
Abstract
Automated essay scoring can produce reliable scores that are highly correlated with human scores, but is limited in its evaluation of content and other higher-order aspects of writing. The increased use of automated essay scoring in high-stakes testing underscores the need for human scoring that is focused on higher-order aspects of writing. This study experimentally evaluated several alternative procedures for eliciting distinct human scores and improving their reliability. Essays written in response to the argument and issue tasks of the Analytical Writing measure of the GRE General Test were scored by experienced raters under different conditions. Criteria for evaluation included inter-rater agreement, agreement with machine scores, and cross-task reliability. First, the use of a modified scoring rubric that focused on higher-order writing skills increased the reliability for one type of task but decreased it for another. Second, scoring in batches of similar length essays did not have any effect on scores. Third, scoring with available automated essay scores increased reliability of human scores, but also increased their similarity with automated scores. Finally, the use of a more refined 18-point scoring scale significantly increased reliability.
Performance assessments necessarily involve subjective judgments. This fact accords a central place to the rater and the rating process, and nowhere more so than for direct writing assessments. This inherent subjectivity can be at odds with the concept of psychometric reliability (Moss, 1994). In the context of large-scale, high-stakes writing assessments in particular, a primary goal is to ensure that raters think similarly enough about what constitutes a high- or low-quality student response to achieve reasonable consistency of scores across ratings.
Achieving this goal is a continuous challenge, as numerous studies of rater behavior have shown substantial differences in the way in which raters interpret scoring criteria (see, e.g., Engelhard, 1994; Bachman, Lynch & Mason, 1995; Lumley & McNamara, 1995; Weigle, 1998; Engelhard & Myford, 2003, Eckes, 2008). Moreover, rater training has not been able to eliminate completely these differences (Lumley & McNamara, 1995; Weigle, 1998, 1999; Barrett, 2001; Elder, Knoch, Barkhuizen, & von Randow, 2005).
As a result, reliability of large-scale essay writing assessments is mediocre relative to the time required to write essays, typically 30–45 minutes. Breland, Camp, Jones, Morris, & Rock (1987) conducted an extensive reliability study of essay ratings. Examinees wrote six essays in three modes of writing, and each essay was scored by three experienced raters. The reliability estimate for a test composed of two essays (in a single mode) was .59 when each essay was scored by one rater, and .70 when each essay was scored by two raters. Breland, Bridgeman, and Fowles (1999) summarized the findings of reliability studies conducted before the Breland et al. (1987) study, and found that the mean reliability estimates for two double-rated essay examinations was .71. They also report on unpublished results from the writing assessment of the Graduate Management Admissions Test (GMAT), which consist of two tasks. The mean reliability estimate for a two-essay, double-rated assessment was .71.
The relatively low reliability and the high cost of human essay rating have led to a growing interest in the application of automated natural language processing techniques for the development of automated essay scoring (AES) as a supplement to human scoring of essays. In recent years, several high-stakes graduate admissions programs have implemented AES in the operational scoring of their writing assessments. The first of these programs was the GMAT®, which started to use e-rater (Burstein, Kukich, Wolff, Lu, & Chodorow, 1998) in 1999. In 2006, The GMAT transitioned to Intellimetric (Elliot, 2001), when the GMAT contract changed from ETS to ACT. Since October of 2008, a version of e-rater based on e-rater V.2 (Attali & Burstein, 2006) is used operationally as part of the scoring process for the GRE Issue and Argument prompts. E-rater has also been used for scoring TOEFL independent prompts since July of 2009, and for TOEFL integrated prompts since October of 2010. Finally, the Intelligent Essay Assessor™ (IEA) by Knowledge Analysis Technologies™ (Landauer, Laham, & Foltz, 2003) is deployed in the Pearson Test of English since 2009.
The operational implementation of AES was performed in all cases by replacing one human rater with AES, without changing the scoring rubrics of human raters. In other words, the automated score is seen as interchangeable with the human score. There is indeed empirical support for the close resemblance between human and automated scores. Based on a sample of 2000 sixth- to twelfth-grade students, each of whom wrote two essays, Attali and Burstein (2006) estimated the true-score correlations between e-rater and human essay scores to be .97. In other words, the alternate-form correlations between human and machine scores (e.g. correlation between human score of essay 1 and e-rater score of essay 2) were almost the same as the alternate-form reliability of the human scores (correlation between human score of essay 1 and human score of essay 2). Similarly, based on 5000 computer-based TOEFL (the previous version of the current iBT TOEFL) examinees who repeated the test within a few weeks, Attali (2007) estimated the true-score correlations between e-rater and human essay scores to be again .97.
Nevertheless, it is clear that AES is limited in its evaluation of higher-order aspects of writing, such as the quality of ideas, their development, and organization. For example, AES evaluates content and ideas mostly with ‘bag-of-words’ approaches (Landauer, Foltz, & Laham, 1998; Attali & Burstein, 2006; Attali, 2011a). Humans can assess these higher-order aspects more easily simply because they can comprehend the text. The major premise of this study is that it is not reasonable to expect and strive for AES that is indistinguishable from human scoring (Attali, 2012). The advances in AES and its operational implementation underscore the need for a ‘division of labor’ between human and machine assessment that takes into account the relative strengths of both methods. By encouraging raters to focus on higher-order aspects of writing it might be possible to achieve (a) higher reliability of human scoring, (b) lower correlations between human and machine scores, and consequently (c) higher reliability of combined human and machine scores.
This paper explores the effects of several methods intended to encourage raters to focus their attention on higher-order aspects of writing. The first method was the use of a modified scoring rubric that emphasizes higher-order aspects of the original rubric. Although this approach seems straightforward, past research suggests that raters find it difficult to focus on a certain trait while ignoring others (Huot, 1990). For example, Lee, Gentile, and Kantor (2008) found very high correlations (in the 80s) between trait scores (organization, development, vocabulary, sentence variety, grammar/usage, and mechanics), higher than their estimated reliabilities. Therefore, to help raters ignore lower-order aspects of the essay, the information that raters were asked to ignore was emphasized or revealed in different ways. First, the order of essays was manipulated to purposefully group together essays that are similar in shallow characteristics. In particular, raters were asked to score essays in batches that were composed of similar-length essays. Essay length is a strong predictor of human scores (e.g. Lee et al., 2008, report correlations of .90 between holistic scores and essay length). This result may be a natural side effect of the need to provide supporting detail (Powers, 2005), but the usual random ordering of essays for scoring may make it harder for raters to take into account the differences in quality of essays that are similar in length. Second, in an even more explicit effort to help raters ignore lower order aspects of writing, the e-rater score of the essay was shown to the raters. In both cases, the purpose of the manipulations was explained to the raters as part of the goal of focusing on higher-order aspects of writing.
This study evaluated an additional technical modification to the rating process, one that directly addresses the reliability of ratings. Essay ratings typically use a small number of categories that correspond to the descriptor levels in the scoring rubrics. Many large-scale assessment programs use a six-point scale (Weigle, 2002, p. 123). Alderson, Clapham, and Wall (1995) recommend using scales ‘with no more than about seven points, as it is difficult to make much finer distinctions’ (p. 111). However, to our knowledge there is no research on the limits of rater distinctions in essay ratings. Peculiarly, during training raters use both benchmarks – clear examples of a score point, and rangefinders – responses exemplifying the range of each score point (Baldwin, Fowles, & Livingston, 2005, p. 13). That is, rangefinders are essays that may be ‘low’ or ‘high’ for a specific score category. If raters are able to distinguish between at least three levels of a score point (low, typical, and high), using a finer grained score scale would increase the reliability of scores. In this study, a six-point score scale was augmented to 18 score points by defining a low and high level for each category.
An experimental design was used in this study to investigate the different manipulations – higher-order versus regular rubric, ordering of essays by essay length versus random ordering, and availability of e-rater scores. Professional raters, highly familiar with the rubrics and type of tasks they were asked to score, rated essays in different conditions. Examinees wrote two essays each, and each rater scored both essays of each examinee. The effects of the different scoring conditions were evaluated with respect to the following outcomes: relation between ratings of the same essay (inter-rater agreement), relation between human and e-rater scores, and relation between scores of different essays written by the same student. In addition, the effect of using the augmented score scale was investigated by comparing original (augmented) scores with rounded scores with respect to inter-rater agreement and alternate-form reliability.
Method
Writing tasks
The Analytical Writing measure of the GRE General Test comprises two essay writing tasks. In the issue task, the student is asked to discuss and express his or her perspective on a topic of general interest. In the argument task, a brief passage is presented in which the author makes a case for some course of action or interpretation of events by presenting claims backed by reasons and evidence. The student’s task is to discuss the logical soundness of the author’s case by critically examining the line of reasoning and the use of evidence.
The two tasks are scored by human raters using a holistic scoring rubric with six points, and since October of 2008, e-rater is used operationally as part of the scoring process of both tasks. E-rater does not, however, directly contribute to essay scores. Instead, one human rating is obtained for the essay. If the difference between this rating and the e-rater essay score does not exceed a .5 threshold, the final essay score is equal to the human score. If this threshold is exceeded, a second human rater provides an additional rating, and the final essay score is the average of the two human ratings. Finally, the scores for the two tasks are averaged and only one writing score is reported.
Scoring rubrics
The GRE scoring rubrics emphasize ideas, development and organization, word choice, sentence fluency, and conventions, as the following description of a typical high-scored ‘outstanding’ issue response shows (GRE, 2011):
articulates a clear and insightful position on the issue in accordance with the assigned task;
develops the position fully with compelling reasons and/or persuasive examples;
sustains a well-focused, well-organized analysis, connecting ideas logically;
conveys ideas fluently and precisely, using effective vocabulary and sentence variety;
demonstrates facility with the conventions of standard written English (i.e. grammar, usage and mechanics), but may have minor errors.
A typical ‘outstanding’ argument essay is described as:
clearly identifies important features of the argument and analyzes them insightfully;
develops ideas cogently, organizes them logically, and connects them with clear transitions;
effectively supports the main points of the critique;
demonstrates control of language, including appropriate word choice and sentence variety;
demonstrates facility with the conventions (i.e. grammar, usage, and mechanics) of standard written English but may have minor errors.
The modified rubric that emphasized higher-order aspects of writing included only the first three bullets of the preceding description. In addition, each prompt (in each rubric) is accompanied by prompt notes and benchmark essays that exemplify each score point.
Design: First stage
The following design factors were used in the first stage of the study.
Task
Each examinee wrote two essays in response to an argument and issue prompts. Each participating rater (without being aware of this fact) scored both the argument and issue essays written by examinees.
Prompt pair
Two pairs of argument and issue prompts were used in the study. Each rater scored only one of the pairs.
Examinee group
For each prompt pair, the essays of 200 examinees were used in the study. They were separated into two equivalent groups (labeled A and B), matched on their GRE verbal scores. Each rater scored the essays of both groups of examinees, but in different scoring conditions.
Scoring rubric
In addition to the regular GRE scoring rubric, a special scoring rubric was prepared for each task. This special rubric emphasized higher-order writing skills. Each rater used (and was aware of) only one scoring rubric.
Essay order
Scoring was performed separately for each set of 100 essays written by one of the examinee groups (A or B) in response to one of the tasks (argument or issue). Each such set of essays was scored in one of two orders: according to essay length from shortest to longest or in a specific random order. Each rater was presented with both orders, one for essays written by examinee group A and the other for essays written by examinee group B.
Task order
Participating raters were assigned to one of four task order conditions, defined by which examinee group is scored in random order, and which order is scored first. The task orders of the four conditions are presented in Table 1.
Task order conditions (Task/Examinee group/Essay order)
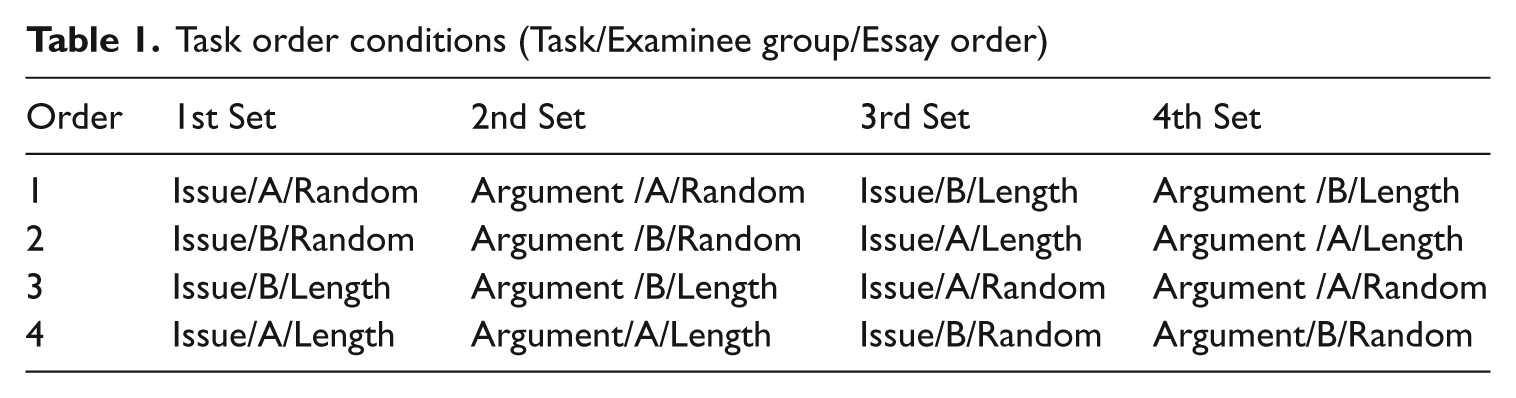
In summary, participant raters used (and were aware of) only one scoring rubric, either the regular or higher order. They also scored essays written to only one pair of argument and issue prompts. Each rater scored both argument and issue essays written by 200 examinees, for a total of 400 ratings. Each rater scored two sets of 100 essays in random order and two other sets in essay length order, from shortest to longest. Finally, there were four different task order conditions.
A total of 32 professional GRE raters participated in the study. For each of the two prompt pairs, four raters were randomly assigned to each task order condition, for a total of 32 raters (4 raters × 4 order conditions × 2 pairs of prompts). Participants were paid an honorarium of $450. All scoring was performed in a special website for the study. The score scale for the study was augmented beyond the standard 1–6 GRE scale to include a + and – for each score point (e.g. to the score of 1 were added the scores 1− and 1+), for a total of 18 score points.
After completing the tasks, raters were asked to share their thoughts about the method of essay ordering by length, about the augmented score scale, and about the special higher-order rubric for those who used it.
Design: Second stage
The purpose of the second stage of the study was to evaluate the effect of presenting the e-rater score to raters during their assessment of essays. This stage took place about two months after the first stage, and only the 16 raters who used the higher-order rubric participated in it. In this stage, the raters scored the 400 essays for the prompt pair they were not exposed to in the first stage. Only random essay ordering was used and only one task order: Issue/A, Argument/A, Issue/B, Argument/B. After completing this task, raters were asked again to share their thoughts about scoring with e-rater scores present.
Analyses
All the following analyses interpreted the ‘low’ and ‘high’ levels of each score point as one third below or above the rounded score. The main purpose of the analyses was to compare the effects of the different essay orders and rubrics on study scores. Essays were presented in two orders, random and according to essay length (shortest to longest). In addition, three scoring conditions were used: the regular GRE rubric, the higher-order (HO) rubric, and the HO rubric in conjunction with the presentation of e-rater scores (termed HOE, for higher order + E-rater).
Several types of possible effects of order and condition were evaluated. First, inter-rater correlations were computed for each set of 100 essays between all pairs of raters scoring under the same condition and order. Second, correlations between human and e-rater scores were computed for each set of 100 essays. Third, inter-rater partial correlations controlling for e-rater scores were computed for each set of 100 essays. And fourth, cross-task correlations between the two essays each student wrote were computed for each set of 100 essays and each rater across the different scoring conditions. To interpret these four types of analyses, two-level analyses of variance were performed on the Fisher transformation of the sample correlations, with prompt and rater as random effects (or only prompt for inter-rater correlations), and task, order, and condition as independent variables. The main interest was in possible order and condition main effects or interactions.
Results
Descriptive statistics
Table 2 presents mean study scores across conditions. The table shows small differences across the different essay orders, as well as across sets (1 or 2 versus 3 or 4). The scores for the issue task are higher than the argument task by about half a point, and the scores for the regular rubric are lower than other rubrics by about .20–.25 points. Finally, the scores for the second argument prompt were higher than the first by .22 points overall, and the scores for the second issue prompt were higher than the first by .09 points overall.
Means (and SDs) of scores
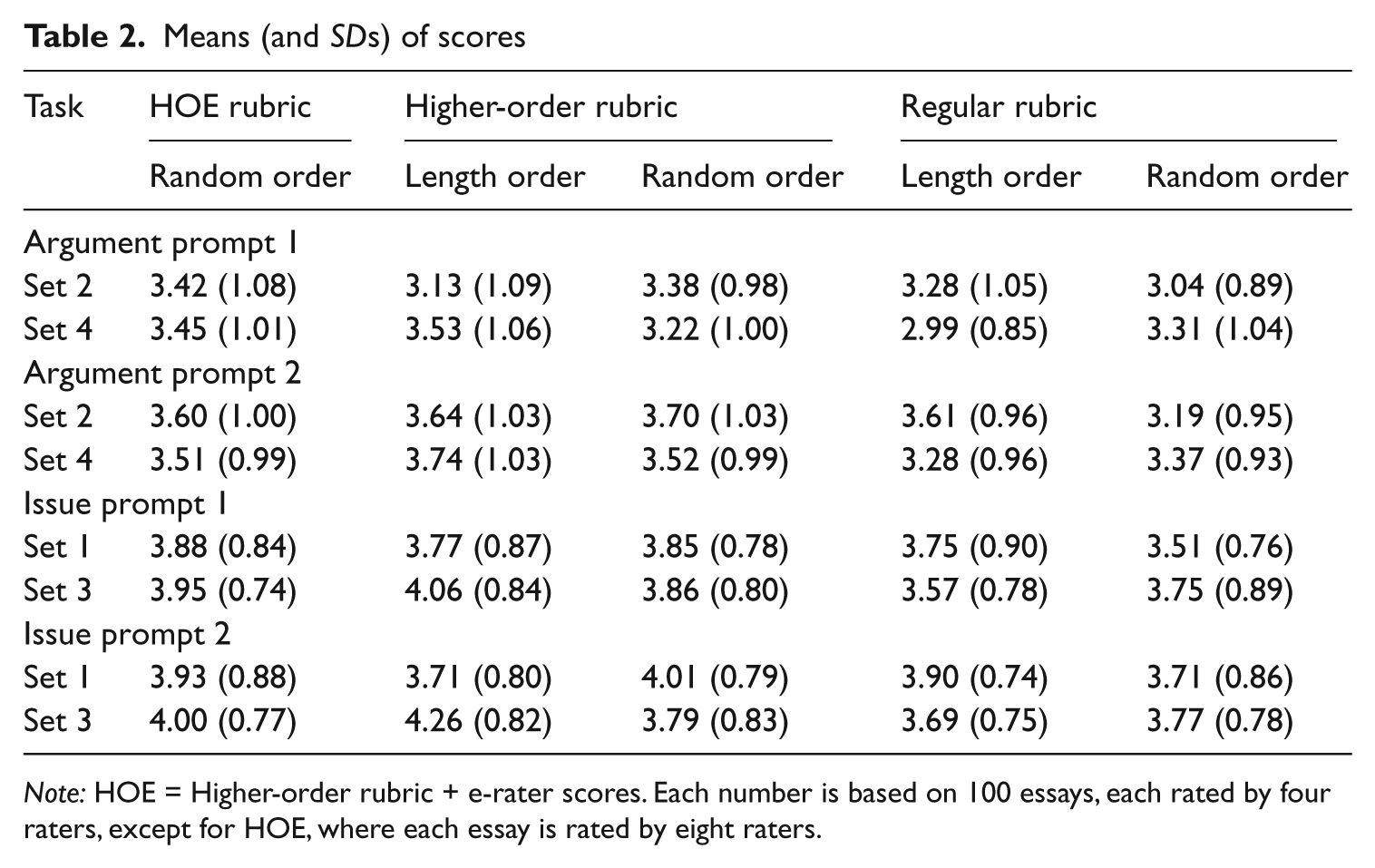
Note: HOE = Higher-order rubric + e-rater scores. Each number is based on 100 essays, each rated by four raters, except for HOE, where each essay is rated by eight raters.
Inter-rater correlations
To compare levels of agreement between raters across study conditions, all 100-essay pair-wise correlations between raters were computed. For each set of 100 essays, either 8 raters (for the HOE condition) or 4 raters (for the two other rubrics) provided scores, resulting in 28 or 6 pair-wise correlations, respectively. Table 3 presents the mean (and SD) of these correlations for each prompt, rubric, and essay order. Each cell in the table is based on all pair-wise correlations for each of the two examinee groups.
Means (and SDs) of 100-essay inter-rater correlations for study scores
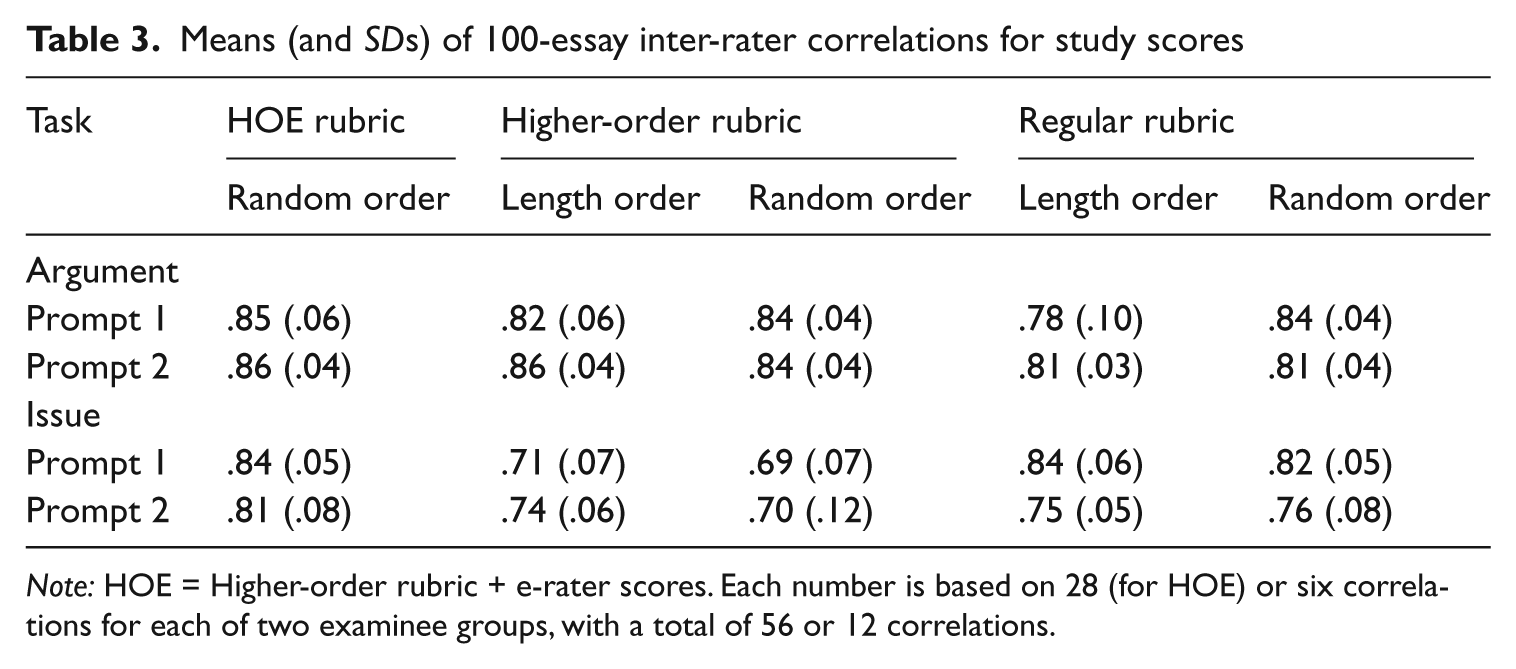
Note: HOE = Higher-order rubric + e-rater scores. Each number is based on 28 (for HOE) or six correlations for each of two examinee groups, with a total of 56 or 12 correlations.
To interpret these results, a two-level analysis of variance was conducted on the Fisher transformation of the sample correlations, with prompt as a random effect, and task, order, and rubric as independent variables. The main interest was in possible order and rubric main effects or interactions.
Initial results showed no main effect or interaction for order, so a modified analysis was conducted without the order factor. 1 No significant main effect for task was found (F[1, 2.1] = 10.5, p = .08), with an average correlation of .84 for argument and .79 for issue. Significant effects were found for both the rubric effect (F[2, 408] = 41.7, p < .01) and the rubric-task interaction (F[2, 408] = 18.2, p < .01). Post-hoc comparisons found significant differences (p < .05) between all three rubrics in both tasks. For argument, the average correlations in the HOE, HO, and regular rubrics were .86, .84, and .81, respectively. For issue, the average correlations in the HOE, HO, and regular rubrics were .83, .71, and .79, respectively. That is, the HOE correlations were highest in both tasks, and the HO correlations for issue were especially low.
Correlations with e-rater scores
For each rater and 100-essay set, the correlation between e-rater and human scores was computed. Table 4 presents the mean (and SD) of these correlations for each prompt, rubric, and essay order. A two-level analysis of variance was conducted on the Fisher transformation of the sample correlations, with prompt and rater as random effects, and task, order, and rubric as independent variables. The main interest was in possible order and rubric main effects or interactions.
Means (and SDs) of 100-essay correlations between e-rater and study scores
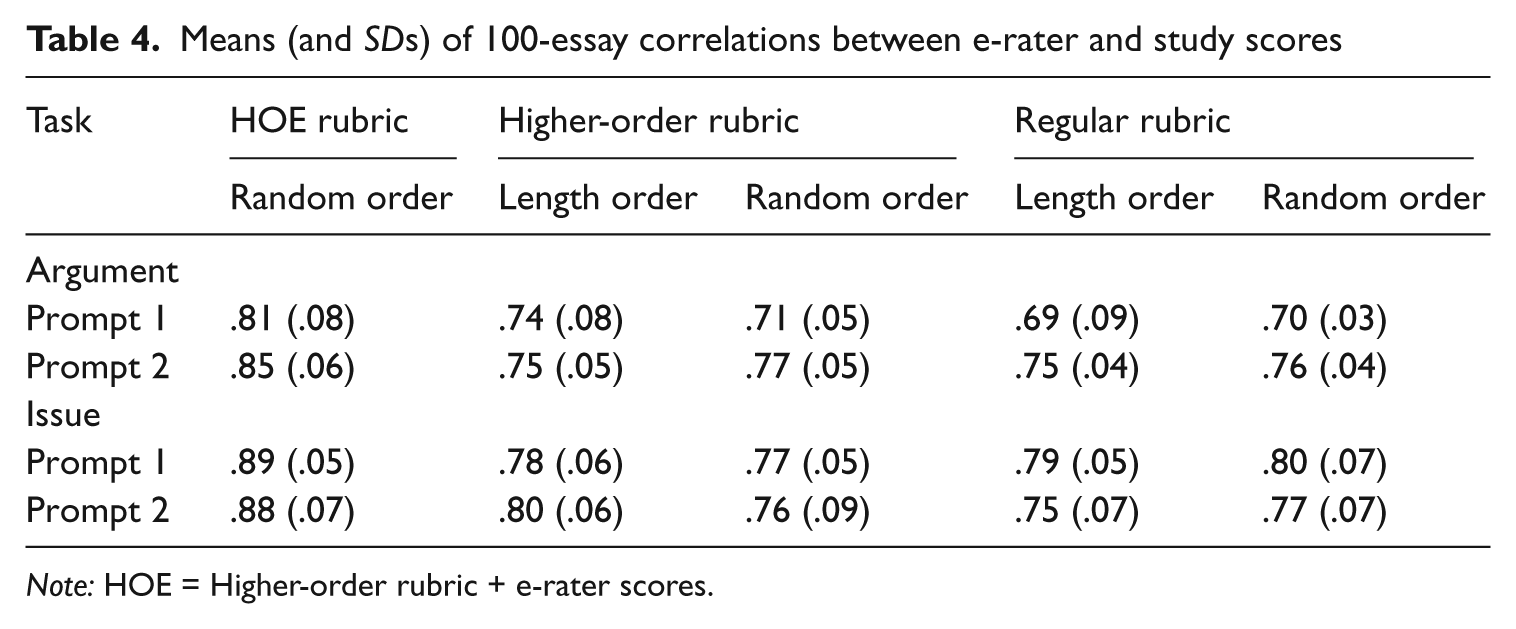
Note: HOE = Higher-order rubric + e-rater scores.
Initial results showed no main effect or interaction for order, so a modified analysis was conducted without the order factor. No significant main effect for task was found, (F[1, 2.0] = 6.6, p = .12), with an average correlation of .77 for argument and .81 for issue. A significant effect was found only for the rubric effect (F[2, 184] = 62.2, p < .01) but not the rubric-task interaction (F[2, 184] = .9, p = .41). Post-hoc comparisons found significant differences (p < .05) between the HOE rubric (average correlation of .86) and both the HO (.76) and regular (.79) rubrics. That is, the HOE correlations with e-rater scores were highest in both tasks.
Inter-rater partial correlations, controlled for e-rater scores
To compare levels of agreement between raters across study conditions after controlling for e-rater scores, all 100-essay pair-wise partial correlations between raters were computed. Table 5 presents the mean (and SD) of these partial correlations for each prompt, rubric, and essay order. A two-level analysis of variance was conducted on the Fisher transformation of the sample correlations, with prompt as random effect, and task, order, and rubric as independent variables.
Means (and SDs) of 100-essay inter-rater partial correlations for study scores
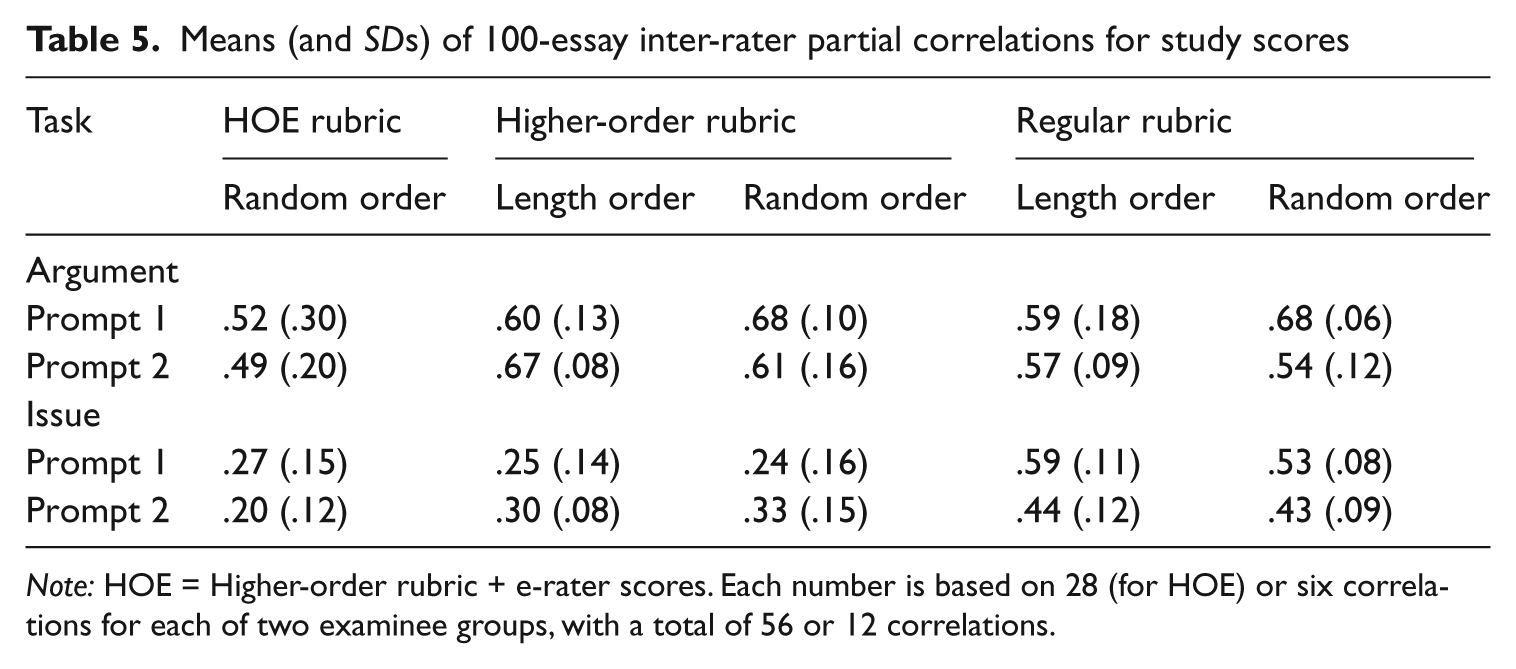
Note: HOE = Higher-order rubric + e-rater scores. Each number is based on 28 (for HOE) or six correlations for each of two examinee groups, with a total of 56 or 12 correlations.
Initial results showed no main effect or interaction for order, so a modified analysis was conducted without the order factor. A significant main effect for task was found, (F[1, 2.1] = 49.4, p = .02), with an average partial correlation of .56 for argument and .31 for issue. Significant effects were found for both the rubric effect (F[2, 408] = 31.2, p < .01) and the rubric-task interaction (F[2, 408] = 14.0, p < .01). For the argument task, post-hoc comparisons found significant differences (p < .05) between the HOE rubric (average partial correlation of .51) and both the HO (.64) and regular (.61) rubrics. For the issue task, post-hoc comparisons found significant differences (p < .05) between the regular rubric (average partial correlation of .50) and both the HOE (.23) and HO (.28) rubrics. That is, the HOE partial correlations were lowest in both tasks, and the HO partial correlations were lower than regular partial correlations for issue.
Cross-task correlations
Cross-task correlations between argument and issue examinee scores awarded by the same raters were calculated for each 100-examinee group. Both human scores and the average of human and e-rater scores were correlated. Table 6 presents the mean (and SD) of these cross-task correlations for each prompt, rubric, and essay order. A two-level analysis of variance was conducted on the Fisher transformation of the sample correlations, with prompt and rater as random effects, and order and rubric as independent variables.
Means (and SDs) of 100-essay cross-task correlations
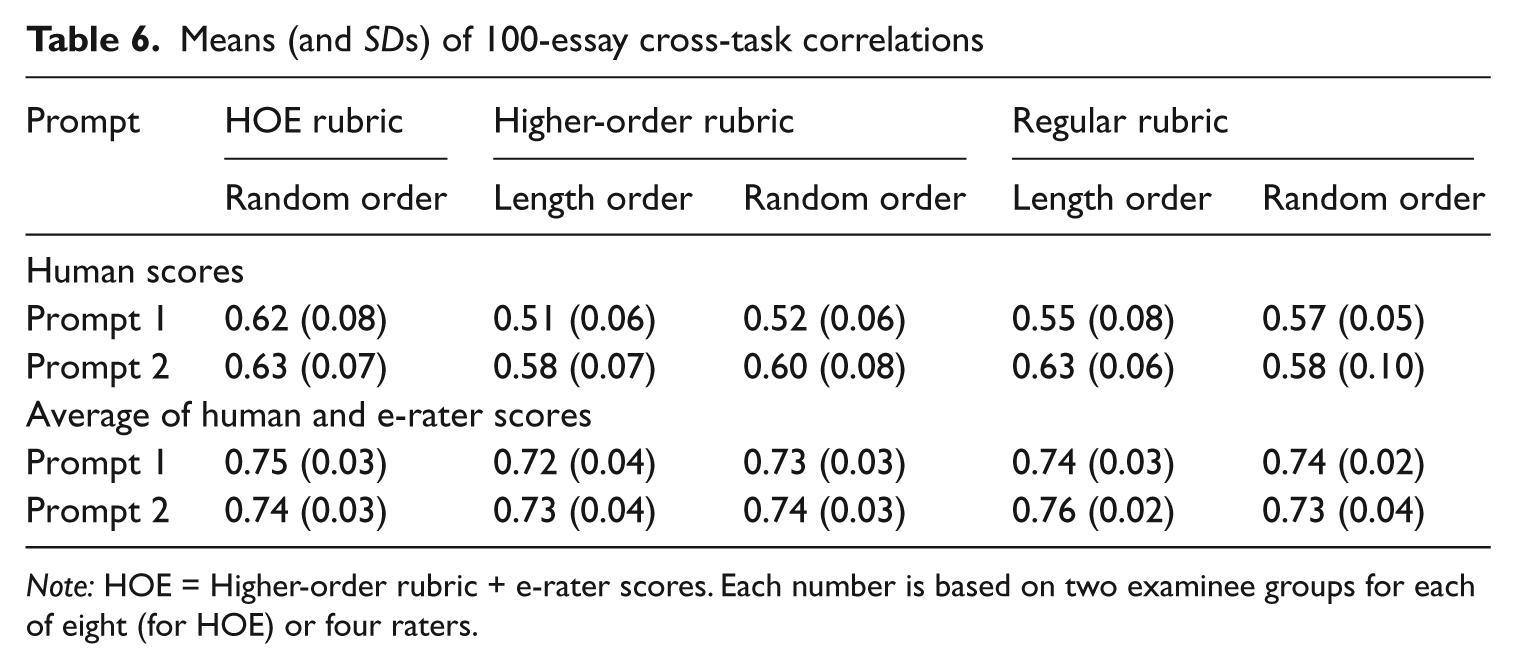
Note: HOE = Higher-order rubric + e-rater scores. Each number is based on two examinee groups for each of eight (for HOE) or four raters.
Initial results showed no main effect or interaction for order, so a modified analysis was conducted without the order factor. For human scores only, a significant effect for rubric was found, (F[2, 55.2] = 11.2, p < .01). Post-hoc comparisons found significant differences (p < .05) between the HOE rubric (average correlation of .62) and both the HO (.56) and regular (.58) rubrics. That is, HOE correlations were higher than the other two rubrics.
For the average of human and e-rater scores, the effect for rubric was not significant, (F[2, 65.0] = 1.3, p = .28), and therefore no significant differences were found between the HOE rubric (average correlation of .74), the HO rubric (.73) and regular rubric (.73).
Comparison of augmented and round scores
Figure 1 shows the distributions of study scores for each task, limited to the regular rubric (other rubrics have similar distributions). The figure shows that the most common score is 3 for argument and 4 for issue. Overall, a significant proportion of ratings, 27% for each task, used either the high (+) or low (−) levels of score points. In most cases, the mid-level score is used more often than either the low or high levels, with some exceptions, such as score category 1, categories 2 for issue, and 5 for argument.

Histogram of augmented scores for regular rubric
To estimate the effect of using the augmented scores on reliability, G-theory analyses were conducted on the original augmented scores and on the rounded scores. For each rubric and pair of prompts, the random effects variance components of a fully crossed two-facet (person-by-item-by-rater) design were estimated. For example, the following variances were estimated for augmented scores of prompt pair A of the regular rubric:
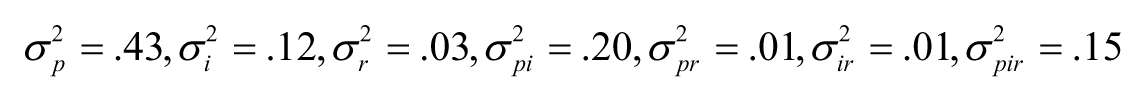
Figure 2 presents the G-coefficients for different numbers of raters and items (essays) for augmented and rounded scores. Results are shown for the regular rubric (results for other rubrics are similar) and G-coefficients were averaged across the two prompt pairs (results are almost identical across pairs). The figure shows that augmented scores have consistently higher reliabilities than rounded scores. The size of the effect is equivalent to around 50% of the number of raters. For example, for one essay the reliability of rounded scores increases from .51 with one rater to .59 with two raters, but it is .55 for augmented scores and one rater. Similarly, the reliability of rounded scores is .62 with three raters, but it is also .62 for augmented scores and two raters. Finally, the reliability of rounded scores is .64 with four raters, but it is also .64 (and slightly higher) for augmented scores and three raters. The same picture emerges for two essays.
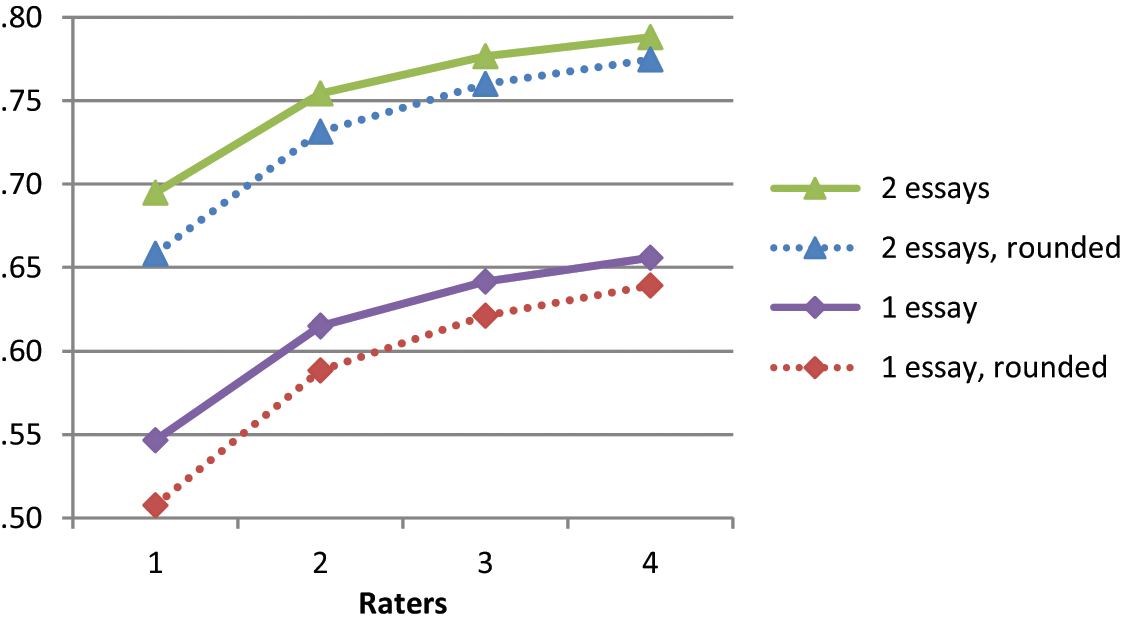
G-coefficients for regular rubric
Rater reactions
Participants were asked to share their thoughts about the study manipulations. Comments were received from 26 participants in the first stage and eight in the second stage. Overall, participants liked the experience and thought these manipulations were interesting. With respect to the ordering of essays according to length, opinions were mixed. Eight raters expressed a positive attitude mainly because it makes scoring easier. Scoring by length ‘facilitated in determining subtleties in scoring’, ‘helped me to focus the finer points of an essay of a particular length’, and ‘makes scoring the top and the bottom essays easier – that is the decisions one makes between ones and twos or fives and sixes.’ On the other hand, eight other raters did not like this ordering. One reason given was that it made scoring harder, especially batches of longer essays: ‘scoring the groups of long responses was quite exhausting’, ‘It can be very refreshing to work with and within the entire score range, not only for variety, but for clarity’, and ‘it did get tedious when there were whole folders of long essays to score.’ More importantly, some raters felt that contrary to intention, length might become an even more important factor in scoring: ‘It’s almost as if you can become conditioned to expect a certain score after looking at ones of similar size over time’ and it ‘might unduly influence a rater’s thinking to even subconsciously tend towards “longer must be better”.’
With respect to the higher-order rubric, opinions were also mixed. Three raters thought it important to focus on these aspects: ‘When focusing on content, you truly understand a person’s critical analysis, argumentative skills. Sometimes, this can be overlooked when reading for too many things’ and ‘it means the scorer has to take even a badly-ESL-impaired paper seriously.’ However, other raters had negative or mixed opinions. Some doubted whether it is possible to ignore or separate language control from content and organization: ‘Ultimately, I doubt that I can judge whether an example is relevant without somehow taking into account whether it is clear’ or ‘one cannot entirely separate development and the quality of thought from the use of language’ or ‘the language problems made it difficult to determine the adequacy or complexity of ideas.’ However, some of the same raters did find the special rubric useful, especially for certain types of essays: ‘That said, there are always those responses that make me think – If only this person had a slightly better command of the language’ and ‘The real difference then was that many responses that I would have scored a 3 under the current scoring guide received a score in the 4− to 4+ range in this study.’
Surprisingly, raters did not have strong opinions about the availability of e-rater scores. They thought it was interesting, even ‘fascinating,’ to compare their own scores with those of the machine, and they noted that in most cases of large discrepancies, e-rater awarded higher scores because it did not take into account problems in content or organization. Some raters felt it helped them to focus on higher-order aspects of writing, but others thought e-rater scores could confuse less confident raters.
Finally, participants expressed overwhelming support (with 22 of 26 positive opinions) for the augmented score scale. They especially liked the ability to provide a more precise score: ‘I LOVE the freedom of having a finer, and more accurate, scale’, ‘The finer scale was remarkable. It made me, as a scorer, really think about the lines between scores’, and ‘I think it is nice to have more options because the range of a score point can vary so much.’ The few negative opinions focused on the fact that the augmented scale made scoring more complex. A somewhat related comment by some raters noted that the study did not include scoring guides to help define the distinctions between low, solid, and high levels, which will be necessary if this scale would be used operationally. One rater also noted, somewhat humorously, that the augmented scale does not make it easier to discern the difference between a 3+ and a 4−; ‘That breaking point will remain as arduous a threshold as ever’.
Discussion
The purpose of this study was to explore several procedural changes to the process of rating essays in the wake of the adoption of AES. Their purpose was to increase the reliability of human scoring, but even more importantly, to increase the reliability of the combined human and machine scores. This goal could be achieved by decreasing the overlap between the aspects of writing that human raters and e-rater are considering. However, it could also be achieved simply by increasing the reliability of human scores. Both approaches were explored in this study. A direct approach for decreasing the overlap was attempted by asking raters to use a rubric that focuses on higher-order aspects of writing (that are not well covered by AES). An indirect approach was attempted by making certain kinds of information, essay length or the e-rater score, more salient in the hope that raters will find it easier to ignore it.
Although the main purpose of the attempts to reduce the overlap between human and automated scores was to decrease the correlation between them, they could also have direct effects on the reliability of scores. It might be easier for raters to provide consistent scores that are based on higher-order aspects of writing. It might also be easier to discern differences in essay quality when a batch of essays of similar lengths is presented for evaluation, and a similar argument could be made for the availability of e-rater scores.
However, the results of this study did not confirm these expectations. Remarkably, the essay order manipulation did not have any effect on scores, their levels of agreement across raters, nor their agreement with e-rater scores. As some of the raters remarked, the order of essays did not seem to make a difference on the rating process.
The use of the higher-order (HO) rubric did have measurable effects, but not always in the expected direction. The HO rubric inter-rater agreement was higher (relative to the regular rubric) for the argument task, but lower for the issue task. In addition, the HO rubric did not have an effect on correlations with e-rater scores. Finally, as a result of the contradicting results for the two tasks, the cross-task correlations for HO were similar to those of the regular rubric. These results suggest fundamental differences between the two tasks. Whereas raters were able to take advantage of a focus on content and organization to increase reliability of the argument task, this same focus created more confusion for the issue task. This implies that the quality of ideas and organization is more important for argument, and conversely, that the issue task lends itself more easily to assessment of language control. These implications are supported by an examination of the scoring rubrics for the two tasks, as well as the lower performance of e-rater on the argument task. However, the results of this study provide more direct evidence of how the design of writing tasks can affect the types of evaluations that they support.
Surprising results were also obtained for the HOE condition. The availability of e-rater scores significantly increased inter-rater agreement for both tasks. However, contrary to expectation, it also increased agreement with e-rater scores. As a result, the cross-task reliability of HOE scores was significantly higher than the other two scoring conditions, but the difference disappeared when combined human and e-rater scores were compared. These results suggest that raters were not able to discount the information that was provided to them, but rather assimilated it into their own judgments.
From a cognitive perspective, the order manipulation and e-rater score availability are similar in that they aim to change the context of the rating process. Several studies investigated contextual effects in essay ratings by asking whether raters are influenced from the quality of previous responses they judged. In particular, a contrast effect was found by several authors (Daly & Dickson-Markman, 1982; Hales & Tokar, 1975; Spear, 1997), whereby a previous response of lower quality makes the current response look better, and vice versa. However, Attali (2011b) found that professional essay raters of a large-scale standardized testing program produced ratings that were slightly drawn towards previous ratings, creating an assimilation effect. Attali (2011b) explained these differences in results by relating them to the larger psychological literature on assimilation and contrast in judgments. Perceived similarity between target and context or anchor (Mussweiler, 2003; Sherif, Taub, & Hovland, 1958) and confidence and certainty in one’s own views (Pelham & Wachsmuth, 1995) are factors that may favor the assimilation of the context into the judgment of a target stimulus. In contrast to previous research that used inexperienced raters, a very small number of ratings, and artificial contexts, raters in Attali’s study were highly experienced and rated thousands of essays each.
For the present study, the lack of effects for the order manipulation is consistent with the very weak effects that Attali (2011b) found for professional raters. The conclusions of both studies suggest that experienced raters do not pay much attention to previous rated essays. However, the availability of another rating for the same essay is a different matter, even if this is a machine score. The assimilation effect found in this study is reminiscent of the results of the classic experiment by Sherif, Taub, and Hovland (1958), who found that the availability of an anchor weight that was similar to a target weight resulted in weight judgments that were drawn towards the anchor.
It is somewhat ironic that the simplest manipulation in this study had the most consistent and striking results. Specifically, allowing raters to express their evaluations with an augmented scale that includes three levels of performance within each score category had a significant beneficial effect on reliability. Their enthusiasm with the augmented scale suggests that they find these distinctions relatively easy to make, contrary to previous suggestions in the literature on essay assessment. It is important to note that the raters did not have any formal training or supporting materials for the augmented scale, but nevertheless successfully used the entire scale. This suggests that highly experienced raters might even be able to use a finer grained scale.