
Abstract
Artificial intelligence (AI) is transforming library information services by enhancing user interaction, resource management, and academic support. However, fine-grained topic identification and evolution analysis in this field remain underexplored. This study identifies key research topics and tracks their development to uncover AI’s trajectory in library information services. Leveraging deep learning-based topic modeling techniques—BERTopic and Dynamic Topic Modeling (DTM)—we analyzed 2,789 filtered article abstracts retrieved from the Web of Science Core Collection and Scopus databases published between 2015 and 2024. The modeling process involved several steps: we first generated document embeddings using Sentence-BERT, followed by dimensionality reduction with UMAP to project the high-dimensional vectors into a lower-dimensional space. We then applied HDBSCAN, a density-based clustering algorithm, to group semantically similar documents. Topic representations were constructed using class-based TF-IDF (c-TF-IDF) to identify the most representative keywords for each cluster. Finally, we employed DTM to examine the temporal evolution of these topics over the 2015–2024 period. The study identified 27 topics, including OCR for historical documents, multilingual processing, book recommendation systems, author name disambiguation, and misinformation detection, among others. These were further categorized into ten research directions, such as digital transformation, information retrieval, and scholarly communication. Temporal analysis revealed emerging AI-driven trends alongside steady growth in traditional areas like information literacy education. Findings highlight the growing integration of AI technologies into library information services. This study offers strategic insights for researchers and practitioners to innovate library information services and responsibly adopt AI technologies.
Keywords
Introduction
With the rapid advancement of information technology, artificial intelligence (AI) has been widely applied across various industries, with the transformation of the library field standing out prominently (Luca et al., 2022). Libraries, as hubs of knowledge dissemination and centers for public services, are experiencing profound changes brought by AI technology in their service models and management practices (Cox & Mazumdar, 2022). From user services to resource management, AI is increasingly integrating into various aspects of library operations, presenting both new opportunities and challenges (Echedom & Okuonghae, 2021).
In recent years, the application of AI technology in libraries includes book recommendation systems (Rosidah & Dellia, 2024), natural language processing (NLP) for analyzing chat reference transcripts (Wang, 2022), and document digitization using computer vision and machine learning (Ali et al., 2023). These technologies have not only improved the efficiency and quality of library services but have also enabled traditional libraries to transition into more interactive and intelligent modern information centers. For instance, AI-based virtual assistants help users locate desired resources (Panda & Chakravarty, 2022), OCR technology has enabled the digitization and recognition of ancient texts (Ma et al., 2024), and NLP techniques allow for the automatic analysis of user queries to provide more precise personalized recommendations (Majhi & Mukherjee, 2023). These specific examples demonstrate the immense potential of AI applications in libraries. However, there is still a lack of systematic research in the literature on the comprehensive application of AI in libraries and its evolution over time. Moreover, while these technologies have the potential to fundamentally change library operations and services, questions regarding their long-term impact, the interplay between different technologies to advance library services, and how these changes affect user experience and the roles of librarians remain insufficiently explored. Therefore, this study aims to fill these gaps by using the BERTopic model to identify and analyze the key research topics of AI in the library field, and Dynamic Topic Modeling (DTM) to explore the evolution of these topics. The study is guided by the following three primary research questions:
By addressing these questions, the study aims to uncover the current state and development trends of AI technologies in library information services, providing significant references for both academia and practice.
Related Work
Current Research Status of AI Technologies in Library Information Services
With the rapid advancement of information technology, AI is gradually becoming an essential innovation tool in the library field, with applications spanning across user services, resource management, knowledge discovery, and academic support (Ali et al., 2020). In recent years, academic research and practical applications have jointly promoted the deep integration of AI technologies in libraries. Through NLP (Taskin & Al, 2019), machine learning (Mupaikwa, 2023), computer vision (Llerena-Izquierdo et al., 2020), and robotics (Wójcik, 2023), both operational efficiency and user service experiences in libraries have been significantly improved.
In the domain of user services, recommendation systems have become an important means for libraries to enhance personalized experiences (Khademizadeh et al., 2022). Traditional resource recommendation approaches are based on book classifications and users’ borrowing histories, whereas AI-driven recommendation systems utilize machine learning algorithms and big data analysis to provide more accurate content suggestions. Haffenden et al. (2023) explained how the National Library of Sweden developed a Swedish BERT language model by leveraging its extensive collections, illustrating the innovative application of NLP technologies within library settings. Additionally, AI-powered virtual assistants and chatbots are increasingly being adopted in library reference services, offering 24/7 support to help users answer questions and improve service responsiveness (Nawaz & Mohamed, 2020). In terms of resource management, computer vision technologies have automated and enhanced the efficiency of document digitization processes (Shi et al., 2020). Bangdiwala et al. (2023) examined an Automated Library Management System that uses OCR and face recognition to simplify book issuing, reduce queues and scanner costs, and improve user experience by making transactions and information access easier. At the same time, AI has been applied in areas such as metadata extraction (Choudhury et al., 2021) and Ontology (Meghini et al., 2020), significantly optimizing knowledge organization and information retrieval services in libraries.
Despite the immense potential of AI technologies in library information services, their adoption still faces multiple challenges. Issues such as user privacy protection, ethical concerns, and the changing skill requirements introduced by AI pose new demands on both librarians and users (Barsha & Munshi, 2023). Hamad et al. (2022) highlighted privacy and confidentiality concerns as significant challenges in deploying smart services within libraries. Additionally, financial issues, including inadequate infrastructure and insufficient staff training, were identified as major barriers that hinder librarians from developing and offering these advanced services. Moreover, the ethical implications have garnered extensive discussion. One major concern is how to protect user data privacy while leveraging AI technologies, as well as ensuring algorithmic transparency and fairness. For example, book recommendation systems and chatbots require the collection and analysis of large amounts of user data to deliver personalized services, which raises significant privacy challenges (Coghlan et al., 2023; Milano et al., 2020). Although AI technologies in libraries show potential, particularly in personalized services and resource management, their successful implementation demands more than just technical innovation. It also requires addressing ethical, privacy, and human resource challenges.
Topic Modeling and Current Research Status of BERTopic
Topic modeling is an unsupervised learning technique used to identify latent thematic patterns in large text corpora. It assumes that each document is a mixture of various topics, with each topic characterized by a distribution over keywords. In bibliometric studies, topic modeling enables researchers to uncover hidden thematic structures and organize large volumes of textual data without requiring labeled input, thereby facilitating the analysis of intellectual landscapes, the detection of emerging trends, and the summarization of evolving research fields. Common topic modeling approaches include Latent Semantic Analysis (LSA) (Deerwester et al., 1990), Non-negative Matrix Factorization (NMF) (Lee & Seung, 2000), Latent Dirichlet Allocation (LDA) (Blei et al., 2003), Biterm Topic Model (BTM) (Yan et al., 2013), Top2Vec (Angelov, 2020), and more recently, neural embedding-based models such as BERTopic (Grootendorst, 2022).
Traditional methods such as LDA and LSA rely on word co-occurrence statistics and probabilistic distributions, often assuming a “bag-of-words” representation that disregards word order and contextual semantics. While effective for basic topic extraction, these models often struggle with semantic ambiguity and are limited in their ability to capture nuanced topic structures in domain-specific or semantically rich corpora. Recent advances in deep learning have enabled more powerful and semantically aware approaches to topic modeling by leveraging contextual embeddings from pretrained language models, which significantly enhance topic coherence and semantic representation. Instead of relying on predefined taxonomies or keyword matching, these models automatically group documents based on shared semantic content, making them especially effective for exploratory analysis of unstructured text corpora. BERTopic is one such method that integrates pretrained transformer-based language models with unsupervised clustering techniques (Grootendorst, 2022). The BERTopic framework typically comprises four stages: (1) generating contextualized document embeddings, (2) reducing the dimensionality of these embeddings, (3) clustering semantically similar documents, and (4) extracting representative topic keywords using class-based TF-IDF (c-TF-IDF). Compared to probabilistic models like LDA, BERTopic is better suited for capturing subtle semantic relationships, handling overlapping or evolving themes, and generating more interpretable topics in large, heterogeneous corpora (Egger & Yu, 2022; Gan et al., 2024).
In recent years, many researchers have used the BERTopic model to extract themes from policies, patents, papers, and online reviews (Egger & Yu, 2022; Raman et al., 2024; Wang et al., 2023; Yang et al., 2024). These studies have demonstrated the feasibility and applicability of BERTopic in analyzing different types of texts, but there has yet to be research applying the BERTopic model to the themes of AI technologies in library information services. Existing studies have used bibliometric methods to analyze thematic trends of AI in the library field, primarily focusing on topic identification at the “text” level, without delving into sentence-level topic recognition. In this research, sentence-level topic identification and evolution analysis are conducted based on document abstracts. The aim is to understand and reveal the frontier of research on AI technologies in library information services, providing a reference for researchers in understanding research progress, choosing research directions, and assisting libraries or information organizations in investment decisions and project planning.
Research Methods
Data Sources
Search Queries in Database

The initial search retrieved 4,910 records from Scopus and 2,118 records from WoSCC, resulting in a combined total of 7,028 records. After deduplication and data cleaning, a total of 1,598 records were excluded including duplicate entries and records with missing abstracts. The remaining 5,430 records proceeded to the screening stage. During screening, 2,454 records were excluded for not meeting the selection criteria. These included publications that fell outside the specified time frame (2015–2024), were not written in English, or were categorized as review articles, editorial materials, book chapters, corrections, retractions, or meeting abstracts.
Following this step, 2,976 records were further assessed for topical relevance by reviewing their titles, abstracts, and keywords. This manual check led to the exclusion of an additional 187 records that were deemed not closely aligned with the research focus on AI applications in library contexts. After completing this process, a final dataset of 2,789 records was retained for topic modeling and subsequent analyses. The full workflow of identification, screening, eligibility assessment, and inclusion is illustrated in Figure 1, following the PRISMA workflow. Data Collection and Screening Flowchat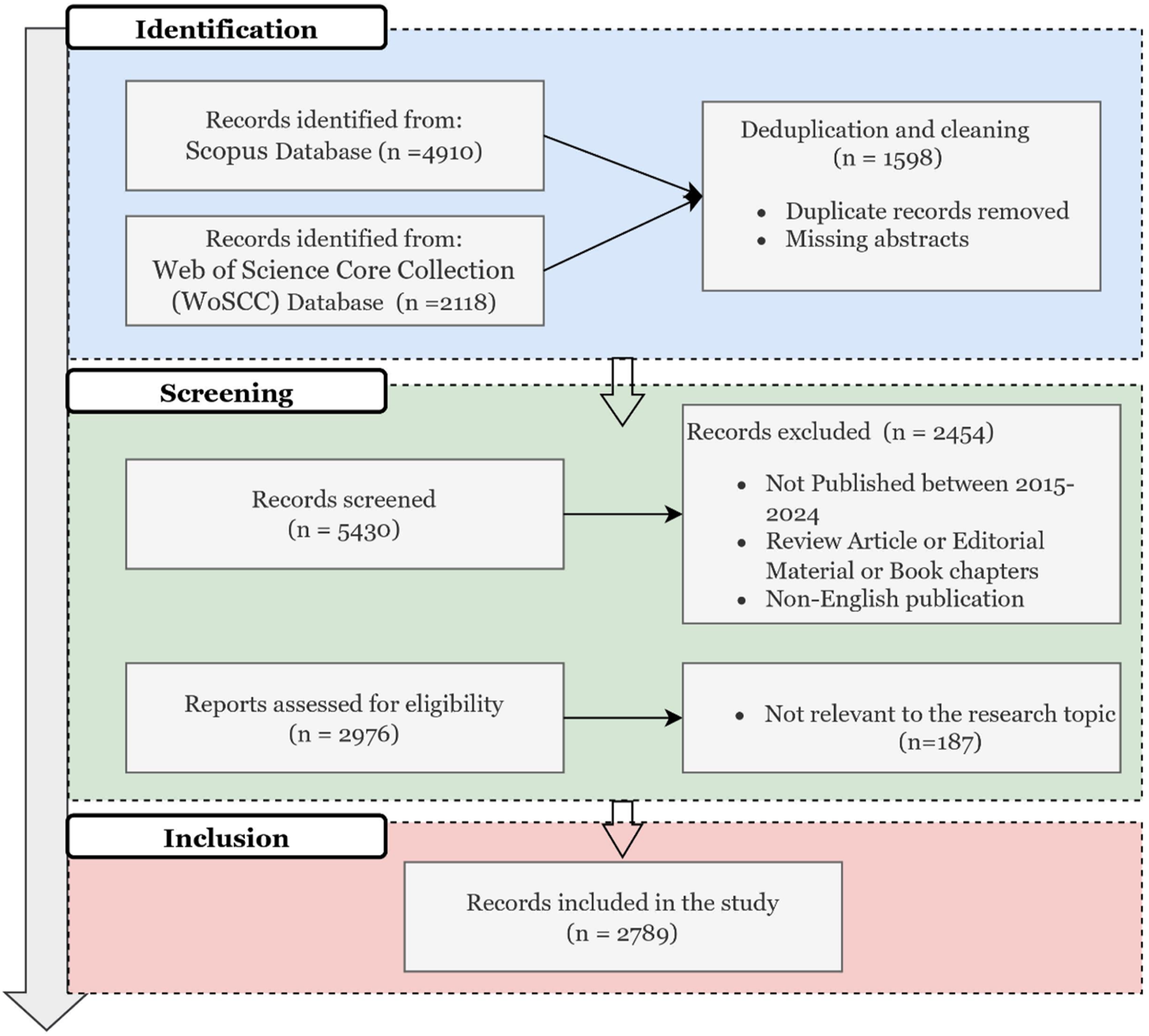
Research Design and Procedures
This study utilized the unsupervised deep learning model BERTopic for topic modeling. BERTopic is a BERT-based topic modeling technique that leverages BERT embeddings for semantic representation. It then applies dimensionality reduction using Uniform Manifold Approximation and Projection (UMAP) (McInnes et al., 2018) and clusters the reduced vectors using the density-based algorithm Hierarchical Density-Based Spatial Clustering of Applications with Noise (HDBSCAN) (Campello et al., 2013) to generate topic clusters. A key advantage of BERTopic over models like LDA is HDBSCAN’s ability to automatically determine the number of topics and identify noise documents. To interpret the clusters, BERTopic applies the class-based TF-IDF (c-TF-IDF) algorithm (Grootendorst, 2022) to the documents within each topic cluster. This c-TF-IDF weighting identifies the most important and representative keywords for each topic. A detailed overview of the topic modeling process is provided in Figure 2. Topic Modeling Process and Methods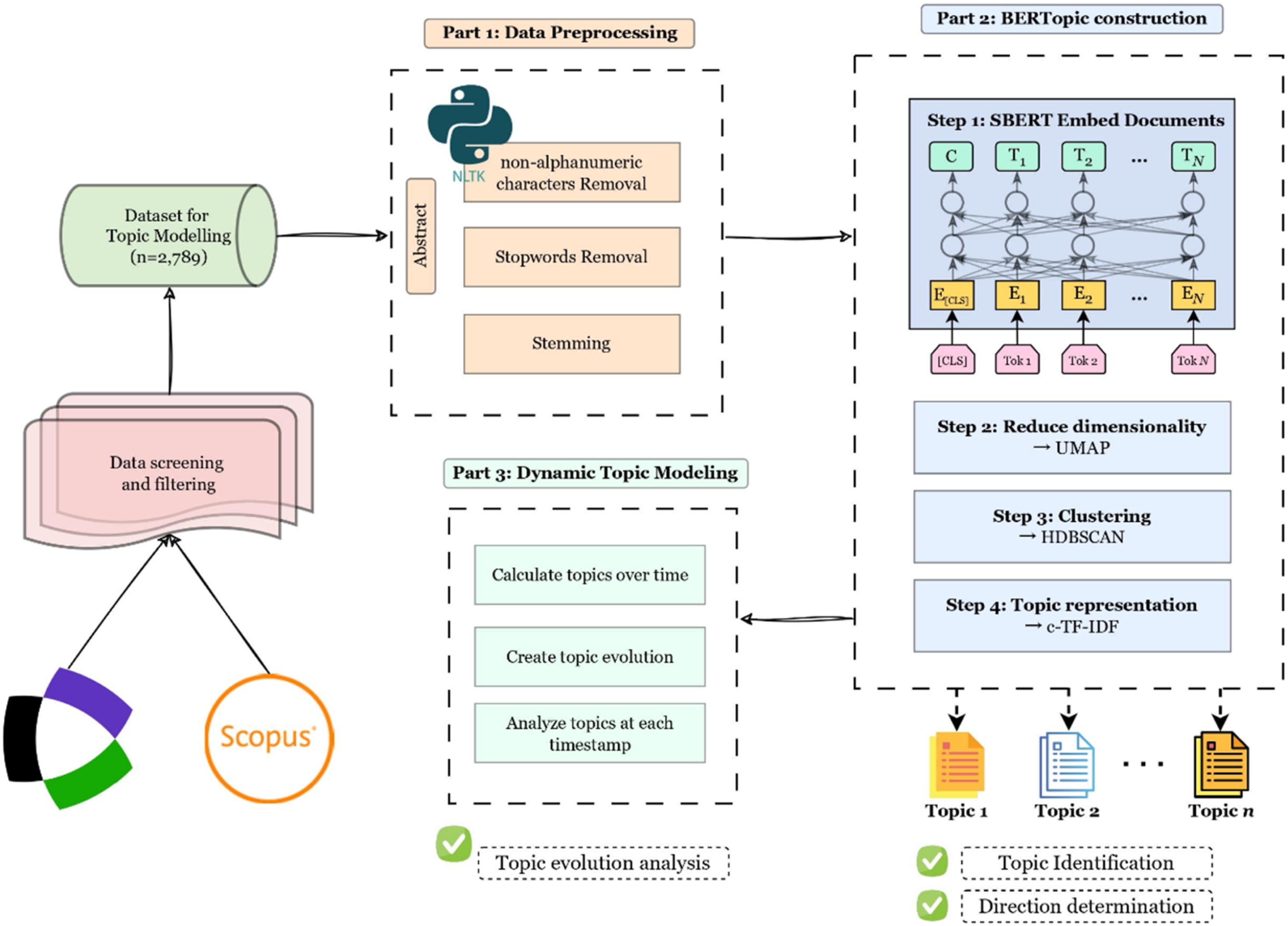
Preparation and Preprocessing
Python Libraries Employed

To prepare the text data for topic modeling, we applied a lightweight preprocessing pipeline aimed at reducing surface-level noise while preserving semantic content. Basic normalization was first performed using the Natural Language Toolkit (NLTK), including lowercasing, punctuation removal, and stopword filtering using the NLTK stopword list to reduce interference from high-frequency, low-information terms. Stemming was also applied using the Porter stemmer to reduce morphological redundancy and improve lexical consistency, particularly in technical terms that appear in variant forms. Importantly, this preprocessing was applied only to normalize the abstracts prior to embedding. Semantic representations of each document were generated using Sentence-BERT, which produces contextual embeddings that capture semantic similarity at the sentence level. These embeddings were first subjected to dimensionality reduction and then clustered to identify semantically coherent topic groups. Topic representations were subsequently generated based on clustered embeddings using c-TF-IDF method, which identifies the most representative terms for each topic.
BERTopic Model Construction
The BERTopic model was constructed by integrating several components: contextual embeddings generated via Sentence-BERT (Reimers & Gurevych, 2019), UMAP for dimensionality reduction, HDBSCAN for clustering, and c-TF-IDF for topic representation. The following steps outline the BERTopic modeling process.
Text Embedding/Embedding Model (Sentence-BERT)
To extract semantic features, BERTopic employs sentence-level embeddings. Sentence-level embedding converts short texts into dense vectors capturing contextual meaning. For document processing, we treated each abstract as a single textual unit, generating embeddings that provide the semantic foundation for clustering. We used Sentence-BERT (SBERT), specifically the pretrained all-mpnet-base-v2 model from the SentenceTransformers library. This model utilizes the MPNet architecture—an optimized transformer variant pretrained for semantic similarity tasks. SBERT generates token-level embeddings, then applies a mean-pooling strategy over all output tokens embeddings to produce a fixed-length vector per input. This vector preserves contextual information and allows documents with similar meanings to be positioned close together in the embedding space. To generate a single vector 
Dimensionality Reduction
To make the high-dimensional document embeddings generated by Sentence-BERT more suitable for clustering, we applied UMAP as a dimensionality reduction technique. UMAP is a nonlinear algorithm that projects high-dimensional vectors into a lower-dimensional space while preserving the local and global semantic structure of the data. This step is essential because subsequent clustering and topic representation benefit from lower-dimensional, topology-preserving representations that highlight the intrinsic relationships among documents.
In this study, we reduced the embeddings to 10 dimensions using UMAP, which allowed the model to capture the essential structure of the document space while improving the efficiency of subsequent clustering. We set n_neighbors = 15 to balance attention between local and global structure and min_dist = 0.0 to ensure compact clustering. To measure the similarity between documents during this projection, UMAP used cosine distance as the distance metric: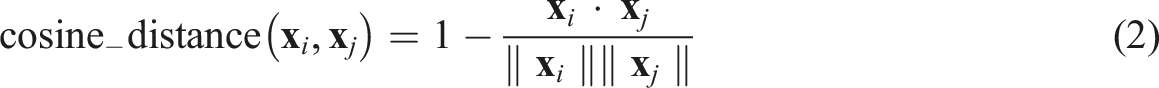
Clustering Algorithm
To group semantically similar documents into coherent topic clusters, we applied a density-based clustering algorithm to the reduced document embeddings. In topic modeling, clustering serves as a key step for identifying latent thematic groupings without prior labels. Among various clustering families, methods generally fall into categories such as partition-based (e.g., k-means), hierarchical (e.g., agglomerative clustering), and density-based approaches (e.g., DBSCAN and HDBSCAN).
In this study, we employed HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise), a robust density-based algorithm introduced by Campello et al. (2013, 2015) as an extension of the foundational DBSCAN method developed by Ester et al. (1996), combining ideas from density-based clustering and hierarchical clustering. McInnes et al. (2017) implemented an efficient and scalable Python version of HDBSCAN with significant algorithmic optimizations, enabling its widespread adoption in machine learning workflows.
We selected HDBSCAN over centroid-based approaches like K-means due to its ability to automatically determine the optimal number of clusters without a predefined number of clusters, inherent robustness to noise documents that do not belong to any coherent topic, and capacity to discover arbitrarily shaped semantic clusters in the embedding space, which are critical advantages for uncovering latent thematic structures in textual data. HDBSCAN first calculates the core distance for each point 
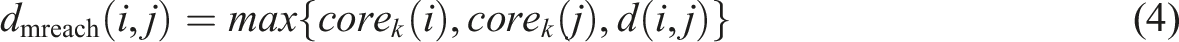
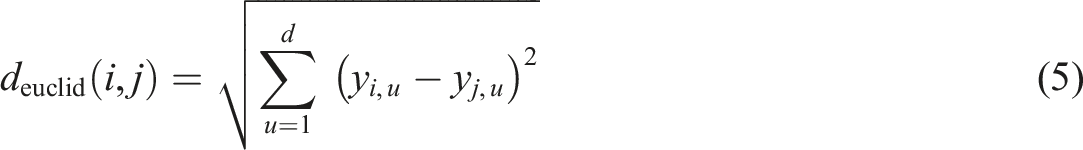
For this study, we set min_cluster_size=10, ensuring that each topic cluster included at least ten documents, and prediction_data=True, enabling HDBSCAN to predict cluster assignments for new data.
Topic Representation Construction
BERTopic employs a class-based TF-IDF approach to extract topic-representative terms. This approach adapts the traditional TF-IDF technique by treating each document cluster as a single concatenated document, enabling the extraction of keywords that best characterize the overall content of that cluster. The traditional TF-IDF algorithm evaluates the importance of a term within a document (Joachims, 1997), as represented by equation (6):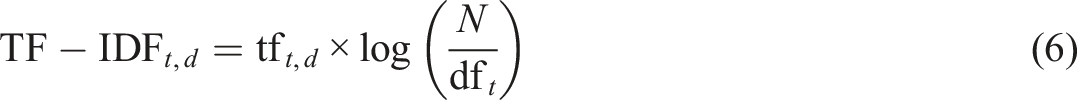
The c-TF-IDF algorithm employed by BERTopic builds upon this principle by redefining 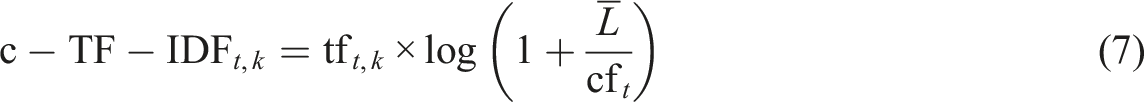
Equation (8) extends this concept to DTM, which accounts for topics evolving over time. For this purpose, 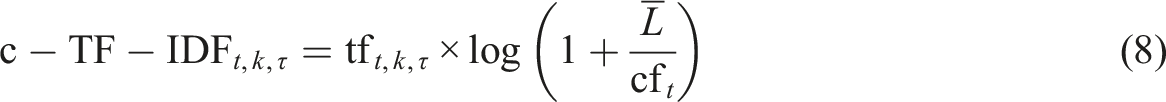
Hyperparameters Tuning
Upon completing the dimensionality reduction and clustering steps, several hyperparameters in BERTopic were tuned to further refine and optimize the topic modeling process. To ensure that each identified topic maintains adequate representativeness, a minimum topic size of 10 was set, meaning that any cluster containing fewer than 10 documents was automatically merged with the most similar cluster. Furthermore, to enhance the adaptability of the model and avoid predefining the number of topics, the parameter nr_topics was set to “auto,” allowing the algorithm to determine the optimal number of topics based on the structure of the data. Additionally, to facilitate the interpretability of each topic, the model was configured to extract the ten most representative keywords per topic, ensuring that the resulting topics were both meaningful and distinguishable.
Dynamic Topic Modeling
To investigate how research topics have evolved over time, we applied DTM based on the BERTopic framework. DTM refers to a set of techniques that track the temporal dynamics of topics across sequential time intervals (Grootendorst, 2022). In our implementation, BERTopic was first fitted to the full dataset without considering time, producing a static topic model that captures the overall thematic structure across the entire corpus. After identifying stable topic clusters, we introduced the temporal component by segmenting the data by publication year. Rather than reapplying clustering for each time slice, BERTopic’s DTM module computes topic-specific representations at each timepoint using c-TF-IDF. This method leverages the globally learned topic-document associations and recalculates term importance over time. As a result, each topic is dynamically described by a unique set of keywords at each timestep, reflecting how its semantic focus shifts across years. This design eliminates the need to recluster embeddings at each temporal stage and ensures consistency in topic tracking, enabling meaningful longitudinal analysis of topic evolution.
Findings
Key Research Topics
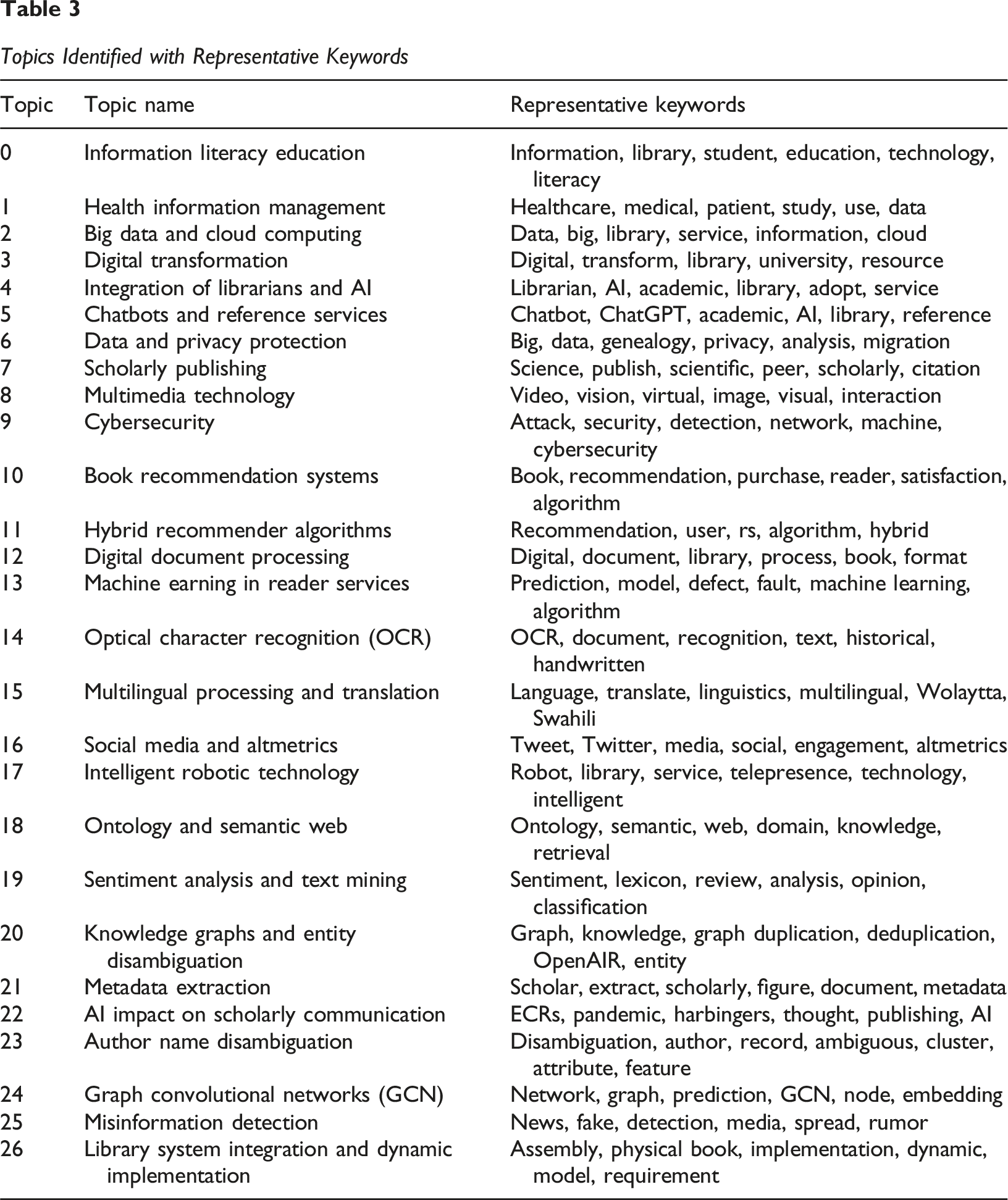
In the context of rapid advancement in information technologies, AI is profoundly transforming various aspects of libraries. From information management to user services, academic communication, and intelligent development, the application of AI technologies in libraries is expanding, giving rise to diverse research topics (S & Mulimani, 2024). To comprehensively understand and analyze the current state and development trends, this study identified 27 AI-related research topics in library information services by training the BERTopic model. Figure 3 provides an overview of the topic word scores for the top 16 topics, while a full listing of the topics is included in Table 3. The following section presents an analysis of several representative topics that capture the core advancements and challenges of AI technologies and applications in library information services. Top 5 Terms for the First 16 Research Topics Topics Identified with Representative Keywords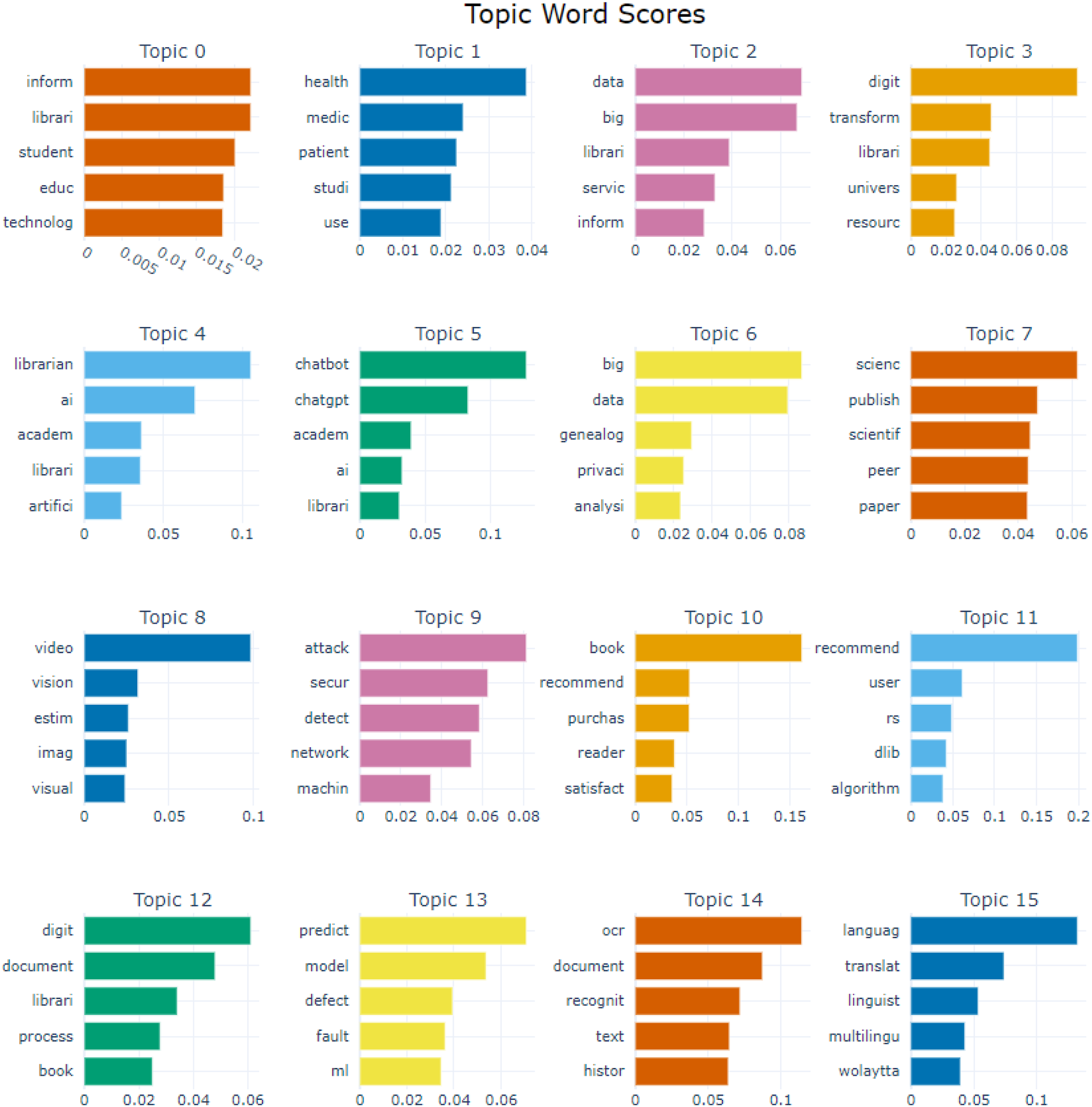
To begin with, Topic 0 (Information Literacy Education), which has keywords such as “information,” “library,” “student,” “education,” “technology,” and “literacy,” focuses primarily on the role of libraries in information management and information literacy education. This topic covers how AI technology can enhance the efficiency of information management, conduct information literacy training, disseminate health information, and manage medical information resources. Similarly, Topic 1 (Health Information Management) with keywords such as “healthcare,” “medical,” “patient,” “study,” “use,” and “data,” involves the role of libraries in managing healthcare information and the application of AI. Specifically, this topic emphasizes the use of AI technologies to manage and analyze medical data, support patient information access, and facilitate medical research. Through AI, the efficiency and accuracy of healthcare information management have been significantly improved, thereby better supporting medical research and education.
In addition, Topic 2 (Big Data and Cloud Computing) with keywords including “data,” “big,” “library,” “service,” “information,” and “cloud,” explores the application of big data and cloud computing in library services. This topic covers, for example, how big data analytics can optimize resource management, how cloud computing can enhance service flexibility and scalability, and how AI technology can ultimately improve the efficiency and quality of information services. This combination allows libraries to better manage resources and respond flexibly to user demands.
Moving forward, Topic 5 (Chatbots and Reference Services) with keywords such as “chatbot,” “ChatGPT,” “academic,” “AI,” “library,” and “reference,” examines the use of chatbots in library reference services. AI-driven chatbots enhance online reference service efficiency and user experience by offering immediate responses and personalized interactions. For example, these chatbots can answer user queries, and guide users through library procedures, thereby significantly improving accessibility and the quality of library services. This demonstrates how AI is instrumental in transforming traditional reference services into dynamic and responsive user interactions.
Topic10 (Book Recommendation Systems), with keywords like “book,” “recommendation,” “purchase,” “reader,” “satisfaction,” and “algorithm,” investigates the application of AI-driven book recommendation systems in libraries. For instance, recommendation algorithms can improve the accuracy and personalization of book recommendations, thus enhancing reader experience and satisfaction, as well as optimizing book purchasing strategies through data analysis. On a related note, Topic 11 (Hybrid Recommender Algorithms), with keywords like “recommendation,” “user,” “recommender system,” “algorithm,” and “hybrid,” studies the application of hybrid recommender systems in library services. Hybrid recommender systems combine multiple recommendation techniques, such as content-based filtering, collaborative filtering, and deep learning, to improve recommendation accuracy, diversity, and meet user needs more effectively.
Topic 14 (Optical Character Recognition (OCR)), with keywords like “OCR,” “document,” “recognition,” “text,” “historical,” and “handwritten,” focuses on the use of OCR to digitize handwritten and historical documents, enhancing their searchability and accessibility, as well as utilizing AI to automatically recognize and convert handwritten text. Additionally, Topic 15 (Multilingual Processing and Translation), with keywords such as “language,” “translate,” “linguistics,” “multilingual,” “Wolaytta,” and “Swahili,” emphasizes the application of multilingual processing and translation technologies in libraries. For instance, AI can be used for the translation and recognition of books in minority languages (e.g., Wolaytta, Swahili), thereby supporting access to multilingual resources and facilitating cross-language information exchange.
Moreover, Topic 18 (Ontology and Semantic Web) with keywords such as “ontology,” “semantic,” “web,” “domain,” “knowledge,” and “retrieval,” focuses on the application of ontology construction and semantic networks in information retrieval in libraries. This topic involves using AI technologies to construct domain ontologies, and develop semantic networks to enhance retrieval accuracy and efficiency. Relatedly, Topic 20 (Knowledge Graphs and Entity Disambiguation) with keywords such as “graph,” “knowledge,” “graph duplication,” “deduplication,” “OpenAIR,” and “entity,” studies the role of knowledge graph construction and entity disambiguation technologies in libraries. AI supports advanced information retrieval and user services through the construction and optimization of knowledge graphs, as well as entity disambiguation and data deduplication.
Topic 21 (Metadata Extraction), with keywords such as “scholar,” “extract,” “scholarly,” “figure,” “document,” and “metadata,” addresses the application of metadata extraction techniques in academic literature management. This topic includes using AI to automatically extract critical information from scholarly literature (e.g., author, title, abstract, and figures) to enhance the accuracy and efficiency of literature retrieval and management. Similarly, Topic 23 (Author Name Disambiguation), with keywords such as “disambiguation,” “author,” “record,” “ambiguous,” “cluster,” “attribute,” and “feature,” studies the application of author name disambiguation and literature clustering technologies in academic literature management. The research includes using AI algorithms to solve the problem of identifying authors with the same name, clustering similar literature to optimize document management and retrieval, and improving the accuracy of literature classification through attribute and feature analysis.
In parallel, Topic 25 (Misinformation Detection), with keywords such as “news,” “fake,” “detection,” “media,” “spread,” and “rumor,” focuses on the application of fake news detection and media analysis technologies in the library information environment. Libraries increasingly rely on AI technologies to detect and filter false information, prevent the spread of rumors, analyze media dissemination patterns, and maintain the authenticity and reliability of their information resources. This is particularly relevant in the current digital landscape, where misinformation can spread rapidly and libraries need to ensure they provide trustworthy information to their patrons.
Major Research Directions
By embedding documents using the embedding_model.encode function and invoking model. visualize_documents(), we obtained the vector representation of document-topic distribution (see Figure 4). The figure visualizes the distribution of research topics and their associated documents, offering insights into topic relationships and document distribution. Each point represents a document, with its color and position determined by the topic it belongs to. Documents of the same color form distinct clusters, indicating a high degree of internal consistency within these documents. For example, “Health Information Management” (Topic 1) and “Information Literacy Education” (Topic 0) form well-defined document clusters, demonstrating a high level of internal consistency within these topics. In contrast, the distribution of documents under some topics, such as “Chatbots and Reference Services” (Topic 5) and “Optical Character Recognition (OCR)” (Topic 14), is relatively dispersed, indicating the diverse nature of these topics and their association with multiple subdomains. Document-Topic Distribution
This visualization of topics and documents reveals the complex interrelationships between research areas, highlighting both their intersections and independence. To enhance thematic clarity and interpretability, we made slight adjustments and organized the 27 topics into 10 fine-grained research directions based on domain knowledge, thematic relevance, semantic similarity among topics, and visual patterns observed. These directions include information management, digital transformation, text and image recognition, reader services, intelligent development, information retrieval, recommendation systems, NLP, metadata extraction, and scholarly communication.
Research Direction 1: Information Literacy Education includes Topic 0 and Topic 1. These topics explore how AI can enhance information management capabilities in libraries and promote information literacy education, including information literacy and the dissemination of health information, particularly in medical information management and student education. By leveraging the automation and intelligent functionalities of AI, libraries can more effectively organize, manage, and disseminate information, thus helping users improve their information access and utilization skills.
Research Direction 2: Digital Transformation encompasses Topic 3, Topic 6, and Topic 12. This direction focuses on the challenges and applications of libraries in the digital transformation process, including the preservation, migration, storage of digital resources, and the automation of document processing. AI plays an important role in this transformation, particularly by using big data analysis and privacy protection technologies to manage data, such as genealogy which involves extensive private information, and optimizing the processes of digital document management to enable libraries to achieve efficient and sustainable digital transformation.
Research Direction 3: Text and Image Recognition comprises Topic 14 and Topic 15, primarily focusing on the application of OCR, handwritten character recognition, and multilingual processing and translation technologies in libraries. By using OCR and translation for rare languages, AI can digitize handwritten and historical documents, such as ancient texts, enhancing the searchability and accessibility of documents and supporting better services for multilingual library users.
Research Direction 4: Library User Services covers Topic 4, Topic 5, Topic 8, and Topic 13, concentrating on AI-driven changes in library services, such as chatbots assisting online readers, the impact of generative AI on library reference services, and the role of data visualization and human-computer interaction technologies in improving user engagement and experience. Additionally, machine learning is used to predict readers’ preferences, analyze borrowing records, and forecast library traffic. AI applications in these areas significantly improve the quality of library services and the user experience.
Research Direction 5: Library Intelligent Development includes Topic 2, Topic 9, Topic 17, and Topic 26, focusing primarily on the intelligent management of libraries, robotic services, library system integration, and issues related to library database security and user privacy protection. The research direction encompasses using cloud computing, big data, and intelligent robotics to enhance the automation and intelligence levels of libraries. Moreover, it explores how AI can detect and defend against cyberattacks, ensuring the security of library databases and user data, while dynamic system implementation optimizes overall library management efficiency. The intelligent development of libraries enhances resource management automation, boosts information system security and flexibility, and ultimately provides users with a more efficient service experience.
Research Direction 6: Information Retrieval and Knowledge Organization comprises Topic 18, Topic 20, and Topic 24. It explores the application of ontologies, semantic networks, knowledge graphs, and graph convolutional networks (GCN) in library information retrieval and knowledge organization. These technologies enhance the information retrieval capabilities of libraries and provide more accurate and efficient user services through intelligent searches.
Research Direction 7: Recommender Systems and Personalized Services includes Topic 10 and Topic 11, focusing on personalized book recommendation systems and hybrid recommendation algorithms. These algorithms analyze reader portraits, including reader attributes, behaviors, and preferences, to recommend relevant books and provide personalized reading suggestions. This also optimizes library collection procurement and resource allocation, enhancing readers’ experiences and satisfaction.
Research Direction 8: Natural Language Processing and Text Analysis covers Topic 19 and Topic 25, focusing on library-related applications, such as fake news detection, rumor prevention, social media sentiment analysis, reader comment analysis, and opinion mining. By using sentiment analysis and text classification techniques to analyze reader feedback and comments, libraries can better understand user needs and optimize service content. Furthermore, detecting misinformation ensures the authenticity and reliability of the information environment.
Research Direction 9: Metadata Extraction consists of Topic 21 and Topic 23, examining the use of AI in metadata extraction and author name disambiguation, particularly in managing scholarly publications. Author name disambiguation involves assigning papers to the correct author profile based on information such as the title, authors, affiliations, abstract, and keywords. Various methods have been proposed for addressing name ambiguity, including rule-based matching using document metadata or using representation learning approaches where learned representations are clustered using methods like hierarchical clustering or DBSCAN. By automating the extraction of key metadata and resolving name ambiguities, AI improves accuracy and efficiency in managing academic literature, providing reliable tools for document organization and retrieval in academic libraries.
Lastly, Research Direction 10: Scholarly Communication and Publishing includes Topic 7, Topic 16, and Topic 22, covering AI’s impact on academic communication, scientific publishing, and its effect on early-career researchers (ECRs). The research investigates AI’s role in the publication process, enhancing fairness in peer review, and using altmetrics, such as social media data, to assess research impact. These studies analyze AI’s positive or negative influence on the transparency, efficiency, and impact of academic communication.
As shown in Figure 5, the visualization results include the similarity heatmap and the intertopic distance map. From Figure 5(a), it can be observed that the similarity matrix illustrates the relationships among the 27 research topics identified, using color and similarity scores to indicate the degree of association between different topics. The dark areas along the diagonal represent the comparison of each topic with itself, with a similarity of 1, as expected. The color intensity in the matrix reflects the level of similarity, with darker colors representing higher similarity and lighter colors representing lower similarity. It can be seen that most topics have similarity scores ranging between 0.65 and 0.95, indicating a certain degree of association between them. Some topics exhibit darker colors, suggesting a higher similarity in research content. For example, “Digital Transformation” (Topic 3) and “Digital Document Processing” (Topic 12) show a high level of similarity, likely because both involve aspects of “digital management and resource processing in libraries.” On the other hand, lighter regions, such as between “Cybersecurity” (Topic 9) and “Multilingual Processing and Translation” (Topic 15), reflect significant differences in their research content. Similarity Heatmap and Intertopic Distance Map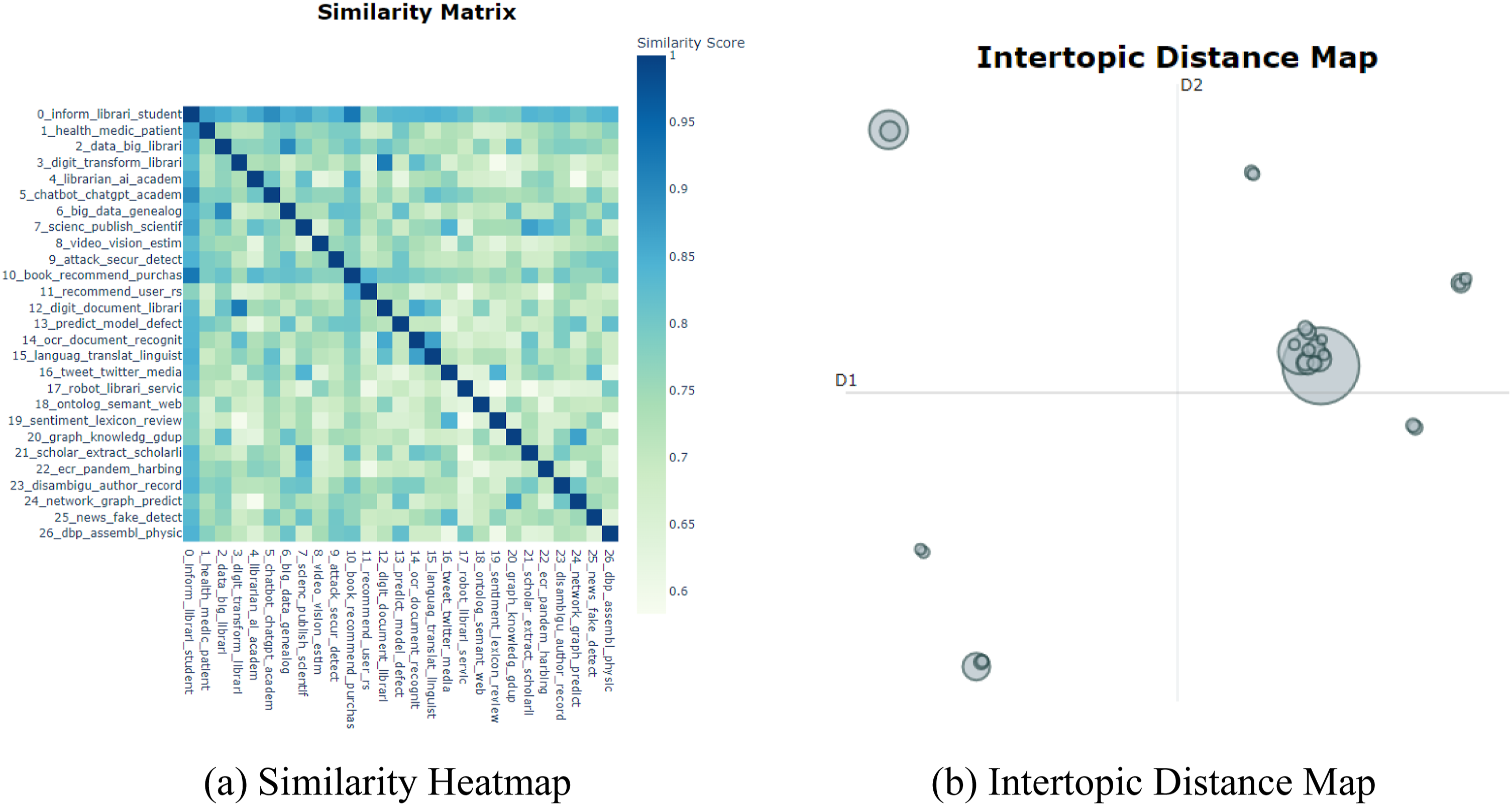
In the Intertopic Distance Map, each circle represents an individual topic, with the size of the circle indicating the importance of that topic in the corpus, while the distance between the circles represents their similarity or difference. From Figure 5(b), it is evident that some topics are located close to each other, indicating a high similarity in their research content, often sharing related research domains, such as information management or directions related to digital transformation. Relatively isolated circles represent more independent topics that are emerging or unique research areas, potentially involving issues such as network security, privacy protection, or fake news detection. Overall, the figure displays both clusters of related topics, indicating stronger associations among some research directions, and scattered independent topics, reflecting the diversity and variation inherent in AI research within the library domain.
Evolution of Research Directions
The DTM analysis revealed the evolution trends of the 27 identified topics, which were aggregated into 10 broader research directions, as shown in Figure 6. The analysis demonstrates that most topics have experienced significant growth in research activity post-2020, especially in areas such as information management, user services, and intelligent development. This growth indicates that the application of AI technologies in library information services has expanded across various aspects, driven by technological advancements and increased user needs. The demand for remote information services, particularly during the global pandemic, has accelerated the adoption and development of emerging technologies like chatbots and virtual visitation tools. Evolutionary Trends of Each Research Direction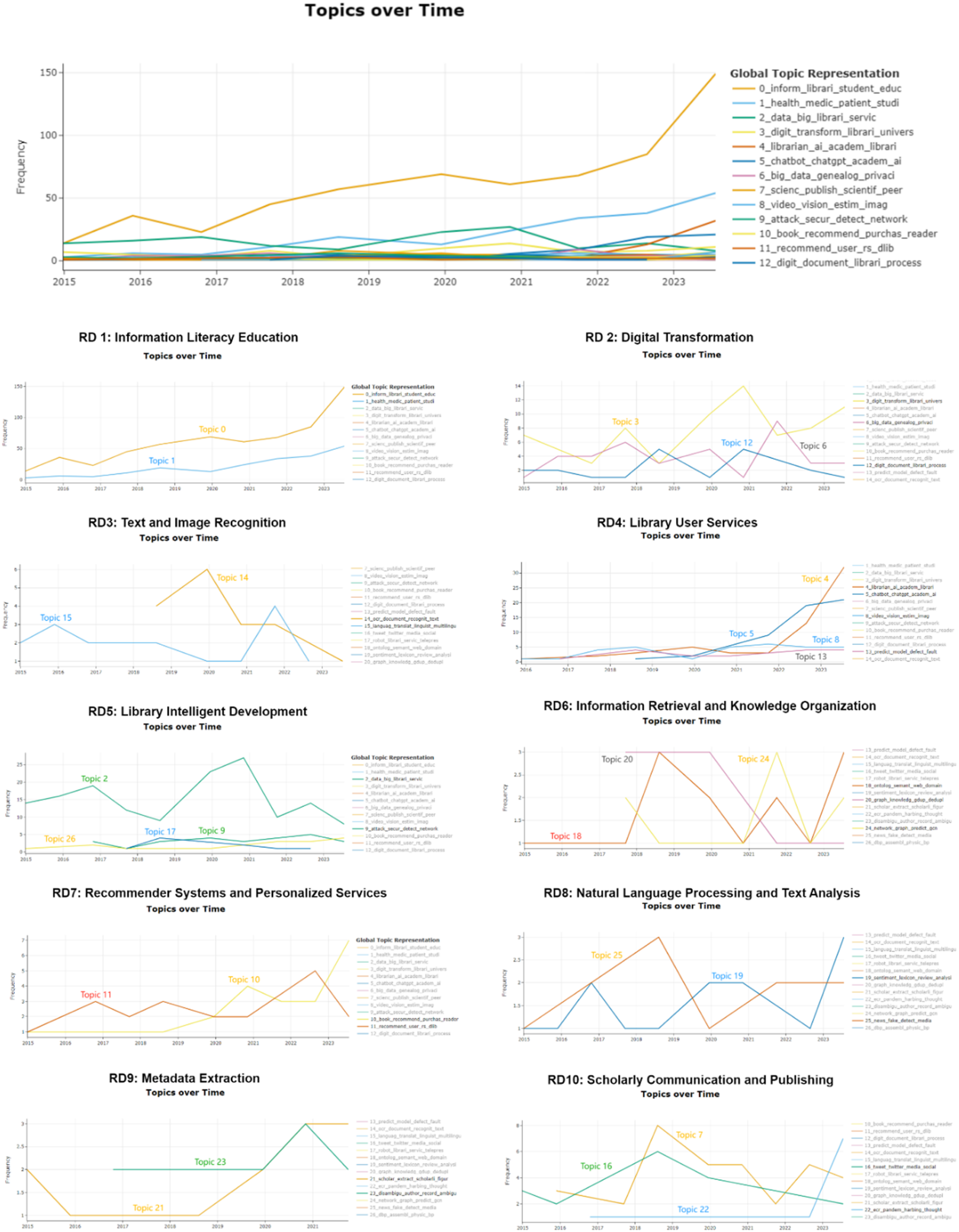
The trends for Information Literacy Education (Topics 0 and 1) illustrate a significant increase in research activity in these topics after 2019, particularly in Topic 0, suggesting the growing importance of information literacy as a key library function. This change is linked to increased public demand for the ability to identify and utilize information effectively in an era of information overload. The growth in medical information management research, especially in 2020, underscores the library’s role in promoting health information and providing reliable medical resources, particularly during public health crises like COVID-19.
The research direction of Digital Transformation (Topics 3, 6, and 12) showed varied evolution trends that reflect different stages in the library digitalization process, Topic 3 peaked in 2018, highlighting interest in digital resource management during that period. The focus on transitioning from physical to digital resources and managing them effectively in a digital environment has been ongoing. Topic 6, concerning data privacy, showed significant growth from 2019 to 2021, reflecting rising concerns about privacy and data management. Topic 12 shows a steady increase, indicating that digital processing and resource management are becoming standard tasks in libraries, enhancing users’ digital access.
The trends for Text and Image Recognition (Topics 14 and 15) reveal specific dynamics in this area, the sharp increase in Topic 14 in 2022 suggests growing use of OCR and handwriting recognition in digitizing historical manuscripts and documents, enhancing accessibility. Topic 15 peaked in 2020, then stabilized, reflecting maturity in multilingual processing and the provision of services to non-mainstream language users, further supporting libraries’ global and diverse services.
The evolution trends in Library User Services (Topics 4, 5, 8, and 13) clearly show the influence of AI on library service models. Topics 4 and 5 have risen significantly since 2020, indicating a greater reliance on smart user services (e.g., chatbots) during the pandemic. Topic 8, which involves multimedia interaction methods like VR and data visualization, has shown steady growth, reflecting libraries’ exploration of new service methods to enhance user engagement. Topic 13’s rise illustrates the growing application of machine learning in predicting user needs and optimizing in-library resource use.
Library Intelligent Development (Topic 2, 9, 17, 26) has seen growth since 2020, particularly regarding cloud computing and big data (Topic 2), highlighting the importance of using intelligent methods for resource management and optimization. Topic 9 peaked in 2021, emphasizing data security and defense against cyberattacks as digital services expand. Topic 17’s focus on robotics and remote services shows a growing trend towards using intelligent robots for daily operations.
Information Retrieval and Knowledge Organization (Topics 18, 20, and 24) demonstrated various evolution trends. Topic 24 peaked in 2018, mainly involving graph convolutional networks and knowledge graph applications, indicating increased interest in using advanced technologies for knowledge organization. Topics 18 and 20 have risen steadily since 2022, reflecting the expanding application of semantic technologies and knowledge graphs to enhance information retrieval and knowledge management.
Recommendation Systems and Personalized Services (Topics 10 and 11) showed notable growth in 2023, indicating a rising demand for personalized services among library users. Topic 10 highlights the role of recommendation algorithms in enhancing user satisfaction and reading experiences. Topic 11 indicates the library’s move towards hybrid recommendation strategies to meet diverse user needs, shifting from passive resource provision to proactive personalized services.
The evolution trends in Natural Language Processing and Text Analysis (Topics 19 and 25) highlight their critical role in user sentiment analysis and misinformation detection. Topic 25 peaked in 2021, likely due to the spread of misinformation during the pandemic, emphasizing libraries’ role in detecting fake news and analyzing public sentiment to maintain a healthy information environment. Topic 19 also showed an upward trend, reflecting increased interest in sentiment analysis of user feedback, helping libraries better understand users’ needs and optimize their services.
Metadata Extraction (Topics 21 and 23) saw increasing attention post-2019, particularly in Topic 23, which deals with author name disambiguation. This growth reflects the importance of automated metadata extraction in efficiently managing and retrieving academic literature, thereby improving library services.
Finally, Scholarly Communication and Publishing (Topics 7, 16, and 22) has shown notable growth since 2020. Topic 7, in particular, reflects increased AI applications in scholarly publishing, enhancing the efficiency and fairness of publishing workflows. Topic 22, concerning the impact on early-career researchers during the pandemic, also rose notably, highlighting the profound influence of AI on scholarly communication during crises.
Discussion
This study reveals the distinct research topics and applications of AI technologies in library information services and their evolutionary trends over time. Through BERTopic analysis, 27 unique research topics were identified and categorized into ten research directions. DTM analysis provided further insight into each direction’s development from 2015 to 2024, reflecting shifts in technological capabilities, user needs, and institutional priorities.
The application of AI technologies in library information services has garnered increasing attention, particularly in areas such as information literacy education, digital transformation, and personalized user services. Information Literacy Education has emerged as a critical library function, especially given the current landscape of information overload and misinformation. This role has expanded to include medical information management, underscoring libraries’ importance in supporting public health through reliable information, a trend that became pronounced during the COVID-19 pandemic. In addition, the continuous growth in digital transformation reflects libraries’ emphasis on resource digitization, document preservation, and digital asset management. AI-driven text and image recognition technologies, such as OCR and multilingual processing, have made rare manuscripts and non-mainstream languages more accessible, thereby enhancing global inclusivity. Moreover, AI’s integration into library user services has transformed traditional service models to become more personalized and responsive. Specifically, technologies such as chatbots, virtual reality, and predictive analytics have significantly improved service efficiency and user experiences, which highlights AI’s role in making services more adaptive to user needs. At the same time, intelligent development and management of libraries involves adopting technologies like cloud computing and intelligent robots to enhance operational efficiency and enable dynamic system integration. This approach ultimately leads to more flexible and responsive services. Similarly, information retrieval and knowledge organization have also evolved, as ontologies, semantic networks, and knowledge graphs enhance advanced information discovery. This shift positions libraries not just as repositories but as proactive agents aiding in knowledge understanding. Furthermore, the growing focus on recommender systems and personalized services suggests a shift towards active, data-driven user engagement. The implementation of hybrid recommendation algorithms supports diverse user preferences, thereby enhancing user satisfaction. Meanwhile, natural language processing and text analysis play a crucial role in maintaining a healthy information environment through user sentiment analysis and misinformation detection, which aligns with libraries’ responsibility to ensure information integrity. Lastly, metadata extraction and scholarly communication and publishing highlight AI’s contribution to enhancing scholarly workflows. Automated metadata extraction has significantly simplified literature management. However, AI applications in scholarly communication and publishing have also introduced challenges to academic transparency and integrity, particularly during the pandemic.
The evolution of these topics indicates that AI is becoming an indispensable component of library information services, transitioning from experimental initiatives to core functionalities. Technologies like AIGC, machine learning, and knowledge graphs have evolved from emerging features into integral aspects of everyday library operations. This maturation reflects an AI-driven ecosystem that enhances information services, optimizes management practices, and strengthens libraries’ roles as dynamic knowledge centers.
While this study offers a comprehensive overview of the research landscape on AI applications in library information services, it is important to acknowledge that the findings reflect trends in scholarly publications rather than direct measurements of real-world implementation. Published literature often captures emerging interests, proposed methods, and experimental applications, which may not always translate into immediate or widespread adoption in practice. Therefore, the results should be interpreted as indicative of academic focus and potential development trajectories, rather than as a direct reflection of the current state of AI deployment in library operations.
Additionlly, we would like to acknowledge that although stemming is not typically required for transformer-based models, we observed in our experiments that applying light stemming helped reduce morphological redundancy in the corpus. This effect was particularly beneficial in the context of technical terminology, where multiple inflected forms of a concept could otherwise fragment semantically coherent clusters. Despite this normalization step, semantic distinctions were preserved in the final topic structures. While stemming can risk reducing lexical nuance, in our specific dataset it contributed positively to topic stability and interpretability. Given that our aim was to explore a broader range of potential topics, we found this approach to be helpful within our modeling framework.
Conclusion
This study conducted a comprehensive analysis of the application of AI technologies in library information services, identifying key research topics and emerging trends from 2015 to 2024. A total of 27 distinct topics were extracted and further categorized into ten research directions, each examined through a temporal lens to uncover its developmental trajectory. The findings highlight AI’s transformative potential in library information services, from enhancing user engagement via recommender systems and chatbots to supporting scholarly activities through metadata management and publishing analysis. As AI continues to evolve, libraries must not only integrate these technologies but also address critical challenges such as ethical data governance, user privacy protection, and the development of inclusive and equitable information services. The insights gained from this study offer valuable guidance for future research and professional practice, emphasizing the need for libraries to adopt AI responsibly and innovatively to meet the dynamic information needs of users. Despite its contributions, this study has certain limitations. First, the insights gained from this study primarily reflect academic discourse and research activity, which may not fully align with the pace or scale of AI implementation in actual library environments. Future research could benefit from integrating case studies or survey data to directly assess the extent of AI adoption across different library systems. Second, as the dataset was mainly sourced from indexed academic literature, it may not comprehensively capture non-English publications or community-driven documentation, potentially overlooking diverse perspectives. Future research should broaden the scope of data sources to ensure a more inclusive analysis.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.