
Abstract
Increase in the number of open-access academic publications and open-access institutional academic archives led more researchers use these archives. No model offers personalised publication suggestions in academic archives. A central service architecture has been proposed towards personalised academic article recommendations for open-access digital archives. Thus, it has been possible to make personalised suggestions for open-access digital archives and enable researchers to discover new publications. A service based on the centralised micro-service architecture model was proposed in the study. Also, TF-IDF and article classification methods were used together for the personalised publication suggestion system. For the first time globally, the proposed method was used with 1464 real users in 49 open-access archives. F-measure success value was found to be higher than 0.8 for recommended publications.
Keywords
1. Introduction
Libraries have played a critical role in transferring information throughout human history as they host written documents. Libraries have an essential place in preserving written works and delivering them to the reader. Also, libraries are more than just a repository of publications for researchers. Libraries are important building blocks in the development of science, where research is learned, resources are arranged in a certain classification, support the user in the search process, have business models planned to serve the reader. After the industrial revolution, technology developed rapidly, and every point of our lives has changed with technology. Technological innovations in the field of information and documentation have changed the behaviour of both publishers and readers.
In the 21st century, with the developing and cheaper technology, almost every user has a personal computer and is connected to the Internet. Besides, with mobile devices’ popularisation, users spend a significant part of their day on mobile devices [1]. Maanes [2] suggested that libraries should be more user-centred, multi-media, open to social interaction with the term Library 2.0.
1.1. Digitalisation in academic publication
In recent years, major and important studies have been carried out on the digitalisation of old publications and the digitalisation of non-digital publications printed with modern printing systems [3].
With the digitalising world and digital research tools, digital publications have started to be used rather than printed publications, especially in the academic field [4]. Libraries, the home of information and documents, now host digital collections as well as print collections.
With the prominence of digital publishing in academic studies, many academic publications [5] and a database covering these publications have emerged [6]. In an academic sense, the database can be called digital collections that generally index publications in certain fields. Today, most of the considered academically important collections and frequently used by researchers serve as commercial databases and are sold on a subscription basis [6]. Any library that tries to provide resources for its researchers must subscribe to these paid databases. Today, almost all journals and conference publications with high-impact academic staff and academic promotion are indexed by at least one paid database [7,8]. Researchers regularly send their studies to these journals, conferences and publishing houses for publication. Universities and research centres provide much support to researchers both in terms of salary and project expenses. On the other hand, institutions had to pay a fee again to reach the academic work developed using their own fees. In other words, the organisation that provided the researcher with a budget for research later had to pay to reach that research [9,10].
1.2. Widespread use of open access
On the other hand, open-access documents are a form of publishing that does not require any fees or memberships for readers to access, and scientific studies have a licence that is accessible to everyone for the development of science. Although open access, which has become popular especially in the last 10 years, is included in a commercial database, it is licenced in a format that is accessible to everyone [11]. On the other hand, even if the produced publication is open access, it is still under the commercial database’s control [12,13].
In recent years, there have been many incidents between publishers and universities in which they have come into conflict due to commercial concerns [14,15]. Due to all these situations, universities have started to encourage articles with the open-access model. Plus, most scientific institutions want to store their own publications and publications produced by their researchers in their own institutional archives and make them available to everyone digitally. Therefore, institutions have started to publish their open-access institutional archives online. These archives are also a platform for institutions to present their digitised documents [16,17].
Today, open-access digital archive software with open source code is offered free of charge to facilitate the establishment and use of open-access digital archives. The most well-known and used software are Digital Commons, DSpace and EPrints [18]. According to the statistics of OpenDOAR, there were 78 open-access digital archives in 2005, while today, this number is 5627 [18]. Millions of publications in commercial databases can also be accessed from these open digital archives. Nowadays, both commercial and free academic search engines have started to index these open-access digital archives.
1.3. Research tools – finding similar articles
Today, open-access digital archives contain the full text of the publication and present various information, such as citation and DOI information on the publication page with integrations. Many developed databases try to encourage research and attract the attention of the researcher. It offers publications similar to the publication it is interested into the publication’s page [19].
Similar publications are often found by measuring the similarity of the keywords describing the publication or the similarity of the part of the publication, such as the summary, with other publications [20,21]. In other words, similar publications can be found with the common word number between two publications. On the other hand, there are also publications with common (key) words but unrelated.
Furthermore, it is not enough to show a single type of result for a keyword or a search term to the user regarding the quality of recommendation. Almost all modern search engines provide a personalised search service based on where users connect, the words users have searched before and the sites users visit [22,23]. With personalisation services, users can access more accurate data faster [24]. On the other hand, no personalised results were found in open source open archive software, in popular open-access academic search engines, or known digital academic databases.
Open-access digital archives, whose value is increasing day by day in scientific research, should contain a personalised result and a personalised suggestion system. Personalised suggestion systems can increase the research quality by recommending the researcher a publication that he is not aware of in the research field, that he should search in different categories and he will never encounter because of the search Word [25]. It can also address new researchers who do not already have good practice searching the difficulties of finding similar publications on different platforms and different types. While providing users with a personalised discovery service with discovering modules on almost all social networks, it is unthinkable that open-access digital archives do not provide this feature. On the other hand, no academic study offered a personalised recommendation model for open-access systems. A free service that enables personalised similar publication and search options and can serve open-access digital archives will significantly improve researchers’ search experience.
2. Proposed framework
In this study, a customised recommendation module architecture, which can be integrated into existing software as quickly and efficiently as possible, is proposed for open-access digital archives. Suggestions will be made using the meta-information of the publications that the user has reviewed. The user’s past activities will be used to find the user’s interest and find similar publications to recommend to the user. A much more successful recommendation system has been proposed as data can be retrieved from all archives in which the system is integrated. Since the data of the publications come from the SOBIAD and DOI services, the title, keyword and summary information about the publications are known. The study has proposed a model that encourages the user to research and make a user-specific recommendation.
With this architecture, the open-access digital archive infrastructure can be integrated regardless of its version or platform. In order for a method to offer personalised results, it must be designed algorithmically for this purpose. The success of the algorithm can often be achieved by finding comprehensive data for the past.
2.1. User identification and historical data finding problem
All software developers who develop open-access digital archives or search engines require the searcher or other users in the user profile to keep historical search records to produce personalised results. Unlike search engines, each institution establishes its own corporate open-access digital archive. Therefore, open-access digital archives have different servers with different domain names for each institution. It is a complicated issue due to technical and ethical problems that enable different systems on different servers to communicate and save all data in a single repository from the past.
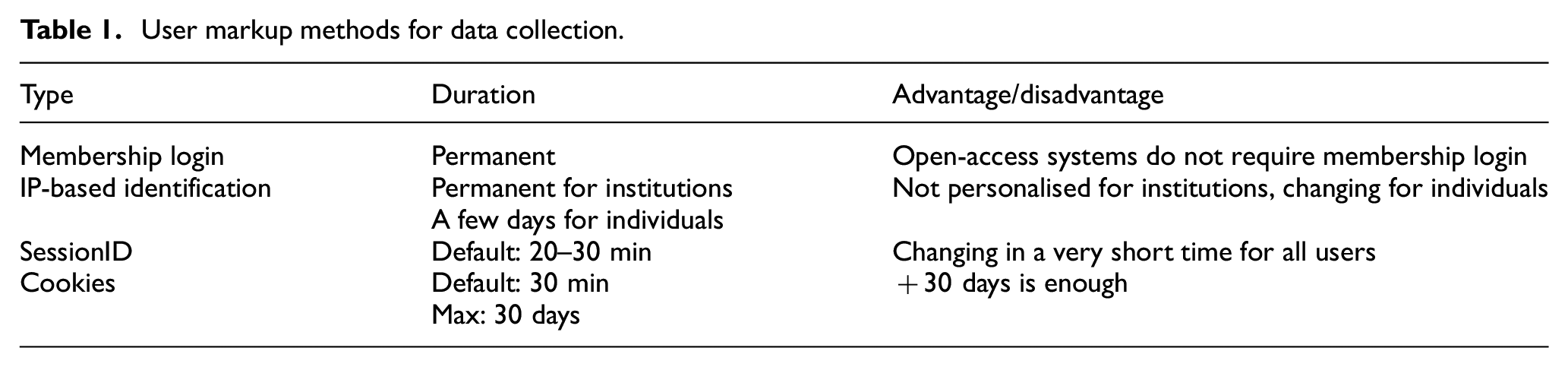
Open-access digital archives serve without the need to log in with any membership, so that, open-access digital archives cannot apply the personalised discover page method, which is frequently seen in social networks, without changing. Although Internet protocol (IP) based recognition and authorisation are useful in location-based search result improvements, academic information systems require person-based improvement rather than location-based improvement. In addition, since the institutions’ IP outlets are generally less than the number of people in the institution, hundreds of people use the same IP simultaneously. Since remote access and proxy systems generally enable users to access the Internet from a single IP, IP-based personalisation will not be a system that works with high success.
In most modern web technology tools, a SessionID is kept for each user. SessionID often closes with the browser and usually has a lifespan of 20 or 30 min. SessionID also does not provide enough time for a long-term personalised advice and recommendation system.
In Table 1, the four popular methods used to collect data, the lifespan of these methods and the prominent features of the methods are indicated. SessionID does not have enough time, IP-based identification does not work with sufficient precision, member entry-based identification works against the logic of open-access digital archives. For these reasons, it has been decided to use cookies, which do not require any registration or membership and remain for up to 30 days. The method suggested in this study is possible by assigning a unique value to each user’s cookies and giving the user a special ID. However, cookies are processed exclusively for the domain name. Therefore, independent domain names that do not communicate with each other and IDs independent of independent servers will be given. The assignment of independent IDs raises the problem that only the movement history on a single site can be taken into account when personalising the user. In other words, a separate ID will be generated for each corporate archive for the user.
User markup methods for data collection.
2.2. System architecture
Open-source digital archives have flexible architectures where many different integrations can be made easily. Today, organisations, such as ORCID, Scopus, Pubmed, WOS and Altmetric, have integrated services with open-access digital archives. Open-access digital archives can display information from these services for each article [19]. Open-access digital archives do not integrate through their own systems, unlike known software processes. Instead, it organises the widgets/objects offered by the service companies as parameters and presents them to their users on their pages. Thus, what calls the service is actually the user’s browser, not open-access digital archives. While this is a feature that can be seen negatively in many aspects of security and privacy, it is a feature that allows the method proposed in this study to be easily applied to all open access. Since all the data in the system are open data that everyone can access and do not contain personal user data, there is no security risk.
The proposed method starts from a central recommendation platform, opening a connection from an object to the article display pages of open-access digital archives to the central recommendation platform and sending the DOI information of the article as a parameter.
The Central Suggestion Platform (CRP) checks whether cookies belonging to CRP in the user’s request for each connection opened on the object. If there are no cookies, it creates a new cookie and sends it to the browser to be saved on the user’s computer on behalf of CRP. A user who has previously received service over CRP receives the user ID through the cookies on the user’s computer. Every call the user makes and every article he browses are recorded in the central database and the parameters from the CRP service.
In Table 2, the object’s parameters are sent to the user by the open-access digital archive, and the contents of the values in the parameters are listed. Derived values include values saved by the system for later use. Both the service parameters and the values derived are saved to provide personalised service to the user.
Parameters sent to the CRP service.

The service records all similar publications it offers and the user’s reactions to these suggestions for use in future similarity suggestions. Table 3 contains a list of information used on the proposed publications. While CRP keeps records/logs for suggestions, it adds the records that are probably to be a bot because it makes frequent requests with the bots specified in the user-agent. Thus, it prevents bots from adding incorrect data to the statistics and suggestion system.
Similar recommendation parameters recorded in the CRP service.

The relationship between users, open-access digital archives and CRP is shown in Figure 1. In the proposed architecture, normal users do not know that they are associated with CRP. Since users see the results on the screen of open-access digital archives, they think that the results come from open-access digital archives. On the other hand, only the interface hosted the open-access digital archive, the results of which came in response to a request from their own computers through their own browsers. Screens coming from CRP are in HTML design form. Thus, in an open-access digital archive, the object only adds the current HTML result from the service to the part reserved for it.
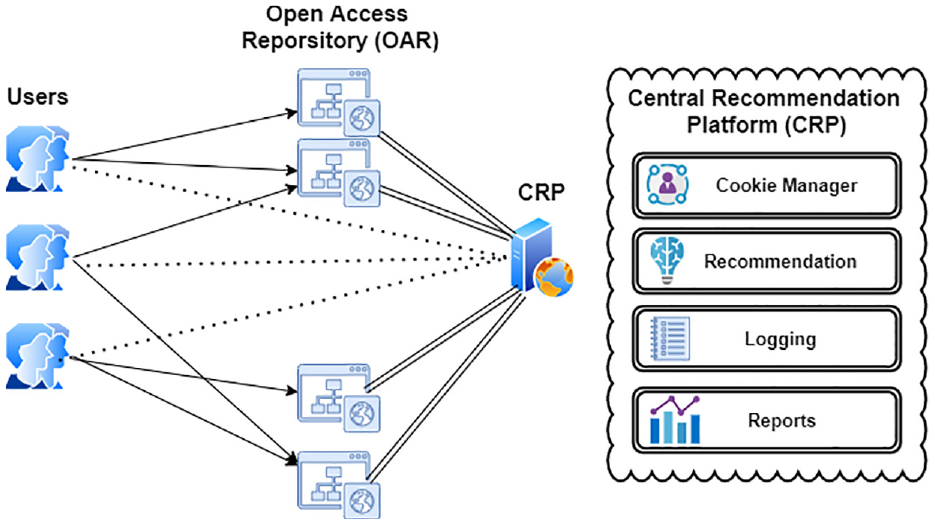
Connection diagram between users, open-access digital archive (OAR) and system.
Figure 2 includes the method of users calling the service. The open-access digital archive sends an instruction to the user’s browser to call the service. The browser connects directly to the service and displays the results.
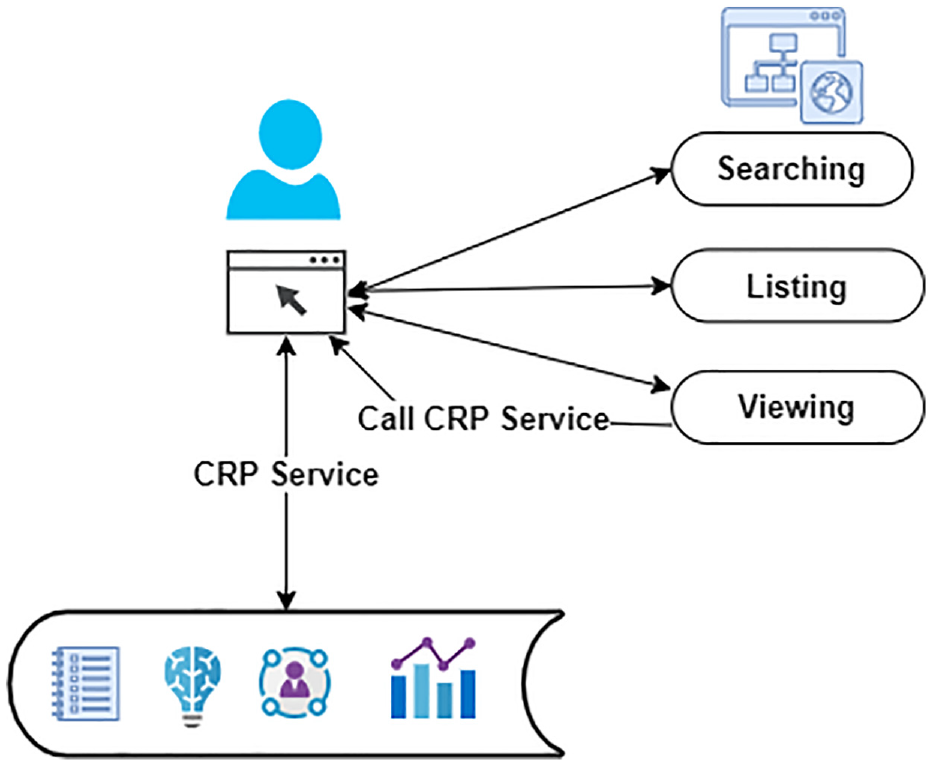
Users service interaction.
2.3. Application and experimental results
Sobiad Citation Index (SOBIAD) is a citation index and database [26] that scans more than 1500 journals and subscribes to more than 120 universities. SOBIAD within the borders of Turkey is a popular academic database that almost all universities have subscribed to. With its open and free service developed for DSpace since 2020, SOBIAD offers the citation numbers of publications of institutions similar to the Scopus example. Thus, the citation of the publication in SOBIAD can be placed on the page of the publication in open-access digital archives [27]. Institutions can use this service for their open-access archives, regardless of whether they subscribe to SOBIAD or not. Until today, the open archives of 74 different institutions have integrated their own open-access systems into this free plugin, allowing the citation numbers to be displayed on the open-access system’s publication page. Citation information is up to date and changes frequently. Therefore, the service does not share the previously recorded data but the data obtained from the instant inquiry. This free service works as users visit the publication pages incorporate archives and provides the most up-to-date information to the user. In 2020, 1.7 million queries were made through this service through 74 different open-access corporate archives.
Due to the structure of both DSpace and SOBIAD, these queries are provided with a JavaScript object run by the user’s browser as described in the system architecture section. Thus, a model close to that expressed in the system architecture was used. On the other hand, like its counterparts, SOBIAD does not make any recommendations through the service and does not offer a personalised recommendation system. Within the scope of this academic study, open-access digital archive officials and SOBIAD officials were interviewed. An agreement has been reached on permanent cookies for the users of open-access digital archives of voluntary institutions and a similarity recommendation system.
First, a 30-day permanent cookie has been defined for all connections going through the SOBIAD service. When each user first logs in to one of the open-access sites, a cookie is created and stored on the user’s computer for 30 days. Cookies are renewed for another 30 days as soon as the same user enters one of the open-access pages integrated into the service for 30 days. Most researchers’ cookies at least once a month to visit one of the popular open-access digital archives in Turkey, same user represents the long term. To design a personal publication similarity algorithm, the publications visited by the users were stored in the database of this research for a while. The details of the proposed similarity algorithm are explained in the similarity detection algorithm section of this publication.
Table 4 gives information about the type and amount of data used within the scope of the research. It is thought that the number of data is sufficient to conduct an academic study and to analyse success.
Some statistics about the data.

The algorithm’s success is expected to increase in direct proportion to how many times users access the system and how many different publications they look at. Figure 3 shows how many times users entered open-access digital archives according to the records in the system. Users who logged in once were not taken into account because no suggestions were made. Most of the users have entered two or three times. As the study duration increases, the amount of data will increase, and users are expected to enter more. Since the proposed method’s success is calculated from data where 80% of users’ log in two or three times, it is predicted that the success will increase as the usage increases.
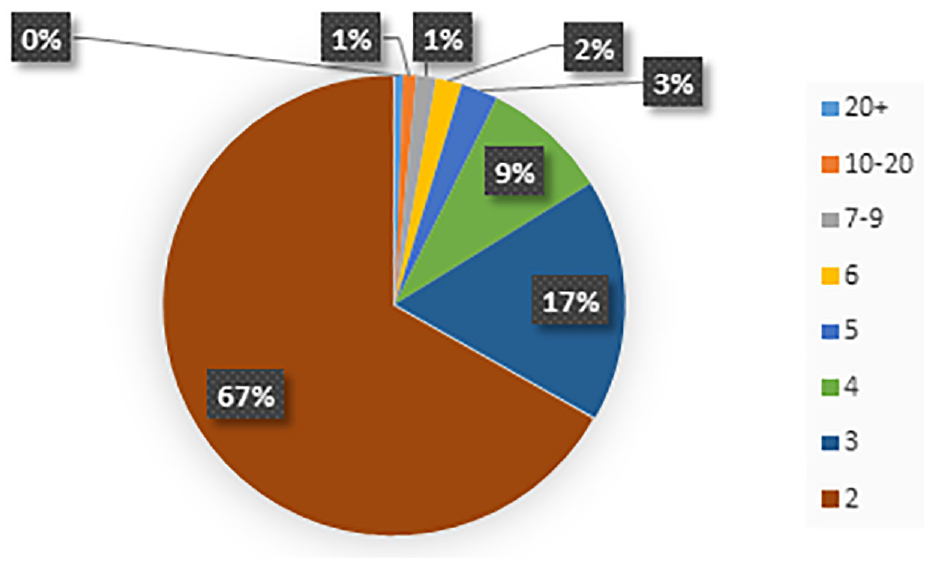
The ratio of users by the number of interactions with the service.
It is known that users visit this type of system more frequently during working hours according to the flow of daily life and do academic studies at night according to the habits of the researchers. Figure 4 shows in the graph the frequency of the users’ service hours from the service. This graph shows that bots and other programmatic snaps are also cleared without correctly logging.
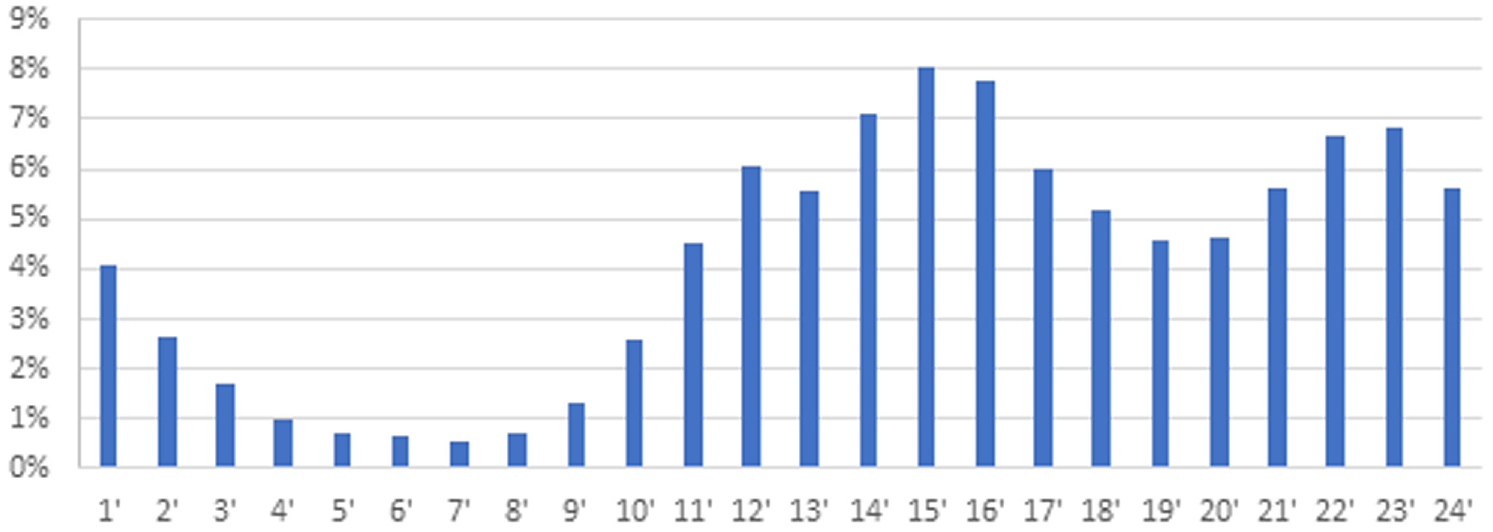
Graph of users’ service calling times.
The recommended publications in the proposed application can consist of in-house publications or open-access publications within and outside the institution, depending on the open-access system manager’s request. These publications are selected from the publications queried from the service. The service does not regularly receive the list of publications in open-access digital archives. Instead, due to the inquiries from the institutional open archive, the publications covered by the institutional open archive are recorded. Although this method does not contain all publications, it is thought that it will cause incomplete suggestions in the recommendation system, but it is not thought that there will be a huge data loss because individuals or bots visit most pages in a short time. To propose a publication, DOI must first be resolved. Within the scope of the agreement between Crossref, the main provider of DOI, and SOBIAD, more than 100,000 million Crossref (n.d.) data were used for DOI analysis. With this proposed service, articles similar to 1449 of 10,466 users from 49 different open-access digital archives were proposed. Similar article suggestions have received very positive responses from open-access repository administrators and users.
The proposed model revealed that all open-access digital archives could use personalised search and personalised similarity advice modules. The proposed method will speed up researchers’ research process, encourage research and play an important role in facilitating research, which is the primary purpose of libraries. The success rates and results of the participants who saw the open-access digital archive suggestions and filled out the questionnaire regarding their suggestions are included in the similarity detection algorithm section of this study.
2.4. Similarity detection algorithm
There are many suggested methods for finding similarities between two documents. Basic methods, such as Jaccard and Cosine, have also been studied in the similarity of academic publications [28]. On the other hand, it is impossible to apply these methods in real-time in large datasets. Word2Vec is an unsupervised and predictive model that expresses words in vector space and Doc2Vec in vector space. Using word embedding models, similarity studies have been carried out in the metadata of academic publications [29,30,31,32,33,34]. Model training is required for some word embedding methods. Also, most methods determine the similarity of the texts with each other or the texts’ similarity according to the previously classified reference texts [35,36]. Due to the size and the updates frequent of the data, word embedding models were not used. Also, motifs and patterns were used for the detection of similarities between documents [37].
Most algorithms use word frequency-based similarity detection algorithms, such as Term Frequency-Inverse Document Frequency (TF-IDF) and Okapi Best Matching 25 (BM25) [38]. TF-IDF or a similar algorithm is used in many full-text search infrastructures, which have gained a large place in the industry [39]. Supervised text classification algorithms made a similarity proposition by determining the text’s class according to the trust score among the specific classes that were already taught according to the educational data [40]. BM-25 is an algorithm produced as an advanced version of TF-IDF and proposed to overcome some of the problems faced by TF-IDF [38].
Similarity detection algorithm based on frequency-based detection or only text classification is not sufficient to suggest paper recommendations. Furthermore, this algorithm alone cannot provide a personalised publication recommendation. The method used in this study consists of three parts. The first part is to determine the researcher’s science field according to the publications that the researcher visited before. The science area can be determined for the researcher who visits only one entry and three to four publications. In the second part, TF-IDF is used for similar paper recommendations. To find similar publications, the title, keywords and summary of the previously viewed publications were taken. Due to the inverse index matrix structure, the number of uses of the words in the publications that the user has read before is calculated. Similar publications were concluded according to the frequency of these words in other papers in the pool. The third step is to compare the found similar publications with the researcher’s science field and present only the relevant similar publications. With this method, publications with similar words and on the same subject were presented to the researcher. Although there are not as many different suggestions as the number of users, thousands of different suggestions have been made with the proposed method. There is a questionnaire presented to the user after each publication proposal. The user can fill out the questionnaire whether he clicks on one of the suggested papers’ options or not.
The survey tried to measure two different outcomes. The first was to measure the satisfaction of the recommendation system. In the survey, it was requested that the suggestion system be scored out of five stars. The second is the evaluation of the proposed publications one by one with a questionnaire. Volunteers rated the suggested publications as relevant and irrelevant. We also asked the volunteers for relevant publications that were not included in the recommendations.
Second test were evaluated on four metrics: accuracy (A), precision (P), recall (R) and F-measure (F). Mean is true-positive which algorithm labelling as ‘True’ at true decisions. Mean is false-positive which algorithm labelling as ‘False’ at true decisions. Mean is false-negative which algorithm labelling as ‘False’ at false decisions. Mean is false-positive which algorithm labelling as ‘True’ at false decisions. The evaluation methods of the four selected metrics are shown in Formula 1. All results obtained using these methods are shown in Table 5
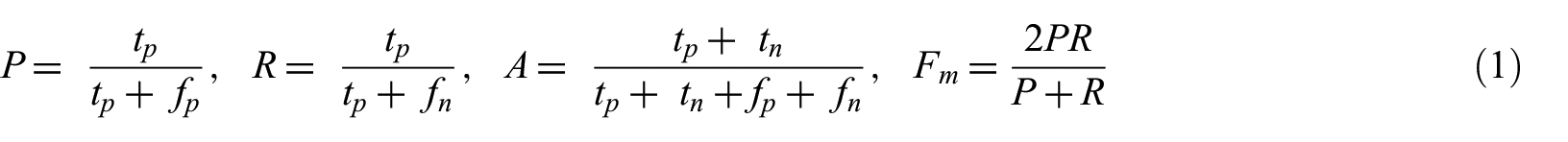
Results of the proposed method.

In the first part of the survey, more than half of the users found the publications offered by the recommendation system successful. In this study, scores 4 and 5 were chosen as the metric of success. In this context, 77% of the users think positively about this study. It has been revealed that the proposed model makes recommendations with around 80% success. The factor affecting this success is both the similarity algorithm and the proposed model. It has been determined that the recommendations made with BM-25 give partially more successful results than the recommendations made with TF-IDF.
2.5. Discussion
The cold-start problem prevents recommendations to the new user for many recommendation systems. For users who do not have historical data, a word frequency-based similarity algorithm can be applied by applying only TF-IDF to the recommendation to be proposed. Thus, the problem called ‘cold-start’, which represents users’ logins for the first time is partially overcome. Since SOBIAD only accepts academic peer-reviewed articles, this study was conducted to include only peer-reviewed articles. Since the study was conducted with TF-IDF, the language of the paper was used for recommendations. Therefore, the proposed method is not suitable for recommending publications in a language other than the language of the publication. Most of the publications included in SOBIAD and DSpaces are in English. On the other hand, few publications in different languages were included in the test results.
We ethically believe that keeping cookies on the user’s computer that changes the user’s service requires the user’s consent. Although it is not clear which user’s ID is given, no classification study will be conducted. It is considered that the data is kept in an anonymised form, and it is not directly subject to the law because it does not contain personal data. In the long term, it is recommended that all open-access digital archives that join the system receive cookies permission to access the site and not call the service object for users who do not allow them. One disadvantage of using data by anonymisation is that we do not know the academic level of the participants who filled out the questionnaire. Therefore, we do not have information about whether the survey was mostly filled by academics or students. The method can be re-evaluated with a specially selected participant model instead of a random survey participant.
This academic study has been carried out over the system of a licenced academic database. On the other hand, the study database can be converted independently to be fed only from Crossref and re-opened to the use of all open-access digital archives. The HTML sent to the open-access portal in the study is one type and cannot be customised in design. This uniform design, which seems quite incompatible with some designs, needs to be customised to suit the theme it is published on.
The applied method suggests similarity by looking at word frequencies. However, there are many disadvantages of making suggestions based on word frequency only. It treats each word independently, including the TF-IDF and BM-25 method used in this publication. However, terms consisting of more than one word are much more important in academic studies. A similarity suggestion system can also make more successful suggestions using long short-term memory (LSTM) or Markov chain. While making suggestions, considering the up-to-dateness of the publications will increase user satisfaction. Measuring user satisfaction per suggested publication, not per recommendation series, and measuring which publications clicked on can provide a more accurate assessment of the study.
3. Conclusion
Within the study’s scope, a personalised recommendation method was developed for open-access digital archives, whose popularity is increasing day by day. The proposed architecture can be easily integrated into existing open-access digital archives. In addition to finding publications similar to the publications with the study, it has also made similar publication suggestions for users according to the publications visited by the users. It has been revealed that all open-access digital archives using the system can be linked to each other through a common data repository and can use services together.