
Abstract
Tests of Aptitude for Language Learning (TALL) is an openly accessible internet-based battery to measure the multifaceted construct of foreign language aptitude, using language domain–specific instruments and L1-sensitive instructions and stimuli. This brief report introduces the components of this theory-informed battery and methodological considerations for developing it into an open research instrument. It also presents the preliminary results from the initial validation of TALL carried out on data collected from Chinese L1 participants (n = 165) from a university setting who took two rounds of tests (with counterbalanced test items) with a minimum 30-day interval. The results of data analyses at subtest, item, and battery levels suggest that, in general, TALL has satisfactory reliability and can be used to measure aptitude conceptualized in the theoretical frameworks on which it has been developed. This report also highlights the value of TALL as a convenient data collection tool openly accessible to any researcher for free, its potential for facilitating an open data pool for high-quality syntheses of aptitude-related research findings, and its implications for Open Research practices in testing language-related constructs.
Introduction
Foreign language aptitude (also referred to as language aptitude or simply aptitude throughout this article) is defined as the special ability to learn an additional language beyond one’s first language (L1) efficiently (Carroll, 1981). It has been conceptualized as a componential construct of cognitive individual differences that predict and explain language learning outcomes. Given the significance of aptitude and the need to measure it in order to investigate its role in learning, it is crucial to ascertain the reliability and validity of any aptitude measures prior to conducting research. However, this step has been surprisingly neglected to date (cf. Bokander & Bylund, 2020). This research gap may primarily be due to limited access to most of the aptitude batteries, which prevents other researchers from scrutinizing their reliability and validity. Ideally, rigorous language test validation should be conducted by researchers who can maintain a higher level of objectivity and scepticism that the test developers themselves may not always provide (Isbell & Kim, 2023)—and this requires that batteries be openly available for (future) independent scrutiny. A notable exception is the widely used LLAMA tests (Meara & Rogers, 2019), which are openly available online. However, item-level data elicited by this battery are not readily available to the researcher (without contacting the test developers) and the data are not openly available to other researchers. The lack of open and easy access to item-level data from aptitude batteries constrains the scrutiny of reliability and validity, eventually reducing confidence in aptitude findings. This logical impasse has been described by Marsden and Morgan-Short (2023) as a “chicken-and-egg conundrum” (p. 17): Appropriate validation procedures are highly desirable to ensure the rigour of measures before making them openly available to other researchers. However, in order to reach a consensus about the validity of the measures, it is necessary to make them openly accessible to accumulate validation evidence from a range of contexts and participants.
This brief report introduces an open research endeavour that attempts to begin to address the conundrum. It provides a summary of Tests of Aptitude for Language Learning (TALL, n.d.), a theory-informed aptitude battery, and discusses methodological considerations relevant to instrument design and technical development. In addition, it presents a subset of results from the initial validation of the battery (Pan, 2023a). Our report highlights the value of TALL as an open research instrument in enhancing the methodological rigour of assessing language-related abilities and its potential as an open data tool for accumulating validation evidence in the long term.
TALL as a measure for aptitude
TALL measures multiple facets of aptitude, drawing together different theoretical models and also informed by previous batteries. Four theoretical components are postulated to represent the aptitude constructs, that is, associative memory, phonetic coding ability, language analytic ability, and working memory (WM). Uniquely, TALL’s design includes two components of Skehan’s (2016) Stages Approach—language analytic ability and WM—that are not both captured by other batteries. TALL was also designed to capture two specific components of WM that are not comprehensively accounted for by the Stages Approach but are foregrounded by Wen’s (2016) Phonological / Executive Model (i.e., phonological short-term memory and executive control). In summary, TALL was designed to operationalize some of the components of the first stage (“Input-oriented”) and all of the components of the second stage (“Interlanguage development”) of Skehan’s Stages Approach, with additionally specified components of WM. It also includes the component of associative memory that is operationalized in most of the existing aptitude batteries. To measure these components, TALL consists of five subtests, each informed by existing batteries: Vocabulary Learning (TALL_VL), informed by LLAMA_B (Meara & Rogers, 2019), measures associative memory; Sound Discrimination (TALL_SD), informed by Part 5 of Pimsleur Language Aptitude Battery (PLAB) (Pimsleur, 1966), measures phonetic coding ability; Language Analysis (TALL_LA), informed by LLAMA_F (Meara & Rogers, 2019), measures language analytic ability; Serial Nonword Recall (TALL_SNWR), informed by the nonword repetition task in Suzuki (2021), measures phonological short-term memory; and Complex Span Tasks (TALL_CST), adapted from the reading span tasks in Gass et al. (2019), measures executive control capacity.
TALL_VL, TALL_SD, and TALL_LA are scored by the software based on the number of accurate responses to test items. For TALL_SNWR, productive data (the recall of nonwords) are manually scored after the completion of the test. TALL_CST’s raw data include both processing data (i.e., semantic judgements of sentence plausibility) and storage data (i.e., letters recalled in sequential order), with only the storage data being scored by the software. This scoring approach aligns with the scoring practices in previous research involving complex span tasks (e.g., Gass et al., 2019). Further details on subtest design, example items, and scoring report are available in the subtest manuals on the Open Science Framework (OSF) (Pan, 2023b).
The development of TALL considered two important potential confounding factors that have not been systematically investigated or controlled in measuring aptitude. First, to address the confounding effect of the modality (aural or written) of presentation, TALL has two test suites. The aural suite includes all subtests in the aural format; the written suite consists of three subtests (TALL_VL, TALL_LA, and TALL_CST) in the written format, and two subtests (TALL_SD and TALL_SNWR) that are—necessarily—in the aural format. Second, to mitigate potential confounds related to learners’ L2 knowledge (as existing aptitude and working memory tests are typically written in English, which is often the L2 of learners), TALL has been specifically designed for Chinese L1 speakers, using Chinese as the instructional language. Also, in TALL_SNWR, nonword stimuli for recall conform to the phonology of participants’ L1 Mandarin Chinese and avoid real meaning associations (which can be challenging in Mandarin, as individual syllables may correspond to one or more meanings). In TALL_CST, sentence stimuli in the processing task are presented in Chinese and are controlled for sentence length, as well as for the sentential location and usage rate of the lexical cues that learners are likely to use to make semantic judgements. In addition, language stimuli were developed in three subtests (TALL_VL, TALL_SD, and TALL_LA) using a miniature language (based on Lithuanian) that ensured novelty for these learners (as it is highly unlikely that they knew any Lithuanian).
TALL as an open research instrument
Developing TALL into an internet-based instrument for research purposes enables accessibility for other researchers. This endeavour involves technical considerations to minimize threats to test validity, following steps recommended by Newman et al. (2021) to ensure data quality in internet-based research. These considerations include (1) archival techniques for recording response times allow the identification of anomalous responses; (2) instructions and warnings displayed on screen before each subtest aim to reduce dishonesty in testing behaviours, for example, note-taking or seeking others’ help; and (3) assigned single-use test codes prohibit participants from reattempting the test.
With an open research infrastructure in mind, we incorporated functionality to separate access for researchers and invited test-takers. Figure 1 shows that, through the Researcher Entry, researchers can generate test codes for their participants, download item-level data that are associated with the test codes they have generated, and upload the scores of TALL_SNWR that they have manually assessed. Crucially for the purposes of sustainability, all of this is possible without relying on administrative support from the owner of TALL, although all functionalities and collected data can be monitored from the backend by the researchers hosting TALL. Researchers can also navigate test manuals and try out demo tests for their own research interests or for pedagogical (e.g., research training) purposes. Meanwhile, access for participants is limited to the Test-taker Entry and requires a test code from a researcher. This controlled access ensures that participants do not have prior knowledge of the test, which is crucial for the test’s validity, as access to the test is impossible without a code. The functionalities for access control and researcher administration not only improve the quality of the data collected but also enhance the sustainability of TALL as a resource that can be used by the community without relying on an individual.
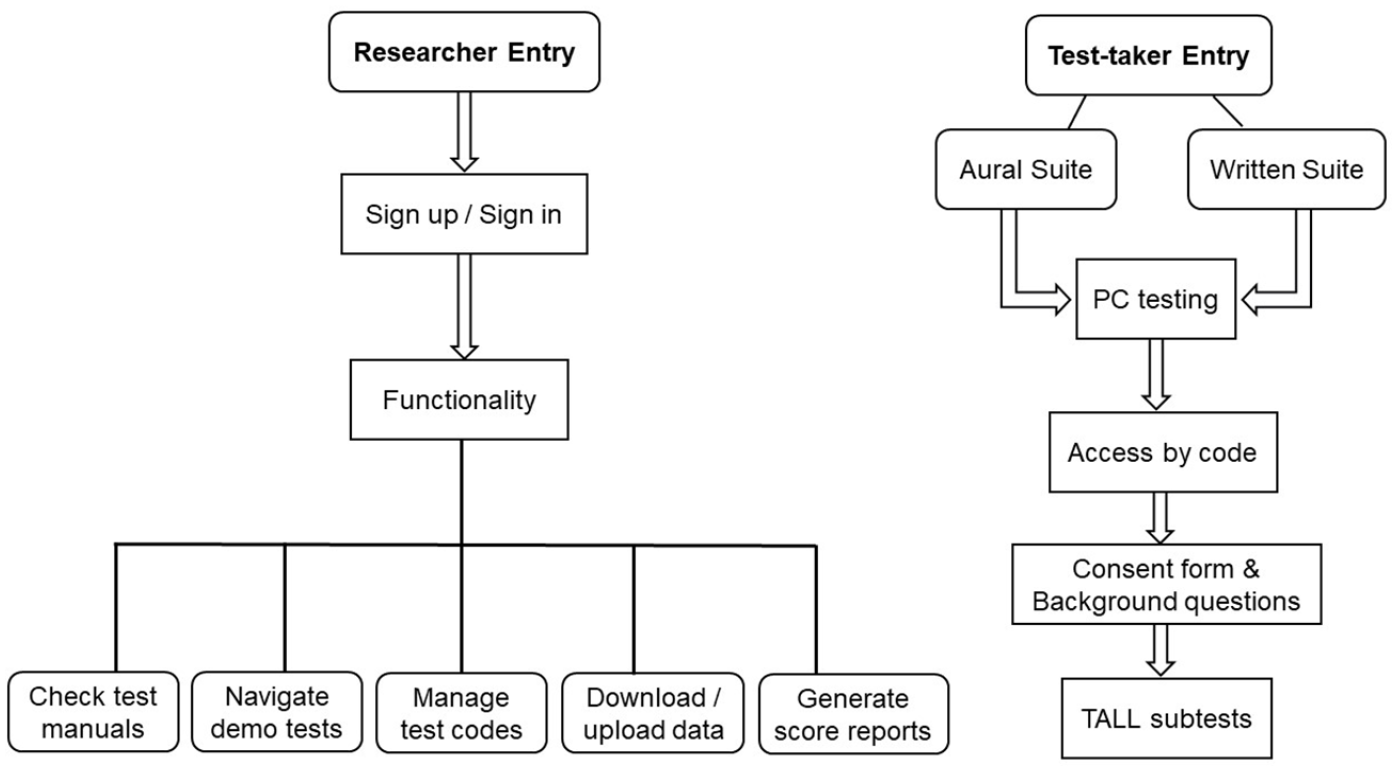
Separate accesses and functionality for researchers and test-takers on TALL.
Initial validation
To assess the reliability and validity of TALL as an aptitude battery, we conducted an initial validation at subtest, item, and battery levels. This validation process was adapted from a schema used by Bokander and Bylund (2020), which draws upon the argument-based validity framework by Kane (2006) and an earlier adaptation of Kane’s framework for L2 learning research by Purpura et al. (2015). In this framework, validation is carried out step-by-step through logical inferences. The three-level schema allowed us to make (1) generalization inferences about each subtest’s reliability in targeting the intended component, (2) scoring inferences about the effectiveness of items in discriminating latent abilities with appropriate levels of difficulty, and (3) explanation inferences about the alignment of the battery’s structure with the theoretical frameworks underlying TALL’s development.
Methods
The final data for analysis were obtained from 165 participants who were Year 1 undergraduates from various disciplines, across 11 universities, in China. As we were examining the effects of two modalities on measuring aptitude, we used a within-subject design (whereby each participant experienced both modalities) to attain higher statistical power compared with a between-subject design (whereby only half our participants would have experienced each modality). All 165 participants took two rounds of TALL on the test website at a time and place of their choosing, with a minimum 30-day interval between rounds. In the first session, one suite (either aural or written) of subtests was presented in the fixed order, that is, TALL_VL, TALL_SD, TALL_LA, TALL_SNWR, and TALL_CST sequentially, while in the second session, another suite of subtests was presented in the same fixed order. Two test suites and two versions of materials were counterbalanced over two sessions, such that an individual experienced one modality at Time 1 and another modality at Time 2, with different versions in each to reduce test familiarity. The order of the test items within each subtest was randomized for every individual iteration.
Data analysis and results
Data analysis started at the subtest level to examine the reliability of each subtest as a measure for a specific component of aptitude. Analysis at the item level determined the fitness of the items in each subtest to Item Response Theory (IRT) models, addressing whether each subtest was composed of well-functioning items that had appropriate levels of difficulty for the participants and were able to discriminate the ability to be measured. Data sets split by version (A or B) and modality (aural or written) were used for analyses at subtest and item levels. Analysis at the battery level investigated the extent to which TALL reflected the structure consistent with the theoretical frameworks that underpinned its conceptualization, using data sets aggregated within each suite (separately for aural or written). Data analysis was carried out in R (R Core Team, 2022) and the code is accessible on OSF (Pan, 2023b).
We used omega estimators for reliability checks, responding to concerns that the use of Cronbach’s alpha often violates certain statistical assumptions, leading to an underestimation of reliability (McNeish, 2018). Omega hierarchical (ω h ) estimated the reliability of the general factor (variance shared by all items) of a test after accounting for item-group factors (variance specific to subsets of items), and omega total (ω t ) estimated the reliability of the total instrument (without taking into account item-group factors). As shown in Table 1, the results showed that all subtests rendered a satisfactory estimate of the total reliability indexed by ω t. In addition, most data sets had results indicating a large part of the score variance was likely to be attributed to a common factor with acceptable ω h . There were just three exceptions to this (Version A of TALL_VL in the aural suite, Version A and Version B of TALL_CST in the written suite) which had lower ω h (range = .31–.35). In general, these findings suggest strong unidimensionality in the data collected by these instruments. We also included Cronbach’s alpha estimator in Table 1, to facilitate comparison with reliability coefficients reported in other studies using alpha.
Descriptive statistics, reliability, and test information of TALL subtests.
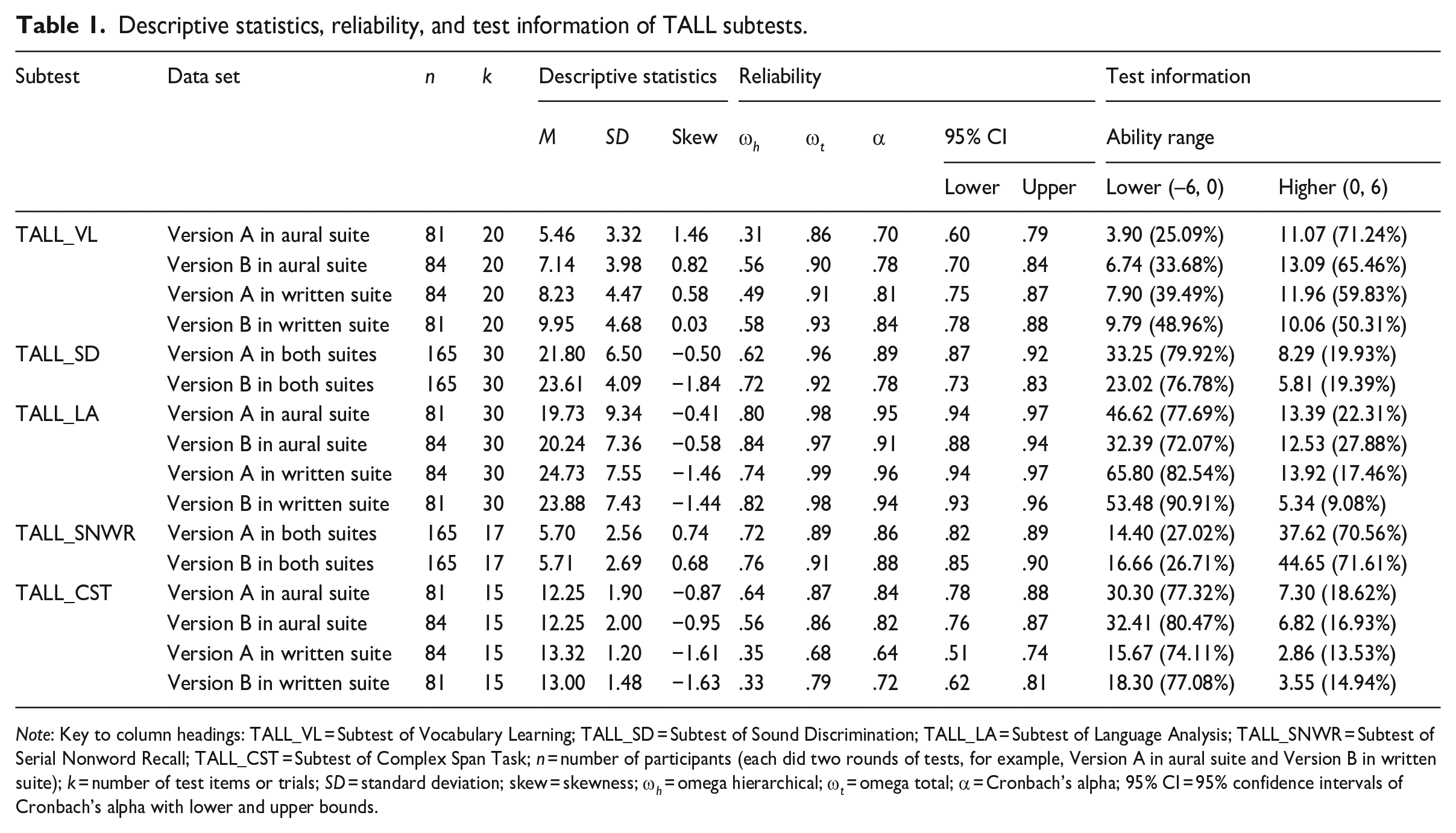
Note: Key to column headings: TALL_VL = Subtest of Vocabulary Learning; TALL_SD = Subtest of Sound Discrimination; TALL_LA = Subtest of Language Analysis; TALL_SNWR = Subtest of Serial Nonword Recall; TALL_CST = Subtest of Complex Span Task; n = number of participants (each did two rounds of tests, for example, Version A in aural suite and Version B in written suite); k = number of test items or trials; SD = standard deviation; skew = skewness; ω h = omega hierarchical; ω t = omega total; α = Cronbach’s alpha; 95% CI = 95% confidence intervals of Cronbach’s alpha with lower and upper bounds.
For the item-level analysis, Rasch models were applied to dichotomous data from the subtests TALL_VL, TALL_SD, and TALL_LA. The infit t statistics range of [–2, 2] is a rule of thumb for detecting potential misfitting items. The infit mean squares range of [0.50, 1.50] were also applied to check the item fit. Generalized Partial Credit models were used on the polytomous data from the two working memory subtests. Specifically, the proportion of correct recalls of nonwords (in TALL_SNWR) or English letters (in TALL_CST) in each trial constituted the item-level data. No clear evidence suggested that any items were of poor quality that may threaten the validity of the instruments, and so deletion of items was not necessary.
Test information was obtained to understand the overall precision of the subtests across the ability level they were designed to measure. In the Rasch models, the information contributed by each item in the subtests was summed to quantify test information (i.e., the sum of the item information that demonstrates the contribution items make to the estimation of ability in both the lower and upper half of the ability range). In the Generalized Partial Credit models, the information provided by each response category across all trials was summed. The results (in Table 1) indicated that test information varied between the subtests, which can be attributed to factors such as the number of items, the types of scores (dichotomous and polytomous), and the reliability of the subtests. Specifically, for the participants in this study, TALL_VL (measuring associative memory) provided the least information overall, whereas TALL_LA (measuring language analytic ability) provided the most information. The results also indicated that TALL_SD, TALL_LA, and TALL_CST lacked challenge for the participants overall, providing less information about participants at higher ability levels. Conversely, TALL_VL and TALL_SNWR were found to be more difficult, offering less information about participants at lower ability levels.
Correlation matrices (in Table 2) showed that scores from most subtests in both suites had low positive correlations with one another at significance levels of p < .05, indicating that no subtests were redundant (as they did not display extremely high correlations). In general, these relationships among subtest scores suggested that the measures probably represent different constructs.
Correlations (in Kendall’s τ) between TALL subtests.
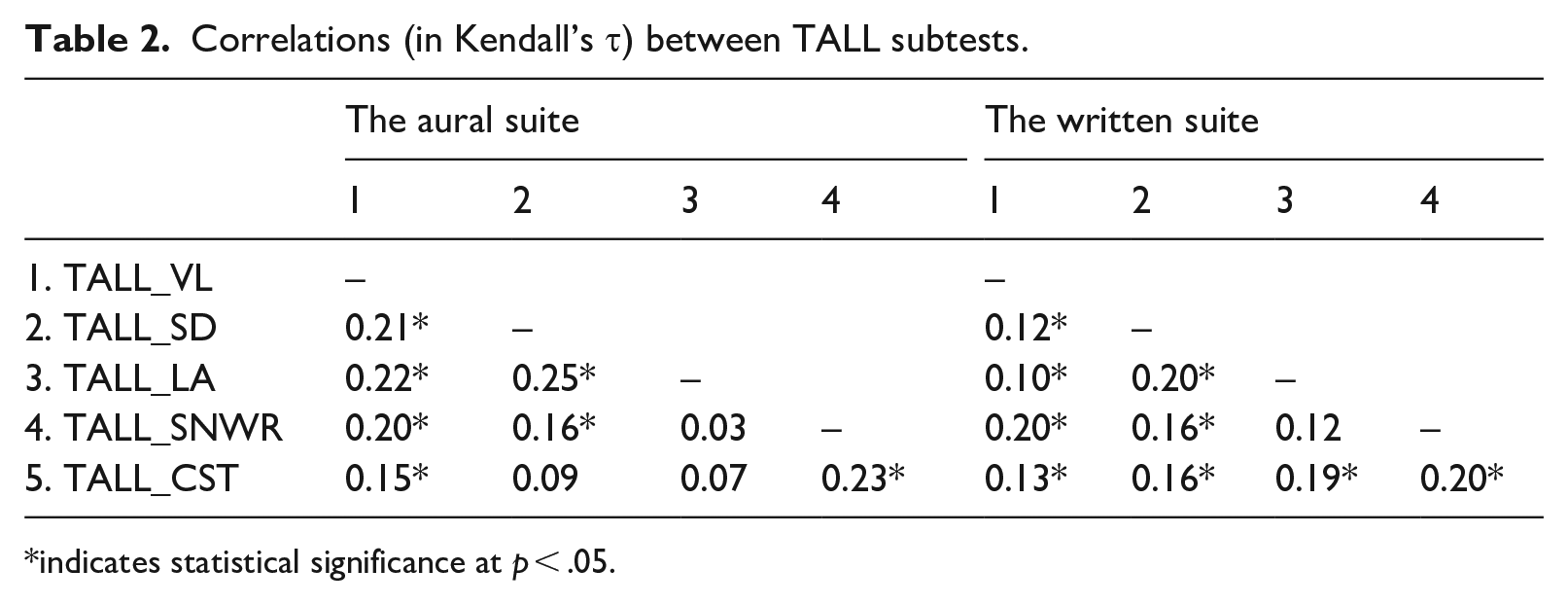
indicates statistical significance at p < .05.
Conclusion
We present preliminary results from the initial validation of a new aptitude battery TALL—which in part draws on existing aptitude batteries but distinguishes itself from them through its commitment to more recent theoretical models of aptitude, namely, Skehan’s (2016) Stages Approach and Wen’s (2016) Phonological / Executive WM model. Our results show that, in general, the scores from the subtests not only demonstrate consistent performance among university participants but also effectively differentiate between varying levels of ability in the theorized subcomponents of a multifaceted aptitude construct. In addition, TALL uniquely comprises two complete and parallel suites in the aural and the written modalities, each with two versions of test items, allowing us to compare the effects of modality and test session in measuring aptitude (Pan, 2023a), although these comparisons are beyond the scope of this brief report.
Some limitations invite further research. We acknowledge that, as the developers of TALL, we are not independent. By making TALL openly accessible, we invite others to validate this battery. Future research may involve, for example, wider learner populations, especially those with low L1 literacy levels. This is needed to reduce our collective reliance on highly educated participants, a field-wide sampling bias that threatens generalizability. Checking divergent validity by comparing TALL with other aptitude measures is also necessary. Substantive research on the predictive validity of TALL in explaining learning outcomes should be included in future research agendas, for which we collected some data beyond the scope of this brief report. In addition, TALL was designed for participants with L1 Chinese, and amendments for use with other populations merit investigation.
We underline the potential of TALL as a shared open research infrastructure for data collection and data accumulation. 1 First, TALL—and its adaptations—can be used as a reliable measure of aptitude constructs that enables data collection to be carried out remotely for free. This may facilitate better sampling practices and multisite studies to obtain larger and more diverse samples. Second, after TALL has been adequately validated, it can constrain researcher degrees of freedom caused by methodological variation, thereby increasing the comparability of results. Third, TALL allows consumers of research about aptitude to access samples of the battery, and producers of research to access the full battery. This should facilitate the scrutiny of replicability and reproducibility of our findings. Finally, in the long run, TALL could amass a cumulative open data pool; that is, aggregated data collected by using a uniform battery, to promote high-quality syntheses of research findings.
In sum, TALL’s development represents a first step towards addressing “the chicken-and-egg conundrum” that researchers face: the demand for openly available validated instruments, which, in itself, requires instruments to be openly available in the first place in order to then validate them multiple times across a range of contexts.
Peer Review File
sj-pdf-1-ltj-10.1177_02655322241241849 – Supplemental material for Developing internet-based Tests of Aptitude for Language Learning (TALL): An open research endeavour
Supplemental material, sj-pdf-1-ltj-10.1177_02655322241241849 for Developing internet-based Tests of Aptitude for Language Learning (TALL): An open research endeavour by Junlan Pan and Emma Marsden in Language Testing
Footnotes
Acknowledgements
This article is based on the first author’s unpublished PhD thesis at the University of York, which was supervised by the second author. We thank Mengqiu Qin for her help in managing the development team at Chongqing University, Dr. Giulia Bovolenta for her input in designing the test items, and Mrs. Daiva Judges for recording the stimuli. We are extremely thankful for the valuable comments from the anonymous reviewers and Dr. Daniel Isbell as the Editor handling this paper of the special issue. Any remaining errors are solely our responsibility.
Author contributions
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was supported by the following funding granted to the first author: Fundamental Research Funds for the Central Universities (Project No. CDJSKJC03) from Chongqing University; Participatory Research Funding (No. H0029608) from the University of York.
Open practice
This article has received badges for Open Data and Open Materials. More information about the Open Practices badges can be found at ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.