
Abstract
Background:
Artificial intelligence (AI) models demonstrate remarkable capabilities in healthcare applications, yet their performance compared to medical trainees in psychiatric education remains unexplored. This study evaluated the comparative performance of large language models (LLMs) against first-year psychiatry residents in standardized assessments at a premier Indian medical educational institute.
Methods:
For this study, the already-scored answer sheets for Theory Papers I and II, as well as unmanned, non-interactive Objective Structured Clinical Examinations (OSCEs) with image-based tasks, from all 25 first-year psychiatry residents (March 2024 exam) were obtained from the examination section of the institute. The same question papers were then uploaded into three AI models (ChatGPT−3.5, Gemini Advanced, and Claude Sonnet). Four blinded faculty members evaluated the responses generated by the AI models. Final, the scores of the AI models and psychiatry residents were analyzed for comparison. Statistical analysis employed Kruskal–Wallis tests with post hoc Mann–Whitney U comparisons.
Results:
AI models outperformed residents in theoretical assessments. In Paper I (theory), AI models achieved mean scores (standard deviation) of Claude Sonnet 67.88 (10.63), ChatGPT−3.5 70.38 (3.95), and Gemini Advanced 71.25 (3.86), compared to residents’ 58.0 (2.58). Paper II (theory) assessments showed even larger gaps, with AI models scoring Claude Sonnet 72.88 (3.77), ChatGPT−3.5 71.0 (3.56), and Gemini Advanced 69.63 (12.86), compared to residents’ 50.96 (2.49). OSCE performance patterns differed markedly. Paper I OSCEs showed equivalent performance: AI: 13.0; residents’: 13.16 (1.49), while Paper II OSCEs revealed variable results: Claude Sonnet excelled at 20.0 (1.41), but ChatGPT−3.5 underperformed at 15.0 (0.50), compared to residents at 16.6 (1.55). Inter-rater reliability coefficients remained excellent ( intraclass correlation coefficients [ICC]: 0.810–0.934).
Conclusions:
While AI demonstrated superior theoretical knowledge, equivalent or variable practical skills performance reveals fundamental limitations in clinical reasoning and contextual understanding. These findings necessitate reconceptualizing psychiatric education to emphasize uniquely human competencies while leveraging AI’s capabilities for knowledge synthesis.
Keywords
Question: How do large language models (LLMs) (ChatGPT−3.5, Gemini Advanced, Claude Sonnet) perform compared to first-year psychiatry residents on standardized institutional assessments in an Indian training context? Findings: AI models outperformed residents by 17%–43% in theoretical exams but showed equivalent or inconsistent OSCE results, with errors in clinical reasoning and cultural application. Meaning: AI excels in knowledge recall but lacks human-centric skills essential for Indian psychiatric practice; curricula must integrate AI as a tool while prioritizing clinical judgment and empathy.Key Messages:
Artificial intelligence (AI) is revolutionizing the healthcare landscape, offering transformative solutions in diagnostics, treatment planning, and operational efficiency. 1 Recent comprehensive reviews have explored AI’s expanding role in digital psychotherapy across diverse conditions, including Attention Deficit Hyperactivity Disorder (ADHD), obsessive compulsive disorder (OCD), schizophrenia, and substance use disorders, highlighting both the transformative potential and implementation challenges. 2 Large language models (LLMs) such as ChatGPT, Gemini Advanced, and Claude Sonnet have emerged as notable advancements in AI, demonstrating impressive capabilities in LLMs that are trained on massive textual data spanning across various domains, including healthcare.
The role of AI in medical education is increasingly being recognized, particularly in resource-constrained settings, such as India, where psychiatric training demands efficient knowledge dissemination. Medical training relies on structured curricula, experiential teaching-learning, and rigorous assessments to cultivate competent professionals. Among these, theoretical knowledge acquisition and Objective Structured Clinical Examinations (OSCEs) play critical roles. Theoretical assessments test the trainee’s grasp of foundational concepts, while OSCEs evaluate their ability to apply this knowledge in simulated clinical scenarios, encompassing communication, reasoning, and problem-solving skills. 3
Despite its potential, integrating AI into medical education raises fundamental questions: Can AI match or exceed the theoretical knowledge demonstrated by medical trainees? How well can AI perform in practical, clinical, and interpersonal domains, particularly in psychiatry, where human interaction, critical thinking, and application of clinical concepts are pivotal? What role should AI play in reshaping medical education frameworks and competency assessments? The current literature reveals a critical gap: No prior study has directly compared AI performance with psychiatry residents using authentic institutional assessments from an apex psychiatry training institute. This absence is particularly relevant in the Indian context, where psychiatric training must address diverse cultural, socioeconomic, and linguistic factors that standardized global tests often overlook.
The novelty of this work lies in its use of real-world residency exams rather than simulated or international benchmarks, providing unprecedented insights into AI’s applicability for Indian psychiatric education. We hypothesized that LLMs would demonstrate superior performance on theoretical knowledge assessments due to their extensive training data and pattern recognition capabilities, but would show limitations in practical clinical skills that require contextual understanding, clinical reasoning, and application in culturally nuanced scenarios. This study aims to evaluate the comparative performance of three state-of-the-art AI models (ChatGPT– 3.5, Gemini Advanced, and Claude Sonnet) against first-year psychiatry residents in standardized assessments covering both theoretical knowledge and practical clinical competencies. Specifically, the objectives are to: (a) Compare AI model performance versus psychiatry residents in theoretical knowledge assessments (basic neurosciences and psychology, sociology, and anthropology); (b) evaluate AI capabilities in practical clinical skills through OSCEs; (c) assess inter-rater reliability of faculty evaluations for AI-generated responses; (d) analyze implications of AI performance patterns for psychiatric education and training curricula.
The study’s objectives extend beyond benchmarking AI capabilities; it also seeks to explore the implications of AI integration in medical education, its limitations in clinical and psychosocial domains, and the ethical considerations surrounding its use. By investigating the comparative performance of AI and residents, this study provides critical insights into the evolving relationship between technology and human expertise in medical education, with direct relevance to Indian psychiatric training paradigms.
Methods
Study Design and Setting
This cross-sectional comparative study was conducted at an apex psychiatry training institute to evaluate the performance of three LLMs against first-year psychiatry residents. The assessment involved randomly selected theoretical knowledge examinations of March 2024 (Papers 1 and 2) and OSCEs covering two core domains: Basic neurosciences and psychology, sociology, and anthropology, which are mandatory requirements for the MD Psychiatry course. Data collection occurred retrospectively for resident scores (from March 2024 examinations) and prospectively for AI evaluations between August and September 2024.
Ethical Approval
The Institutional Ethics Committee granted exemption from formal ethics review under Table 4 of the Indian Council of Medical Research (ICMR) Ethical Guidelines for Biomedical Health Research (2017). 4 The study was classified as “less than minimal risk” as it involved retrospective analysis of anonymized academic records without patient interaction or modification of educational protocols.
Study Population
AI Models
Three commercially available LLMs were evaluated: ChatGPT−3.5 (OpenAI), Gemini Advanced (Google), and Claude Sonnet 3.5 (Anthropic).
Human Participants
All 25 (n = 25) first-year psychiatry residents who appeared for the March 2024 mandatory examination with complete theory/OSCE digital records after completion of their standardized first-year residency curriculum at an apex psychiatry training institute were included. Retrospective marks from the 25 residents who had successfully passed these mandatory assessments were obtained for comparative analysis.
Faculty Evaluators
Four senior faculty members from different departments, each with at least eight years of teaching and assessment experience in psychiatry, served as blinded evaluators for theoretical examinations.
Assessment Details
Theoretical Examinations (Papers 1 and 2):
Basic neurosciences: Questions covering neuroanatomy, neurophysiology, and neuropathology relevant to psychiatric practice. Psychology, sociology, and anthropology: Assessment of psychological theories, sociological concepts, and anthropological perspectives applicable to psychiatry (Table 1).
Assessment Domains and Components.

Objective Structured Clinical Examinations
Standardized, unmanned, non-interactive stations (four per paper) delivered digitally as images with five questions per station (one mark each; max 20/paper), emphasizing identification, interpretation, and description rather than communication or examination skills. Residents viewed on terminals; identical-image questions were presented to the AI, ensuring identical visual stimuli and assessment conditions. This study adheres to the Strengthening the Reporting of Observational Studies in Epidemiology guidelines for cross-sectional reporting, ensuring comprehensive methodological transparency.
Data Collection Procedures
AI models received identical examination materials in the same format as residents. Each model was primed with a standardized prompt:
You are a first-year psychiatry resident at an apex psychiatry training institute. Answer the following questions as part of your shelf exam, providing detailed, evidence-based responses that reflect your clinical reasoning and knowledge. Ensure your answers are structured and comprehensive, as expected in a high-stakes academic assessment.
Residents’ digital examination scripts were graded once in the routine institutional process by the designated examiner; these scores were directly extracted from the examination records and were not regraded for this study. AI-generated responses were exported, anonymized, and printed as standardized typed answer booklets labeled only with study codes. Four senior faculty members independently evaluated these booklets using predefined rubrics, blinded to the specific AI model and without access to residents’ original scripts.
Statistical Analysis
For each AI model and each theory paper or OSCE, a single response was generated and independently rated by four senior faculty examiners using standardized rubrics. The average of these four ratings served as that model’s score for group comparisons (four groups: Residents and three AI models per assessment), while individual ratings were used exclusively to compute intraclass correlation coefficients (ICCs) for inter-rater reliability. Data normality was assessed using the Kolmogorov–Smirnov test. Continuous variables are presented as mean (standard deviation). Categorical variables are reported as frequencies and percentages. Inter-rater reliability was evaluated using ICC with 95% confidence intervals. Between-group comparisons used the nonparametric Kruskal–Wallis test (four groups: Residents and three AI models) with post hoc Mann–Whitney U tests for pairwise comparisons. Between-group comparisons employed a hierarchical testing strategy. Kruskal–Wallis tests served as omnibus tests for overall group differences, with statistical significance set at p < .05. When omnibus tests indicated significant differences, post hoc pairwise Mann–Whitney U tests were conducted to compare each AI model with residents. To control for multiple comparisons, we applied the Bonferroni correction, setting the adjusted significance threshold to α = 0.05/3 = 0.0167 for the three pairwise comparisons per domain. Given the exploratory nature of this study, with each AI model represented by a single aggregated score from four raters versus n = 25 residents, we emphasize descriptive statistics (effect sizes and directional patterns) alongside inferential statistics. All analyses were performed using IBM SPSS Statistics licensed version 29.0.
Performance Comparison Between AI Models and Residents (Maximum Marks: Theory 100 per Paper).

*Residents: n = 25 individual examinees. AI model scores represent the average of four independent examiner ratings for a single AI-generated response per model. SD = Standard deviation reflects inter-rater variation, U = Mann–Whitney U test statistic, *p < .05 for Kruskal–Wallis omnibus test, †Post hoc comparisons between each AI model and residents, ‡Bonferroni correction: α = 0.05/3 = 0.0167, NS = Not significant after correction. Difference calculated as (AI mean − resident mean), with percentage = (Difference/resident mean) × 100.
Results
This comparative assessment evaluated the performance of 25 first-year psychiatry residents against three AI models (ChatGPT−3.5, Gemini Advanced, Claude Sonnet) across theoretical and practical assessments, with responses evaluated by four faculty examiners. Performance scores across all assessment categories are presented in Table 2.
Theory examinations revealed substantial AI performance advantages across both assessment domains (Table 2). In Paper I (Basic Neurosciences), AI models achieved mean (SD) scores of ChatGPT−3.570.38 (3.95), Gemini Advanced 71.25 (3.86), and Claude Sonnet 67.88 (10.63), substantially exceeding the resident mean (SD) of 58.0 (2.58). Gemini Advanced demonstrated the highest theoretical performance in this domain, scoring 13.25 points (23%) higher than residents. ChatGPT−3.5 and Claude Sonnet also showed substantial advantages, exceeding residents by 12.38 points (21%) and 9.88 points (17%), respectively.
In Paper II (Psychology, Sociology, and Anthropology), examinations demonstrated even more pronounced descriptive differences. Claude Sonnet achieved the highest score with a mean (SD) of 72.88 (3.77), followed by ChatGPT−3.5 71.0 (3.56) and Gemini Advanced 69.63 (12.86), all substantially exceeding the resident mean (SD) of 50.96 (2.49) by 18.67–21.92 points (37%–43% higher performance). These represent the largest performance gaps observed across all assessments.
Kruskal–Wallis omnibus analysis revealed statistically significant differences between groups for Paper II (H = 8.78, df = 3, p = .032), while Paper I approached but did not reach significance (H = 6.96, df = 3, p = .073). Post hoc Mann–Whitney U tests with Bonferroni correction (threshold α = 0.0167 for three comparisons) yielded no individually significant pairwise comparisons (Paper I: Raw p = .036–.046; Paper II: Raw p = .021–.035, all exceeding the corrected threshold). However, the observed effect sizes substantially exceed Cohen’s conventions for large effects (d > 0.8), with consistent directional patterns across all three independent AI systems suggesting educationally meaningful performance differences in theoretical knowledge assessments.
The OSCE assessments showed markedly different performance patterns from theory examinations (Table 3). Paper I OSCEs revealed virtually identical performance across all groups, with AI models achieving mean scores of 13.0 (SD = 0.50–1.00) compared to residents’ mean (SD) of 13.16 (1.49), indicating equivalent practical skills performance with differences of less than 1%. This contrasts sharply with the 17%–23% advantage AI demonstrated in Paper I theory assessments.
OSCE Assessment Performance.
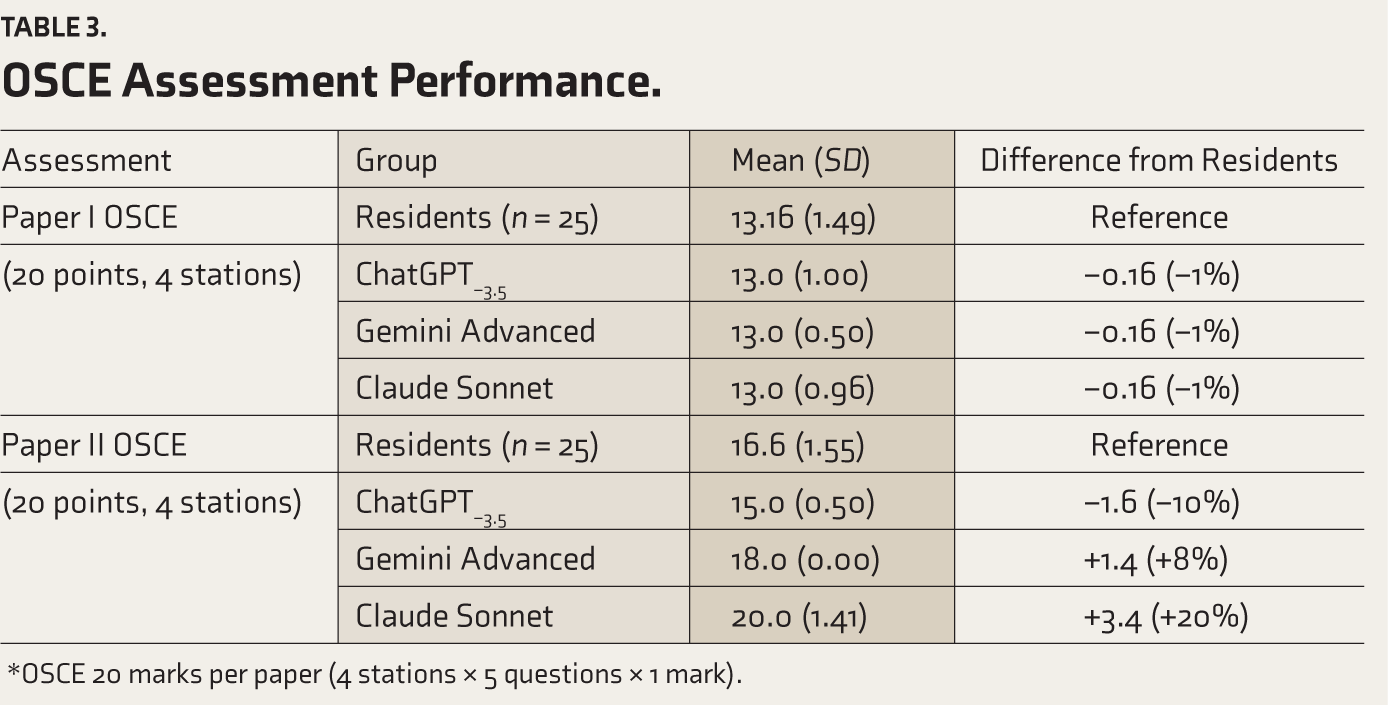
*OSCE 20 marks per paper (4 stations × 5 questions × 1 mark).
Paper II OSCEs demonstrated variable and inconsistent performance patterns across AI models. Claude Sonnet achieved superior performance, with a mean (SD) of 20.0 (1.41), which was 20% higher than that of residents (16.6 [1.55]). Gemini Advanced performed moderately above residents, with a score of 18.0 (0.00), which is 8% higher than residents’ scores. However, ChatGPT−3.5 scored lower than residents, with a mean (SD) of 15.0 (0.50), representing a 10% lower performance. This variability across AI models, combined with the divergence from theory performance patterns, reveals fundamental limitations in AI’s practical clinical reasoning and application capabilities.
Inter-rater reliability analysis demonstrated excellent consistency among faculty evaluators in their assessment of AI model responses across both theoretical knowledge domains and clinical scenario evaluations (Table 4). Claude Sonnet achieved the highest (ICC = 0.934, 95% CI: 0.80–0.99), indicating exceptional agreement among evaluators. Gemini Advanced demonstrated good reliability (ICC = 0.881, 95% CI: 0.65–0.97), while ChatGPT−3.5 showed acceptable consistency (ICC = 0.810, 95% CI: 0.44–0.96).
Inter-rater Reliability Coefficients (Intraclass Correlation) for AI Model Response Evaluations.

Discussion
This study represents a novel contribution to medical education research by directly comparing AI models with psychiatry residents using authentic institutional assessments from a premier training institute, rather than employing standardized examinations or simulated test scenarios. The consistent superiority of all three AI models in theoretical assessments, with AI outperforming residents by a ratio of 1.2:1 to 1.4:1 (AI achieving 17%–43% higher scores than residents), represents a substantial educational performance gap. These effect sizes far exceed Cohen’s conventions for “large” effects (d > 0.8), indicating practically significant differences. While post hoc pairwise comparisons did not reach statistical significance after Bonferroni correction (threshold α = 0.0167), the large and consistent effect sizes across all three independent AI systems suggest educationally meaningful differences warranting attention from psychiatric educators. 5 Some differences reached eight standard deviations above human, a gap so substantial it challenges fundamental assumptions about medical knowledge assessment. When AI demonstrates superior knowledge to trainees destined to become tomorrow’s practicing psychiatrists, we confront profound questions about the evolving nature of medical expertise and the traditional knowledge acquisition model in psychiatric training, particularly in the Indian context, where resource optimization is crucial. 6
Despite impressive knowledge scores, the markedly different pattern observed in OSCEs illuminates fundamental limitations in AI’s clinical reasoning capabilities. When it came to practical clinical skills (OSCEs), AI performed as well as residents in some areas but showed clear limitations in others. The equivalent performance in Paper I OSCEs (mean difference < 0.2 points) initially appears encouraging, but the variable results in Paper II OSCEs reveal critical deficiencies in contextual understanding and practical application.
The AI made concerning errors in practical assessments, revealing major mistakes and fundamental gaps in understanding. These errors occurred across multiple domains: Misidentifying anatomical structures, incorrectly stating the number of components in standardized assessment tools, and misattributing the purpose of well-established clinical tests. These specific errors exemplify what recent literature describes as AI “hallucinations” in medical contexts. 7
These confabulations arise from probabilistic pattern matching rather than genuine conceptual comprehension, with AI responses reflecting common or popular training data patterns rather than precise factual accuracy. The quality and accuracy of AI outputs depend substantially on the breadth and accuracy of information previously incorporated into their training databases. AI learns patterns from training data, but can confidently provide incorrect information when those patterns mislead it. This limitation is critical in psychiatric practice, where the accuracy of assessment tools and diagnostic criteria can directly impact patient care, posing a fundamental barrier to clinical deployment that cannot be addressed solely through improved prompting.
The strong inter-rater reliability coefficients (0.810–0.934) validate both our evaluation methodology and the consistency of AI-generated responses. When four faculty members graded AI responses, they showed high agreement, suggesting that AI produces consistently recognizable patterns in answer quality. This consistency, combined with AI’s superior theoretical performance, indicates AI could grade student exams more reliably than human evaluators. However, the variable standard deviations in AI performance (ranging from 0.50 to 12.86) paradoxically suggest opportunities for more standardized assessment. AI’s consistency could provide more equitable evaluation frameworks, particularly for theoretical knowledge, where human grading subjectivity may introduce inconsistency, especially in diverse Indian training settings.8,9
If AI can access and synthesize medical knowledge better than residents, what should we actually be teaching? Our findings necessitate a fundamental reconsideration of psychiatric training competencies. Traditional models that emphasize knowledge retrieval become less relevant as AI can access and synthesize medical literature instantaneously. The answer is not to compete with AI on memorization, but to focus on uniquely human skills, building relationships with patients, making ethical decisions, and applying knowledge in complex cultural contexts,10,11 skills vital for addressing India’s mental health burden.
Future psychiatric education must prioritize meta-cognitive skills: Knowing when and how to leverage AI capabilities, recognizing AI limitations, and maintaining critical evaluation abilities. Medical education needs to shift from “What do you know?” to “How do you think and connect with people?” The exceptional theoretical performance of AI models suggests transformative potential for knowledge delivery and assessment standardization.
Theory exams of psychiatric residency programs need major restructuring over the next decade. Instead of spending years memorizing facts that AI can instantly provide, residents will need to learn to work with AI effectively, including when to trust it, when to question it, and how to combine AI insights with human judgment. This represents a paradigm shift comparable to the integration of evidence-based medicine in the 1990s. 11
The AI’s superior performance on standardized psychiatric assessments raises a critical question: Does this represent genuine competence or sophisticated pattern recognition on culturally biased content? If current assessments favor Western diagnostic frameworks, as is likely given the AI’s training data, then the AI’s success may actually perpetuate diagnostic disparities for Indian populations rather than improve care quality. 12
This paradox is particularly concerning in psychiatry, where cultural context directly impacts diagnostic accuracy and treatment effectiveness. Rather than celebrating AI achievements, we should question whether these assessments validly measure clinical competence for diverse populations. This challenge presents an opportunity for Indian psychiatric education to pioneer culturally-adaptive AI systems and develop regulatory frameworks that ensure equitable healthcare delivery.13,14
A critical implication of our findings is the need to reconsider the weightage of assessments in psychiatric training. Given AI’s demonstrated superiority in theoretical knowledge, maintaining the current emphasis on theory examinations (typically comprising 70% of the total assessment) may no longer be pedagogically sound. We propose reducing the weight of theory examinations to less than 25% of the total assessment, with the majority (75% or more) dedicated to clinical reasoning through OSCEs and real-world clinical case assessment and management. This shift would better align evaluation with the competencies that distinguish human clinicians from AI systems’ clinical judgment, therapeutic relationships, cultural competence, and contextual decision-making in complex patient scenarios.
Study Strengths and Limitations
This study provides the first head-to-head comparison of AI performance against psychiatric residents using real institutional assessments rather than standardized examinations. We used real exams from actual residency training, had multiple expert evaluators who remained blinded to response sources, tested both knowledge and practical skills, and used appropriate statistical methods for our data. The exceptional inter-rater reliability validates our blinded evaluation protocol, while the use of non-parametric statistics accounts for non-normal score distributions often encountered in educational research.
However, several limitations warrant consideration. The single-institution design limits generalizability to other psychiatric training programs and cultural contexts across India. More importantly, text-based assessments cannot capture essential psychiatric competencies, including empathy, non-verbal communication, therapeutic relationships, and complex clinical decision-making in real patient interactions. The study design could not assess long-term impacts of AI integration on clinical development or the evolution of clinical reasoning skills over time. Comparisons between residents and AI models were based on a full resident cohort (n = 25) and a single aggregated score per AI model (derived from four examiner ratings), making the between-group analysis exploratory and descriptive.
Future Directions
Rather than wholesale adoption, we should begin with pilot programs that leverage AI’s strengths while preserving human expertise where AI clearly falls short. The evidence supports immediate exploration of AI-assisted grading for theoretical assessments while maintaining human evaluation for clinical skills.
The trajectory suggested by our findings forecasts fundamental evolution in psychiatric residency training over the next decade. Research priorities should include longitudinal studies following residents over time to understand how AI training affects clinical development, and better methods to assess the human skills that matter most in psychiatry capabilities, which our current OSCEs do not adequately capture.
Future investigations must address the limitations of text-based evaluation by developing AI assessment protocols that incorporate non-verbal communication, empathy evaluation, and complex clinical reasoning. The global implications of AI in psychiatric education demand systematic evaluation across diverse cultural contexts, exploring AI performance on culture-specific psychiatric conditions, indigenous healing practices, and regional diagnostic frameworks to ensure equitable technological advancement.
Conclusions
The challenge for psychiatric education is preparing residents for a world where technical knowledge is instantly available, but wisdom, empathy, and cultural competence become more valuable than ever. Future psychiatric education must evolve toward hybrid models where AI augments rather than replaces human training, guided by robust empirical evidence, ethical frameworks, and pedagogical best practices. This transition requires thoughtful planning, significant curriculum reform, ongoing research, and careful attention to regulatory compliance to ensure we enhance rather than diminish the quality of psychiatric care, particularly in the Indian healthcare system.
Supplemental Material
Supplemental material for this article is available online.
Footnotes
Acknowledgements
We acknowledge the support and contributions of the institutional staff and trainees at NIMHANS who participated in this study. Special thanks to Dr Prabha S. Chandra, Dean and Member Secretary of the Institutional Ethics Committee (Behavioral Science Division), NIMHANS, for facilitating the ethical exemption process.
Data Sharing Statements
The datasets generated and analyzed during this study are not publicly available due to institutional restrictions on sharing sensitive examination materials and participant data. However, anonymized data may be made available upon reasonable request from the corresponding author.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration Regarding the Use of Generative AI
This research employed AI tools (ChatGPT−3.5, Gemini Advanced, and Claude Sonnet) as study subjects for performance comparison, not as research assistants. The AI models were used exclusively for generating responses to examination questions under controlled conditions. No AI tools were utilized in manuscript preparation, data analysis, or interpretation of results. Human researchers performed all statistical analyses, literature review, and manuscript writing without AI assistance. The authors assume full responsibility for the entire content.
Ethics Committee Details
Name of the Institutional Ethics Committee/ Independent Review Board: NIMHANS Ethics Committee (Behavioral Science Division). Approval Reference Number: NIMHANS/EC/(BEH.SC.DIV.) MEETNG/2024. Date of Approval: 13 May 2024.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Informed Consent/Assent
Not applicable (retrospective analysis of anonymized academic records).
Prior Presentations
Nil.
Registration
Not applicable.
Simultaneous Submission to Another Journal or Resource
NA.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.