
Abstract
Classification of medical documents was mostly carried out on English data sets and these studies were performed on hospital records rather than academic texts. The main reasons behind this situation are the lack of publicly available data sets and the tasks being costly and time-consuming. As the first contribution of this study, two data sets including Turkish and English counterparts of the same abstracts published in Turkish medical journals were constructed. Turkish is one of the widely used agglutinative languages worldwide and English is a good example of non-agglutinative languages. While English abstracts were obtained automatically from MEDLINE database with a computer program, Turkish counterparts of these documents were collected manually from the Internet. As the second contribution of this study, an extensive comparison on classification of abstracts obtained from Turkish medical journals was made by using these two equivalent data sets. Features were extracted from text documents with three different approaches: unigram, bigram and hybrid. Hybrid approach includes a combination of unigram and bigram features. In the experiments, three different feature selection methods and seven different classifiers were utilised. According to the results on both data sets, classification performance of the English abstracts outperformed the Turkish counterparts. Maximum accuracies were obtained from the combination of unigram features, distinguishing feature selector (DFS) and multinomial naïve Bayes (MNB) classifier for both data sets. Unigram features were generally more efficient than bigram and hybrid features. However, analysis of top-10 features indicated that nearly half of the features were translations of each other for Turkish and English data sets.
1. Introduction
Astonishing development of web applications and electronic documents has initiated a lot of research areas. Especially in recent years, due to the high availability of computing facilities, an enormous amount of textual data have been generated. These textual data include such texts as news, messages, e-books, reviews and so on. It is very difficult to handle these kinds of data. Text classification, which can be simply defined as assigning documents into predefined categories according to their content, has gained importance due to the increase in textual data [1]. Text classification can be used to solve miscellaneous problems such as spam e-mail filtering [2,3], SMS spam filtering [4,5], topic detection [6,7], author identification [8,9], language identification [10,11], web page classification [12,13], sentiment analysis [14,15] and medical document classification [16,17].
In this study, an extensive comparison was provided for classification of abstracts obtained from Turkish medical journals in order to fill the gap in the literature. These medical journals include abstracts in two different languages: Turkish and English. While Turkish is one of the widely used agglutinative languages worldwide, English is a good example of non-agglutinative languages. There are not so many Turkish data sets for document classification and researchers have still been conducting new studies by adding new data sets to the literature. Some domains in which researchers constructed Turkish data sets can be listed as spam e-mail [18], news [19] and spam SMS [4]. Although there exists a database, namely, TUBITAK’s National Medical Database (see http://uvt.ulakbim.gov.tr/uvt/), similar to MEDLINE, there is no publicly available data set constructed with the help of this database and there is no study using this system’s data in the literature. As an important contribution of this study, two new data sets including abstracts obtained from Turkish medical journals were constructed. These data sets included Turkish and English counterparts of the same abstracts published in Turkish medical journals. Characteristics of these data sets and details about their construction process are explained in the following sections of the article. The second contribution of this study is the comparative analysis of the settings in terms of the best performances on these two new data sets. In the experiments, features were extracted from text documents with three different approaches: unigram, bigram and hybrid. Hybrid approach includes a combination of unigram and bigram features. Experiments were conducted using three different feature selection methods and seven different classifiers. These feature selection methods are information gain (IG), Gini index (GI) and distinguishing feature selector (DFS). Classifiers used in the experiments are C4.5 decision tree (DT), Bayesian network (BN), random forest (RF), multinomial naïve Bayes (MNB) and three different versions of Support Vector Machines (SVM). While the two versions of SVM are linear and non-linear SVM (nSVM), the third one is an ensemble classification approach using SVM. The findings revealed that classification of English medical abstracts seemed slightly more accurate than its Turkish counterpart. However, the highest classification performance was obtained with the combination of unigram features, DFS and MNB classifier for both data sets.
The rest of the article is organised as follows. Section 2 presents related works in the literature. Section 3 briefly explains feature extraction methods used in the study. Section 4 describes the feature selection methods. Section 5 presents the classification algorithms utilised in the study. Construction steps of Turkish and English data sets containing abstracts from Turkish medical journals are explained in Section 6. Section 7 describes the classification scheme used in this study. Section 8 both presents experimental results for the two data sets and gives some information about feature sets obtained. Finally, some concluding results are given in Section 9.
2. Related works
In the literature, many medical document classification studies exist and most of these studies were carried out with the documents in English language. Under the topic of medical document classification, classification of medical abstracts is known as one of the widely studied application field. The main resource that researchers use to construct medical abstract data sets is MEDLINE database. MEDLINE is a bibliographic database including abstracts belonging to medical journals and many automatic text classification studies have been conducted with the data of the MEDLINE. In these studies, data sets containing a particular portion of MEDLINE documents were used. Ohsumed is a widely known example of these kinds of data sets and it contains multi-label documents belonging to 23 disease categories from MEDLINE. Studies using Ohsumed data set without any processing needs to be performed with multi-label classification approaches. In one of these studies, Yetisgen-Yildiz and Pratt [20] performed classification using either words, medical phrases or a combination of words and medical phrases as features. The results showed that constructing feature sets having used combination of words and medical phrases slightly outperformed the other options. Rak et al. [21] analysed the performance of multi-label classifiers based on an associative classifier for the classification of medical articles. Camous et al. [22] used ontology-based approaches for medical document classification. They concluded that their method for extending the representation of documents leaded to an improvement of 17% over a non-extended baseline in terms of normalised utility. Yi and Beheshti [23] proposed a multi-label classification model using hidden Markov models. They stated that the performance of their model was comparable to those reported in the literature. Uysal and Gunal [24] applied a classification approach including SVM, latent semantic indexing (LSI) and genetic algorithms to several text data sets one of which contains a single-label subset of Ohsumed data set. Parlak and Uysal [25] analysed the performance of BN, C4.5 DT and RF trees on a single-label subset of Ohsumed data set. Yepes et al. [26] analysed the impact of different text representations of biomedical texts on the performance of classification. They concluded that even though traditional features such as unigrams and bigrams had strong performance compared with other features, it was possible to combine them to effectively improve the performance of the bag-of-words representation. Furthermore, Parlak and Uysal [16] investigated the impact of feature selection on medical document classification for two data sets containing MEDLINE documents in English. They used two feature selection methods and two classifiers in the experiments. They stated that the most successful setting was the combination of BN classifier and DFS according to the experimental results. Haltas and Alkan [27] retrieved some medical documents in English from MEDLINE database related to cancer diseases and studied on automatic classification of these documents into predefined cancer types using SVM and naïve Bayes classifiers. They reported that the proposed methodology indicated reasonable classification performance. Drame et al. [28] proposed k-nearest neighbours (kNN) and an explicit semantic analysis based approach for large-scale biomedical document classification on a subset of MEDLINE documents. They stated that the kNN-based method with the RF learning algorithm achieved good performances compared with the current state-of-the-art methods.
While many studies are available on classification of medical documents in English, less number of studies exists on classification of medical documents in different languages in the literature. Some of these studies have been conducted in such languages as German [29], Spanish [30] and Turkish [31,32]. However, those studies were carried on by obtaining medical records from hospitals and they were not related to the classification of academic medical documents. The main reason of this situation is that it is difficult to construct data sets including medical abstracts in different languages.
3. Feature extraction
In this study, features were extracted from text documents through three different approaches: unigram, bigram and hybrid. Hybrid approach includes a combination of unigram and bigram features. Both unigram and bigram approaches are specific examples of widely known n-gram text representation. In this representation, either each unique word or a number of consecutive words correspond to a feature. For example, feature extraction for the sentence ‘he is my best friend’ works as follows. Unigram features can be listed as ‘he’, ‘is’, ‘my’, ‘best’ and ‘friend’. On the contrary, bigram features can be listed as ‘he_is’, ‘is_my’, ‘my_best’ and ‘best_friend’. It should be noted that hybrid features are the combination of unigram and bigram features. Documents are represented with weighted values of these features depending on occurrence frequency of the features inside documents. Term frequency inverse document frequency (TF-IDF) is one of the most common methods for weighting features. TF-IDF value of a feature is calculated by multiplying frequency and inverse document frequency of the corresponding feature. The formula of inverse document frequency is presented in equation (1)

In equation (1), D is the number of documents in the collection and

In equation (2),
4. Feature selection
Feature selection is an important step for text classification to reduce dimension and remove irrelevant features. Filter-based feature selection methods are fast in terms of computation and they are mostly preferred for text classification. Three widely known filter-based feature selection methods used in this study are explained below. These feature selection methods are DFS, GI and IG.
4.1. DFS
DFS was developed regarding four predefined criteria [1]. These criteria are defined to obtain a formula which assigns distinctive features to higher values and irrelevant features to lower values. The formula of DFS is presented in equation (3)

In equation (3), M represents the total number of classes.
4.2. GI
GI is an improved version of the method originally used to find the best split of features in DTs [33]. Its formula is shown in equation (4)

In equation (4), M represents the total number of classes.
4.3. IG
IG is one of the popular feature selection methods which is employed as a term significance criterion for text classification [34]. It is based on information theory and its formula is shown in equation (5)
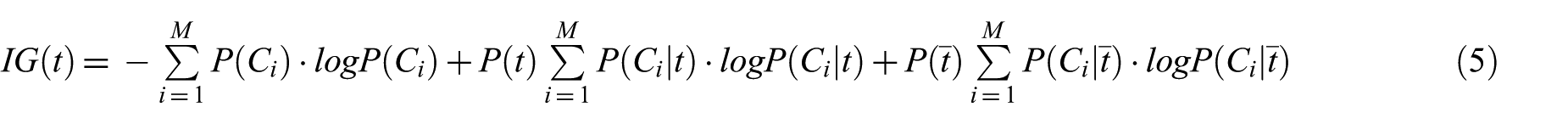
In equation (5), M is the number of classes and
5. Classification algorithms
Seven widely known pattern classifiers have been utilised in this study. These are C4.5 DT, BN, RF, MNB and three different versions of SVM classifiers. Programming API of Weka [35] was used for implementing all classifiers. Detailed information about these classifiers are given in the following subsections.
5.1. C4.5 DT
DT classifier is a widely used classifier which automatically generates hierarchy of decision rules from data. These decision rules are represented as a tree structure where each path ends with a class label assignment. Classification is performed after applying Yes/No decisions along a path of nodes inside tree structure. C4.5 is known as one of the most successful DT classification algorithms.
5.2. BN
BN classifier, which is a belief network, denotes modelling and state transitions. It is frequently used for modelling discrete and continuous variables of data. BN encrypts the relation among different variables in the modelled data. In BN, the nodes are interconnected by arrows to show the direction of the engagement with each other [25].
5.3. RF
RF classifier is an ensemble learning method of DTs. It introduces further randomness into the ensemble operation. Initially, subset of features are randomly selected to construct branches of DTs [36]. Afterwards, training data are created to generate each individual tree. Then, RF classification model is created by combining all individual trees.
5.4. MNB
MNB classifier is a specialised naïve Bayes classifier developed especially for text classification. Multinomial keyword especially represents the event model used during construction of this naïve Bayes classifier. Multinomial and multi-variate Bernoulli event models are widely used for text classification [34]. The difference between multinomial and multi-variate Bernoulli event models is related to the calculation of a part of the formula. While multinomial model takes term frequencies into account, multi-variate Bernoulli event model uses document frequencies in this calculation.
5.5. SVM
SVM is one of the most successful classifiers in the field of text classification. SVM has many advantages such as being effective in high dimensional spaces and in cases where number of dimensions is greater than the number of samples, using a subset of training points in the decision function and being memory efficient. The main point of the SVM classifier is the concept of margin [37]. Classifiers use hyperplanes to separate classes. SVM can be regarded as a linear or non-linear classifier depending on the kernel function used. However, it is possible to use SVM while constructing ensemble classification approaches. There exist such methods as bagging and boosting [38] for constructing ensemble classification approaches.
In this study, three different versions of SVM are utilised. First of all, the linear version of SVM, known as one of the most successful classifiers especially in text classification, is employed. Second, the nSVM is employed. Finally, an ensemble classification approach using SVM (bSVM) is employed. Bagging method is used while constructing the ensemble classification approach using nSVM.
6. Data set construction
The main difficulty for constructing a data set consisting of Turkish medical abstracts is the costly process of annotation. Besides, selecting the document to be used as medical abstracts among so many documents on the Internet is another difficulty of the construction process. For experimental work, we constructed two data sets which include Turkish and English counterparts of the same MEDLINE documents. While Turkish is one of the widely used agglutinative languages worldwide, English is a good example of non-agglutinative languages. These documents are abstracts of articles published in Turkish medical journals. In this study, a different approach was used to construct these data sets with the help of a previous study [16]. As a part of the previous study, a data set including English abstracts of Turkish medical journals was constructed using PubMed (see http://www.ncbi.nlm.nih.gov/pubmed). PubMed is a search platform used for query and retrieving specific documents from MEDLINE database. The data set in the previous study was constructed using queries in 23 disease categories in MEDLINE database. These categories were the same with the ones used in Ohsumed data set including a subset of MEDLINE documents. In this study, a second data set containing Turkish counterparts of the documents in the previous study was constructed. However, it was not possible to retrieve Turkish counterparts of these documents automatically. Therefore, Turkish counterparts of the documents retrieved from PubMed search platform was collected manually from the Internet by the authors and some volunteers. Class information in the first data set was used for this data set. The construction steps of these two data sets are shown in Figure 1.
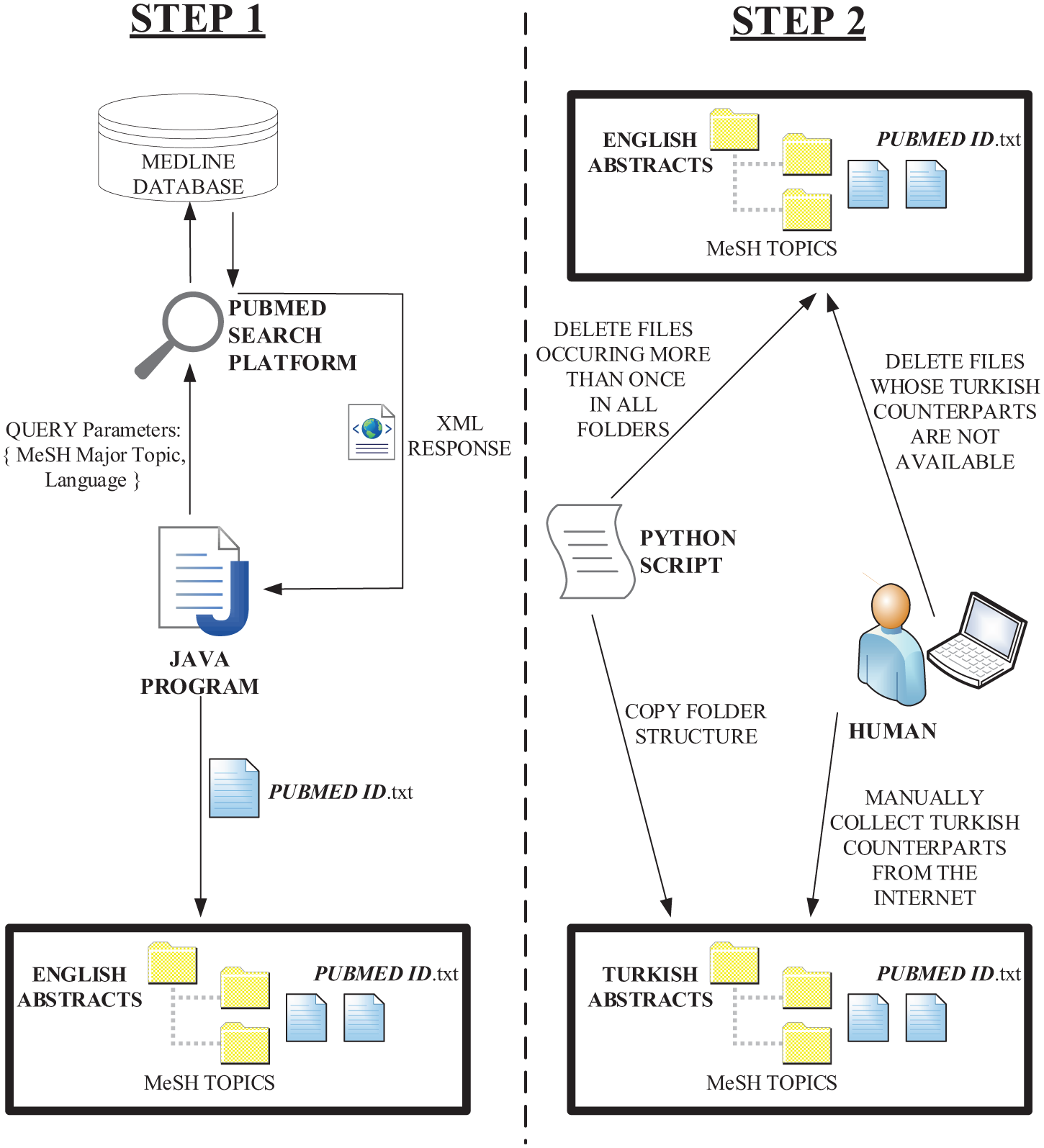
Construction process of Turkish and English data sets.
As seen in the figure, data sets were constructed in two steps. Step 1 started with the query and retrieving records from MEDLINE database with the help of PubMed search platform. Twenty-three disease categories in Ohsumed data set were used in the construction process of these data sets. For queries, MeSH major topic parameter was set as disease categories and language parameter was set as ‘Turkish’ for each query. It should be noted that the term MeSH means medical subject headings [39]. After 23 separate queries, data were retrieved and saved into 23 different folders with a naming convention including PubMed ID values. Each document contains a title and an abstract of medical article consecutively as in the Ohsumed data set. XML documents retrieved from MEDLINE database contain some fields such as the title in English, title in Turkish and abstract in English. Title in English corresponds to <ArticleTitle> and title in Turkish corresponds to <VernacularTitle> in this XML file. An XML parser was used to extract the information and save the files with a standard naming convention including PubMed ID values.
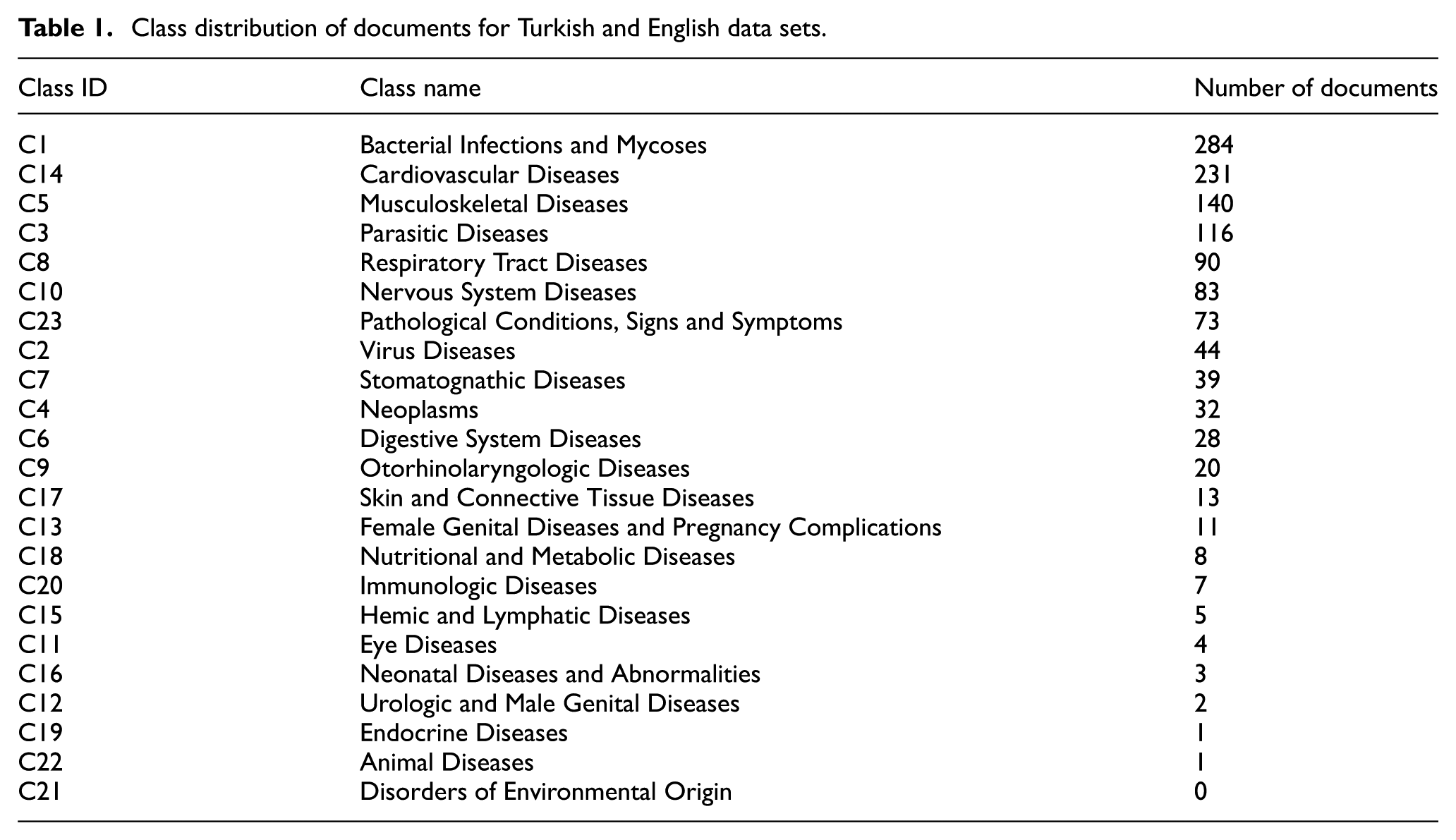
In the beginning of Step 2, we removed documents existing in multiple folders at the same time. We used PubMed ID values in order to detect these kinds of situations. Only the documents not existing in multiple folders were kept. The reason behind this removal was the multi-label structure of MEDLINE database. As the subject of this study was the single-label classification of medical documents, it was necessary to guarantee to have only single-labelled documents. Manual collection of Turkish counterparts of these documents was a difficult part of the study. Authors and some volunteers searched the Internet using bibliographic information obtained before. While some of the articles were found as text documents, some of them were found as PDF files. The information in many of the PDF files was extracted with the help of some conversion tools. A few of them were very old and they had been published in scanned images. These kind of contents were transferred into text files by dictating the text manually. Turkish counterparts of some documents were not available on the Internet. Therefore, we removed the files not having a Turkish equivalent from the data set including medical documents in English in order to equal two data sets. At the end of the second part, two data sets having the same medical abstracts in Turkish and English were constructed. Table 1 shows the distribution of documents for each data set regarding classes.
Class distribution of documents for Turkish and English data sets.
These two data sets are referred as Turkish and English abstract data sets in the following sections. Both of these two data sets contain 1235 medical abstracts. In these two data sets, the publication year of the articles changes from 1976 to 2014. The collection, namely, TurkishMedDoc v1.0, including these two data sets, is publicly available at http://ceng.eskisehir.edu.tr/par/TurkishMedDoc_1_0.zip for researchers.
There is not enough number of documents for some disease categories and there is not any document for one class, so 10 classes having the largest number of documents were used in the experiments. So, the classes used in the experiments are C1, C2, C3, C4, C5, C7, C8, C10, C14 and C23. The total number of documents used in the experiments from both data sets are 1132.
7. Classification scheme
The main research objective of this study is to detect successful settings for classification of medical documents besides providing publicly available data sets for researchers. In this study, an extensive comparison on classification of abstracts obtained from Turkish medical journals was provided by using two data sets in different languages. The text classification scheme showing the flow of the experiments is visualised in Figure 2.
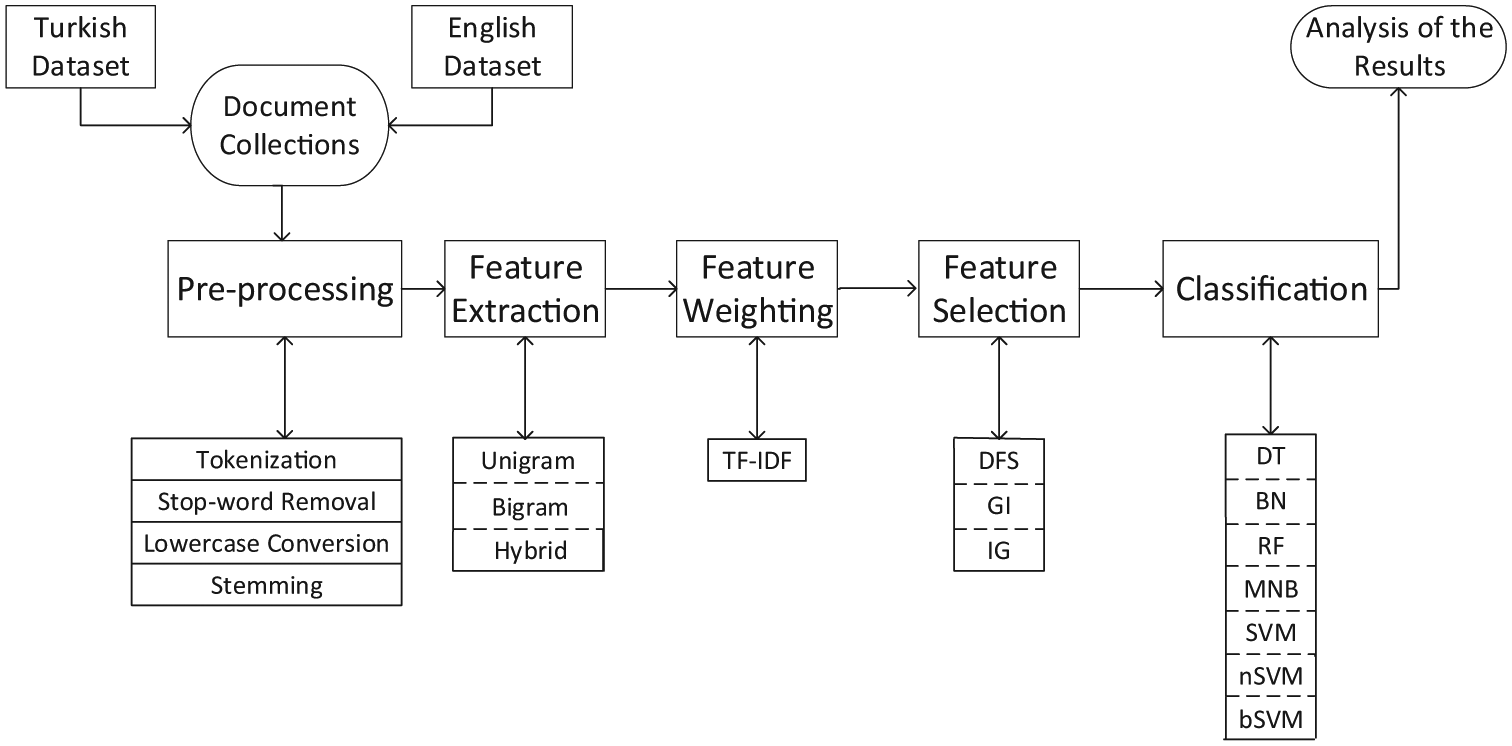
Classification scheme used in the study.
Experiments were conducted using various settings for feature extraction, feature selection and classification. In the figure, the dotted boxes indicate that only one of the following options is utilised in the corresponding experiments. As shown in the figure, tokenization, stop-word removal, lowercase conversion and stemming are default preprocessing operations for all of the experiments. It should be noted that stemming algorithms vary for documents in different languages. Zemberek [40] and Porter [41] algorithms were used for stemming in Turkish language and English language, respectively. One of the three different text representation approaches, namely, unigram, bigram and hybrid, was applied in the feature extraction step. TF-IDF term weighting was applied in the feature-weighting step. One of the three feature selection algorithms, namely, DFS, GI and IG, was utilised. Then, one of the seven classification algorithms was employed to evaluate the performances of feature vectors obtained in the previous steps. Finally, the performances of various classification settings were evaluated in order to detect the settings providing better performances.
8. Experimental works
In the experiments, widely known F score [25] was used to analyse the performance of classification. Ten largest classes for each data set were included in the experiments and 10-fold cross-validation method was applied for fair evaluation. In the following subsections, accuracy and feature set analysis conducted in these two data sets were explained in detail.
8.1. Accuracy analysis
Varying numbers of the features which were selected by each selection method were fed into DT, BN, RF, MNB and different versions of SVM classifiers. Dimension reduction was carried out through constructing feature sets with 300, 500, 1000 and 2000 features. It should be noted that the total number of unigram features are 14,424 and 8989 for Turkish and English data sets, respectively. However, the total number of bigram features are 103,580 and 83,639 for Turkish and English data sets, respectively. Also, the total number of hybrid features are 118,004 and 92,628 for Turkish and English data sets, respectively. Resulting F score values are listed in Tables 2–10 for Turkish abstract data set where the highest scores are indicated in bold.
F scores for Turkish abstract data set using DFS (unigram features).
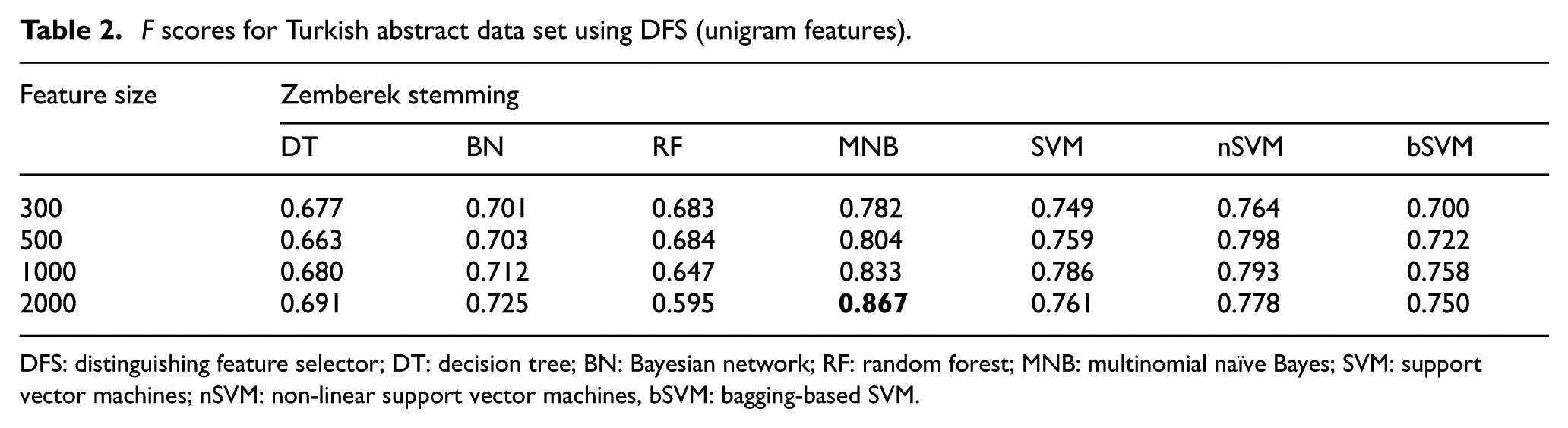
DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines, bSVM: bagging-based SVM.
F scores for Turkish abstract data set using DFS (bigram features).
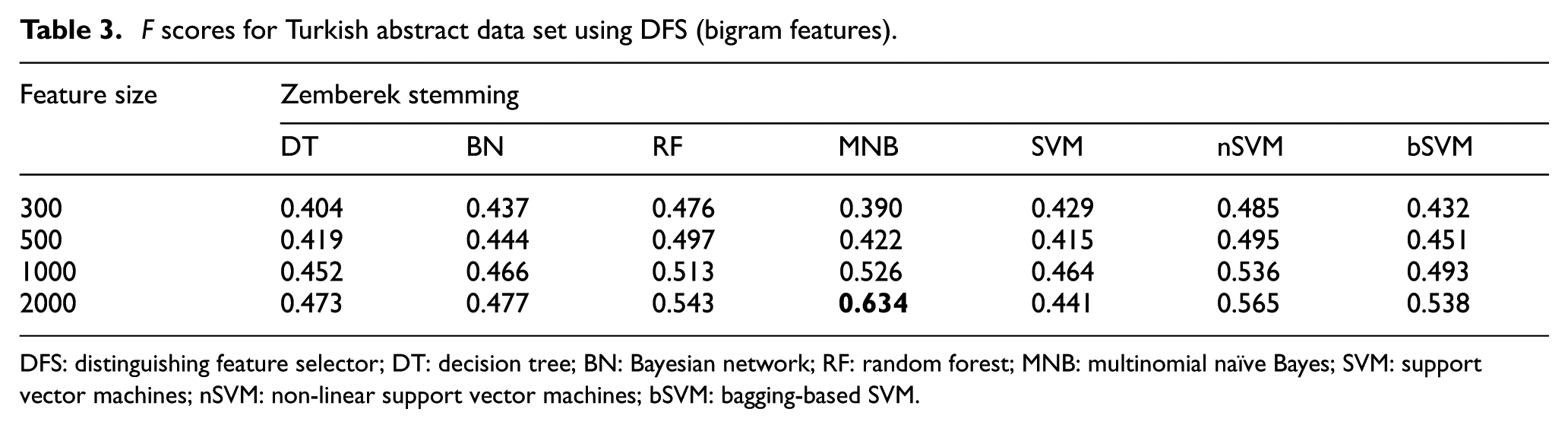
DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using DFS (hybrid features).
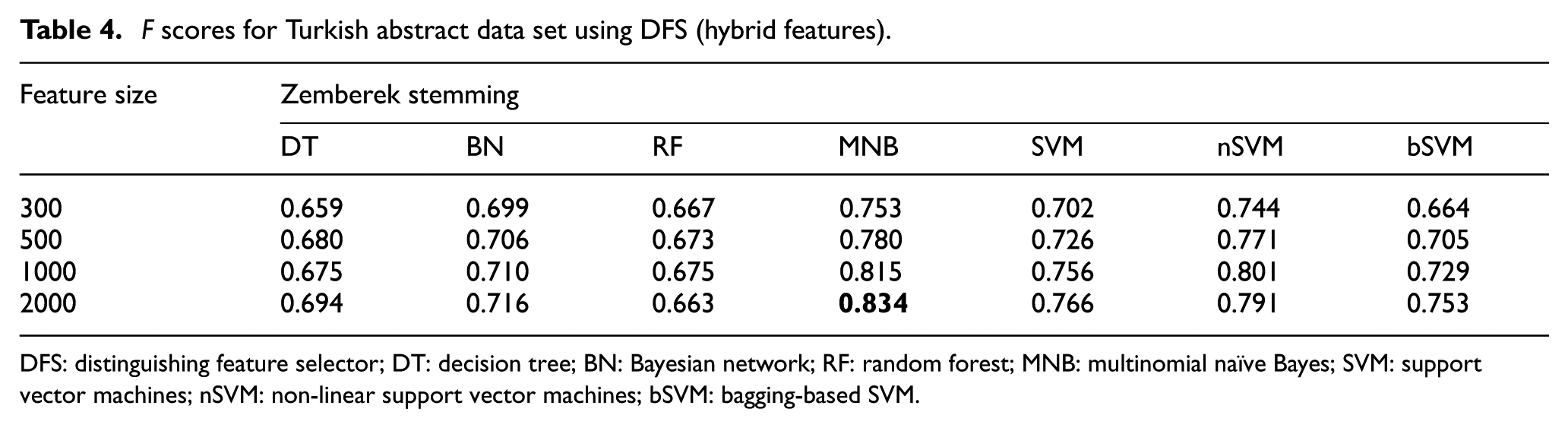
DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using IG (unigram features).

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using IG (bigram features).

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using IG (hybrid features).

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using GI (unigram features).

GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using GI (bigram features).
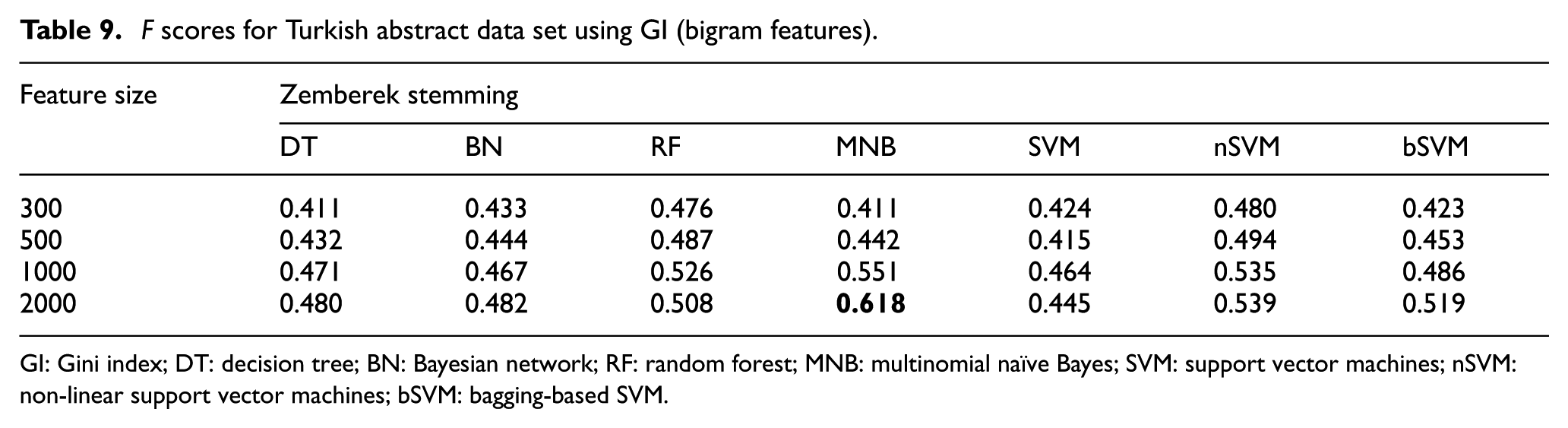
GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for Turkish abstract data set using GI (hybrid features).
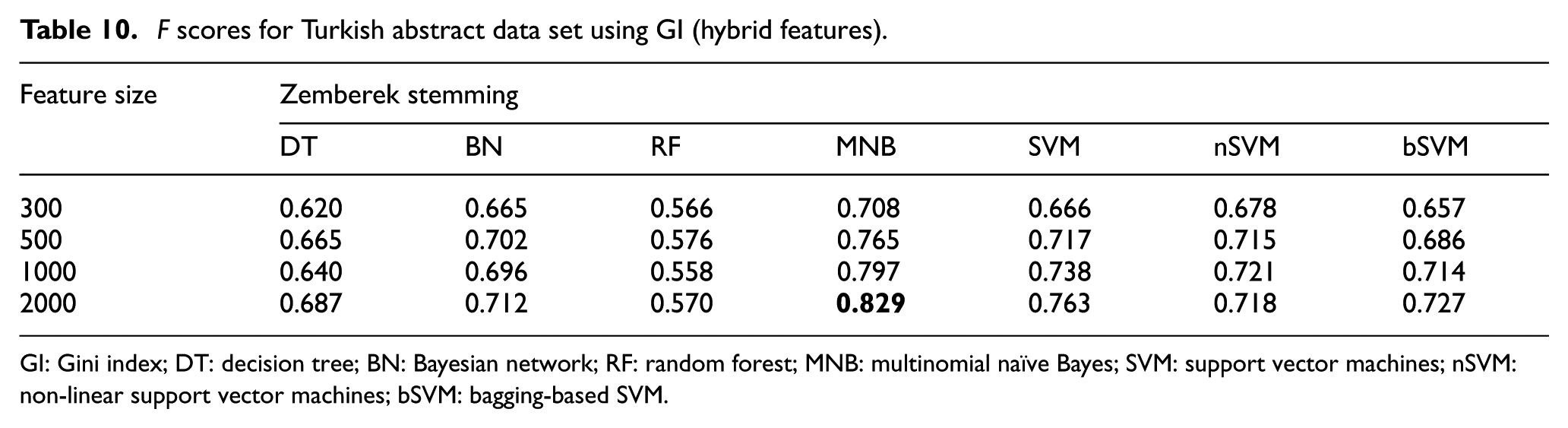
GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
For Turkish abstract data set, highest F score value is 0.867. It is obtained with the combination of unigram features, DFS feature selection method and MNB classifier. SVM classifier, which is generally nSVM (non-linear) version, is the successor classification algorithm for most cases. nSVM generally performed better than other versions of SVM on Turkish data set. For Turkish abstract data set, it is possible to conclude that bigram features generally decrease the performance of classification. However, especially for DT and RF classifiers, hybrid features sometimes can be more efficient than unigram features.
Resulting F score values of English abstract data set are listed in Tables 11–19 where the highest scores are indicated in bold. For English abstracts data set, highest F score value is 0.903. It is obtained with the combination of unigram features, DFS feature selection method and MNB classifier. Linear version of SVM classifier is the successor classification algorithm for most cases. Linear SVM classifier generally performed better than the other versions of SVM on English data set. It is possible to conclude that bigram features generally decrease the performance of classification for English abstracts data set similar to the case in its Turkish counterpart. However, especially for RF classifier, hybrid features sometimes can be more efficient than unigram features.
F scores for English abstract data set using DFS (unigram features).

DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using DFS (bigram features).
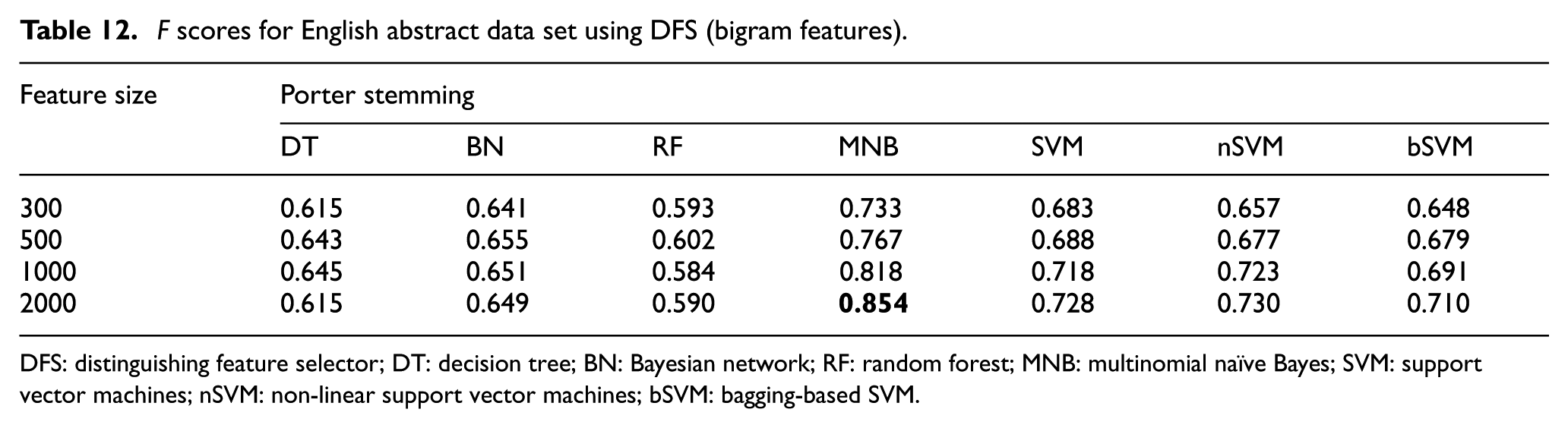
DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using DFS (hybrid features).
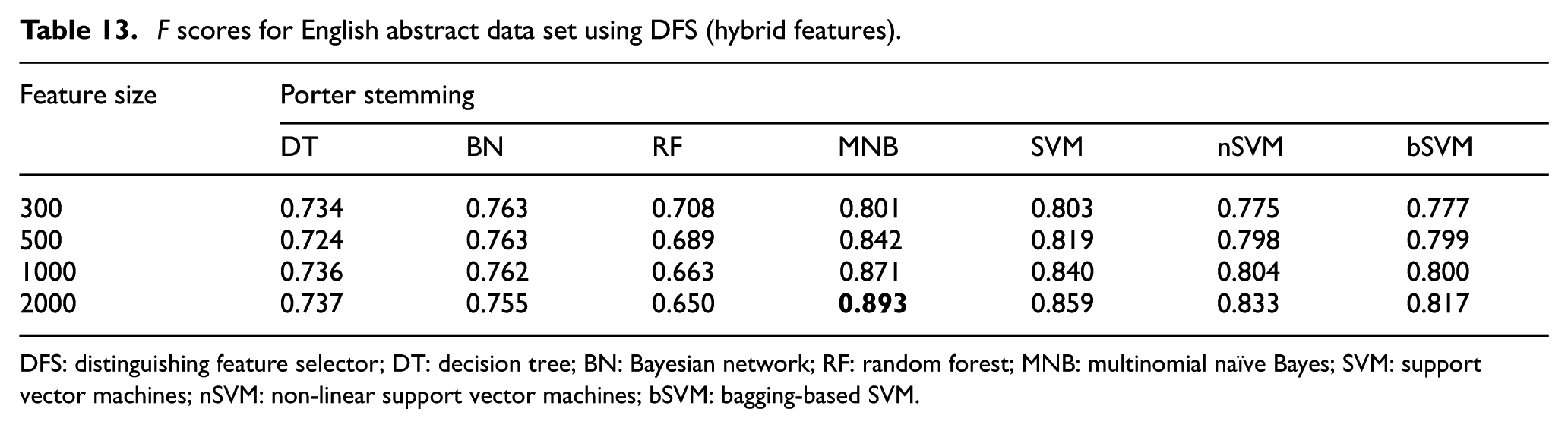
DFS: distinguishing feature selector; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using IG (unigram features).

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using IG (bigram features).

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using IG (hybrid features),

IG: information gain; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using GI (unigram features).

GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using GI (bigram features).
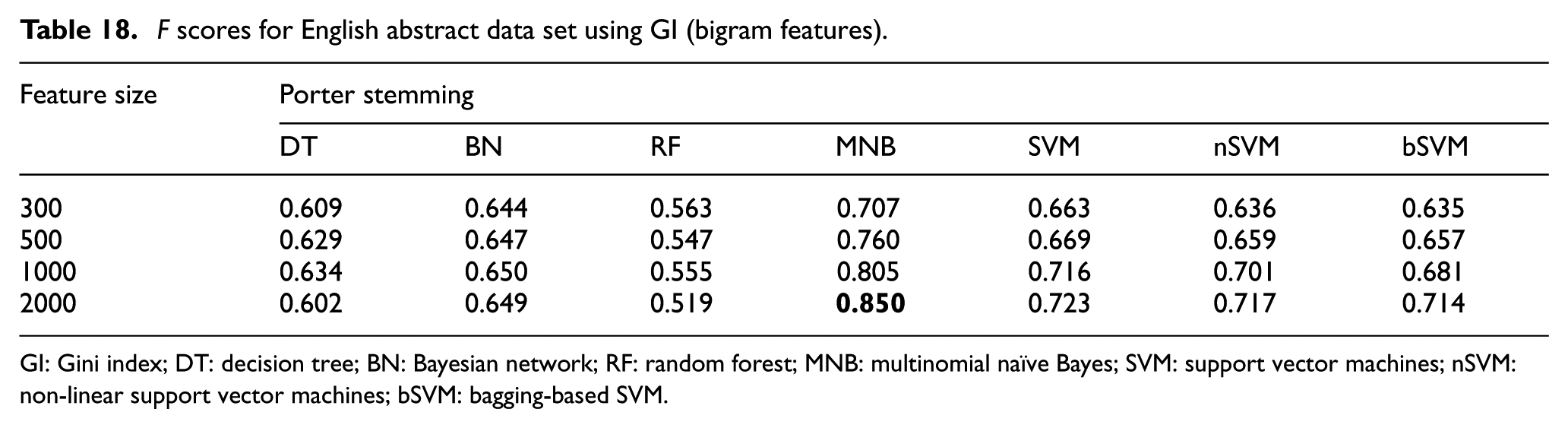
GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
F scores for English abstract data set using GI (hybrid features).

GI: Gini index; DT: decision tree; BN: Bayesian network; RF: random forest; MNB: multinomial naïve Bayes; SVM: support vector machines; nSVM: non-linear support vector machines; bSVM: bagging-based SVM.
While the range of F score values are between 0.404 and 0.867 for Turkish data set, they are between 0.509 and 0.903 for English data set. According to the results on both data sets, classification performance of medical abstracts in English seems more accurate than classification of the same abstracts in Turkish. Maximum accuracies were obtained with the combination of unigram features, DFS feature selection method and MNB classifier for both data sets. Unigram features are generally more efficient than bigram and hybrid features. It should be noted that employing only bigram features always decreases the classification performance for both data sets. The total number of bigram features is more than the number of unigram features. In order to obtain a better performance using bigram features with such feature dimensions, data sets must include many consecutive tokens or terms which can be regarded as phrase. We can infer that the nature of the data sets including medical abstracts does not include so many common phrases which can be detected using bigrams. Besides, it should be noted that F score is the harmonic mean of precision and recall. While precision is the fraction of relevant instances among the retrieved instances, recall is the fraction of relevant instances that have been retrieved over the total amount of relevant instances. When only bigram features are employed instead of unigram features, both precision and recall scores decrease in general according to the further investigation of the results. As F score is the harmonic mean of precision and recall, there is a decrease in F score values. Provided bigram features are used, IG and DFS are the best performers for Turkish and English data sets, respectively. However, when hybrid features are used, DFS is the best performer for both Turkish and English data sets. Although maximum F score is obtained with unigram features for both data sets, hybrid features sometimes perform more efficiently than unigram features especially for RF classifier. For most cases, maximum F score was obtained with 2000 features for both data sets. In terms of feature selection, DFS is generally superior to IG and GI for both data sets. While the linear SVM performed better than the other versions of SVM on English data set, the nSVM performed better than the other versions of SVM on Turkish data set. Besides, classification performance generally increases in direct proportion to the feature size.
8.2. Feature set analysis
In this study, Turkish and English counterparts of the same documents were used in the experiments. So, it was necessary to analyse especially feature sets in lower dimensions in order to find out the similarities between two different languages. For this purpose, top-10 features for Turkish and English data sets obtained with three different feature extraction methods are presented in Tables 20–22. These tables also present feature sets regarding three different feature selection methods. In Tables 20–22, features whose meanings are same in Turkish and English are written in italic letters.
Top-10 features for Turkish and English abstract data sets (unigram features).
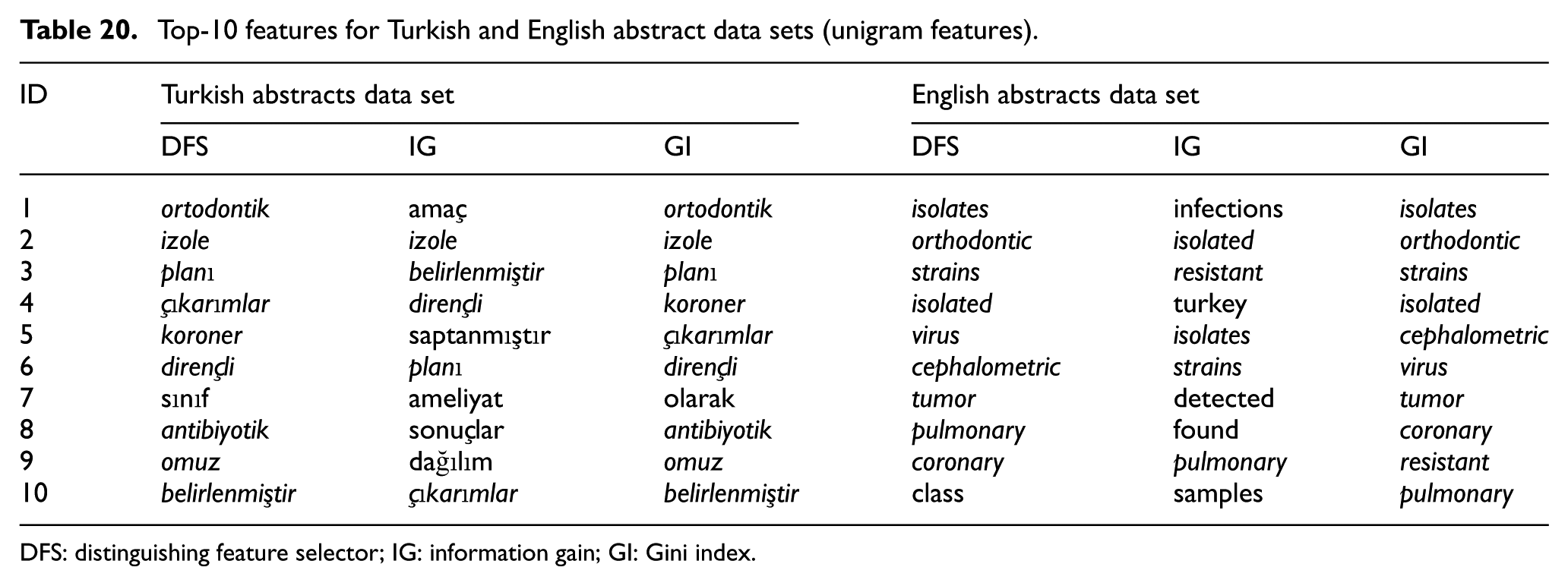
DFS: distinguishing feature selector; IG: information gain; GI: Gini index.
Top-10 features for Turkish and English abstract data sets (bigram features).
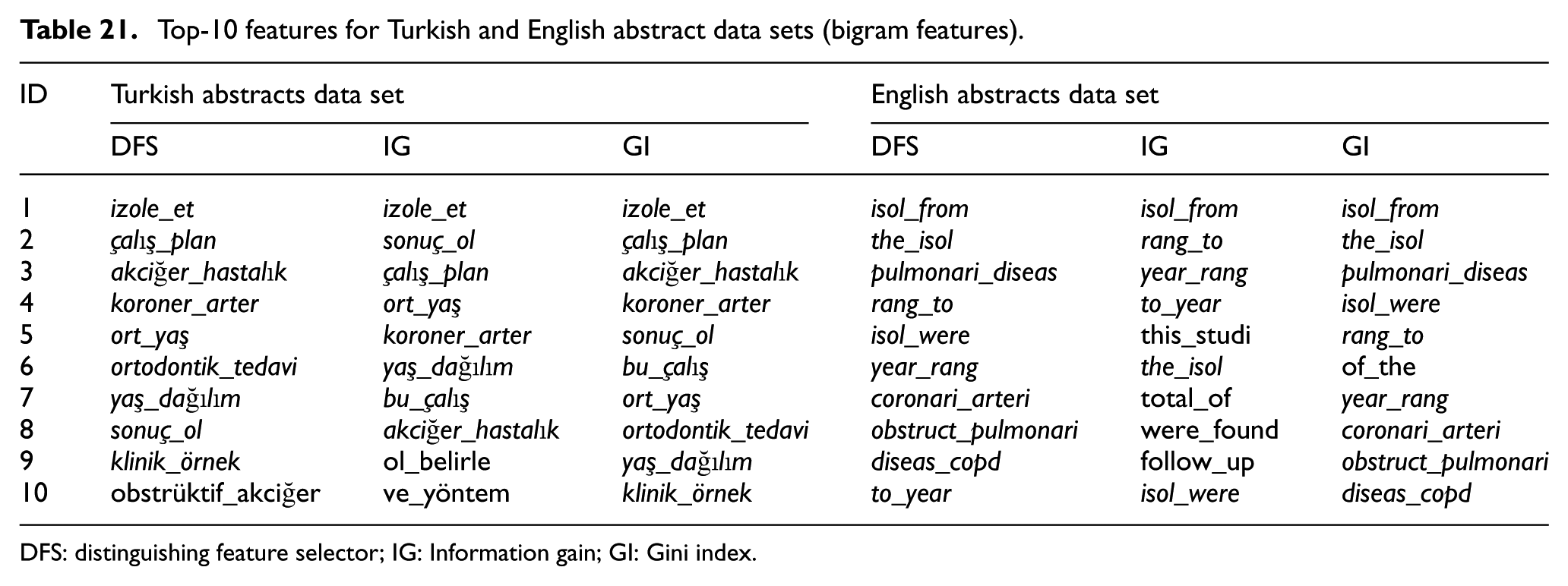
DFS: distinguishing feature selector; IG: Information gain; GI: Gini index.
Top-10 features for Turkish and English abstract data sets (hybrid features).
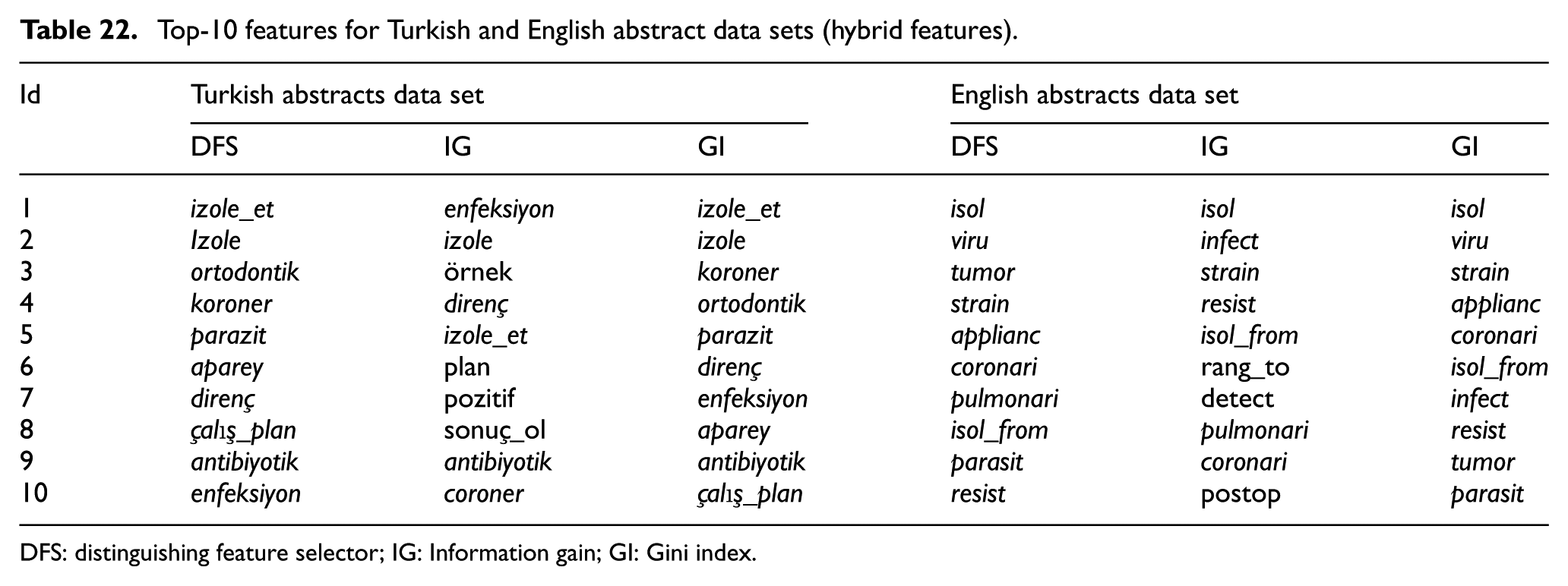
DFS: distinguishing feature selector; IG: Information gain; GI: Gini index.
As seen in the Tables 20–22, around half of the features are translations of each other for Turkish and English data sets. Although these two languages have different characteristics, feature sets of the same medical documents in different languages seem quite similar. As seen in the Table 22, top-10 hybrid features generally include one or two bigram features and most of the features are derived from unigram features. Discriminative features are generally medical terms rather than terms used in daily language. For example, the word ‘coronary’ in English abstract data set exist in top-10 features and the word ‘koroner’ as its Turkish translation exist in top-10 features for Turkish abstracts data set, as well. However, different forms of the word ‘isolate’ is repeated several times inside discriminative features in English data set.
9. Conclusion
In this study, we constructed two data sets consisting of Turkish and English counterparts of the same abstracts obtained from Turkish medical journals. An extensive comparison on classification of abstracts obtained from Turkish medical journals was provided by using these two equivalent data sets. Features were extracted from text documents with three different approaches: unigram, bigram and hybrid. Hybrid approach includes a combination of unigram and bigram features. Classification performances on these two data sets were analysed using three feature selection methods and seven pattern classifiers. According to the experimental results, classification of medical abstracts in English seems more accurate than their counterparts in Turkish. MNB classifier seems more successful than SVM, nSVM, bSVM, DT, BN and RF classifiers on both data sets. The idea behind MNB classifier is the assumption of independence between features. According to the results, we can infer that the independence assumption for the data sets including medical abstracts is strongly supported. Unigram features are generally more efficient than bigram and hybrid features. In terms of feature selection, DFS is generally superior to IG and GI in both data sets. DFS specifically focuses on four pre-determined criteria while ranking features. We can infer that the nature of these data sets including medical abstracts well suits to these kinds of pre-determined criteria. As a future work, some approaches such as LSI and latent Dirichlet allocation (LDA) may be applied in order to show the effect of feature transformation on classification of Turkish and English medical abstracts. Also, the impact of stemming and some other text representation methods in both languages may be investigated.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Anadolu University, Fund of Scientific Research Projects under grant number 1503F136.