
Abstract
This study details the development of a local test designed to place university Spanish students (n = 719) into one of the four different course levels and to distinguish between traditional L2 learners and early bilinguals on the basis of their linguistic knowledge, regardless of the variety of Spanish they were exposed to. Early bilinguals include two groups—heritage learners (HLs), who were exposed to Spanish in their homes and communities growing up, and early L2 learners with extensive Spanish exposure, often through dual immersion education, who are increasingly enrolling in university Spanish courses and tend to pattern with HLs. Expert instructor judgment and learner corpora contributed to item development, and 12 of 15 written multiple-choice test items targeting early-acquired vocabulary had differential item functioning (DIF) according to the Mantel–Haenszel procedure, favoring HLs. Recursive partitioning revealed that vocabulary score correctly identified 597/603 (99%) of L2 learners as such, and the six HLs whose vocabulary scores incorrectly identified them as L2 learners were in the lowest placement groups. Vocabulary scores also correctly identified 100% of the early L2 learners in the sample (n = 7) as having a heritage profile. Implications for the local context and for placement testing in general are provided.
Introduction
Spanish is the most commonly taught language other than English in U.S. classrooms (Looney & Lusin, 2019), both to traditional second language (L2) learners and to heritage learners (HLs), (Carreira & Kagan, 2011) or those who were exposed to the language growing up, and who are underrepresented in assessment research. As dual language immersion programs become increasingly popular, a new, third group of speakers is emerging: L2 learners with extensive, early language exposure who pattern more like HL learners (Pascual y Cabo & Prada, 2022). Research indicates that these groups have differing pedagogical needs for both socioaffective and linguistic reasons (Bowles, 2022; Bowles et al., 2014; Carreira, 2022; Leeman & Serafini, 2016), necessitating appropriate placement testing.
This study details the development of a local university Spanish test designed to place students into one of the four different course levels and to distinguish between traditional L2 learners and early bilinguals (HLs and L2 learners with extensive early exposure) on the basis of their linguistic knowledge, regardless of the variety of Spanish they were exposed to. The test qualifies as a local language test (Dimova et al., 2020) since it emerged from a local need that could not be addressed by existing tests. It was the result of a bottom-up rather than a top-down process; and it was developed, field-tested, and analyzed relying on the local expertise of faculty, graduate students, and instructors in the program.
Background
The most recent report from the Modern Language Association (Looney & Lusin, 2019) indicates that in Fall 2016 at U.S. colleges and universities, there were 1.41 million students enrolled in foreign language courses, and of these, more than half (712,240) were enrolled in Spanish classes, compared to 705,598 students in all other languages combined. The report also indicates increased enrollment in several less commonly taught languages, but the popularity of Spanish likely has much to do with the large number of Spanish speakers in the United States.
According to the most recent American Community Survey data, 64.22 of 301.15 million total respondents, or 21.3% of the U.S. population, reported speaking a language other than English at home (U.S. Census Bureau, American Community Survey, 2017). Some 350 different languages were reported, but the overwhelming majority, 61.9% (39.77 million respondents) spoke Spanish, making it by far the most widely spoken non-English language in the country. In fact, it is very likely that the official Census numbers significantly underrepresent the true number of Spanish speakers in the United States with some estimating that the actual number is closer to 58 million speakers (Instituto Cervantes, 2017, p. 7).
Many Spanish speakers in the United States are immigrants who brought Spanish with them from their countries of origin, but the statistics also show that 53% of the Spanish speakers in the United States were born in the United States. Based on current trends, U.S. Census estimates project that the United States will be the most populous Spanish-speaking country by the year 2050, when it is believed that there will be more than 130 million Spanish speakers.
Given these demographic trends, it comes as little surprise that Spanish classes in the United States have long served the needs of two distinct groups of students: (1) traditional L2 learners, who typically begin learning Spanish through classroom instruction in middle or high school and (2) Spanish HLs, who were exposed to Spanish in their homes and communities growing up (Valdés et al., 1981). In this paper, Valdés’s (2001) definition of an HL is adopted, which is “an individual who is raised in a home where a non-English language is spoken . . . [who] may speak or merely understand the heritage language and be, to some degree, bilingual in English and the heritage language.” This definition is sometimes called a “narrow” definition of HLs because of its focus on linguistic knowledge. A “broad” definition, taken in some research, includes learners who were raised with a strong cultural connection to an ethnolinguistic group but were not exposed to the language itself and as such, are often “linguistically indistinguishable from traditional L2 learners (though their affective needs may differ)” (Beaudrie et al., 2014, p. 2).
HLs are notoriously heterogeneous and can range widely in terms of their ability in the heritage language, from receptive bilinguals who understand but do not produce Spanish to fluent productive bilinguals with an advanced level of proficiency in Spanish. Some HLs have access to print materials in Spanish and/or Spanish-language education materials and therefore are able to develop literacy skills, whereas others do not. Heritage language use is typically restricted to home and family settings, with the majority language (English) being used outside of those contexts. Most often, HLs receive most of their education in English, leading to a shift from heritage language dominance in early childhood to majority language dominance once they begin attending school (more often than not, in English). Because of the nature of their acquisition context, HLs tend to self-rate their listening abilities highest, followed by speaking, then reading and writing (e.g., Bowles & Montrul, 2014; Carreira & Kagan, 2011).
Given their distinct profiles, there is broad consensus that traditional L2 learners and HLs have different linguistic and socioaffective needs, making curricula designed for L2 learners largely inappropriate for HL learners (Carreira & Kagan, 2011; Oh & Au, 2005; Peyton et al., 2008). Excellent resources for teaching HLs exist, including at least a dozen textbooks from commercial publishers for Spanish HLs and a number of research-based books and edited volumes about appropriate curricular approaches and pedagogical techniques (Beaudrie et al., 2014; Beaudrie & Fairclough, 2012; Fairclough & Beaudrie, 2016; Kagan et al., 2017; Zapata & Lacorte, 2018), yet university course offerings are still limited. Beaudrie (2011, 2012) surveyed over 400 U.S. colleges and universities, finding that just 40% offered at least one course for HLs. Of these, 81% offered only one or two heritage-tailored courses and “programs with four or more courses [were] practically nonexistent” (Beaudrie, 2012, p. 210). The reasons for the limited course offerings are likely varied, but HLs’ needs are very much at the forefront of Spanish instructors’ minds. In a survey of more than 700 university Spanish instructors, Brown and Thompson (2018, p. 58) found that out of 55 different curricular issues addressed in the survey, HL placement ranked as 16th most important to instructors overall. And among issues related to HLs, the top issue that instructors ranked of greatest concern was “effective means of placing HLs,” with only 5% of instructors indicating that this issue did not apply to their program.
Now, a third group of learners is starting to enroll in university Spanish classes—those who lack family or cultural connections to Spanish but had the benefit of early, extensive exposure to Spanish through dual language immersion education. The traits of these programs and their students are reviewed next.
Dual language immersion programs
Dual language programs use two languages for literacy and content instruction for all students, regardless of whether their home language is English or the partner language. In the United States, these programs are most commonly available at the elementary school (K-5) level, although recently dual language programs have been expanding into middle and high school levels as well. Crucially, instruction is in the partner language at least 50% of the time, so that there is extended instruction in both languages over a period of years. Students develop high levels of proficiency in the four skills in both their first language and in the additional language, and neither native English speakers nor English learners (ELs) forego development in their native language as their proficiency in the additional language improves, unlike in many other models of bilingual education (Potowski, 2021). Academic performance is found to be at or above grade level for dual language learners as compared to their peers in English medium of instruction classrooms, and dual language learners also benefit from a high degree of cross-cultural competence. Indeed, in the largest study of its kind, Portland Public Schools tracked some 27,000 students over a period of 4 years who were randomly assigned to attend either dual language or regular English classes (Steele et al., 2017). Regardless of whether the partner language was Spanish, Japanese, or Chinese, results showed that the dual language learners outperformed their English medium of instruction peers in standardized assessments of English reading and scored statistically similar to their peers in mathematics and science. In addition, the dual language students demonstrated Intermediate level proficiency or better in the four skills in the partner language. Benefits were similar for both native speakers of English and native speakers of the partner languages.
According to a recent U.S. Department of Education report, 39 U.S. states and the District of Columbia reported offering dual language programs (Boyle et al., 2015). Although there were more than 30 different partner languages represented, the most commonly offered partner languages in these programs were Spanish (35 states) and Chinese (14 states) (Boyle et al., 2015, pp. 30–31). Because research has shown that dual language programs promote bilingualism, biliteracy, and global awareness for both native English speakers and ELs, an increasing number of schools have been adopting this model. In the 1980s, there were just 30 such programs in the United States (Lindholm, 1987), rising to about 260 in 2001, and by 2011, education researchers estimated that there were more than 2000 dual language programs in the United States (D. M. Wilson, 2011). The exact number of dual immersion programs in U.S. schools is unknown, but according to the Center for Applied Linguistics Dual Language Program Directory, there were 833 Spanish–English dual immersion programs at the time of writing, and because the database relies on voluntary self-reporting, this figure likely underestimates the true number of such programs (Center for Applied Linguistics, 2021).
It comes as no surprise that an increasing number of students who were enrolled in dual immersion programs enter university programs in the partner languages. Indeed, Spanish heritage language programs have begun reporting that they are encountering not just heritage speakers of Spanish who attended dual language programs but also a small but growing cadre of native English-speaking learners who attended dual language programs and thereby pattern more like HLs than like traditional L2 learners because of their early extensive exposure to Spanish (Pascual y Cabo & Prada, 2022). As time goes on and more and more students who have been educated in dual immersion programs enter higher education, we will continue to see these students in university courses and will need to place them appropriately based on their linguistic ability.
Existing Spanish placement tests
Commercial tests
Given the large number of students in the United States who enroll in university Spanish courses each year, there is a market for commercially produced assessments that can be used for placement purposes. Two such assessments, the Parisi Assessment System for Spanish (PASS) and the WebCAPE, are reviewed below. The PASS (Teschner, 1983) is a 140-item multiple-choice test that was not designed for placement but rather as a proficiency test “to sort HLs from other types of false beginners” (González Pino & Pino, 2000, p. 27). Because the test was not designed with placement in mind, it lacks links to curricula and was only intended for learners at low proficiency levels, limiting its utility. The lack of documentation on its item development process and item quality has also been critiqued (MacGregor-Mendoza, 2011). The second commercially available test, the WebCAPE (Perpetual Technology Group), is the most widely used placement test in the United States, available in not just Spanish but also French, German, Russian, English as a Second Language (ESL), Italian, and Chinese, and it has been adopted by more than 600 universities. It is a computer-adaptive, multiple-choice test designed to place students into the first 2 years of college language. There is little information publicly available about the test development process or test validation, and apart from being able to set their own cut scores, universities that adopt the test have essentially no control over any other aspect of the assessment. To date, there is relatively little published research on the WebCAPE, but Turner (2017) suggested that although the Spanish version of the WebCAPE can appropriately place learners at the basic level, it is not effective at placing students across the full range of proficiency levels it purports to measure. In addition, the WebCAPE was designed strictly to place traditional L2 learners, so it is not suited for assessing HL learners or others with significant early exposure to Spanish.
Local placement tests
Because the commercial tests are not well suited to meet universities’ needs, many Spanish programs have developed local placement tests to meet the needs of their student populations. Many institutions have relied on a combination of background questionnaires (to determine whether students fall into the traditional L2 category or not) followed by one-on-one interviews with students to determine what course level would be most appropriate for them. Predictably, this is not an ideal solution because it is both time-consuming and the reliability of the interviews, which tend to be informal, can be questioned (Potowski et al., 2012). Additionally, as the number of heritage speakers of Spanish seeking to enroll in Spanish courses increases, the feasibility of such an approach wanes. Indeed, over the years as the number of heritage speakers has increased across the country, so has the need to create valid, reliable placement tests. To date, three such locally developed Spanish placement tests have been described in the literature, and these are reviewed below.
Fairclough (2011) describes the creation of a lexical decision task based on the 5,000 most frequent words in Spanish that sought to distinguish between traditional L2 and HL learners. Her results showed that although the test was quick and easy to administer and score, it was effective only for lower proficiency HL learners; more proficient HL learners scored at or near ceiling, limiting its efficacy.
Whereas Fairclough (2011) relied on word frequency based on Spanish-language corpora to create her test, the two other locally developed Spanish placement tests that have been designed with the needs of heritage speakers in mind (Potowski et al., 2012; D. V. Wilson, 2012) tailored their test items to the variety of Spanish spoken by the population of speakers in their area. Specifically, Potowski et al. (2012) created a written, multiple-choice test to distinguish between traditional L2 learners and HL learners and to place them into one of the four different course levels. Results showed that the items that discriminated well between the two learner groups were focused on a mix of dialect-neutral and colloquial Mexican Spanish vocabulary and expressions. Because Mexican Spanish speakers are the predominant Spanish-speaking group in Chicago, where the study was conducted and where most of the university’s students were raised, it was highly likely that even speakers from other Spanish-speaking backgrounds would have been exposed to Mexican lexical items, making them suitable for the local environment.
In New Mexico, D. V. Wilson (2012) created another locally developed Spanish placement test to meet the specific needs of his population of heritage speakers, who, unlike those in Potowski et al. (2012), tend to be less proficient in Spanish, with many having receptive but very limited productive ability in Spanish. His written, multiple-choice test, therefore, was designed to measure learners’ receptive knowledge of Spanish and included regional lexicon specific to New Mexican Spanish. Linguists typically categorize New Mexican Spanish into two distinct varieties, following the seminal work by Bills and Vigil (2008). The variety spoken in southern New Mexico, which Bills and Vigil (2008) referred to as “Border Spanish,” is heavily influenced by and similar to Spanish spoken in the northern part of Mexico. The variety spoken in northern New Mexico and southern Colorado, on the other hand, which Bills and Vigil (2008) referred to as “Traditional Northern New Mexican Spanish,” is the “oldest continually transmitted variety of Spanish in the United States.” (D. V. Wilson, 2015, pp. 1–2). In northern New Mexico, Spanish has been spoken since the 16th century, when Spanish colonizers established their first settlements there. Distant from other Spanish speech communities, during the colonial period, the variety was largely isolated and then, with the arrival of English-speaking settlers in the 1840s, it came into extensive contact with English. This combination of geographic isolation followed by over a century of prolonged contact with English has made the variety a unique linguistic isolate. Therefore, lexical items in this variety of Spanish often differ substantially from other varieties and would likely be unknown to heritage speakers from outside the region.
It is clear from these descriptions of locally developed Spanish placement tests that their in-house development has enabled them to be tailor-made for the particular needs of their student populations, as a local test should be. The tests are clearly not interchangeable, such that D. V. Wilson’s (2011) test would not be an appropriate measure of learners’ abilities in Potowski et al.’s (2012) context, nor would the reverse work. In this light, I now turn to describing the local context in which the current study was conducted.
Local context
In the large public U.S. university where this research was conducted, general education requirements specify that all students must take either three or four semesters of foreign language courses, depending on their major. Students who believe they have sufficient language knowledge may also fulfill this requirement by achieving a set score on the Advanced Placement Spanish Language or Literature exam, the International Baccalaureate (IB) exam, or by testing out of the requirement with a high score on a departmental exam. Additionally, students who have earned the Seal of Biliteracy are awarded credit for the first two semesters of Spanish-language study.
There is institutional pressure for undergraduate courses to enroll at least 15 students per section, with courses in the required three- or four-semester Spanish-language sequence capped at 19. Only in exceptional circumstances are sections with fewer than 10 students allowed to be offered; in practice, sections with fewer than 10 students are flagged and canceled outside the purview of the department. Until 2009, the university offered a two-semester sequence designed for Spanish HLs that would allow them to complete the language requirement at an accelerated pace due to their prior knowledge. These courses were consistently underenrolled, and a needs analysis, consisting of surveys and focus groups of Spanish HLs, determined that these courses were not meeting their needs (Bowles & Montrul, 2014). As a result, the two-course sequence was discontinued in 2009, and a heritage-tailored fifth-semester Spanish course focused on reading and writing was created. Since that time, the new course has been offered every semester and has had healthy enrollments.
In the local context, the Spanish placement test therefore needs to be able to place students into one of the following four levels: the combined first/second-semester course, the third-semester course, the fourth-semester course, or the fifth-semester course, which is the only course that offers separate sections and curricula for traditional L2 learners and HL learners.
The population of Spanish heritage speakers at this university predominantly consists of second-generation speakers (most often born in the United States to two Spanish-speaking parents), who themselves immigrated from a Spanish-speaking country. Overall, 65% of Spanish heritage speakers at the institution report having at least one Mexican parent, reflecting the large proportion of Spanish speakers who are from a Mexican background nationwide. However, the remaining 35% of speakers come from a variety of Latin American backgrounds, with an occasional student of Peninsular Spanish heritage. We tend to have a higher proportion of sequential than simultaneous bilinguals who tend to have been Spanish-dominant in early childhood and who have gradually become English-dominant since attending school (which for most was an English medium-of-instruction program rather than a dual immersion program). Although a variety of factors affect each individual student’s proficiency in Spanish, such as their birth order and whether they lived with extended family members growing up, most heritage speaker learners at our university have productive ability in Spanish at or above the intermediate level on the ACTFL scale (Bowles & Montrul, 2014). They tend to have received a limited amount of formal instruction in Spanish (most commonly, a couple of years in high school Spanish courses that may or may not have been tailored to heritage speakers). When asked to self-rate their abilities, as with most heritage speaker populations around the world, they tend to rate listening and speaking higher than reading and writing. This pattern has been consistent at least over the past decade since these characteristics match those described in Bowles and Montrul (2014) at the same institution.
Based on these demographic traits in the local context, it is clear that a test for receptive bilinguals is not warranted and that the items in Fairclough’s (2011) lexical decision test would be too basic for most examinees. D. V. Wilson’s (2012) test hinges on receptive abilities in New Mexican Spanish, which our students would most likely never have been exposed to. Potowski et al.’s (2012) test comes closest to being suitable, but the items that discriminated between traditional L2 learners and HL learners hinged on knowledge of colloquial Mexican vocabulary. The authors state that they “sought to ensure that the items ultimately selected . . . were not highly limited to Mexican Spanish; otherwise they would not be valid for speakers of other Spanish dialects” (p. 61). However, it is not clear from their results whether they examined the variety of Spanish that their heritage speakers had been exposed to in order to determine whether the items were effective for all varieties represented in their sample. Although 65% of our HL learners have at least one Mexican parent and have therefore likely been exposed to some amount of colloquial Mexican Spanish, we wanted to see whether we could create a test that could distinguish between traditional L2 learners and heritage speakers without relying on vocabulary from a particular variety of Spanish. It would therefore be suitable regardless of the variety of Spanish a heritage speaker had been exposed to. Additionally, we wanted our test to be able to identify the small but growing number of students who do not fit the profile of a heritage speaker because they do not come from Spanish-speaking families but gained significant early exposure to Spanish through dual immersion education.
Test development
There was strong institutional pressure to develop a machine-scored test due to the large number of examinees requiring placement each semester. The result was a four-section, multiple-choice test; the test specifications for which were drafted and iteratively revised by the author with the assistance of a PhD student, who was an experienced instructor of Spanish and had taken graduate courses in language assessment. Draft passages and items were also reviewed and iteratively revised by the coordinators of the different course levels and experienced graduate student teaching assistants (TAs) teaching at those levels. Specifically, the course coordinators were full-time Spanish instructors in our program with master’s degrees and more than 10 years of experience teaching both L2 and HLs of Spanish. Because they both design and provide daily oversight for those courses, they were considered content experts who knew what could be expected of students at each level. In our program, the required course sequence is taught largely by course coordinators and graduate TAs, rather than adjuncts or lecturers; so TAs who had been teaching in the program for 2 years or more were currently teaching one or more of the courses in the required sequence and were chosen for content review as well. Some TAs had a background in linguistics whereas others had a background in literature, as is typical in most university language departments. This process ensured that the passages and items were level-appropriate and was essential for curriculum-test congruence.
The four sections of the test were error identification, multiple-choice cloze, reading comprehension, and early-acquired vocabulary. The first three sections were linked to curricular goals at the four different course levels, whereas the last section was designed to differentiate between traditional L2 learners and early bilinguals based on their linguistic knowledge. Each section is briefly described below.
Error identification items consisted of one to two short sentences (no more than 25 words in total). Three words were underlined in each item, corresponding to three possible options, and a fourth option (no error) was given for each as well. Underlined words were chosen from among those taught in the course sequence, and errors had to do with spelling and accentuation taught in those levels. For instance, accentuation errors included interrogative wh-words, regular first- and third-person preterite verb endings, and imperfect verb endings in any person. Two sample error identification items are provided below: Juan me * A B C D
In this example, the key is A because written without an accent (invito) is a first-person singular present tense verb (I invite), and in the past tense context of the sentence, it is clear that it needs to be a third-person singular past tense verb form (written with an accent, invitó). This common pattern with regular verbs is expected to be learned in the second course in the sequence.
A second example of an error correction item targeting accent placement in interrogative wh-words and high-frequency verbs, such as estar (to be), and nouns used in the textbook appears below. This item covers the material found early in the first course in the sequence: ¿Dónde *esta la librería? (no errors) A B C D
Multiple-choice cloze items similarly consisted of one to two short sentences, with no more than 25 words in total. One to four words were deleted and replaced with a blank, and examinees had four options from which to choose the correct completion. Individual lexical items, collocations taught as a unit (e.g., tener ganas de “to feel like”), and nominal and verbal inflectional/derivational morphology taught in the course sequence were targeted in this section.
Two sample cloze items are included below: Todos los fines de semana _______ la guitarra con mis amigos. a. tomo *b. toco c. jugo d. juego
In this example, examinees must determine the correct lexical item to complete the sentence, as both tocar and jugar translate as “to play” in English. Tocar is used in the sense of “play an instrument,” whereas jugar is used in the sense of “play a sport or game.” Examinees then had to choose the correct present tense conjugation, and all of this content is expected to be mastered in the first course in the sequence.
Targeting material covered in the fourth course in the sequence is the following cloze item: Imagina que ganas la lotería. ¿Qué _______ con ese dinero? a. habrías b. hiciste *c. harías d. hacerías
In this case, students must decide which verb is appropriate for the context and then conjugate it correctly in the conditional (which for this verb involves a stem change).
Reading comprehension passages consisted of short, informational texts of 250–600 words in length. They were all authentic texts (taken from Spanish-language media) and any editing consisted of shortening the texts to fit the format rather than simplifying sentence structure or vocabulary. Each test form contained a passage at the first/second-semester level, one at the third-semester level, and one at the fourth-semester level, as judged not only by the test developers but also verified by instructors and language coordinators of those courses. All reading comprehension items were presented in English to ensure that examinees were being tested exclusively on their comprehension of the text and not on their ability to understand the items. There were five different possible item types: main idea, facts/details, inference, vocabulary in context, and applying information to other situations. Each passage contained a mix of the different item types. Main idea items measured examinees’ ability to identify the main idea, which was either stated explicitly in the text or could be inferred on the basis of the text as a whole. Main idea items required examinees to identify the statement that captured the main idea or to assign a title to the passage that summarized the main idea. Facts/details items measured examinees’ ability to understand facts and details in a passage that were used to build an argument or to support a main idea. Inference items required examinees to infer things not explicitly stated in the text. They were intended to measure examinees’ ability to understand the implications of sets of facts and details and required examinees to go beyond literal meaning. Vocabulary in context items measured examinees’ ability to determine the meaning of a word or phrase in its context within a text. Vocabulary in context items reproduced a short, relevant portion of the text, with a target word that examinees were unlikely to know underlined. They then had to choose the appropriate equivalent from among four English words or phrases. Finally, applying information to other situations items measured examinees’ ability to draw conclusions based on the information presented in the text. Examples included items requiring examinees to recognize a statement that was consistent with (but not stated in) the text or items requiring them to make decisions based on the ideas presented in the text.
The vocabulary section of the test was the most innovative, and the one designed to discern if an examinee’s linguistic knowledge was consistent with that of a traditional L2 learner who had learned Spanish in middle or high school or an early bilingual (either a heritage speaker or a dual immersion L2 learner of Spanish). High-frequency words might seem at first blush to be a good starting point since early bilinguals are likely to know common, high-frequency vocabulary. However, classroom L2 learners are also exposed to many common, high-frequency vocabulary in L2 textbooks and curricula, so not just any such word is suitable. Therefore, we narrowed our focus to early-acquired vocabulary words in Spanish that have been shown to have an age of acquisition (AoA) of 7 years or less (Łuniewska et al., 2016 1 ). Then, because we wanted to design our items not to favor any particular variety of Spanish, but to be appropriate for speakers coming from any colloquial Spanish background, we removed from consideration any word for which there is lexical variation based on the variety of Spanish. For instance, “banana” can be commonly referred to as banana, plátano, guineo, and cambur, depending on the variety of Spanish, so although it has an early AoA, it would not be a suitable item for our purposes. We also eliminated English cognates (e.g., pizza, helicóptero, teléfono) and early-acquired vocabulary common in L2 textbooks (e.g., flor “flower” and avión “airplane”) and relied on the expert judgments of the experienced instructors and language coordinators to choose words that they believed would be known to early bilingual learners but not to traditional L2 learners. These criteria resulted in 56 possible target vocabulary items being selected from Łuniewska et al.’s (2016) list of 299 words. As a final check, we then searched two Spanish L2 learner corpora, one oral (Spanish Language Learner Oral Corpus, SPLLOC, http://www.splloc.soton.ac.uk/, which uses the CHILDES interface, MacWhinney, 2000) and one written (Corpus Escrito del Español como L2, CEDEL2, http://cedel2.learnercorpora.com/, Lozano, 2009; Lozano & Mendikoetxea, 2013), for the 56 words. If we found even a single occurrence of the word in either of the corpora at any proficiency level, we discarded it. This process resulted in 24 of the 56 words being discarded since some words that instructors believed their students in the course sequence would not know did appear in one or both corpora (e.g., columpio “swing set,” tejer “to knit,” chaleco “vest”). Even though in many cases a word appeared in only one or two learners’ data in the corpora and even when the learners’ proficiency was listed as being above that expected of a student in our course sequence, we took a conservative position of eliminating these words from consideration. There were, therefore, a total of 32 words from the original list that met all of our criteria. From those, we pared down the list to 15 early-acquired words that the traditional L2 examinee population who are taking our placement test would likely not know but would be amenable to item writing (e.g., pellizcar “to pinch,” nido “nest,” ordeñar “to milk,” guiñar “to wink”). We then wrote 15 cloze items, each targeting one such word, as shown in the sample items below. For the complete list of 15 words targeted in the test, see Table 2.
Mi vecina va de vacaciones y tengo que __________ sus plantas y alimentar a su gato. a. batir b. *regar c. remard. d. fregar Los pájaros ponen sus huevos en __________. a. un nicho b. un bicho c. *un nido d. un pitido Los perros muerden y los mosquitos _________. a. rascan b. *pican c. pegan d. raspan
Two comparable test forms were assembled such that two items (one for each form) were developed for each feature being targeted. For instance, two cloze items were written targeting lexical choice between the verbs tocar and jugar, and one was placed in Form A and one in Form B. Each form contained 87 total items (24 error identification, 24 multiple-choice cloze, 24 reading comprehension, and 15 early-acquired vocabulary). The first three sections were designed to assess learners’ knowledge of the content taught in the curriculum, whereas the last section was designed to distinguish between traditional L2 learners and early bilinguals. The assembled test forms were once again reviewed in their entirety by instructors at the course levels being targeted and revised one last time.
On the basis of these needs, this study sought to answer the following research questions:
Can a written, multiple-choice placement test identify traditional L2 learners and HL learners based on their Spanish knowledge, regardless of what variety of Spanish they were exposed to?
Can the placement test also identify the small number of L2 learners who, because of dual language immersion education or other extensive early Spanish exposure, have linguistic knowledge more akin to an HL learner without the family background?
Method
Differential Item Functioning
In high-stakes testing, differential item functioning (DIF) is commonly used to determine whether items on a test favor or disfavor members of a subgroup (e.g., by gender or race/ethnicity), and DIF is an important component of analyses of test bias/test fairness. Among high-stakes language proficiency tests, DIF has been profitably used to examine such issues as whether test items favor speakers from a particular first language group or country of origin (Aryadoust et al., 2011; Ryan & Bachman, 1992; Young et al., 2013). In this context, DIF analyses are performed as a component of the bias review process, and items that are flagged as DIF either benefit or disadvantage a particular subgroup(s) and are therefore eliminated from the assessment.
DIF is far less common in low-stakes language assessment contexts, such as placement testing. Nevertheless, DIF is well suited to the task at hand in the current placement test since “DIF studies are directed to identifying test items that elicit different kinds of response from subgroups within the test population” (Elder, 1996, p. 236). Indeed, one prior study (Elder, 1996) used DIF with learner type (heritage vs L2) as the grouping variable. In this study, the concept of DIF is essentially turned on its head in the sense that we wanted to develop items that would show DIF based on learner background—the opposite of what is usually done in large-scale testing.
There are many different statistical methods that can be used to calculate DIF, each with strengths and weaknesses. Because our focal group of HLs had an n size of less than 200, the Mantel–Haenszel (MH) method, a classic DIF technique, was selected because it is effective with small sample sizes, unlike IRT-based methods, which in addition to requiring large n sizes, also tend to be less straightforward to interpret (Zumbo et al., 2015). The MH method is an extension of the chi-square test for contingency tables and it sorts students into groups based on their total test scores. DIF is not detected in an item if the odds of answering the item correctly (at a given total score level) are about the same for the focal and reference group.
The early-acquired vocabulary items in this study were designed to favor HLs of Spanish, based on the idea that by virtue of their early acquisition context, they should have better knowledge of early-acquired words than traditional L2 learners in the first few semesters of university language study. That is, the expectation is that the vocabulary items should show DIF in favor of HL learners.
Participants
All participants enrolled in first- through fifth-semester Spanish courses were invited to participate in the field test and received extra credit in exchange for their participation. Field test examinees were 719 learners drawn from four course levels (317 males and 402 females, ranging in age from 18 to 27 years, with a mean of 20.4). Reflecting the nature of the learner populations in our courses, the examinees were diverse in terms of their race/ethnicity, first language, and prior formal and informal exposure to Spanish.
Field testing process
Field testing was conducted in person in a large university classroom on several different dates near the end of the semester to accommodate a range of student schedules. After signing a consent form, participants completed a background questionnaire that inquired about their formal and informal language exposure and language learning. Immediately after completing the background questionnaire, participants were randomly assigned either Form A or Form B of the placement test. They marked their answers on a Scantron sheet and were given up to 90 minutes to complete the test while being proctored to ensure that they relied only on their own knowledge to answer.
On the basis of classical item analysis, 15 poorly performing items (those with the discrimination values of less than 0.2 and difficulty values less than 0.4 or above 0.8) were removed from each form, resulting in the operational forms of each test having 72 items (57 items distributed across sections one through three and the in-tact 15-item vocabulary section). Cronbach’s alpha coefficient of Form A was .899 and for Form B it was .923. Scores were reported out of the total of 57, with the score on the vocabulary section intended to be used as a supplement to assign a learner profile (traditional L2 or early bilingual) since it was not linked to the curriculum. The score distribution provided in Table 1 reveals that although there were both types of learners in all score bands, HLs on average scored significantly higher than L2 learners (p < .001, d = .41). Because the focus of this study is the ability of the vocabulary section to discriminate between traditional L2 learners and early bilinguals, the process of setting cut scores for the different course levels is not further detailed here due to space constraints.
Score distribution on placement test (k = 57) by language background.
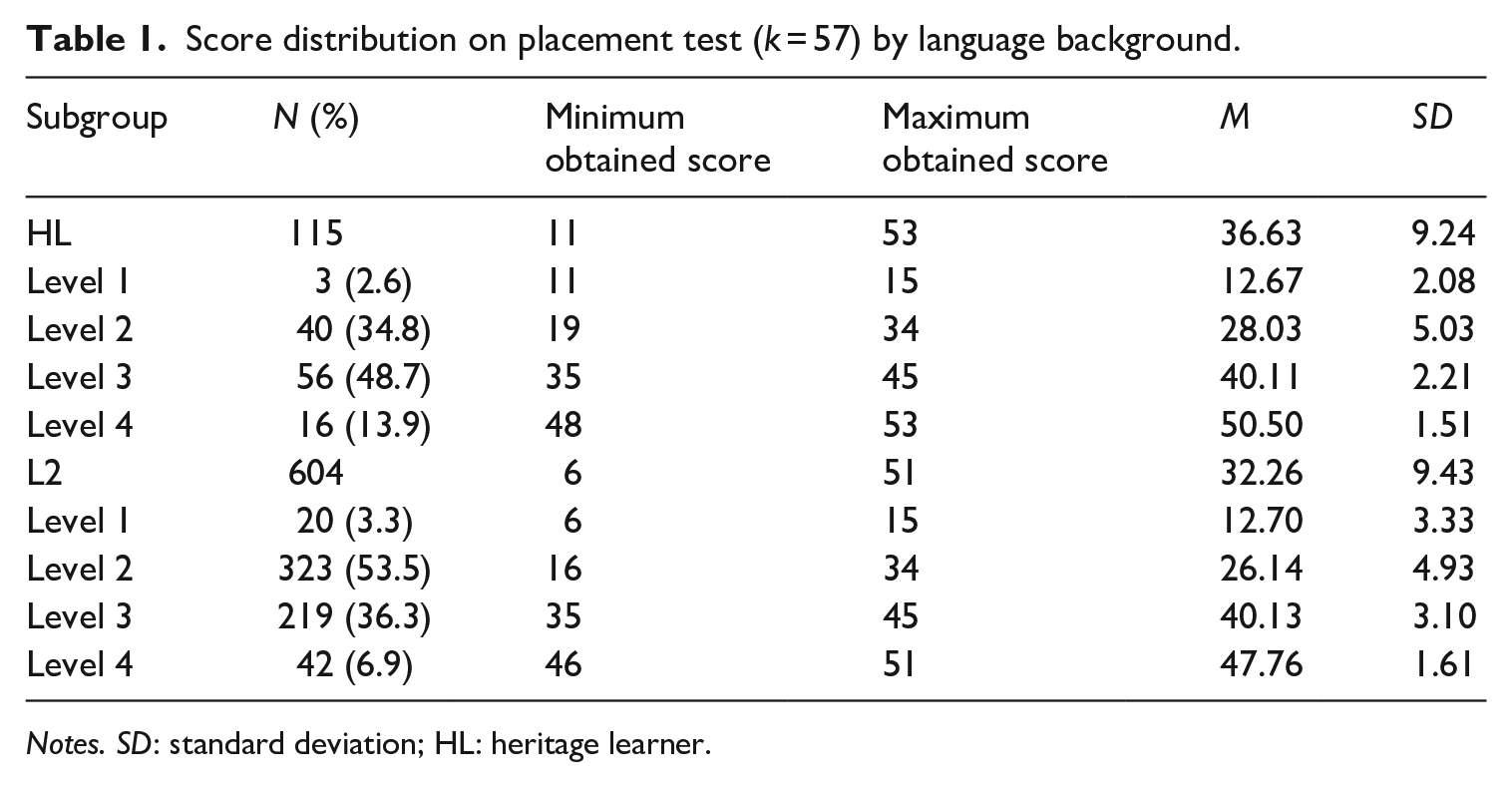
Notes. SD: standard deviation; HL: heritage learner.
Results
DIF results
DIF analyses were run on each entire test form using the difR package in R (Magis et al., 2010), with traditional L2 learners (n = 604) as the reference group and HLs (n = 115) as the focal group. The package contains many different methods for calculating DIF, and the Mantel–Haenszel method (difMH) was chosen because it is accurate even with small focal groups. Because MH involves multiple comparisons being made, the Benjamini–Hochberg p-value correction was applied to maximize the power while simultaneously limiting the false identification of DIF items (Kim & Oshima, 2013).
DIF results of the 15 early-acquired vocabulary items are shown in Table 2. In addition to the χ2 statistic and the adjusted p-value, results also include αMH and ΔMH values commonly reported in DIF studies. A negative ΔMH value indicates that the focal group’s (HL) odds of responding correctly to a given item are less than the reference group’s (L2) odds (in other words, the item was more difficult for HLs than for L2s), whereas a value of zero indicates an item was of equal difficulty for both groups, and a positive value indicates the item was more difficult for L2s than HLs. The final column in the table shows the DIF effect size following the Educational Testing Service classification system (Zwick & Ercikan, 1989) and Elder (1996). Negligible DIF (A) occurs when either ΔMH is not statistically different from zero or when the absolute value is less than 1. Intermediate DIF items (B) have ΔMH values between 1 and 1.5, and large DIF items (C) have ΔMH values above 1.5 and statistically larger than 1.0 in absolute value.
DIF statistics for early-acquired vocabulary items.
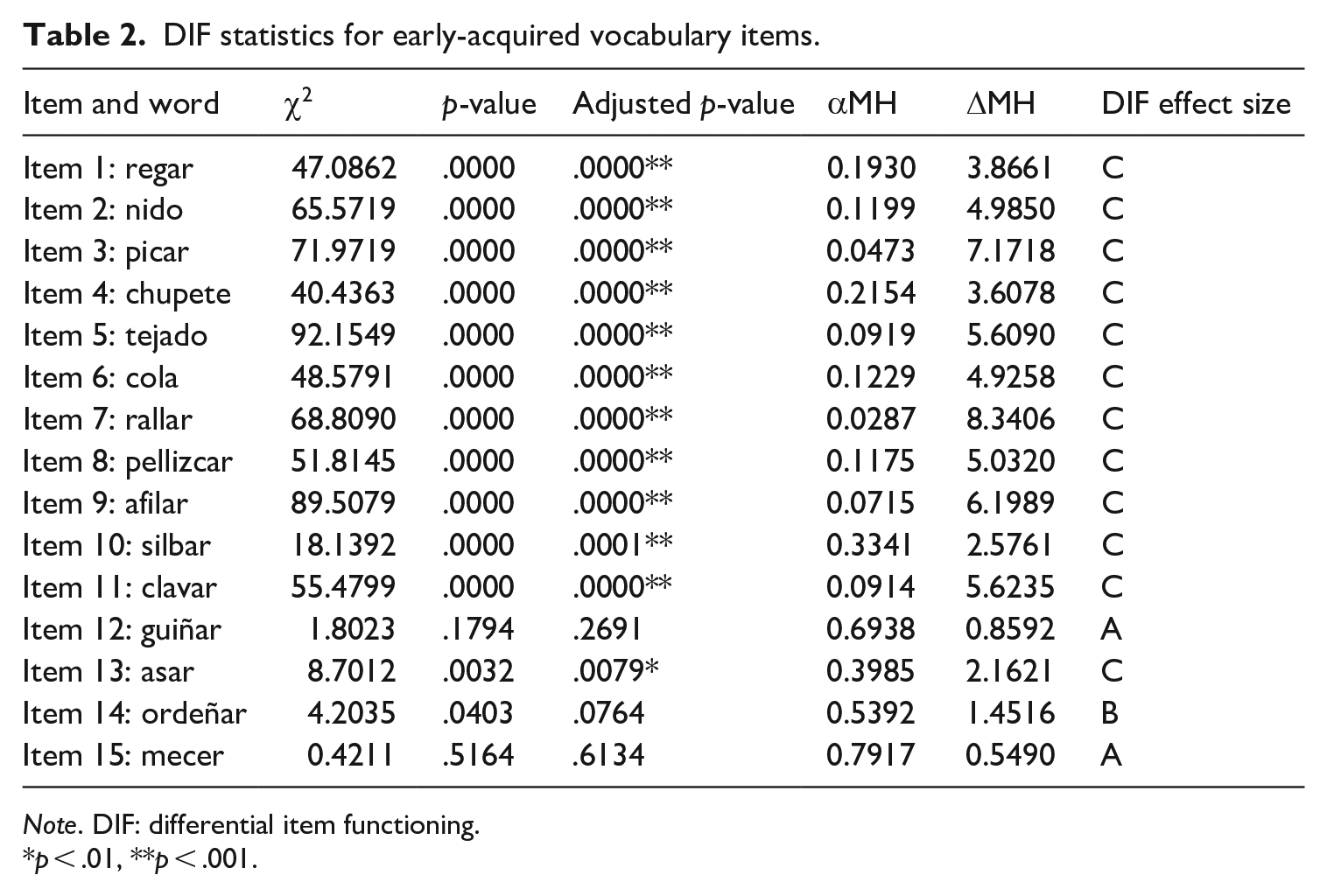
Note. DIF: differential item functioning.
p < .01, **p < .001.
As Table 2 shows, 12 of the 15 items in the early-acquired words section showed large DIF in the expected direction, favoring HLs. The remaining three items in that section also leaned toward favoring HLs but did not reach statistical significance and therefore were not classified as DIF items.
One other item, Item 63 on Form B of the test, also revealed DIF, also with a large effect size (αMH = 4.7040, ΔMH = −3.6388, χ2 = 8.1868, p = .0042, adjusted p = .0276). This particular item in the reading comprehension section was significantly more difficult for the HL learners than for the L2 learners; in other words, it favored L2 learners. Across all total score bands, 57.1% of L2 learners responded correctly, indicating that the passage included only factual information, whereas 41.2% of HL learners responded correctly. For both groups, the most popular distractor was, “an equal balance of facts and the author’s opinion” but 47.1% of HL learners chose this incorrect option, compared to 27% of L2 learners. Apart from the fact that L2 learners may have had more experience reading in Spanish than their HL counterparts, there is nothing about the item characteristics that the item developers believe would have caused this differential performance. And since no other reading comprehension items showed DIF, they reasoned it was unlikely that overall reading ability in Spanish caused this difference. No other items on either form of the test showed DIF.
Classification ability of early-acquired vocabulary items
With the DIF analysis complete, further analysis of the scores on the early-acquired vocabulary section was conducted. Descriptive statistics on that section (overall and by placement level), are shown in Table 3. Recursive partitioning was conducted using the rpart package in R (Therneau & Atkinson, 2019) to determine how accurately the early-acquired vocabulary score could predict learner background. It correctly identified that 597 of 603 examinees (99%) who scored less than 3.5 on the vocabulary section were L2 learners (based on their background questionnaire data). Just 6 of 603 (0.009%) were incorrectly classified as L2 learners by their score when in fact they had grown up in a Spanish-speaking home. A closer examination of these six learners revealed that they scored low on the placement test (M = 19.67, SD = 6.15), with three placed into the Level 1 course and three scoring just above the cut score to be placed into the Level 2 course. This suggests that the early-acquired vocabulary section does not discriminate very well for the lowest proficiency HLs in our sample, of which we have very few, but it is effective for the majority of our population.
Score distribution on early-acquired vocabulary showing DIF (k = 12) by language background.
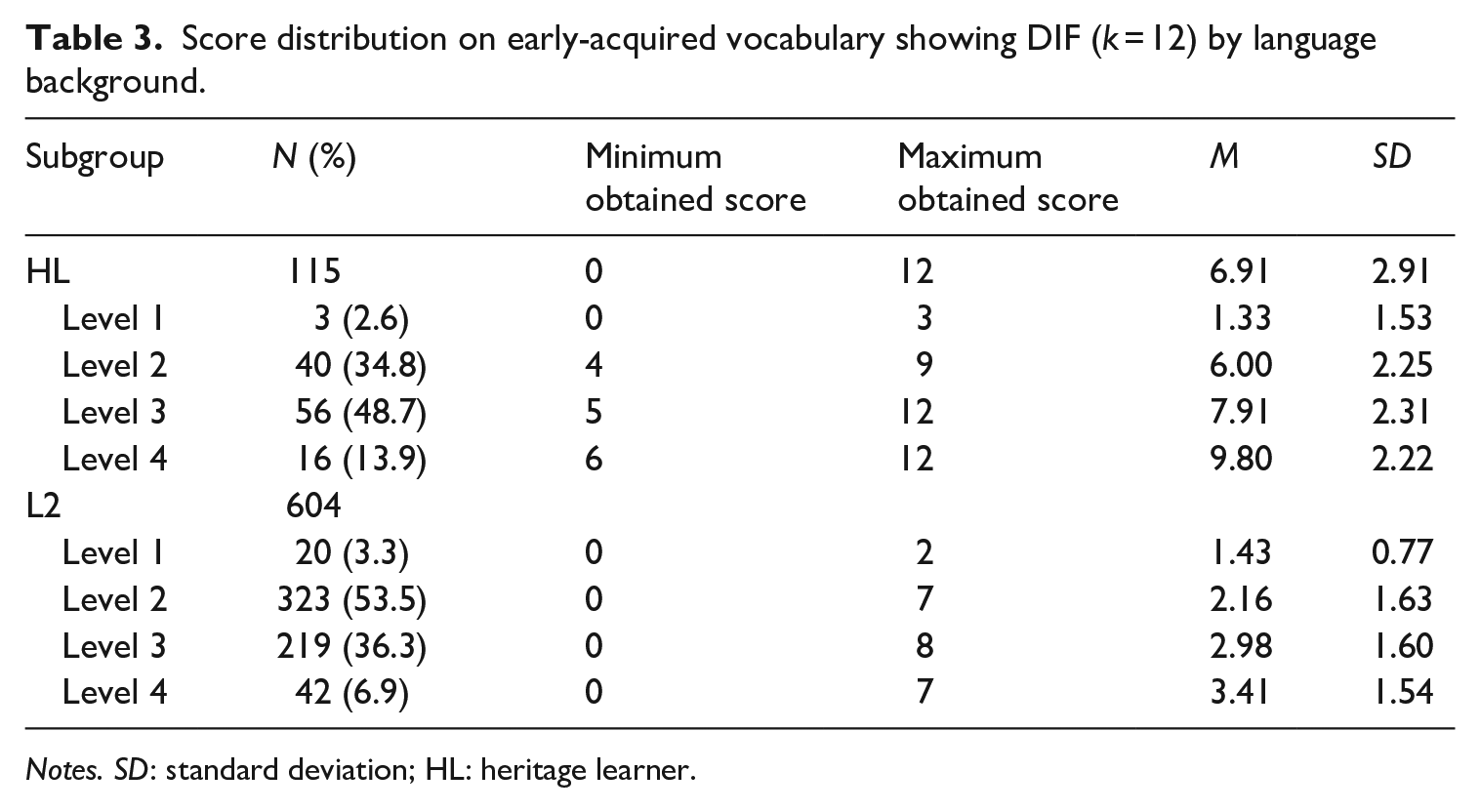
Notes. SD: standard deviation; HL: heritage learner.
HLs in the sample came from Mexican, Puerto Rican, and Ecuadorian backgrounds and because the test did not rely on vocabulary particular to one variety of Spanish, it was able to reliably identify students from all of those backgrounds as HLs and distinguish them from traditional L2 learners. The six HL learners whose early-acquired vocabulary scores did not identify them as having an HL profile had all been exposed to Mexican Spanish, but their questionnaire responses indicated that just one of their parents (their father) was a Spanish-speaker, as opposed to the rest of the sample, which had either two Spanish-speaking parents or a Spanish-speaking mother.
Moving on to the second research question, we wanted to see whether early-acquired vocabulary scores could identify L2 learners with significant, early exposure to Spanish. Recursive partitioning results indicated that 109 of 116 examinees (93.97%) who scored 3.5 or greater on the vocabulary section were correctly identified as HLs based on their background questionnaire data. A closer examination of the profiles of the seven examinees who were incorrectly identified as HLs revealed that six had attended Spanish–English dual immersion programs and one had early significant exposure through Spanish-speaking friends. It was therefore determined that these learners were accurately identified as having an early bilingual profile based on their linguistic knowledge. Similar to their HL peers, these students were placed in different course levels. None placed into the lowest level course, two placed into the third-semester course, three placed into the fourth-semester course, and two placed into the fifth-semester course.
Finally, the background questionnaire information for all L2 learners was reviewed to determine whether any other students with significant early exposure to Spanish had not been identified by vocabulary score; none were found. A graphical representation of the placement procedures appears in Figure 1.

Placement procedures.
Discussion
The results show that for this population of students, the early-acquired vocabulary section of the test was able to distinguish between traditional L2 learners and early bilinguals, both HLs and early L2s, except in the case of the lowest scoring HLs, of which there were very few in the sample. Placement is a necessarily local issue, and although this is not problematic in our context because our curriculum does not offer a first-semester course for Spanish HLs, it could be a problem in other contexts, such as those with larger populations of lower proficiency learners or receptive bilinguals, like the ones described in Fairclough (2011) and D. V. Wilson (2012). The field test sample contained learners from Mexican, Puerto Rican, and Ecuadorian backgrounds, so the data indicate that for learners from these varieties, the items are effective. Although our item development team and experienced instructors reviewed all items in an effort to ensure that they were not variety-specific, it remains to be shown empirically if that is indeed the case because learners from all varieties were not present in the sample.
In addition to showing that 12 of 15 early-acquired vocabulary items differentiated between traditional L2 learners and HLs, running DIF analyses on all test items also revealed that the items that contribute to the placement score (error identification, cloze, and reading comprehension items) do not favor either L2 or HL learners by and large since only 1 item out of the total 114 items across the two final forms showed DIF2. Item developers examined the DIF item and could not determine any reason it should be easier for L2s than for their HL peers. Initially when an item outside the early vocabulary section was flagged for DIF, the expectation was that it could have been an item targeting spelling or orthography since these are the areas where HLs sometimes struggle compared to L2s due to the relatively lower proportion of written input they tend to have received. The fact that this was not the case suggests that HLs and L2s in our sample were assessed on a level playing field on these items.
Just as placement is a necessarily local issue, change is certain as well. As demographics in our language courses change, curricula and placement tests will need to adapt to keep the pace. So although lower proficiency HLs do not currently represent a substantial proportion of our student population, as time goes on that may change, and as more third- and fourth-generation Spanish HLs enroll in our institution, it is likely that the trend may change, as research shows that language shift to the majority language tends to happen by the third or fourth generation (Fishman, 1966). Similarly, as dual immersion programs increase across the country, it is likely that more and more students with early bilingual but not HL profiles will need to be placed in language courses. In that regard, the early-acquired vocabulary test can serve as a model for other language programs looking to identify students based on their linguistic knowledge.
Indeed, along the lines of changing demographics, both K-12 dual language programs (Boyle et al., 2015) and university language programs (Looney & Lusin, 2019) are seeing increases in Chinese and Arabic enrollments. Years down the road we can therefore expect to see larger populations of Chinese and Arabic early bilinguals enrolling in the university classes in either their heritage language or early-acquired L2, and perhaps the method described here relying on corpora, expert judgment, and DIF will help those programs to develop tests that will distinguish traditional L2 learners from early bilinguals as well.
Conclusion
In conclusion, it is crucial to understand the development of the placement test in this study in the context of the university language program from which it grew. The test was developed as an attempt to address a local problem in our local context, with our own curriculum and learner populations at the forefront3. The test development team designed it to be a placement test by our program, for our program, and it was never intended to meet the needs of other programs or learner groups. Indeed, as suggested above, it would likely be ineffective in contexts other than the local one for which it was designed, both because of curriculum-test incongruence and because of differences in early bilingual learners’ knowledge that might exist in other areas (cf., receptive HLs in the southwest). The hope is that this small study showcases one way in which language testers collaborated with language program coordinators and instructors to identify and design a novel solution to a local placement issue by relying on local knowledge and skill sets. Other programs will draw their inspiration from their own needs analysis and come up with creative solutions to their own unique local challenges.
Footnotes
Acknowledgements
The author thanks Florencia Henshaw, Melanie Waters, Brenden Carollo, and all of the graduate teaching assistants and undergraduate students who participated in various stages of this project and also takes responsibility for any errors or omissions.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publicatio of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author thanks the University of Illinois at Urbana-Champaign Office of the Provost for providing funds for the development of the tests on which this research is based.