
Abstract
The aspect-level sentiment analysis is widely used in public opinion analysis. However, the problem of context information loss and distortion with the increase of the model depth is rarely considered in previous research. Few studies have attempted to combine the feature extracted from different embedding models. Based on the correction strategy, the ensemble correction (EC) model proposed in this study can correct context information loss and distortion. Based on the ensemble learning strategy and the weight sharing strategy, EC can extract features from different word embedding models and can reduce computational complexity. Experiments on the resturant14, laptop14, resturant16 and twitter datasets show that the accuracies of the EC model are 0.8848, 0.8213, 0.9301 and 0.7731, respectively. The accuracy of the EC model is higher than state-of-the-art models. Ablation studies and case studies are used to verify the model structure. The optimal number of graph convolutional network (GCN) layers is also verified.
Keywords
1. Introduction
Sentiment analysis plays an important role in natural language processing (NLP). With the development of the Internet, sentiment analysis is widely used in public opinion analysis [1–3]. By analysing what people are talking about public events on social media, public opinion can be accurately grasped [4,5]. In one text, people can simultaneously express positive emotion for one aspect and negative emotion for another aspect. Sentiment analysis focusing on the overall sentiment polarity ignores the fine-grained sentiment polarity associated with a certain aspect. Thus, it is necessary to conduct aspect-level sentiment studies to understand people’s complex sentiment. There are two main sub-tasks in aspect-level sentiment studies, namely, aspects identification and aspect-level sentiment classification. There are abundant studies about aspects identification [6–8]. This study focuses on another sub-tasks, namely, aspect-level sentiment classification.
Introducing rich context information is helpful to improve the performance of aspect-level sentiment classification model. With the development of deep learning, techniques, including memory network, syntactic dependency tree and attention mechanisms are used to extract context information. However, current studies have not been able to capture the context features sufficiently. Moreover, with the increase of model depth, the information contained in the feature vector may be lost and distorted.
This article aims to design a method to integrate context information extracted with multiple methods and correct the loss and distortion of context information in aspect-level sentiment classification task. The ensemble correction (EC) model proposed in this article adopts three strategies to improve model performance. The EC model contains three sub-models. Based on the ensemble learning strategy, a pre-trained global vectors (GloVe) model [9], a pre-trained bi-directional encoder representations from transformers (BERT) model [10] and a pre-trained generalised autoregressive pre-training for language understanding model, namely, the XLNet model [11] are used as sources of context information. Based on the correction strategy, two correction components are used to correct the context information loss and distortion. Besides, a weight sharing strategy is used to reduce the computational complexity. The validity of the EC model is proved by a series of experiments. As shown in Section 4.2, in terms of accuracy, the EC model performs better than state-of-the-art models. The EC model can be applied to public opinion analysis, user demand analysis and other fields. The three strategies used in this model can also be applied to other machine learning models.
The remainder of the article is as follows. Literature review is presented in Section 2. The specific algorithm of the EC model is shown in Section 3. The results and analysis of comparative experiments are shown in Section 4. The summary of the study and the future research direction are shown in Section 5.
2. Literature review
2.1. Aspect-level sentiment classification
Aspect-level sentiment classification focuses on analysing sentiment polarities related to aspects. Traditional researches usually rely on artificial design rules for feature selection. Author information and sentiment flow can be used in sentiment classification [12]. Author information usually includes a number of attributes. Principal component analysis (PCA) can be used to determine the key attributes for aspect-level emotion classification [13].
In recent research, deep learning methods have been used to extract context features. Attention mechanism is a deep learning technique that can screen out important features [14–16]. Combined with attention mechanism, classic deep learning architectures, such as long short-term memory (LSTM) model and convolutional neural network (CNN) can accurately capture important context information. For example, compared with the LSTM model, the attention-based LSTM network (ATAE-LSTM) improves the accuracy of aspect-level sentiment classification by 2% [17].
Memory networks have been applied to aspect-level sentiment classification. It can be used to extract rich aspect-aware context information [18]. Combined with attention mechanism, the performances of memory networks [19,20] can be improved. In document- and sentence-level sentiment analyses, classification methods based on sentiment lexicon are widely used [21,22]. In aspect-level sentiment classification, sentiment lexicon can still be helpful [19].
Some models, such as aspect-specific graph convolutional network (ASGCN) [23] and syntax- and knowledge-based graph convolutional network (SK-GCN) [24], introduce graph convolutional network (GCN) to acquire context information. Based on syntactic dependency tree, GCN can obtain dependencies between words. Extracting features based on the dependencies between words helps to capture aspect context information. GCNs are often used in conjunction with other deep learning techniques to achieve excellent emotional classification performance. For example, ASGCN combines GCN and an attention mechanism [23]. The performance of ASGCN is better than that of ATAE-LSTM, which consists of LSTM and attention mechanism [17].
During training, the mean value and variance of feature vectors may change, which will cause the loss and distortion of context features. Most studies have ignored the problem. In this study, the correction strategy is adopted to correct context information loss and distortion.
2.2. Word embedding
The word embedding technique can map words to vectors while retaining the context features [25]. Different word embedding methods can reflect different context features.
Based on word frequency statistics, GloVe [9] can reflect local context features and the overall statistics features of the corpus. The GloVe pre-trained model trained on a large dataset can be directly used. It is also possible to retrain a new GloVe pre-trained model for a specific dataset. However, the GloVe pre-trained model trained on a large dataset generally performs better when the specific dataset is small.
BERT [10] can obtain context features by combining the left and right context sequences. The structure of XLNet [11] is similar to that of BERT. Different from Bert, XLNet takes the syntactic dependency between the masked positions into account. BERT and XLNet do not rely on overall statistics features [10,11]. Thus, it is possible to fine-tune BERT and XLNet. Models trained in a large corpus usually have better performance. Thus, BERT or XLNet usually first trained in a large corpus. Then, BERT or XLNet can be fine-tuned on a specific dataset.
Word embeddings enable deep learning to handle NLP tasks [26]. The above three models are the advanced word embedding models. Many aspect-level sentiment classification models use these three methods for word embedding [27–29]. Word feature vectors obtained by different word embedding methods contain different context features [30]. In the process of word embedding, some context features may be lost. However, most sentiment classification studies only use a single word embedding method, which will lead to the lack of context information. In this study, three word embedding methods were combined to extract more context features.
2.3. Ensemble learning
Ensemble learning combines multiple machine learning models into a unified framework [31]. It can improve model performance based on multiple weak sub-models [32]. Ensemble learning has achieved excellent performance in aspect category detection [33], solar radiation prediction [34], false data attack detection [35], time series prediction [36] and other fields.
Many ensemble learning algorithms use non-deep learning sub-models. For example, the improved random forest model that is composed of multiple decision trees achieves good results when applied to urban landmark extraction [37]. Deep learning models outperform non-deep learning models in some domains [38]. Thus, some ensemble learning models use deep learning models as sub-models. For example, the ensemble learning model composed of artificial neural networks (ANNs) is used to predict the project outcome [39].
In sentiment analysis, sub-models can be used to extract different context features. Zhang and He [40] employed an ensemble learning model consisting of two sub-classifiers that can capture text topics and linguistic characteristics of related words. Non-deep learning models can be used as sub-classifiers. To predict sentiment, Bansal and Srivastava [41] proposed an ensemble model which was composed of three sub-models based on skip-gram, cosine similarity and term frequency–inverse document frequency, respectively. Compared with traditional machine learning models, deep learning models perform better in sentiment analysis [42]. Combined with CNN, gated recurrent unit (GRU), LSTM and bi-directional LSTM (BiLSTM), Mohammadi and Shaverizade [43] came up with an ensemble model to predict aspect-level sentiment. Compared with the basic models, the accuracy was improved by at least 5% [43]. Aydln and Gungor [44] combined recursive and recurrent neural networks to classify the aspect-level sentiment.
The use of sub-models results in a large number of completely independent parameters which increase the computational complexity, especially when using deep learning sub-models. As deep learning models perform better than traditional machine learning models in sentiment analysis [42], the lack of using deep learning models may limit the model performance. In this study, deep learning sub-models with the same structure and different word embedding methods are used. With the help of the weight sharing strategy, the EC model can reduce the amount of computation on the basis of ensuring the depth and difference of sub-models.
Most aspect-level sentiment classification models fail to fully extract context information and do not consider the loss and distortion of context information in the calculation process. Most ensemble learning models face the problem of increasing computational complexity. This study uses the ensemble learning strategy to extract rich context information from three pre-trained word embedding models. The correction strategy uses two correction components to solve the problem of context information loss and distortion. To solve the problem of high computational complexity in ensemble learning, three sub-models with the same structure and different pre-trained word embedding models are designed. The weight sharing strategy is adopted to reduce the amount of calculation and improve the performance of the model.
3. Research methods
In the EC model, a context can be transformed into three vectors by three different word embedding models. Context information is extracted and corrected by the correction network. Integrating different context information, the ensemble network outputs the final classification results. The structure diagram of the EC model is shown in Figure 1.
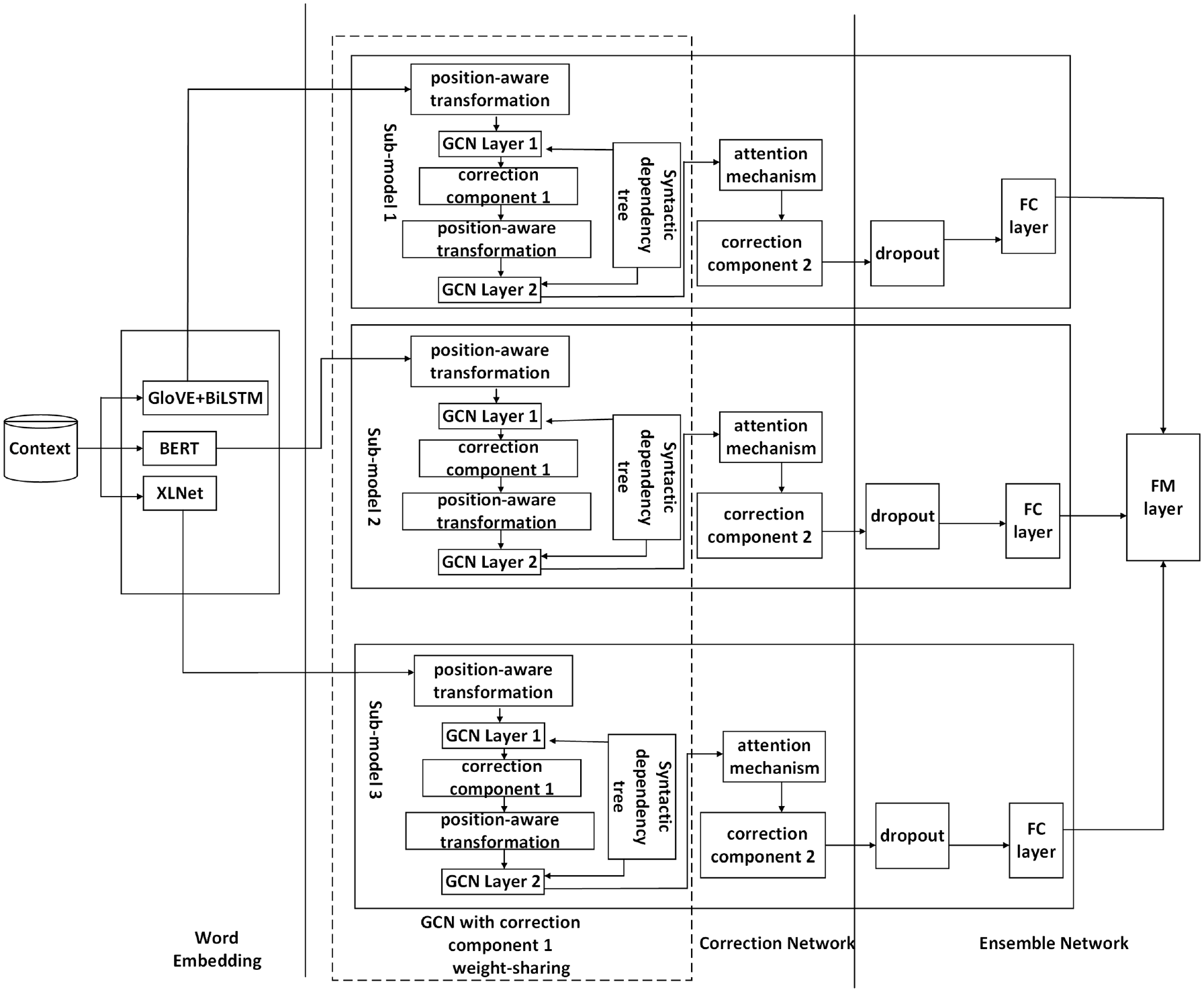
The structure of the Ensemble Correction model.
3.1. Word embedding
To obtain more context information, three pre-trained models are adopted. Sub-model 1 adopts the pre-trained GloVe model [9]. Sub-model 2 adopts the pre-trained BERT [10]. Sub-model 3 adopts the pre-trained XLNet [11].
A text composed of m aspects words and n-m normal words can be described as
The BERT model and the XLNet model are fine-tuned in a similar way. To fine-tune the parameters of the BERT/ XLNet model, a fully connected layer is connected to the BERT/XLNet model. The BERT and the XLNet models both have 12 hidden layers. The output of last hidden layer is adopted to initialise the feature vectors. A single word may be tokenised into several tokens. The mean vector of these tokens is used to represent a word vector. Through the above process, we can acquire embedding vector of the pre-trained BERT model
As the GloVe model relies on overall statistics features, the GloVe model that has been trained on a large corpus cannot be fine-tuned like the BERT/ XLNet model [9]. Thus, a different approach is adopted to acquire more comprehensive context information. The GloVe model trained on a large corpus is used to initialise words’ feature vectors
3.2. Correction network
The correction network is composed of GCN with correction component 1, an attention mechanism and correction component 2.
3.2.1. GCN with correction component 1
The correction network consists of three sub-models that share the same structure with different embedding methods. The sub-models are improvements on the ASGCN model [23]. In this work, two correction components are combined with ASGCN to improve the performance of the sub-models.
The syntactic dependency tree is used to construct the adjacency matrix of words, namely,
To reduce the computation complexity, the weight sharing strategy is adopted.
3.2.1.1. ReLu and Softmax
ReLu is an activation function that converts all negative values to 0. For a vector composed of t elements, namely,


where
The Softmax function can map data to the (0, 1) interval. For a vector composed of t elements, namely,


where both
3.2.1.2. GCN

where
The calculation method of GCN layer is as equation (6).
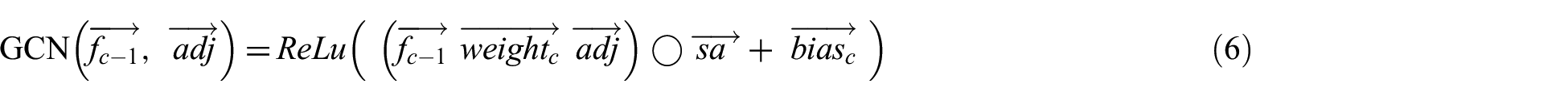
where
3.2.1.3. Position-aware Transformation
The position-aware transformation can improve the ability of the model to learn the relevant information of aspect.

where
The position-aware transformation can be expressed as equation (8).

where
3.2.1.4. Correction component 1
Using correction component 1, the network combines the output information and input information of each GCN layers. The calculation method is as equation (9).

where weightSEC1 is a trainable parameter.
According to the above definition, GCN with correction component 1 can be expressed as equations (10)– (12).



where
3.2.2. Attention mechanism
To accurately obtain information about aspect words, feature vectors of other words are removed. For vector

where the dimensions of the vector

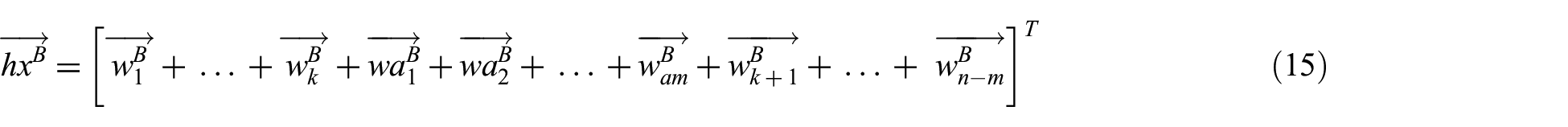
The calculation method of the output of attention mechanism is shown in equations (16) and (17).


where
Based on the same calculation method, the other two aspect words-text attentions
3.2.3. Correction component 2
The output of attention mechanism is concatenated with the mean value of the original input vectors of the EC model. The calculation methods are as equations (18)–(20).



where
3.3. Ensemble network
In this section, three sub-classifiers are combined into the final classifier. The dropout technique is used to avoid over fitting. The dropout technique can randomly mask certain neurons in neural network. The classification results of the three sub-models are obtained using three different fully connected layers. The vector dimension of the output of the full connection layers equals the number of categories. The outputs of the three sub-models are multiplied by weights and added together. The final maximum (FM) layer determines the classification result according to the position of the maximum value in the vector. The calculation method is shown in equations (21)–(27).






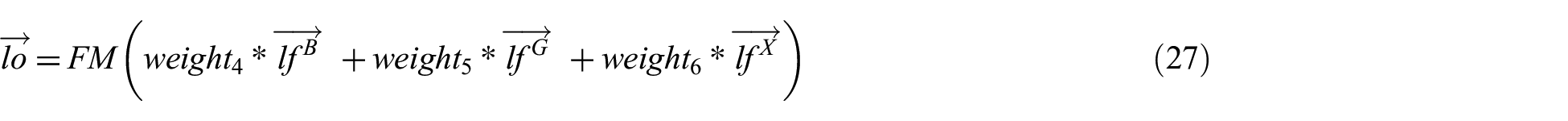
where weight4, weight5 and weight6 are trainable parameters, and
3.4. Baseline models
Twenty baseline models are described below.
ASGCN [23]. Combining position-aware transformation and aspect-sentence attention mechanism, this model uses a BiLSTM layer and two GCN layers to obtain the context representation. A pre-trained GloVe model is adopted for word embedding.
ASGCN-BERT. The input and BiLSTM layers of ASGCN model are replaced by a pre-trained BERT model.
ASGCN-XLNet. The input and BiLSTM layers of ASGCN model are replaced by the embeddings of XLNet pre-trained model.
Ensemble-ASGCN. To verify the effectiveness of EC model structure, ensemble-ASGCN is proposed by us as a baseline model. The structure of ensemble-ASGCN is similar to that of the EC model proposed in this study. Unlike the EC model, the sub-models of ensemble-ASGCN are the ASGCN models. Three sub-models adopt three different word embedding model, namely, GloVe, BERT and XLNet.
Recurrent attention on memory (RAM) [45]. Based on BiLSTM, GRU and multiple-attention mechanism, this model can capture long-distance sentiment information. A pre-trained GloVe model is adopted for word embedding.
Target-specific transformation networks–adaptive scaling (TNet-AS) [46]. This model is a transformation network. It uses bi-directional RNN layer to generate transformed word representations. Then, a component is designed to combine the information of the target and context. Finally, features are extracted from a CNN layer. A pre-trained GloVe model is adopted for word embedding.
Content attention-based aspect sentiment classification (CABASC) [47]. Based on context attention mechanism and sentence-level content attention mechanism, this model can capture aspect information, word order and the relationship between aspects and context. A pre-trained GloVe model is adopted for word embedding.
ATAE-LSTM [17]. Based on attention mechanism and LSTM network, this model can extract context features according to aspects. A pre-trained GloVe model is adopted for word embedding.
Multi-grained attention network (MGAN) [48]. Based on multi-grained attention mechanisms and aspect alignment loss, this model can capture the relationship between aspects and context as well as the relationship between the aspects in the same context. A pre-trained GloVe model is adopted for word embedding.
MGAN-BERT. The original GloVe embedding layer is replaced by a pre-trained BERT model.
MGAN-XLNet. The original GloVe embedding layer is replaced by the XLNet pre-trained model.
Interactive attention networks (IAN) [49]. Based on two LSTM networks and attention mechanism, this model can capture aspect information and context information. Based on the interactive information of aspect and context, the sentiment polarity is identified. A pre-trained GloVe model is adopted for word embedding.
BERT-SPC [28]. Based on the BERT model, this model uses a dropout layer and a full-connection layer to predict sentiment polarity. It takes the concatenating of context and aspect as input data.
XLNet-SPC. The BERT layer of BERT-SPC model is replaced by the XLNet layer.
Attentional encoder network _BERT (AEN_BERT) [28]. This model uses an attentional encoder network to capture the relationship between context and aspect. A pre-trained BERT model is adopted for word embedding.
Filter gate network based on multi-head attention (FGNMH) with Avg-pooling [14]. Based on CNN networks, a multi-head attention mechanism and a gate mechanism, this model can extract context information and remove the irrelevant information. A pre-trained BERT model is adopted for word embedding.
Attention capsule network-BERT (ABASCap-BERT) [15]. Based on an improved multi-head self-attention mechanism and a capsule network, this model can capture the relationship between aspects and context. A pre-trained BERT model is adopted for word embedding.
Memory network with hierarchical multi-head attention (MNHMA) [20]. Based on a memory building layer, this model is possible to extract long-term semantic information. Based on a position-aware mechanism and a hierarchical multi-head attention mechanism, aspect-related information and important global information are extracted. A pre-trained GloVe model is adopted for word embedding.
Ensemble deep learning (EDL) [43]. EDL is an ensemble deep learning model that employs four sub-models, including CNN, GRU, LSTM and BiLSTM. These four sub-models are widely used in previous NLP studies. In the article that presents this model, the method of word embedding is not specified [43].
Combination of recursive and recurrent neural networks (CRRNN) [44]. CRRNN is an ensemble model consists of recursive neural network and recurrent neural network. According to the dependencies between words, the contexts are segmented into sub-contexts. Recursive neural networks are trained on these sub-contexts. The output vector of the recursive neural network is the input vector of the recurrent neural network. A pre-trained GloVe model is adopted for word embedding.
4. Result analysis and discussion
4.1. Dataset
As the sub-models are improvements of ASGCN, the four open benchmark datasets in the work of Zhang et al. [23] are chosen to verify the EC model. These datasets are widely used in deep learning-based aspect-level sentiment classification [14,15,20]. SemEval-2014 Task4 [50] has two benchmark datasets, including restaurant comments (Resturant14) and laptop comments (Lapotop14). Resturant16 is a benchmark dataset of SemEval-2016 [51]. Twitter benchmark dataset is composed of comments on Twitter [52]. All texts in the dataset contain at least one aspect word. Each aspect and its original text are used as an unclassified instance. Each dataset contains three labels, including positive, neutral and negative. Table 1 shows the sample partition and the number of instances in the four datasets.
Statistics of the datasets.
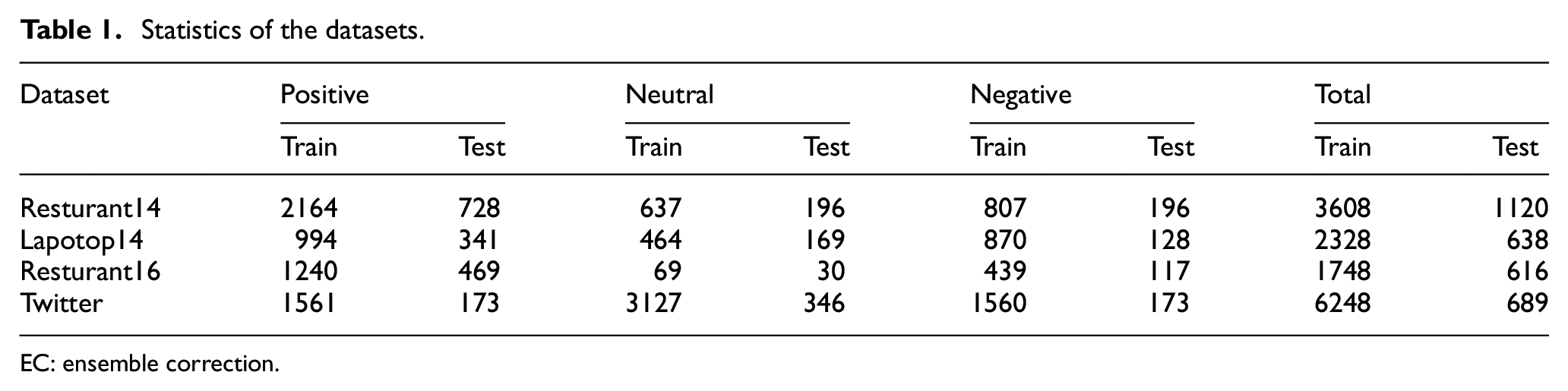
EC: ensemble correction.
4.2. Comparison with baseline models
In the EC model, the spaCy toolkit 1 in Python is used to build the syntactic dependency tree. Three pre-trained models are adopted to initialise the word vectors. For BERT and XLNet, the dimension of the word vectors is 768. For GloVe, the dimension of the word vectors is 300. The dimension of the output of BiLSTM is set to 768. The batch size is 32. The Adam optimiser is adopted to optimise parameters. The dichotomy is used to determine the best learning rate. According to the learning rate of ASGN [23], we conduct experiments with different learning rates between 0 and 0.01. It is found that when the learning rate is 0.006, the EC model has good results on the four datasets. The rate of dropout regulation is 0.5.
The accuracy and the macro F1 are adopted to evaluate the performance. The accuracy can reflect the proportion of correct classification. The macro F1 can comprehensively reflect the precision and recall of a model.
The effectiveness of the EC model is verified by comparing with the baseline models. As shown in Table 2, when the same model structure is used, different embedding methods have different effects. In general, the models using XLNet or BERT have better performance than the models using GloVe. When using the same pre-trained model, those models that introduce syntactic dependency tree have better performance.
The results of the EC model and baseline models.
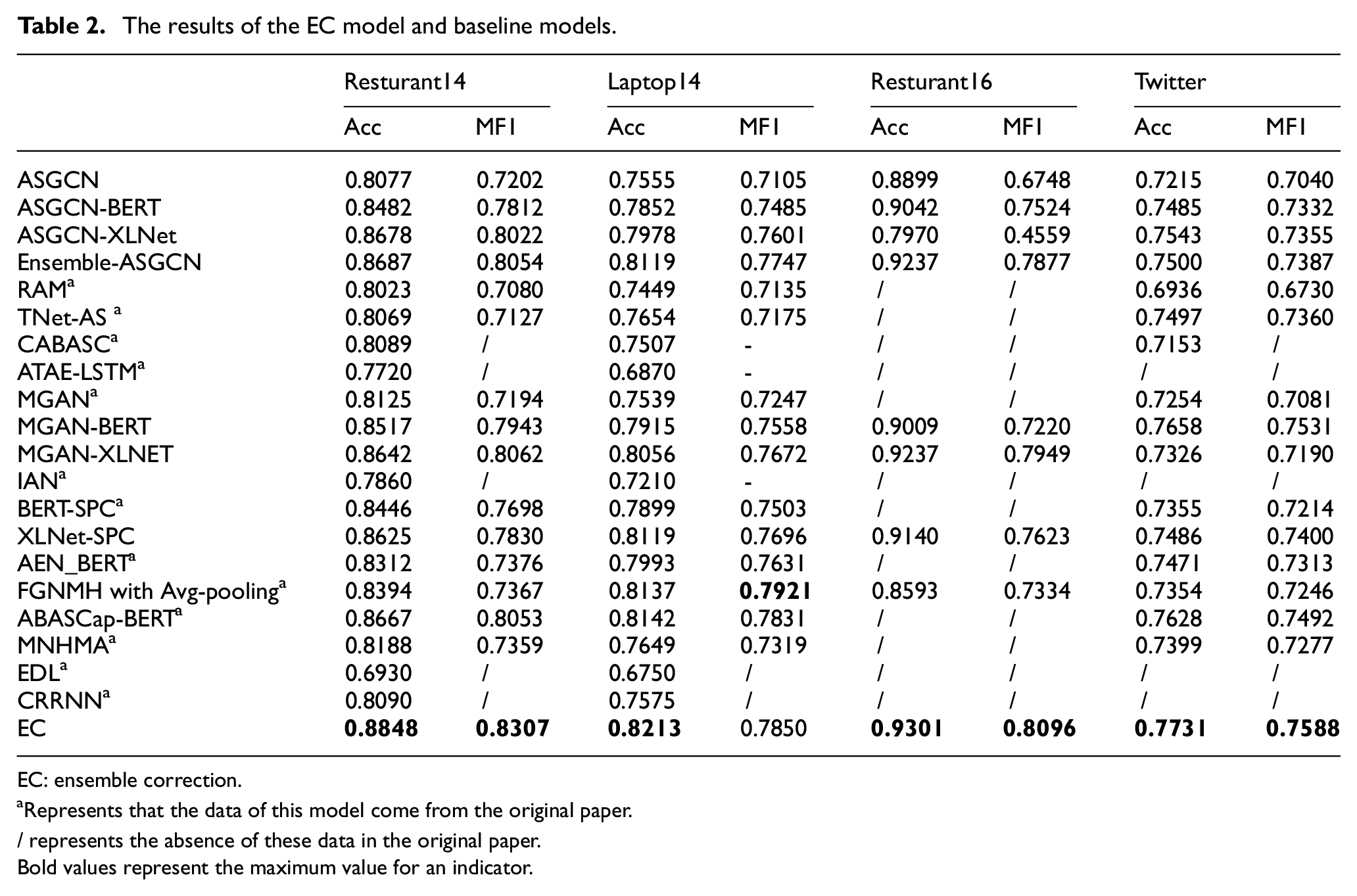
EC: ensemble correction.
Represents that the data of this model come from the original paper.
/ represents the absence of these data in the original paper.Bold values represent the maximum value for an indicator.
In all the datasets, the EC model has the best accuracy. Apart from the FGNMH with Avg-pooling for Laptop14, the EC model also has the best Marco F1. The sub-models of the EC model are improvements of ASGCN. To verify the effectiveness of our improvement of the model structure, the Ensemble-ASGCN model is designed for comparison. Ensemble-ASGCN uses the same embedding method as the EC model, but the sub-models are replaced by ASGCN. On Restaurant14, Laptop14 and Resturant16, the Ensemble-ASGCN model not only outperforms ASGCN, ASGCN-BERT and ASGCN-XLNet, but also has highest accuracy among all baseline models. On twitter dataset, the ensemble-ASGCN model outperforms ASGCN and ASGCN-BERT. It is strongly proved that ensemble learning can improve the model performance on the aspect-level sentiment classification task. However, the EC model has better performance than ensemble-ASGCN on all datasets. This proves that our improvement on the structure of sub-models is effective.
4.3. Validity analysis of the three strategies
The EC model adopts the ensemble learning strategy, the correction strategy and the weight sharing strategy. A series of ablation experiments are designed to verify the above strategies. In addition, case studies are conducted. The appropriate number of GCN layer is also explored.
4.3.1. Analysis of the ensemble learning strategy
The ablation results of ensemble learning are shown in Table 3. In sub-model 1, GloVe + BiLSTM is used for word embedding. In sub-model 2, BERT is used for word embedding. In sub-model 3, XLNet is used for word embedding. The three sub-models have the same structure. According to the accuracy and the macro F1, sub-model 3 has a better performance on all datasets than other sub-models.
The ablation study of the ensemble learning strategy.

EC: ensemble correction.Bold values represent the maximum value for an indicator.
The three sub-models are combined in pairs for ensemble learning. For example, the ensemble learning model 1 (sub-model 2 + sub-model 3) is a combination of sub-models 2 and 3. Although the macro F1 of ensemble learning model 3 is slightly lower than that of sub-model 2, the accuracy of ensemble learning model 3 is equal to that of sub-model 2. Apart from that, the performance of ensemble learning is better than its constituent sub-models. It shows that the ensemble learning strategy can improve the performance of the EC model.
It is worth noting that when using the same word embedding method, the sub-models not always perform better than ASGCN. However, from Table 2, the EC model outperforms the ensemble-ASGCN. It indicates that the sub-model structure is effective. This may be due to the diversity of classifiers required in ensemble learning strategies. The structure of the sub-model can achieve differentiated learning of context information.
From Table 3, it can be seen that the EC model performs better than the three sub-models and the three ensemble models. It shows that in the EC model, each sub-model has an important contribution.
4.3.2. Analysis of the correction strategy
In the EC model, two correction components are used to modify information. Correction component 1 is used after each GCN layer. Correction component 2 is used after attention mechanism in each sub-model. To verify the effectiveness of the correction strategy, the correction components are removed separately. The results of the ablation study are shown in Table 4.
The ablation study of the correction strategy.
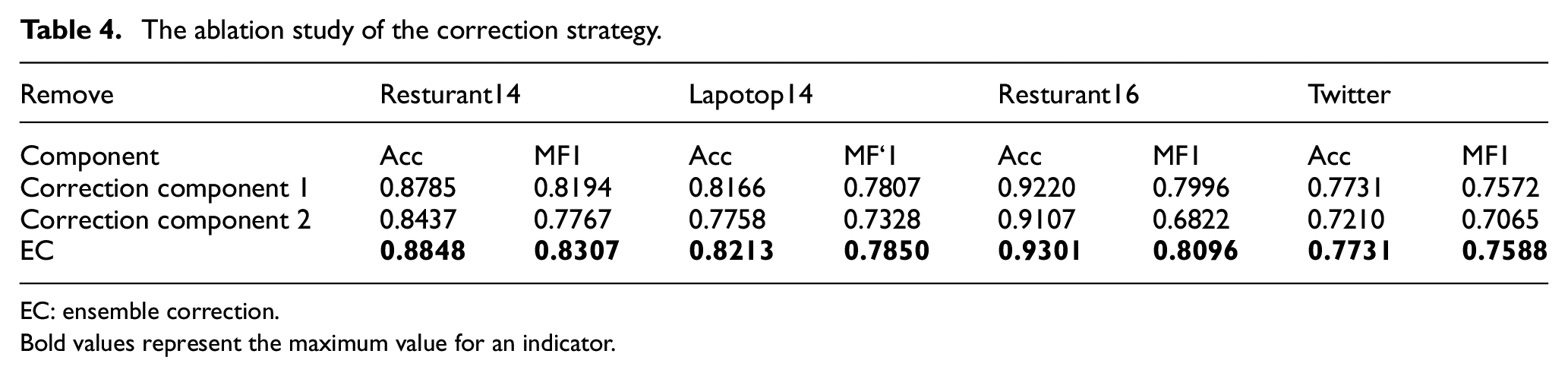
EC: ensemble correction.Bold values represent the maximum value for an indicator.
Table 4 shows that when correction component 1 is removed, the performance of the model deteriorates on the four datasets. On resturant14, laptop14 and resturant16, accuracy and macro F1 both decrease. On twitter dataset, the accuracy does not decrease but the macro F1 decreases. When correction component 2 is removed, the performance of the model deteriorates on the four datasets. It shows that the two correction components are effective.
From the degree of accuracy drop and the degree macro F1 drop, correction component 2 contributes more than correction component 1. It is probably due to the fact that the correction component 1 is located in the shallow layer of the network while correction component 2 is located in the deep layer of the network. With the deepening of the network layer, the information of the shallow network will be lost and distorted which may result in the decreasing effect of correction component 1.
4.3.3. Analysis of the weight sharing strategy
It is obvious that the weight sharing strategy can reduce the computation in the backward propagation. However, the influence of the weight sharing strategy on model performance is still unclear. To verify the influence of the weight sharing strategy on the performance of EC model, an EC model without the weight sharing strategy is designed. The EC model without the weight sharing strategy has the same structure as the EC model. The parameters of the GCN layer in this model are not shared. The performance of the EC model without the weight sharing strategy is shown in Table 5.
The comparison between the performance of the EC model without weight sharing and the performance of the EC model with weight sharing.
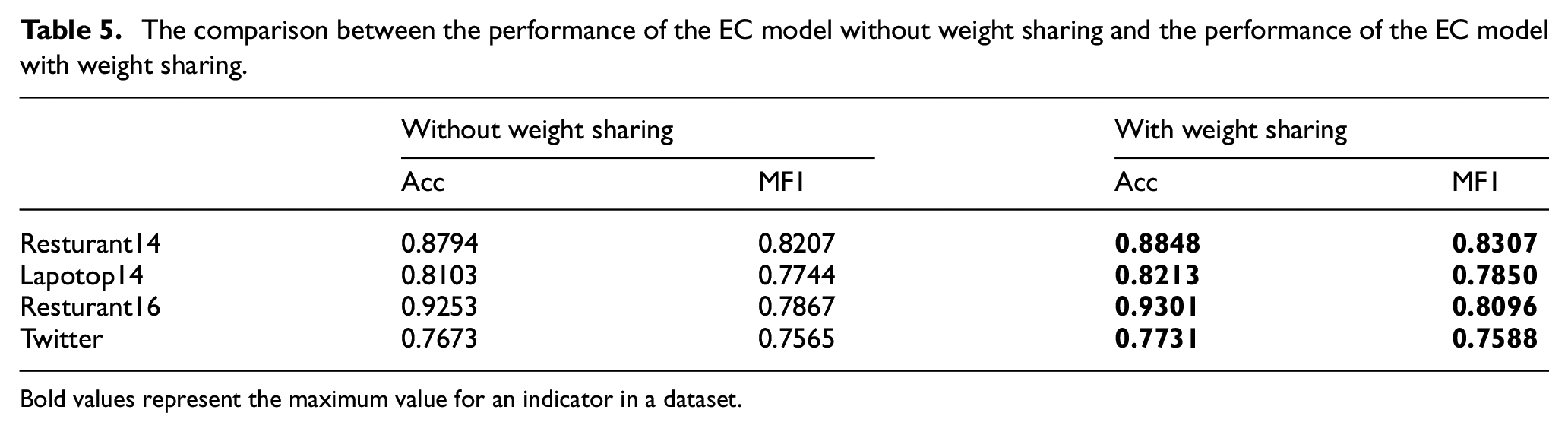
Bold values represent the maximum value for an indicator in a dataset.
The EC model performs better than the EC model without the weight sharing strategy on all datasets. It can be concluded that the weight sharing strategy not only can reduce computational complexity, but also can improve model performance.
4.4. Analysis of the computing time
To evaluate the impact of the correction components and the weight sharing strategy on the execution time, the average time of each instance calculated by a model in the process of five repeated training is used as the evaluating indicator. The EC model without the weight sharing strategy, the EC model without correction component 1, and the EC model without correction component 2 are used as baseline models. The results are shown in Table 6.
The average time of each instance calculated by baseline models and the EC model.

EC: ensemble correction.
The execution time of the EC model without correction component 1 and that of the EC model without correction component 2 are less than that of the EC model. It shows that the correction components 1 and 2 lead to the increased execution time. The execution time of the EC model without the weight sharing strategy is greater than that of the EC model. It shows that the weight sharing strategy can reduce the execution time.
4.5. Case study
To verify the effect of the EC model, two case studies are conducted. The attention mechanism assigns different weights to each word. Through the weight of each word in the attention mechanism, the difference of learning preference of each sub-model can be understood.
Taking the context ‘Their brunch menu had something for everyone’, for example, Figure 2 is drawn. The aspect is ‘brunch menu’. In Figure 2, colour bars represent weights of words in the attention mechanism. The darker the colour is, the greater the weight is. In this case, all three sub-models successfully predict sentiment polarity. Sub-models 2 and 3 focus on important sentiment words, namely, ‘had’ and ‘something’. Sub-model 1 focuses on the irrelated word ‘their’ and aspect word ‘brunch’. Although the attention mechanism of sub-model 1 focuses mainly on irrelated words, it still produced the correct result when combined with the sentiment correction component 2.

The heat map of case 1.
As shown in Figure 3, the context ‘Then she made a fuss about not being able to add 1 or 2 chairs on either end of the table for additional people’ is also analysed. The aspect word is ‘chair’. It is interesting that the EC model successfully predicts sentiment polarity while all the sub-models get it wrong. The real sentiment polarity is ‘neutral’. The predicted outcome of sub-model 1 is ‘negative’. The predicted outcomes of sub-models 2 and 3 are ‘positive’. From Figure 3, it is clear that none of the three sub-models focuses on exactly the same words. By combining the three sub-models, the EC model can learn context features more comprehensively and make the correct prediction.
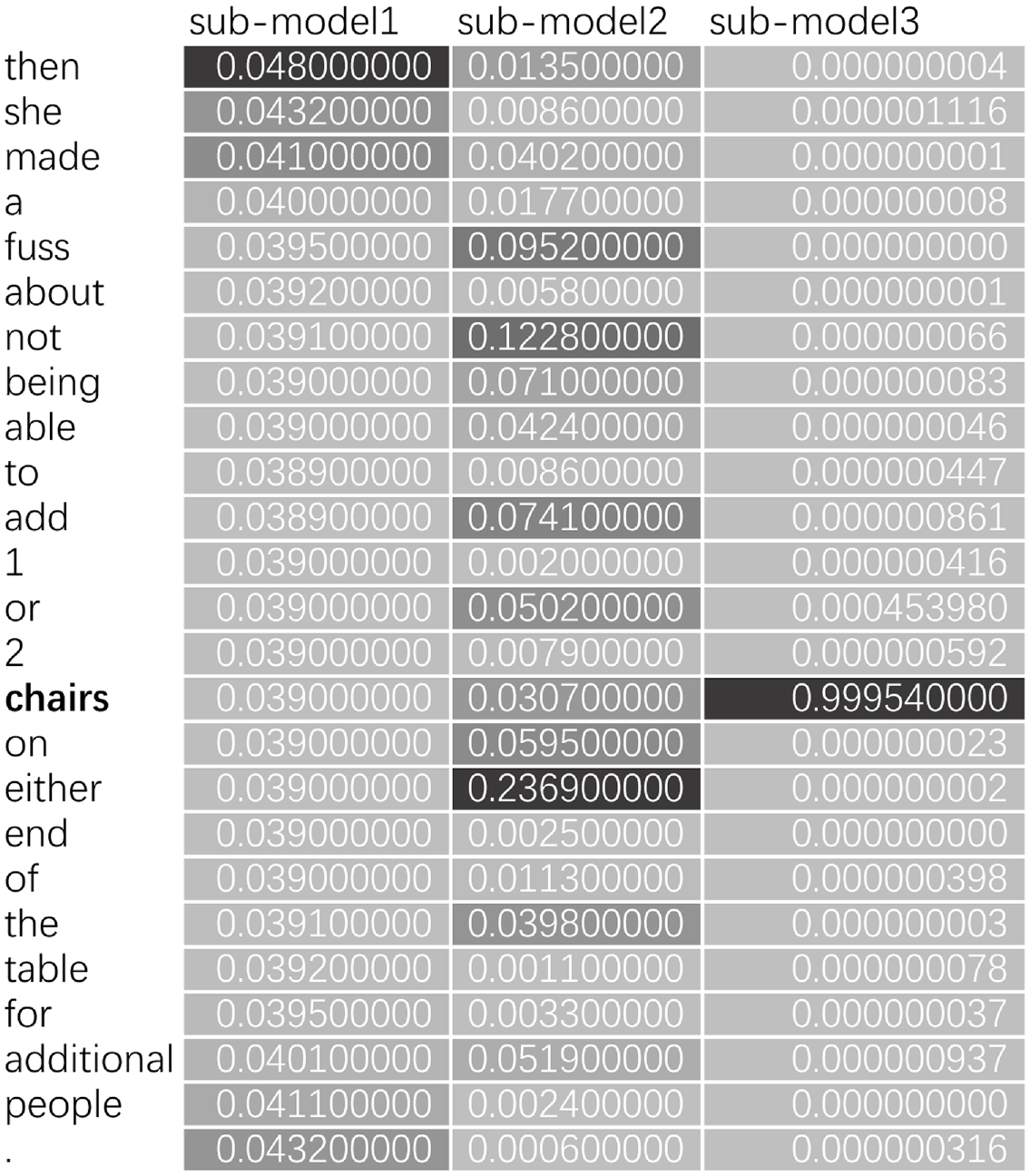
The heat map of case 2.
Based on the above analysis, it can be concluded that the sub-models can learn differentiated context features. The EC model can accurately classify aspect-level sentiment, even if the performance of sub-models is poor.
4.6. Layer of GCN
To evaluate the impact of the number of GCN layers on the performance of the proposed model, experiments are carried out on models with different GCN layers. The range of the number of GCN layers is set from 1 to 10. The accuracy and the macro F1 are used to evaluate the performance. The results are shown in Figures 4 and 5.
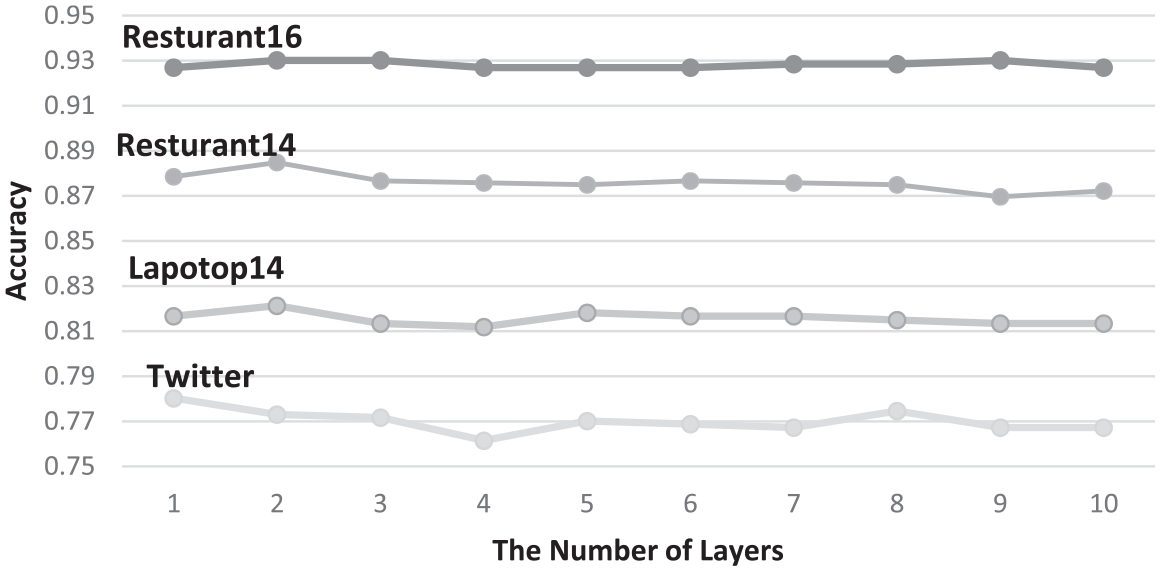
The accuracy of the proposed model with different GCN layers.
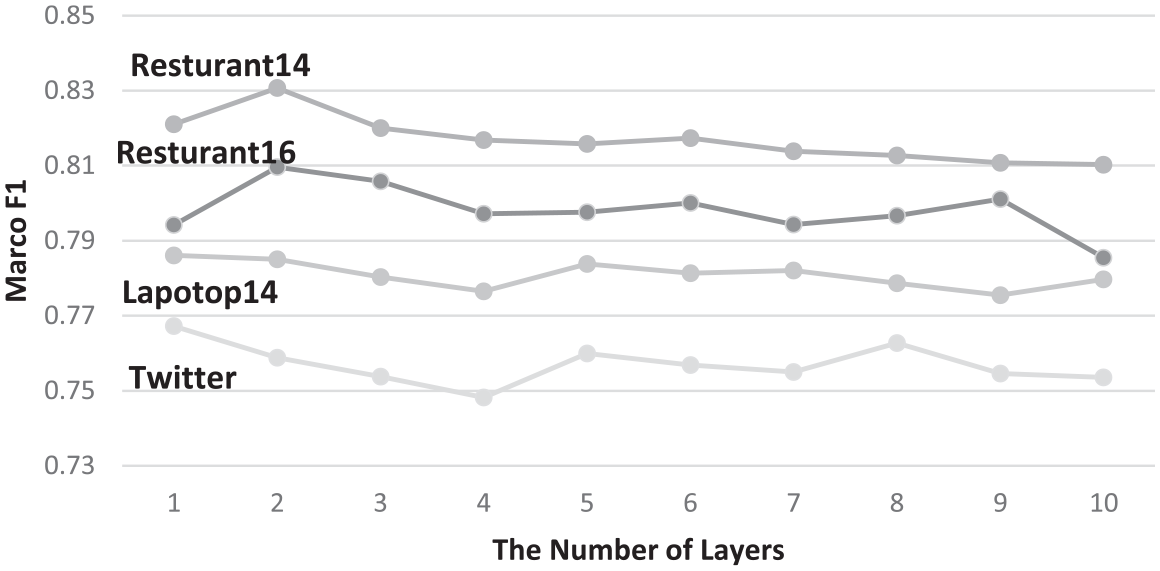
The macro F1 value of the proposed model with different GCN layers.
On the Resturant16, Resturant14 and Laptop14 datasets, when the number of GCN layers is 2, the model has the best performance. On the Twitter dataset, when the number of GCN layers is 2, the model has second best performance. Considering the performance of the model on all datasets, the number of GCN layers should be set to 2.
When the number of GCN layers more than 2, the performance of the EC model decreases with the increase of GCN model layers. Our analysis of the possible causes of this phenomenon is as follows. The GCN layers gather context information along the syntactic dependency tree. When the number of layers increases to a certain value, the model has already gathered all the text information. Thus, increasing the number of layers cannot improve the performance of the model. In addition, when more context information is used, the EC model may lose its sensitivity to aspect words. As the number of model layers increases, the possibility of missing or distorted context information increases. These three reasons may jointly lead to a downward trend of model effect.
5. Conclusion and future work
Based on the ensemble learning strategy, the correction strategy and the weight sharing strategy, an aspect-level sentiment analysis model is proposed. The effectiveness of the model is verified on four datasets. Based on the accuracy and macro F1, it is proved that the proposed EC model is better than baseline models. The validity of the model is analysed by a series of experiments.
To verify the effectiveness of the ensemble learning strategy, the performances of the three sub-models are compared with the performance of the EC model. It is proved that the EC model performs better than the sub-models. To verify the effectiveness of the correction strategy, the correction components in the EC model are removed respectively. It demonstrates the effectiveness of the two correction components. In addition, the reasons why these two correction components have different effects on the model are analysed. To verify the effectiveness of the weight-sharing strategy, the performance of the none-weight sharing EC model is analysed. It is proved that the weight sharing strategy can not only reduce the computational complexity, but also improve the model performance. Case studies are conducted to verify the effectiveness of the model. In addition, the optimal number of GCN layers is verified. Experimental results show that the model has better performance when the number of GCN layers is 2.
Through the above experiments, it can be concluded that the EC model proposed in this article can effectively perform aspect-level sentiment classification. In future studies, different word embedding methods, and different structures of sub-models could be used to improve the model performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the Natural Science Foundation of China (grant nos 72174153, 71921002, 71790612 and 71974202); the Major Project of the Ministry of Education of China (grant no. 17JZD034).