
Abstract
In this study, I investigate the construct validity and fairness pertaining to the use of a variety of Englishes in listening test input. I obtained data from a post-entry English language placement test administered at a public university in the United States. In addition to expectedly familiar American English, the test features Hawai’i, Filipino, and Indian English, which are expectedly less familiar to our test takers, but justified by the context. I used confirmatory factor analysis to test whether the category of unfamiliar English items formed a latent factor distinct from the other category of more familiar American English items. I used Rasch-based differential item functioning analysis to examine item biases as a function of examinees’ place of origin. The results from the confirmatory factor analysis suggested that the unfamiliar English items tapped into the same underlying construct as the familiar English items. The Rasch-based differential item functioning analysis revealed many instances of item bias among unfamiliar English items with higher proportions of item biases for items targeting narrow comprehension than broad comprehension. However, at the test level, the unfamiliar English items did not substantially influence raw total scores. These findings offer support for using a variety of Englishes in listening tests.
Introduction
One major validity concern in language tests is the degree to which tests capture the target language use (TLU) domain: the closeness between experiences during the test and the language used in the real world (Bachman & Palmer, 2010). A close match is essential for better inferences regarding examinees’ ability, and misalignments are likely to result in invalid decision-making. Moreover, the accurate capturing of the TLU domain is vital for positive washback (Messick, 1996). That is, the preparation for the test should also prepare learners for the real-world language use.
For academic English listening tests, an accurate capturing of the TLU domain suggests the use of more than one variety of English to reflect the non-negligible presence of foreign-born students and instructors in the United States (National Science Board, 1989; Wells, 2007), the United Kingdom (Universities UK International, 2020), and many other parts of the world. Especially in the United States, 38% of doctorate recipients were international in 2019 (National Center for Science and Engineering Statistics, National Science Foundation, 2019), begging the question of what English varieties represent university education. Given that doctorate students are often involved in instructional duties, university students in the United States are likely to encounter foreign-origin instructors who speak with a large variety of Englishes. In prior research, English varieties were sometimes categorized into “standard” and “nonstandard.” However, I agree with Jenkins and Leung (2019) that such a dichotomous view is outdated, counterproductive, and restrictive. In the context of the present study, approximately 23% of full-time instructional faculties and approximately 15% of graduate students are international (Mānoa Institutional Research Office, 2021). Thus, the presence of speakers with a variety of different Englishes in academia is notable and, one might add, quite standard.
With the present study, I investigate the construct validity and fairness of an operational second language (L2) listening test featuring a variety of English input. I investigate the underlying factor structure of the test, and this investigation has implications for the test construct (Messick, 1989). I employ Kunnan’s (2018) framework to investigate any unfair differences in scores among test takers.
My goal is to show some real-life evidence of possible consequences of the use of a variety of Englishes in listening input. To do this, I examine a post-entry placement test currently in use. The test is considered high stakes because it is used to place test takers into supplemental academic English courses or to give an exemption from taking such courses. Thus, unlike previous studies that were typically conducted in laboratory contexts (e.g., Kang et al., 2019; Shin et al., 2021), test takers were motivated to perform well. My aim is to see whether real-life data provide further insights into how a variety of Englishes function in the real world. In addition, I offer item-level analysis to present more detailed data about the test. I believe the findings will provide evidence on how to conceptualize L2 listening ability within a multiaccented and international English-use context.
Literature review
Fairness
Fairness concerns if tests treat all test takers with equal respect, which is vital for fair test use and decision-making. Kunnan (2018) discussed four subprinciples for tests to be fair: opportunity-to-learn, meaningfulness, bias, and appropriate administration, access, and standardized procedures. Previous work on L2 listening assessment with a variety of Englishes primarily focused on bias (e.g., Harding, 2012; Major et al., 2002). A prime concern of these studies has been if the inclusion of multiple English varieties advantages certain test takers over others. If some test takers are advantaged, the test can be considered unfair because tests ought to treat all test takers equally. Typically, researchers investigated the shared-L1 effect, whereby a shared first language (L1) background between test takers and the speakers within the test input generally has a positive influence on test performance (i.e., shared-L1 effect). That is, the test could be unfair for test takers who do not share the language background with speakers. Major et al. (2002) were the first to investigate this issue using the TOEFL iBT. They found that Spanish test takers scored higher when reacting to a L1 Spanish speaker relative to a L1 American English speaker. However, Japanese test takers did not show such a benefit. Moreover, Chinese test takers scored lower when reacting to a L1 Chinese speaker compared to the L1 speaker of American English. Thus, Major et al. (2002) evidenced some benefits of sharing the L1, but the effect was inconsistent across the test-taker groups.
Kang et al. (2019) also examined the shared-L1 effect within the context of the TOEFL iBT, showing that the shared-L1 effect was specific to some L1 backgrounds (e.g., Indian and South African), but not to others (e.g., Mexican and Chinese). They also found that speakers’ comprehensibility (i.e., ease of understanding; Derwing & Munro, 2015) and accentedness (i.e., how distinguishable an accent is compared to the target community’s accent; Derwing & Munro, 2015) mediated the shared-L1 effect. When only the speech samples judged as the most comprehensible and least accented were analyzed, no differences were found across the language groups. That is, when speakers are highly comprehensible and the accent is not strong, there was no advantage for test takers who were sharing the L1 background.
Similarly, Ockey and French (2016) found that speakers’ strength of accent (Australian English) as judged by the US university students and instructors influenced test takers’ English listening comprehension scores, whereby as the estimated strength of accent increased, the comprehension scores decreased. However, for the test takers who were more familiar with Australian English, comprehension was higher as familiarity with the English increased.
The effect of familiarity was also reported in Dai and Roever (2019), who examined young Chinese learners of English. The participants took a listening test that used Australian, Mandarin, Spanish, and Vietnamese English. They found that learners’ self-reported familiarity had a small but significant correlation with test scores. Overall past research suggests that speaker variables (i.e., accentedness and comprehensibility) and test takers variables (e.g., familiarity with a particular accent) influence test performance.
Dai and Roever (2019), following Harding (2012), also examined task types in relation to a variety of English inputs. The investigation of the task/item effect is essential to help test developers decide which task/item type to use when presenting potentially unfamiliar English to test takers. For instance, since open-ended tasks are more difficult than multiple-choice tasks in L2 listening assessment (In’nami & Koizumi, 2009), test developers might expect a different degree of English-variety influence on listening performance across task types. Harding (2012) and Dai and Roever (2019) found that the shared-L1 effect was more pronounced in open-ended tasks than in multiple-choice tasks. The researchers attributed the difference to the increased bottom-up processing in the open-ended tasks relative to multiple-choice tasks. Bottom-up processing is a comprehension process beginning from phoneme decoding and word recognition and proceeding to larger units of comprehension (Field, 2013). Thus, a greater familiarity with the English variety due to the shared language background facilitated decoding.
Recently, Shin et al. (2021) took a further step to investigate variabilities among multiple-choice items. They coded multiple-choice items either as narrow or broad following Bachman and Palmer’s (2010) definition: Shin et al. defined narrow items as the items whose answer can be explicitly located in the listening stimulus, while broad items were the ones whose answer could not be located. Examples of broad items include making an inference and getting the main idea. Thus, broad items require less accurate recognition of each word than narrow items do. The results showed a stronger shared-L1 effect for narrow items than for broad items. Taken together, task/item types seem to mediate the effects of the variety of English input on test performance (Dai & Roever, 2019; Harding, 2012; Shin et al., 2021). Yet, apart from Shin et al. (2021), there is no empirical study on item types in relation to English varieties in listening input, which warrants further investigation.
The studies reviewed above were typically conducted in laboratory settings. Based on the findings, Harding (2012) proposed three approaches for operational language tests to select a variety of Englishes for listening input. One is the use of selected English based on a thorough needs analysis. This approach ensures that the selected English is construct-relevant, in which case Harding (2012) argued the shared-L1 is not of concern. Yet, as detailed below, being construct-relevant might not be sufficient for tests to be fair (Kunnan, 2018). The second approach suggests using only highly proficient speakers in specific task types to minimize the shared-L1 effect. Yet this approach has a risk of under-representation of the test construct (Messick, 1996) as all individuals in the TLU domain are unlikely to have a homogeneous level of proficiency. The third approach suggests using multiple Englishes across several tasks to balance biases. Harding further suggested using Englishes that are equally unfamiliar to all test takers. If learners have equal opportunity to learn the English variety, test takers should have comparable familiarity with the variety and it should not influence test performance, which warrants an investigation. The test investigated in this study is more in line with the second and third approaches (see below for further discussion).
As reviewed above, previous studies on L2 listening assessment with English varieties investigated fairness issues focusing on bias. Yet Kunnan (2018) argued that fairness is multifaceted and bias is just one aspect of it. This implies that there need to be further investigations on other aspects of fairness, such as the opportunity to learn. The opportunity-to-learn principle suggests that test takers ought to have equal learning opportunities for tests to be fair. For instance, if one group of learners has limited access to learning, they may be disadvantaged, perpetuating a colonial view of access to what high scores on the test provide. For instance, Abedi et al. (2006) investigated if learning opportunities are available for English language learners in US elementary schools. They found that compared to L1 English students, English language learners had fewer opportunities, suggesting that learners’ low scores might be attributable to the limited learning opportunities.
In the context of listening tests featuring a variety of Englishes, it would be desirable for all test takers to have roughly equal experience with the Englishes to the extent that it does not systematically influence test performance and subsequent decision-making. However, test takers might have varying opportunities to be exposed to a variety of Englishes depending on their country of origin as governments’ policies on English language education are unlikely to be identical from one country to another. Varying levels of exposure influence familiarity with certain varieties of English, which might influence test performance (Dai & Roever, 2019; Ockey & French, 2016). While some studies evidence the exclusive use of certain varieties of L1 English (i.e., North American, British, Australian, etc., given the context) in local English as a foreign language (EFL) textbooks (Guerra et al., 2022; Takahashi, 2011), textbooks are not the sole source of input. For instance, due to an increasing number of remote instructors from the Philippines (Martinez, 2022), Japanese learners of English might have a greater familiarity with Filipino English than other test takers. For the test to be fair, differences in test performance due to unequal learning opportunities should be too small to make any meaningful differences in the test score, which warrants an empirical investigation. Note, however, that differences in learning opportunities might not be the sole reason for differences in test scores. As Bent and Bradlow (2003) showed, some L2 speakers might understand each other well due to the proximity of their L1 phonology.
Construct validity
Construct validity is defined as the evaluative judgment based on “an integration of any evidence that bears on the interpretation or meaning of the test scores” (Messick, 1989, p. 17). To investigate construct validity, researchers can utilize confirmatory factor analysis (CFA), which tests hypothesized underlying factor structures. CFA can help test developers understand which latent factor(s) explain test performance. Many studies have investigated the factor structure of large-scale tests to better understand their constructs. In such studies, listening is commonly represented as a single factor. For instance, In’nami and Koizumi (2012) investigated the factor structure of the Test of English for International Communication (TOEIC) listening and reading test. Using CFA, they found evidence for there being two highly correlated factors represented by the test: listening and reading. They suggested that the finding validates a separate subscore reporting for listening and reading because each forms a distinct latent factor. Other studies have focused more narrowly on listening tests. Alavi et al. (2018) investigated the listening section of the International English Language Test System (IELTS). They investigated if different task types result in different factors (e.g., gap-filling and multiple-choice items). A higher-order, four-factor model indicated a sufficient model fit, indicating that each task measures different constructs, while the higher-order latent factor accounted for them all. A similar task-based factor structure was reported by Goh and Aryadoust (2010), who found three factors in the Michigan English Language Assessment Battery. While the higher-order factor model indicated a slightly less favorable model fit, the three factors of ability to understand minimal context stimuli, ability to understand short conversations, and ability to understand longer radio interviews were strongly correlated with each other (r = .89–.96). This suggests that while different factors were identified based on tasks, listening ability is generally conceived of as unidimensional, meaning that various listening tasks draw on the same underlying construct.
For listening tests featuring a variety of Englishes, there is no empirical validation of the factor structure. Yet, there are some theoretical suggestions on the operationalization of listening ability in English as an International Language (EIL) or English as a Lingua Franca (ELF) contexts. 1 Canagarajah (2006) discussed the ability to negotiate diverse varieties of Englishes as a part of language proficiency. That is, Canagarajah conceptualized an accommodation skill (the ability to cope with a variety of Englishes) as an integral property of proficiency. Harding and McNamara (2018) further developed this idea into interactional contexts and included adjusting to the interlocutor’s accent as one of the competence areas. Additionally, Elder and Davies (2006) argued that the use of L2 speakers (or speakers of World Englishes) in the listening input might require reconsideration of the test construct, which, they argued, would be modernizing, as the construct of listening should have a strong emphasis on meaning rather than on a perhaps biased notion of form.
Despite the increasing interest and theoretical suggestions, validation of the operationalizations of EIL/ELF competence is extremely limited. Using qualitative data, Harding (2018) conducted the first empirical validation by exposing L1 French listeners to Southern British English, a familiar accent to the listeners, and Thai English, an unfamiliar accent to the listeners. While there were some individual differences, he found that test takers had difficulties with Thai-accented English such that they had to use compensatory strategies that they did not use when listening to Southern British English. The difference in the elicited strategies might indicate that listening to unfamiliar English might tap into a different language construct as discussed by Elder and Davies (2006). Yet, there is no empirical validation of this matter.
The study
Despite the growing interest in English varieties in listening input, the issue of fairness in using a variety of Englishes in L2 listening testing has been narrowly investigated, and the issue of English varieties and construct validity has been only lightly addressed. To address these issues, I employ Rasch-based differential item functioning (DIF) analysis and CFA to investigate the opportunity-to-learn perspective of fairness and construct validity of a particular listening test. Importantly, the study is, to the best of my knowledge, the first study to investigate unfamiliar English input such as Indian English and Filipino English in operational listening tests. In addition, the examination of fairness aside from bias and factor structure is unique to the present study. As for fairness, if there are systematic differences in test performance among test takers, this might indicate that some test takers were more familiar with the English variety than others. That is, a systematic trend might suggest meaningful differences in the learning opportunities that test takers previously had. For a grouping variable, I used test takers’ home country to test if test takers from one specific country had more learning opportunities than others. Moreover, I investigated item types to provide further evidence on how English varieties in listening inputs interact with item types. As for factor structure, I used CFA. A specific interest is whether unfamiliar English items form a different underlying factor from familiar English items that are more traditionally represented on an academic English test.
The test
The test investigated in the study is a post-entry English placement test administered at a public university in the United States that was developed by Clark in 2007. The test features spontaneous speech production and includes a female Indian speaker (L1 Hindi) and male L1 speakers of English (Clark, 2007). The Indian speaker was included because the use of only “native” speakers (see Cheng et al., 2021, for modern discussions on this term) would not be in line with the sociolinguistic reality of the “instructional faculty which includes many non-native speakers” (Clark, 2007, p. 81). There are two L1 English speakers in the current version of the test. One is from New Jersey and the other is from Michigan. 2 Hereafter, I will refer to them as Northeast for New Jersey and Midwest for Michigan. All the speakers were doctoral students and had experience teaching undergraduate courses. Thus, the Indian speaker was considered to be as proficient, as high, and as expert in English as the others.
The test was revised in 2017 by Brown et al. (2018) to include “the notions of World Englishes, so that the speakers’ proficiency levels would be high but with detectable accents” (p. 6). That is, the TLU domain of the revision emphasized a wide variety of Englishes that test takers might encounter on campus. To do this, a male speaker of Hawai’i English and a female speaker of Filipino English were used. 3 Thus, the current listening input utilizes speakers from the Northeast, Midwest, India, the Philippines, and Hawai’i. I conceptualized that Northeastern English and Midwestern English were more familiar to test takers than Indian English, Filipino English, and Hawai’i English as textbooks in the EFL context typically use L1 Englishes of those North American varieties (Takahashi, 2011), and Hawai’i English exhibits some phonetic differences from “those found in the continental United States” (Drager, 2012, p. 65).
Among the three approaches discussed in Harding (2012), the second and third approaches seem to be more relevant to the test. That is, the test uses only highly proficient L2 speakers (proposal 2), and the accents are considered to be equally unfamiliar to the test takers (proposal 3). As described below, the majority of the test takers are from East Asia (i.e., Japan, Korea, and China). In other words, the majority of test takers do not have a shared language background with the speakers. Yet, as mentioned, some test takers might have a greater familiarity with a certain English variety: Japanese learners might be familiar with Filipino English due to the increasing number of remote instructors from the Philippines (Martinez, 2022). If there are any systematic differences in test performance across the groups, it might indicate unequal (or perhaps different) learning opportunities.
As one of the assumptions of the Rasch model is unidimensionality, which can be assessed by the latent factor structure, I will present the issue of construct validity before fairness. The research questions are as follows:
Does input with familiar English (Northeastern and Midwestern) result in a different factor from input with unfamiliar English (Hawai’i, Indian, and Filipino)?
To what degree does input with unfamiliar English (Hawai’i, Filipino, and Indian) display item bias in relation to test takers’ country of origin?
What are the characteristics of items (narrow or broad) that indicate item bias?
Before investigating the research questions, I hypothesized factor structures. Figures 1 and 2 show two different models, where ovals represent latent factors, rectangles represent observed variables, circles represent error terms, one-headed arrows indicate factor loadings, and two-headed arrows indicate correlations (see method for the description of the test, i.e., short/long passages). Figure 1 shows the one-factor model, where items with all English varieties load onto one factor (i.e., a unified academic listening ability). Figure 2 illustrates the two-factor model, where two factors, the academic listening ability for expectedly familiar and expectedly unfamiliar English, compose different but correlated factors.

Hypothesized one-factor model.

Hypothesized two-factor model.
The one-factor model is motivated by current score reporting and interpretation. That is, a current interpretation of the score is based on the total score, instead of subscores based on English varieties. In addition, the model seems to be in accordance with previous findings that listening ability is relatively unidimensional (e.g., Alavi et al., 2018).
The one-factor model suggests that the listening ability for familiar English (Northeastern and Midwestern) and the one for unfamiliar English (Hawai’i, Filipino, and Indian) draw largely on the same underlying construct. For score reporting and interpretation, support for this model would validate current practices. While this might also suggest that listening ability could be measured solely by one English variety, such tests have issues of negative washback, under-representation, and a lack of extrapolation to the TLU domain. Rather, the one-factor model offers support for the mixed-use of a variety of Englishes because test developers can better represent the TLU domain without requiring more complicated scoring and interpretations. Moreover, it can bring positive washback (Messick, 1996). That is, learners are more motivated to seek exposure to different varieties of Englishes when preparing for the test if the test is known to cover more than one English variety. This proposal is in line with Global Englishes studies that advocate more exposure to a variety of Englishes in the language classroom (Galloway & Rose, 2015). Thus, if familiar English items and unfamiliar English items load on the same latent factor, it seems to be encouraging for test developers to incorporate justified varieties of Englishes in their tests to better represent the TLU domain, be more inclusive and representative, and better guide teaching and learning.
Another interest of the one-factor model is factor loadings. If similar loadings are found among all the English varieties, it would provide further support for the use of justified English varieties because the latent factor equally predicts test performance. However, a large difference in loadings would suggest that factors other than English-language ability, such as familiarity with a particular English variety, could be affecting the observed scores, which would be undesired.
In the two-factor model, on the other hand, Filipino English, Hawai’i English, and Indian English form a latent factor of generally unfamiliar English items. Hawai’i English was included as an unfamiliar variety alongside Filipino and Indian English to reflect Brown et al.’s (2018) motivation to incorporate World Englishes. Moreover, Hawai’i English features distinct vowel realizations from those in the mainland United States (Drager, 2012); thus, Hawai’i English, similar to Filipino English and Indian English, was considered to be potentially less familiar to the test takers than Northeastern and Midwestern American English.
The two-factor model is in line with Harding (2018), who found increased difficulty and a greater number of strategies appeared when the listening comprised unfamiliar Thai English. The model suggests that separate score reporting for each construct (familiar and unfamiliar English) is more informative than summed scores for more precise inference. The strength of correlation between the factors is another interest. If highly correlated, it still poses a question of whether they are truly distinct.
For the second and third research questions, I used Rasch-based DIF analysis. For the second research question, it is hypothesized that some item biases in the unfamiliar English passages will be found. This is because some test takers might have a greater chance of being exposed to a certain English variety. As discussed, Japanese learners might be more familiar with Filipino English (Martinez, 2022). If the flagged items substantially influence the test score, that might suggest unequal or different learning opportunities. If such flagged items do not result in a possible change in raw score, this provides support for fairness.
For the third research question, broad items are expected to exhibit fewer item biases. This is because broad items require less bottom-up processing in answering the item correctly; thus, the effect of unfamiliar English should be less than narrow items (Shin et al., 2021).
Method
Participants
I obtained the data from the English Language Institute at the University of Hawaiʻi at Mānoa. The center provided me with anonymized test data from Spring 2017 to Spring 2020 administrations (n = 539). Test takers were from Japan (n = 141), Korea (n = 101), China (n = 94), Taiwan (n = 24), Philippines (n = 22), and 47 other countries that had fewer than 20 test takers. While test scores from standardized tests were not available for all the test takers, 291 and 75 test takers reported scores in the TOEFL iBT (M = 80.92, SD = 11.62) and IELTS Academic (M = 6.23, SD = .35), respectively.
Among the test takers, those from the Philippines (n = 22) and India (n = 1) were removed because they were considered to have higher familiarity with one of the speakers than other test takers. The small sample sizes made it difficult to compare these test takers with greater familiarity with one of the English varieties to those with less familiarity, as Linacre (1994) recommends a sample size of at least 30 per group for DIF analysis. Thus, the examinees from the Philippines and India were removed, resulting in a total of 516 test takers. Table 1 summarizes the demographic information of major countries by student type, with specific information from countries with few test takers suppressed as Other.
Summary of test takers.

Material
The test investigated in the study is a post-entry English placement test. The purpose of the test is to assess the academic English ability of upcoming international students whose L1 is not English. Incoming L2 students are required to take the test unless they report sufficient proficiency at the time of application (e.g., ≥100 on TOEFL iBT or ≥ 7.0 on IELTS Academic). The minimum English ability to be admitted to the university is 61 in TOEFL iBT or a total band score of 5.0 in the IELTS Academic module. 4 Thus, the target test population is from 61 to 99 in TOEFL iBT and a total band score of 5.0–6.5 in IELTS. If examinees demonstrate adequate levels of academic English ability in the test, they are exempt from taking academic English support courses. However, if the scores are below the cut score, they are placed into English language courses. Note that this English language proficiency requirement can delay graduation, thus, the decision made from this test is relatively high stakes. The test data, R script, and short audio clips are available on the Open Science Framework (OSF) (Nishizawa, 2022).
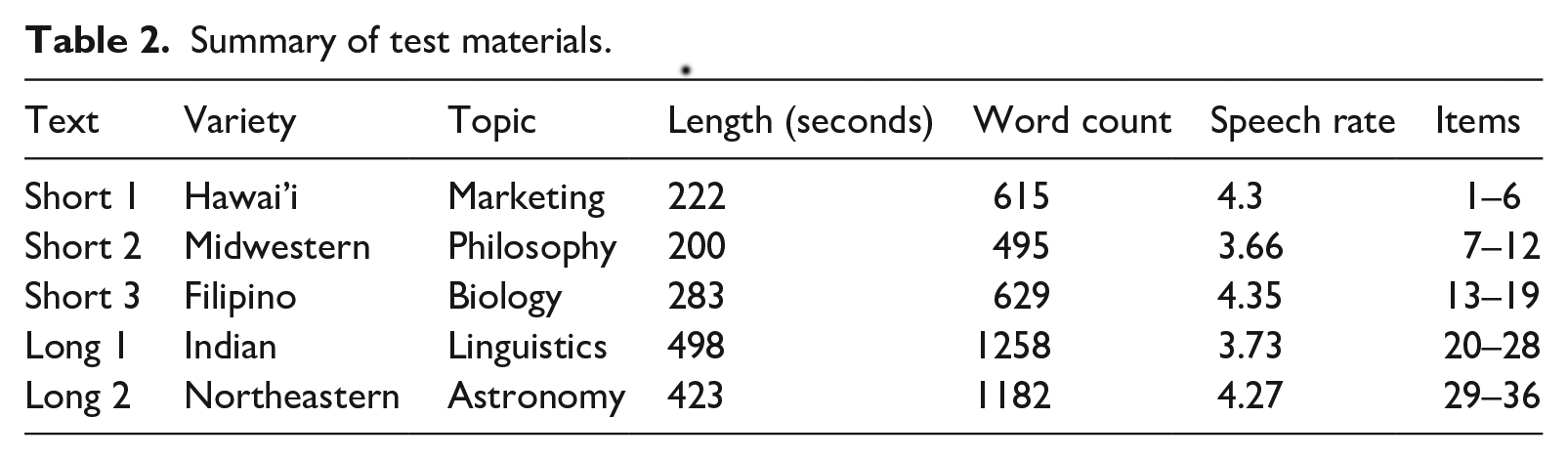
The listening section contains three short and two long academic lecture monologues (k = 36; Table 2 for a summary). The passages feature spontaneous speech production, and a variety of topics are represented. There was some variation in the length (222–498 seconds) and speech rate (syllable per second; 3.66–4.35). Note that speech rate influences comprehensibility (Munro & Derwing, 2001), while the effect might not be substantial on comprehension (Griffiths, 1992). All the questions are 4-option multiple-choice items. Previewing items is not permitted, while note-taking is allowed.
Summary of test materials.
Analysis
To answer the first research question, I conducted CFA in R (version 4.0.4; R Core Team, 2020) using lavaan (version 0.6-8; Rosseel, 2012). I assessed univariate and multivariate normality to determine the estimation. Due to the relatively small sample size, I computed sub-scores by aggregating scores based on passages. I assessed model fit by the chi-square test, the comparative fit index (CFI), the normed fit index (NFI), the Tucker-Lewis index (TLI), Akaike’s Information Criterion (AIC), the root square error of approximation (RMSEA), and the standardized root mean square residual (SRMR). I set the cutoff values for these indices at .95 for CFI, NFI, and TLI and .08 for SRMR and RMSEA (Mueller & Hancock, 2018). AIC does not have a specific threshold; however, a lower value indicates better fits to data. For modification, I considered modification indices (MIs) greater than four as long as the modification theoretically made sense. In addition, I estimated reliability to examine the proportion of true-score variance to total variance observed (Brown, 2015), that is, to determine the amount of variance explained by the latent factor. The higher the value, the better the latent factor can explain test performance. Instead of simply reporting Cronbach’s alpha, I also calculated and reported the coefficient omega because Cronbach’s alpha tends to underestimate reliability in many situations (Brown, 2015).
To answer the second and third research questions, I conducted Rasch-based DIF analysis using Winsteps (version 5.2.2.0; Linacre, 2022). It statistically compares estimated item difficulty for the entire sample and each subgroup (which are the country information listed in Table 1). If one group of test takers systematically and substantially has better odds of a correct response than the others, the item is flagged, meaning that a certain group of test takers might be advantaged over others. I chose Rasch-based DIF over the Mantel-Haenszel method to address the issue of dependency on the raw scores (Raquel, 2019). The use of raw scores is problematic because item difficulty and person ability are inseparable (McNamara et al., 2019).
For a grouping variable, I used the examinees’ country of origin. The groups included test takers from Japan (n = 141), Korea (n = 101), China (n = 94), and Other (n = 180). As mentioned, Filipino (n = 22) and Indian (n = 1) test takers were removed from the analysis due to their high familiarity with one of the speakers in the listening input. It should be noted that the Other group included examinees from Taiwan (n = 24), Hong Kong (n = 9), and Macau (n = 2), who are likely to have a similar language background as those from China. Notably the operationalization of this grouping is to examine the opportunity-to-learn aspect of fairness, rather than language background. Because language policy and sociolinguistic environment are unlikely to be identical, Taiwan, Hong Kong, and Macau were grouped into the Other group despite the proximity of the language background.
As suggested in Zieky (1993), DIF size was interpreted as negligible (<|.43| logits), slight to moderate (≥ |.43| logits), and moderate to large (≥|.64| logits). Due to the relatively large number of groups being compared, each group was compared against the whole-group estimates instead of arbitrarily making one group a reference group or numerous pairwise comparisons.
Several measures were taken to assess the assumptions of Rasch analysis. Dimensionality was checked using principal component analysis of linearized Rasch residuals (PCAR), scree plot, and standardized residual variance, while local independence was examined via Q3 coefficient. If data are unidimensional, the PCAR plot should not indicate any patterns, the scree plot should not show an elbow, and the eigenvalue of unexplained residuals should be less than 2.0 (Linacre, 2021). The assumption of local independence is met if residuals are not highly correlated (<|.3|; Aryadoust et al., 2021).
The test items were coded either as broad or narrow, following Bachman and Palmer (2010). The author and a secondary coder, a graduate student with a background in language testing, coded the items separately. The Kappa value suggested sufficient inter-coder reliability (.79). Disagreements were resolved through discussion. Two broad items were identified in each passage. Due to the proportional difference across the item types (10 board vs. 26 narrow), I report proportional as well as numeric data.
Results
Descriptive statistics
Overall, descriptive statistics are comparable to Brown et al. (2018). 5 The mean score was 19.39 (SD = 4.85) of 36, with median and mode of 19 and 20, respectively. The scores ranged from seven to 33 and the skewness (.10) and kurtosis (−.33) validated univariate normality.
Confirmatory factor analysis
While the data indicated univariate normality, Mardia’s multivariate normality test suggested non-multivariate normality (p < .05). Thus, I used maximum likelihood with robust standard errors and chi-squares (Bentler, 1995). The one-factor model and the two-factor model were tested with the data. As shown in Table 3, both models indicated sufficient model fit with all indices within acceptable ranges. Moreover, standardized residuals in both models were also within the cutoff (i.e., |2.0|), with the values ranging from −1.34 to 1.38 in the one-factor model and from −1.61 to 1.43 in the two-factor model. However, reliability was lower in the two-factor model (Cronbach’s alpha = .42, Omega = .43 for the familiar English factor, Cronbach’s alpha = .46, Omega = .48 for the unfamiliar English factor) than in the one-factor model (Cronbach’s alpha = .63, Omega = .64). This indicates that the factors in the two-factor model poorly explain the test performance. In addition, the likelihood ratio test was not significant (p > .05), supporting the less constraining model (i.e., the one-factor model). Most importantly, the factors in the two-factor model showed a perfect correlation (r = 1.00), meaning that they are not distinguishable from each other. Hence, the two-factor model was revised by adding an error covariance between the long passages as suggested by MI and previous studies, which found factors based on task types (Alavi et al., 2018). The one-factor model did not indicate MI greater than 4.0; hence, no modification was made.
Fit indices and reliability.
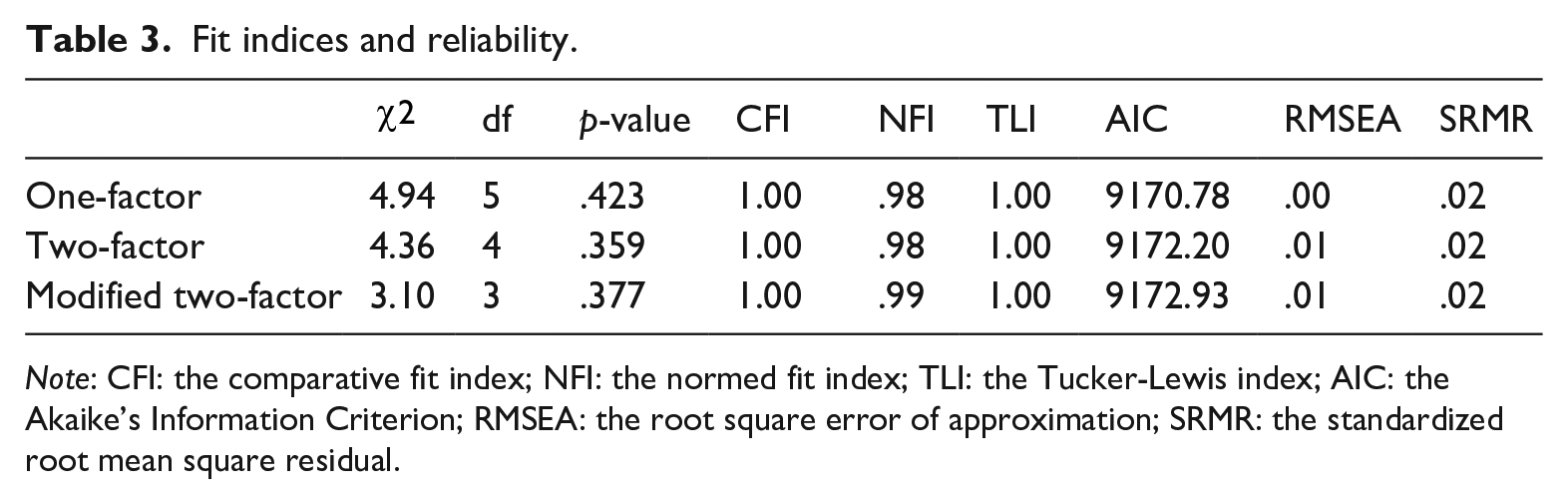
Note: CFI: the comparative fit index; NFI: the normed fit index; TLI: the Tucker-Lewis index; AIC: the Akaike’s Information Criterion; RMSEA: the root square error of approximation; SRMR: the standardized root mean square residual.
The model fit for the modified model are presented in Table 3. While the model showed comparable fit including the standardized residuals that ranged from −1.15 to 1.68, reliability estimates were still low (Cronbach’s alpha = .42, Omega = .43 for the familiar English factor, Cronbach’s alpha = .46, Omega = .48 for the unfamiliar English factor). Moreover, the modified two-factor model still indicated a perfect correlation between the two factors (r = 1.00). In addition, the likelihood ratio test was insignificant (p > .05). These findings show that despite model fit, the two factors are statistically inseparable, and the one-factor model is the best solution for the data. Figure 3 presents the model with standardized values, where factor loadings are comparable regardless of expected familiarity (r = .40–.59). Interestingly, long passages (r = .57–.59) had stronger loadings than the short passages (r = .40–.51) and Indian passage had the strongest loading (r = .59), while the Hawai’i and Filipino passages indicated smaller loadings (r = .40, .46). This indicates that the long passages were more predictive of the listening comprehension skills than the shorter passages.

The final model for the placement test.
The dichotomous Rasch model
Table 4 summarizes the dichotomous Rasch model. It shows higher mean ability (M = .19, SD = .66) and a wider spread of examinees (from −1.57 to 2.61) than items (M = .00, SD = .73; from −1.32 to 1.29). The separation index suggests at least seven different strata in item difficulty (separation index = 7.30) and one stratum in examinees (1.42), meaning a somewhat homogeneous level of ability among examinees. Note that this result is expected as the target proficiency of test takers is narrow (e.g., TOEFL iBT 61–99). The low separation power is reflected in relatively low-reliability estimates (r = .67), while item reliability was very high (r = .98). These results echo Brown et al. (2018) except for their somewhat lower item separation index (4.32). The restricted range of the test-taker population also resulted in a small amount of variance explained by examinees (4.6%). This resulted in low raw variance explained by Rasch measures (17.1%), which was below the common 20% threshold (Reckase, 1979; also see Figure 6 below). While this seems worrisome, almost identical values between observed and expected values of explained variance in the standardized residual variance (i.e., raw variance explained by measures, persons, and items) suggest the correct model estimation (Linacre, 2021); thus, the low variance is less concerning.
Rasch summary.
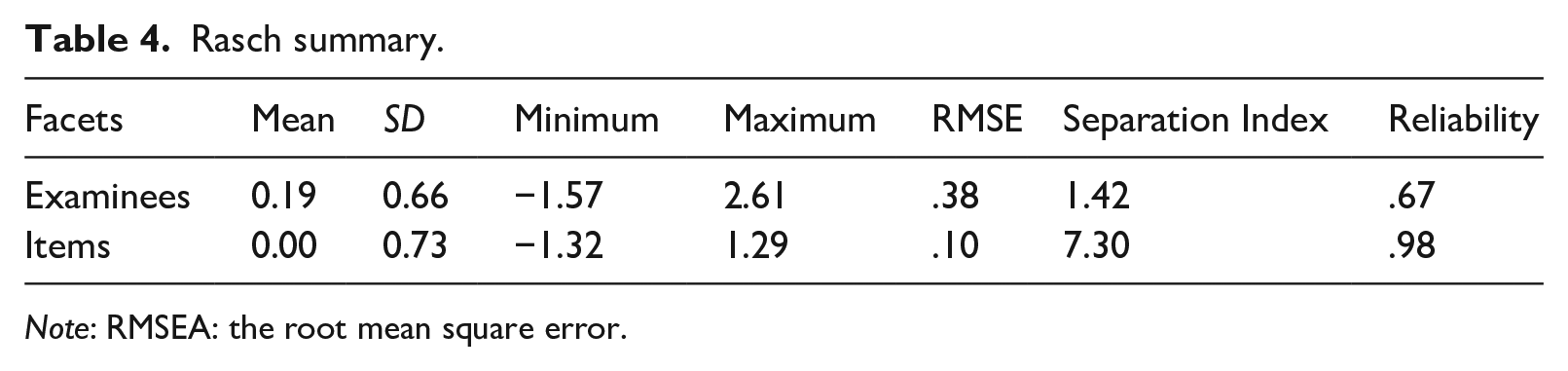
Note: RMSEA: the root mean square error.
Figure 4 shows the Wright map. Each node indicates the passage, item number, and English variety (e.g., P1_1_HE indicates passage 1, item 1, Hawai’i English). The six most difficult items (4, 6, 14, 18, 25, and 35) were broad items (see Table 5), including five items from unfamiliar English passages. This indicates that broad items in unfamiliar English were generally difficult.
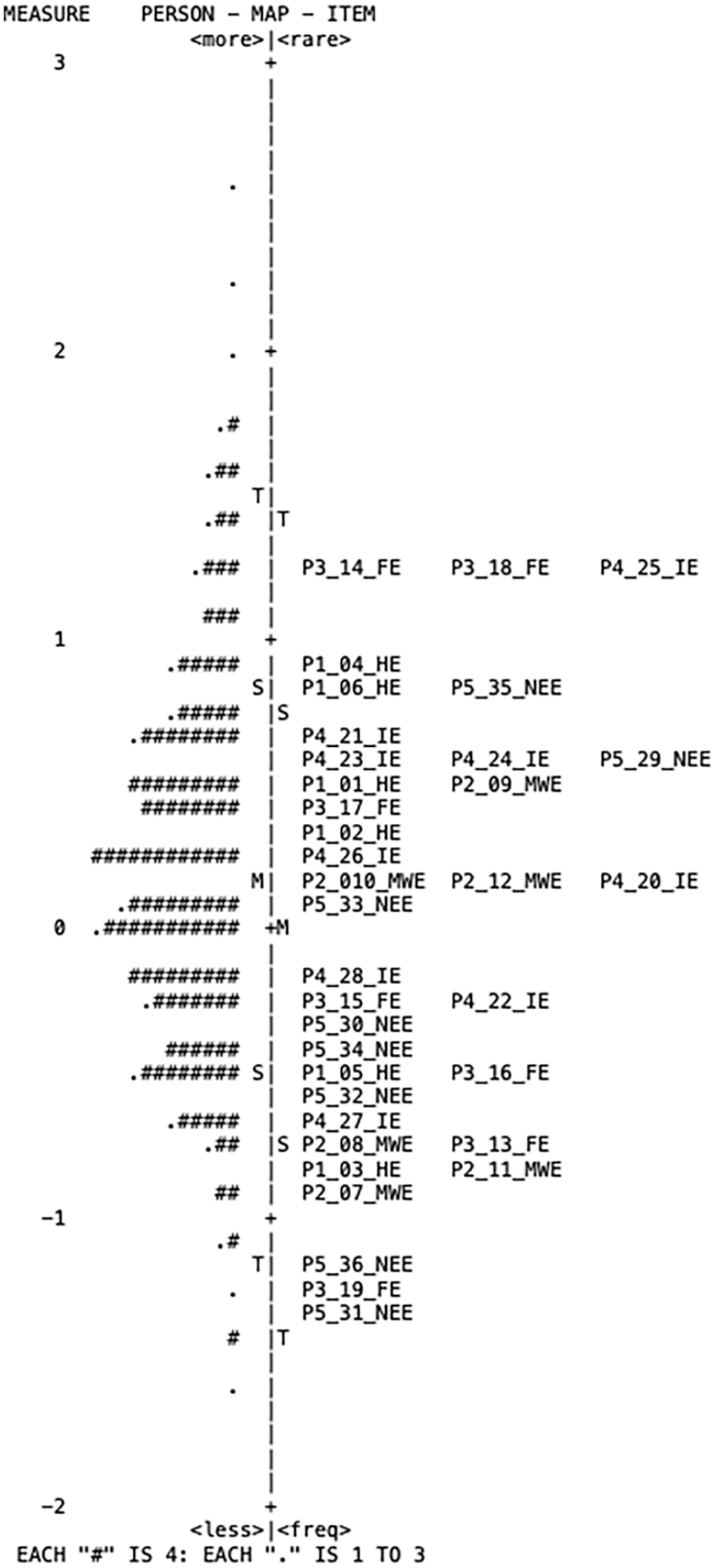
Wright map.
Item statistics.
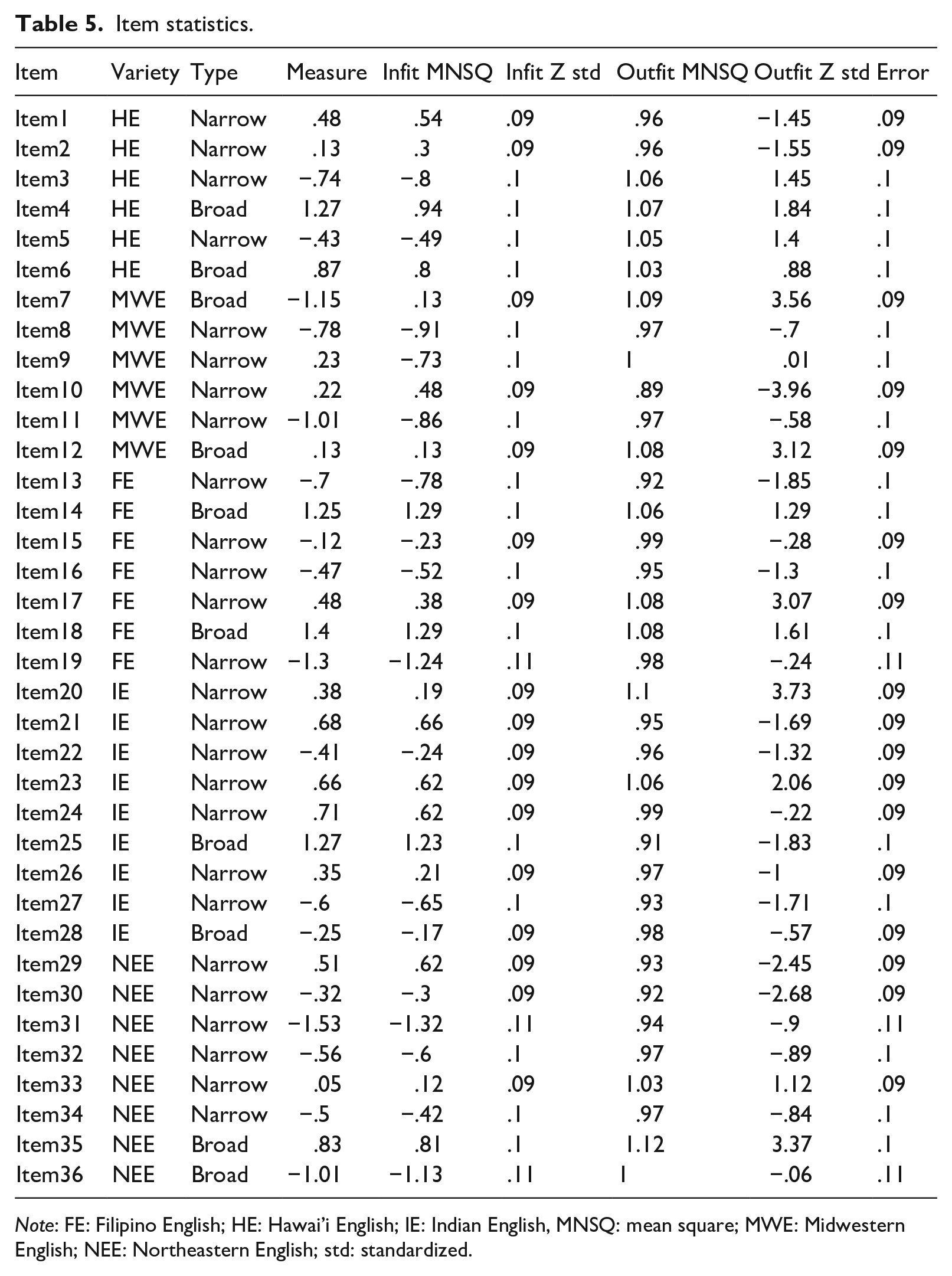
Note: FE: Filipino English; HE: Hawai’i English; IE: Indian English, MNSQ: mean square; MWE: Midwestern English; NEE: Northeastern English; std: standardized.
Table 5 illustrates item statistics with all the items within the acceptable range (.7–1.3; Wright et al., 1994). The mean difficulty in logits indicates a slight difficulty of the Indian (.27), Hawai’i (.22), and Filipino (.03) items relative to the Midwestern (−.29) and Northeastern items (−.28).
Two assumptions of the Rasch model were assessed: unidimensionality and local independence. The unidimensionality was assessed by the standardized residual contrast plot (Figure 5), scree plot (Figure 6), and standardized residual variance. All the measures supported the unidimensionality assumption showing a fair spread of items without any major patterns in the residual plot, no elbow in the scree plot, and a small unexplained variance in the first contrast (eigenvalue = 1.72; 4.0% of the total variance observed). As for the local independence assumption, the Q3 coefficient found small correlations among items (<.|3|). Thus, the assumptions of Rasch analysis were met, which supports the use of Rasch-based DIF for the data.
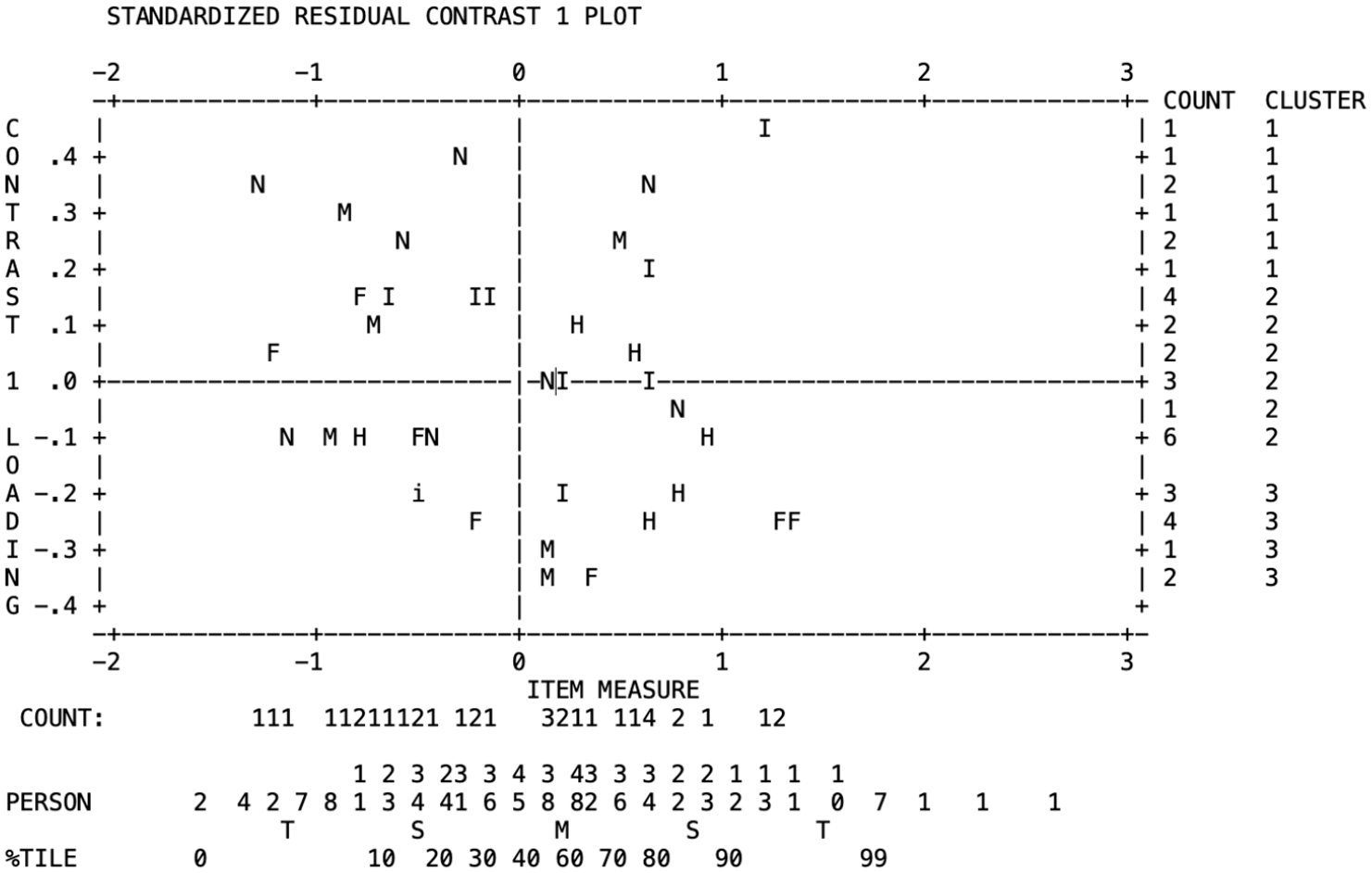
Plot of standardized residual contrast.

Standardized residual variance scree plot.
DIF analysis
To answer the second and third research questions, a DIF analysis was run. Table 6 displays significant (t > |2.0|) DIF items with a DIF size of above .42. The DIF measure indicates the level of difficulty in logits with a higher value being more difficult. The DIF score indicates discrepancies between the observed average scores and the expected scores inferred from examinees’ overall ability. Positive values suggest that a given group’s performance was above the expectation, while negative values indicate poorer performance than the model expectation. The DIF size shows directions and sizes of effects, in which positive values indicate difficulty for a given group relative to the whole population, while negative values indicate easiness. The level shows the interpretation of effect size, where B indicates slight to moderate, whereas C indicates moderate to large (Zieky, 1993).
Summary of flagged items.
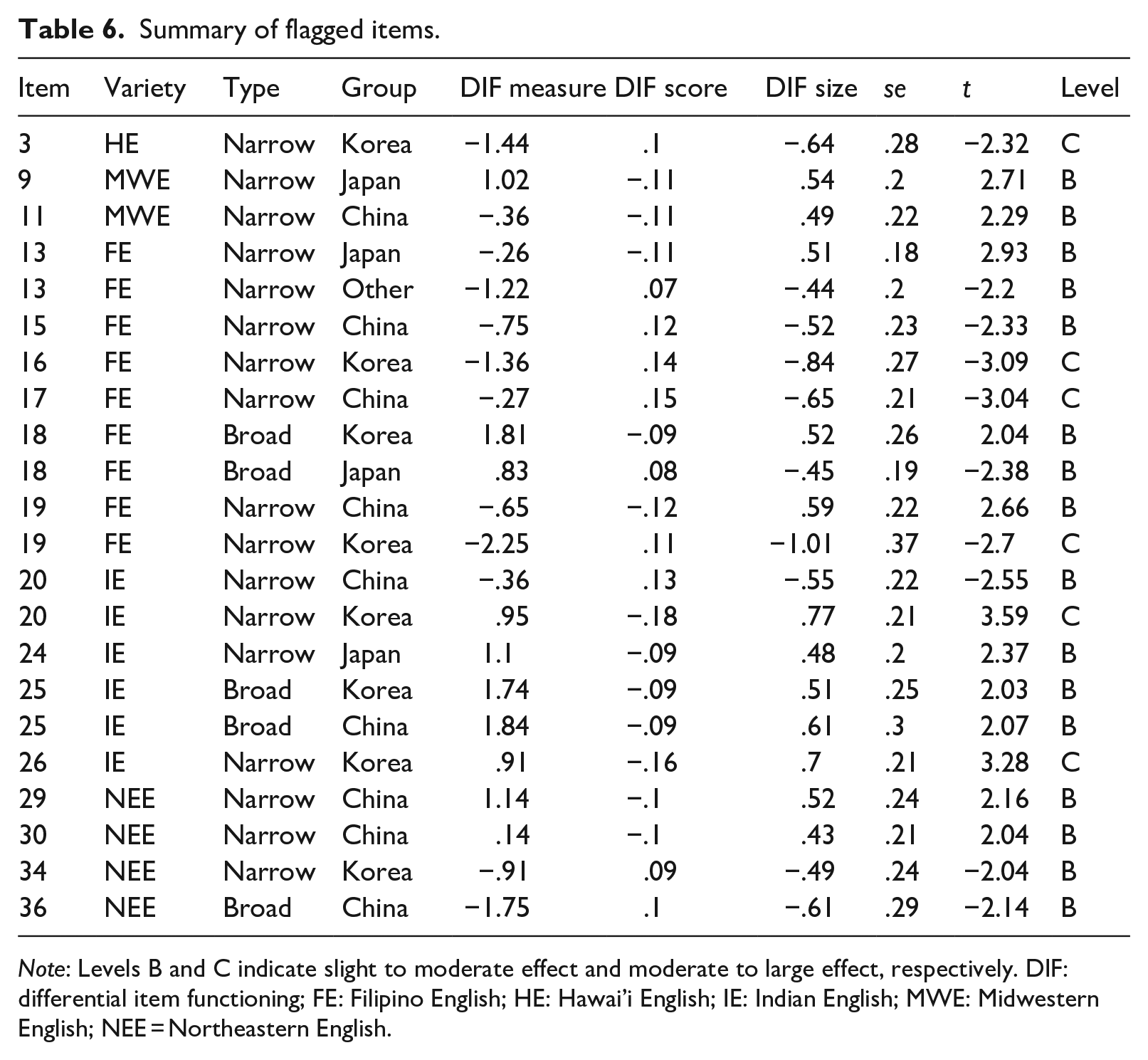
Note: Levels B and C indicate slight to moderate effect and moderate to large effect, respectively. DIF: differential item functioning; FE: Filipino English; HE: Hawai’i English; IE: Indian English; MWE: Midwestern English; NEE = Northeastern English.
There were a total of 22 DIF instances. Among them, 16 were B levels, while six were C levels. Those included one instance from the Hawai’i passage, nine instances from the Filipino passage (six items), six instances from the Indian passage (four items), two instances from the Midwestern passage (two items), and four instances from the Northeastern passage (four items). Note that the number of instances does not always match the number of flagged items as one item can be flagged for multiple groups. In total, 11 items of 22 were flagged from the unfamiliar English passages (50%), which is proportionally slightly higher than the familiar English passages (six items of 14; 43%). This suggests unfamiliar English items were more likely to be flagged than familiar English items. Close observation of Table 6 suggests an inconsistent direction of flagged items, indicating that, overall, unfamiliar English items did not systematically advantage or disadvantage a certain test taker group over others.
In terms of item types, there were numerically more flagged items in narrow items (k = 14) than in broad items (k = 3) in the test. Among the unfamiliar English passages, two flagged items were broad items, while nine items were narrow items. Proportionally, broad items were less likely to be flagged (2/6 = 34%) than narrow items (9/16 = 56%) among the unfamiliar English items. The same pattern was observed for the familiar English items, where broad items were proportionally less likely to be flagged (1/4 = 20%) than narrow items (5/10 = 50%)
To investigate the overall effect of DIF, the cumulative DIF size was computed for (a) all significant flagged items regardless of the English varieties and (b) significant flagged items from the unfamiliar English passages only (Table 7). Japanese examinees were disadvantaged in both indices (all = 1.08, unfamiliar English items = .54). This suggests that, collectively, the Hawai’i, Filipino, and Indian English items were more difficult for Japanese test takers by .54 logits. On the other hand, the Other group showed the same cumulative DIF size in both indices. This is because the Other group had only one DIF instance (i.e., Filipino item). The negative value suggests that the Filipino item was generally easier for the Other group. Interestingly, the Korean and Chinese groups showed a different pattern across the indices. They indicated a positive cumulative value for one index and a negative cumulative value for the other. Although the values were relatively small, this might indicate that the test performance by Korean and Chinese test takers was slightly different as a function of familiarity with the English variety.
Cumulative differential item functioning size.
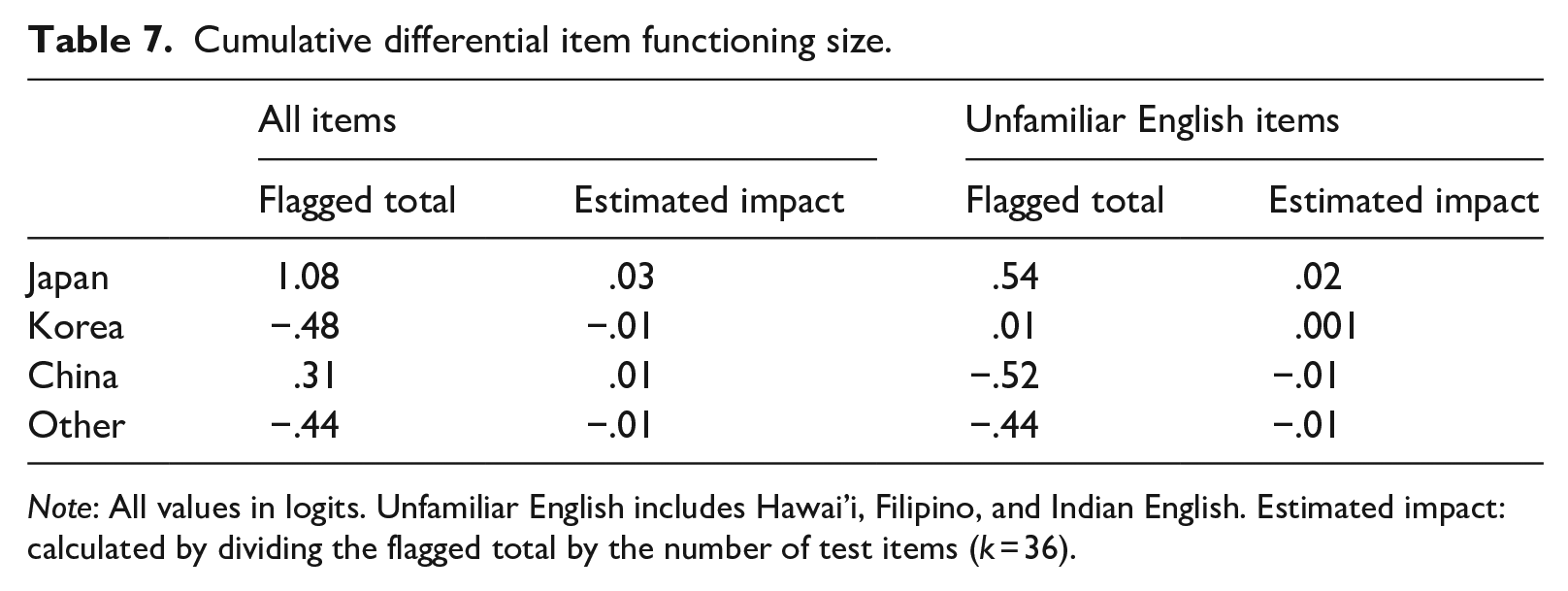
Note: All values in logits. Unfamiliar English includes Hawai’i, Filipino, and Indian English. Estimated impact: calculated by dividing the flagged total by the number of test items (k = 36).
To examine the estimated impact on measurement at the test level, the cumulative DIF size for each group was divided by the length of the test (i.e., 36 items) as all the questions have equal weight (Linacre, 2021). The largest cumulative values for unfamiliar English items by the Japanese examinees resulted in .02 logits (.54/36). For this particular test, the smallest value that could cause an increase/decrease of 1 point on the raw score scale was |.12|, which is larger than the cumulative value. Thus, while the test indicated many flagged items, the effect seems to be negligible since it was not likely to influence raw total test scores. This low cumulative value is partly attributable to the inconsistent direction of the effects. That is, in general, unfamiliar English items did not systematically advantage or disadvantage one group of test takers over others. This finding for the Japanese group suggests that the effects were also trivial for the rest of the groups since their cumulative DIF sizes were smaller.
Discussion
The current study investigated construct validity and fairness in the inclusion of less familiar Hawai’i, Filipino, and Indian English alongside more familiar Midwestern and Northeastern American English in the listening input of an academic English placement test in Hawai’i. Data were taken from a post-entry placement test that uses highly proficient or first-language/home-language speakers of English (Brown et al., 2018; Clark, 2007). To assess the construct validity of including these Englishes, I used CFA to test two hypothesized models: a one-factor model and a two-factor model, with the two-factor model separating expectedly unfamiliar English items from the expectedly familiar English items. To test fairness in presenting unfamiliar English, I used Rasch-based DIF analysis to find if there were differences among test takers as a function of the test takers’ country of origin.
The first research question asked whether the familiar American English items yielded a different latent factor from the Hawai’i, Filipino, and Indian English items. CFA suggested that the one-factor model was the best solution for the data. The model suggests that the familiar American English items and the unfamiliar Hawai’i, Filipino, and Indian English items measure the same underlying construct. This provides evidence that the listening ability for unfamiliar English varieties is not substantially different from the listening ability for more familiar continental United States English in academic lecture settings. The comparable loadings further suggest that the underlying construct equally predicts the success in understanding Hawai’i, Filipino, Indian, and familiar American English.
However, somewhat low factor loadings (.40–.59) require some considerations. When squared, the single factor of listening comprising all English varieties explains only 16% to 35% of the variance in test scores. This indicates that there is a substantial amount of variance left unexplained. This issue was corroborated by the findings from the Rasch analysis, which revealed that the Rasch measure, especially the person measure, explained a limited amount of variance. The issue was caused by the limited range of the test-taker population. As discussed, in TOEFL iBT, those with a score of 60–99 are required to take the test, while those with 100 and more are exempted. Thus, the low factor loadings can be attributable to the restricted range of the test-taker population.
The one-factor model suggests that subscore reporting and interpretation based on English variety are not required. Thus, it validates the current score reporting and use. This contradicts earlier findings that familiarity with the English variety influenced strategy use (Harding, 2018). In Harding, six French learners of English listened to Southern British English, which was familiar to them, and Thai English, which was unfamiliar to them. They reported greater difficulties with Thai English and reported that they used more strategies to comprehend it. However, Harding also found some differences among individuals. That is, some listeners reported that they did not have issues with Thai English. One possible explanation might be that the degree of difficulty reported in Harding was not too severe to influence test scores. That is, while unfamiliarity might add some difficulties to comprehension, test takers might be able to cope with it using some strategies. For instance, some participants in Harding used directed attention, selective attention, comprehension monitoring, and inferencing. In fact, these strategies are commonly discussed in L2 listening studies that are typically based on English comprehension in general (Goh & Vandergrift, 2021). That is, the use of unfamiliar or less familiar varieties of English, which might include proficient or expert L2 speakers of any English varieity, might end up requiring the strategies that are also necessary for overcoming difficulties in more familiar L1 English varieties. Therefore, the present study offers support for the use of justified English varieties in listening input, even if the variety is unfamiliar to test takers.
The suggestion is also in line with previous studies (e.g., Kang et al., 2019; Shin et al., 2021). The finding from CFA offers support for the inclusion of a variety of English, both L1 and L2 varieties, in listening input. While the one-factor model could be interpreted as support for the use of any single English variety to measure English listening skills, such tests still have shortcomings in terms of authenticity, inclusion, fairness, representation, extrapolation, and washback. Rather, I argue that the finding is encouraging for test developers who are interested in including a variety of English because the TLU domain can be represented more faithfully without a major reconsideration of the test construct and score reporting. In addition, test developers can expect more positive washback (Messick, 1996). That is, the inclusion of English varieties guides test takers’ learning, which better prepares them for real-life language use. Interested test developers may be able to tweak a test specification slightly to be more inclusive and representative of speakers in the TLU domain. A variety of English can be employed with much less statistical concern than previously thought.
Of note, an exploratory model where the Hawai’i English items were grouped with the Midwestern and Northeastern English items to form a latent factor of L1 found the same result: two latent factors (L1 and L2) were perfectly correlated. This indicates that the listening ability of highly proficient L2 speakers is psychometrically indistinguishable from the one of L1.
However it is still unknown if the findings can be generalized to different contexts (e.g., business), different task types (e.g., dialogue), different populations (e.g., beginner learners, L1 listeners), and speakers with different levels of proficiency. In particular, it would be interesting to know whether the findings from this study hold true when test takers and speakers share their L1. Future studies should investigate such issues.
The second research question examined the degree to which Filipino, Indian, and Hawai’i English items are flagged for DIF. While some flagged items were expected, those items should not substantially influence the total score if the test is fair. That is, a lack of substantial DIF effect from the unfamiliar English items on raw total scores would demonstrate fairness: no test taker groups had particularly different reactions to the English varieties. The results indicated many flagged items across the items with a greater proportion of the flagged items within the Filipino, Indian, and Hawai’i items as a group. This indicates that unfamiliar English items are more likely to be flagged for a difference in difficulty for at least one group. However, the direction of the observed effect was relatively inconsistent such that flagged items generally indicated both positive and negative effects for a given group. This should be seen positively, as the test takers were not exclusively dis/advantaged. In addition, the overall DIF effect at the test level seemed to be negligible. When the effect of observed DIF items was translated into the metric of raw score estimates, it amounted to a small fraction of a single point on the raw total score scale. This suggests that the overall effect of unfamiliar English input is negligible at the test level. Thus, it would not seem that any group of test takers had a particularly higher familiarity with the English variety to the extent that it influenced test scores. This provides some indirect evidence relevant to Kunnan’s (2018) equal learning opportunities. However, note that the study did not have a direct measure to assess familiarity, thus, the findings remain hypothetical. Yet, together with the finding from CFA, it provides support for the inclusion of a variety of Englishes in listening input as the overall influence of unfamiliar English items on raw scores across the test taker groups is negligible.
The last research question examined item biases in relation to item types. The hypothesis was that narrow items were more likely to be flagged. The result supported this hypothesis showing a higher proportion of DIF in narrow items than in broad items. This is in line with Shin et al. (2021) who found that the shared-L1 effect was more likely in narrow items. Taken together, unfamiliar English items seem to be flagged more in narrow items than in broad items. Interestingly, familiar American English items also had a higher proportion of flagged items in narrow items than broad items. This might indicate that narrow items are more likely to advantage/disadvantage certain test takers over others because bottom-up processing is more dependent on L1 background and language distance between learners’ L1 and accents.
The finding that broad items were less likely to be flagged has an implication for test developers. Together with the previous studies (Harding, 2012; Shin et al., 2021), the study suggests that the occurrence of DIF is different across task types and item types. Thus, test developers who would like to use a variety of Englishes but want to minimize the impact of DIF might be able to use items that target broader, rather than narrower, comprehension. Yet, as the present study showed, the overall DIF effect, at the test level, might be negligible even though narrow items are employed.
Limitations
Although the current study provided unique insight into the function of a variety of English listening inputs in the real world, some limitations should be acknowledged. First and foremost, the modest sample size limited the generalizability of the findings. For CFA, a larger sample size would have allowed item-level analysis instead of passage-based subscores. For DIF analysis, large standard errors were observed, which might have influenced the detection and precision of DIF findings. The smallest group only had 94 test takers (Chinese group), while Linacre (2021) recommended responses from approximately 1000 test takers in each group for dichotomous items. However, Linacre (1994) also suggested a sample size of as small as 50 for useful and stable estimates. Thus, the findings from the present study deserve serious consideration. In addition, the difference in the speech rate among the passages might have influenced the findings. Future studies should examine the effects of English variety and speech rate on factor structure and DIF. Moreover, the lack of a direct assessment of familiarity with each English variety would have allowed more confidence in interpreting the findings.
Conclusion
The study investigated the construct validity and fairness of an operational language test, which utilizes listening passages with a variety of English that broadly represents the test’s TLU domain: Midwestern English, Northeastern English, Hawai’i English, Filipino English, and Indian English. The use of multiple proficient L2 speakers who are expectedly equally unfamiliar to test takers is in line with Harding’s (2012) second and third proposals. The study exemplified how the suggestions from the laboratory-based studies can be implemented and validated using the real-world data. The findings from the real-world operational test offered a promising example of how a variety of justifiable English can be incorporated into an academic English listening test by showing that, in the specific test and context: (a) the various Englishes tap into the same underlying ability and (b) overall DIF effect of the unfamiliar (Hawai’i, Filipino, and Indian) English only results in a slight fraction of a single point on the total score scale. Test developers who are interested in using a variety of English listening input to better represent the TLU domain and to have a more positive washback are able to do so without bifurcating the listening construct or compromising fairness.
Footnotes
Acknowledgements
I would like to thank Dr. Daniel Isbell, Dr. Dustin Crowther, three anonymous reviewers, and the editor for their extensive and constructive feedback. I also thank Kenton Harsch, Justin Kanda, and Priscilla Faucette for their professional support for the study. However, any shortcomings are my own.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.