
Abstract
Wikipedia is becoming increasingly critical in helping people obtain information and knowledge. Its leading advantage is that users can not only access information but also modify it. However, this presents a challenging issue: how can we measure the quality of a Wikipedia article? The existing approaches assess Wikipedia quality by statistical models or traditional machine learning algorithms. However, their performance is not satisfactory. Moreover, most existing models fail to extract complete information from articles, which degrades the model’s performance. In this article, we first survey related works and summarise a comprehensive feature framework. Then, state-of-the-art deep learning models are introduced and applied to assess Wikipedia quality. Finally, a comparison among deep learning models and traditional machine learning models is conducted to validate the effectiveness of the proposed model. The models are compared extensively in terms of their training and classification performance. Moreover, the importance of each feature and the importance of different feature sets are analysed separately.
1. Introduction
Since 2001, Wikipedia has become the most popular web-based, collaboratively edited document repository. The quality improvement of articles has been the main concern for Wikipedia [1]. Currently, there are approximately 40 million articles in more than 270 languages. In contrast to traditional media, users can not only access the information but also edit Wikipedia content immediately and arbitrarily. There are few staff members who review users’ modifications before they are published [1]. Due to its large volume and flexibility, Wikipedia has attracted substantial attention from academia and industry.
Recently, Wikipedia has grown considerably. However, its growth raises a serious challenge: How good is the information quality in Wikipedia? Another issue is that only 0.1% of the articles are of high quality [1,2]. Therefore, there is a strong demand to improve article quality. First, we need to measure article quality, but there are so many articles that it is infeasible to assess every article manually. Some researchers have proposed statistics or formulas to measure article quality [3,4]. However, some of these metrics are so oversimplified that they cannot accurately assess article quality. In addition, some methods are not automatic and need considerable human labour. Traditional machine learning algorithms, such as support vector regression (SVR) and k-nearest neighbours (KNN), have also been applied [5–11]. Although there are some automatic classification methods, their performances are unsatisfactory. In addition, some methods fail to use comprehensive feature sets when training models. Moreover, some models treat the quality classification problem as a one-class classification problem, which leads to a nonexclusive classification result. Since there is a specific classifier for each class, it might result in one sample belonging to multiple classes at the same time. To solve these problems, a deep learning-based multiclass quality assessment model with a comprehensive feature framework is proposed. Our contributions are as follows.
To the best of our knowledge, this is the first comprehensive and extensive comparison of state-of-the-art deep learning models and traditional machine learning models such as the convolutional neural network (CNN), deep neural network (DNN), long short-term memory (LSTM), CNN-LSTM, bidirectional LSTM (biLSTM), stacked LSTM, KNN, support vector machine (SVM), naïve Bayes and decision tree in terms of assessing Wikipedia article quality.
A comprehensive feature framework is proposed and used for deep learning models.
A detailed and complete comparison of deep learning models and several traditional machine learning models is conducted from different dimensions, including classification performance and training performance.
The importance of different features and feature sets is investigated separately, which can provide better guidelines for feature selection.
The remainder of this article is organised as follows. Section 2 investigates the related work. Section 3 summarises the different features that represent articles. Section 4 introduces the basic concept of deep learning models and how models handle features. Section 5 introduces the Wikipedia data set and discusses the experimental results. Finally, Section 6 concludes the article.
2. Related work
In this section, we discuss how to assess the quality of Wikipedia articles using different existing approaches, and we also analyse the previous feature framework and attach the contributions of the article at the end of the section.
Wikipedia has been the most popular online encyclopaedia and knowledge database. However, the quality of the articles on Wikipedia is a serious issue since any users can edit content in Wikipedia immediately and arbitrarily. It is infeasible to estimate each article quality manually, so an efficient and automatic approach is necessary. In this section, studies on the quality assessment of Wikipedia articles are discussed.
Previous studies employed formulas or statistics to assess article quality. Some studies hypothesised that the author was the critical factor affecting article quality. Hu et al. [12] assessed Wikipedia quality based on contributions and the authority of contributors. de La Robertie et al. [3] proposed a generic formulation between authors’ interactions and article quality score. The model was tested by extracting the incorporating features from a coedit graph. Several studies have attempted to quantify author reputation. Adler et al. [13] used an improved algorithm to compute the quality of English Wikipedia articles based on the reputation of original authors through the revision history of each article. The authority of the reviewers was considered [12]. In Javanmardi et al. [14], the authors derived three computational models of user reputation according to user edit patterns and statistics [15]. However, the defect is that most of these methods need too much human effort. It is infeasible to manually estimate the quality of each article, so an efficient and automatic approach is necessary.
Article stability is also considered to evaluate article quality. The literature works [16–19] proposed persistent word revisions (PWR) to count the number of revisions that a word survives. Priedhorsky et al. [20] devised a similar index called persistent word view (PWV) by calculating the retention time of an author’s contribution. Suzuki and Yoshikawa [21] extended this method and considered the impact of vandals who deliberately deleted good-quality texts; they proposed a computing method that took advantage of not only the text survival rate but also the editor’s qualities, but this approach is not scalable. In addition, Nemoto et al. [22] considered the preexisting social capital of editors and thought it had a positive correlation with the article quality level. However, classification performance is not preferable, especially for high-quality articles. These methods failed to consider other important features, such as article content and structure.
Intuitively, article quality is directly related to the text, so features based on the wiki page were proposed. Hardik et al. [4] conducted a detailed analysis of Wikipedia documents with some big data techniques. There are usually two types of features that are commonly used in the evaluation of article quality [23,24]. One feature is content, such as the count of various types of sentences and words. For instance, Blumenstock [25] simply chose word count as the Wikipedia quality metric and obtained good results in detecting featured articles. The other feature is structural features, such as the number and ratio of pictures, sections, paragraphs and lists in the article. Dang and Ignat [8] presented an automatic assessment model that combined these two feature sets with some traditional readability indicators into the model, such as the Flesh–Kincaid grade level [26], the Smog index [27], the Coleman–Liau index [28] and the Linsear write formula [29]. Moreover, the writing style was proposed as a metric to measure textual information. Lipka and Stein [30] pioneered the application of writing style by employing various trigram vectors to describe featured articles. Xu and Luo [31] assumed that high-quality articles had more statistical features on lexical usage, so they selected eight basic metrics to measure article quality, including the numbers of verbs, nouns and sentences.
Website link analysis was applied to assess the quality of Wikipedia pages. Kamps and Koolen [32] introduced Wikipedia link analysis. Their work suggested a possible relationship among out-links, in-links and the importance of articles. In the work described in Pateman and Johnson [33], Wikipedia articles were evaluated and corrected using inherent links. Using the MapReduce-based link analysis system, Hardik et al. [4] applied a link-ability factor to describe the diversity and expandability of Wikipedia. de Ruvo and Santone [34] investigated the influence of the article network by PageRank. In addition, the author relationship network has attracted more attention because the editors’ intensive cooperative behaviours lead to high-quality articles [35]. However, various collaboration patterns among contributors have a negative effect on article quality [36]. Li et al. [37] studied relationships among article editors and quality assessment. Bykau et al. [10] applied a novel multivariable algorithm that was based on the page revision history. Their experiments on the entire English Wikipedia data set suggested that the approach had higher precision and recall than conventional approaches. With regard to these approaches, researchers usually adopt few metrics to assess article quality. Few of them consider article quality from a comprehensive perspective.
To describe an article completely, comprehensive quality metric systems have been introduced. Anderka [1] constructed a multidimensional and multilevel wiki quality evaluation system. In Dalip et al. [6], the feature framework was organised into six views. It was reduced by using the SPEA2 multiobjective genetic algorithm. Warncke-Wang et al. [38] initially adopted 17 features. They used empirical research to simplify the model. Finally, an actional model with five dimensions, including Completeness, Informativeness, NumHeadings, ArticleLength and NumReferences/ArticleLength, was established. Halfaker [39] improved Warncke-Wang’s actional model by examining the dynamics of Wikipedia quality at a finer granularity through historical versions of articles. In addition, some researchers simplified quality evaluation by merging relevant metrics. For example, based on peer-reviewed data, Suzuki [40] presented a Wikipedia article assessment method that combined the h-index with the p-ratio. Ofek and Rokach [41] proposed a set of indicators that referred to meta-content features and author-based features. This model could predict whether a Wikipedia biography would be accepted with nearly 97% AUC. However, these models are not completely automatic, and the assessment still needs considerable manual intervention.
Recently, machine learning models were applied to classify Wikipedia article quality. Some models were adopted, such as SVM, KNN, multinomial logistic regression and regression trees. Wang applied a decision tree and SVM to some actionable features [38]. Dalip et al. [23,42] applied SVR to classify Wikipedia article quality. The impact of features on assessment was studied in detail. However, this model failed to achieve good performance. In Dalip et al. [5], a general multiview framework that applied a meta learning method to obtaining features was developed. The quality was thought to be a continuous value. This framework was also extended to estimate the quality of Q&A forums. In contrast to previous works, Agrawal and DeAlfaro [43] developed a quality prediction model combining LSTM and neural networks (NN) that outperformed NN. Quang-Vinh Dang et al. assessed Wikipedia quality using content format features and readability scores. However, it considers only limited Wikipedia article information [44]. Kapugama et al. [9] categorised and labelled Wikipedia search results. In their methodology, K-means clustering, and agglomerative hierarchical clustering algorithms were used to group clusters. Then, the latent Dirichlet allocation was used for labelling groups.
There are some recent studies that introduce deep learning models to assess Wikipedia article quality. In Dang and Ignat [8], doc2vec was used to represent Wikipedia articles, and DNN was applied to classify article quality. Subsequently, scholars adopted a deep learning method based on a recurrent neural network (RNN) and LSTM to achieve higher accuracy and efficiency compared with previous approaches [45]. Moreover, Shen et al. [46] created a hybrid model that combined biLSTMs with hand-engineered features. However, they fail to use a comprehensive feature framework when classifying article quality.
Our research aims to fill the following gaps. (a) There are few papers that adopt a comprehensive feature framework. They usually only take advantage of certain aspects of Wikipedia articles. (b) There is still a lack of research that has applied deep learning models to Wikipedia article quality assessment. (c) There is no extensive performance comparison of various deep learning and conventional machine learning models to classify Wikipedia article quality. (d) There are few studies that discuss selecting a better feature set to achieve satisfactory classification performance. In our research, a complete performance comparison with a comprehensive feature framework was conducted. Seven different deep learning and four traditional machine learning models are adopted in the experiment. The importance of different features or feature sets is investigated separately, which can provide better guidelines for feature selection.
3. Representation of Wikipedia articles
In this section, the proposed representation of Wikipedia articles in this article is introduced. After the analysis and summarization of existing research, a comprehensive feature framework is presented with each feature and related studies listed and described.
Currently, there are many studies on how to conduct feature engineering for Wikipedia articles. However, most of this work focuses on only partial features. Few studies have analysed and summarised the existing work. In this section, we perform an extensive review of the existing feature frameworks [1,2,5,6,12,23–27,35,42,44,47–54] and propose a comprehensive feature framework as a representation of Wikipedia articles. Text statistics are indicators that measure basic article statistics [1,23], including word count and character count. Structural features describe how an article is organised. These features are summarised in the studies of Dalip et al. and Stvilia et al. [23,49]. Intuitively, the better the article structure is, the better the article will be. Writing styles quantify parts of speech and usages of different types of words [2,5,6]. The writing styles tend to represent the writing level achieved by the author. Therefore, it is highly related to article quality. Readability scores represent the grade level or education level that readers need to understand the texts [26,27,42,48,50–52]. Edit history represents the revision history for each Wikipedia article [12,23,24,35,42,49,53]. Usually, more editing will make Wikipedia articles more understandable and readable. Network features are based on a Wikipedia link graph [1,23,54]. Network features focus on relationships among different Wikipedia articles. The features are shown in Table 1. In Table 1, each feature is described and examples of research works which use the feature are listed. For each article, we extract features in Table 1 and concatenate them as a feature vector. Consequently, for each Wikipedia article, we obtain one feature vector including text statistics, article structure, writing styles, readability score, edit history and network features. Each feature for the Wikipedia article is a numeric value, so the feature vector is a vector of numeric values. This feature vector is input to machine learning models. Initially, we assume that each feature is equally important in our model, so the weights for all features are one by default. We conduct an importance analysis for features and feature sets given classification labels in the experiment section. This assigns different weights to each feature or feature set.
Feature description.

4. Quality assessment models
In this section, we present quality assessment models in more detail. It starts with the introduction of input representation, followed by the description of seven deep learning models used in our experiment.
4.1. Input representation
For each Wikipedia article, the feature vector

4.2. RNN
An RNN is a kind of NN that can memorise training information from previous time steps [55]. For each time step t, the input of an RNN includes input vector

where
4.3. Bidirectional RNNs
The current RNN takes only training information from the past. However, regarding the language processing problem, the subsequent context is also important. Therefore, two RNNs are stacked. The forward layer processes the subsequent context, while the backward layer processes the past context [56].



where
4.4. LSTM
To solve the long-term memory problem, LSTM is applied since it can process the training information at much earlier time steps. LSTM includes three gates: forget gate, input gate and output gate. The forget gate is used to decide which cell state is thrown away. The input gate controls the states to be updated. The output gate controls the results to be output. The output is based on the cell states with filtering conditions [57,58]. For each Wikipedia article, feature vector





where
4.5. Variants of LSTMs
4.5.1. BiLSTMs
BiLSTMs are combinations of bidirectional RNNs and LSTMs that use both past and future information. The extracted features for each article are fed into bidirectional LSTMs. The forward LSTM processes Wikipedia articles in the same way as LSTM, while backward LSTM processes Wikipedia articles in a reverse order. This model has two advantages. (a) It considers the dependence not only among previous Wikipedia articles and current Wikipedia articles but also subsequent Wikipedia articles and current Wikipedia articles. (b) It solves the long-term memory problem. When
4.5.2. Stacked LSTMs
Stacked LSTMs have multiple LSTMs. Unlike biLSTMs, all LSTMs in this model take only training information from previous time steps. The features for each Wikipedia article are put into stacked LSTMs. Due to a more sophisticated architecture, stacked LSTMs extract more important features based on the input from the Wikipedia article, which contributes to classification performance.
4.6. CNN
A CNN focuses on a data set with a grid-like topology. Usually, there are three different layers in a CNN: a convolution layer, pooling layer and classification layer [60]. The input vector

where

Then, we can conduct the pooling operation on the feature map. The pooling layer can effectively reduce the feature dimensions. Consequently, a CNN can yield high classification performance with less training time. The dense layer conducts classification based on the output from the pooling layer [61].
4.7. CNN-LSTM
In CNN-LSTM, the CNN is used to extract features from text representations for each Wikipedia article. Then, LSTM classifies article quality based on features from CNN [62]. Finally, the dense layer outputs the classification result. CNN-LSTM combines advantages from a CNN and LSTM, including considering long-term dependence among Wikipedia articles and better classification performance with less training time.
5. Experiments
In this section, we discuss our experiments and their results. First, we introduce the data set. Second, we review the seven deep learning models and compare four typical machine learning models in terms of classification and training performance. Finally, we present the most important features and feature set which contributes to the quality classification of Wikipedia articles.
5.1. Data set
Wikipedia articles in English are chosen for experiments. The source files are available from Wikimedia Downloads. The content and metadata are embedded in XML. To obtain text content, a wiki extractor is adopted (Wikipedia Extractor). The structural features are extracted from the source files. The revision history and network information can be obtained from the wiki data set website (Wikimedia Downloads). There are six Wikipedia quality levels: featured article (FA), A class (AC), good article (GA), B class (BC), start class (ST), and stub class (SB) [1]. After review of some samples in each class, we noticed that the differences among adjacent classes are not significant due to the manual classification. For instance, the quality of FA and AC articles is close, while the quality of AC and SB is very different. Therefore, to improve the classification performance, three quality classes, high, medium and low, are proposed. The high-quality class includes FA and AC. The medium class includes GA and BC. The low quality includes ST and SB. These three classes are distributed equally. In our experiment, only 3294 articles were selected. There are two reasons. First, some articles are too short to extract enough features. Second, the information such as edit history or reference/link relationship for many articles is incomplete. The data set is partitioned randomly into a training set and testing set with proportions of 60% and 40%, respectively. The experiment was repeated 20 times to obtain the average performance metrics.
5.2. Result analysis
In this section, the results are discussed. All experiments are implemented in Keras 2.0.8 and TensorFlow 1.1.0. For the parameters, epochs, batch size, and dropout rate are set as 15, 195 and 0.2, respectively.
5.2.1. Classification performance
Accuracy, precision, recall, F1-score and F-beta score are adopted to measure classification performance. These are informative and direct indicators of a model’s performance [63,64]. Tables 2 and 3 show the classification performance of the deep learning models and conventional machine learning models, respectively.
Classification performance of deep learning models.
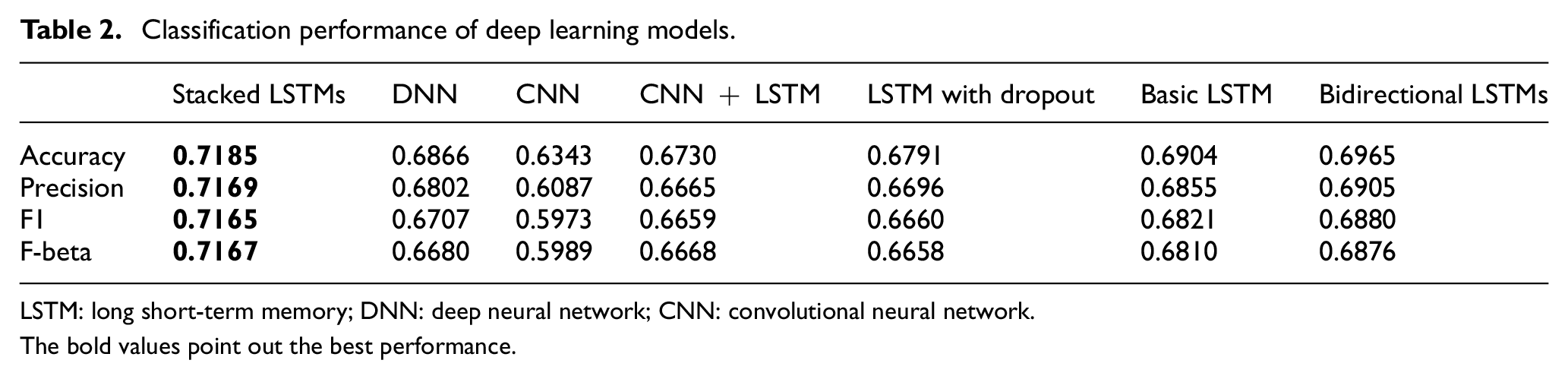
LSTM: long short-term memory; DNN: deep neural network; CNN: convolutional neural network.
The bold values point out the best performance.
Classification performance of conventional machine learning models.
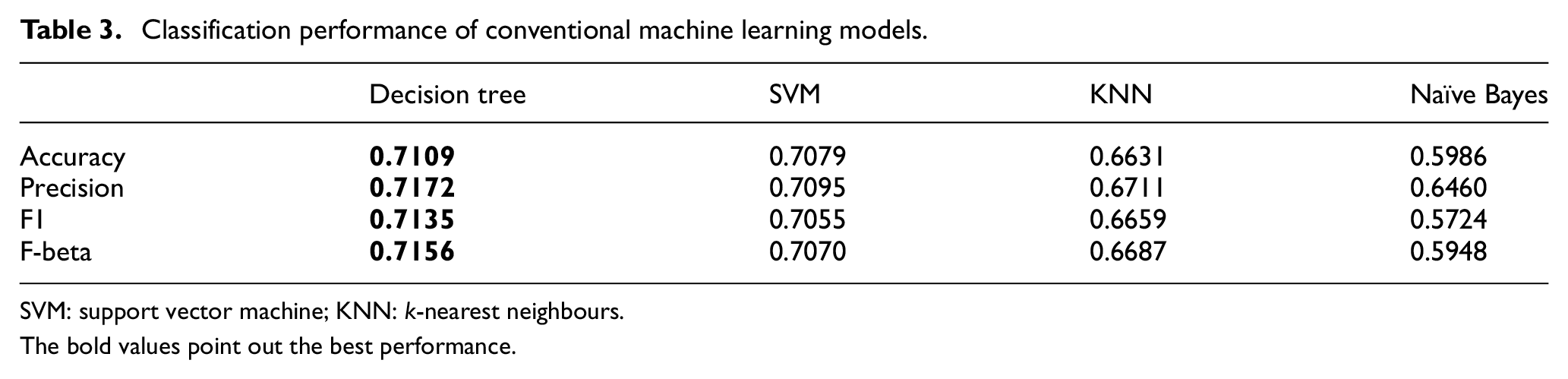
SVM: support vector machine; KNN: k-nearest neighbours.
The bold values point out the best performance.
Table 2 reports that stacked LSTMs acquire the best performance for all the metrics. This is due to its complicated model architecture. Three layers of LSTMs are stacked together, which can extract more minute but important patterns. Compared with basic LSTM, dropout leads to performance degradation. Dropout is specific for avoiding overfitting in the model [65]. It might make performance worse. Contrary to what we expect, the CNN performs the worst. In most cases, the CNN has high performance in learning relevant features and ruling out irrelevant features [54,62]. Moreover, after comparison of basic LSTM and CNN-LSTM, we find that the CNN degrades the model performance.
According to Table 3, we can determine that both the decision tree and SVM yield preferable classification performance. However, the decision tree is slightly better than SVM. The decision tree has a leading classification performance. It generates better scores than other models in terms of accuracy, precision, F1 and F-beta. Naïve Bayes is not suitable for classifying Wikipedia article quality. It has low F1 and F-beta scores.
LSTM and its variants are proficient in classifying Wikipedia article quality. Regarding conventional machine learning algorithms, both the decision tree and SVM perform better than most deep learning models except stacked LSTMs. Due to the complex model architecture, stacked LSTMs have slightly better performance than decision trees. In addition, we compare our classification accuracy with other state-of-art models. The accuracy of our model is 12.3% better than the accuracy of the random forest, which is 64% [8].
In summary, stacked LSTMs are the best model among deep learning models, while the decision tree performs the best in traditional machine learning models. Except for precision, stacked LSTMs are slightly better than the decision tree for the other three metrics.
5.2.2. Confusion matrix
The confusion matrix for each model is reported in Figure 1. Generally, these models can identify low-quality articles very well, but they fail to identify the other two classes. This can be explained partially by the fact that the articles are originally classified manually. This classification is subjective, and the boundary between medium and good/low articles is not clear. The CNN and DNN perform poorly when classifying medium-quality articles. However, the DNN performs very well when classifying good-quality articles. Stacked LSTMs outperform other deep learning models when classifying medium-quality articles. However, traditional machine learning models are better at classifying medium-quality articles than deep learning models. Naïve Bayes yields preferable performance in classifying low-quality articles, while it fails to distinguish good-quality articles from others. Averagely, the decision tree has a balanced classification result, even though it is not very good at classifying low-quality articles. Comparing stacked LSTMs and decision trees, we find that stacked LSTMs are much better than decision trees when classifying low-quality Wikipedia articles, while decision trees have better performance when classifying good-quality articles. The accuracy is very close when classifying medium-quality articles for two models.
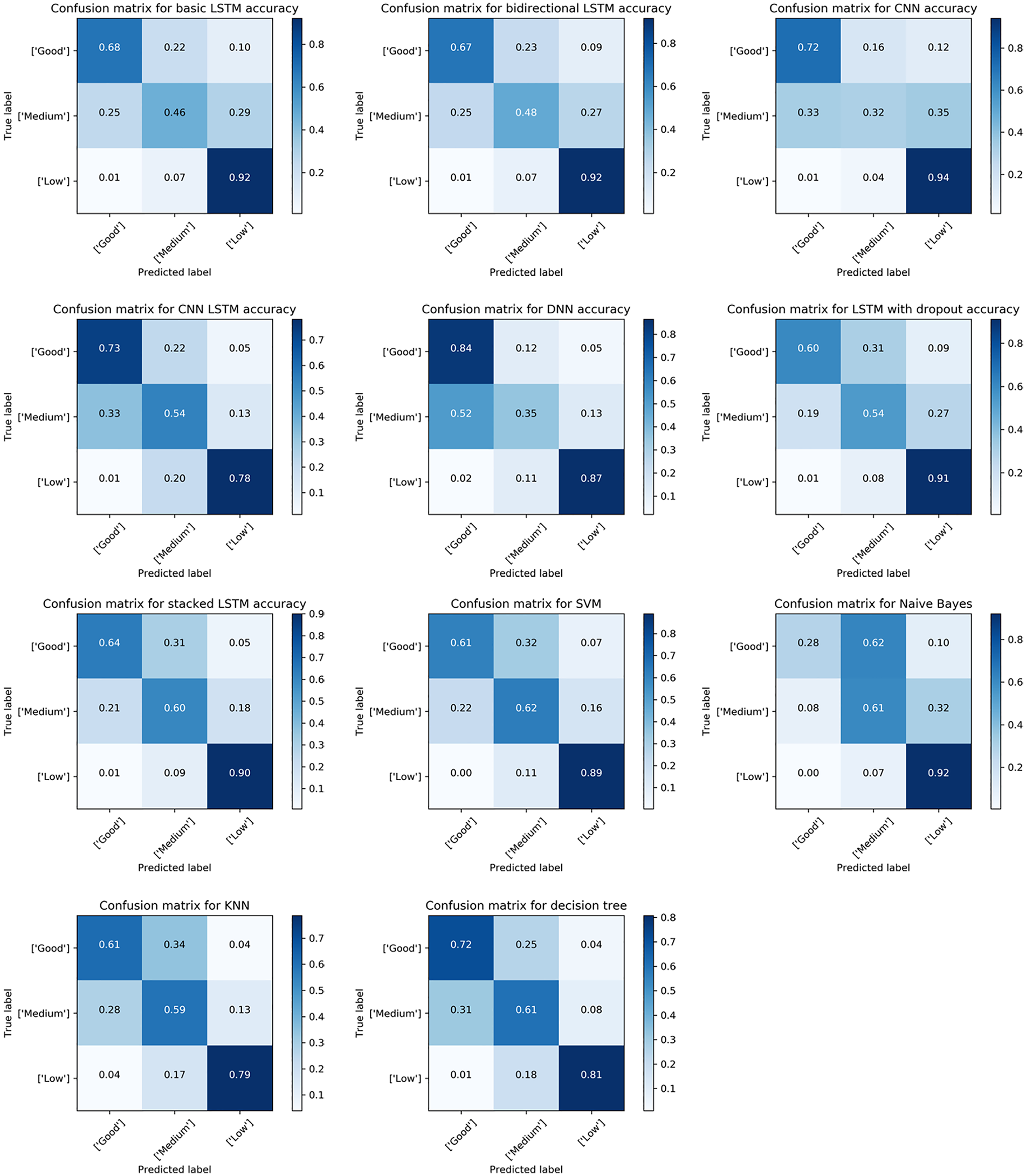
Confusion matrices for different models.
5.2.3. Training performance
In Figure 2, the accuracy of most models increases slowly at first. Then, it rises quickly and reaches a plateau. In addition, stacked LSTMs perform the best, while the CNN has the worst performance. Moreover, the training accuracy of basic LSTM is close to that of LSTM with dropout. This indicates that dropout has little impact on training performance. Figure 3 gives the training cross-entropy loss for each model. The cross-entropy is the metric that measures error probabilities in discrete classifications (Objectives). The training loss for most models decreases monotonically except for CNN-LSTM. Stacked LSTMs reach the lowest training loss, while the loss for the CNN is the highest. For CNN-LSTM, the training loss first decreases. However, its loss rises from epoch 10 to 11 and ends with a high value. Moreover, CNN performs the worst and reaches approximately 0.52. For LSTM with dropout and basic LSTM, their model training losses are almost the same. Compared with basic LSTM and LSTM with dropout, bidirectional LSTM performs better.
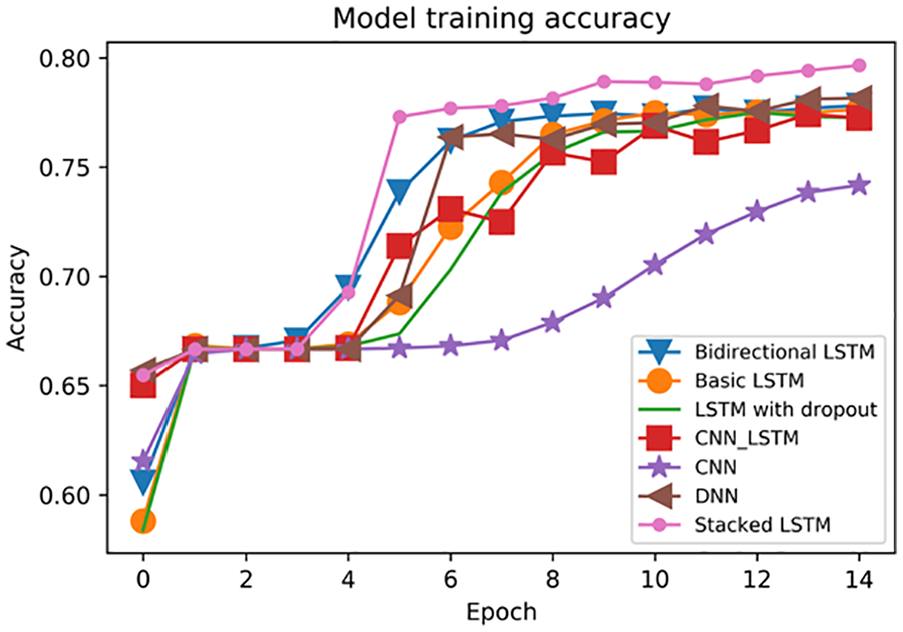
Model training accuracy.
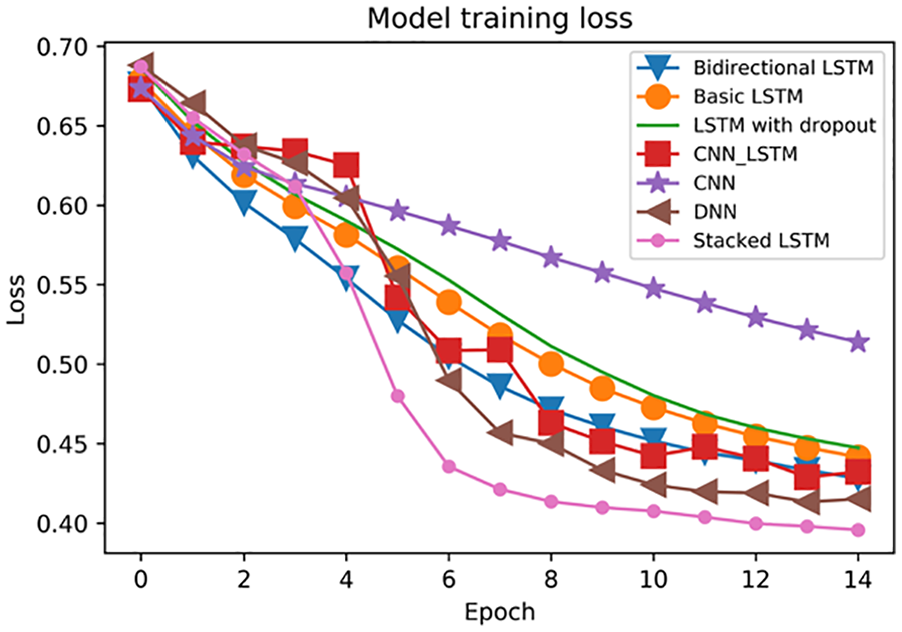
Model training loss.
5.2.4. Feature importance analysis
In this section, we conduct feature importance analysis. Stacked LSTMs are applied due to their best performance. We run the model several times. Every time, we delete one feature and train models with the other remaining features. The feature importance is different between the results of the stacked LSTMs with a complete feature set and those with a reduced feature set. The larger the feature importance is, the more important the feature is. A positive importance means that the feature contributes to the increase in classification accuracy, while a negative importance means that the feature worsens the performance.
Due to page restrictions, we show only the top ten features with the highest importance and lowest importance in Table 4. Conjunction, sub_conjunction and passive_sentence_count are the three most important features. This suggests that the writing style is highly related to article quality. If the author uses more conjunctions, subconjunctions and passive sentences, the article will be more sophisticated. However, len_sentences, reciprocity and clustering_coefficient are the features with the least importance. Len_sentences is the feature that contradicts our expectation. Intuitively, the better article usually has more long sentences. This is because Wikipedia is for the public with different knowledge backgrounds. The shorter sentence can also help the public to obtain knowledge much easier. Therefore, both long and short sentences are preferable for a good-quality article.
Feature importance.

5.2.5. Feature set analysis
In this section, each feature set is analysed. The feature framework has six feature sets: writing style, text statistics, structural features, readability scores, network features and edit history. The stacked LSTMs are used due to their best classification performance.
In Table 5, we observe that text statistics outperform other feature sets. Intuitively, an article with more words tends to be of better quality. In addition, structural features yield good performance. Therefore, the length and structure of an article are highly related to its quality. However, readability scores perform the worst. This is because readability scores focus on how difficult an article is to understand and read. Generally, the feature framework with all feature sets performs better than only one feature set as a feature framework.
Accuracy for each feature set.

Figure 4 presents the model training accuracy for different feature sets. The accuracy for most models increases slowly at first and then reaches a plateau. After epoch three, the training accuracy increases sharply. It eventually achieves good training accuracy. However, unlike other feature sets, the training accuracy for the readability scores increases slowly and ends with a small value. The accuracy for text statistics is the highest in the end. Figure 5 shows that the loss for most models decreases significantly at first and reaches a plateau with a low training loss, while the loss for readability scores remains high and has only a slight decrease. The model with readability scores has a high training loss in the end. However, text statistics yield a preferable model training loss.
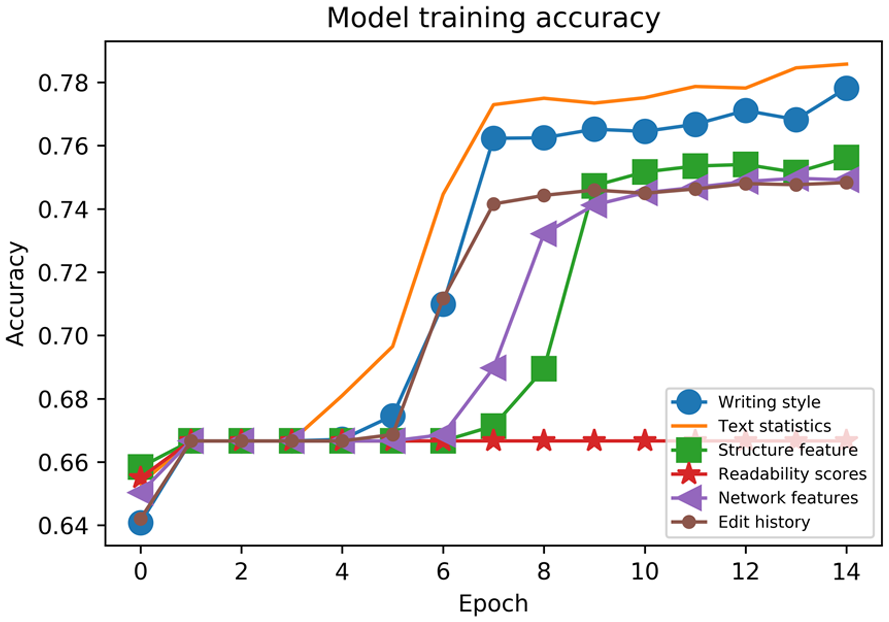
Model training accuracy.
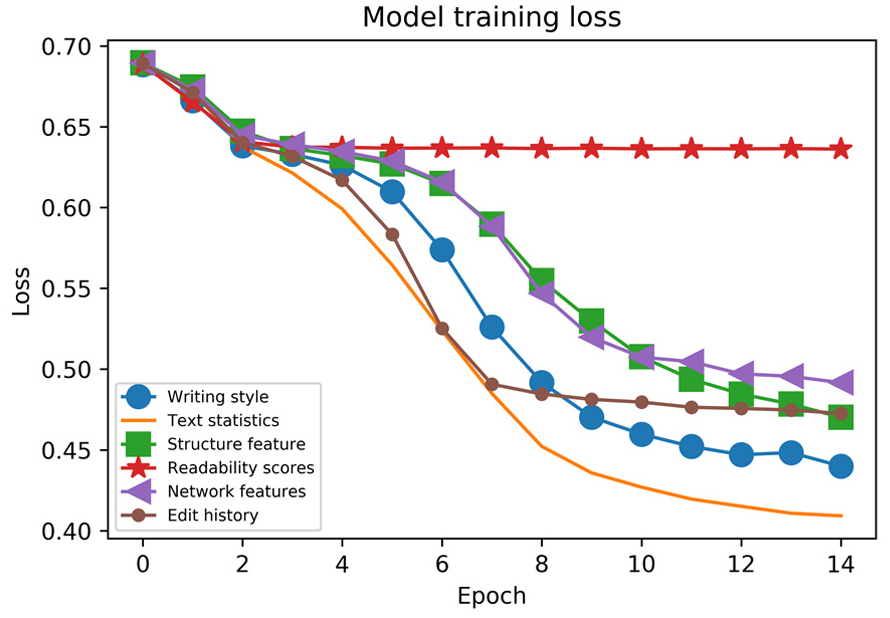
Model training loss.
6. Conclusion and discussion
In this article, a novel deep learning-based quality assessment approach for Wikipedia is presented. First, based on related works, a comprehensive feature framework is summarised. The feature framework is fed into a deep learning model and traditional machine learning models: CNN, DNN, basic LSTM, LSTM with dropout, stacked LSTMs, biLSTMs, CNN-LSTM, SVM, naïve bayes, KNN and decision tree. Extensive and detailed experiments based on these models and feature frameworks are conducted. The results show that stacked LSTMs are the best model that can efficiently distinguish Wikipedia articles with different article qualities. Stacked LSTMs are the best model among deep learning models, while the decision tree performs the best in traditional machine learning models. Except for precision, stacked LSTMs are slightly better than the decision tree for the other three metrics. According to the confusion matrix, stacked LSTMs yield much better performance when classifying low-quality articles. The decision tree has a significantly better accuracy when classifying good-quality articles. The accuracy is very close when classifying medium-quality articles with two models.
There are many theoretical and practical implications to our research. As far as we know, this is the first article that proposes an extensive comparison among different deep learning models to classify Wikipedia article quality using a comprehensive feature framework. The existing Wikipedia quality assessment models tend to adopt only partial Wikipedia features, such as content features or structural features. Our feature framework collects information for Wikipedia articles, such as content features, structural features, and author-related features. This framework can offer a more complete description of each Wikipedia article with a better article quality classification accuracy. Our findings also provide several important implications for practice. Currently, there are many Wikipedia articles. It is impossible to assess each article manually. The first practical implication is that our project proposes an automatic and practical quality classification method that can accelerate Wikipedia article quality assessments and save considerable human effort. Another critical implication is that our research has provided a guideline for the best deep learning model and feature sets to assess Wikipedia article quality. After the experiments, we found that stacked LSTMs are the best classification models. The readability scores contribute the least to the classification performance. Generally, our findings suggest that stacked LSTMs with all feature sets, including writing style, text statistics, structural features, network features and edit history, are the best classification methods for Wikipedia articles.
In terms of limitations, only approximately 3000 articles are selected. The size of the data set is insufficient for training for two reasons. First, some articles are too short to extract enough features. Second, the information related to many articles is incomplete. For example, some articles do not have a long enough edit history or network information to generate related features. Another limitation is that this classification framework is applicable to Wikipedia articles in only English since some features in text statistics and writing style are based on only English grammar.
In future work, to generalise the classification framework, we will further investigate feature design to enlarge the sample size. In addition, we will introduce some other state-of-the-art machine learning models, such as the attention model and transformer into our framework to improve the model classification performance.
Footnotes
Acknowledgements
The authors thank Daniel Hasan Dalip and Dr Pável Calado for their helpful guidance and support.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by National Natural Science Foundation of China (No. 71774121) and the worldclass discipline "Library, Information and Data Science" by the Ministry of Education of the People’s Republic of China.