
Abstract
Translation language resources, such as bilingual word lists and parallel corpora, are important factors affecting the effectiveness of cross-language information retrieval (CLIR) systems. In particular, when large domain-appropriate parallel corpora are not available, developing an effective CLIR system is particularly difficult. Furthermore, creating a large parallel corpus is costly and requires considerable effort. Therefore, we here demonstrate the construction of parallel corpora from Wikipedia as well as improved query translation, wherein the queries are used for a CLIR system. To do so, we first constructed a bilingual dictionary, termed WikiDic. Then, we evaluated individual language resources and combinations of them in terms of their ability to extract parallel sentences; the combinations of our proposed WikiDic with the translation probability from the Web’s bilingual example sentence pairs and WikiDic was found to be best suited to parallel sentence extraction. Finally, to evaluate the parallel corpus generated from this best combination of language resources, we compared its performance in query translation for CLIR to that of a manually created English–Korean parallel corpus. As a result, the corpus generated by our proposed method achieved a better performance than did the manually created corpus, thus demonstrating the effectiveness of the proposed method for automatic parallel corpus extraction. Not only can the method demonstrated herein be used to inform the construction of other parallel corpora from language resources that are readily available, but also, the parallel sentence extraction method will naturally improve as Wikipedia continues to be used and its content develops.
1. Introduction
The purpose of information retrieval (IR) systems is to search for documents to satisfy users’ information needs. As an information retrieval system operates based on users’ queries, most traditional systems are dependent upon the language in which the query is written. However, as the number of documents on the Web is growing rapidly and relevant Web documents may not be written in the query language alone, users may miss important information if IR systems search for documents in only the query language. Cross-language information retrieval (CLIR) is the retrieval of information written in one language based on a query expressed in another [1,2]. With the current rapid development of the social Web, lots of information is rapidly uploaded and updated on the Web in various languages and surely most users hope to find information written by other language as well as their native language by inputting only query in their native language. In particular, as CLIR often relies on translation methods to cross the language barriers between a query and the documents, query translation becomes an important part in CLIR; however, it requires different techniques as compared with traditional machine translation (MT) ones because a query is commonly composed of just several terms or not a sentence but a phrase.
As the problem is typically formulated, CLIR requires ranking documents that are written in one language based on a query that is expressed in a different language. Performing CLIR requires a method of mapping terms from one language to another. Machine-readable dictionaries (MRDs) have been widely used for this purpose because they are widely available, easily used and moderately effective. MRDs typically seek to provide all possible translations, leaving the CLIR system to make choices among all such alternatives. The alternative to MRDs is to learn translation probabilities from corpora, for which translation-equivalent ‘parallel’ corpora have proven to be an effective source. However, to be useful for CLIR, the language use in the parallel corpus must be reasonably similar to that in the documents to be searched, and the parallel corpus must be sufficiently large to permit the inference of reasonably accurate translation probabilities. Thus, much research has been conducted to automatically build a high-quality parallel corpus in large quantities [3,4]. Parallel corpora can be used in conjunction with co-occurrence evidence from language models to build complete one-best machine translation systems, which can then be used directly in CLIR for query or document translation; additionally, the translation probabilities can be used with a weighted evidence combination technique. However, domain-matched parallel corpora can be difficult to obtain, and a form of alignment is typically needed as a preprocessing step. Currently, Wikipedia has been contributed to by authors to such an extent that a parallel corpus has been naturally constructed; that is, it has comparable documents with the same title [5,6].
In this research, we aim to improve the quality of CLIR using bilingual resources from Wikipedia: the bilingual dictionary, WikiDic (WD), and the parallel corpus. Our proposed method can have two benefits by constructing them from Wikipedia: (1) it uses only language resources that are commonly available and (2) it can be further improved simply with the passage of time and the continuing use of Wikipedia. Thus, we claim that constructing language resources from Wikipedia, such as a parallel corpus or a bilingual dictionary, is particularly effective for improving query translation for a CLIR system. To construct a parallel corpus with sufficient quality, we selected document pairs in Wikipedia with the same title as comparable documents and regarded sentences in those documents as parallel sentence candidates. The goal of this task is to extract a pair of parallel sentences describing the same content from the parallel sentence candidates. Therefore, we explored new sentence similarity-measure methods using a variety of language resources. Conventionally, these methods have used term-matching techniques that use MRDs. However, these methods involve two main challenges: first, most of the comparable sentences in Wikipedia include out-of-vocabulary (OOV) words; second, the use of MRDs involves translation ambiguity, as many words have several different meanings in MRDs.
To address the presence of OOVs, we constructed a bilingual dictionary using inter-wiki links, redirect pages and disambiguation pages from Wikipedia, called WD. As WD contains many named entities with multi-terms, such as the name of a person, location and titles of movies, it can be particularly useful for detecting and resolving the OOVs [5]. To address translation ambiguity, we utilised bilingual example sentence pairs extracted from a Web dictionary; 1 extracted bilingual example sentence pairs are then utilised to estimate translation probabilities and thus improve the selection of translation words. Consequently, WD and the parallel corpus from Wikipedia are utilised for our query translation technique with co-occurrence evidence and translation probabilities in CLIR systems. To evaluate our method, its performance was then compared with that of using translation probabilities from an English–Korean parallel corpus, which is created by manual annotation.
The remainder of this article is organised as follows: section 2 describes related works surrounding CLIR and parallel corpus construction, section 3 identifies translation language resources, section 4 describes how to build a parallel corpus from Wikipedia, section 5 explains our query translation technique by combining probabilities and association, section 6 presents experiment results and section 7 concludes the article.
2. Related work
As query translation implementations have straightforward document translation implementations, that is, the translation mapping is simply pre-compiled into the document representation, here we focus on query translation because this approach offers the greatest flexibility for experiment design. Regarding query translation, three basic types of translation resources have been developed: machine translation, corpora and lexicons [7,8].
When suitable parallel corpora are not available, effective machine translation systems are able to be easily built and bilingual lexicons assembled from a bilingual word list, an MRD or a bilingual thesaurus can be used as a source for encoded translation relations. Because such lexicons typically lack the types of statistical translation preference evidence that can be found when using corpora, it can be useful to instead rely on evidence from the co-occurrence of alternate translations of query terms, which are then used to constrain translation alternatives. Evidence for such co-occurrence is typically available from the document collection to be searched; although, when the collection is small, it can be useful to obtain co-occurrence evidence from other corpora. Seo et al. [9] have demonstrated one effective way of doing so using rich lexical resources. At the time of that work, such resources were available only for a few language pairs; however, today, suitable resources are available in greater quantity and can be easily assembled from Wikipedia.
When bilingual corpora are available, wherein language is used similar to the way in which it is used in the queries and documents, alternative approaches that do not rely on MRDs can be employed. Two types of bilingual corpora can be used for CLIR: parallel corpora and comparable corpora. A parallel corpus is constructed by actually translating documents between languages. Document alignments naturally result from the process, but sentence and ultimately term alignments must be inferred based on heuristics that capture conventions of the translation process and statistical regularities. These alignments can then be used to estimate translation probabilities, which then can be used as a basis for CLIR [10]. In contrast, a comparable corpus consists of independently authored documents on related or comparable topics. Because, in the case of comparable corpora, document alignments do not naturally result from the generation process, they must be inferred in some other way. Though it is possible to draw on statistical regularities to construct a bilingual lexicon from a comparable corpus [11], the resulting corpus is rarely as useful as that which could be constructed using a parallel corpus.
Wikipedia has emerged in recent years as a potentially important resource for CLIR. One example of the use of Wikipedia in CLIR is found in the work of Gaillard et al. [12], who investigated two successive steps for translation: the identification of translation alternatives from Wikipedia cross-lingual links and disambiguation using Wikipedia categories of target language. Schönhofen et al. [13] also utilised linked pairs of English and Hungarian Wikipedia article titles, and then exploited Wikipedia hyperlinks for query term disambiguation. Tang et al. [14] searched for the best English Wikipedia pages using Google and then followed the inter-wiki links to identify the corresponding Chinese Wikipedia pages, ultimately using the titles of those Chinese pages as the translation of the query.
Tasks intended to build parallel corpora have been recently performed because of the increasing importance of CLIR and machine translation. In the traditional methods for extracting parallel sentences, comparable document pairs are first extracted, and then parallel sentences are judged by comparing the sentences in each document. However, these tasks for building parallel corpora are costly and time intensive. Methods to find similar documents were widely studied before those for finding similar sentences. Resnik and Smith [15] proposed a method to extract similar documents from the Web using the similarity of their HTML structures. Talvensaari [16] proposed a method to find similar documents based on translating words in the source language to the target language by using the main keywords. Munteanu and Marcu [17] and Vu et al. [18] found important words by using meta-information of documents and a bilingual dictionary, and they then judged similar documents by word frequency. Regarding studies intending to find similar sentences as a means to construct a parallel corpus, Utiyama and Isahara [19] exploited a method of information retrieval that uses term frequency (TF) in each document and document frequency (DF) in total documents. Ramírez and Matsumoto [20] proposed a method of mapping morpheme rules between a source language and a target language in documents. Adafre and De Rijke [5] judged similar texts across multiple languages in Wikipedia, using a bilingual title translation lexicon automatically induced with the link structure of Wikipedia.
In our experiments, we introduced the results of parallel sentence extraction using a bilingual title translation lexicon built from Wikipedia in the same manner as the method by Adafre and Rijke, called WD. This lexicon is also compared in our experiments with other language resources from our proposed methods in section 6.1.2. However, because Adafre and Rijke did not apply their constructed parallel corpus to CLIR, it is difficult to directly compare the parallel corpus from our method with that from their method.
As neural network structures have been actively researched, there have been studies on word embedding, which is a kind of method of digitising words constituting text. For CLIR Vulić and Moens [21] proposed a BWESG word representation learning model from Wikipedia data; they represented words, queries and documents in vector space and compared them with the latent Dirichlet allocation (LDA) model. Lachraf et al. [22] compared the word embedding techniques (CBOW, Skip-Gram) derived from a large amount of an Arabic–English parallel corpus for the word translation work of CLIR.
Recently, deep learning has become mainstream in CLIR. Li and Cheng [23] proposed a text representation approach for CLIR based on the adversarial learning framework. They used the optimal textual representation obtained from the generative adversarial network (GAN) implemented by the interaction of the embedding generator trained to consider ranking and the adversarial discriminator. Liu et al. [24] used a parallel CNN network that combines semantic and lexical information, rather than primitive lexical information, in CLIR.
However, to utilise deep learning or word embedding in CLIR, a large amount of bilingual training data is required. Furthermore, building a large amount of bilingual data with sufficient quality is a difficult and time-consuming task that depends on the linguistic characteristics, especially in Korean. Accordingly, our objective is to develop a method to automatically build a parallel corpus using an appropriate amount of comparable data from Wikipedia, which is easily accessible. In our experiments, the quality of the constructed parallel corpus is verified as sufficient, despite the relatively small amount of data.
3. Translation linguistic resources
We obtained translation resources from Wikipedia using a bilingual MRD and parallel texts.
3.1. Translation resources from Wikipedia
Wikipedia links offer a source of evidence for both cross-language and within-language term relationships. Cross-language mappings are available from the ‘inter-wiki’ links that link pages on the same topic in different languages. Evidence for within-language synonymy is available from redirect pages, and language-specific polysemy information can be obtained from disambiguation pages. These three lexicons are used together to translate the query; we refer to them as our English–Korean WD. Details regarding the quantities of each of the components of the WD are presented in Table 1. As an open source project, Wikipedia content is readily downloadable. 2
Bilingual pair lexicon: For example, the English page ‘President of the United States’ has corresponding pages in several languages (French: ‘Président des États-Unis’; Korean: ‘미국의 대통령’; German: ‘Präsident der Vereinigten Staaten’ and so on). These correspondences are expressed in Wikipedia as so-called Inter-wiki links, which are included in the body of each article. Using these links, we constructed a bilingual term pair lexicon.
Synonymy lexicon: Wikipedia redirect pages identify alternative names that can be used to refer to a Wikipedia concept. For example, the page ‘U.S.A.’ redirects to the article ‘United States’, which contains information about that nation. We constructed synonymy lexicons for English and Korean from this information.
Polysemy Lexicon: Disambiguation pages in Wikipedia are intended to allow users to choose among several Wikipedia concepts for an ambiguous word. They list the referents of ambiguous words and phrases that denote two or more concepts in Wikipedia, for example, the page ‘Washington’ contains three meanings that can be denoted as ‘George Washington’, ‘Washington (state)’ and ‘Washington, D.C.’.
WikiDic: knowledge set constructed by Wikipedia.

As a translation resource, WD was assembled from these components according to the following procedure: first, starting with each English term in the bilingual pair lexicon, each term was expanded to a set of related English terms by first using the English polysemy lexicon and then the English synonymy lexicon; second, every word in that set was translated using the bilingual pair lexicon; third, each Korean term in the resulting set was expanded by first using the Korean polysemy lexicon and then the Korean synonymy lexicon.
3.2. Bilingual MRD
Wikipedia has sufficient coverage for highly specific terms, but less so for more general terms. Therefore, we augmented the WD with an English-to-Korean MRD that contains 200,195 unique English terms, 885,642 unique Korean terms and 1,851,587 English–Korean equivalent terms pairs.
3.3. Combined translation lexicon
We create a combined translation lexicon (WikiDic+MRD) of ‘equivalents’ (which may not strictly be translations) by taking all Korean equivalents for an English term from WD when the English term is present in the WD, and for other English terms by taking all Korean translations from the MRD. The number of English word expressions in the WD and the MRD are 105,643 and 200,195, respectively. Table 2 shows the number of matching terms in the 50 English NTCIR-5 title queries for the MRD, WD and WikiDic+MRD.
Matching query terms in title.
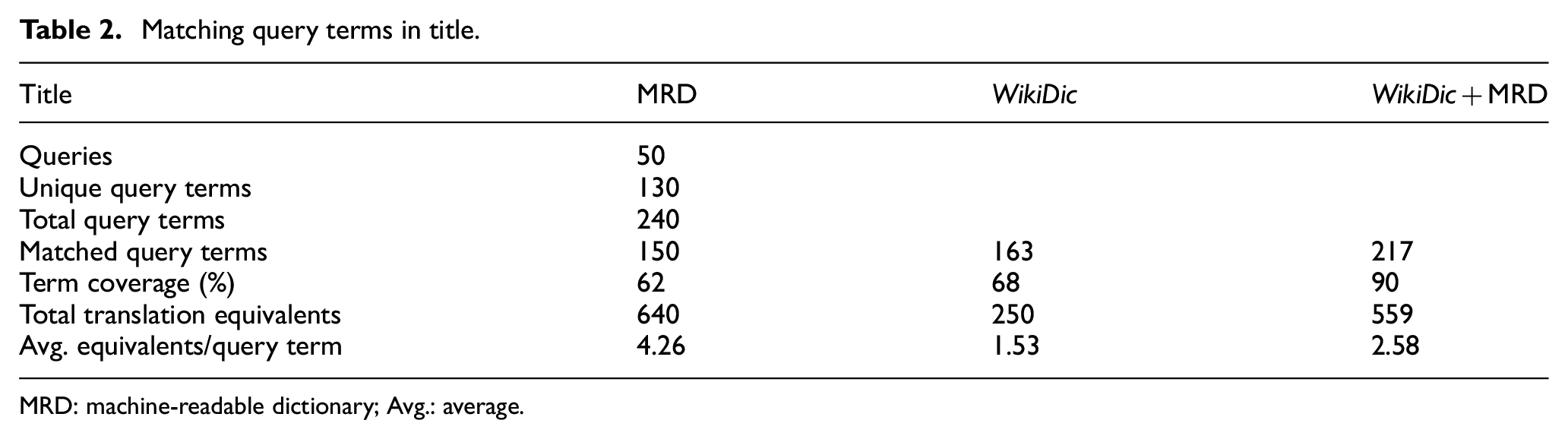
MRD: machine-readable dictionary; Avg.: average.
In the combination of WikiDic+MRD, WD takes priority when a word occurs in both of the translation lexicons, the WD and the MRD. In addition, as WD also has less averaged equivalents than the MRD in Table 2, the WikiDic+MRD has less translation equivalents.
4. Automatically extracting parallel sentences
Wikipedia has a massive number of articles written in more than 200 languages; as such, it is one of the most varied language resources in the world. The current version of Wikipedia expresses multilingual relationships by only inter-links. Therefore, Wikipedia can be used to extract document pairs of the same topic as a comparable corpus and to extract sentence pairs from the document pairs as parallel sentences. The entire process used to extract parallel sentences from Wikipedia is shown in Figure 1.
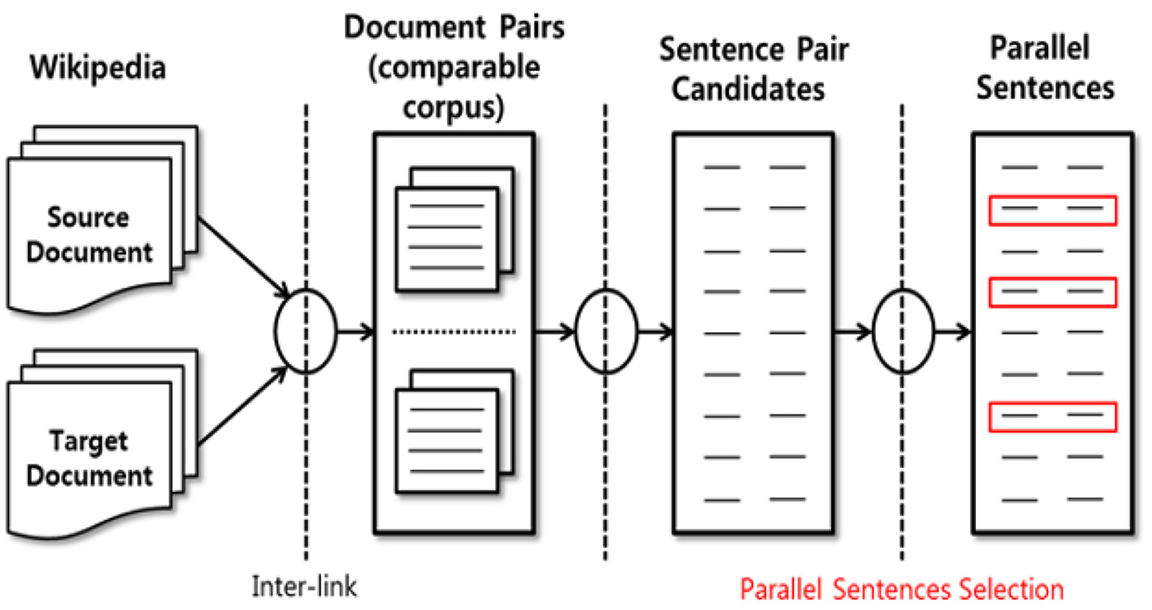
Process of parallel sentence extraction from Wikipedia.
If there are inter-links of connection between document titles for each language, the content of these documents could be similar. Figure 2 shows an example of Wikipedia document pairs with inter-link. Thus, sentence pairs in similar document pairs are regarded as parallel sentence candidates, and the final parallel sentence pairs are selected from these candidates by using the proposed sentence similarity-measure based on language resources. In pre-processing for similarity calculation between Wikipedia documents, we extracted and used terms with noun, verb and adjective part-of-speech (POS) tags by POS taggers for each language, English and Korean. The Korean POS tagger 3 removed postpositions, endings, suffixes and so on; the Stanford POS tagger 4 is used for English, providing a stop-word list and stemmer.

Example of Wikipedia document pairs with inter-link.
Traditionally, to calculate sentence similarity for parallel sentence extraction, term-matching methods are used with MRDs. However, this method has two challenges. First, most of the comparable sentences of Wikipedia contain OOV words. Second, MRDs are unable to sufficiently handle translation ambiguity, as many words have several different meanings in MRDs. To address these challenges, we exploit the WD constructed on inter-wiki links, redirect pages and disambiguation pages from Wikipedia. This dictionary has many named entities with multi-terms, such as titles of movies. Furthermore, we also use bilingual example sentence pairs of a Web dictionary to estimate translation probability, which improves the selection of translation words. Bilingual example sentence pairs are extracted from sample sentences of each dictionary word to show their real usage. In addition, the multi-term pairs of WD are added to the bilingual example sentence pairs, as only parts of the multi-term named entities occur in many Wikipedia sentences as abbreviations, such as ‘Obama’ for ‘Barack Obama’. Eventually, translation probabilities are estimated by applying the GIZA++ toolkit 5 to the bilingual example sentences and multi-term pairs.
A sequential word-matching method was developed for measuring similarity between sentences using the language resources described above. The matching order of a word, number and translation probability are determined according to the importance of the language resources. As many multi-terms occur in Wikipedia sentences, most of which are named entities, multi-term matching with the WD has the highest priority. As the second priority, numbers are another important evidence that two sentences tell a similar story. Translation probability, given the last priority, is used to solve translation ambiguity in common words.
To reflect the above conditions, we modify the equation using a Jaccard similarity. Thus, to select parallel sentences from parallel sentence candidates, the modified Jaccard similarity based on the sequential word matching, which is calculated as follows, is used for the similarity calculation

The three steps of the sequential word-matching method for measuring similarity between sentences are further detailed as follows:
Step 1. Multi-term matching is conducted between two sentences with WD. Multi-terms occurring in source and target candidate sentences are extracted using the WD. The number of matching multi-terms are added to
Step 2. Number matching is performed between two sentences. As in step 1, all number pairs occurring in both candidate sentences are extracted from each sentence. Furthermore, the number of matched numbers is also added to
Step 3. Finally, single-term matching is conducted between two sentences using translation probabilities. If there are plural single-terms matched with translation probabilities, single-terms with the highest translation probability are selected. That is, we allowed only one-to-one alignment between the words for only calculating
Overall,
An example of sentence similarity calculation using sequential word matching in our proposed method is shown in Figure 3. The matching scores
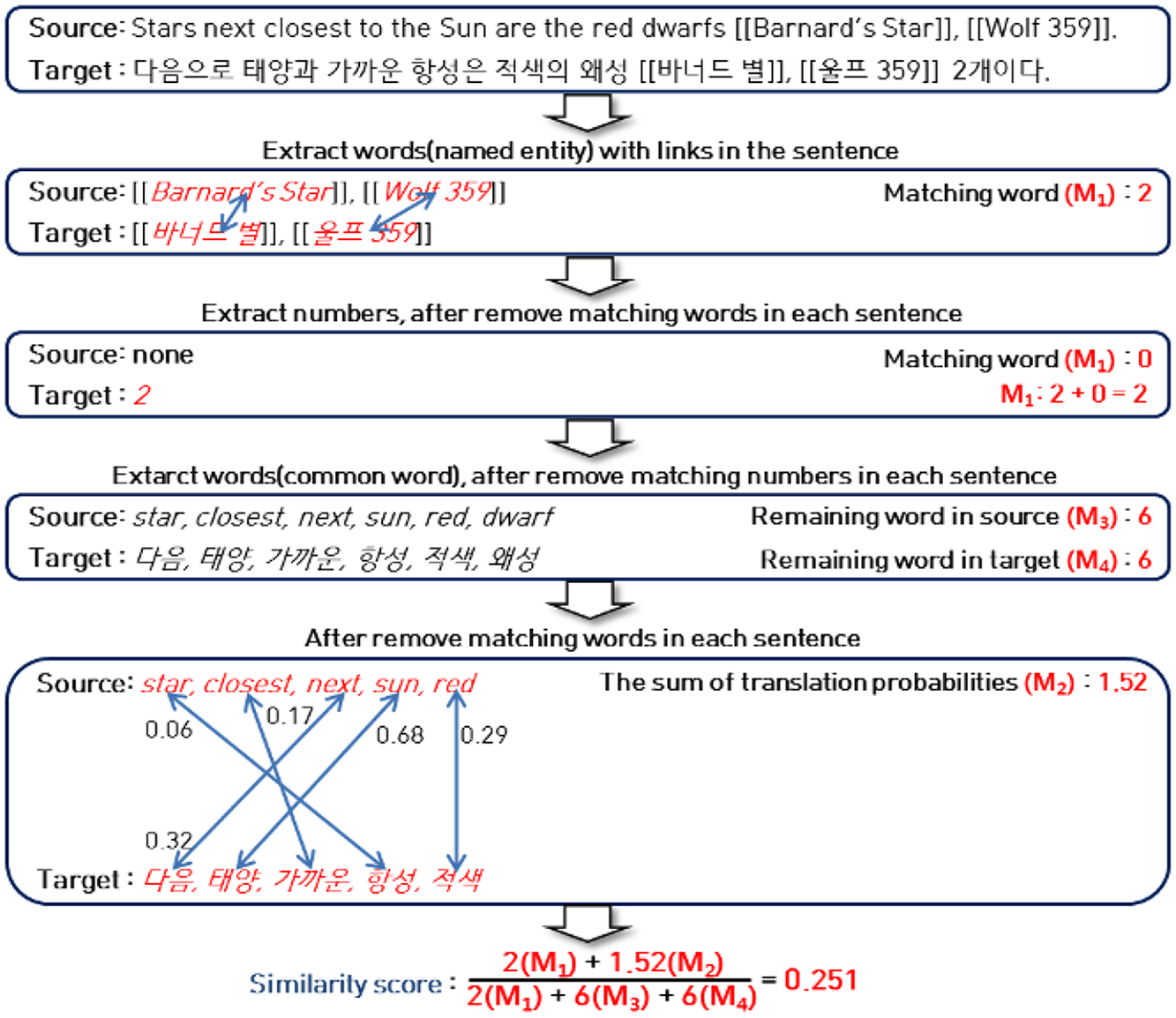
Example of sentence similarity calculation using sequential word matching.
5. Query translation technique by combining probabilities and association
Our query translation method is called query translation by probabilities and association (QTPA) [25]. The proposed method generates all the candidate target queries for the source query


where
We employ the same total divergence to the mean (TDM) technique as a measure of computing the association scores between two terms [9]; however, in this calculation it is done in such a way that it estimates the transition probabilities. TDM measures the divergence between two vectors by calculating the Kullback–Leibler divergence from the average of the two vectors. Thus, the association scores are calculated as follows
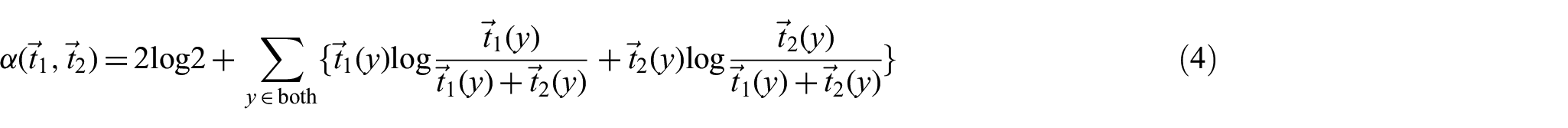
where


where vector
Suppose that the (

where
Translation probabilities

6. Experimental evaluation
6.1. Parallel sentence extraction
6.1.1. Experimental settings
For parallel corpus construction, 105,643 document pairs with the same title in English–Korean Wikipedia were used as comparable documents. To evaluate the parallel sentence extraction method, 100 document pairs with comparatively lengthy content and few gaps in length between each other were randomly selected. Details regarding the test dataset used for evaluation of our method are presented in Table 3. Correct parallel sentence pairs existing in these document pairs were manually labelled by five annotators. The same 40 document pairs were assigned to two annotators and then only the sentence pairs that were identically labelled as correct by the two annotators were selected as the final correct parallel sentence pairs. The agreement score of the constructed test data was 0.713 according to the Jaccard similarity. It was difficult to estimate a pair of candidate sentences because the annotator selected the correct pair of sentences by comparing the sentences in the two documents in order at the top. Therefore, we calculated the agreement score between the evaluators using the Jaccard similarity score instead of Cohen’s Kappa coefficient. Annotators employed two master students and three undergraduate students who are studying natural language processing, including an author. This manual labelling task was done for about two months. The proposed method and those to which it is compared were evaluated in terms of precision, recall and F1 scores.
Test dataset to evaluate our parallel sentence extraction method.

Moreover, only a portion of entire document pairs with the same title were chosen as comparable documents; the criteria for selection of comparable documents was as follows: they must contain a sufficient number of sentences (more than 10 sentences) and have similar document lengths (less than 1.5 times for the ratio of a number of sentences). Consequently, 43,075 document pairs were selected and the parallel sentence candidates were extracted from them.
6.1.2. Experimental results of individual language resource
To evaluate individual language resources for parallel sentence extraction, we first conducted several experiments using the MRD (baseline), WD, TPES and TPSW. The experimental results are shown in Table 4. Herein, the baseline system (MRD) and WD are methods using MRD and WD to calculate
Experimental results of individual language resources (%).
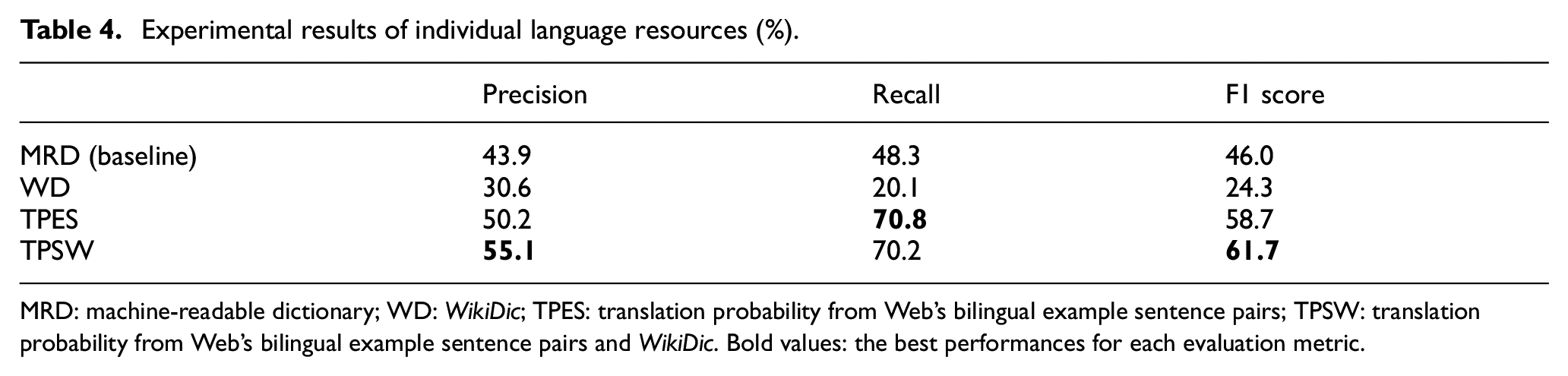
MRD: machine-readable dictionary; WD: WikiDic; TPES: translation probability from Web’s bilingual example sentence pairs; TPSW: translation probability from Web’s bilingual example sentence pairs and WikiDic. Bold values: the best performances for each evaluation metric.
In these results, TPSW achieved the best performance, with an F1 score of 61.7%. The method using only WD showed a significantly lower performance than that using only MRD. However, WD showed better results in the sequential combination with TPES and TPSW, as is discussed in section 6.1.3.
6.1.3. Experimental results of sequential matching with language resources
Experimental results from combining each language resource in turn are presented in Table 5. In Table 5, the method using a combination of MRD and TPES is denoted by MRD+TPES and the method using a combination of WD and TPES by WD+TPES. These experimental results were obtained by the sequential combination of methods for calculating
Experimental results using combined language resources (%).
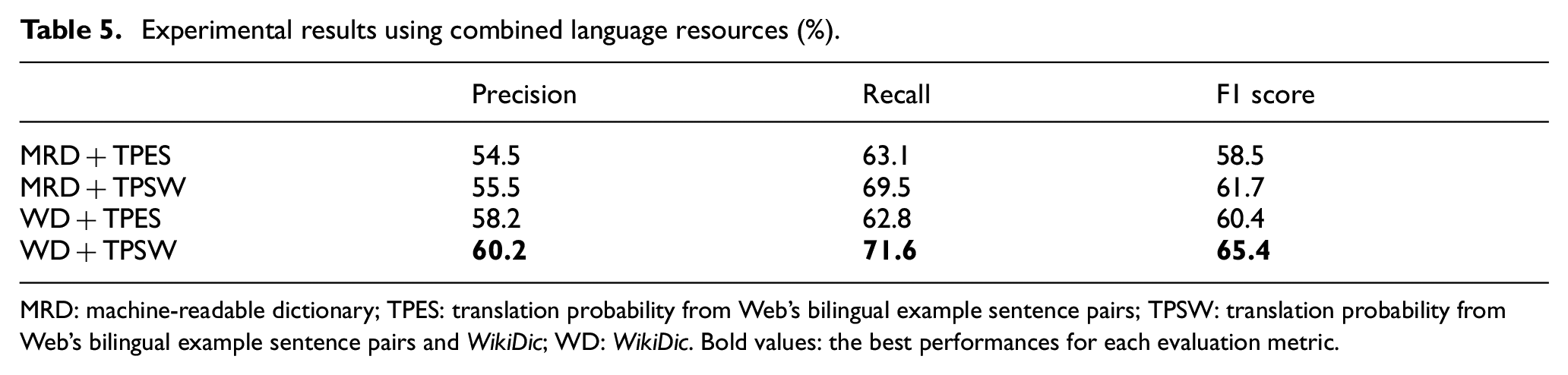
MRD: machine-readable dictionary; TPES: translation probability from Web’s bilingual example sentence pairs; TPSW: translation probability from Web’s bilingual example sentence pairs and WikiDic; WD: WikiDic. Bold values: the best performances for each evaluation metric.
Although the method using only WD showed a lower performance than that using only the MRD, both WD+TPES and WD+TPSW outperformed MRD+TPES and MRD+TPSW, respectively, as shown in Table 5. This is because parallel sentence candidates from Wikipedia contain several named entities that can be matched with WD, wherein their matching is almost always correct. Moreover, our proposed method using TPSW can effectively match common words as well as single-terms or component terms of named entities. Overall, WD+TPSW achieved the best performance, with an F1 score of 65.4%. A comparison of the performance of the combined language resources in extracting parallel sentences is shown in Figure 4.
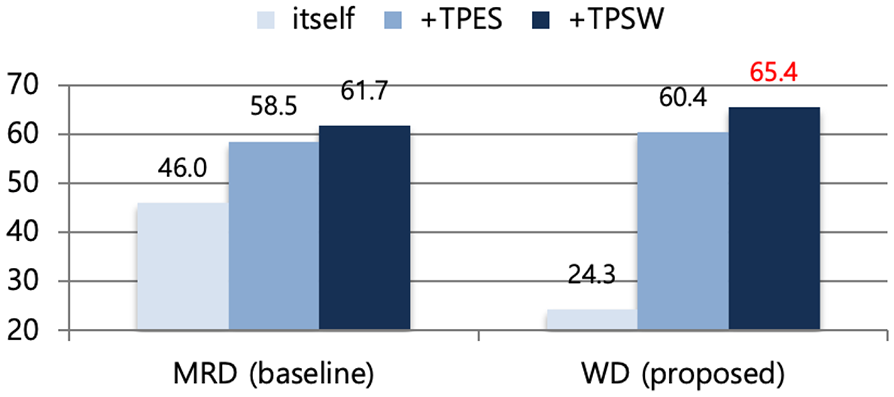
Comparison of overall experimental results by combined language resources (%).
Commonly, precision is more important than recall for automatically extracting parallel sentences. However, because we used the F1 score to evaluate the matching method using various language resources, we had to adjust the threshold value to obtain the highest F1 score. Table 6 shows the experimental results for adjusting the similarity score thresholds in WD+TPSW.
Experimental results depending on different similarity thresholds in WD+TPSW (%).
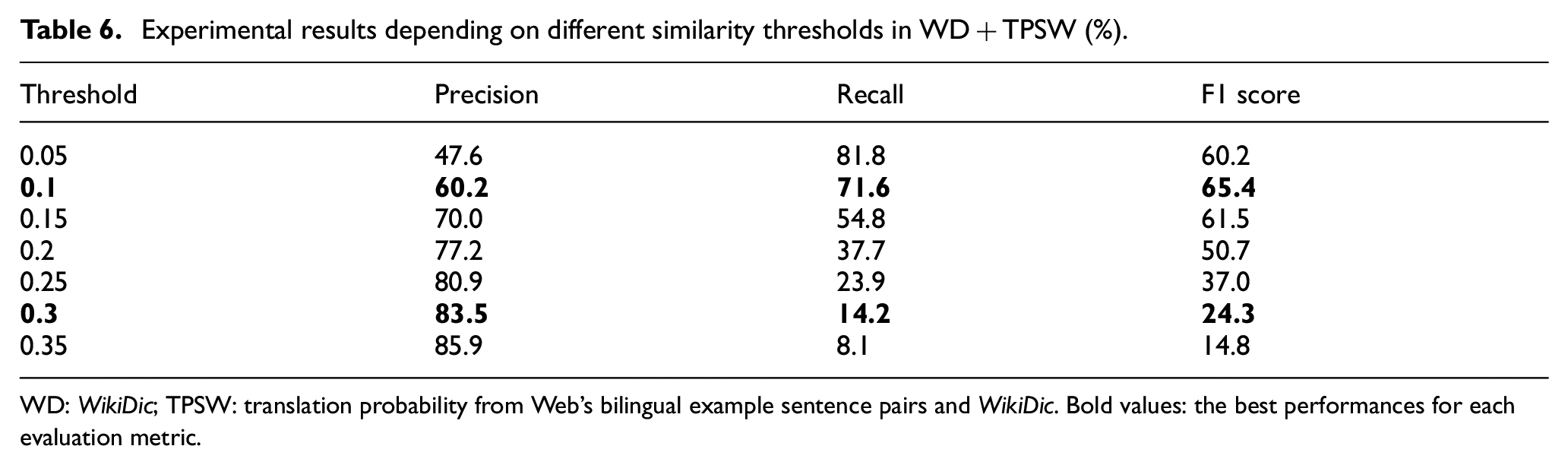
WD: WikiDic; TPSW: translation probability from Web’s bilingual example sentence pairs and WikiDic. Bold values: the best performances for each evaluation metric.
The best F1 score was obtained when we set the similarity threshold to 0.1. However, in CLIR, the threshold should be raised in order to achieve a higher precision, as we aim to use a parallel corpus with few errors. Therefore, when parallel sentences were extracted from Wikipedia for CLIR (as discussed in section 6.2), we set a higher threshold value to obtain higher precision. Accordingly, the 0.1 threshold value was applied for the parallel sentence extraction discussed in this section, whereas a 0.3 threshold value was applied for CLIR experiments discussed in section 6.2.
6.2. Query translation using parallel corpus for CLIR
6.2.1. Experimental settings
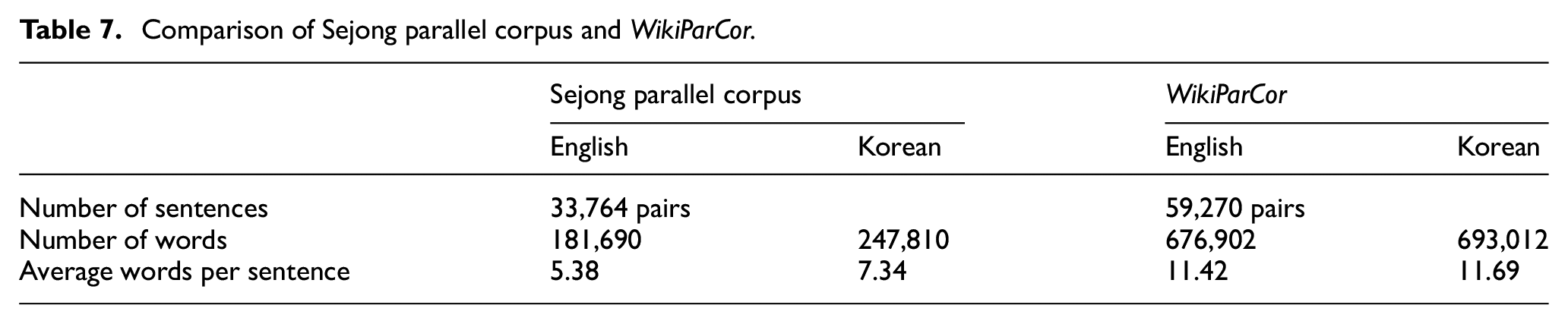
To compare the parallel corpus from the proposed method (WikiParCor) with a manually created parallel corpus, we considered the sentence-aligned 21st Century Sejong Project Korean–English manually created parallel corpus, which contains 33,764 sentence pairs. 6 Table 7 shows a comparison of the Sejong parallel corpus and WikiParCor. WikiParCor contains approximately 25,000 more parallel sentence pairs than the Sejong parallel corpus, and its average number of words in a sentence is almost two times more than that of the Sejong parallel corpus. Notably, as the size of Wikipedia continues to naturally grow, a parallel corpus with improved quality and more data will be generated in the future.
Comparison of Sejong parallel corpus and WikiParCor.
For CLIR, the NTCIR-5 CLIR test collection used includes 50 English topics and 220,374 Korean documents. We report results for queries formulated using all words from the title field of the queries. There are two interpretations of relevance that are commonly reported for the NTCIR-5 test collection: rigid and relaxed. We report results for rigid relevance. We indexed the Korean NTCIR-5 articles using Indri, a language model-based search engine for complex queries that supports an extensive set of query operators. As evaluation measures, we report mean uninterpolated average precision (MAP) and mean R-Precision (R-Prec). We report the statistical significance for observed differences in MAP when the
6.2.2. Experimental results of query translation for CLIR
In this subsection, we present results from several experiments, which aimed to compare the effectiveness of query translation techniques between two different parallel corpora, the Sejong parallel corpus and WikiParCor, for CLIR. The Sejong parallel corpus consists of various domains from news and conversation resources and its parallel sentences for colloquial resources have short lengths. Thus, our constructed parallel corpus can contribute to an improved CLIR performance for the following reason: most of the constructed parallel sentences are long and contain various vocabulary elements because they are extracted from Wikipedia. Eventually, we intend to study methods of automatically extracting more parallel sentences, according to the size of Wikipedia, by our proposed method.
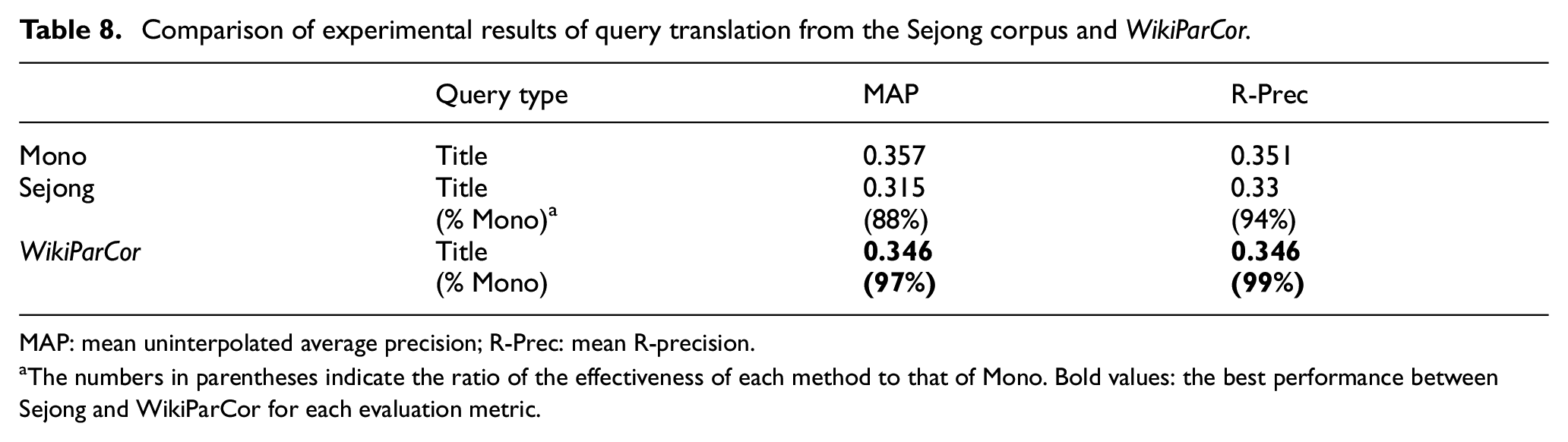
Table 8 shows the results of query translation when the Sejong parallel corpus and WikiParCor were used to estimate translation probabilities for our query translation technique described in section 5. The numbers in parentheses indicate the ratio of the effectiveness of each method to that of the Mono-BRF baseline (Mono), a monolingual baseline using Korean queries provided with the NTCIR-5 CLIR test collection.
Comparison of experimental results of query translation from the Sejong corpus and WikiParCor.
MAP: mean uninterpolated average precision; R-Prec: mean R-precision.
The numbers in parentheses indicate the ratio of the effectiveness of each method to that of Mono. Bold values: the best performance between Sejong and WikiParCor for each evaluation metric.
As can be seen in Table 8 and Figure 5, query translation with WikiParCor gives considerably better results than does the Sejong corpus according to both of the evaluation measures; however, those results are still inferior to those of Mono. Despite this, the results of both measures of the ratio of WikiParCor’s effectiveness to Mono’s effectiveness had nearly the same performance scores, 97% for MAP and 99% for R-Prec. It must be noted that the Korean queries in Mono were translated by humans. The MAP difference (relative 9.8% improvement) between query translation results with the Sejong parallel corpus and those of WikiParCor is statistically significant, at
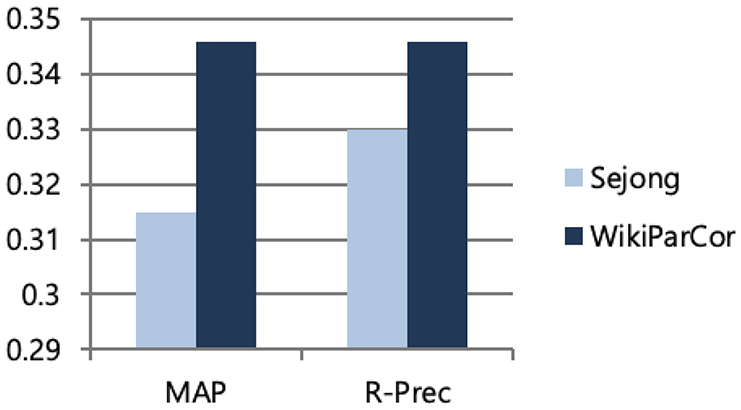
Comparison of the effectiveness of query translation between that by Sejong corpus and that by WikiParCor.
7. Conclusion and future work
Parallel corpora have been used as an essential resource in language translation and analysis. Therefore, we proposed a method for automatically extracting parallel sentences between English and Korean Wikipedia texts. Our proposed method achieved a significantly high performance in parallel sentence extraction. In addition, the parallel corpus, WikiParCor, generated by the proposed method contributed to the improvement of the query translation of CLIR. The performance of our proposed method in parallel sentence extraction showed 65.4% of F1-score. This result is to extract better quality of the parallel sentences than 46.0% with the MRD. In addition, the performance of CLIR using WikiParCor constructed by the proposed method showed nearly the same quality as the Mono translated by humans, and showed a MAP difference of 9.8% relative to Sejong Parallel Corpus. In particular, one of the main contributions of our parallel sentence extraction method are that it uses only language resources that are commonly available and it can be further improved simply with the passage of time and the continuing use of Wikipedia.
For future work, we aim to further improve the performance of methods for automatically extracting parallel sentences. Moreover, our proposed method is intended to not only be applied to English–Korean texts, but also to various other language translations. Accordingly, we intend to expand our work to include a broad range of mixed-language information retrieval tasks.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Institute for Information communications Technology Planning Evaluation(IITP) grant funded by the Korea government (MSIT; Grant No. 2020-0-00368, A Neural-Symbolic Model for Knowledge Acquisition and Inference Techniques). The National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2020R1A2C2100362).