
Abstract
This exploratory study investigated whether joint attention through eye gaze was predictive of second language (L2) speakers’ responses to recasts. L2 English learners (N = 20) carried out communicative tasks with research assistants who provided feedback in response to non-targetlike (non-TL) forms. Their interaction was audio-recorded and their eye gaze behavior was tracked simultaneously using the faceLAB system. Transcripts were coded for characteristics of the feedback episodes (linguistic target, feedback type, intonation, prosody) and types of response (no opportunity, no reformulation, non-TL response, TL response). Eye gaze length for the researcher (when producing the feedback move) and the L2 speaker (when responding to feedback) were obtained in seconds using Captiv software. Following data pruning to reduce the data set to clausal recasts in response to grammatical errors, a logistic regression model revealed that both L2 speaker and mutual eye gaze were predictive of TL responses. Methodological issues for eye-tracking research during L2 interaction are provided, and suggestions for future research are discussed.
I Introduction
During conversation, interlocutors use visual cues like gesture and eye gaze to coordinate their attention with each other, which is referred to as ‘joint attention’ (Moore and Dunham, 1995). Joint attention is established through eye gaze and gestures when interlocutors either initiate or respond to eye gaze, typically in order to establish a common point of reference. Speakers also use mutual eye gaze to signal that they are attending to each other’s speech (Argyle and Cook, 1976; Argyle et al., 1968), and often alter their utterances if their interlocutor is not returning eye gaze (Goodwin, 1981). Eye gaze, alone or combined with gestures, may also be used to elicit help from an interlocutor (Bavelas and Chovil, 2000; Goodwin and Goodwin, 1986; Goodwin, 1986), and is associated with requests for repair (Rossano et al., 2009). Within the view of conversation as a joint activity (Clark, 1996; Garrod and Pickering, 2004, 2009; Pickering and Garrod, 2004), interlocutors establish successful communication by converging in their use of both linguistic forms and visual cues (gesture, posture, laughs, yawns) through what is known as interactive alignment. Just as alignment at one linguistic level can facilitate alignment at another linguistic level, convergence in visual cues, like eye gaze, can lead to shared interpretations (Richardson and Dale, 2005).
Although joint attention is widely accepted as a crucial component of children’s first language (L1) development, its role in adult second language (L2) learning remains underexplored. Recent studies have shown that gestures may facilitate the learning of L2 words (Gullberg et al., 2012; Kelly et al., 2009; Macedonia and Knösche, 2011) and new sound contrasts (Hirata and Kelly, 2010; Kelly and Lee, 2012), but the potential role of eye gaze in face-to-face L2 interaction has not been investigated. From Bruner’s (Bruner, 1995) socio-pragmatic view of joint attention, which is compatible with both interactionist and emergentist approaches to L2 learning and use (e.g. Ellis, 2008; Gass and Mackey, 2006; Verspoor et al., 2011), eye gaze could illuminate how L2 learners benefit from interacting with other speakers. For example, L1 research has shown that when speakers look at listeners, it initiates a brief period of mutual gaze (i.e. a gaze window) in which listener responses are likely to occur (Bavelas et al., 2002), after which speakers terminate the mutual gaze by looking away.
The purpose of this exploratory study was to investigate whether eye gaze plays a role in conversations between English L1 and L2 speakers and, specifically, whether L1 interlocutor eye gaze is associated with L2 speakers’ responses to recasts. The study was situated within interactional feedback literature because, as highlighted in a recent review (Plonsky and Brown, 2014), research on interactional feedback has reached sufficient size and prominence with nearly 20 meta-analyses (e.g. Brown, 2014; Mackey and Goo, 2007; Plonsky and Gass, 2011; Russell and Spada, 2006). This body of research has primarily focused on the types of learner errors addressed (i.e. grammatical, phonological) and the varieties of feedback used (i.e. recasts, clarification requests), with the goal of investigating the general effectiveness of interactional feedback and the role of linguistic variables, such as stress and intonation, in determining its impact (see Brown, 2014). However, no study has to date addressed the potential role that eye gaze may play in the effectiveness of interactional feedback. Assuming that eye gaze, like gesture, is a key component of interaction, representing one way in which interlocutors establish joint attention in dialogue, eye gaze might influence the extent to which L2 speakers respond to interactional feedback. Therefore, this study explored if eye gaze provides additional insight into learner responses to recasts – one frequent type of interactional feedback – either alone or in combination with other feedback characteristics previously shown to impact responses (e.g. recast length, emphasis). Thus, the research question was as follows:
Is eye gaze, alone or in combination with other recast characteristics, associated with L2 speakers’ responses to recasts?
We speculated that a gaze window could occur at the time an L2 speaker receives feedback from an interlocutor, which could potentially elicit responses to recasts. However, because the types of listener responses documented in previous studies were largely related to content rather than form (Bavelas et al., 2002), it was not clear whether L2 speakers’ responses would involve a reformulation of the linguistic forms targeted in the interlocutors’ recasts.
II Method
1 Participants
The participants were 20 L2 speakers of English (5 female) studying full-time in an intensive English program at a university in Montreal, Canada. The majority of participants (16) were Chinese, speaking Mandarin as their L1, while the remaining participants were L1 Arabic (3) or Spanish (1) speakers. Their mean age was 21.1 years (SD = 3.2). They had studied English for 6.0 years (SD = 4.2) and resided in Canada for less than one year (M = .81, SD = .79). As for their English proficiency, the participants reported IELTS scores ranging from 4.5 to 6.5 (M = 5.0, SD = 1.5.), which is approximately equivalent to level B in the Common European Framework of Reference.
2 Materials
a Communicative tasks
Four communicative tasks were created by the researchers to create opportunities for meaning-based interaction, during which a research assistant (RA) provided feedback when an L2 speaker produced non-targetlike (non-TL) forms. Due to the lack of previous research involving eye-tracking during face-to-face L2 interaction 1 and the exploratory nature of the study, a variety of communicative tasks targeting diverse topics and eliciting a variety of lexico-grammatical features were used. The World Records trivia task was a quiz in which the L2 speakers generated questions using factual information and question word prompts (e.g. who, when, where) to test their partner’s knowledge. The Story Telling task was a collaborative narration activity in which the L2 speakers and RA co-constructed a story from eight pictures. Each person received four pictures, and took turns adding information to build upon prior contributions, using their pictures in any order they chose. The Interview task was an open-ended activity in which they asked each other questions about general interest topics. The Truth or Lie task was a guessing game in which L2 speakers asked the RA questions in order to decide whether a statement was true or false. They asked as many questions as required to determine whether the RA was telling the truth or lying.
b Eye-tracking equipment
The faceLAB 5 eye-tracking system developed by Seeing Machines was used to capture the eye movements of the RA and L2 speaker during the communicative tasks. They were seated at a table opposite each other with four cameras positioned on two stereo-heads in the middle of the table, so that two cameras tracked and recorded the eye gaze and movement of each person. Two Logitech webcams were placed on tripods behind each person to record the scene, which included the interlocutor’s head and upper body as well as the wall behind them. Together these three cameras integrated the eye movement and field of vision data, specifically where in the scene (as depicted visually by a green dot in the field of vision) each interlocutor looked while conversing. The cameras were connected to two synchronized Dell Latitude E5520 laptops that recorded both interlocutors’ eye gaze and movement within the scenes. The eye-tracking data on the computers were monitored by a researcher in an adjacent room using a Skype screen share. The experimental setup is illustrated in Figure 1.

Experimental configuration.
3 Procedure
The L2 speakers carried out the communicative tasks during individual, 120-minute sessions with a researcher and one of three RAs. The researcher was responsible for explaining the project, administering forms, and monitoring the eye-tracking equipment, while the RAs carried out the communicative tasks only. The RAs were informed that the purpose of the study was to explore L2 speakers’ verbal and non-verbal behavior while carrying out communicative tasks, and were instructed to provide feedback when the participants made errors. Reflecting the exploratory nature of the study and a desire to maintain a primary focus on meaning, the RAs were not given strict guidelines about the amount or type of feedback they should provide or the types of linguistic errors they should target. They were instructed to maintain a primary focus on communication, interact and give feedback as naturally as possible, and adjust their feedback if a participant showed any anxiety or frustration.
After completing a consent form and background questionnaire (10 minutes), the L2 speakers underwent a brief calibration process for the eye-tracking equipment (15 minutes). They then completed four communicative tasks with one of the RAs following one of two orders randomized across participants, with each task lasting approximately 15 minutes (60 minutes). While World Records and Truth or Lie were always first and fourth, respectively, the Story Telling and Interview tasks were counterbalanced. During the communicative tasks, the researcher monitored the eye-tracking data in an adjacent room to ensure that there were no disruptions to the systems (e.g. the table was jostled or a participant moved out of range). Adjustments typically occurred during the first activity when the interlocutors relaxed into their seats and the researcher had to remind them to maintain their posture from the calibration stage. When recalibration was necessary, it was carried out between communicative tasks. After the communicative activities, each participant underwent an exit interview (15 minutes). All verbal interaction was audio-recorded using a Sony portable digital recorder.
4 Data coding
The audio-recordings of the communicative activities were transcribed and verified by the researchers and RAs. The researchers created, pilot tested, and revised the coding categories collaboratively, after which RAs were trained to code the transcripts. Every transcript coded by the RAs was checked by one of the researchers, and disagreements were resolved through discussion. Feedback episodes were operationalized as three-part exchanges consisting of an error, a feedback move, and the L2 speaker’s turn immediately following the feedback move. Although the data were initially coded for multiple types of feedback moves (recasts, clarification requests, repetition) and linguistic foci (grammatical, lexical, phonological, pragmatic), only grammatical recasts were considered for detailed analysis, due to their higher frequency in L2 interaction (e.g. Brown, 2014).
Once the recast episodes were identified, the L2 speakers’ responses to feedback were classified according to four categories: no opportunity, no reformulation, non-TL response, and TL response. If the recast did not provide a chance to respond, such as if the researcher continued talking, then it was classified as no opportunity. If the L2 speakers responded by continuing the topic or acknowledging the recast (e.g. yeah), it was coded as no reformulation. If they reformulated their previous utterance, it was coded as non-TL response if the new utterance failed to repair the initial error or contained an error of the same type, or coded as TL response if the new utterance repaired the initial error. Next, each recast episode was coded in terms of the feedback characteristics (summarized in Table 1), used in previous research (Loewen, 2004; Loewen and Philp, 2006; Philp, 2003; Sheen, 2006).
Characteristics of recasts.
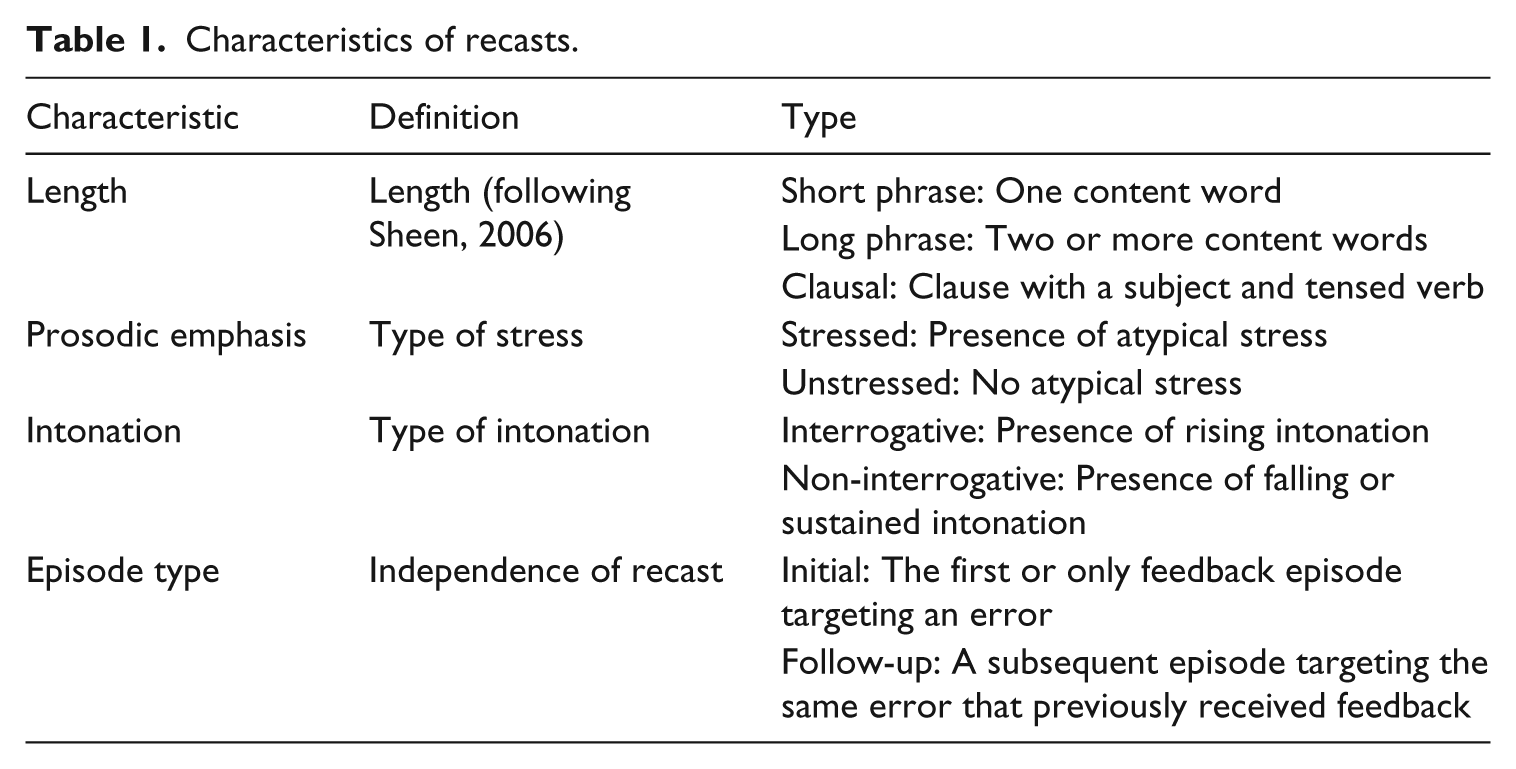
Finally, the eye-tracking data were coded for length of eye gaze during recasts, specifically how long (in milliseconds) the RA looked at the L2 speaker while delivering the recast, and how long the L2 speaker looked at the RA when responding to the recast. A look began the moment that the speaker’s gaze first landed on the face of their interlocutor, and ended the moment their gaze left their speaking partner’s face. Only the initial pass was considered for analysis, with no minimum benchmark for length determined a priori. Whether a look occurred was determined using each interlocutor’s webcam-recorded scene video, featuring a moving green dot over the speaker’s field of vision to indicate eye movement. The analysis program Captiv allowed for a simultaneous viewing of both videos, and coding for when a look occurred and its duration. Based on previous research that revealed an association between requests for other-repair and mutual eye gaze (Rossano et al., 2009), a binary coding category was also used to indicate whether the interlocutors looked at each other during an episode. Interrater reliability for the identification of feedback episodes, feedback characteristics, and eye gaze was calculated for a subset of the checked transcripts (25%), which were then analyzed by an independent coder. Interrater reliability was obtained using Cohen’s kappa (κ) or Pearson correlations (r): Response κ = .83, Length κ = .69, Prosodic emphasis κ = .54, Intonation κ = .84, Length of eye gaze (L2 speaker and RA) r = .70; Mutual eye gaze κ = .71. Based on Landis and Koch’s (1977) guide to interpreting kappa values, interrater agreement was substantial (.61–.80) or almost perfect (.81–1.0) in all cases but prosodic emphasis, where it was moderate (.41–60).
5 Data analysis
Due to the exploratory nature of the study, the amount, type, and linguistic targets of the RAs feedback were not controlled a priori. Instead, the RAs were instructed to give feedback as naturally as possible while maintaining a primary focus on the communication of meaning. Based on previous interaction research, it was expected that RAs would naturally provide recasts in response to the learners’ grammatical errors, and the data were examined to confirm this prediction (see below) and identify recast episodes for entry into a logistic regression model. To create a binary response variable, no reformulation and non-TL responses were combined and coded as 0, while TL responses were coded as 1. Recast episodes not providing L2 speakers with an opportunity to reformulate were excluded from the analysis, as there was no expectation that the predictor variables could explain those instances. Predictor variables included prosody (binary), intonation (binary), length of L2 speaker and RA eye gaze (both numeric), and mutual eye gaze (binary). Alpha was set at .05 for all statistical tests.
III Results
1 Data pruning
The data set contained 1,067 feedback episodes, with a mean of 53.5 episodes per L2 speaker (SD = 22.3) across the four communicative tasks in a one-hour period. As predicted by the meta-analytic interaction research to date, the L2 speakers produced grammatical errors most frequently (52%), and the RAs responded to 87% of those grammatical errors with recasts, thereby creating a total of 482 recast episodes available for analysis. However, in order to create greater independence of the episodes included in the logistic regression model, all follow-up recasts (n = 119) were removed from the data set. Finally, in order to control for the potential interaction between recast length and RA eye gaze duration, short and long phrasal recasts were removed from the analyses (n = 87). 2 Therefore, the final set of episodes for inclusion in the logistic regression model consisted of 276 clausal recasts provided in response to grammatical errors, which represented a mean of 13.8 recasts per L2 speaker (SD = 8.9).
2 Predicting responses to recasts
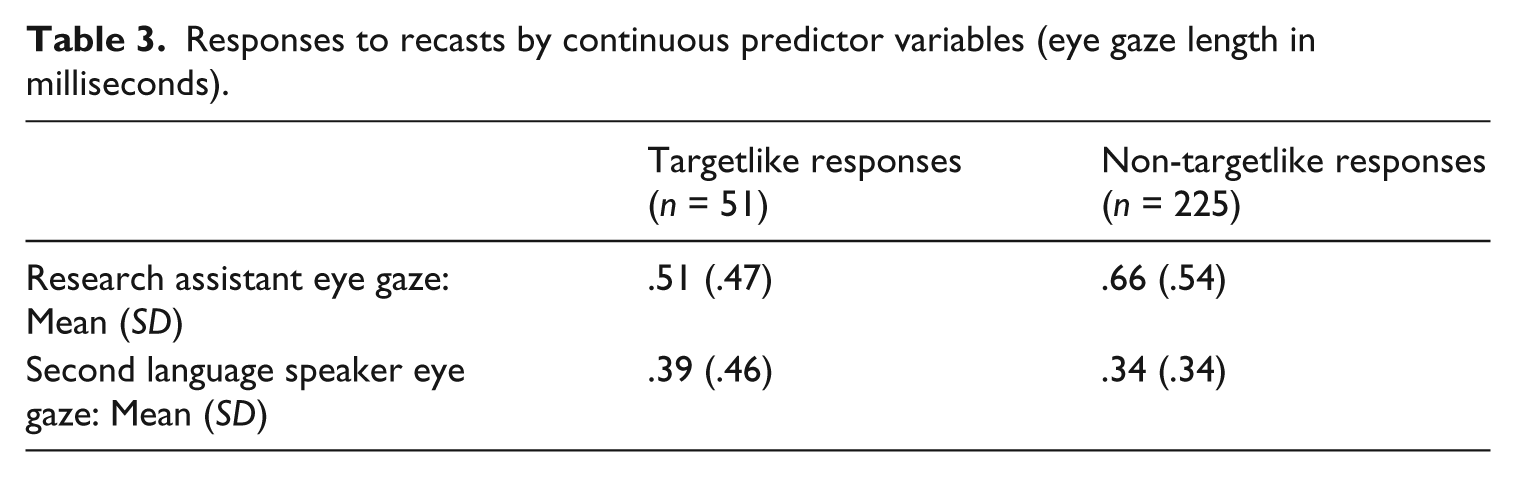
To explore the relationships among the predictor variables and responses to recasts, a binary logistic regression was performed. For the binary variables of prosody, intonation, and mutual eye gaze, the reference categories were unstressed feedback, declarative feedback, and no mutual eye gaze, respectively. The frequency counts (for binary variables) and descriptive statistics (for continuous variables) for each level of the outcome variable are provided in Table 2 and Table 3, respectively.
Responses to recasts by binary predictor variables.

Responses to recasts by continuous predictor variables (eye gaze length in milliseconds).
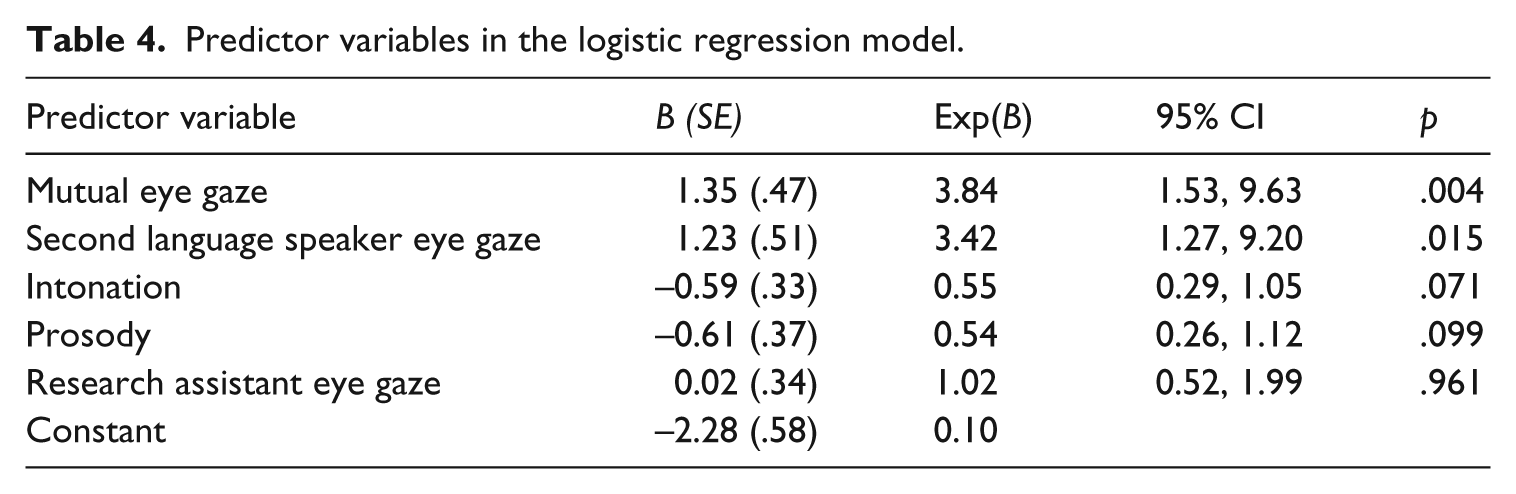
The five predictor variables were included in the logistic regression model using an enter selection method. The results of logistic regression indicated that the model was significant: χ2 (5, 276) = 19.28, p = .002. Goodness of fit measures showed that the model accounted for 11% of the pseudovariance (Nagelkerk R2 = .11), which estimates the variance in the outcome variable accounted for by the model, and successfully predicted 83% of the outcomes. 3 Analysis of the predictor variables showed that mutual eye gaze and L2 speaker eye gaze were the only significant predictors of TL responses (see Table 4). Mutual eye gaze increased the odds of a TL response by a multiple of 3.84, while longer L2 speaker eye gazes increased those odds by a multiple of 3.42. This is equal to an increase in the probability of a TL response from 9% to 28% when mutual eye gaze occurred and to 26% when the L2 speaker demonstrated longer eye gaze.
Predictor variables in the logistic regression model.
IV Discussion
The research question asked whether eye gaze, alone or in combination with other recast characteristics, was associated with L2 speakers’ responses to recasts. The results of the logistic regression model indicated that L2 speaker eye gaze and mutual eye gaze (i.e. shared eye contact between the RA and the L2 speaker) predicted TL responses to grammatical recasts. This is a surprising finding considering the numerous factors that make reformulations in response to this specific type of feedback unlikely. Previous research has shown that longer feedback moves are less likely to lead to accurate recall (Philp, 2003), even if speakers are aware that they are receiving feedback. In addition, L2 speakers are less likely to perceive feedback as corrective when it occurs as a recast of a grammatical error (Mackey, Gass, and McDonough, 2000). Furthermore, because recasts targeted a range of grammatical errors, they likely contained multiple changes to L2 speakers’ original utterance, which is also associated with less accurate reformulation (Loewen and Philp, 2006; Philp, 2003). These patterns were evident in the current data, as the L2 speakers produced more non-TL responses than TL responses (225 and 51, respectively). Nevertheless, despite these potential obstacles, L2 speaker and mutual eye gaze were predictive of TL responses.
That RA eye gaze alone was not predictive of a TL response is not surprising. While the RA’s gaze may be designed to increase awareness of their feedback move, essentially placing pressure on the L2 speaker to reformulate their utterance (Bavelas et al., 2002), it is still necessary for the listener to be aware of this gaze. It is when this gaze is met that shared interpretations are likely to occur (Richardson and Dale, 2005), as shown by the predictive nature of L2 speaker and mutual eye gaze. In other words, it is not enough for the RA to simply look at the listener; a successful feedback episode relies on gaze behavior being interrelated as opposed to independent (Goodwin, 1981). The L2 speaker must be a willing participant for eye gaze to matter, which may help explain the lack of TL responses found during these interactions. Rossano et al. (2009) summarized a series of studies that indicated that an interlocutor tends to look more at their speaking partner when listening than when speaking. If the RA is primarily looking at the L2 speaker when giving feedback (72% of the time in this study), it creates the possibility for a high number of episodes with mutual eye gaze. However, the number of instances where mutual eye gaze occurred was relatively low (43%), which suggests that L2 speakers were not responding to the RA’s eye gaze. Additionally, the mean length of L2 speaker eye gaze was short (.39 seconds), which may not have been long enough for them to discern that a response was expected. As L2 speaker eye gaze increased, however, TL reformulation was more likely. One possible explanation for the relatively short L2 speaker eye gaze and low occurrence of mutual eye gaze may be the influence of cultural norms, as previous studies have shown that the amount and type of eye gaze considered appropriate varies cross-culturally (Dhindsa and Abdul-Latif, 2012; Lee and Carrasquillo, 2006; Rossano et al., 2009; Zhang and Kalinowski, 2012). While these findings indicate the predictive power of L2 speaker and mutual eye gaze in eliciting TL reformulations, it may only be relevant if their cultural backgrounds are compatible with shared eye gaze behavior.
As an exploratory study, the findings have highlighted areas for future research that can overcome its methodological limitations and provide greater insight into the relationship between eye gaze and responses to feedback. As the participants in the current study were mostly Chinese (80%), future research with larger and more culturally diverse samples would provide greater insight into the potential role of cultural norms in how L2 speakers respond to interlocutor eye gaze and feedback. Rather than control the amount or type of feedback and the targeted linguistic forms a priori, our approach was to elicit meaningful communication as naturally as possible. We achieved some control over potentially-intervening variables through data pruning (i.e. limiting the regression analysis to clausal recasts in response to grammatical errors) but future research could aim for greater experimental control by training interlocutors to provide specific types of feedback exclusively. Such studies might also provide feedback for specific linguistic errors only, and then assess L2 speakers’ existing knowledge of that form to explore whether their knowledge affects TL responses.
Future research should also investigate the potential impact of task type on L2 speakers’ eye gaze, as this exploratory study was not designed to isolate task features. Three tasks used in this study (World Records, Story Telling, Truth or Lie) required both interlocutors to use visual information (pictures and texts) to complete the task. This design feature likely impacted their eye gaze behavior, as the tasks required that they seek information from their task materials. Tasks allowing the participant to rely on self-knowledge and opinion (like the Interview task) may allow for more eye contact during face-to-face interactions. Another important consideration is the tasks’ information-exchange requirement. Tasks requiring an exchange of information (World Records, Interview) accounted for more feedback (177/276 or 64% of the episodes). However, when the interlocutors worked together from shared materials (Story Telling), the L2 speakers produced the highest percentage of TL responses (28%). Previous research has shown that monitoring a shared work-space during interaction facilitates task performance in terms of efficiency and accuracy, whereas monitoring eye gaze alone does not (Clark and Krych, 2004; Whittaker, 2003). Based on the Story Telling task, feedback may be more effective at eliciting TL responses when interlocutors share the materials needed for successful task completion.
In this exploratory study assessing the potential contribution of simultaneous eye-tracking during L2 interaction, several technical challenges emerged that should be addressed in future research. First, it was necessary for the researcher to periodically interrupt the interaction between the L2 speaker and the RA to readjust cameras and maintain proper calibration because the equipment had been inadvertently jostled. Although the breaks largely occurred between tasks, the interruptions potentially disrupted an established interactional flow. Although no L2 speakers stated in an exit interview that the cameras bothered them or negatively affected their communication, future research may look to analyze the same L2 speakers in different interactive situations. Second, the scene cameras’ position behind the interlocutors created some difficulty for accurate eye-tracking due to the distance from the eye-tracking cameras. Our experimental setup has since been modified to place the scene cameras beside the stereo heads, thus reducing the region being tracked. By investigating a wider range of communicative tasks and refining the technical aspects of simultaneous eye-tracking, our long-term research agenda is to uncover the potential contribution of eye gaze for helping L2 speakers benefit from learning opportunities made available through interaction.
Footnotes
Acknowledgements
We would like to thank the research assistants who helped with data collection and coding: Andrew Bates, Suzanne Cerreta, Yuan Chen, Angelica Fulga, and Stella Carolina Stella.
Declaration of conflicting interest
The authors declare that there is no conflict of interest.
Funding
Funding for this project was provided from the Quebec Ministry of Education (Fonds Québécois de la recherche sur la société et la culture), the Social Studies and Humanities Research Council of Canada, and the Canada Research Chairs program.