
Abstract
Despite extensive research on assessing collocational knowledge, valid measures of academic collocations remain elusive. With the present study, we employ an argument-based approach to validate two Academic Collocation Tests (ACTs) that assess the ability to recognize and produce academic collocations (i.e., two-word units such as key element and well established) in written contexts. A total of 343 tertiary students completed a background questionnaire (including demographic information, IELTS scores, and learning experience), the ACTs, and the Vocabulary Size Test. Forty-four participants also took part in post-test interviews to share reflections on the tests and retook the ACTs verbally. The findings showed that the scoring inference based on analyses of test item characteristics, testing conditions, and scoring procedures was partially supported. The generalization inference, based on the consistency of item measures and testing occasions, was justified. The extrapolation inference, drawn from correlations with other measures and factors such as collocation frequency and learning experience, received partial support. Suggestions for increasing the degree of support for the inferences are discussed. The present study reinforces the value of validation research and generates the momentum for test developers to continue this practice with other vocabulary tests.
Keywords
Introduction
Over the past two decades, a growing body of research on assessment of second language (L2) collocation knowledge has greatly contributed to the advancement of L2 researchers’ understandings of collocations as an assessment construct (e.g., Gyllstad, 2009; Nguyen & Webb, 2017; Nizonkiza et al., 2020; Revier, 2009). However, research on testing collocational knowledge in written academic contexts remains limited and faces challenges of validation. In particular, valid measures of knowledge of academic collocations (two-word combinations frequently occurring in a wide range of academic disciplines, e.g., significant difference and ultimate goal) are needed for the field of English for Academic Purposes. Fitzpatrick and Clenton (2010) noted that vocabulary testing research was lagging behind other fields. Schmitt et al. (2020) continued to advocate for more rigorous test validation in vocabulary assessment and suggested argument-based validation (Kane, 2006, 2013) as a recent approach to inform validity. The socio-cognitive framework (see Weir & Shaw, 2005) has been used by many test developers as a practical way to achieve the same goals. With this study, however, we adopt the argument-based framework because it has been successfully applied to various language proficiency tests, such as TOEFL (e.g., Chapelle et al., 2008) and IELTS (e.g., Aryadoust, 2011), but it has yet to be widely employed in the field of vocabulary assessment.
With the present study, we aim to investigate the validity of two Academic Collocation Tests (ACTs) using the argument-based framework (Kane, 2006, 2013). The ACTs are paired tests (i.e., assessing the same academic collocations in different formats): the Academic Collocation (AC) Recognition Test assesses the ability to recognize academic collocations and the AC Recall Test measures learners’ ability to produce academic collocations in written contexts (the modalities of recall and recognition were also used by Laufer & Goldstein, 2004). To the best of our knowledge, these are the first such paired tests. Students may have less difficulty in comprehending academic collocations in reading than producing them in written texts, as research suggests that learners often develop receptive skills faster than productive skills in L2 acquisition (Fernández & Schmitt, 2020; Webb, 2008). Hence, separate measures are necessary to have a better insight into learners’ knowledge of academic collocations.
Argument-based validation
“Validity refers to the degree to which evidence and theory support the interpretations of test scores for proposed uses of tests” (American Educational Research Association et al., 2014, p. 11). In validating the interpretation or use of test scores, researchers are evaluating the plausibility of the claims people make based on the test scores. In argument-based validation, researchers first outline explicitly the proposed interpretation and use, and then evaluate the plausibility of these proposals (Kane, 2013). Specifically, researchers start by listing all potential claims (proposed interpretations and uses based on test scores) in a chain of score-based inferences. Next, each claim or inference is examined using the Toulmin (2003) framework of argumentation to provide the warrants (general statements that are used to justify a claim) and/or rebuttals (alternative explanations or counterarguments to a claim). Warrants and/or rebuttals can be supported (or overturned) based on backings or evidence collected from theoretical and/or empirical research. All of these elements are connected in an argument structure as shown in Figure 1.
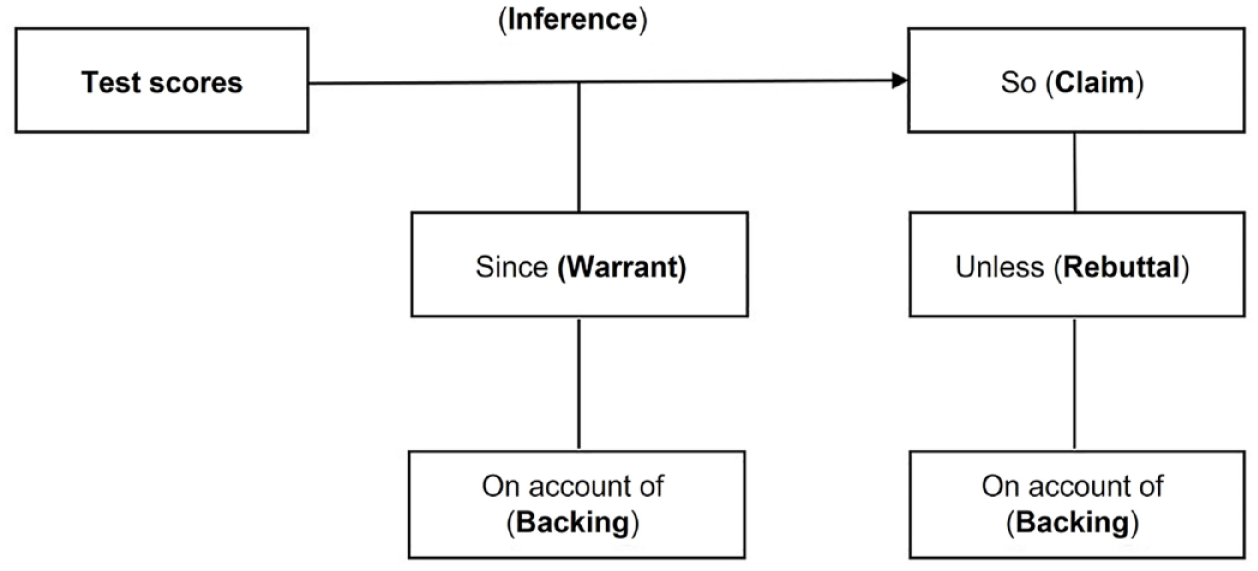
The argument structure (based on Kane, 1992, and Toulmin, 2003).
Original conceptualizations of the argument-based approach (Kane, 1992; Kane et al., 1999) included three inferences: scoring, generalization, and extrapolation. Later, especially after Bachman and Palmer’s (2010) assessment use argument was proposed, Kane added a decision inference (Kane, 2013) and changed the terminology from “interpretive argument” to “interpretation/use argument.” The scoring inference takes people from the observation of test-taker performance to a score. In this inference, researchers and test-score users are claiming that the scoring procedures are appropriate and that the scoring rule is applied accurately and consistently. The generalization inference takes people from the observed score to a universal score. Test designers and scorers are claiming that sample performance they observe is representative of all possible performances. The extrapolation inference is the link between the universe score to a level of real-life ability or skill. Researchers, test designers, and test-score users are claiming that test scores are indicative of test-takers’ real-world abilities in the target domain. The decision inference takes people from score interpretation to score use. Test scores are used to make decisions which entail actions and consequences.
Argument-based validation in language testing
Dursun and Li (2021) identified a clear trend for the growing use of the argument-based framework for validation. It has been employed for both high-stakes tests such as TOEFL iBT (e.g., Chapelle et al., 2008) and low-stakes tests (e.g., a pragmatic test by Youn, 2015; a web-based English as a second language (ESL) test by Chapelle et al., 2003). The number of inferences and the amount of evidence vary depending on what is being claimed. For instance, Knoch and Chapelle (2018) included six inferences to investigate the rating of test-takers’ writing performance, while Beigman Klebanov et al. (2019) focused on the extrapolation inference to explore the relationship between test scores and real-life tasks. These examples illustrate the broad applicability and flexibility of the framework to different aspects of language testing.
Various methods of empirical research can be designed to collect evidence for the assessment of inferences in a validation framework (see Chapelle, 2021, p. 115 for more examples). For the scoring inference, evidence can include analysis of test-taking conditions, test characteristics, and scoring procedures (Dursun & Li, 2021). Quantitative evidence is commonly used in validation research (see Aryadoust, 2009), for example, through the use of tools such as a Rasch model (Rasch, 1993) and analysis of test scores for statistical characteristics of test items. Several researchers have employed qualitative evidence for the scoring inference. Youn (2015), for example, used both Rasch analysis based on test scores and qualitative analysis of role-play performances to provide backings for the scoring inference.
Reliability indices for the generalization inference are frequently utilized to indicate the consistency of test scores. For example, Jang (2009) used Cronbach’s alpha to provide estimates of internal consistency for L2 reading comprehension tests, whereas Youn (2015) used Rasch reliability estimates as backings for the generalization inference. Correlation analysis is often used to demonstrate that test scores appropriately reflect the intended test construct, especially for new test development (Dursun & Li, 2021). Voss’s (2012) finding of a positive correlation between the Collocation Ability Test and an academic vocabulary subtest gives support for the validity of the collocation test, for example. The methods used for collecting empirical evidence in previous validation studies provide useful references for the process of gathering validity evidence for the ACTs for our study.
Argument-based validation of collocation tests
Validation has not yet been a common practice in vocabulary assessment, particularly in testing collocational knowledge. Most previous studies focus on measuring either receptive (e.g., Nguyen & Webb, 2017; Nizonkiza, 2015) or productive knowledge of collocations (e.g., Nizonkiza et al., 2020; Van Dyk et al., 2016). More research has focused on test development than on the validation process (see Gyllstad, 2020; Gyllstad & Schmitt, 2019 for more). Often, neither the validation approach nor justification is given in such studies (Chapelle & Lee, 2021). Evidence (if any) usually includes reliability indices (e.g., Nizonkiza, 2015; Revier, 2009). Several studies compare scores on the collocation test with scores on other tests of a similar construct (e.g., Gyllstad, 2009). Without a clear reference to a specific framework, it can be hard to assess test validity.
With many layers of concepts, the argument-based framework is challenging, and interpreting results connected to a complicated network of inferences may not always be straightforward for readers who are unfamiliar with this framework. Only two unpublished doctoral projects appear to have applied the argument-based validation to collocation tests: (1) Voss (2012) designed a gap-filling test to assess productive knowledge of academic collocations; and (2) Chen (2019) employed a matching format to measure receptive knowledge of general collocations. With a restricted audience for such dissertations and several hundreds of pages of reading needed to fully understand the value of the validation approach, there are clearly challenges with its application to language testing. This study aims to keep the validation framework as brief and straightforward as possible for readers, in the hope that doing so might encourage other vocabulary researchers and practitioners to apply this framework.
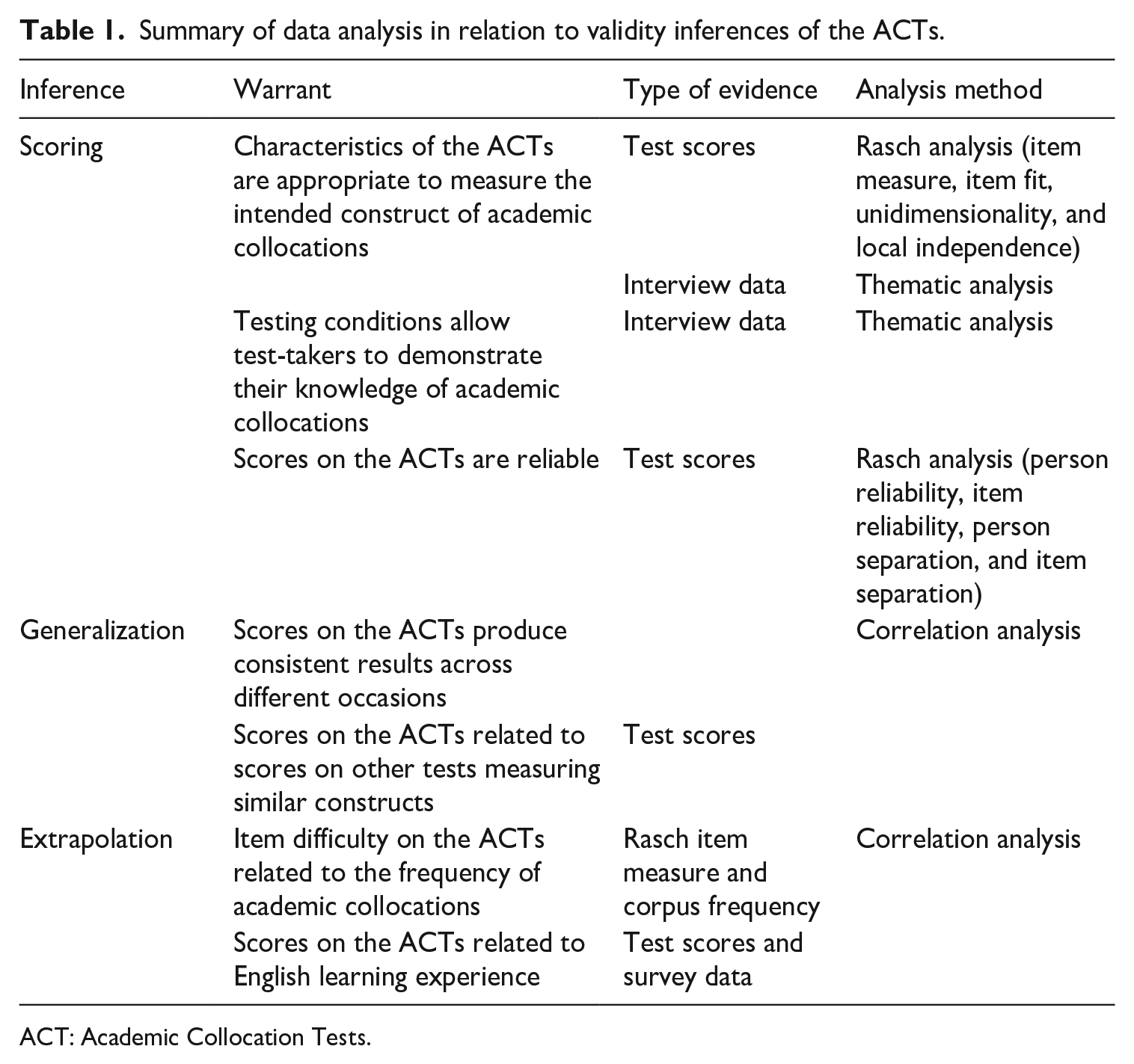
The proposed inferences and warrants based on the ACT scores are summarized in Figure 2. The scoring inference is concerned with the core elements of a test, including test characteristics, testing conditions, and the scoring system. The generalization inference is related to reliability. The extrapolation inference provides a better understanding of the relationship between academic collocation knowledge and other factors such as vocabulary size, general language proficiency, and English learning experience. The decision inference about test use is not discussed in this paper. Although the ACTs are potentially useful for diagnostic purposes, these tests have not been employed in any classroom contexts where evidence could be collected to justify this inference.

Proposed inferences and warrants of the ACTs.
Method
This section presents the methodology which guided the collection of empirical evidence to assess the validity of the proposed inferences of the ACTs.
Participants
A total of 343 university students participated in this study: 233 in Vietnam and 110 in New Zealand. The Vietnam cohort was all English majors with on average more than 9 years of formal English as a foreign language (EFL) learning. The New Zealand participants were all L2 English speakers who had been studying in English-speaking countries for at least a year. The majors of this ESL group ranged widely, including Linguistics, Applied Linguistics, Education, Economics, and Finance. Forty-four participated in post-test interviews. Pseudonyms with a tag of “VN” or “NZ” (e.g., Trang NZ) are used in the interview data.
Instruments
We employed five data collection instruments: the AC Recognition Test, the AC Recall Test, the Vocabulary Size Test (VST; Nation & Beglar, 2007), a background questionnaire, and a post-test interview, which are now described in turn.
The ACTs
The ACTs are newly created tests which are part of a larger project (Nguyen, 2022). We created them from the Academic Collocation List (ACL, Ackermann & Chen, 2013) based on an evaluation of two published lists of academic collocations (Nguyen & Coxhead, 2023). A wide range of frequency and collocation kinds (e.g., adjective + noun, verb + noun, etc.) were selected from the ACL to develop 60 test items for both ACTs. The tests use different test formats, but share the same academic collocations and context sentences, which allows the two tests to be used independently or together to compare recognition and recall knowledge of academic collocations. The tests aim to provide diagnostic feedback for English for Academic Purposes (EAP) teachers about learners’ knowledge of academic collocations so that further support could be provided if necessary. When administered in the same sitting, the use of the same context sentences in both tests might reduce the reading burden for test-takers.
The AC Recall Test (see Appendix 1) aims to measure test-takers’ ability to produce a suitable academic collocation for a written context. This test includes 60 items using an adapted c-test item format in which two initial letters of each word in a collocation are provided and the meaning of the collocation is given in brackets at the end of the context sentence. Test-takers are requested to provide a complete academic collocation in a box below each question (see Figure 3).

Example of an AC Recall Test item.
The AC Recognition Test
The AC Recognition Test (see Appendix 2) aims to measure the ability to recognize the form and meaning of an academic collocation in a written context. Using the multiple-choice format (see Figure 4), the AC Recognition Test contains 60 items, each of which has a context sentence with two blanks: one for each word in the academic collocation being tested. Two-word collocations are always presented without any other words in between (except for possible articles in some cases). Four options of academic collocations are given for test-takers to select the most suitable one to fill the blanks.

Example of an AC Recognition Test item.
The VST
The VST (Nation & Beglar, 2007) is a measure of learners’ overall English vocabulary size (i.e., how many English words they recognize). It has a total of 140 items in a multiple-choice format. Test-takers are presented with a target word in a non-defining context and four different definitions of the word to select from (Figure 5).

Example of a VST item (Nation & Beglar, 2007, p. 11).
As a concurrent validity measure, we used the VST in the present study, mainly because vocabulary knowledge is related to collocation knowledge, but also because at the time we did not have access to another highly reliable collocation test. The VST was chosen over the Vocabulary Levels Test (VLT) (Schmitt et al., 2001) for this study because the VST has a wider coverage of frequency bands (from 1000 to 14,000 word levels), while the VLT only includes several sample levels (2000; 3000; 5000, and 10,000 word levels). Nation and Beglar (2007) argued that the VST is closer to a vocabulary proficiency test, whereas the VLT is more of a diagnostic measure (see Stoeckel et al., 2021 for a systematic distinction between the VST and the VLT). Despite being found to be a reliable and valid instrument to measure vocabulary size using Rasch analysis (Beglar, 2010), the VST has been criticized for overestimation issues (see Stoeckel et al., 2021). That said, we used the VST as an exploratory measure of concurrent validity, expecting a medium to high correlation between the tests.
Background questionnaire
A questionnaire (see Appendix 3) was developed to obtain participants’ background information including name, gender, age, first language, study level and major, length of learning English, and length of studying in an English-speaking country. The New Zealand questionnaire had two additional screening questions to ensure that participants were not first-language speakers of English and they had been studying in an English-speaking country for at least a year. These ESL participants were also asked to report on any of their past English language proficiency test results.
Post-test interviews
The aims of the interviews were to have test-takers reflect on the ACTs and to explore whether the answers given on the online tests would correspond with their verbalized knowledge. The interview included three parts: introduction, reflection, and retaking the ACTs verbally (Figure 6).

Summary of post-test interview sections.
Data collection
Qualtrics was used as a questionnaire and testing platform after COVID caused a change from pen and paper administration. Participants took the questionnaire and the three low-stakes tests at their convenience. There was no time limit. The online questionnaire and tests were delivered in the following order:
Questionnaire
The AC Recall Test
The VST
The AC Recognition Test
The semi-structured interviews were conducted within 2 weeks of the online tests on Zoom. They were conducted one-on-one in Vietnamese or English and were audio-recorded.
Data analysis
The data analysis aims to provide evidence pertaining to the inferences in the validation framework of the ACTs. Table 1 shows three main analysis methods: Rasch analysis and correlation analysis for the quantitative data, and thematic analysis for the qualitative data. First, Rasch analysis (using Winsteps; Linacre, 2019) provided a measurement model to investigate the score sets and determine whether items on the ACTs work well together to measure the intended construct. Four properties of the tests were examined: item measure, item fit, unidimensionality, and local independence. If the test items conformed to the model predicted by Rasch, a possible conclusion might be that the tests are measuring the single construct of academic collocations and there is no significant construct-irrelevant variance.
Summary of data analysis in relation to validity inferences of the ACTs.
ACT: Academic Collocation Tests.
Second, Spearman’s correlation (rs) was employed because the score sets were not normally distributed (see descriptive statistics in Table 2). Scores of tests with similar constructs (ACTs, the VST and the IELTS) were correlated. The ACT item difficulty (as indicated by the Rasch item measure) was then correlated with the frequency of academic collocations, and the ACT test scores were correlated with years of studying English. Spearman’s correlation coefficient was also used to indicate the test–retest reliability. If the ACTs could consistently produce the same results, then the relationship between the two score sets (online tests and verbal tests in the interviews) should be high.
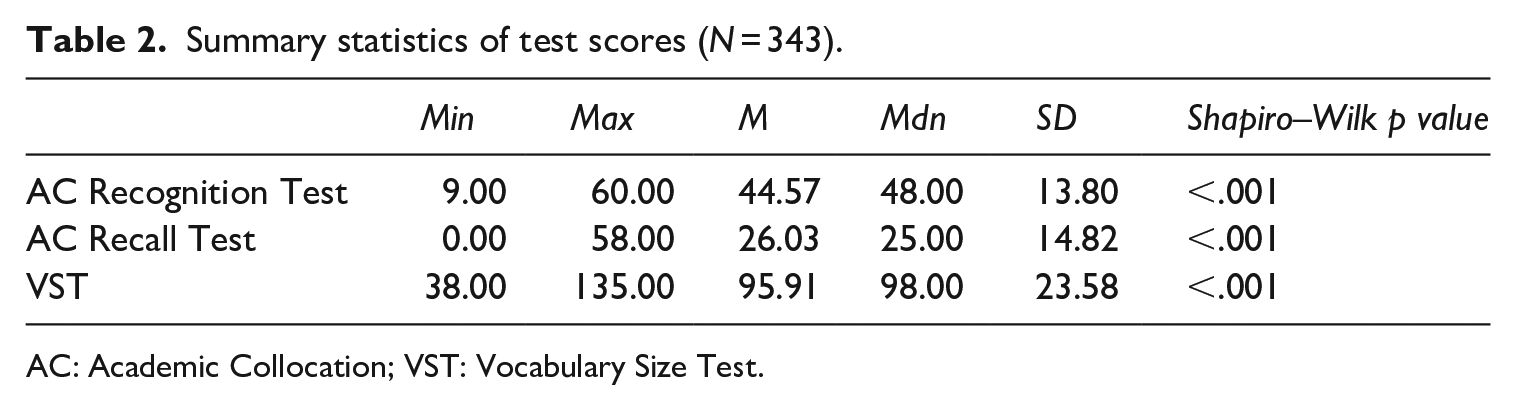
Summary statistics of test scores (N = 343).
AC: Academic Collocation; VST: Vocabulary Size Test.
The interviews were transcribed and the Vietnamese scripts were then translated into English. The validation framework of the ACTs (Figure 2) was then employed to search for themes within the data following Braun and Clarke (2012).
Results
This section reports the findings that served as evidence for the assessment of the inferences in the argument-based validation framework applied for the ACTs. The participants’ scores on the ACTs and VST (Nation & Beglar, 2007) are in Table 2, which forms the basis for further statistical analysis. All three score sets covered a wide range of scores with a large amount of variation in the group of participants being tested.
Scoring inference
The scoring inference states that test-takers’ performance on the ACTs was appropriately observed and scored. This inference relies on warrants concerning the appropriateness of the test characteristics, testing condition, and scoring method. The evidence used to evaluate these warrants is detailed below.
Test characteristics
Rasch model analysis of test items and test-takers’ opinions about the ACTs are the evidence for the test characteristics. We now look at them in turn.
Rasch analysis of the AC Recall Test
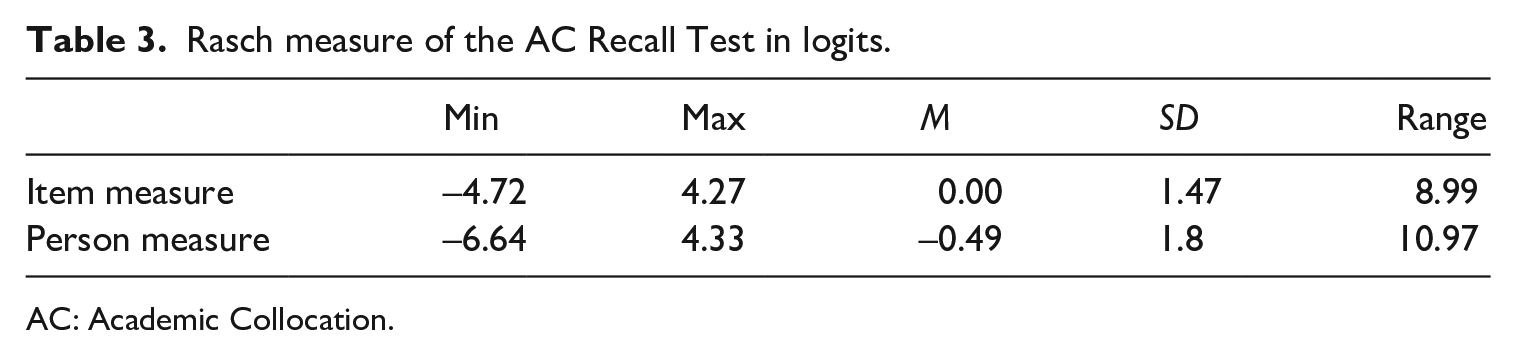
The items of the AC Recall Test showed a wide range of item measures from −4.27 to 4.72 logits (Table 3), which indicates that the items in this test are very different in terms of item difficulty. The mean item measure was set at 0.00 logit by default and a lower mean at −0.49 logit of person measure suggested that the AC Recall Test was difficult for this group of candidates.
Rasch measure of the AC Recall Test in logits.
AC: Academic Collocation.
The Wright Map in Figure 7 gives a fuller picture of the alignment of the item difficulty with the person ability. The person column on the left refers to test-takers, and the item column on the right indicates the AC Recall Test items. Those with better knowledge of academic collocations (i.e., higher ability) and items that are more difficult are at the top of the map. Lower-performing participants and easier items are at the bottom of the map. Figure 7 clearly shows that the distribution of items on the right relatively matched the distribution of persons on the left, although a few people seemed to have lower recall knowledge of academic collocations than what the test could capture.

Wright Map of the AC Recall Test (343 persons, 60 items).
Items in the AC Recall Test were regarded as misfits if their MNSQ values did not fall between 0.5 and 1.5, or their ZSTD values were not from −2.0 to 2.0 (Linacre, 2019). Table 4 shows there is one overfit item (14) and two underfit items (6 and 7) in the AC Recall Test (misfit values are denoted in bold). Underfit refers to items that contain more unexpected responses than the model could predict and therefore may degrade the quality of the measurement. Overfit means the items show less variability than predicted, so the reliability may be overestimated. Underfit items are hence of greater concern and should be revised.
Misfit items in the AC Recall Test.
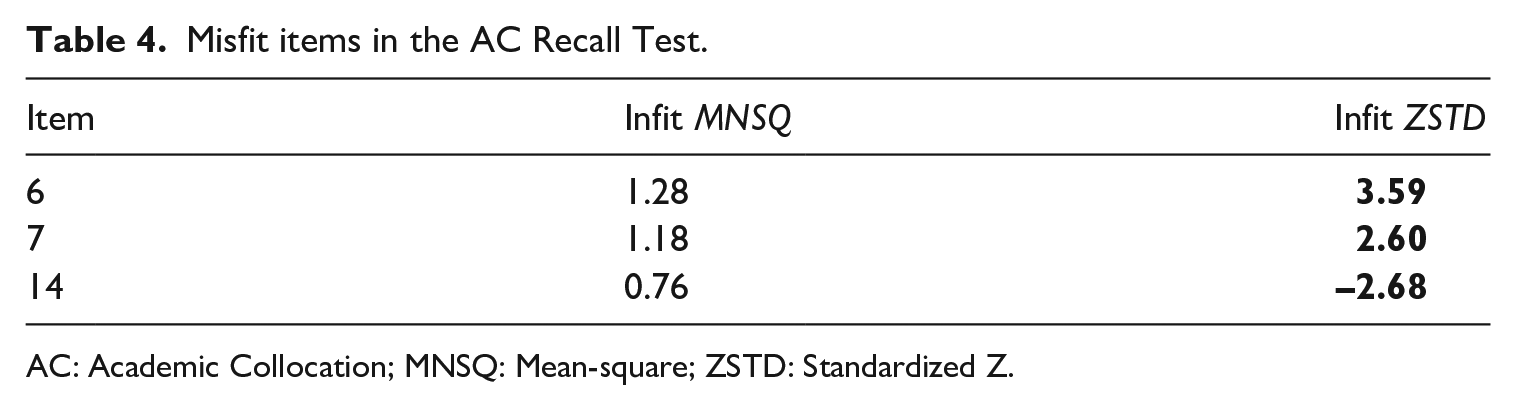
AC: Academic Collocation; MNSQ: Mean-square; ZSTD: Standardized Z.
The unidimensionality of the AC Recall Test items were confirmed by the principal component analysis of residuals. The first contrast of the test had an eigenvalue of 2.5 and accounted for a small variance (2.4%) in the data, suggesting a minor violation to unidimensionality (Raîche, 2005). In reality, complete unidimensionality is rarely achieved. A local independence analysis confirmed the unidimensionality of the test when the Q3 coefficients of the item pairs in the AC Recall Test were very low (from −0.17 to 0.30) (Appendix 4). This finding suggested that no pair of items in the test has a strong relationship to constitute a secondary construct of the measure. All the test items are independent, which means that the answer of one item does not affect how the other items are answered.
Rasch analysis of the AC Recognition Test
The item measures of the AC Recognition Test were from −2.20 to 1.29 logits, while the person measures varied from −1.96 to 5.56 logits (Table 5). The item measures (3.49 logits) have a narrower range than the person measures (7.52 logits). The mean of item measures was set at 0.00 logit by default, and on average the person ability at 1.83 logits was higher than the item difficulty in the AC Recognition Test. The results indicated that generally, the AC Recognition Test was easy for this group of test-takers.
Rasch measure of the AC Recognition Test in logits.

AC: Academic Collocation.
The Wright Map in Figure 8 provides a visualization of the relationship between test-takers’ knowledge and item measures on the same scale of measurement. The mean of person distribution lies above the mean of item distribution on the measurement scale. The majority of the AC Recognition Test items are clustered around a narrow band of person abilities, and the abilities of more than half of the test-takers were well above what the test could capture. In other words, the majority of the test-takers found this test very easy.

Wright Map of the AC Recognition Test (343 persons, 60 items).
To gain insight into the test items, the fit statistics (infit MNSQ and infit ZSTD) of 60 AC Recognition Test items were examined. For mid- or low-stakes multiple-choice questions, a more stringent range of 0.7–1.3 is suggested (Linacre, 2019). All items with MNSQ values outside the above range and ZSTD values outside the range of −2.0 to 2.0 were identified as misfits. A total of 11 misfit items were detected in this test (Table 6, misfit values are denoted in bold): five items (11, 31, 38, 39 and 47) were overfit (ZSTD < −2.0) and six items (10, 18, 19, 25, 37, and 53) were underfit (MNSQ > 1.3 and ZSTD > 2.0).
Misfit items in the AC Recognition Test.
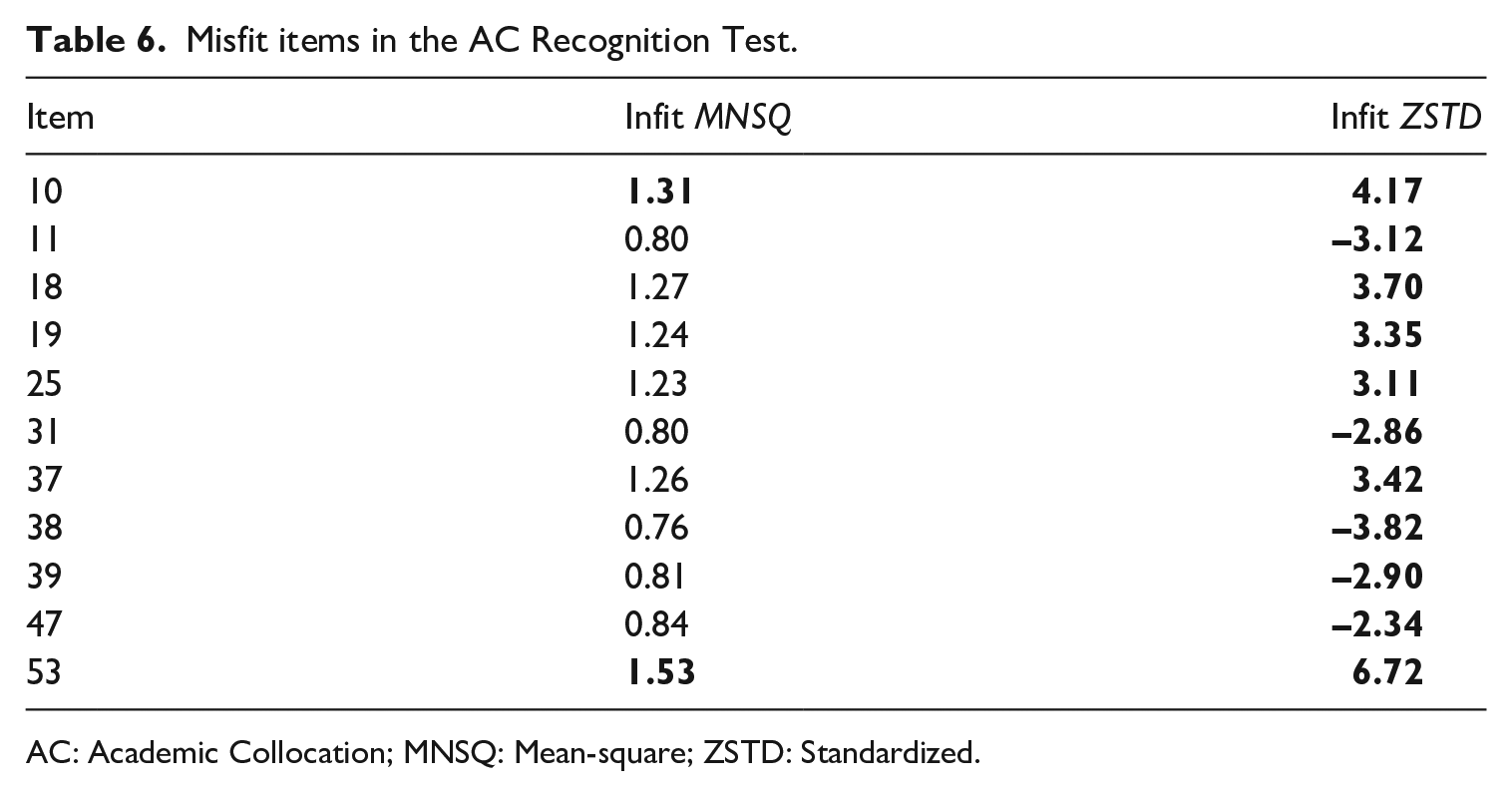
AC: Academic Collocation; MNSQ: Mean-square; ZSTD: Standardized.
To check whether distractors could be a source of misfit, further investigation into item distraction efficiency of the AC Recognition Test items with unsatisfactory fit statistics was conducted. All the distractors of 11 misfit items were selected by people with lower abilities than those who selected the correct answers. The quality of the distractors shows in that they attracted many of the test-takers. If a distractor looked clearly wrong or irrelevant, no test-taker would consider it. This means no distractor needs replacing. Seven items (11, 25, 37, 38, 39, 47, and 53) were not answered by some test-takers. The count for blank answers was under 1% of the total count for each item and the Rasch model is robust to missing data, so they may not have an impact on the item fit.
Our analysis so far has revealed some overfit items which might not degrade the quality of the instruments (Linacre, 2019) and could be the best items of the test as the other items are not as discriminating as these (Wu et al., 2016), especially when no source of misfit could be identified. Because this is not a high-stakes test, 10% of underfit items (10, 18, 19, 25, 37, and 53) should not cause a serious threat to the overall quality of the test for its diagnostic purpose. Although no major issues with the psychometric characteristics of the AC Recognition Test were found, misfit items identified by Rasch analysis reduce the accuracy of the scoring inference.
Principal component analysis of residuals was further conducted to address the dimensionality issue. In the AC Recognition Test, the first contrast had an eigenvalue of 2.4 and accounted for the small variance of 2.8% in the data. This contrast might simply be a result of a random effect in the data (Linacre, 2019), as the analysis of the local independence did not identify significant standardized residual correlations between any item pair. The Q3 coefficient values of all the item pairs (see Appendix 5) fell well within the suggested range between −0.3 and 0.3 (Fan & Bond, 2019), except for the first pair of items 2 and 38 (r = .32), whose value was slightly higher. Looking more closely at these two items, the wordings are very different, and test-takers would find it difficult to form any association between them. This means the answer to one item would not affect how the other item was answered. Therefore, items 2 and 38 seem to be sufficiently independent of each other. The findings suggest that the requirement of local independence is satisfied for the AC Recognition Test. The following sections provide qualitative evidence to add to the assessment of the test characteristics.
Test-takers’ opinions on the AC Recall Test
Three themes related to the format of the AC Recall Test emerged: the sentence prompts, the two-initial-letter hints, and the meanings of the collocations. First, 37/44 (over 84%) of the interviewees provided positive feedback on the sentence prompts. They reported that the sentences were “very clear,” “easy to understand,” “straightforward,” “understandable,” or “reasonable.” This feedback suggests that the context sentences acted as intended. Only seven respondents expressed uncertainty with some sentence prompts. For example, Ngoc VN reported that: I found the context sentences more difficult to understand in the first test [AC Recall Test] with the blanks because the meaning was incomplete (Excerpt 1).
A total of 11 respondents commented on the two-initial-letter hint in the AC Recall Test format. Three acknowledged the usefulness of the initial letters. For example, Dieu VN reported that: For me, with a phrase that I know, the initial letters helped me to recall it more quickly, but with a phrase I didn’t know, even with the initial letters, I still didn’t know. (Excerpt 2)
Four respondents stated that providing only two initial letters for each word was not enough for them to produce the needed collocations. Kim VN, said that: If there had been more initial letters provided, the first test [AC Recall Test] could have been easier. (Excerpt 3)
The remaining four respondents thought that the initial letter hints were not helpful. Nhi VN explained that: Without the two initial letters, various answers could have been accepted, and the difficulty level would have been decreased. With the initial letters, test-takers might not remember exactly the phrases needed in that case. (Excerpt 4)
The participants’ opinions pointed out both pros and cons of this test format. While these letters helped to elicit the intended collocations, they also restricted the possible answers, which might cause difficulty for test-takers when they only knew equivalent phrases but not the elicited collocations.
Thirdly, the meanings in brackets of the academic collocations seem to be an important feature of the AC Recall Test. The participants referred to them favorably, as can be seen in the following representative comment: The meanings in the brackets were very close to the needed phrases. There were cases I couldn’t guess the answers when reading the context sentences, but the meanings in the brackets helped me know the answers. (Dieu VN, Excerpt 5)
Overall, the features of the AC Recall Test format, including the context sentences and the provided meanings of collocations, seemed to work well. Although the initial letter hints might cause difficulty for some test-takers, these hints still fulfilled their task to limit possible correct answers and elicit the intended academic collocations.
Test-takers’ opinions on the AC Recognition Test
The test format received no criticism from the interviewees, possibly because of their familiarity with multiple-choice test formats. Their comments all reflected on the ease of the format. For example, Hong NZ and Linka NZ said they could easily recognize the collocations that they knew among the given options. Ngoc VN and Dung NZ added that the same context sentences being used in both the AC Recall Test and the AC Recognition Test also supported them. This feature of the test worked as intended to reduce the reading burden for test-takers when they had to take the two collocation tests.
An important feature of the AC Recognition Test was acknowledged by Trang NZ, who showed a preference for the current format to test knowledge of academic collocations: I like the way that the phrases go together in your tests rather than being separated. For example, if I gave a wrong answer in a matching test, I would easily remember that incorrect combination. Your tests avoid that issue because the words go together. (Excerpt 6)
The collocations in the AC Recognition Test were intentionally presented as whole units to raise learners’ awareness about this group of multiword units. Even the distractors in this test are real academic collocations. The test, therefore, has no potential side effects on test-takers’ memory trace (see Boers et al., 2014, 2017).
In sum, the respondents’ opinions about the AC Recognition Test format were positive and the respondents were comfortable with the format. The repetition of context sentences from the AC Recall Test to the AC Recognition Test helped to ease the reading burden. The representation of the collocations as whole units was also recognized as an advantage of the test format.
Testing conditions
This section highlights three themes related to test-taking processes by test-takers: test-taking time, dictionary use, and priming effect (i.e., carryover memory from one test to another).
Test-taking time
A time limit was not set for test-takers to increase the chance of the tests being completed. Qualtrics was set to allow test-takers to save their progress and return to the test battery at any time. The completion time varied from almost 1 hour to 151 hours. The respondents were asked whether they finished the tests in one sitting or stopped and returned later. Among 44 interviewees, 20 participants explained that the length of the completion time was extended because they needed to change locations, or they had to stop to do other tasks. For example, Khanh VN said that she returned to the tests three times to complete them. Clearly, the 260-item test battery was potentially affected by a fatigue effect, and multiple test-taking sections could affect data quality, both of which served as partial evidence supporting the rebuttal to the scoring inference.
Dictionary use
Referring to external sources, such as dictionaries, when taking the ACTs would cause a threat to the validity of the test results. About a third of the respondents (16/44) reported using dictionaries to some extent for the AC Recall Test. The frequency of dictionary consultation varied across the respondents, but no interviewee looked up every test item. Nhi VN and Thom VN reported that they relied on dictionaries “quite often” during the test. Others reported their use as “not much,” “for a couple of items,” “just a little,” or “only for one word.” The resources on hand were not collocation or phrase dictionaries, which limited the kind of lexical information needed to complete test items on collocations, and the interviewees expressed disappointment with this strategy: I looked up a couple of items in the first test [AC Recall Test] but it was in vain, so I did the rest on my own. (Khanh VN, Excerpt 7) I used the thesaurus to find synonyms, but I couldn’t find anything. It wasn’t effective. (Morgan NZ, Excerpt 8)
In brief, the use of dictionaries in this testing context provided weak evidence supporting a rebuttal against the scoring inference. Dictionaries were not used often; and it was difficult to find the answers in dictionaries.
Priming effect
All the interviewees confirmed that they were able to recognize the resemblance between the AC tests. Because the two collocation tests use the same context sentences to elicit the same academic collocations, participants taking the two tests in sequence could still remember some aspects of the first test (i.e., the AC Recall Test) to do the latter test (i.e., the AC Recognition Test). Even with the VST as a filler task between the two collocation tests, the priming effect might not be able to be completely ruled out. Participants did not report relying on their memory of the AC Recall Test as a main strategy for taking the AC Recognition Test. When being asked whether she did the AC Recognition Test on her own or remembered the answers from the AC Recall Test, Tran NZ said that: It was a combination of both, but I would do it on my own first. Basically, the phrases were already in my head. I just needed to look at them again and I would remember and choose the correct ones. (Excerpt 9)
Depending on the aspects of the AC Recall Test that participants remembered, the validity of the AC Recognition Test results might or might not be affected. The general impression of having met some phrases or sentences before did not appear to cause any harm. The memory of the sentence prompts reduced the reading burden but did not reveal the answers, so the validity of the AC Recognition Test results should be unaffected. Recall of correct answers in the previous test indicated that test-takers had knowledge of the collocations in the test and, therefore, their correct answers in the AC Recognition Test were expected. Remembering initial letter hints in the AC Recall Test might reveal the correct answer in the AC Recognition Test and thus might negatively affect the validity of the test results. That said, very little evidence was found concerning the ability of the participants to remember the initial letters.
Scoring procedures
The third warrant of the scoring procedure was fully supported. The scoring procedure was carefully developed, piloted, and consistently applied for the AC Recall Test. The lenient scoring method which accepted spelling and grammatical errors resulted in scores that reflected knowledge of academic collocations, and not the knowledge of written form and grammar. The AC Recognition Test was scored automatically using Qualtrics for objectivity and consistency. In sum, the backing provides complete support for the third warrant.
Generalization inference
The generalization inference states that test-takers’ scores on the ACTs are consistent across tasks and occasions. This is based on the warrant that the ACTs exhibited high internal consistency and high test–retest reliability. Different reliability indices are presented as evidence below.
Coefficient alpha and Rasch reliability of the ACTs
Table 7 shows that both the AC Recognition Test and the AC Recall Test achieved Coefficient alpha value of .96, indicating very high reliability.
Reliability indices of the ACTs.
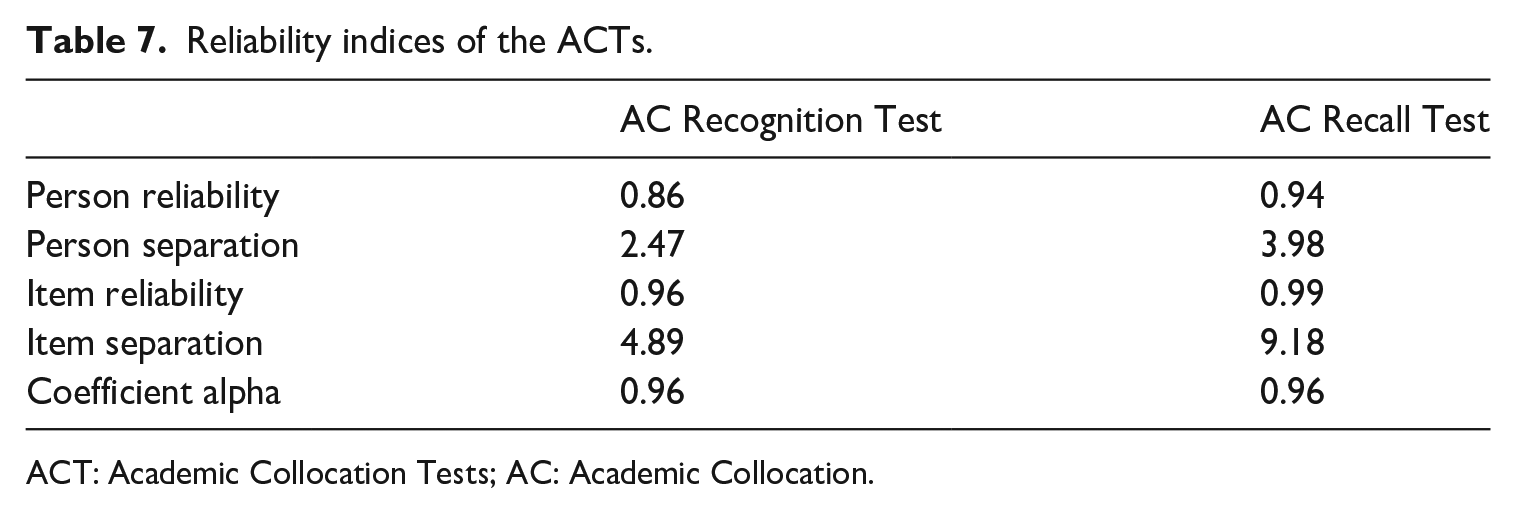
ACT: Academic Collocation Tests; AC: Academic Collocation.
Coefficient alpha may overstate test reliability because it reports the reliability of raw scores that are sample-dependent, while Rasch reliability is less misleading for inference beyond the sample (Linacre, 2019). Using Rasch, the AC Recognition Test with the person reliability of .86 can discriminate the person sample into two or three levels, while the AC Recall Test with the reliability of .94 can divide the sample into three or four levels (see Linacre, 2019). The person separation indices of 2.47 for the AC Recognition Test and 3.98 for the AC Recall Test show that both tests are sensitive enough to distinguish between high and low performers. The item reliability indices (above .90) and the item separation indices (above 3.00) of the two tests imply that the person sample was large enough to confirm the item difficulty hierarchy of the instrument (Linacre, 2019). Overall, the findings provided validity evidence that the ACTs were highly reliable.
Test–retest reliability of the ACTs
Both the AC Recognition Test and the AC Recall Test were found to have high test–retest reliability. Table 8 reports the summary of participants’ results of the online tests (i.e., “Test” columns) and results of the verbal tests (i.e., “Retest” columns).
Summary of ACT Test–retest results (N = 44).
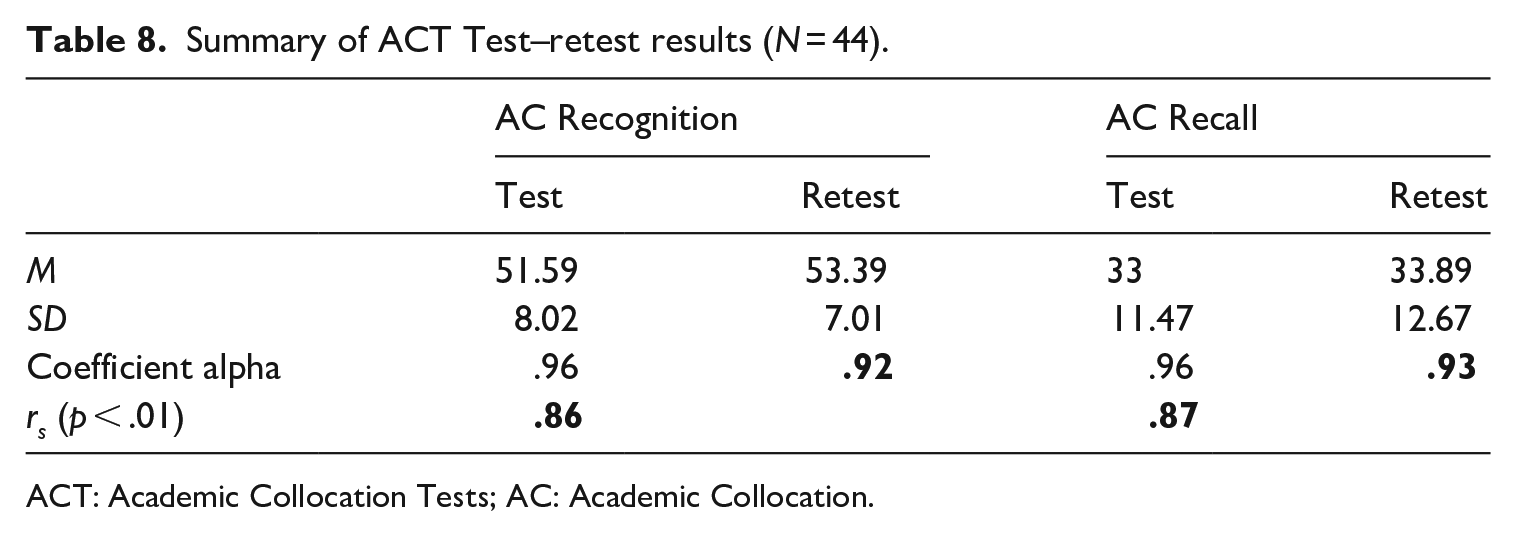
ACT: Academic Collocation Tests; AC: Academic Collocation.
The mean scores of the ACTs in Table 8 are higher in the “Retest” columns than the “Test” column, indicating that participants tended to score slightly higher when they retook the ACTs. The findings showed significantly strong relationships between test and retest results in both the AC Recognition Test (rs = .86, p < .01) and the AC Recall Test (rs = .87, p < .01).
Extrapolation inference
The extrapolation inference states that performance on the ACTs is indicative of the target construct of academic collocations. This inference relies on three warrants: (1) scores on the ACTs are related to scores on other tests that measure similar constructs; (2) item difficulty on the ACTs is related to the frequency of academic collocations, and (3) scores on the ACTs are related to English learning experience. The evidence is reported as follows.
Correlations between tests of similar constructs
Scores on tests of similar constructs are expected to have positive relationships, including the following:
The AC Recognition Test and the AC Recall Test, which measure knowledge of academic collocations;
The ACTs and the VST (Nation & Beglar, 2007), which measure knowledge of English vocabulary;
The ACTs and English language proficiency tests (e.g., IELTS or TOEFL), which measure knowledge of the English language.
The first warrant on the relationship between ACT scores and other tests of similar constructs was supported, as the findings (Table 9) showed that the ACTs were positively correlated with the VST and IELTS (overall scores), with the correlation sizes being weak (.28) and medium (.52, .53). The AC Recognition Test and the AC Recall Test had a strong correlation with .86. Scatter plots of the five correlations are in Appendix 6.
Correlations between tests of similar constructs.
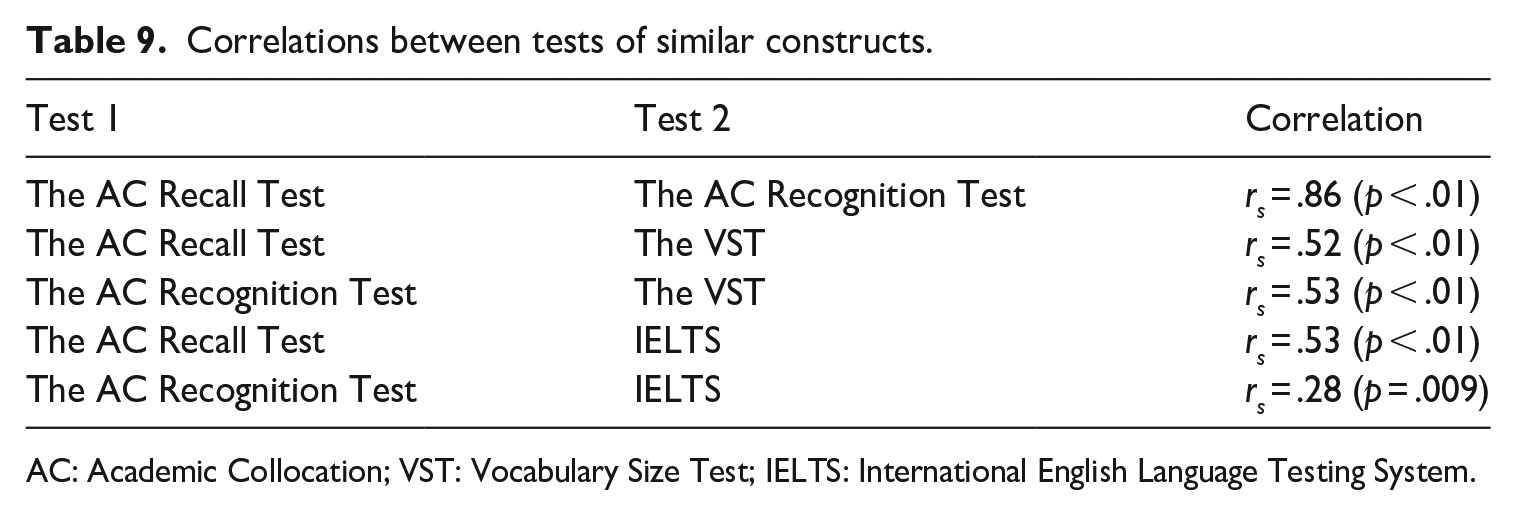
AC: Academic Collocation; VST: Vocabulary Size Test; IELTS: International English Language Testing System.
Correlations between item difficulty of the ACTs and the frequency of academic collocations
Further correlation analysis helps to test an assumption that the test items containing more frequent academic collocations will be easier than items using less frequent collocations. In other words, the more frequent collocations would have a lower Rasch item measure value. Frequency of academic collocations was checked against the Corpus of Contemporary American English (COCA) Academic corpus of 111 million words (Davies, 2017). The range of item frequency is from 112 to 7220 occurrences in 112 million words. The results revealed significant but relatively weak (rs = .29, p < .05) and moderate correlations (rs = .48, p < .05) between corpus frequency and test item difficulty in the AC Recall Test and the AC Recognition Test, respectively. These scatter plots are also in Appendix 6.
Correlations between scores on the ACTs and English learning experience
Table 10 summarizes the time of studying English reported by both EFL students in Vietnam and ESL participants in New Zealand. On average, the respondents had more than 12 years of learning English at the time of taking the ACTs. Participants’ time of studying English has a moderate correlation with their scores on both the AC Recognition Test (rs = .39, p < .01) and the AC Recall Test (rs = .43, p < .01). The scatter plots are given in Appendix 6.
Participants’ time of studying English in years.
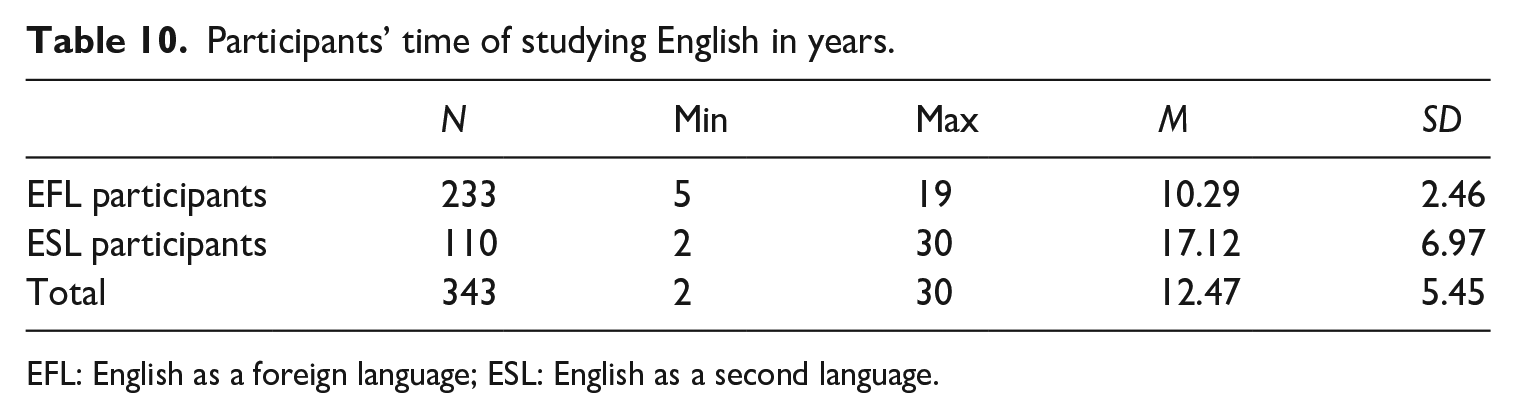
EFL: English as a foreign language; ESL: English as a second language.
Only participants in New Zealand reported the time they studied in English-speaking countries (Table 11). For example, a third-year PhD student in New Zealand who had spent 2 years doing her MA in Australia reported a total time of 5 years learning in English-speaking countries. The average time recorded for all the ESL participants was around 4 years.
ESL participants’ time of studying in an English-speaking country in years.
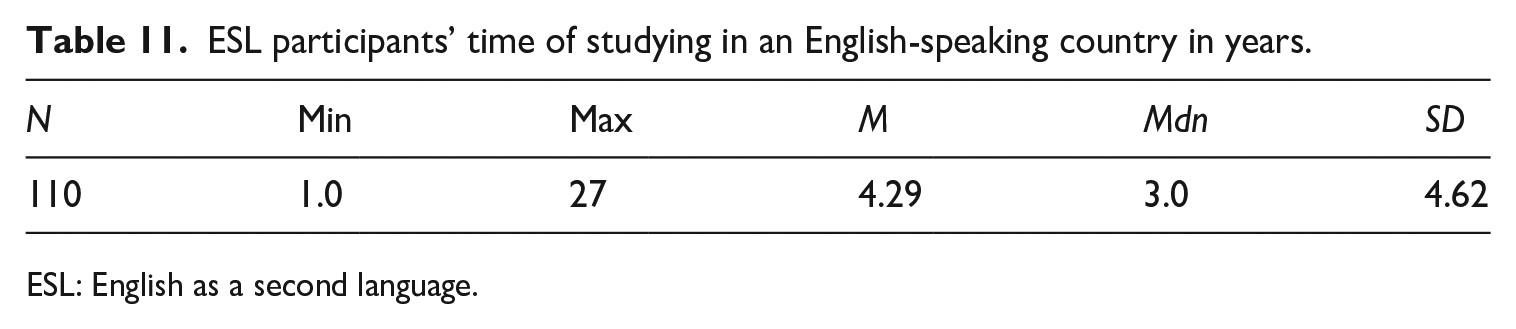
ESL: English as a second language.
The results showed nonsignificant correlations between the time of studying in an ESL context with scores on both the AC Recognition Test (rs = .02, p = .88) and the AC Recall Test (rs = .15, p = .11). The lack of correlation between the two variables indicated that the ESL learning context did not affect learners’ knowledge of academic collocations to a significant degree.
Discussion
This research is among the first few studies (e.g., Chen, 2019; Voss, 2012) that apply the argument-based framework to validating vocabulary tests. This section first provides an overall judgment based on the validation process of the ACTs, and then discusses how to improve the level of support for the inferences. Figure 9 summarizes the main findings in relation to the inferences in the validation framework of the ACTs.

Validity argument for the ACTs with the main findings.
What is the overall judgment of the ACTs?
The characteristics of the ACTs proved to be appropriate to measure knowledge of academic collocations, though further improvements in test administration are required. Ideally, all the inferences in a validation framework should be fully supported, although this is not always the case. Figure 9 shows the generalization was fully justified, while the scoring and extrapolation inferences received partial support.
The scoring inference was not completely justified for three reasons: (1) some interruptions during the test-taking time with dictionary use by some test-takers, (2) a possible priming effect caused by administering the two ACTs sequentially, and (3) test characteristics with the identification of a few misfit items. However, the majority of the test items conformed to the Rasch model, and the qualitative evidence also supported the test characteristics. Note that the ACTs were low-stakes tests for diagnostic purposes, and the results of the ACTs did not affect the participants in any way. High-stakes tests would result in a negative impact on test-takers, such as being assigned to the wrong course level.
The extrapolation inference was not fully supported because knowledge of academic collocations was found to have insignificant relationships with the time spent in an L2 learning context. One possible explanation is that the length of immersion might not be long enough to improve learners’ knowledge of academic collocations. At the time of testing, most of the ESL participants in this study had spent 3–4 years at university in New Zealand. Li and Schmitt’s (2010) longitudinal study showed that the development of L2 learners’ collocation knowledge tends to be slow, even for highly proficient students. Laufer (2011) also found that the use of collocations is problematic for L2 learners, irrespective of the years of instruction they received in L2. Another possible reason is that the ESL context displays great variability (e.g., first language backgrounds and the amount of interaction using English), which may contribute to the insignificant correlation with learners’ academic collocation knowledge in this study.
Although not all of the backings were found for the extrapolation inference, there appeared to be no serious impact on the results of this study. The most crucial warrant of this inference was supported in that scores on the ACTs correlated with scores on other tests of similar constructs, such as the VST (Nation & Beglar, 2007) and IELTS. This clearly demonstrated that the construct of academic collocations is related to vocabulary size and general language proficiency. However, such relationships are rather simple validity supports (Chapelle, 2021); needed more are sophisticated, multi-componential collections of validity evidence (Read & Chapelle, 2001, p. 3). It should be added that this study did not collect evidence to address all the inferences in the argument-based framework, as “validation is not simply a one-off-study but a programme: potentially, a very intensive programme” (Newton & Shaw, 2014, p. 142). This demonstrates that more investigations, and longitudinal planning for them, are needed.
How can the inferences be further supported?
One way to improve the level of support for the scoring inference would be to explicitly state in the test instructions that test-takers are encouraged to complete the tests in a place without any noise disturbance or distractions, and not to consult dictionaries or any other external resources. Administering the tests under the supervision of researchers or assistants would have helped and spacing the two ACTs out by a few weeks or months would lessen the priming effect.
To improve the level of support for the extrapolation inference, further correlation analyses could be conducted. One possible option would be to link the scores on the ACTs with academic literacy tests, such as academic reading and writing tests to examine the relationship between learners’ knowledge of academic collocations and their ability to comprehend and produce academic texts. This kind of research would provide evidence to assess whether scores on the ACTs could be used to predict the ability to apply this knowledge in a real target language use domain. Other tests of similar constructs could be used for correlation analyses instead of the VST (Nation & Beglar, 2007), such as multiword units tests like the Phrasal VST (Martinez, 2011) or tests of general collocations (e.g., Gyllstad, 2009; Nguyen & Webb, 2017). Stronger relationships would be expected with these tests. At the same time, we must point out that more than correlation is needed for the purposes of robust validation, as explained by Chapelle (2021). Multiple layers of evidence to support the inferences of the tests are needed, and each piece of evidence will help build trust in score interpretation.
A natural progression of this study is to add the decision inference into the validation framework of the ACTs and examine whether the test scores are valid for application in a specific context. For instance, the test scores could be used to decide on whether learners would benefit from a supplementary course on academic writing to increase their awareness, practice and use of academic collocations. This inference would then require evidence that a higher test score on the ACTs corresponds to better writing skills. A robust cut-off score needs to be identified for determining whether learners need extra support, including administration to a large number of learners and collecting and analyzing learners’ writing. The ACTs have yet to be employed in any course or program, so further research is needed to explore the uses of the test scores. Thus, a large question that remains is, what are the ACTs valid for? Chapelle (2021) noted that validity argument design needs to start with the uses and consequences of test scores. Chapelle (2021, p. 6) quoted Cronbach from 1971 (p. 447), in which he wrote: “One validates, not a test, but an interpretation of data arising from a specified procedure.” Thus, the validation argument in this paper is incomplete without the uses and consequences of the ACTs being investigated. However, the validation argument design presented here will help the ACTs be transparently described as they are further developed and implemented.
Conclusion
This study investigated the validity of three major inferences based on scores of the ACTs. The mixed methods generated evidence to justify the generalization inference and partially support the scoring and extrapolation inferences. Enough evidence was found to back up the claim that the ACTs are reliable instruments that can appropriately measure test-takers’ knowledge of academic collocations. However, there were some limitations with the online test administration that should be addressed in future use of the tests. The current research provides the foundation needed for further investigation of the decision inference.
The present study contributed to the ongoing demand for validation of vocabulary measures. It can act as an example to illustrate how the argument-based validation framework works for tests of vocabulary. With two simple steps of proposing inferences and presenting evidence, the validation research of the ACTs provided potential stakeholders with useful information about the test quality. The application of the argument-based framework to the ACTs lent support for the framework’s value and hopefully generated motivation for test developers to apply the framework to other vocabulary tests.
Footnotes
Appendix 1
Appendix 2
Appendix 3
Appendix 4
Largest standardized residual correlations of the AC Recall Test items
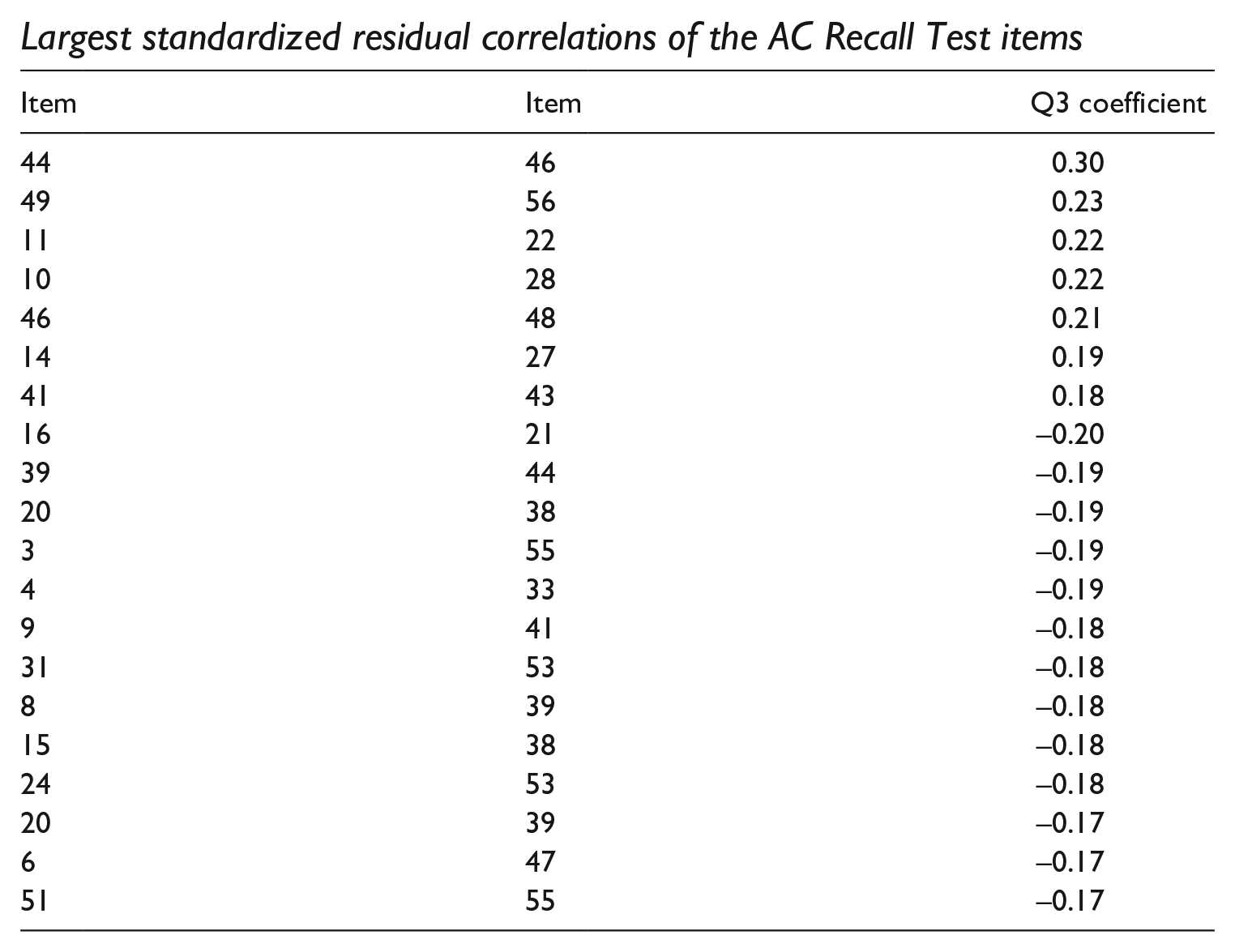
| Item | Item | Q3 coefficient |
|---|---|---|
| 44 | 46 | 0.30 |
| 49 | 56 | 0.23 |
| 11 | 22 | 0.22 |
| 10 | 28 | 0.22 |
| 46 | 48 | 0.21 |
| 14 | 27 | 0.19 |
| 41 | 43 | 0.18 |
| 16 | 21 | –0.20 |
| 39 | 44 | –0.19 |
| 20 | 38 | –0.19 |
| 3 | 55 | –0.19 |
| 4 | 33 | –0.19 |
| 9 | 41 | –0.18 |
| 31 | 53 | –0.18 |
| 8 | 39 | –0.18 |
| 15 | 38 | –0.18 |
| 24 | 53 | –0.18 |
| 20 | 39 | –0.17 |
| 6 | 47 | –0.17 |
| 51 | 55 | –0.17 |
Appendix 5
Largest Standardized Residual Correlations of the AC Recognition Test Items

| Item | Item | Q3 coefficient |
|---|---|---|
| 2 | 38 | 0.32 |
| 31 | 38 | 0.29 |
| 12 | 26 | 0.24 |
| 5 | 46 | 0.22 |
| 13 | 48 | 0.21 |
| 4 | 7 | 0.20 |
| 5 | 22 | 0.19 |
| 18 | 27 | 0.18 |
| 21 | 24 | 0.18 |
| 3 | 51 | 0.18 |
| 24 | 45 | 0.17 |
| 7 | 11 | 0.17 |
| 47 | 48 | 0.17 |
| 40 | 45 | –0.19 |
| 8 | 46 | –0.18 |
| 37 | 38 | –0.17 |
| 27 | 54 | –0.17 |
| 8 | 33 | –0.17 |
| 4 | 54 | –0.16 |
| 7 | 54 | –0.16 |
Appendix 6
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We gratefully acknowledge the financial support provided by Victoria University of Wellington, New Zealand under grant number 223802. This support facilitated data collection, allowing us to conduct the research presented in this article.