
Abstract
As a mechanism to guide users towards a better representation of their information needs, the query reformulation method generates new queries based on users’ historical queries. To preserve the original search intent, query reformulations should be context-aware and should attempt to meet users’ personal information needs. The mainstream method aims to generate candidate queries first, according to their past frequencies, and then score (re-rank) these candidates based on the semantic consistency of terms, dependency among latent semantic topics and user preferences. We exploit embeddings (i.e. term, user and topic embeddings) to use contextual information and individual preferences more effectively to improve personalised query reformulation. Our work involves two major tasks. In the first task, candidate queries are generated from an original query by substituting or adding one term, and the contextual similarities between the terms are calculated based on the term embeddings and augmented with user personalisation. In the second task, the candidate queries generated in the first task are evaluated and scored (re-ranked) according to the consistency of the semantic meaning of the candidate query and the user preferences based on a graphical model with the term, user and topic embeddings. Experiments show that our proposed model yields significant improvements compared with the current state-of-the-art methods.
1. Introduction
Web search queries are typically short, ill-defined representations of more complex information needs [1]. Consequently, they can lead to poor retrieval performance. To alleviate this problem, modern search engines provide some services that assist users to find their desired content quickly by presenting a list of related queries. One such service is query auto-completion, which helps users to formulate their queries while typing in the search box [2]. Query auto-completion is restricted to using queries containing the same prefix with the original query entered by users to locate the possible user intentions. Another type of service is provided in the search result page after one or more queries have already been issued to the search engine. This is generated using two techniques. One is query recommendation (suggestion), which seeks to generate candidate queries by locating historical queries in a query log according to its relational proximity to the input query. The query generated is usually one already present in the query log. The other is query reformulation, which seeks to modify the part of the original query mainly by (1) adding, (2) deleting or (3) replacing terms in the query [3]. Unlike suggestion, reformulation offers candidates diverse expressions (new queries that were previously unseen in the query log) to describe a wider variety of users’ potential information needs. In addition, it can return relevant candidate queries.
Song et al. [3] and Bing et al. [4] observed that the terms addition and substitution are performed in most cases by users while reformulating queries, and such users generally only modify one of the terms in their queries. These findings explain why most previous work on query reformulation only modifies one term [3–6]. Therefore, we address query reformulation and focus on one-term additions and substitutions in this study. Sullivan [7] showed that over 80% of users preferred to receive personalised search results and that different users with different backgrounds may have different personalised preferences, even if they issue the same query. Therefore, it may be more beneficial to provide candidate query lists in light of individual user’s interests rather than a generalised candidate query list. Given this, we further validate the benefits of providing users with candidate query reformulations based on their interests.
To date, popular solutions [5] for generating personalised query reformulations generally rely on query logs and typically involve two tasks: (1) generating candidate queries – it is assumed that two terms with a similar context (co-occurring with a similar set of terms in queries) can be substituted with each other and the terms that co-occur frequently with words in the query have a higher probability of being added to the query. A context-based translation model is employed to generate candidate queries that maintain semantic relations with the input query; (2) scoring (re-ranking) candidate queries – typically, the latent Dirichlet allocation (LDA) model estimates the latent semantic topic for each term, after which a graphical model is applied to evaluate the quality of the candidates generated. The graphical model is used to estimate consistency in the semantic meaning of a candidate query by considering both the semantic dependency of query terms and dependency among latent topics of terms. User personalisation is incorporated into the graphical model. These methods, though quite successful, suffer from three major shortcomings. First, the context-based candidate generation method involves a global analysis over the entire collection. It is expensive and time-consuming to use the translation model to capture the contextual similarity between two terms. Therefore, only the first encapsulating term on the left side (1st left) and the first one on the right side (1st right) of each given term were taken into account. Second, only the users’ individual preferences were considered while scoring the candidate queries. However, personalisation is also important for candidate generation as users usually formulate a distinct set of queries. Third, the graphical model is restricted to modelling dependency between latent topics and terms by capturing the term context in the historical queries, but without considering other evidence, such as the contexts of latent topics.
Word embedding, also known as word representation, has become increasingly popular in encoding words as vectors, and this is attributed to an algorithm called Word2vec proposed by Mikolov et al. [8] and to the availability of the related software package. 1 These word embeddings (embedded vector representations) learned through word embedding techniques have been proven to accurately capture meaningful semantic and contextual word information. The distance between vectors serves as a proxy for their semantic or contextual similarity. While word embeddings have been used to represent query terms and queries successfully [9,10], the straightforward method of using embeddings to personalise query reformulation has been rarely explored. Motivated by the fact that word embeddings are capable of providing a convenient means of identifying a set of words that have contexts similar to those of a given word, we use this property to resolve the shortcomings in the previous work [4,6]. Along the lines of past research [4,5], our work involves two subtasks: candidate query generation and scoring; the latter is completed using the graphical model proposed by Bing and Lam [5]. This article aims to investigate the utilisation of word embeddings while generating candidate queries according to user preferences and the contextual similarity between terms. We make use of word embeddings to improve the effectiveness of candidate query scoring by providing more evidence that captures the semantic consistency of terms, the dependency among latent topics and user preferences for the graphical model. Compared with previous works [4,6], the major contributions of our study are as follows:
While generating query substitution or addition candidates, context information for each term is derived using term embedding that applies the sliding window-based context around the terms. More flexible contexts are allowed; making it is easier to allow richer contexts, rather than relying solely on the 1st left and the 1st right contextual terms. This may lead to better modelling of contextual similarity between terms.
In addition, we investigate the personalisation capability by constructing user vectors based on term embeddings while generating candidate queries. This ensures that candidate queries can be generated based on each user’s individual preference.
We propose a new topic embedding approach to obtain the context word distribution for each latent topic. It is useful to consider richer contexts in modelling the semantic dependency of terms and the dependency among latent topics while scoring candidate queries.
We conduct extensive experiments on a real-world query log and perform a thorough analysis to verify the effectiveness of our proposed model.
The rest of this article is organised as follows. In the ‘Related work’ section, we review the related work on query log-based query suggestion and word embedding for information retrieval. The sections ‘Models for personalised query reformulation’ and ‘Embeddings’ present a detailed description of the proposed approaches, including candidate query generation and scoring, and embeddings, respectively. The experimental setup and results are introduced in detail in the ‘Experimental setup’ and ‘Experimental results’ sections, respectively. The ‘Conclusion’ section concludes the article and offers possible directions for future research.
2. Related work
In this section, we discuss work related to different aspects of our study, focusing on
Query log-based query suggestion;
Query log-based query reformulation;
Word embedding for information retrieval.
2.1. Query log-based query suggestion
As a result of having a considerable commercial value, extensive research on query suggestion has been performed over the past few years, and the search engine query log, known as ‘wisdom of crowds’, has proven to be a key asset in most of the literature. Most query log-based approaches estimate the relevance of candidate items by exploiting the observable evidence in a query log, including shared terms [11], common user sessions [11,12] and commonly clicked results [13]. Based on the evidence, some methods, such as the association rule [14] and random walk [13,15,16], have been adopted successfully to generate relevant candidate query suggestions. However, such strategies are often limited to generating relevance-oriented query suggestions. To overcome this problem, a few researchers have attempted other techniques, such as learning-to-rank, LDA and deep learning, to mine more unobservable features that are hidden in a query log to produce higher quality queries. For example, Ozertem et al. [17] applied a learning-to-rank approach and trained rankers on features derived from queries that share sessions and clicks to find useful and relevant queries. Saeedeh and Fabian [18] constructed virtual documents from a query log by combining all unique queries derived from all successful sessions that share the same final query and then used the LDA model to infer topic distributions for virtual documents. The topics inferred were subsequently employed to retrieve the virtual documents that were thematically similar to the original query, and the virtual document’s corresponding title is returned as a suggestion. Sordoni et al. [19] introduced a novel hierarchical recurrent encoder–decoder architecture to interpret sequences of previous queries of any length and produced context-aware suggestions. Dehghani et al. [20] attempted to employ the sequence-to-sequence model with a query-aware attention mechanism to encode the structure of the session while acquiring session-based query suggestions. Jiang and Wang [21] presented a novel approach called the Reformulation Inference Network (RIN) for context-aware query suggestions by learning to represent query reformulations and modelling the way in which users reformulate queries over search sessions.
A few researchers assumed that users’ interests are recorded in the query log and attempted to infer users’ preferences from the query log to provide personalised query suggestions. For instance, Mei et al. [13] proposed a query suggestion algorithm for ranking candidate queries using hitting time by random walking on a large bipartite query-click graph and adopted personalisation with back-off of the second and the third bytes of IP addresses to the proposed algorithm. Jiang et al. [22] designed a novel query suggestion framework known as the personalised query suggestion with diversity awareness (PQS-DA) to effectively integrate diversification and personalisation. They first proposed a multi-bipartite representation to use the query log to its full potential and developed a regularisation framework to determine the most relevant candidate suggestion. The cross-bipartite hitting time model was then leveraged to determine the remaining query candidates that were not only relevant to the initial query but also different from each other. Finally, the user profiling model constructed (beta distribution) based on previously used words and clicked URL was used to generate personalised candidate suggestions according to each user’s interests. Chen et al. [23] proposed a model for query suggestion with personalisation and diversification, and they exploited users’ short-term search context in their current session and their long-term search history to identify users’ search interests. Chen et al. [24] proposed an attention-based hierarchical neural query suggestion model to realise personalised query suggestions by combining a hierarchical structure with a session-level neural network and a user-level network to demonstrate the short- and long-term search behaviours of a user while the attention mechanism captures the user’s preference.
2.2. Query log-based query reformulation
Inspired by the intuition that a good query suggestion system should reproduce users’ natural reformulation patterns [20], a few researchers have examined query reformulation, which considers the special type of reformulations that users should perform to produce satisfactory queries. A more recent query reformulation technique primarily exploited query logs, and almost all of them only considered changing one term from the original queries to generate candidates. For example, Wang and Zhai [6] calculated the contextual similarity of terms in a search history to perform query addition and substitution, and a context-based translation model was exploited to generate and score candidate queries. Song et al. [3] built a term-level query graph based on data sourced from query logs and proposed two models to address topic- and term-level query suggestions (one of the three techniques, namely term deletion, expansion or modification, was leveraged). Their second (term-level) model followed the framework of supervised learning-to-rank, and term modifications were cast as documents to treat each query reformulation as a training instance. Features were extracted for each (query, document) pair from ODP, Wikipedia and so on.
By exploiting the method used by Wang and Zhai [6] to generate substitution candidate queries, Bing and Lam [5] introduced a graphical model that detects semantic dependencies between terms and topics by exploiting the latent topic space inferred from a query log. This work has been extended further by Bing et al., [4] who implemented both query addition and substitution and proposed social tagging data (i.e. Delicious bookmark) and query log-based candidate pattern generation. While generating additional candidates based on query logs, they also considered whether the query providing the term context attracted a click or was located at the end of a session, and then the smoothed probability method was used to obtain candidate terms. For query substitution, they leveraged a method similar to that by Wang and Zhai [6] to obtain substitution candidates. Then, they applied a scoring method proposed by Bing and Lam [5] but exploited different methods to set the parameters. They utilised the n-gram and skip-bigram approaches to capture the term context in the historical query for modelling the dependency among topics and terms, respectively. Although capable of achieving a reasonable performance, this study only considered individual preferences, when scoring candidate queries, and the term context but ignored other indicators, such as the context of latent topics while scoring candidate queries.
2.3. Word embedding for information retrieval
Word embedding techniques have been effective in learning low-dimensional vector space representations of an input word and capturing semantic relationships among words. Word embedding has been extended to the representations of sentences and paragraphs [24], relational entities [25,26], descriptive texts of images [27,28], entities [29,30] and so on. It is computationally more efficient than many other competitive techniques [8,31,32] and thus, many IR systems have recently attained enhanced performance with less human engineering using such techniques. For example, Zuccon et al. [33] and Ganguly et al. [34] focused on exploiting word embeddings to enhance the effectiveness of information retrieval, and the transformation probabilities between words were derived by calculating the distance between the vector embeddings for words. Zamani and Croft [35] explored the use of word embedding to improve the accuracy of query language models in the ad hoc retrieval task. Vu et al. [36] presented an embedding approach to learn user profiles, and each user profile was represented by two projection matrices and one user embedding. The two matrices were intended to detect the user interest-dependent aspects from the users’ input queries and the corresponding relevant documents while the user embeddings aimed to identify the relationship between the queries and documents. Subsequently, user profiles were used directly for search personalisation.
A few researchers have exploited word embedding (Word2vec) in query-related research. For example, Grbovic et al. [37] proposed a query rewriting method based on a new query embedding algorithm in which the vector embeddings of a query were learned from its content (content2vec), context (context2vec) or both context and content (context-content2vec) within a search session, and the final results showed that context-content2vec had achieved the best performance. Zamani and Croft [10] estimated embedding vectors of a query from pseudo-relevant documents, and the estimated query embeddings were applied to query expansion and classification. Roy et al. [38] presented a framework for automatic query expansion by leveraging Word2vec to learn the semantic and contextual relationships between terms, and the terms related to a query were acquired by exploiting the K-nearest neighbour approach to expand the original query. Kuzi et al. [39] exploited Word2vec term embedding trained from an entire document corpus to select terms that were semantically similar to the entire original query or the terms contained in the query. They leveraged the terms selected to expand the initial query using a unigram language model framework. Akbiket et al. [40] proposed a method for producing contextual string embeddings using the neural character language model. They captured syntactic–semantic word features and disambiguated words in a context, achieving the best performance in the classic natural language processing (NLP) sequence labelling tasks.
However, to the best of our knowledge, our work is the first to exploit word embedding in the task of personalised query reformulation. Distinct from previous work, our article pioneers the application of the term, user and topic embeddings to personalise query reformulation; the embeddings are used not only for better model-term similarity but also for personalisation, semantic dependency of terms and topic dependency.
3. Models for personalised query reformulation
The main framework of this article is depicted in Figure 1. Our work comprises two major sub-tasks: candidate query generation and scoring. These two sub-tasks are performed with the assistance of pre-learned embeddings (i.e. term, user and topic embeddings). In this section, we first detail our proposed models for the two sub-tasks and then specify the embeddings on which they rely. The main notations used in this article are listed in Table 1.
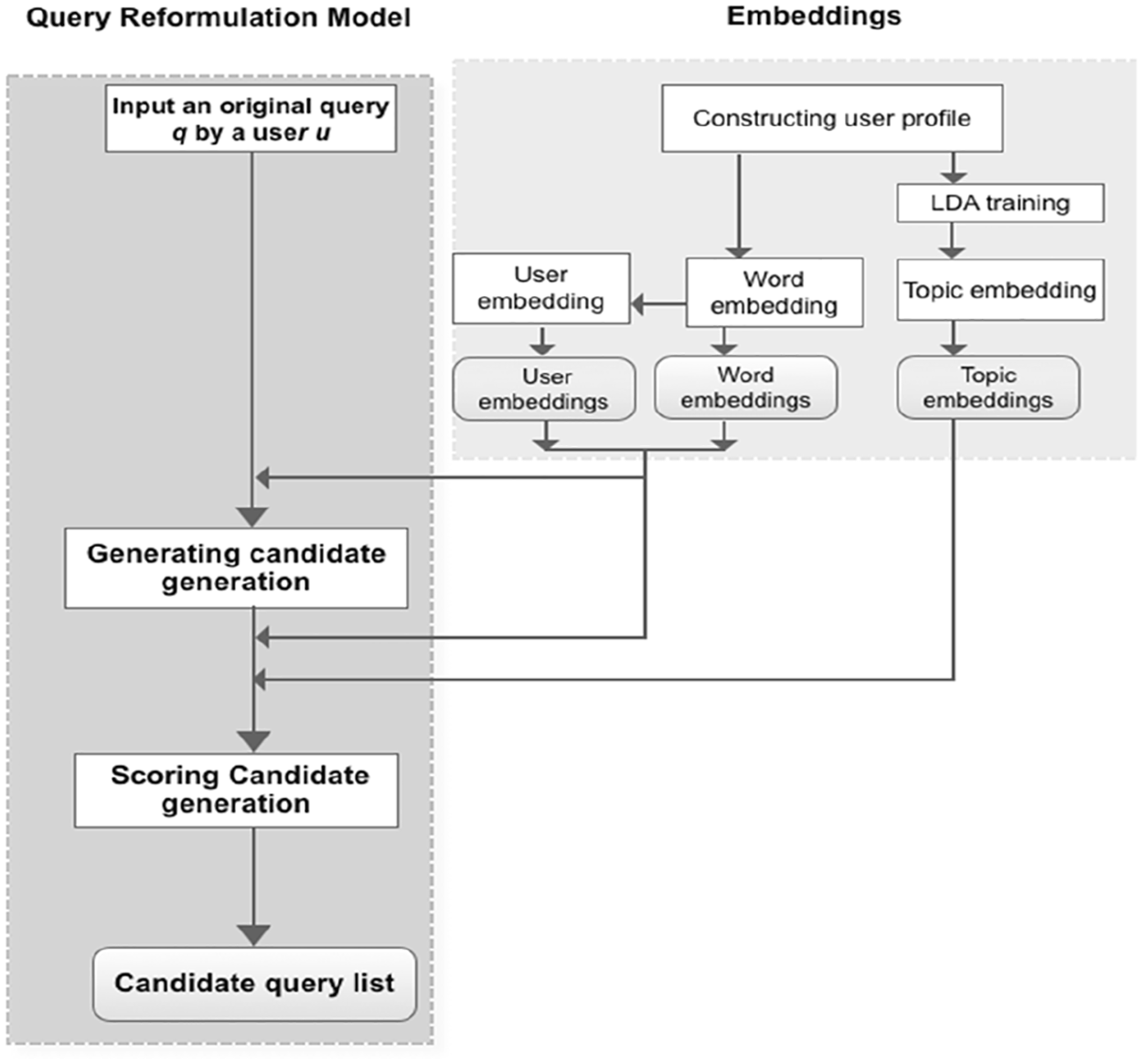
The framework of our proposed approach.
Main notations used in this article.

3.1. Candidate query generation
The outputs of this step are candidate queries formulated by substituting or adding one term in the original query. The model proposed by Wang and Zhai [6] is used with the difference that the contextual similarity between terms is calculated by exploiting embeddings and is augmented by user personalisation.
3.1.1. Query substitution
Given a query
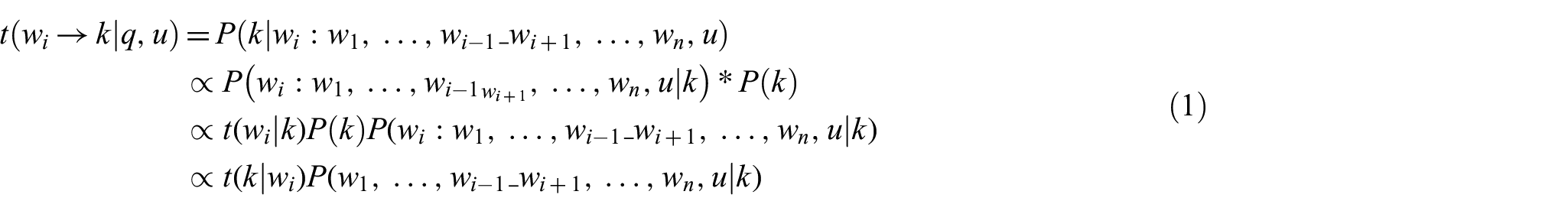
We assume that

where

where

Here,
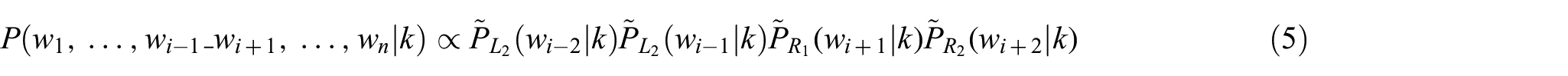
Owing to space limitations in this article, readers are required to refer to the work by Wang and Zhai [6] for details on the derivation. Where

where
As most word embeddings have a common shortcoming wherein each word is represented by a single vector, they subsequently ignore polysemy [41]. If we only consider the query context generated by word embedding in the preliminary candidate term generation process, the noise problem may surface when addressing ambiguous terms. For example, the underlying possible subtopics of the query Flash may refer to Adobe Flash player, a 1990 American superhero series, or the Israeli politician Flash Gordon. Thus, the term ‘flash’ has widely diverse contexts in historical queries. When we try to explore the contexts for the term ‘flash’, which is restricted to terms related to flash player, considerable noise is involved in its candidate list, such as ‘boiler’ and ‘tank’. Furthermore, a few typing errors, such as ‘flahs’ and ‘falsh’ also cause the degradation of performance while handling typo-prone terms, such as ‘flash’. Similar to previous work [5,6], we rely on user sessions in our search log and the normalised mutual information (NMI) threshold [6] is employed to filter out the possible noise. Next, we iterate over all positions of this query, and queries for all positions are merged to generate the final list of candidate queries.
3.1.2. Query addition
Given a query
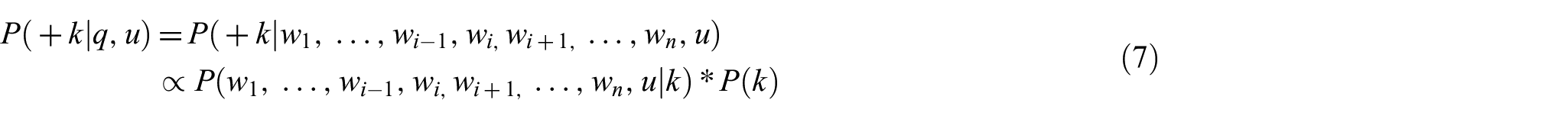
where

3.2. Candidate query scoring
The rationale for our candidate-scoring approach is based on the assumption that an individual query shares the unique search intention of a user, and thus the topics in the same query should be prone to remaining consistent from the semantic perspective. Consequently, an ideal candidate query list is the one that formulates queries for which the semantic meanings consistently remain at the top of the ranking list. However, since candidate queries generated in the first sub-task purely depend on the contextual similarity between terms in the historical queries, it is almost impossible to capture and maintain consistency in the semantic meaning within a new query. For example, as shown in Table 2, the query ‘artisan chocolate flavor’ is an ideal output for the original query ‘artisan chocolate bread’ from the point of view of semantic consistency; however, it is ranked eighth. In contrast, the semantic meaning of ‘artisian casserole bread’ seems inconsistent, though it is ranked first.
Top 15 results given by substituting one term in the original query ‘artisan chocolate bread’.

A score function that can model consistency in semantic meaning in the candidate query is necessary to deal with this problem. Subsequently, all candidate queries of the given original query
3.2.1. Query scoring model
The design of the graphical model used in our scoring work is shown in Figure 2. While the filled nodes denote the observable query terms, the empty ones represent the unobservable latent topics. Let a candidate query

The graphical model for scoring query.
The final candidate query score is arrived at by calculating the marginal joint probability of the term sequence

where
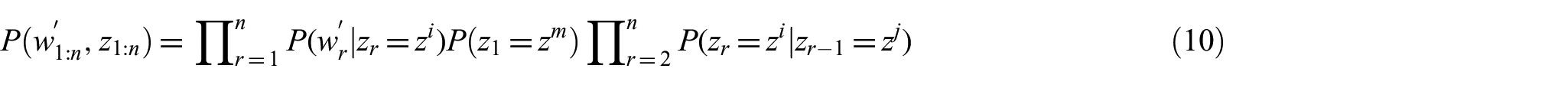
where
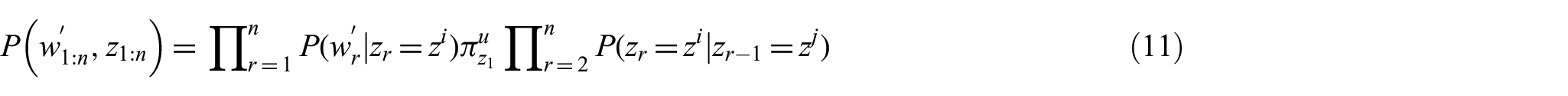
To compute the probability of

where

where

In certain circumstances, some candidate queries for an input query may be generated by substituting one term while others can be generated by adding a new term. Thus, the candidate queries returned for the same input query probably have varying lengths. To render the candidate queries with distinct lengths comparable, we consider the normalisation

where
3.2.2. Latent topic detection
Latent topics are critical factors in the candidate query scoring function discussed above and in the topic embedding that will be discussed later. We first constructed a personal pseudo-document for individual users by aggregating all the queries issued by them. Then, we exploited the pseudo-document of each user to represent their interest based on the previous work [5,23], which have proved that users’ interests can be inferred from their historical queries. Next, we treated each user’s profile (pseudo-document) as a single document unit to detect latent topics. The widely used and standard LDA algorithm [43] was leveraged to implement the latent semantic topic analysis on the collection of pseudo-documents. The Gibbs LDA
2
package was used, and the collapsed Gibbs sampling [44] was performed to iteratively assign latent topics for each query term. In this manner, given a sequence of words T = {t1, …, tM}, after the LDA converged, each term
3.2.3. Model parameter design
To calculate the candidate query score, we require three types of model parameters, namely



where
4. Embeddings
Three types of embeddings (i.e. term, user and topic embeddings) are associated with our proposed model. The main structure used to derive them is demonstrated in Figure 1. In this section, we offer a detailed description of how to learn these embeddings.
4.1. Term embedding
This aims to learn low-dimensional vectors of query terms from search logs by employing the notation of a query as ‘sentence’ and terms within the query as ‘words’. It learns query term representations using a state-of-the-art word embedding model [8], called the skip-gram model, which aims to predict multiple surrounding (contextual) words for a given word in a sliding window. The objective of this embedding model is to maximise the log-likelihood over the entire set

The probability

where
4.2. User embedding
Assuming that users’ interests are revealed by their search histories, we obtain the vector of a user
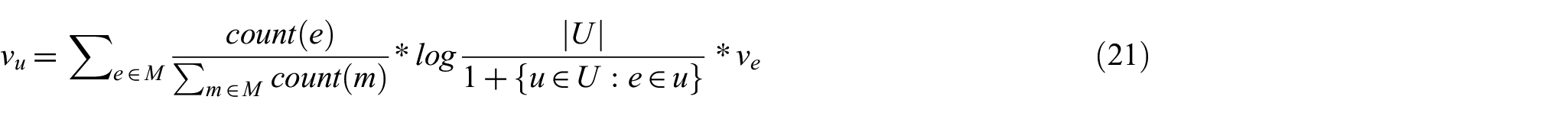
where
4.3. Topic embedding
This aims to learn the vector representation for each latent topic and is trained based on obtaining the specific topic for each term using topic analysis on users’ pseudo-documents. The basic idea of topic embedding is to consider each topic to be a pseudo term. Terms appearing in the context window

Probability

where
5. Experimental setup
In this section, we discuss the experimental setup that supports the evaluation of our proposed frameworks. First, we introduce our datasets and then give a detailed description of our evaluation metrics and baselines. Finally, the additional experimental settings and parameters are presented. The research questions that our experiments aim to answer are as follows:
RQ1: Is the overall performance of our method better than those of the state-of-the-art baselines?
RQ2: Is our candidate generation method better than that of the baselines?
RQ3: Does our scoring method outperform that of the baselines?
RQ4: How does the query frequency impact the results?
RQ5: How does the query length impact the results?
RQ6: Does the number of latent topics affect the overall performance of our method?
5.1. Dataset
Our experiments were executed on the America Online (AOL) search log, which is the largest publicly available query log and, in recent studies, has been considered a credible experimental dataset [4,20,24]. This log dataset spans 3 months from 1 March 2006 to 31 May 2006. As shown in Table 3, each record contains the following fields: (1) UserID: an anonymous user ID; (2) Query: the actual query terms; (3) Item-rank: the rank of the clicked result and (4) Clicked URL: the result the user clicked. We divide the entire dataset into two parts based on time. Queries in the first 2/3 data (queries submitted before 1 May 2006) were used as our training set, while the last 1/3 data (the last month of the data) were used as our testing set. All non-alphanumeric characters were removed from the queries. To reduce the noise further, we removed a large number of navigational queries (containing URL substrings, such as .net, http, .org, .edu and .com, for which query suggestions may not be as useful) and queries starting with special characters (such as &, $ and #) from the dataset. We defined the end of a session using a 10-min idle-time window [45] and deleted the queries that were repeated in each session. Finally, sessions with less than two queries or no clicked URL were also removed because we intended to identify those in the subsequent queries if the first query submitted by a user could not meet his or her information needs in the current session. While constructing user profiles we only considered the users in both the training and testing sets only. We deleted user profiles with fewer than 50 unique queries. Finally, we obtained 35,368 user profiles, and the term and topic embeddings were trained on this profile dataset.
Examples of AOL query log datasets.
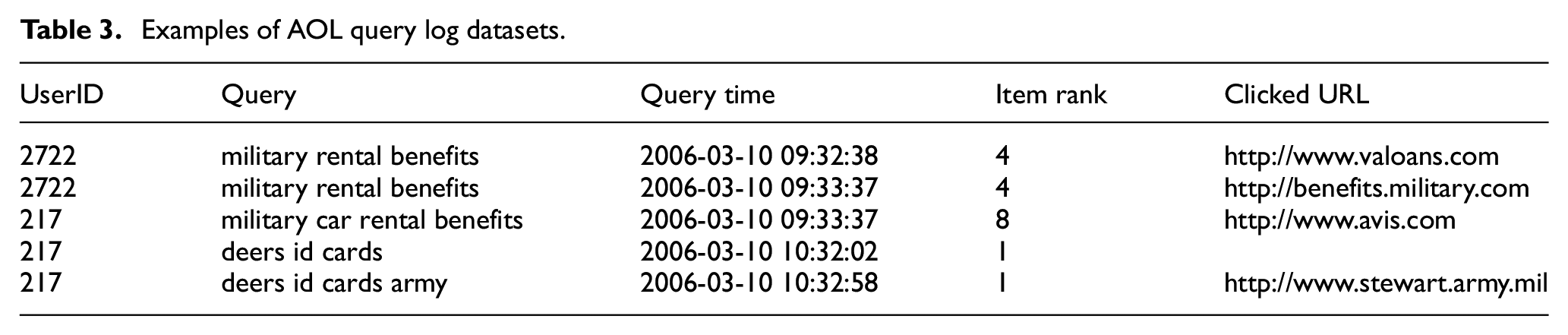
5.2. Evaluation and baselines
It is well known that the effectiveness of query suggestion methods can be evaluated mainly through human evaluation [20,23] or session information [4,5,45]. Human evaluation is a resource-intensive process that requires labour, time, evaluator expertise and funding. Often, therefore, only a small number of query reformulation results can be evaluated, and the results of human evaluation are often influenced by the evaluators’ subjectivity. Conversely, session-based evaluation is implemented using session information from the query log that records the query reformulating behaviours performed by users to acquire satisfactory results. Automatic evaluations are conducted by investigating these behaviours. Compared with human evaluation, session-based evaluation can measure more query reformulation results automatically and its evaluation results are more objective. Consequently, session-based evaluation is applied in our work and the ground truth for a query reformulation is defined as follows. First, we utilised the same method as Bing et al. [4] to collect satisfactory and unsatisfactory queries. At the end of a search session, a query that led to at least one URL being clicked was selected as a satisfactory query. The query previous to the satisfactory one in the same search session was designated an unsatisfactory query. Second, we adopted unsatisfactory and satisfactory queries as inputs and the ground truth of our experiment, respectively. Given the unsatisfactory query as an input, the corresponding satisfactory query generated by a query reformulation method was accepted as the output. We selected sessions generated by users who produced sessions in both the training and testing set to evaluate our method, and 15,336 one-term query addition sessions and 57,556 one-term query substitution sessions were obtained in the testing set. From the statistical analysis, we found that approximately 70% of the satisfactory queries were not found in the training set because of the dataset limit, implying that no query suggestion method successfully recommended correct queries for these cases.
We found that only about 1.3% of satisfactory queries were generated by adding or substituting a stop word, and only approximately of 1.2% users added or substituted the stop words in original queries. These data suggest that stop words were not very useful for generating satisfactory queries, and they were removed. We also found that approximately 0.7% of the satisfactory queries were generated by substituting or adding words with their lengths denoted by characters, and this gave us a reason to rule out such words. We also found that the probability of new terms co-occurring with the terms of initial queries in the same query was 37%, and that the probability of a new term co-occurring with the terms in the initial queries in the same session was 79%, which proves once again that it is essential to exploit session information to filter noise while generating term substitution candidates. There are 2,848,149 unique queries in all and 633,372 distinct terms in the collection of pseudo-documents.
To evaluate the effectiveness of query reformulation, we followed the state-of-the-art query reformulation method [4] and used the metric Recall@K to measure the accuracy of each work. This metric signifies that if the true answer is returned among the top-K candidates, the reformulation of an input query is recognised as successful and is equal to the ratio of the successful cases of all adopted testing cases. A higher value of Recall@K indicates better performance. Actually, some metrics, such as MRR@K and nDCG@K, can also be used to evaluate the effectiveness of query reformulation. Like the work by Bing et al. [4], we simply intend to present the rate of successful cases and thus only Recall@K was leveraged in our work. Since previous studies on query reformulation were based on the assumption that users are generally provided with a list of top
To compare our approach with those of others, we reimplemented two comparative baselines, namely those taken from Wang and Zhai [6] and Bing et al. [4] with the same experimental setup. They are denoted as ‘CTA’ and ‘TALP’, respectively. Detailed descriptions of both baselines are provided in the work section. Bing et al. [4] used the query log- and social tag-based methods to generate candidate queries. Owing to the unavailability of the social tagging data resource and to ensure that the experimental setup (i.e. dataset) of the comparative method was consistent with that of our new method, we only implemented the query log-based method, and Model 3 scoring was reproduced with window size x = 3 for skip-gram because of its superior performance.
5.3. Settings and parameters
While generating query candidates by either term substitution or addition, we constructed the vocabulary set T by selecting the top 100,000 terms in the training set. We then set the filtering NMI threshold [6] to 0.001 to filter the noise while generating substitution candidates. We learned topic models by exploiting LDA in the training set, and the number of topics while training the LDA model was set to 80. We conducted additional experiments and present a detailed discussion of the results generated when the topic number changed.
There are several parameters in the Word2vec algorithm, such as vector dimensionality, window size, word-sampling threshold, whether to employ hierarchical softmax and the number of negative examples [8]. As the vector dimensionality and the sliding window size in most Word2vec algorithm-based work (irrespective of being related to the query), respectively, are set to 300 and 5 by default, we employed these parameter settings in both the term and topic embedding. Both embedding models were optimised using stochastic gradient ascent. Negative sampling was used to accelerate the training, and 10 random samples in each vector update were leveraged. Given that some very frequent words, such as ‘google’, ‘yahoo’, ‘facebook’, may cause hindrances, such as shrinking the embedding space, we deal with frequent terms using the subsampling approach [8]: each term
6. Experimental results
We first implement single and hybrid operations to generate final candidate queries for each of the aforementioned methods. We then provide an analysis of the effect of query frequency and length on the overall performance of query reformulation. Finally, we examine how the number of topics affects our model.
6.1. Performance comparison of single and hybrid operations
In this experiment, we aim to answer
Comparing different methods for query substitution.

Comparing different methods for query addition.

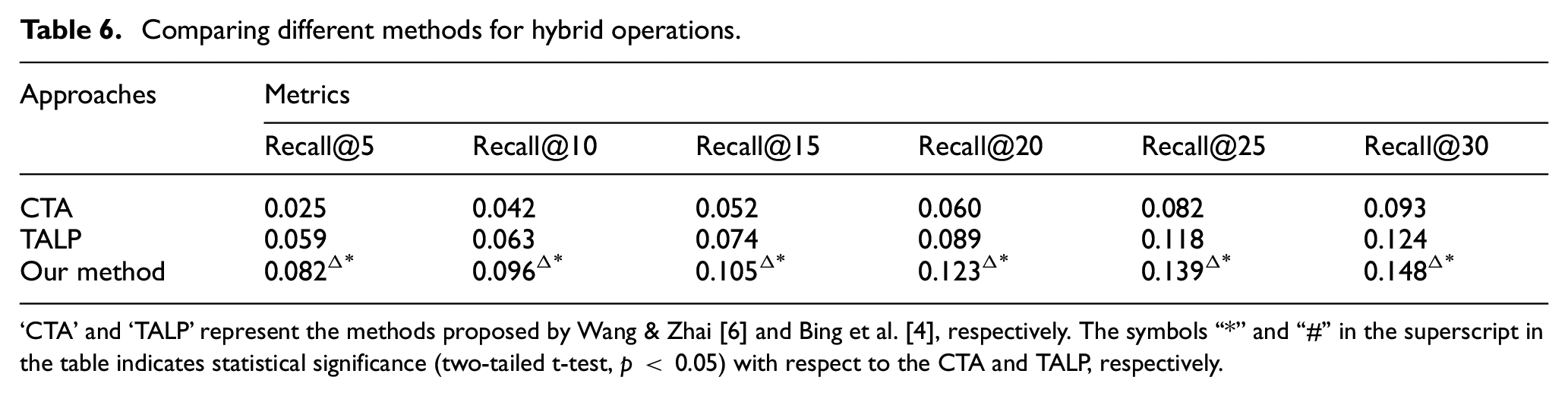
Comparing different methods for hybrid operations.
First, we compare the performance of the single operation of our method against that of state-of-the-art methods. It is assumed that we have already known the particular type of operation (i.e. term substation or addition) that should be performed by users to obtain satisfactory queries, and we discuss the overall performance of query substitution and addition on one term, separately. That is, all 57,556 one-term query substitution sessions are used as test cases to assess the performance of query substitution, and 15,336 one-term query addition sessions are employed for query addition. We compare the performance of our method with CTA and TALP, while the overall results from different methods in query substitution and addition are shown in Tables 4 and 5, respectively. There are some differences between the baseline scores obtained in this article and those published in others studies [4,6], and the scores calculated in this article are slightly lower than those found in previous work. This may be mainly because we chose different test queries as the test queries were not made public, and we ruled out a large volume of words comprising only one character. Besides, from the experimental results, we also found that our model achieved considerably more effective results than the baselines for single reformulation operations (i.e. query substitution and addition).
The overall performance increases when more query reformulation candidates are returned for re-ranking. A larger value of
Considering that it is likely for a user to perform both addition and substitution operations to reformulate a query, it is necessary to explore the effectiveness of our method while generating hybrid query reformulation candidates through addition or substitution. Thus, we relax the assumption that we know the operation type that should be carried to obtain a satisfactory query in this experiment. We also restrict the operations for one new term along the lines of the above experiments. Thus, the testing cases all involve substitution and additional testing sessions mentioned above, and we obtain 13,669 sessions in all. For a given testing query, the substitution and additional candidate queries are generated separately, and all candidate queries are re-ranked based on scores calculated by the scoring method to achieve the final candidate list. The results of different methods for hybrid operations are presented in Table 6. While allowing for hybrid operations, the absolute performance figures decrease when compared with single operations primarily because the number of possible operations increases. This, in turn, challenges the scoring methods. Despite this reduction, our method continues to significantly outperform CTA and TALP on all metrics, when
Tables 7 and 8 contain the top 10 final candidate queries generated by the hybrid operations of different methods for the input queries ‘enterprise rental car’ and ‘mexican recipes’, respectively. Table 7 demonstrates the candidates generated in a setting where the original query was issued by a user who used to submit queries related to ‘car’. Users’ historical queries can represent their preferences. Thus, we can infer that the car-related candidates in Table 7 can be expected to be satisfactory. The candidates produced in Table 8 for a user who searched for information on ‘recipes’ and recipe-related queries can be determined as ideal candidates. From these two tables, we find that more closely related queries can be returned by our method. The candidate queries generated by our method tend to correspond more accurately with users’ interests. Thus, we conclude that our method performs the best among the given methods.
The top 10 final outputs generated by hybrid operations of different competing methods for the query ‘enterprise rental car’ submitted by a user who often searches information related to ‘car’.

The top 10 final outputs generated by hybrid operations of different competing methods for the query ‘mexican recipes’ submitted by a user who often searches information related to ‘recipes’.

6.2. Comparing different methods for the generation of candidate and scoring queries
To answer
Comparison of different combinations of candidate generation and scoring methods in generating hybrid query reformulations.

We consistently benefit from using our scoring approach as opposed to the TALP approach, regardless of the generation approach used. The use of our approach for generation instead of the CTA or TALP produces consistent improvements. Both findings are consistent across all combinations and values of K. There are some possible reasons for this. First, the contextual information of each query term is derived by term embeddings that consider richer contextual information. Term embeddings provide better semantic similarity measures than the translation model based on co-occurrence for generating query reformulations. Second, taking the users’ personalisation into account in the generation of candidate queries can help filter out some unrelated terms. Our scoring model considers the context of both a term and its corresponding topic and can provide more valuable contextual evidence for calculating the consistency of the semantic meaning of a candidate query.
6.3. Performances of queries with different frequencies
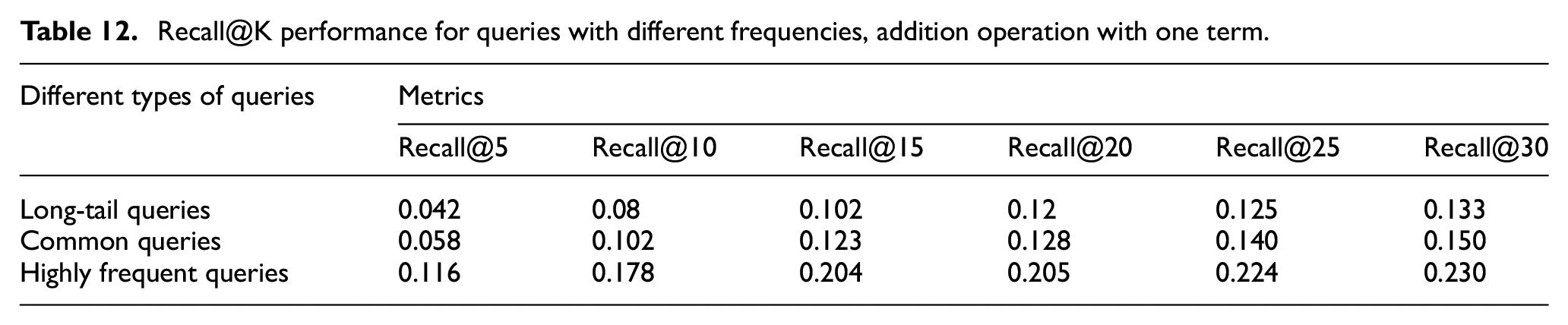
Finally, we focus on the impact of query frequency on the overall query reformulation performance to answer RQ4. Queries submitted to Web search engines are known to follow a heavy-tailed Zipf distribution [46]. A large number of queries are issued infrequently. Thus, we distinguish among ‘long-tail queries’ (those that occur less than twice or those that are only issued once by a user), ‘highly frequent’ queries (those that are issued more than a hundred times) and ‘common queries’ (all others). The proportion of these three types of testing queries is presented in Table 10. The performances of query substitution and addition for each frequency group in terms of Recall@K are shown in Tables 11 and 12. Query frequency has an impact on performance, with better performance achieved with highly frequent queries both in the query substitution and addition. These results may arise from queries with lower frequencies having less context information thus rendering the completion of the query reformulation task more challenging. We found that the gap between highly frequent and common queries is larger than that between common and long-tail queries in most cases. For example, at cutoff K = 20 in query substitution, highly frequent queries show a 48.1% improvement over the performance of common queries, and common queries show 23% improvements over long-tail queries. At cutoff K = 20 in query addition, highly frequent queries reported a 60% improvement against the performance of common queries, and common queries showed an improvement of 6% over the long-tail queries. Therefore, we infer that queries with higher frequency are more likely to be advantageous in our method.
Proportion (%) of long-tail, common and highly frequent queries in our testing set.

Recall@K performance for queries with different frequencies and substitution operation with one term.

Recall@K performance for queries with different frequencies, addition operation with one term.
6.4. Performance of queries of different length
To answer RQ5, we closely examined the results across different term lengths. The proportion (%) of testing queries with different lengths is shown in Table 13. Most queries contain two or three terms. We implemented query substitution and addition experiments to test the effect of query length on the performances, and the results are seen in Figures 3 and 4. The horizontal axis represents the specific value of
Proportion (%) of queries with different lengths in our testing set.

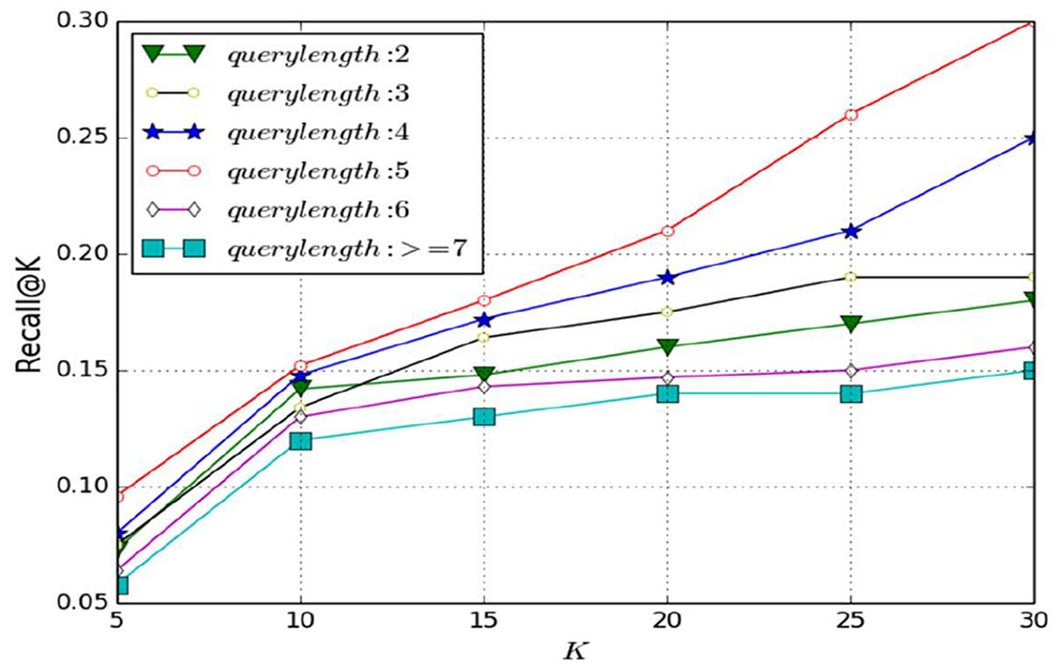
Recall@K performance for queries with different lengths when substitution operation with one term being performed.
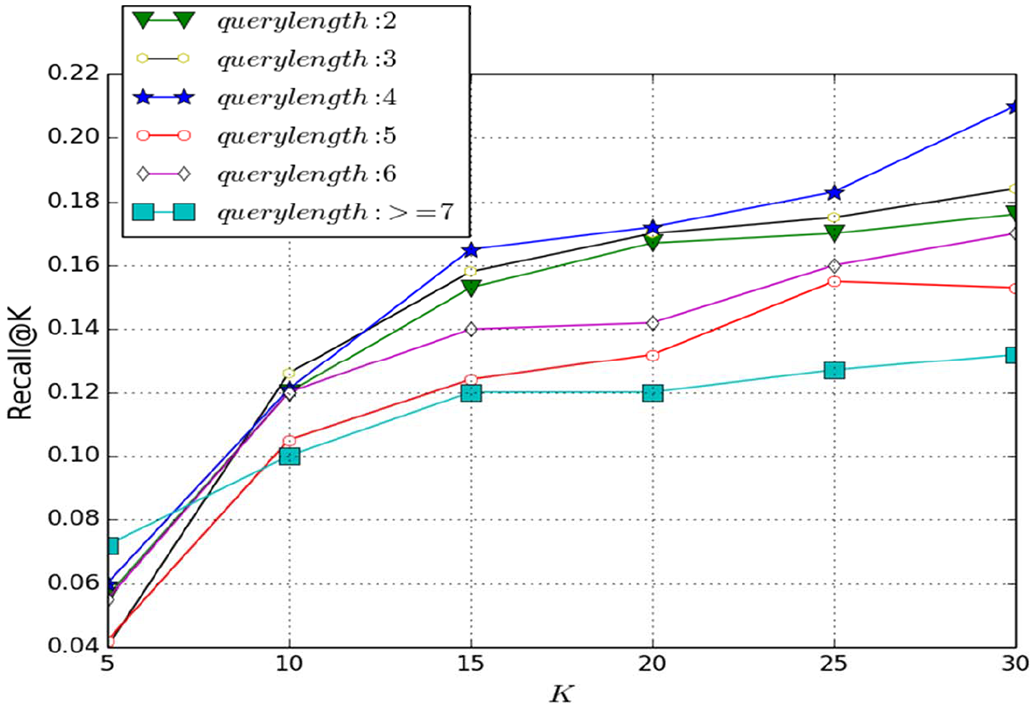
Recall@K performance of queries with different lengths when addition operation with one term being performed.
6.5. Performance of topic number
The number of latent topics is a critical parameter in our framework and is exploited in latent topic detection. In this experiment, we aimed to answer RQ6 and changed the number of topics from 10 to 100 with step intervals of 10 to discuss the impact of the topic number on the overall performances. For each topic number, the substitution and additional experiments on one term were implemented, and the performance results were demonstrated in Figures 5 and 6, respectively. The X-axis shows the parameter of the topic number, while the Y-axis shows the value Recall@K. As the number of topics increases, the Recall@K values exhibit a dramatic rise until K = 80 for both query substitution and addition; a decline of Recall@K value followed when

Comparison of performance of query substitution with one term when the topic number changing.
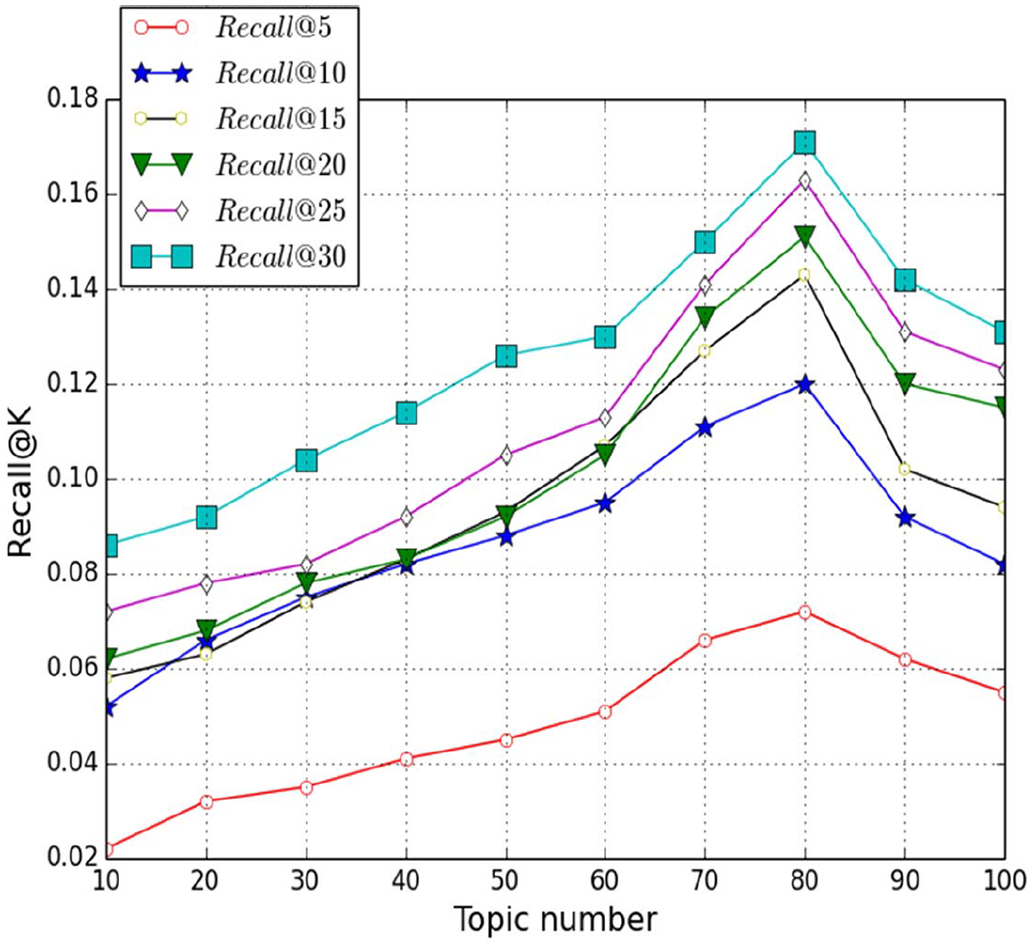
Comparison of performance of query addition with one term when the topic number changing.
7. Conclusion
In this article, we demonstrated how embeddings (i.e. term, user and topic embeddings) contribute to the two major tasks of personalised query reformulation, namely candidate query generation and scoring. To track the task of candidate query generation, term and user embeddings were used to generate candidate queries according to the contextual similarity among terms and user preferences. The candidate queries generated in the first task were evaluated and scored (re-ranked) for consistency in the second task. The factors considered were the semantic meaning of a candidate query and user preference based on a graphical model with the term, user and topic embeddings. Our experiments demonstrate that our model consistently and significantly improved over the state-of-the-art method results and that the performance of our method was affected by the query frequency, length and latent topic number. The findings in this study are useful for enhancing the search experience of users by helping them formulate accurate queries for their search tasks. We are also confident that the approaches explored in our study are general enough to be applied to other query-related studies, such as query expansion or rewriting.
Several ideas are worth investigating further to improve our solution. Single-word-level operation for query reformulation was discussed in our article. One future direction is to enhance our single-word level to more complex operations for query reformulation. The topic-based interest profile is derived from historical queries. However, some users may not have abundant historical queries. One possible approach for overcoming this problem may be an investigation of other types of personal information, such as web browsing history and browser bookmarks. In addition, we also plan to evaluate the effectiveness of reformulation method from the perspective of meeting the information need of the user by measuring the web search quality of candidate queries.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author would like to thank the editor and reviewers for their useful comments and suggestions, which were very helpful in improving the quality of the paper. This research is supported by the Open Project of Xihua University under grant no.XSCG 2020-005 and Postdoctoral Science fund of China under grant no. 2017M620871.