtained by plotting the precision and recall on a graph. So, we use AUC instead of accuracy because percentage of correctly identifying the positive opinion is not sensitive to a single cut-off value, hence recall rate and AUC are more adequate measures to evaluate sentiment prediction model.
4. Experimental results and discussion
In this section, we present the experimental results and evaluate the effectiveness of our proposed aspects-based sentiment classification framework. We evaluate the proposed framework in term of its ability to recognise the various types of aspects and its ability to accurately classify the sentiments of each aspect.
4.1 Results pertaining to aspect identification
As mentioned previously, the experiments were conducted on restaurants and hotels data sets. The purpose of the experiments was to measure the accuracy of aspect identification. The three challenging types of aspects were targeted in our experiments and the goal was to achieve high accuracy rates for explicit, implicit and co-referential aspects. Figure 5 shows the percentage correctness of each aspect type for both restaurants and hotels data sets.
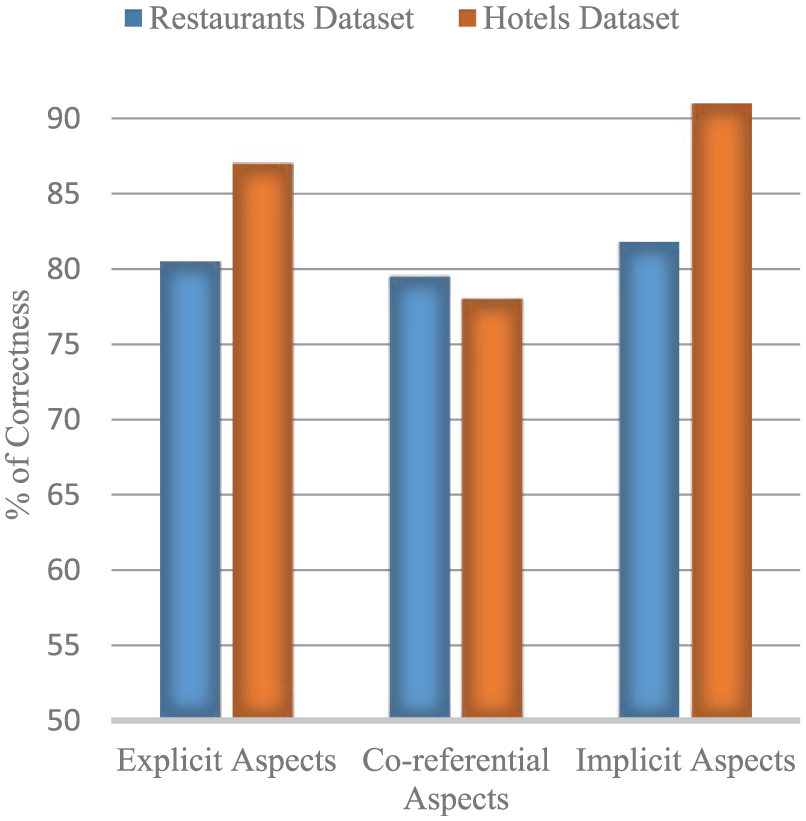
Correctly identified aspect percentages.
It can be seen from the results depicted in Figure 5 that our proposed aspect identification method achieved impressive performance. For explicit aspect identification, 80.5% accuracy was achieved for restaurants data sets and 87% for the hotel data set. Similarly, for implicit aspect identification, 82% implicit aspects were correctly identified for restaurants data set and 91% for Hotel data set. It is important to highlight here that the most challenging type of aspects is co-referential aspects, but our proposed tree-enabled method performed well to achieve accuracy around 78.5% for both the data sets. The primary reason to achieve these high accuracy result is a through pre-processing step to remove irrelevant, opinion-less and redundant reviews. It is a fact that the presence of noise in the data hinders the recognition accuracy. Unlike the previous approaches, we not only tackled these difficult to identify aspect types but also provided novel integration of tree-based methods with existing approaches to achieve better recognition rates.
It is also very important to highlight the percentage of aspects present in each data set. Figure 6 show the percentage of each type of identified aspects in restaurants and hotels data sets. If we analyse Figure 6, we can see that restaurants and hotels had 60% and 52% explicit aspects, respectively, from which high recognition rates were achieved. In other words, 80% of the 60% explicit aspects were correctly recognised. Similarly, the challenging type of aspect is the co-referential one, around 15% were identified and approximately 78% of this 15% were correctly identified with the help of our proposed methods.

Percentage of identified aspects in both data sets.
4.2. Aspect-based sentiment classification results
The second part of our evaluation is for the sentiment classification step. In aspect-based sentiment classification, we evaluate the performance of each ML classifier by conducting experiments on different data sizes, feature-weighting methods and feature types. Moreover, we examine the time taken by each classifier on different sizes of data sets to establish the scalability issue of various classifiers used in our experiments. Table 7 shows the results of the classifiers. It can be seen that the advanced evaluation measures (precision, recall, F-measure and ROC) have been used to determine the superiority of a particular classifier. It is obvious from Table 7 that NBM classifier achieves best accuracy results for both the data sets. An accuracy of 89.34% and 91.53% has been achieved for restaurants and hotels data set, respectively. NBM works on the probability calculation method for each class. One of the reasons of getting better accuracies using NBM is that the probability calculation mechanism of NBM algorithm suits this two class problem of sentiment classification.
Classifiers performance on restaurants and hotels data sets.
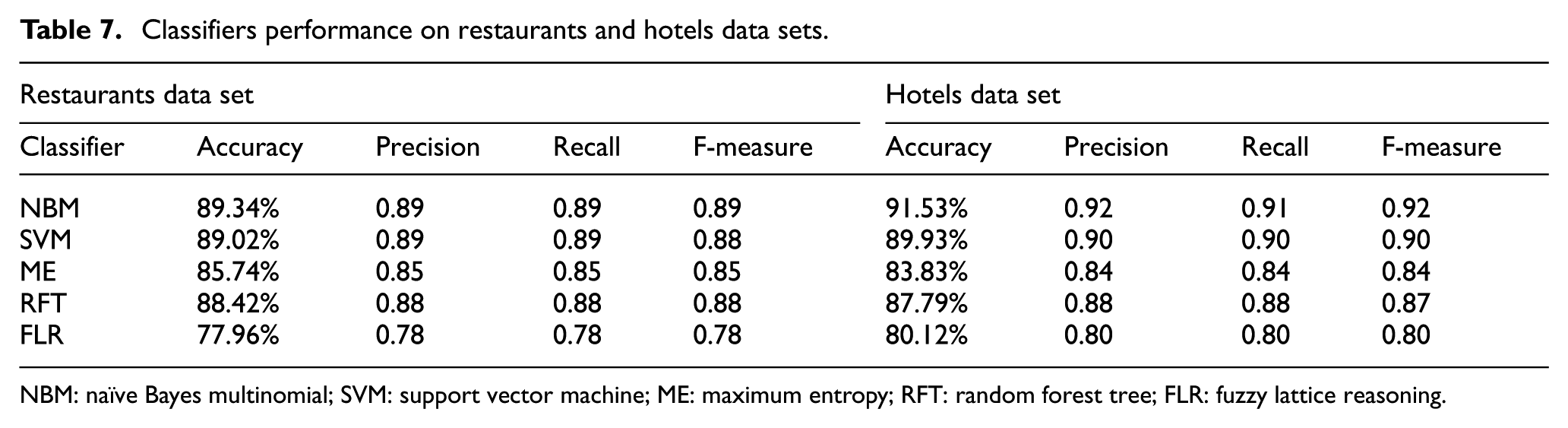
NBM: naïve Bayes multinomial; SVM: support vector machine; ME: maximum entropy; RFT: random forest tree; FLR: fuzzy lattice reasoning.
However, approaches in the past utilised this algorithm without proper pre-processing of the review text data. In our proposed method, the major reason of getting this accuracy improvement for NBM is the proper identification of aspects including implicit, co-referential and infrequent. Moreover, our proposed pre-processing method along with aspect identification mechanism has the power to augment not only NBM but also other classifiers which are known to be very accurate for two class problem such as SVM. Area under the ROC curve is an established measure to determine the supremacy of a classifier. It can be seen from Figures 7 and 8 that ROC curves plotted based also reflect that NBM and SVM outperformed other classifiers for both data sets.

ROC curve on restaurants data set.

ROC curve on hotels data set.
Figures 9 and 10 present accuracy of each algorithm according to the time taken to predict labels of reviews. This experiment was performed on a 64-bit Windows-based system with an Intel core (i7), 2.80 GHz processor machine with 8 Gb of RAM. The results on time-based experiments show that NBM takes the least time on both restaurants and hotels data sets while FLR takes the worst time. We argue that NBM is faster than SVM, ME, RFT, FLR or any other ML algorithm for review-related data sets and scales well with the increase in data size.

Classifiers prediction time with different instances sizes on restaurants data set.
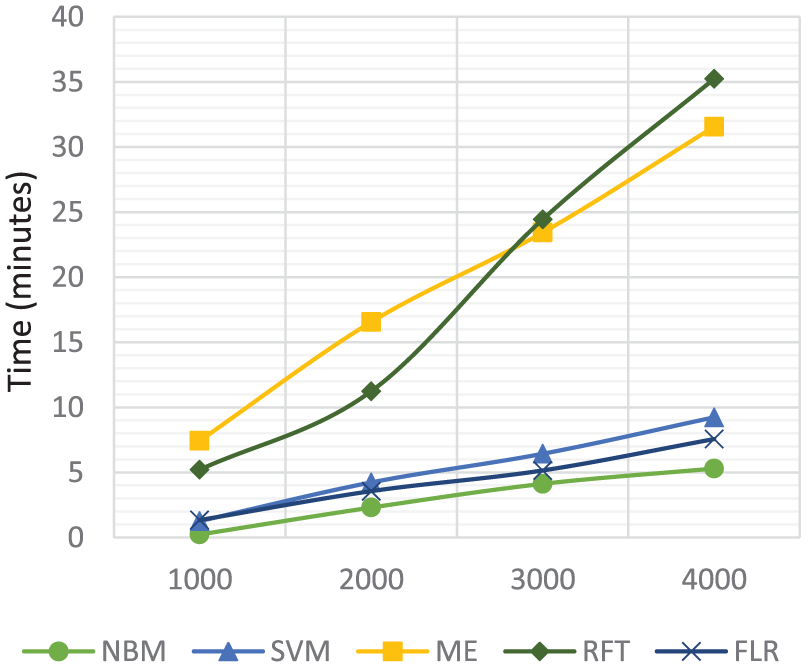
Classifiers prediction time with different instances sizes on hotels data set.
Figures 11 and 12 present the effect of feature types like unigrams, bigrams, trigrams and POS on the performance of aspect-based sentiment classification. We run each algorithm on each feature type. We record that unigrams and POS provide better accuracy with NBM on both data sets, while bigrams and trigrams provide better accuracy with FLR on restaurants data set. The reason is that unigram takes single word for classification, and POS has the advantage of employing rule-based tagging algorithms. This gives an edge to POS over other feature types, as it covers computational linguistics and rule-based mechanisms.
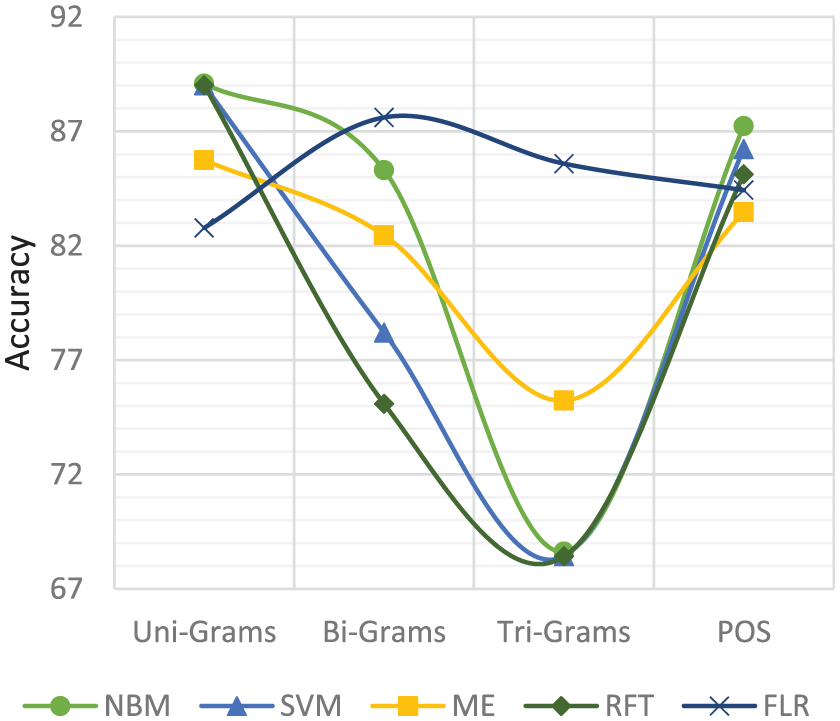
Classifiers performance with different feature types on restaurants data set.
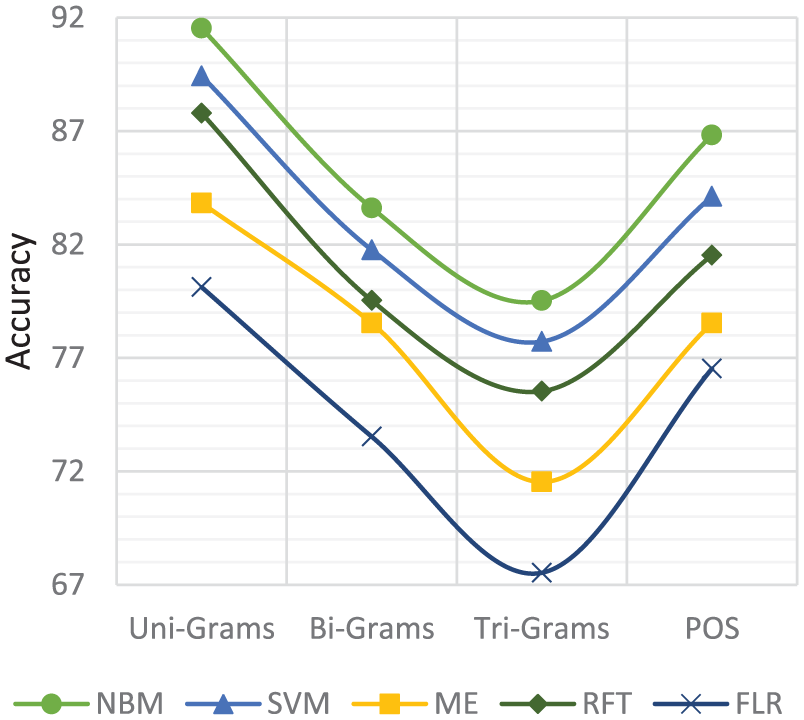
Classifiers performance with different feature types on hotels data set.
Figures 13 and 14 present the effect of feature-weighting methods such as presence, term’s frequency (TF) and term’s frequency with its inverse document frequency (TF-IDF) on the performance of aspect-based sentiment classification. We use the same approach in this experiment as applied in feature types. We run each feature-weighting method on each algorithm. We record that the presence-weighting method provides better accuracy with NBM on both data sets while TF and TF-IDF provide little bit less accuracy than presence.
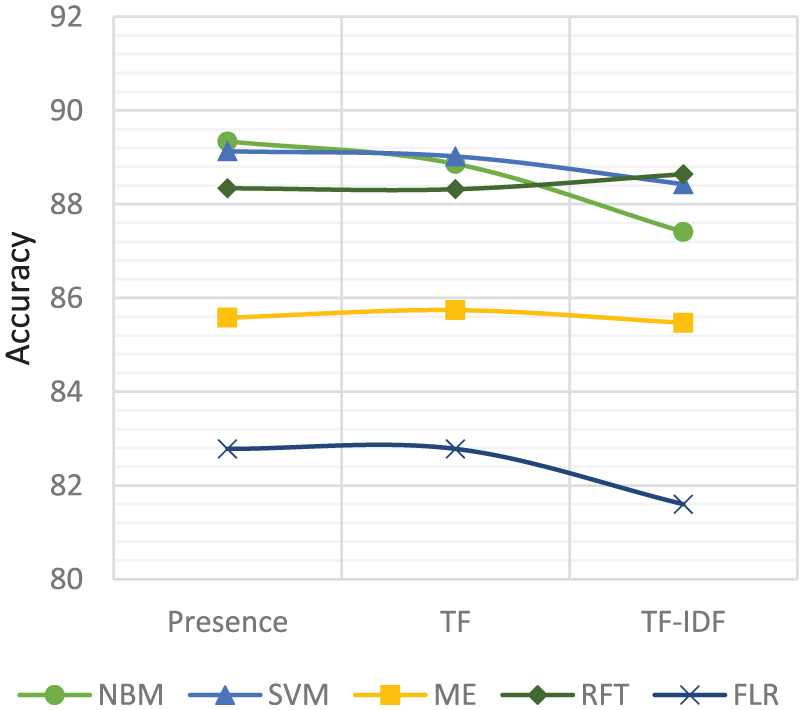
Classifiers performance with different feature methods on restaurants data set.
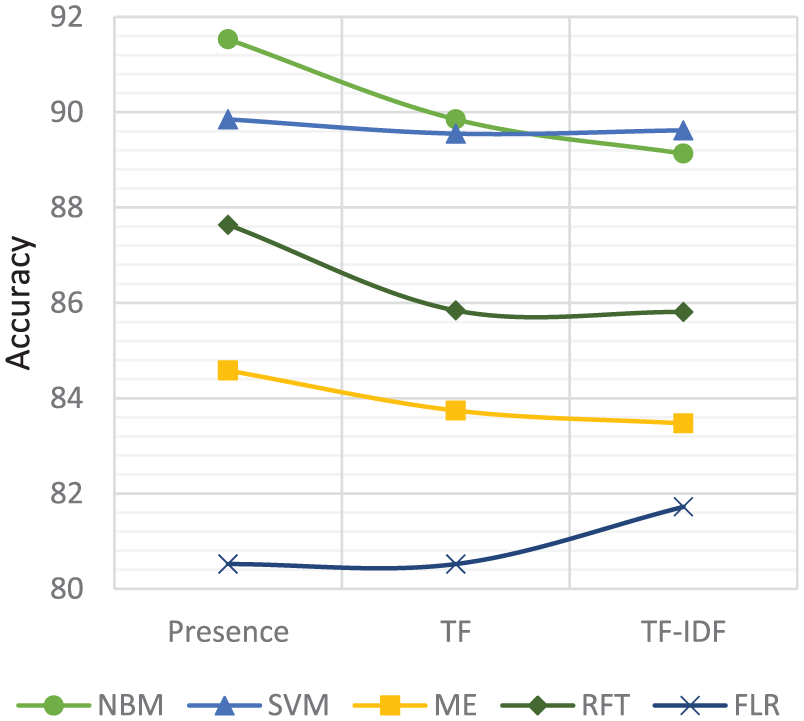
Classifiers performance with different feature methods on hotels data set.
Figures 15 and 16 present effect of data set size on the performance of our proposed framework. We have two major data sets, one of 2000 restaurant reviews and second of 4000 hotel reviews. We split restaurant reviews into four chunks of 500, 1000, 1500 and 2000. Similarly, we split hotel reviews into four chunks of 1000, 2000, 3000 and 4000. We run each algorithm on each data set, and the results show that restaurants data set with 1000 reviews chunk provides better accuracy with NBM and hotels data set with 4000 reviews chunk provides better accuracy with NBM.
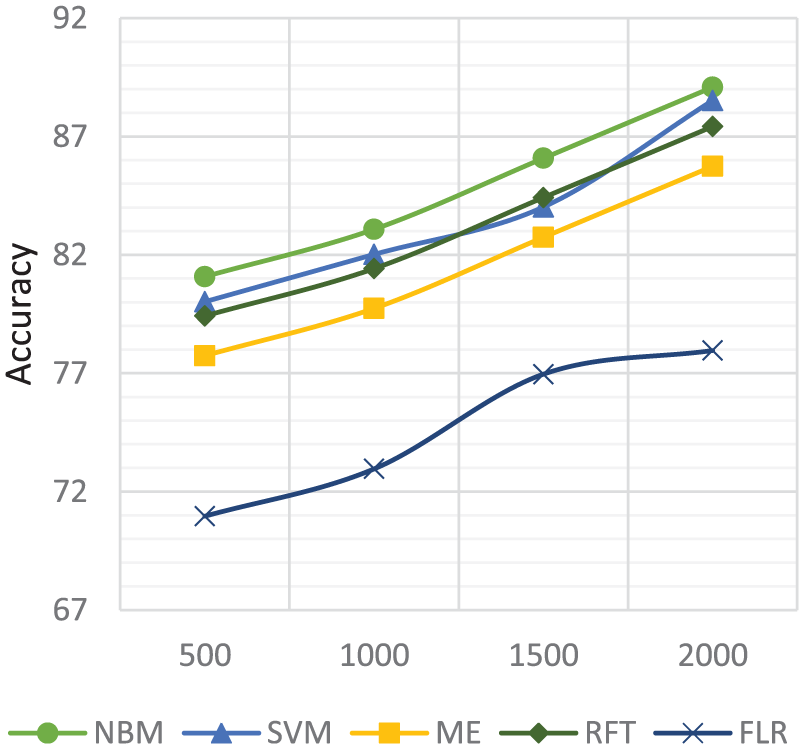
Classifiers performance with different instances sizes on restaurants data set.
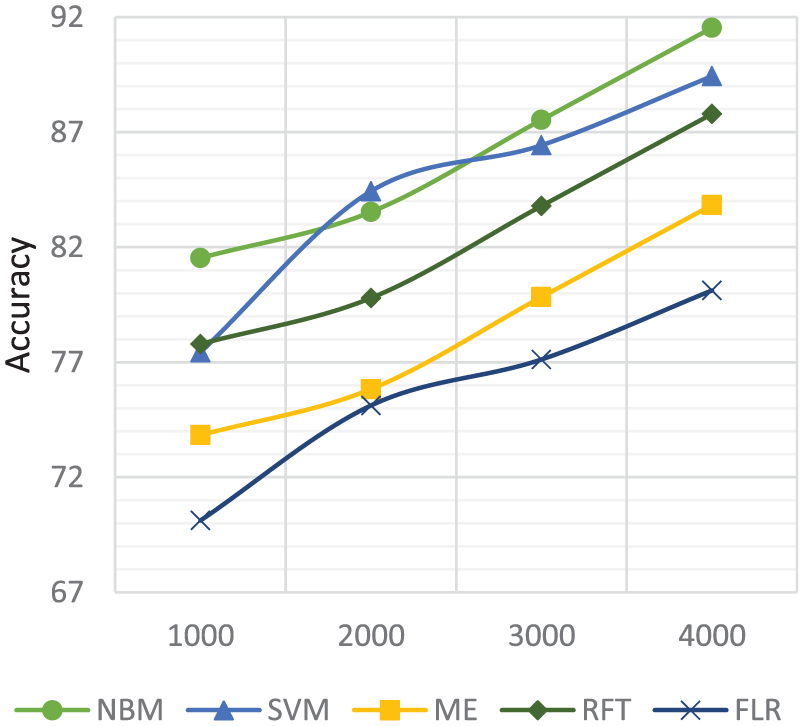
Classifiers performance with different instances sizes on hotels data set.
The proposed framework has been implemented in the form of a mobile application by utilising DrupalGap and PhoneGap technologies. The developed prototype has all the methods incorporated, and it helps the tourist in situations where tourists want to know the best restaurants and hotels in a particular city he plans to visit. The other advantages of this application include intelligent recommendations about tourist places on the basis of aspects ratings, graphical representation of positive and negative opinions regarding each aspect.
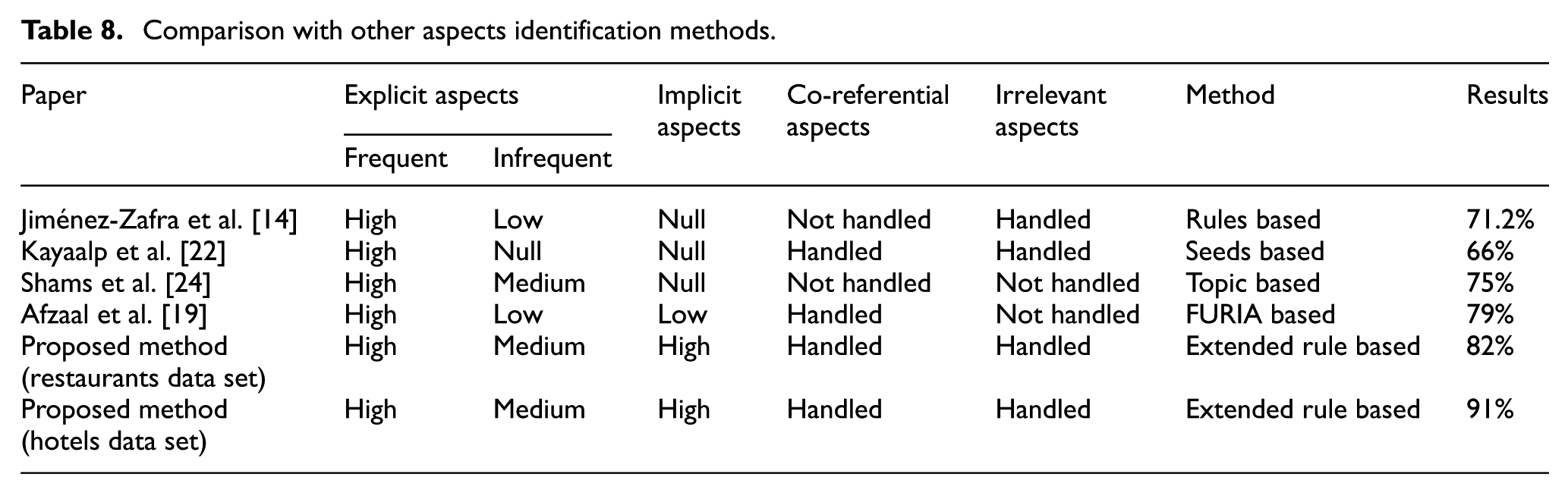
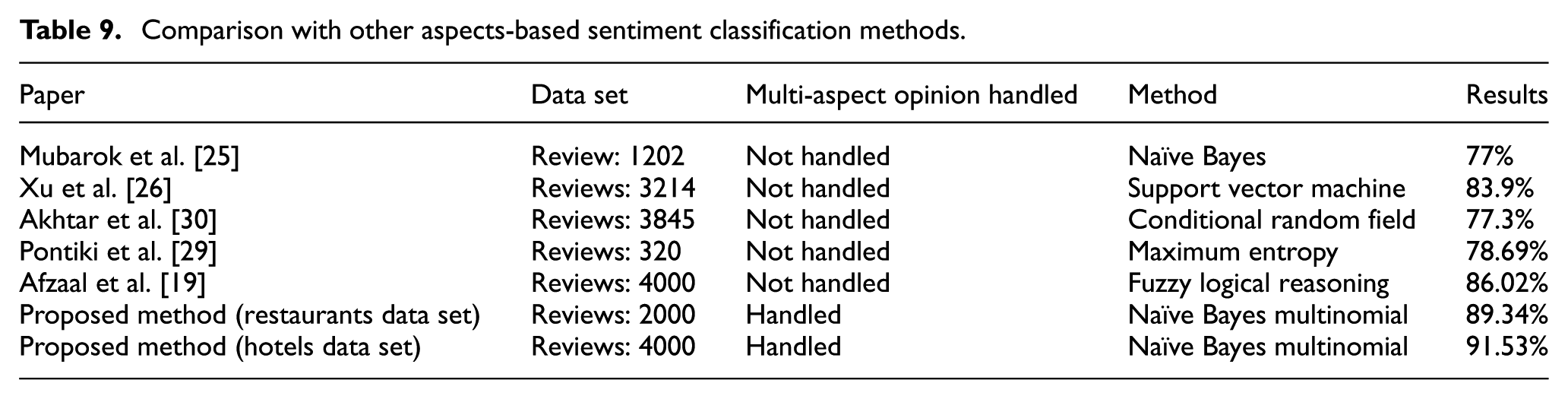
5. Comparative analysis of the results
In this section, our proposed framework of aspects-based sentiment classification was compared with other aspects-based sentiment classification methods reported in the literature. Tables 8 and 9 present this comparison in which the results of our experiments were compared with the similar techniques reported in the literature. It is important to highlight at this point that we have not taken exactly the same data sets for comparison as it is not made available by the authors. We have similar data set and we compare our work in terms of overall accuracy achieved. Moreover, we compare that if the previously reported techniques have handled the various types of aspect using their proposed methods.
Comparison with other aspects identification methods.
Comparison with other aspects-based sentiment classification methods.
The results of comparison show that our proposed framework performs more efficient and improved way during tasks of aspects identification and aspect-based sentiment classification.
In terms of aspect extraction, proposed framework handles irrelevant aspects efficiently by calculating the relevance of each aspect. On the other hand, existing approaches use ‘frequency constraint’ due to which many frequently occurring irrelevant aspects are left to discard. Our framework also focuses on implicit aspects extraction along explicit ones because of their most often occurrence in tourism domain; however, literature work less emphasised on implicit aspects extraction.
In terms of aspect-based opinion classification, proposed framework classifies the multi-aspect opinions into positive or negative by transforming into multiple single-aspect opinions, whereas existing approaches only deal with single-aspect opinions. Moreover, our framework utilised efficient ML algorithms for the classification of these multi-aspect opinions into positive and negative. Finally, we argue that our method outperforms similar methods reported in the past in terms of accuracy. For both data sets, we managed to improve the accuracy percentage from 79% to 91%. This shows that our predictive framework is more accurate, handles more types of aspects and flexible enough to accommodate different ML classifiers to achieve even better results than the reported ones in this study.
6. Conclusion and future work
In this article, a predictive aspect-based sentiment classification framework has been proposed which enables users to classify sentiments regarding the various aspects of a tourist destination. In this framework, a novel aspect identification method has been proposed that automatically identifies the explicit, implicit and co-referential aspects from tourist opinions. An ML algorithm–based opinion classification approach is proposed that classifies the opinion about extracted aspects into positive or negative. Experiments were performed on real-world on data sets taken from restaurant and hotel reviews to evaluate the proposed framework. The results of the proposed framework were better than already reported results in the literature. In aspects extraction, proposed method achieved impressive performance with 82% correctly identified aspects in restaurants data set and 91% correctly identified aspects in hotels data set. In opinion classification method, NBM algorithm showed better results than other ML classifiers with 89.34% and 91.53% accuracy on restaurants and hotels data sets, respectively. A detailed comparative analysis highlights the supremacy of our proposed framework over the exiting similar approaches reported in the past.
In future, we intend to utilise multi-label learning classifiers for classification instead of transforming multi-label review to single label for classification. Moreover, we plan to experiment with the reviews of other tourist attractions, that is, museums, beaches and parks instead of hotel and restaurant reviews which have been used quite often in the aspect-based opinion-mining literature.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.