
Abstract
Previous research in second language writing has shown that when scoring performance assessments even trained raters can exhibit significant differences in severity. When raters disagree, using discussion to try to reach a consensus is one popular form of score resolution, particularly in contexts with limited resources, as it does not require adjudication by at third rater. However, from an assessment validation standpoint, questions remain about the impact of negotiation on the scoring inference of a validation argument (Kane, 2006, 2012). Thus, this mixed-methods study evaluates the impact of score negotiation on scoring consistency in second language writing assessment, as well as negotiation’s potential contributions to raters’ understanding of test constructs and the local curriculum. Many-faceted Rasch measurement (MFRM) was used to analyze scores (n = 524) from the writing section an EAP placement exam and to quantify how negotiation affected rater severity, self-consistency, and bias toward individual categories and test takers. Semi-structured interviews with raters (n = 3) documented their perspectives about how negotiation affects scoring and teaching. In this study, negotiation did not change rater severity, though it greatly reduced measures of rater bias. Furthermore, rater comments indicated that negotiation supports a nuanced understanding of the rubric categories and increases positive washback on teaching practices.
To date, there has been an important discussion considering how raters may introduce construct irrelevant variance in the score of performance assessments. Raters – because of their subjectivity or inconsistency – can exhibit significant differences in the severity of their scoring (e.g., Bonk & Ockey, 2003; Weigle, 1998). Rater related variance may also be related to other facets of the testing situation, such as the tasks (Wigglesworth, 1993), testing occasions (Lumley & McNamara, 1995), test takers (Kondo-Brown, 2002; Lynch & McNamara, 1998; Schaefer, 2008), and rubric scoring criteria (Eckes, 2005; Kondo-Brown, 2002; Lynch & McNamara, 1998). Consequently, when two or more raters score a performance assessment, it is almost inevitable that scores may not be in exact, or even adjacent, agreement. When raters assign discrepant scores, several options are available to resolve these differences and to produce a single operational score. Many of these options incorporate the scores of a third rater. These include the following: (a) the tertium quid model, in which the score of a third rater is typically combined with the closer of the two original scores, while the more discrepant original score is discarded; (b) the expert judgment model, in which the score of a third, more experienced rater replaces both of the original scores; and (c) the parity model, in which the scores of the third rater and the two original raters contribute equally to the operational score (Johnson, Penny, Gordon, Shumate, & Fisher, 2005).
Score resolution methods that do not involve a third rater include simply summing or averaging the discrepant scores and using discussion – what we will hereafter refer to as negotiation – as a means of generating greater agreement. During score negotiation, two original raters are involved in a reciprocal exchange of ideas and evidence as they examine the essay in question, the scoring rubric, and benchmark essays in order to arrive at a consensus score (Johnson et al., 2005). Like other score resolution methods, this process may affect the validity of the scoring inference in the exam’s validation argument. Additionally, because negotiation involves raters in sustained discussions of rubric constructs in relation to specific examinee performances, it also has the potential to help raters co-construct a more grounded and elaborated understanding of these rubric constructs. To date, however, these aspects of score negotiation have not received sustained empirical attention in relation to second language writing assessment.
In this paper we use quantitative and qualitative methods to investigate the consequences of negotiation as a score resolution method when applied to the writing section of a high-stakes English language placement exam for prospective PhD students at one Colombian research university. While the use of negotiation was originally adopted due to resource constraints – in particular, the lack of trained raters – ethics and accountability demand that careful attention be paid to ensuring the reliability and validity of all aspects of the scoring process. In this paper, we first briefly summarize the existing research on score resolution options and the importance of scoring procedures in establishing the validity of the scoring inference in an exam’s interpretation/use argument (Kane, 2006, 2012, 2013) and then present the results of both the many-faceted Rasch analyses and semi-structured interviews that we conducted.
Literature review
Score resolution options
As differences in the ways discrepant scores are handled may impact the reliability or validity of score interpretations, one line of inquiry has sought to quantify the effects of different score resolution methods. Johnson, Penny, and Gordon (2000) explored the outcomes of four different score resolution methods using a 4-point analytic rubric to assess 11th-grade persuasive essays. They found that the parity model produced more reliable scores than either the expert judgment or tertium quid models, which in turn produced more reliable scores than simply combining the two original scores. Johnson et al. (2000) concluded that the choice of score resolution method had a negligible impact on the rank ordering or mean scores of student performances. However, when they used the parity model as the criterion for comparing pass–fail decisions, they found that methods that relied on expert judgments produced lower pass rates. In a subsequent study, Johnson, Penny, and Gordon (2001) investigated the impact of these same four score resolution methods with raters using a 6-point holistic rubric to assess 5th-grade narratives; once again, they found that the parity method produced the most reliable scores and that combining the original raters’ scores produced the least reliable scores. In this same study, Johnson et al. (2001) included a fifth method – discussion – when examining the impact of score resolution method on the rank order of student performances, means, and pass–fail decisions. They found that the choice of method mattered for rank order, means, and pass–fail decisions, indicating that, “in the holistic scoring of essays, methods of score resolution do not appear to be interchangeable” (p. 245, our emphasis).
Although these first two studies focused on reliability, in a third study Johnson et al. (2005) reanalyzed the data from their 2000 and 2001 studies and considered whether discussion as a score resolution method could contribute to the validity of test scores. They reasoned that if discussion improves score accuracy, one would expect this to be reflected in strong correlations between criterion and consensus scores. However, when they compared the correlations between a criterion score, formed by averaging the ratings of two independent experts, with (a) a score calculated by averaging the original discrepant scores and (b) the consensus score that resulted from negotiation, they did not find any significant differences. This implies that in this context discussion did not seem to promote greater score validity. In addition, Johnson and colleagues also explored whether raters were “equally engaged in the resolution process” (2005, p. 139) and found evidence of rater dominance when using the holistic rubric but none when using the analytic rubric. Taken together, these studies suggest that score resolution methods can potentially impact score reliability and validity, but that this impact is likely to vary according to contextual factors, such as the type of rubric used.
Assessment validation
Assigning scores and making inferences based on those scores play a substantial role in recent theories of argument-based validation (Bachman & Palmer, 2010; Kane, 2006, 2012, 2013). Argument-based validation is generally considered one of the best ways to define and ensure the intended interpretations and uses of an exam. Kane’s conception of argument-based validation is based on the application of an interpretation/use argument (IUA), which “provides an explicit statement of the reasoning inherent in the interpretations and uses of test scores, and specifies the steps involved in getting from the observed test performances to the claims based on test scores” (2013, p. 14). Each step in Kane’s IUA is argued based on the logical model proposed by Toulmin (1958) concerning inferential argumentation. This logical model is depicted in Figure 1.

Toulmin’s model of inference. From Kane (2012, p. 11).
As shown in Figure 1, Toulmin’s model of inferences starts with datum, about which a claim is made. An if-then rule – a warrant – is posited in order to make the inference that the claim is true for the data in question (should the rule be true). The truth value of the claim is based on the evidence that one develops – the backing – to support that the rule is true (e.g., relevant data or the theoretical or empirical support). Depending on how strong the warrant is and the amount of backing we have, the claim will be mitigated – or qualified – to varying degrees.
Kane (2013) describes four principal categories of inferences that should be evidenced within a placement exam’s IUA. The first of these is the scoring inference (i.e., how one goes from the test score to the inferences made about the score), followed by generalization inferences (i.e., supporting claims about the representativeness of the observed scores among all possible performances), extrapolation inferences (i.e., supporting claims about how performance in the test domain can be extended into other non-test domains) and decision inferences (i.e., how one determines student placement into the different possible courses based on their test scores) (p. 24). This study concerns itself with elements of the scoring inference.
Scoring inferences
Kane describes several qualities of an assessment instrument that should be true in order to successfully make the scoring inference. In particular, this inference “depends on a number of assumptions: that the scoring procedures are appropriate, are applied as intended, and are free of overt bias” (2013, p. 25). In other words, scores should be used appropriately, accurately, and consistently. Claims of appropriateness and accuracy are backed by expert judgments and guidance of the scoring procedure, while claims of consistency can be backed by quantitative measures in terms of rater severity, bias, and reliability.
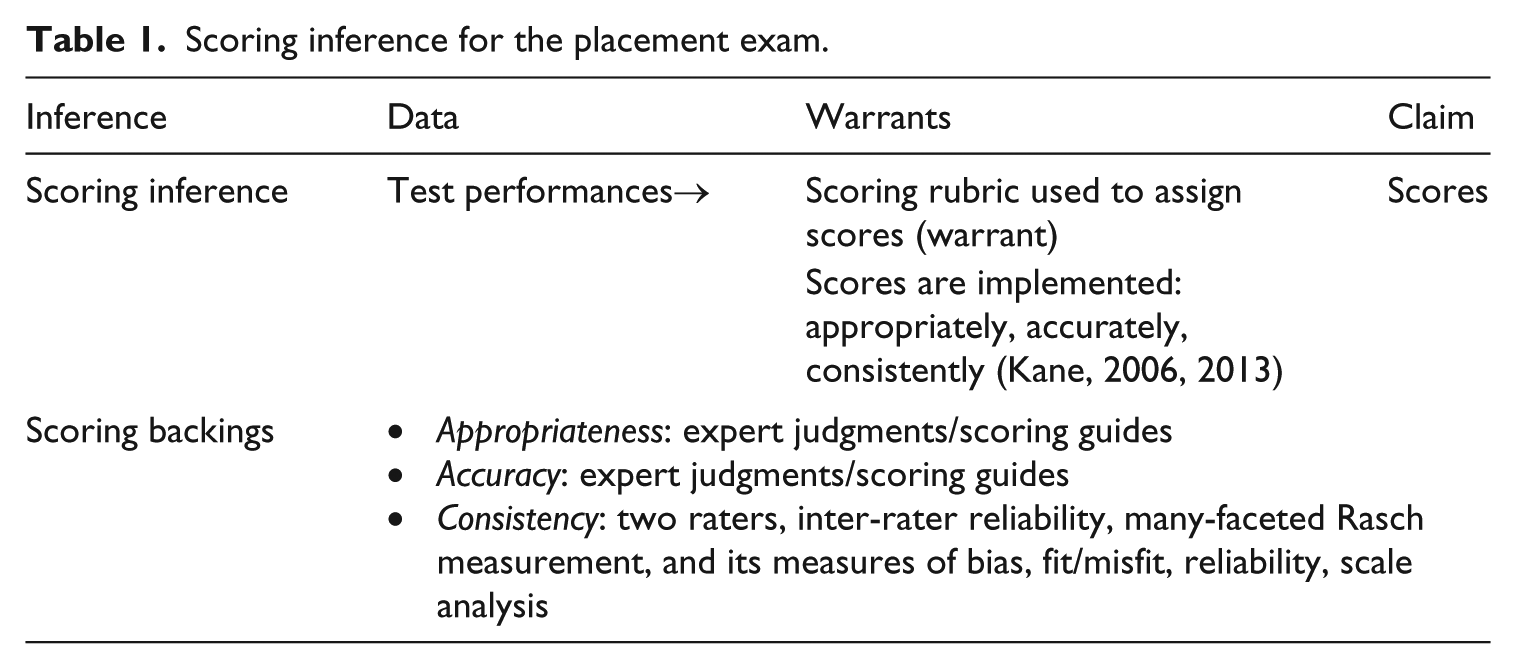
Table 1 models the scoring inference we might expect for the test studied in this paper. On the most basic level, the scoring inference validates the way in which the assigned scores (the claim) are derived from written test performances (i.e., the data; the essay exam). To justify the assigned scores, we need to assess the scoring rules (i.e., the rubric) that are applied to the performances. The backing or justifications for the scoring rules are based upon the appropriateness, accuracy, and consistency of the scoring procedures. To ensure appropriateness and accuracy, test developers have compiled a book of benchmark essays exemplifying the salient characteristics of student writing at each score point for each rubric category; this book is used in rater training and for reference during operational scoring sessions. Additionally, raters norm before each scoring session; during the session, they independently score each of the exams, and then discuss initial category scores that vary by more than a predetermined number of points. Consistency is ensured by having two raters instead of one and by reviewing a variety of different statistical measures provided by Rasch measurement.
Scoring inference for the placement exam.
Research questions
The consistency of this exam has been studied in prior internal studies. Using many-faceted Rasch measurement (MFRM), these studies have assessed the degree to which raters differ in their severity, are consistent in their judgments, or exhibit bias (i.e., systematic sources of extraneous variance impacting particular rubric categories or test takers, Crocker & Algina, 2008). In this study, however, we are interested in how one procedure designed to promote accuracy in the scoring process – the practice of negotiating discrepant scores – affects indicators of scoring consistency (i.e., rater severity, fit, and bias). To this end, we pose the following research questions:
What impact does the negotiation process have on measurement consistency, including measures of rater severity and fit?
What impact does the negotiation process have on measurement consistency in terms of rater bias?
What are raters’ perceptions of the negotiation process, and to what extent do these perceptions provide evidence that negotiation contributes to a more appropriate, accurate, and/or consistent scoring process?
Methods
Context
PhD students and professors in countries where the language of society and instruction is not English regularly need to participate in the international academic discussions taking place in their field. Thus, a number of tertiary institutions have developed English for Academic Purposes (EAP) programs focused on studying the different genres of writing and speaking relevant to advanced language learners (Hamp-Lyons, 2011). In 2009, one private Colombian research university, in the belief that English proficiency contributes to international academic success, both created an EAP language program for its PhD students and developed an in-house exam to be used to place prospective students into one of five program levels. While this exam is primarily used for placement purposes, some university departments have adopted prospective students’ scores as part of a set of admission criteria for PhD studies at the university. Consequently, ensuring the exam’s reliability and validity has become especially important for reasons of ethics and accountability.
Test instrument and procedures
The placement exam includes subtests for reading, writing, and speaking. The writing portion of the exam requires examinees to hand write a two-paragraph statement of purpose regarding their qualifications for PhD study and future professional goals. This prompt is used for all administrations, and examinees are given 30 minutes to complete the task.
Essays are scored using the Jacobs, Zinkgraf, Wormuth, Hartfiel, and Hughey (1981) writing performance rubric, which measures examinee performance across five differently weighted scales: (a) Content (e.g., level of detail and support, relation to topic); (b) Organization (e.g., sequencing, cohesion); (c) Vocabulary (e.g., register, use of idioms, word choice); (d) Language Use (e.g., complexity of constructions, use of grammar and articles); and (e) Mechanics (e.g., spelling, formatting) (see Appendix A). Each rubric category is subdivided by a general ability rating (e.g., good to average, excellent to very good) that includes a set of criteria and a range of possible numerical scores, ranging from 2 to 30 points depending on the category (e.g., 2–5 for Mechanics, 13–30 for Content).
The weighted categories and wide range of possible scores for each category are somewhat unusual features in a scoring rubric, and so it is worth briefly explaining why this rubric was originally adopted. As the placement test and the program itself were being created together, program developers were searching for an analytic rubric that would allow them to gain a better understanding of where language learners struggled and succeeded in the writing process. Also important to program developers were the specific categories included in the rubric, which were all thought to be important to assess. Finally, because it is positioned as a model analytic rubric in Weigle’s (2002) Assessing Writing, this rubric had been used in an earlier project in the department and was familiar to exam raters.
Following each exam administration, essays are scored by two raters. Raters first independently read and assign a score on each rubric category for three or four examinee essays and then compare their results for these examinees. If any category scores are discrepant by a set number of points, raters negotiate by providing an explanation and justification for their score assignment. To guide the negotiation process and to support the scoring inference of the exam’s validation argument, raters created a reference binder of elaborated rubric descriptions and sample exam files, to be used as a resource when negotiating scores. After the negotiation process, raters can do as follows: (a) retain their original score; (b) change their score to reflect the score of the other rater; or (c) assign a new, intermediate score. Although the goal is consensus among raters on scores – and this is generally the case – raters are free to disagree. Final placement decisions are made based on the average total scores of both raters.
Participants
Data for this study were based on writing scores collected over a three year period from 524 test takers on the writing subtest. Examinees were all prospective PhD students in various departments across the university. No direct biographical data on the examinees exists, though it is assumed that with the exception of two or three test takers, all were Spanish L1 users of English.
Rater data were collected from four different raters who currently work or have previously worked with rating the writing section of this exam. One rater (Rater 1) participated in every administration of the exam included in this study, while the remaining three raters only scored select exam administrations. Raters 1, 2, and 3 have extensive teaching experience in the language program for which this test is used, while Rater 4 has been teaching in the undergraduate English program at the same university. The raters consisted of two L1 users of Spanish (Raters 1 and 3), one L1 user of English (Rater 2), and one L1 user of German (Rater 4).
Data analysis
Many-faceted Rasch measurement was conducted using FACETS 3.67 (Linacre, 2010a). The model specifications included three facets: raters, test takers, and rubric categories. Because only two categories of the Jacobs et al. (1981) rubric use the same range of scores, a different scale structure was specified for each category. In order to gauge the effects of negotiation, separate analyses of both the original (non-negotiated) and final (negotiated) scores were conducted for each of the three pairs of raters who worked together, resulting in a total of six analyses. For each pair of raters, MFRM results for the non-negotiated and negotiated scores were then compared in terms of rater severity, rater self-consistency, and biased rater by category and rater by test taker interactions.
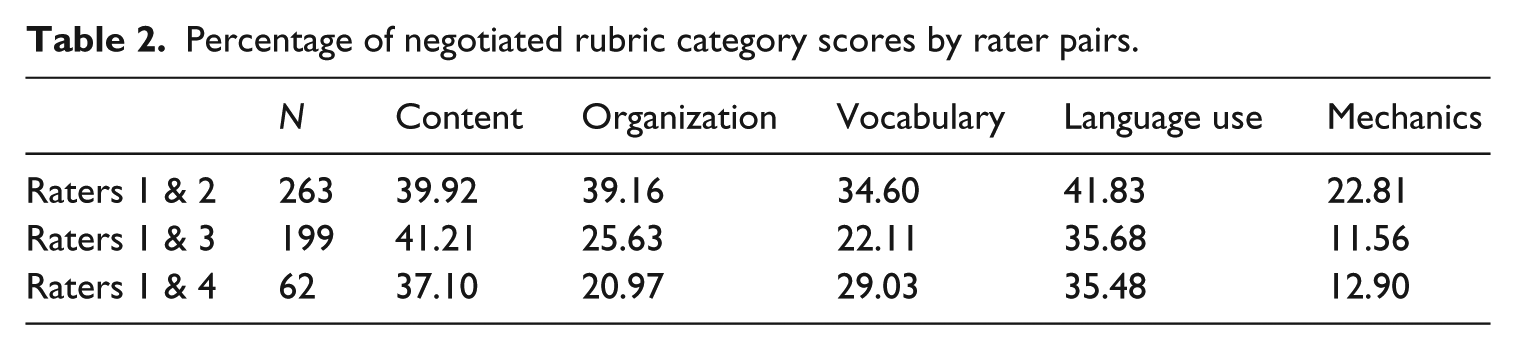
Table 2 presents descriptive data about rater performance, indicating the total number of essays each pair of raters scored and the percentage of scores in each rubric category that were eligible for negotiation. It is important to note that while the criteria used to determine whether raters should negotiate – a discrepancy of two or more points – were constant across the first four categories (for the category Mechanics, negotiation was triggered by differences of one point or more), the scale structure of the Jacobs et al. (1981) rubric results in a variable number of possible scores in each category. Consequently, the relatively higher percentage of negotiated scores for the categories of Content and Language Use could be an artifact of the finer-grained distinctions raters were asked to make and differences across categories should not be over-interpreted.
Percentage of negotiated rubric category scores by rater pairs.
Semi-structured interviews were also conducted with three of the writing raters (Raters 1, 3, and 4) to gather qualitative data about their perspectives concerning the rating process and use of the rubric. 1 Interview questions were designed and revised by the researchers to cover a broad range of topics including raters’ experience rating this placement exam, the use of rubric scoring bands, the negotiation process, perceptions of biases, and the effect of rating on classroom practices. All interviews were conducted by one of the primary researchers and responses were audio-recorded. Each researcher listened to the audio data independently and categorized salient trends. Notes were then compared and discussed to reach agreement on interpretations of the interview data.
Results
MFRM
Basic fit statistics
Before drawing any conclusions based on the results of MFRM, it is important to examine the extent to which the data fit the model and meet assumptions of psychometric unidimensionality. This can be assessed using one of several fit statistics, which indicate the extent to which elements in a facet do or do not conform to expected response patterns. Here we have used infit mean square (IMS) values, as they are weighted toward typical responses and are generally considered more informative. Test takers were considered misfitting only if they had IMS values above 2.0, which indicates misfit severe enough to potentially compromise measurement (Linacre 2010b). Based on these criteria, approximately 10% of test takers were categorized as misfitting in both the non-negotiated and negotiated conditions. While this is a larger percentage of misfitting test takers than is considered desirable, interpreting examinee misfit on a performance test is not straightforward and could be an artifact of the “undesirable but unavoidable use of rating categories as ‘items’ in Rasch models” (Bonk & Ockey, 2003, p. 99). For the present analysis, we were primarily concerned that examinee misfit would not degrade the measurement model as a whole. As analyses that were run with and without these misfitting test takers produced comparable category and rater measures, misfitting test takers were retained in all analyses. Both rubric categories and raters with IMS values within 2 standard deviations of the mean were considered to fit the model (McNamara, 1996); based on these criteria, in both the negotiated and non-negotiated conditions all five categories and all pairs of raters demonstrated adequate fit. As the effect of negotiation on rater performance is one focus of the present research, the rater IMS values are considered in more detail in the next section.
Rater severity and consistency
Table 3 presents Rasch estimates of rater severity for each pair of raters that worked together; estimates of rater severity in the NON column are based on scores raters assigned before negotiation, while estimates of rater severity in the NEG column are based on scores raters assigned after negotiation. These measures show that for each rater the NON and NEG measures are quite similar; that is, negotiation has little direct impact on how severe or lenient a particular rater was. In fact, when we take into account standard error and add +/− two SEs to each severity measure, the NON and NEG values for each rater overlap. From this perspective, the intra-rater differences between NON and NEG scores do not appear to be statistically significant.
Measure differences, non-negotiated (NON) and negotiated (NEG) scores.
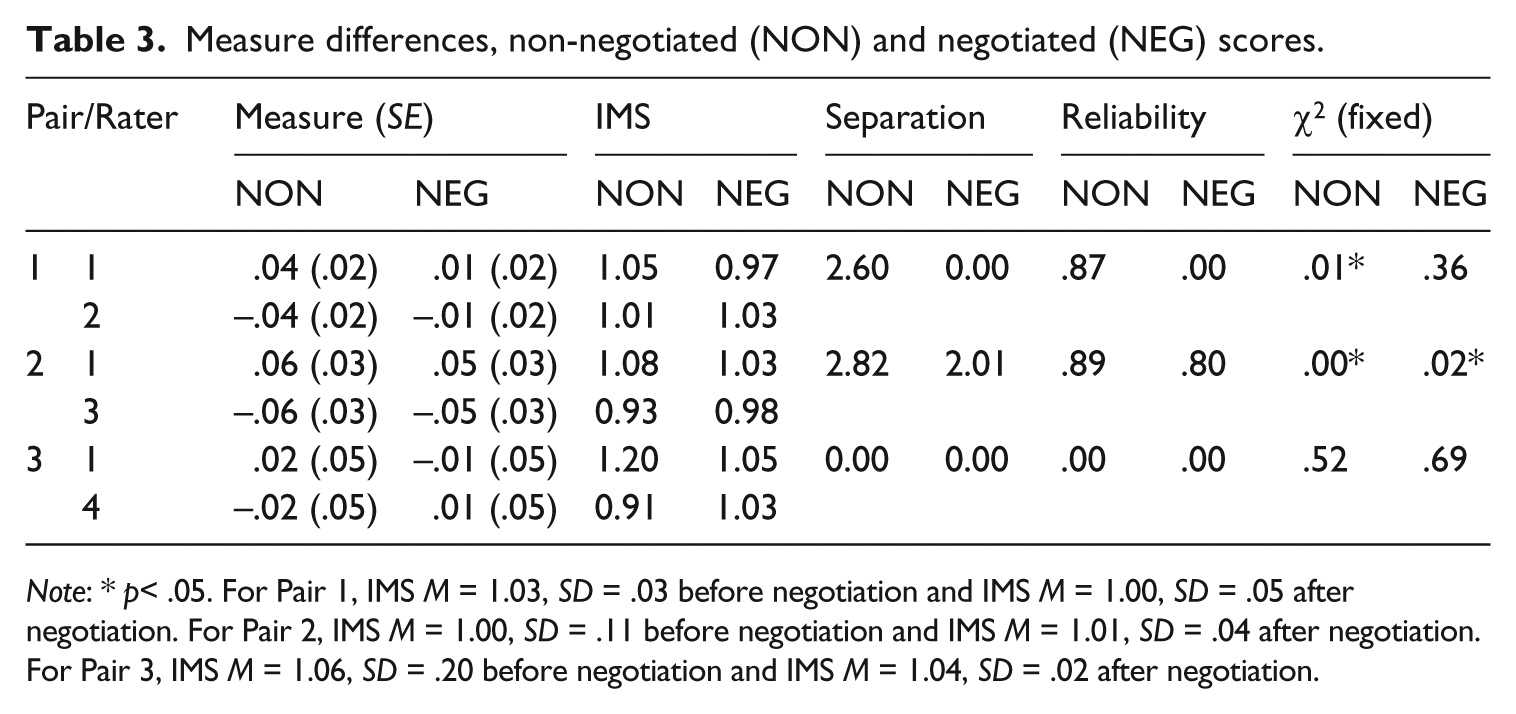
Note: * p< .05. For Pair 1, IMS M = 1.03, SD = .03 before negotiation and IMS M = 1.00, SD = .05 after negotiation. For Pair 2, IMS M = 1.00, SD = .11 before negotiation and IMS M = 1.01, SD = .04 after negotiation. For Pair 3, IMS M = 1.06, SD = .20 before negotiation and IMS M = 1.04, SD = .02 after negotiation.
At the same time, the separation, reliability, and χ2 values presented in Table 3 show that negotiation did have some impact on inter-rater differences in severity. Separation values indicate the number of statistically distinguishable levels of rater severity, with higher values indicating greater differences in severity. In other words, separation tells us the extent to which differences in severity are minor. Reliability values signal the degree to which these differences in severity are reproducible. For raters, values close to 0 are desirable, as low values indicate that differences in severity are not consistently reproducible (Linacre, 2010a). Lastly, the fixed (all same) χ2 tests the hypothesis that there are no differences in rater severity. Statistically significant differences indicate that there are differences in severity.
Taken together, these three complementary measures show that even before negotiation the raters in Pair 3 were equally severe, and that after negotiation, there were still slight differences in severity between the raters in Pair 2. For the raters in Pair 1, however, negotiation seems to have eliminated differences in rater severity. This is potentially promising, as differences in rater severity can disadvantage test takers; eliminating such differences can contribute to a fairer test. Nonetheless, the impact of negotiation on rater severity should not be overstated, as any statistically significant differences in rater severity that do exist in our data were slight to begin with. Given the wide spread of test taker abilities (approximately 16 logits), the elimination of such differences is of little practical import in this testing context. Thus in terms of both intra- and inter-rater differences in rater severity, negotiation seems to have had only minimal impact.
Table 3 tells a similar story about rater self-consistency, which, as evidenced by IMS values, was acceptable both before and after negotiation for all four raters in our study. For Pair 2 and Pair 3, negotiation resulted in IMS scores closer to the expected mean of 1.00, suggesting negotiation can help mitigate raters’ tendency to score more erratically than expected (Rater 1) or more predictably than expected (Rater 3 and Rater 4). This too is potentially promising, but as with changes in rater severity, the impact of negotiation is only slight.
Biased interactions
While measures of rater severity can indicate their overall rating tendencies, bias analysis also makes it possible to determine whether raters are severe or lenient in systematic ways in relation to specific facets (Crocker & Algina, 2008). Of particular interest was the impact negotiation might have on raters’ tendencies to be systematically more or less lenient when scoring particular rubric categories or test takers. Thus bias analyses were conducted for each rater pairing, with values greater than +/− 2.00 indicating statistically significant interactions (McNamara, 1996, p. 230).
Table 4 indicates that even prior to negotiation, significantly biased rater by rubric category interactions were not common: only the raters in Pair 1 displayed bias in relation to one rubric category, Organization. For each rater, Table 4 shows the observed total score (i.e., across all essays), the expected total score, the number of essays scored, the average difference between observed and expected scores, and lastly the bias size in terms of measure, standard error, z-score, and infit mean square. Both bias measures and z-scores are oriented so that positive values correspond to rater severity that is greater than expected and negative values correspond to rater leniency that is greater than expected. In other words, Rater 2 was on average more severe than expected, while Rater 1 was more lenient. After negotiation, there were no longer any significantly biased rater-by-category interactions.
Pair 1 significantly biased rater by category interactions, non-negotiated scores.
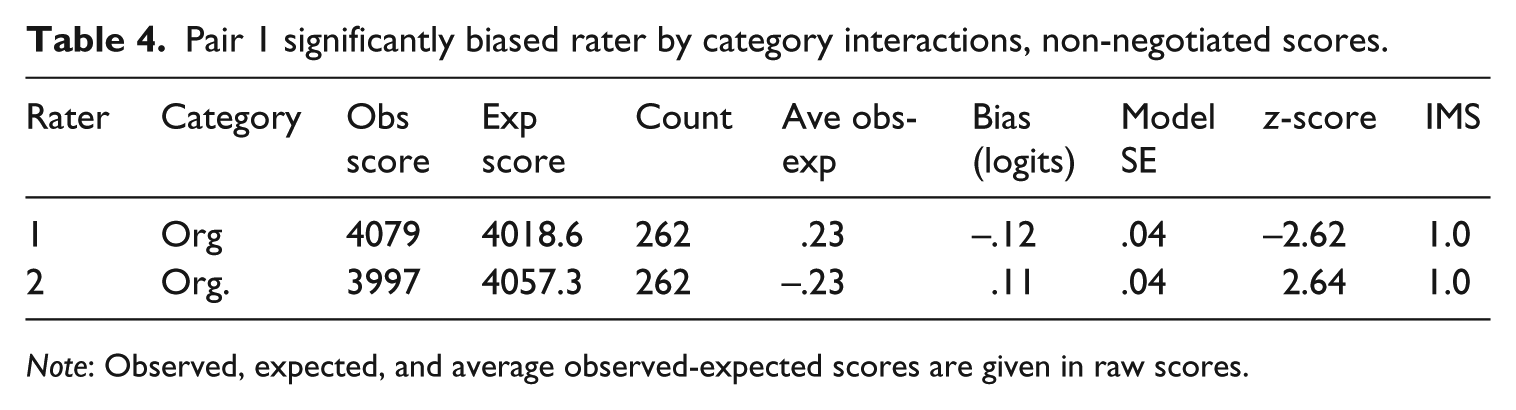
Note: Observed, expected, and average observed-expected scores are given in raw scores.
Table 5 shows that prior to negotiation, significantly biased rater by test taker interactions were somewhat more widespread, though these interactions were by no means pervasive, occurring in less than 2% of cases. The vast majority (approximately 90%) of these interactions involved raters biased in opposite directions, with one rater judging a test taker more severely than expected and the other rater judging the same test taker more leniently. For each of these test takers, raters gave discrepant scores on at least two – and sometimes all five – rubric categories, and their differing interpretations of the test taker’s performance resulted in total scores that were on average 14.06 points apart (SD = 3.27). Thus before negotiation, raters had markedly different initial impressions of the quality of a small number of essays. After negotiation, only one significantly biased rater by test taker interaction remained. Moreover, for each test taker, both raters changed their scores for at least one of the initially discrepant rubric categories, so that the difference in total test scores narrowed considerably, to an average of 4.38 points (SD = 1.56).
Significantly biased rater by test-taker interactions, non-negotiated scores.
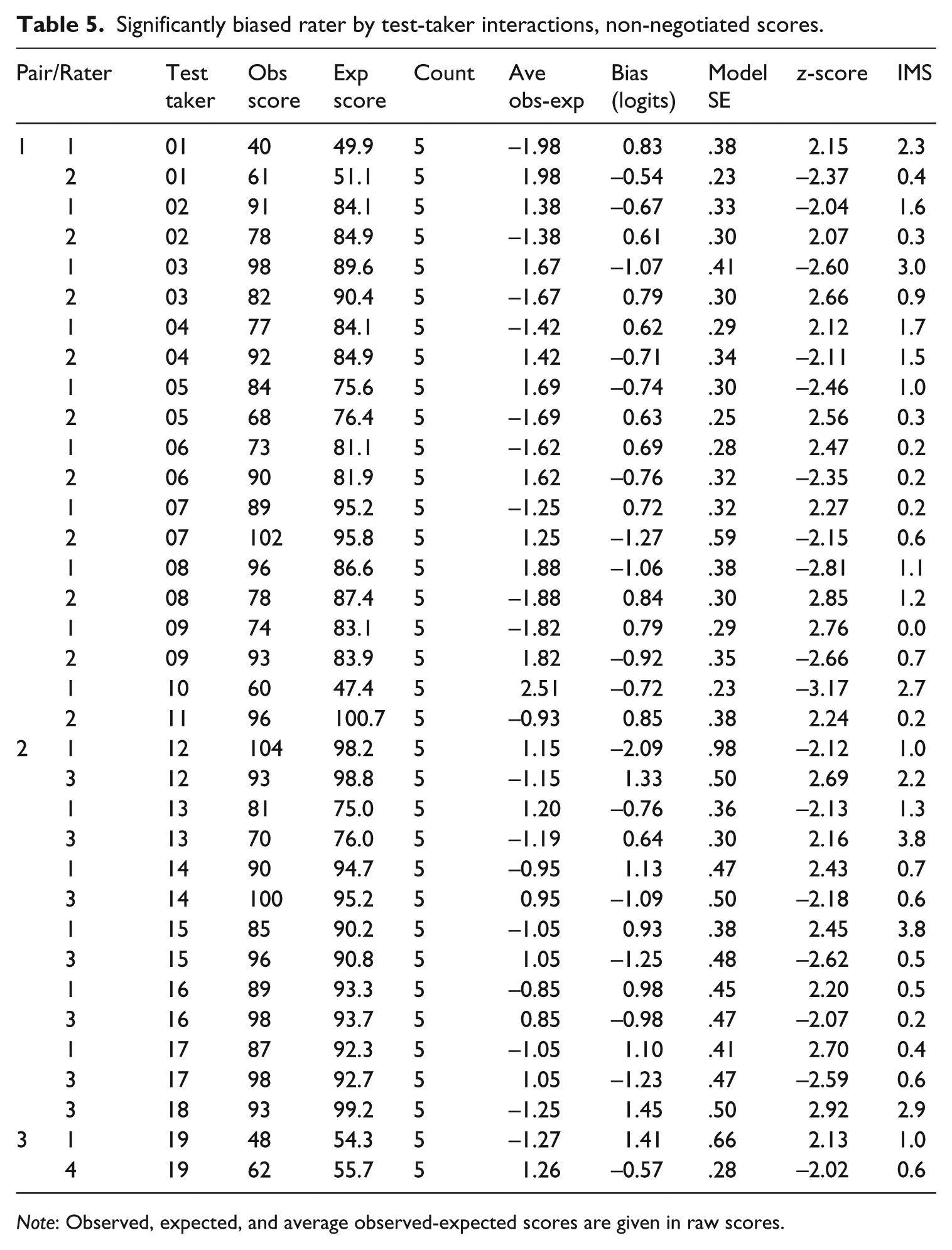
Note: Observed, expected, and average observed-expected scores are given in raw scores.
These results suggest that negotiation was useful for moderating raters’ uncharacteristically severe or lenient behavior towards both specific rubric categories and individual test takers. When taken in conjunction with the interview results presented below, these findings suggest a potentially important role for negotiation in tempering certain idiosyncrasies – the tendency to react especially negatively to some features of a piece of writing or make undue allowances for others – that persist despite rater training.
Chi-square tests of rater dominance
To identify possible instances where negotiated scores were overly influenced by one rater, a series of chi-square tests were run for each rater pair on each of the five rubric categories. Similar to Johnson et al. (2005), the tests were set up to compare the distributions of how rater pairs (a) maintained their original, pre-negotiated scores, (b) adopted the scores of the other rater, or (c) assigned a new, mediated score. As the raters in each pair reported their own negotiated score rather than a composite score, two-way chi-square tests were used. None of the distributions were statistically significant, indicating that there was no effect of rater dominance among the writing raters.
Rater interview data
While our MFRM results have demonstrated the ways in which negotiation impacts measurement consistency, rater interviews provided us with insights into the rating process itself. Some of the themes that emerged from rater interviews included rater perspectives on (a) the characteristics of the process itself, (b) the co-construction of scoring meaning, and (c) the effect of negotiation on positive washback. While it is important to recognize that negotiation is inherently different for each rater pairing, the interview data here helps to get at the general tone of how raters approach and carry out the task of negotiation in this context. Each of these themes will be discussed in further detail below.
Characteristics of the negotiation process
In general, raters seemed to perceive the negotiation process itself as being systematic and logical, while at the same time subjective to a certain extent. This can be seen below in Rater 4’s response to a question about how decisions are made during discussion.
(1) The stronger one wins (laughter). Of course we have like a serious discussion about the points, and then each one explains why we get the points, and so on. And the one with the stronger argument wins. (Rater 4)
Here Rater 4 jokingly responds that negotiation is based on power relations, and while there is likely some measure of truth to this claim, she follows up by pointing out the need for “serious discussion” as it relates to each rater’s decision-making process and assignment of points based on the rubric. She alludes to a sense of structure in the discussions that persists throughout the process. Rater 1 reiterates this idea in (2), but also stresses the importance of approaching the discussion of scores with an open mindset.
(2) Each one of us grades the exam, and what we do is look at each other’s grade. And then when we see that categories are very far apart, what we do is try to listen to the other person. And then discuss after we have read again the essay, and sometimes I think that’s good because sometimes you either, you overlook something or you’re being too strict about something that is not that [important] … but I mean it does not affect the essay that much. (Rater 1)
Discussion is not just about presenting a stronger argument but also making the raters aware of their possible biases. Raters reveal that they are aware of their own idiosyncrasies, and also the points where they have different interpretations of the rubric categories, which can lead to scoring discrepancies. Rater 4 discusses this awareness in (3):
(3) [Rater 1] is really picky about some things, I’m really picky about other things…I think I’m like pickier when it comes to content, like I really get mad when people don’t answer the question and don’t support the content … we had like, we just had different things that we focused on in language use. (Rater 4)
What is especially interesting about this excerpt is that Rater 4 is able to identify a specific category, Language Use, where she and Rater 1 tend to differ based on having varying interpretations of the construct. Because of negotiation, it seems that the raters have a point of comparison upon which to judge their own habits and tendencies as they assign scores. Rater 4 is not only able to pinpoint her own potential for biases, but also identifies where different interpretations are likely to arise. This awareness can help raters be receptive to alternative justifications, which may have been otherwise overlooked at the individual level. Indeed, both raters comment that this is one of the greatest strengths of negotiation.
(4) Sometimes we focus on very specific things that may distort the whole…so for me it’s important because sometimes that happens so it’s good to see that maybe you’re being either too strict or you overlooked a lot of things. (Rater 1)
(5) Sometimes as I said you know you get distracted by one thing that you either find like really great or really horrible and then you tend to lower the grade or give a better grade based on that. And then you sometimes, you don’t like focus on all the aspects of the writing. (Rater 4)
Even though raters use the rubric as a guide, certain categories or qualities of the writing stand out for particular raters, which can contribute to undesired variance in scoring. An additional voice, however, can help raters become aware of these instances and make adjustments that ideally lead to a more accurate scoring decision than what can be accomplished individually.
Co-construction of meaning
In addition to helping raters recognize their own subjectivity in the scoring process, raters also mentioned that negotiation was helpful for them in establishing meaning for each of the five rubric categories. This helped clarify decisions about exam scoring as well as inform their knowledge of these constructs as they are related to program goals and their individual teaching.
(6) I believe that the scoring rubric per se is very important in our understanding of the categories and how to grade them or measure them. However, it is more important, at least for me, the discussion I may have with my partners in terms of why a score is used or what was our reasoning behind the score we have given. (Rater 1)
Rater 1’s comment – and others similar to this comment – do interesting work in establishing a link between the negotiation of scores and rubric categories and different parts of this exam’s validation argument. This sort of negotiation is essential from a construct validity perspective, in that the rubric categories have their own independent meaning, yet without the element of negotiation, these constructs remain detached from the particular program and context in which they are being used. Through the exercise of negotiation, where the rubric’s use and interpretation are clearly examined and contextualized within a specific writing sample, raters not surprisingly were able to gain a better understanding of these language constructs, and then extend these constructs into their own classroom as well.
Positive washback
Finding a connection between the constructs evaluated on the test and local curriculum not only supports arguments for the exam’s construct validity, but also reflects, at a minimum, self-reported positive washback of this test onto the classroom setting. Washback refers to the effect of assessment practices on teaching and curriculum (see Alderson & Hamp-Lyons, 1996; Shohamy, Donista-Schmidt, & Ferman, 1996). Positive washback can be said to occur when assessment does not inhibit instruction, but rather supports teaching and innovation in the classroom (Brown, 1997, 2005; Cheng & Curtis, 2004). In the case of a placement examination and the extrapolation inference that is part of its validation argument (Kane, 2012), the assessment, program objectives, and curriculum should all positively reflect one another, and positive washback is one way of gauging the degree of this reflection. Raters indicate that it was the negotiation process that facilitated this connection.
(7) The scoring rubrics for the writing section are clear with respect to the categories content and mechanics, but they are not as self-explanatory concerning organization, language use, and vocabulary. There are many overlaps between these categories and many mistakes might be placed into two or three categories at the same time…thanks to our discussions, I feel that I have reached a deeper understanding of the categories, which helps me to evaluate and teach the underlying constructs more effectively. (Rater 4)
The effect of washback here seems clear. Rater 4 posits that negotiation assists in making more accurate scoring decisions and reports that this has an effect at the level of instruction in terms of both having a better understanding of the underlying constructs necessary for successful academic writing and in helping to make these constructs salient for aspiring second language writers. It is interesting to note that raters linked this idea of washback not to the use of the rubric itself, as we might expect, but specifically to the discussion process that accompanies its use.
(8) It is more important, at least for me, the discussion I may have with my partners in terms of why a score is used or what was our reasoning behind the score we have given. Thus, the negotiation process that happens especially at the beginning of each grading session – the calibration – is more meaningful for the understanding of the categories than the rubric as such. (Rater 1)
Though these interview segments are self-reports – and are not a direct proof of either the teaching or learning of these language constructs in these teachers’ classrooms – it is important to highlight how these comments provide initial evidence for the test’s construct validity and positive washback effects. These comments also provide indirect evidence for the decision inference in this exam’s validation argument. As described in this paper’s literature review, the extrapolation inference supports claims about how performance in the test domain can be extended into other non-test domains, such as on classroom tasks (Kane, 2013, p. 24). In this regard, we do see evidence that the tasks and concepts shared by instructors with their students matches what is developed on the test.
Discussion
To begin, it is important to note that because of the small number of different rater pairs (three), this study should be interpreted as a case study. Any conclusions drawn from our quantitative results pertain only to the effects of negotiation by the individual pairs of raters who worked together in this study; we cannot, for example, make any broad statements about the effects of negotiation on differences in rater severity across all rater pairs. That said, the findings of this study all seem to point to the notion that negotiation has an important role in performance assessment scoring.
Many-faceted Rasch measurement showed that no differences were found for rater severity before and after negotiation. One reason we might not expect to find differences in severity between non-negotiated and negotiated scores is the nature of the negotiation process in this particular context. Specifically, raters negotiate each time they finish scoring two or three essays, meaning that only the essays that are scored at the very beginning of each session are not influenced in some way by negotiation. It is likely that raters are basing their independent scoring decisions on their ongoing, co-constructed interpretations of categories and performance indicators, and for this reason, it is important not to overgeneralize to other contexts where negotiation might be structured differently and have a larger impact on scoring decisions. One benefit of this finding, however, is that because negotiation is not influencing rater severity overall, we have a clearer picture of what is happening at the level of individual rater biases, a result that might not have been as salient had overall differences in rater severity been more extreme. That we are able to see clearly this change in bias suggests to us that even in a context with practiced and relatively homogenous raters, negotiation still contributes to the validity of scoring decisions.
The results of many-faceted Rasch measurement show that negotiation seemed to have almost entirely eliminated significantly biased interactions between raters and either the rubric categories or the individual test takers and thus to have enhanced scoring consistency. Our interview data complement these findings, indicating that the raters are aware of their potential to be biased – to “focus on very specific things that may distort the whole (Rater 1)” – and appreciate the ways in which the negotiation can prompt more balanced judgments of test takers’ performances. Importantly, the chi-square results showed there was no evidence of rater dominance, suggesting that in revising their judgments, raters are engaged in an equitable process. As part of our goal with validation and ensuring the quality, accuracy, and appropriateness of our scoring inferences is to limit the influence of subjectivity, negotiation appears to offer a systematic and practical restraint on individual biases.
Perhaps of most importance, rater interviews also highlight that the practice of negotiation during exam scoring contributes to this exam’s validation argument. By discussing different aspects of the scoring rubric, raters co-construct with other raters a more precise understanding of what each category signifies in their particular context, and they report that this knowledge is easily carried over into their classrooms. While this study does not measure whether or not the teaching or learning of these constructs actually happens in the classroom, these self-reports do provide initial anecdotal evidence that this is happening. This evidences positive test washback on teaching practices, argues for the content validity of the test (i.e., that the test constructs being measured are the constructs taught), and supports the extrapolation inference of the test’s validation argument (i.e., again, that the test constructs being measured are those being taught).
Conclusions
While some form of score resolution is a necessary component in any kind of high-stakes performance assessment, we wanted to explore the relationship between negotiation, the validity of scoring inferences, and their contribution to raters’ co-constructed understanding of rubric constructs. Perhaps most surprising among our findings was that while raters did change their scores for individual test takers, rater severity was consistent across both negotiated and non-negotiated scores. Other research has also found that discussion made little difference in scoring reliability (Smolik, 2008) or validity (Johnson et al., 2005). Given these results, it is reasonable to wonder whether negotiation is really necessary, especially in contexts with limited resources, where the time raters spend discussing their discrepant scores leads to longer scoring sessions and the potential for rater fatigue.
However, our results indicate that the time raters devote to negotiation is, in fact, well spent. Interview data from this study point to the real benefit of negotiation from an accountability standpoint: negotiation seems to help strengthen or even create important connections between the test and what instructors believe they teach in class. Using the rubric may already make raters aware of the constructs essential for academic writing in English, but through negotiation raters are able to co-construct the meaning underlying these constructs. This affords raters, who are also teachers, the ability to bring these expanded and developed constructs into the classroom. As large-scale assessments of this kind can often be criticized for being detached from the context within which they are situated, negotiation can connect assessment to the learners and the curriculum.
Several potential directions remain for future research into the effects of negotiation on scoring decisions. In terms of raters, while the raters in this study were very familiar with one another and thus open to discussion and reaching common ground when determining scores, there are certainly cases where some raters can exhibit a degree of dominance over other raters. It would certainly be useful to explore further how and why this happens through an examination of rater characteristics, cultural backgrounds, or intercultural issues between raters of different backgrounds.
Another area of future research could look at the possibility of patterns in negotiation based on category and time effects. Category comparisons with regard to which categories were more likely to require negotiation could be useful in identifying constructs that are difficult to conceptualize or are open to multiple interpretations, and likewise could inform performance descriptors in future rubric design studies. While we explored this notion briefly above, because the original Jacobs et al. (1981) rubric contains different scoring bands for each category, it is difficult to make clear interpretations of any possible effect. However, a future study by the authors (Janssen, Meier, & Trace, 2015) incorporates a revised rubric using consistent scoring bands, from which these comparisons could be studied. Lastly, discourse analysis could describe how practices of negotiation change over time within a particular negotiation session. In general, these different approaches might better inform how negotiation contributes to rater co-construction of understanding and not rely solely on retrospective reflections.
In the end, the value of positive washback as an effect of negotiation cannot be overstated, as part of the validation process in any placement exam is concerned with matching test use to real-world outcomes. We want our test to have meaning beyond the decision itself and take into account the consequences of that decision for our students and teachers. It is thus important to be able to make scoring judgments that are tied to the curriculum. Negotiation provides one way for teachers to further develop their own understanding of material and outcomes in relation to student needs and program outcomes. It is therefore our strong conclusion that in this research setting, the practice of negotiation is an effective way to reduce bias and match test constructs to those developed in the curriculum.
Footnotes
Appendix A
Acknowledgements
We would like to acknowledge and thank the following people for their generous support that made this project possible. Dr. James Dean Brown provided us with our technical training; Alcira Saavedra at the Department of Languages and Sociocultural Studies at Universidad de los Andes – Colombia provided us with access to the exam records. Thanks to the exam raters Christina Kirschbaum, Ricardo Nausa, and Cristina Soto, who provided us with their time and insights. We are grateful for the funding we received from Universidad de los Andes–Colombia and the University of Hawai’i, Mānoa, Graduate Student Organization. Finally, we would like to thank the anonymous reviewers for their incisive comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.