
Abstract
Sentiment analysis of the text deals with the mining of the opinions of people from their written communication. With the increasing usage of online social media platforms for user interactions, abundant opinionated textual data emerges. Therefore, it leads to increased mining of opinions and sentiments and hence greater interest in sentiment analysis. The article introduces the novel Lexico-Semantic features and their use in the sentiment polarity task of English language text. These features are derived using the semantic extension of the lexicons by employing sentiment lexicons and semantic models. These features make data sample size consistent when used in deep learning settings, thereby eliminating the zero padding. For evaluation, we use different semantic models and lexicons to determine the role and impact of Lexico-Semantic features in classification performance. These features, along with the other features, are used to train the different classifiers. Our experimental evaluation shows that introducing Lexico-Semantic features to various state-of-the-art methods of both machine and deep learning improves the overall performance of classifiers.
1. Introduction
Sentiment analysis or opinion analysis is the research field in cognitive computing used for effective mining and leveraging of individual’s opinion or sentiments towards issues, such as product use, organisation topics or their attributes [1]. Sentiment analysis provides insights about the perception of people towards some specific events, products or services.
Sentiment analysis uses machine learning, natural language processing (NLP), data mining and computational linguistics. It has a deeper connection with sociology and psychology, although it emerged in the early 1950s but started gaining more considerable interest since 2005, with the widespread usage of social media [2–4]. The volume of opinionated data is increasing since the inception and growth of online social media networks; sentiment analysis becomes more relevant and desirable.
Sentiment analysis is leveraged across various domains ranging from commercial use to social–political forums. On the commercial end, both customers and the sellers use it. Customers check user reviews before buying anything. Online reviews help e-commerce sites to obtain valuable feedback of their products and improve their products and services. From political end, the political parties leverage the public sentiments about their policies. Online social media users typically share their political opinions with their network, and these conversations are mined for public sentiments towards political parties. Moreover, sociopolitical events are controlled by efficient sentiment analysis systems to maintain the public security [5].
Typically, sentiment analysis engines receive textual data stream as input, look for different patterns and then classify the text into positive or negative polarity based on identified patterns. Automatic sentiment analyzers use computer programs to classify the text. The methods that the automatic analyzers use are categorised into three groups, namely supervised, unsupervised and semi-supervised. The supervised learning algorithms learn from the sufficient number of training examples annotated with sentiment labels, leading to the generation of trained models that are used to infer unseen data for classification into different classes. These supervised algorithms produce excellent results. However, they require abundant training data that are difficult to create. Unsupervised algorithms employ sentiment lexicons that are then used to bootstrap the classification task. Usually, techniques such as clustering and bagging are used by these classes of algorithms.
Both these approaches of sentiment analysis rely on the presence of affective words in the text. However, they lack the critical component of any textual form of communication, that is, the semantics of text. Some advances are made on using semantics for sentiment analysis [6–11]. The approach used by previous works [7–10] uses Framester API 1 and BabelNet synsets to obtain semantic frames and then replaces the data set using these frames, and thus obtain semantic extensions of sentence in the data set. Saif et al. [11] use AlchemyAPI and Zemanta API to obtain semantic frames for the text. The main drawback of both these approaches is that they rely on the external API for obtaining semantic frames. These semantic frames are then used to replace the original data set. This extension is computationally expensive. Also, this approach may fail in cases where an empty semantic frame is obtained for data in the data set.
We propose to use semantics through sentiment lexicons and distributional semantic models. We incorporate sentiment lexicons and semantic models to obtain new features during feature engineering. We use these expanded features to train sentiment classifiers. Our system uses the data set in its original form instead of relying on external APIs and hence, overcomes the drawbacks of previous studies that change the data set using semantic frames.
The sentiment lexicons are rich source of polarity words. The lexicon contains lists of positive and negative words that describe the polarity. However, the scope of these lexicons is limited and domain-dependent; for example, the National Research Council Canada (NRC) hashtag lexicon is mainly useful for social media posts [12,13]. Thus, to improve lexicon coverage and make it domain-independent, we propose using the semantic extension of lexicon using distributional semantic models. The distributional semantic models work on distributional hypothesis, which states that the words used in the same context have similar meanings and can infer and correlate the words based on their usage.
In the classification tasks, if lexicons are used in their original form, they contribute as lexical features. We propose using semantic extensions of the lexicons to obtain new features, which we call the Lexico-Semantic features that aid in sentiment classification tasks. We use these features to make the data of uniform length when used with deep learning systems. In deep learning settings, data need to be of uniform length and usually zero padding is employed. The zero padding leads to bias, we augment the data with the semantically rich sentiment words instead of adding zeros. The main motive is to study how Lexico-Semantic features enhance the accuracy in sentiment classification.
Our proposed approach consists of three main steps: (1) extension of the lexicon, (2) capturing Lexico-Semantic features and (3) classification using Lexico-Semantic features into binary sentiment polarity. Our usage of Lexico-Semantic features allows us to achieve cross-data set generalisation [14]. To validate our approach’s applicability in different domains, we evaluated our approach on eight different state-of-art sentiment data sets. The data sets include reviews, social media tweets and comments. We also use different classifiers and lexicons to investigate the performance of Lexico-Semantic features. We compare our method with other semantic approaches of sentiment analysis and found our approach outperforming them.
In this article, we also investigate whether the usage of different sentiment lexicons has any effect on the generation of Lexico-Semantic features. In particular, we try to answer the following research questions:
How beneficial are the Lexico-Semantic features for boosting the performance of the classification task?
Is there any effect on the performance of the classifier if we use different lexicons?
The rest of the article is organised into following sections: section ‘Related works’ discusses the methods, lexicons and data sets used in sentiment analysis, section ‘Methodology’ discusses the methodology employed, section ‘Evaluation’ discusses experiments and results obtained, section ‘Discussion’ includes discussion, and section ‘Conclusions and future work’ describes conclusions and future work.
2. Related works
In this section, we emphasise on the various aspects of sentiment analysis and highlight the drawbacks and benefits of each area to draw conclusions and determine the outstanding issues. On the one hand, we present the review of methods and data sets, and on the other hand, we analyse the lexicons and semantic approaches employed in sentiment analysis.
2.1. Supervised learning
Supervised learning aims to infer unseen data from a sufficient number of training examples that are annotated by human annotators. Several widely used supervised algorithms are as follows.
2.1.1. Decision tree algorithms
In the sentiment classification tasks, decision trees are commonly employed. A decision tree is a tree with branches that leads to many classification paths. For sentiment classification of English documents, Phu et al. [15] use the Iterative Dichotomiser 3 (ID3) algorithm. They use training examples to build an ID3 tree that classifies text into positive, negative and neutral categories.
2.1.2. Rule-based algorithms
For the sentiment polarity detection task, this method employs if-then-else with lexicon. The rules classify text using the rule-sets that are related to words of the lexicon. Asghar et al. [16] developed a lexicon based on public product feedback. The lexicon is divided into positive and negative labels to identify and classify sentiments in text using the rule-based method. This method is simple to use but has limited scope and results in classification bias. The lexicon expansion can improve this strategy.
2.1.3. Support vector machine
In the literature, support vector machines (SVMs) are often used for classification task. The different features are extracted for the training of classifiers. Go et al. [17] employed n-grams and part-of-speech (POS) tags to train the binary SVM for the detection of sentiment polarity of tweets. Gu et al. [18] employ v-parameters to generalise the support vectors. Balabantaray et al. [19] used a multi-class SVM for emotion mining of Twitter data. Huq et al. [20] use SVM for the classification of the Twitter data set into positive and negative polarities. Liu et al. [21] employ the one-vs-one method with the multi-class SVM, and the features are identified by information gain.
2.2. Unsupervised algorithms
Unsupervised learning is an observed learning that employs examples without labels to identify patterns rather than sampled supervised learning. Some of the most popular unsupervised methods used for sentiment analysis are described in the following.
2.2.1. Clustering
Clustering is the method for arranging data into clusters or groups wherein elements in the same group are highly similar and elements in two different groups are highly distinct. The lexicon is composed of two sets of positive and negative words employed as cluster centroids, and sentences are mapped for polarities based on similarities to the centroids. Suresh and Raj [22] employed a fuzzy clustering for sentiment classification of the tweets [23]. Phu et al. [24] used parallel network, and also the Hadoop platform with fuzzy c-means for sentiment identification in big data. Hassan et al. [25] employed density-based clustering to detect outliers and produced an effective sentiment detection model. Riaz et al. [26] used the k-means clustering at the phrase level and mapped sentences to different clusters based on the coherence of centroid and the sentences [27].
Wu et al. [28] created an opinion-flow system for visual analysis by Bayesian rose tree and stacked topic tree, which is used for training opinion flow among Twitter users. Vaziripour et al. [29] employed cluster merging to detect the change in user sentiments over time. Data are organised in a tree-like cluster structure called a dendrogram in hierarchical clustering [30]. The dendrograms are useful for determining the appropriate level of clustering for a particular process.
2.3. Artificial neural networks and deep learning
The artificial neural networks (ANNs) act in the same way as the human central nervous system does. Yessenalina and Cardie [31] utilised iterative matrix multiplication to represent all the words of the document as matrices. Tang et al. [32] employed neural networks in a bottom-up strategy to learn vector-based document representation. They used gated recurrent neural network (RNN) on IMDB and Yelp data sets for document-level sentiment classification.
Deep learning is based on learning data representations rather than being task-specific and falls in the machine learning paradigm. Bespalov et al. [33] employed latent semantic analysis (LSA) to initialise word embeddings and represented the documents as weighted n-grams for document-level sentiment analysis. Glorot et al. [34] employed auto-encoders for sentiment analysis. Hermann and Blunsom [35] used recursive auto-encoder and combinatory categorical encoders for the sentiment classification. Bengio [36] employed continuous representations of words as a feature for sentiment detection. Tang et al. [37] acquired Sentiment-Specific Word Embeddings (SSWE) by training their system on 10 million tweets containing both positive and negative words. They proposed the ‘COOOOLL’ sentiment analysis system, which combined the SSWE and handcrafted features. Ombabi et al. [38] use one-layer convolutional neural network (CNN) architecture and two-layered long short-term memory (LSTM). The features generated by CNNs and LSTM are fed to SVM classifier for classification. Maqsood et al. [39] use stock exchange-related tweets to determine event sentiments by employing deep learning, linear regression and support vector regression. Yang et al. [40] proposed sentiment analysis model based on sentiment lexicon, CNN and bidirectional gated recurrent unit.
2.4. Ensemble learning
Ensemble learning combines multiple learning algorithms to produce better results. The existing machine learning techniques are integrated with a deep layering strategy for effective classification and thus reducing error rates. Araque et al. [41] created a sentiment analysis system by the word embedding model and linear machine learning model. They also employed models to integrate the deep- and surface-level features. Akhtar et al. [42] employed an ensemble classifier using cascaded features for aspect-based sentiment classification.
2.5. Sentiment lexicon
The lexicons are the principal part of unsupervised learning techniques used for sentiment analysis. Furthermore, lexicon-based features are used for sentiment detection in both supervised and unsupervised techniques. Thus, the lexicon is a central component for an efficient sentiment detection process. Sentiment lexicons are a collection of polarity words annotated as per their polarity orientations, for example, Afinn lexicon uses integer between −5 (negative) and +5 (positive) to describe the polarity of the words.
Lexicons are created using three approaches, namely manual approach, dictionary approach and corpus-based approach. In the manual approach, all the entries in the lexicon are added manually by the compiler of the lexicon. In dictionary-based approach, compiler of lexicon starts with a small set of words that are known to have positive and negative polarities. Then these words are searched for synonyms in WordNet [43] or other online dictionaries. The process continues till no new words can be added to the lexicon [44,45]. In literature, we wind the following commonly used sentiment lexicons.
General Inquirer [46]: General Inquirer is the oldest sentiment lexicon available. Harvard IV-4 and Laswell’s dictionary are used to derive different category words. As far as valence is concerned, there are 1915 positive and 2291 negative words in it.
SentiWordNet [47]: SentiWordNet is a lexical recourse built using the synsets of WordNet. There are two versions of SentiWordNet available, 1.0 [47] and 3.0 [48], built using the two versions of WordNet 2.0 and 3.0, respectively. There are three annotations to the synsets: positive, negative and neutral.
NTUSD [49]: National Taiwan University Sentiment Dictionary has 8726 negative words and 2812 positive words. It is constructed automatically by translating General Inquirer and Chinese network sentiment dictionary.
Bing Liu’s opinion lexicon [50]: This lexicon is widely used and created using manual annotations. There are 2006 positive and 4783 negative words in the lexicon.
Sentiment140 [51]: The Sentiment140 lexicon is a list of words and their associations with positive and negative sentiment. The lexicon has both unigrams and bigrams with positive and negative scores for each term.
WordNet Affect [45]: WordNet Affect created a lexical extension of affective words using WordNet [43] synonyms called WordNet affect. WordNet affect is a subset of synsets of affective words built over the WordNet. It is organised as a collection of synsets of affective labels (a-label).
Emolex [52]: Emolex created NRC word-emotion lexicon also called Emolex of 14,000 English words annotated with Plutchik’s eight basic emotions and two sentiments: positive and negative. The annotations for each lexical entry are done using Amazon Mechanical Turk (AMT).
AFFIN [53]: AFFIN has 2477 words and phrases. There are 1610 negative words and 867 positive words.
MPQA [54]: Multi-Perspective Question Answering is a subjectivity lexicon developed automatically from several sources. There are 4914 negative words, 2721 positive words and 571 neutral words in the MPQA lexicon.
LIWC [55]: The LIWC2015 is the master lexicon composed of LIWC2001, LIWC2007 and LIWC 2015. It has 6400 words, word stems and emoticons. The lexicon is arranged in a way that, for each word, there exists one or more categories corresponding to that word.
Table 1 summarises the details about the lexicon.
Sentiment lexicons.

NTUSD: National Taiwan University Sentiment Dictionary; AMT: Amazon Mechanical Turk; MPQA: Multi-Perspective Question Answering.
2.6. Sentiment data sets
Sentiment data sets are key for evaluating the performance of the system. Several studies annotated rich sentiment corpus by employing annotators or AMT. Table 2 summarises the commonly used data sets for sentiment polarity detection task. Table 2 also defines the nomenclature that is used for naming data sets in the rest of the article.
Statistics of sentiment data sets.

BBC: British Broadcasting Corporation; AMT: Amazon Mechanical Turk; TED: technology, entertainment and design; IMDB: Internet Movie Database; UMICH: University of Michigan.
2.7. Semantic approach
The sentiment conveyed through the text is not limited to the individual words, rather relations and dependencies between words. These relations and inter-dependencies are directly related to the semantics of text. Hence, semantics should be leveraged for extracting meaning and related semantic features. Saif et al. [11] introduced semantic features to the sentiment analysis. They added semantic features to the training set by extracting entities from the data set and added entity semantic concept to the training set. Using this approach, they recorded an increase of around 6.5% to the baseline of unigrams and 4.8% to the baseline of POS. Furthermore, Saif et al. [62] designed a system called ‘SentiCircle’ that involves lexicon-based approach, conceptual and contextual features. An extension of SentiCircle, Saif et al. [63], uses fixed and static prior sentiment polarities of lexicon words regardless of the context of words. Their system took into account the co-occurrence of patterns of words used in different contexts to capture semantics. Maas et al. [61] captured semantics using word vectors through the probabilistic model of documents. Dridi et al. [7] used BableNet to extract semantic features for sentiment classification of social media posts.
The supervised algorithms are data-dependent, that is, they learn through the annotated training examples, and hence these approaches are domain-dependent. To overcome this problem, unsupervised algorithms are centred around lexicons. Lexicons play an important role to capture the domain-dependent aspects of sentiment analysis. Although these algorithms overcome the data domain-dependency shortcomings of supervised algorithms, they are not competitive in comparison to the supervised approach in terms of accuracy. Moreover, several systems are using semantics as a feature, but none used it as a Lexico-Semantic feature; instead, they created extensions of the data set by including semantic features in the data sets.
In this article, we propose the Lexico-Semantic feature in the supervised setting. We capture semantics using distributional hypothesis and then use these features in the supervised learning for sentiment classification. We compare our system with the baseline features and report the effects introduced by Lexico-Semantic features. We also compare our system with the other semantic approaches to show the competitive efficacy of our algorithm. Figure 1 shows the steps followed during literature selection.

Research flow diagram.
3. Methodology
This section describes our model for sentiment analysis using a supervised learning approach based on lexicon supervision. We extend the lexicon with the distributional semantic model and then extract Lexico-Semantic features from the text along with other features. We classify the sentences based on these extracted features. The architecture of our model is shown in Figure 2. Precisely, our approach consists of (1) preprocessing for removing irregularities and normalisation of the data set; (2) lexicon expansion using distributional semantic models; (3) feature engineering; (4) vectorisation of all the extracted features and (5) classification.
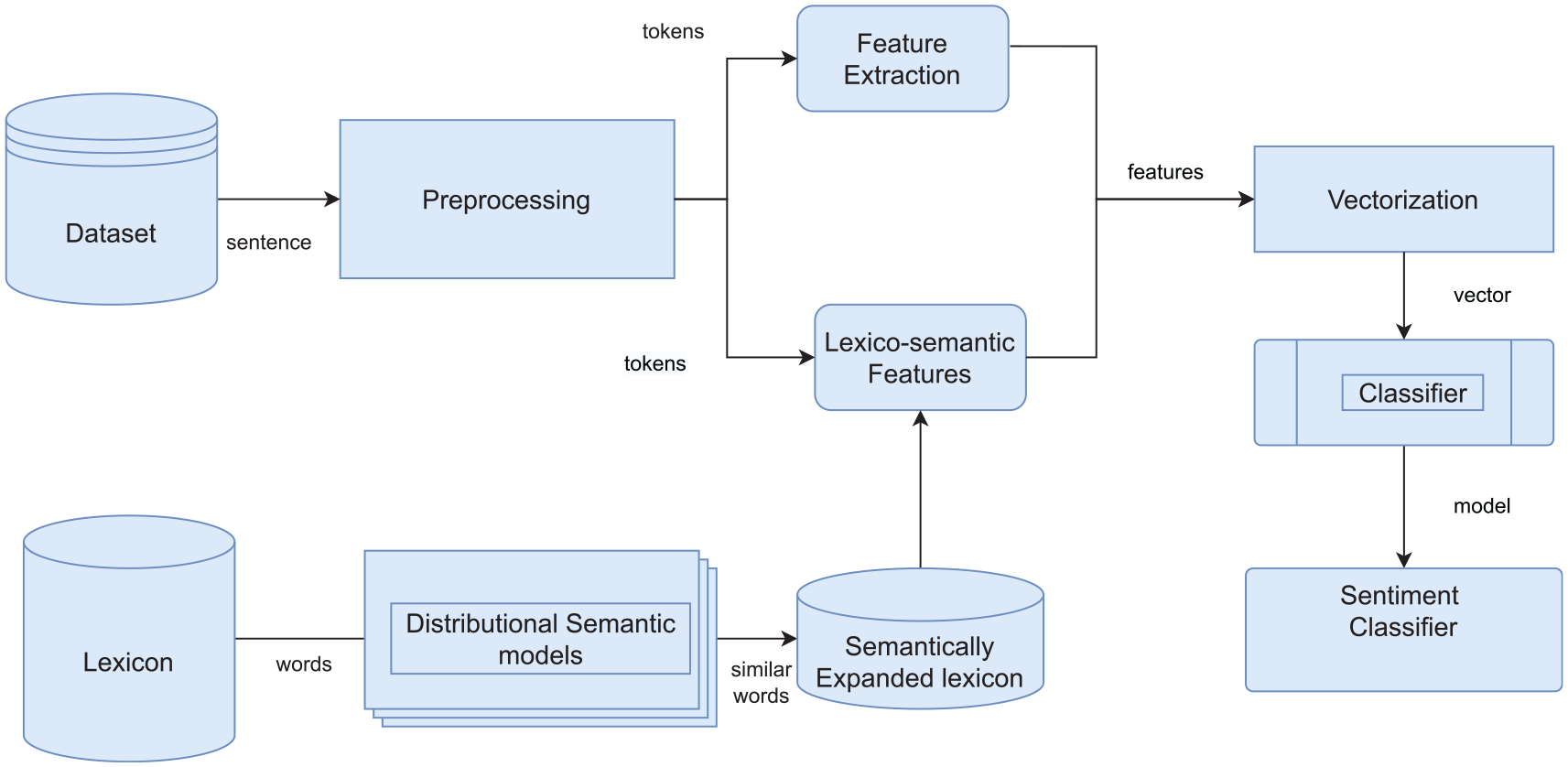
Overall working of the system.
3.1. Preprocessing
Preprocessing is the primary and first step in our sentiment classification process. It cleans data for uniformity, removes noise and inconsistencies. Preprocessing has the following steps:
3.2. Lexicon expansion
We use the distributional semantic models (Word2Vec, Glove and FastText) to expand the lexicon since they are generic and do not require any lexical and linguistic training. The expansion incorporates semantics in the lexicon to make it semantically rich, thus enabling us to extract Lexico-Semantic features under lexicon supervision. The distributional semantic models capture semantics by creating a semantic information base. Moreover, these models are independent of external sources [65].
The distributional semantic models employ the distributional hypothesis, which states that the words used in the same context have similar meanings and can infer and correlate the words based on their usage. The distributional models use statistics derived from the occurrences of words to construct vector space model. Thus for all words, we have high-dimensional real-valued vectors represented as word vectors or semantically rich word embeddings. These word embeddings, along with their geometric properties, are syntactically, semantically and contextually useful for finding coherence of words and hence leveraged for finding semantics at different granularity levels of text [66].
To capture the semantics of the lexical units for the expansion of lexicon, we employ the distributional semantic models Word2Vec [67], FastText [68] and Glove [69] to capture the semantics of text. These models are used in several NLP tasks for the purpose of capturing semantics, such as [70,71] and [72] employed Word2Vec for emotion mining, [73,74] used Word2Vec and LSA for bootstrapping opinion corpus, [66] used in the process of text summarisation, [75] used Word2Vec for recommending different multi-media in a recommendation settings. Word2Vec has been effectively used in different domains as well such as graph embeddings [76–82] to learn the embedding of nodes in the graph for machine learning tasks.
Word2Vec is a two-layer neural network that processes textual data and produces vectors for each given word. The produced vectors are semantically rich feature vectors. Moreover, there is a one-to-one correspondence between each word and its retrieved feature vector. The Word2Vec model is trained as a vector space representation of terms. It has a two-layered neural network and uses a distributional hypothesis for deriving semantics of the lexical entity.
Word2Vec has two architectures; the skip-gram model and continuous bag of words (CBOW). These architectures define how embeddings are created and used in different ways. The CBOW model predicts words from the context, and the skip-gram model predicts it from different contexts. In this article, we use pretrained Word2Vec model 2 , trained on the Google news data set.
FastText is a free and open-source tool that enables users to learn text representations and classification. It is premised on n-gram attributes, dimension reduction and approximation method. It transforms the input tokens into n-gram characters. It is a resource for effective learning of token representations and categorising sentences. It also performs better with rare words. If a word is not observed during training, its embeddings could be determined by splitting it into n-grams [83].
Glove is an unsupervised learning technique that generates word vector representations. It creates the paradigm for transforming the frequency of co-occurring words present in the overall data. The inferring is based on compiled global co-occurrence of word-stats of data [69].
The need to expand the lexicon is since the approaches using lexicon for sentiment analysis employ sentiment-conveying terms in their general purpose lexicon and thus are not scalable because recall of these lexicons depends on the coverage of lexicon terms used. We first use Semantic models (Word2Vec, FastText and Glove) to obtain semantics, and then WordNet [43] to further expand the lexicon’s semantic version and hence increases recall and overall coverage of the lexicon. The lexicon expansion is explained in Algorithm 1.
Lexicon expansion.

The expansion consists of the following steps:
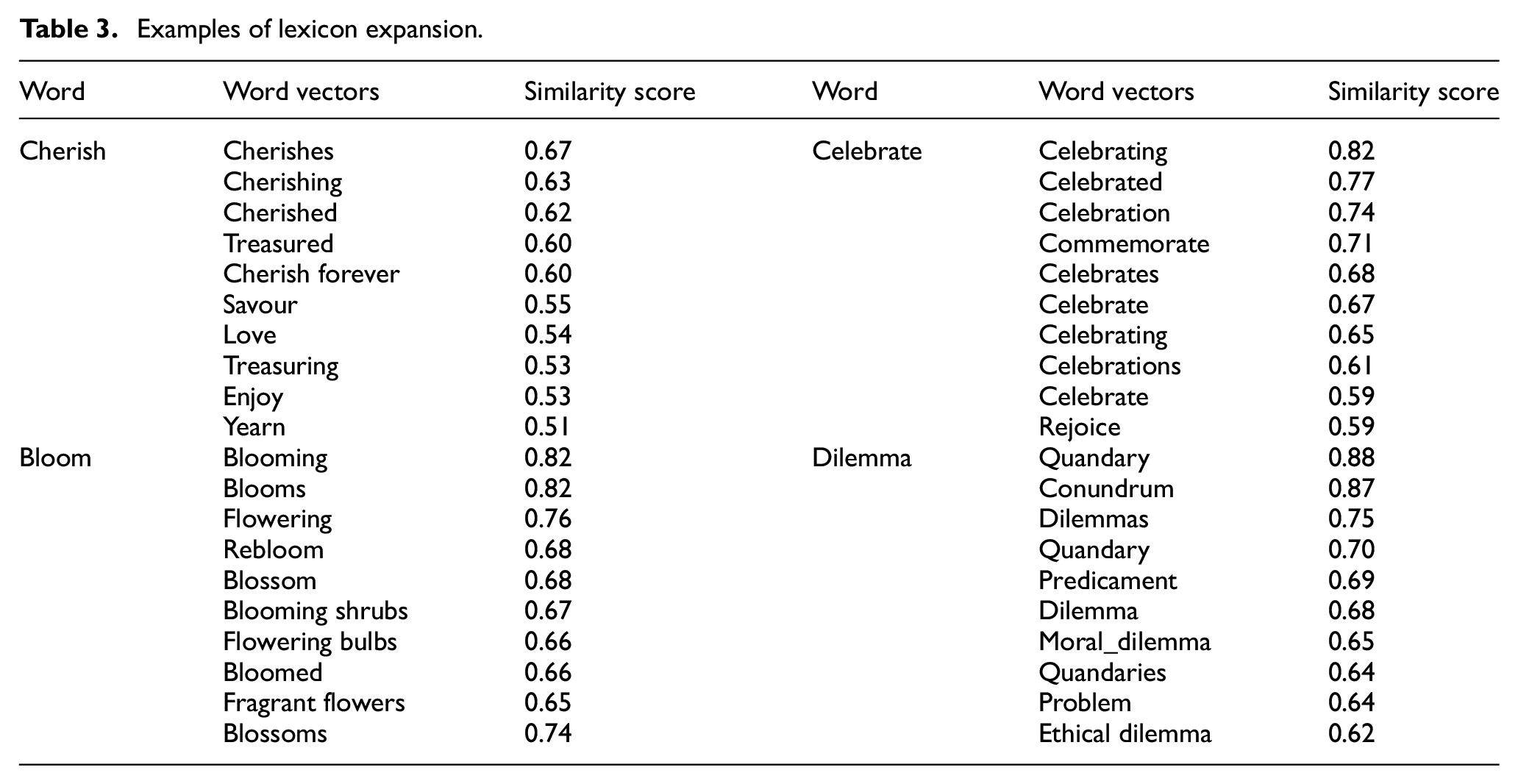
To understand lexicon expansion, let us take an example of some words: Cherish, Bloom, Celebrate and Dilemma of the lexicons Bing Liu, AFFIN, MPQA subjectivity lexicon and AFFIN, respectively. These words are then fed to semantic models to retrieve their word vectors. The retrieved word vectors for the corresponding word along with its semantic score are described in Table 3.
Examples of lexicon expansion.
Figures 3 and 4 summarise the lexicon expansion process using Semantic Models and WordNet, respectively.
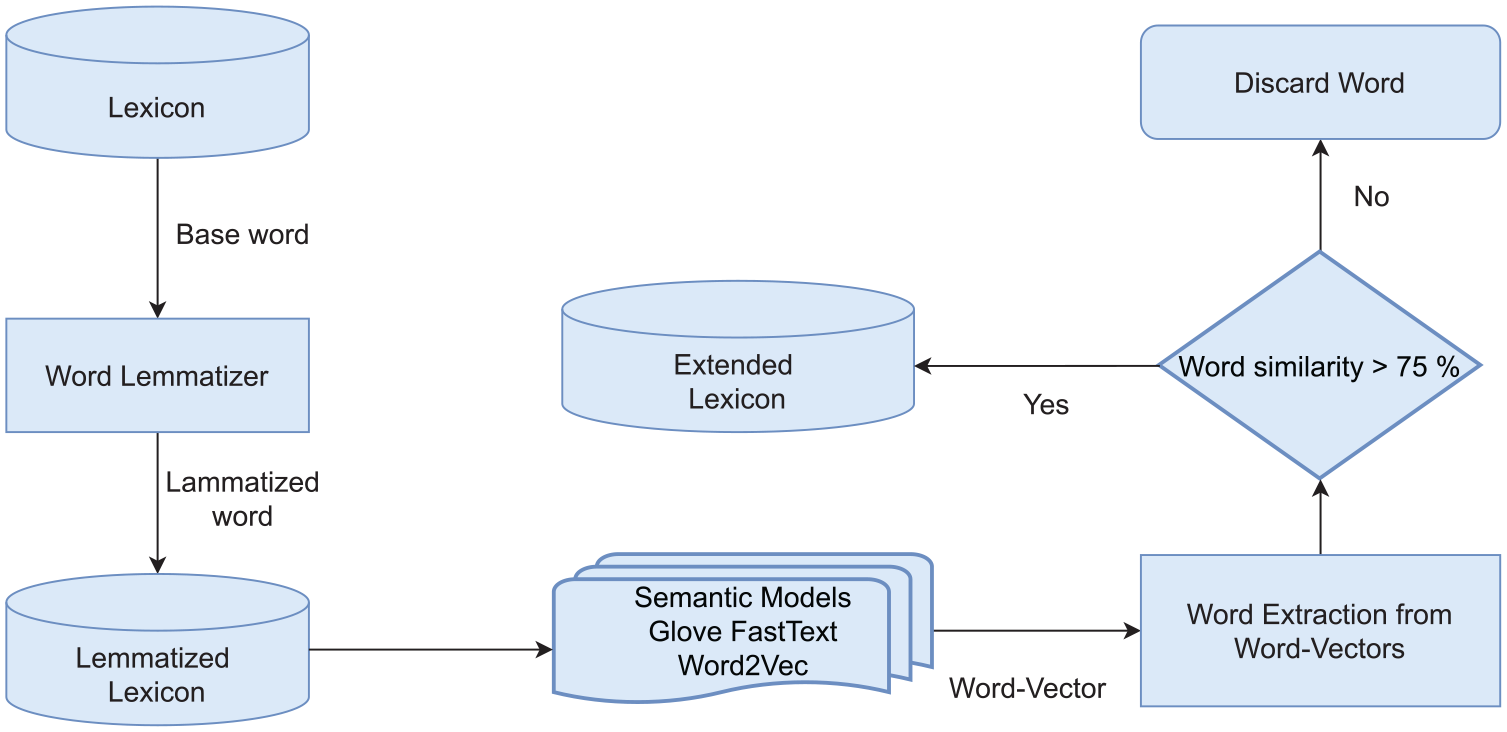
Lexicon expansion using Semantic Models.
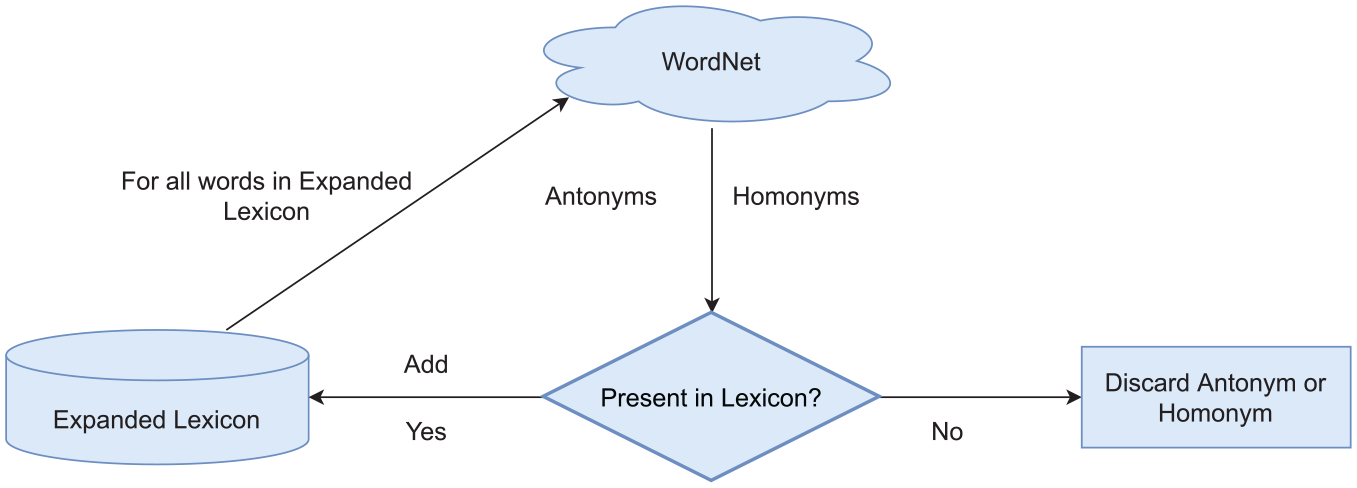
Lexicon expansion using WordNet.
3.3. Classification
In this section, we discuss the classification and the classifiers. We create sentiment classifiers that classify any domain text as per its sentiment polarity. The classifier predicts the positive and negative labels of the text [86]. For classification, we use a supervised learning algorithm. Particularly, we use SVM, Random Forest and LSTM as classifiers. SVM is a state-of-art machine learning algorithm effective for text classification tasks with robust performance on large vector spaces. We use SVM light with the linear kernel, which is a C implementation of SVMs [87]. The advantage of using SVM light is that it supports standard kernel functions and allows the definition of extra functionalities over the basic ones. SVM light is a widely used algorithm for several tasks: text classification, image recognition, medical and bioinformatics application. SVM light is publicly available 3 .
Random Forest is composed of an enormous number of individual decision trees that operate as an ensemble [88]. Each tree in the Random Forest spits out a class prediction, and the class with the most votes become our model’s prediction. The rationale behind Random Forest is a simple but powerful one, that is, the wisdom of crowds. It uses bagging and feature randomness to build each tree to create an uncorrelated forest of trees whose prediction is more accurate than any individual tree.
LSTM maintains a separate memory cell inside it to learn long-term dependencies, which updates and exposes its content only when deemed necessary, thus making it possible to capture the content as needed [89,90].
3.4. Feature engineering
Feature extraction is the process of selecting a subset of features that are relevant for model construction. The key to successful sentiment classification is selection of useful features. The selection of effective features leads to better classification as it simplifies the model and reduces the classifier’s training time. Following surface-level features are used during the training:
All these surface-level features are assigned equal weights by our system.
Identification and extraction of Lexico-Semantic features using lexical supervision: Successful sentiment classification relies mainly on the proper selection of polarity words as features since they represent sentiment polarities. Unsupervised algorithms are centred around lexicon. We use lexicon in supervised settings, we call it lexicon supervision. We extract additional features through sentiment lexicons and distributional semantic models, if the sentence contains a lexicon word. These features are given extra importance by setting their weight higher than the features discussed in section ‘Feature engineering’, and we call these features as Lexico-Semantic features.
Identification and extraction of Lexico-Semantic features for LSTM: We use high-quality sentiment lexicons to generate the Lexico-Semantic features that are then feed to the LSTM model to generate the sentiment classifier. However, the LSTM model requires consistent data samples for processing. To make the text of uniform length, text is padded with extra zeroes. One of the biggest challenges for text classification is the variable length data instances in the data set. Usually the length of a sentence ranges from one word to almost one hundred words in the text data sets. To counter this, the text is padded by adding zeros to the sentences, commonly known as zero padding. Zero padding is commonly used in image classification to pad the borders of an image. However when used with textual systems, it results in a bias since the length of text changes frequently. To overcome this problem, we employ our Lexico-Semantic features to make data of uniform length and exploit the benefits of our Lexico-Semantic features. Enhancing using Lexico-Semantic information enlarges the proportion of sentiment information in text, which is useful for sentiment polarity classification.
Zero padding leads to large quantities of invalid information and reduces the performance of classifiers. In addition, it has a large effect on the result of the LSTM and CNN family model in text classification since it influences the pooling and weight updating. For instance, if there are two sentences with different sentiment polarities containing only one or two words, the zero padding operation makes it impossible to classify these two sentences into correct sentiment polarities. Thus, we propose introducing Lexico-Semantic features, which extend a sentence or message to a fixed length to better match text classification tasks.
We fix the length of all sentences to be 300. Thus, all sentences should be 300 words in length. We apply our padding algorithm to achieve sentence uniformity if a sentence is less than 300 words long.
Given a sentence
We then use the TensorDataset utility from PyTorch to create batches of data. Then, we use the four-layered LSTM architecture with 0.2 dropout in between the layers for the Lexico-Semantic LSTM model.
3.5. Vectorisation
Vectorisation is the process of converting extracted features into their vector representation. We introduce a new scheme for vectorisation of features: for all the extracted features, we create a dictionary of features with one feature per line of dictionary along with the class of feature to which this feature belongs. Each extracted feature is identified uniquely by appending a unique label according to the type of feature: for example, unigram features are appended by the label ‘unigram’, POS feature by POS. Features are not repeated in the dictionary. Each new feature generated is checked in the dictionary and added if it is not present in the dictionary, thus ensuring uniqueness. Since each line uniquely represents a feature in the dictionary, we choose its line number to represent the feature numerically, and hence, we map each feature uniquely to a numerical representation using this scheme.
To understand the vectorisation properly, let us consider the example ‘John likes the blue house at the end of the street’. In this sentence, the POS tags are John – noun, likes – verb, the – determiner, blue – adjective, house – noun, at – preposition, end – preposition and street – noun. The n-grams possible with this sentence are John-likes, likes-blue, blue-house, house-end and end-street. These features are then added to the dictionary of features, each at a unique line in the dictionary. The line numbers of these features are then mappings that are used to represent these features.
4. Evaluation
We hypothesised that using Lexico-Semantic features for sentiment analysis under lexicon supervision will improve sentiment detection. The following section describes the test setup and data sets used to verify the hypothesis.
This research aims to assess the effect of using Lexico-Semantic features for sentiment detection under lexicon supervision. To capture Lexico-Semantic features, a standard lexicon is extended by semantic algorithms, and then the model uses lexicon supervision to extract Lexico-Semantic features, combined with other features to study the effect on the classification process. To check our algorithm’s scalability, we check it on two fronts: effectiveness of expanded lexicon using different lexicons and the impact of lexicon expansion on classification by extracting Lexico-Semantic features. Another novel characteristic of our algorithm is that it is flexible to work on different domain data streams since we employ distributional semantic algorithms for capturing semantics. The distributional semantic models employ a generic model that requires no lexical or linguistic analysis and are trained in such a way that they require no external source of semantic knowledge. To test this claim, we tested our system on different genres of text data sets.
4.1. Data sets
We test our approach on eight different sentiment data sets. These data sets contain both long and short texts for an extensive evaluation of our approach. Also, these data sets are publicly available and used in various sentiment detection approaches. Hence, our algorithm can be used for different comparison studies. Table 4 shows the stats of different data sets used for the evaluation.
Statistics of the data sets.
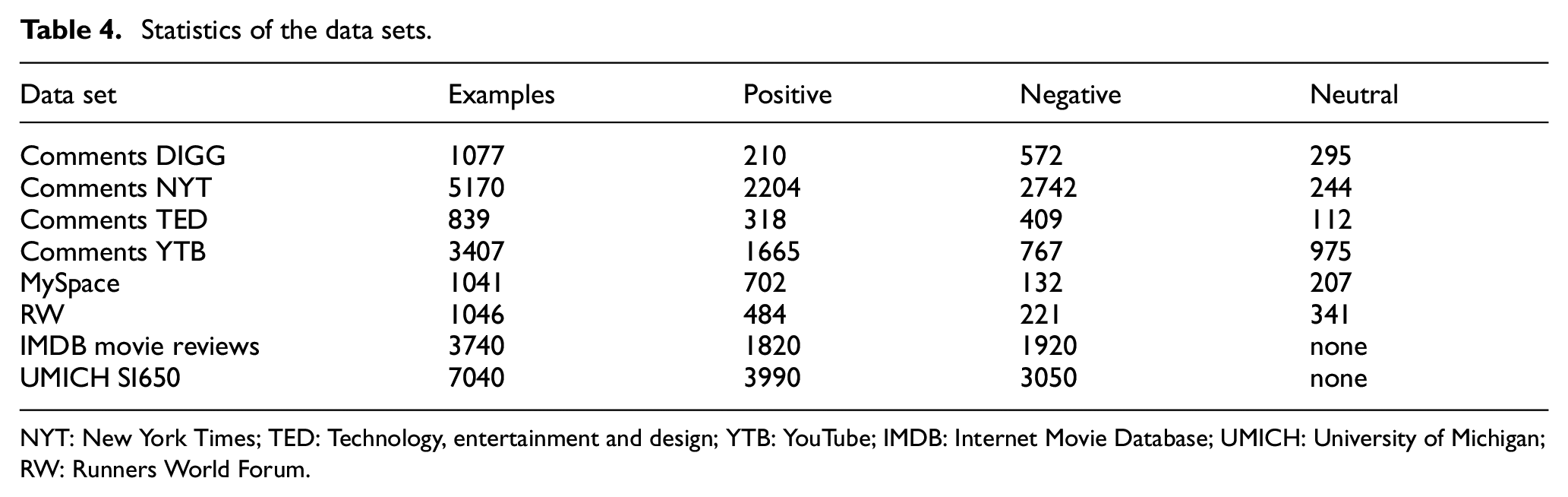
NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan; RW: Runners World Forum.
In our experiments, all neutral labelled sentences are dropped. To create a balanced data set for classification, we use Synthetic Minority Oversampling Technique (SMOTE) [94] to have an equal number of positive and negative examples. Thus, all the data sets contain a balanced number of training examples.
4.2. Baselines
To compare the competitive performance of our system for the sentiment analysis task in different text domains, we use the following Baselines:
4.3. Evaluation methodology
We evaluate our approach of lexicon expansion and its effect on capturing Lexico-Semantic features for sentiment classification using three widely used standard sentiment lexicons. To validate our hypothesis, that Lexico-Semantic features aid in sentiment classification tasks, we used three different lexicons for three separate experiments. The aim is to investigate the ability of distributional semantic algorithms to capture Lexico-Semantic features and their subsequent usage in the sentiment classification task. We selected three state-of-the-art sentiment lexicons for this study: (1) Bing Liu’s opinion lexicon [50], (2) the MPQA subjectivity lexicon [54] and (3) AFFIN [53]. Tables 5–7 summarise the number of lexical entries in each lexicon before and after the different stages of the lexicon expansion using Word2Vec, Glove and FastText semantic expansion algorithms, respectively.
Statistics of lexicon using Word2Vec.

MPQA: Multi-Perspective Question Answering.
Statistics of lexicon using Glove.

MPQA: Multi-Perspective Question Answering.
Statistics of lexicon using FastText.

MPQA: Multi-Perspective Question Answering.
All lexical entries from the three different lexicons are passed to Word2Vec, Glove and FastText for semantic expansion, and then hyponyms and antonyms of the combined lexicon are retrieved from the WordNet.
For Bing Liu’s lexicon, the initial entries in the lexicon are 6788, the Word2Vec expansion yields 700 semantic extensions of the initial entries in the lexicon and we retrieve 9310 hyponyms and antonyms. Thus, the total number of entries in the extended Bing Liu’s lexicon is 16,798. By the expansion using Glove, we obtained 574 semantic extensions, and then WordNet yields 9266; thus, the total entries extended are 16,628. The FastText expansion yields 810 semantic extensions of the initial entries in the lexicon, and then WordNet yields 9255; thus, we retrieve 16,853 total entries in Bing Liu’s lexicon.
Initial lexical entries in the MPQA subjectivity lexicon are 8222. After Word2Vec extension, the number of semantic entries added is 922, and then 3050 antonyms and hyponyms are added to the lexicon, and thus the total number of entries is 12,194. By the expansion using Glove, we obtained 810 semantic extensions, and then WordNet yields 2996; thus, the total entries extended is 12,028. The FastText expansion yields 983 semantic extensions of the initial entries in the lexicon, and then WordNet yields 3058; thus, we retrieve 12,263 total entries in MPQA lexicon.
For AFFIN, the initial entries are 4087, the Word2Vec semantic extension yields 3190 entries and from WordNet, we retrieve 2250 antonyms and hyponyms. Hence, the total number of lexical entities in AFFIN is 9527. By the expansion using Glove, we obtained 3081 semantic extensions, and then WordNet yields 2268; thus, the total entries extended is 12,028. The FastText expansion yields 3225 semantic extensions of the initial entries in the lexicon, and then WordNet yields 2308; thus, we retrieve 9620 total entries in AFFIN lexicon.
After the lexicon expansion, we extract the features as discussed in section 3.4.
Then, the extracted features are vectorised using our vectorising algorithms described in section 3.5, and the vectors are passed to the different classifiers: Random Forest and SVM light for training. Each sentence is represented as a feature vector where each feature is represented as a combination of feature and its corresponding weight.
After extracting the features as discussed in section 3.4.2, the extracted features are passed to four-layered LSTM architecture for training.
4.4. Results
For each data set, we use leave-one-out cross-validation and report precision-positive (PP), precision-negative (PN), recall-positive (RP), recall-negative (RN), F1-positive (F1-P) and F1-negative (F1-N) scores. Results obtained by the SVM on different lexicons using Baseline-1, Baseline-2 and Lexico-Semantic supervision are reported in Tables 8 and 9, respectively. The results obtained by the Random Forest on different lexicons using Baseline-1, Baseline-2 and Lexico-Semantic supervision are reported in Tables 10 and 11. We use three lexicons AFFIN [53], Bing Liu’s lexicon [50] and MPQA [54]. The Baseline-1 uses original unexpanded lexicon, and the classifier is simply fed with the lexical features. For Baseline-2, no lexical features are fed to the classifier and in our approach, Lexico-Semantic features are fed to the classifier. The Baseline-3 uses features extracted by LSTM. Precision (PP and PN), Recall (RP and RN) and F1-values (F1-P and F1-N) are used for evaluation of four systems (Baseline-1, Baseline-2, Baseline-3 and our system). However, comparison of our system with the state-of-the-art system that uses semantic features is reported in Table 16.
Results of the Lexico-Semantic approach and Baseline-1 using SVM.
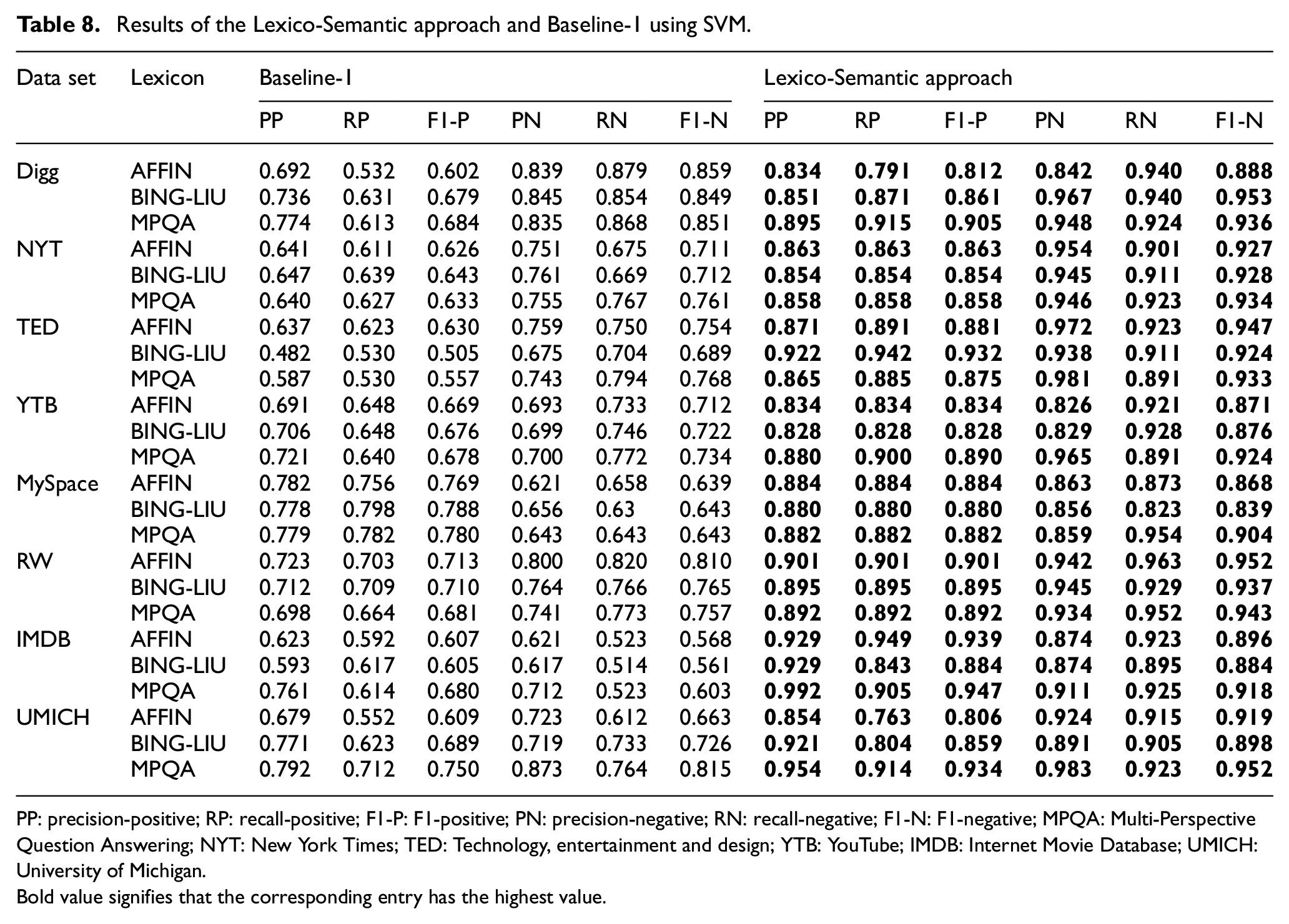
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; MPQA: Multi-Perspective Question Answering; NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan.Bold value signifies that the corresponding entry has the highest value.
Results of the Lexico-Semantic approach and Baseline-2 using SVM.
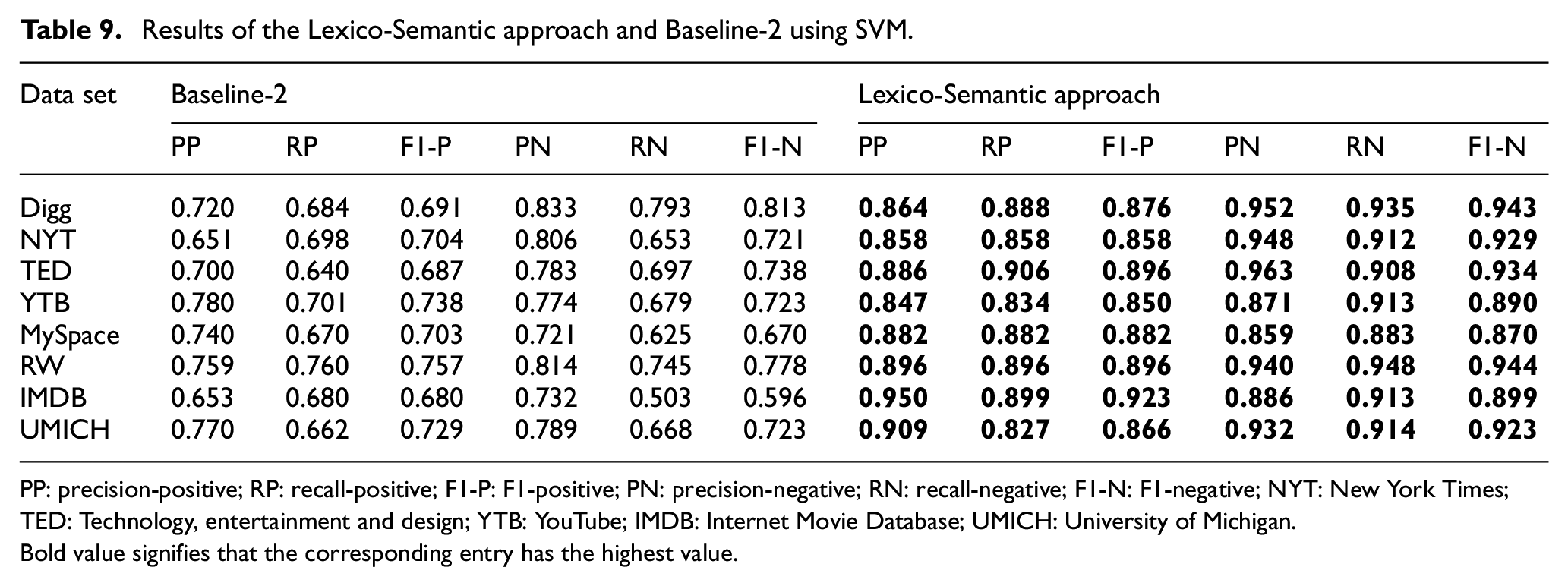
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan.Bold value signifies that the corresponding entry has the highest value.
Results of the Lexico-Semantic approach and Baseline-1 using Random Forest.

PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; MPQA: Multi-Perspective Question Answering; NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan.Bold value signifies that the corresponding entry has the highest value.
Results of the Lexico-Semantic approach and Baseline-2 using Random Forest.
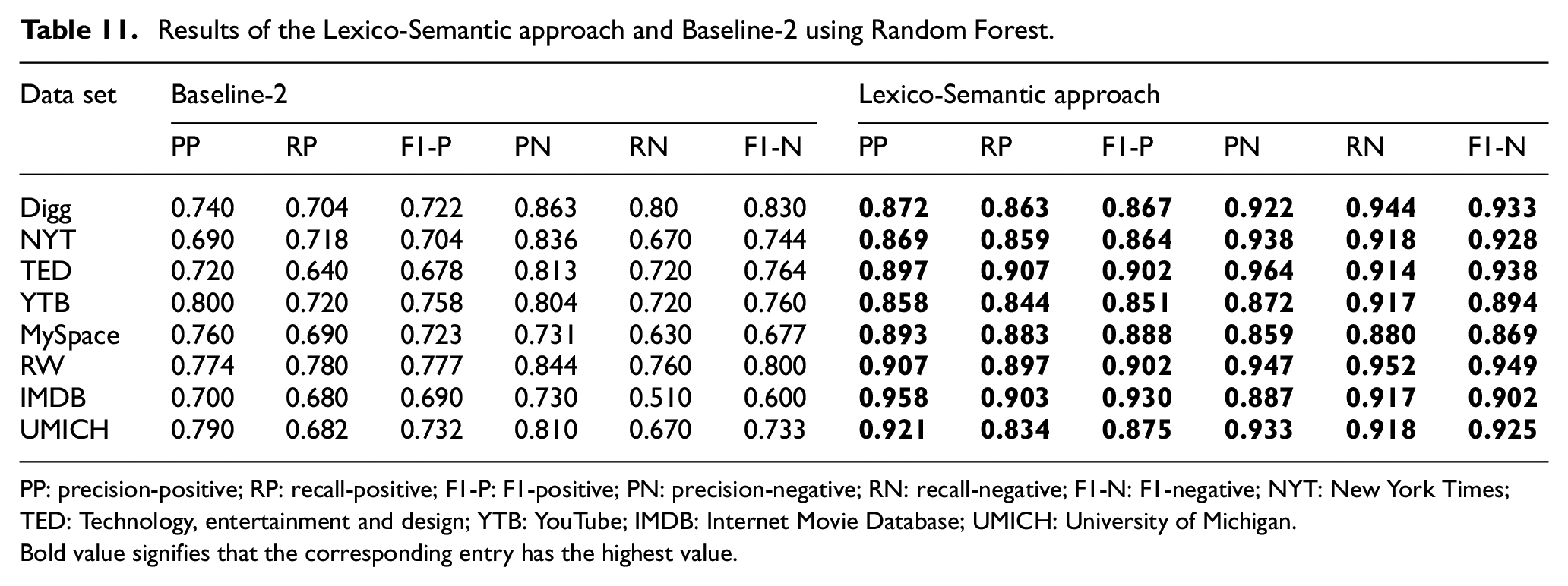
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan.Bold value signifies that the corresponding entry has the highest value.
5. Discussion
In this section, we discuss in detail the results obtained on the data sets using our Lexico-Semantic approach. We evaluate the integration of the Lexico-Semantic features on the sentiment polarity detection classifiers.
First, we investigate the ability of distributional semantic algorithms to capture Lexico-Semantic features and their subsequent usage to enhance the sentiment classification task. Second, we discuss the scalability of our approach for application in different domain data sets since we employ distributional semantic algorithms for capturing Lexico-Semantic features. These algorithms employ a generic model that requires no lexical, linguistic analysis or external source of semantic knowledge and hence can be used with different domains. To verify this claim, we tested our system on different genres of text data sets. Questions that we want to answer are: How beneficial Lexico-Semantic features are for the sentiment classification task? What will be the effect of the usage of different lexicons on the performance of different classifiers? and What is the impact of using different semantic models on classification?
Tables 8 and 10 report the results of our system on eight data sets using SVM and Random Forests, respectively, and compare the system with the Baseline-1. Baseline-1 uses lexical and other surface-level features while as our system employs the Lexico-Semantic features in combination with other surface-level features as discussed in section 3.4.
Tables 9 and 11 report results of our system on eight data sets using SVM and Random Forests, respectively, and compares the system with the Baseline-2. Baseline-2 does not employ lexical features at all, while our system employs the Lexico-Semantic features. For comparison with the Baseline-2, we averaged the Lexico-Semantic approach obtained on a data set over the three lexicons because the Baseline-2 does not employ lexicon as a feature.
Table 12 reports results of our system on eight data sets using LSTM and compares the system with the Baseline-3. Baseline-3 employs features extracted by LSTM, while our system employs the Lexico-Semantic features. For comparison with the Baseline-3, we averaged the Lexico-Semantic approach obtained on a data set over the three lexicons because the Baseline-3 does not employ lexicon as a feature.
Results of the Lexico-Semantic approach and Baseline-3.
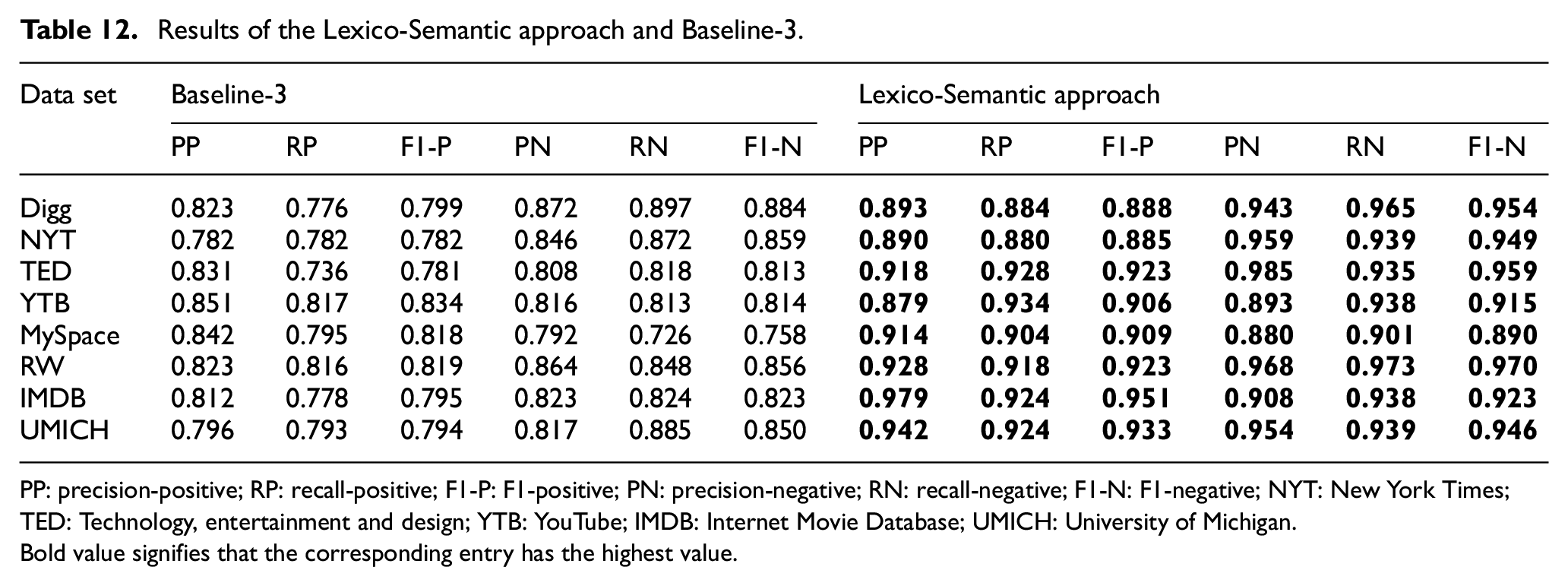
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; NYT: New York Times; TED: Technology, entertainment and design; YTB: YouTube; IMDB: Internet Movie Database; UMICH: University of Michigan.Bold value signifies that the corresponding entry has the highest value.
Table 13 reports the results of different baselines and our system. From the results of Table 13, it is evident that the Lexico-Semantic features improve the results of sentiment classification in comparison with the three baselines. Thus, we conclude that the Lexico-semantic features aid in the sentiment classification task. All the three baselines and our system employ the same set of features apart from Lexico-Semantic features with same classifier settings. The improved functionality of our system is attributed to Lexico-Semantic features and hence, better results.
Comparison of the Lexico-Semantic approach and other baselines based on averages.
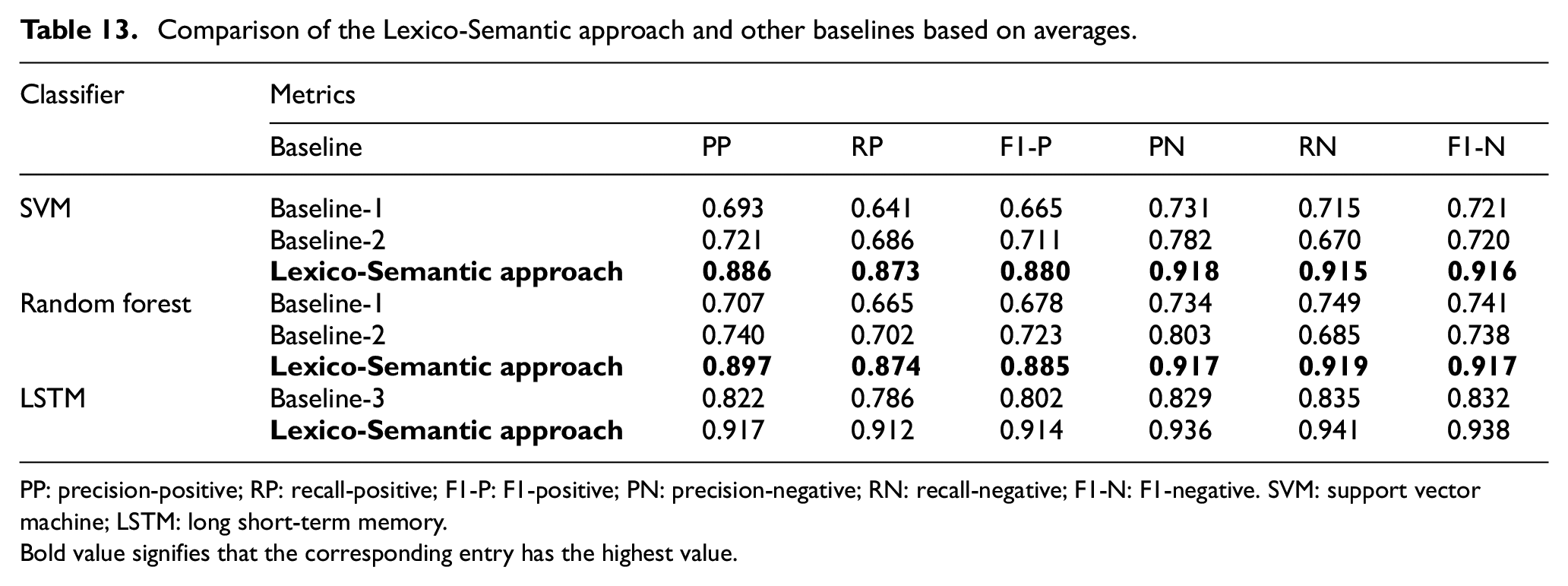
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative. SVM: support vector machine; LSTM: long short-term memory.Bold value signifies that the corresponding entry has the highest value.
Tables 14 and 15 show the comparison of averaged results of the Baseline-1 and our system with lexicons: MPQA, AFFIN and Bing Liu’s using SVM and Random Forest, respectively. From this, we get the answer to our second research question: what is the impact of using different lexicons on the performance of the classifier? Since the changes in the effective performance are negligible, thus, we conclude it as the process of obtaining Lexico-Semantic features and not the lexicon itself, that aids in the better performance of the classifier. We also tested our Lexico-Semantic approach using two other semantic models: Glove and FastText. We found that all the semantic models produce an excellent mechanism for incorporating Lexico-Semantic features. All the semantic models yield consistent results when compared with the baselines. The results are almost identical, and hence, we have omitted reporting Glove and FastText results in the tables.
Comparison of the averages of Baseline-1 and Lexico-Semantic approach of all lexicons using SVM.
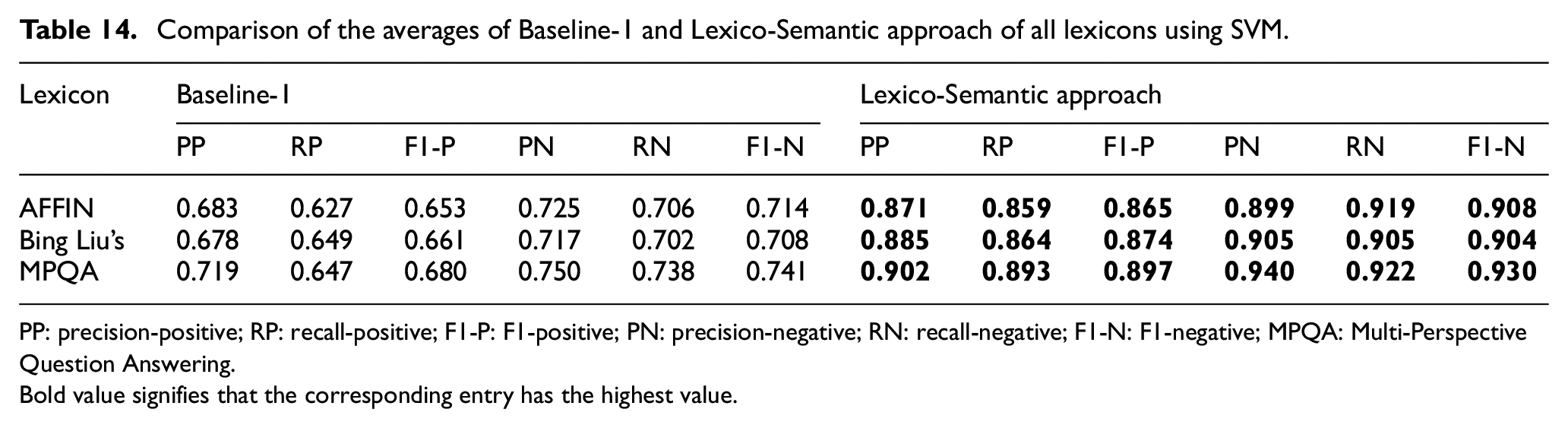
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; MPQA: Multi-Perspective Question Answering.Bold value signifies that the corresponding entry has the highest value.
Comparison of the averages of Baseline-1 and Lexico-Semantic approach of all lexicons using Random Forest.
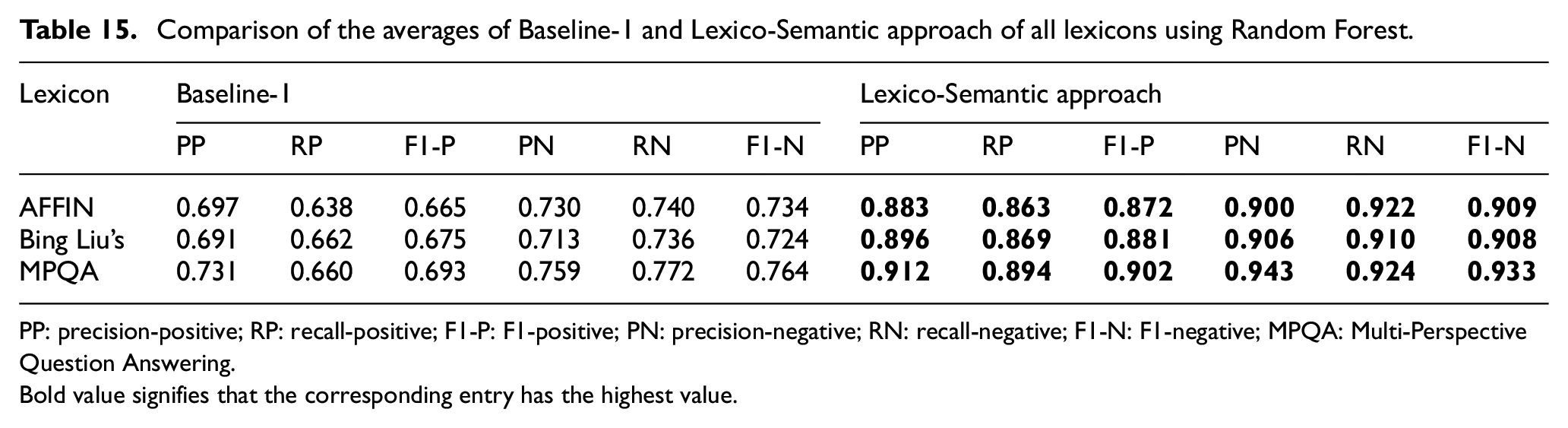
PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative; MPQA: Multi-Perspective Question Answering.Bold value signifies that the corresponding entry has the highest value.
The comparison of our Lexico-Semantic system with other system using semantic features is reported in Table 16. From Table 16, it is evident that our system outperforms the system using semantics [62].
Comparison of the Lexico-Semantic approach and other system using semantics.

PP: precision-positive; RP: recall-positive; F1-P: F1-positive; PN: precision-negative; RN: recall-negative; F1-N: F1-negative.Bold value signifies that the corresponding entry has the highest value.
6. Conclusion and future work
The article presents a sentiment polarity classifier employing the Lexico-Semantic features to aid the sentiment classification task. According to the evaluation and comparative analysis, the appropriateness, reliability and scalability of sentiment classifier are better than the baselines. Our main conclusions are as follows: (1) The Lexico-Semantic features aid in the sentiment classification task. (2) The choice of the lexicon is not important since all the results are overall consistent. (3) The distributional semantic algorithms are an excellent choice for capturing semantic features since they do not require domain knowledge, and thus our algorithm becomes scalable and hence applicable for testing different domain data sets. The main drawback of our approach is that it is computationally exhaustive and thus requires more time to execute.
Future scope of the work could deal with (1) using more than one distributional semantic models in different combinations for capturing semantics in the text so that semantics are captured at the fine-grain level and (2) using transformers for capturing semantics.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.