
Abstract
To help students learn how to programme, we have to give them a clear knowledge map and sufficient materials. Question-based websites, such as stackoverflow, are excellent information sources for this goal. However, for beginners, the process can be a little tricky since they may not know how to ask correct questions if they do not have sufficient background knowledge, and a knowledge tree is usually considered more helpful in such a scenario. In this research, a method to infer a knowledge tree automatically from the type of websites and to group documents based on the resulting knowledge tree is proposed. The proposed method mainly addresses two issues: first, the quality of tags cannot be guaranteed, and second, clustering-based methods usually generate the flat schema. The occurrence count and the co-occurrence ratio were used together to identify important tags. Then, an algorithm was developed to infer the hierarchical relationship between tags. Using these tags as centres, the clustering performance is better than applying k-means alone.
1. Motivation
As a teacher who mostly focused on giving programming related courses, I found it difficult to keep my materials always up-to-date even though I have already trying very hard to keep up with new technologies. To ensure that most students in a class can understand the course materials, school teachers have to find the balance between chasing flashing new technologies and embracing fundamental backgrounds. What we can do is help students establish fundamental concepts and hopefully give them sufficient skills and knowledge to do further learning. In most scenarios, what students learn in a classroom is far from enough when they are facing challenges at work or in their future research. Therefore, the ability to get knowledge from other information sources is required for students who want to polish their programming skills. To help students achieve this, we usually use one or both of these approaches:
Give students a clear knowledge map about what they are learning.
Give students related supplementary materials for what they are learning.
In this research, we will show how an information source with rich data can help teachers in the two approaches above and how to infer the needed information from question-based information sources.
Question-based websites such as stackoverflow are excellent information sources for students to get more programming knowledge. Such websites are frequently used by people who are trying to improve their coding skills. The workflow is usually like this:
Search for existing answers; if not found, enter the next step.
Raise a question and wait for the community to give answers.
After the answers are posted, the original questioner can pick the best answer.
During the process, one may tag her or his questions or answers.
The process above runs fluently for coders at medium or higher levels. However, for beginners, the process can be a little tricky since they may not know how to ask a correct questions if they do not have sufficient background knowledge. A knowledge roadmap or a knowledge tree is considered helpful for one who has just started learning how to programme. Usually, such a roadmap can come from their teachers or textbooks. However, for students on the Internet age, they may feel using content from websites that make them more comfortable. Roadmaps from school teachers and textbooks suffer from being outdated since programming technologies can change at a quick pace. For example, Figure 1 shows a small portion of the contents grabbed from the official python tutorial.

Table of contents of the official python tutorial.
From the figure above, we see some fundamental concepts including control flow statements, built-in types, and so on. However, by collecting popular tags from stackoverflow, one can easily find out that popular terms associated with python are pandas, generators, and machine-learning. There is a huge gap between the two cases, but it appears that there are no bridges to help students get across the gap.
The situation motivates this research: Is there a way to take advantage of both of the worlds? Is there a mechanism to help students learn from websites like stackoverflow while still giving them organised content? Past researches showed that we can meet the expectations to a certain degree by using some knowledge tree construction tools. For example, Gemmell et al. [1] proposed a method to personalise search and navigation based on unsupervised hierarchical agglomerative tag clustering. Heymann and Garcia-Molina proposed a greedy algorithm for hierarchical taxonomy generation from social tagging systems using graph centrality [2]. These algorithms can generate knowledge trees or folksonomies by analysing relationships between tags, users, and documents. From the generated knowledge trees or folksonomies, readers can get an overview picture of what she or he is learning. However, existing algorithms tend to rely on the crowd tagging nature of collaborative working websites. In such websites, multiple users will tag on one document and thus generate (user, tag, document) tuples, which allows the similarity between tags to be evaluated. Question-based websites, on the other hand, may allow only the original questioner to tag her or his question, which makes it difficult to assess the similarity between tags. Another side effect is, without crowd tagging, tagging quality can be significantly lower since it will be difficult to remove bad tags without crowd intelligence.
Besides, as pointed out by Tan, Guo, and Li, recommending a set of related learning materials to students is helpful [3]. This raises another goal in this research: even if we have a sound solution for figuring out the knowledge tree of such websites, to place existing content onto the resulting tree is still challenging and we want to figure out an efficient way to solve it. This can be modelled as a clustering problem if considering knowledge tree nodes as centres. Several clustering algorithms, for example, k-means have been designed for solving such problems. However, the diverse nature of tags makes it difficult to generate good clustering results. Using the tag summary page from stackoverflow as an example, we see there are 1702 pages of tags with each page containing 36 tags (see Figure 2).
Tag summary page of stackoverflow.
Even if considering only those articles that are related to a specific programming language, the amount of tags is still huge. In our experiment, python was chosen as the target language, and 2731 tags were obtained from the top 26,415 most popular questions. With such a huge amount of tags, considering that each question (or article) usually contains 2–4 tags only, the relationship between question and tag will form a very sparse matrix, which makes clustering difficult.
The goal of this research is to develop a method to help programme learners at their beginning stages. In our experiment, python was chosen as the target programming language. The proposed method will:
Analyse contents collected from stackoverflow and collect tags from them.
Construct a knowledge tree from the collected tags.
Cluster the contents based on the resulting knowledge tree.
2. Literature review
The web is surely one of the largest information sources. However, the huge amount of information makes it difficult to get the needed information efficiently and accurately. Search engines are partial remedies but have their limitations. Search engines are usually syntax-based and, as pointed out by Fatima, Luca, and Wilson, ‘the existing search engines have some limitations, in particular, their difficulty in returning relevant results’ [4]. Semantic-based search technologies, on the other hand, are still emerging and have many challenges to overcome, for example, some knowledge may be too specific to the domain of users [5]. In this research, the information source understudy was stackoverflow, which is a programming-specific website, and the topic being studied was limited to python. Even with these constraints, the corpus was still full of ambiguous terms such as ‘string’ and the situation did limit the functionality of the information source. Furthermore, it is not ready for semantic-based search technologies.
A perhaps partial solution is to facilitate access to information sources by using tags and folksonomies. Folksonomy construction is a form of document clustering. Clustering facilitates users’ quick browsing [6]. As pointed out by Ramage, Heymann, Manning, and Garcia-Molina, using tags and page text for clustering outperform using page text alone [7]. Folksonomy is a technology that works to classify the information over the web through tagging the bookmarks, photos, or other web-based contents [8]. It is not practical to construct knowledge trees manually in most cases, and folksonomies are often used to simulate knowledge trees. Lu, Hu, and Park proposed ‘Tripartite Clustering’ which is a clustering method that clusters the three types of nodes (resources, users, and tags) simultaneously by only utilising the links in the social tagging network [9]. They evaluated the clustering against a human-maintained web directory. The resulting F-score is more than two times better than applying k-means on word vectors alone in terms of term frequency. The research work of Inbarani and Kumar presented a hybrid Tolerance Rough Set Based Firefly (TRS-Firefly-K-Means) clustering algorithm for clustering tags in social systems [10].
However, folksonomies also have their limitations. Allowing users to apply any tag they wish to a resource freely often results in numerous tags that are redundant, ambiguous, or idiosyncratic [1]. Tang pointed out several technical challenges: existing methods usually treat the tagging space as a flat schema and do not consider the hierarchical relations; relations between tags are usually ignored [11]. Lin, Davis, and Zhou summarised that using unsupervised tags to generate flat and non-hierarchical structure leads to low search precision and poor resource navigation and retrieval [12]. Although there are hierarchical clustering methods, partitioning clustering methods usually outperform hierarchical ones in terms of speed and F-score [13]. Web-based information sources such as stackoverflow tend to grow extremely fast, so using a hierarchical clustering method may not be a feasible option.
Prior researches mainly pointed out two types of problems: first, the quality of tags cannot be guaranteed, and second, clustering-based methods usually generate flat schema which lacks hierarchical information. These problems pose limitations on the usability of folksonomies. To overcome the problems, external resources are sometimes utilised to enhance the tag vectors that are used for document clustering. In the research work of Bouras and Tsogkas, the WordNet database was used to enrich the ‘bag of words’ used before the clustering process and assisting the label generation procedure following it [14]. Roul and Sahay utilised term-term correlation and support based count for feature selection to remove tags that may cause noises [4]. In this research, since stackoverflow is a large corpus, a support-based method was utilised to filter out unimportant tags. Furthermore, co-occurrence relationships among tags are translated into hierarchical information. We tried to take advantage of both hierarchical clustering and partitioning clustering by using hierarchical centre nodes with partitioning clustering methods.
Many research efforts have been devoted to the construction of taxonomies and folksonomies. Zafar, Cochez, and Qamar proposed a taxonomy induction system which was based on a word embedding trained from a large corpus [15]. Their research was based on the word2vec model and was focused on hyponym-and-hypernym identification. Zhu et al. [16] proposed a machine-learning-based method that incorporated lexical features, co-occurrence-based features, and topic-based features. The research used a semi-supervised learning approach to predict subsumption relations between tags. The result was a very big taxonomy with 38,205 concepts and 68,098 relations but did not focus on a specific programming domain. Compared with existing works, this research had a different goal. Instead of identifying the hyponym-and-hypernym relationship between tags, we focused on constructing a knowledge tree and grouping related documents based on the tree. The proposed method utilised only the co-occurrence-based features but required a much smaller corpus and needed no pre-training.
Another popular research field is to extract sub-topics from information sources. The research of Barua, Thomas, and Hassan also used stackoverflow as their information source, but they focused on inferring sub-topics of stackoverflow posts via the LDA algorithm [17]. The research of Zhitomirsky-Geffet and Daya focused on similar issues but took a different approach. They used the Delicious social bookmarking site as their information source to mine sub-topics for search results from the Google search engine [18]. Zou et al. [19] used the LDA algorithm and an NFR (Non-Functional Requirements) word list to extract non-functional requirements from stackoverflow discussions. Joorabchi, English, and Mahdi proposed a method to map user tags from stackoverflow to Wikipedia concepts [20]. The method can help overcome the uncontrolled nature of user tags.
3. The proposed method
In this research, we propose an algorithm capable of generating knowledge trees based on questions posted to stackoverflow. In the experiment, we used python as the target programming language. The algorithm contains two parts: first, the identification of important tags as the starting nodes, and second, inferring the hierarchical relationship among tags. The remaining of this section will explain these two steps in detail.
3.1. Identifying important tags
First, what is an important tag? The ‘Ask a Question’ function of stackoverflow allows five tags for each question and provides hints of possible tags which makes tags chosen more meaningful. However, the flexibility of tag selection makes it difficult to define the importance of a tag. A naïve solution is to use the popularity of a tag as its importance indicator. However, there are exceptions. For example, ‘string’ is a very popular tag in stackoverflow. It is used in 150,109 questions. As a comparison, ‘pandas’ is also a very popular term on the Internet, but it is ‘only’ used in 143,696 questions posted on stackoverflow. The reason ‘string’ is more popular is that it is co-occurred with many other tags (two tags are co-occurred once if they are used to annotate the same question once; in this article, we first construct occurrence matrix for each tag and then compute the inner product of the transpose of the matrix and itself to obtain the co-occurrence matrix). An important tag should be a tag that has its uniqueness and will not cause ambiguity. Hence, an important may not be always a popular tag. As a result, it appears that it is reasonable to define important tags as being popular and independent tags. By popular, it means that a tag should be used in many questions; by independent, it means that a tag should not be co-occurred with other tags too many times.
The independence level of a tag is defined as in listing 1:
The calculation of independence level.

Using the algorithm above, we calculate the independence level of each tag, which indicates the possibility that a tag is used independently of other tags. Figure 3 shows the distribution of the IND value (only tags that are used in more than 200 questions are included).
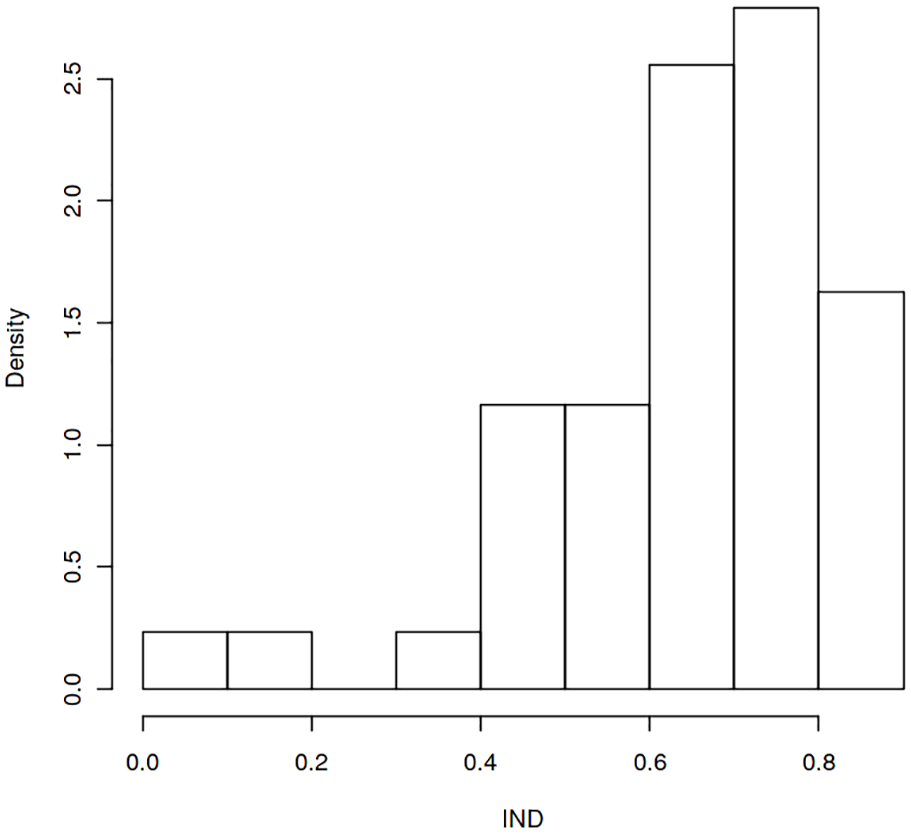
Histogram distribution of the IND value.
Note that few tags are used truly alone. However, since the algorithm above considers only popular tags, a tag still gets high independence level if it is co-occurred with many unpopular tags. With the algorithm, we can identify tags that are both popular and independent of other tags. These tags are defined as important tags in this research.
3.2. Inferring hierarchical information
Important tags identified in the previous step are used as top-level branching nodes. We then developed an algorithm to infer the hierarchical information based on these nodes. The execution result of the algorithm is a knowledge tree. An abstract pseudo root node will be generated and used as the parent node of the initial branching nodes. Each node is identified with its path on the resulting tree, and a path is a list of tags. Formally, a tree node is defined using the definition below:
{tag}: the set of all tags node: [t0, t1,......, tn], t0 is the pseudo root node and ti is a tag in {tag} given two nodes n1 and n2, n1 is the parent node of n2 if n1 is the initial sub-list of n2 Given a node n, the number of questions tagged using the tag list associated with n is calculated with the function countQuestions which is defined in definition 2.
n: a node on the current knowledge tree tagList[n]: the list of tags associated with n countQuestions(n): the number of questions tagged with all the tags except the pseudo root node on tagList[n] Given two nodes n1 and n2, whether n2 is a child node of n1 or not is determined via the function isChildNodeOf which is defined in definition 3.
n1, n2: two different nodes and n1 is the initial sub-list of n2 BRANCH_OCCURRENCE_THRESHOLD: a predefined threshold number; a new child node must have at least BRANCH_OCCURRENCE_THRESHOLD questions tagged with it BRANCH_RATIO_THRESHOLD: similar to BRANCH_OCCURRENCE_THRESHOLD, but controls the ratio instead of the number isChildNodeOf(n2, n1): return true if countQuestions(n2) > BRANCH_OCCURRENCE_THRESHOLD and countQuestions(n2)/countQuestions(n1) > BRANCH_RATIO_THRESHOLD
Using the definitions above, the algorithm is explained in the listing below:
The algorithm for constructing the knowledge tree.

3.3. Clustering
Nodes on the resulting knowledge are then used as centres for executing the k-means algorithm on the corpus. Note that the corpus is a set of questions and each question is annotated with several tags. Assume there are m tags G = [t1, t2, ..., tm] in the corpus and a question qi is encoded as a tag vector [di1, di2, ..., dim] in which each element dij is defined with the equation:

Given the resulting knowledge tree T with k nodes N = {n1, n2, ..., nk} and each node is represented with the syntax in definition 2, the resulting set of centre nodes C ={c1, c2, ..., ck} is generated via the algorithm below:
The algorithm to find clustering centres.

With the identified k centre nodes, a one-iteration k-means is then applied. The clustering result is semi-hierarchical since the centre nodes are hierarchically related.
4. The experiment
As a proof and assessment of the proposed concept, an experiment using stackoverflow as the information source was performed. In the experiment, we at first issued a query with the keyword ‘python’ to obtain a list of questions tagged with ‘python’ and then apply the proposed algorithm to the returned results.
4.1. Data preparation
For convenience, the StackExchange API was adopted to collect data from the stackoverflow website. By issuing a query with its question API, questions tagged with the specified keyword will be returned. Figure 4 demonstrates a sample response.

Response of the query above.
We then sorted the returned question list via its popularity and obtained a total of 26,415 python-related questions and 2731 tags. Since the number of questions referencing each tag varies a lot, the top 10% of tags being referenced too many or too few times were removed. After the removal, only 217 tags were kept and the distribution of the ratio of questions referencing each tag is shown in Figure 5.

Distribution of the ratio of questions referencing each tag.
As shown in the figure, most tags were referenced by less than 1% of the questions, which demonstrates high diversity even if the domain of the questions were already limited (only python-related questions were included; note that the tag ‘python’ itself were removed from the tag list).
4.2. Knowledge tree construction
Assuming the number of questions containing all tags of the tag representation of a node n in the resulting knowledge tree is defined as count(n), the proposed algorithm has several parameters:
IND_TAG_RATIO_THRESHOLD_AS_STARTING_TAGS: the minimum IND value a node must have to become a first-level branching node
TAG_BRANCHING_OCCURRENCE_THRESHOLD: for a node n, if count(n) is larger than TAG_BRANCHING_OCCURRENCE_THRESHOLD, the node will be treated as a non-leaf node; otherwise, the node is a leaf node
BRANCH_OCCURRENCE_THRESHOLD: considering a node n1 which satisfies TAG_BRANCHING_OCCURRENCE_THRESHOLD, given a node n2 which is a direct follower of n1 (i.e. the tag representation of n2 is the tag representation n1 plus a new tag), n2 may become a direct child node of n1 on the resulting knowledge tree if count(n2) is larger than BRANCH_OCCURRENCE_THRESHOLD
BRANCH_RATIO_THRESHOLD: considering a node n1 and its direct follower n2, n2 may become a direct child node of n1 on the resulting knowledge tree if count(n2)/count(n1) is larger than BRANCH_RATIO_THRESHOLD
Figure 6 demonstrates a portion of the generated knowledge tree using TAG_BRANCHING_OCCURRENCE_THRESHOLD = 200, BRANCH_OCCURRENCE_THRESHOLD = 50, BRANCH_RATIO_THRESHOLD = 0.01, and IND_TAG_RATIO_THRESHOLD_AS_STARTING_TAGS = 0.5.

A portion of the generated knowledge tree.
Note that the involved tags were extracted from some most recent questions, so a significant amount of the resulting tree was highly related to recent hot topics such as tensorflow and numpy. However, the algorithm still kept a certain degree of diversity. Software framework related tags such as selenium and django were also identified in the experiment. Besides, the algorithm can handle context-aware tags. For example, the tag ‘numpy’ were identified under the tag ‘matplotlib’ and ‘performance’, which are two different contexts.
4.3. A running example
In this section, we used the configuration below to form a running example:
IND_TAG_RATIO_THRESHOLD_AS_STARTING_TAGS: 0.5
TAG_BRANCHING_OCCURRENCE_THRESHOLD: 300
BRANCH_OCCURRENCE_THRESHOLD: 50
BRANCH_RATIO_THRESHOLD: 0.01
First, the IND value is used to filter important starting points. Using 0.5 as the threshold value, there were 35 tags including algorithm, anaconda, beautifulsoup, class, keras, performance, and opencv. Next, more frequently used tags in this set are chosen as branching nodes, and others are left as leaf nodes. Now, these 35 nodes are treated as the first-level child nodes and the next thing to do is to branch when appropriate. There are three parameters, TAG_BRANCHING_OCCURRENCE_THRESHOLD, BRANCH_OCCURRENCE_THRESHOLD, and BRANCH_RATIO_THRESHOLD controlling the branching behaviour.
In this example, 300 is used as the threshold value for TAG_BRANCHING_OCCURRENCE_THRESHOLD, and thus tags that occurred less than 300 times will be treated as leaf nodes. Let’s take the tag performance as an example, its IND value is higher than 0.5 and it was used to annotate questions for more than 300 times, so it is considered a branching node. Then, we iterate through other tags to test whether they can be a valid child node for performance or not. Considering the tag numpy as an instance, the three tags, python (the root node), performance, and numpy form a path on the constructing knowledge tree. Assume that python and performance are co-occurred α times while python, performance, and numpy are co-occurred β times, the new child node, numpy will be kept if β ≥ BRANCH_OCCURRENCE_THRESHOLD and β/α ≥ BRANCH_RATIO_THRESHOLD. In this case, both requirements are met, so numpy will become a child node of performance.
The proposed algorithm allows multiple instances of a tag to appear on the resulting tree. In this example, the tag numpy appears in several paths including:
python, pandas, numpy
python, performance, numpy
This indicates that there are multiple contexts for numpy. Since pandas is based on data types defined in numpy, the first path appears reasonable. On the other hand, when talking about numpy, performance is an important topic.
4.4. Clustering and evaluation
Nodes on the resulting knowledge tree were then used as cluster centres for clustering. In this experiment, k-means was adopted as the clustering algorithm. Note that both non-leaf and leaf nodes were used as centre nodes. For example, both (performance) and (performance, numpy) were chosen as k-means centres. To evaluate the clustering result, the ratio between BSS (Between Cluster Sum of Squares) and TSS (Total Cluster Sum of Squares) were used. The clustering result is better if the ratio value is higher. In the experiment, we used the parameters mentioned in the previous subsection to control the size of the resulting knowledge tree as well as the number of centre nodes. In the experiment, the value of TAG_BRANCHING_OCCURRENCE_THRESHOLD was fixed to 200, the value of BRANCH_OCCURRENCE_THRESHOLD was set to one of (100, 70, 50, 30, 10, 1), the value of BRANCH_RATIO_THRESHOLD was set to one of (0.1, 0.05, 0.01, 0.005), and the value of IND_TAG_RATIO_THRESHOLD_AS_STARTING_TAGS was set to one of (0.5, 0.4, 0.3). The resulting number of centre nodes was between 38 and 114. Using these centre nodes, a one-iteration k-means was then performed. As a comparison, normal k-means with the same k values were also executed. Figure 7 demonstrates the comparison between the proposed method and the original k-means.
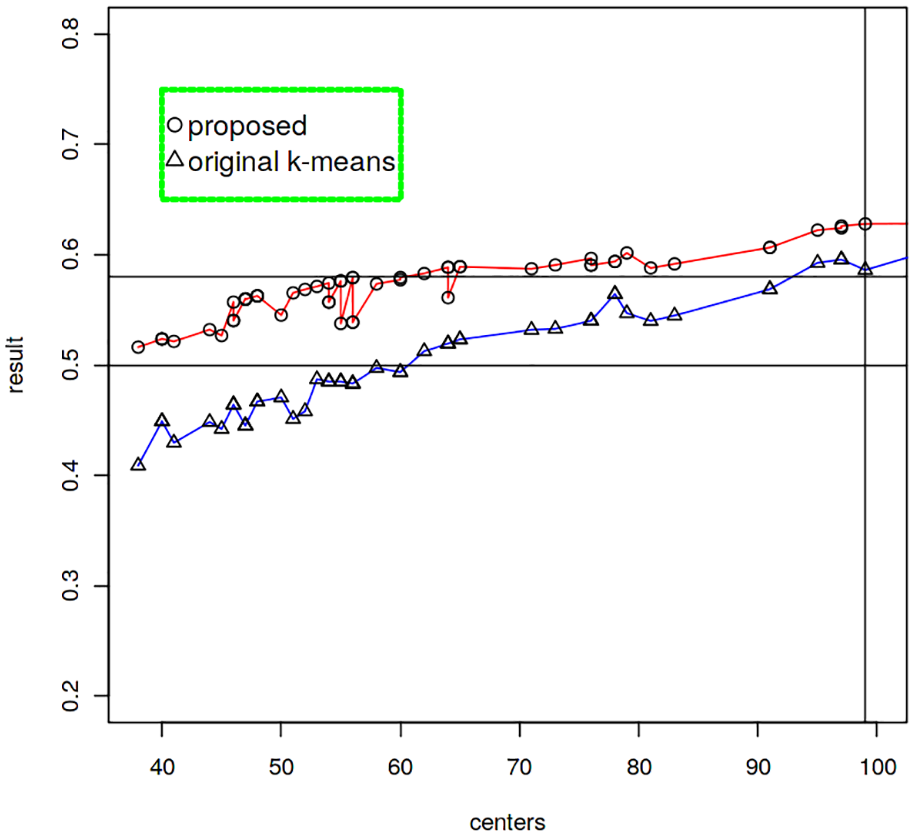
Comparison between the proposed method and the original k-means.
On average, the BSS/TSS value of the proposed value was 0.57 while the value of the original k-means was 0.50. The proposed algorithm performed 13.53% better than the original k-means.
5. Discussions
Generally, for a clustering problem using the k-means algorithm, better BSS/TSS values can be obtained when the k value is setting to higher values. However, with too many clusters, the result can be difficult to interpret. As mentioned in the research work of Kodinariya and Makwana, a rule of thumb is to set the k value to roughly
In addition to the clustering performance, the quality of the resulting knowledge tree is also an issue. Because topics of python are still emerging, assessing the quality of a given knowledge tree is difficult if not impossible. To do a minimum degree verification, we compare the resulting knowledge to the topics listed on a website that offers python tutorials. The table below compares the resulting knowledge tree to the topic listed on Real Python:
Topics listed on a Website and identified by the proposed method.

As shown in the table above, most topics listed on Real Python are also covered by the knowledge tree generated by the proposed method. First, we would like to skip some very generic topics including advanced, api, tools, and best-practices (numbered 1–3, 12) since they can cover a very wide range of tags. On the other hand, some topics such as devops and docker (numbered 6 and 8) are very specific and thus they will also be excluded in this discussion. Topics and the corresponding tags are compared below:
databases: sqlalchemy1 is a python-based database toolkit and the two tree paths, sqlalchemy-> mysql and sqlalchemy-> postgresql, point to two sub-modules of the toolkit
data-science and machine-learning: anaconda, pandas, and tensorflow-related tree paths point to some very popular data-science and machine-learning toolkits; ipython is a software tool that helps users utilising these toolkits; matplotlib2 itself is a professional data plotting library; pyspark is the python interface to a unified analytics engine for large-scale data processing spark3; opencv is frequently used in the image data processing
django: django is a python-based web application framework; the tree paths on the right-hand side cover django-related topics
flask: flask is a python-based web service framework; the tree paths on the right-hand side cover flask-related topics
front-end: tkinter is a python-based window programming framework while the tag window point to questions about the usage of window components
testing: selenium is a very popular python-based library for testing web applications
web-dev: this topic focuses on web application development, and both django and flask are web application frameworks; the corresponding tags demonstrate this overlap
web-scraping: both beautifulsoup and selenium are frequently used in web scraping
As shown above, all topics identified by the proposed method are also listed on Real Python. This proves the correctness of the proposed method. On the other hand, most topics listed on Real Python are covered by the topic set generated by the proposed method, which proves the usability of the proposed method. Note that the tags used in this experiment were extracted from stackoverflow questions and may miss some topics that are less popular in the python world.
To test generality, we have tested the proposed method against JavaScript, which is also a very popular programming language and obtained the result below (partially):
We did not verify the resulting knowledge tree against other Web sites that offer JavaScript tutorials; however, as shown in Figure 8, jQuery-related tags and CSS-related tags were automatically grouped and formed two sub-topics, which was a reasonable result.
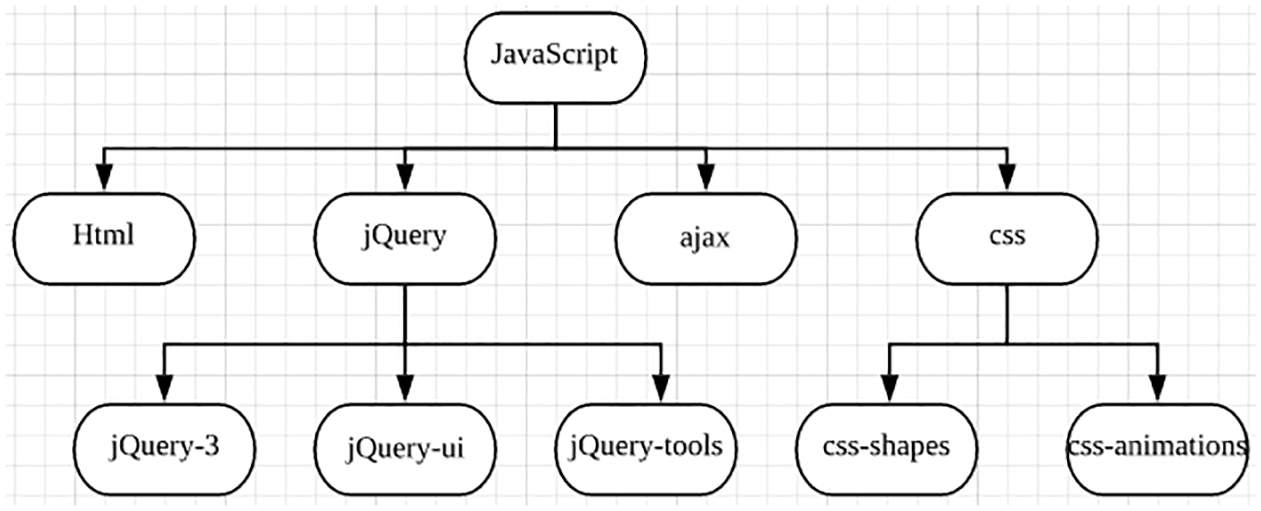
A portion of the JavaScript knowledge tree.
6. Conclusions and future works
In this research, a method to generate a knowledge tree from a corpus extracted from stackoverflow is proposed. At first, a crawler was designed to extract data from stackoverflow. We collected python-related questions and their corresponding tags. The independence value of each tag was then calculated to filter out unimportant tags. Among the identified important tags, an algorithm was then executed to infer the hierarchical relationship between tags. Based on the resulting knowledge tree, a partitioning based clustering method was then applied to cluster the questions. In comparison with the original k-means, the proposed method achieves better BSS/TSS and requires fewer centre nodes. Furthermore, it appears the resulting knowledge tree does cover most python topics listed on other python tutorial websites.
In the future, we have several plans:
During the experiment, we observed that tags have different characteristics. For example, some tags are evenly co-occurred with a different set of tags and some tags usually appear alone. With the information, tags have higher centrality may become a better choice as initial centre nodes.
It appears reasonable to use a knowledge tree to understand the weakness and strengthens of students during their learning. If a student fails on a certain topic, with the corresponding knowledge tree, we can help the student by instructing she or he to review the prior knowledge nodes to figure out where the problem is.
Knowledge trees can be used as input materials to virtual tutor systems to give learners intelligent recommendations.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.