
Abstract
The present study investigates integrated writing assessment performances with regard to the linguistic features of complexity, accuracy, and fluency (CAF). Given the increasing presence of integrated tasks in large-scale and classroom assessments, validity evidence is needed for the claim that their scores reflect targeted language abilities. Four hundred and eighty integrated writing essays from the Internet-based Test of English as a Foreign Language (TOEFL) were analyzed using CAF measures with correlation and regression to determine how well these linguistic features predict scores on reading–listening–writing tasks. The results indicate a cumulative impact on scores from these three features. Fluency was found to be the strongest predictor of integrated writing scores. Analysis of error type revealed that morphological errors contributed more to the regression statistic than syntactic or lexical errors. Complexity was significant but had the lowest correlation to score across all variables.
Integrated writing assessment tasks have appeared with increasing regularity in language testing to assess academic English language ability. Along with this proliferation, research has sought to fill in details related to these tasks’ validity (Acención, 2005; Cumming et al., 2006; Gebril & Plakans, 2013; Plakans, 2009b; Plakans & Gebril, 2012; Watanabe, 2001; Yang, 2014); however, much of this work has centered on tasks that include two skills, reading and writing. In the past decade, a large-scale standardized test – the Test of English as a Foreign Language (TOEFL) – introduced tasks that require examinees to synthesize information across listening and reading components of the prompt and then to respond in writing, adding another skill to consider. These multi-skill tasks present test takers with greater challenges in terms of skill elicitation and content integration, which may be reflected in their scores on these tasks. As language test tasks evolve, new tasks warrant investigation to clarify score interpretations.
Interpreting scores from language tests is a critical component of test use and validity (Chapelle, Enright, & Jamieson, 2008, 2010; Messick, 1989). Research is required to extrapolate detailed profiles of test-takers’ language ability from the numerical values or levels produced by tests. The present study examines the meaning of scores from integrated reading–listening–writing tasks on TOEFL. The results of the study will elucidate the relationship between linguistic features measured in the performances on the integrated tasks and the scores on the tasks.
To describe second language performances in linguistic terms, the field of second language acquisition (SLA) has highlighted three features of language on which to focus in explorations of language development and quality – complexity, accuracy, and fluency (CAF) (Housen, Kuiken, & Vedder, 2012; Larsen-Freeman, 1978, 2009; Wolfe-Quintero, Inagaki, & Kim, 1998). In SLA, CAF has been used to understand the impact of instruction, tasks, and planning on written and spoken performance (Ahmadian, 2010, 2011; Armstrong, 2010; Biber & Gray, 2010, 2013; Foster & Tavakoli, 2009; Johnson, Mercado, & Acevado, 2012; Kuiken et al., 2005). While research on CAF and writing is emerging, attention has been largely relegated to tasks that isolate writing from other language skills. In addition to defining CAF in writing-only tasks, investigation of integrated tasks is necessary as research has shown that task type affects CAF (Ellis, 2009; Lu, 2011; Way et al., 2000; Wigglesworth & Storch, 2009). For example, Way, Joiner, and Seaman (2000) found significant differences in CAF when comparing students’ writing across narrative, descriptive, and expository writing tasks. Lu (2011) determined that 14 measures of syntactic complexity were significantly different between two writing genres, argumentative and narrative. These studies of task effect on CAF in written performances indicate that, in order to apply these linguistic features to understand integrated TOEFL scores, studies of integrated writing are necessary.
Only a few studies, however, have employed integrated writing tasks in CAF research (Biber & Gray, 2013; Cumming et al., 2006; Gebril & Plakans, 2013), which leaves the field without a complete picture of how these particular tasks affect the written performance of second language writers and how scores from three-skill integrated tasks can be interpreted in light of these common metrics in SLA. These features will be explored in performances from integrated writing tasks to see how scores reflect test-takers’ CAF in written performance.
Complexity, accuracy, and fluency (CAF) in language testing and second language writing
Constructs and scoring rubrics in written assessment are commonly derived from fields such as composition and rhetoric or the psychology of writing. However, as mentioned previously, CAF are features emerging from SLA research. Informing language testing research with SLA was a topic in a recent joint conference session between the American Association of Applied Linguistics and the International Language Testing Association (2015) titled, “Revisiting the Interfaces between SLA and Language Assessment Research.” 1 Shohamy (2000) has pointed to areas where language testing could inform SLA and where SLA might provide foundations for language testing, for example, in “identifying language components for elicitation and for assessment criteria” (p. 543). This topic was also presented in a 2010 EuroSLA monograph, Communicative proficiency and linguistic development: Intersections between SLA and language testing research (Barting, Martin, & Vedder, 2010). CAF is an example of a framework from SLA that can be applied to language testing to help in understanding assessment performances; in fact, it has had some traction for this purpose in recent research (Cumming et al., 2006; Kuiken, Vedder, & Gilabert, 2010; Wigglesworth, & Storch, 2009).
However, in a review of the scoring rubric for TOEFL integrated writing 2 for CAF, accuracy is found to be the only one of the three features that is overtly addressed through phrases such as “occasional language errors” and “errors of usage and/or grammar.” Complexity and fluency may be implied or connected to criteria in the scale related to “imprecise presentation” and the inclusion of main ideas from the source texts, yet the rubric does not directly mention either fluency/development or complexity/sophistication. In contrast, the rubric for independent writing on TOEFL 3 includes accuracy as well as a reference to “well developed” writing; it also includes “syntactic variety,” which relates to complexity. This raises the question of the importance of CAF in integrated writing and how predictive scores of such tasks are to these three features of language.
Complexity
Pallotti (2009) names complexity as the most problematic construct of the three because it includes at least eight aspects of communication and language (“lexical, interactional, propositional, and several types of grammatical complexity” p. 593). Of these aspects, our study focused on syntactic complexity, which includes language sophistication through grammatical forms and the writer’s use of a wide range of structures (Ortega, 2003; Wolfe-Quintero et al., 1998). Ahmadian describes complexity as “the learner’s tendency to take risks and use the cutting edge of their linguistic knowledge” (2011, p. 272).
Syntactic complexity is frequently measured through length, sentence complexity, subordination, coordination, and other structures such as verb phrases and nominals (Bardovi-Harlig & Bofman, 1989; Ferris, 1994; Kobayashi & Rinnert, 1992; Kuiken, Vedder, & Gilabert, 2010; Lu, 2011). Lu (2011) analyzed a large sample of ESL writing data from the Written English Corpus of Chinese Learners, which was composed of independent writing essays, to evaluate syntactic complexity measures. Only seven of the 14 complexity measures produced a linear progression in relation to proficiency: three measures were related to length, two were nominal measures, and two were coordinate phrase measures. As shown by Lu’s study, complexity is intricate and prone to subjectivity, varying definitions of clauses, and sentence versus discourse-bound views (Biber & Gray, 2010; Rimmer, 2006).
Investigating complexity with two-skill integrated tasks, Cumming et al. (2006) found significance with the number of words per T-unit used to measure complexity across proficiency levels. However, using clauses per T-unit, a measure of subordination, no significance was found across levels. Using another measure of subordination, T-units per sentence, Gebril and Plakans (2013) also found no significant difference. Biber and Gray (2013) looked at linguistic measures across TOEFL score level performances on speaking and writing tasks including integrated writing. They measured grammatical variation, which included grammatical complexity structures, but did not find these structures to be consistently or significantly different across score levels. These studies support the position that traditional features such as clause-related subordination and coordination are not strong indicators of high-scoring writing performance, and that phrasal or length measures hold more promise.
Accuracy
Accuracy, similar to syntactic complexity, has been measured using a number of different strategies, all essentially focused on norm-based correctness of grammar and certain lexical errors, but not inclusive of semantic or pragmatic accuracy. Pallotti (2009) identifies accuracy as “the simplest and most internally coherent construct, referring to the degree of conformity to norms” (p. 592). Indeed, accuracy is closely tied to judgments of target-like use (Ellis, 2009; Wolfe-Quintero et al., 1998); thus, in contrast to complexity, accuracy is a measure of language control rather than flexibility. Accuracy in writing has been captured by counting errors; calculating ratios of phrases, clauses, or T-units with and without errors; using holistic/analytic rating; and weighted error ratios (Evans, Hartshorn, Cox, & de Jel, 2014; Way et al., 2000; Kuiken, Vedder, & Gilabert, 2010). Studies on grammatical accuracy in second language writing have reported consistently that a positive relationship between accuracy and proficiency score exists (Bardovi-Harlig & Bofman, 1989; Hamp-Lyons & Henning, 1991; Kroll, 1990; Neumann, 2014; Polio, 1997, 2001).
Focusing on accuracy in integrated assessment, Cumming et al. (2006) and Gebril and Plakans (2013) used holistic scales to compare grammatical accuracy across writing score levels on integrated tasks. In their studies, a significant difference was found, indicating that lower scoring writing was less accurate and higher scoring writing more so. In a follow-up analysis by Gebril and Plakans (2013), the lowest scoring writing was significantly less accurate but writing at mid and high levels did not differ significantly, leading to the possibility that this feature is more pronounced at lower levels.
Fluency
Wolfe-Quintero et al. (1998) describe fluency as an indicator of comfort in producing language or the ease of language retrieval. Fluency, most frequently operationalized as length, is often considered a proxy for automatic processing of language (Ahmadian, 2011) and is argued to capture a communicator’s ability to think, compose, and deliver language in real time. Fluency is undoubtedly a measure of speed and automaticity in using language, and, as such, it overlaps with accuracy and complexity, perhaps creating some tension across CAF features. For example, as Sakuragi (2011) points out, some measures of length have been used for fluency study as well as for complexity study. Of the three CAF features, fluency has been measured the most consistently across L2 writing research studies through overall word, T-unit or sentence counts, all of which are length measures. Fluency has most persistently distinguished writing across proficiency/score levels for both independent and integrated tasks (Cumming et al., 2006; Ferris, 1994; Gebril & Plakans, 2013; Hirano, 1991; Watanabe, 2001). Higher proficiency writers produce longer texts than those with lower proficiency or lower writing test scores. Studies of integrated writing have corroborated findings from independent writing regarding the significant and positive correlation between essay length and score (Cumming et al., 2006; Gebril & Plakans, 2013).
Relationships between CAF variables
One of the criticisms of CAF research in SLA has been the separate treatment of the three constructs. Larsen-Freeman (2009) argues that research should consider CAF in combination, stating, “if we examine the dimensions one by one, we miss the fact that the way that they interact changes with time as well” (p. 582). Norris and Ortega (2009) argue that CAF require more organic modeling to include the ecology of their relationships with each other in learning contexts, rather than considering them as separate features of language. Skehan (2009) has discussed potential relationships in CAF, called the Trade-off Hypothesis, which proposes that all three features will not have the same strength concurrently in language tasks; for example an increase in fluency results in a decrease in accuracy. While some (Robinson, 2001) have challenged the Trade-off Hypothesis Nevertheless, the case has been made for CAF research to coalesce the measures rather than treating them separately.
The present study explores assessment of writing integrated with reading and listening to consider how scores from these multi-skill, multi-text, content-related tasks reflect test-takers’ language ability as defined by CAF. Understanding this relationship can inform score interpretation of these tasks. The integrated tasks require examinees to both comprehend texts through listening and reading and produce responses that combine the ideas from these texts with their own. This complexity may inhibit examinees’ ability to produce accurate, complex or extended discourse. On the other hand, the source material may provide wording, phrases or other structures to writers that could improve their writing or allow them to increase their output, which could also affect CAF. The studies by Cumming et al. (2006) and Gebril and Plakans (2013) provide a foundation for this work; however, both studies used tasks that only required two skills. To extend this research, our exploratory study centered on tasks that require three skills – listening, reading and writing. Incorporating two input source texts with different modalities furthers the complexity of language processing in the task. Lastly, this study analyzes CAF in the same model, rather than separately as in previous integrated writing studies. The research questions focus on the interpretation of integrated writing scores for CAF:
What is the relationship between CAF measures and integrated assessment performances?
Does CAF help predict scores on integrated assessment tasks?
Methods
To investigate the predictive power of CAF, 480 written performances on two TOEFL iBT integrated writing tasks supplied by Educational Testing Service (ETS) were analyzed. The sample data were collected from two TOEFL test administrations in 2006 and 2007 using different test forms with integrated tasks on different topics. The data included 480 participants from 73 countries, speaking 47 languages, with ages ranging from 14 to 51 (M = 23, SD = 6.46). Their overall writing scores spanned the full range from the lowest (1) to the highest (10), with a mean of 5 and standard deviation of 2.64. The integrated writing essays had been scored by ETS with a range from 1.0 to 5.5, including half scores (i.e. 1.5, 2.5). Table 1 shows the number of writing tests at each score level (only one response scored 5.5 and was combined with the 5.0 group).
Distribution of scores.
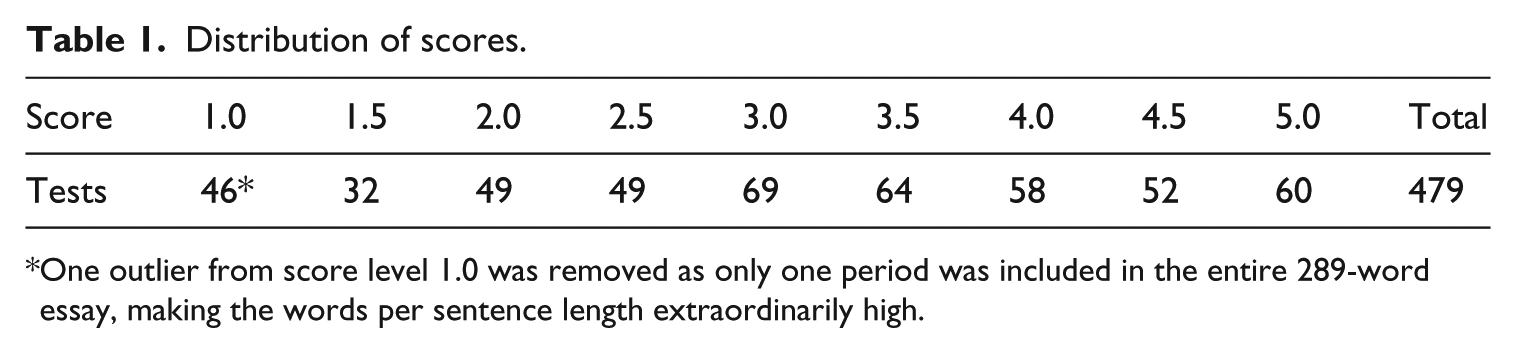
One outlier from score level 1.0 was removed as only one period was included in the entire 289-word essay, making the words per sentence length extraordinarily high.
The writing samples used in this study were from 480 different test takers. The writing was in response to an integrated writing task, which required test takers to read a passage and then listen to a short lecture presenting opposing views on natural science topics. After reading and listening, test takers had 20 minutes to write a summary of the listening text explaining how it differed from the opinion in the reading text. Two test forms were used (240 performances from Form 1 and 240 from Form 2). A preliminary study with the data indicated that a topic effect was not significant for complexity or accuracy, and, although a significant effect did occur with fluency, it was small. Based on these findings, the two forms were combined; however, we recognize that the issue of topic can be an important and significant variable in studies of written performance.
Integrated TOEFL writing is scored holistically by ETS using the rubric mentioned previously, composed of descriptors such as the following: selection of information from source texts; coherence and organization; and errors of usage and grammar.
Fluency and complexity
As discussed in the previous sections, a variety of measures have been used in CAF studies. Given the exploratory nature of this study, the CAF measures selected were fairly global, particularly in fluency and complexity. We chose approaches found to be significant in previous writing research to see if they also were significant for the multi-skill tasks. We also selected measures that could be combined in analyses to consider their interrelatedness. Therefore, fluency was measured as total word count, which is the most common metric for this feature and captures the amount of discourse an examinee can produce in a set time frame. To evaluate complexity, one measure was selected – mean length of T-units. This measure reflects the length of clauses or sentences with the underlying assumption that longer T-units indicate more complex clause or sentence structures. These two measures both consider length, but in different ways, that is, length of essay versus length of clause/sentence. The correlation between these two variables was checked and is reported on in the Analysis section.
To prepare the data for these measures, basic textual elements were counted using Microsoft Word 2007. The readability feature in Microsoft Word provides information about the number of words, number of sentences, and also average word length and sentences in a specific text. We checked the data for punctuation and spacing issues that Word might misconstrue.
T-units were coded by human raters and defined as the smallest possible unit that could stand alone grammatically, which could also be roughly defined as an independent clause or as an independent clause plus its dependent clause. We used raters in this coding as the dataset required some reader interpretation when essays included non-standard grammatical structures or sentence fragments that could obscure meaning or obfuscate clause boundaries. Therefore, an initial coding was conducted with two raters to calibrate and determine additional guidelines for marking these units. Two raters coded 20% of the writing samples, with an acceptable agreement ratio of 75/90 (83%). After discussion on the areas of discrepancy, one rater coded the rest of the essays for T-units. This set of textual coding provided data for the fluency and syntactic complexity measures.
Grammatical accuracy
In a review of research on linguistic accuracy, Evans et al. (2014) pointed to the limitations of using scales, particularly the subjectivity that comes with interpreting accuracy holistically. For this reason, we counted and categorized errors in the essays to explore grammatical accuracy. To begin, two raters analyzed 10 essays for errors to pilot the following coding scheme below (based on Bardovi-Harlig & Bofman, 1989; also used by Neumann, 2014): Syntactic errors: word order, errors resulting from absence of major or minor constituents (subject, verb, object), errors in combining sentences (complementation, relativization or coordination). Morphological errors: errors that are not a result of sentence combining and not lexical-idiomatic or vocabulary errors. Inflectional morphemes, grammatical functions (articles & prepositions), plural, number agreement, and possessive, tense, subject–verb agreement, passives.
Vocabulary/lexical-idiomatic errors.
This scheme was used by two raters on half of the data. A check on rater agreement found syntactic and lexical/idiomatic error ratings with acceptable agreement, 78.9% and 82.57% respectively. However, morphological error rating had low agreement, 43.15%
4
. Raters met and discussed issues with coding each error category and worked to refine their understanding of each error type. Then a subset of essays was re-rated and checked, leading to an acceptable level of agreement for morphological errors (70%). Once raters had confirmed improved clarity with the scale, the 480 essays were divided so that each rater scored 240 essays for error types. The raw scores for error count are potentially impacted by essay length – a higher word count creates more opportunities for error. To mitigate this issue, we followed earlier studies that have looked at error counts with corrective feedback (Truscott & Hsu, 2008; Van Beuningen, De Jong, & Kuiken, 2012) and used a ratio for accuracy for each error type (number of errors/total number of words × 10). Examples of each type of error follow:
Syntactic
At first, irrigation is that it causes negative effect. Risk caused by the water should be not the main reason.
Morphological
Food is more healthier. First problem is …
Vocabulary/idiomatic
Pollution may be disadvantage a health problem. The lecture hung several reasons.
Analysis
To explore CAF and integrated writing scores, descriptive statistics, correlation, and hierarchical linear regression (stepwise 5 ), analyses were used. For the correlation and regression analyses, each predictor variable was checked for independence. As mentioned previously with the accuracy measure, essay length impacts all variables in CAF to a certain degree. Although we attempted to limit this for accuracy by using a ratio, the complexity measure could also be potentially related to length (the longer the T-units, the longer the essay). Thus we ran correlations across the CAF measures to determine the strength of the impact of length on complexity and accuracy measures. All the correlations with fluency and other predictor variables were significant, but in the weak range (r < .3). The complexity measure (mean length of T-units) held a significant but weak correlation to fluency (r = .28), which suggests that writing longer essays was not equal to having longer clauses or sentences. Thus we proceeded with the analysis bearing in mind that length is intertwined with all complexity and accuracy measures, but recognizing that covariance is accounted for in multiple regression analysis.
Other assumptions for regression analysis were reviewed (Field, 2009) and none were violated by the data: (1) normality was checked by looking at histograms and normal probability (P-P) plots; (2) homogeneity of variance was considered by examining the plots of standardized residuals by standardized predicted values, (3) the assumption of multicollinearity was satisfied as tolerance statistics were > 0.1: word count = .90; morphological errors = .77; syntactic errors = .85; lexical errors = .82; mean length of T-units = .88.
For the regression analysis, there was one criterion variable, score, and five predictor variables, which will be written with the letter of the associated CAF construct throughout the results section: total word count (F), mean T-unit length (C), syntactic error count (A), morphological error count (A), and lexical error count (A). The analysis was completed by using SPSS.
Results
The descriptive statistics illustrate the general patterns in CAF across integrated writing score levels. Table 2 and Figures 1 and 2 show that fluency (word count) and complexity (mean T-unit length) increase with score. While the general trend for these variables was linear, it is worth noting that some differences between adjacent scores are quite small. For example, with fluency, word counts between scores 3.5 and 4.0 as well as 4.5 and 5.0 are smaller than the differences between other adjacent scores. In addition, for complexity, mean T-units length decreases between scores 2.0 and 3.0, and the overall change for complexity seems rather small from level to level (range of 0.06–1.91).
Descriptive statistics for variables across score levels.

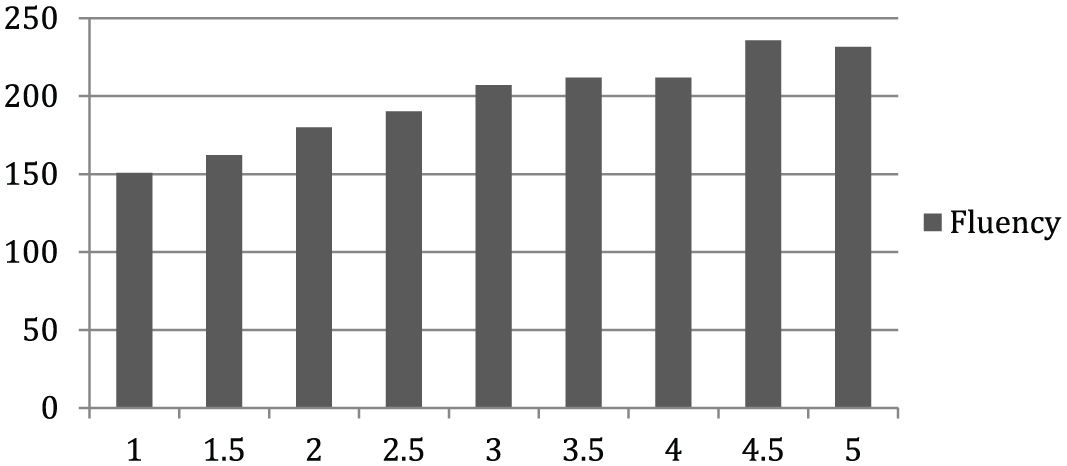
Fluency across score levels.

Complexity across score levels.
Bearing in mind that accuracy (error count) measures were converted to ratios, lexical, syntactic, and morphological errors decrease as score improves (see Figure 3). For all levels, morphological errors make up the largest percentage of errors, more than 50%, with lexical and syntactic errors being fairly equal. Similar to complexity, there are some scores levels that show change in the opposite direction; morphological errors and, to a lesser degree lexical and syntactic errors, show an increase in error count between score levels 1.5 and 2.0.

Accuracy (errors) across score levels.
The results from the descriptive statistics indicate that most CAF variables improve with score level: essays get longer and more complex, while errors become fewer. This holds true particularly for the whole numbered scores (1.0, 2.0, 3.0, 4.0, 5.0) and comparing the lowest to the highest scores. With the half-level scores included, some changes appear smaller at adjacent levels and some reversals of the pattern emerge. Further analysis is needed in order to understand the strength of relationships between CAF constructs in the integrated performances and how predictive CAF is of integrated assessment scores.
Correlations
Bivariate correlations (Table 3) show that integrated scores are significantly and moderately correlated across all measures of CAF. Word count (F) has the highest correlation (r = .50) followed by the three accuracy measures: syntactic (r = −.46) and morphological (r = −.46), then lexical errors (r = −.44). The weakest correlation is with mean T-unit length (C) (r = .32). These correlations confirm the descriptive results with evidence for a significant connection between CAF features and the scores on the integrated writing tasks, but also suggest that they might not all have the same impact.
Correlations across all CAF measures.
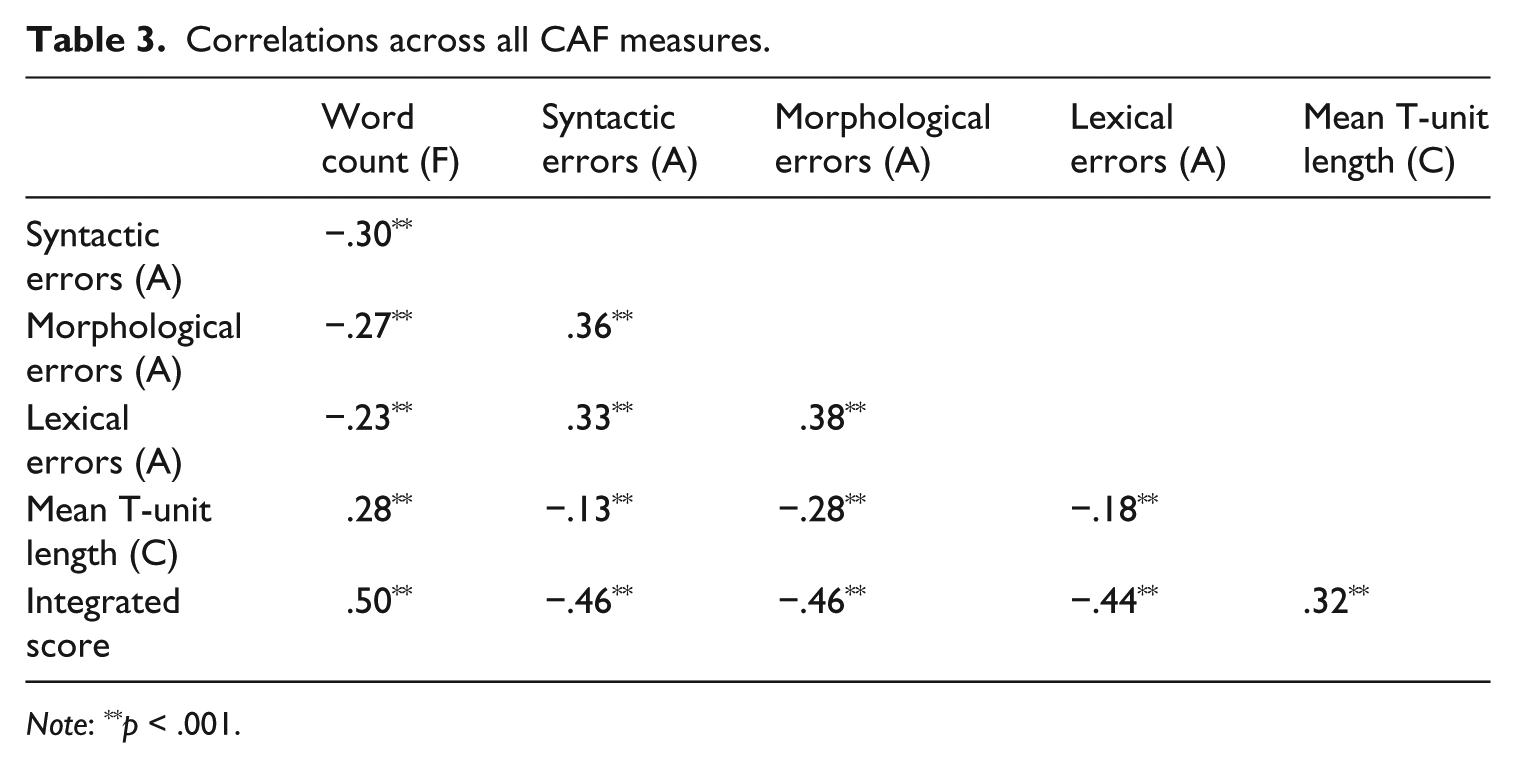
Note: **p < .001.
Regression
To continue the exploration of integrated scores and CAF, research question two asked how CAF variables predict score on integrated reading–listening–writing task performances. Stepwise regression analysis was conducted (results are shown in Table 4), which allows SPSS to determine the order that variables are entered into the regression model based on predictive power.
Regression analysis for CAF predictors of integrated writing score.
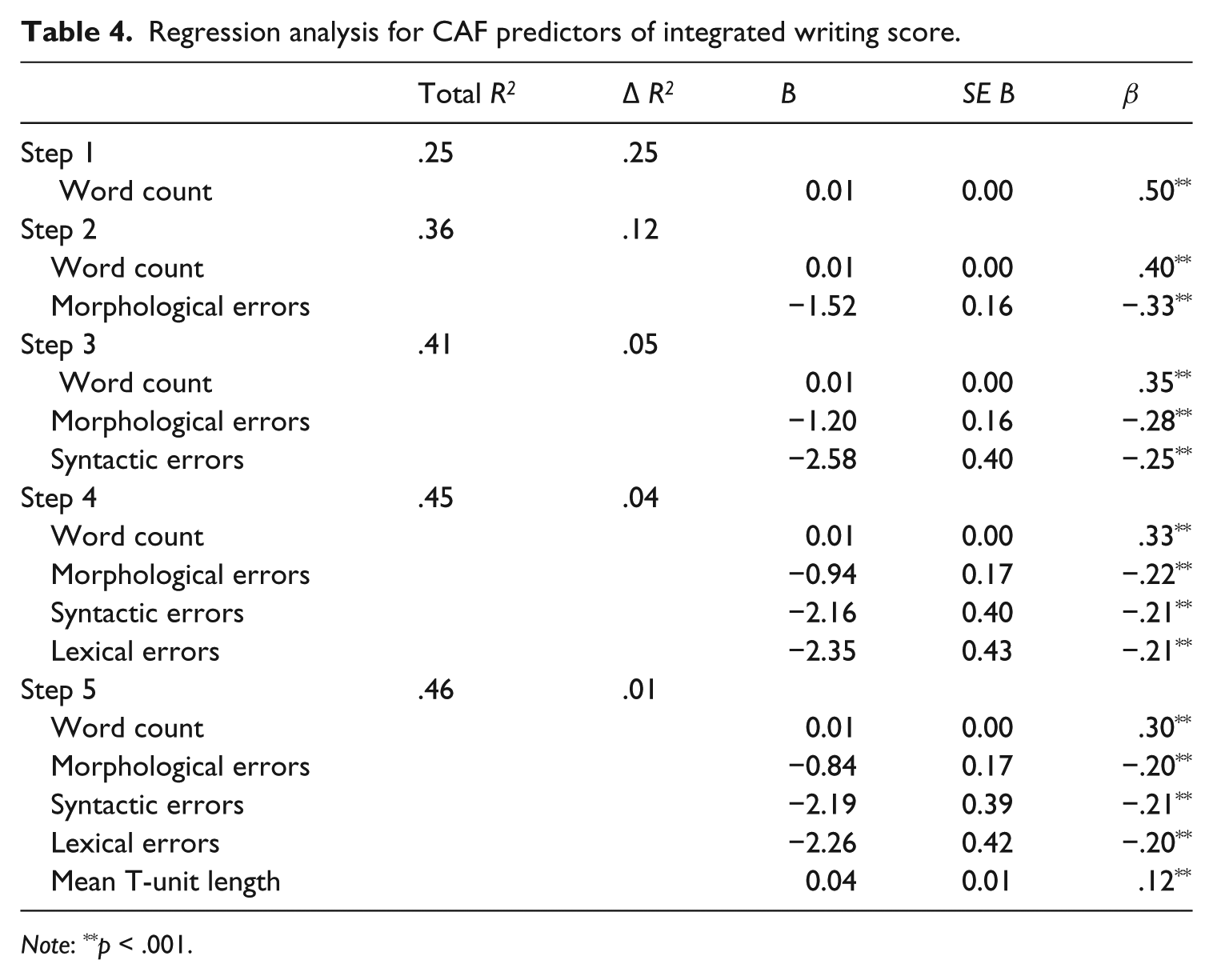
Note: **p < .001.
Model 5 indicates that the measures of CAF explain 46% of the variance in integrated writing scores, with much of that being determined by word count (F) (Model 1, R2 = .25). This aligns with the correlation being stronger for fluency. When added, each variable increases R2 significantly. After word count (F) is included in the model, the variable that explains the most variance is found with morphological errors (A). Syntactic and lexical errors (A) contributed to the model significantly but with fairly small changes in R2 after word count (F) and morphological error (A) are accounted for. Mean T-unit length (C) has the smallest impact, when the other variables are already in the model.
In sum, all the measures used in the regression model have a significant impact on the variance of scores in the reading-listening-writing task from the TOEFL iBT. This relationship is shown in the correlations, where each variable has a significant correlation to score. The regression analysis looks at the variables together finding that, while there are differences across the three CAF constructs in their relationship to score, even the last predictor entered into the model, mean length of T-unit (C), contributes to explaining the variance of scores. Thus, the results of the study confirm that, based on the measures used in this study, CAF is captured and assessed by integrated writing tasks, with fluency and morphological errors being the most predictive of integrated writing score.
Discussion
The results obtained by using an established combination of linguistic features from SLA research add to the understanding of the written performances from integrated tasks. The findings inform the interpretation of scores from listening–reading–writing tasks based on CAF measures. Fluency, accuracy, and, to some degree, complexity are reflected in the TOEFL integrated writing score. This discussion provides possible explanations for the results as well as implications.
The strongest predictor of score variance in our study was fluency or word count. Studies of CAF have agreed that fluency is a clear indicator of level for independent and two-skill writing tasks (Cumming et al., 2006; Ferris, 1994; Gebril & Plakans, 2013; Grant & Ginther, 2000). Our study further supports this relationship for writing integrated with listening and reading. There are several potential explanations for this finding. In a study of how writers use source material in integrated tasks, Plakans and Gebril (2012) found that language support is provided by source texts in these tasks – the writers borrow key words and get ideas from the sources; both strategies could lead to more developed and longer essays. Higher proficiency writers’ increased ability to comprehend source texts, making them more able to select key ideas and words from these source texts, could lead to higher numbers of words in their writing. Researchers (Cumming et al., 2006; Gebril & Plakans, 2013) have also referred to the demanding nature of integrated tasks that require students to process source materials, comprehend ideas from these sources, and then use their own language to present source information in their writing. These requirements are likely to give higher proficiency writers an advantage over students at lower levels time-wise, and consequently contribute to this positive relationship between length and writing quality. The findings that fluency is measured by these tasks and reflected in their scores is not explicit in the rating rubric but can be implied by the result. This implication is important for test users to recognize. While fluency is not mentioned directly in the rubric, it could be related to phrasing about the selection of important ideas from the source texts. However, given the consistent findings across research, including our study, test developers should consider more overt descriptors regarding length.
The regression analysis showed that accuracy made a significant contribution to predicting scores on the integrated tasks. Similar to fluency, this feature has also been regularly identified as related to performance in L2 writing on for both independent and two-skill integrated tasks; Cumming et al. (2006) and Gebril and Plakans (2013) found holistic scores of grammatical accuracy on integrated writing tasks increase as score level increases. In our study, breaking errors down into type, morphological errors appeared in a lower ratio in higher level performances and contributed more to predicting the score than either syntactic or lexical errors. Several explanations for this result are possible. In English, more opportunities may exist to make morphological errors at the word level, compared to syntactic errors, which are related to clause or sentence structures. Furthermore, lexical errors could be neutralized somewhat by test-takers’ access to vocabulary in context from the source texts. The test materials could be providing writers with vocabulary, thus reducing their lexical errors; however, writers may not be able to use this borrowed vocabulary flexibly, for example changing word functions, leading to errors in morphology. The interplay between error types or accuracy with use of source text content is a compelling area for further study. The greater contribution of fluency to score variance, in contrast to grammatical accuracy, is worth contemplating, given that the rubric used with the integrated tasks mentions accuracy more directly than fluency.
Complexity had an effect on score with an Δ R2 of 0.01 when the fluency and accuracy variables were accounted for. Our study, together with the work of Cumming et al. (2006) and Lu (2011), found significant results when using complexity measures related to length. However, this variable had a small predictive value and descriptive statistics showed fairly minimal differences between scores, which may indicate more work is needed to identify robust complexity measures for analyzing integrated writing assessment. The finding may also be explained by the limited mention of complexity in the integrated scoring rubric, and, therefore, raters may not be attending much to this feature in their scoring. If complexity is a desirable feature of academic English writing, then attention is needed to find appropriate measures and scoring rubric descriptors to evaluate complexity systematically.
The combination of the three features in the analysis provided insights as well. The negative correlations between complexity and the three accuracy measures indicated that as complexity increased accuracy was not lost, but in fact errors became fewer, and this finding provides some evidence that there was no trade-off between these features for these tasks. This pattern suggests that the relationship between CAF features is not a balancing act or that the interplay between them is more complex, thus supporting alternative hypotheses. For example, Robinson’s Cognition Hypothesis (2001, 2015), which is related to Skehan’s Trade-off Hypothesis, seeks to explain task complexity and spoken interaction in relation to language development. However, in contrast to viewing an inverse relationship between accuracy and complexity, this hypothesis states that, “complex tasks will promote both increased accuracy and complexity” (2015, p. 108) depending on the amount of interaction required of the task. Related to this, research in language testing on the use of holistic versus analytic scales suggests, given the strong, positive relationships among analytic components, that these aspects of proficiency develop together (Lee, Gentile, & Kantor, 2008 on writing scales; Xi & Mollaun, 2006 on speaking scales).
Implications
The results of this study hold implications related to integrated writing, score interpretation, and rubrics. The findings indicate that rating of integrated scores, for the TOEFL iBT in particular, is affected by CAF in written performance, as 46% of the score variance can be explained by these features. The integrated writing assessment rubric does not currently reflect all three of these linguistic features directly although the score appears to be capturing them. This may be owing to the relationship of CAF to other features that are more explicit in the rubric or from raters’ inclusion of CAF in their “subconscious” rating despite the rubric. In other words, the score reflects differences in these features across performances even though the rubric only includes descriptors regarding accuracy. These features are interacting with scoring and might need more attention in integrated rubric criteria. The other half of the variance, not accounted for by CAF is probably owing to other rubric criteria, such as the organization, coherence or selection of ideas from the source texts (Plakans & Gebril, 2013).
The descriptive statistics suggest that whole scores provide more differentiation for CAF between test takers and that for fluency and complexity the differences are larger at lower score levels. However, the distribution between whole scores might be diminished if the essays on the borderline (1.5, 2.5, 3.5, 4.5) are folded into five levels. More research on the optimal levels for distinctive scoring on integrated writing is needed to investigate this issue more fully.
This research study provides positive evidence for CAF being elicited and measured by integrated reading–listening–writing tasks to distinguish levels in L2 writing performance. The results imply that fluency, accuracy, and complexity are important skills to build for multi-skill, multi-text integrated writing. Being able to read, listen, comprehend, compare, synthesize, and summarize are all needed for integrated writing performance (Grabe, 2003; Leki & Carson, 1994, 1997; Plakans, 2009a, 2009b); however, fundamental language ability is also critical. Thus, writers need instruction and practice in how to manage discourse synthesis skills while composing linguistically accurate, complex, and fluent essays.
Limitations
Several limitations to this study need to be recognized. First of all, the measures for CAF are broad. We utilized easily accessible word counts as well as nuanced ratings by human raters. In particular, the measure used for complexity is both general and quantifiable (Housen, Kuiken, & Vedder, 2012). Although the measures in our study are fairly blunt, we chose them in order to explore how CAF might be related to integrated writing scores. With the findings from our study regarding this relationship showing significant patterns, further research should delve more deeply into the nuances of this relationship with finer-grained approaches, such as phrasal-level corpus analysis (see Biber & Gray, 2013 for examples of such work with spoken and written TOEFL iBT performances). Our focus on five variables may be considered rather narrow in contrast to corpus studies (Biber et al., 2001; Lu, 2011) that utilize computer analysis. Our study was exploratory and employed human rating heavily, which limits the breadth of coverage but enhances coding based on reader interpretation. All variables in our study had some degree of impact from length; we checked correlations between them and used multiple regression analysis, which handles shared variance. However, recognizing this limitation in the measures is important for the field as we look for other robust ways to measure complexity or accuracy. Further study of CAF in integrated writing could overcome some of these limitations through other approaches (e.g. corpus studies) or employing different measures. In addition, investigating the interaction between CAF and source materials would provide an insight into the key element that sets these tasks apart from traditional independent writing assessment tasks.
Conclusion
This study contributes to the existing language testing and CAF literature by investigating L2 writing from a multi-skill, multi-source task, including the three features in one analysis. Although the study was not a direct comparison with other tasks, results are similar to what has been found in non-integrated L2 writing: (1) fluency is a strong predictor of writing level; (2) grammatical accuracy, as considered through error types, decreases as scores increases, and (3) complexity has a significant but relatively smaller impact than other CAF features.
The study of language development and proficiency has benefitted from the conceptualization of language quality captured by CAF. The field of SLA and language testing has found evidence that these features emerge with writing; however, they are not necessarily following a strictly linear progression nor do they affect writing in the same magnitude at every level of proficiency or with every type of task. In task use and the interpretation of test results, the contribution of CAF in shaping scores is critical in creating a profile of test-takers’ abilities through scores from integrated writing tasks. When making inferences from scores on integrated assessments, test users should recognize the weight of these three variables when they characterize writers at different score levels.
Footnotes
Acknowledgements
We thank the anonymous reviewers, and before that the ETS internal reviewers, for their comments on previous versions of the paper. However, the authors are solely responsible for the content and any inaccuracies.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Our study was funded by the Educational Testing Service TOEFL Committee of Examiners.