
Abstract
We investigated how same-sex strangers develop latent semantic similarity (LSS)—that is, how they come to use words in the same way—in their initial interactions. In a previous study, Babcock, Ta, and Ickes found evidence suggesting that dyad members’ talking, looking, and acknowledging are important behaviors for the development of dyad-level LSS. Using a different sample of initial interactions, we replicated the major findings of Babcock et al., but found that, in both data sets, only those behaviors that introduced words into the conversation were uniquely predictive of LSS. These findings suggest that “the words may be all you need,” and that LSS might develop as effectively in non–face-to-face (i.e., computer-mediated) conversations in which only words are exchanged as in face-to-face conversations in which nonverbal behaviors are exchanged as well.
The ability of humans to acquire and speak one or more languages is widely regarded as one of the most significant and distinctive characteristics of our species (Chomsky, 1986; Pinker, 1994, 1999). Many writers have observed that sharing a common language is a prerequisite to humans being able to communicate about an astonishingly broad and diverse array of topics―from the most abstract to the most concrete―and to do so with great descriptive precision and nuance (Harzing & Pudelko, 2014; Schooling, Toth, & Marzano, 2013). However, with approximately 7,000 different languages in the world today (Anderson, 2010), the experience of speaking a common language with a stranger is by no means guaranteed.
And speaking the same language is only the first step. As many writers have noted (e.g., Bowker & Richards, 2004; Erlich, 1983; Lidz & Peña, 2009), even people who speak the same language are not always on the same page linguistically. Mutual understanding does not depend solely upon interaction partners speaking the same language; it also depends upon them coming to use words in essentially the same way. How interaction partners come to do this is an important topic for researchers in a number of overlapping disciplines such as communication, linguistics, psychology, and philosophy, to name the more obvious ones.
Writers in these disciplines have argued that interaction partners rely on language to develop a “common-ground understanding” (Abbeduto, Short-Meyerson, Benson, Dolish, & Weissman, 1998; Kecskes & Zhang, 2009; Krauss & Fussell, 1991; Schober & Clark, 1989; Wilkes-Gibbs & Clark, 1992) or an “intersubjective meaning context” (Ickes, 2002a, 2002b; Morganti, 2008). Although this process requires them to have a large and overlapping store of latent background knowledge about the world and their experience of it (Bechky, 2003; Clark, Schreuder, & Buttrick, 1983; Gibbs, Mueller, & Cox, 1988), this process is manifested in real-time interaction by the partners synchronizing their language use in their conversation so they come to use their words in essentially the same way. But how, exactly, are they able to do this?
At least three contemporary theories address the question of how interaction partners synchronize their language use during conversation. First, communication accommodation theory (Giles, Coupland, & Coupland, 1991; Giles & Ogay, 2007; Soliz & Giles, 2014) argues that, during their interactions, dyad members adjust their word choices, vocal patterns, and gestures to accommodate each other. There is considerable evidence that these mutual accommodations do indeed occur (Aronsson, Jonsson, & Linell, 1987; Hale & Burgoon, 1984; Natale, 1973). Second, uncertainty reduction theory (Berger & Calabrese, 1975; West & Turner, 2010) proposes that when two people interact for the first time, their focus is on reducing their levels of uncertainty within the interaction. Interaction partners may be unsure of how to behave or may question their partner’s perceptions in a given situation. Thus, each partner must both actively elicit and closely attend to information provided by the other partner in order to reduce this uncertainty. Third, coordinated management of meaning theory (Cronen, 1994, 1995; Pearce, 2005) asserts that the dyad members bring to their interaction their own respective meaning systems. As they interact, the partners not only construct their own individual interpretations of the interaction; they also attempt to co-construct a shared (i.e., intersubjective) interpretation of it.
The processes implied by each of these theories vary in their amenability to empirical study, such that the first theory is empirically more “tractable” than the second and, in particular, the third. Suppose, however, that it were possible to measure the overall “shared meaning” that dyad members develop as an outcome variable, and then empirically identify the specific dyad-level behaviors that best predict this outcome variable? Such an approach, if feasible, could be used to sharpen the focus of theorists’ and researchers’ efforts, by targeting some interaction behaviors as being more important and more deserving of intensive study than other behaviors are.
Using a Measure of Latent Semantic Similarity to Identify Key Predictor Variables
In a previous study, Babcock, Ta, and Ickes (2014) offered evidence that such an approach is both viable and informative. They noted that, using algorithms developed by computational linguists, it is possible to assess the degree to which two dyad members “get in synch” linguistically and develop shared meaning in their interaction. Because many social interaction researchers are unaware of this work, a bit of background on the key outcome measure―Latent Semantic Similarity (LSS)―is essential at this point.
When it is based on the conversation between two individuals, LSS can be thought of as an overall index of the degree of shared meaning that has developed in their dyadic interaction. It is crucial to note that the LSS index that Babcock et al. (2014) used in their research measures shared meaning (LSS) and not simply shared word usage (lexical similarity), as we explain below. The LSS index is derived from latent semantic analysis (LSA), an automated statistical method that establishes the contextual meaning of any text by analyzing the relationship among the words that are used (Landauer & Dumais, 1997; Landauer, Foltz, & Laham, 1998). Among other applications, LSA can be used to compare two blocks of text and assess the degree of their LSS, that is, the degree to which words are used in the same way in both blocks of text. This measure of the overall degree of LSS, represented by a value between −1 and 1 (higher values indicate higher levels of LSS), is called the LSS index.
Based on whether or not a word does or does not appear in various contexts, the LSA program combines the contexts in which a word is used and then implements a set of rules that determines the similarity of meanings of words and groups of words. One of the options in Landauer’s online software program, the LSA Pairwise Comparison program (Laham et al., 1998; http://lsa.colorado.edu), enables the user to input two blocks of texts into the program’s high-dimensional semantic space (computations can be made using up to 150 dimensions). The program then computes the cosine of the angles between the two resulting vectors to estimate the overall degree of LSS between the two blocks of text based on the words that are used and how those words are used in relation to other words. In essence, when two words that are similar in meaning and context occur within the same text, LSA identifies them as similar even if the words rarely occur within the same passage or sentence.
Arnulf, Larsen, Martinsen, and Bong (2014) provide a nice example of how the LSA program identifies words that are similar in meaning and/or context: The LSA program generated a LSS index of .80 for the sentences “Doctors operate on patients” and “Physicians do surgery.” Although these two sentences do not have any words in common, the LSA program recognizes a shared meaning between the two sentences. Thus, the LSS index measures the degree of latent semantic similarity (i.e., the extent of shared meaning) rather than the degree of lexical similarity (i.e., the extent to which the same exact words are used, which could be computed simply as a ratio of the words used by both partners divided by the total words used). Note that programs that assess only lexical similarity do not take into account the specific meanings of the words being used (Arnulf et al., 2014). This can be particularly troublesome when a word has multiple meanings (i.e., homographs) and is used in several different contexts. For this reason, assessing LSS, rather than lexical similarity, is more appropriate for analyzing the conversation that occurs in unstructured dyadic interactions, because it alone captures what theorists have in mind when they talk about the development of “shared meaning” between interaction partners.
Early research using the LSS index primarily examined the LSS between certain “target” texts and a single, standard “criterion” text (see, e.g., Caspar, Berger, & Hautle, 2004; Landauer, Laham, & Foltz, 2003; Lautenschlager, Dunn, Bonney, Flicker, & Almeida, 2006). More recently, interest in the LSS construct has extended to the similarity between two texts that appear on the Internet, for example, the similarity between the words that two friends use or the similarity between the words that advertisers use and the words used by their target audience. (For more specific examples, see Katsanos, Tselios, & Avouris, 2008; Mihalcea, Corley, & Strapparava, 2006; Recchia & Jones, 2009.) The results of these and other studies suggest that LSA analysis is capable of evaluating the meaning that resides within corpora of text, but is this ability comparable to that of humans? More specifically, and with respect to the present study, is the LSS index a valid measure of the shared meaning that develops in human face-to-face interaction?
The results of two relevant studies suggest that it is. In a study by Dam and Kaufmann (2008), a sample of 13 students were subjected to a series of periodic interviews that sought to measure the amount of knowledge that they had acquired about a particular topic as they continued to receive additional instruction on the topic over time. The LSA program, when compared with the combined ratings of several human raters, was able to accurately assess the students’ conceptual change in thinking and knowledge over time. In fact, its accuracy reached 90%—a value that demonstrated not only its ability to capture the nuanced changes of human comprehension but also its ability to assess understanding on a conceptual level, similar to humans.
In a study by Lautenschlager et al. (2006), older adults underwent a cognitive assessment that was scored by using either the LSA method or the standard scoring method that employed human raters. The older adults in this sample had either an English-speaking background or a non-English-speaking background. This feature of the design was particularly important because it had been suspected that cultural and linguistic differences between those who have an English-speaking background versus those who have a non-English-speaking background influenced the outcome of such cognitive assessments, consequently compromising the validity of the measures. The results revealed that LSA was in fact a more reliable and accurate measure of cognitive function than the standard scoring methods that employ human raters. Thus, not only have previous studies demonstrated the applicability of LSA analysis in both research and commercial domains; they have also shown its ability to assess meaning in a manner remarkably similar to humans on complex knowledge management tasks, integration tests, and human language learning tasks (Arnulf et al., 2014; Landauer et al., 1998).
Of present interest, however, is Babcock et al.’s (2014) use of the LSS index to measure the level of LSS that develops in the initial interactions of same-sex strangers. Babcock et al. (2014, p. 79) proposed that three specific behaviors should be of particular importance in this process:
Even a casual observation of everyday social interaction suggests that this process depends on (1) how much the interaction partners talk to each other (a behavior that is essential for the sampling and eventual mutual alignment of what words are used and how they are used in relation to other words); (2) how much the interaction partners look at each other (a behavior that is essential for the detection of those nonverbal cues—including the emotional ones—that help the partners achieve a more qualified and nuanced understanding of what their partner’s words mean in context); and (3) how much the interaction partners acknowledge each other, both verbally and nonverbally (behaviors that often, though not always, signal that one’s partner feels that he or she has grasped one’s intended meaning and wishes to express that perceived understanding, see Abbeduto et al., 1998).
To test these predictions, Babcock et al. (2014) used partner-specific transcripts of conversations that were obtained from a previous study of initial, unstructured dyadic interactions by Cuperman and Ickes (2009). These transcripts served as the basis for computing the level of LSS between each pair of dyad members. Then, using other data obtained in the same study, Babcock et al. (2014) assessed the relationship between each dyad’s level of LSS and their behavioral and thought/feeling content measures. The results of this study were consistent with the predictions. The level of LSS that the dyad members achieved was positively correlated with: (a) how much they talked to each other (LSS was higher when partners exchanged a lot of verbal information during their conversation); (b) how much they looked at each other (LSS was higher when the partners displayed more individual and mutual gazing); and (c) how much they acknowledged each other, both verbally and nonverbally (LSS was higher when the partners displayed more head nods and verbal acknowledgements).
However, although the results from this study appeared to be promising, at least three important questions were left unanswered. The first question was as follows: Could these findings be replicated in a new sample that included a different set of initial, unstructured dyadic interactions? The second question was as follows: Are there any additional dyad-level correlates of LSS that were not identified in the study by Babcock et al. (2014) but would add to our conceptualization of LSS and how it develops between interaction partners? Among these additional dyad-level correlates that were not included in the Babcock et al. (2014) study, a behavior of particular interest was expressive gestures. Because previous literature has argued for the importance of expressive gestures in communication (Birdwhistell, 1970; Key, 1975; Leathers, 1978; Mehrabian, 1972; Scheflen, 1973), we took the opportunity to measure it and examine its role as a potential predictor in the current study.
The third and final question was perhaps the most important of the three: Which of the significant dyad-level behavioral predictors of LSS are uniquely predictive of LSS when the remaining behaviors are statistically controlled? In the previous study by Babcock et al. (2014), the researchers identified a number of dyad-level behaviors (e.g., talking, looking, acknowledging) that were positively associated with LSS when they were tested using zero-order correlations. However, if these and other behaviors also predict LSS in a replication-and-extension study, we should not simply assume that they all function as independent predictors. Instead, we should determine whether these predictors are in fact independent or are, in some respects, redundant (i.e., we should determine whether they can be reduced to a smaller number of relatively independent behavioral factors). Once we have done that, we should then go on to determine which of these behavioral factors is/are uniquely predictive of LSS when the effects of the remaining factors are statistically controlled.
The Present Investigation
To address the first question of whether the findings by Babcock et al. (2014) could be replicated in a new sample of initial, unstructured dyadic interactions, the present investigation used data that were obtained from a separate study (Ickes, Tooke, Stinson, Baker, & Bissonnette, 1988). To address the second question of whether there are additional dyad-level correlates of LSS, we examined the data for certain dyad-level behaviors (e.g., expressive gestures) that were not measured in the previous study we reported (Babcock et al., 2014). To address the third question of whether certain behaviors are uniquely predictive of LSS when the remaining behaviors are statistically controlled, we used factor analysis techniques to identify a reduced set of relatively independent behavioral factors, and then tested their effects in a multiple regression model to see which of these factors were predictively important.
Previous findings (Babcock et al., 2014) led us to predict that the dyad-level behaviors that reflected the amount of talking that occurred would be the strongest predictors of LSS because they enabled the interaction partners to sample the words that each of them used and determine how these words were used in relation to other words. Other behavioral factors (e.g., looking, acknowledging, gesturing) might also prove to be significant, though perhaps less powerful, predictors of LSS, or they might prove to be insignificant predictors when the amount of talking is statistically controlled. Whatever the outcome, however, we expected the findings from the present study to provide a clearer understanding of how LSS develops in initial, unstructured dyadic interactions.
Method
Participants
As noted above, the data for the current study were obtained from a previous study of unstructured dyadic interactions between strangers (Ickes et al., 1988). The participants in this previous study were 92 students (46 stranger dyads that were composed of 26 female–female dyads and 20 male–male dyads) from undergraduate psychology classes at the University of Texas at Arlington. 1 The participants received course credit in their introductory psychology courses for taking part in the study. Because an institutional review board had not been established at the university before the collection of the data for the previous study on which we conducted our secondary data analyses, approval for the previous study’s data collection was granted by an internal review committee in the Department of Psychology instead of an institutional review board. On the other hand, approval for the secondary data analyses that we report here was granted by the institutional review board at the University of Texas at Arlington when we first proposed to conduct the current investigations.
In the previous study by Ickes et al. (1988), the participants were recruited through apparently unrelated experimental sign-up sheets that were posted on a sign-up board in the Department of Psychology at the University of Texas at Arlington, with separate sign-up sheets used for male and female participants. Two same-sex participants who signed up for the same day and time were paired to create a dyad of same-sex strangers (see Appendix A for additional information regarding the sign-up process). When the two participants in each session were brought together in the lab, the experimenter looked for any indication that they were already acquainted. 2
Upon determining that the participants were strangers to each other, the experimenter then seated them on a couch in a “waiting room” situation, where their initial, unstructured interaction was covertly video- and audiotaped for 5 minutes while the experimenter left to run an errand before starting the session. The resulting video- and audiotapes captured the entire duration of each dyadic interaction while the participants were waiting for the experimenter to return (see Ickes et al., 1988, for more detailed information about the unstructured dyadic interaction procedure). Upon return, the experimenter conducted a partial debriefing and obtained written consent to use the dyad members’ interaction tape as data (see Ickes et al., 1988, for details).
In Ickes et al.’s (1988) original study, two independent judges used the video- and audiotapes to code a large number of verbal and nonverbal behavioral measures. For example, these measures included the total frequency and duration of verbalizations, directed gazes, verbal reinforcers, and others. The interrater reliabilities of the coded behavioral measures in this study were acceptable, and ranged from a low of .70 to a high of .98 (for details, see Ickes et al., 1988).
In the present investigation, we attempted to determine whether certain dyad-level behaviors were uniquely predictive of LSS when the remaining behaviors were statistically controlled, and to study these relationships across two separate data sets. Doing so required that both data sets (Cuperman & Ickes, 2009; Ickes et al., 1988) include the same dyad-level behavioral measures of interest. To maximize this overlap between studies, four independent judges used the video- and audiotapes from the Cuperman and Ickes (2009) study to code two additional behaviors (i.e., total frequency and duration of expressive gestures) that were not measured in the original study. The reliabilities of these two behaviors across the four judges were high, with a range of .98 to .99.
Procedure Used in the Present Investigation
Using the covertly video- and audiotaped interactions of each of the dyads as our data source, text file transcripts were created for each dyadic conversation by three research assistants. The speaking turns within each transcript were divided into two electronic text files, each of which contained only one dyad member’s portion of the conversation (i.e., one dyad member’s portion of the conversation was put into a different electronic text file from the other member’s portion). Each electronic text file was edited down into a solid block of text by deleting all indentions and line breaks, thereby enabling us to enter the two text files as input into the LSA program (Laham et al., 1998; http://lsa.colorado.edu) that computed the LSS index for each dyad.
To compute the LSS index, the two solid blocks of text that represented each dyad member’s portion of the conversation were copied and pasted into the input box provided on the LSA website (http://lsa.colorado.edu). A blank line was inserted between each block of text to indicate the end of the first block of text and the beginning of the second. The program options: “Pairwise Comparison” (which allows one block of text to be semantically compared with another); “Document-to-Document” (indicating that the two blocks of text are to be semantically compared with each other as documents rather than terms); “Maximum Factors Available” (to determine LSS using the maximum number of dimensions possible); and “General Reading up to 1st Year College” were selected for each computation.
These options were selected based on the written recommendations that were provided for using the “pairwise comparisons” option within the LSA program (Dennis, 2014). When the two blocks of text for each dyad were submitted for analysis, the LSA program generated an LSS index that ranged between −1 and 1, with a higher positive score indicating greater semantic similarity between the dyad members. More specifically, the LSS index represents how similar two text samples are in the words that are used and in how those words are used in relation to other words (Laham et al., 1998).
Results
We had three main goals for the current study. First, we sought to replicate the general pattern of correlations between the LSS index and various dyad-level behaviors and thought/feeling content measures that were first identified in a previous study (Babcock et al., 2014). Second, we sought to extend these previous findings by examining other potential correlates of the LSS index that were unique to the present data set. Third, we sought to further extend the previous findings by determining which of these behaviors, when represented as relatively independent factors, make unique and independent contributions to LSS.
Data Screening
Prior to data analysis, all identifiers were removed and the data for all variables were screened for missing values and outliers. There were instances of missing values and outliers for a few of the variables. The a priori criterion for outliers was any score on a measure that was at least ±2.5 standard deviations from the overall sample mean. After the outliers had been removed, all variables were screened for assumptions of normality. Three variables (frequency and duration of expressive gestures, duration of mutual gazes) were positively skewed even after the deletion of outliers, so appropriate normalizing transformations were applied to these variables. 3 (All of our results that include these three variables will identify them as transformed variables in the data tables.) After the appropriate square root transformations were performed, all variables appeared to be normally or near-normally distributed (see Appendix B for the descriptive statistics for all variables prior to any transformations that were needed).
Correlations of LSS With the Dyad-Level Behaviors and Thought/Feeling Content Measures
Could the previous findings by Babcock et al. (2014) be replicated in an independent sample of initial, unstructured dyadic interactions? Standard Pearson zero-order correlations were used to determine the relationship between each dyad’s LSS index and the dyad-level behavioral and thought/feeling content measures that were collected in the study by Ickes et al. (1988). The significant correlations are reported in the left-most column of Table 1.
Replicated Dyad-Level Correlates of LSS in both the Babcock et al. (2014) Study and the Present Study.
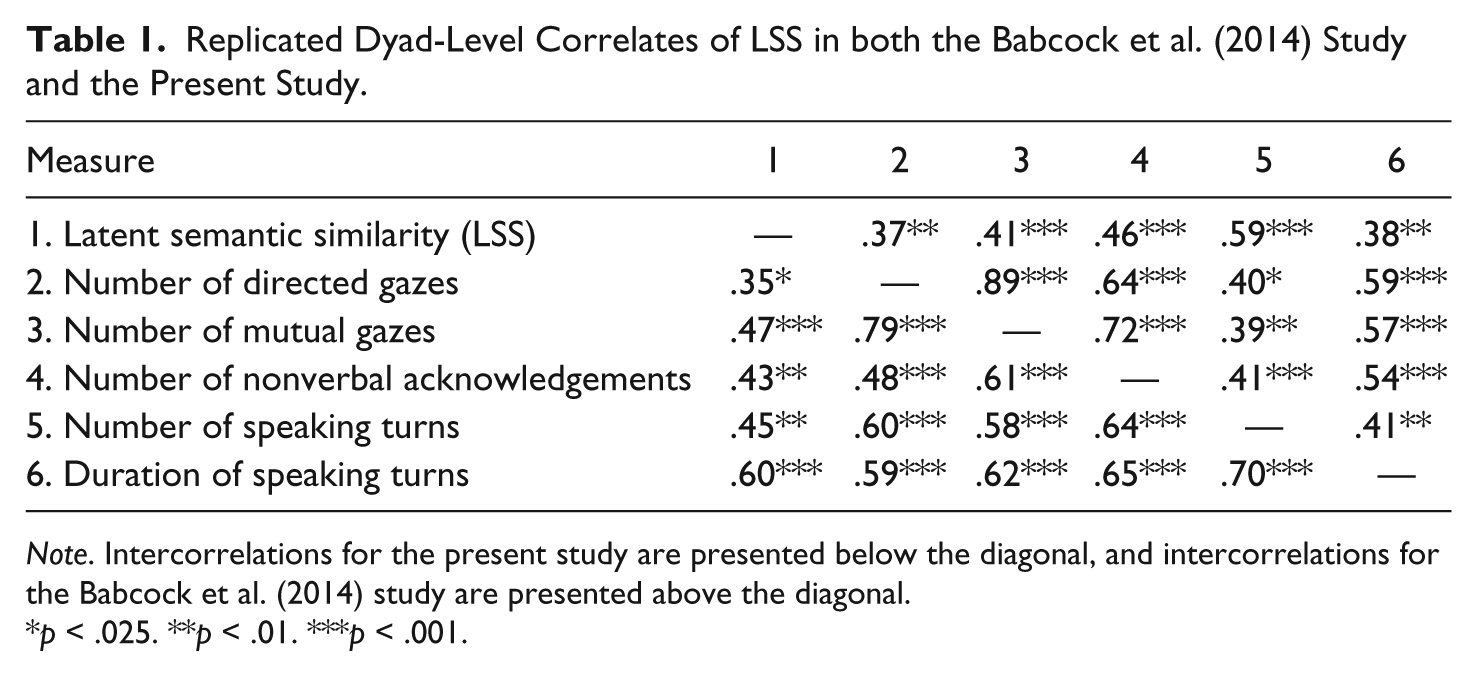
Note. Intercorrelations for the present study are presented below the diagonal, and intercorrelations for the Babcock et al. (2014) study are presented above the diagonal.
p < .025. **p < .01. ***p < .001.
These correlations reveal strong, positive relationships between LSS and the amount of talking that occurred during the interaction, as assessed by the total number of speaking turns and the total duration of speaking turns. LSS was also positively correlated with the total number of directed gazes during the dyadic interaction (i.e., instances in which one dyad member looked directly toward the other dyad member’s face, regardless of whether or not the other dyad member returned the gaze); the total number of mutual gazes (i.e., instances in which both dyad members simultaneously engaged in a directed gaze); and the total number of nonverbal acknowledgements (i.e., head nods). These results replicate the previous findings of Babcock et al. (2014) and provide further evidence that LSS develops out of highly involving interactions in which a large amount of verbal and nonverbal information is exchanged between mutually attentive and acknowledging partners. Table 1 permits a comparison of the magnitude of the correlations in the present study with those previously reported by Babcock et al. (2014).
Additional (New) Dyad-Level Correlates of LSS
Were there additional dyad-level correlates of LSS that were not observed in the previous study by Babcock et al. (2014)? Beyond the replicated correlates we report in Table 1, some new correlates emerged in the data for the present study. As indicated in Table 2, these new behavioral correlates included the total number of words exchanged (r = .61), the total frequency and duration of expressive gestures (r = .54 and r = .41, respectively), the frequency of positive affect (i.e., the number of instances of smiling and laughing, r = .47), and the number of questions asked (r = .43). We also found two thought/feeling content correlates: the percentage of other-directed thought/feeling entries (how often the dyad members thought about other people during their interaction; r = −.42), and the percentage of positive thought/feeling entries (r = .38). 4
Additional Correlates Between Latent Semantic Similarity and Dyad-Level Behavioral and Thought/Feeling Content Measures Unique to the Present Study.
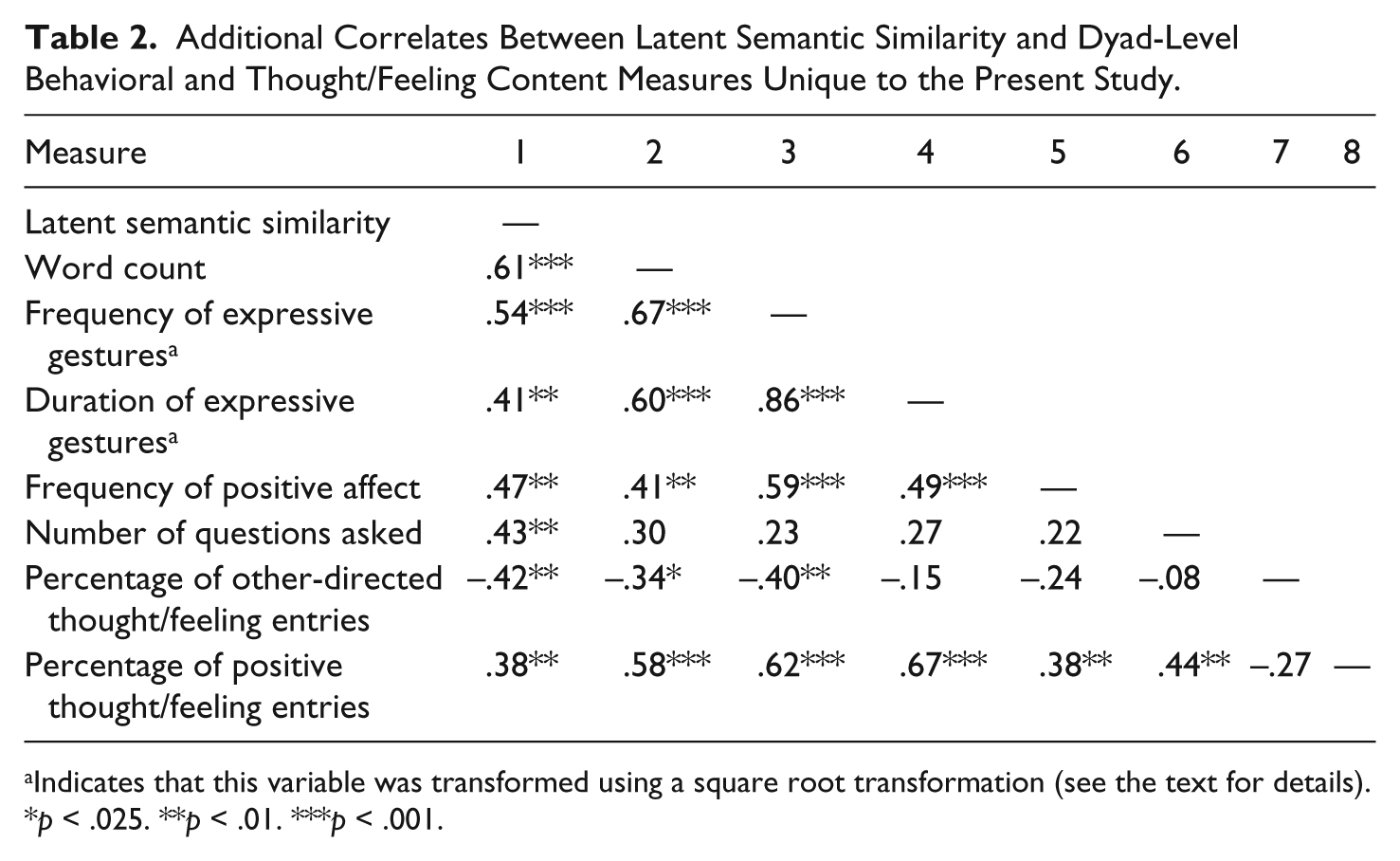
Indicates that this variable was transformed using a square root transformation (see the text for details).
p < .025. **p < .01. ***p < .001.
These additional correlations suggest that the dyad members achieved higher levels of LSS when they exchanged more words with each other and elicited additional information by asking a large number of questions. In addition, the dyad members achieved higher levels of LSS when they used more gestures to qualify and/or emphasize the meaning of what they said, and when they smiled and laughed more to signal moments of emotional rapport. Finally, higher levels of LSS were also associated with more positive thoughts and feelings, but with fewer thoughts and feelings about third-party others, possibly reflecting greater enjoyment of the interaction and a focus on each other rather than on other people.
Factor Analysis of the Dyad-Level Behavioral Correlates of LSS
Are all of these significant behavioral correlates important to the development of LSS between interaction partners, or can they be reduced to a smaller number of behavioral factors, perhaps only one/some of which is/are uniquely important? Because the dyad-level behavioral correlates of LSS were themselves intercorrelated, we tested to see if they could be reduced to a smaller set of relatively independent behavioral factors. Specifically, we conducted a varimax rotation factor analysis on the 13 dyad-level behavioral measures that were common to the present study and our previous study of LSS in initial dyadic interactions (see Table 3). Four factors with eigenvalues greater than .99 were extracted that collectively accounted for 80.81% of the total factor variance. These factors were labeled: “Looking and Acknowledging,” “Gesturing,” “Talking and Asking Questions,” and “Smiling and Laughing” (see Table 3 for the respective factor loadings and percentages of the total factor variance accounted for).
Factor Loadings of the Dyad-Level Behavioral Correlates of Latent Semantic Similarity in the Present Study.
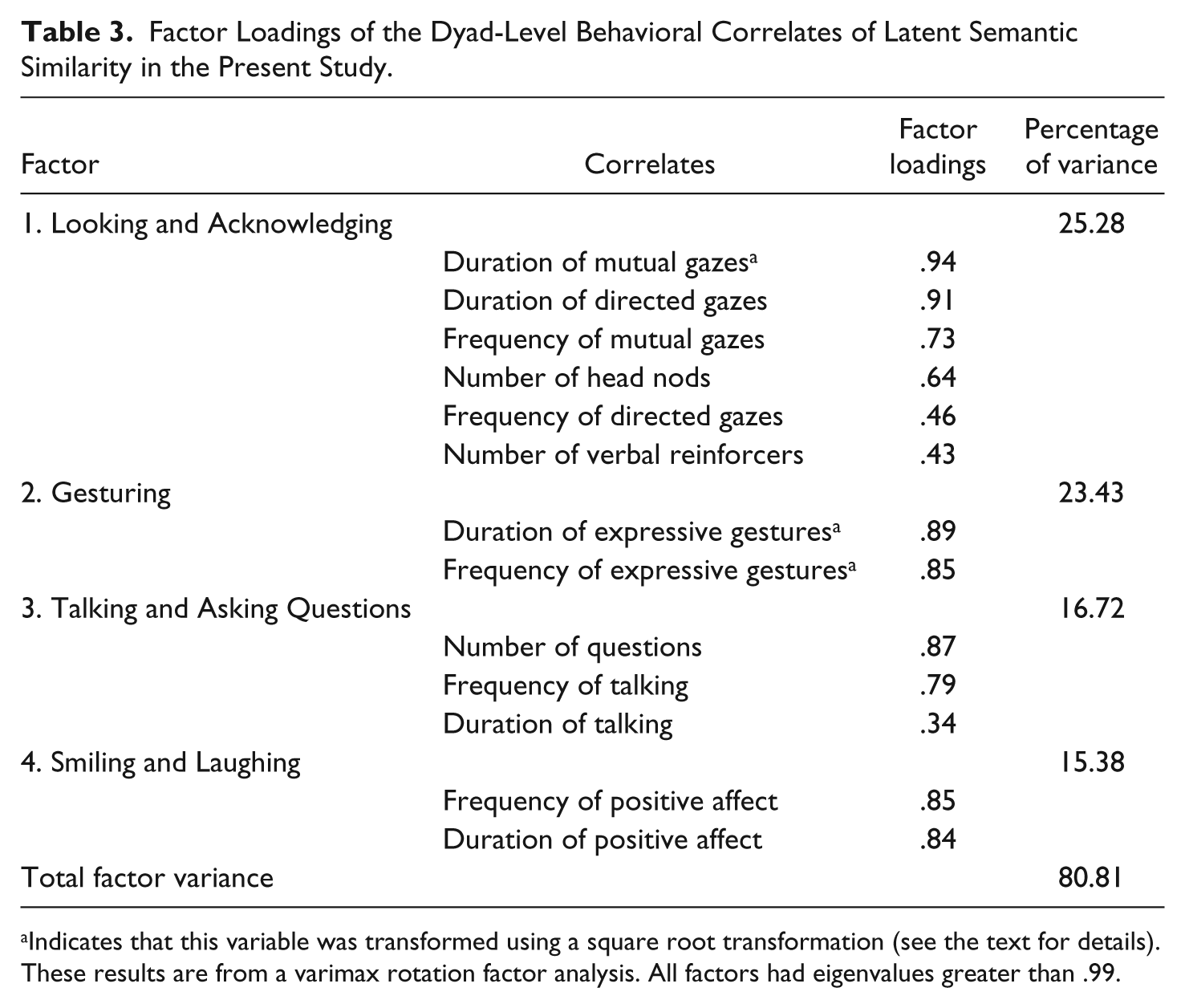
Indicates that this variable was transformed using a square root transformation (see the text for details). These results are from a varimax rotation factor analysis. All factors had eigenvalues greater than .99.
The first factor, “Looking and Acknowledging” represented six behavioral measures: verbal reinforcers (“Right,” “Okay,” “I see,” etc.), nonverbal acknowledgements (i.e., head nods), the duration and frequency of mutual gazes, and the duration and frequency of directed gazes. The second factor, “Gesturing,” represented two behavioral measures: the duration and frequency of expressive gestures. The third factor, “Talking and Asking Questions” represented three behavioral measures: the number of questions asked, and the duration and frequency of verbalizations (talking). The fourth factor, “Smiling and Laughing” represented two behavioral measures: the duration and frequency of positive affect.
The dyad-level behavioral measures that defined each of the four factors were summed to obtain a composite score for each factor. Standard Pearson correlations were used to determine the relationship between the dyads’ LSS index score and the composite score that defined each dyad-level behavioral factor. As zero-order correlates, all four behavioral factors were positively and significantly correlated with the LSS index score: Factor 1 (r = .43, p = .003), Factor 2 (r = .46, p = .001), Factor 3 (r = .61, p < .001), and Factor 4 (r = .38, p = .01). However, the next question to ask is an important one: Which of these behavioral factors predict LSS when the effects of the remaining factors are statistically controlled?
Assessing the Unique Contribution of the Dyad-Level Behavioral Factors in Multiple Regression Analyses
To answer this question, the composite score for each of the four factors, along with a dummy-coded variable that represented the dyad’s gender composition (MM and FF), were entered into a multiple regression model to predict LSS. The results revealed that the overall regression model was significant, and that the predictors collectively accounted for 39.70% of the variance in LSS, F(5, 39) = 5.14, p = .001, R2 = .397. However, Factor 3 (Talking and Asking Questions) was the only unique predictor of LSS, b = .004, SE = .002, β = .59, t(39) = 2.62, p = .012, sr2 = .11, suggesting that only those behaviors that resulted in words being added to the conversation were essential in predicting the level of LSS that the dyad members achieved. Table 4 provides the parameter estimates for the effects.
Regression Analysis for Behavioral Factors, Controlling for Gender Composition in the Present Study.
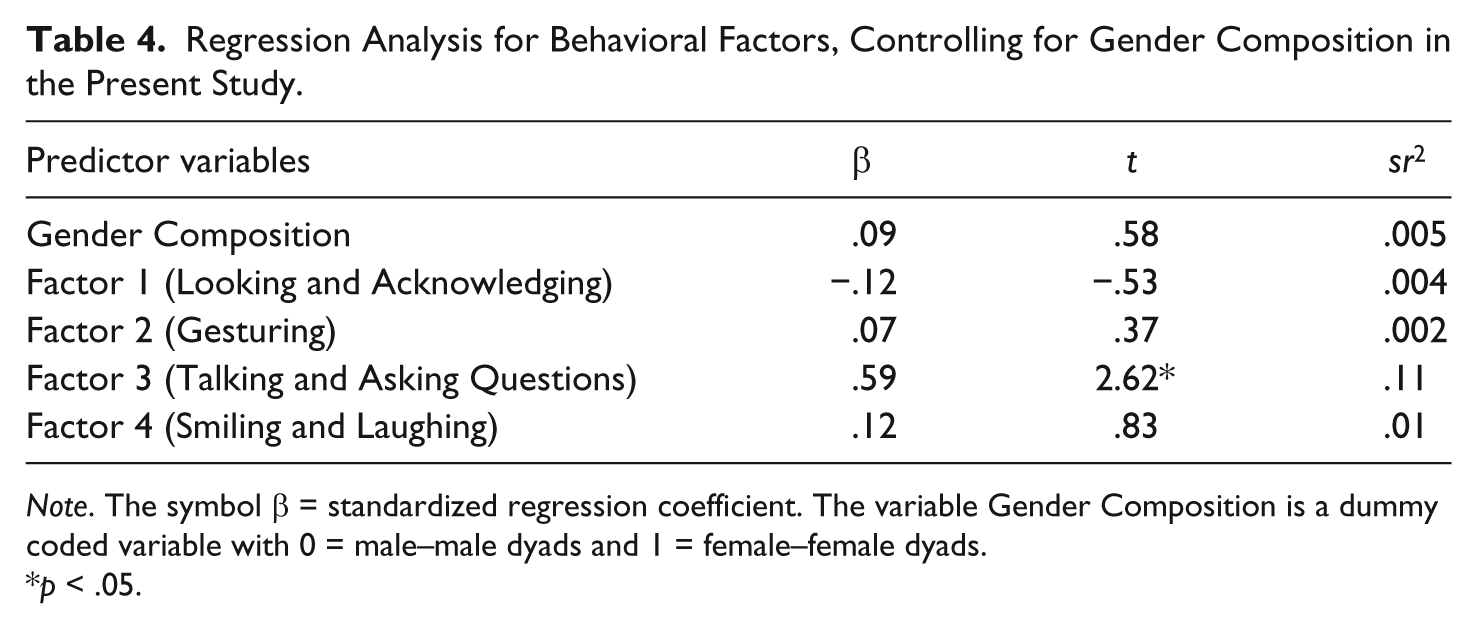
Note. The symbol β = standardized regression coefficient. The variable Gender Composition is a dummy coded variable with 0 = male–male dyads and 1 = female–female dyads.
p < .05.
Could we replicate these findings in an independent data set―specifically, the data set from the Cuperman and Ickes (2009) study that was used in the previous study of the behavioral correlates of LSS scores (Babcock et al., 2014)? To see if we could, we first attempted to replicate the results of our exploratory factor analysis by conducting a confirmatory factor analysis on the same 13 dyad-level behavioral measures in the Cuperman and Ickes (2009) data. When we did this, we found that the results were essentially the same as before. The confirmatory factor analysis with four factors extracted accounted for 72.47% of the total factor variance, 5 and these four factors and their respective factor loadings mirrored the four-factor solution reported above (see Table 5).
Factor Loadings of the Dyad-Level Behavioral Correlates of Latent Semantic Similarity in the Cuperman and Ickes (2009) Study.
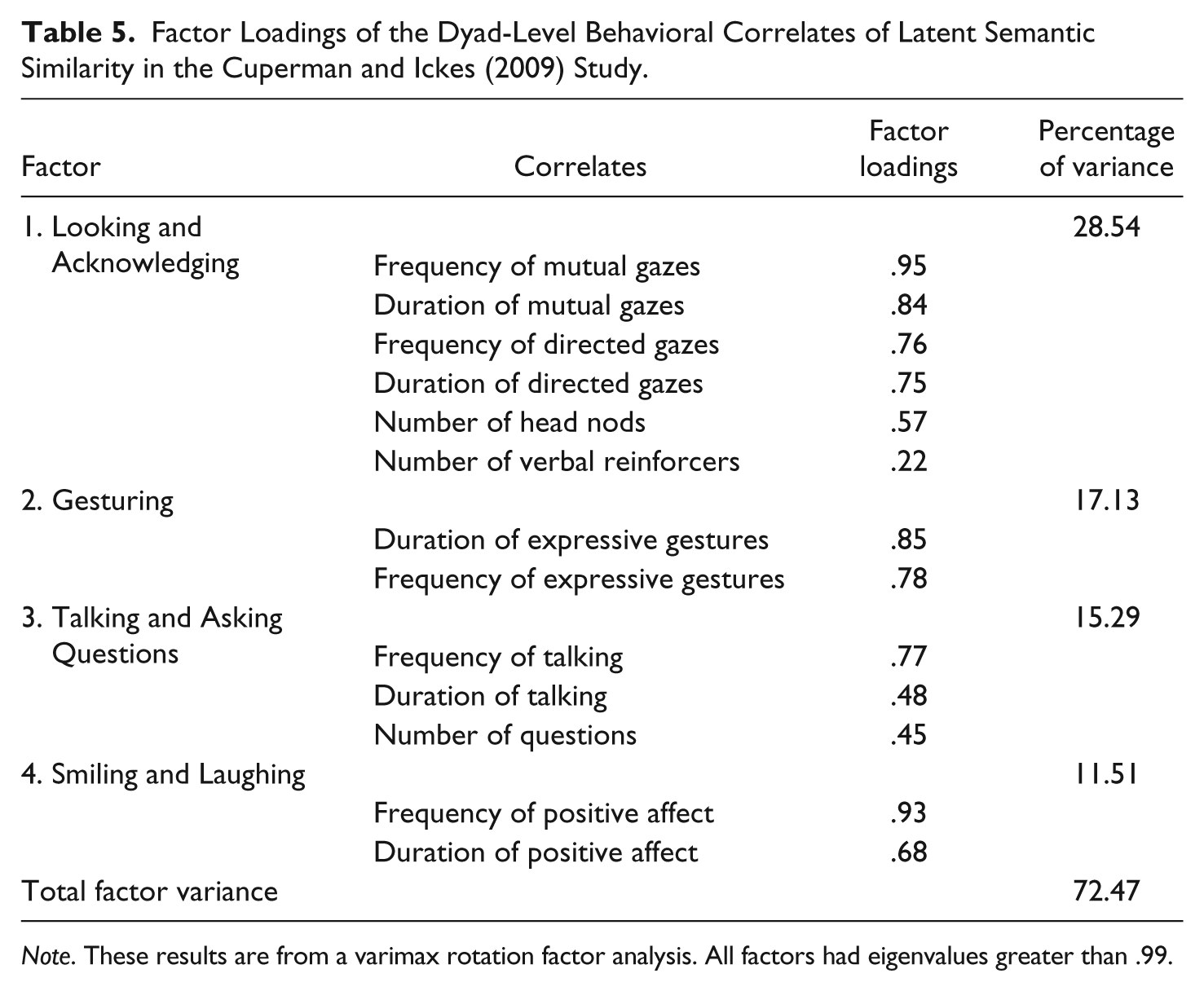
Note. These results are from a varimax rotation factor analysis. All factors had eigenvalues greater than .99.
Given the replicated factor structure, we then sought to replicate the findings we have just reported above using the data from the Cuperman and Ickes (2009) study. In contrast to the Ickes et al. (1988) data, only two of the four behavioral factors were significantly correlated as zero-order predictors with the LSS index scores in the Cuperman and Ickes (2009) data: Factor 1 (r = .36, p = .003) and Factor 3 (r = .45, p < .001). The correlations between LSS and Factor 2 (r = .23, p = .07) and LSS and Factor 4 (r = .13, p = .33) were positive but not significant.
Having examined these zero-order correlations, we next conducted a multiple regression model in which LSS was predicted by the composite score for each of the four dyad-level behavioral factors as well as two dummy-coded gender composition variables (those needed to distinguish the MM, FF, MF dyads). As before, the overall regression model was significant, indicating that the predictors collectively accounted for 24% of the variance in LSS, F(6, 56) = 2.97, p = .014, R2 = .24. And, as before, Factor 3 (Talking and Asking Questions) was the only unique predictor of LSS, b = .002, SE = .001, β = .42, t(56) = 2.47, p = .016, sr2 =.08. Table 6 provides the parameter estimates for the effects.
Regression Analysis Summary for Behavioral Factors, Controlling for Gender Composition in the Cuperman and Ickes (2009) Study.
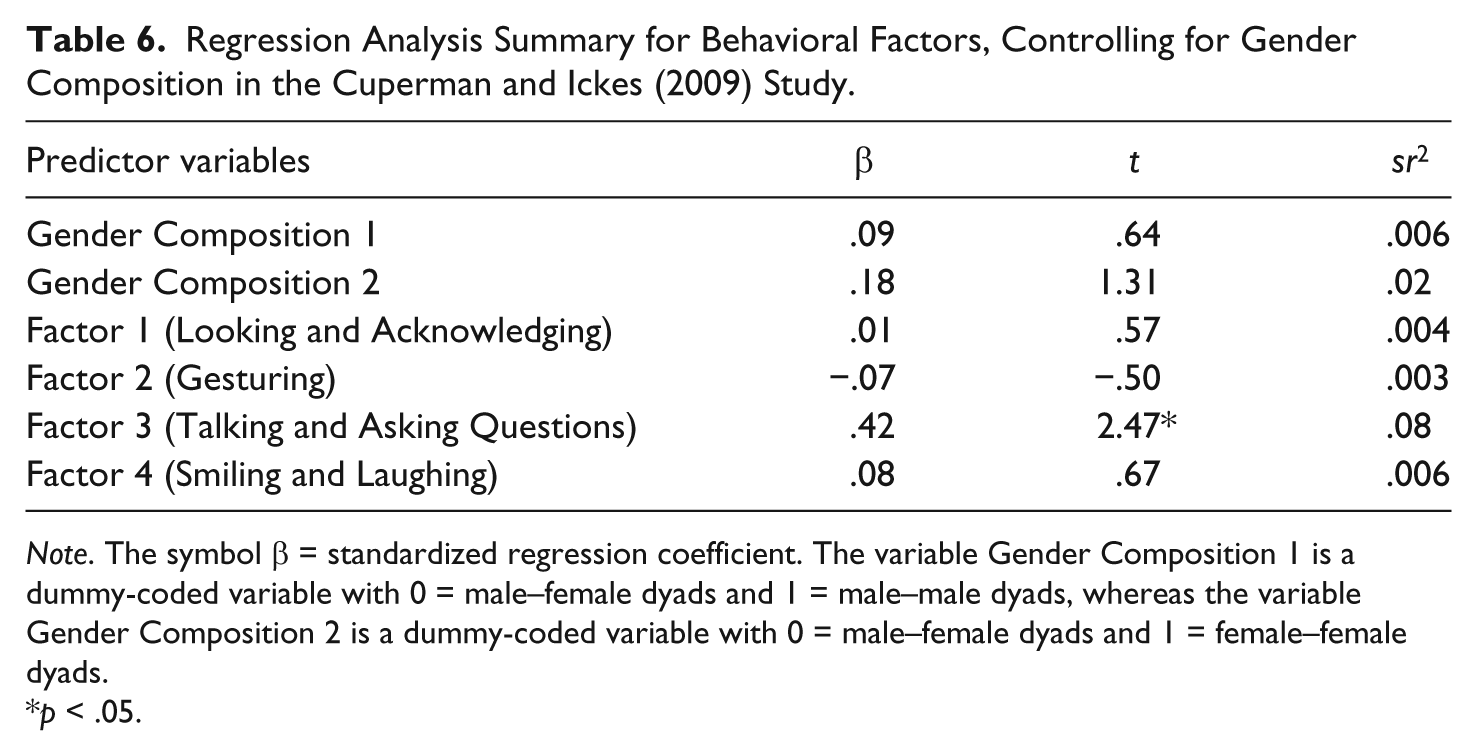
Note. The symbol β = standardized regression coefficient. The variable Gender Composition 1 is a dummy-coded variable with 0 = male–female dyads and 1 = male–male dyads, whereas the variable Gender Composition 2 is a dummy-coded variable with 0 = male–female dyads and 1 = female–female dyads.
p < .05.
Overall, the results from both data sets revealed that the amount of talking (as a proxy measure of the number of words being sampled during a conversation) is the only unique and essential predictor of the level of LSS that dyad members achieve in their initial, unstructured interactions. This effect makes sense because dyad members are given more opportunities to practice using their words in the same way as more words are introduced and repeated during their conversation. Or, to state it differently, dyad members are better able to align the intended meanings of the words they use the more often they sample how these words are used in relation to other words by both partners.
More surprisingly, however, the results revealed that all other dyad-level behaviorial factors, though significant zero-order predictors of LSS, were actually nonessential predictors when evaluated in a multiple regression model in which the effect of the Talking and Asking Questions factor was statistically controlled. Although these other behaviors (looking and acknowledging, gesturing, smiling and laughing) may play an essential role in the nonverbal exchange that occurs in dyadic interactions (Bruder, Dosmukhambetova, Nerb, & Manstead, 2012; Manusov & Patterson, 2006; Patterson, 2014), they do not appear to play an essential role in helping interaction partners “get on the same page” linguistically. In both data sets, the results revealed that, for LSS to develop between first-time interaction partners, the words themselves may be all you need. 6
Discussion
When viewed in the context of previous findings (Babcock et al., 2014), the present findings provide a clearer but distinctly different view of how dyad members develop LSS in their initial interaction. With regard to the zero-order correlations, the findings from both studies revealed that LSS is positively correlated with (a) how much the dyad members talk to each other, (b) how much the dyad members look at each other, and (c) how much the dyad members verbally and nonverbally acknowledge each other. At first glance, these findings appeared to support Babcock et al.’s (2014) argument that dyad members’ talking and looking are essential behaviors for the development of LSS and that acknowledgments (both verbal and nonverbal) might also play an important role in this regard.
Upon further consideration, however, we identified some additional dyad-level correlates of LSS that were not included in Babcock et al.’s (2014) study. These new zero-order correlates included (a) the total number of words exchanged by the dyad members, (b) the frequency and duration of their expressive gestures, (c) the frequency of their positive affect (smiling and laughing), (d) the number of questions they asked, (e) the percentage of other-directed thought/feeling entries, and (f) the percentage of positive thought/feeling entries. This expanded set of behavioral correlates raised two further issues that needed to be addressed. Could the 13 dyad-level behavioral measures that were common to the present study and the previous study of LSS (Babcock et al., 2014) be reduced to a smaller number of relatively independent behavioral factors? And, if so, which of these behavioral factors would prove to be uniquely predictive of LSS when the effects of the remaining factors were statistically controlled?
The answer to the first question was that four behavioral factors (Looking and Acknowledging, Gesturing, Talking and Asking Questions, and Smiling and Laughing) appeared to underlie the 13 behaviors that were measured in both studies. The answer to the second question was that only one of these factors―Talking and Asking Questions―was significantly associated with the dyad members’ LSS when the effects of the remaining factors were statistically controlled in a multiple regression model. Although the other factors were correlated with LSS when their relationships were tested using zero-order correlations, they proved to have no incremental validity beyond the effect of the factor that represented the amount of talking that occurred and the extent to which the partners could sample each other’s word usage and attempt to align it with their own. Dyads in which the partners looked at each other more did not achieve significantly greater LSS scores than dyads in which the partners looked at each other less, and the same was true when comparing dyads in which the partners acknowledged each other more versus less or dyads in which the partners gestured to each other more versus less.
Note that if these mostly nonverbal behaviors had made an incremental difference in LSS, the design and procedures used in the research should have been sufficient to detect it. In all dyads, the length of the interaction period was roughly the same. Dyads interacted for 5 minutes in the Ickes et al. (1988) study and 6 minutes in the Cuperman and Ickes (2009) study. The partners had not met before and were not given an instruction to interact in the experimenter’s absence. Any interaction they had was unstructured and occurred on their own initiative. Finally, and most importantly, there were no constraints on the dyad member’s nonverbal behavior; they were free to look at each other, acknowledge each other, gesture to each other, and smile and laugh with each other as much or as little as they chose. Nevertheless, the substantial variation the dyads displayed in these nonverbal behaviors did not account for any incremental validity in the level of LSS that the dyad members achieved.
Our conclusion―replicated across two different samples―is that the exchange of words in conversation is all that is needed for the development of LSS (i.e., shared meaning) in the initial, unstructured interactions of strangers. Although nonverbal behaviors such as looking, smiling, acknowledging, and gesturing are clearly important in creating an affectively pleasant and involving interaction between strangers (Ickes et al., 1988; Palmer & Simmons, 1995; Wada, 1988), these behaviors are apparently not essential to partners coming to use words in the same way. What is essential is the increasingly intricate and interconnected “web of meaning” that is created when new interaction partners begin to talk to each other, take advantage of opportunities to sample each other’s word choices, and then align their own word choices and intended meanings to achieve a greater semantic similarity with their partner. Indeed, this “web of meaning” is what previous writers have characterized as the “intersubjective meaning context” that develops whenever two people have a conversation (Ickes, 2002a, 2002b; Merleau-Ponty, 1945; Schutz, 1970). Furthermore, the relationship between the introduction of more words (i.e., the Talking and Asking Questions factor) and LSS is not just an empirical relationship, but one that is necessitated by both logic and common sense. Logically, before dyad members can sample each other’s word use and develop LSS, words must be introduced into their conversation by some means; and, common sense would implicate talking and asking questions as the most plausible means there is.
With the benefit of hindsight, it may be easier to see that interaction partners’ acts of looking at, smiling at, or acknowledging each other do not exert any systematic constraints on the meanings of their words―constraints that are strong and systematic enough to produce significant effects for these behaviors in our data. But what about gestures? Aren’t gestures supposed to qualify the meaning of people’s words in a way that might influence the degree of LSS they achieve? Perhaps gestures do have a significant influence on LSS in some interactions―for example, in interactions between individuals who are already so well-acquainted that they can readily interpret what each other’s nonverbal gestures mean. In interactions between strangers, however, it seems likely that the partners will have to take the time to learn what each other’s gestures are intended to signify, a process that could take as much or more time as it takes them to develop their level of LSS. We suggest that researchers who want to document an influence of gesturing on LSS might look for it first in the interactions of close friends and intimates, where its role is more likely to be evident from the earliest moments of their conversation.
Again, the lack of any unique effects for the nonverbal behaviors of looking, smiling, gesturing, or acknowledging (via head nods), in the present studies in no way discredits their importance in increasing a sense of rapport and involvement between interaction partners. It does, however, suggest that these behaviors are not essential to the process whereby new interaction partners synchronize both the words that they use and their intended meanings. By implication, the present results further suggest that because this process is essentially dependent on the conversational exchange of words alone, it might occur as effectively in written (e.g., “instant messaging”) and telephone conversations as in face-to-face encounters.
The present findings suggest that the study of LSS can inform theories, such as those mentioned earlier, that address the question of how interaction partners synchronize their language use during conversation. For example, with respect to communication accommodation theory, the study of LSS could provide additional insights into the role of “shared meaning” in cases of under- and overaccommodation. For example, expending little or no effort to “sync” one’s word use with the partner’s in order to make one’s meaning clear should result in lower LSS and underaccommodation, whereas being overly pedantic and repetitive in doing so might result in high LSS paired with annoyance at being “talked down to.”
Strengths and Limitations of the Present Study
To our knowledge, the current study and the previous one (Babcock et al., 2014) are the first to test how the LSS achieved by new interaction partners is related to the dyad-level behaviors they display in their initial interactions. Moreover, as noted above, the interactions that we examined in these studies were unstructured and spontaneous, yet comparable because they all occurred in the same laboratory setting and for roughly the same observation interval (5 or 6 minutes). They were also unconstrained by any instruction for the dyad members to interact; the partners were free to interact as much or as little as they choose (though, in order to test our hypothesis, we had to follow the LSA program guidelines and limit our samples to dyads in which at least a modicum of conversation occurred).
On the other hand, a couple of limitations of these studies should be noted. First, our college student samples lacked a broad range of diversity in their age and academic ability, although they were acceptably diverse with regard to gender and race/ethnicity. Future LSS research should attempt to use more diverse samples, if possible. Second, because the observation period was only 5 or 6 minutes long in these studies, the sample of conversation was adequate to compute an LSS index for each dyad but insufficient to compute an LSS index for different successive stages of the interaction so that the development of LSS could be tracked over time. In a future investigation, we plan to extend the observation period so that each dyad’s level of LSS can be tested in the beginning (first 6 minutes), middle (next 6 minutes), and end (final 6 minutes) of their initial interaction. This procedure should enable us to track the development of LSS over time and determine whether certain dyad-level behaviors play a greater or lesser role in some phases of an initial interaction than others.
As previously noted, LSS is a measure that is based on the analysis of the meaning of words based on how they are used in relation to other words. Thus, LSS can be used to address the question of whether interaction partners use emotion-relevant words in essentially the same way, but it cannot be used to identify the paralinguistic aspects of speech that are associated with verbal communication such as vocal inflections and changes in pitch and amplitude. However, LSS might get at these “feeling-related” variables indirectly insofar as humans are able to put them into words, either intentionally or unintentionally (Landauer et al., 1998).
Despite these limitations, LSS differs from other text-analysis approaches in a number of important ways. First, LSS does not only use the summed contiguous pairwise occurrences of words in its initial data; it also uses the detailed patterns of occurrences of words over the entire available set of local meaning-bearing contexts (i.e., contexts that are treated as unitary wholes, such as sentences of paragraphs). Second, LSA ascribes high significance to dimensionality (i.e., to a simultaneous representation all of the local word-context relations), such that reducing dimensionality 7 of the observed data from the number of initial contexts to a smaller (but still large) number will generally produce results that are more similar to human cognitive relations.
Third, LSS takes into account the overall distribution of words over usage contexts that is evaluated apart from their correlations. Fourth, the computational procedure by which the LSS index is generated depends not only on how often similar words are used or on the contingencies of the occurrence of words in a given corpus but also on a statistical analysis that is able to accurately interpret the associations that go beyond first-order co-occurrences (e.g., the context in which a given word is used). This computational procedure therefore produces broad and inclusive measures of semantic similarity that have been shown to relate in predictable ways to a number of human cognitive phenomena involving association or semantic similarity (Landauer & Dumais, 1996, 1997). It is this broader and more inclusive way of measuring LSS that differentiates LSS from other methods and enhances the degree to which it captures “shared meaning” over an entire interaction rather than in more isolated parts of it (Landauer et al., 1998).
Directions for Future Research
Because the present results suggest that the conversational exchange of words alone is sufficient for the development of LSS, future researchers should be encouraged to study this process in written exchanges (e.g., “instant messages” and text messages) and in telephone conversations as well as in face-to-face interactions. For example, it would be interesting to learn whether the shape of the “LSS function” over time is the same for all of these modes of verbal interaction, or whether it differs from one mode to another. With regard to written exchanges, these exchanges occur online not only through standard communication methods, such as e-mail or instant messages, but also through social media websites, such as Facebook, Twitter, and Reddit. There has been an explosion in the amount of activity and interaction on these social media websites, and future research could profitably study how dyad members develop LSS both within and between these websites. For example, do certain social media websites provide a better “environment” for dyad members to achieve higher LSS than others? Or, when message exchanges are restricted to a certain number of characters (e.g., Twitter only allows a maximum of 140 characters in message exchanges), does this constraint push communicating site members to try to achieve higher LSS earlier in the interaction rather than later?
Another interesting direction for future research would be to explore whether certain types of interaction partners find it easier to achieve a high level of LSS than others. For example, if both dyad members score high on the verbal portion of standard IQ tests, will they achieve higher levels of LSS than dyad members who both score low in verbal IQ, and will they achieve these higher levels more quickly? Or, to take another example, will new interaction partners who have grown up in the same municipality, attended the same schools, and participated in the same local language community achieve higher LSS scores, and do so more readily, than ones who have grown up in different regions, attended different schools, and participated in different local language communities?
In addition to examining these dyad-level characteristics, future research should also examine how individual-level characteristics influence the level of LSS that develops within the dyad. For example, might a partner with lower social status be more likely to adopt a higher status partner’s word choice and associated meanings within their interaction? Or might a partner with a weak sense of self be more likely to adopt the word usages of a partner with a strong sense of self than vice versa (cf. Cuperman, Robinson, & Ickes, 2014)? These are just some of the many interesting questions that future LSS research could address.
Footnotes
Appendix A
Appendix B
Acknowledgements
The authors would like to thank Ben Bolding, Keith Gryder, and Marianne Zafra for their assistance in transcribing the dyadic interactions. The authors would also like to thank the editor, Dr. Giles, and the reviewers who provided their input on previous versions of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.