
Abstract
As the next step in the development of intelligent computing systems is the addition of human expertise and knowledge, it is a priority to build strong computable and well-documented knowledge bases. Ontologies partially respond to this challenge by providing formalisms for knowledge representation. However, one major remaining task is the population of these ontologies with concrete application. Based on Model-Driven Engineering principles, a generic metamodel for the extraction of heterogeneous data is presented in this article. The metamodel has been designed with two objectives, namely (1) the need of genericity regarding the source of collected pieces of knowledge and (2) the intent to stick to a structure close to an ontological structure. As well, an example of instantiation of the metamodel for textual data in chemistry domain and an insight of how this metamodel could be integrated in a larger automated domain independent ontology population framework are given.
1. Introduction
Every domain has its own experts who are constantly producing knowledge through the experiments they conduct, the data they organise and contextualise, and all the resources they produce. In each domain, the study or the monitoring of a system, whatever it is, is no longer possible without the acquisition of this previously established knowledge. To be easily understood, aggregated knowledge needs to be organised. There is a tremendous amount of studies that focus on the problem of knowledge structuration or knowledge organisation that either adopt and support a manual approach [1–3] or propose automated systems [4–7].
Since the early 1990s, the definition of an ontology by Gruber [8] as an explicit ‘specification of a conceptualization’ ontologies have been developed in a lot of fields from the medical and healthcare domain [9,10] to the chemical domain [11–14] or the juridical one [15,16] to name a few. Some of these domains such as the medical domain are considered as a driving force for the development of ontologies. The aim of ontologies is to structure the knowledge acquired in these fields. This emergence is considered as a breakthrough in how one represents knowledge by providing tools to express concepts of a domain and how one relates them.
More largely, ontologies have been an area of interest for their application in many computing-related domain notably to build predictive models [17] and assist decision makers, to help the monitoring of complex systems such as crisis management expert systems [18] or to drive model transformation [19] and to compute semantic similarity measures [20]. Their ability to structure the information in a machine readable format with basic elementary bricks make them a powerful tool to help machine-assisted deduction and logical inference, prerequisites towards Berners-Lee et al.’s [21] definition of the Semantic Web.
As the capability of ontologies is not to prove anymore and as their potential has been widely exploited in many domains, ongoing challenges still remain on the management of ontologies which covers several tasks including ontology alignment, ontology construction, and ontology population. Among these challenges, automated ontology population is a true milestone because most of the ontologies that exist today remain unpopulated and thus cannot be integrated in wider ontology-based decision systems unless domain experts populate it manually.
As stated before, domain experts generate lots of data. Once treated and interpreted, they lead to new knowledge produced. That constitutes as much data that can be extracted and exploited in a generic and automated ontology population framework. Yet this knowledge is widespread in diverse formats with very varying structure levels which adds complexity. If some systems exist for knowledge gathering from unstructured sources of data, most of them remain very domain specific [7,22,23] in order to keep accuracy performances. The few systems that might cover several domains [24,25] are rebuilding their own ontology structure instead of populating an existing predefined structure without altering it. This approach is also limited because all the knowledge structure preset by the experts is not reused. As a result, the task of domain-independent automated ontology population can be presented with two constraints which are (1) the need of data sources coverage and (2) the search for genericity.
To achieve such defined objectives, one of the first obstacle is the organisation of extracted data in an ontological structure without referring to a single specific ontology. Alongside the development of ontologies, the Model-Driven Engineering (MDE) conducted mainly by the Object Management Group (OMG) provides modelling frameworks and methods. They are tools to bridge the semantic and structural gap between unstructured heterogeneous data and the formalisation of knowledge that the ontologies are made for. If the two fields, namely ontologies and MDE, correspond to two different approaches, they still present non-negligible overlappings and similarities in both their objectives and methods. In that sense, MDE modelling and metamodeling frameworks and concepts can be reused as a background architecture supporting the transition between unstructured data and domain ontologies.
Based on this observation, the main contribution of this article is the definition of a generic metamodel for the organisation of extracted data from heterogeneous data sources. This metamodel and the MDE methods are used to formalise the transition between unstructured heterogeneous data and domain-related ontologies. The presented metamodel has two main advantages:
Classes of the metamodel are generic enough to allow the representation of any domain-related extracted data.
The metamodel provides classes to gather textual contextual information about extracted data which are not the case in many similar metamodels mentioned in the literature review (section 2).
As the metamodel is designed in order to be part of a wider generic automated and unsupervised ontology population system, this article presents an overview of how this metamodel can be integrated in such a system. It is supposed that the metamodel can be derived into specific models.
The remainder of this article is organised as follows. Section 2 is dedicated to the literature review concerning on the one hand the conjoint use of MDE and ontologies, on the other hand the existing metamodels for the generic representation of extracted data. The third section presents the contribution of this article which is the definition of a metamodel for heterogeneous extracted data organisation and its inclusion into a larger framework for ontology population from heterogeneous data sources. In the fourth section, an instantiation example from short chemical-related plain text sample is given as an illustration before drawing conclusion.
2. Related work
2.1. Combined use of MDE and ontologies
Automated reasoning on real-world complex systems is a complex task for computer systems because of their diversity and single specificity. As a response to these limiting aspects of the real world for common understanding and sharing of knowledge, the MDE provided modelling tools and languages such as the widely used Unified Modelling Language (UML). They currently help us to build models that represent the world with chosen degrees of complexity and genericity. In its modelling methodology, the OMG defines four modelling levels: real-world data level (M0), model level (M1), metamodel level (M2) and meta-metamodel level (M3) all of them allowing to represent common objects with different levels of abstraction. This structure in modelling has been widely adopted and reused by the community [26,27]. Thanks to the M2 level, it is possible to formalise knowledge with the building of adaptable and generic metamodels. Using a metamodel defined at the M2 level, many models can be derived to represent different use cases. These modelling tools participate in abstracting and simplifying complex knowledge.
However, one of the ongoing challenges concerning knowledge management is the representation of the knowledge in a machine readable format. To be properly processed and exploited, the knowledge leaking in real-world data cannot be stored in its original unstructured format. Bridging the gap in terms of knowledge representation means through modelling formalism has been the concern of many researchers until now. This interest in knowledge modelling and management gave birth to many projects such as the well-known Semantic Web and led to the building of modelling and structuring languages mainly reported as ontology definition languages.
Metamodels, models and ontologies share not only deep similarities but also remarkable differences. The use of MDE inherited models is commonly reserved to generic types of conceptualisation not necessarily intended for computation or reasoning. On the contrary, ontologies have been mostly developed for case-based studies and have a practical application. However, both of them are still adopting a similar structure, linking entities or classes through relations. Despite this fact, few studies concentrated their work to build links between these structures. As a result, it seems natural to investigate possible coupling between them.
Henderson-Sellers [28] proposes some representations to fill the gap between MDE standards and ontologies in the specific domain of software engineering. All along his study, the author points the similarities existing between the levels of abstraction of the MDE and the different kinds of existing ontologies (domain ontologies, upper ontologies) using Guizzardi [29] and Aßmann et al. [30] representations as a reference. In the adopted methodology, ontologies are compared to model and metamodels. This comparison is made to set whether an ontology should rather be integrated as a model or as a metamodel in software development systems. The author concludes that given the description of it, it seems more natural to consider ontologies as a specific kind of model. In this article, the term knowledge base is never mentioned. However, as it can be defined as the result of the instantiation of an ontology, it could be relevant to integrate the concept of knowledge base in Guizzardi [29] and Aßmann et al. [30] representations.
Saeki and Kaiya [31] illustrate the mapping possibilities between ontologies, metamodels and models with an example on the information systems domain and an applicative case of an automatic lift-door system management. The mappings with the ontology are used to reason and bring semantics in MDE models. In this article, the term knowledge base is not evoked either but the term domain ontology seems to include it. The main goal of this article is to integrate ontologies in the modelling world to support the development of models. In this approach, the ontologies are considered as an additional tool and the model remains quite passive. In contrast, it could be complementary to investigate how it is possible to use models as a pivot between data and domain ontologies. This would then make the MDE models and metamodels be tools for the instantiation of ontologies.
Silva Parreiras et al. [32] propose a common typology to merge the terms and rules that define the modelling objects and methods (also called technical spaces in their article) for both ontologies and metamodels. This common typology allows the author to show how technical spaces taken from the ontological domain may be reusable with metamodel and model from the MDE.
A metamodel for the integration of ontologies in computer systems is also defined by the OMG under the name of Ontology Definition Metamodel (ODM) [33]. This metamodel stands for Web Ontology Language (OWL) and Resource Description Framework (RDF) formatted ontologies. Unless it is restricted to a certain type of ontologies (OWL and RDF), such a metamodel is a first step towards a full merge between any kind of ontology and the MDE domain.
2.2. Representation of extracted data
Many extraction methods can be found in the literature going from Natural Language Processing (NLP) methods (rule-based extraction, Named Entity Recognition) to image processing methods. As the ongoing development of these methods constitutes crucial steps in the range of knowledge acquisition for the development of ontologies, another step is to be achieved in the seek of genericity. This step concerns the definition of generic metamodels in order to represent the extracted knowledge in models without directly specifying it in an ontology.
As the aim of the metamodel is to ensure interoperability between any raw extracted data and any domain ontology, previous related efforts have been studied with the following criteria in mind:
Domain independency, to be able to populate any domain ontology, whatever the domain.
Source independency, to be able to gather and analyse any data extracted from various data sources (raw, semi-structured or structured data, regardless of the format (text, PDF, HTML, etc.)).
Embedded context, as the ability to refer to the exact context from where the data are extracted (e.g. a sentence, a paragraph).
Term/concept distinction, as the ability to isolate the piece of knowledge (concept) from its occurrence in data (term).
Free ontology format representing the ability to deal with different ontology formats.
In the literature, two kinds of studies for the representation of extracted data can be identified: on the one hand domain-specific metamodels for knowledge extraction and on the other hand generic metamodels which are less precise in terms of granularity but that can cover any domain.
The first one is case-driven and defines structures to gather data directly on a specific domain for restricted applications. Meski et al. [34] define a knowledge structuring framework and propose improving applications supported by it. At the highest level of abstraction of this previous framework, authors detail a metamodel that contains concepts such as Process, People, Product or Resource, to name a few. These concepts seem generic regarding the domain of application (i.e. decision making) but are still very specific regarding the larger domain of knowledge extraction. Similarly, Yang et al. [35] propose a metamodel for manufacturing domain that allows manufacturing systems to derive models from it. But as for the previous metamodel, this metamodel is not generic enough to cover other domains. As well Othman and Beydoun [36] define a metamodel for disaster management to support the building and management of a knowledge repository dedicated to expert systems. Once again, this metamodel is restricted to a specific domain. Moreover, the three presented examples are much more describing the meaning of domain related objects and relations that they share between them than the source they are extracted from.
The second kind of metamodels is designed with higher abstraction. This approach is closer to the set objective than the previous one. Belkadi et al. [37] propose a metamodel for knowledge representation and knowledge sharing in a collaborative context. This metamodel organises knowledge in two types of elements which are the relation and the entity but does not provide more classes for contextualization. In order to orchestrate the definition of their domain-related ontologies, Falbo et al. [38] use a meta-ontology model based on the Meta-Object Facility (MOF). This meta-ontology model is then instantiated into a domain-specific ontology. Hence, they define generic classes such as Concept, Relation and Property classes. Bijlsma et al. [39] describe nine language elements and give recommendations for the application of these language elements in the building of an information structure. No structured metamodel is given in their paper, but the association between these language elements and the related recommendations can be considered as a metamodel. Nevertheless, these presented models, despite their genericity, do not address the question of contextualization of extracted data.
Another way to look to such a metamodel is to search a specific metamodel (or a specific ontology) related to the domain of data extraction or data representation. Especially, terminological metamodels are pretty close to what can be defined as a generic data extraction metamodel. It is then relevant to investigate this field. Reymonet et al. [40] underline the similarities existing between ontologies and terminological metamodels. Dramé et al. [41] design a conceptual model – considered as a metamodel in this paper – to organise ontological entities. Their model includes relations between ontological objects representing classes such as Concept class and Relation class. Inside their conceptual model, the Relation class is specified into two different subclasses namely Taxonomic relation class and Non-taxonomic relation class, depicting the two types of relations existing in an ontology. This kind of metamodel does not contain concepts describing inference rules and constraints existing in many ontologies. Despite this fact, it can be considered representative enough for the ontological metamodeling part of a data extraction metamodel as it includes the fundamental Concept and Relation concepts for the description of an ontology. However, this kind of metamodel is incomplete in terms of data extraction which is not necessarily the purpose of their study. The Terminological, linguistic, and Ontological Knowledge resource management model proposed by Ghoula et al. [42] copes with the need of contextual information of the extracted data. To that extent, it provides classes such as the domain class and the annotation class describing the original source data comes from. Moreover, this metamodel organises the data resources through associations between these resources such as contains association or associated with association for instance. Unfortunately, and despite the large range of covered context elements, the context definition of this model is not fully satisfying. This is due to the fact that most of the defined classes in it are linked to the resources. Instead, having less exhaustive and more fine grained contextual class definitions is preferred (i.e. term-level context). Another interesting aspect in the approach proposed by Ghoula et al. [42] is the distinction between the Concept concept, the Term concept and the Ontology element concept which is materialised by three different classes. In their purely respective terminological metamodels, Vandenbussche and Charlet [43] and Reymonet et al. [40] do the same distinction between the class defining a Term and the class defining a Concept except that the terms representing a concept are aggregated under a Prefered term class. This distinction is necessary because in real applications, as soon as one extracts terms which are representative of a concept, the raw extracted term and the concept cannot be represented as the same object.
Table 1 sums up the different approaches adopted in the literature for the building of a generic data extraction metamodel. The approaches are analysed through the metamodel characteristics that are required in a generic domain independent ontology population system. The three groups of approaches presented in this section (domain specific metamodels, high level metamodels and terminological metamodels) are represented in Table 1. The OMG metamodel, mentioned in section 2.1, is also represented to insist on the fact that some metamodels are built from already existing ontology terminology (OWL, RDF) which is restrictive. Domain-specific metamodels are really far from the objectives as they are designed for specific cases and not for generic purpose. High-level metamodels are slightly more convincing as they bring more genericity. However, they remain designed for concrete applications and not really for data or ontology description in general. The need for contextual information about extracted data and for distinction between raw data and associated concepts is considered in some terminological metamodels despite few of them combine both. Hence, the metamodel proposed in this article will include classes for both contextual information gathering and entity/extracted data distinction.
Comparative analysis of the different mentioned metamodels.

3. Towards a generic metamodel
3.1. Problem setting and objectives
As detailed in the previous sections, most of the studies conducted for ontology population deal with one single source. On the contrary, when considering the semantic web or the Internet of Things, information and knowledge can be extracted from a large number of different data sources, which can be of a different nature (text, image, database), and in different formats (HTML, XML, plain text, PDF to name a few). This diversity leads to the examination of data with a large spectrum of structure levels and whose processing is more or less complex to set up. The final goal of extracted pieces of data from each source is to feed an ontological structure. Hence, another challenge is to find a way of transforming the unstructured knowledge extracted from heterogeneous sources into an intermediate structural form that can further correspond to the ontology standards regardless the domain of the ontology.
Common knowledge representation systems dealing with ontologies such as Neo4J, MongoDB or OWL represent knowledge that is highly structured. Thus, they do not fit to represent knowledge that is not structured yet. This is why an intermediate metamodel is needed. This metamodel should be seen as an interoperability bridge to highly structured knowledge representation that includes the concepts shared by the main knowledge representation languages more than as a new ontology language. As a bridge, this metamodel needs to provide classes that explicitly propose a representation of original extracted data and some contextual data for further use, which is not necessarily proposed in other standards.
The main contribution of this proposition is then to define a common and generic metamodel following three requirements:
The first requirement is to set up a reference to organise extracted data regardless of the kind of source it comes from. This requirement involves defining balanced concepts that are broad enough to encompass a wide spectrum of sources and fine enough to allow a relevant and structured gathering of extracted entities.
The second requirement concerns the structure of the metamodel. Because the metamodel is a bridge that links extracted data to ontologies, a structure as close as possible to the structure of this ontology is needed. When satisfying this requirement, it becomes easier to conduct mappings between an instantiated version of the metamodel (i.e. model) and an ontology.
Then the third requirement is about the diversity of the information that should be represented in the metamodel. Having different types of information brings more flexibility to the instantiation process and facilitates further mappings.
3.2. Presentation of the metamodel
The presented metamodel is built with the formal semantics of UML which is a standard for the representation of classes and relations occurring between them. As shown in Figure 1, the metamodel contains six 1 instantiable classes that correspond to different kinds and different granular levels of knowledge representation depending on where the extracted data comes from. Each of these classes can be specified for chosen sources of data. Details about the purpose of each class are given in the following sections (3.2.1 to 3.2.3).
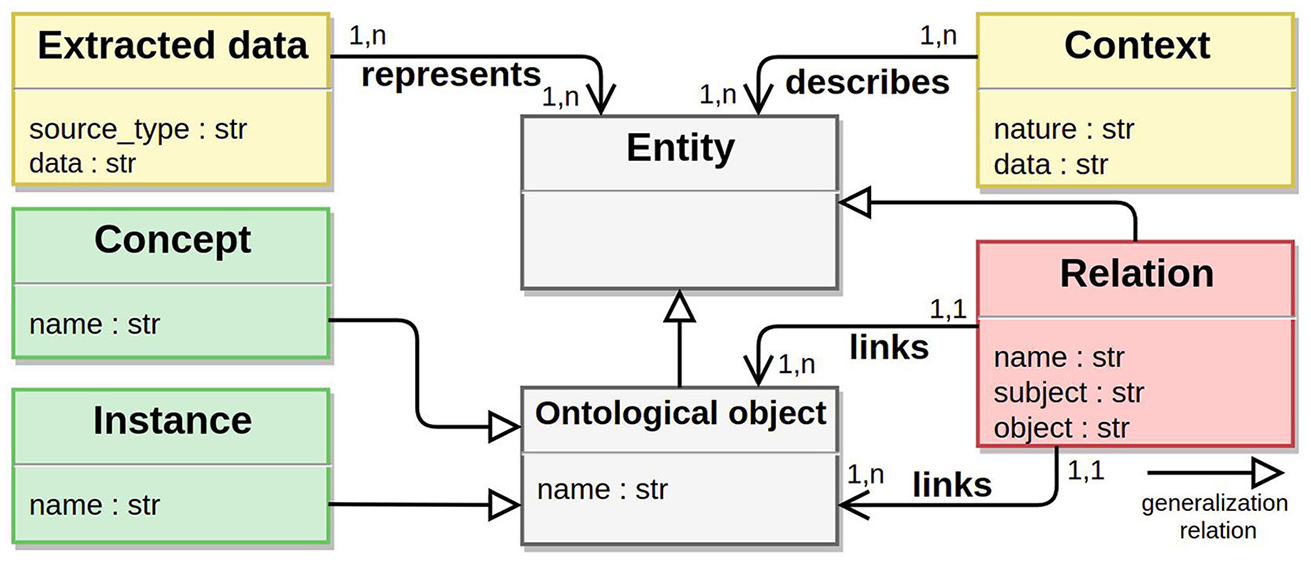
Metamodel for generic data extraction.
3.2.1. Entity class and entity-derived classes: Ontological object class and relation class
The Entity class is a very generic class describing all possible entities that can be extracted from data and linked to a resource defined in an ontology. The Entity class is an abstraction of common ontological elements (classes of RDFS language, nodes of Neo4j schema or elements of XML schema for example). This class is specified with the Ontological object class and Relation class. It is important to notice that the Entity class is an abstract class and that no object in the instantiated version of the metamodel will be directly linked to the Entity class. The Ontological object class, like the Entity class, can be specified in more detailed classes. These classes (Concept class and Instance class) are detailed in the next section. In the current section, the Relation class that is defined to link two Ontological objects is detailed.
Some extraction methods can focus on the extraction of relations [44–47] between extracted terms (represented as Ontological objects). Moreover, extracted relations can also be matched to relations contained in an ontology. When designing an ontology, a relation that can occur between two concepts is considered as a constituent of the ontology and has its own definition. In OWL and RDF formatted ontologies, a property (i.e. relation) is defined with a range and a domain specifying which concepts are concerned by this relation. For this reason, a modelling decision is made to represent the Relation between two Ontological objects in the metamodel with a Relation class rather than with a simple edge between two classes (UML’s representation of a relation).
Hence, the Relation class is defined as a specification of the Entity class and allows to store the relations which link Ontological objects. These Relations can then be matched with the relations (or properties) already existing in the ontology. Moreover, each time a relation is detected between two Ontological objects, a unique Relation instance is created and the Ontological object instances taking part in the relation are referenced in the subject and object attributes.
3.2.2. Ontological object derived classes: concept class and instance class
As stated before, Ontological object instances can be classified as an Instance if it is supposed that the Entity can correspond to an ontological instance or as a Concept if it is more likely to be associated to a concept of the ontology. If the way the Ontological object has been extracted does not give any structural knowledge about it (whether it seems to be an instance or a concept) then it remains an Ontological object. This particularity distinguishes the Ontological object class from the Entity class because the Ontological object class can give direct derived instances what an Entity class does not. A Relation can then link either one Instance to one Concept, one Concept to another Concept, or one Instance to another Instance. 2
3.2.3. Raw data–related classes: extracted data and context classes
Extracted data is the class of the metamodel which is directly linked to raw data. This class contains the exact extracted piece of data before it has been modified (by NLP techniques for example). Some instances of the Extracted data class can be extracted elements such as single terms or expressions, whole sentences, tables or even pictures depending on the type of data that is analysed. At first sight, keeping raw version of extracted data that has to be processed further does not seem logical because it contains low machine readable knowledge. Nevertheless, the choice is made to keep it for the particular step of human validation (as detailed in section 4.3). It is easier to make a decision about whether or not an instance should be added to the ontology if one has access to the original piece of data from which the data has been extracted. Extracted data class has two attributes which are source_type attribute and data attribute. The source_type attribute specifies the kind of data source where the data comes from and the data attribute stores the raw data that can later be used to help the ontology population through human validation (see section 4.3).
The Context class is similar to the Extracted data class, except that the Context class stores and provides a more selected view of the elements that constitute the context of an extracted data because this data are stored to support further matching process and semantic similarity measures. A possible use of context elements is the building of a word vector for example. The Context class should contain textual objects which is the prerequisite format for further analysis. Nevertheless, the origin of the context can be very wide and depends on the different processes of extraction that are used. Naturally, contextual objects will be of different origin for an entity extracted from a database than for an entity extracted from a picture or simply raw text. Hence, the origin of a context element is given by the nature attribute that depends on the way the context element has been defined (co-occurrence, synonym, similar term, contextual image processing). The content of a context element is stored in the data attribute. The final objective of the Context class is to gather more information about an Entity instance. The gathered information can then be used to derive better matching with the concepts, instances and relations of a target ontology.
4. Metamodel integration in a wider framework for generic ontology population
4.1. Bringing MDE models and ontologies into line
In this section, it is explained how the previously defined metamodel is reused in a wider instance extraction system. The final goal is to use this metamodel to support the transition from heterogeneous data to an ontology providing this way, a knowledge base. To achieve this goal, alignment rules need to be defined between the meta modelling side of the framework and the ontological part of the same framework. To guarantee genericity, the metamodel does not have a dedicated upper ontology but it can be easily aligned with common upper ontology abstract class definitions (OWL schema, graph databases schema, relational databases schema). For instance, in OWL and RDFS languages, concepts such as Individual, Class or Relation may be considered as the upper ontology. Thus, they can easily be related to the Concept, Relation and Instance classes of the metamodel. An illustration of this alignment is given in Figure 2 where alignment rules between a typical RDFS upper ontology and the metamodel are represented by dashed arrows. The alignment rules are then used to transform elements of the data model into resources (individuals in RDFS for example) of the ontology. As explained in section 2, the conjoint use of modelling tools and ontologies is not a common practice despite the similarities existing between the two fields. As the reconciliation of these two similar but distant domains is not the main concern of this article, a simple representation of conjoint modelling levels and ontological levels use is proposed in this section that will permit the use of the metamodel in a wider framework.

Example of alignment between the metamodel classes and an RDFS schema (upper ontology).
Whereas the MDE has a very well-defined structural organisation among the modelling levels and representation levels, ontologies are more technical objects. The hierarchy defined between the levels of ontologies varies a lot depending on the domain and the granularity of the domain the ontologies are designed for.
The biggest question when ontological domain and MDE are compared is the question of genericity. On the one hand, a knowledge base is often defined as an instantiation of an ontology. The use of this term suggests that an ontology and a knowledge base are not defined at the same modelling level, one being the instantiated version of the other. In the common representation of modelling levels, metamodels and derived models are distinct objects. However, one tends to include the ontology structure in the definition of a knowledge base which differs from this representation. On the other hand, a knowledge base is an organised and structured representation of real world data and thus cannot be defined at the level M0, as this level is used only to qualify real world raw data.
Then, when trying to strictly follow these two constraints, it would force the knowledge base to be defined at the level M1 of the MOF, that is, the model level, and the domain ontology that gives birth to the knowledge base at the metamodeling level (M2). Unfortunately, it is not acceptable for the metamodel, given its role – giving generic classes for the organisation of objects that will become Concepts and Instances– to be represented on the same level of granularity than the domain ontology whose content might be matched with instances of these generic classes.
To avoid this drawback, a more flexible representation could be adopted which balances the notion of genericity (modelling level) with the notion of granularity (whether the modelling objects are close to the real world or not). Such a representation is shown in Figure 3. This scheme highlights the alignment limit of the genericity reconciliation between ontologies and models (dashed arrow). This representation is still not convincing because as soon as one tries to align both sides of the framework, the alignment process necessarily implies interactions between modelling object from different modelling levels (model and ontology). Such an alignment is in conflict with the basic rules of MDE.

Modified representation of conjoint levels of modelling domain and knowledge management domain for genericity coherence with derived model for extracted data.
Our framework has some particularities brought by the metamodel. As presented, the metamodel contains at the same level (M2) the three following classes: Instance, Concept and Relation which are gathered under the same abstract class, Entity. From an ontological point of view, the class Concept and the class Instance are a representation of objects that, respectively, belong to the ontology level and the knowledge base level. To be coherent with the metamodel and its instantiation, it is necessary to bundle the ontology and the instantiated version of the ontology at the same level of modelisation. This idea matches up to the alignments proposed by Saeki and Kaiya [31] and Henderson-Sellers [28] that set the domain ontology at the modelling level (M1) without mentioning the knowledge base.
To make this modelling choice, it is a priority to make the difference between the ontological concept-instance taxonomic relation (also named instantiation) and the metamodel-to-model instantiation relation. Even if these two relations are similar because of the process they initiate, it is assumed that they cannot be mistaken. This can be observed in Figure 4 where the domain ontology and the instantiated version of it have been gathered under the same object called knowledge base. This is the proposed solution under this hypothesis to make the modelling framework and ontology framework be in line. At the metamodel level (M2), Saeki and Kaiya [31] and Henderson-Sellers [28] use the concept of upper ontology as the metamodel equivalent on ontology side.
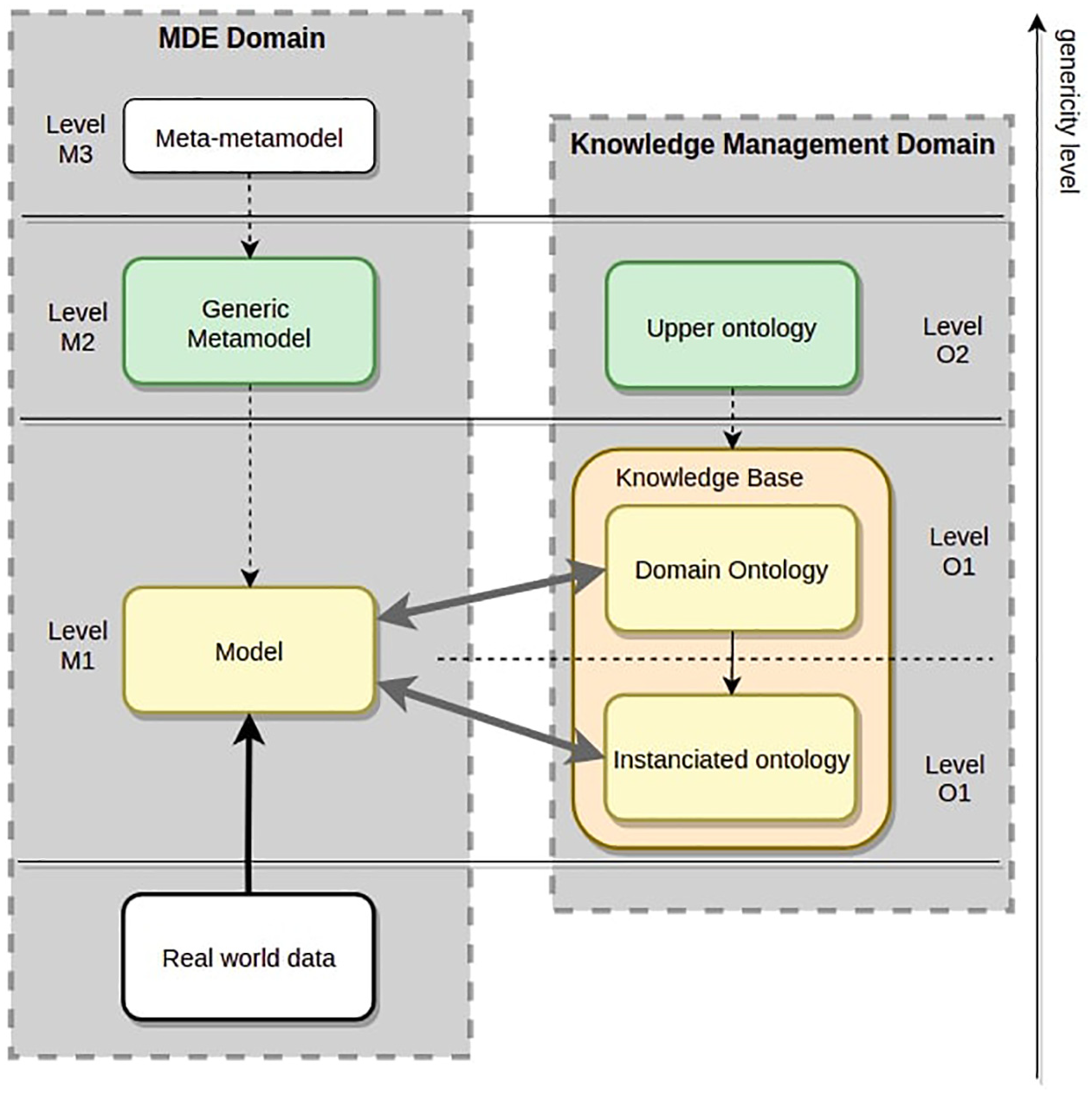
Proposed representation for domain ontology instantiation with respect of MDE principles.
4.2. Presentation of the framework concepts
In the previous section, the links between modelling levels and ontological levels have been defined for the specific case of ontology population. It is then possible to formulate how the metamodel is used to align the extracted data with the ontology. In this section, a conceptual vision of the proposed framework and how it is built are detailed.
Figure 5 gives an overview of the framework and how it has been built. The overall objective is to transform heterogeneous raw data into knowledge stored in a knowledge base. To reach this objective, two levels of conceptualisation are used: the metamodel level and the model level [48]. From the metamodel level representations (Pivot metamodel, Alignment rules, Ontology terminology) the objective is to define a full process for knowledge extraction that can be specified for any source of data and any ontology. This way, the Pivot metamodel is specified into a Data model, 3 Alignment rules are specified into a Model transformation and the Target ontology is then populated from the Data model thanks to the Alignment rules and the tools used to specify alignment rules into a model transformation. Once the Target ontology has been populated with its instances, the knowledge base is created.
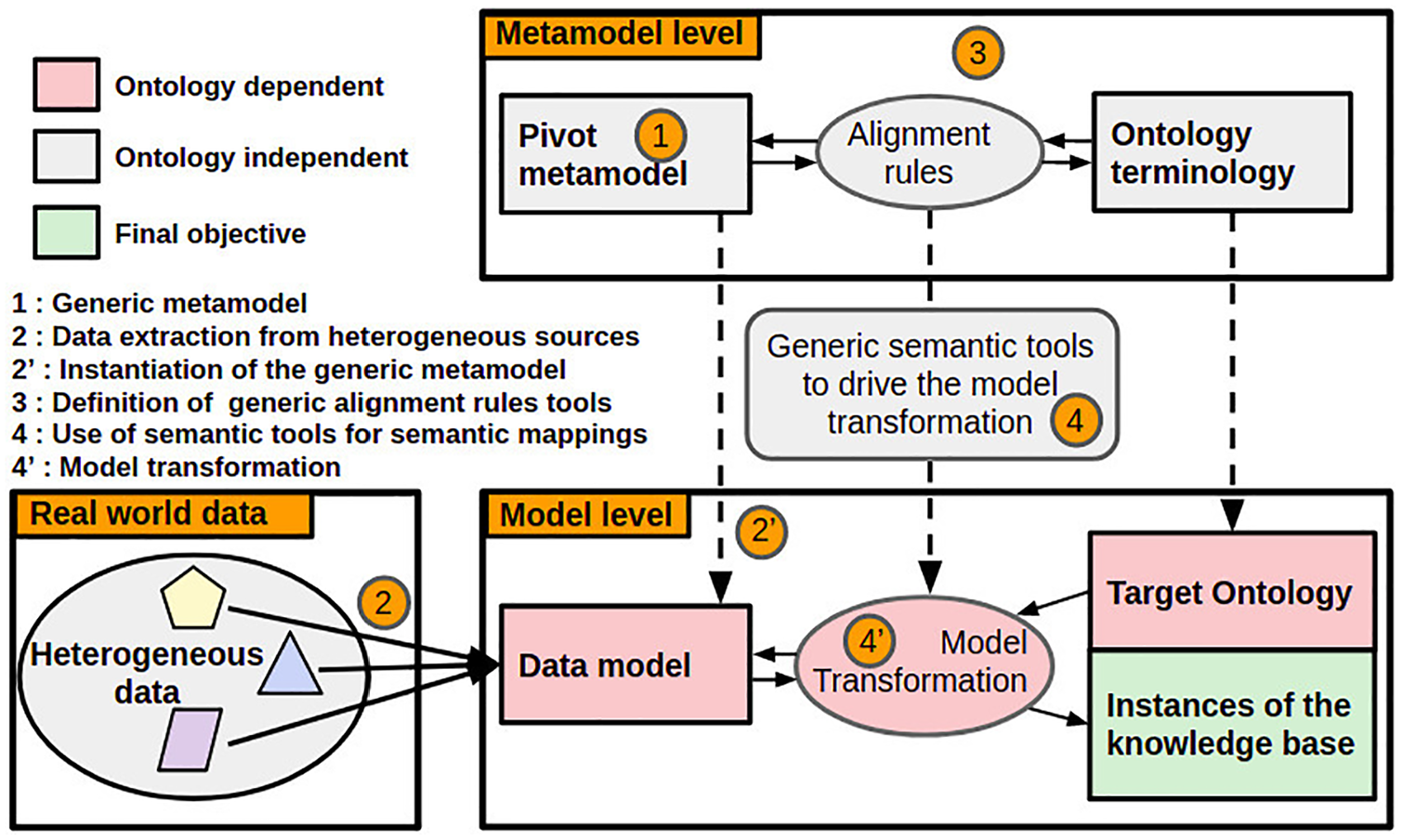
Model-driven approach for the transformation of heterogeneous data into a knowledge base.
It should be noted here that the derived Data model is closely related to the sources that are used for the data extraction. Similarly, the Model transformation is closely related to the ontology that is instantiated. The Model transformation is derived from the Alignment rules and the Data model. Then, it also depends on the Target ontology. In stark contrast, the generic Pivot metamodel and the Generic tools for the definition of alignment rules are the same for every kind of data processed and do not depend on the Target ontology. Defining generic semantic tools allows us to generically and automatically create specific transformation rules based on the Target ontology. To sum up, in this representation, some elements are related to the ontology because defined from it (Alignment rules, Model transformation). Other elements (Pivot metamodel, Data model, Generic semantic tools) are not related to the ontology because they are first designed to describe heterogeneous data and are not domain related.
The alignment process proposed here has a specificity compared to classical MDE alignment processes regarding the adopted direction. In general, a model transformation is processed in a single direction to build a target model from a source model respecting alignment rules defined between the source metamodel and the target metamodel [19]. In the case of ontology population, the Model transformation is bidirectional because the Data model is partly built from the targeted domain ontology in the first place. Then, the same targeted domain ontology is extended into a knowledge base thanks to Ontological objects taken from the Data model. The fact that the transformation occurs in a two-directed way (from knowledge base to Data model and then from Data model to the knowledge base) is indicated by the doubled arrows in Figure 5.
Using a knowledge base or an ontology to help finding mappings is a popular strategy. In this case, however, the ontology is a part of the knowledge base, which is the final objective. Thus, despite the ontology is used to guide the Metamodel to Data model instantiation, it should not be seen as an external tool but really as a component of the framework that cannot be avoided.
4.3. Description of the framework and integration of the data model
In this section, the integration of a model derived from the metamodel in a wider framework for ontology population is proposed. Figure 6 gives an overview of the framework for semi-automated domain independent ontology population.
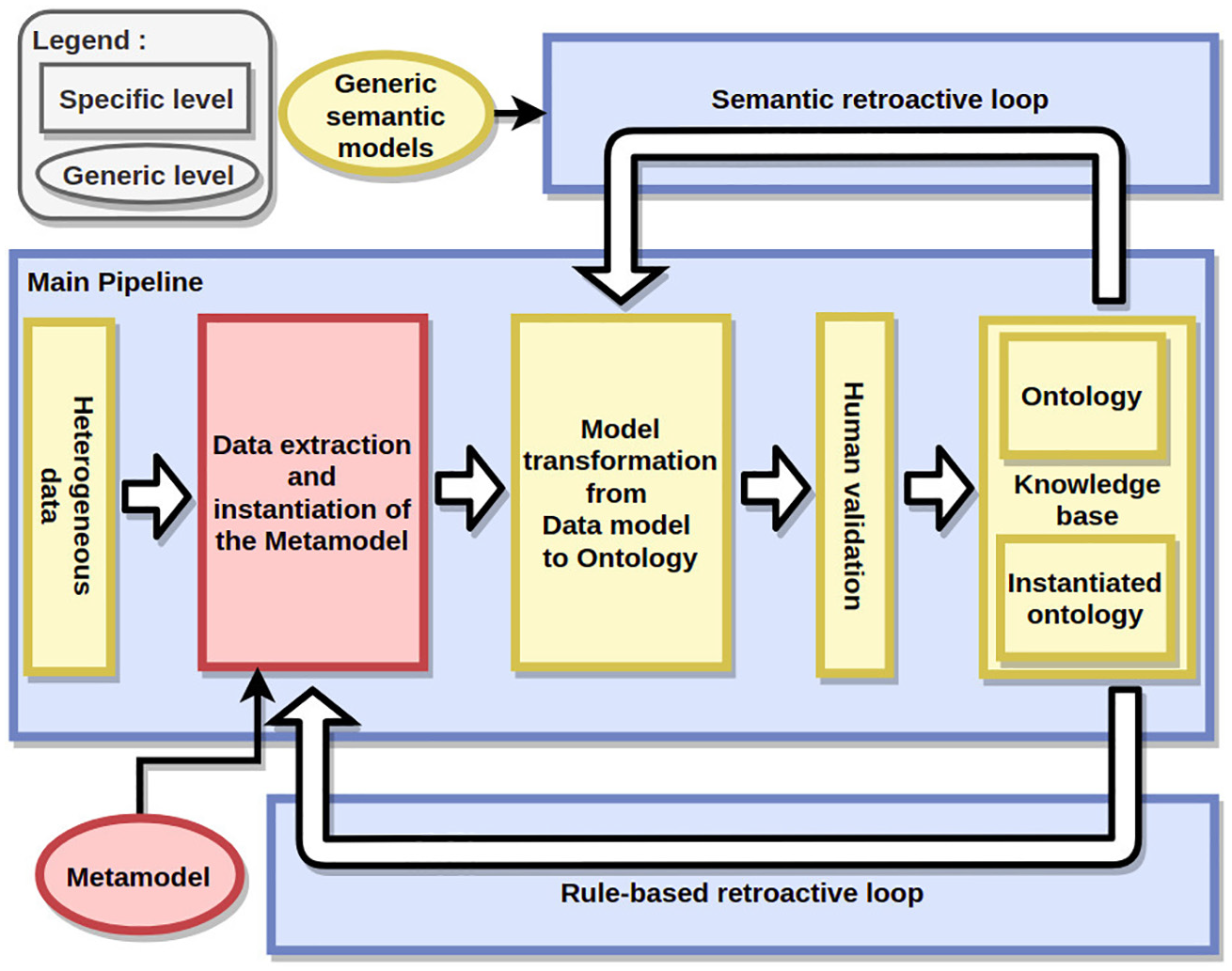
Description of the framework in which the metamodel and the model can be integrated.
The objective of this framework is to use the two classical approaches used for data extraction which are, the rule-based approach and the statistics and machine learning-driven approach. The rule-based method is known for precision and then is very efficient to conduct an accurate extraction of entities. However, this method is limited in terms of range covering, because the number of matched data remains low compared to the whole information that can be contained in a data source. Moreover, defined rules should be generic enough to be applied with any domain ontology related terms which demand a huge effort in the conception of rules that cannot be as precise as rules defined for a single domain. Statistical and machine learning–driven approach allows to gather more information about the extracted entities and then precise their meaning in order to find the corresponding resources (if relevant) in the ontology.
The conceived framework is an iterative process composed of three blocks: the main pipeline, the rule-based retroactive loop and the semantic retroactive loop. These blocks are briefly described here:
The main pipeline starts with the acquisition of heterogeneous data that are analysed in the light of the data extraction metamodel and extraction rules to create the data model. In the processing pipeline, two types of extraction are used. The first one is inspired by Hearst patterns and uses knowledge contained in the ontology to automatically create extraction patterns and the second one extracts terms from data thanks to lexical and statistical analysis (appearance rate, part of speech tag, etc.). After being created, the data model is then reused in an alignment process to operate its transformation. To operate this transformation, elements of the data model are matched with elements of the ontology thanks to the alignment rules defined among the metamodel and the upper ontology and derived model transformation rules. A human validation step is included in this main pipeline in order to validate the extracted instances and definitely include it in the knowledge base. The human validation step can be guided with the extracted data corresponding to detected instances previously stored in the data model. It is intended to limit this human validation after a given number of iteration.
The rule-based retroactive loop is used to build new rules based on the previously gathered knowledge. This rule-based retroactive loop is used to extend the set of rules based on previously validated instances with the use of bootstrapping techniques for example [49]. In this loop, classes and properties defined in the ontology can also be used in order to specify generic extraction rules with given targeted terms.
The semantic retroactive loop is used to feed generic semantic models with previously acquired knowledge and derive transformation rules for the model transformation from data model to domain ontology. Just as the rule-based retroactive loop, the semantic retroactive loop uses previously validated instances as reference.
5. Data model and framework specifications for text processing
In this section, an instantiation of the metamodel from raw text is proposed to illustrate its usability (see Figure 8). Later, a specified version of the framework defined in section 4.3 is given for text processing illustrating how the data model derived from the metamodel is used in this framework.
5.1. Metamodel instantiation into a data model from textual data: two examples
In this section, the proposal will be illustrated with two use cases, in the area of chemical engineering and wine and food pairing. The aim of these use cases is to show how the metamodel can be instantiated from data describing distinct domains. Further work will concentrate on the evaluation of the performance of the whole extraction system based on expert validation and machine learning performances measures such as confusion matrices adapted for the context of unsupervised learning.
The objective of the first use case is to gather information about chemical entities based on concepts that can be contained in a chemical ontology. The obtained result (instantiation of the metamodel) is then discussed. In this example, the Ontological objects are organised and Relations are identified thanks to the corresponding metamodel classes. To conduct the metamodel instantiation, the chemistry related plain text sample given in Figure 7 is used as raw data. This raw text is extracted from Soderberg’s [50] book on organic chemistry.

Plain text data for the instantiation of the metamodel (chemical domain).
A graph-based representation is used where each node represents a single object and each edge (solid arrows) represents the link between two objects based on the links defined in the metamodel. Figure 8 contains the data model where objects are instantiated from the metamodel classes. In this example, it is assumed that each extracted Ontological object has been classified either as a Concept or an Instance. This explains why there is no Ontological object derived instances appearing in the data model. Similarly, as the Entity class is an abstract class, it is not represented here. To ensure the semantic correctness of the derived data model, it has been reviewed and validated by an expert of the chemical domain.
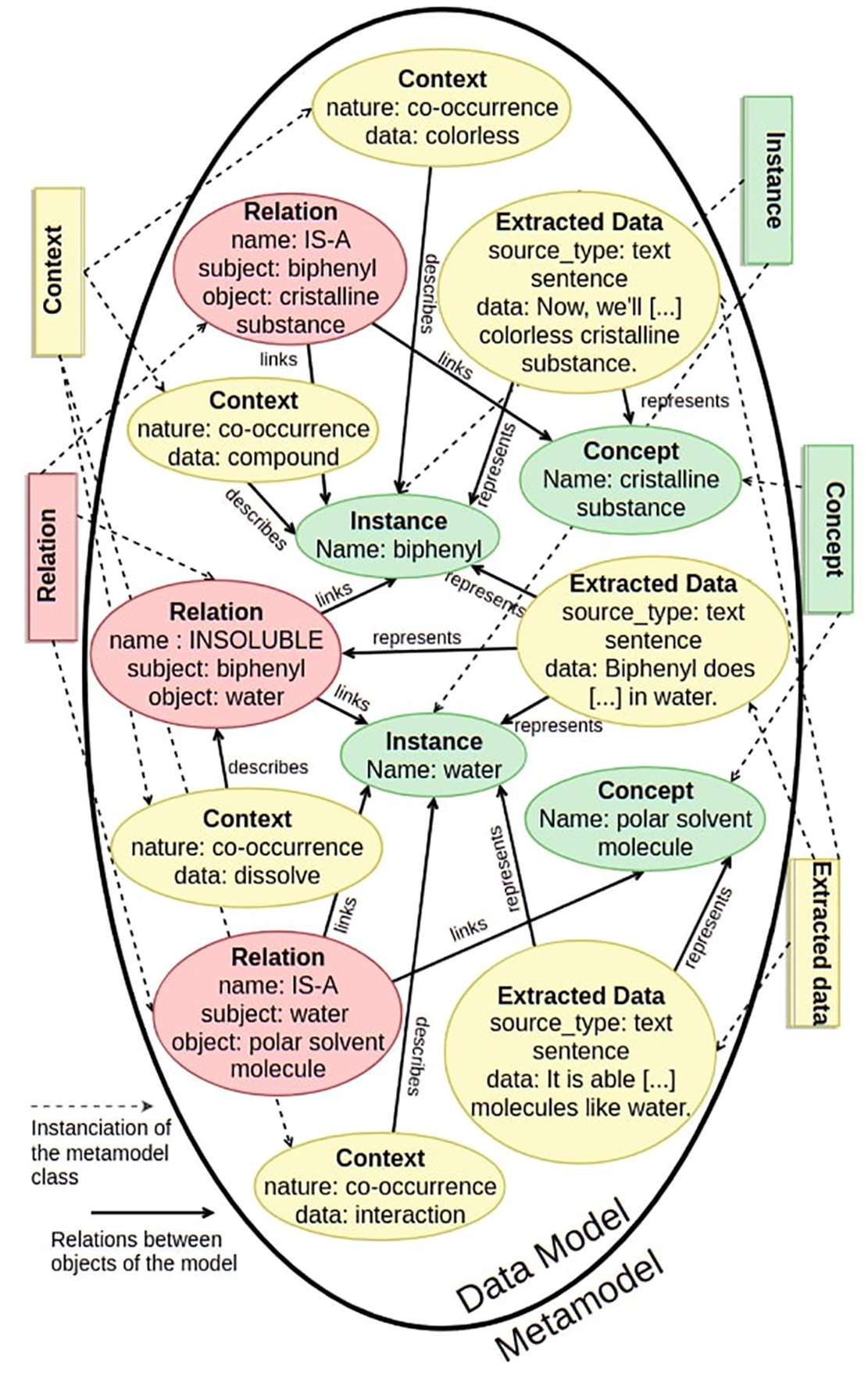
Example of a data model derived from the presented metamodel for chemistry domain extracted sentences (graph representation).
From the given text, four Ontological object instances named crystalline substance, polar solvent molecule, biphenyl and water are extracted. The assumption is made that some extraction process that are able to identify hyponymy relation between entities exist [25,51].
In this example, it can then be considered that crystalline substance, polar solvent molecule, biphenyl and water have been extracted with such kind of extraction process and the corresponding IS-A relation between biphenyl and crystalline substance and between polar solvent molecule and water can be defined. It is also supposed that a third relation can be extracted from the text based on the group of terms does not dissolve that occurs between terms biphenyl and water.
Extraction processes are not defined here because the aim is only to instantiate the metamodel from extracted data. However there are many studies focusing on this task using NLP techniques [52–55] and rule-based extraction [56] or entity recognition methods [57,58]. To keep the data model as clear as possible, only entities that can surely be extracted thanks to rule-based extraction are represented. Also, the extraction process is driven by the ontology to instantiate. Thus, the extraction techniques do not necessarily intend to extract instances for concepts that are not specified in the ontology as these techniques are not supposed to alter the ontology. For these reasons not all the potential knowledge can be found in the data model even if it could have been represented.
Each Entity instance has some associated Context instances, that are defined in this case through co-occurring words, because it is the easiest and most understandable way to build context elements. The definition of a co-occurrence is a whole subject. For this example, it is simply defined that two nouns are co-occurring if they appear in the same sentence. Applying this definition, it can be observed that the term biphenyl co-occurs with colourless and compound and that the term water co-occurs with interactions in the sample text. These co-occurring terms then gave the three Context instances whose data attributes are colourless, compound and interaction. As well, the term dissolve is included in the group of terms does not dissolve that gave the Relation instance named INSOLUBLE. Then it can be defined as a context element of the Relation instance named INSOLUBLE. Selected co-occurring words for the building of Context instances are intentionally meaningful but more of them can obviously be extracted from the given text. The Concept instance named crystalline substance could for example be linked with the same Context instances as biphenyl (namely colourless and compound), but these links are not represented to avoid complexifying the example representation. Moreover, the choice is made in this case to define the context with co-occurring words because the entities are extracted from raw text, but the context of an entity can be of different nature. The only constraint existing on the context is that it should be presented as textual form in order to be processed afterwards. Context elements can then be textual items such as the title of an article, a figure’s title or a picture’s metadata to name a few.
To instantiate a chemical domain ontology [11,12,59], it is then possible to rely on the extracted context by computing distances between the Entity instances (Relation instances and Ontological object instances) of the metamodel and the chemistry related ontological concepts. This way, Ontological object instances can be identified as Instance instances as they are semantically close to ontological concepts or share some context with previously identified Instance instances. For example, propanol, if extracted, can be identified as an alcohol as it appears in a context similar to the context of ethanol, already identified as an alcohol. Then it is easy to derive this new taxonomic relation in the ontology, thanks to predefined alignment rules.
Concerning Extracted data instances, the instantiation process creates one Extracted data per sentence linking each Entity instance to its corresponding Extracted data. Nevertheless, the same instantiation can also be done with one single Extracted data instance containing the whole sample, depending on the wanted granularity.
To illustrate the genericity of the metamodel, another example is presented. In this use case, the final goal is to instantiate a wine ontology in order to support wine and food pairing. Data sources used are articles from Wikipedia talking about wine and wine domain specific web resources [60]. Similarly to the previous example, an extract of the data taken from Wikipedia is shown in Figure 9 and the corresponding data model is shown in Figure 10. For more clarity, not all the relations are represented in the data model. Nevertheless, SOFTEN relations between meat and cabernet sauvignon or even between hard cheese and barolo, for example, are also contained in the data model and could have been represented.
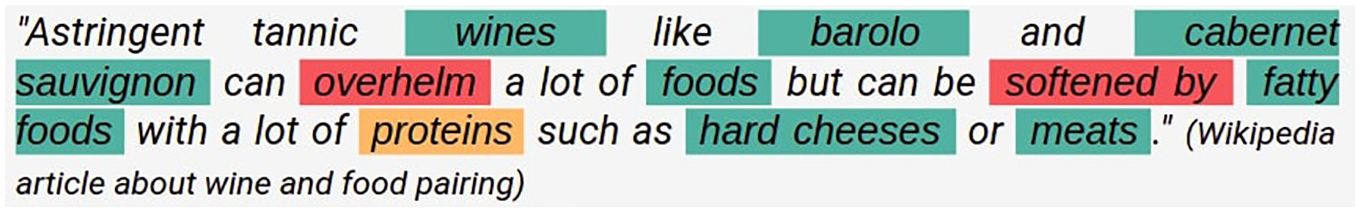
Plain text data for the instantiation of the metamodel (wine domain).
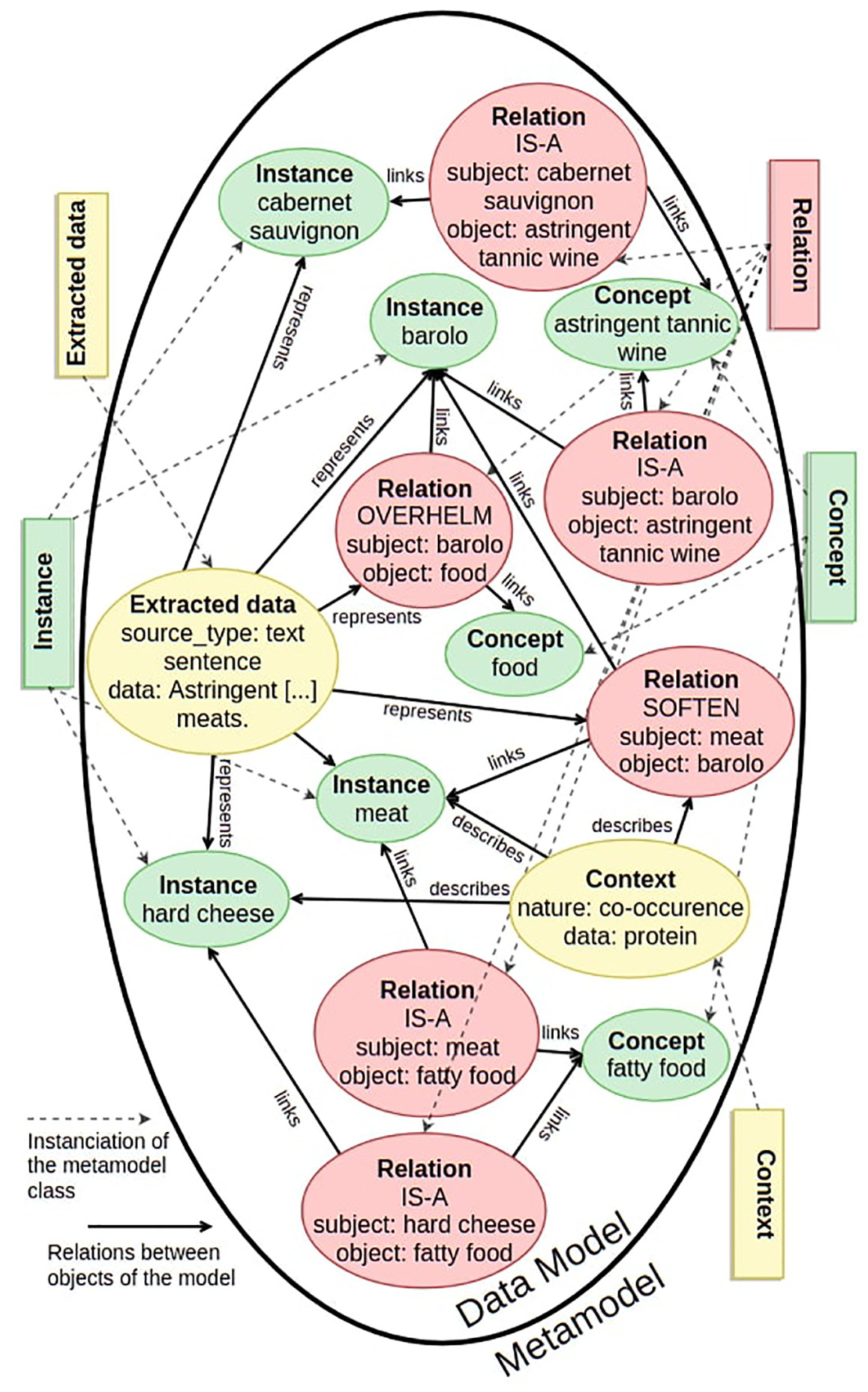
Example of a data model derived from the presented metamodel for wine domain extracted sentence (graph representation).
5.2. Framework specification for text processing
Thanks to the genericity of both the metamodel and the framework, it is possible to define as many extraction methods as it exists data types and data sources and include it in the framework. Despite the metamodel allows the representation of instances from any data source, extraction methods for each of these sources still have to be defined. Studies that focus on specific data extraction [61–63] can still provide some clues to expand the scope of explored data. Nevertheless, one of the main advantages of the presented system resides in its interoperability. Hence, data extraction methods, whatever techniques they use should easily fit in the structure of both the metamodel and the system as they are defined.
In the instantiation of the metamodel, it is assumed that extraction methods for Relation and Ontological object detection exist but no method has been defined yet in this paper. Then the objective of this section is to provide an insight into the set up of an extraction pipeline for textual data following the framework defined in section 3 and illustrated in Figure 6. Figure 11 presents this specified pipeline which uses the metamodel as one of its bricks and is planned to be developed in future work. This pipeline involves the following techniques:
NLP techniques (namely generic rule-based extraction and pattern based entity recognition) for the extraction of possible concepts and instances from the text. These techniques have two objectives. The first one is the direct extraction of hyponymy relations based on the concepts of the ontology and generic dependency based patterns. The second one is the extraction of Ontological object instances that might be matched to an existing concept as an instance afterwards thanks to word vectorisation.
Word vectorisation and matching methods based on semantic distance computation and Wordnet [63] reference matching to evaluate which extracted entities are semantically close to each others. The end goal of the matching step is to identify new instances by comparing them to instances that have been directly extracted from hyponymy relation extraction.
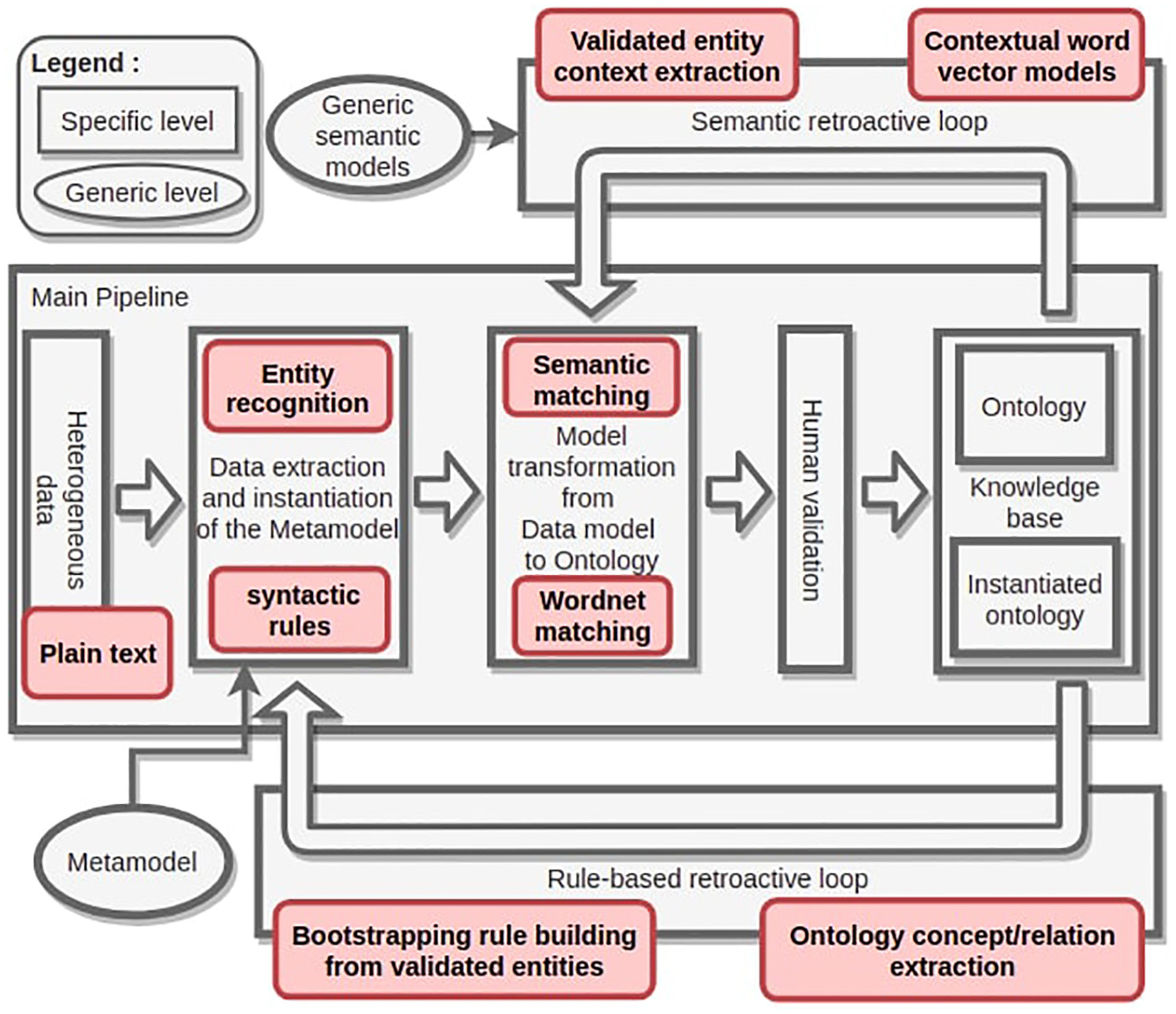
Specification of the framework for plain text processing.
These extraction techniques rely on the ontology but remain domain-independent as they can be automatically adapted to any ontology. From a technical perspective, three processing pipelines can be briefly described. These pipelines are built on top of a classical NLP pipeline. The common pipeline applies tokenization, lemmatization, part-of-speech tagging and dependency parsing to textual data. Then, the first specific pipeline aims at identifying classes of the ontology from their lemma in the text and applies dependency patterns to extract instances. The second specific pipeline aims at extracting some new candidates based on their appearance rate and through statistical filters. The third pipeline extracts contextual data, by computing co-occurrences between terms and using Word Embeddings to build a vector for extracted terms.
6. Conclusion
In this article, the MDE methods are used as a strategy to organise heterogeneous data extracted from different documents in order to facilitate further mappings with domain specific ontologies. The current limits of generic ontology population are presented highlighting the imbalance existing between heterogeneous data and domain specific ontologies and the fact that most of the existing metamodels for data extraction either remain domain-specific or do not embed enough information.
With this in mind, a metamodel for heterogeneous extracted data representation is presented that already adopts an ontological shape to organise data in a generic way. To illustrate the use of this metamodel a simple use case on chemical related piece of text is proposed to derive the metamodel into a data model. Then, with a view of building a semi-automated domain independent ontology population system, a textual data specific framework is proposed in which the aforementioned metamodel can be used to drive the instantiation of a domain ontology.
This presented framework, involves different processing techniques including rule-based data extraction and semantic-driven model alignment. In combination with the metamodel, it allows a generic extraction of instances from textual data. As a lot of knowledge is expressed in many different textual data sources (PDF, XML, HTML), this specification can be applied to many kind of documents with the same processing techniques. Moreover, it is not excluded to extend the processing methods to be able to analyse images, figures, databases or other kind of data types as the initial framework permits it. Nevertheless, some components have to hold our interest in the seek of genericity regarding the domain. These are extraction rules, extraction patterns and matching rules definition. It is of course not excluded to define specific rules or extraction methods depending on the type of document analysed. Still, such a framework is efficient only if the defined basic rules remain generic regarding the domain. Generic relation extraction is possible when talking about domain free relation, hyponymy relation being one of them. This is the aim of Hearst patterns. Despite Hachey et al. [64] proposes a methodology to create generic relation extraction patterns, it is agreed that when coming to domain specific relations, these rules cannot be built without a minimal context. However, knowing that an ontology carries some information not only about its concepts but about its relations as well, there is some lead to investigate in the specification of generic relation extraction rules into simple contextualised patterns thanks to this information. This is one of the biggest challenge coming with the setup of the framework. A proof of concept of this framework for the case of chemical extracted data is currently under development and should be applied on chemistry related textual content using a chemical ontology defined by experts of the domain.
In the presented metamodel, the context elements are forced to be textual so that it can be processed with semantic tools to derive alignment. The reason why the context is limited to textual form is that all the methods mentioned to derive mappings between terms are based on textual content analysis. One of the perspectives is to widen the range of alignment or pre-alignment methods to handle other kind of context elements. One direction could be for instance to add clustering methods before alignment based on numerical and statistical context features. This will by implication also allow to exploit other kind of contextual data during data model construction (contextual word vector computation or ontology concepts contextual vectors [65] for example).
Another aspect that could be investigated concerns the selection of sources. During the setup of the framework, it is supposed that data sources used for knowledge extraction are preselected to stick to the targeted domain. In the theoretical case where the objective is to harvest all the available web data for example, there is for sure a huge amount of data and associated knowledge that will not be relevant for the domain of interest. Even worse, some domain related extracted knowledge could bring contradictions and imprecision into the knowledge extraction system because it has a different meaning in a different context which is often the case for disjoint domains. To tackle this issue, some techniques such as document clustering or keyword extraction should be applied before using data in the framework in order to extract the most relevant sources of data.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.