
Abstract
In this study, we define the term screener test, elaborate key considerations in test design, and describe how to incorporate the concepts of practicality and argument-based validation to drive an evaluation of screener tests for language assessment. A screener test is defined as a brief assessment designed to identify an examinee as a member of a particular population or subpopulation. Consequently, its focus of measurement is to provide information that distinguishes the targeted subpopulations. Although the trade-off between measurement quality and practicality is an important consideration for any assessment (Bachman & Palmer, 1996), practicality is a particularly critical feature of low-stakes screener tests in language assessment given their use in routing examinees to other assessments, rather than serving as the basis for higher-stakes decision making. In order to demonstrate how an evaluation may be applied to a screener test, we describe the development and evaluation of a proposed screener test for the TOEFL Primary Reading test. The claims articulated through the development process and evidence collected throughout development and pilot testing enable a wide-ranging, comparative evaluation of five- and 10-item TOEFL Primary Reading screener tests that systematically incorporate the concepts of measurement quality, impact, and practicality.
Overview
When test takers or administrators need to make an inference about the group to which a test taker belongs, a screener test may be a useful tool. A screener is a brief test designed to identify a test taker as a member of a population, subpopulation, or group. In medicine and psychology, it may be used as a first step towards identifying an illness, impairment, or condition (e.g., Callahan, Unverzagt, Hui, Perkins, & Hendrie, 2002; Lipton et al., 2003). In education, screener tests are typically used to streamline decision-making processes, including identification (i.e., as a member of a population of learners) and classification (i.e., as a member of a higher- or lower-proficiency group of learners) decisions. Screeners used for identification may help educators identify a student as an English learner (EL) for administrative and instructional purposes (Abedi, 2008; Bailey & Kelly, 2011; Lopez, Pooler, & Linquanti, 2016; Mahoney & MacSwan, 2005). Screeners used for classification may identify a student as a member of a more- or less-proficient group (Xi, 2008), or help a test taker to decide on whether his or her level of ability is appropriate for a particular test (Stansfield & Hewitt, 2005). In the latter situation, the use of the screener helps to ensure that students take an appropriate test and educators are given useful information without wasting time or money on a less suitable test.
Given the proliferation of language assessments targeted to candidates of various ability levels and intended language use contexts – and the costs associated with them – screener tests have become potentially important tools for both learners and instructors. Stansfield and Hewitt (2005) described a screener test that was designed to determine whether applicants seeking certification as a court interpreter were qualified to take an oral certification test. Given the high cost of administering the oral certification test, and the relatively low probability of receiving a passing score, the screener was developed in order to identify viable candidates for the oral certification test (i.e., members of the target population), in a format that was easy to score and administer (i.e., four-option selected response). In order to justify the use of the screener for this purpose, the researchers examined the predictive validity of the screener in a two-part study. In the first part, correlations between the screener and certification test were estimated in order to quantify the strength of the relationship between the two measures. In the second part, a contingency table was created in order to estimate the likelihood of false positive and false negative cases. The second aspect of the study provided the most direct support for the intended use of the screener: using a categorization based on the screener (i.e., Pass, Fail) to determine whether the candidate is part of the target population of the oral certification test. When the researchers determined that the rate of false negatives was extremely small (i.e., very few candidates who failed the screener subsequently passed the oral certification test), they interpreted that finding as positive evidence for the intended use of the screener.
A variety of other screener tests have been developed for this intended use, often characterized as level or placement tests. The Cambridge English Placement Test, or CEPT (www.cambridgeenglish.org/test-your-english/), is available online and provides learners with a recommendation regarding which Cambridge English test to take, as well as an estimate of their CEFR (Council of Europe, 2001) level. The Exam English level tests (www.examenglish.com/leveltest/) are available online as either grammar and vocabulary or listening screeners that provide an estimate of a learner’s CEFR level that can be used to guide the selection of a full-length assessment from a compiled list. Neither of these screener tests is clearly supported by research evidence or a formal evaluation, although the CEPT reports reliability to registered test administrators. The CEPT is also presented with the qualification that “test scores and levels are very approximate” (www.cambridgeenglish.org/test-your-english/), and testimonials from score users (www.cambridgeenglish.org/find-a-centre/exam-centres/support-for-centres/placing-students-in-the-right-exam/).
Screener tests may be offered as low-cost and often lower-stakes tools to facilitate decision making, but their use should be supported by research evidence or a formal evaluation. This paper proceeds with an overview of the TOEFL Primary suite of tests and the need for a low-stakes screener test. It describes how the particular measurement focus of screener tests informed test development, and then proposes and applies an evaluation framework that compares the measurement quality, impact, and practicality of two proposed screener tests. It concludes with a brief discussion of several key considerations for screener tests in language assessment, including the importance of evidence that links score interpretations with decisions and the potential misuse of screener tests.
The TOEFL Primary test suite and the need for a screener test
The TOEFL Primary tests are designed to assess the English language proficiency of young non-native learners of English in order to monitor progress, inform instruction, and place students in levels of English instruction (www.ets.org/toefl_primary/about). The tests are used by English language programs or schools that teach English as part of their curriculum. There are components for Reading and Listening, and Speaking. The Reading and Listening component is paper delivered and offered at two levels based on learners’ stage of English language proficiency. The Reading and Listening Step 1 component is designed for young learners at early stages of English language development, and Step 2 is intended for students at slightly higher levels of development. The Step 1 and Step 2 level tests share some item types and content by design, and are vertically equated (Cho et al., 2016). As a result, the score scales and interpretations about English language proficiency slightly overlap across the Step 1 and Step 2 level tests, as shown for the TOEFL Primary Reading test in Table 1.
TOEFL Primary Reading Step levels, scale scores, and performance descriptors (Educational Testing Service, 2015).

Students receiving a level of  and a scale score of 100 may be at the very beginning stages of learning English. Students receiving a level of
and a scale score of 100 may be at the very beginning stages of learning English. Students receiving a level of  and a scale score of 100 may receive better information about their proficiency levels by taking Step 1. Score reports with a scale score of 100 show a Lexile measure of BR250L and a CEFR level of below A1.
and a scale score of 100 may receive better information about their proficiency levels by taking Step 1. Score reports with a scale score of 100 show a Lexile measure of BR250L and a CEFR level of below A1.
One potential challenge for users of the TOEFL Primary Reading and Listening components is identifying the Step level most appropriate to administer to a learner. Although descriptions of the abilities assessed by each test and Step are provided to teachers in the TOEFL Primary Teacher Handbook (Educational Testing Service, 2013), these descriptors may not facilitate decision making when a teacher is unfamiliar with a learner’s English language proficiency. Even when teachers are familiar with learner abilities and the abilities targeted at each Step level, teachers or administrators might simply prefer the convenience of using a screener test to determine which full-length TOEFL Primary Reading or Listening Step level is most appropriate for a learner or group of learners. This study subsequently focuses on the development of a screener test for the TOEFL Primary Reading component to illustrate more clearly the various design and validation issues that pertain to screener tests.
The usefulness of a screener test can be examined with respect to its measurement quality (reliability, construct validity, authenticity, interactiveness, fairness), impact, and practicality (Bachman & Palmer, 1996). The measurement quality and impact of the screener test can be evaluated by specifying claims in a validity argument – such as the assessment use argument (Bachman & Palmer, 2010) – and collecting evidence that supports or undermines these claims. Although practicality has been described as a function of whether the resources available to a test developer exceed the resources needed (Bachman & Palmer, 1996, 2010), we suggest that a screener test may be more or less practical based on (1) its ease to administer (i.e., minimal technical or administrative requirements), (2) its ease to score, and (3) its length (i.e., the number of items).
Since the length of an assessment may directly impact its measurement quality, impact, and practicality, we propose developing and evaluating the usefulness of screener tests of differing lengths. Thus, test length is the distinguishing feature that sets up potential trade-offs between measurement quality and practicality; for example, a shorter test is more practical but likely to be less reliable, potentially undermining claims about measurement quality. In the following sections we describe the development of five- and 10-item screener test forms and a comparative evaluation framework that allows us to explicitly examine potential trade-offs between practicality, measurement quality, and impact.
Development of the TOEFL Primary Reading five- and 10-item screener test forms
A screener test is intended to identify or differentiate subpopulations. In this case, the targeted subpopulations are TOEFL Primary Reading Step 1 and Step 2 test takers. The first step in the development of the TOEFL Primary Reading screener test was identifying the level of performance that best differentiated the Step 1 and Step 2 test populations. The TOEFL Primary Reading Step 1 and Step 2 levels are vertically equated, which greatly facilitated this initial task. As shown previously in Table 1, Reading Step 1 scaled scores range from 100 to 109, and Step 2 scaled scores effectively range from 104 to 115. There is overlap between the Step 1 and 2 levels from 104 to 109 on the scale. This implies that learners in this overlapping score range (104–109) may be appropriately placed in either level. Thus, a screener test could theoretically result in three decisions: a learner is associated with the Step 1 population, the Step 2 population, or both/either.
Owing to the need to minimize test length, researchers determined that the screener test should be designed with two decision categories in mind (Step 1 or Step 2) and selected a level on the scale to distinguish these categories. The ability level (θ) between scaled scores 106 and 107 was used to differentiate the populations since it bisected the overlapping portions of the scales and would presumably minimize overall decision error. Scaled scores of above 106 were associated with the highest level of performance on Step 1, and scaled scores of below 107 were associated with lower levels of performance on Step 2. As shown in Table 1, the ability level (θ) between scaled scores of 106 and 107 is also used to differentiate other indicators of language ability (i.e., Lexile measures and CEFR levels).
Next, researchers identified and cloned existing operational TOEFL Primary Reading items that maximized item information near the targeted ability level (θ). Owing to the desire to minimize administration time, this list of items was filtered to include only discrete reading items that could appear on either Step level test, and was supplemented by other discrete reading item types that may be expected to target a similar level of latent ability. Each item was cloned (in the case of TOEFL Primary operational items) or adapted (in the case of the pre-existing discrete complete-the-sentence items) for the purpose of the screener. Cloning involved recreating the item so that it would parallel the original in terms of content and difficulty but still be unique enough to be considered a new item; in other words, surface features of an item are manipulated with the intention of preserving its deeper structure. Adapting generally involved simplifying stems and option sets as needed to be more appropriate for the targeted population. Each item also underwent two rounds of review by test developers familiar with TOEFL Primary items and the targeted population. Adjustments to the items were made as appropriate based on reviewers’ expert judgments. An assembled form of 28 items received a fairness and sensitivity review to flag any potential construct-irrelevant sources of variance.
The assembled form was administered in a pilot study to a representative sample of TOEFL Primary Reading test takers (described below in the Method section). Items on the form were then analyzed using classical item analysis, item response theory (IRT) modeling, and equating in order to select items for five- and 10-item screener test forms. First, classical item analysis was used to estimate p+ (the proportion of students who answered an item correctly), biserial correlations, and empirical item characteristic curves (see Crocker & Algina, 2008) for the 28 items in the screener field test form. Two items with low biserial correlations were eliminated from further analysis, and the reliability of the 26-item test was α = 0.86. Next, items were fitted by a one-parameter (1PL) IRT model and a two-parameter (2PL) IRT model using PARSCALE (Muraki & Bock, 1997). Item parameter estimates from the better-fitting 2PL model were retained and used to obtain the expected a posteriori (EAP; Bock & Mislevy, 1982) estimates of students’ latent ability and used in subsequent analysis.
Next, latent ability as determined by screener test performance was linked to latent ability based on TOEFL Primary Reading test performance. Based on the sample of students that had valid latent ability scores on both the TOEFL Primary Reading and screener field test (n = 392), a single group direct equipercentile linking procedure (Zu & Puhan, 2014) was used to identify the level on the screener field test latent ability scale that was equivalent to targeted level on the TOEFL Primary Reading latent ability scale. Item information function plots of the 26 screener field test items were plotted, and items with larger information at the specified theta level were prioritized for inclusion on five- and 10-item screener test forms.
In order to build a screener test that better classifies test takers into Step 1 and Step 2, we rank ordered and selected items with larger information at the targeted latent ability level based on their item information function (IIF). The five- and 10-item screener tests were composed by selecting the top five- and 10-ranked items respectively. For each test, the expected raw score corresponding to the latent ability cut score was found through the test characteristic curve. The raw cut scores were then obtained by rounding up to the nearest whole number, which reflected the expectation that decision makers would prefer to minimize false positive decision errors.
An evaluation framework for the TOEFL Primary screener test
Unless a low-stakes screener test is highly practical (i.e., brief, easy to administer and score), it would not be useful. Conversely, if it lacks sufficient measurement quality and evidence of its positive impact its use may not be justified. The evaluation framework proposed in Figure 1 draws upon Bachman and Palmer’s framework for test usefulness (Bachman & Palmer, 1996) and their assessment use argument (Bachman & Palmer, 2010) in order to explicitly characterize measurement quality, impact, and practicality for the purpose of a principled evaluation. The figure shows how most concepts of test usefulness are incorporated into the assessment use argument with the exception of practicality, which Bachman and Palmer (2010) characterize as a threshold to be obtained rather than a quality to be maximized.
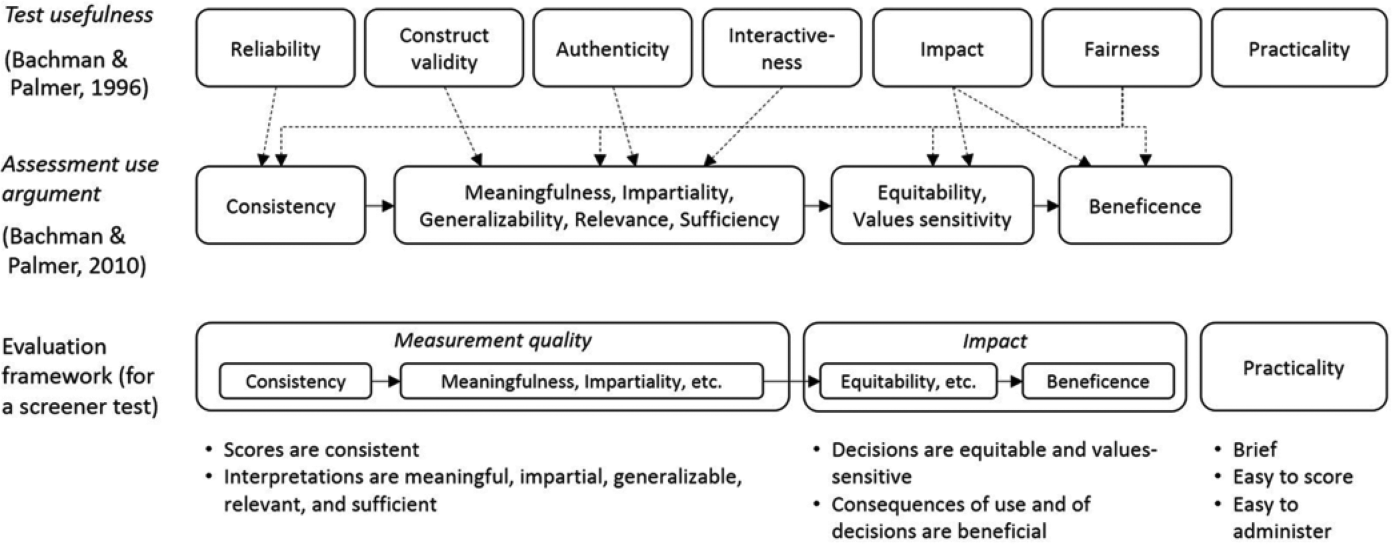
An evaluation framework for a screener test based on qualities of test usefulness and the assessment use argument.
Figure 1 suggests that the usefulness of a screener test can be evaluated by simultaneously considering its measurement quality, impact, and practicality. Measurement quality can be evaluated by specifying claims about the qualities of screener test scores (i.e., scores are consistent) and of the interpretations of those scores (i.e., interpretations are meaningful, impartial, generalizable, relevant, and sufficient). Impact can be evaluated by extending the assessment use argument to articulate claims about the qualities of decisions based on score interpretations (i.e., decisions are equitable and values-sensitive) and of the consequences of decisions and test use (i.e., consequences are beneficial). This entire series of claims corresponds to an assessment use argument (Bachman & Palmer, 2010), which incorporates most qualities of test usefulness and establishes a clear chain of logical inference between data and claims that provides a higher degree of conceptual coherence.
The evaluation framework introduced in Figure 1 has been adapted into a series of claims (for measurement quality and impact) and qualities (for practicality) for a TOEFL Primary Reading screener test. For each claim or quality, suggestions have been provided in Table 2 that will guide the collection of evidence to inform the evaluation of test usefulness. It should be noted that a fully specified assessment use argument should contain a more elaborate series of warrants, or supporting statements for a primary claim (see Bachman & Palmer, 2010). For example, a primary claim may state that “scores on the screener test are consistent.” This claim may be supported by number of more specific statements (or warrants) that elaborate the ways in which scores are expected to be consistent or reliable (e.g., “scores are internally consistent,” “scores are consistent across testing occasions”). For the purpose of this evaluation, we have focused on a smaller number of warrants in order to illustrate how evidence can be collected across the entire chain of inferences. Although claims about score interpretations can and should be supported by a broad array of warrants, we have focused on the meaningfulness of score interpretations and the sufficiency of score interpretations for making decisions. Evidence regarding meaningfulness is central for any assessment, and evidence of sufficiency is particularly critical for evaluating the link between a test’s measurement quality and its intended use. This selective prioritization of claims and warrants is consistent with Bachman and Palmer’s (2010) recommendation to focus initial backing on potential stakeholder concerns and the test’s particular use in mind.
Evaluation framework for a TOEFL Primary Reading screener test.

Measurement quality: Scores on the screener test are consistent
Student performance on the test is the foundational data that is transformed into a score, and the important quality of scores is their consistency (Bachman & Palmer, 2010). Score consistency for a selected response test can be characterized in a variety of ways: consistency across equivalent test forms, across items within a form (internal consistency), or across occasions (test–retest reliability). This claim about score consistency is foundational in that it reflects the view that reliability is a prerequisite to validity (Haertel, 2006). In other words, to support subsequent claims about the interpretations of test scores and their use to make decisions, a threshold level of consistency is necessary. In the case of the TOEFL Primary screener test, a relatively high level of internal consistency would be desirable.
Measurement quality: Interpretations of scores on the screener test are meaningful and sufficient
Based on test scores, interpretations will be made about whether students are most likely in the Step 1 population (lower ability) or Step 2 population (higher ability). Thus, test scores serve as the foundational data that is transformed into an interpretation about population membership. Although these score-based interpretations should be characterized by a number of qualities (i.e., meaningfulness, impartiality, generalizability, relevance, sufficiency), for the purpose of the current TOEFL Primary Reading screener test evaluation we will focus on two of these qualities: the meaningfulness of interpretations, and the sufficiency of interpretations for making decisions about which Step level is most appropriate. In order to provide evidence for the claim that “interpretations of scores can be interpreted as indicators of population membership with respect to TOEFL Primary Reading component Step levels,” we will examine the relationship between screener test scores and a criterion measure: TOEFL Primary Reading test scaled scores.
A critical quality of screener test score interpretations is their sufficiency for making decisions about a learner’s Step level. When score interpretations are sufficient for decision making, classification errors will be minimal or tolerable, and adding additional information to predict the decision may not substantially improve the quality of decision making. With this in mind, we will conduct several analyses to provide evidence for the claim that interpretations of scores provide information that is sufficient to deciding a learner’s Step level.
Since the intended use of scores is to support a classification decision, information about classification accuracy and consistency would be relevant. For single form administrations, classification accuracy refers to the agreement between classifications based on observed scores and classifications based on true scores, and classification consistency refers to the agreement between classifications based on two parallel forms of a test (Livingston & Lewis, 1995). In classical test theory, a true score is the score that an examinee would be expected to obtain “over an infinite number of repeated testings with the same test” (Crocker & Algina, 2008, p. 109).
In addition to these reliability-like estimates for decisions, we will examine the agreement between classifications based on screener test scores and TOEFL Primary Reading scaled scores. If a learner’s classification based on the screener test is Step 2, and her actual classification based on the TOEFL Primary Reading is Step 1, this will be treated as a false positive decision error. Conversely, a Step 1 classification based on the screener test and Step 2 classification based on the actual TOEFL Primary Reading will be treated as a false negative decision error. This analysis of decision accuracy will provide a more direct evaluation of the predictive utility of screener test scores.
Finally, we will investigate whether classification decisions are best predicted by a single measure (such as the screener test) or multiple measures. We will conduct a series of logistic regression analyses to compare prediction of actual Step levels based on the screener tests with other possible predictors, such as teacher evaluations and students’ self-reported years of studying English. In addition, we will investigate whether adding additional variables (teacher judgment, student background) to a baseline model in which screener test scores predict Step level substantially increases the amount of variation in Step level explained by the model.
Impact: Decisions based on the interpretations of screener test scores are values-sensitive
Score interpretations serve as the basis for decisions about which Step level is most appropriate for each student. An important quality of these decisions is that they are values-sensitive: they reflect the priorities or values of the institutional decision maker. In this case, false positive decision errors are expected to be slightly more serious than false negative decision errors. In other words, the consequences of students taking TOEFL Primary Reading Step 2 when they should be taking Step 1 are slightly more serious than the antithesis. This is based on the underlying view that stakeholders would like to err on the side of making assessment a positive experience for students, in terms of the difficulty of the test component that students take. This implies that it would be preferable for a student to complete a test form with slightly easier items than slightly more difficult items. This claim is primarily supported by the procedure used to set the raw cut scores for five- and 10-item tests as described in the previous section.
Impact: Consequences of screener test use are beneficial
The use of the test and decisions based on the test are intended to have beneficial consequences for teachers and administrators. The claim that the consequences of test use and of decisions will be beneficial is critical in that it links decisions to the ultimate intended effects of test use. One of the assumed beneficial consequences is that the test will be a useful tool for teachers and administrators, and a survey question will elicit evidence about whether teachers perceive it to be useful.
Practicality: Brief, easy to administer, and easy to score
In order for the screener test to be practical to teachers and administrators, it should have the qualities of being brief, easy to administer, and easy to score. With this in mind, we will provide a comparative evaluation of two relatively brief screener tests (five items, 10 items) and an estimation of the administration time for each form based on the items that compose them. The screener test will be paper-based, but a computer-based format may be more desirable to some stakeholders and increase its ease of administration; a survey question will elicit evidence about teacher preferences. Finally, an important quality of the practicality of the paper-based screener test is that it would be easy for teachers to score; again, a survey question will elicit teacher feedback regarding this intended quality.
Method
Participants
In order to obtain a sample that is representative of the population of TOEFL Primary Reading test users, we recruited participants (students and their teachers) from schools or institutes in four countries across three regions: Africa, East Asia, and South America. In total, 614 students and 22 teachers participated from Brazil, China, Japan, and Kenya. Among the 614 students, 606 of them answered at least 14 out of the 26 retained screener field test items. Among the students who completed the screener field test, 392 of them also completed a TOEFL Primary Reading test. Characteristics of these student participants are summarized in Table 3.
Characteristics of student participants in the TOEFL Primary Screener field test.

Although the study design called for all student participants to complete both the screener field test and TOEFL Primary Reading test, students from China did not complete the TOEFL Primary Reading test owing to a mistake by a local administrator. As a result, two samples were used for different stages of the analysis: A larger sample that included all students who completed the screener field test (N = 606), and a subsample of these students who also completed the TOEFL Primary Reading test (n = 392). The latter sample will be referred to as the evaluation sample. Demographic information (gender, age) was only available for students in the evaluation sample. In general, demographic characteristics of students were consistent with expectations regarding the TOEFL Primary test population (i.e., young learners of English). Demographic characteristics were largely comparable across countries, although the English proficiency level as indicated by TOEFL Primary Reading scores was lower for the sample from Brazil. The grand mean of TOEFL Primary Reading scaled scores was 104.4 (SD = 3.4), and scores ranged from 100 to 114.
A total of 22 teachers participated from the four countries. The number of participating teachers per country was determined by the class size and structure of participating schools or institutions in each country (China = 10; Japan = five; Kenya = five; Brazil = two). A majority of participating teachers were female (15 of 22) and were evenly distributed across the age range of 20 to 50. Most teachers had no experience with TOEFL Primary test administration (20 of 22) or score reports (19 of 22) prior to this study.
Instruments
Teacher surveys
Each participating teacher was asked to complete a two-page survey that included 13 items (see Appendix). The items were grouped into sections that asked questions about (1) the teacher’s background, (2) previous experience with TOEFL Primary tests, and (3) the TOEFL Primary screener test. Prior to the survey, teachers were asked to read a one-page summary description of the differences between TOEFL Primary Reading Step levels. This summary description was based on material provided in a handbook (Educational Testing Service, 2013) that is the best source of information available to distinguish the levels. The section about previous experience with TOEFL Primary tests included a question about whether these descriptions were perceived to be adequate to facilitate decision making. The section about the screener test included open-ended questions to encourage teachers to elaborate on their opinions. Based on feedback from local administrators in each country, the survey was translated from English to Chinese, Japanese, and Brazilian Portuguese for teachers in China, Japan, and Brazil.
Teacher evaluations of students
Teachers were asked to estimate the best TOEFL Primary Reading Step level for every student who participated in the screener field test. In other words, every student was expected to be evaluated by one teacher. Teachers provided estimates by checking one of the following options: Definitely Step 1, Probably Step 1, Probably Step 2, Definitely Step 2. Teachers also indicated their level of familiarity with the evaluated student’s English language skills by choosing one of the following options: Not familiar, Somewhat familiar, Very familiar.
TOEFL Primary screener field test form
The paper-delivered screener field test form included 28 selected response items, each scored correct or incorrect.
TOEFL Primary Step 1 or Step 2 Reading (and Listening) tests
The paper-delivered TOEFL Primary Reading (and Listening) tests contain 30 scored questions, and each administration is expected to take 30 minutes. Each raw score is converted to a scale score ranging from 100 to 115. For the purpose of this study, only the Reading tests were included in the analysis.
Procedure
The screener field test study was administered within each country by a site coordinator who was compensated for participating. Researchers met with each site coordinator individually to review the procedure, which consisted of four phases. In the first phase, site coordinators received a package that included directions that were translated into their native language, the study instruments described above, and consent and administrative forms. During this phase, site coordinators distributed and collected consent forms and asked teachers to complete an administrative form.
Once the administrative work of this first phase was complete, site coordinators administered the field test in the second phase. First, participating teachers and administrators at each school or institute read administration instructions; teachers then completed their “Teacher evaluation of students” form; the TOEFL Primary screener test form was administered to students; teachers scored a sample of completed test forms; teachers completed the teacher survey; and then all material was returned to the site coordinator. The procedure in this phase was designed to ensure that teacher evaluations of students were not influenced by student performance on the screener test form.
In the third phase, students were expected to complete a TOEFL Primary Reading and Listening test administration within one week of the screener field test administration. This requirement was imposed to minimize the influence of student language development between the two test administrations. In the fourth phase, site coordinators then collected all of the data (screener forms, teacher surveys and evaluations, consent forms) and mailed them back to the researchers with return postage that had been provided.
Analysis
Consistency of scores
An estimate of internal consistency was obtained for each form using Cronbach’s alpha, which provided evidence relevant to the warrant that “[s]cores on different items in the test are internally consistent.” All else being equal, as the number of items decreases the estimate of internal consistency is expected to decrease (Crocker & Algina, 2008).
Meaningfulness of scores interpretations
For each screener test form, we investigated the relationship between screener test raw scores and a criterion measure. Since screener test scores are intended to be interpreted as likelihood of population membership in TOEFL Primary Reading Step 1 (lower scores) or Step 2 (higher scores), the ideal criterion would be TOEFL Primary Reading test scaled scores, which could be viewed as the most precise indicators of likely population membership. Pearson correlations were used to examine the relationship between screener test raw scores and TOEFL Primary Reading scaled scores.
Sufficiency of score interpretations
Four separate analyses were used to provide evidence for the claim of sufficiency. First, the reliability of classification decisions was estimated using the RELCLASS (ETS proprietary software) program, based on a statistical method developed by Livingston and Lewis (1995). This method estimates the classification accuracy and classification consistency of a test form. Classification accuracy is a measure of the degree to which classifications based on test scores would correspond to classifications made based on true scores if they could be obtained. Classification consistency indicates the degree to which classifications based on one test form would correspond to classifications on a parallel form (for further description, see Papageorgiou, Xi, Morgan, & So, 2015).
Decision accuracy was investigated by comparing “observed” student classification based on screener test scores to “actual” classification based on TOEFL Primary Reading test scaled scores. Students whose “actual” classification was not unique to Step 1 or Step 2 were removed from the sample prior to the analysis. Since students with TOEFL Primary Reading scaled scores in the 104–109 range could be reasonably classified as either Step 1 or Step 2, they did not have a unique “actual” classification. Thus, the analysis sample only included the unique “actual” Step 1 (n = 173) and Step 2 (n = 32) classifications. The analysis of decision accuracy included estimates of accuracy, precision, and recall. The overall accuracy of a decision corresponds to the number of true positives (i.e., an observed Step 2 also classified as an actual Step 2) and true negatives, divided by the total number of classifications. Precision is the ratio of positive predictions that were correct; in other words, the ratio of true positives to all correct classifications (i.e., true positives and true negatives). Recall is the ratio of actual positive cases that were caught by the measure, or the number of true positives divided by the sum of true positives and false negatives.
A series of logistic regression analyses were conducted using the glm function with logit link in the software program R to model the relationship between Step level (as determined by TOEFL Primary Reading test scaled score) and various predictors. First, three models with one predictor (either screener test scores, teacher evaluations, or student background variables) were evaluated, and the improvement in the fit of each model over the null model was estimated using the deviance, Akaike information criterion (AIC), and Nagelkerke’s R2 (Nagelkerke, 1991). For the deviance statistic and AIC, lower values indicate better fit (Agresti & Finlay, 2009). Nagelkerke’s R2 is used in logistic regression as an indicator of the model’s explanatory power. It is scaled from 0 to 1 with higher values indicating better model fit.
Next, a series of nested logistic regression models were evaluated in order to determine whether the addition of relevant predictors substantially improved the amount of variance explained by the model. Again, the deviance statistic, AIC, and Nagelkerke’s R2 were reported as indicators of model fit. The logistic regression analyses only included data from Kenya (n = 179) and Japan (n = 43), owing to missing teacher evaluations from Brazil and missing TOEFL Primary Reading test scores from China.
Impact
Descriptive statistics were used for questions on the teacher survey in order to provide evidence for the warrant that “Teachers and/or administrators believe the screener test is a useful tool” (see Table 2).
Practicality
Descriptive statistics were used for questions on the teacher survey in order to provide evidence regarding several qualities of practicality, including the screener test’s perceived ease of administration and scoring.
Results
This section summarizes the results of analyses as they correspond to the components of the evaluation framework.
Consistency of scores
Estimates of internal consistency using Cronbach’s alpha were obtained for the five-item (α = 0.74) and 10-item (α = 0.81) screener tests. Both estimates were higher than thresholds traditionally considered acceptable (Knapp & Mueller, 2010).
Meaningfulness and sufficiency of score interpretations
Meaningfulness
Correlations between screener test raw scores and TOEFL Primary Reading scaled scores were obtained for the five-item (r = 0.64) and 10-item (r = 0.69) screener tests. Both correlations may be interpreted as large, following Cohen’s (1969) guidelines.
Sufficiency
Classification accuracy was estimated to be 0.87 and 0.90 for the five- and 10-item screener tests, respectively. Classification consistency was estimated to be 0.82 and 0.85 for the five- and 10-item screener tests, respectively. These results suggest that the consistency of classification with respect to true scores (0.87, 0.90) and parallel forms (0.82, 0.85) was acceptable.
A 2 × 2 contingency table was prepared for each screener test to facilitate the analysis of decision accuracy and is shown in Table 4.
2 × 2 contingency table based on five- and 10-item screener test (observed) and TOEFL Primary Reading scaled scores (actual), n = 205.

The accuracy rates for the five- and 10-item screener tests were 97% and 96%, respectively. For the five-item screener test, the false positive rate was 2% and false negative rate was 6%. For the 10-item screener test, the false positive rate was 5% and false negative rate was 0%. The rates of precision for the five- and 10-item screener tests were 88% and 78%, respectively, whereas the rates of recall were 94% and 100%, respectively.
Several independent logistic regression analyses were performed to examine the relationship between potential predictors of Step classification (i.e., five- or 10-item screener test score, teacher evaluation, or student background) and actual Step classification (Step 1 or 2, as determined by TOEFL Primary Reading scaled score). Each model that was evaluated and the corresponding results are summarized in Table 5.
Results of independent logistic regression analyses with a single predictor: five-item screener test, 10-item screener test, teacher evaluation, or years of studying English (n = 213).
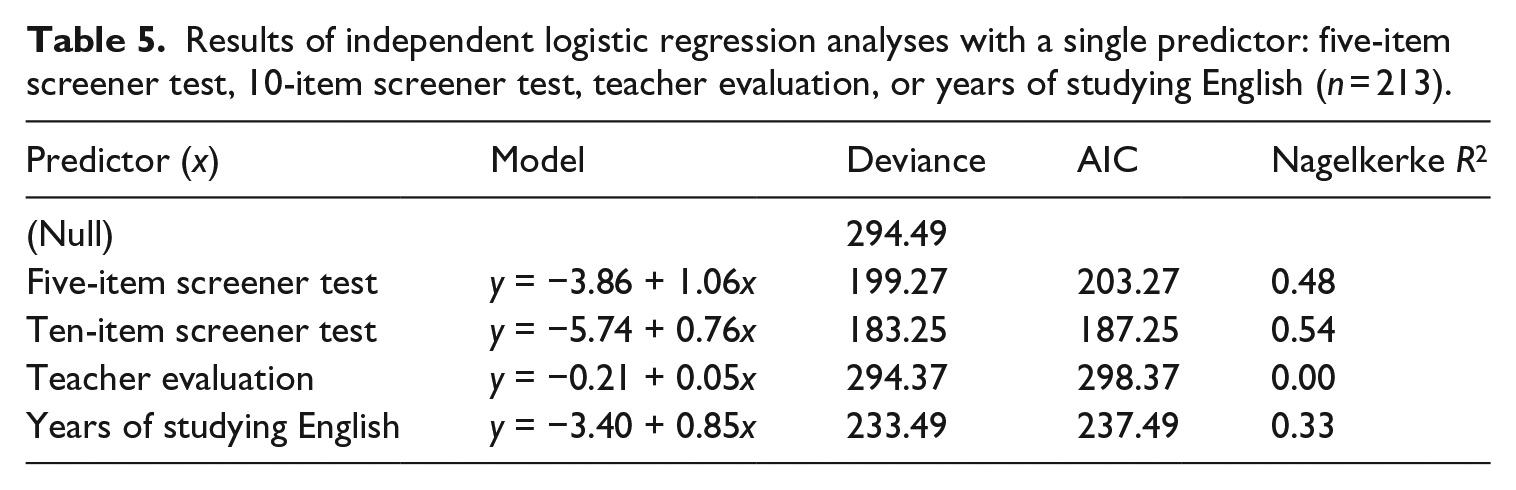
Among the models explored for this sample, the models in which five- and 10-item screener test scores predicted Step level minimized residual deviance and the information criteria function (AIC). The model with the 10-item screener test provided the best fit (AIC = 187.25), followed by the model with the five-item screener test (AIC = 203.27), the model with self-reported years of English study (AIC = 237.49), and the model based on teacher evaluation (AIC = 298.37).
The models with the five- and 10-item screener tests improved fit over the null model (Nagelkerke R2 = 0.48, 0.54) to a greater extent than the models with years of studying English (Nagelkerke R2 = 0.33) and teacher evaluation (Nagelkerke R2 = 0.00). This latter result suggested that under some conditions – for example, the conditions of this sample in which teachers were largely unfamiliar with TOEFL Primary tests – teacher judgment may operate at the level of chance.
Next, a series of models were specified to investigate the potential benefit of using more than one predictor to make decisions about a student’s Step level. The results are summarized in Table 6.
Results of a series of nested logistic regression analyses with multiple predictors: five- or 10-item screener test score, teacher evaluation, and years of studying English (n = 213).
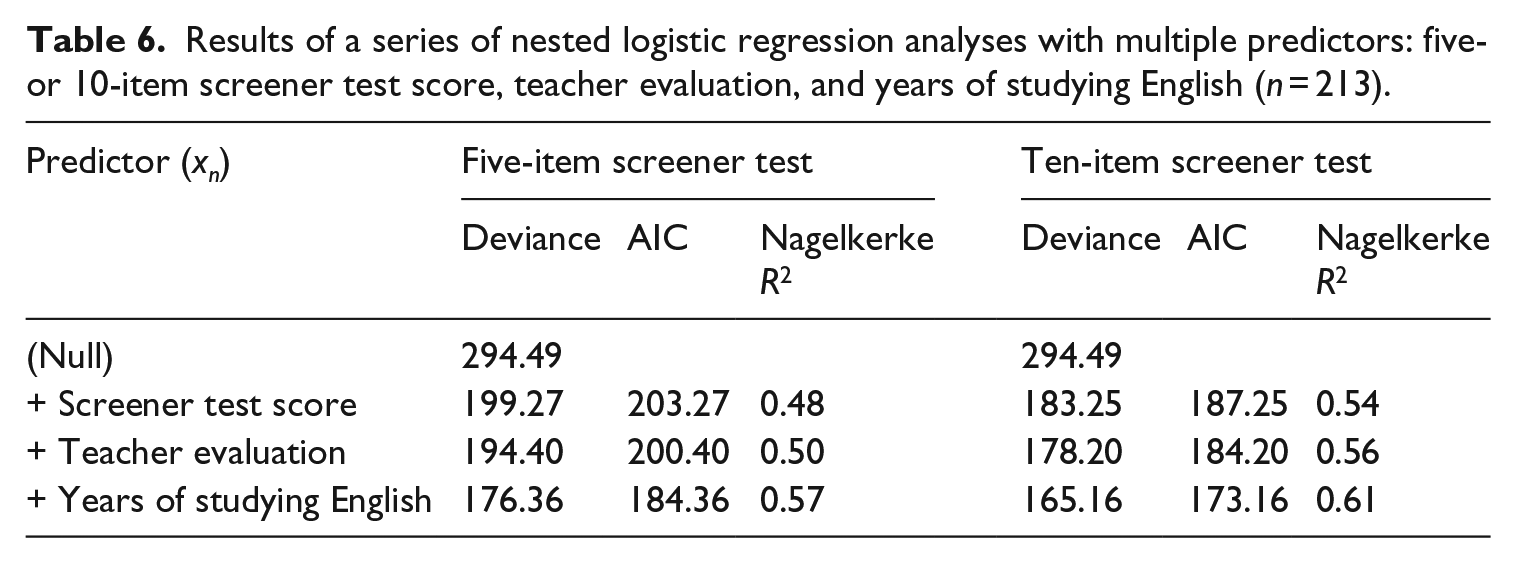
Each predictor in Table 6 that was added to expand the baseline model of either the five- or 10-item screener test helped reduce residual deviance and AIC, suggesting incrementally better model fit. Estimates of Nagelkerke R2 may be slightly overestimated owing to a lack of correction for shrinkage, but the increasing estimates also imply that model fit slightly improves with the addition of predictors and is consistently better for the model with the 10-item screener test. The addition of the predictor years of studying English appeared to have a more substantial impact than the predictor Teacher evaluation. However, the most substantial improvement in model fit occurred with the addition of screener test scores. Although years of studying English provided some complementary information to help improve model fit, the improvement was relatively modest.
Impact
Most teachers believed that they had the information they needed to make decisions about a student’s Step level, but still thought a screener test would be useful. As part of the survey, most teachers (17 of 22) indicated that the descriptive information they received was sufficient to help them make a decision about which Step level was appropriate for a student. Teachers were also asked whether a short test to help determine which Step level would be most appropriate for a student would be useful to them. Most teachers (19 of 21) subsequently indicated that a screener test would be useful to them.
Teachers were also given the opportunity to provide comments about why a screener test might (or might not) be useful. Among the eight teachers who provided comments, several (four of eight) believed that the screener’s ability to provide a quick estimate of a student’s Step level would be useful (e.g., “Helps me to understand the level of the learners well”). In addition, another teacher thought its use could benefit students directly, as “[i]t gives the students an overview of the test.” Another teacher that thought the test would be useful seemed to view the screener as a potentially useful option, rather than a vital tool: “Nothing special, but I think it’s better to have it than not have it.” Finally, a teacher who did not think that the screener test would be useful commented that “[t]he levels are generally clear from looking at the test.”
Practicality
Ease of administration
Most teachers (16 of 20) believed that the prototype screener test was easy to administer. Among the eight teachers who provided comments about its ease of administration, seven provided various explanations: instructions were clear, training was provided, the procedure itself was well-structured and clear, it was brief, and students were able to follow the instructions easily. One teacher who indicated that the prototype was not easy to administer commented that it took some time to collect all the tests, and that she “doubted the transparency/reliability of the test.”
When asked if it was important to have administration instructions administered in their native language, all of the teachers in Kenya said “no” (n = 5), whereas the rest of the teachers said “yes” (n = 17). This is consistent with how administration instructions were prepared for the field test; in other words, administration instructions were provided in English in Kenya (where teachers’ native language was Kikuyu), and in teachers’ native language in Brazil, China, and Japan. This preference may also reflect differences in the educational systems, as English has historically played a central role in academic curricula in Kenya (Michieka, 2005).
Ease of scoring
A strong majority of teachers (15 of 18, or 83%) believed that the prototype screener test was easy to score, based on a sample of five student tests that they were asked to score as an exercise. Five teachers provided additional comments on the scoring process, and included several reasons why the scoring process seemed easy (e.g., “Because the responses were all written in alphabet letters”).
Although the prototype screener test was paper based, a computer-based screener test would increase the ease of scoring by eliminating the need for teachers to score tests. A slight majority of teachers (13 of 22, or 59%) indicated that they would prefer for the screener test to be administered and scored by computer. Teacher preferences regarding computer administration were generally mixed within study locations, although the sample of teachers in China tended to prefer the idea of computer administration (eight of 10) and teachers in Kenya tended to prefer paper-based testing (four of five).
Brief
In order to minimize the administration time of the screener test, discrete item types were prioritized for inclusion on the prototype screener field test. Consequently, only discrete (non-passage-based, selected response) items are included in the five- and 10-item screener tests. Although the screener test is not timed, students are expected to complete each item within one minute. Thus, the five-item screener test could be expected to take 5 minutes to complete, and the 10-item test could be expected to take up to 10 minutes. Both of these tests would be substantially shorter than the TOEFL Primary Reading test, which is expected to take 30 minutes to complete. The full administration time for each screener test would slightly increase by a fixed amount in order to accommodate administration instructions.
Discussion
Table 7 summarizes the evidence for each claim, warrant, and quality specified in the evaluation framework for both the five- and 10-item screener tests.
Comparative evaluation of a five- and 10-item TOEFL Primary Reading screener test.
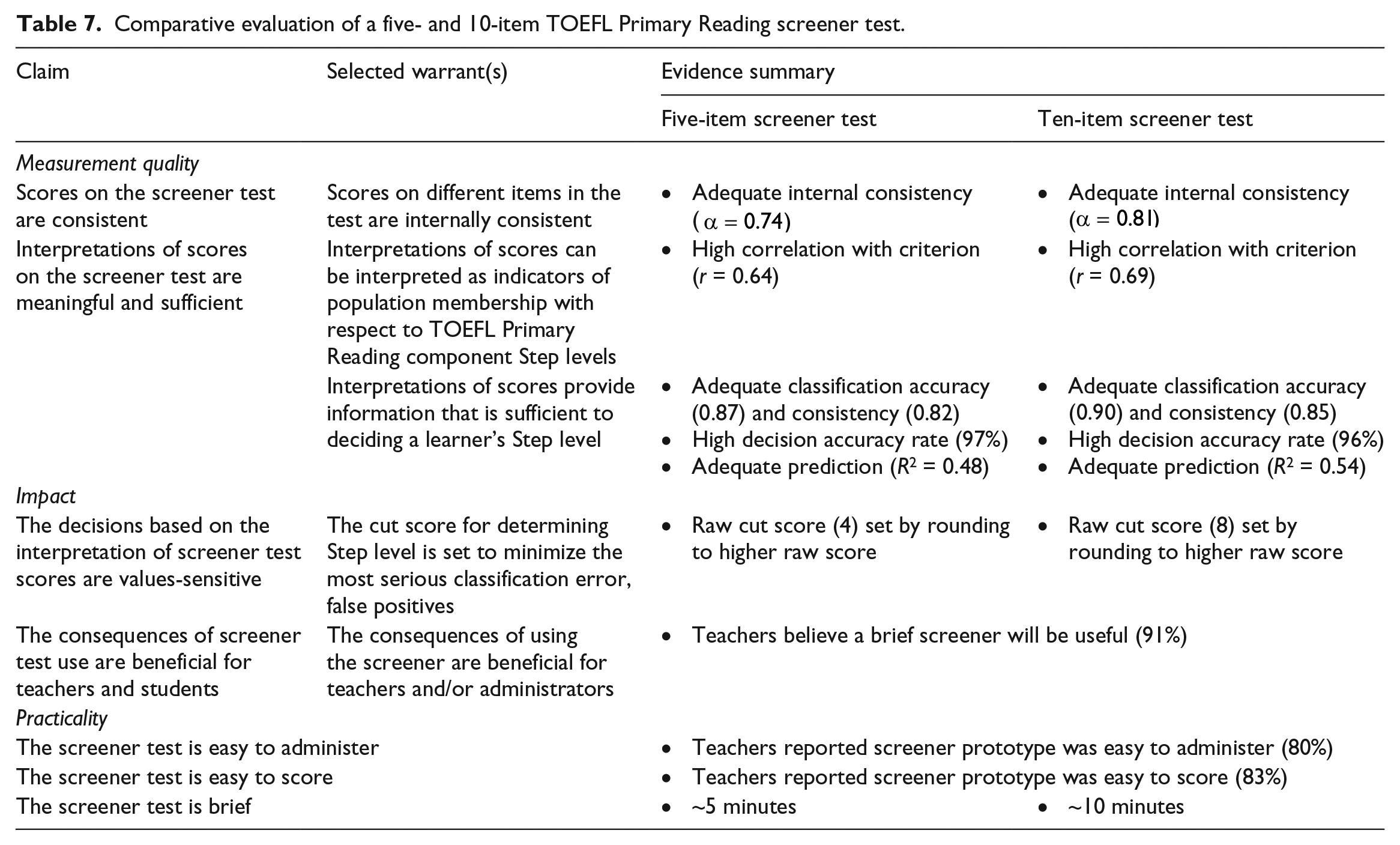
The most substantial differences in the evidential basis to support claims appear in warrants relating to the measurement quality of the tests: in most instances, claims about the 10-item screener are supported by slightly stronger evidence. The distinction between the two tests is more pronounced in evidence that relates more directly to the consistency of scores (internal consistency, classification accuracy and consistency). This is not necessarily a surprise, given that internal consistency is influenced by test length. Perhaps most surprisingly, the internal consistency of the relatively short five-item form (α = 0.74) is probably adequate for the lower-stakes use of the screener test.
Other evidence supporting claims about the measurement quality of the screener tests is similar in comparative magnitude, but provides positive support for both tests. The correlation with a criterion measure was relatively strong for both the five-item (r = 0.63) and 10-item (r = 0.69) tests. The criterion used in this study was TOEFL Primary Reading scaled scores, and their level of precision in ordering individuals in the population is intended to be much higher than that of the screener tests. In other words, the measurement range of the screener test is intended to be much more restricted. However, one may still expect to observe a moderate correlation between the two measures.
The warrant that screener test scores are sufficient to make decisions about Step levels was more comprehensively investigated, and produced evidence of high classification accuracy and consistency, high decision accuracy, and adequate prediction for both screener tests. The improvement in model fit for each screener test over the null model (i.e., Nagelkerke R2) was viewed as adequate, owing in part to its superiority over other potentially useful measures (e.g., teacher evaluation and student background variables).
With respect to claims about the impact of the test, the evidence produced by this study provides support for but does not clearly differentiate between the two tests. Both cut scores were set by rounding up from the cut point on the theta scale to the higher raw score equivalent, which was consistent with the values score users are expected to have: minimizing all decision errors, but false positives in particular given the preference to provide a “success experience” or more positive feedback. In addition, most teachers believed that the screener test would be a useful tool, providing initial evidence to support the warrant that the consequences of using the screener are beneficial for teachers and/or administrators.
The evidence that supports claims about the practicality of the test is also positive, but the nature of their design leads to different conclusions about their practicality. The 10-item test is twice as long, and would take more time to administer and score. Teachers indicated that the screener prototype was easy to administer and score, which provides some limited evidence to support the claim that the more abbreviated five- and 10-item tests would also be easy for teachers to administer and score. One way to reduce the difference in practicality between the five- and 10-item screener tests (and perhaps the practicality of the screener in general) would be to create a computer-based version; in school environments where this is an option, the burden of scoring the screener would be eliminated. Ultimately, the expected practicality of a computer-based version could be estimated by weighing the additional development cost against the expected benefit for stakeholders.
Given the difference in practicality between the five- and 10-item screener tests, differences between the two with respect to measurement quality and impact may not be substantial enough to favor the 10-item screener test. The evidence supporting claims and warrants for measurement quality and impact appeared to be adequate in most cases, and strong in several for the five-item screener test. The warrants articulated in this evaluation do not represent an exhaustive list, but strategically support claims that span the range of an assessment use argument. The warrant that score interpretations should be sufficient to support decisions about a student’s Step level classification was considered particularly critical, and the evidence supported that claim for the five-item screener test.
The finding that teacher evaluations were not a significant predictor of Step level classification based on the TOEFL Primary Reading test underscored the potential value of screener tests, although several features of the sample limit the findings of this study. First, the sample of teachers was relatively small (n = 22) and about half came from one of the four participating sites. In addition, most of the teachers who participated in this study had limited familiarity with the TOEFL Primary tests. Although most teachers believed that the descriptive information they were provided about Step levels was adequate for them to make decisions, their lack of familiarity with the tests may have contributed to their inability to provide accurate evaluations. As teachers become more familiar with the distinctions between the two Step levels, they may be able to play a role in mitigating the risk of decision errors by reviewing test results, and questioning those that are inconsistent with their expectations.
Conclusions
The definition of screener tests advocated in this paper places the focus of measurement on information about language ability that most efficiently identifies or distinguishes the target subpopulation(s). In most ways, our example provides a best-case scenario for this type of measurement: two clearly defined subpopulations (i.e., TOEFL Primary Reading Step 1 and Step 2) with pre-existing items that maximize information that distinguishes the subpopulations (i.e., an item bank with known parameters on a vertically equated scale). If more ambiguously defined subpopulations that can be operationalized in a variety of ways are targeted (e.g., multiple CEFR levels), or the characteristics of items or tasks that discriminate the subpopulations are not known in advance, the challenge of developing a screener test and producing convincing evidence to support its use would increase dramatically.
Specifying and insisting on a narrowly prescribed use for a screener test make it easier to justify this measurement approach. In developing the TOEFL Primary Reading screener test, we did not intend to make inferences about overall reading proficiency, just the likelihood of membership in a test subpopulation. In other words, higher scores are indicative of being more likely to be in the Step 2 subpopulation. The items that composed the screener tests almost certainly underrepresent a broader construct of language proficiency, including the construct of reading proficiency operationalized for the TOEFL Primary Reading Step 1 and Step 2 levels. This particular approach to measurement may narrow the scope of a language proficiency construct and needs to be explicitly aligned with an appropriate use.
The narrowly prescribed use of a screener test may help minimize its likelihood of misuse. In an assessment use argument, test developers are expected to anticipate potential negative consequences, and propose ways to mitigate their effects (Bachman & Palmer, 2010). In the case of the TOEFL Primary Reading screener test, scores can be interpreted as the likelihood of membership in the TOEFL Primary Step 1 or Step 2 Reading test populations, and their sole intended use is to facilitate a Step 1 or Step 2 classification. If stakeholders were to interpret screener test scores with respect to broader hypothetical populations – particularly those for which no single identifying measure is universally recognized (e.g., CEFR levels) – this would represent a substantial misuse of the test, and one not supported by the test developer. Given that some test users may be interested in an inexpensive, quick, and generalized estimate of ability with respect to a broad standard, developers of screener tests should be aware of the danger of this potential misuse and consider reporting scores and classification decisions accordingly. Quite simply, classification categories aligned with broader standards such as the CEFR may not only be more challenging to operationalize, but more likely to be misused.
Finally, our evaluation framework demonstrated how argument-based validation can potentially be used in a simplified but principled manner that explicitly recognizes important trade-offs between practicality, measurement quality, and impact. By highlighting key claims related to measurement quality, impact, and practicality, our study was able to prioritize a few initial research activities related to these claims and explicitly weigh the strength of a validation argument against practical concerns. Although researchers have discussed the trade-offs that may exist between practicality, measurement quality, and impact (e.g., Bachman & Palmer, 2010), the approach used in this study requires them to be explicitly stated and evaluated. In some test development projects, most practical constraints may be known from the outset and inform decisions that influence measurement quality and impact. For other projects, a pilot test may be designed with several possible test blueprints in mind. In our example, versions of the new test were differentiated based on the number of items because we viewed this as a key feature necessitating a trade-off between practicality, and measurement quality and impact. Thus, viewing practicality as a quality to be maximized rather than a threshold to be attained may benefit test development contexts – such as low-stakes screener tests – where these trade-offs need to be considered somewhat differently.
Footnotes
Appendix: Teacher/administrator background survey
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.