
Abstract
The relational database (RDB) to resource description framework (RDF) transformation is a major semantic information extraction method because most web data are managed by RDBs. Existing automatic RDB-to-RDF transformation methods generate RDF data without losing the semantics of original relational data. However, two major problems have been observed during the mapping of multi-column key constraints: repetitive data generation and semantic information loss. In this article, we propose an improved RDB-to-RDF transformation method that ensures mapping without the aforementioned problems. Optimised rules are defined to generate an accurate semantic data structure for a multi-column key constraint and to reduce repetitive constraint data. Experimental results show that the proposed method achieves better accuracy in transforming multi-column key constraints and generates compact semantic results without repetitive data.
Keywords
1. Introduction
Semantic web data publication methods based on relational data are widely studied because more than 70% of web documents are backed up by relational databases (RDBs) [1]. The relational database-to-resource description framework (RDB2RDF) transformation is a major semantic data publication method that extracts semantic data from relational data [2,3]. In particular, direct mapping [4] is a representative automatic RDB2RDF mapping method recommended by the World Wide Web Consortium (W3C). The rules of direct mapping are defined to transform relational instance data, including attributes and attribute values, into semantic RDF graph data. Figure 1 illustrates an example of the RDB2RDF transformation. In the transformation, relational data are mapped to RDF triples. Suppose ‘Student’ is a relational table, ‘age’ is an attribute in Student, ‘r1’ is a primary key of an instance record of Student and ‘21’ is an instance value of age in r1. Then, the relational data are transformed into a triple (r1, age, 21).

Example of direct mapping of a single-column primary key: (a) example of an RDB-to-RDF transformation (instance data) and (b) RDB-to-RDF transformation with RDFS and OWL (Semantics-preserving).
However, existing works have experienced problems in the transformation of multi-column key constraints into semantic data. Multi-column key constraints are primary, foreign or unique key constraints that are composed of two or more attributes. First, it has been observed that information loss occurs if multi-column key constraints are included in relational input data because most existing methods define key constraint mapping rules based on single-column key constraints [5 –8]. They may generate incorrect semantic data, and transformed data may not be equivalent to original input data. A few of these methods consider scenarios in which key constraints can be composed of one or more attributes. Nevertheless, these methods do not implement rules and algorithms to resolve multi-column key constraint mapping issues. Second, a repetitive constraint data generation problem is inevitable during the mapping of multi-column key constraints based on previous rules. The main reason for this problem is that each column data item for a multi-column key constraint shares identical key constraint semantics. Repetitive constraint data generation may cause a storage overlay with additional computation costs, reduced readability and fewer intuitive semantics. Therefore, in this article, we propose an optimised method to improve the direct mapping in the RDB2RDF transformation for the specific case of multi-column key constraints existing in input data.
Figure 2 shows the generic comparisons of our scheme with existing methods. To the best of our knowledge, the implementation of multi-column key constraint mapping rules has not yet been addressed. The contributions of this work are as follows: Presentation of semantics-preserving multi-column key constraint transformation: We consider the prevention of two major problems, that is, semantic information loss and repetitive data generation, and define semantics-preserving mapping rules. These problems occur in the mapping of multi-column key constraints because mapping at the schema level has not yet been appropriately implemented. However, a direct mapping method recommended by W3C involves multi-column key mapping at the instance data level. Thus, we aim to resolve the above problems for building a semantics-preserving direct mapping method. Accurate mapping of multi-column key constraints: We define mapping rules that compensate for the structural difference between relational data and semantic data to transform multi-column key constraints without semantic information loss. As the defined rules cover key constraints and multi-columned hierarchical structures, we can prevent the generation of incorrect semantic data, which are different from original relational data. Pruning of repetitive output data: We optimise mapping rules to eliminate repetitive data, which are generated during multi-column key constraint mapping. Unlike in existing methods, optimised rules generate compact constraint semantic data. Moreover, we use an experimental approach and show that the output data transformed by the provided mapping rules still preserve the semantics of input relational data.

Semantics-preserving RDB-to-RDF transformation.
The remainder of this article is structured as follows: In section 2, we introduce an overview of RDB2RDF transformation methods. Next, we provide the preliminaries of direct mapping and describe the problems that occur during the mapping of multi-column key constraints. In section 4, we present our mapping method in detail. Section 5 reports experimental results. Finally, we present the conclusions and the perspectives for future work.
2. Related work
The RDB2RDF transformation is a mapping method for generating semantic data from relational data. The format of semantic output data is defined by RDF. RDF is a modelling language for describing semantic resources on the semantic web [8]. The structure of RDF data is graph data, in which nodes are semantic resources and edges are the relationships among resources [9]. RDF graph data are composed of RDF triples, which are the sets of semantic resources formed by (subject, property and object). A subject is a semantic resource that contains a uniform resource identifier (URI) [10] to be uniquely identified. An object can be a semantic resource that contains a URI, a literal value or a blank node [11] containing no URI or literal value information. A property (also referred to as a predicate) is a semantic resource that expresses a relationship between a subject and an object.
Two types of approaches exist for mapping generation: domain semantics-driven mapping and direct mapping [12,13]. The first approach manually transforms relational data into RDF data [14,15]. The RDB2RDF mapping language [16,17] is a representative mapping language for manual mapping. It was developed in 2010 and recommended in 2012 by W3C. Manual mapping applications are provided for users to manage mapping processes, such as D2RQ [18], Virtuoso [19] and Ultrawrap [20]. Direct mapping was developed in 2010 as an automatic mapping approach, and it was recommended in 2012 by W3C [21]. Direct mapping uses relational instance data and schema data as input data, and it outputs RDF semantic data.
Methods have been developed for improving the performance of direct mapping [7,8,22 –27]. resource description framework schema (RDFS) [28] is an extension of the RDF vocabulary for describing classes, properties and utility properties. Web Ontology Language (OWL) [29] is a description-logic-based language that extends RDF and RDFS. Therefore, the improved approaches adopt RDFS and OWL to generate semantic data without information loss. The entire integrity constraint information in schema data cannot be transformed into semantic data. Thus, Lim et al. [7] proposed an improved approach for generating semantics-preserving output data. However, the method still lacks support for the transformation of all integrity constraints. In particular, a multi-column primary key or a foreign key cannot be transformed by the method. Thus, we focus on solving the transformation of multi-column key constraints and reducing the output data size in mapping multi-column key constraints. Other recent approaches on mapping into RDF data transform various types of data (heterogeneous data [30], object-oriented database [31] and Unified Modeling Language (UML) [32] to RDF data. However, we mainly focus on direct mapping to manage large-scale data on the web.
3. Preliminaries and problem description
In this section, we explain existing direct mapping rules 1 with examples. Then, we describe two problems of mapping multi-column key constraints: semantic information loss and the generation of repetitive constraint data.
3.1. Direct mapping rules
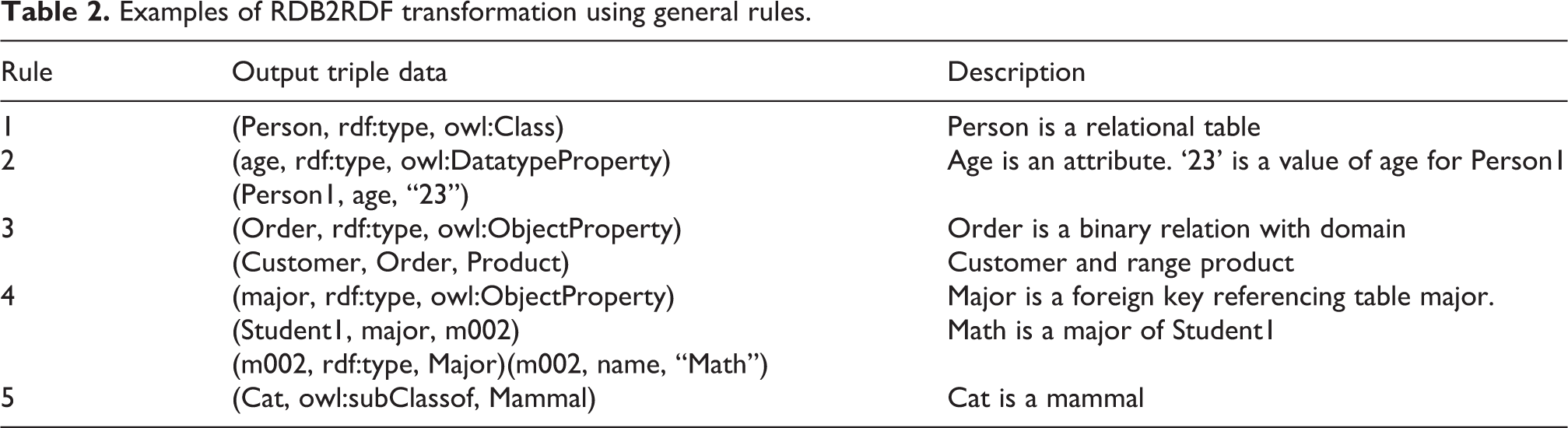
Table 1 shows the general rules for mapping relational data. A relational table is transformed into an OWL class by Rule 1. Rule 2 transforms an attribute of the table into an OWL data-type property. It contains a relational instance defined by a URI as a subject and a literal value defined as an object in RDF triple data, such as (instance of a table, attribute, literal value). A binary relation is transformed by Rule 3. A foreign key attribute is transformed by Rule 4. The relationship between a parent table and a child table is transformed by Rule 5. The simplified examples of the general rules are outlined in Table 2 for better understanding. Constraint rules are defined to transform the integrity constraints of relational schema data (Table 3). 2 Suppose an attribute, x, contains a primary key constraint. Then, the rules for mapping constraints are used to transform attribute x. First, attribute x is transformed by Rule 2 because it is a nonforeign key attribute. Second, attribute x is transformed by Rule 6 to assign an atomic value constraint of relational data. Finally, attribute x is transformed by Rule 9 to generate primary key constraint semantic data.
General rules for mapping relational data.

RDB: relational database; RDF: resource description framework; OWL: Web Ontology Language.
Examples of RDB2RDF transformation using general rules.
Constraint rules for mapping relational data.

RDB: relational database; RDF: resource description framework; OWL: Web Ontology Language.
3.2. Problem description
In this section, we define two challenging problems that occur during the mapping of multi-column key constraints. The first is the generation of repetitive constraint data; the second is semantic information loss. Problem 1 illustrates the generation of repetitive constraint data during the mapping of multi-column key constraints, as described in the following.
3.2.1. Problem 1
Suppose r is a relational table, A is a set of attributes used to define a primary key (or a foreign key) of table r and n is the number of attributes in A. To transform the semantics of multi-column key constraints, mapping by Rule 2 is performed n times, mapping by Rule 6 is performed n times and Rule 9 for the primary key constraint (Rule 10 for the foreign key) is performed n times. Thus, n 3 mapping processes are required to transform a single multi-column primary constraint.
Problem 1 does not violate the semantics preservation of direct mapping. Rather, it outputs a repetitive and complex semantic data structure for a single multi-column key constraint. Thus, we define advanced rules to resolve Problem 1. Problem 2 illustrates the semantic information loss of mapping multi-column primary key constraints (comments on the foreign key constraints are omitted because the same description can be applied to the foreign key constraints), as described in the following.
3.2.2. Problem 2
Suppose r is a relational table, A is a set of attributes used to define a primary key of table r and n is the number of attributes in A. To transform the semantics of multi-column key constraints, PKey(a1, r), PKey(a2, r),…, PKey(an, r) are performed by Rule 9. However, on a machine level, the results are understood as there being n primary keys in table r and not a single primary key that comprises a set of attributes.
Figure 3 illustrates the examples of Problem 2. If a single-column key is transformed by Rule 9, then output data are generated without semantic loss (Figure 3(a)). On the contrary, if a multi-column key is transformed by Rule 9, then constraint data are processed identically as a single-column key constraint. The results contain no explicit metadata such that it is a multi-column primary key (Figure 3(b) and (c)). As a result, transformed data (more than one primary key in a table) are not equivalent to original input data (a single primary key of a table). Thus, we define advanced rules to resolve Problem 2 in the next section.

Examples of mapping primary keys: (a) key constraint composed of a single attribute, (b) key constraint composed of three attributes and (c) key constraint composed of many attributes.
4. Improved approach
In this section, a set of rules are provided for mapping a multi-column primary key and a multi-column foreign key to solve the problems described in the previous section. Predicate logic is used to define rules, and graphical examples are provided for improved comprehension.
4.1. Base rules for key constraint mapping
The following rules are used for mapping primary key and foreign key constraints:
Base primary key rule: NonFKeyAttr(a, r)
Base foreign key rule: FKeyAttr(a, r, s)
where a is an attribute of relational table r, _b is a blank node, v is an attribute value and s is a table referenced by table r. A detailed explanation of the predicates on the left side is provided in Appendix 1. The base primary key rule specifies the primary key by Card(a,_b, 1) to assign attribute a with a primary key (Figure 4(a)). The base foreign key rule uses MinCard(a, _b, 1) to specify a lower bound of the cardinality because relational tables can reference more than one other table. In addition, the base foreign key rule uses FKeyAttr(a, r, s) to describe the semantics of the type of attribute a being an OWL object property with domain r and range s (Figure 4(b)). Note that the two base key rules use FunctionalP(a), which is the OWL functional property, to notify an N:1 relationship to assign the constraint that attribute a must contain at most one attribute value. Therefore, the mapping by the base key rules can circumvent the processes of Rule 6, thereby reduce the output size compared with the previous rules.

Example of mapping a single-column primary key and a foreign key: (a) input schema, (b) mapping result of a primary key constraint, (c) input schema and (d) mapping result of a foreign key constraint.
Problem 1 can be solved using the base key rules. However, Problem 2 still occurs during mapping with the base key rules. For example, if the base key rules are used to transform a table with a primary key or a foreign key comprised of multiple attributes, then multiple subgraphs that express key constraints are generated by the mapping rule (Figure 5). The output result contains the repetitive subgraphs of constraint data and can be misinterpreted as a table having more than one key. To solve Problem 2, the base rules are modified in the next section using additional features.

Transformation of a multi-column primary key and a foreign key using the base key rules: (a) input schema, (b) primary key constraint with three attributes, (c) input schema and (d) foreign key constraint with three attributes.
4.2. Rules for relational integrity constraints
The following rules are employed for mapping the primary key and foreign key constraints without information loss:
Primary key grouping rule: NonFKeyAttr(A, r) FunctionalP(a)
Foreign key grouping rule: FKeyAttr(A, r, s)
where A is a set of attributes of which a multi-column key is composed, r is a relational table that contains A, _B is a blank node set that represents the key constraints of A, _g is a blank node for grouping constraints and V is a value set of A. The details of the predicates on the left side are provided in Appendix 1. The primary key grouping rule specifies a primary key using Card(A, _B, 1) to assign attribute set A with a multi-column primary key.
The foreign key grouping rule specifies a foreign key using MinCard(A, _B, 1) to assign attribute set A with a multi-column foreign key. The output results contain merged key subgraphs to resolve Problem 2, that is, the misinterpretation problem.
The repetitive data generated by Rule 6 can be reduced using the base key rules, and semantic information loss can be prevented by utilising the grouping rules. However, repetitive constraint data generation still exists because of the semantic data structure of the multi-column key constraints that comprise two or more constraint subgraphs (Figure 6). To reduce repetitive constraint data, the grouping rules are modified in the next section by employing separating mapping processes.

Example of transformation using the grouped primary key and foreign key rules: (a) the grouped primary key and (b) the grouped foreign key.
4.3. Optimised rules for multi-column key mapping
The following rules are employed for mapping primary key and foreign key constraints without information loss:
Optimised primary key rule: NonFKeyAttr(pkey, r)
Optimised foreign key rule: FKeyAttr(fkey, r, s)
where A is a set of the attributes of which a multi-column key is composed, r is a relational table that contains A, pkey is an OWL property used to represent a primary key constraint of r, fkey is an OWL property to represent a foreign key constraint of r, _b is a blank node and V is a value set of A. The details of the predicates on the left side are presented in Appendix 1. The optimised primary key rule specifies a primary key using Card(pkey, _b, 1) and type(A, pkey) to assign attribute set A with the primary key.
The optimised foreign key rule specifies a foreign key using MinCard(fkey, _b, 1) and type(A, fkey) to assign attribute set A with the foreign key. As shown in Figure 7, the optimised key rules output less constraint data. Instead of producing every key constraint subgraph (Figure 7(a) and (c)), each optimised key rule only generates a single key constraint, which is linked by key column attributes (Figure 7(b) and (d)). The output result contains a merged key subgraph to resolve Problem 2. Moreover, the rule generates compact output data with reduced repetitive constraint data; this solves Problem 1. Figure 8 describes an example of how the optimised rules are applied to actual tables.

Transformation of a multi-column primary key and a foreign key using the optimised key rules: (a) the result of a straightforward primary key mapping method, (b) optimisation of repetitive semantic data generation processes, (c) the result of a straightforward foreign key mapping method and (d) optimisation of repetitive semantic data generation processes.

Example of transformation using the optimised key rules.
5. Experimental evaluation
5.1. System setup
Evaluations were conducted using a single node of a 3.1 GHz quad-core CPU, 4 GB of memory and a 2-TB hard disc. The experiments were conducted on real data and synthetic data. Each real data item was defined by relational schema, including integrity constraints: Ensembl-compara (DB1), 3 Ensembl (DB2), 4 phpMyAdmin (DB3) 5 and MusicBrainz (DB4). 6 The DBT2 benchmark was used as synthetic data. 7 A synthetic dataset was generated by DBT2, and schema data were restructured by adding integrity constraints to evaluate the performance of mapping multi-column key constraints. The previous approach (OWL-ontology-based augmented direct mapping) was employed [7] to analyse the direct mapping methods.
5.2. Results
Figures 9 and 10 depict the performances of mapping multi-column primary key constraints and multi-column foreign key constraints, respectively. Single-column primary keys, multi-column primary keys, single-column foreign keys and multi-column foreign keys are used as input data. The previous approach, base key rules, key grouping rules and optimised key rules are compared.

Comparative results of mapping multi-column primary key constraints: (a) number of triples over relational data and (b) average number of triples for one input data item.

Comparative results of mapping multi-column foreign key constraints: (a) number of triples over relational data and (b) average number of triples for one input data item.
In Figure 9(a), the horizontal axis represents the size of the synthetic primary key constraint data (synthetic foreign key constraint data in Figure 10(a). The vertical axis represents the number of semantic triples as output data. According to Figures 9(a) and 10(a), our approach generates fewer triples compared with the previous method, and the optimised key rule generates the smallest output data. Assuming that two output results are identical in terms of semantics, the method that generates a result with a smaller size result is better with regard to space and computation.
Figures 9(b) and 10(b) show the average number of triples obtained as a result of each transformation method. The horizontal axis represents the key constraint data (primary key constraints in Figure 9(b) and foreign key constraints in Figure 10(b)) from each real dataset. The vertical axis represents the average number of triples generated from transforming a key constraint. The results show that the optimised key rule, which reduces repetitive multi-column key constraint data, generates compact output data with fewer resources.
Figure 11 shows the performance of all mapping rules. In Figure 11(a), the horizontal axis represents the size of the synthetic relational dataset as input data. The vertical axis is the number of semantic triples as output data. According to Figure 11(a), the proposed approach generates fewer triples compared with the previous method and the optimised key rule generates the smallest output data.

Comparative results of mapping rules: (a) number of triples over relational data and (b) average number of triples for one input data item.
Figure 11(b) shows the average number of triples obtained as a result of each mapping rule. The horizontal axis represents each real dataset; the vertical axis represents the average number of triples generated from transforming a single relational element. The results show that the optimised key rule generates the fewest output data among the mapping methods. In Figure 12, the failure rates of the mapping methods in each database are presented. The failure rates are calculated by dividing the total number of output data by the number of failed transformed output data with semantic information loss. The horizontal axis represents each relational dataset; the vertical axis is the failure rate of the transformation of relational data into semantic data. The previous approach produces the most failed outputs because it lacks support for multi-column key constraints. In contrast, the proposed approach improves the mapping rules and generates fewer false mapping results. False mapping results could be generated by our method when input data are defined based on the practical SQL statements that are not included in the SQL standard. Figure 13 shows the evaluation of the performance of solving Problem 2. The key constraint mapping failure rates are calculated by dividing the total number of output key constraint data by the number of failed transformed key constraint output data with semantic information loss. The horizontal axis represents the total size of the synthetic key constraint data (single-column primary/foreign key constraint data and multi-column primary/foreign key constraint data). The vertical axis is the failure rate of the transformation of the key constraint data. The method that uses the base key rules is more semantic preserving compared with the previous approach, except for solving Problem 2. Thus, the previous approach and the method that uses the base key rules produce similar failed outputs in view of solving Problem 2. The method that utilises the key grouping rules and optimised key rules is defined to transform multi-column key constraint data. The only difference between the key grouping rules and optimised key rules is the performance of reducing redundant output data. Hence, the two methods show better performance of solving Problem 2 compared with the previous approach. Consequently, we have observed that our method outputs compact semantic data and generates multi-column key constraints without information loss.

Results of failure rates of mapping.

Results of failure rates of key constraint mapping.
6. Conclusion
In this article, we proposed an optimised direct mapping method to transform multi-column key constraints. A key constraint may comprise one or more attributes. Thus, repetitive data generation and semantic information loss can occur during mapping processes. Therefore, we therefore proposed a set of rules to regulate the mapping of multi-column key constraints. First, base key rules were defined for mapping the multi-column key constraints to be transformed with a smaller output data size. The rules covered primary keys and foreign keys when the constraints comprised two or more attributes. Second, key grouping rules were defined to prevent semantic information loss during the mapping of multi-column key constraints. Finally, we defined optimised key rules, which ensured that the mapping results contained only one constraint definition for one multi-column key constraint without repetitive data and semantic information loss. The results of an evaluation showed that the proposed approach generated significantly less output data while retaining original input data semantics without losing semantics information. The management of data consistency between updated relational data and semantic data remains a challenging issue for future research [33].
Footnotes
Appendix 1
Predicates of relational integrity constraints

| Predicates | Descriptions |
|---|---|
| NotNull(x, r) | x is an attribute in relation r with not-null constraint |
| Unique(x, r) | x is an attribute in relation r with unique constraint |
| PKey(x, r) | x is a primary key of relation r |
| FKey(x, r, s) | x is a foreign key of relation r, referencing relation s |
| Default(x, r, v) | x is an attribute in relation r |
| defValue(x, r, v) | v is a value of attribute x in relation r and is used in Default(x, r, v) |
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by a grant from the National Research Foundation of Korea (NRF), funded by the Korean government (no. NRF-2017R1C1B1003600) and supported by the Ministry of Science and ICT (MSIT), Korea, with a programme at the Information Technology Research Centre (IITP-2020-2018-0-01417) supervised by the Institute for Information & Communications Technology Promotion (IITP).