
Abstract
The current study is an interdisciplinary examination of the interplay among music, language, and emotions. It consisted of two experiments designed to investigate the relationship between musical abilities and vocal emotional recognition. In experiment 1 (N = 24), we compared the influence of two short-term intervention programs – music and art – on vocal emotion recognition. In experiment 2 (N = 47), we compared musicians, who had undergone long-term music training, to non-musicians regarding their vocal emotion recognition. The results from experiment 1 revealed that short-term music intervention, which focused on ways music conveys emotions, significantly improved the vocal emotion recognition of the participants., In experiment 2, which examined the long-term effects of music training, there were no significant differences between musicians and non-musicians in vocal emotion recognition. The uniqueness of the short-term intervention and the inconsistency between the two experiments’ findings are discussed, and possible directions for future studies are proposed.
The various aspects of the non-musical benefits of musical training have been widely researched within the scope of music education (Hetland, 2002; Schellenberg, 2000, 2005). Among these aspects, one of the most relevant benefits to daily life is that practicing music facilitates recognizing emotional cues in linguistic communication (Nilsonne & Sundberg, 1985; Thompson, Schellenberg, & Husain, 2004), which is considered as a fundamental ability for everyday social functioning.
Music and language, two auditory modalities of human communication, share common components: they are organized in the time dimension, they arrive to the auditory system in a broad range of frequencies, and they are both composed of a few discrete basic elements (phonemes, sounds) organized according to accepted principles that create an endless variety of meaningful units (McMullen & Saffran, 2004). Brain scans of healthy and injured adults display hemispheric lateralization regarding music and language processing: the right auditory cortex processes musical stimuli, whereas the left one processes language stimuli (Tervaniemi et al., 2000; Zatorre, Belin, & Penhune, 2002). On the other hand, other studies indicate overlapping between music and language brain areas (Koelsch et al., 2002; Koelsch & Siebel, 2005; Maess, Koelsch, Gunter, & Friederici, 2001; Patel, 2003). In accordance with the latter studies, researchers found significant correlations between music and language abilities in adults (Dancovicova, House, Crooks, & Jones, 2007; Foxton et al., 2003) as well as in children (Anvari, Trainor, Woodside, & Levy, 2002; Barwick, Valentine, West, & Wilding, 1989; Lamb & Gregory, 1993). In addition, several researchers suggest that since the same neuronal network is involved in music and language comprehension, music experience might develop and nurture the language system. For example, music training improves the comprehension of linguistic melodic contour (Schön, Magne, & Besson, 2004), and improves lexical stress processing (Kolinsky, Cuvelier, Goetry, Peretz, & Morais, 2009), learning language (Schön et al., 2008), verbal memory (Chan, Ho, & Cheung, 1998), children’s phonological and reading abilities (Forgeard et al., 2008), and dyslectic children’s language capabilities (Overy, 2003).
More specifically, music and language are similar in the ways that they convey emotions. Emotions conveyed in speech are expressed and recognized through acoustic cues that are comprehensible to both the sender and to the sendee (Johnstone & Scherer, 2000). Those acoustic properties of speech, such as changes in duration, intensity, pitch or timbre, are known as the prosodic features or the musical components of speech; in addition to emotion communication (Scherer, 1986; Scherer, Banse, & Wallbott, 2001), they function in linguistic syntax and stress communication (Cooper, Eady, & Mueller, 1985; Cooper & Sorensen, 1981; Patel, Foxton, & Griffiths, 2005).
Communicating emotions by means of duration, intensity, pitch or timbre variations is also a basic and inherent part of music perception and production (Husain, Thompson, & Schellenberg, 2002; Juslin & Sloboda, 2001). According to Juslin & Laukka (2003), who performed a meta-analysis review of 104 studies of vocal expression and 41 studies of music performance, similarities were found between the two modalities in terms of the acoustic cues used to communicate each emotion. For example, happiness is expressed mainly by the fast speech rate/tempo, the medium–high voice intensity/sound level, the high F0 (fundamental frequency)/pitch level, much F0/pitch variability, and the rising F0/pitch contour. Similarly, sadness is expressed mainly by a slow speech rate/tempo, a low voice intensity/sound level, a low F0/pitch level, little F0/pitch variability, and a falling F0/pitch contour. These cross-modal similarities led some researchers to suggest that a correlation exists between musical ability and speech prosody perception.
Nilsonne and Sundberg (1985) showed that music students were superior at identifying the emotional state of speakers. The stimulus was presented in tone sequences consisting of the fundamental frequencies of voice samples recorded from depressed and non-depressed individuals. The technique of tone sequences, that is, melodic analogues of spoken sentences, was also used in three different experiments reported in the study by Thompson and colleagues (2004). In the first experiment, musically-trained undergraduate students performed better than an untrained group in recognizing four emotions (happiness, sadness, fear, or anger) from the tone sequences. In the second experiment, in which auditory emotional sentences were presented in English and in an unfamiliar language (Tagalog), the musically trained group performed better for the sad and for the fearful-sounding stimuli across languages and modalities. In addition, training significantly affected the responses to the Tagalog-spoken utterances but not the responses to the English or tone sequence stimuli.
Thompson et al. (2004) further examined whether 6-year-olds assigned randomly to 1 year of music lessons would exhibit similar advantages in recognizing speech prosodies. The results of the study indicated that the children that participated in the various arts groups (music, singing, or drama) outperformed the no-lessons group, but there was no clear advantage for the music groups compared with the drama group.
In contrast to the above-mentioned studies, Trimmer and Cuddy (2008) suggested that emotional intelligence was a reliable predictor of emotional speech recognition and not music training. The music training of the 100 undergraduate university students that participated in the study was assessed by requesting them to complete an extended questionnaire about their music education and activities. No correlations were found between the music training factor and the emotional prosody recognition scores. Instead, a more general emotional intelligence factor was correlated to emotional prosody recognition.
In conclusion, it seems that the hitherto research findings are not definitive regarding musicians’ ability to comprehend and recognize vocal emotional prosody.
In the current research, which comprised two experiments, we aimed to further examine the relationship between musical abilities and vocal emotional recognition. Since no studies were found that involve short-term music education interventions, we preferred to employ in the current research a short-term music intervention method (comprising four lessons of 30 minutes each) in order to examine, for the first time, its influence on vocal emotion recognition.
Research questions
In light of the above-mentioned theoretical background, the specific research questions are as follows:
Does a short-term music education intervention improve vocal emotion recognition?
Is there a significant distinction between musicians (who are enrolled in long-term music training) and non-musicians regarding their vocal emotion recognition?
Experiment 1 – Short-term intervention
Method
Participants
A total of 24 non-musician college students aged 20–35 years participated in the study. They were divided into two groups: 12 participants took part in the music intervention group (8 women and 4 men; mean age = 23.5 years, SD = 3.1) and 12 participants took part in the art intervention group (10 women and 2 men; mean age = 25.4 years, SD = 4.9). They were recruited from two colleges in exchange for monetary compensation. Subjects were all native Hebrew speakers with no known neurological or psychiatric conditions. Non-musicians were defined as those who had never played a musical instrument or those who had learned to play for up to one year only in their early childhood.
Research instruments
Vocal Emotion Recognition Task (VERT)
All the stimuli for the VERT (Globerson, Lavidor, Golan, Kishon-Rabin, & Amir, 2010) were recorded at a professional recording studio by four professional actors (two female and two male actors). A total of 302 stimuli were included in the VERT. The stimuli were composed of monosyllabic utterances, nonsense words, neutral Hebrew words, and neutral sentences, unrelated to the emotions expressed by the actors. Prior to the experimental process, the recorded stimuli were validated by a panel of 20 judges, thus ensuring that the emotional meaning intended by the actors was reliably expressed. All stimuli were normalized for identical RMS amplitude. Participants heard the stimuli and had to decide which emotion was conveyed by the actors. The possible choices were anger, fear, happiness, sadness, or neutral feelings. The battery was divided into blocks, characterized by the nature of the utterances (monosyllabic utterances, words, etc.). The order of the blocks was randomized, as was the order of the stimuli within the blocks. The “neutral” option was not one of the designated emotions (i.e., the actors were not instructed to convey a “neutral emotion”). This option was given to test the inclination of the participant to define non-neutral utterances as neutral. The battery was divided into two separate tasks: the pre-intervention task and the post-intervention task, each comprising 151 stimuli. The separate tasks contained approximately the same number of stimuli from each emotion category and from each of the professional actors.
From the VERT, four scores were obtained for each participant: (1) The pre-intervention VERT score (in the percentage correct) – the VERT score is the arithmetic average of the scores in the individual sections of the VERT battery. Factor analysis confirmed that all the scores of the individual VERT blocks (monosyllabic utterances, non-words, words, and sentences) have a similar weight in the general factor. (2) The pre-intervention VERT “neutral score” (NS) – the percentage of stimuli rated as “neutral” by the participant. (3) The post-intervention VERT score (in the percentage correct). (4) The post-intervention VERT “neutral score”.
Music Emotion Recognition Task (MERT)
The 90 MERT stimuli were a combination of two validated sets of music excerpts. Forty excerpts were piano timbre MIDI files representing four discrete emotional categories: happiness, sadness, fear, and tenderness (Vieillard et al., 2008). Fifty excerpts consisted of film soundtracks representing five discrete emotional categories: happiness, sadness, fear, tenderness, and anger (Eerola & Vuoskoski, 2011). Combining the two sets generated an integral battery comprising two kinds of music excerpts: on the one hand mono-timber computerized excerpts, and on the other hand, original instruments and orchestral excerpts.
Two separate tasks were formed: pre-intervention task and post-intervention task. Each task consisted of 20 piano timbre MIDI files and 25 film soundtracks, maintaining the same number of stimuli from each emotion category for every task. The participants listened to the stimuli and had to decide which emotion was conveyed by the music. The possible choices were happiness, sadness, fear, tenderness, and anger. The order of the 45 stimuli was randomized. From the MERT, two scores were obtained for each participant: (1) The pre-intervention MERT score (in the percentage correct), (2) The post-intervention MERT score (in the percentage correct).
Advanced Measures of Music Audiation (AMMA)
The Advanced Measures of Music Audiation (Gordon, 1989) includes 30 pairs of short piano timbre MIDI files of musical phrases. The participants indicate by filling in a space on an answer sheet whether each two musical phrases sound the same, whether they sound different because of a tonal change, or whether they sound different because of a change in rhythm. The 30 pairs, preceding three practice pairs, were played continuously, thus enabling only one hearing of the musical phrases. Using a special scoring mask, the correct and the incorrect answers were counted and the raw scores for the tonal and the rhythm subtests were collected. The raw scores were then converted to percentile ranks according to Gordon’s tables (Gordon, 1989). From the AMMA, three scores were obtained for each participant: (1) The AMMA Tonal score, in percentile ranks, (2) The AMMA Rhythm score, in percentile ranks, (3) The AMMA Total score (sum of the Tonal and the Rhythm scores), in percentile ranks.
Procedure
The six research sessions consisted of four weekly 30-minute group sessions, and two individual sessions, one prior to the group sessions and one following them. In the first individual session, each participant performed the three research tasks: the pre-intervention VERT, the pre-intervention MERT, and the AMMA. On average, participants took 50 minutes to complete all three tasks. In the second individual session, after completing the intervention group sessions, each participant performed two research tasks: the post-intervention VERT and the post-intervention MERT. The individual sessions took place in a small and quiet room. The VER and MER tasks were presented to the participants through preplanned Matlab software and using Sennheiser HD-201 linear headphones.
The music and art intervention sessions
Four 30-minute music sessions and four 30-minute art sessions were designed for the purpose of this study in collaboration with a specialist in teaching music and a specialist in teaching art, who were also in charge of the sessions. The objective of the intervention sessions was to discuss and learn about emotions and their manifestation in music (the music intervention group) and in art (the art intervention group).
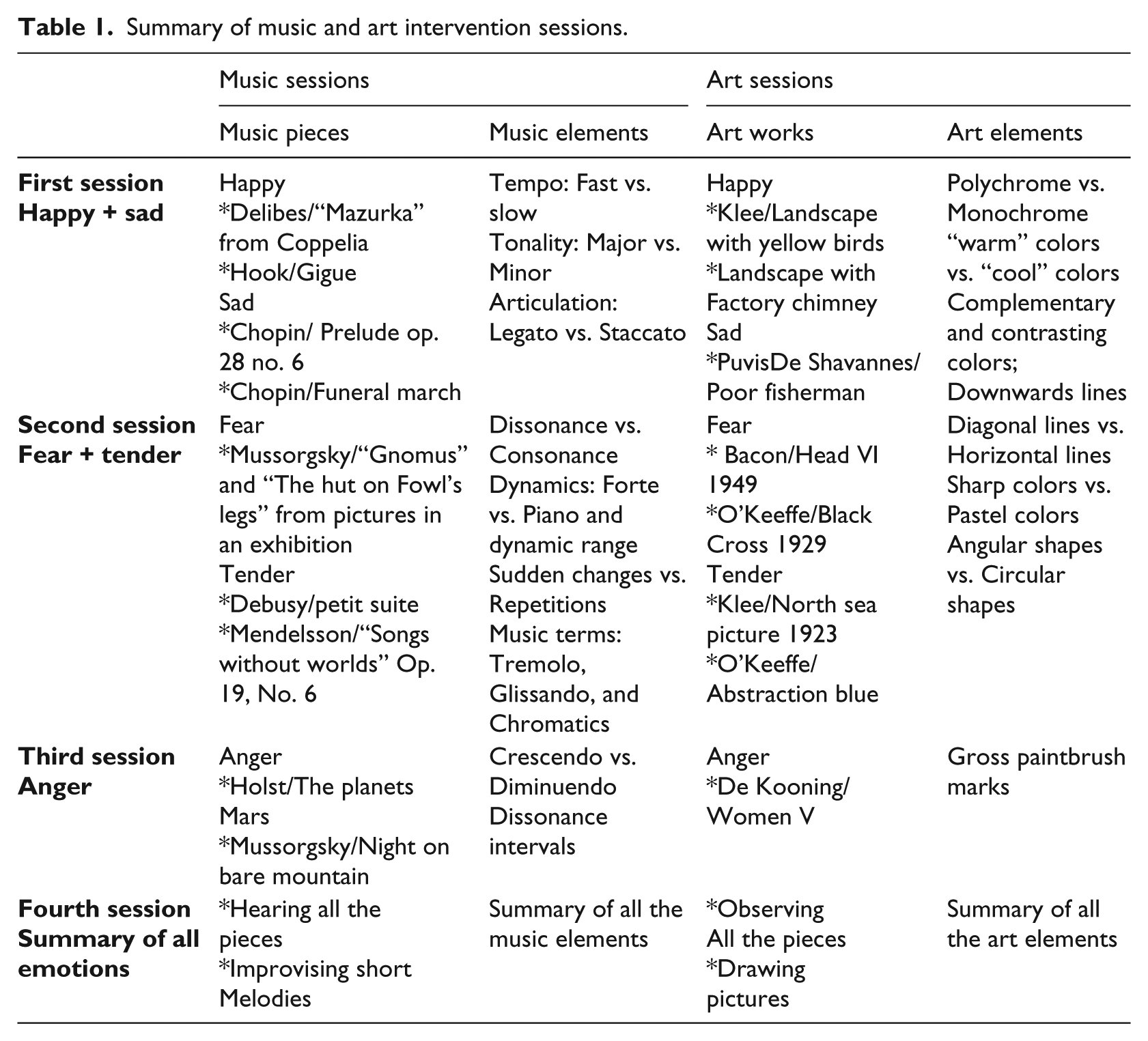
The two interventions were planned similarly in terms of each session’s outline and the emotions being discussed. The sessions began by introducing specific music or art pieces and asking the participants which emotions they recognize in the pieces. Then, a talk about the music or the art components that arouse the specific emotion took place. The talk was accompanied by examples of live piano pieces for the music group and by examples of live sketching for the art group. At the end of each session, the participants heard or observed again the pieces and in some cases they were also exposed to novel pieces, thus they tried to implement the things that had been learned. In each of these sessions, the participants experienced diverse learning, primary intuitive experience, analyses, and synthesis. With both interventions, in the first session, the emotions of happiness and sadness were the focus; in the second session, fear and tenderness were the focus; and in the third session, the emotion of anger was the focus. The fourth and last session summarized all the five emotions that had previously been discussed with an additional creative finale of drawing pictures that express each emotion (in the art group) or improvising short melodies that expressed each emotion (in the music group). Table 1 presents a summary of the music and art sessions including the pieces of music and art that were chosen to demonstrate each emotion and the music and visual art elements that were discussed in relation to the specific emotion.
Summary of music and art intervention sessions.
Results and discussion
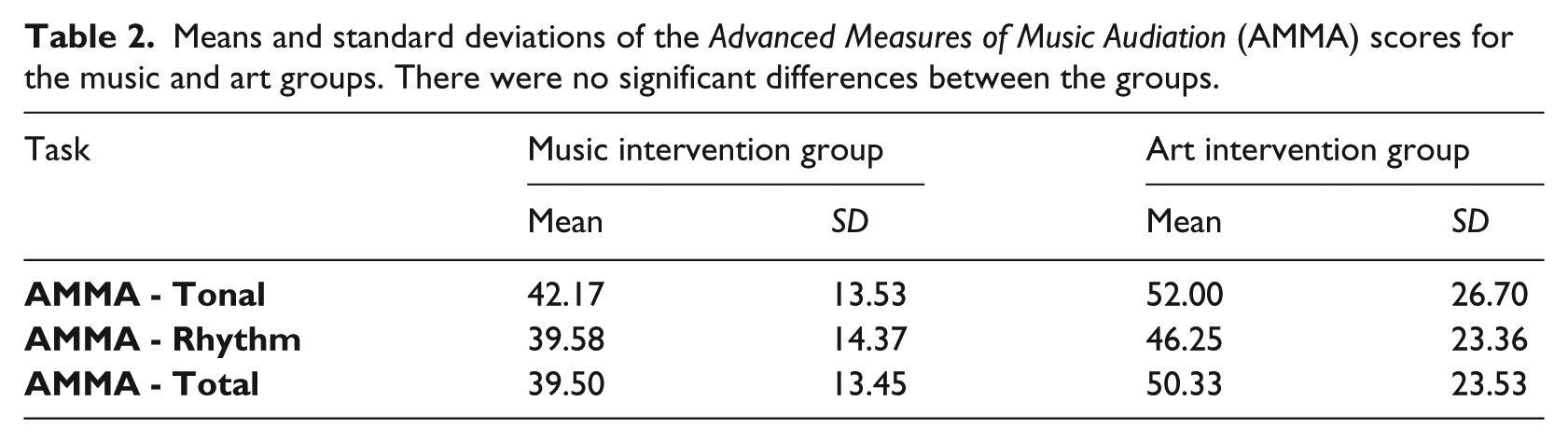
For all participants, the AMMA Tonal and Rhythm scores had a significant correlation of r = .82 (df = 23, p < .01) between them. The participants in the music and art group intervention did not differ in their musical ability, as measured by the AMMA scores before the intervention (see Table 2).
Means and standard deviations of the Advanced Measures of Music Audiation (AMMA) scores for the music and art groups. There were no significant differences between the groups.
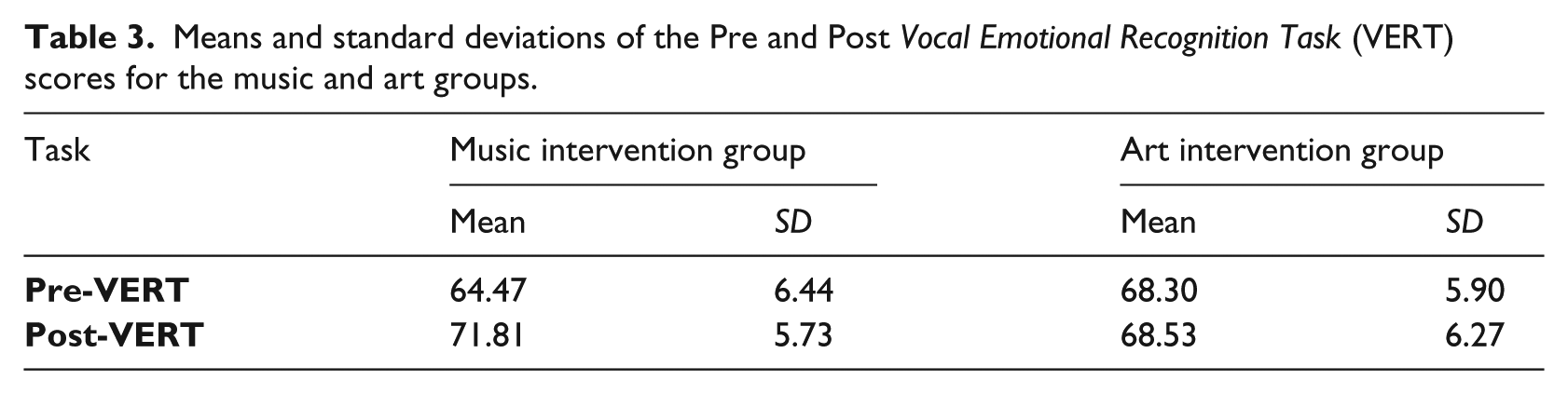
The main assumption of this study was that vocal emotion recognition will be significantly improved after participating in music intervention lessons, when compared with participating in the art intervention lessons. To test our hypotheses, a mixed-design Anova with repeated measures (2 × 2) was calculated, with Group (music intervention vs. art intervention) as the between-subjects factor and Time (before and after the intervention) as the within-subjects factor. The dependent variable was vocal emotion recognition. Table 3 presents the means and standard deviations of the Pre-VERT and Post-VERT scores for the two research groups.
Means and standard deviations of the Pre and Post Vocal Emotional Recognition Task (VERT) scores for the music and art groups.
The Anova revealed no significant main effect for Group, F(1, 22) = 0.02, p = ns. A significant main effect was found for Time, F(1, 22) = 9.82, p < .01, η²p = .31, and, crucially, for Group × Time interaction, F(1, 22) = 4.42, p < .05, η²p = .17. Posthoc comparisons with Bonferroni corrections (p < .05) revealed that only the music intervention group showed a significant improvement in the general vocal emotional prosody recognition score. Note that although the improvement was statistically significant, the pre-post improvement was not very ample. The individual and group improvements, as measured by the difference between the post-test and pre-test VERT scores (prosody scores), in the two intervention groups, are presented in Figure 1.
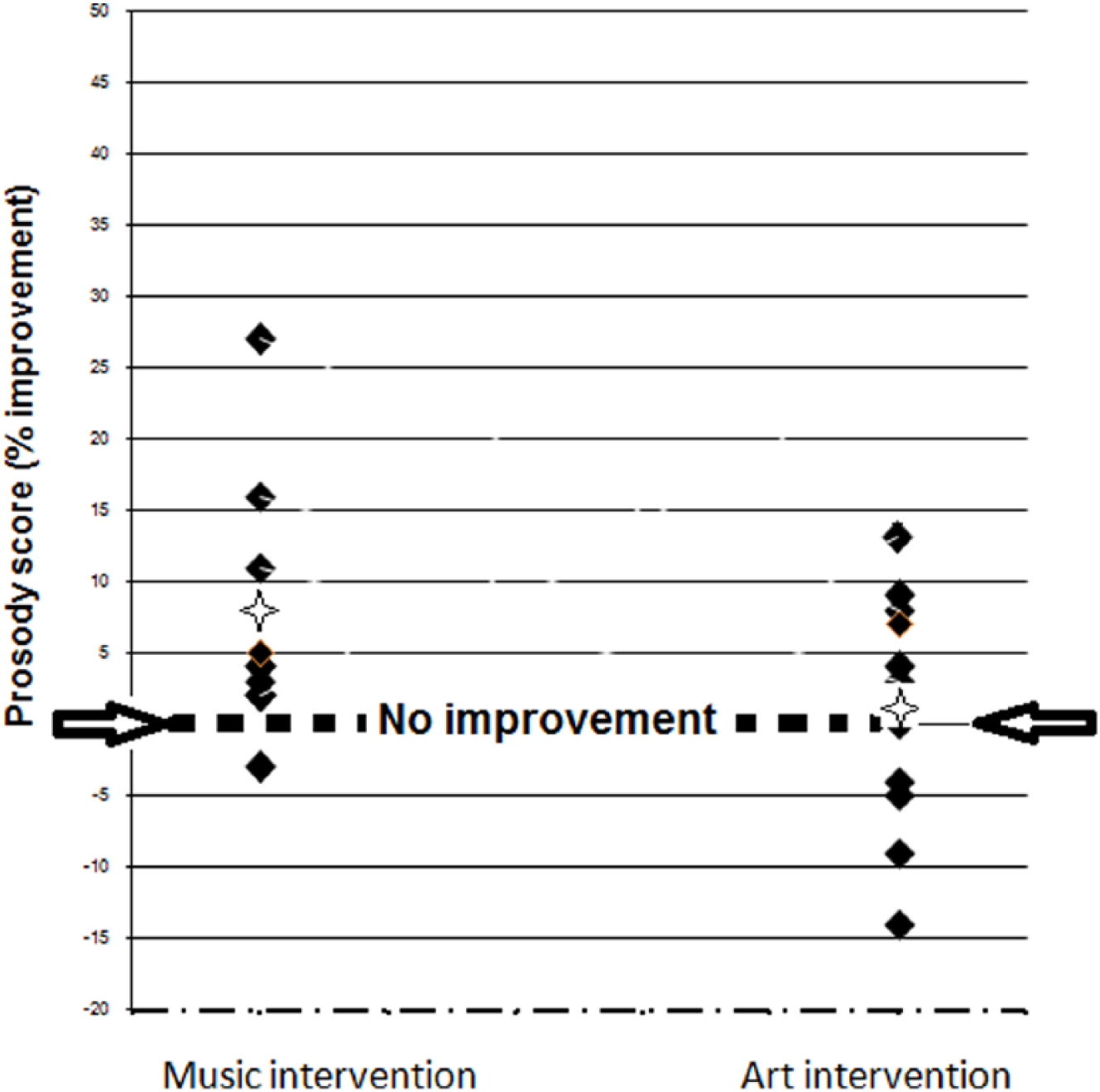
The individual and group improvements in the Vocal Emotion Recognition Task (VERT) scores in the two intervention groups
Regarding the VERT “neutral score”, the ANOVA revealed no significant Group main effect, F(1, 22) = 0.82, p = ns. A significant main effect was found for Time, F(1, 22) = 11.46, p < .001, η²p = .84, but not for the Group × Time interaction, F(1, 22) = 0.58, p = ns. It can be concluded that the two groups exhibited a similar significant decrease from the pre- to post-intervention phase. The music group decreased from M = 19.92 (SD = 10.69) to M = 13.9 (SD = 7.69) and the art group decreased from M = 21.90 (SD = 7.95) to M = 18.10 (SD = 9.59).
Regarding the MERT score, the ANOVA revealed no significant Group main effect, F(1, 22) = 2.32, p = ns. No significant main effect was found for Time, F(1, 22) = 1.87, p = ns, and for the Group × Time interaction, F(1, 22) = 2.57, p = ns. These results imply that despite training, there was no change in the participants’ ability to detect emotions in music in both intervention groups. However, since all participants had no musical background, we did not expect the short-term intervention to enhance their sensitivity to music.
The main conclusion is that although the two groups showed improvement in recognizing emotional prosody from the pre- to post-intervention phase, only the music intervention group showed a significant improvement. The music intervention group also showed a decreased tendency to classify emotions as neutral; however, this aspect of improved prosody comprehension did not reach significance. These findings triggered the next study, in which we explored the effects of long-term music training on emotional prosody comprehension.
Experiment 2 – Long-term training
Following the first experiment, which showed significant enhancement of Vocal Emotion Recognition (VER) after short-term music sessions, we further examined the relation between VER and music, this time exploring the long-term music training effect. In this experiment we compared the pre-intervention scores of the 24 participants from experiment 1 to the musicians’ scores.
Method
Participants
The participants consisted of two groups: 24 non-musician college students and 23 college students who were musicians (14 women and 9 men; mean age = 26.15, SD = 4.57). The participants in the non-musicians group consisted of the combination of the two groups from experiment 1. The participants in the musicians group were music students from two colleges that were recruited in exchange for monetary compensation. The subjects were all native Hebrew speakers with no known neurological or psychiatric conditions. Musicians were defined as those who had formal music lessons, that is, they learned to play an instrument or had undergone voice training, for at least 6 years (M = 9.43, SD = 3.17, range 6–18).
Research instruments
The research instruments were the same as in the pre-intervention tests in experiment 1: pre-intervention VERT, pre-intervention MERT, and the AMMA test.
Procedure
Each participant from the musicians group performed individually the three research tasks (VERT, MERT, and AMMA) using the same procedure as described in experiment 1. The measures that were obtained are (1) The pre-intervention VERT score, (2) the pre-intervention VERT “neutral score” (NS), (3) the pre-intervention MERT score, (4) the AMMA Tonal score, (5) the AMMA Rhythm score, and (6) the AMMA Total score.
Results and discussion
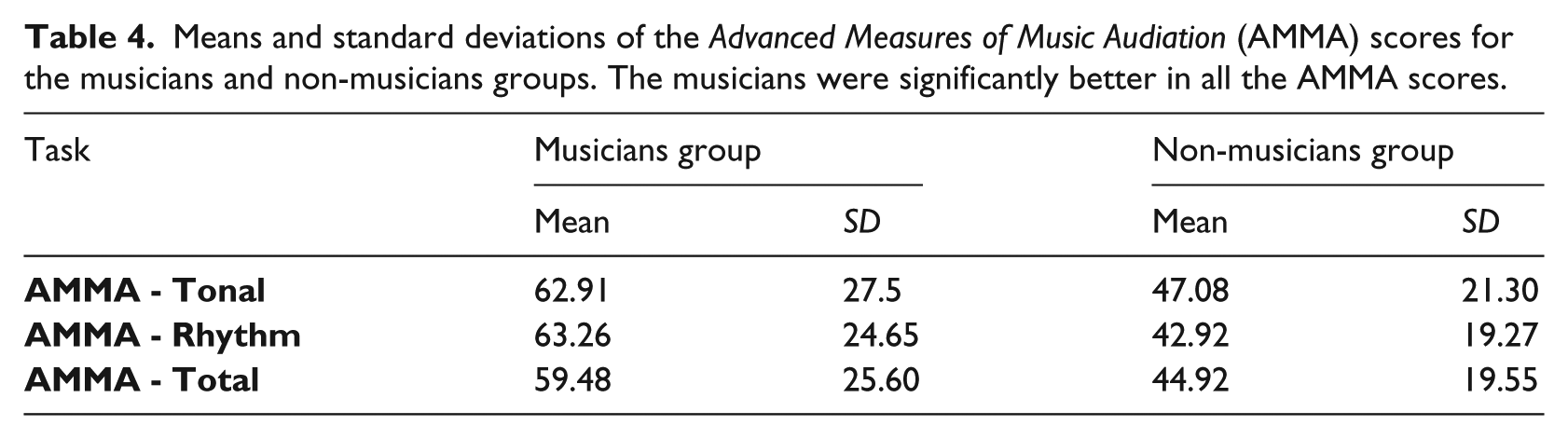
A multivariate analysis of variance (MANOVA) was conducted by comparing the groups (musicians vs. non-musicians) with the dependent variables of music ability and the AMMA Tonal and Rhythm scores. The MANOVA revealed a significant difference between the groups F(2, 44) = 5.13, p < .01, η²p = .19. Individual statistics for each measure revealed significant differences in the Tonal ability F(1, 45) = 4.89, p < .05, η²p = .10 and in the Rhythm ability F(1, 45) = 9.98, p < .01, η²p = .18. The musicians’ music ability (M = 59.48, SD = 25.60) was, as expected, significantly higher than that of the non-musicians (M = 44.92, SD = 19.55). Table 4 presents the means and standard deviations of the AMMA scores for the musicians group and the non-musicians group.
Means and standard deviations of the Advanced Measures of Music Audiation (AMMA) scores for the musicians and non-musicians groups. The musicians were significantly better in all the AMMA scores.
To examine the differences between the groups (Musicians vs. Non-Musicians) regarding emotion recognition, a mixed-design analysis of variance (ANOVA) was calculated (2 × 2). The within-subjects factor was a type of Emotion Recognition (Vocal vs. Music) and the between-subjects factor was Group (musicians vs. non-musicians), and the dependent variable was the Emotion Recognition score. The ANOVA revealed no significant Group main effect, F(1, 45) = 0.66, p = ns. No significant main effect was found for Emotion Recognition, F(1, 45) = 0.91, p = ns, and for the Group × Emotional Recognition interaction, F(1, 45) = 0.17, p = ns. Table 5 presents the means and standard deviations of the VERT, VERT neutral, and MERT scores for the musicians and non-musicians groups.
Means and standard deviations of the Vocal Emotion Recognition Task (VERT), the Vocal Emotion Recognition Task neutral (VERT neutral), and the Music Emotion Recognition Task (MERT) scores for the musicians and non-musicians groups.

Note: There was no difference in the ability to detect emotion in music and in speech between the two groups.
In Experiment 2, we tested prosody comprehension in a group of professional musicians and compared them to non-musicians. Although the musicians were clearly better in their musical abilities, as we demonstrated in the AMMA test, they were not better than the non-musicians in detecting emotion. This lack of advantage was true for speech, and surprisingly, for music as well.
Conclusions
The results of Experiment 1 show that short-term music intervention, focusing on the ways music conveys emotions, significantly improved the vocal emotion recognition of the participants, as opposed to the vocal emotion recognition of the art intervention group participants. Thus, we may suggest that since the two interventions were similar in terms of their length, the outline of each session, as well as the emotions being discussed – the different kinds of art, that is, music or visual art, was the crucial factor. Apparently learning about the ways music conveys emotions influenced more significantly the recognition of emotions conveyed in speech than did learning about the ways visual art conveys emotions. A good explanation of the uniqueness of the musical medium was given by Thompson (2009), in the context of the analysis of inducing fear in film soundtracks; According to Thompson, music is apparently capable of inducing fear to a greater extent than visual images do, since “visual images are experienced as ‘out there’, whereas sounds are experienced both outside and inside our heads. We feel sounds in our very bones, making it difficult to distance ourselves from them” (p. 176).
The significant finding regarding the influence of musical practice on vocal emotion recognition is in accordance with research regarding the strong connections between music and language in general (McMullen & Saffran, 2004), in terms of overlapping brain areas (Koelsch et al., 2002; Koelsch & Siebel, 2005; Maess et al., 2001; Patel, 2003), and regarding significant correlations between music and language abilities in adults (Dancovicova et al., 2007; Foxton et al., 2003) as well as in children (Anvari et al., 2002; Barwick et al., 1989; Lamb & Gregory, 1993).
Our research findings support and strengthen earlier studies suggesting that since the same neuronal network is involved in music and language comprehension, music experience might develop and nurture the language system (Chan et al., 1998; Forgeard et al., 2008; Kolinsky et al., 2009; Overy, 2003; Schön et al., 2008; Schön et al., 2004). The results of the current research suggest that a short-term music education intervention program, concentrating on specific musical elements and their contribution to specific emotions in the music pieces, might nurture prosodic perceptual abilities.
Interestingly, in the second experiment, which examined the long-term music training effect, there were no significant differences found between musicians and non-musicians in vocal emotion recognition. We assumed that long-term music training will have a significant and similar effect as the short-term music training. In other words, we expected that musicians who had learned to play an instrument for at least 6 years had nurtured their language system in a way that enhanced vocal emotion recognition abilities. Our results, however, did not support this assumption.
Although Trimmer and Cuddy’s (2008) suggestion that emotional intelligence was a reliable predictor of emotional speech recognition and not musical training, which can explain the findings of experiment 2, it still does not explain the surprising inconsistency between the findings of experiment 1 and 2. An alternative suggestion that does explain this inconsistency is to consider the unique content of the short-term intervention (in experiment 1) that highlighted, through an intensive program, the aspect of communicating emotions through music – whereas this aspect was not dominant in cognitively oriented long-term academic musical training, which characterized the musicians who participated in experiment 2. Furthermore, it might be concluded that in the process of learning to play a musical instrument (which was a central criterion of recruiting musician participants in experiment 2), the focus is mainly on technical issues, which require intensive cognitive attention, rather than on the aspect of communicating emotions through music.
It is worthwhile to further illuminate at this point two pivotal traits of the short-term music intervention. First, four of five emotions have been examined in the framework of opposite emotions, namely, happiness vs. sadness and fear vs. tranquility. It is quite possible that this dichotomous pattern of learning sheds light on the differences, as well as the uniqueness of each emotion. The second point, mentioned above in the methodological section, relates to the general pattern of each lesson, each of which comprised three sequential phases of learning – in accordance with the U-Curve learning pattern (Strauss, 1982). The first phase was based upon intuitive learning, the second upon analysis, and the last upon synthesis, that is, a more holistic and profound comprehension of the entire musical piece on the basis of analysis and intuition. It can be assumed that these two traits of the short-term music intervention, which seem to correspond to the natural inclination of learning, significantly enhanced the effective outcome of the intervention.
As was mentioned, the musicians group was not better than the non-musicians in detecting emotion in music as well as in speech. Perhaps the MERT tests were not sensitive enough. The 90 MERT stimuli, as was detailed earlier in this article, were a combination of two validated sets of music excerpts. They consisted of piano timbre MIDI files representing four discrete emotional categories: happiness, sadness, fear, and tenderness (Vieillard et al., 2008) and 50 film soundtracks representing five discrete emotional categories: happiness, sadness, fear, tenderness, and anger (Eerola & Vuoskoski, 2011). It is possible that a detailed examination in terms of analysing each emotion separately or analysing each set of stimuli separately might have exposed significant differences between musicians and non-musicians. Moreover, the 50 film soundtracks included not only the best examples of target emotions but also moderate examples that are less easily attributable to a category. Each emotion had five high examples and five moderate examples. Note that the current research did not examine the impact of the difference between the above-mentioned high and moderate excerpts. Future research should consider further analysing this stimulus differentiation, which might point out specific idiosyncrasies in the musicians group.
Natural prosodic perceptual and productive skills are a vital part of any sort of individual communication. Deficiencies in these abilities, either linguistic or emotive, may have a significantly harmful impact on human social relations. Such deficiencies are usually reported in the case of individuals on the autistic spectrum (McCann & Peppe, 2003) and schizophrenias (Murphy & Cutting, 1990). In light of the current research’s results, we suggest a model for short-term clinical intervention and a new rehabilitation therapy that can be employed in pathological cases as well as in the general population. Employing our model may help to nurture a better understanding of the mechanisms involved in prosodic impairment.
Directions for future research may include applying experiment 1 to children; naturally, such an application requires minute adaptation of the intervention’s contents and the research tasks. Positive results of the experiment, namely, a significant improvement in vocal emotion recognition following short-term music intervention, may indicate that the short-term intervention plan may serve as a possible treatment procedure in the early stages of acquiring communication skills. Other directions should relate to the inconsistency between short-term and long-term musical training, manifested in the inconsistent results of experiments 1 and 2. Since the musicians participating in experiment 2 were all enrolled in academic music programs, which are cognitively oriented, we suggest that experiment 2 be performed with non-academic musical participants, such as professional musicians in traditional cultures, who possess no theoretical training and thus might maintain a more emotive approach to music. Furthermore, we suggest examining current research education programs in public schools and at various ages in order to determine the extent of their emotional aspects, and thereafter develop emotionally oriented music education programs.
We suggest the following implications for music education. First, we recommend concluding emotionally-oriented teaching units to music education programs, including academic musical programs. Second, it would be beneficial to create emotionally-oriented music educational programs, based on the method of the program implemented in the current research, especially in early childhood education and during the process of language acquisition. Third, we may advise using both the framework of opposite emotions and the U-curve learning pattern while designing music education lessons.
In sum, the current research advances our understanding of prosody comprehension and not only provides new insights to cognitive neuroscientists; it also helps our community in everyday situations where prosody is involved. In addition, it also sheds light on the complex music-language relationship in general and on music education programs in particular.
Footnotes
Acknowledgements
We thank Dr. Eitan Globerson for developing the VERT battery.
Funding
This study was part of the PRE-MUS research (Number 252967) supported by the Marie Curie actions of the European Union (FP7-PEOPLE-2009-IEF).