
Abstract
This study examined single-word code-mixing produced by bilingual preschoolers in order to better understand lexical choice patterns in each language. Analysis included item-level code-mixed responses of 606 five-year-old children. Per parent report, children were separated by language dominance based on language exposure and use. Children were assigned to a no-risk or at-risk for language impairment group based on individual performance from an English–Spanish screening battery. Data analysis compared the prevalence, frequency, and accuracy of code-mixed responses on expressive semantic items across participants’ language dominance and risk status. Language dominance and risk status impacted children’s code-mixing patterns. The correct number of code-mixed responses on the English screener was influenced by risk status, whereas language dominance determined the number of correct code-mixed answers on the Spanish screener. Lexical choice and language selection depend on linguistic knowledge and skill. During this emergent stage of bilingualism, preschoolers demonstrate the use of code-mixing as a compensatory strategy to fill lexical gaps. Consistent with previous studies, findings indicate that code-mixing necessitates linguistic competence in more than one language.
I Introduction
1 Outline
Young bilinguals acquire lexical knowledge to match semantic representation in two languages. While bilinguals generally distinguish and separate their two languages they can alternate between languages during communicative tasks. Code-switching refers to the intersentential use of alternating languages across sentences at the conversational or narrative level (Gardner-Chloros, 2009; Heredia and Altarriba, 2001; Poplack, 2000). Code-mixing characterizes switches at the word level embedded within a phrase or utterance (Deuchar and Quay, 2000; Muysken, 2000). Extra-linguistic and social-situational factors such as communicative context, audience, identity, and objectives potentially influence lexical choice and language selection (Genesee et al., 1996; Toribio, 2001). For our study, we offer the term code-mixing (CM) to describe how bilingual children switch between languages at the single-word level to items administered on an English and Spanish semantic screener. Examination within this constrained task allows one to evaluate whether children code-mix accurately specific to semantic screening items.
Upon school entry, preschoolers learning English as a second language confront challenging new language activities. Within this setting, bilingual children code-mix according to the cognitive task requirements dependent upon contextual demands such as interlocutor, topic, and environment (Genesee et al., 2004; Miccio et al., 2009). To date, studies have primarily focused on children’s code-mixing patterns at home with family members (Brice and Anderson, 1999; Lanza, 1997). Thus limited information exists that considers how young bilinguals with and without risk for language impairment code-mix during formal testing. For this reason, we examined preschoolers’ code-mixed responses on a semantic assessment in the following ways: prevalence (whether children code-mixed or not); frequency (how often children code-mix); and the success rate (accuracy of code-mixed responses) specific to semantic test items.
Code-mixing highlights how bilinguals activate, separate, and select lexical items between two languages. For example, when a Spanish-dominant bilingual is speaking their first language (L1) Spanish, less effort is required to suppress the less-dominant or second language (L2) (Costa and Santesteban, 2004; Finkbeiner et al., 2006). Studies imply that switching into L1 presents more challenges than switching into L2, because dominant language inhibition requires more cognitive resources (Bialystok et al., 2008; Kroll et al., 2008).
At times, bilinguals code-mix to fill knowledge gaps specific to the lexical demands of a language task (Grosjean, 1999; Peña et al., 2012). Usually bilinguals demonstrate relative ease when selecting between two competing languages to achieve communication goals. Speech production models address how message conceptualization, language formulation, and articulatory output occur incrementally (De Bot, 2004; Levelt, 1989, 1995). To complete a word-naming task, first a semantic concept is retrieved. Second, the phonological and lexical word components are formulated, and finally the word is articulated to match the language context. Since a bilingual’s two languages share conceptual characteristics, both languages are potentially activated during the semantic system’s incremental lexical selection process (Isurin et al., 2009; Kormos, 2006; Patterson and Pearson, 2012). In a test situation, the test-taker may face challenges in suppressing the response from the language in which the lexical item is more strongly activated since a concept has activated two lexical items.
2 Code-mixing and children at-risk for language impairment
Limited expressive vocabulary plays a key role when identifying chidren with suspected language impairment (McGregor et al., 2002; Spaulding, 2010). Naming errors, word approximations, and word retrieval difficulties are associated with language impairment (Sheng and McGregor, 2010; Spaulding, 2010). In schools, educators may interpret a bilingual child’s CM to denote language confusion or inadequate word knowledge suggestive of language impairment (Miccio et al., 2009; Peña et al., 2003).
Likewise CM is associated with lexical gaps; but these occur within an intact system. Typically developing bilingual children might code-mix and commit naming errors due to lexical uncertainty. Lexical challenges could be exacerbated in bilingual children with language impairment. For these reasons, a better understanding of emerging bilinguals’ lexical choice and language selection patterns may assist in differentiating language differences from language disorders.
Pertaining to word-learning challenges, Dollaghan (1998) noted that children with language impairment present with three lexical processing difficulties: limited word inventory, fewer lexical elaborations, and weak connections between entries in the mental lexicon. Bilingual children possess distributed but uneven knowledge across two languages (Ordoñez et al., 2002; Patterson and Pearson, 2012; Peña et al., 2012). As a result, a bilingual’s word knowledge may appear limited relative to monolingual peers (Bedore et al., 2005; Peña et al., 2011).
A bilingual child’s perception of the sociolinguistic context further influences lexical choice and language selection. Studies establish how Spanish-dominant bilingual children are more likely to code-switch into English during language testing than code-switch from English to Spanish (Bedore et al., 2005; Miccio et al., 2009). One recent study examined code-switched utterances in bilingual children with and without language impairment (Gutiérrez-Clellen et al., 2009). In this case, the grammatically produced code-switched utterances identified in children’s language samples were associated with language dominance rather than ability. Also, context played a pivotal role, given that children increased the frequency of code-switched utterances during conversational exchanges over narrative samples. Consistent with previous reports, children code-switched more from Spanish into English than English into Spanish, regardless of language dominance profiles.
Collectively these studies reveal that bilingual children alternate languages during testing, narrative, and conversational tasks. Little is understood about how dominance and risk factors influence bilingual preschoolers’ lexical choices and language selection on a formal semantic screener. Less is known as to whether preschoolers identified at-risk for language impairment are equally successful in the correct production of code-mixed words compared to no-risk peers. This study explores the prevalence, frequency, and accuracy of code-mixed responses among bilinguals in relation to language dominance and risk status. Our goal is to evaluate preschoolers’ lexical choices on comparable semantic screening measures in both languages. We investigate these questions based on responses from an English and Spanish semantic screener administered to a large group of bilingual preschoolers. Specific goals include:
to document the proportion of preschoolers who produce single-word code-mixed responses across expressive semantic items administered in two languages;
to evaluate if language dominance (English-dominant bilingual, balanced bilingual, and Spanish-dominant bilingual) and risk status (no-risk or at-risk for language impairment) influence whether or not children code-mix;
to compare the accuracy of correct or incorrect code-mixed responses specific to each test language across participants’ language dominance and risk status.
II Method
1 Participants
For these analyses, 606 five-year-old preschoolers were selected from a three-year longitudinal study of 1198 English–Spanish bilingual children. Cases were selected from the first two of three screening phases (n = 757). The five-year-old preschoolers were chosen as they represented a larger proportion of eligible children. Additionally, the five-year-old semantic screening version contained more expressive test items for analysis. Participants came from three school districts with high percentages of Latino American students: two in Central Texas and one in Northern Utah. There were 302 (49.83%) female and 304 (50.17%) male students with a mean age in months of 65.45 (SD 6.24). The majority of children came from low socio-economic households determined by school-lunch program (Bohman et al., 2010; Peña et al., 2011). All participants passed a school-based hearing test. Consistent with criteria established from the parent study, participants were placed into no-risk and at-risk groups based on their combined performance on the Bilingual English–Spanish Oral Screener (BESOS, Peña, Bedore et al., in preparation).
2 Materials
The BESOS five-year-old version consists of morphosyntax and semantic subtests in English and Spanish. The screening items represent a subset drawn from the comprehensive Bilingual English Spanish Assessment (BESA; Peña, Gutiérrez-Clellen et al., in preparation). The BESOS morphosyntax subtests contains cloze and sentence repetition items with 17 English items and 16 Spanish. Research using the BESA morphosyntax subtest indicates good sensitivity and specificity for five-year-olds (Gutiérrez-Clellen et al., 2007). Correlation between the BESA and BESOS morphosyntax indicate a significant relationship in each language of .826 (Spanish) and .893 (English).
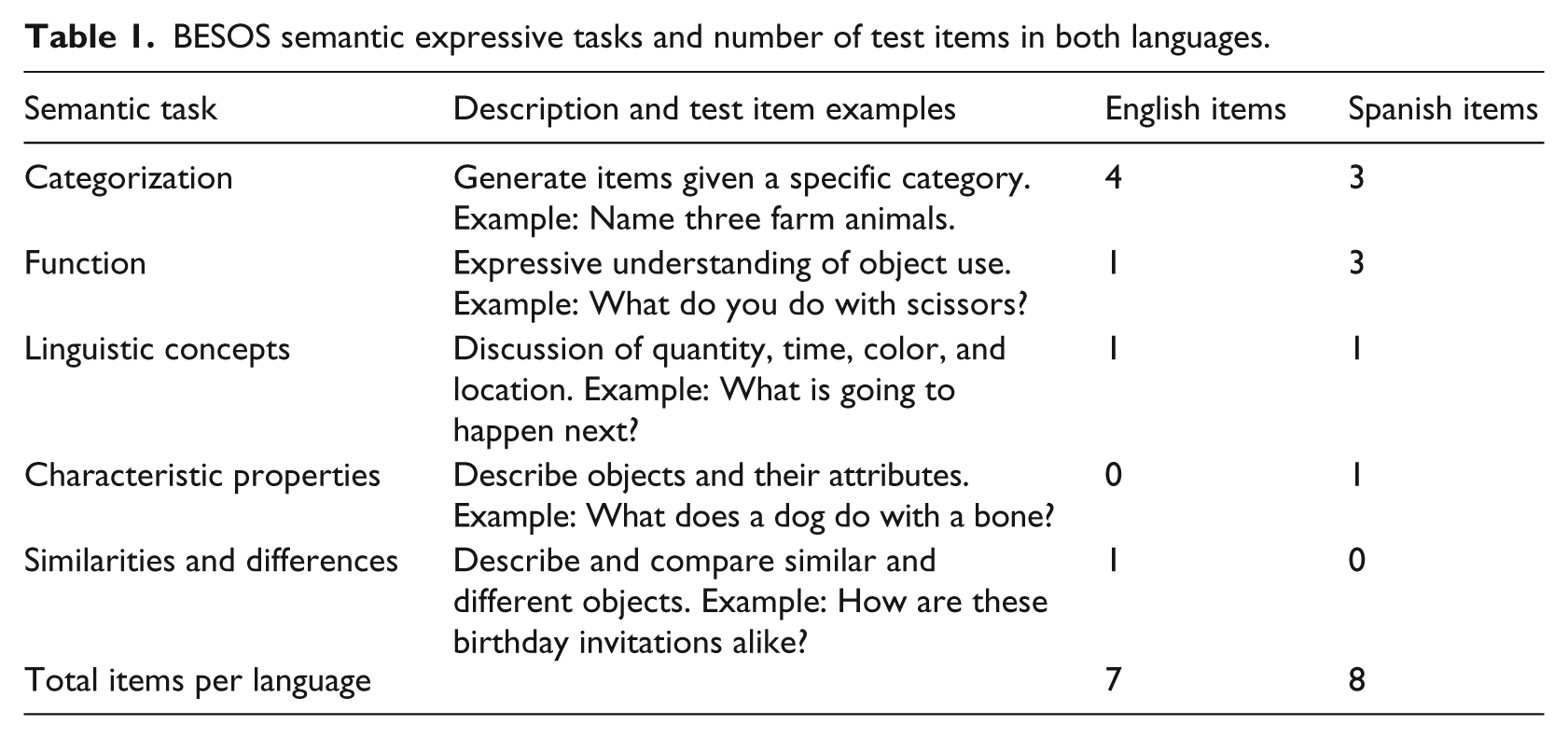
The BESOS semantic subtests measure vocabulary skills on various tasks across both languages (see Table 1). The English semantic subtest includes 11 items (4 receptive, 7 expressive) while the Spanish version contains 12 tasks (5 receptive, 8 expressive). Strong positive correlations of .855 (Spanish) and .887 (English) link the individual BESOS subtests in the corresponding language with the BESA (Summers et al., 2010). Parents completed a questionnaire based on an hour-by-hour report of weekly English and Spanish use and exposure to complete each participant’s language dominance profile. Previous use of this questionnaire demonstrates significant correlation with measures of language dominance based on morphosyntax and semantic skills (Bedore et al., 2012; Bohman et al., 2010; Gutiérrez-Clellen and Kreiter, 2003).
BESOS semantic expressive tasks and number of test items in both languages.
3 Procedures
Participants were grouped based on their average percentage of receptive and expressive language use at the time of testing: English-dominant bilinguals (EDBs) used and heard English more than 60% of the time and Spanish less than 40% of the time; balanced bilinguals (BBs) used and heard English and Spanish between 60% and 40% of the time; and Spanish-dominant bilinguals (SDBs) used and heard Spanish more than 60% of the time and English less than 40% of the time (see Table 2). Dividing children by language exposure allows us to examine risk status independently via direct performance on the language measures, avoiding possibly conflating the two. Bilingual certified speech-language pathologists and bilingual graduate students individually administered the screeners in random order by language, requiring approximately 15–25 minutes for each child to complete. Conceptual scoring where correct non-target language responses are credited was only applied on the semantic screeners. Consistent with previous language screening studies (e.g. Law et al., 2000), children were identified at-risk for language impairment if they scored below the 25th percentile on three of the four BESOS subtests (Table 3 displays subtest mean scores). This cut-off was selected to identify children with no-risk and those at-risk for language impairment.
Participants’ language dominance and risk status group numbers.
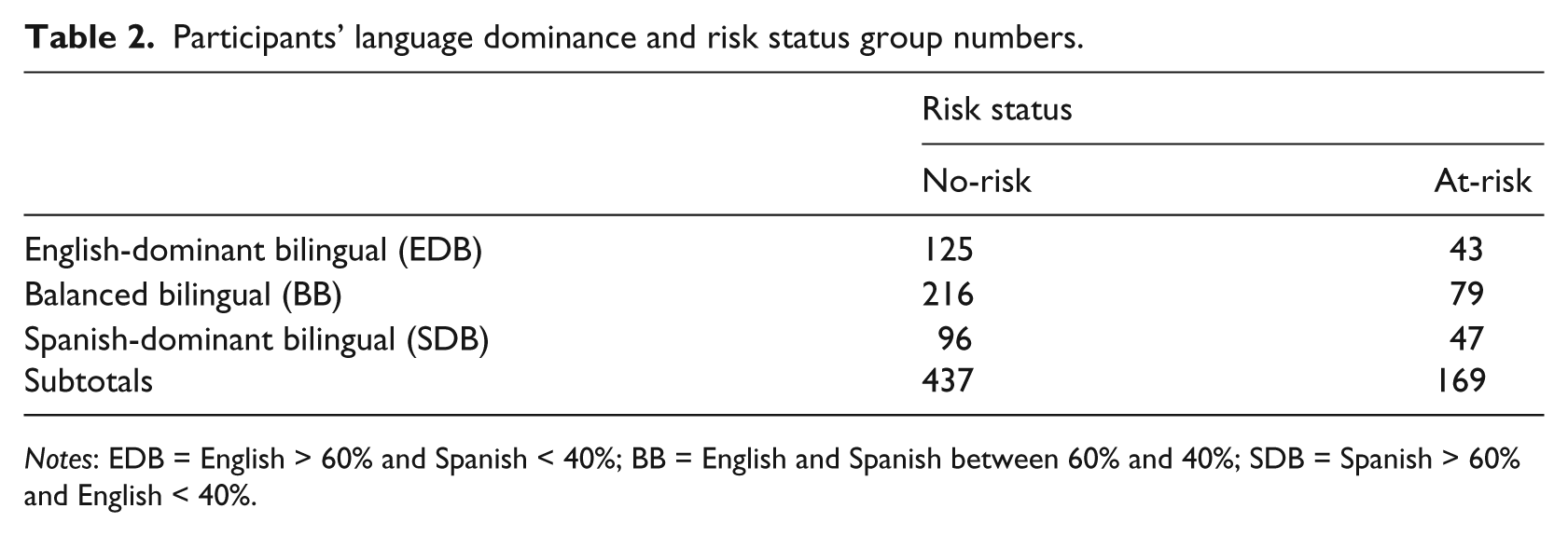
Notes: EDB = English > 60% and Spanish < 40%; BB = English and Spanish between 60% and 40%; SDB = Spanish > 60% and English < 40%.
Summary of participants’ BESOS subtest raw scores: Mean values (with SD in parentheses).
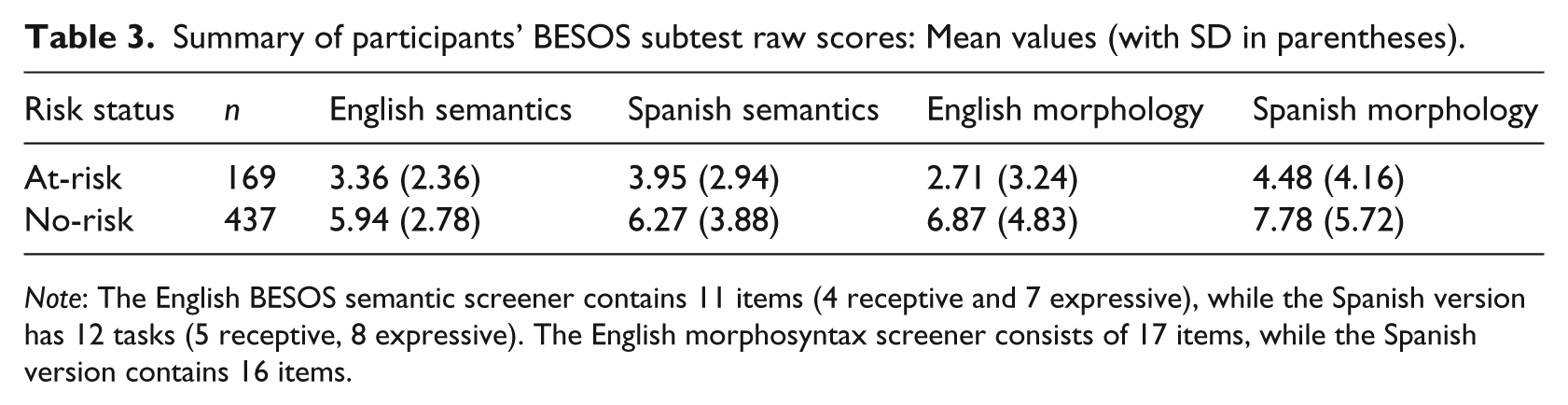
Note: The English BESOS semantic screener contains 11 items (4 receptive and 7 expressive), while the Spanish version has 12 tasks (5 receptive, 8 expressive). The English morphosyntax screener consists of 17 items, while the Spanish version contains 16 items.
4 Coding and analysis
Only the 15 combined BESOS expressive semantic items were considered for this analysis. Responses were recorded on-line as either correct or incorrect in the test target language or a code-mixed response in the non-test target language. Thus, four possible scoring options existed for each child’s response: correct/target language, incorrect/target language, correct/other language, and incorrect/other language.
For descriptive purposes, we tallied the number of children who code-mixed and used the other language at least once during testing in English and Spanish, and compared patterns of CM by language exposure using chi-square. Then we compared lexical code-mixed patterns by language dominance and risk status using log-linear analysis (Knoke and Burke, 1980). Next we conducted log-linear analysis for each test language to explore possible code-mixed differences related to language dominance and risk status. Finally, we used analysis of variance (ANOVA) to compare code-mix accuracy levels among the children who code-mixed on each screener to determine how often participants produced correct/other language versus incorrect/other language responses.
III Results
1 Participants’ code-mixed patterns across English and Spanish screeners
The first question examined the prevalence of participants’ code-mixed responses across both screeners. Of the 606 children, 298 (49.2%) did not code-mix and 265 children (43.8%) code-mixed in one direction or asymmetrically on at least one test item. On the English subtest, 113 participants (18.6%) code-mixed from English into Spanish, while 152 participants (25.1%) code-mixed from Spanish into English on the Spanish version. Only 43 children (7.1%) produced symmetrical (Spanish to English and English to Spanish) code-mixed answers when tested in English and Spanish. Chi-square analysis compared the proportion of children from the three dominance groups who code-mixed in Spanish, English, both languages, or neither language. Results indicate significant association between CM and dominance group, χ2(6), 119.49, p < .001. We compared expected and actual cell frequency differences using a +1 z-score cut-off. When tested in English, children in the SDB group were more likely to code-mix (35.75%; z = +5.89), while those in the EDB group were less likely to code-mix (1.30%; z = −6.09). When tested in Spanish, the opposite pattern emerged. SDB children were less likely to code-mix (9.04%; z = −4.76); but EDB children were more likely to switch (40.00%; +4.52). Finally, children in the BB group were more likely to code-mix in both Spanish and English (10.32%; z = +1.51) compared to EDB (6.08%) and SDB (5.88%). Next we examined CM within each language to examine the role of language proficiency and risk status by test language.
2 Participants’ code-mixing patterns, language dominance, and risk status
We explored whether language dominance (EDB, BB, and SDB) and risk status (no-risk vs at-risk) influenced CM. For each test language, we conducted log-linear analysis to explore associations among language dominance, risk status, and CM. For the English screener, log-linear results were significant, G2(7), 92.12, p < .001. Post hoc analysis indicated a significant association between risk status and CM, G 2 (1), 5.52, p = .0188, φ .225; proportionally more children in the at-risk group (32.5%) code-mixed compared to the no-risk group (23.1%). Also, there was a significant association between dominance and CM, G2(2), 79.64, p < .001, φ .258. Proportionally fewer EDB children code-mixed (5.4%) compared to BB children (27.5%), while a greater proportion of the SDB children code-mixed (46.2%). There was no association between dominance and risk status, G2(2), 1.98, p = .372, φ .075.
For the Spanish screener, log-linear results were significant, G2(7), 71.02, p < .001. Post hoc analysis of two-way associations indicated a significant association between risk status and CM, G2(1), 10.52, p = .0012, φ .129; proportionally more no-risk children (35.9%) code-mixed compared to the at-risk group (22.5%). There was also a significant association between language dominance and CM, G2(2), 54.84, p < .001, φ .242. Fewer SDB children code-mixed (12.6%) compared to BB children (35.6%), while a greater proportion of the EDB children code-mixed (42.9%). No association was found between dominance and risk status, G2(2), 1.98, p = .372, φ .063.
Due to the BB group’s CM patterns on both screeners, we were particularly interested in how test language was associated on both screeners. We conducted a chi-square analysis to examine risk status by number of children who produced CM in Spanish, English, both, or neither language. Results demonstrate a significant association for test language (English, Spanish, both, neither) and risk status, χ2(3) = 9.95, p = .019. Post hoc analysis examined the degree to which the observed chi-square frequencies differed from expected values. Using a +1 z-score difference as the critical value, children in the at-risk group did not use CM in either language (z = −1.29). Specific to the Spanish screener, children in the risk group code-mixed less often than expected (z = −2.10). In contrast, the children in the no-risk group code-mixed more often than expected (z = 1.41) when tested in Spanish.
3 Accuracy of code-mixed responses
The third research question considered whether language dominance (EDB, BB, SDB) and risk status (no-risk vs at-risk) influenced response accuracy (correct vs incorrect) on the screening items. Of interest was to establish whether language dominance and/or risk status played a significant role in the successful production of code-mixed responses. Thus, the dependent variable includes only items that were generated in the non-target language scored correct or incorrect per BESOS guidelines.
4 BESOS English semantic items
The 156 children who code-mixed at least once on the English screener were included in the analyses. A repeated measures ANOVA was conducted with language dominance and risk status as the between-participants variables, and response type as the within-participants variable. Results revealed a main effect for dominance, F(2, 150) = 9.95, p > .001, ηp2 = .117. On average, the BB children code-mixed more (M = 1.66) compared to the SDB (M = 1.32) and the EDB groups (M = 0.60), whose frequency of code-mixed responses differed significantly. Figure 1 shows a language dominance by risk status interaction, F(2, 150) = 6.075, p = .003, ηp2 = .075. The BB at-risk children significantly produced more code-mixed responses than the other dominance and risk groups. Figure 2 shows a significant two-way risk by response accuracy interaction, F(1, 150) = 4.68, p = .032, ηp2 = .030. The no-risk children code-mixed in order to respond correctly to the target, while the at-risk children were more likely to produce an inaccurate code-mixed response.
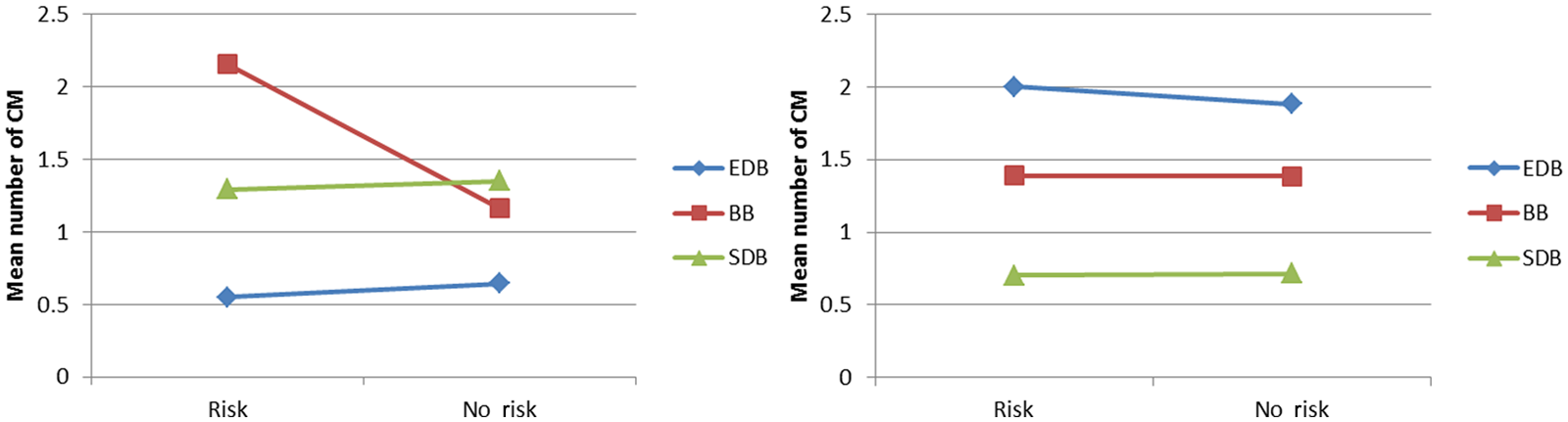
Risk status by language dominance interactions: English (left) and Spanish (right).
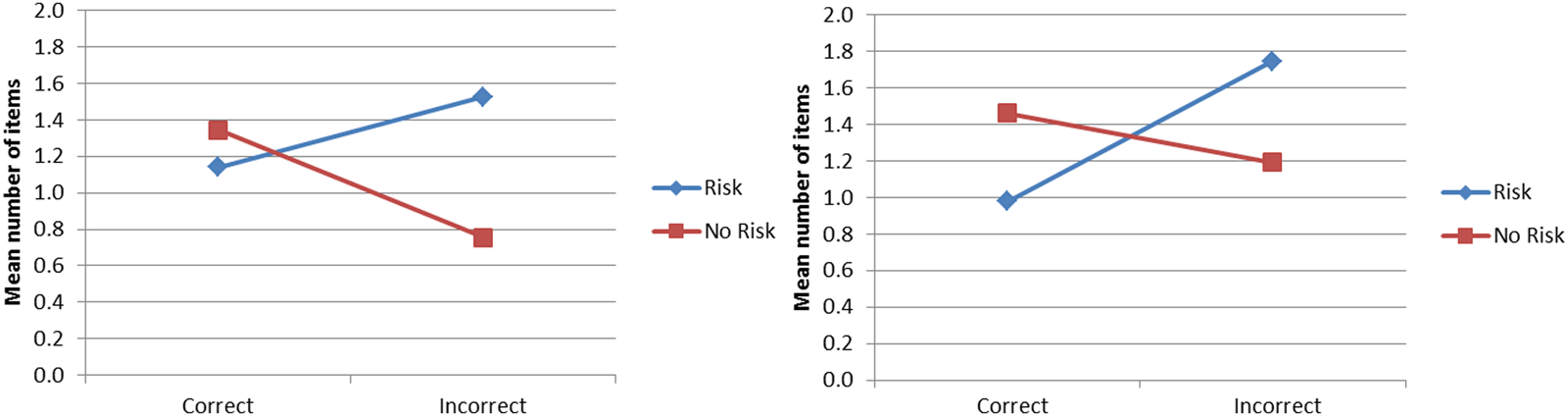
Risk status by response type interactions: English and Spanish.
5 BESOS Spanish semantic items
The same analyses were completed for the 238 children who code-mixed on the Spanish screener. As before, a repeated measures ANOVA was conducted with dominance and risk as the between-participants variables and response accuracy as the within-participants factor. Results revealed a main effect for dominance, F(2, 189) = 11.171, p > .001, ηp2 = .105. On average, children in the EDB group code-mixed more (M = 1.94) compared to the BB (M = 1.39) and the SDB groups (M = 0.71). Figure 3 shows a significant response type by proficiency interaction F(2, 189) = 6.13, p = .003, ηp2 = .061. When tested in Spanish, the EDB children were more likely to provide an incorrect code-mixed response, while the SDB produced more correct than incorrect code-mixed answers. The BB children produced comparable numbers of correct and incorrect responses.
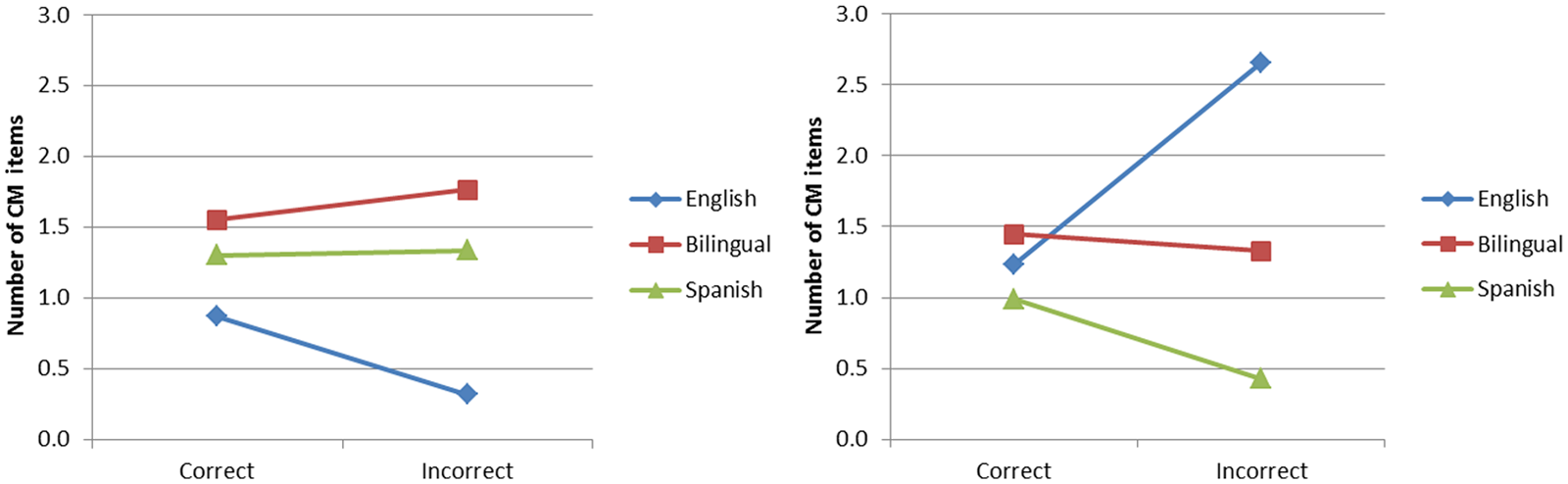
Dominance by response type interactions: English and Spanish.
IV Discussion
1 Prevalence of code-mixing across both languages
The first research question addressed the prevalence of bilingual preschoolers’ code-mixed responses in both languages. We observed that while not all children code-mix, nearly one-half of the participants code-mixed at least once on either screener. Various factors such as language input, word-learning capacity, facility in handling two languages, and the commonplace of CM within a bilingual community guide our understanding of these findings (Bedore et al., 2005; Hammer and Rodriguez, 2012). In the semantic domain, CM is possible because semantic meaning can be encoded or lexicalized in either of a child’s two languages without grammatical constraints (De Bot, 2004). Given the formal demands of a screening task, children code-mixed as an attempt to fill gaps in lexical knowledge.
2 Code-mixing patterns by test language: Language dominance and risk status
Bilinguals acquire distinct linguistic knowledge based on their simultaneous learning and understanding of two languages (Genesee et al., 2004; Kohnert and Medina, 2009). Balanced bilinguals possess a language profile reflective of equally distributed amounts of language input and output in both languages that potentially sets them apart from their English- and Spanish-dominant bilingual peers. As a result for the BB group, smaller differences between activated words should exist in both languages. The BB children produced more symmetrical code-mixed responses across Spanish and English, therefore establishing a pattern of lexical flexibility in at least one language over the other dominance groups (see Figures 1 and 3). Additionally, among the 43 children (7%) who code-mixed symmetrically, these tended to be balanced bilinguals.
Language dominance and test language influenced participant’s code-mixed responses. The overall percentage (approximately 25%) of preschoolers who code-mixed in each test language is relatively low compared to the total number of participants. Evidence that bilinguals are less likely to code-mix from their L1 into the L2 is established based on the inverse patterns of the English- and Spanish-dominant language groups’ CM on both screeners (De Bot, 2004; Kroll et al., 2008). Bilingual language selection models suggest that dependence on L1 knowledge to mediate L2 meaning is characteristic of emergent dual language development (Bedore et al., 2012; Jisa, 2000).
Specific to test language, participants’ risk status influenced the frequency of code-mixed responses. The at-risk group code-mixed proportionally more than the no-risk group on the English screener. Conversely the no-risk group proportionally code-mixed more on the Spanish screener than the at-risk group. Bilingual preschoolers develop conceptual and lexical links in not just one but two languages. Patterns of language alternating are impacted by a bilingual speaker’s language environment and interactions with different interlocutors (Kohnert and Bates, 2002; Kohnert et al., 1999). The bilingual children are grouped by language experience and exposure, which allows us to examine children with and without risk for language impairment across a broad range of different language experiences. One possible explanation for these findings considers children’s level of awareness with respect to the social-pragmatic context of the test setting and the linguistic environment. How successful a speaker is in message delivery reflects communicative competence (Heredia and Altarriba, 2001; Martin-Rhee and Bialystok, 2008). Bilingual communicative competence reflects not only how well a speaker conceptualizes, formulates, and generates a message, but also the speaker’s ability to discern if the intended message is stated effectively between two languages (Hammer and Rodriguez, 2012; Reyes, 2004; Rodriguez et al., 2005; Toribio, 2004). Increased frequency of code-mixed responses produced by the at-risk group might be indicative of limited meta-linguistic awareness in terms of the preferred use of English as the majority language within a school setting. Additionally, at-risk children may exhibit challenges inherent with language negotiation and social interaction strategies (Marton et al., 2005), deficits with resolving lexical competition (Patterson and Pearson, 2012; Peña et al., 2012), and inhibitory control in terms of suppressing irrelevant information (Sheng and McGregor, 2010; Spaulding, 2010). While children at-risk for language impairment demonstrate lexical–semantic difficulties associated with conceptual organization, lack of sociolinguistic awareness presents another potential factor that provides an explanation of these CM patterns (Leonard, 1998; Marton et al., 2005).
3 Accuracy levels of code-mixed responses
The third question addressed the success rate of code-mixed responses per screening item. We found that language dominance and risk status did not differentiate accurate production of correct code-mixed responses on either language screener; however, language dominance and risk status influenced the number of incorrect code-mixed responses. On the English screener, the at-risk group committed more code-mixed errors than the no-risk group. Recall how the no-risk group code-mixed more on the English screener than the at-risk group. Bilinguals are required to regulate language selection specific to task performance and eventually choose one language over the other. The at-risk group’s increase in error production on the English screener reflects apparent challenges in the ability to exert competitive control between languages for activated word candidates that compete for threshold during output production. Additionally, code-mixed errors may be attributed to a young emerging bilingual’s limited language experience, coupled with a lack of meta-linguistic awareness determined by factors such as language use with an examiner in the school setting.
On the Spanish screener, the EDB group was more likely to commit lexical naming errors from Spanish into English than the BB and the SDB groups. Here there were no differences between risk groups. The EDB group’s increase of code-mixed errors reflects inherent challenges when attempting to lexicalize semantic representations from the weaker L2 into the dominant L1. Additionally, this pattern suggests how language dominance potentially determines a group’s preferential use of English over Spanish (Kohnert and Bates, 2002; Zentella, 1997).
4 Clinical implications
Researchers view language mixing as an opportunity to explore various aspects of linguistic processing and cognitive functioning unique to bilinguals (Bialystok et al., 2008; Bullock and Toribio, 2009). Code-mixing is a result of lexical selection during bilingual speech production that requires a particular degree of linguistic competence in two languages (Heredia and Altarriba, 2001; MacSwan, 2004; Reyes, 2004). Bilinguals with lexical access in two languages code-mix as a beneficial strategy to optimize bi-directional knowledge to bridge lexical gaps, provide translation equivalents or implement single-word borrowings (Kormos, 2006; Zentella, 1997). Results from this study show how CM serves a dual purpose for bilingual preschoolers. First, at an early age young bilinguals, despite variance in language dominance and risk status, are able to leverage knowledge in both languages in response to formal semantic test questions. Second, dual language speakers code-mix to provide an appropriate message contingent upon the linguistic setting, cognitive task demands, and interlocutor.
Empirical information that contributes to a knowledge base of how young bilinguals process and produce two languages carries significant implications for evidence-based instruction and intervention. In order to adequately address the unique educational needs of school-age dual language populations, continued research of bilingual children’s early language development is necessary (Kohnert and Medina, 2009). School-based speech-language pathologists express concern regarding accurate diagnostic decisions and appropriate clinical intervention methods specific to bilingual students (Caesar and Kohler, 2009; Kritikos, 2003). A model approach to bilingual vocabulary intervention would integrate inter-language relationships to minimize classroom time spent teaching the same concepts or words in both languages (Bedore et al., 2005; Peña et al., 2003, 2012). When possible, educators should take advantage of bilingual students’ ability to code-mix as a beneficial educational resource.
Footnotes
Funding
This research was funded by grant R01DC007439 from the National Institute on Deafness and Other Communication Disorders (NIDCD).