
Abstract
With the increasingly huge amount of data located in various databases and the need for users to access them, distributed information retrieval (DIR) has been at the core of the preoccupations of a number of researchers. Indeed, numerous DIR systems and architectures have been proposed including the broker-based architecture. Moreover, providing DIR with more flexibility and adaptability has led researchers thinking to build DIR with software agents. Thus, this research proposes a design and an implementation of a novel system based on the broker-based architecture and the peer-to-peer (P2P) network called broker-based P2P network. The proposed architecture is implemented with a multi-agent system (MAS) where the main agent playing the role of the broker, receives query from a peer agent and forwards them to other peer agents each with their index and resources. Upon completing retrieval process at each peer agent, results are directly sent to the peer agent that initiated the query without using the broker agent. Java Agent DEvelopment framework (JADE) is used to implement the agents and, for experiments, TERRIER (TERabyte RetRIEveR) is extended and used as the search engine to retrieve the Text Retrieval Conference (TREC) collections dataset notably TREC-6. The peer agent that originated the query progressively collects results coming from other peer agents, normalises and merges them and then proceeds with re-ranking. For normalisation, MinMax and Sum that are unsupervised normalisation methods are used.
Keywords
1. Introduction
In recent years, digital information sector has experienced a very fast development due to the increasingly growing volume of stored data. Those data mostly exchanged via the web are either publicly (Internet) accessible or shared privately among a limited number of clients (intranet, private networks, etc.). In general, stored data can be in the form of text documents, images, audios or videos. Information retrieval (IR) concerns the development of techniques for indexing, processing and retrieving of information queried by users from large data collections. Depending on the type of data to deal with, the process can include more or less other steps. For instance, retrieving text documents generally involves removal of stop-words, stemming and weighting. In text documents, some very frequent words (of, by, so, thus, etc.) that have less influences on the topics addressed in the corpus (collections of words) are systematically removed. This is called stop-words removal. Stemming consists of splitting words by removing suffixes as to keep the radical that is common to them (begging, begged → beg). In order to compute the relevancy of each document according to the search query, weighting (ranking) algorithms are used (see Figure 1). The most spread text documents weighting algorithm is TF–IDF (Term Frequency–Inverse Document Frequency). However, in this work, BM25, IFB2 and DFIZ are used for documents ranking. According to the weighting algorithm used, the ranking order of retrieved documents may change. Similarly, for specific data contents like images, audios or videos, the retrieval process may involve different steps. This research is concerned with IR of large data collections comprised of full-text documents.

Architecture of a textual IR system.
On one hand, the rapid growth of data volume and the problem raised by the limited capacity of storage and the access to data have shaped the interests of researchers in IR systems. Thus, to keep the balance between the distributed storage of information – that came as solution to limited capacity of storing devices and the concurrent access to data – and the need of effective and rapid retrieval of data from their various locations, many distributed information retrieval (DIR) architectures and systems have been provided. The most common are the peer-to-peer (P2P) network, the broker-based architecture, the crawling, the metadata harvesting and the hybrid. In a broker-based architecture, distributed resources are located with their respective indexes and broker forwards requests to resources, collects results and merges them [1]. The multi-agent-based system for DIR proposed in this research is based on a novel architecture: the broker-based P2P network. As its denomination suggests, this new architecture is inspired from both the broker-based architecture and the P2P network.
On the other hand, IR systems or more specifically DIR systems’ performances are inherent to the various search engines that encapsulate resources spread over the network. In an experimental DIR environment, one can decide to deploy the same or different search engines for several resources locations depending on the targeted goal and performances of search engines. However, before performance consideration, IR researchers pay attention to whether a search engine is commercial or open source. Mostly, commercial search engines are not realistic solutions because of the fees and the fact that they are not adapted for experimental uses [2]. On the contrary, open source search engines are more suitable for researches because there are not only free but they allow modifications to meet specific needs. When it comes to make a choice of an open search engine for the development of a research project, some parameters as the programming language used, the development status, the continuity and the robustness of the project behind the search engine are highly considered. Beyond the aforementioned criteria, there are the type and origin of documents to use as testbed. In the situation of web search, it is essential to use a search engine with crawling ability that deeply navigates through the web and downloads the pages it accesses according to a given algorithm. Furthermore, for experimental IR operations and testing of academic-dedicated search engines, a group of researchers generated the TREC (Text Retrieval Conference) document collections [3]. TREC document collections comprise full text from newspapers, articles and US government records. They are primarily dedicated to researchers in IR systems and natural language processing (NLP) for the development of their works. Fortunately, last development and researches in search engines have yielded platforms capable to index various document collections, including TREC and web collections. Accordingly, we have chosen TERRIER (TERabyte RetRIEveR), one of the most famous of them as our test-bed [4]. TERRIER is a highly flexible, efficient and effective open source search engine, readily deployable on large-scale collections of documents, designed and distributed by the School of Computing Science of the University of Glasgow under the Mozilla Public License (MPL) [5]. Due to its flexibility and extensibility, TERRIER is easily deployable on a distributed and collaborative environment such as multi-agent systems (MASs).
More than in the past, software agents are increasingly used in the implementation of systems in collaborative and distributed environments [6]. Especially in the Sea-of-Data (SOD) applications in which the user is interested in processing large amounts of data in several distributed locations, these data may not leave their location for a number of reasons, such as legal requirements, bandwidth limitation or restrictions due to the acquisition process (the data may be acquired on demand) [7]. Some researchers use agents to implement DIR systems in the fact that they comply well with SOD applications idea. From the broker-based architecture to P2P network, many DIR architectures now use these autonomous software entities (agents) that increase their resilience and their flexibility [8]. In a collaborative environment, agents can pursue common goals and selfish goals. Meaning that agents can come together and realise a set of actions one after another with the ability to migrate from one platform to another regardless of the operating systems (OSs) used. Environments with such characteristics are called multi-agents systems [9]. However, this has not been always the case since early adopters of this technology tend to diverge where there is no unanimity across appropriate industries on a norm to use. To cope with that situation, some institutions and industries came together and founded the Foundation for Intelligent Physical Agents (FIPA) in December 1995 as a non-profit organisation for defining specifications for open agent interfaces. Its major aim was to create consensus between different organisations involved in agent technology, and therefore commence the agent standardisation process [10]. Since FIPA has defined the specifications for a standard language for agents (Agent Communication Language – ACL), several agent systems have emerged. In addition, to date, one of the most used agent development platforms by researchers in the field of software agents is the Java Agent DEvelopment framework (JADE). JADE is a software platform that offers basic middleware-layer functionalities, which are autonomous of the specific application and which facilitate the realisation of distributed applications that use the software agent concept. One of the essential merits of JADE is that it implements this concept over a famous object-oriented programming language, Java, providing a simple and friendly application programming interface (API) [11]. The contributions of this work include:
A novel DIR architecture resulting from a combination of some functionalities of broker-based architecture and P2P network.
A broker agent that routes queries from originating peer agent to other peer agents with available resources. The latter upon retrieval send results directly to the peer agent that originated the query.
Inexistent permanent connection between peer agents that are very independent from each other. This increases the flexibility and the extensibility of the system and allows a peer to quit and join the system unbeknown to other peers.
The use of both direct indexing and inverted indexing and the effects of the latter over the mean average precision (MAP) with the number of peer agents increasing.
We assume in this article that the system meets the following configurations. First, each peer agent keeps autonomous indexing files and an IR search engine to query its local data collection. On the contrary, no additional constraints are introduced on the local search engines. Therefore, peer agents with very different local search engines can join the system. Second, the experimental results exposed here are obtained from local optimal search engines in that they yield all appropriate documents in the collection for a given query. Third, we assume that each peer agent at its convenience possesses an algorithm in place to merge the returned results. However, for experimental purposes, we have used a merging protocol that includes linear score normalisation techniques. Fourth, we assume that the document collections held on peer agents do not overlap, and therefore the total number of relevant documents for a certain query is the sum of the relevant documents returned from each peer agent. We also assume that each peer agent source contains at least one relevant document to all of the queries. Finally, we assume that the broker agent possesses a unique protocol that all peer agents should use to advertise their resources to it. In return, broker agent should use these resources advertisement to maintain a double-entry table and routes the query received from a given peer agent only to other peer agents that put their resources at the disposal of the broker agent. The double-entry table contains all the peer agents connected to the system and those that have advertised their resources to the broker agent.
The rest of this article is structured as follows: section 2 discusses related research; section 3 introduces our proposed broker-based P2P network. Section 4 provides the experimental settings – including JADE, a FIPA-compliant container for our agents and TERRIER, an efficient search engine encapsulated in each of our peer agents. Section 5 analyses the results obtained with discs 4 and 5 that constitute TREC-6 testbed and presents the linear normalisation methods used. Section 6 discusses future work and perspective, and section 7 condenses the main contributions of this article.
2. Related research
2.1. Use of software agents in IR
Because of their flexibility, their autonomous and collaborative abilities, software agents are increasingly used in applications that involve large amount of data. This makes more sense when it is question of IR where there is a need to building systems that are more robust and to making them cognitive [12]. An environment where multiple software agents interact, inform each other of their actions is an MAS. An MAS is, therefore, a computerised system in which multiple agents interact, inform each other about their status and actions via well-defined communication protocols [13]. The agent communication language (ACL) defined by FIPA governs these protocols. In IR, implementations of MASs are very diverse and sometimes are related to the architecture and the expected functionalities of the apparatus [14].
Accordingly, some researchers have found it relevant to assign an agent to each step of their IR systems. It is the case of Mubarak and Simon [15], who have proposed a system architecture and a UML modelling for agent-based IR. In their proposal, considerable number of dedicated agents is used. First, the crawling agent uses an automatic process to identify and gather the keywords and documents contained in the document collection. The indexing agent assembles the information from the crawling agent and fills the database. Search agent looks for the most relevant data in the database and retrieves the most relevant results related to the combination of queried terms. Indexing agent indexes and stores the information collected from the crawler. Query agent processes the query sent by the user agent and this agent delegates the search task to the search agent. Retrieval agent checks that the pages retrieved are relevant in nature and matches the user query and the retrieved results and decides which results to display to the user. Combination agent learns from the keywords stored by the indexing agent and generates a combination of the keywords that do not have any related meaning.
The work by Mahdi et al. [16] proposes a theoretical framework of an agent-based IR in a cloud for an institutional repository. For this research, they considered the effect of user traffic on the performance of retrieval of information from the cloud environment. User traffic refers to the number of cloud users trying to retrieve information from the cloud database at the same time. Although most cloud competing systems are considered to have high scalability, user traffic can affect the performance of the system. When the user traffic is too high, the system performance in terms of retrieval of information is low. On the contrary, when the user traffic is low, the system performance is high. The performance of the retrieval system in this case is based on the speed of retrieval. We should notice that the performance evaluated here is not related to the agent but to the capacity of the bandwidth between information repository and users. The bandwidth is, therefore, a limiting factor.
Very often, to improve efficiency of IR systems, software agents are associated with other technologies. It is the case of Fouad et al. [17] who scanned a large range of then existing proposals before bringing out an effective system for IR that they have called SPIRS (Semantic and Personalised IR system). As its denomination reveals, SPIRS is an IR system using both semantic web and personalised agents. The authors used many concepts for calculating and increasing relevancy of search results including personalised algorithms based on WordNet domain. In their work, they used a search and crawler agent that scrutinises the web and collects documents related to the medical domain. They proceeded with documents retrieval in a selective way by using crawling-related restricted queries. However, they still needed a mechanism to assess and attest the relevance of these documents to the predefined domain in the ontology. The agent systematically proceeds with documents cleaning up by removing unneeded, blank, too short and duplicated documents, or those with formats that are not suitable for text processing. Then, the agent calculates the relevancy of documents to extract the significant ones and remove the unrelated ones to the specified domain. These techniques implemented in SPIRS have significantly improved the MAP.
2.2. DIR systems and search engines
IR, for sure, involves techniques used to access information (mostly in large volumes) to serve human needs. However, we gave a definition that seems to be ‘too much’ general to avoid entering into ‘quarrels’ of IR researchers on how IR should be defined or not. It is in that sense that Zobel [18] has raised the rewording issue by questioning the previous definitions to try and find a more unbiased and conciliatory definition of IR. The substance of those arguments is that all the IR steps (representation, indexing, storing, accessing information) should be performed in view so as to meet an interest or a need in the best way; that is, to serve humans.
The first steps of the IR occurred in the first half of the 20th century with the development of electro-mechanical searching devices [19]. However, the techniques used were primitive and then time consuming for an eventually less effective result. The evolution of hardware and the apparition of Internet (web) throughout the second half of the 20th century have considerably improved the IR techniques. The creation of numerous network services has given a new shape to IR. This resulted in the distribution of data (resources) in different locations and their connection with network protocols. The field (IR sub-field) that deals with accessing and retrieving these data spread across a network is called DIR.
Unlike IR that consists of querying a single database with a single index, DIR generally involves many indexes and resources distributed across a network. As a result, for an efficient and good functioning, DIR systems [20] require crucial and correlated [21] complex operations that are:
Resource description: it consists of the acquisition of the description of each data collection by the system component to perform query forwarding (the broker for broker-based architecture and each peer for P2P network) to specific database(s).
Resource selection: decision should be taken as to which database(s) a given information should be queried considering a number of resource descriptions.
Result merging: it is the integration and re-ranking of ranked results lists from different databases. Moreover, when weighting models (ranking algorithms) used by search engines that encapsulate databases are different (it is often the case in real-world DIR environment), this step also includes scores normalisation.
To date, there are about five common DIR architectures that we can classify into two main groups according to the locations of indexes: decentralised and centralised (see Figure 2). In decentralised architectures, indexes are located in different places that are generally far from each other. We have the P2P network and broker-based architecture. On the contrary, in centralised architectures, we have only one index. It is the case of the crawling and the meta-data harvesting [22]. Moreover, another architecture is not classified between the two groups but is rather their combination. The hybrid architecture is generally the combination of the broker-based architecture and the crawling.
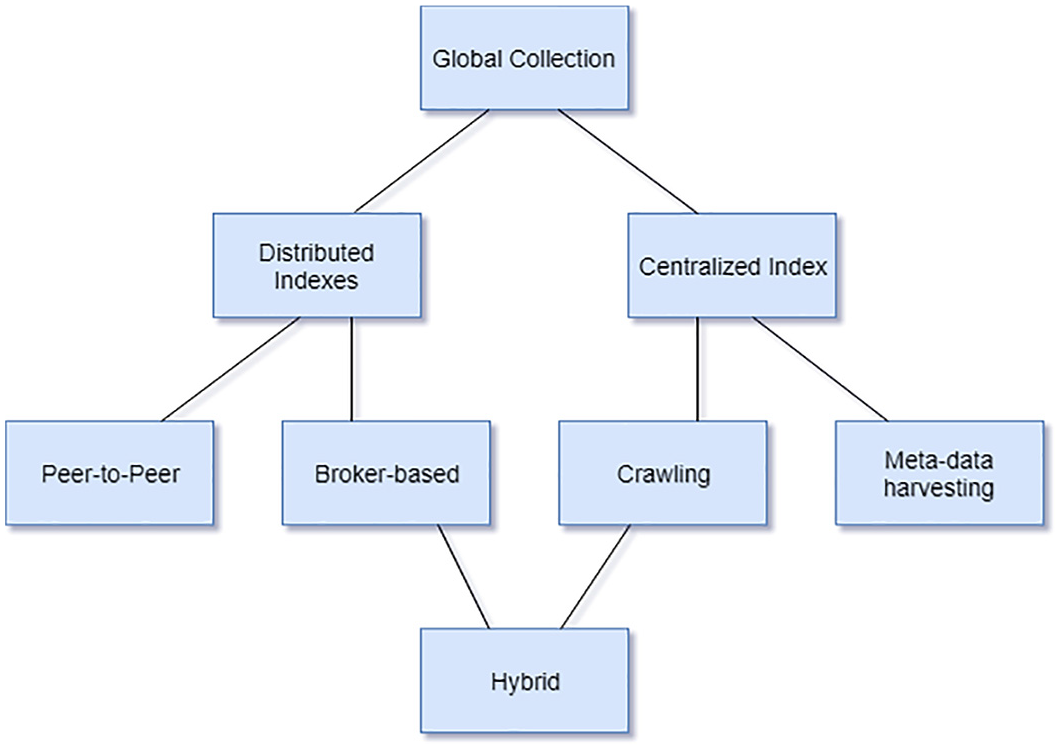
DIR architectures.
All DIR systems encapsulate one or many search engines. The latter constitute the essential and the vital components of DIR systems. Although the architecture of a DIR influences its performance, one can claim that DIR systems built on efficient search engines will probably also be efficient [23].
In general, search engines are discriminated into two main groups: commercial search engines and open source search engines that are mostly used for academic researches [24]. However, researchers in IR have made another classification of search engines, this time according to their applications. We have among others, the web search, the vertical search, the enterprise search, the desktop search and the P2P search [25]. For instance, MEDLINE [26] is one of the first vertical search engines that appeared in the 1970s and dedicated to retrieve online medical literature. Undoubtedly, web search now constitutes one of the major uses of the web by internauts and has even become necessary. That is why popular web search engines such as Google and Yahoo capture and crawl thousands of terabytes of data and respond in sub-second of time to millions of users around the world.
On the contrary, several open source search engines with high adaptability capacity to various applications have emerged. These open source search engines are, however, dedicated to completely different goals than those of commercial search engines. The most popular, among others, are the Indri C++-based search engine that is part of the Lemur project, Galago, a Java-based search engine inspired from both Indri and Lemur projects [27]. However, TERRIER is the open source search engine used in this work and its increasing preference by IR researchers for their work is no more to demonstrate [28].
3. A broker-based P2P network
3.1. Rationale
Among DIR architectures, the P2P network and the broker-based architecture have the highest merit when we talk about decentralisation and scalability [29]. However, both architectures have some drawbacks. One of the problems with P2P network resides on the fact that query routing is not controllable, because each peer autonomously decides whether it needs to forward the query to its neighbours and to which neighbours [30]. In this case, there is no guarantee about query processing time, that is, when a query reaches peers with relevant information. On the contrary, although broker-based architecture guarantees efficient query-processing time thanks to its single broker that has a certain knowledge about each source and performs intelligent query routing, it has only a single point of query entry (broker) that does not allow simultaneous users . In view of the above reasons, we have thought about a new architecture that, while keeping advantages of both architectures, will cope with their deficiencies.
3.2. Proposed architecture’s description and design
Because the P2P network and the broker-based DIR architecture both maintain distributed indexes and resources, they are DIR architectures par excellence. However, as introduced above, both architectures have some inconveniences that can be corrected. Hence, we propose a broker-based P2P architecture. This novel hybrid architecture is optimal when implemented with software agents. The architecture comprises a broker agent and several peer agents, which are not connected to each other but only to the broker agent when the system is in stable mode (see Figure 3). The broker agent maintains a two-entry table (see Figure 4): the first entry contains the list of all the peer agents connected to the system and the second contains the list of peer agents with available resources to which documents can be queried. Each peer agent joins the system by sending a connection notification message to the broker agent, the address of which is public and known to everyone. This connection notification message is governed by certain rules (via ACL messages) that should be known to the joining peer agent. Upon joining the system, a peer agent decides whether it makes its resources available or not to the broker agent. In case the peer agent decides to make its resources available to the broker agent, resource description is performed and the newly joined peer agent’s name appears in the table entry of peer agents with available resources [31]. On the contrary, if the joining peer agent does not advertise its resources to the broker agent, it will not be added to the list of peers with available resources but will remain in the list of peers connected to the system instead.
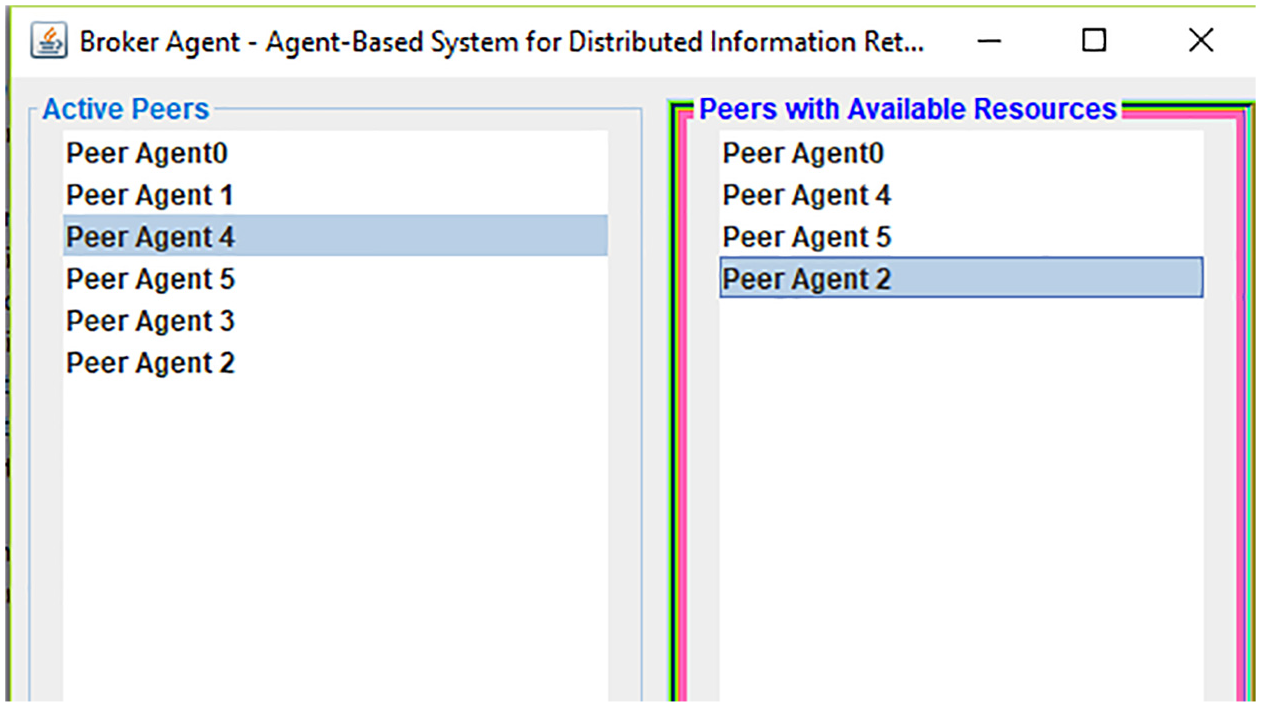
Broker agent’s two-entry table showing peer agents.
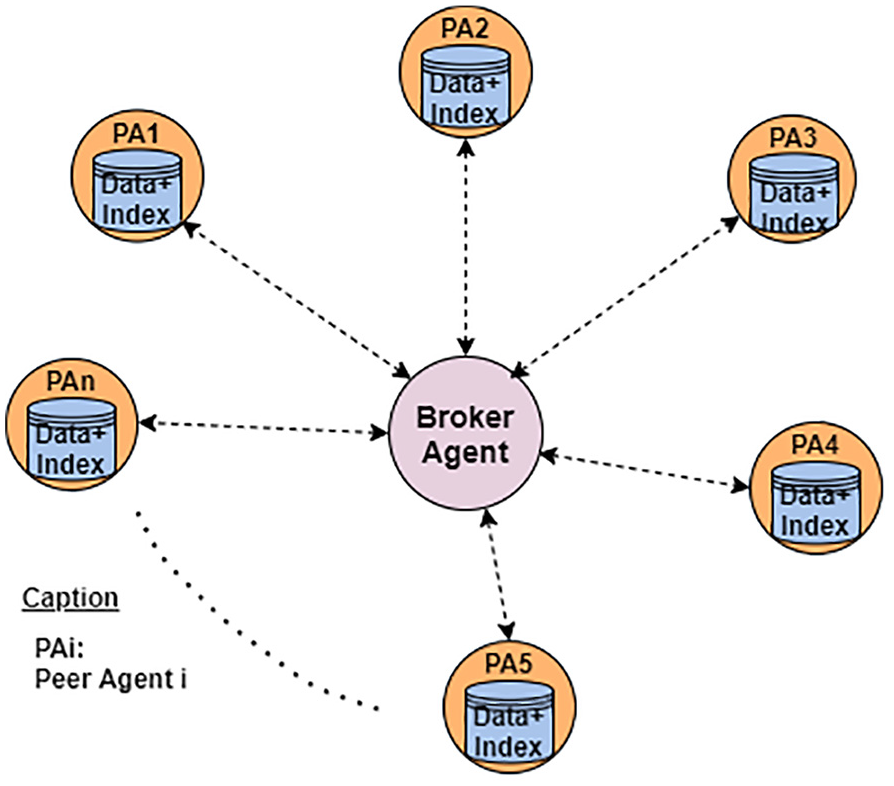
Broker-based peer-to-peer architecture (stable).
Unlike the classical P2P network, peer agents are not permanently connected to each other [32]. This connection handled by the broker agent is triggered by sending the query results to the peer agent, query originator, upon retrieval by peer agents that received forwarded query from the broker agent. In addition, the address (name + IP) of the peer agent that originated the query is forwarded together with the query to other peer agents (see Figure 5). This system of functioning addresses two fundamental issues in the existing architectures. First, in the P2P network, peers may join and leave the network at any time and at any logical location. In addition, because some part of indexes of the joining peer should be distributed to other peers, such an operation always requires information transfers between peers and might be costly in terms of bandwidth use. This is to say whenever a peer leaves or joins the network, the overall system is affected and should be reorganised. In our proposed architecture, only the broker agent is aware of a connection/disconnection of a peer agent. This limits extra bandwidth use and allows a faster reorganisation of the system. Second, in the traditional broker-based architecture, queries are originated from a single point, the broker. We, therefore, have a system with completed decentralised resources but with a centralised source of queries [8]. This is a limiting factor and does not allow simultaneous numerous queries from many users. The system is thus underused. In our novel architecture, queries are originated from peer agents. This allows each peer agent to independently send its queries to the broker agent for routing and in return will wait for results from other peer agents that the broker agent has prior notified with a list containing their addresses. The task of the broker agent is thus limited to the routing of received queries to relevant peer agents whose resources are consistent with said queries according to an efficient resource selection mechanism [33]. Although resource selection is a very crucial part of the functioning of this architecture, we have not addressed it in this article. It will be the subject for further research.
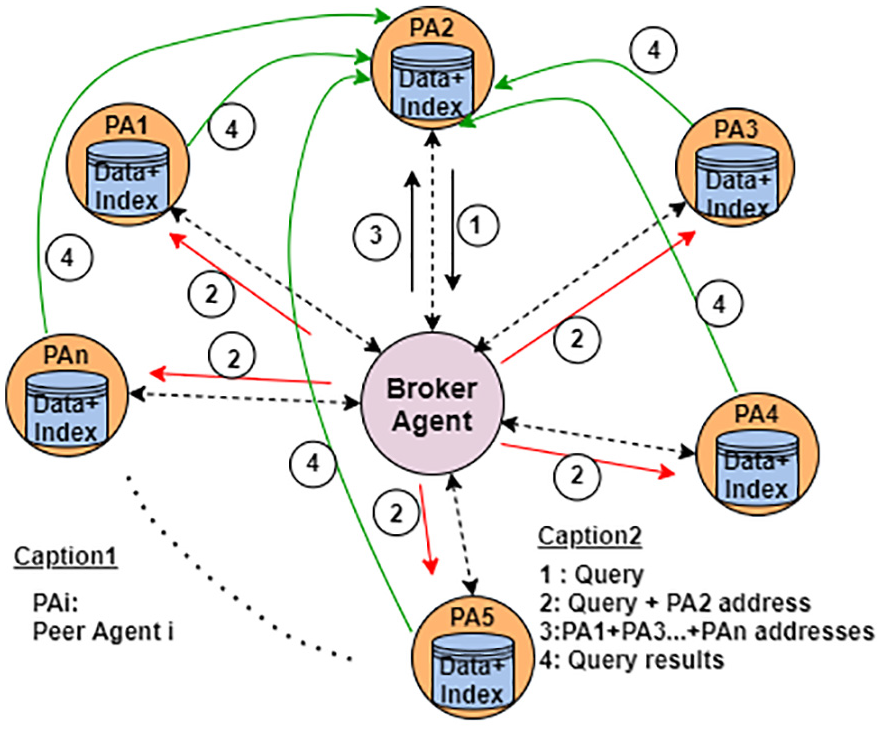
Broker-based peer-to-peer architecture (retrieval).
4. Experimental setup
To carry out experiments related to this work and to implement the DIR novel architecture proposed above, three main components have been used: an agent container, a search engine and a corpus (data collection). JADE, one of the most popular FIPA-compliant agent containers has been used to wrap our broker and peer agents. TERRIER platform version 4.2 that encapsulates a powerful IR system is used as search engine and discs 4 and 5 from TREC-6 have been used as test documents collection [34].
JADE version 4.4 has been extended to create two main agent classes: a broker agent class and a peer agent class. In the system, only one broker agent can operate. However, the system allows more than one peer agent to operate. All peer agents have the same Java coding and the ability to interact well with each other and with the broker agent. The tests conducted in this research consist of running the system with a single retrieval source, 2, 4, 8, 16 and then 32 retrieval sources. Every retrieval source consists of one peer agent. A peer agent encapsulates a TERRIER search engine (Indexing and Querying components) and possesses its own data collections to which topics are queried. Queries here are the titles of well-known topics 301–350 usually used to query TREC collections. Table 1 shows TERRIER parameter settings defined prior to the index building.
TERRIER parameter settings.

TERRIER: TERabyte RetRIEveR; Trec: Text Retrieval Conference.
For querying process, DFIZ [28], BM25 and IFB2 [35] have been used as weighting models [34] in this work. None of these models has been implemented from scratch; we just specify one of them prior to launch the retrieval as they are fully implemented and provided with TERRIER. In the system, any peer agent can initiate a query to the direction of the broker agent that dispatches it to other peer agents that have previously advertised the availability of their resources to the broker agent [36]. Any connected peer agent that has not announced its readiness to proceed with retrieval tasks to the broker agent will not be forwarded a query. Whenever a peer agent initiates a query to the direction of the broker agent, it immediately launches the IR towards its own data collection, holds the result, waits for incoming results from other peer agents to progressively normalise and merge them [33]. The query-initiating peer agent first normalises its result that comprises a maximum of 1000 (limit set by TERRIER) retrieved documents. Then, it waits for results coming from other peers that it progressively normalises and merges them as per the First In First Out (FIFO) rule. The result of previous merging is shortened to 1000 documents so as to keep those with highest scores in descending order before the new merging occurs with the next normalised result in the queue. For the normalisation, MinMax and Sum algorithms have been used [37].
4.1. JADE: a FIPA-compliant agent container
The standard model of an agent platform according to the FIPA definition is represented in the study by Bellifemine et al. [38].
The agent who exerts supervisory control over access to and use of the agent platform is the agent management system (AMS). A sole platform cannot support more than one AMS. The maintenance of the agent identifiers directory (AID) and agent state and the provision of white-page and life cycle service are performed by the AMS. Each agent is required to register with an AMS to get a valid AID.
The directory facilitator (DF) is the agent who provides the default yellow page service in the platform. The message transport system (MTS), also called agent communication channel (ACC), is the software component controlling all the exchange of messages within the platform, including messages to/from remote platforms.
JADE fully obeys the reference architecture in the study by Bellifemine et al. [11] and on launching of the JADE platform, the AMS and DF are immediately created. In addition, the messaging service (implementing the ACC component) is always activated to allow message-based communication. The agent platform can be split on several hosts. Typically (but not necessarily) only one Java application, and therefore only one Java Virtual Machine (JVM), is executed on each host. Each JVM is a basic container of agents that provides a complete run time environment for agent execution and allows several agents to concurrently execute on the same host. The AMS and DF are located in the main container. The other containers, instead, connect to the main container and provide a complete run-time environment for the execution of any set of JADE agents [38].
A remote agent management graphical user interface (RAM GUI) allows an easy manipulation of agents. From this user-friendly interface, a user can name and start an agent whose Java class needs to be previously implemented. A running agent can be suspended, resumed or even killed.
In this research, tests have been progressively performed on the broker-based n peer agents where n = 1, 2, 4, 8, 16, 32.
4.2. TERRIER: a multi-platform open source search engine
In the world of IR, there are plenty of search engines; some are academic dedicated and others are designed for commercial purposes [23]. Among the most popular academic search engines, we have Zettair, Indri developed by the Lemur Project [27], and, of course TERRIER, the one that interests us in this research.
TERRIER is a highly flexible, efficient and effective open source search engine, readily deployable on large-scale collections of documents, designed and distributed by the School of Computing Science of the University of Glasgow under the MPL [5]. It can index various types of documents including TREC collections, web documents (html pages) and any unformatted plain text documents. Due to its flexibility and extensibility, TERRIER is easily deployable on a distributed and collaborative environment such as MASs. The most important feature of TERRIER is its portability. It can be deployed on any platform regardless of the OS running it. Another charm of TERRIER resides on its modularity. Their modules are independent from each other and can be easily used and integrated with other applications separately. Thanks to its API, developer can decide to use only some modules to develop its application. TERRIER API has two major components: the indexing API and the querying API [39].
4.3. TREC collections
Throughout this work, the dataset used is from the TREC collections [40]. TREC document collections are newspapers, articles and US government records. They are primarily dedicated to researchers in IR systems and NLP for the development of their works [41]. A single TREC file or collection comprises numerous documents that obey to a certain rule. Every document framed in between two markups
5. Experimental results and analysis
We carried out all of our experiments on TERRIER platform. Both direct and inverted indexers were used for indexing. The built-in default-matching model is InL2 [39] and is automatically used when weighting function has not been specified. Fortunately, TERRIER has implemented and integrated several weighting functions including DIFZ, BM25 and IFB2 that are used in these experiments. We just need to specify one of them before launching querying process. Similarly, TERRIER allows a certain number of configurations. One may decide during indexing process to use stop-words filtering and/or a Porter Stemmer (PS) for consideration of stemming process or not [43]. Both have been used in these experiments. Moreover, query expansion (QE) has been also used during querying process [44].
As mentioned above, the experiments of DIR are carried out here over a broker-based P2P system that was run with upto 32 peer agents excluding the broker agent. Meaning that, retrieved results emerging from different peers may be of different natures. Although, peer agents are built with the ability to proceed incoming queries with self-chosen weighting model, the peer agent, query generator always sends its query with the weighting function it uses to query its own database. However, we have imposed the use by other peer agents of the weighting model forwarded with the query to retrieve their data collections. This, because we are also interested in observing the evolution of the MAP and R-precision (R-prec) values with number of peer agents increasing for each of our weighting functions used in the experiments [45].
In this research, we use the TREC documents collection from discs 4 and 5 that forms the TREC-6 [3]. For this collection, we apply the 50 topics 301–350 on TREC-6. The TREC-6 test collection consists of about 2.1 GB of data with nearly 556,000 documents from the Financial Times, the Congressional Record (CR), the Federal Register (FR), the Foreign Broadcast Information Service (FBIS) and the Los Angeles Times (LA) [46].
Moreover, as observed in the most popular retrieval test collections, there are three different components considered and used in TREC proceedings: the documents collection, the queries or topics to retrieve documents from the corpus (collection) and the relevance judgements or ‘right answers’ that are used for evaluation in order to assess the retrieval operation [47]. Each of these pieces for the TREC-6 collections are used in the experiment processes of this research. Discs 4 and 5 of TREC-6 have been first used as a single resource and then split into 2, 4, 8, 16 and finally 32 resources by our self-coded algorithm that carefully and randomly distributes documents to avoid overlaps [48].
Furthermore, in TERRIER, only the first 1000 results are provided upon retrieving. In our system, for n peer agents, there will be a maximum of
5.1. Linear score normalisation
In DIR, it is important even fundamentally to normalise and re-rank different results collected from different sources. This allows obtaining better-homogenised results and contributing to an easier and objective evaluation of DIR systems. Typically, there are three unsupervised linear normalisation methods namely MinMax, Sum and Z-Score [51]. However, only the first two are used in this article.
5.1.1. MinMax
MinMax [37] is a decimal scaling normalisation technique. It gives the range of values between 0 and 1. For a given document

where
The above formula logically assigns the score 1 to the top-ranked document and the score 0 to the least-ranked document of every result list received from different sources.
The assignment of the value 1 to all the top-ranked documents from different sources by MinMax may raise some inconsistencies in the way irrelevant top documents from certain sources probably will be ranked at the top of relevant documents in the final merged results list. However, these inconsistencies can be countered with some assumptions that are de facto MinMax assumptions:
Each source contains at least one relevant document.
The search engines of sources can place that relevant document at the top of their result list.
In the real world of DIR, the second assumption can always hold since most of the DIR systems encapsulate powerful search engines with a good ranking ability and capable to meet such an assumption. On the contrary, the first assumption would be more difficult to meet especially for the DIR systems that do not perform resource selection. The resource selection ensures that the broker agent only forwards queries to peer agents that contain relevant documents to the said queries. This allows obtaining pertinent results and contributing to increase the performance of the DIR system. In the introduction of this article, we assumed that each peer agent source will always provide relevant documents to a given query or will not provide at all (this has been the case for some topics during experiments). Consequently, though we have not implemented resource selection, there is no risk that our retrieved results would comprise noises.
5.1.2. Sum
Sum is an unsupervised linear score normalisation that comprises two steps [40]:
1. The first step consists of the subtraction of the least-ranked document score from the scores produced by a given source. This process generates a new score list with the minimum score equal to zero. This step is defined by the following formula

where
2. The second and the last step consists of the score normalisation itself and is given by the following formula

The above formula suggests the sum of normalised scores to be equal to one. In this way, normalised scores act as probabilities. Some opinions we found about the efficiency of the Sum normalisation method are mixed. Namatha and Sever [40] claimed that Sum shows good results in the normalisation of non-relevant score distributions of different search engines. This implies that Sum should still provide good results with the length of ranked list increasing since noises are found at the bottom of the list with less relevant documents. However, Markov [1] reached the conclusion after experiment that the performance of Sum is negatively affected with the length of the ranked lists increasing.
The above mixed opinions might explain the unexpected trends in the MAP and R-prec graphs obtained from scores normalised with Sum (see Figure 7(a) and (b)). However, we cannot elucidate or emit a firm opinion on the matter in this article since we proceed with normalisation as results arrive and never accumulate them. Therefore, none of the ranked list exceeds 1000 documents.
5.2. Cross-analysis of the effects of normalisation methods over the results
MinMax and Sum, the two unsupervised linear normalisation methods studied in this article are essential for the experiments that surround this research. They are used to normalise document scores of results forwarded by other peer agents to the peer agent, query generator. This allowed the latter peer agent, upon normalising, to easily merge and then re-rank them. Although all the graphs (see Figures 6(a) and (b); 7(a) and (b)) have a decreasing trend, the effects of normalisation methods are clearly noticeable.

MinMax for discs 4 and 5 of TREC-6, topics 301–350. (a) MAP versus #agents and (b) R-prec versus #agents.

Sum for discs 4 and 5 of TREC-6, topics 301–350. (a) MAP versus #agents and (b) R-prec versus #agents.
If all the graphs decrease with the number of peer agents increasing – that might be the effect of the distributed indexing – the variation of MAP and R-prec graphs obtained from Sum’s scores normalisation is a little bit intriguing while the graphs of MAP and R-prec from MinMax’s scores normalisation steadily decrease. Figure 7(a) and (b) show that the values of MAP and R-prec obtained from Sum’s scores normalisation of results retrieved using the DFIZ weighting model normally decrease with number of peer agents increasing until 4. Then, these values slightly increase when peer agents reach the number 8 and finally steadily decrease.
The above observations reveal the high accuracy of MinMax method in score normalisation and, therefore, confirm and back the analysis and conclusion of Ilya Markov in his PhD thesis that MinMax is the least assuming, the most robust and the best-performing unsupervised linear score normalisation method [1]. However, in-depth studies of these unsupervised normalisation functions in our future works will allow us to have better opinion about them.
6. Discussion and future work
In this work, we presented a novel DIR architecture that we designed and implemented as a solution to overcome some deficiencies observed in existing DIR architectures, notably those with decentralised and completed distributed indexes and resources. Unlike IR that consists of querying a single database with a single index, DIR generally involves many indexes and resources distributed across a network.
Agent-based framework is one of the fundamental approaches to implement a distributed system. The main purpose of this study was to construct a communication architecture for the novel DIR system. Herein, the retrieval performance of several methods used for two basic operations are investigated on proposed architecture. One of these key operations is the term weighting and the other is the result merging. As a result of our experiments, DFIZ and MinMax have been observed to be more successful in terms of chosen performance metrics and normalisation functions, respectively. The second phase of our study will be about implementing learning to rank techniques and query-based model selection approaches on the multi-agent-based system. Finally, resource selection property will be added to the DIR system. Along this progress, the overall system architecture will naturally change and develop.
7. Conclusion
The increase in digital data raises serious storage and accessibility challenges for researchers [52]. While the distribution and the decentralisation of storage devices solved the issue of limited storage, the distributed information retrieval came as the solution to accessing those data efficiently. According to the locations of indexes and resources, DIR researchers proposed several architectures that can be classified into centralised and decentralised architectures. The centralised architectures comprise the crawling and the meta-data harvesting characterised by a single and centralised index. The decentralised architectures encompass the P2P network and the broker-based architecture, both characterised by several indexes located with resources and distributed all over the system. These are considered to be optimal DIR architectures, nevertheless having some inefficiencies inherent to their structures. Our study proposed a novel architecture to solve these inefficiencies, built considering the assets provided by the P2P network and the broker-based architecture.
The novel architecture that we named the broker-based P2P network and presented in this work, as its name reveals, combines major functionalities of the P2P network and the broker-based architecture. Moreover, for the sake of increasing adaptability of our system, we built it with autonomous software agents provided by the JADE platform version 4.4. TERRIER version 4.2 was used as search engine because of its robustness and its easy reusability. Eventually, TREC-6 from TREC collections were used as testbed and merged results normalised with two unsupervised normalisation functions: MinMax and Sum.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.